Автоматизируем десктопный GUI на Python + pywinauto: как подружиться c MS UI Automation |
Python библиотека pywinauto — это open source проект по автоматизации десктопных GUI приложений на Windows. За последние два года в ней появились новые крупные фичи:
"win32" и новый "uia"). Дальше плавно двигаемся в сторону кросс-платформенности.Также сделаем небольшой обзор того, что есть в open source для десктопной автоматизации (без претензий на серьезное сравнение).
Эта статья — частично расшифровка доклада с конференции SQA Days 20 в Минске (видеозапись и слайды), частично русская версия Getting Started Guide для pywinauto.
Начнём с краткого обзора опен сорса в этой области. Для десктопных GUI приложений всё несколько сложнее, чем для веба, у которого есть Selenium. Вот основные подходы:
Хардкодим точки кликов, надеемся на удачные попадания.
[+] Кросс-платформенный, легко реализуемый.
[+] Легко сделать "record-replay" запись тестов.
[-] Самый нестабильный к изменению разрешения экрана, темы, шрифтов, размеров окон и т.п.
[-] Нужны огромные усилия на поддержку, часто проще перегенерить тесты с нуля или тестировать вручную.
[-] Автоматизирует только действия, для верификации и извлечения данных есть другие методы.
Инструменты (кросс-платформенные): autopy, PyAutoGUI, PyUserInput и многие другие. Как правило, более сложные инструменты включают в себя эту функциональность (не всегда кросс-платформенно).
Стоит сказать, что координатный метод может дополнять остальные подходы. Например, для кастомной графики можно кликать по относительным координатам (от левого верхнего угла окна/элемента, а не всего экрана) — обычно это достаточно надежно, особенно если учитывать длину/ширину всего элемента (тогда и разное разрешение экрана не помешает).
Другой вариант: выделять для тестов только одну машину со стабильными настройками (не кросс-платформенно, но в каких-то случаях годится).
[+] Кросс-платформенный
[+-] Относительно надежный (лучше, чем координатный метод), но всё же требует хитростей.
[-+] Относительно медленный, т.к. требует ресурсов CPU для алгоритмов распознавания.
[-] О распознавании текста (OCR), как правило, речи не идёт => нельзя достать текстовые данные. Насколько мне известно, существующие OCR решения не слишком надежны для этого типа задач, и широкого применения не имеют (welcome в комменты, если это уже не так).
Инструменты: Sikuli, Lackey (Sikuli-совместимый, на чистом Python), PyAutoGUI.
[+] Самый надежный метод, т.к. позволяет искать по тексту, независимо от того, как он отрисован системой или фреймворком.
[+] Позволяет извлекать текстовые данные => проще верифицировать результаты тестов.
[+] Как правило, самый быстрый, т.к. почти не расходует ресурсы CPU.
[-] Тяжело сделать кросс-платформенный инструмент: абсолютно все open-source библиотеки поддерживают одну-две accessibility технологии. Windows/Linux/MacOS целиком не поддерживает никто, кроме платных типа TestComplete, UFT или Squish.
[-] Не всегда такая технология в принципе доступна. Например, тестирование загрузочного экрана внутри VirtualBox'а — тут без распознавания изображений не обойтись. Но во многих классических случаях все-таки accessibility подход применим. О нем дальше и пойдет речь.
Инструменты: TestStack.White на C#, Winium.Desktop на C# (Selenium совместимый), MS WinAppDriver на C# (Appium совместимый), pywinauto, pyatom (совместим с LDTP), Python-UIAutomation-for-Windows, RAutomation на Ruby, LDTP (Linux Desktop Testing Project) и его Windows версия Cobra.
LDTP — пожалуй, единственный кросс-платформенный open-source инструмент (точнее семейство библиотек) на основе accessibility технологий. Однако он не слишком популярен. Сам не пользовался им, но по отзывам интерфейс у него не самый удобный. Если есть позитивные отзывы, прошу поделиться в комментах.
Для кросс-платформенных приложений сами разработчики часто делают внутренний механизм для обеспечения testability. Например, создают служебный TCP сервер в приложении, тесты к нему подключаются и посылают текстовые команды: на что нажать, откуда взять данные и т.п. Надежно, но не универсально.
Большинство Windows приложений, написанных до выхода WPF и затем Windows Store, построены так или иначе на Win32 API. А именно, MFC, WTL, C++ Builder, Delphi, VB6 — все эти инструменты используют Win32 API. Даже Windows Forms — в значительной степени Win32 API совместимые.
Инструменты: AutoIt (похож на VB) и Python обертка pyautoit, AutoHotkey (собственный язык, есть IDispatch COM интерфейс), pywinauto (Python), RAutomation (Ruby), win32-autogui (Ruby).
Главный плюс: технология MS UI Automation поддерживает подавляющее большинство GUI приложений на Windows за редкими исключениями. Проблема: она не сильно легче в изучении, чем Win32 API. Иначе никто бы не делал оберток над ней.
Фактически это набор custom COM интерфейсов (в основном, UIAutomationCore.dll), а также имеет .NET оболочку в виде namespace System.Windows.Automation. Она, кстати, имеет привнесенный баг, из-за которого некоторые UI элементы могут быть пропущены. Поэтому лучше использовать UIAutomationCore.dll напрямую (если слышали про UiaComWrapper на C#, то это оно).
Разновидности COM интерфейсов:
(1) Базовый IUknown — "the root of all evil". Самый низкоуровневый, ни разу не user-friendly.
(2) IDispatch и производные (например, Excel.Application), которые можно использовать в Python с помощью пакета win32com.client (входит в pyWin32). Самый удобный и красивый вариант.
(3) Custom интерфейсы, с которыми умеет работать сторонний Python пакет comtypes.
Инструменты: TestStack.White на C#, pywinauto 0.6.0+, Winium.Desktop на C#, Python-UIAutomation-for-Windows (у них исходный код сишных оберток над UIAutomationCore.dll не раскрыт), RAutomation на Ruby.
Несмотря на то, что почти все оси семейства Linux построены на X Window System (в Fedora 25 "иксы" поменяли на Wayland), "иксы" позволяют оперировать только окнами верхнего уровня и мышью/клавиатурой. Для детального разбора по кнопкам, лист боксам и так далее — существует технология AT-SPI. У самых популярных оконных менеджеров есть так называемый AT-SPI registry демон, который и обеспечивает для приложений автоматизируемый GUI (как минимум поддерживаются Qt и GTK).
Инструменты: pyatspi2.
pyatspi2, на мой взгляд, содержит слишком много зависимостей типа того же PyGObject. Сама технология доступна в виде обычной динамической библиотеки libatspi.so. К ней имеется Reference Manual. Для библиотеки pywinauto планируем реализовать поддержку AT-SPI имеено так: через загрузку libatspi.so и модуль ctypes. Есть небольшая проблема только в использовании нужной версии, ведь для GTK+ и Qt приложений они немного разные. Вероятный выпуск pywinauto 0.7.0 с полноценной поддержкой Linux можно ожидать в первой половине 2018-го.
На MacOS есть собственный язык автоматизации AppleScript. Для реализации чего-то подобного на Python, разумеется, нужно использовать функции из ObjectiveC. Начиная, кажется, еще с MacOS 10.6 в предустановленный питон включается пакет pyobjc. Это также облегчит список зависимостей для будущей поддержки в pywinauto.
Инструменты: Кроме языка Apple Script, стоит обратить внимание на ATOMac, он же pyatom. Он совместим по интерфейсу с LDTP, но также является самостоятельной библиотекой. На нем есть пример автоматизации iTunes на macOs, написанный моим студентом. Есть известная проблема: не работают гибкие тайминги (методы waitFor*). Но, в целом, неплохая вещь.
Первым делом стоит вооружиться инспектором GUI объектов (то, что называют Spy tool). Он поможет изучить приложение изнутри: как устроена иерархия элементов, какие свойства доступны. Самые известные инспекторы объектов:
C:\Program Files (x86)\Windows Kits\\bin\x64 . В самом инспекторе нужно выбрать режим UI Automation вместо MS AA (Active Accessibility, предок UI Automation).Просветив приложение насквозь, выбираем бэкенд, который будем использовать. Достаточно указать имя бэкенда при создании объекта Application.
--force-renderer-accessibility, чтобы увидеть элементы на страницах в Inspect.exe). Конечно, конкуренция с Selenium в этой области навряд ли возможна. Просто еще один способ работать с браузером (может пригодиться для кросс-продуктового сценария).Приложение достаточно изучено. Пора создать объект Application и запустить его или присоединиться к уже запущенному. Это не просто клон стандартного класса subprocess.Popen, а именно вводный объект, который ограничивает все ваши действия границами процесса. Это очень полезно, если запущено несколько экземпляров приложения, а остальные трогать не хочется.
from pywinauto.application import Application
app = Application(backend="uia").start('notepad.exe')
# Опишем окно, которое хотим найти в процессе Notepad.exe
dlg_spec = app.UntitledNotepad
# ждем пока окно реально появится
actionable_dlg = dlg_spec.wait('visible')Если хочется управлять сразу несколькими приложениями, вам поможет класс Desktop. Например, в калькуляторе на Win10 иерархия элементов размазана аж по нескольким процессам (не только calc.exe). Так что без объекта Desktop не обойтись.
from subprocess import Popen
from pywinauto import Desktop
Popen('calc.exe', shell=True)
dlg = Desktop(backend="uia").Calculator
dlg.wait('visible')Корневой объект (Application или Desktop) — это единственное место, где нужно указывать бэкенд. Все остальное прозрачно ложится в концепцию "спецификация->враппер", о которой дальше.
Это основная концепция, на которой строится интерфейс pywinauto. Вы можете описать окно/элемент приближенно или более детально, даже если оно еще не существует или уже закрыто. Спецификация окна (объект WindowSpecification) хранит в себе критерии, по которым нужно искать реальное окно или элемент.
Пример детальной спецификации окна:
>>> dlg_spec = app.window(title='Untitled - Notepad')
>>> dlg_spec
>>> dlg_spec.wrapper_object()
Сам поиск окна происходит по вызову метода .wrapper_object(). Он возвращает некий "враппер" для реального окна/элемента или кидает ElementNotFoundError (иногда ElementAmbiguousError, если найдено несколько элементов, то есть требуется уточнить критерий поиска). Этот "враппер" уже умеет делать какие-то действия с элементом или получать данные из него.
Python может скрывать вызов .wrapper_object(), так что финальный код становится короче. Рекомендуем использовать его только для отладки. Следующие две строки делают абсолютно одно и то же:
dlg_spec.wrapper_object().minimize() # debugging
dlg_spec.minimize() # productionЕсть множество критериев поиска для спецификации окна. Вот лишь несколько примеров:
# могут иметь несколько уровней
app.window(title_re='.* - Notepad$').window(class_name='Edit')
# можно комбинировать критерии (как AND) и не ограничиваться одним процессом приложения
dlg = Desktop(backend="uia").Calculator
dlg.window(auto_id='num8Button', control_type='Button')Список всех возможных критериев есть в доках функции pywinauto.findwindows.find_elements(...).
Python упрощает создание спецификаций окна и распознает атрибуты объекта динамически (внутри переопределен метод __getattribute__). Разумеется, на имя атрибута накладываются такие же ограничения, как и на имя любой переменной (нельзя вставлять пробелы, запятые и прочие спецсимволы). К счастью, pywinauto использует так называемый "best match" алгоритм поиска, который устойчив к опечаткам и небольшим вариациям.
app.UntitledNotepad
# то же самое, что
app.window(best_match='UntitledNotepad')Если все-таки нужны Unicode строки (например, для русского языка), пробелы и т.п., можно делать доступ по ключу (как будто это обычный словарь):
app['Untitled - Notepad']
# то же самое, что
app.window(best_match='Untitled - Notepad')Как узнать эталонные магические имена? Те, которые присваиваются элементу перед поиском. Если вы указали имя, достаточно похожее на эталон, значит элемент будет найден.
app.Properties.OK.click()app.Properties.OKButton.click()app.Properties.Button3.click() (имена Button0 и Button1 привязаны к первому найденному элементу, Button2 — ко второму, и дальше уже по порядку — так исторически сложилось)app.OpenDialog.FileNameEdit.set_text("") (полезно для элементов с динамическим текстом)app.Properties.TabControlSharing.select("General")Обычно два-три правила применяются одновременно, редко больше. Чтобы проверить, какие конкретно имена доступны для каждого элемента, можно использовать метод print_control_identifiers(). Он может печатать дерево элементов как на экран, так и в файл. Для каждого элемента печатаются его эталонные магические имена. Также можно скопипастить оттуда более детальные спецификации дочерних элементов. Результат в скрипте будет выглядеть так:
app.Properties.child_window(title="Contains:", auto_id="13087", control_type="Edit")>>> app.Properties.print_control_identifiers()
Control Identifiers:
Dialog - 'Windows NT Properties' (L688, T518, R1065, B1006)
[u'Windows NT PropertiesDialog', u'Dialog', u'Windows NT Properties']
child_window(title="Windows NT Properties", control_type="Window")
|
| Image - '' (L717, T589, R749, B622)
| [u'', u'0', u'Image1', u'Image0', 'Image', u'1']
| child_window(auto_id="13057", control_type="Image")
|
| Image - '' (L717, T630, R1035, B632)
| ['Image2', u'2']
| child_window(auto_id="13095", control_type="Image")
|
| Edit - 'Folder name:' (L790, T596, R1036, B619)
| [u'3', 'Edit', u'Edit1', u'Edit0']
| child_window(title="Folder name:", auto_id="13156", control_type="Edit")
|
| Static - 'Type:' (L717, T643, R780, B658)
| [u'Type:Static', u'Static', u'Static1', u'Static0', u'Type:']
| child_window(title="Type:", auto_id="13080", control_type="Text")
|
| Edit - 'Type:' (L790, T643, R1036, B666)
| [u'4', 'Edit2', u'Type:Edit']
| child_window(title="Type:", auto_id="13059", control_type="Edit")
|
| Static - 'Location:' (L717, T669, R780, B684)
| [u'Location:Static', u'Location:', u'Static2']
| child_window(title="Location:", auto_id="13089", control_type="Text")
|
| Edit - 'Location:' (L790, T669, R1036, B692)
| ['Edit3', u'Location:Edit', u'5']
| child_window(title="Location:", auto_id="13065", control_type="Edit")
|
| Static - 'Size:' (L717, T695, R780, B710)
| [u'Size:Static', u'Size:', u'Static3']
| child_window(title="Size:", auto_id="13081", control_type="Text")
|
| Edit - 'Size:' (L790, T695, R1036, B718)
| ['Edit4', u'6', u'Size:Edit']
| child_window(title="Size:", auto_id="13064", control_type="Edit")
|
| Static - 'Size on disk:' (L717, T721, R780, B736)
| [u'Size on disk:', u'Size on disk:Static', u'Static4']
| child_window(title="Size on disk:", auto_id="13107", control_type="Text")
|
| Edit - 'Size on disk:' (L790, T721, R1036, B744)
| ['Edit5', u'7', u'Size on disk:Edit']
| child_window(title="Size on disk:", auto_id="13106", control_type="Edit")
|
| Static - 'Contains:' (L717, T747, R780, B762)
| [u'Contains:1', u'Contains:0', u'Contains:Static', u'Static5', u'Contains:']
| child_window(title="Contains:", auto_id="13088", control_type="Text")
|
| Edit - 'Contains:' (L790, T747, R1036, B770)
| [u'8', 'Edit6', u'Contains:Edit']
| child_window(title="Contains:", auto_id="13087", control_type="Edit")
|
| Image - 'Contains:' (L717, T773, R1035, B775)
| [u'Contains:Image', 'Image3', u'Contains:2']
| child_window(title="Contains:", auto_id="13096", control_type="Image")
|
| Static - 'Created:' (L717, T786, R780, B801)
| [u'Created:', u'Created:Static', u'Static6', u'Created:1', u'Created:0']
| child_window(title="Created:", auto_id="13092", control_type="Text")
|
| Edit - 'Created:' (L790, T786, R1036, B809)
| [u'Created:Edit', 'Edit7', u'9']
| child_window(title="Created:", auto_id="13072", control_type="Edit")
|
| Image - 'Created:' (L717, T812, R1035, B814)
| [u'Created:Image', 'Image4', u'Created:2']
| child_window(title="Created:", auto_id="13097", control_type="Image")
|
| Static - 'Attributes:' (L717, T825, R780, B840)
| [u'Attributes:Static', u'Static7', u'Attributes:']
| child_window(title="Attributes:", auto_id="13091", control_type="Text")
|
| CheckBox - 'Read-only (Only applies to files in folder)' (L790, T825, R1035, B841)
| [u'CheckBox0', u'CheckBox1', 'CheckBox', u'Read-only (Only applies to files in folder)CheckBox', u'Read-only (Only applies to files in folder)']
| child_window(title="Read-only (Only applies to files in folder)", auto_id="13075", control_type="CheckBox")
|
| CheckBox - 'Hidden' (L790, T848, R865, B864)
| ['CheckBox2', u'HiddenCheckBox', u'Hidden']
| child_window(title="Hidden", auto_id="13076", control_type="CheckBox")
|
| Button - 'Advanced...' (L930, T845, R1035, B868)
| [u'Advanced...', u'Advanced...Button', 'Button', u'Button1', u'Button0']
| child_window(title="Advanced...", auto_id="13154", control_type="Button")
|
| Button - 'OK' (L814, T968, R889, B991)
| ['Button2', u'OK', u'OKButton']
| child_window(title="OK", auto_id="1", control_type="Button")
|
| Button - 'Cancel' (L895, T968, R970, B991)
| ['Button3', u'CancelButton', u'Cancel']
| child_window(title="Cancel", auto_id="2", control_type="Button")
|
| Button - 'Apply' (L976, T968, R1051, B991)
| ['Button4', u'ApplyButton', u'Apply']
| child_window(title="Apply", auto_id="12321", control_type="Button")
|
| TabControl - '' (L702, T556, R1051, B962)
| [u'10', u'TabControlSharing', u'TabControlPrevious Versions', u'TabControlSecurity', u'TabControl', u'TabControlCustomize']
| child_window(auto_id="12320", control_type="Tab")
| |
| | TabItem - 'General' (L704, T558, R753, B576)
| | [u'GeneralTabItem', 'TabItem', u'General', u'TabItem0', u'TabItem1']
| | child_window(title="General", control_type="TabItem")
| |
| | TabItem - 'Sharing' (L753, T558, R801, B576)
| | [u'Sharing', u'SharingTabItem', 'TabItem2']
| | child_window(title="Sharing", control_type="TabItem")
| |
| | TabItem - 'Security' (L801, T558, R851, B576)
| | [u'Security', 'TabItem3', u'SecurityTabItem']
| | child_window(title="Security", control_type="TabItem")
| |
| | TabItem - 'Previous Versions' (L851, T558, R947, B576)
| | [u'Previous VersionsTabItem', u'Previous Versions', 'TabItem4']
| | child_window(title="Previous Versions", control_type="TabItem")
| |
| | TabItem - 'Customize' (L947, T558, R1007, B576)
| | [u'CustomizeTabItem', 'TabItem5', u'Customize']
| | child_window(title="Customize", control_type="TabItem")
|
| TitleBar - 'None' (L712, T521, R1057, B549)
| ['TitleBar', u'11']
| |
| | Menu - 'System' (L696, T526, R718, B548)
| | [u'System0', u'System', u'System1', u'Menu', u'SystemMenu']
| | child_window(title="System", auto_id="MenuBar", control_type="MenuBar")
| | |
| | | MenuItem - 'System' (L696, T526, R718, B548)
| | | [u'System2', u'MenuItem', u'SystemMenuItem']
| | | child_window(title="System", control_type="MenuItem")
| |
| | Button - 'Close' (L1024, T519, R1058, B549)
| | [u'CloseButton', u'Close', 'Button5']
| | child_window(title="Close", control_type="Button")В некоторых случаях печать всего дерева может тормозить (например, в iTunes на одной вкладке аж три тысячи элементов!), но можно использовать параметр depth (глубина): depth=1 — сам элемент, depth=2 — только непосредственные дети, и так далее. Его же можно указывать в спецификациях при создании child_window.
Мы постоянно пополняем список примеров в репозитории. Из свежих стоит отметить автоматизацию сетевого анализатора WireShark (это хороший пример Qt5 приложения; хотя эту задачу можно решать и без GUI, ведь есть scapy.Sniffer из питоновского пакета scapy). Также есть пример автоматизации MS Paint с его Ribbon тулбаром.
Еще один отличный пример, написанный моим студентом: перетаскивание файла из explorer.exe на Chrome страницу для Google Drive (он перекочует в главный репозиторий чуть позже).
И, конечно, пример подписки на события клавиатуры (hot keys) и мыши:
hook_and_listen.py.
Отдельное спасибо — тем, кто постоянно помогает развивать проект. Для меня и Валентина это постоянное хобби. Двое моих студентов из ННГУ недавно защитили дипломы бакалавра по этой теме. Александр внес большой вклад в поддержку MS UI Automation и недавно начал делать автоматический генератор кода по принципу "запись-воспроизведение" на основе текстовых свойств (это самая сложная фича), пока только для "uia" бэкенда. Иван разрабатывает новый бэкенд под Linux на основе AT-SPI (модули mouse и keyboard на основе python-xlib — уже в релизах 0.6.x).
Поскольку я довольно давно читаю спецкурс по автоматизации на Python, часть студентов-магистров выполняют домашние задания, реализуя небольшие фичи или примеры автоматизации. Некоторые ключевые вещи на стадии исследований тоже когда-то раскопали именно студенты. Хотя иногда за качеством кода приходится строго следить. В этом сильно помогают статические анализаторы (QuantifiedCode, Codacy и Landscape) и автоматические тесты в облаке (сервис AppVeyor) с покрытием кода в районе 95%.
Также спасибо всем, кто оставляет отзывы, заводит баги и присылает пулл реквесты!
За вопросами мы следим по тегу на StackOverflow (недавно появился тег в русской версии SO) и по ключевому слову на Тостере. Есть русскоязычный чат в Gitter'е.
Каждый месяц обновляем рейтинг open-source библиотек для GUI тестирования. По количеству звезд на гитхабе быстрее растут только Autohotkey (у них очень большое сообщество и длинная история) и PyAutoGUI (во многом благодаря популярности книг ее автора Al Sweigart: "Automate the Boring Stuff with Python" и других).
|
|
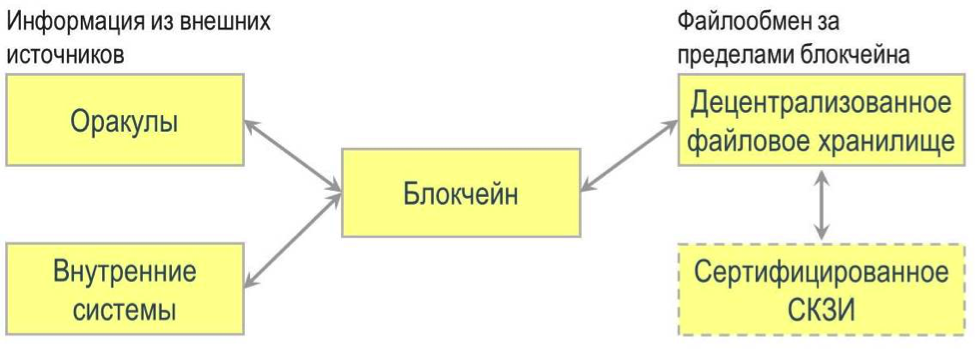
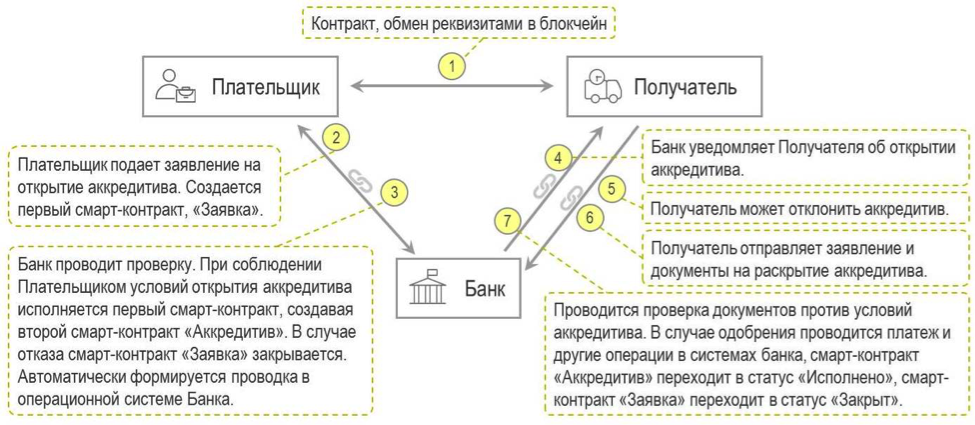
Блокчейн-платформа для сделок торгового финансирования на базе смарт-контрактов |




