Создание приложений с использованием Firebird, jOOQ и Spring MVC |
4.0.0
ru.ibase
fbjavaex
1.0-SNAPSHOT
war
Firebird Java Example
${project.build.directory}/endorsed
UTF-8
4.3.4.RELEASE
1.2
3.0.1
jdbc:firebirdsql://localhost:3050/examples
org.firebirdsql.jdbc.FBDriver
SYSDBA
masterkey
javax
javaee-web-api
7.0
provided
javax.servlet
javax.servlet-api
${javax.servlet.version}
provided
jstl
jstl
${jstl.version}
com.fasterxml.jackson.core
jackson-core
2.8.5
com.fasterxml.jackson.core
jackson-annotations
2.8.5
com.fasterxml.jackson.core
jackson-databind
2.8.5
org.springframework
spring-core
${spring.version}
org.springframework
spring-web
${spring.version}
org.springframework
spring-webmvc
${spring.version}
org.springframework
spring-context
${spring.version}
org.springframework
spring-jdbc
${spring.version}
org.firebirdsql.jdbc
jaybird-jdk18
3.0.0
commons-dbcp
commons-dbcp
1.4
org.jooq
jooq
3.9.2
org.jooq
jooq-meta
3.9.2
org.jooq
jooq-codegen
3.9.2
junit
junit
4.11
jar
test
org.springframework
spring-test
${spring.version}
test
org.apache.maven.plugins
maven-compiler-plugin
3.1
1.7
1.7
${endorsed.dir}
org.apache.maven.plugins
maven-war-plugin
2.3
false
org.apache.maven.plugins
maven-dependency-plugin
2.6
validate
copy
${endorsed.dir}
true
javax
javaee-endorsed-api
7.0
jar

package ru.ibase.fbjavaex.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.EnableWebMvc;
import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurerAdapter;
import org.springframework.web.servlet.view.JstlView;
import org.springframework.web.servlet.view.UrlBasedViewResolver;
import org.springframework.http.converter.json.MappingJackson2HttpMessageConverter;
import org.springframework.http.converter.HttpMessageConverter;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
import java.util.List;
@Configuration
@ComponentScan("ru.ibase.fbjavaex")
@EnableWebMvc
public class WebAppConfig extends WebMvcConfigurerAdapter {
@Override
public void configureMessageConverters(List> httpMessageConverters) {
MappingJackson2HttpMessageConverter jsonConverter = new MappingJackson2HttpMessageConverter();
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.configure(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS, false);
jsonConverter.setObjectMapper(objectMapper);
httpMessageConverters.add(jsonConverter);
}
@Bean
public UrlBasedViewResolver setupViewResolver() {
UrlBasedViewResolver resolver = new UrlBasedViewResolver();
resolver.setPrefix("/WEB-INF/jsp/");
resolver.setSuffix(".jsp");
resolver.setViewClass(JstlView.class);
return resolver;
}
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("/resources/**").addResourceLocations("/WEB-INF/resources/");
}
}
package ru.ibase.fbjavaex.config;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.ServletRegistration.Dynamic;
import org.springframework.web.WebApplicationInitializer;
import org.springframework.web.context.support.AnnotationConfigWebApplicationContext;
import org.springframework.web.servlet.DispatcherServlet;
public class WebInitializer implements WebApplicationInitializer {
@Override
public void onStartup(ServletContext servletContext) throws ServletException {
AnnotationConfigWebApplicationContext ctx = new AnnotationConfigWebApplicationContext();
ctx.register(WebAppConfig.class);
ctx.setServletContext(servletContext);
Dynamic servlet = servletContext.addServlet("dispatcher", new DispatcherServlet(ctx));
servlet.addMapping("/");
servlet.setLoadOnStartup(1);
}
}
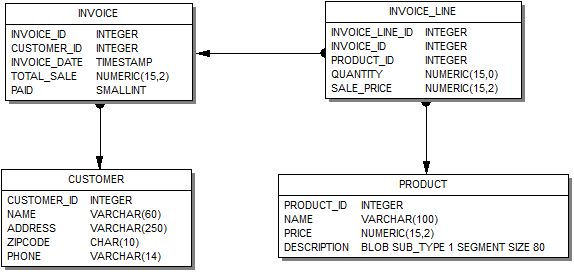
| Внимание! Эта модель является просто примером. Ваша предметная область может быть сложнее, или полностью другой. Модель, используемая в этой статье, максимально упрощена для того, чтобы не загромождать описание работы с компонентами описанием создания и модификации модели данных. |
org.firebirdsql.jdbc.FBDriver
jdbc:firebirdsql://localhost:3050/examples
SYSDBA
masterkey
charSet
utf-8
org.jooq.util.JavaGenerator
org.jooq.util.firebird.FirebirdDatabase
.*
RDB\$.*
| MON\$.*
| SEC\$.*
ru.ibase.fbjavaex.exampledb
e:/OpenServer/domains/localhost/fbjavaex/src/main/java/
java -cp jooq-3.9.2.jar;jooq-meta-3.9.2.jar;jooq-codegen-3.9.2.jar;jaybird-full-3.0.0.jar;. org.jooq.util.GenerationTool example.xml
/**
* Конфигурация IoC контейнера
* для осуществления внедрения зависимостей.
