[Перевод] Что делает язык программирования «модным»? |

|
Метки: author arielf программирование ооп smalltalk pharo squeak |
Тандем офисной и мобильной телефонии. Как мы разрабатывали FMC |
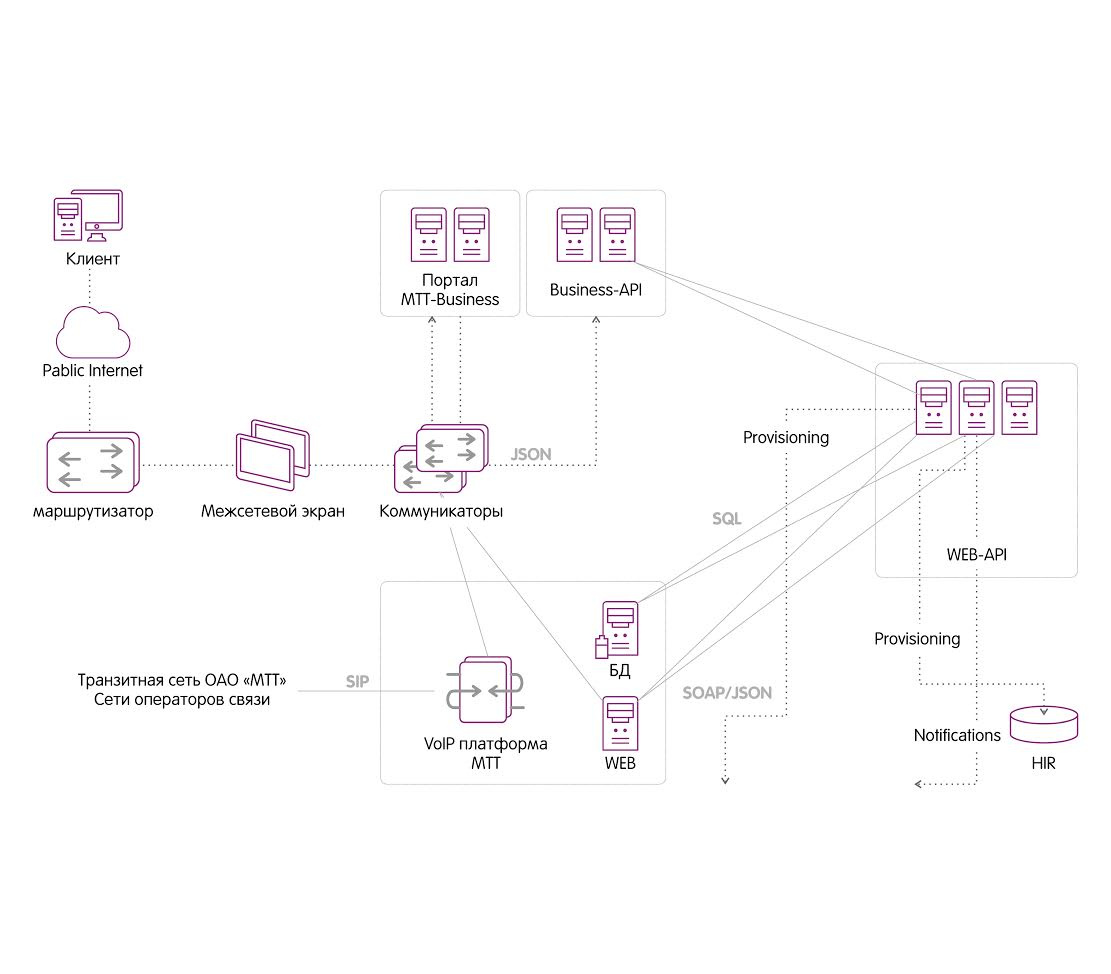
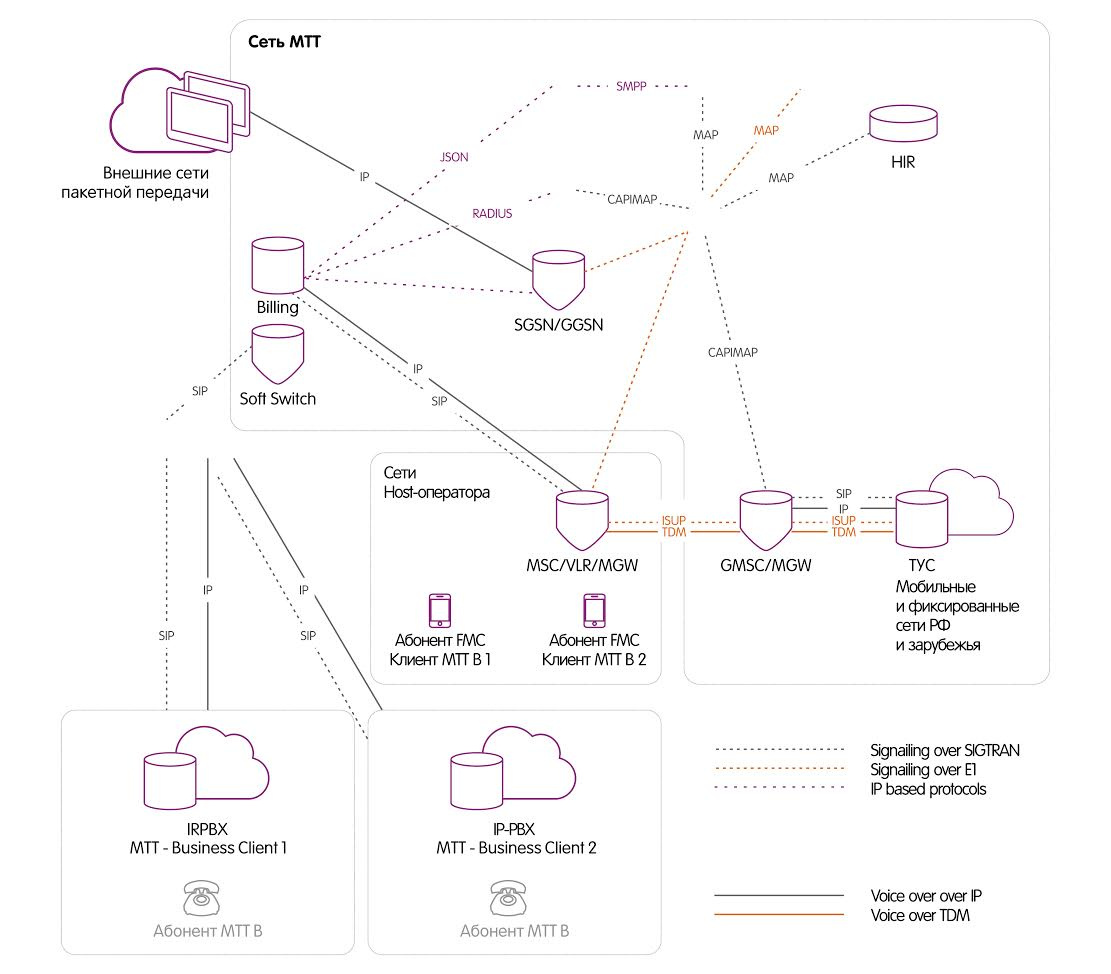
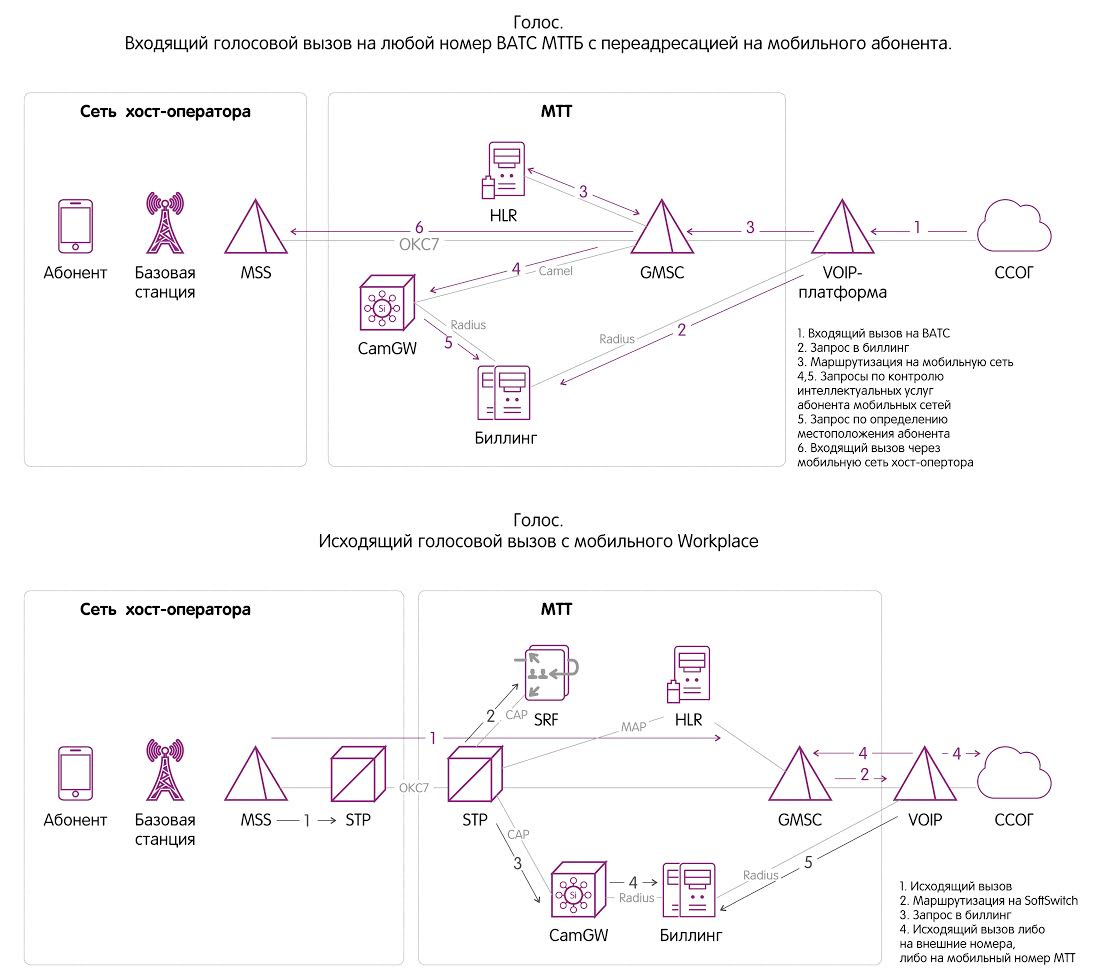
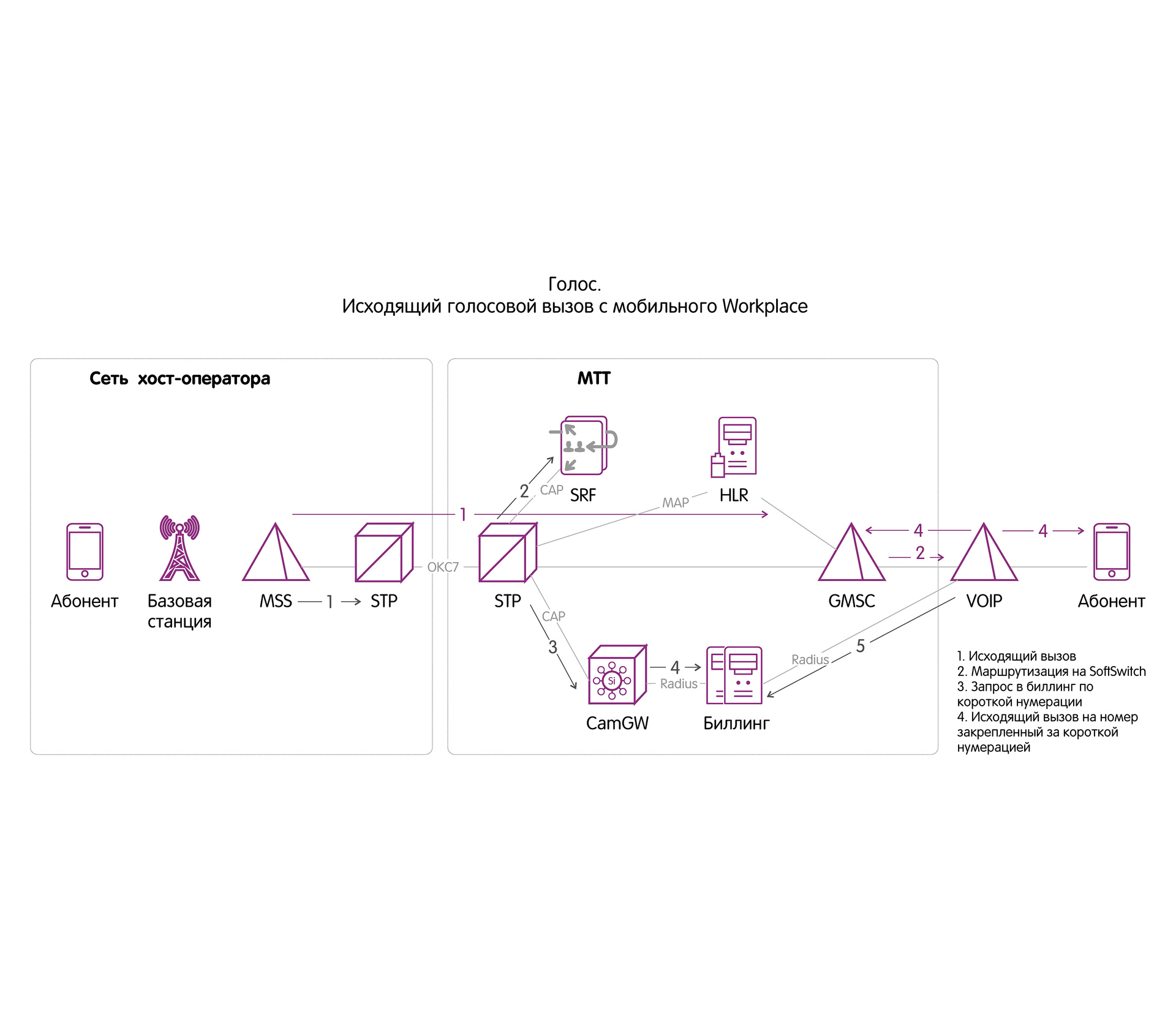
|
Метки: author MTTBusiness разработка систем связи программирование анализ и проектирование систем блог компании мтт fmc sim- карта sim телефония связь голосовая связь мтт |
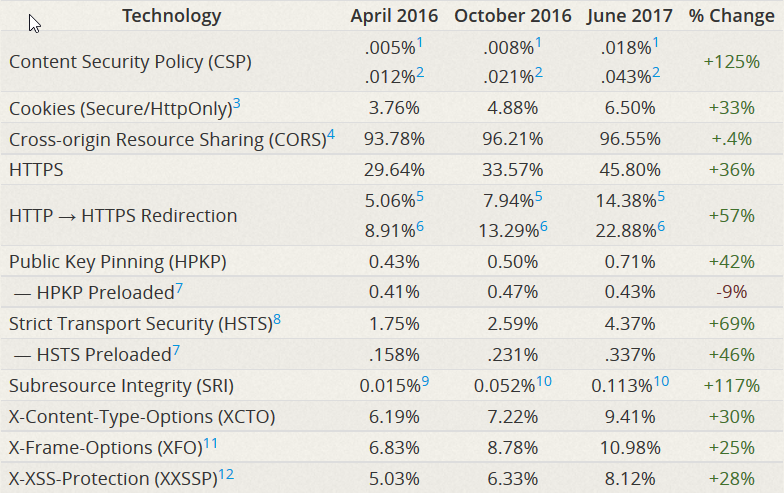
Security Week 27: ExPetr = BlackEnergy, более 90% сайтов небезопасны, в Linux закрыли RCE-уязвимость |
 Зловещий ExPetr, поставивший на колени несколько весьма солидных учреждений, продолжает преподносить сюрпризы. Наши аналитики из команды GReAT обнаружили его родство со стирателем, атаковавшим пару лет назад украинские электростанции в рамках кампании BlackEnergy.
Зловещий ExPetr, поставивший на колени несколько весьма солидных учреждений, продолжает преподносить сюрпризы. Наши аналитики из команды GReAT обнаружили его родство со стирателем, атаковавшим пару лет назад украинские электростанции в рамках кампании BlackEnergy.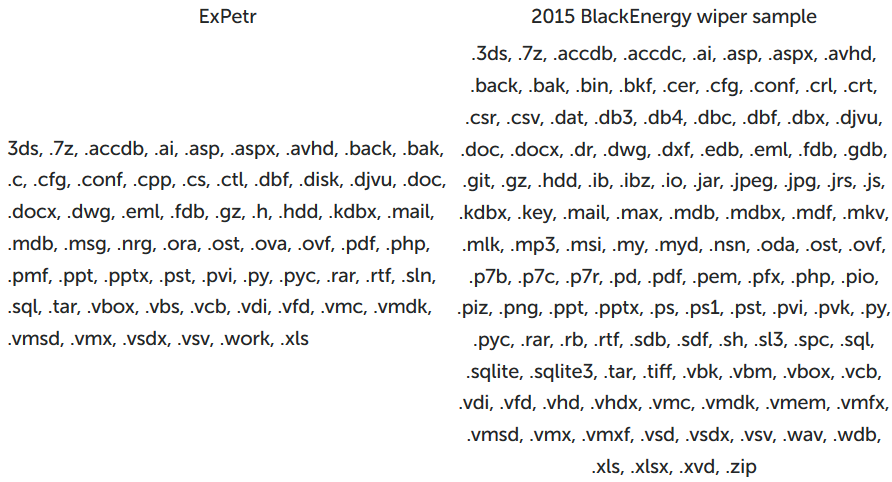