| Добавить запрос в очередь | Входные параметры:
|
|
| Удаление запроса из очереди | Входные параметры:
|
|
| Проверка наличия запроса в очереди | Входные параметры:
|
|
| Выдать список идентификаторов запросов из очереди | Входных параметров нет. Выходные параметры:
|
|
| Добавить адрес в список уполномоченных адресов | Входные параметры:
|
|
| Проверить наличие адреса в списке уполномоченных адресов | Входные параметры:
|
| Выдать параметры запроса | Входные параметры:
|
|
| Принять ответ на запрос | Входные параметры:
|
|
| Проверить факт обработки ответа на запрос | Входные параметры:
Выходные данные:
|
bytes32 Status ;
bytes32 ExpireDate ;
bytes32 OrgName ;
address Queue ;
bytes32[] Request_1 ;
bytes32[] Request_2 ;
bytes32 Request_id_1 ;
bytes32 Request_id_2 ;
bytes32 Response_id_1 ;
bytes32 Response_id_2 ;function SomeContract(..., bytes32[] logics)
{
Owner =msg.sender ;
ExpireDate=logics[0] ;
OrgName =logics[1] ;
Status ="New" ;
Queue =0xd9b076d0b559f70782f379582bd3d54b85fc42cb ;
Request_1.length= 3 ;
Request_1[0] ="DAILY 00:10" ;
Request_1[1] ="OVERDUE" ;
Request_1[2] = ExpireDate ;
Request_2.length= 3 ;
Request_2[0] ="PERIOD 10" ;
Request_2[1] ="DADATA_EXISTS_WAIT" ;
Request_2[2] = OrgName ;
}
function SetStatus(bytes32 status_, ...)
{
address self_addr ;
Status=status_ ;
if(status_=="Released_") {
self_addr=this ;
Request_id_1=bytes32(bytes20(self_addr)) | "\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x001" ;
Request_id_2=bytes32(bytes20(self_addr)) | "\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x002" ;
Queue.call.gas(0x30000).value(0)(bytes4(sha3("AddRequest(bytes32)")), Request_id_1) ;
Queue.call.gas(0x30000).value(0)(bytes4(sha3("AddRequest(bytes32)")), Request_id_2) ;
}
}
function GetExternalRequest(bytes32 request_id_) constant returns (bytes32[] retVal)
{
if(request_id_==Request_id_1) return(Request_1) ;
if(request_id_==Request_id_2) return(Request_2) ;
}function SetExternalResponse(bytes32 response_id_, bytes32 request_id_, bytes32[] response_)
{
if(tx.origin!=Owner) return ;
if(Status!="Released_") return ;
if(request_id_==Request_id_1) {
Response_id_1=response_id_ ;
Status ="Overdue__" ;
}
if(request_id_==Request_id_2) {
Response_id_2=response_id_ ;
Status ="ToBank___" ;
}
}contract Check_request
{
Calendar Oracle ; // Оракул-переменная
bytes32 Date ;
function Check_request()
{
// Инициализация Оракул-переменной на адрес Оракула
Oracle=Calendar(0x79548a65e3ce179ec8d208c22ee84435dc34058f) ;
// Получение информации из Оракула
Date=Oracle.GetDate() ;
}
}
//
// Описание абстрактного метода с интерфейсами Оракула
//
contract Calendar
{
function GetDate() constant returns (bytes32 retVal) ;
}|
Метки: author MadJackal программирование блог компании райффайзенбанк blockchain блокчейн ethereum solidity storj.io банки финансы разработка |
[Перевод] Красный, белый, голубой: восемь правил подбора цветовой палитры, которые должны знать все |



























|
Метки: author nanton интерфейсы дизайн мобильных приложений графический дизайн веб-дизайн блог компании everyday tools теория цвета цветовая схема цветовая палитра дизайн интерфейсов |
[Перевод] Почему изменения в новом Phoenix 1.3 так важны |

Phoenix Framework всегда был классным. Но он никогда не был таким классным, как с новым релизом 1.3 (который сейчас находится в стадии RC2).
Произошло много значительных изменений. Крис МакКорд написал полный путеводитель по изменениям. Так же доступна его речь с LonestarElixir, где он подробно рассказывает про ключевые моменты. Вдохновленный его трудами, в своей статье я постараюсь рассказать вам про самые важные изменения в проекте Phoenix.
Давайте начнем!
Перевод выполнен самим автором оригинальной статьи Никитой Соболевым.
Phoenix – новый фреймворк. И, естественно, у него есть некоторые проблемы. Основная команда работала очень старательно, чтобы решить некоторые из самых важных. Итак, каковы эти проблемы?
При работе над проектом с использованием Phoenix у вас есть два места для исходного кода: lib/ и web/. Концепция такова:
lib/.web/.Но понятно ли это разработчикам? Я так не думаю.
Откуда появился этот веб-каталог? Это особенность Phoenix? Или другие фреймворки тоже используют его? Должен ли я использовать lib/ с Phoenix-проектами или он зарезервирован для некоторой глубинной магии? Все эти вопросы появились у меня после моей первой встречи с Phoenix.
До версии 1.2 только директория web/ автоматически перезагружалась. Итак, зачем мне создавать какие-либо файлы внутри lib/ и перезапускать сервер, когда я могу поместить их где-то внутри web/ для быстрой перезагрузки?
Это приводит нас к еще более важным вопросам: относятся ли мои файлы-модели (назовем их моделями в этом конкретном контексте) к web-части приложения или к основной логике? Можно ли разделить логику на разные домены или приложения (например, как в Django)?
Эти вопросы остаются без ответа.
Более того, код шаблона, который идет в Phoenix, предполагает другой способ. Можно получить следующий код в новом проекте:
defmodule Example.UserController do
use Example.Web, :controller
# ...
def update(conn, %{"id" => id, "user" => user_params}) do
user = Repo.get!(User, id)
changeset = User.changeset(user, user_params)
case Repo.update(changeset) do
{:ok, user} ->
render(conn, Example.UserView, "show.json", user: user)
{:error, changeset} ->
conn
|> put_status(:unprocessable_entity)
|> render(Example.ChangesetView, "error.json", changeset: changeset)
end
end
endЧто должен делать разработчик, когда пользователю после успешного обновления должно быть отправлено электронное письмо? Контроллер так и просится, чтобы его расширили. Просто поставьте еще одну строку кода перед render/4, что может пойти не так? Но. Только что Phoenix сам подтолкнул нас к неправильному использованию своей кодовой базы: мы пишем бизнес логику в контроллере!
На самом деле, одна дополнительная строка в контроллере это нормально. Все проблемы возникают, когда приложение растет. Таких строк становится много, приложение становится неустойчивым, неподъемным и повторяет само себя.
В какой-то момент без особых причин схемы Ecto стали называться «моделями». В чем разница между «моделью» и «схемой»? Схема — это всего лишь способ определить структуру — структуру базы данных в данном конкретном случае. Модели как концепция намного сложнее схем. Модели должны обеспечивать способ управления данными и выполнять различные действия, как модели в Django или Rails. Elixir как функциональный язык не подходит для концепции «модели», поэтому они были упразднены в проекте Ecto.
Файлы внутри models/ не были организованы. По мере своего роста ваше приложение становится хаотичным. Как эти файлы связаны между собой? В каком контексте мы используем их? Это было трудно понять.
Кроме того, директория models/ рассматривалась как еще одно место для размещения вашей бизнес-логики, что нормально для других языков и фреймворков. Существует уже знакомая концепция «fat models». Но такая концепция, опять же, не подходит для Phoenix по уже названным причинам.
С момента последнего крупного релиза многое изменилось. Самый простой способ показать все изменения — на примере.
В этом руководстве предполагается, что у вас есть elixir-1.4, и он работает. Нет? Значит, установите его!
Для начала вам нужно будет установить новую версию Phoenix:
mix archive.install
https://github.com/phoenixframework/archives/raw/master/phx_new.ezПо завершению установки надо проверить, всё ли на месте. mix help вернет вам что-то вроде этого:
mix phoenix.new # Creates a new Phoenix v1.1.4 application
mix phx.new # Creates a new Phoenix v1.3.0-rc.1 application using the experimental generatorsВот тут и проявляется первое изменение: новые генераторы. Старые генераторы назывались phoenix, а новые — просто phx. Теперь нужно меньше печатать. И, что более важно, новое сообщение разработчикам: эти генераторы новые, они будут делать что-то новое для вашего проекта.
Затем нужно создать структуру нового проекта, запустив:
mix phx.new medium_phx_example --no-html --no-brunchПрежде чем мы увидим какие-либо результаты этой команды, давайте обсудим параметры. --no-html удаляет некоторые компоненты для работы с html, поэтому phx.gen.html больше не будет работать. Но мы строим json API, и нам не нужен html. Аналогично --no-brunch означает: не создавайте brunch-файл для работы со статикой.
Глядя на ваши новые файлы, вы можете задаться вопросом: где находится веб-директория? Ну, вот и второе изменение. И довольно большое. Теперь ваша веб-директория находится внутри lib/. Она была особенной, многие люди неправильно поняли его главную цель, которая состояла в содержании веб-интерфейса для вашего приложения. Это не место для вашей бизнес-логики. Теперь все ясно. Поместите всё внутрь lib/. И оставьте только свои контроллеры, шаблоны и представления внутри новой web-директории. Вот как это выглядит:
lib
+-- medium_phx_example
+-- application.ex
+-- repo.ex
+-- web
+-- channels
| +-- user_socket.ex
+-- controllers
+-- endpoint.ex
+-- gettext.ex
+-- router.ex
+-- views
| +-- error_helpers.ex
| +-- error_view.ex
+-- web.exГде medium_phx_example — имя текущего приложения. Приложений может быть много. Итак, теперь весь код живет в одной и той же директории.
Третье изменение откроется вскоре после просмотра файла web.ex:
defmodule MediumPhxExample.Web do
def controller do
quote do
use Phoenix.Controller, namespace: MediumPhxExample.Web
import Plug.Conn
# Before 1.3 it was just:
# import MediumPhxExample.Router.Helpers
import MediumPhxExample.Web.Router.Helpers
import MediumPhxExample.Web.Gettext
end
end
# Some extra code:
# ...
endPhoenix теперь создает пространство имен .Web, которое очень хорошо сочетается с новой файловой структурой.
Это четвертое и моё любимое изменение. Раньше у нас была директория web/models/, которая использовалась для хранения схем. Теперь концепция моделей полностью мертва. Внедрена новая философия:
Наше приложение будет содержать только один контекст: Audio. Начнем с создания Audio контекста с двумя схемами Album и Song:
mix phx.gen.json Audio Album albums name:string release:utc_datetime
mix phx.gen.json Audio Song songs album_id:references:audio_albums name:string duration:integerСинтаксис этого генератора также изменился. Теперь требуется, чтобы имя контекста было первым аргументом. Также обратите внимание на audio_albums, схемы теперь содержат префикс с именем контекста. И вот что происходит со структурой проекта после запуска двух генераторов:
lib
+-- medium_phx_example
+-- application.ex
+-- audio
| +-- album.ex
| +-- audio.ex
| +-- song.ex
+-- repo.ex
+-- web
+-- channels
| +-- user_socket.ex
+-- controllers
| +-- album_controller.ex
| +-- fallback_controller.ex
| +-- song_controller.ex
+-- endpoint.ex
+-- gettext.ex
+-- router.ex
+-- views
| +-- album_view.ex
| +-- changeset_view.ex
| +-- error_helpers.ex
| +-- error_view.ex
| +-- song_view.ex
+-- web.exКаковы основные изменения в структурах по сравнению с предыдущей версией?
web/, а директория models/ вообще исчезла. И схемы прямо сейчас являются не более чем описанием таблицы. Чем и должна быть схема в первую очередь. Вот как выглядят наши схемы:
defmodule MediumPhxExample.Audio.Album do
use Ecto.Schema
schema "audio_albums" do
field :name, :string
field :release, :utc_datetime
timestamps()
end
enddefmodule MediumPhxExample.Audio.Song do
use Ecto.Schema
schema "audio_songs" do
field :duration, :integer
field :name, :string
field :album_id, :id
timestamps()
end
endВсё за исключением самой схемы исчезло. Нет обязательных полей, никаких функций changeset/2 или каких-либо других. Генератор теперь даже не создает belongs_to для вас. Вы сами управляете связями ваших схем.
Итак, теперь это довольно ясно: схема — не место для вашей бизнес-логики. Всё это обрабатывается контекстом, который выглядит следующим образом:
defmodule MediumPhxExample.Audio do
@moduledoc """
The boundary for the Audio system.
"""
import Ecto.{Query, Changeset}, warn: false
alias MediumPhxExample.Repo
alias MediumPhxExample.Audio.Album
def list_albums do
Repo.all(Album)
end
def get_album!(id), do: Repo.get!(Album, id)
def create_album(attrs \\ %{}) do
%Album{}
|> album_changeset(attrs)
|> Repo.insert()
end
# ...
defp album_changeset(%Album{} = album, attrs) do
album
|> cast(attrs, [:name, :release])
|> validate_required([:name, :release])
end
alias MediumPhxExample.Audio.Song
def list_songs do
Repo.all(Song)
end
def get_song!(id), do: Repo.get!(Song, id)
def create_song(attrs \\ %{}) do
%Song{}
|> song_changeset(attrs)
|> Repo.insert()
end
# ...
defp song_changeset(%Song{} = song, attrs) do
song
|> cast(attrs, [:name, :duration])
|> validate_required([:name, :duration])
end
endСам вид контекста отправляет ясный посыл: вот место, где нужно поместить свой код! Но будьте осторожны, файлы контекста могут разрастись. Разделите их на несколько модулей в таком случае.
Раньше у нас было много кода в контроллере по-умолчанию и разработчику было легко расширить шаблонный код. Здесь появляется пятое изменение. Начиная с нового выпуска, шаблонный код в контроллере был уменьшен и реорганизован:
defmodule MediumPhxExample.Web.AlbumController do
use MediumPhxExample.Web, :controller
alias MediumPhxExample.Audio
alias MediumPhxExample.Audio.Album
action_fallback MediumPhxExample.Web.FallbackController
# ...
def update(conn, %{"id" => id, "album" => album_params}) do
album = Audio.get_album!(id)
with {:ok, %Album{} = album} <- Audio.update_album(album, album_params) do
render(conn, "show.json", album: album)
end
end
# ...
endВ действии update/2 теперь есть только три осмысленные строчки кода.
В настоящее время контроллеры используют контексты напрямую, что делает их очень тонким слоем в приложении. Очень трудно найти место для дополнительной логики в контроллере. Что и было основной задачей при реорганизации.
Контроллеры даже не обрабатывают ошибки. Для работы с ошибками предназначен специальный новый fallback_controller. Эта новая концепция — шестое изменение. Оно позволяет иметь все обработчики ошибок и коды ошибок в одном месте:
defmodule MediumPhxExample.Web.FallbackController do
@moduledoc """
Translates controller action results into valid `Plug.Conn` responses.
See `Phoenix.Controller.action_fallback/1` for more details.
"""
use MediumPhxExample.Web, :controller
def call(conn, {:error, %Ecto.Changeset{} = changeset}) do
conn
|> put_status(:unprocessable_entity)
|> render(MediumPhxExample.Web.ChangesetView, "error.json", changeset: changeset)
end
def call(conn, {:error, :not_found}) do
conn
|> put_status(:not_found)
|> render(MediumPhxExample.Web.ErrorView, :"404")
end
endЧто происходит, когда результат из Audio.update_album(album, album_params) не соответствует {:ok, %Album{} = album}? В этой ситуации вызывается контроллер, определенный в action_fallback. И будет выбран правильный call/2, что в свою очередь возвращает правильный ответ. Легко и приятно. Никаких обработок исключений в контроллере.
Внесенные изменения весьма интересны. Их много, они все сфокусированы на том, чтобы загубить старые привычки программистов, которые пришли из других языков программирования. И новые изменения стараются пополнить философию Phoenix-Way новыми практиками. Надеюсь, эта статья была полезна и побудила вас использовать Phoenix Framework по максимуму. Заходите ко мне на GitHub.
Благодарим Никиту за подготовку перевода своей собственной оригинальной статьи и с радостью публикуем материал на Хабре. Никита представляет сообщество ElixirLangMoscow, которое организует митапы по Эликсиру в Москве, а также является активным контрибьютером в опенсорс и вносит значительный вклад в наше сообщество Вунш. На сайте вас ждут 3 десятка тематических статей, еженедельная рассылка и новости из мира Эликсира. А для вопросов у нас есть чат в Телеграме с отличными участниками.
|
Метки: author jarosluv функциональное программирование ruby on rails elixir/phoenix elixir phoenix |
Идентификация коинтегрированных пар акций на фондовых рынках |
|
Метки: author AdrenaLeen математика тест энгла-грэнджера коинтеграция случайные процессы анализ временных рядов регрессия |
IoT на страже порядка, или как сделать наш мир немного безопаснее |