*/
package ru.ibase.fbjavaex.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import org.apache.commons.dbcp.BasicDataSource;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.jdbc.datasource.TransactionAwareDataSourceProxy;
import org.jooq.impl.DataSourceConnectionProvider;
import org.jooq.DSLContext;
import org.jooq.impl.DefaultDSLContext;
import org.jooq.impl.DefaultConfiguration;
import org.jooq.SQLDialect;
import org.jooq.impl.DefaultExecuteListenerProvider;
import ru.ibase.fbjavaex.exception.ExceptionTranslator;
import ru.ibase.fbjavaex.managers.*;
import ru.ibase.fbjavaex.jqgrid.*;
/**
* Конфигурационный класс Spring IoC контейнера
*/
@Configuration
public class JooqConfig {
/**
* Возвращает пул коннектов
*
* @return
*/
@Bean(name = "dataSource")
public DataSource getDataSource() {
BasicDataSource dataSource = new BasicDataSource();
// определяем конфигурацию подключения
dataSource.setUrl("jdbc:firebirdsql://localhost:3050/examples");
dataSource.setDriverClassName("org.firebirdsql.jdbc.FBDriver");
dataSource.setUsername("SYSDBA");
dataSource.setPassword("masterkey");
dataSource.setConnectionProperties("charSet=utf-8");
return dataSource;
}
/**
* Возращает менеджер транзакций
*
* @return
*/
@Bean(name = "transactionManager")
public DataSourceTransactionManager getTransactionManager() {
return new DataSourceTransactionManager(getDataSource());
}
@Bean(name = "transactionAwareDataSource")
public TransactionAwareDataSourceProxy getTransactionAwareDataSource() {
return new TransactionAwareDataSourceProxy(getDataSource());
}
/**
* Возвращает провайдер подключений
*
* @return
*/
@Bean(name = "connectionProvider")
public DataSourceConnectionProvider getConnectionProvider() {
return new DataSourceConnectionProvider(getTransactionAwareDataSource());
}
/**
* Возвращает транслятор исключений
*
* @return
*/
@Bean(name = "exceptionTranslator")
public ExceptionTranslator getExceptionTranslator() {
return new ExceptionTranslator();
}
/**
* Возвращает конфигурацию DSL контекста
*
* @return
*/
@Bean(name = "dslConfig")
public org.jooq.Configuration getDslConfig() {
DefaultConfiguration config = new DefaultConfiguration();
// используем диалект SQL СУБД Firebird
config.setSQLDialect(SQLDialect.FIREBIRD);
config.setConnectionProvider(getConnectionProvider());
DefaultExecuteListenerProvider listenerProvider = new DefaultExecuteListenerProvider(getExceptionTranslator());
config.setExecuteListenerProvider(listenerProvider);
return config;
}
/**
* Возвращает DSL контекст
*
* @return
*/
@Bean(name = "dsl")
public DSLContext getDsl() {
org.jooq.Configuration config = this.getDslConfig();
return new DefaultDSLContext(config);
}
/**
* Возвращает менеджер заказчиков
*
* @return
*/
@Bean(name = "customerManager")
public CustomerManager getCustomerManager() {
return new CustomerManager();
}
/**
* Возвращает грид с заказчиками
*
* @return
*/
@Bean(name = "customerGrid")
public JqGridCustomer getCustomerGrid() {
return new JqGridCustomer();
}
/**
* Возвращает менеджер продуктов
*
* @return
*/
@Bean(name = "productManager")
public ProductManager getProductManager() {
return new ProductManager();
}
/**
* Возвращает грид с товарами
*
* @return
*/
@Bean(name = "productGrid")
public JqGridProduct getProductGrid() {
return new JqGridProduct();
}
/**
* Возвращает менеджер счёт фактур
*
* @return
*/
@Bean(name = "invoiceManager")
public InvoiceManager getInvoiceManager() {
return new InvoiceManager();
}
/**
* Возвращает грид с заголовками счёт фактур
*
* @return
*/
@Bean(name = "invoiceGrid")
public JqGridInvoice getInvoiceGrid() {
return new JqGridInvoice();
}
/**
* Возвращает грид с позициями счёт фактуры
*
* @return
*/
@Bean(name = "invoiceLineGrid")
public JqGridInvoiceLine getInvoiceLineGrid() {
return new JqGridInvoiceLine();
}
/**
* Возвращает рабочий период
*
* @return
*/
@Bean(name = "workingPeriod")
public WorkingPeriod getWorkingPeriod() {
return new WorkingPeriod();
}
}
SELECT *
FROM author a
JOIN book b ON a.id = b.author_id
WHERE a.year_of_birth > 1920
AND a.first_name = 'Paulo'
ORDER BY b.title
Result result =
dsl.select()
.from(AUTHOR.as("a"))
.join(BOOK.as("b")).on(a.ID.equal(b.AUTHOR_ID))
.where(a.YEAR_OF_BIRTH.greaterThan(1920)
.and(a.FIRST_NAME.equal("Paulo")))
.orderBy(b.TITLE)
.fetch();
Result result =
dsl.select()
.from(AUTHOR)
.join(BOOK).on(AUTHOR.ID.equal(BOOK.AUTHOR_ID))
.where(AUTHOR.YEAR_OF_BIRTH.greaterThan(1920)
.and(AUTHOR.FIRST_NAME.equal("Paulo")))
.orderBy(BOOK.TITLE)
.fetch();
SELECT AUTHOR.FIRST_NAME, AUTHOR.LAST_NAME, COUNT(*)
FROM AUTHOR
JOIN BOOK ON AUTHOR.ID = BOOK.AUTHOR_ID
WHERE BOOK.LANGUAGE = 'DE'
AND BOOK.PUBLISHED > '2008-01-01'
GROUP BY AUTHOR.FIRST_NAME, AUTHOR.LAST_NAME
HAVING COUNT(*) > 5
ORDER BY AUTHOR.LAST_NAME ASC NULLS FIRST
OFFSET 1 ROWS
FETCH FIRST 2 ROWS ONLY
dsl.select(AUTHOR.FIRST_NAME, AUTHOR.LAST_NAME, count())
.from(AUTHOR)
.join(BOOK).on(BOOK.AUTHOR_ID.equal(AUTHOR.ID))
.where(BOOK.LANGUAGE.equal("DE"))
.and(BOOK.PUBLISHED.greaterThan("2008-01-01"))
.groupBy(AUTHOR.FIRST_NAME, AUTHOR.LAST_NAME)
.having(count().greaterThan(5))
.orderBy(AUTHOR.LAST_NAME.asc().nullsFirst())
.limit(2)
.offset(1)
.fetch();
SelectFinalStep query = select.getQuery();
switch (searchOper) {
case "eq":
query.addConditions(PRODUCT.NAME.eq(searchString));
break;
case "bw":
query.addConditions(PRODUCT.NAME.startsWith(searchString));
break;
case "cn":
query.addConditions(PRODUCT.NAME.contains(searchString));
break;
}
switch (sOrd) {
case "asc":
query.addOrderBy(PRODUCT.NAME.asc());
break;
case "desc":
query.addOrderBy(PRODUCT.NAME.desc());
break;
}
return query.fetchMaps();
dsl.select()
.from(BOOK)
.where(BOOK.ID.equal(5))
.and(BOOK.TITLE.equal("Animal Farm"))
.fetch();
dsl.select()
.from(BOOK)
.where(BOOK.ID.equal(val(5)))
.and(BOOK.TITLE.equal(val("Animal Farm")))
.fetch();
SELECT *
FROM BOOK
WHERE BOOK.ID = ?