|
|
Расширение, изменение и создание элементов управления на платформе UWP. Часть 2 |
|
Метки: author MobileDimension разработка под windows разработка мобильных приложений .net блог компании mobile dimension uwp элементы управления |
Simple Field Validation |
public interface Validator {
boolean isValid(T value);
String getDescription();
} public class ValidatorsComposer implements Validator {
private final List> validators;
private String description;
public ValidatorsComposer(Validator... validators) {
this.validators = Arrays.asList(validators);
}
@Override
public boolean isValid(T value) {
for (Validator validator : validators) {
if (!validator.isValid(value)) {
description = validator.getDescription();
return false;
}
}
return true;
}
@Override
public String getDescription() {
return description;
}
} public class EmptyValidator implements Validator {
@Override
public boolean isValid(String value) {
return !TextUtils.isEmpty(value);
}
@Override
public String getDescription() {
return "Field must not be empty";
}
} public class EmailValidator implements Validator {
@Override
public boolean isValid(String value) {
return Patterns.EMAIL_ADDRESS.matcher(value).matches();
}
@Override
public String getDescription() {
return "Email should be in 'a@a.com' format";
}
} final ValidatorsComposer emailValidatorsComposer =
new ValidatorsComposer<>(new EmptyValidator(), new EmailValidator());
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
if (emailValidatorsComposer.isValid(emailEditText.getText().toString())) {
errorTextView.setText(null);
} else {
errorTextView.setText(emailValidatorsComposer.getDescription());
}
}
}); public class User {
public final String name;
public final Integer age;
public final Gender gender;
public enum Gender {MALE, FEMALE}
public User(String name, Integer age, Gender gender) {
this.name = name;
this.age = age;
this.gender = gender;
}
}public class UserValidator implements Validator {
private String description;
@Override
public boolean isValid(User value) {
if (value == null) {
description = "User must not be null";
return false;
}
final String name = value.name;
if (TextUtils.isEmpty(name)) {
description = "User name must not be blank";
return false;
}
final Integer age = value.age;
if (age == null) {
description = "User age must not be blank";
return false;
} else if (age < 0) {
description = "User age must be above zero";
return false;
} else if (age > 100) {
description = "User age is to much";
return false;
}
final User.Gender gender = value.gender;
if (gender == null) {
description = "User gender must not be blank";
return false;
}
return true;
}
@Override
public String getDescription() {
return description;
}
} final Validator userValidator = new UserValidator();
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
User user = new User(null, 12, User.Gender.MALE);
if (userValidator.isValid(user)) {
errorTextView.setText(null);
} else {
errorTextView.setText(userValidator.getDescription());
}
}
}); emailEditText.addTextChangedListener(new SimpleTextWatcher() {
@Override
public void afterTextChanged(Editable s) {
if (!emailValidatorsComposer.isValid(s.toString())) {
errorTextView.setText(emailValidatorsComposer.getDescription());
}
}
});|
Метки: author ZemtsovVU разработка под android android android development form validation валидация форм |
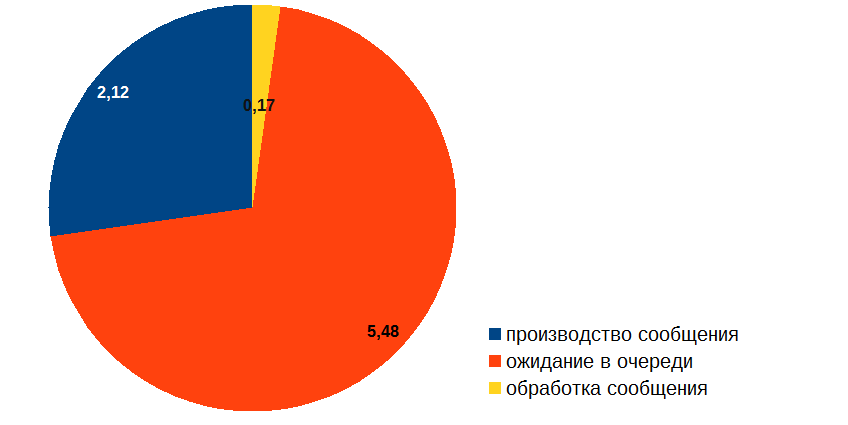
Вещи, которые мне надо было знать прежде, чем создавать систему с очередью |
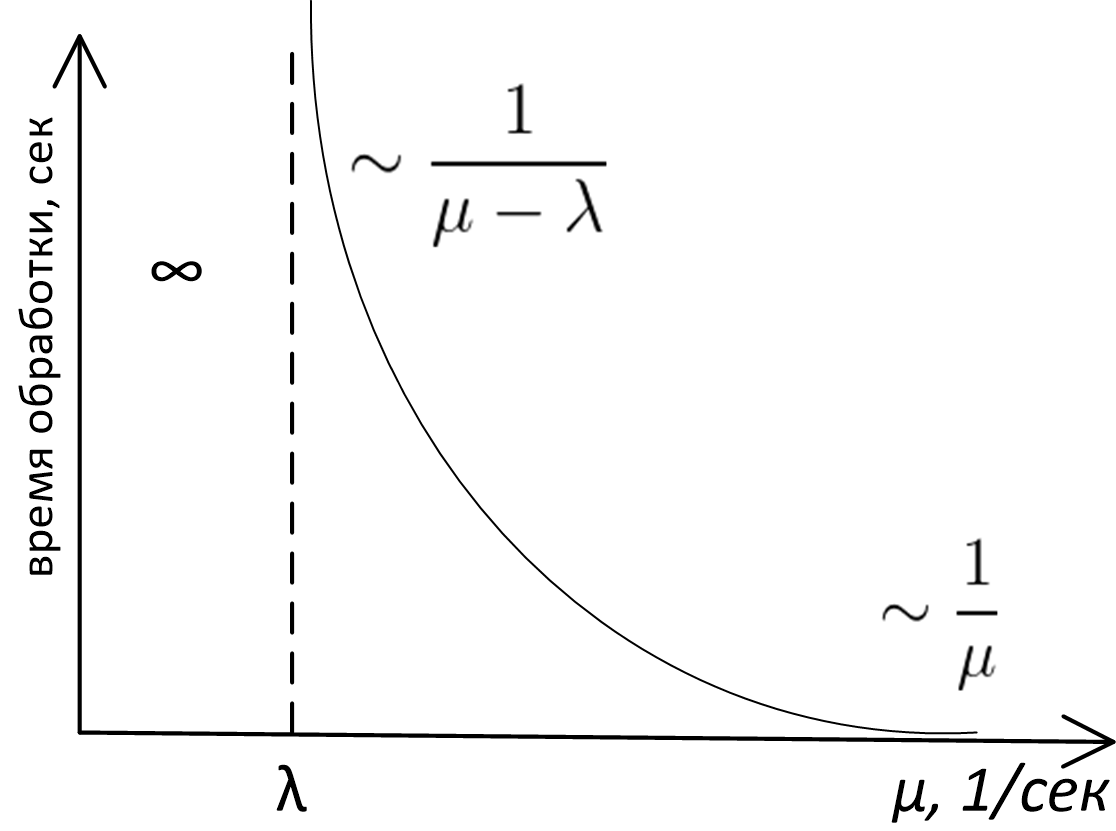