 У пользователей имеется возможность создавать цифровые связки ключей для разных замков и просматривать историю использования созданных ключей. В довершение к этому, система отправляет пользователям уведомление в случае попытки взлома двери и включает сигнализацию. Ожидается, что глобальный рынок умных замков будет стремительно развиваться в ближайшие годы, до 18% каждый год, достигнув 1 млрд долларов к 2024 году, помимо повышения безопасности, создавая дополнительные удобства при совместном использовании жилых и офисных помещений.
У пользователей имеется возможность создавать цифровые связки ключей для разных замков и просматривать историю использования созданных ключей. В довершение к этому, система отправляет пользователям уведомление в случае попытки взлома двери и включает сигнализацию. Ожидается, что глобальный рынок умных замков будет стремительно развиваться в ближайшие годы, до 18% каждый год, достигнув 1 млрд долларов к 2024 году, помимо повышения безопасности, создавая дополнительные удобства при совместном использовании жилых и офисных помещений.|
Метки: author GemaltoRussia блог компании gemalto russia iot интернет вещей m2m безопасность |
Как мы ловим Deadlock`и на PostgreSQL и чиним их |

ERROR: deadlock detected
DETAIL: Process 18293 waits for ShareLock on transaction 639; blocked by process 18254.
Process 18254 waits for ShareLock on transaction 640; blocked by process 18293.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,9) in relation "users"
ERROR: deadlock detected
DETAIL: Process 18293 waits for ShareLock on transaction 639; blocked by process 18254.
Process 18254 waits for ShareLock on transaction 640; blocked by process 18293.
Process 18293: update users set balance = balance + 10 where id = 2;
Process 18254: update users set balance = balance + 10 where id = 3;
HINT: See server log for query details.
CONTEXT: while updating tuple (0,9) in relation "users"
STATEMENT: update users set balance = balance + 10 where id = 2;
Логирование запросов при этом не обязано быть включено.
SELECT * FROM pg_stat_activity;from contextlib import contextmanager
from sqlalchemy import create_engine
from sqlalchemy.exc import OperationalError
engine = create_engine('postgresql+psycopg2://postgres:12345678@localhost/postgres')
def log_pg_stat_activity():
'''Log, write or send through Sentry pg_stat_activity'''
debug_conn = engine.connect()
for process in debug_conn.execute('''
SELECT pid, application_name, state, query FROM pg_stat_activity;
''').fetchall():
print(process)
@contextmanager
def connection():
conn = engine.connect()
try:
yield conn
except OperationalError as ex:
log_pg_stat_activity()
raise
@contextmanager
def transaction():
with connection() as conn:
with conn.begin() as trans:
try:
yield conn
except OperationalError as ex:
if 'deadlock detected' in ex.args[0]:
log_pg_stat_activity()
# Log exception
print(ex)
trans.rollback()
else:
raise
from multiprocessing import Process
from time import sleep
from threading import Thread
from sqlalchemy.orm import sessionmaker
from db import transaction
def process1():
with transaction() as tran:
tran.execute('UPDATE users SET balance = balance + 10 WHERE id = 3;')
sleep(1)
tran.execute('UPDATE users SET balance = balance + 10 WHERE id = 1 RETURNING pg_sleep(1);')
def process2():
with transaction() as tran:
tran.execute('UPDATE users SET balance = balance + 10 WHERE id = 1;')
sleep(1)
tran.execute('UPDATE users SET balance = balance + 10 WHERE id = 3 RETURNING pg_sleep(1);')
if __name__ == '__main__':
p1 = Thread(target=process1)
p2 = Thread(target=process2)
p1.start()
p2.start()
sleep(4)
from traceback import extract_stack
@contextmanager
def transaction(application_name=None):
with connection() as conn:
if application_name is None:
caller = extract_stack()[-3]
conn.execution_options(autocommit=True).execute("SET application_name = %s", '%s:%s' % (caller[0], caller[1]))
with conn.begin() as trans:
try:
yield conn
except OperationalError as ex:
if 'deadlock detected' in ex.args[0]:
log_pg_stat_activity()
# Log exception
print(ex)
trans.rollback()
else:
raise
| pid | application_name | state | query | |
|---|---|---|---|---|
| 1 | 8613 | deadlock_test.py:10 | idle in transaction (aborted) | UPDATE users SET balance = balance + 10 WHERE id = 1 RETURNING pg_sleep(1); |
| 2 | 8614 | deadlock_test.py:17 | active | UPDATE users SET balance = balance + 10 WHERE id = 3 RETURNING pg_sleep(1); |
| 3 | 8617 | active | SELECT pid, application_name, state, query FROM pg_stat_activity; |
log_line_prefix = 'APP:%a PID:%p TR:%x '.
--P1:
BEGIN;
--P2:
BEGIN;
--P1:
SELECT id FROM clans WHERE id=1 FOR UPDATE;
--P2:
INSERT INTO users(clan_id, name) VALUES(1, 'Alpha');
CONTEXT: while updating tuple (0,9) in relation "users"SELECT ctid, id, nickname, balance FROM public.users;
|
Метки: author gnomeby python postgresql блог компании wargaming deadlock wargaming |
О защите персональных данных на российском и европейских рынках |

 / фото Blue Coat Photos CC
/ фото Blue Coat Photos CC / фото Wikimedia Commons CC
/ фото Wikimedia Commons CC|
Метки: author it_man законодательство и it-бизнес блог компании ит-град ит-град фз-152 gdpr |
Уведомления о пропущенных звонках с Asterisk на Битрикс24 |

#! /bin/bash
date=`date +%H:%M`
curl --cookie-jar cookies.txt 'https://portal.domain.ru/?login=yes' -H 'Host: portal.domain.ru' \
--data 'AUTH_FORM=Y&TYPE=AUTH&backurl=%2F&USER_LOGIN=asterisk&USER_PASSWORD=perasperaadastra&USER_REMEMBER=Y' > /dev/null 2>&1
curl --cookie cookies.txt --data "message=Вам не смогли дозвониться. Абонент $1 звонил вам в $date&number=$2" \
https://portal.domain.ru/send_from_pbx.php > /dev/null 2>&1[macro-mobile]
exten => s,1,Set(CDR(userfield)=LOCAL)
exten => s,n,ExecIf($[${LEN(${CALLERID(num)})}=3]?Set(name=${SHELL( mysql asterisk -uasterisk -pperasperaadastra -sse 'SELECT callerid FROM peers WHERE defaultuser=${CALLERID(num)}' )$
exten => s,n,Macro(record,local)
exten => s,n,Dial(SIP/${MACRO_EXTEN},20)
exten => s,n,Dial(SIP/tel_out/${ARG1})
exten => s,n,System(/srv/asterisk/send2bitrix/send.sh "${name} (номер ${CALLERID(num)})" ${EXTEN})exten => 100,1,Macro(mobile,79251122333)|
Метки: author StraNNicK системное администрирование asterisk php bitrix24 уведомления о пропущенных звонках |
Метод безъитеративного обучения однослойного персептрона с линейной активационной функцией |
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Zachar_5 машинное обучение математика нейронная сеть дифференциальные уравнения |
Каким должен быть идеальный конфигуратор отчетов |




Универсальный справочник
Теперь сделаем необходимое отступление. Что такое «Универсальный справочник»? который я упоминал чуть выше, и которому выделен целый столбец при редактировании полей таблицы.
Для краткости будем называть его УС.
В первую очередь УС — способ существенно снизить трудозатраты на разработку.
Замечено, что большинство справочников состоят из 4 полей:
1) ID параметра
2) Название параметра
3) Числовое значение параметра
4) Текстовое значение параметра
Например. Справочник Валюта:
Или справочник Статус задачи:
И еще можно привести сотню примеров.
Они состоят из одинакового набора полей одного типа. Т.е. можно для всех таких справочников использовать один редактор, одну процедуру для запроса данных и т.д.
Не надо каждый раз, когда понадобился справочник, рисовать интерфейсы, делать ссылки, писать запросы и выполнять т.п. муторную работу.
В общем УС — мегаудобно.





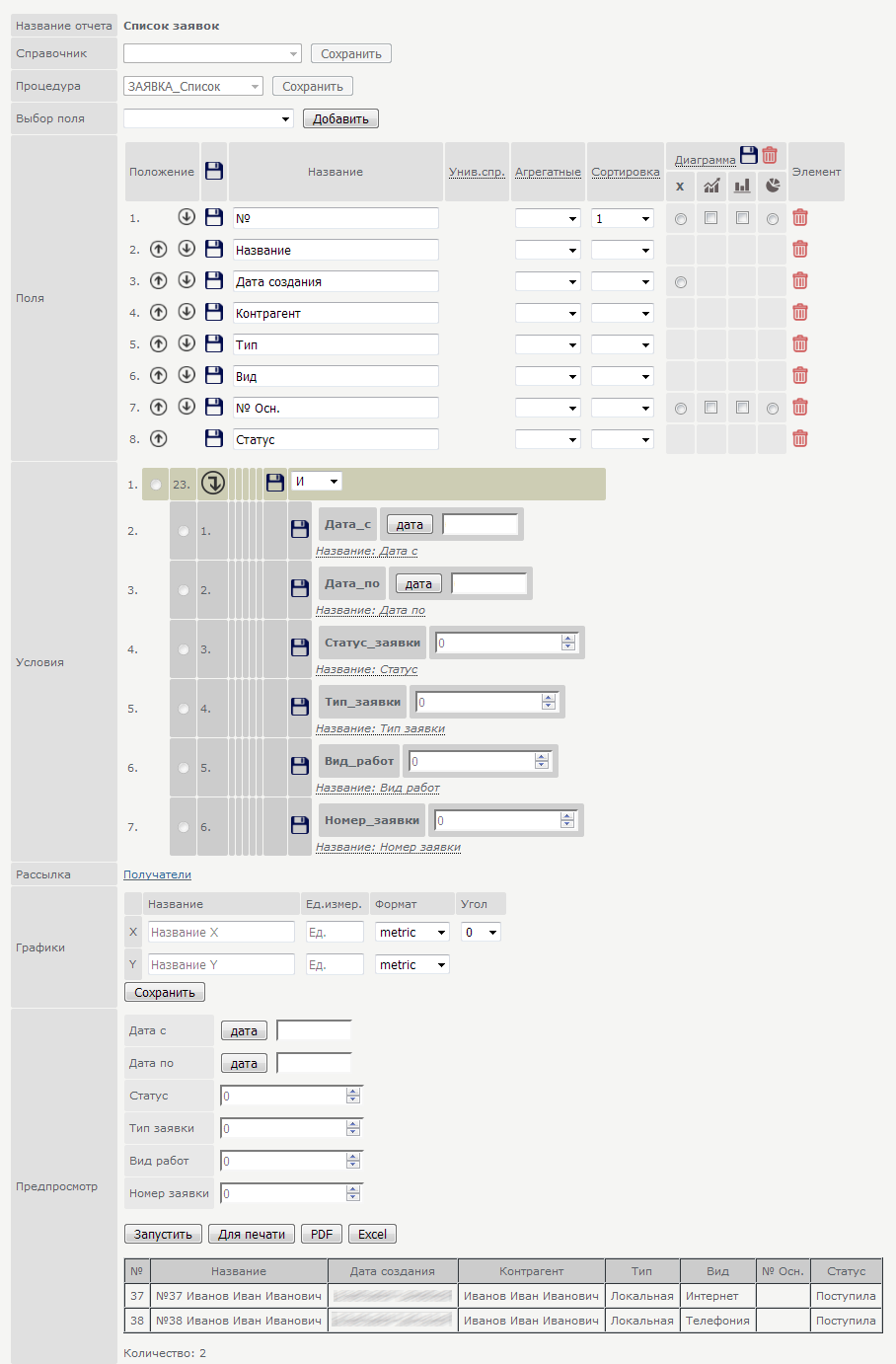






|
Метки: author mail-online управление проектами help desk software erp- системы crm- конфигуратор отчетов |
[Перевод] Покажите мне бизнес-проблему, и я постараюсь её избежать |

|
|
Вы используете интерфейсы в Go неправильно!. |

// файл habr.go
package habr
type Article struct { title string }
func (a *Article) String() string { return a.title }
// файл main.go
package main
import (
"fmt"
"habr"
)
func main() {
a := &habr.Article{title: "Вы используете интерфейсы в Go неправильно!"}
fmt.Printf("The article: %s\n", a)
}
|
Метки: author youROCK программирование go golang интерфейсы |
Tcl/Tk. Разработка графического пользовательского интерфейса для утилит командной строки |
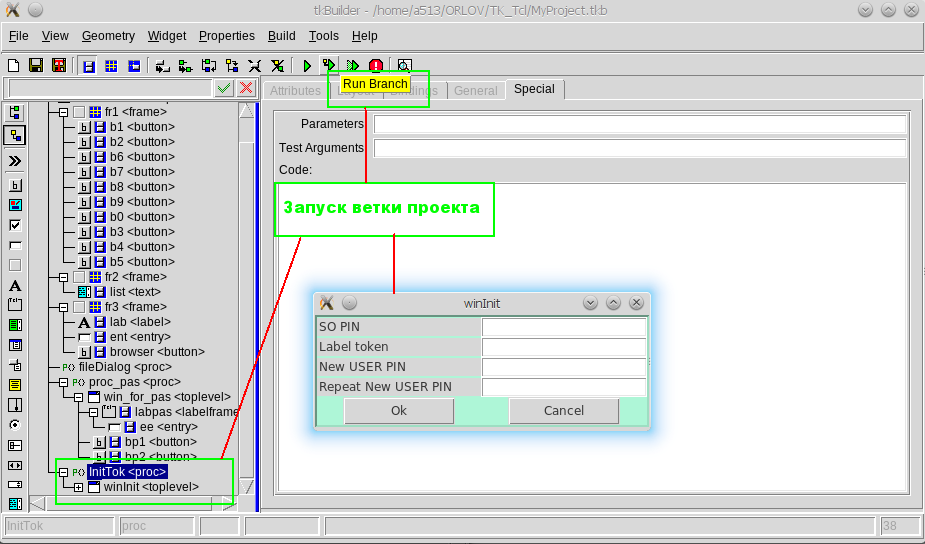
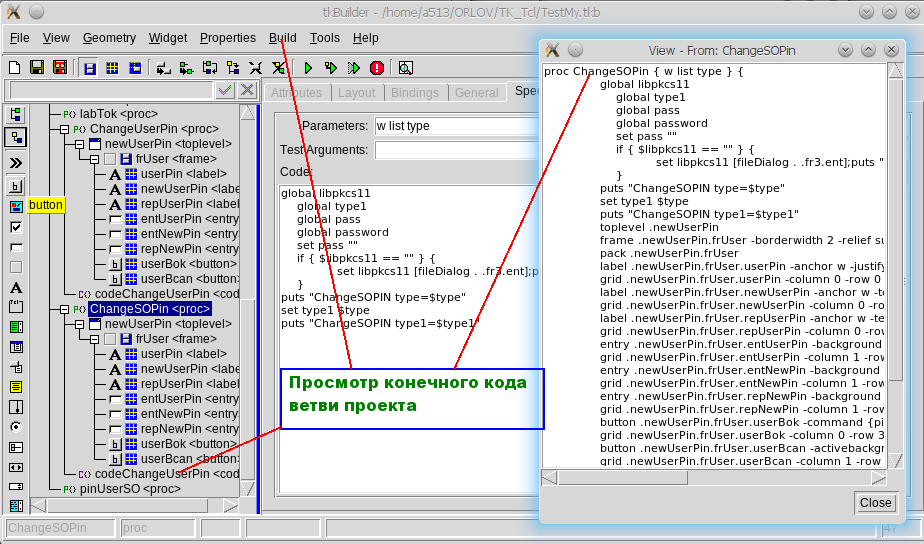
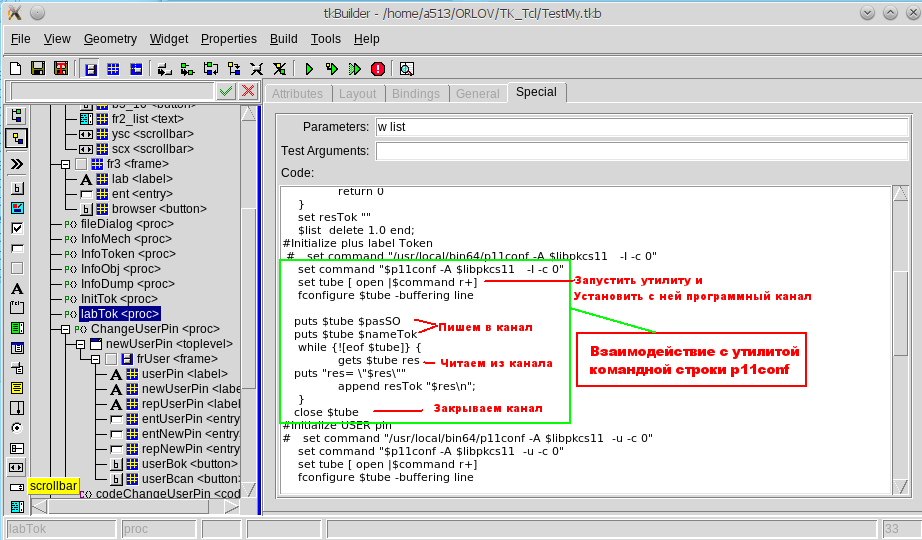
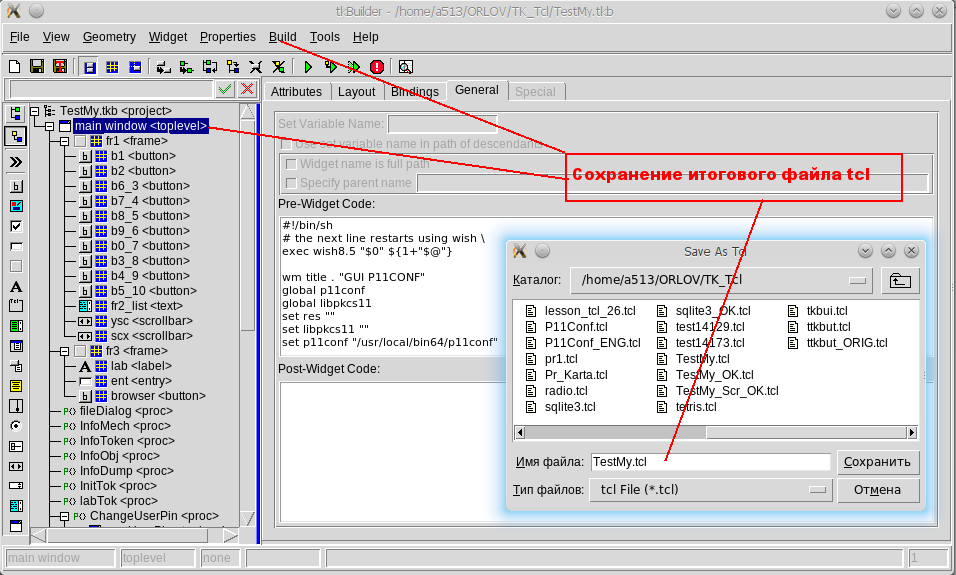
text .fr1.fr2_list -background #ffffff \
-yscrollcommand [list .fr1.ysc set] -xscrollcommand [list .fr1.scx set]
#!/bin/sh
# the next line restarts using wish \
exec wish8.5 "$0" ${1+"$@"}
wm title . "GUI P11CONF"
global p11conf
global libpkcs11
set res ""
set libpkcs11 ""
set p11conf "/usr/local/bin64/p11conf"
. configure -background #18f1d7
frame .fr1 -background #18f1d7
grid .fr1 -column 0 -row 0
button .fr1.b1 -command {InitTok . .fr1.fr2_list;} -padx 1 -text "Инициализировать" -width 24
grid .fr1.b1 -column 0 -row 0
button .fr1.b2 -command {ChangeUserPin . .fr1.fr2_list; } -padx 1 -text "Сменить USER PIN" -width 24
grid .fr1.b2 -column 0 -row 1
button .fr1.b6_3 -command {ChangeSOPin . .fr1.fr2_list "SO"; } -padx 1 -text "Сменить SO PIN" -width 24
grid .fr1.b6_3 -column 0 -row 2
button .fr1.b7 -command {InfoObj . .fr1.fr2_list "Obj"; } -padx 1 -text "Просмотреть объекты" -width 24
grid .fr1.b7 -column 0 -row 3
button .fr1.b8 -command {InfoObj . .fr1.fr2_list "Clear";} -padx 1 -text "Удалить все объекты" -width 24
grid .fr1.b8 -column 0 -row 4
button .fr1.b9_6 -command {InfoToken . .fr1.fr2_list; } -padx 1 -text "Информация о токене" -width 24
grid .fr1.b9_6 -column 0 -row 5
button .fr1.b0 -command {InfoMech . .fr1.fr2_list;} -padx 1 -text "Поддерживаемые механизмы" -width 24
grid .fr1.b0 -column 0 -row 6
button .fr1.b3_8 -command {ChangeSOPin . .fr1.fr2_list "Deblock"; } -padx 1 -text "Разблоктровать USER PIN" -width 24
grid .fr1.b3_8 -column 0 -row 7
button .fr1.b4_9 -command {InfoDump . .fr1.fr2_list; } -padx 1 -text "DUMP всех объектов" -width 24
grid .fr1.b4_9 -column 0 -row 8
button .fr1.b5_10 -command {exit} -text "Выход" -width 10bash-4.3$ ./GUITKP11Conf.tcl