AND BOOK.TITLE = ?
Select param = select.getParam("2");
Param.setValue("Animals as Leaders");
Query query1 =
dsl.select()
.from(AUTHOR)
.where(LAST_NAME.equal("Poe"));
query1.bind(1, "Orwell");
// Create a query with a named parameter. You can then use that name for
// accessing the parameter again
Query query1 =
dsl.select()
.from(AUTHOR)
.where(LAST_NAME.equal(param("lastName", "Poe")));
Param query) {
switch (this.searchOper) {
case "eq":
// CUSTOMER.NAME = ?
query.addConditions(CUSTOMER.NAME.eq(this.searchString));
break;
case "bw":
// CUSTOMER.NAME STARTING WITH ?
query.addConditions(CUSTOMER.NAME.startsWith(this.searchString));
break;
case "cn":
// CUSTOMER.NAME CONTAINING ?
query.addConditions(CUSTOMER.NAME.contains(this.searchString));
break;
}
}
/**
* Возвращает общее количество записей
*
* @return
*/
@Override
public int getCountRecord() {
// запрос, возвращающий количество записей
SelectFinalStep query = select.getQuery();
// если мы осуществляем поиск, то добавляем условие поиска
if (this.searchFlag) {
makeSearchCondition(query);
}
// возарщаем количество
return (int) query.fetch().getValue(0, 0);
}
/**
* Возвращает записи грида
*
* @return
*/
@Override
public List> getRecords() {
// Базовый запрос на выборку
SelectFinalStep query = select.getQuery();
// если мы осуществляем поиск, то добавляем условие поиска
if (this.searchFlag) {
makeSearchCondition(query);
}
// задаём порядок сортировки
switch (this.sOrd) {
case "asc":
query.addOrderBy(CUSTOMER.NAME.asc());
break;
case "desc":
query.addOrderBy(CUSTOMER.NAME.desc());
break;
}
// ограничиваем количество записей
if (this.limit != 0) {
query.addLimit(this.limit);
}
// смещение
if (this.offset != 0) {
query.addOffset(this.offset);
}
// возвращаем массив карт
return query.fetchMaps();
}
}
package ru.ibase.fbjavaex.managers;
import org.jooq.DSLContext;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Isolation;
import static ru.ibase.fbjavaex.exampledb.Tables.CUSTOMER;
import static ru.ibase.fbjavaex.exampledb.Sequences.GEN_CUSTOMER_ID;
/**
* Менеджер заказчиков
*
* @author Simonov Denis
*/
public class CustomerManager {
@Autowired(required = true)
private DSLContext dsl;
/**
* Добавление заказчика
*
* @param name
* @param address
* @param zipcode
* @param phone
*/
@Transactional(propagation = Propagation.REQUIRED, isolation = Isolation.REPEATABLE_READ)
public void create(String name, String address, String zipcode, String phone) {
if (zipcode != null) {
if (zipcode.trim().isEmpty()) {
zipcode = null;
}
}
int customerId = this.dsl.nextval(GEN_CUSTOMER_ID).intValue();
this.dsl
.insertInto(CUSTOMER,
CUSTOMER.CUSTOMER_ID,
CUSTOMER.NAME,
CUSTOMER.ADDRESS,
CUSTOMER.ZIPCODE,
CUSTOMER.PHONE)
.values(
customerId,
name,
address,
zipcode,
phone
)
.execute();
}
/**
* Редактирование заказчика
*
* @param customerId
* @param name
* @param address
* @param zipcode
* @param phone
*/
@Transactional(propagation = Propagation.REQUIRED, isolation = Isolation.REPEATABLE_READ)
public void edit(int customerId, String name, String address, String zipcode, String phone) {
if (zipcode != null) {
if (zipcode.trim().isEmpty()) {
zipcode = null;
}
}
this.dsl.update(CUSTOMER)
.set(CUSTOMER.NAME, name)
.set(CUSTOMER.ADDRESS, address)
.set(CUSTOMER.ZIPCODE, zipcode)
.set(CUSTOMER.PHONE, phone)
.where(CUSTOMER.CUSTOMER_ID.eq(customerId))
.execute();
}
/**
* Удаление заказчика
*
* @param customerId
*/
@Transactional(propagation = Propagation.REQUIRED, isolation = Isolation.REPEATABLE_READ)
public void delete(int customerId) {
this.dsl.deleteFrom(CUSTOMER)
.where(CUSTOMER.CUSTOMER_ID.eq(customerId))
.execute();
}
}
package ru.ibase.fbjavaex.controllers;
import java.util.HashMap;
import java.util.Map;
import org.springframework.stereotype.Controller;
import org.springframework.ui.ModelMap;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RequestParam;