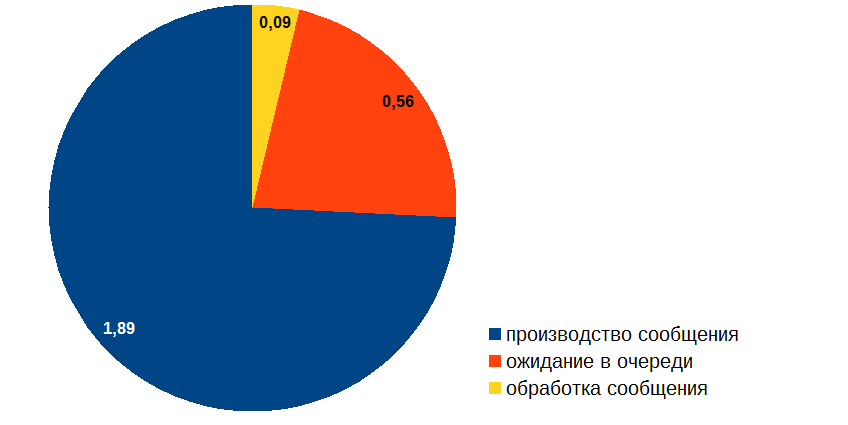
|
Метки: author IvanPonomarev анализ и проектирование систем производительность очереди message queue |
[Из песочницы] Как generic-и нас спасают от упаковки |
При заходе в метод мы часто выполняемым проверку на null. Кто-то выносит проверку в отдельный метод, что бы код выглядел чище, и получается что то-такое:
public void ThrowIfNull(object obj)
{
if(obj == null)
{
throw new ArgumentNullException();
}
}И что интересно при такой проверке, я массово вижу использование именно object атрибута, можно ведь воспользоватся generic-ом. Давайте попробуем заменить наш метод на generic и сравнить производительность.
Перед тестированием нужно учесть ещё один недостаток object аргумента. Значимые типы(value types) никогда не могут быть равны null(Nullable тип не в счёт). Вызов метода, вроде ThrowIfNull(5), бессмыслен, однако, поскольку тип аргумента у нас object, компилятор позволит вызвать метод. Как по мне, это снижает качество кода, что в некоторых ситуациях гораздо важнее производительности. Для того что бы избавится от такого поведения, и улучшить сигнатуру метода, generic метод придётся разделить на два, с указанием ограничений(constraints). Беда в том что нельзя указать Nullable ограничение, однако, можно указать nullable аргумент, с ограничением struct.
Приступаем к тестированию производительности, и воспользуемся библиотекой BenchmarkDotNet. Навешиваем атрибуты, запускаем, и смотрим на результаты.
public class ObjectArgVsGenericArg
{
public string str = "some string";
public Nullable num = 5;
[MethodImpl(MethodImplOptions.NoInlining)]
public void ThrowIfNullGenericArg(T arg)
where T : class
{
if (arg == null)
{
throw new ArgumentNullException();
}
}
[MethodImpl(MethodImplOptions.NoInlining)]
public void ThrowIfNullGenericArg(Nullable arg)
where T : struct
{
if(arg == null)
{
throw new ArgumentNullException();
}
}
[MethodImpl(MethodImplOptions.NoInlining)]
public void ThrowIfNullObjectArg(object arg)
{
if(arg == null)
{
throw new ArgumentNullException();
}
}
[Benchmark]
public void CallMethodWithObjArgString()
{
ThrowIfNullObjectArg(str);
}
[Benchmark]
public void CallMethodWithObjArgNullableInt()
{
ThrowIfNullObjectArg(num);
}
[Benchmark]
public void CallMethodWithGenericArgString()
{
ThrowIfNullGenericArg(str);
}
[Benchmark]
public void CallMethodWithGenericArgNullableInt()
{
ThrowIfNullGenericArg(num);
}
}
class Program
{
static void Main(string[] args)
{
var summary = BenchmarkRunner.Run();
}
} | Method | Mean | Error | StdDev |
|---|---|---|---|
| CallMethodWithObjArgString | 1.784 ns | 0.0166 ns | 0.0138 ns |
| CallMethodWithObjArgNullableInt | 124.335 ns | 0.2480 ns | 0.2320 ns |
| CallMethodWithGenericArgString | 1.746 ns | 0.0290 ns | 0.0271 ns |
| CallMethodWithGenericArgNullableInt | 2.158 ns | 0.0089 ns | 0.0083 ns |
Наш generic на nullable типе отработал в 2000 раз быстрее! А всё из-за пресловутой упаковки(boxing). Когда мы вызываем CallMethodWithObjArgNullableInt, то наш nullable-int "упаковывается" и размещается в куче. Упаковка очень дорогая операция, от того метод и проседает по производительности. Таким образом использую generic мы можем избежать упаковки.
Итак, generic аргумент лучше object потому что:
Upd. Спасибо хабраюзеру zelyony за замечание. Методы инлайнились, для более точных замеров добавил атрибут MethodImpl(MethodImplOptions.NoInlining).
|
Метки: author unsafePtr c# generics boxing |
RAML-роутинг в Play Framework |









|
Метки: author Raiffeisenbank scala java блог компании райффайзенбанк play framework github raml raml 1.0 |
Rewarded Video: лучшие сценарии показа или как сделать так, чтобы вашу рекламу посмотрели |