global p11conf
…
set p11conf "/usr/local/bin64/p11conf"|
Метки: author saipr программирование графические оболочки gtk+ api tk tcl tkinter gui widgets buttons cloud pkcs11 |
Опыт внедрения сервиса мобильных платежей Apple Pay в банке |
|
Метки: author Otkritie блог компании открытие apple pay visa mastercard scrum agile |
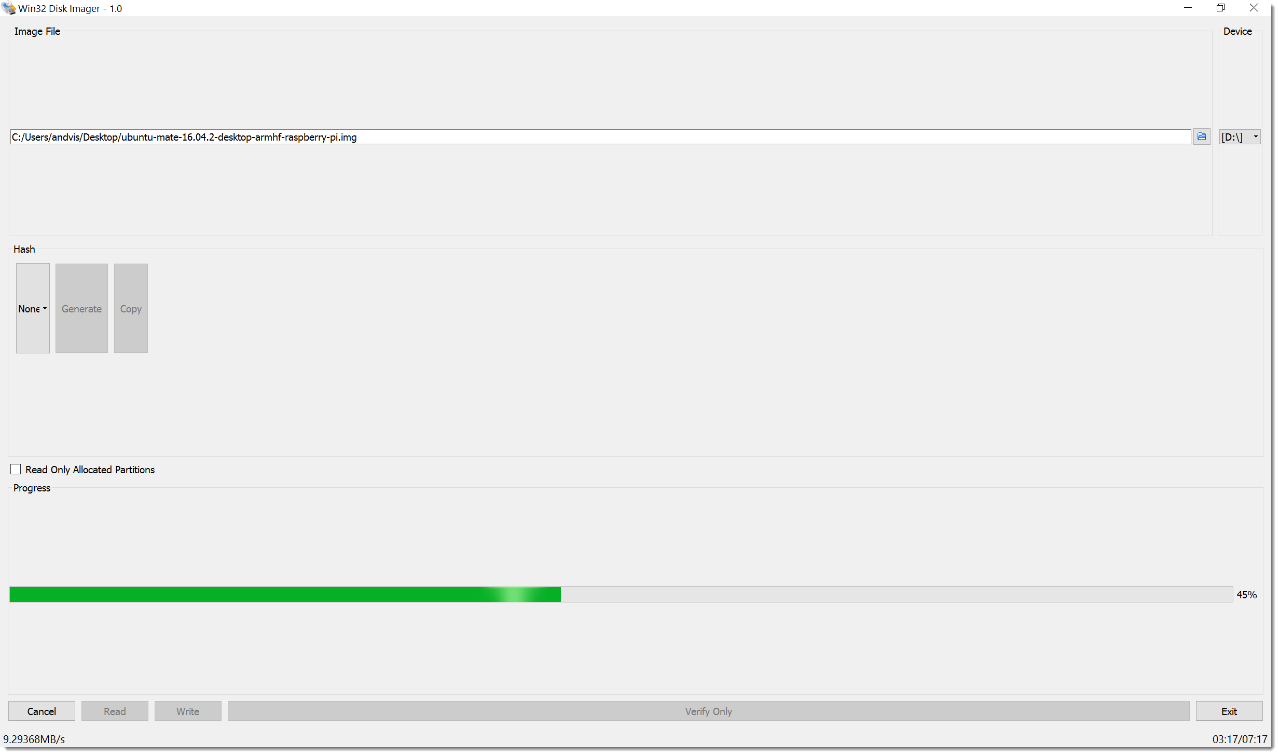
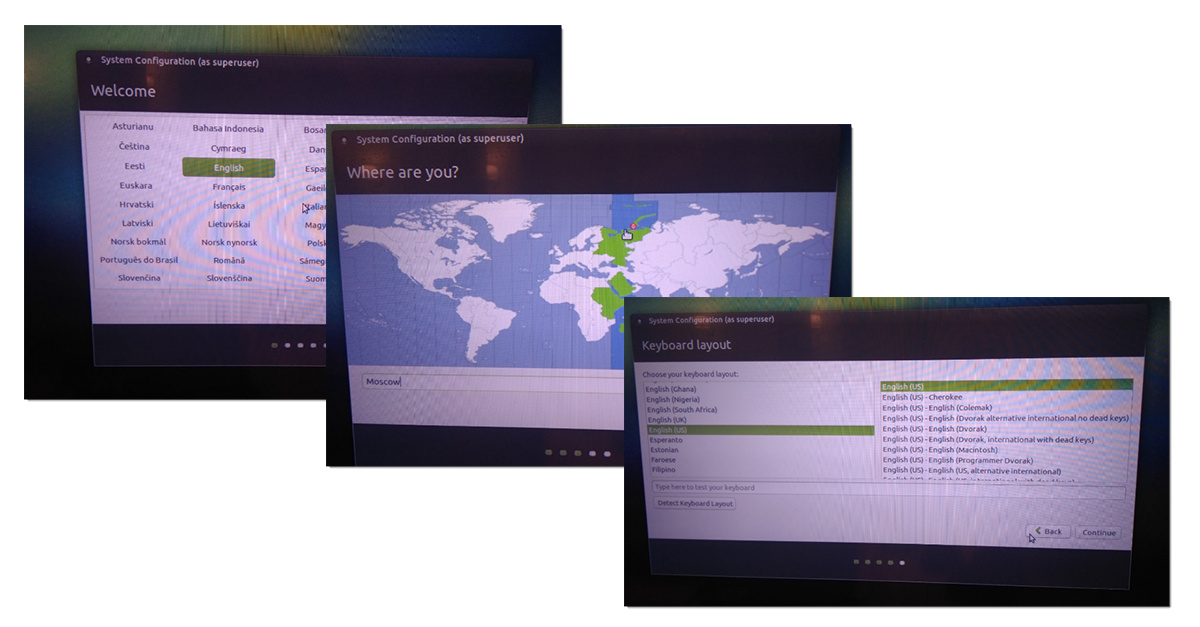
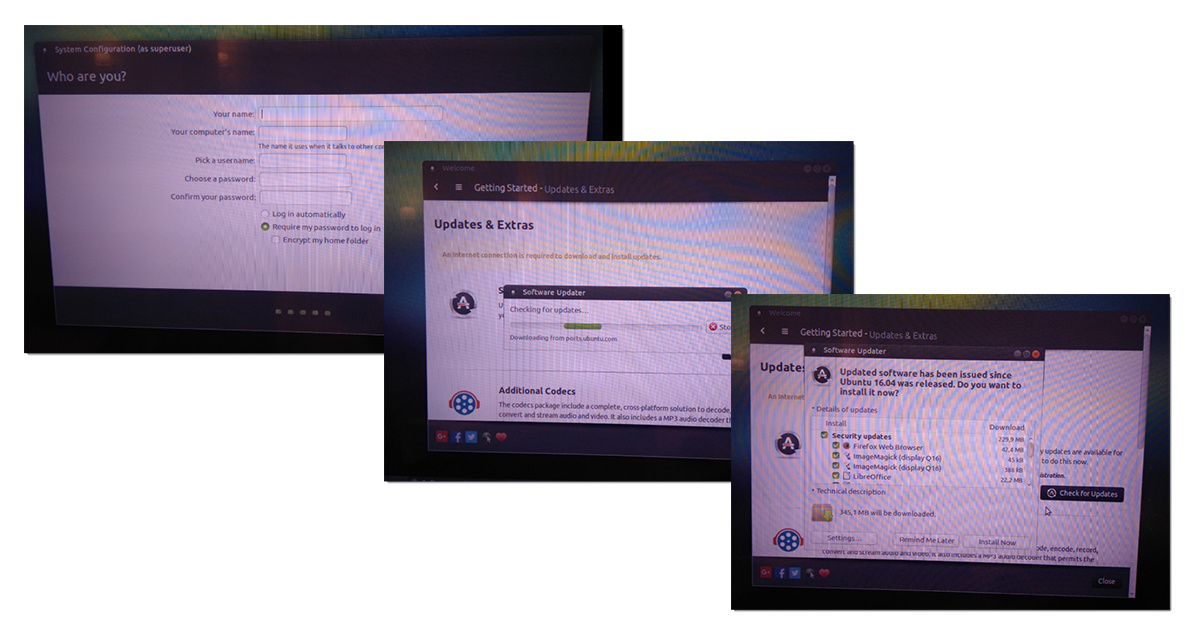
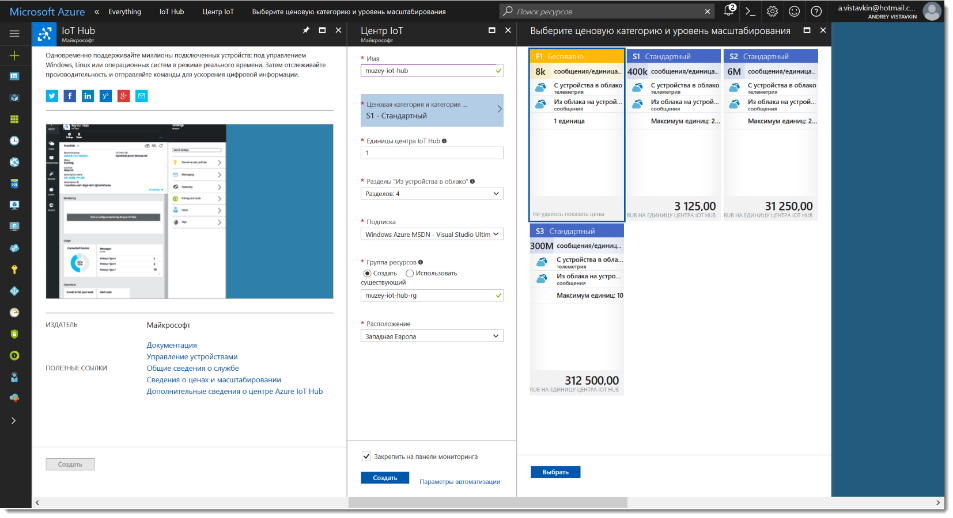
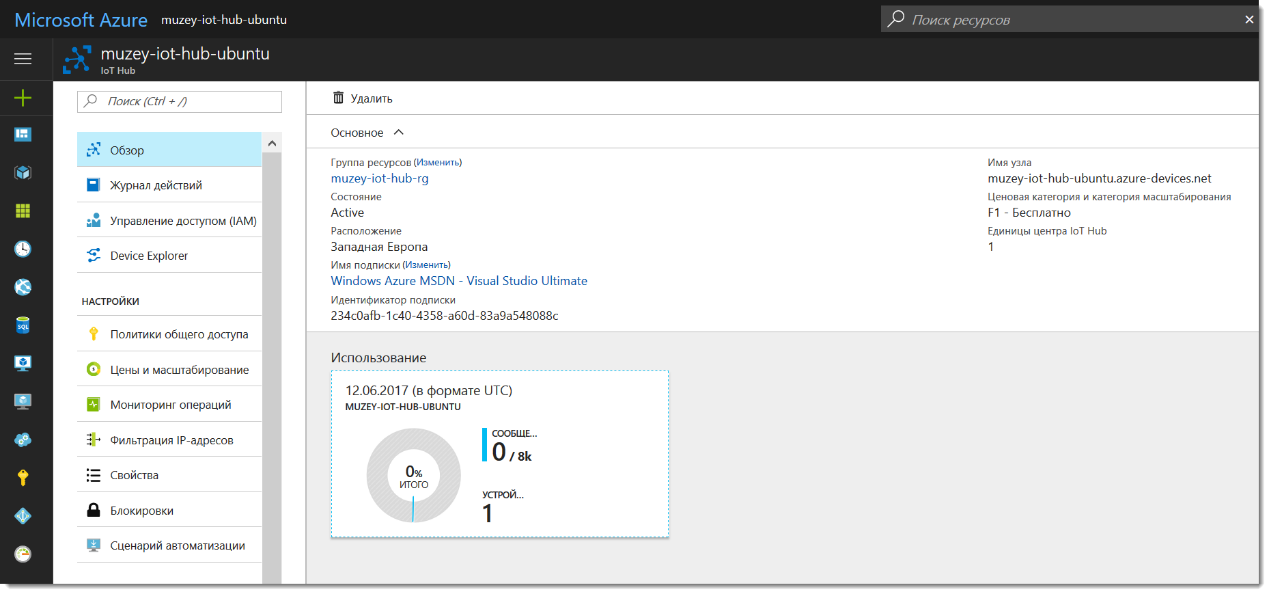
Заметки маркетолога: Как поставить Ubuntu на RPI и подключить к Azure IoT Hub |

Disclaimer:
Коллеги, не претендую на истину в первой инстанции – просто делюсь своим опытом. Возможно он сэкономит кому-то немного сил и времени. И да, в момент написания статьи я первый раз в жизни видел командную строку Linux.

sudo update-rc.d ssh enable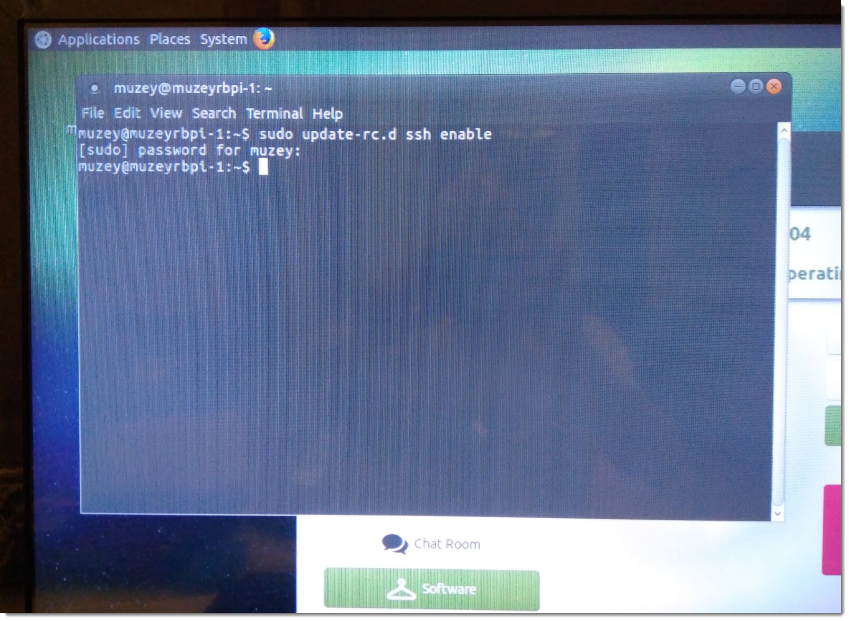
sudo service ssh restart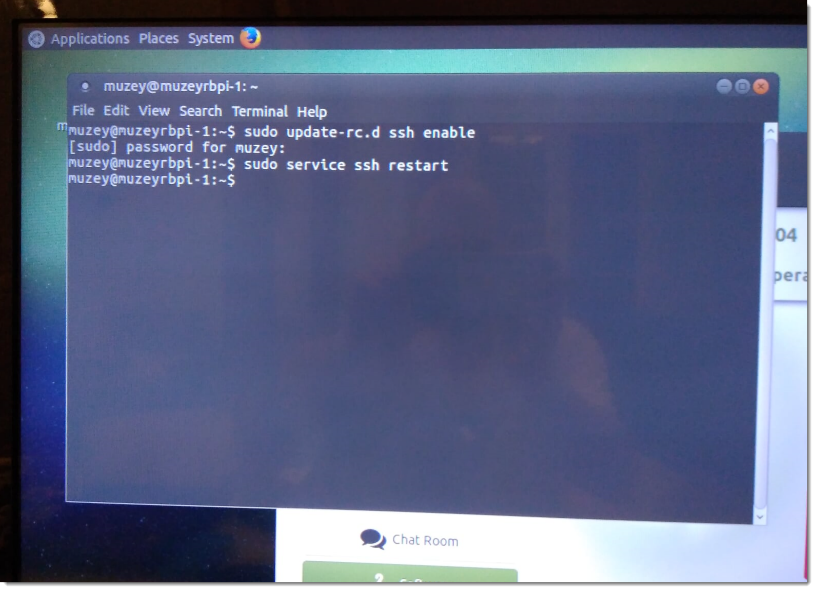
sudo ifconfig – покажет нам сетевые настройки устройства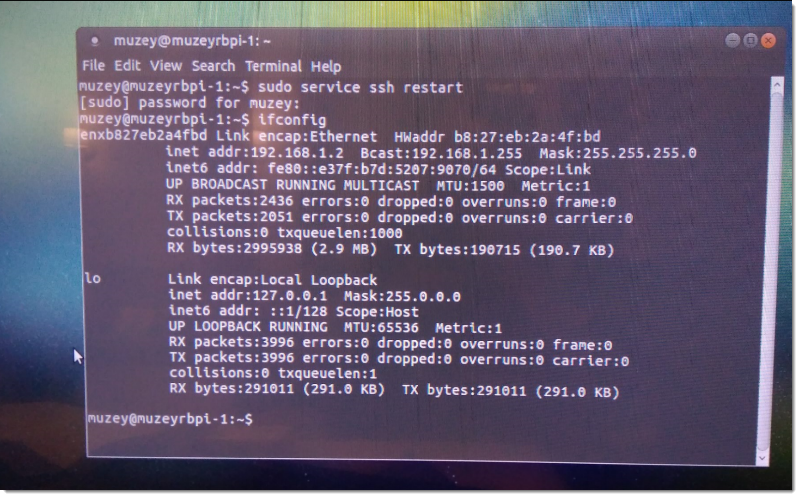
sudo apt-get update
sudo apt-get upgrade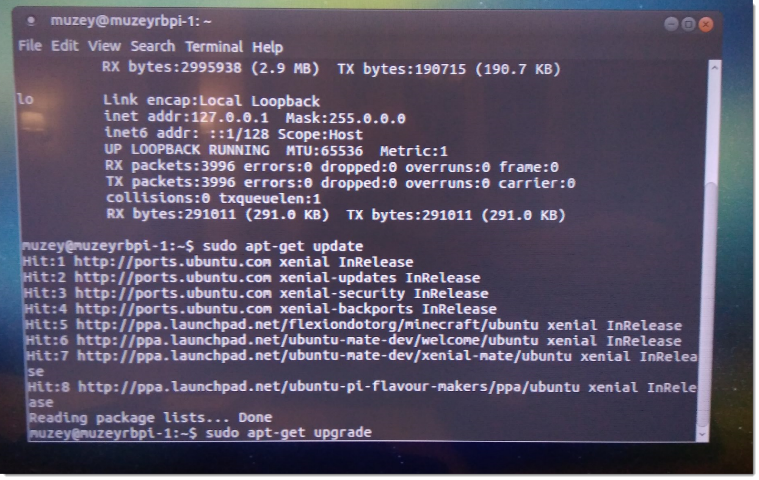
sudo raspi-config. 