import javax.ws.rs.core.MediaType;
import org.springframework.beans.factory.annotation.Autowired;
import ru.ibase.fbjavaex.managers.CustomerManager;
import ru.ibase.fbjavaex.jqgrid.JqGridCustomer;
import ru.ibase.fbjavaex.jqgrid.JqGridData;
/**
* Контроллер заказчиков
*
* @author Simonov Denis
*/
@Controller
public class CustomerController {
@Autowired(required = true)
private JqGridCustomer customerGrid;
@Autowired(required = true)
private CustomerManager customerManager;
/**
* Действие по умолчанию
* Возвращает имя JSP страницы (представления) для отображения
*
* @param map
* @return имя JSP шаблона
*/
@RequestMapping(value = "/customer/", method = RequestMethod.GET)
public String index(ModelMap map) {
return "customer";
}
/**
* Возвращает данные в формате JSON для jqGrid
*
* @param rows количество строк на страницу
* @param page номер страницы
* @param sIdx поле для сортировки
* @param sOrd порядок сортировки
* @param search должен ли осуществляться поиск
* @param searchField поле поиска
* @param searchString значение поиска
* @param searchOper операция поиска
* @return JSON для jqGrid
*/
@RequestMapping(value = "/customer/getdata",
method = RequestMethod.GET,
produces = MediaType.APPLICATION_JSON)
@ResponseBody
public JqGridData getData(
// количество записей на странице
@RequestParam(value = "rows", required = false, defaultValue = "20") int rows,
// номер текущей страницы
@RequestParam(value = "page", required = false, defaultValue = "1") int page,
// поле для сортировки
@RequestParam(value = "sidx", required = false, defaultValue = "") String sIdx,
// направление сортировки
@RequestParam(value = "sord", required = false, defaultValue = "asc") String sOrd,
// осуществляется ли поиск
@RequestParam(value = "_search", required = false, defaultValue = "false") Boolean search,
// поле поиска
@RequestParam(value = "searchField", required = false, defaultValue = "") String searchField,
// значение поиска
@RequestParam(value = "searchString", required = false, defaultValue = "") String searchString,
// операция поиска
@RequestParam(value = "searchOper", required = false, defaultValue = "") String searchOper,
// фильтр
@RequestParam(value="filters", required=false, defaultValue="") String filters) {
customerGrid.setLimit(rows);
customerGrid.setPageNo(page);
customerGrid.setOrderBy(sIdx, sOrd);
if (search) {
customerGrid.setSearchCondition(searchField, searchString, searchOper);
}
return customerGrid.getJqGridData();
}
@RequestMapping(value = "/customer/create",
method = RequestMethod.POST,
produces = MediaType.APPLICATION_JSON)
@ResponseBody
public Map addCustomer(
@RequestParam(value = "NAME", required = true, defaultValue = "") String name,
@RequestParam(value = "ADDRESS", required = false, defaultValue = "") String address,
@RequestParam(value = "ZIPCODE", required = false, defaultValue = "") String zipcode,
@RequestParam(value = "PHONE", required = false, defaultValue = "") String phone) {
Map map = new HashMap<>();
try {
customerManager.create(name, address, zipcode, phone);
map.put("success", true);
} catch (Exception ex) {
map.put("error", ex.getMessage());
}
return map;
}
@RequestMapping(value = "/customer/edit",
method = RequestMethod.POST,
produces = MediaType.APPLICATION_JSON)
@ResponseBody
public Map editCustomer(
@RequestParam(value = "CUSTOMER_ID", required = true, defaultValue = "0") int customerId,
@RequestParam(value = "NAME", required = true, defaultValue = "") String name,
@RequestParam(value = "ADDRESS", required = false, defaultValue = "") String address,
@RequestParam(value = "ZIPCODE", required = false, defaultValue = "") String zipcode,
@RequestParam(value = "PHONE", required = false, defaultValue = "") String phone) {
Map map = new HashMap<>();
try {