|
|
5 приемов в помощь разработке на vue.js + vuex |
Object.defineProperty(Vue.prototype,"$bus",{
get: function() {
return this.$root.bus;
}
});
new Vue({
el: '#app',
data: {
bus: new Vue({}) // Here we bind our event bus to our $root Vue model.
}
});
mounted: function() {
this._someEvent = (..) => {
..
}
this._otherEvent = (..) => {
..
}
this.$bus.$on("someEvent",this._someEvent);
this.$bus.$on("otherEvent",this._otherEvent);
},
beforeDestroy: function() {
this._someEvent && this.$bus.$off("someEvent",this._someEvent);
this._otherEvent && this.$bus.$off("otherEvent",this._otherEvent);
}
projects: [{
id: 1,
layers: [{
id: 1,
pages: [{
id: 1,
name: "page1"
},{
id: 2,
name: "page2"
}]
}]
}];
$store.dispatch("changePageName",{projectId:1,layerId:1,id:1,name:"new name"})projects: [{id:1}],
layers: [{id:1,projectId:1}],
pages: [{
id: 1,
name: "page1",
layerId: 1,
projectId: 1
},{
id: 2,
name: "page2",
layerId: 1,
projectId: 1
}]
projects: [{
id: 1,
layersIds: [1]
}],
layers: {
1: {
pagesIds: [1,2]
}
},
pages: {
1: {name:"page1"},
2: {name:"page2"}
}
layerPages: (state,getters) => (layerId) => {
const layer = state.layers[layerId];
if (!layer || !layer.pagesIds || layer.pagesIds.length==0) return [];
return layer.pagesIds.map(pageId => state.pages[pageId]);
}
const results = {};
const state = {resultIds:[]};
const getters = {
results: function(state) {
return _.map(state.resultsIds,id => results[id]);
}
}
const mutations = {
updateResults: function(state,data) {
const new = {};
const newIds = [];
data.forEach(r => {
new[r.id] = r;
newIds.push(r.id);
});
results = new;
state.resultsIds = newIds;
}
}
|
Метки: author Kasheftin разработка веб-сайтов javascript vue.js vuex normalizr |
Обработка многократно возникающих SIGSEGV-подобных ошибок |
Тема изъезжена и уже не мало копий было сломано из-за неё. Так или иначе люди продолжают задаваться вопросом о том может ли приложение написанное на C/C++ не упасть после разыменования нулевого указателя, например. Краткий ответ — да, даже на Хабре есть статьи на сей счёт.
Одним из наиболее частых ответов на данный вопрос является фраза "А зачем? Такого просто не должно случаться!". Истинные причины того почему люди продолжают интересоваться данной тематикой могут быть разные, одной из них может быть лень. В случая когда лениво или дорого проверять всё и вся, а исключительные ситуации случаются крайне редко можно, не усложняя кода, завернуть потенциально падающие фрагменты кода в некий try/catch который позволит красиво свернуть приложение или даже восстановится и продолжить работу как ни в чём не бывало. Наиболее ненормальным как раз таки может показаться желание снова и снова ловить ошибки, обычно приводящие к падению приложения, обрабатывать их и продолжать работу.
Итак попробуем создать нечто позволяющее решать проблему обработки SIGSEGV-подобных ошибок. Решение должно быть по максимуму кроссплатформенным, работать на всех наиболее распространённых десктопных и мобильных платформах в однопоточных и многопоточных окружениях. Так же сделаем возможным существование вложенных try/catch секций. Обрабатывать будем следующие виды исключительных ситуаций: доступ к памяти по неправильным адресам, выполнение невалидных инструкций и деление на ноль. Апофеозом будет то, что произошедшие аппаратные исключения будут превращаться в обычные C++ исключения.
Наиболее часто для решения аналогичным поставленной задачам рекомендуется использовать POSIX сигналы на не Windows системах, а на Windows Structured Exception Handling (SEH). Поступим примерно следующим образом, но вместо SEH будем использовать Vectored Exception Handling (VEH), которые очень часто обделены вниманием. Вообще, со слов Microsoft, VEH является расширением SEH, т.е. чем-то более функциональным и современным. VEH чем-то схож c POSIX сигналами, для того чтобы начать ловить какие либо события обработчик надо зарегистрировать. Однако в отличии от сигналов для VEH можно регистрировать несколько обработчиков, которые будут вызываться по очереди до тех пор пока один из них не обработает возникшее событие.
В довесок к обработчикам сигналов возьмём на вооружение пару setjmp/longjmp, которые позволят нам возвращаться туда куда нам хочется после возникновения аварийной ситуации и каким-либо способом обрабатывать эту самую исключительную ситуацию. Так же, чтобы наша поделка работала в многопоточных средах нам понадобится старый добрый thread local storage (TLS), который также доступен во всех интересующих нас средах.
Самое простое, что необходимо сделать чтобы просто не упасть в случае аварийной ситуации — это написать свой обработчик и зарегистрировать его. В большинстве случаев людям достаточно просто собрать необходимое количество информации и красиво свернуть приложение. Так или иначе обработчик сигналов регистрируется всем известным способом. Для POSIX-совместимых систем это выглядит следующим образом:
stack_t ss;
ss.ss_sp = exception_handler_stack;
ss.ss_flags = 0;
ss.ss_size = SIGSTKSZ;
sigaltstack(&ss, 0);
struct sigaction sa;
sigemptyset(&sa.sa_mask);
sa.sa_flags = SA_ONSTACK;
sa.sa_handler = signalHandler;
for (int signum : handled_signals)
sigaction(signum, &sa, &prev_handlers[signum - MIN_SIGNUM]);Выше приведённый фрагмент кода регистрирует обработчик для следующий сигналов: SIGBUS, SIGFPE, SIGILL, SIGSEGV. Помимо этого с помощью вызова sigaltstack указываться, что обработчик сигнала должен запускаться на альтернативном, своём собственном, стеке. Это позволяет выживать приложению даже в условиях stack overflow, который легко может возникнуть в случае бесконечно рекурсии. Если не задать альтернативный стек, то подобного рода ошибки не возможно будет обработать, приложение будет просто падать, т.к. для вызова и выполнения обработчика просто не будет стека и с этим ничего нельзя будет сделать. Так же сохраняются указатели на ранее зарегистрированные обработчики, что позволит их вызывать, если наш обработчик поймёт, что делать ему нечего.
Для Windows код намного короче:
exception_handler_handle = AddVectoredExceptionHandler(1, vectoredExceptionHandler);Обработчик один, он ловит сразу все события (не только аппаратные исключения надо сказать) и нет никакой возможности что-либо сделать со стеком как в Linux, например. Единица, подаваемая первым аргументом в функцию AddVectoredExceptionHandler, говорит о том, что наш обработчик должен вызываться первым, перед любыми другими уже имеющимися. Это даёт нам шанс быть первыми и предпринять необходимые нам действия.
Сам обработчик для POSIX систем выглядит следующим образом:
static void signalHandler(int signum)
{
if (execution_context) {
sigset_t signals;
sigemptyset(&signals);
sigaddset(&signals, signum);
sigprocmask(SIG_UNBLOCK, &signals, NULL);
reinterpret_cast(static_cast(execution_context))->exception_type = signum;
longjmp(execution_context->environment, 0);
}
else if (prev_handlers[signum - MIN_SIGNUM].sa_handler) {
prev_handlers[signum - MIN_SIGNUM].sa_handler(signum);
}
else {
signal(signum, SIG_DFL);
raise(signum);
}
} Надо сказать, что для того чтобы наш обработчик сигналов стал многоразовым, т.е. мог вызываться снова и снова в случае возникновения новых ошибок, мы должны при каждом заходе разблокировать сработавший сигал. Это необходимо в тех случаях, когда обработчик знает, что исключительная ситуация возникла в участке кода, который завёрнут в некие try/catch о которых речь пойдёт позже. Если же аварийная ситуация сложилась там где мы её совсем не ожидали, дела будут переданы ранее зарегистрированному обработчику сигналов, если такового нет, то вызывается обработчик по умолчанию, который завершит терпящее аварию приложение.
Обработчик для Windows выглядит следующим образом:
static LONG WINAPI vectoredExceptionHandler(struct _EXCEPTION_POINTERS *_exception_info)
{
if (!execution_context ||
_exception_info->ExceptionRecord->ExceptionCode == DBG_PRINTEXCEPTION_C ||
_exception_info->ExceptionRecord->ExceptionCode == 0xE06D7363L /* C++ exception */
)
return EXCEPTION_CONTINUE_SEARCH;
reinterpret_cast(static_cast(execution_context))->dirty = true;
reinterpret_cast(static_cast(execution_context))->exception_type = _exception_info->ExceptionRecord->ExceptionCode;
longjmp(execution_context->environment, 0);
} Как уже упоминалось выше VEH обработчик на Windows ловит много чего ещё помимо аппаратных исключений. Например при вызове OutputDebugString возникает исключение с кодом DBG_PRINTEXCEPTION_C. Подобные события мы обрабатывать не будем и просто вернём EXCEPTION_CONTINUE_SEARCH, что приведёт к тому что ОС пойдёт искать следующий обработчик, который обработает данное событие. Также мы не хотим обрабатывать C++ исключения, которым соответствует магический код 0xE06D7363L не имеющий нормального имени.
Как на POSIX-совместимых системах так и на Windows в конце обработчика вызывается longjmp, который позволяет нам вернуться вверх по стеку, до самого начала секции try и обойти её попав в ветку catch, в которой можно будет сделать все необходимые для восстановления работы действия и продолжить работу так как будто ничего страшного не произошло.
Для того, чтобы обычный C++ try начал ловить не свойственные ему исключительные ситуации необходимо в самое начало поместить небольшой макрос HW_TO_SW_CONVERTER:
#define HW_TO_SW_CONVERTER_UNIQUE_NAME(NAME, LINE) NAME ## LINE
#define HW_TO_SW_CONVERTER_INTERNAL(NAME, LINE) ExecutionContext HW_TO_SW_CONVERTER_UNIQUE_NAME(NAME, LINE); if (setjmp(HW_TO_SW_CONVERTER_UNIQUE_NAME(NAME, LINE).environment)) throw HwException(HW_TO_SW_CONVERTER_UNIQUE_NAME(NAME, LINE))
#define HW_TO_SW_CONVERTER() HW_TO_SW_CONVERTER_INTERNAL(execution_context, __LINE__)Выглядит довольно кудряво, но по факту здесь делается очень простая вещь:
setjmp, который позволяет нам запомнить место где мы начали и куда нам надо вернуться в случае аварии.setjmp вернёт не нулевое значение, после того как где-то по пути был вызван longjmp. Это приведёт к тому, что будет брошено C++ исключение типа HwException, которое будет содержать информацию о том какого вида ошибка случилась. Брошенное исключение без проблем ловится стандартным catch.Упрощённо приведённый выше макрос разворачивается в следующий псевдокод:
if (setjmp(environment))
throw HwException();У подхода setjmp/longjmp есть один существенный недостаток. В случае обычных C++ исключений, происходит размотка стека при которой вызываются деструкторы всех созданных по пути объектов. В случае же с longjmp мы сразу прыгаем в исходную позицию, никакой размотки стека не происходит. Это накладывает соответствующие ограничения на код, который находится внутри таких секций try, там нельзя выделять какие-либо ресурсы ибо есть риск их навсегда потерять, что приведёт к утечкам.
Ещё одним ограничением является то, что setjmp нельзя использовать в функциях/методах объявленных как inline. Это ограничение самого setjmp. В лучшем случае компилятор просто откажется собирать подобный код, в худшем он его соберёт, но полученный бинарный файл будет просто аварийно завершать свою работу.
Самым ненормальным действием, которое приходится принимать после обработки аппаратного исключения на Windows является необходимость вызова RemoveVectoredExceptionHandler. Если этого не сделать, то после каждого входа в наш обработчик VEH и выполнения longjmp там будет складываться ситуация как-будто наш обработчик был зарегистрирован ещё один раз. Это приводит к тому, что при каждой последующей аварийной ситуации обработчик будет вызываться всё больше и больше раз подряд, что будет приводить к плачевным последствиям. Данное решение было найдено исключительно путём многочисленных магических экспериментов и нигде никак не документировано.
Для того, чтобы решение работало в многопоточных окружениях необходимо чтобы каждый поток имел собственное место где можно сохранять контекст исполнения с помощью setjmp. Для этих целей и используется TLS, в использовании которого нет ничего хитрого.
Сам контекст исполнения оформлен в виде простого класса имеющего следующие конструктор и деструктор:
ExecutionContext::ExecutionContext() : prev_context(execution_context)
{
#if defined(PLATFORM_OS_WINDOWS)
dirty = false;
#endif
execution_context = this;
}
ExecutionContext::~ExecutionContext()
{
#if defined(PLATFORM_OS_WINDOWS)
if (execution_context->dirty)
RemoveVectoredExceptionHandler(exception_handler_handle);
#endif
execution_context = execution_context->prev_context;
}Данный класс имеет поле prev_context, которое даёт нам возможность создавать цепочки из вложенных секций try/catch.
Полный листинг описанного выше изделия доступен в GitHub'е:
https://github.com/kutelev/hwtrycatch
В доказательство того, что всё работает как описано имеется автоматическая сборка и тесты под платформы Windows, Linux, Mac OS X и Android:
https://ci.appveyor.com/project/kutelev/hwtrycatch
https://travis-ci.org/kutelev/hwtrycatch
Под iOS это тоже работает, но за неимением устройства для тестирования нет и автоматических тестов.
В заключение скажем, что подобный подход можно использовать и в обычном C. Надо лишь написать несколько макросов, которые будут имитировать работу try/catch из C++.
Так же стоит сказать, что использование описанных методов в большинстве случаев является очень плохой идеей, особенно, если учесть, что на уровне сигналов нельзя выяснить, что же привело к возникновению SIGSEGV или SIGBUS. Это равновероятно может быть как и чтение по неправильным адресам так и запись. Если же чтение по произвольным адресам является операцией не деструктивной, то запись может приводить к плачевным результатам таким как разрушением стека, кучи или даже самого кода.
|
Метки: author kutelev ненормальное программирование c++ sigsegv segmentation fault access violation signal seh veh setjmp longjmp |
Выбор алгоритма вычисления квантилей для распределённой системы |