node -v возвращает ошибку на моём RPI.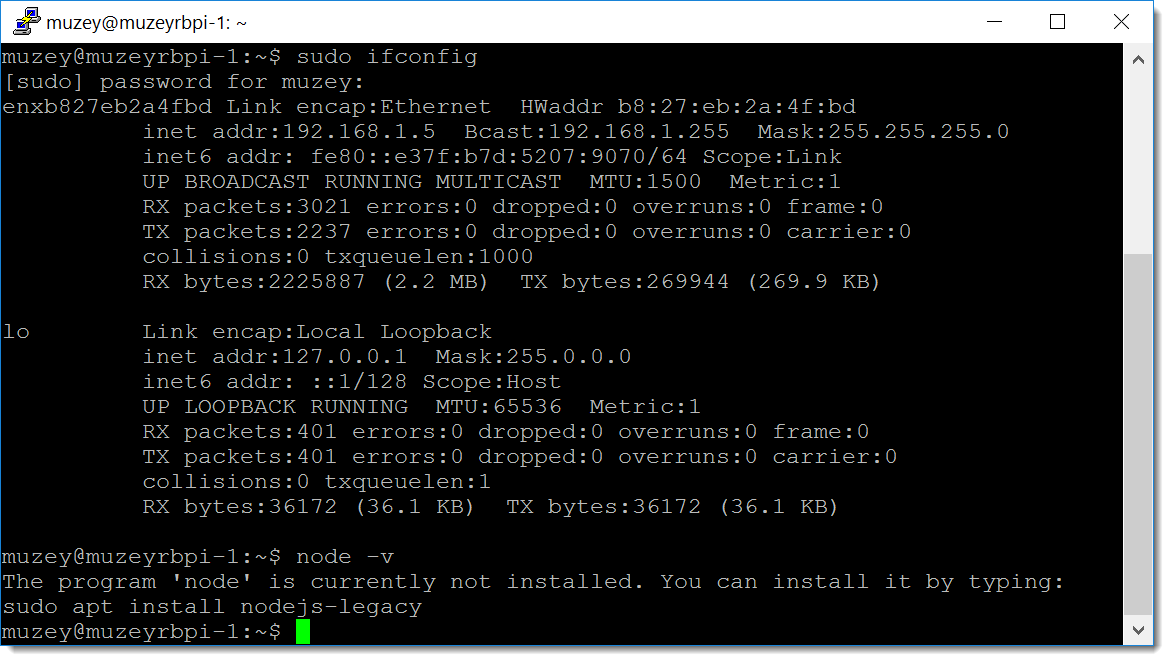
sudo apt install nodejs-legacy.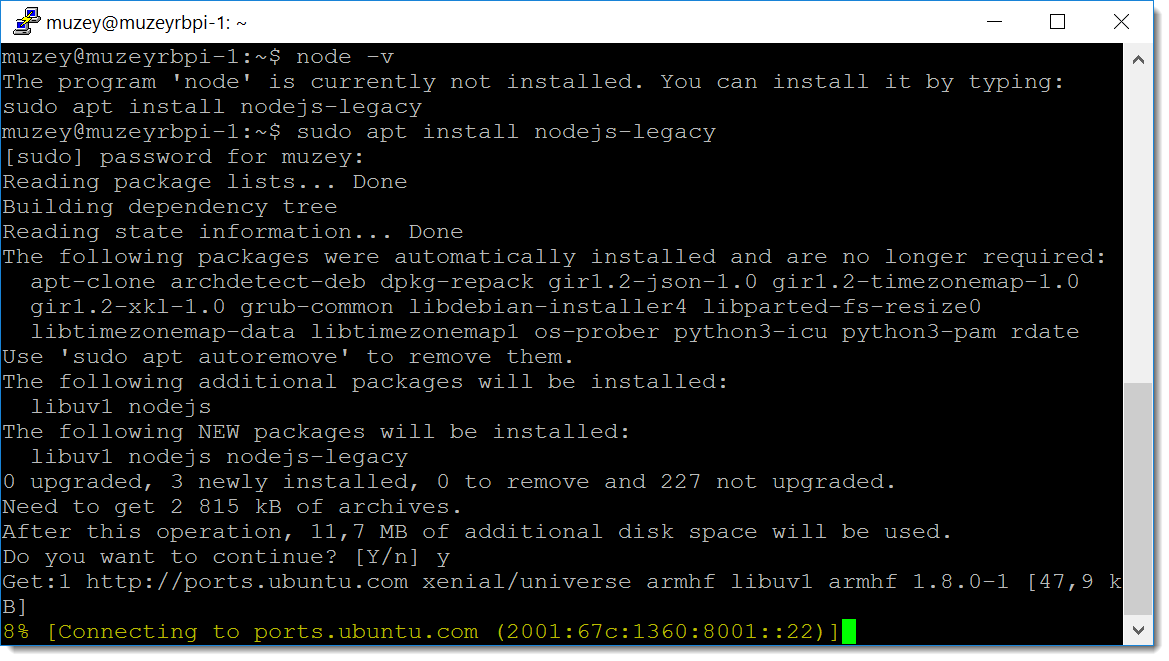
node -v возвращает текущую версию.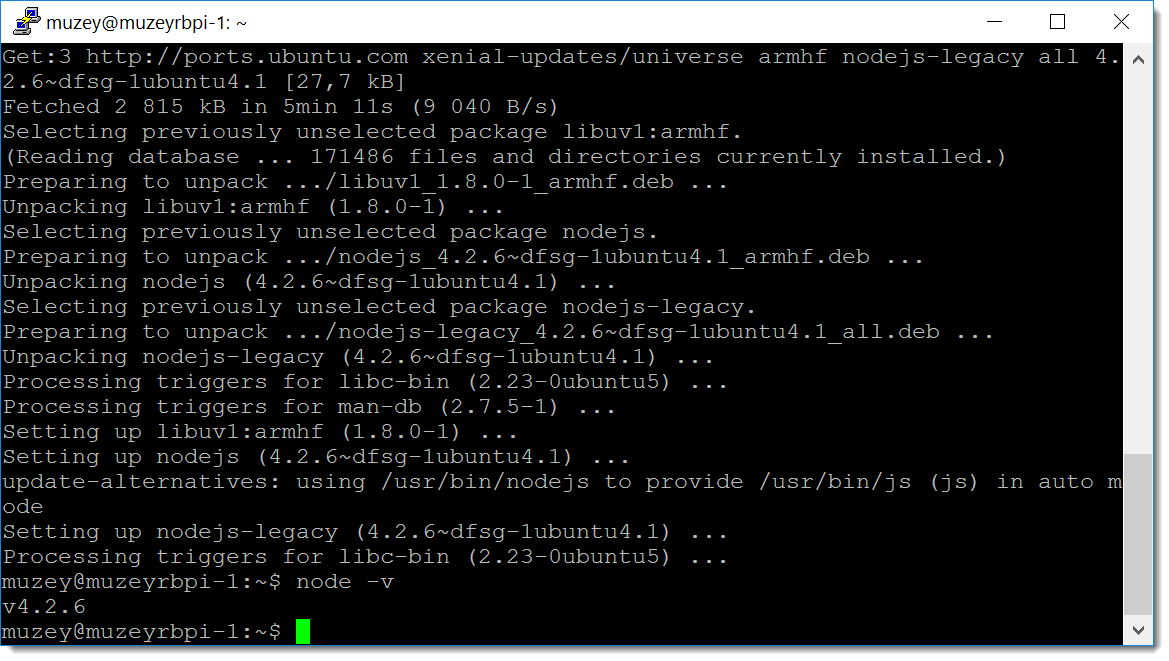
sudo apt-get install npm. Команда не быстро, но отработала!
sudo npm install -g npm@2.x.
sudo npm install -g azure-iot-device@latest.
sudo npm install -g azure-iot-device-http@latest.
sudo npm install -g iothub-explorer@latest.
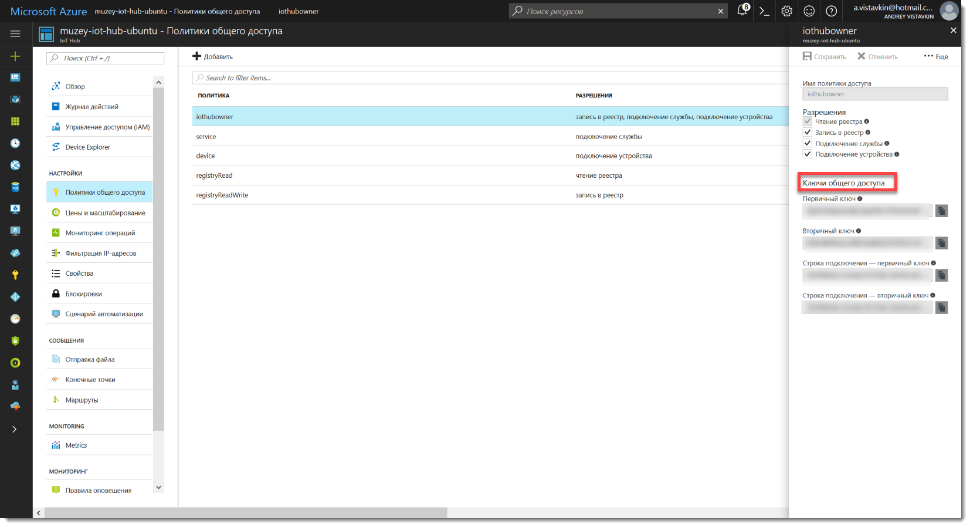
iothub-explorer login "строка подключения".
iothub-explorer create muzeyrpi-1 --connection-string. Успешно!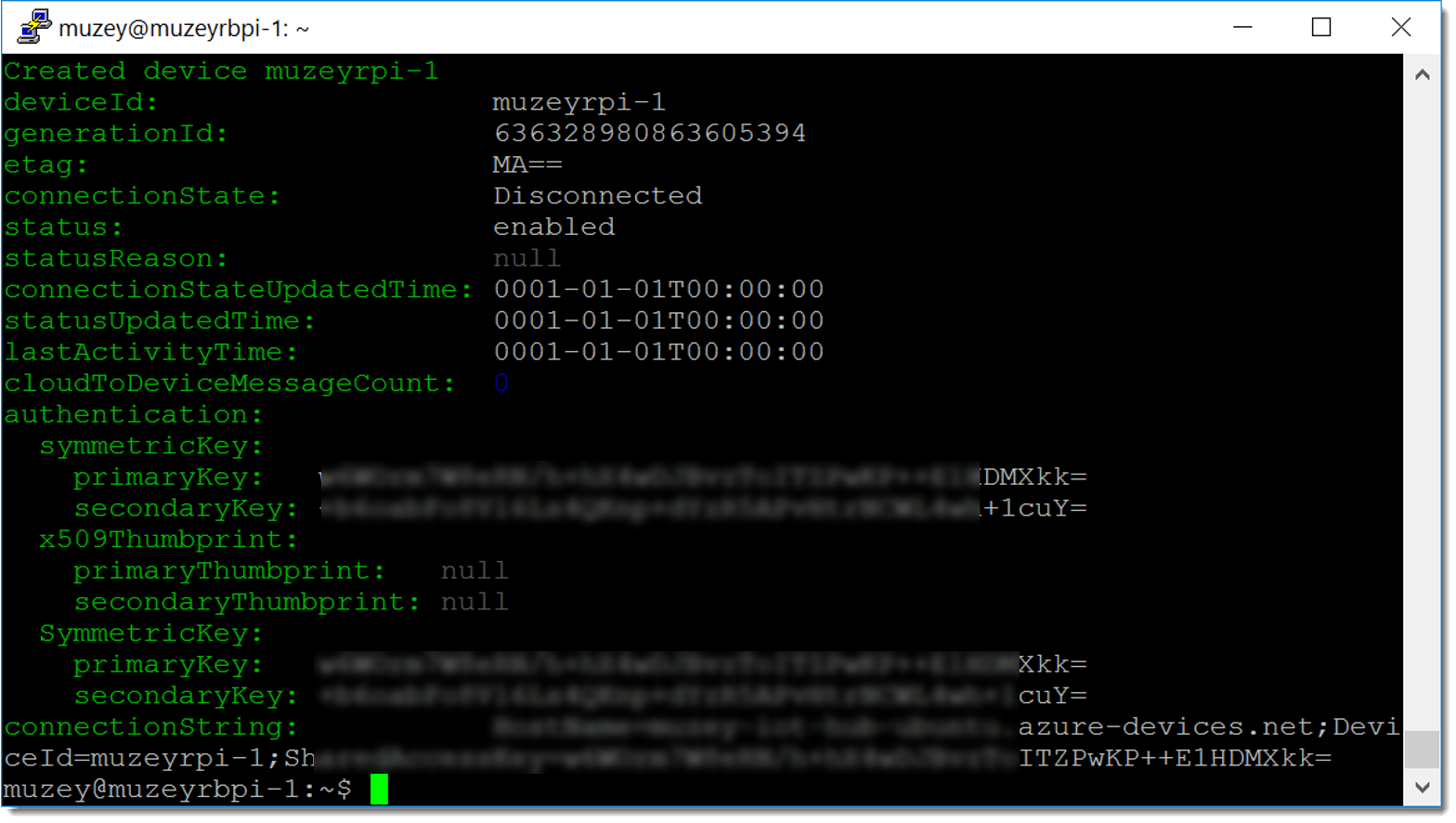
var connectionString = '';
var clientFromConnectionString = require('/usr/lib/node_modules/azure-iot-device-http').clientFromConnectionString;
var client = clientFromConnectionString(connectionString);
var Message = require('/usr/lib/node_modules/azure-iot-device').Message;
var msg = new Message('some data from my device');
var connectCallback = function (err) {
if (err) {
console.error('Could not connect: ' + err);
} else {
console.log('Client connected');
var message = new Message('some data from my device');
client.sendEvent(message, function (err) {
if (err) console.log(err.toString());
});
client.on('message', function (msg) {
console.log(msg);
client.complete(msg, function () {
console.log('completed');
});
});
}
};
client.open(connectCallback); /usr/lib на /usr/local/lib.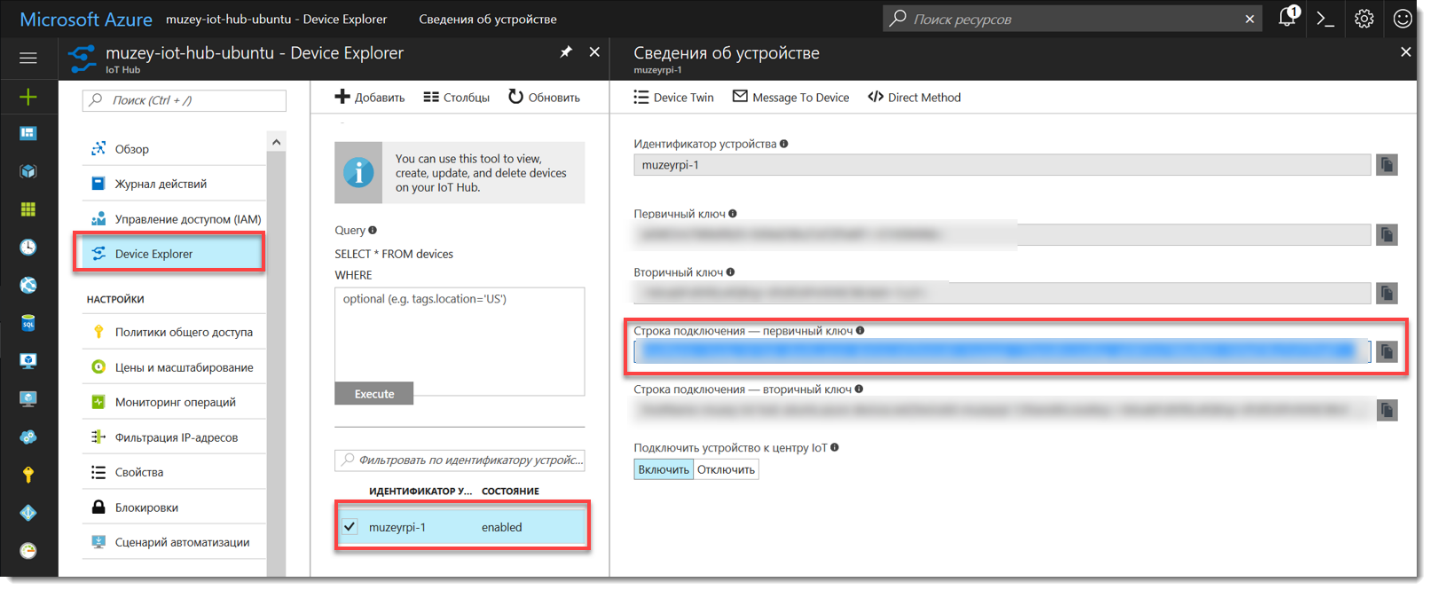
node MyScript.js из папки, где лежит скрипт.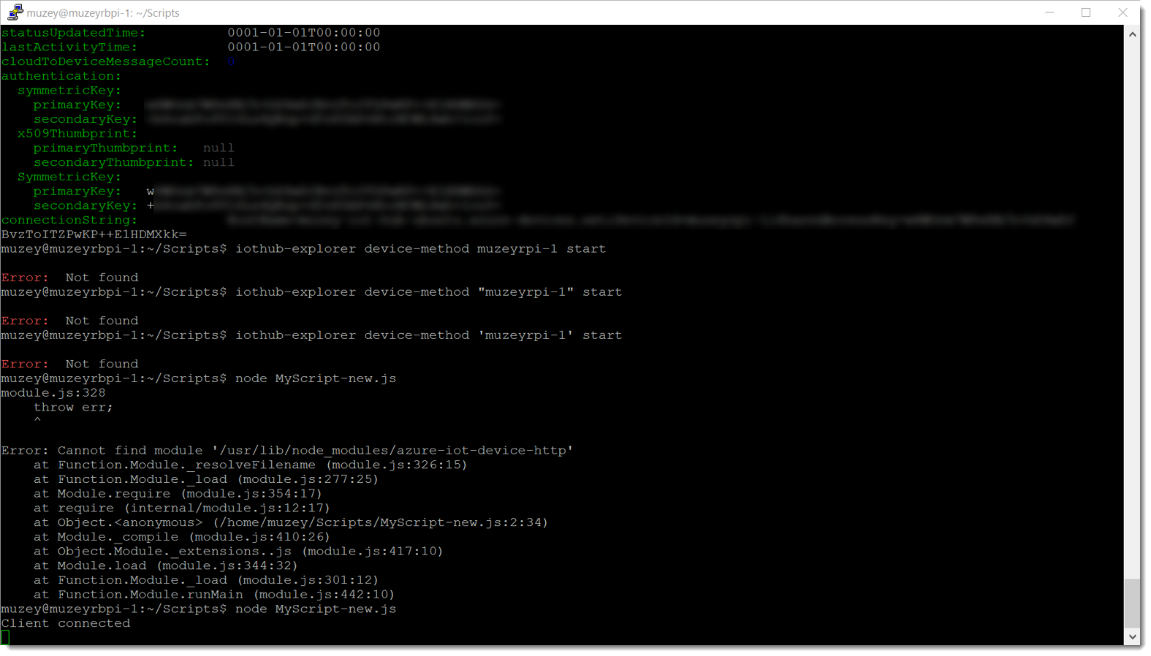
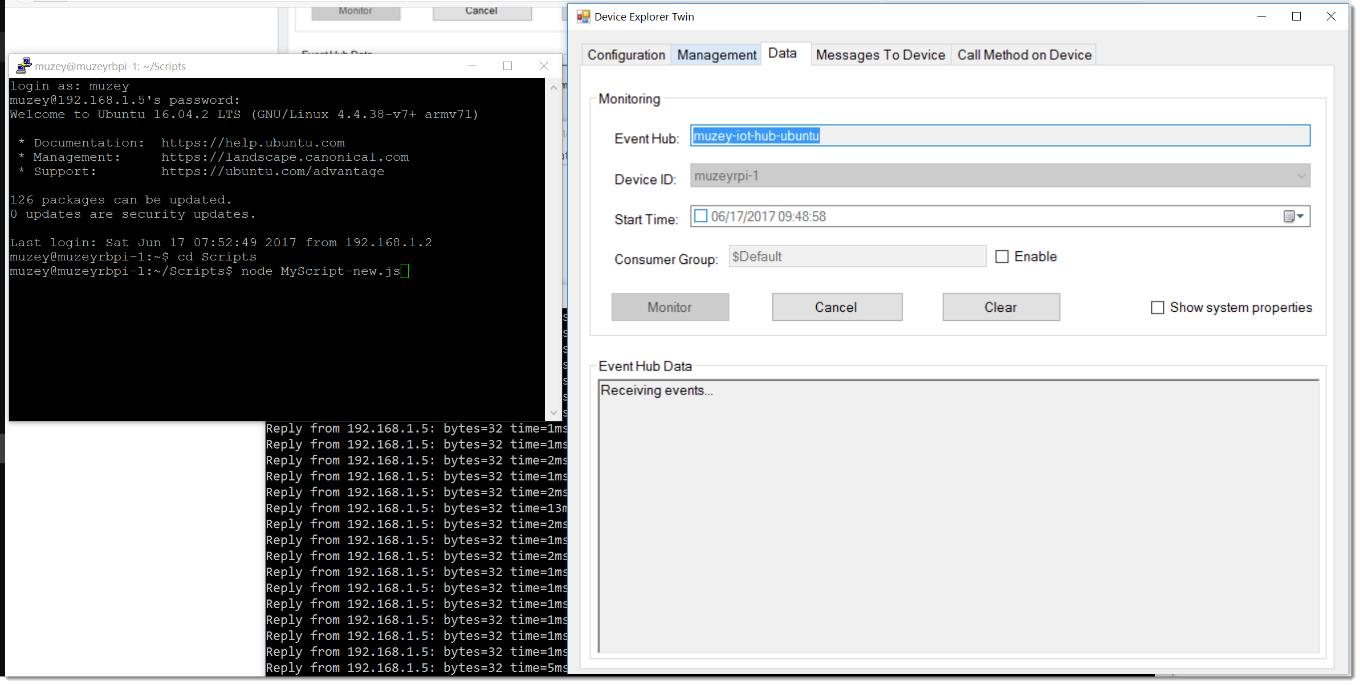