customerManager.edit(customerId, name, address, zipcode, phone);
map.put("success", true);
} catch (Exception ex) {
map.put("error", ex.getMessage());
}
return map;
}
@RequestMapping(value = "/customer/delete",
method = RequestMethod.POST,
produces = MediaType.APPLICATION_JSON)
@ResponseBody
public Map deleteCustomer(
@RequestParam(value = "CUSTOMER_ID", required = true, defaultValue = "0") int customerId) {
Map map = new HashMap<>();
try {
customerManager.delete(customerId);
map.put("success", true);
} catch (Exception ex) {
map.put("error", ex.getMessage());
}
return map;
}
}
Customers
var JqGridCustomer = (function ($) {
return function (options) {
var jqGridCustomer = {
dbGrid: null,
// опции
options: $.extend({
baseAddress: null,
showEditorPanel: true
}, options),
// возвращает модель
getColModel: function () {
return [
{
label: 'Id', // подпись
name: 'CUSTOMER_ID', // имя поля
key: true, // признак ключевого поля
hidden: true // скрыт
},
{
label: 'Name', // подпись поля
name: 'NAME', // имя поля
width: 240, // ширина
sortable: true, // разрешена сортировка
editable: true, // разрешено редактирование
edittype: "text", // тип поля в редакторе
search: true, // разрешён поиск
searchoptions: {
sopt: ['eq', 'bw', 'cn'] // разрешённые операторы поиска
},
editoptions: {size: 30, maxlength: 60}, // размер и максимальная длина для поля ввода
editrules: {required: true} // говорит о том, что поле обязательное
},
{
label: 'Address',
name: 'ADDRESS',
width: 300,
sortable: false, // запрещаем сортировку
editable: true, // редактируемое
search: false, // запрещаем поиск
edittype: "textarea", // мемо поле
editoptions: {maxlength: 250, cols: 30, rows: 4}
},
{
label: 'Zip Code',
name: 'ZIPCODE',
width: 30,
sortable: false,
editable: true,
search: false,
edittype: "text",
editoptions: {size: 30, maxlength: 10}
},
{
label: 'Phone',
name: 'PHONE',
width: 80,
sortable: false,
editable: true,
search: false,
edittype: "text",
editoptions: {size: 30, maxlength: 14}
}
];
},
// инициализация грида
initGrid: function () {
// url для получения данных
var url = jqGridCustomer.options.baseAddress + '/customer/getdata';
jqGridCustomer.dbGrid = $("#jqGridCustomer").jqGrid({
url: url,
datatype: "json", // формат получения данных
mtype: "GET", // тип http запроса
colModel: jqGridCustomer.getColModel(),
rowNum: 500, // число отображаемых строк
loadonce: false, // загрузка только один раз
sortname: 'NAME', // сортировка по умолчанию по столбцу NAME
sortorder: "asc", // порядок сортировки
width: window.innerWidth - 80, // ширина грида
height: 500, // высота грида
viewrecords: true, // отображать количество записей
guiStyle: "bootstrap",
iconSet: "fontAwesome",
caption: "Customers", // подпись к гриду
// элемент для отображения навигации
pager: 'jqPagerCustomer'
});
},
// опции редактирования
getEditOptions: function () {
return {
url: jqGridCustomer.options.baseAddress + '/customer/edit',
reloadAfterSubmit: true,
closeOnEscape: true,
closeAfterEdit: true,
drag: true,
width: 400,
afterSubmit: jqGridCustomer.afterSubmit,
editData: {
// дополнительно к значениям из формы передаём ключевое поле
CUSTOMER_ID: function () {
// получаем текущую строку
var selectedRow = jqGridCustomer.dbGrid.getGridParam("selrow");
// получаем значение интересующего нас поля
var value = jqGridCustomer.dbGrid.getCell(selectedRow, 'CUSTOMER_ID');
return value;
}
}
};
},
// опции добавления
getAddOptions: function () {
return {
url: jqGridCustomer.options.baseAddress + '/customer/create',
reloadAfterSubmit: true,
closeOnEscape: true,
closeAfterAdd: true,
drag: true,
width: 400,
afterSubmit: jqGridCustomer.afterSubmit
};
},
// опции удаления
getDeleteOptions: function () {
return {
url: jqGridCustomer.options.baseAddress + '/customer/delete',
reloadAfterSubmit: true,
closeOnEscape: true,
closeAfterDelete: true,
drag: true,