Всем привет!
Меня зовут Александр, я руковожу отделом Data Team в Badoo. Сегодня я расскажу вам о том, как мы выбирали оптимальный алгоритм для вычисления квантилей в нашей распределённой системе обработки событий.
Ранее мы рассказывали о том, как устроена наша система обработки событий UDS (Unified Data Stream). Вкратце – у нас есть поток гетерогенных событий, на котором нужно в скользящем окне проводить агрегацию данных в различных разрезах. Каждый тип события характеризуется своим набором агрегатных функций и измерений.
В ходе развития системы нам потребовалось внедрить поддержку агрегатной функции для квантилей. Более подробно о том, что такое перцентили и почему они лучше представляют поведение метрики, чем min/avg/max, вы можете узнать из нашего поста про использование Pinba в Badoo. Вероятно, мы могли бы взять ту же имплементацию, что используется в Pinba, но стоит принять во внимание следующие особенности UDS:
Исходя из этих архитектурных особенностей, мы выдвинули ряд параметров, по которым будем оценивать алгоритмы расчёта квантилей:
Мы решили, что нас устроит точность вычислений вплоть до 1,5%.
Нам важно минимизировать период времени от возникновения события до визуализации его квантилей на графиках. Этот фактор складывается из трёх других:
В нашей системе обрабатываются миллионы метрик, и нам важно следить за разумным использованием вычислительных ресурсов. Под памятью мы подразумеваем следующее:
Также мы выдвигаем следующие условия:
Алгоритм должен поддерживать вычисления для неотрицательных величин, представленных типом double.
Должна присутствовать имплементация на Java без использования JNI.

Чтобы иметь некий референс для сравнения, мы написали реализацию «в лоб», которая хранит все входящие значения в double[]. При необходимости вычисления квантиля массив сортируется, вычисляется ячейка, соответствующая квантилю, и берётся её значение. Слияние двух промежуточных результатов происходит путём конкатенации двух массивов.
Это решение было найдено нами в ходе рассмотрения алгоритмов, заточенных под Spark (используется в основе UDS). Библиотека Twitter Algebird предназначена для расширения алгебраических операций, доступных в языке Scala. Она содержит ряд широко используемых функций ApproximateDistinct, CountMinSketch и, помимо всего прочего, реализацию перцентилей на основании алгоритма Q-Digest. Математическое обоснование алгоритма вы можете найти здесь. Вкратце структура представляет собой бинарное дерево, в котором каждый узел хранит некоторые дополнительные атрибуты.
Библиотека представляет собой улучшение вышеупомянутого алгоритма Q-Digest с заявленным меньшим потреблением памяти, улучшенной производительностью и более высокой точностью.
На этот продукт мы наткнулись при реверс-инжиниринге распределённого SQL-движка Facebook Presto. Было несколько удивительно увидеть реализацию квантилей в REST-фреймворке, но высокая скорость работы и архитектура Presto (схожая с Map/Reduce) подтолкнули нас к тому, чтобы протестировать это решение. В качестве математического аппарата используется опять же Q-Digest.
Это решение являлось идейным вдохновителем реализации перцентилей в Pinba. Его отличительной особенностью является то, что при инициализации структуры необходимо знать верхний диапазон данных. Весь диапазон значений разбивается на N-ное количество ячеек, и при добавлении мы инкрементируем значение в какой-то из них.

Каждое из рассматриваемых программных решений было обёрнуто некоторой прослойкой (моделью) (чтобы адаптировать его под фреймворк для тестирования). Перед проведением performance-тестов для каждой модели были написаны unit-тесты для проверки её достоверности. Эти тесты проверяют, что модель (её нижележащее программное решение) может выдавать квантили с заданной точностью (проверялись точности 1% и 0,5%).
Для каждой из моделей были написаны тесты с использованием JMH. Они были разделены на категории, про каждую из которых я расскажу подробно. Не буду «засорять» пост сырыми выводом от JMH – лучше сразу буду визуализировать в виде графиков.
В этом тесте мы измеряем производительность структур данных на вставку, то есть производятся замеры времени, требуемого на инициализацию структуры и на заполнение её данными. Также мы рассмотрим, как изменяется это время в зависимости от точности и количества элементов. Измерения производились для последовательностей монотонно возрастающих чисел в диапазонах 10, 100, 1000, 10000, 100000, 1000000 при погрешности вычисления 0,5% и 1%. Вставка производилась пачкой (если структура поддерживает) или поэлементно.
В результате мы получили следующую картину (шкала ординат логарифмическая, меньшие значения – лучше):
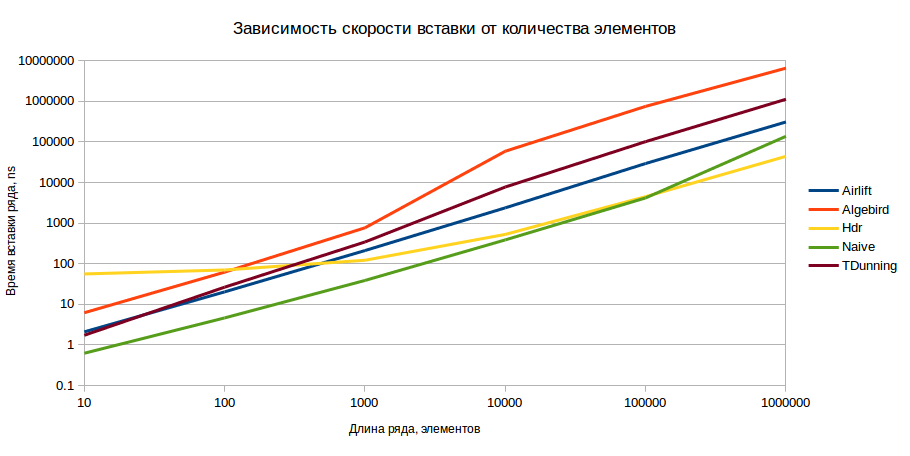
Результаты приведены для точности 1%, но для точности 0,5% картина принципиально не меняется. Невооружённым глазом видно, что с точки зрения вставки HDR является оптимальным вариантом при условии наличия более чем 1000 элементов в модели.
В этом тесте мы производим замеры объёма, занимаемого моделями в памяти и в сериализованном виде. Модель заполняется последовательностями данных, затем производится оценка её размера. Ожидается, что лучшей окажется модель с меньшим объёмом занимаемой памяти. Замер производится с использованием SizeEstimator из Spark.