|
Метки: author Schvepsss разработка под linux разработка для интернета вещей microsoft azure блог компании microsoft microsoft azure iot hub raspberry pi |
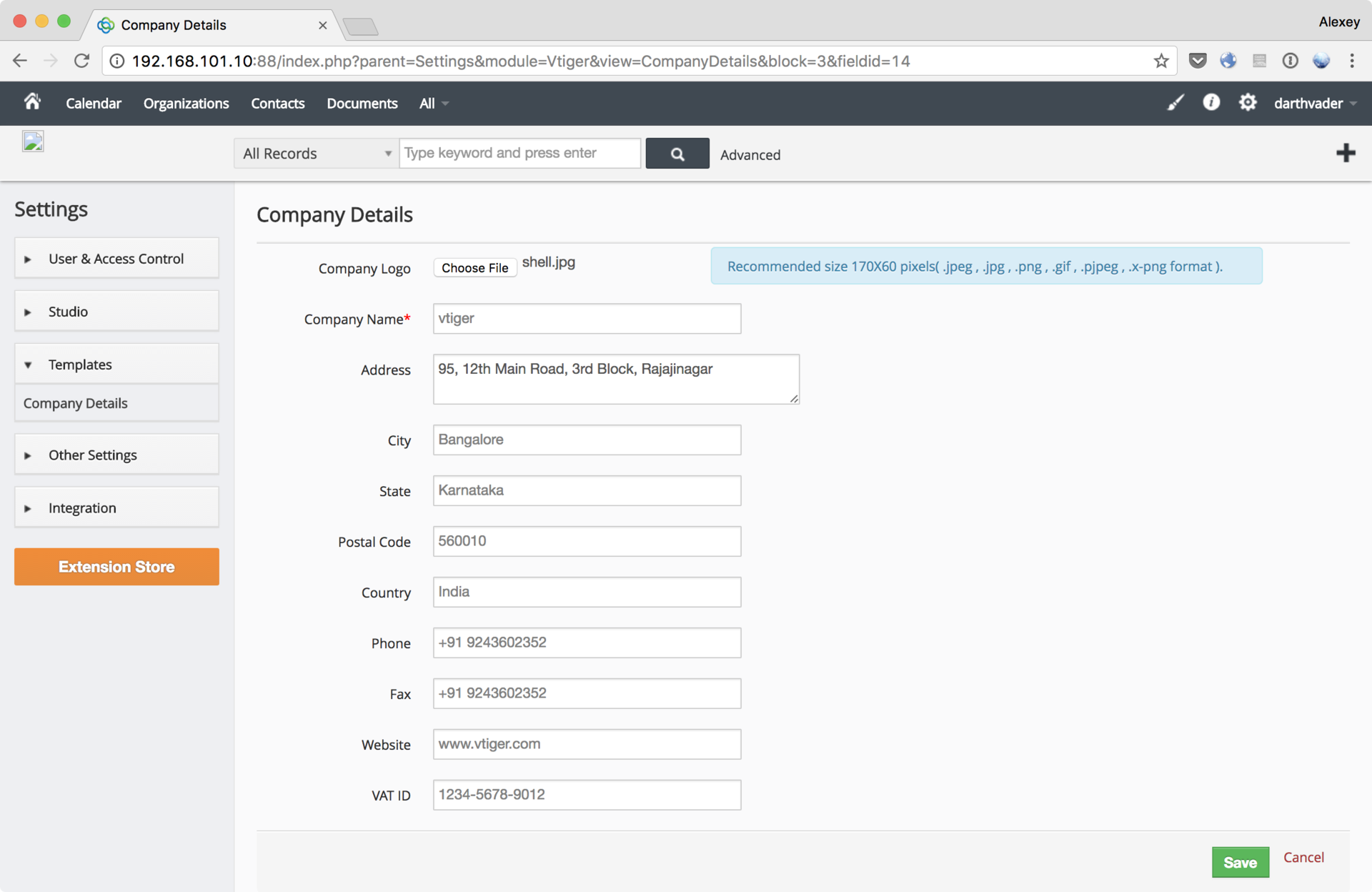
Пентест-лаборатория «Pentestit Test.Lab 11» — полное прохождение |