msg: "Удалить выделенного заказчика?",
afterSubmit: jqGridCustomer.afterSubmit,
delData: {
// передаём ключевое поле
CUSTOMER_ID: function () {
var selectedRow = jqGridCustomer.dbGrid.getGridParam("selrow");
var value = jqGridCustomer.dbGrid.getCell(selectedRow, 'CUSTOMER_ID');
return value;
}
}
};
},
// инициализация панели навигации вместе с диалогами редактирования
initPagerWithEditors: function () {
jqGridCustomer.dbGrid.jqGrid('navGrid', '#jqPagerCustomer',
{
// кнопки
search: true, // поиск
add: true, // добавление
edit: true, // редактирование
del: true, // удаление
view: true, // просмотр записи
refresh: true, // обновление
// подписи кнопок
searchtext: "Поиск",
addtext: "Добавить",
edittext: "Изменить",
deltext: "Удалить",
viewtext: "Смотреть",
viewtitle: "Выбранная запись",
refreshtext: "Обновить"
},
jqGridCustomer.getEditOptions(),
jqGridCustomer.getAddOptions(),
jqGridCustomer.getDeleteOptions()
);
},
// инициализация панели навигации вместе без диалогов редактирования
initPagerWithoutEditors: function () {
jqGridCustomer.dbGrid.jqGrid('navGrid', '#jqPagerCustomer',
{
// кнопки
search: true, // поиск
add: false, // добавление
edit: false, // редактирование
del: false, // удаление
view: false, // просмотр записи
refresh: true, // обновление
// подписи кнопок
searchtext: "Поиск",
viewtext: "Смотреть",
viewtitle: "Выбранная запись",
refreshtext: "Обновить"
}
);
},
// инициализация панели навигации
initPager: function () {
if (jqGridCustomer.options.showEditorPanel) {
jqGridCustomer.initPagerWithEditors();
} else {
jqGridCustomer.initPagerWithoutEditors();
}
},
// инициализация
init: function () {
jqGridCustomer.initGrid();
jqGridCustomer.initPager();
},
// обработчик результатов обработки форм (операций)
afterSubmit: function (response, postdata) {
var responseData = response.responseJSON;
// проверяем результат на наличие сообщений об ошибках
if (responseData.hasOwnProperty("error")) {
if (responseData.error.length) {
return [false, responseData.error];
}
} else {
// если не была возвращена ошибка обновляем грид
$(this).jqGrid(
'setGridParam',
{
datatype: 'json'
}
).trigger('reloadGrid');
}
return [true, "", 0];
}
};
jqGridCustomer.init();
return jqGridCustomer;
};
})(jQuery);
package ru.ibase.fbjavaex.config;
import java.sql.Timestamp;
import java.time.LocalDateTime;
/**
* Рабочий период
*
* @author Simonov Denis
*/
public class WorkingPeriod {
private Timestamp beginDate;
private Timestamp endDate;
/**
* Конструктор
*/
WorkingPeriod() {
// в реальных приложениях вычисляется от текущей даты
this.beginDate = Timestamp.valueOf("2015-06-01 00:00:00");
this.endDate = Timestamp.valueOf(LocalDateTime.now().plusDays(1));
}
/**
* Возвращает дату начала рабочего периода
*
* @return
*/
public Timestamp getBeginDate() {
return this.beginDate;
}
/**
* Возвращает дату окончания рабочего периода
*
* @return
*/
public Timestamp getEndDate() {
return this.endDate;
}
/**
* Установка даты начала рабочего периода
*
* @param value
*/
public void setBeginDate(Timestamp value) {
this.beginDate = value;
}
/**
* Установка даты окончания рабочего периода
*
* @param value
*/
public void setEndDate(Timestamp value) {
this.endDate = value;
}
/**
* Установка рабочего периода
*
* @param beginDate
* @param endDate
*/
public void setRangeDate(Timestamp beginDate, Timestamp endDate) {
this.beginDate = beginDate;
this.endDate = endDate;
}
}
package ru.ibase.fbjavaex.jqgrid;
import java.sql.*;
import org.jooq.*;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import ru.ibase.fbjavaex.config.WorkingPeriod;
import static ru.ibase.fbjavaex.exampledb.Tables.INVOICE;
import static ru.ibase.fbjavaex.exampledb.Tables.CUSTOMER;
/**
* Обработчик грида для журнала счёт-фактур
*
* @author Simonov Denis
*/
public class JqGridInvoice extends JqGrid {
@Autowired(required = true)