Как видно, при незначительном количестве элементов HDR проигрывает прочим имплементациям, однако имеет лучшую скорость роста в дальнейшем.
Оценка сериализованного размера производилась путём сериализации модели через Kryo, являющийся де-факто стандартом в области сериализации. Для каждой модели был написан свой сериализатор, который преобразует её максимально быстрым и компактным образом.

Абсолютным чемпионом вновь является HDR.
Этот тест наиболее полно отражает поведение системы в боевой ситуации. Методика теста следующая:
Результаты теста (меньшие значения – лучше):
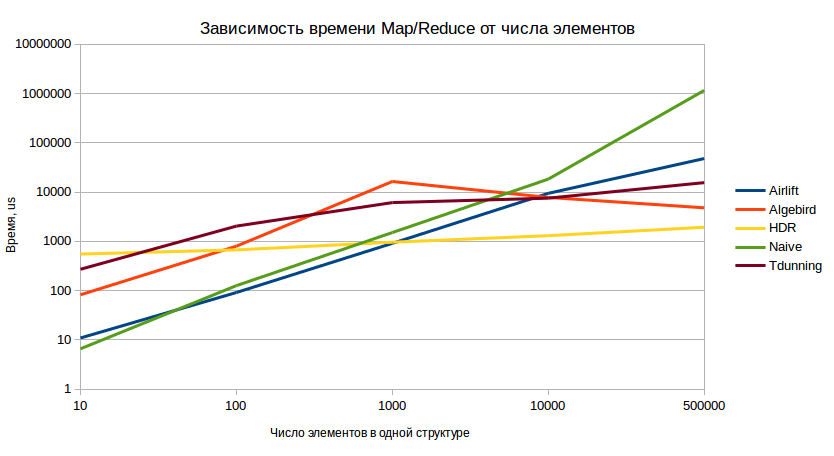
И в данном тесте мы снова отчётливо видим уверенное доминирование HDR в долгосрочной перспективе.
Проанализировав результаты, мы пришли к выводу, что HDR является оптимальной имплементацией на большом количестве элементов, в то время как на моделях с небольшим количеством данных есть более выгодные реализации. Специфика агрегации по многим измерениям такова, что одно физическое событие влияет на несколько ключей агрегации. Представим себе, что одно событие EPayment должно быть сгруппировано по стране и полу пользователя. В этом случае мы получаем четыре ключа агрегации:

Очевидно, что при обработке потока событий ключи с меньшим числом измерений будут иметь большее число значений для перцентилей. Статистика использования нашей системы даёт нам следующую картину:

Эта статистика позволила нам принять решение о необходимости посмотреть на поведение метрик с большим количеством измерений. В результате мы выяснили, что 90 перцентиль числа событий на одну метрику (то есть нашу тестовую модель) находится в пределах 2000. Как мы видели ранее, при подобном количестве элементов есть модели, которые ведут себя лучше, чем HDR. Так у нас появилась новая модель – Combined, которая объединяет в себе лучшее от двух миров:
Смотрим результаты этого нового участника!



Как видно из приведённых графиков, Combined-модель действительно ведёт себя лучше HDR на малой выборке и сравнивается с ней при увеличении числа элементов.
Если вас интересуют код исследования и примеры API рассмотренных алгоритмов, вы можете найти всё это на GitHub. И если вы знаете реализацию, которую мы могли бы добавить к сравнению, напишите о ней в комментариях!
|
Метки: author alexkrash программирование алгоритмы java big data блог компании badoo map reduce квантиль spark |
Как выигрывать в конкурсах Вконтакте? Другой подход |

«надо участвовать во всех конкурсах и по теории вероятностей, чем больше конкурсов, тем больше шанс выиграть хоть что-то»

certutil -hashfile c:file SHA512
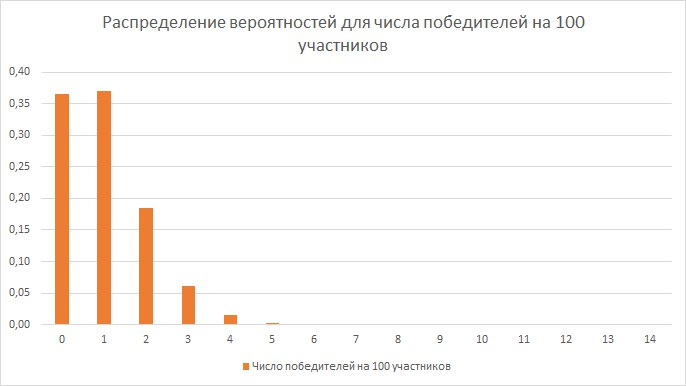


|
Метки: author Cloud4Y повышение конверсии монетизация игр контент-маркетинг блог компании cloud4y vkontakte api конкурсы социальные сети sha-512 |
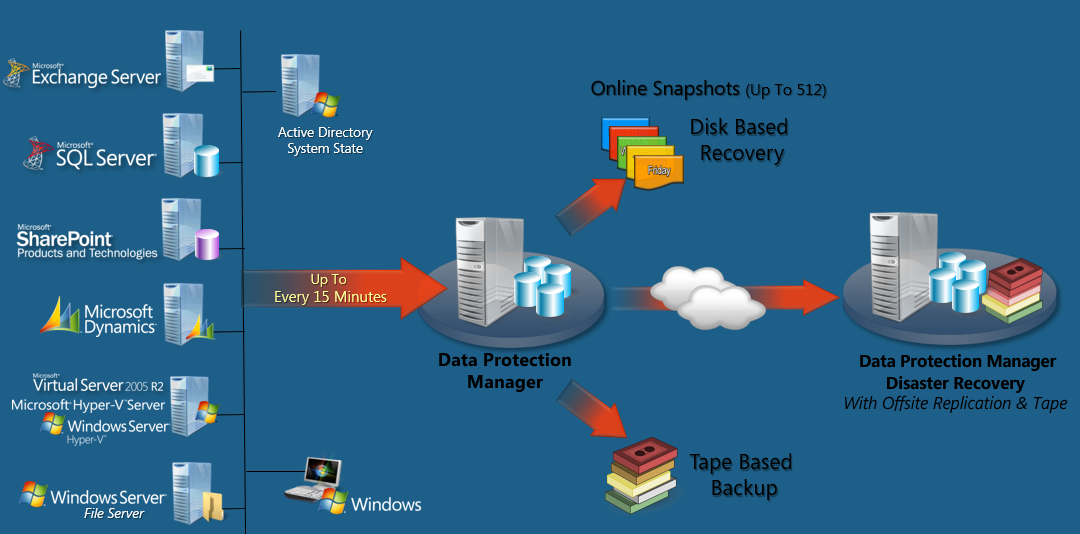
DPM: Почему он такой? |

В первой части мы поговорим про исторический контекст Microsoft Data Protection Manager, и то, почему он такой.
Вовторой — о том, как он работает технически, с заглядыванием на страшного зверя VSS.
Ну а в третьей — текущее положение дел, что он умеет и как мы это сможем использовать, в том числе и с Microsoft Azure Backup.




|
|
LibGDX + Scene2d (программируем на Kotlin). Часть 1 |



class TableStage : Stage() {
init {
val stageLayout = Table()
addActor(stageLayout.apply {
debugAll()
setFillParent(true)
pad(AppConstants.PADDING)
defaults().expand().space(AppConstants.PADDING)
row().let {
add(Image(uiSkin.getDrawable("sample")))
add(Image(uiSkin.getDrawable("sample"))).top().right()
add(Image(uiSkin.getDrawable("sample"))).fill()
}
row().let {
add(Image(uiSkin.getTiledDrawable("sample"))).fillY().left().colspan(2)
add(Image(uiSkin.getTiledDrawable("sample"))).width(64f).height(64f).right().bottom()
}
row().let {
add(Image(uiSkin.getDrawable("sample")))
add(Image(uiSkin.getTiledDrawable("sample"))).fill().pad(AppConstants.PADDING)
add(Image(uiSkin.getDrawable("sample"))).width(64f).height(64f)
}
})
}
} ...
val stageLayout = Table()
addActor(stageLayout.apply { // добавление таблицы в сцену
debugAll() // Включаем дебаг для всех элементов таблицы
setFillParent(true) // Указываем что таблица принимает размеры родителя
pad(AppConstants.PADDING)
defaults().expand().space(AppConstants.PADDING)
row().let {
add(Image(uiSkin.getDrawable("sample")))
add(Image(uiSkin.getDrawable("sample"))).top().right()
add(Image(uiSkin.getDrawable("sample"))).fill()
}
...
Table stageLayout = new Table();
stageLayout.debugAll();
stageLayout.setFillParent(true);
stageLayout.pad(AppConstants.PADDING);
stageLayout.defaults().expand().space(AppConstants.PADDING);
stageLayout.row();
stageLayout.add(Image(uiSkin.getDrawable("sample")));
stageLayout.add(Image(uiSkin.getDrawable("sample"))).top().right();
stageLayout.add(Image(uiSkin.getDrawable("sample"))).fill();
addActor(stageLayout);
var name: String? = ...
name?.let {
if (it == "Alex") ...
}