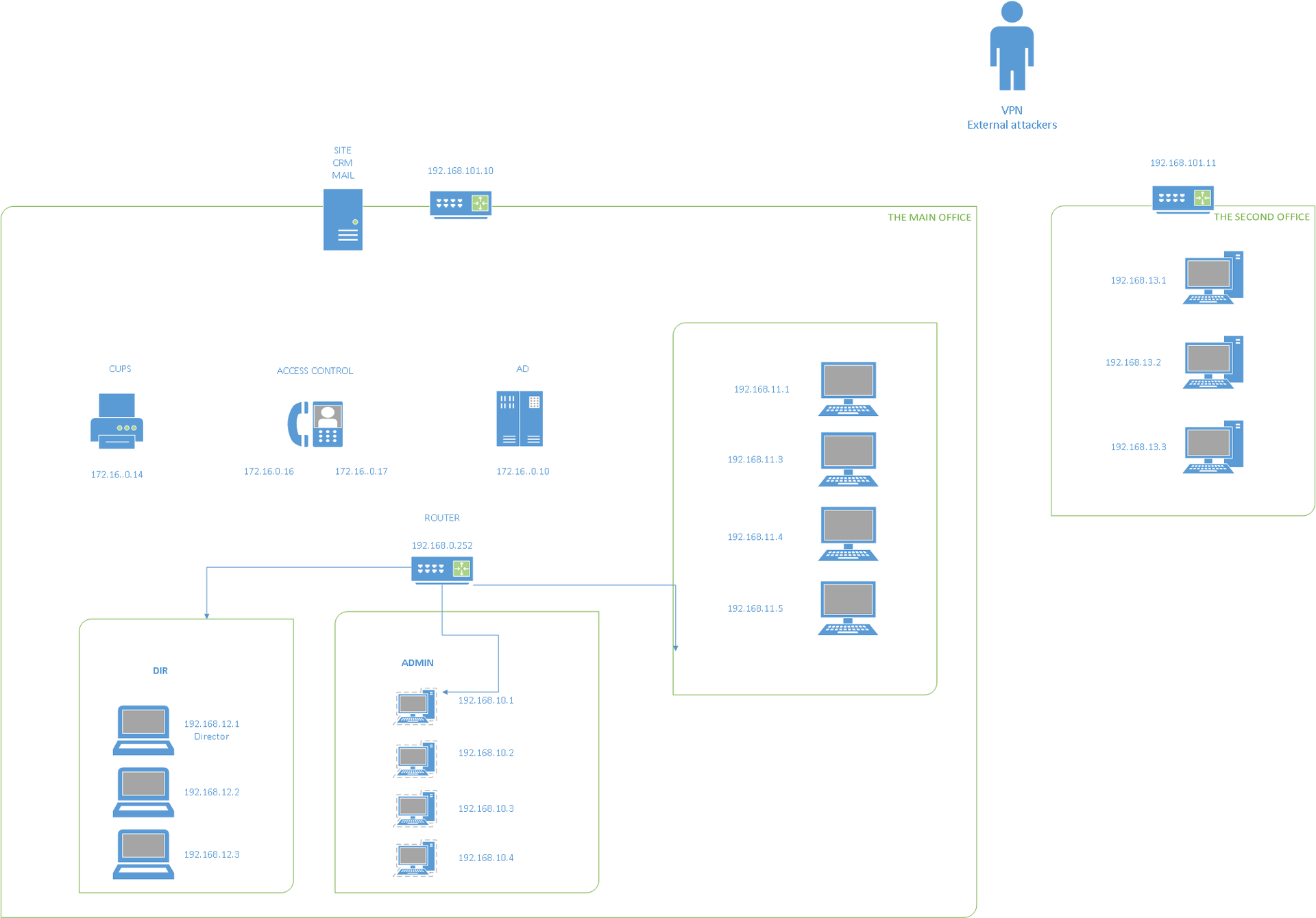
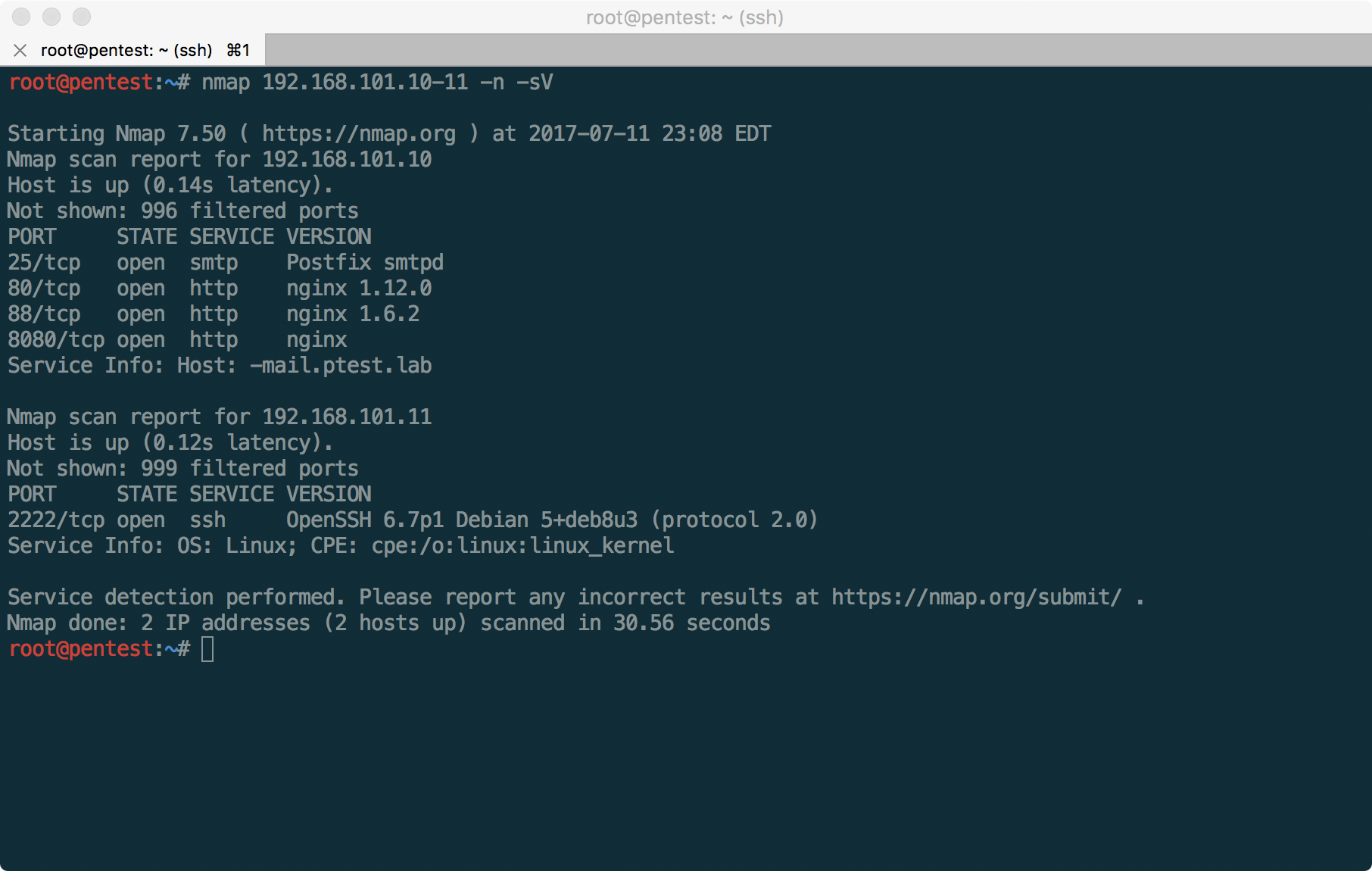
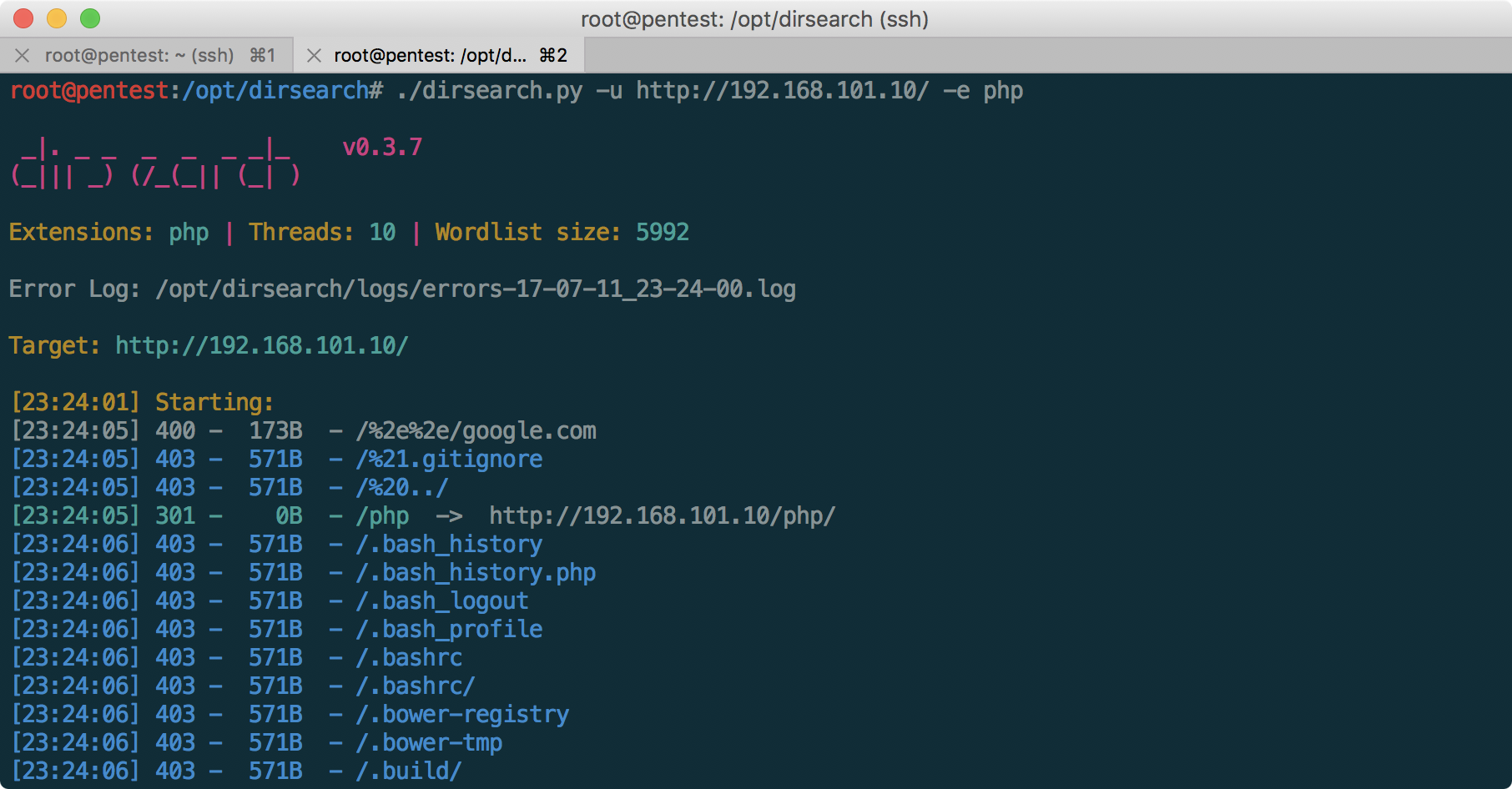
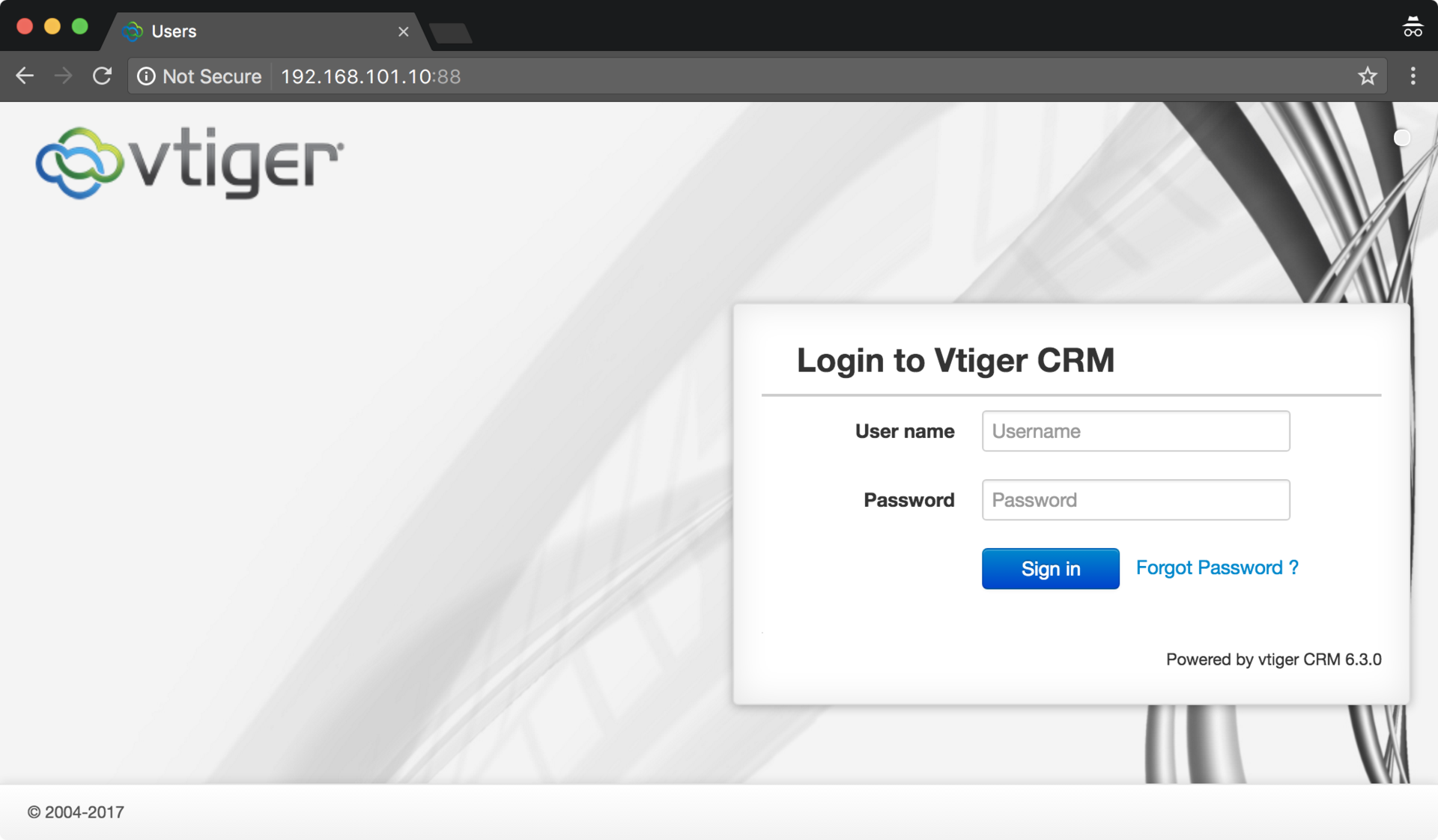
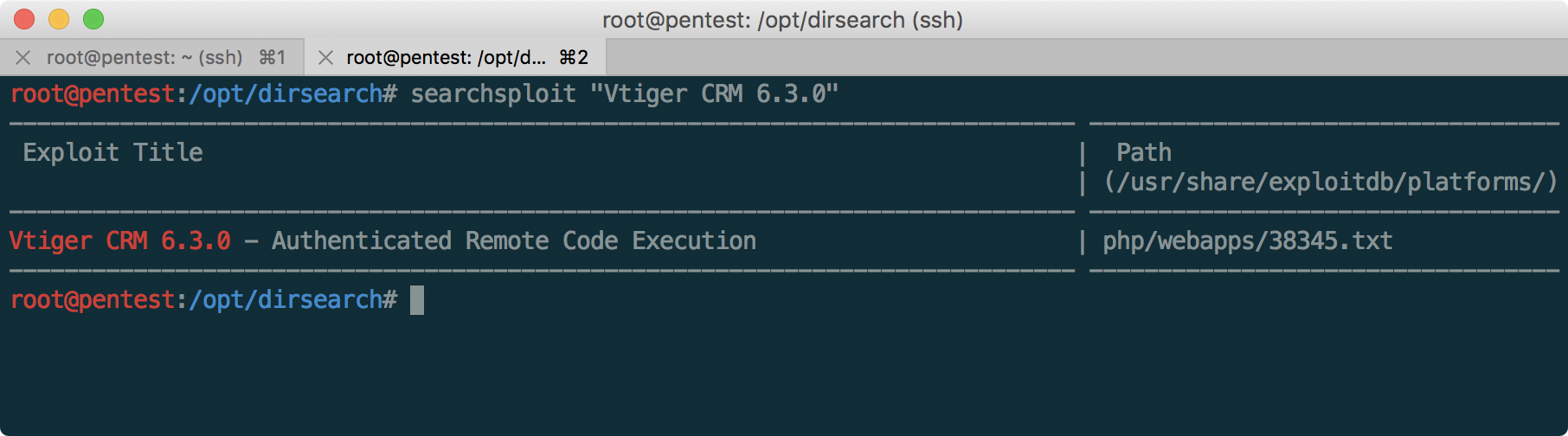
CRM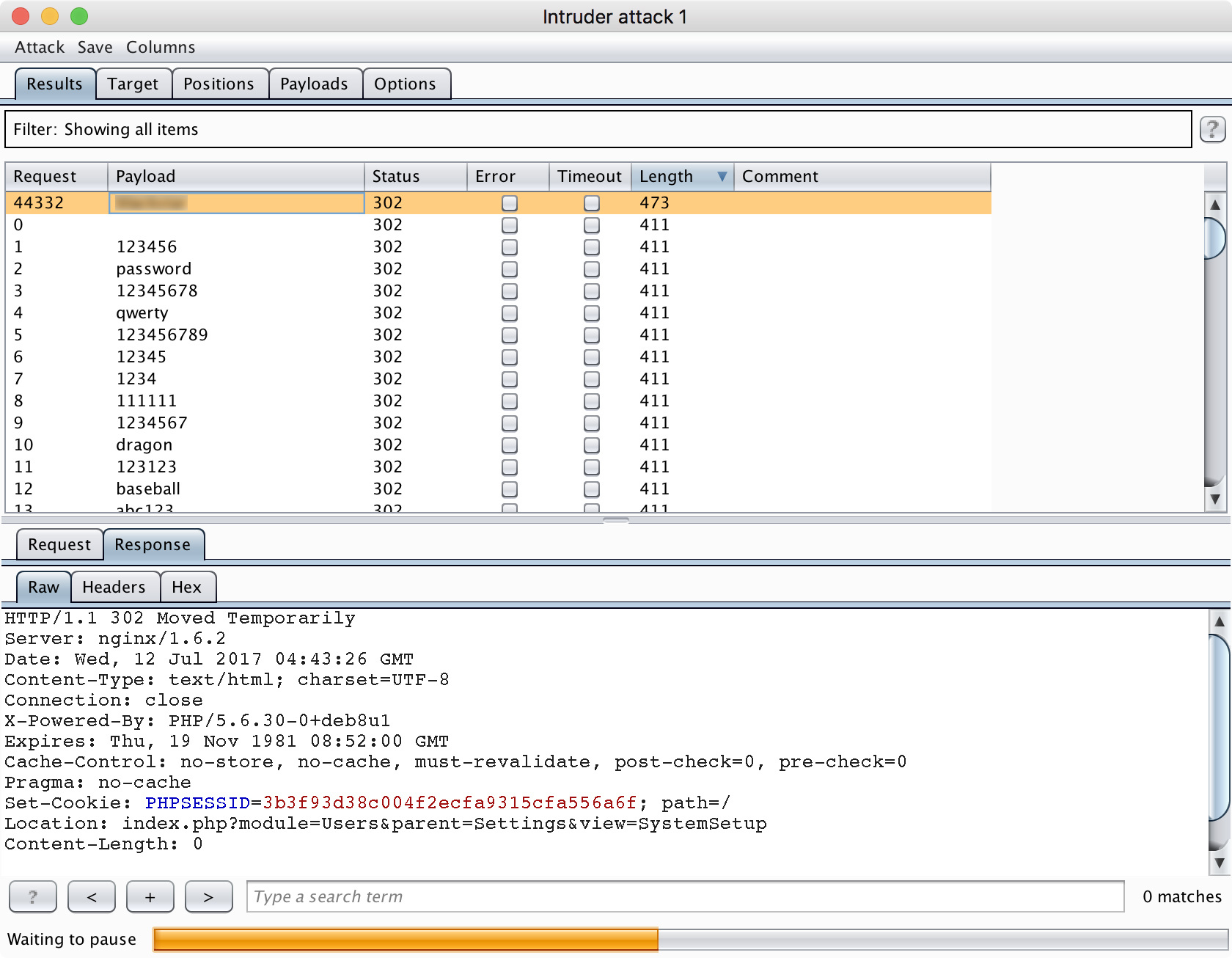
|
|
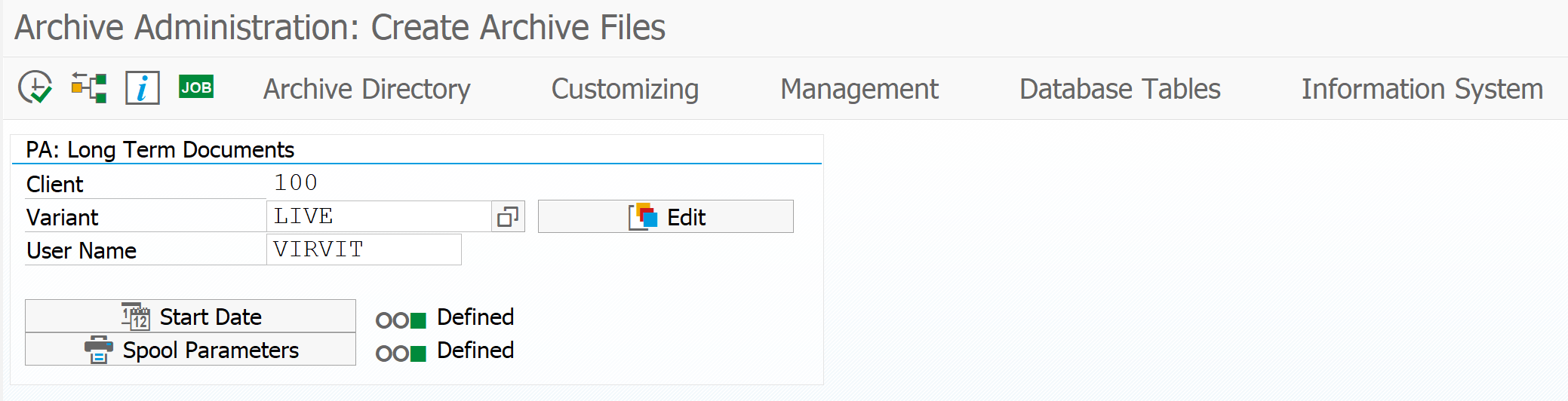
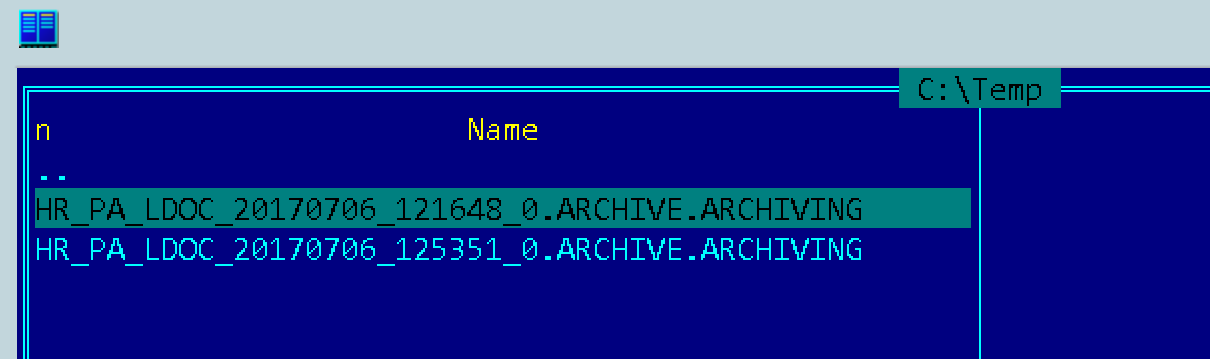
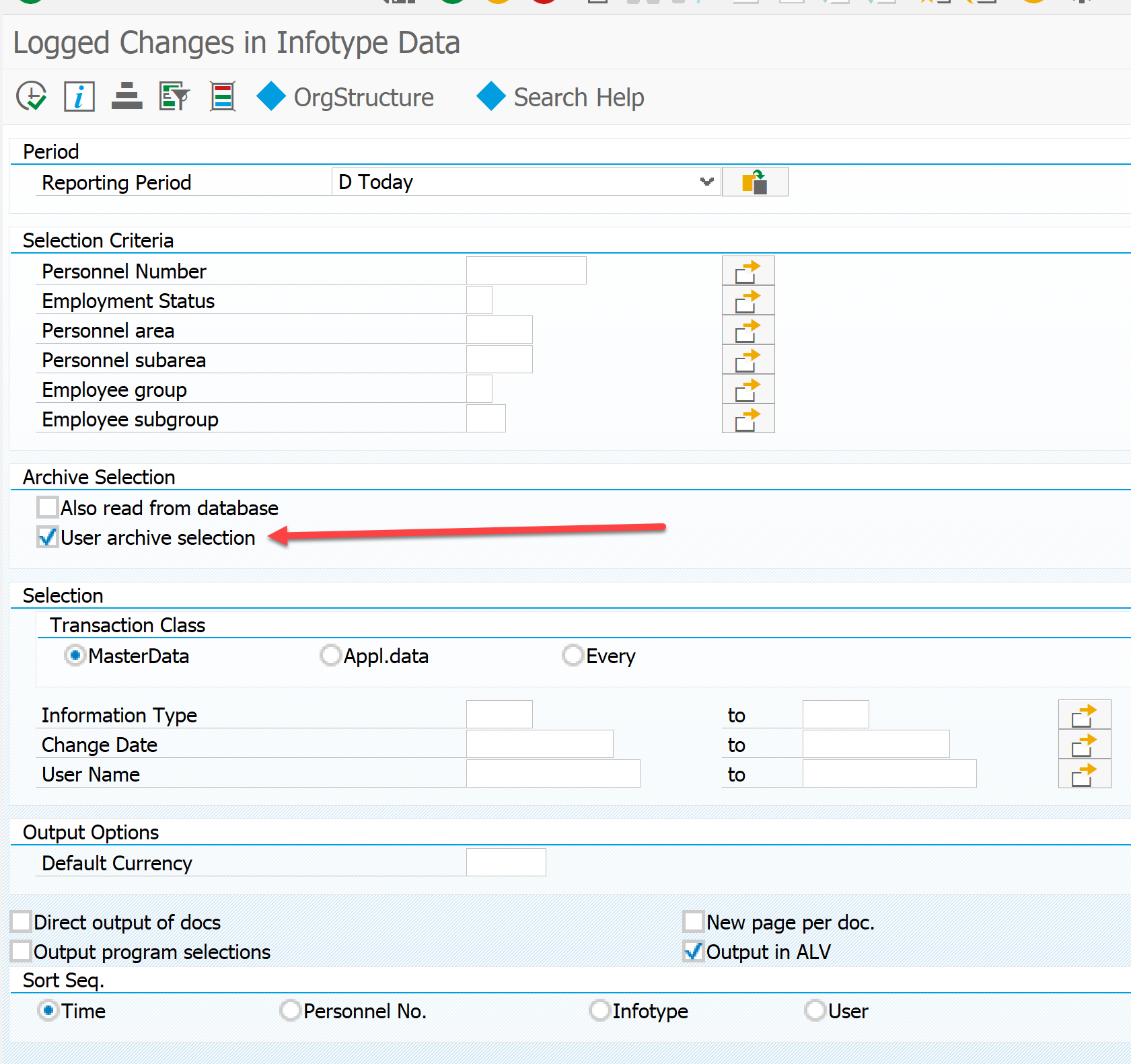
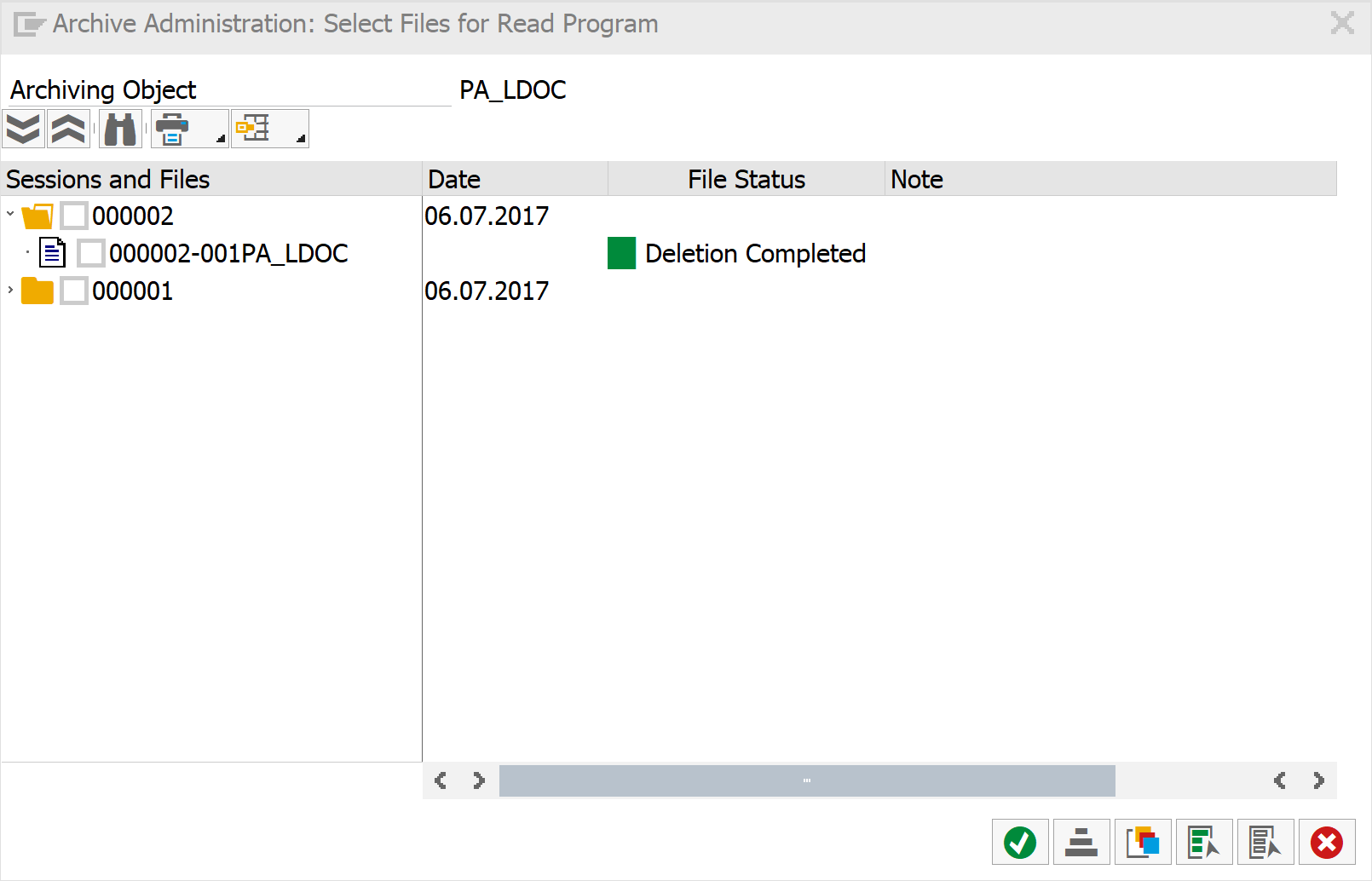
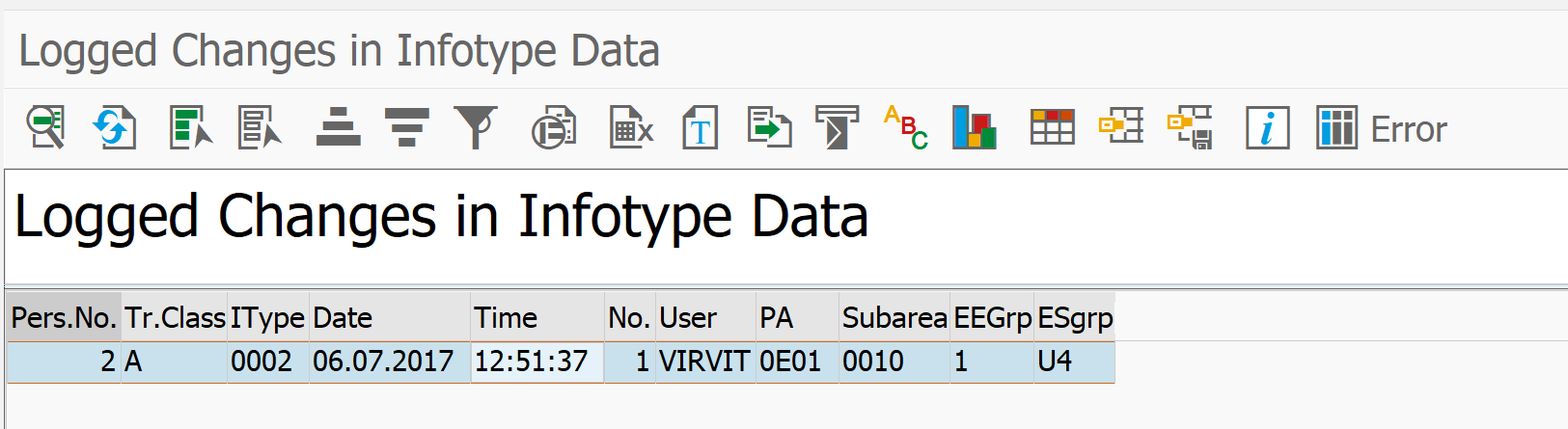
[Из песочницы] Настройка архивирования объектов в SAP ERP для начинающих |
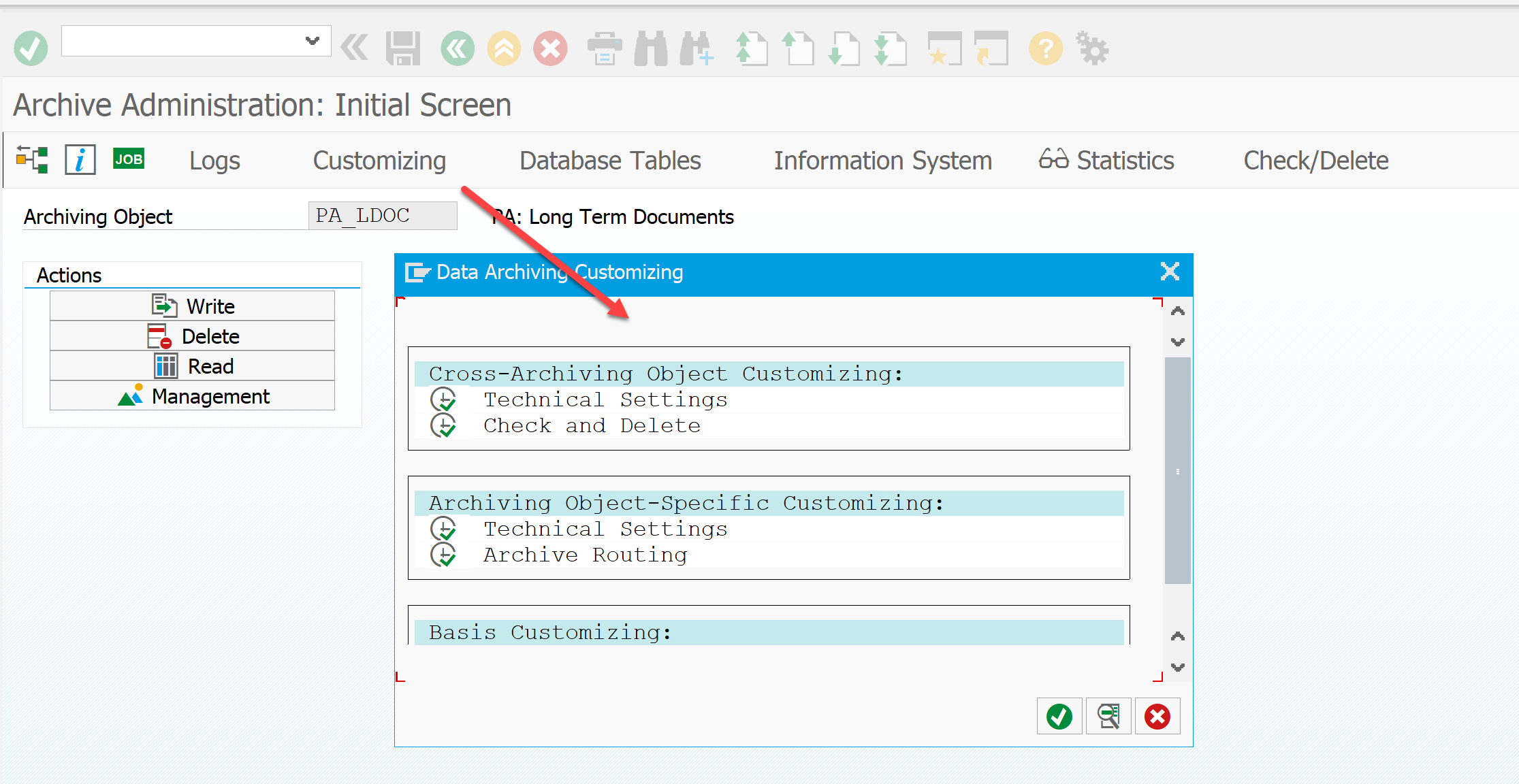
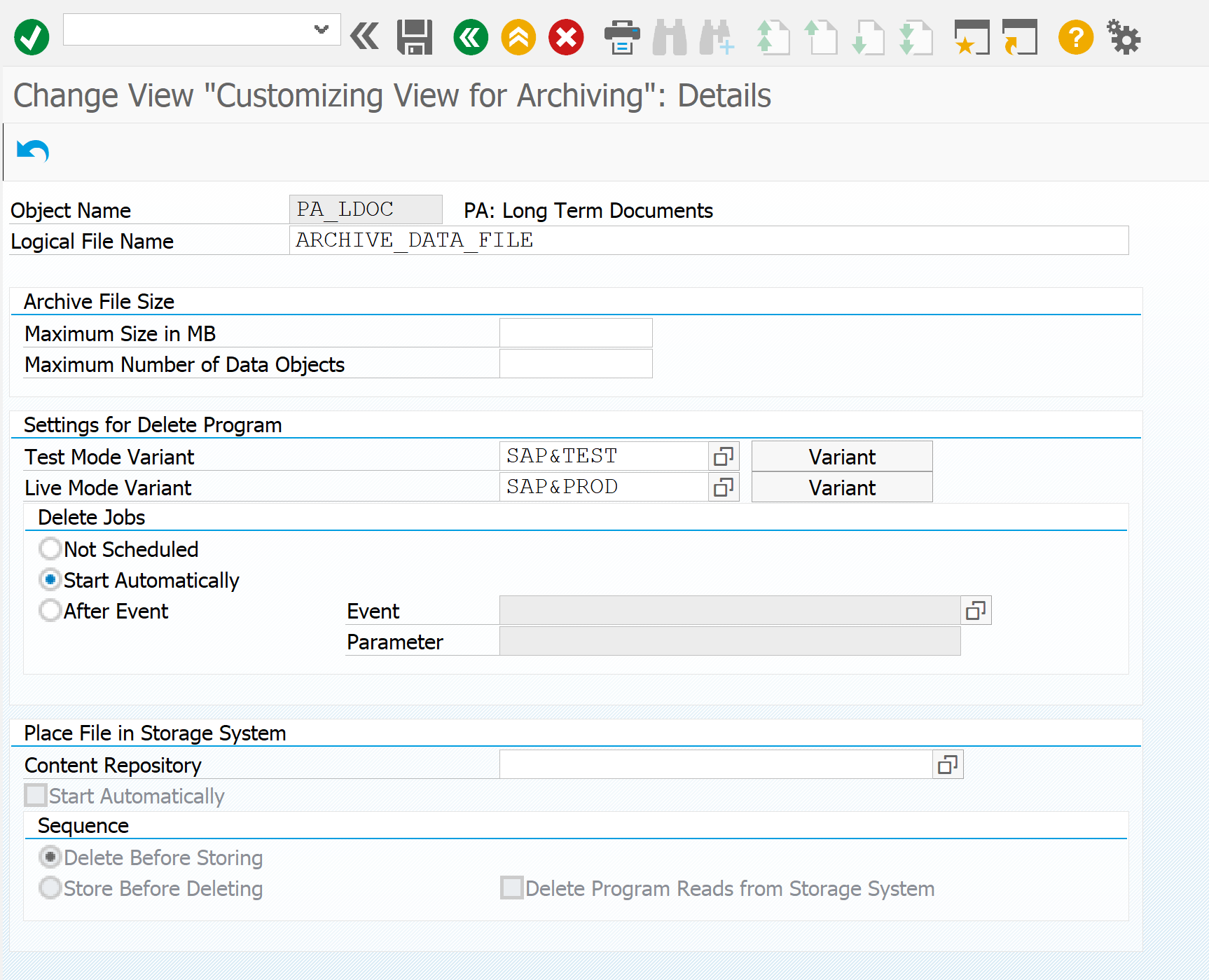
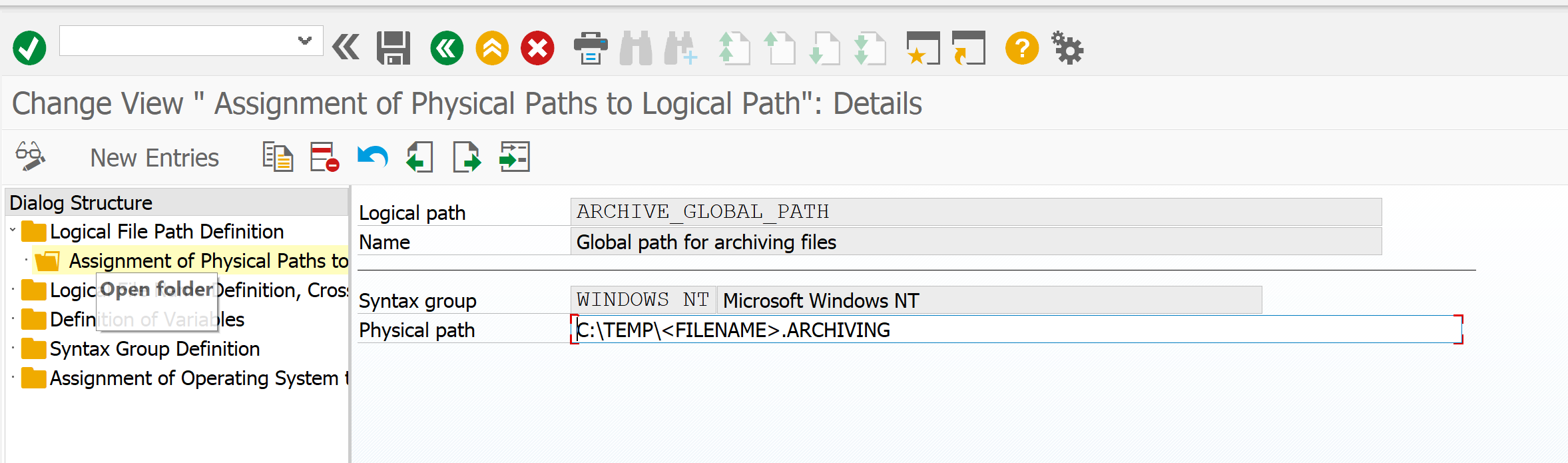
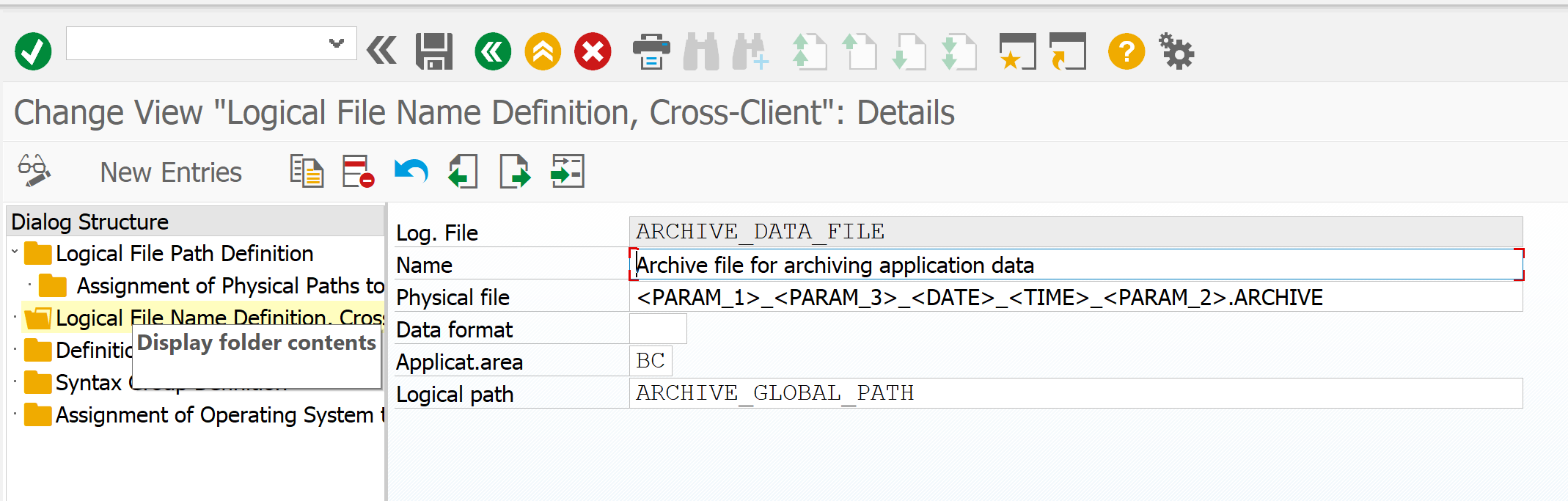
|
Метки: author virvit системное администрирование sap sara архивирование данных |
20 материалов о методах успешного привлечения трафика на сайт |