private WorkingPeriod workingPeriod;
/**
* Добавление условия поиска
*
* @param query
*/
private void makeSearchCondition(SelectQuery select
= dsl.selectCount()
.from(INVOICE)
.where(INVOICE.INVOICE_DATE.between(this.workingPeriod.getBeginDate(), this.workingPeriod.getEndDate()));
SelectQuery select
= dsl.select(
INVOICE.INVOICE_ID,
INVOICE.CUSTOMER_ID,
CUSTOMER.NAME.as("CUSTOMER_NAME"),
INVOICE.INVOICE_DATE,
INVOICE.PAID,
INVOICE.TOTAL_SALE)
.from(INVOICE)
.innerJoin(CUSTOMER).on(CUSTOMER.CUSTOMER_ID.eq(INVOICE.CUSTOMER_ID))
.where(INVOICE.INVOICE_DATE.between(this.workingPeriod.getBeginDate(), this.workingPeriod.getEndDate()));
SelectQuery select
= dsl.selectCount()
.from(INVOICE_LINE)
.where(INVOICE_LINE.INVOICE_ID.eq(this.invoiceId));
SelectQuery select
= dsl.select(
INVOICE_LINE.INVOICE_LINE_ID,
INVOICE_LINE.INVOICE_ID,
INVOICE_LINE.PRODUCT_ID,
PRODUCT.NAME.as("PRODUCT_NAME"),
INVOICE_LINE.QUANTITY,
INVOICE_LINE.SALE_PRICE,
INVOICE_LINE.SALE_PRICE.mul(INVOICE_LINE.QUANTITY).as("TOTAL"))
.from(INVOICE_LINE)
.innerJoin(PRODUCT).on(PRODUCT.PRODUCT_ID.eq(INVOICE_LINE.PRODUCT_ID))
.where(INVOICE_LINE.INVOICE_ID.eq(this.invoiceId));
SelectQuery> httpMessageConverters) {
MappingJackson2HttpMessageConverter jsonConverter = new MappingJackson2HttpMessageConverter();
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.configure(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS, false);
jsonConverter.setObjectMapper(objectMapper);
httpMessageConverters.add(jsonConverter);
}
…
}
Invoices
var JqGridInvoice = (function ($, jqGridProductFactory, jqGridCustomerFactory) {
return function (options) {
var jqGridInvoice = {
dbGrid: null,
detailGrid: null,
// опции
options: $.extend({
baseAddress: null
}, options),
// возвращает опции колонок (модель) счёт фактуры
getInvoiceColModel: function () {
return [
{
label: 'Id', // подпись
name: 'INVOICE_ID', // имя поля
key: true, // признак ключевого поля
hidden: true // скрыт
},
{
label: 'Customer Id', // подпись
name: 'CUSTOMER_ID', // имя поля
hidden: true, // скрыт
editrules: {edithidden: true, required: true}, // скрытое и требуемое
editable: true, // редактируемое
edittype: 'custom', // собственный тип
editoptions: {
custom_element: function (value, options) {
// добавляем скрытый input
return $("")
.attr('type', 'hidden')
.attr('rowid', options.rowId)
.addClass("FormElement")
.addClass("form-control")
.val(value)
.get(0);
}
}
},
{
label: 'Date',
name: 'INVOICE_DATE',
width: 60, // ширина
sortable: true, // позволять сортировку
editable: true, // редактируемое
search: true, // разрешён поиск
edittype: "text", // тип поля ввода
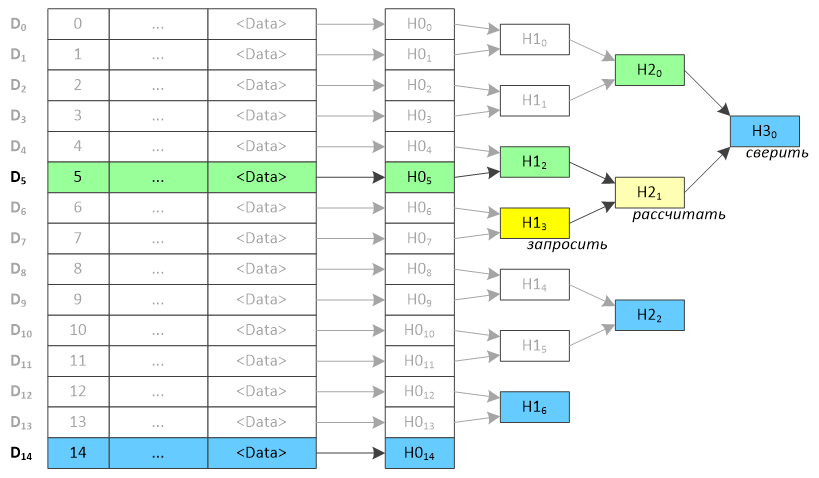
|
Метки: author sim_84 java firebird/interbase firebird jooq spring mvc |
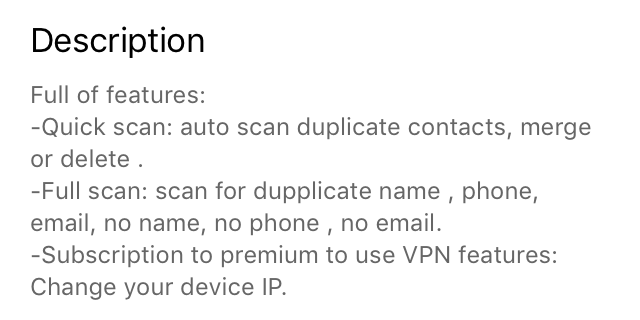
[Перевод] Как заработать 80 000 $ на App Store |


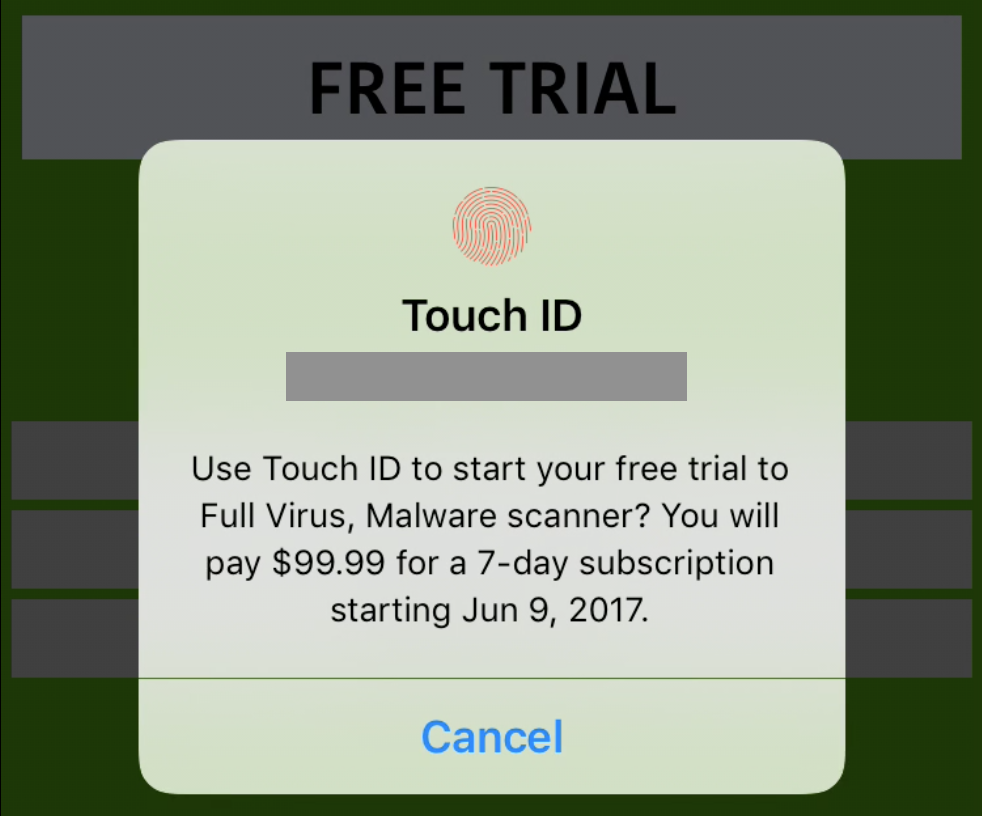
|
Метки: author nanton разработка мобильных приложений блог компании everyday tools app store apple app store search ads touch id мошенничество |
[Перевод] SecureLogin — забудьте о паролях |

В начале июня сотрудник компании Sakurity Егор Хомяков (Egor Homakov) написал пост о созданной им технологии SecureLogin, являющейся заменой парольной аутентификации. Несмотря на то что Егор наверняка прекрасно говорит и пишет по-русски, мы не смогли найти русскоязычного варианта и решили сделать перевод оригинальной статьи. Результат вы можете найти под катом.
Сегодня я с гордостью представляю SecureLogin Authentication Protocol 1.0, над которым работал последние 3 года.
Нет, это не менеджер паролей. Да, это очередная попытка заменить пароли, причем для всех, а не только для гиков.
Кстати, я горжусь не нативными приложениями и реализациями — это была лишь небольшая часть работы, объем которой не превышает нескольких тысяч строк кода.