.width(40f)
.width(Value.percentWidth(.4f, stageLayout)
val stageLayout = Table()
addActor(stageLayout.apply {
...
row().let {
val headerContainer = Container()
add(headerContainer.apply {
background = TextureRegionDrawable(TextureRegion(Texture("images/status-bar-background.png")))
// здесь в следующей части мы добавим панель ресурсов
}).height(100f).expandX()
}
val stageLayout = Table()
addActor(stageLayout.apply {
setFillParent(true)
defaults().fill()
row().let {
val headerContainer = Container()
add(headerContainer.apply {
background = TextureRegionDrawable(TextureRegion(Texture("images/status-bar-background.png")))
}).height(100f).expandX()
}
row().let {
add(Image(Texture("backgrounds/main-screen-background.png")).apply {
setScaling(Scaling.fill)
}).expand()
}
row().let {
val footerContainer = Container()
add(footerContainer.apply {
background = TextureRegionDrawable(TextureRegion(Texture("images/status-bar-background.png")))
fill()
actor = CommandPanel()
}).height(160f).expandX()
}
})

val stageLayout = Table()
addActor(stageLayout.apply {
setFillParent(true)
background = TextureRegionDrawable(TextureRegion(Texture("backgrounds/loading-logo.png")))
})
val stageLayout = Table()
val backgroundImage = Image(Texture("backgrounds/loading-logo.png"))
addActor(backgroundImage.apply {
setFillParent(true)
setScaling(Scaling.fill)
})

init {
val backgroundImage = Image(Texture("backgrounds/loading-logo.png"))
addActor(backgroundImage.apply {
setFillParent(true)
setScaling(Scaling.fill)
})
val stageLayout = Table()
addActor(stageLayout.apply {
setFillParent(true)
row().let {
add().width(Value.percentWidth(.6f, stageLayout)).height(Value.percentHeight(.8f, stageLayout))
}
row().let {
add(progressBar).height(40f).fill() // про progressBar будет в следующих частях
}
})
}

|
Метки: author TerraV разработка под android разработка игр kotlin android libgdx я пиарюсь |
Метод восстановления данных с диска, зашифрованного NotPetya с помощью алгоритма Salsa20 |


enum s20_status_t s20_crypt32(uint8_t *key,
uint8_t nonce[static 8],
uint32_t si,
uint8_t *buf,
uint32_t buflen)// Set the second-to-highest 4 bytes of n to the block number
s20_rev_littleendian(n+8, si / 64);
|
Метки: author ptsecurity информационная безопасность блог компании positive technologies notpetya вирус вымогатель расшифровка |
[Из песочницы] Спасёт ли Python от казни? |

t = linspace(0,15,100)
G = 9.8
L = 1.0
def diffeq(state, t):
th, w = state
return [w, -G*L*sin(th)]
dt = 0.05
t = np.arange(0.0, 20, dt)
th1 = 179.0
w1 = 0.0
state = np.radians([th1, w1])
y = odeint(diffeq, state, t)

import matplotlib.animation as animation
from pylab import *
from scipy.integrate import *
import matplotlib.pyplot as plt
t = linspace(0,15,100)
G = 9.8
L = 10.0
def derivs(state, t):
th, w, r, v = state
if 0. 0, max = L))*sin(y[:, 0])
y2 = -(L-y[:,2].clip(min = 0, max = L))*cos(y[:, 0])
fig = plt.figure()
ax = fig.add_subplot(111, autoscale_on=False, xlim=(-L-0.2, L+0.2), ylim=(-L-0.2, L+0.2))
ax.grid()
line, = ax.plot([], [], '-', lw=2)
point, = ax.plot(0,0,'o', lw=2)
extra, = ax.plot(x1/L*r1,y1/L*r1,'o', lw=2)
time_template = 'time = %.1fs'
time_text = ax.text(0.05, 0.9, '', transform=ax.transAxes)
def init():
line.set_data([], [])
point.set_data(0,0)
time_text.set_text('')
extra.set_data(x1/L*r1,y1/L*r1)
return line, time_text, point, extra
def animate(i):
thisx = [0, x1[i]]
thisy = [0, y1[i]]
thisx2 = x2[i]
thisy2 = y2[i]
point.set_data(thisx[0],thisy[0])
line.set_data(thisx, thisy)
time_text.set_text(time_template % (i*dt))
extra.set_data([thisx2,thisy2])
return line, time_text, point, extra
ani = animation.FuncAnimation(fig, animate, np.arange(1, len(y)),
interval=25, blit=True, init_func=init, repeat = False)
plt.show()|
Метки: author ventosa программирование математика python физика движения моделирование кинематика твердого тела дифференциальные уравнения маятник обербека |
[Перевод] Чему я научился, конвертируя проект в Kotlin при помощи Android Studio |

companion object {
private val TIMER_DELAY = 3000
}
//...
handler.postDelayed({
//...
}, TIMER_DELAY.toLong())companion object {
private val TIMER_DELAY = 3000L
}
//...
handler.postDelayed({
//...
}, TIMER_DELAY)public class ErrorFragment extends Fragment {
void setErrorContent() {
//...
}
}class ErrorFragment : Fragment() {
internal fun setErrorContent() {
//...
}
}
public final void setErrorContent$production_sources_for_module_app() {
//...
}mErrorFragment.setErrorContent()// Accesses the ErrorFragment instance and invokes the actual method
ErrorActivity.access$getMErrorFragment$p(ErrorActivity.this)
.setErrorContent$production_sources_for_module_app();
public class DetailsActivity extends Activity {
public static final String SHARED_ELEMENT_NAME = "hero";
public static final String MOVIE = "Movie";
//...
}class DetailsActivity : Activity() {
companion object {
val SHARED_ELEMENT_NAME = "hero"
val MOVIE = "Movie"
}
//...
}val intent = Intent(context, DetailsActivity::class.java)
intent.putExtra(DetailsActivity.MOVIE, item)intent.putExtra(DetailsActivity.Companion.getMOVIE(), item)public final class DetailsActivity extends Activity {
@NotNull
private static final String SHARED_ELEMENT_NAME = "hero";
@NotNull
private static final String MOVIE = "Movie";
public static final DetailsActivity.Companion Companion = new DetailsActivity.Companion((DefaultConstructorMarker)null);
//...
public static final class Companion {
@NotNull
public final String getSHARED_ELEMENT_NAME() {
return DetailsActivity.SHARED_ELEMENT_NAME;
}
@NotNull
public final String getMOVIE() {
return DetailsActivity.MOVIE;
}
private Companion() {
}
// $FF: synthetic method
public Companion(DefaultConstructorMarker $constructor_marker) {
this();
}
}
}class DetailsActivity : Activity() {
companion object {
const val SHARED_ELEMENT_NAME = "hero"
const val MOVIE = "Movie"
}
//...
}public final class DetailsActivity extends Activity {
@NotNull
public static final String SHARED_ELEMENT_NAME = "hero";
@NotNull
public static final String MOVIE = "Movie";
public static final DetailsActivity.Companion Companion = new DetailsActivity.Companion((DefaultConstructorMarker)null);
//...
public static final class Companion {
private Companion() {
}
// $FF: synthetic method
public Companion(DefaultConstructorMarker $constructor_marker) {
this();
}
}
}
for (int i = 0; i < NUM_ROWS; i++) {
//...
for (int j = 0; j < NUM_COLS; j++) {
//...
}
//...
}for (i in 0..NUM_ROWS - 1) {
//...
for (j in 0..NUM_COLS - 1) {
//...
}
//...
}for (i in 0 until NUM_ROWS) {
//...
for (j in 0 until NUM_COLS) {
//...
}
//...
}public static List getList() {
if (list == null) {
list = createMovies();
}
return list;
}

val list: List by lazy {
createMovies()
} final Movie movie = (Movie) getActivity()
.getIntent().getSerializableExtra(DetailsActivity.MOVIE);
// Access properties from getters
mMediaPlayerGlue.setTitle(movie.getTitle());
mMediaPlayerGlue.setArtist(movie.getDescription());
mMediaPlayerGlue.setVideoUrl(movie.getVideoUrl());val (_, title, description, _, _, videoUrl) = activity
.intent.getSerializableExtra(DetailsActivity.MOVIE) as Movie
// Access properties via variables
mMediaPlayerGlue.setTitle(title)
mMediaPlayerGlue.setArtist(description)
mMediaPlayerGlue.setVideoUrl(videoUrl)Serializable var10000 = this.getActivity().getIntent().getSerializableExtra("Movie");
Movie var5 = (Movie)var10000;
String title = var5.component2();
String description = var5.component3();
String videoUrl = var5.component6();|
Метки: author nanton kotlin java блог компании everyday tools конвертация android studio |
[Перевод] Платформа Node.js обойдёт Java в течение года |