Классические методы по увеличению трафика
О нестандартных методах
Методом проб и ошибок
|
|
О выборе своего «куска» рынка для студий / агентств — глава из книги «33 точки роста» |
Немножко цифр. Статистика по РФ (2017):
· +12 тысяч исполнителей.
· +5 млн. клиентских бизнесов, включая «микро» и «ремесленников».
· +40% из них планируют наращивать маркетинговые инвестиции.
Выглядит аппетитно, да?
А где среди этого пространства вы? Амбиции съесть весь «пирог», заявляя, что работаете с каждым? Так дело не пойдет. Вы не сможете равно соответствовать каждому запросу. Да и не будет всех потенциальных запросов, так как клиент становится все умнее: бизнес уже понимает, что перспективные ребята уходят в свою нишу. Многорукие «оркестры» — пережиток прошлого.
На момент написания этих строк тема позиционирования как раз была на пике тренда. Многие ключевые игроки стали больше уделять ей внимания, выпуская спец. контент. Пережевывать необходимость поиска ниши не будем, контент на эту тему в открытом доступе найдете сами.
Расскажу то, о чем упоминают лишь вскользь: как именно найти свое место на digital-рынке, какие есть подводные камни на этом пути, и как выбрать себе «камень» по душе.
Во-первых, позиционирование позиционированию — рознь. Оно всегда складывается по-разному:
1. «Естественным» образом. Это когда есть либо какой-то бэкграунд (основатель пришел из соответствующего бизнеса, есть «корни» / знакомые и пр.) либо просто «так сложилось»: в самом начале было пару хороших проектов, на которых удалось набить руку. Данная история имеет право на существование, но она должна быть осознанной. Принцип «делайте, что нравится» — скорее для ремесленников. Бизнес строится по-другому. Да и «что попросили, то и начали делать» — тоже не айс.
2. «Хаотичное» / «Экспериментальное». Поначитались / Понаслушались, пришло вдохновение. Срочно собрали планерку с повесткой «Будем репозиционироваться». А так как полного видения картины нет, решили взять «на пробу» сразу пару ниш: запилили лендинги и в путь. Нет, это тоже не по-взрослому, ребята. Ниши нельзя «прощупывать».
3. Осознанное позиционирование. Не страшно, что раньше работали «как попало». Главное, что сейчас вы выбираете путь с холодной головой. Правильный ход событий:
Вот как оно бывает по науке.
Чтобы было проще понять, разрежем наш торт вот так:
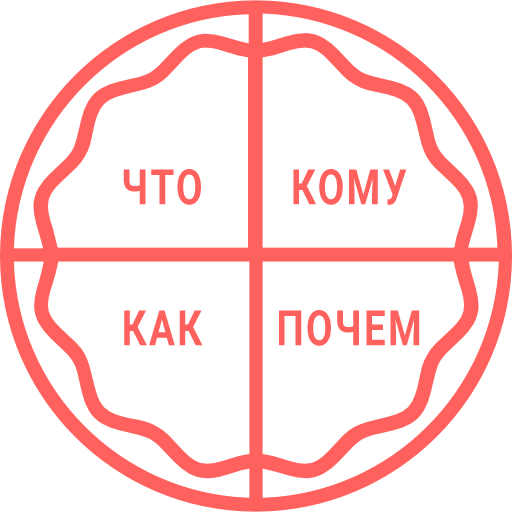
1. ЧТО = ваш продукт:
a. Модель бизнеса:
i. Продакшн — сильные технические навыки. Все (или почти все) своими штатными силами.
ii. Агентство — маркетинг + коммуникации + адаптация под клиента. Штатного продакшна можно вообще не иметь, для этого есть субподрядчики.
b. Услуги. Прежде чем делать громкие заявления о «комплексности», подумайте, насколько вы соответствуете данной претензии. Да и подобный подход сегодня не имеет большой значимости: во-первых, об этом кричит каждый второй; а во-вторых, многие бизнесы хотят уменьшать риски, раскладывая яйца по разным корзинам. Да и вряд ли вы вообще осилите на данном этапе жизни настоящий «комплекс». Лучше сконцентрироваться либо на одной профильной услуге, либо на связке «1 профильная + 2-3 дополнительные» (не вздумайте надеяться, что будете зарабатывать на всем).
2. КОМУ = профиль вашего потенциального клиента:
a. Тип бизнеса. В этой категории можно объединить все оттенки, включая стартапы, сервисы, якобы некоммерческие кооперативы и др.
b. Масштаб бизнеса:
i. Малый:
§ В т.ч. ремесленники (одиночки; возможно с «подмастерьями»).
ii. Средний.
iii. Большой.
c. Сфера. Откройте любой справочник и выберите навигацию по категориям компаний, чтобы оценить масштабы. Сразу скажу, что этот подход уже не является лучшим. Причина №1: клиенты не ценят ваши профильные компетенции (убедитесь, когда проиграете тендер какому-нибудь более сильному конкуренту, у которого нет скиллов по данной тематике). Причина №2: этот метод используют те самые «прощупыватели» ниш, кормя рынок некачественными предложениями; благодаря им этот подход начинает изживать себя. Причина №3: в некоторые ниши проход закрыт; вы можете получить запрос от нефтянщиков, но, даже прочитав все книги по теме и посетив всевозможные мероприятия, не станете «своим» на фоне конкурентов.
d. Подход к бизнесу. Ну вы поняли, чей пример сразу приходит в голову. Ориентация, скажем, на ребят, любящих быстро регистрировать ИП / юр. лицо и за 3 дня собирать офферы, — имеет право на жизнь.
3. КАК = ключевые особенности продукта / процессов:
a. Здесь по определению нельзя расписать все подпункты. Просто приведу примеры:
i. Скоростной запуск – услуги с быстрым стартом / ранними результатами. Типовые решения, упрощающие жизнь сервисы и пр. в помощь.
ii. Глубокая интеграция в бизнес-процессы клиента — вплоть до CRM и даже офиса (полный аутсорс — сдача себя «в аренду»).
iii. Одна из методологий работы:
§ Стандартный «каскад».
§ RAD.
§ Гибкая Agile.
4. ПОЧЕМ = ценообразование:
a. Сегмент:
i. Низкий (будете конкурировать с сервисами; но это не значит, что здесь можно делать продукт на уровне «тяп-ляп»).
ii. Средний (опасно — не входить: мало спроса и много предложений).
iii. Высокий (нужны стальные яйца компетенции).
b. Модель:
i. Фикс (есть шанс «выкатиться» за пределы, если даже обговорен объем работ).
ii. Почасовка (сложно продавать — в глазах клиента цена выше ценности).
iii. Бонусная система — оплата на основе достижения KPI (в большинстве случаев геморрой с расчетами):
§ Лидогенерация (фактически вы «инвестируете» в клиентский бизнес).
Позиционирование можно строить сразу на 2-3 показателей. Только следите, чтобы «кусок» был не слишком маленьким, и чтобы на него не было слишком много «едаков». Иначе не «наедитесь».
SMM премиум-сегмента для небольших автомоек, открытых по методу БМ, с оплатой за обращения.
Почему это не есть гуд?
Разработка сложных сайтов для интеграции по системам франчайзинга.
Почему это гуд?
Полную версию книги можно скачать здесь: http://www.zarutskiy-k.ru/books/33-growth-tips.pdf

|
Метки: author zarutskiy_k читальный зал веб-студии digital- агентства |