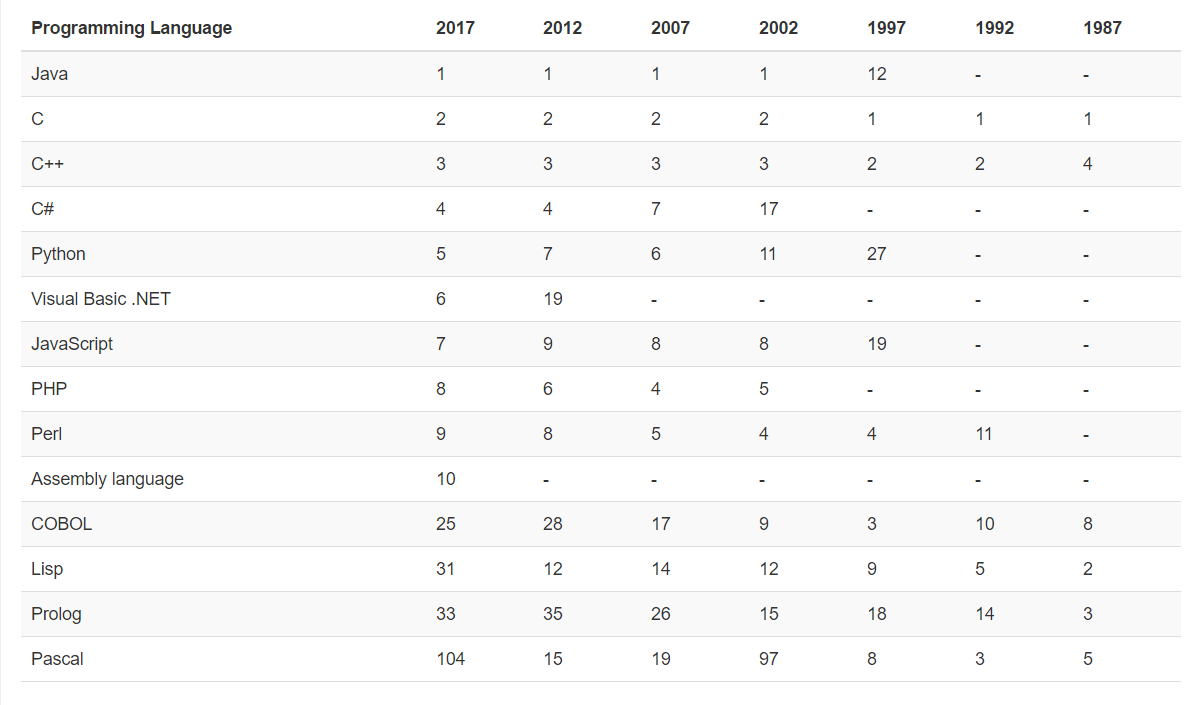
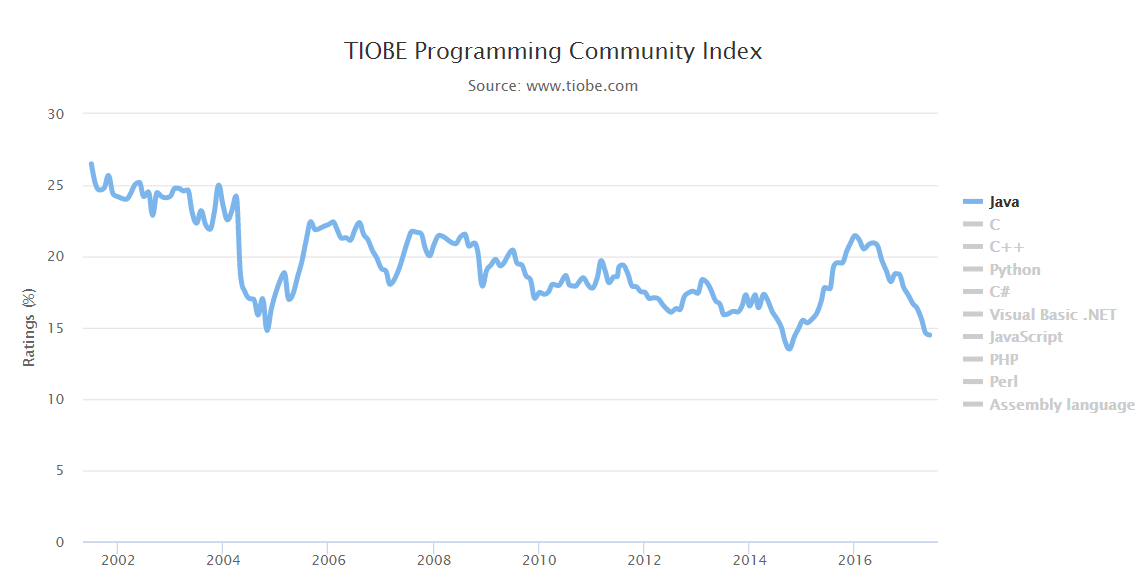
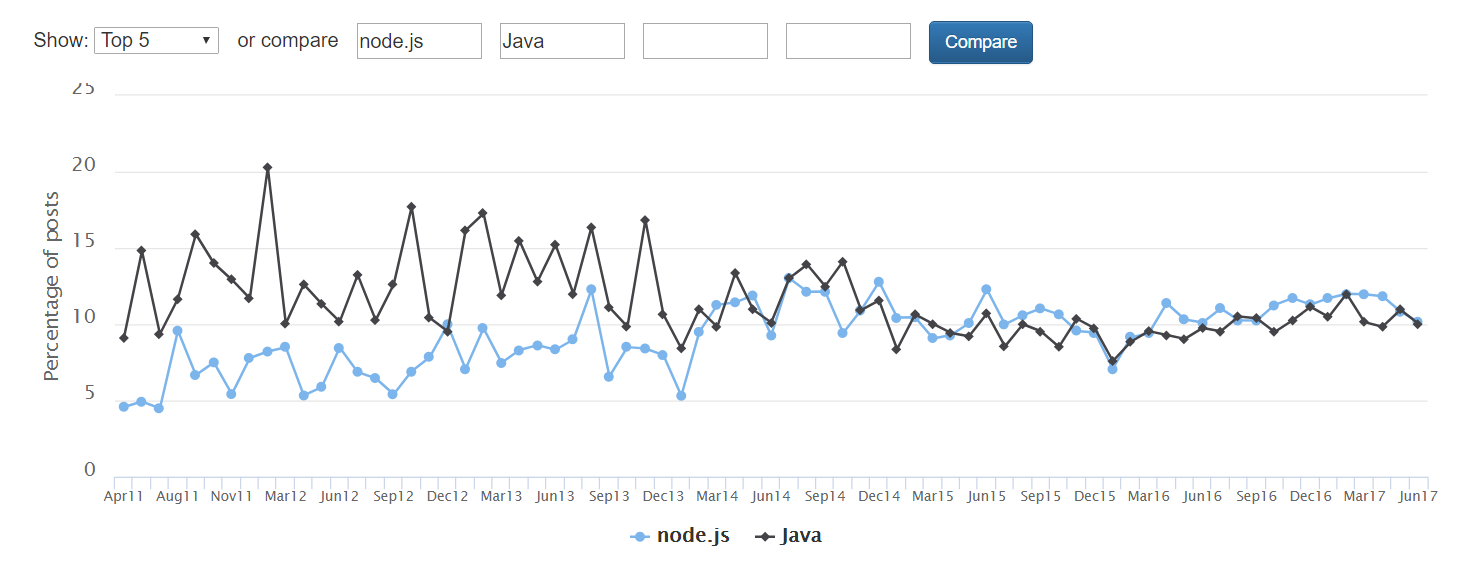

|
Метки: author ru_vds node.js javascript java блог компании ruvds.com разработка |
Резервное копирование томов LVM2 с защитой от перегрузок IO с использованием сигналов SIGSTOP, SIGCONT |
Настройка резервного копирования уверенно занимает одно из важнейших мест в деятельности администратора. В зависимости от задач резервного копирование и типов приложений и вида данных резервное копирование может осуществляться с помощью различных инструментов, таких как rsync, duplicity, rdiff-backup, bacula и других, коих существует огромное множество.
Помимо осуществления самого процесса резервного копирования, который бы отвечал потребностям организации, существует ряд проблем, которые неизбежно возникают при осуществлении резервного копирования, одна из которых — увеличение нагрузки на дисковую подсистему, что может приводить к деградации производительности приложений.
Решение данной задачи не является простым — часто администратор вынужден идти на компромиссы, которые ведут к тому, что продолжительность процедуры увеличивается или периодичность резервного копирования уменьшается с ежедневного до еженедельного. Данные компромиссы неизбежны и являются вынужденной реакцией на существующие технические ограничения.
И, тем не менее, основной вопрос остается открытым. Как же осуществлять резервное копирование таким образом, чтобы основные приложения получали приемлемое качество обслуживания? Операционные системы семейства UNIX предоставляют штатный механизм управления приоритетами ввода-вывода для приложений, который называется ionice, кроме того, конкретные реализации UNIX предоставляют свои механизмы, которые позволяют наложить дополнительные ограничения. К примеру, в случае GNU/Linux существует механизм cgroups, который позволяет ограничить полосу пропускания (для физически подключенных устройств) и установить относительный приоритет для группы процессов.
Тем не менее, в некоторых случаях таких решений недостаточно и необходимо ориентироваться на фактическое "самочувствие" системных процессов, которое отражают такие параметры системы как Load Average или %IOWait. В этом случае на помощь может прийти подход, который я успешно применяю уже достаточно продолжительное время при осуществлении резервного копирования данных с LVM2 с помощью dd.
Имеется сервер GNU/Linux, на котором настроено хранилище, использующее LVM2 и для данного сервера каждую ночь осуществляется процедура резервного копирования тома, которая выполняется с помощью создания снимка раздела и запуска dd + gzip:
ionice -c3 dd if=/dev/vg/volume-snap bs=1M | gzip --fast | ncftpput ...При осуществлении резервного копирования хочется выполнить его максимально быстро, но опытным путем замечено, что при повышение %IOWait до 30%, качество обслуживание дисковой системой приложений становится неприемлемым, поэтому необходимо держать его ниже данного уровня. Требуется реализовать ограничительный механизм, который бы обеспечивал обработку в предельно допустимых значениях %IOWait.
Изначально для решения был применен подход с ionice -с3, но он не давал стабильного результата. Механизмы, основанные на cpipe и cgroups (throttling) были отброшены как не дающие возможности копировать данные быстро, если %IOWait в норме. В итоге было выбрано решение, основанное на мониторинге %IOWait и приостановке/возобновлении процесса dd с помощью сигналов SIGSTOP, SIGCONT совместно с сервисом статистики sar.
Схематично решение выглядит следующим образом:
Скорее всего п.3 вызывает вопросы. Зачем такое странное действие? Дело в том, что в рамках резервного копирования осуществляется передача данных по FTP на удаленный сервер и если процесс копирования остановлен достаточно продолжительное время, то мы можем потерять соединение по таймауту. Для того, чтобы этого не произошло, мы выполняем принудительное возобновление и остановку процесса копирования даже в том случае, если находимся в "красной" зоне.
Код решения приведен ниже.
#!/bin/bash
INTERVAL=10
CNTR=0
while :
do
CUR_LA=`LANG=C sar 1 $INTERVAL | grep Average | awk '{print $6}' | perl -pe 'if ($_ > 30) { print "HIGH "} else {print "LOW "}'`
echo $CUR_LA
MARKER=`echo $CUR_LA | awk '{print $1}'`
if [ "$MARKER" = "LOW" ]
then
CNTR=0
pkill dd -x --signal CONT
continue
else
let "CNTR=$CNTR+1"
pkill dd -x --signal STOP
fi
if [ "$CNTR" = "5" ]
then
echo "CNTR = $CNTR - CONT / 2 sec / STOP to avoid socket timeouts"
CNTR=0
pkill dd -x --signal CONT
sleep 2
pkill dd -x --signal STOP
fi
doneДанное решение успешно решило проблему с перегрузкой IO на сервере, при этом не ограничивает скорость жестко, и уже несколько месяцев служит верой и правдой, в то время, как решения, основанные на предназначенных для этого механизмах, не дали положительного результата. Стоит отметить, что значение параметра, получаемое sar может быть легко заменено на Load Average и иные параметры, которые коррелируют с деградацией сервиса. Данный скрипт вполне подходит и для задач, в которых применяется не LVM2 + dd, а, к примеру, Rsync или другие инструменты резервного копирования.
C помощью cgroups возможно таким же образом реализовать не остановку, а ограничение полосы, если речь идет о копировании данных с физического блочного устройства.
PS: Скрипт приведен без редактуры в оригинальном виде.
|
|