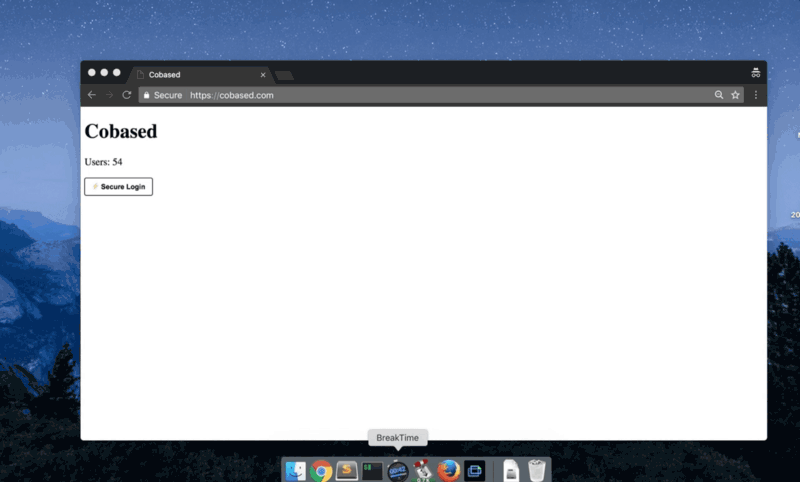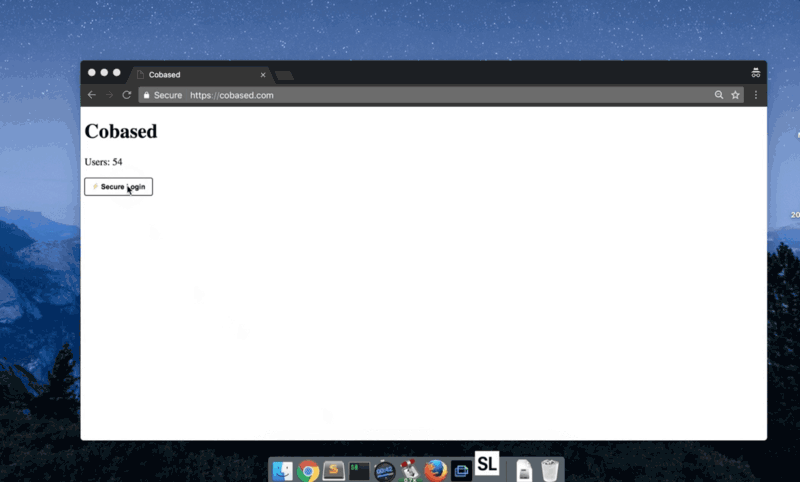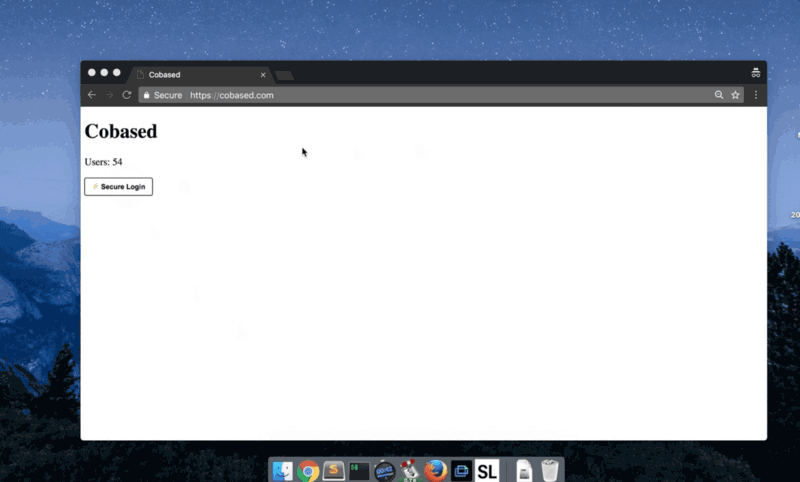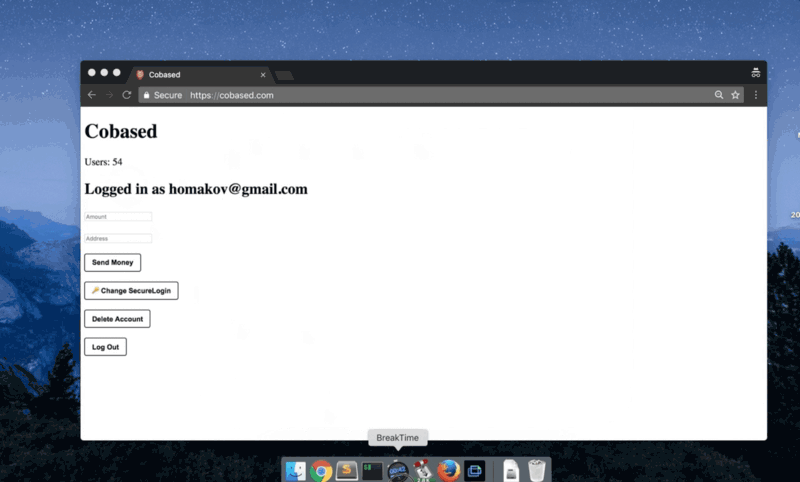
Я горжусь тем, что разработал наиболее сбалансированный протокол, который, как специалист по безопасности, искренне рекомендую.
Этот баланс основывается на 3 принципах.
Никакая третья сторона не должна иметь возможность войти в вашу учетную запись откуда бы то ни было: ни провайдер телефонной связи, сливающий ваши SMS-коды, ни провайдер электронной почты, сбрасывающий ваши пароли, ни Facebook Connect/Google OAuth, выдающий ваш access_token кому-то другому, ни правительства и хакеры, тем или иным способом делающие это через вышеперечисленные сервисы. Только ваше личное устройство должно иметь возможность удостоверять запросы для вашей учетной записи.
На первый взгляд более привлекательные «2FA как сервис»-провайдеры, такие как Authy или Duo, не подпадают под определение end-2-end-децентрализованных, поскольку представляют из себя централизованные службы, подтверждающие запросы от имени пользователя. По большому счету это альтернативная реализация механизма «подтверждение по ссылке в email».
В настоящий момент добиться действительно безопасной аутентификации можно с помощью TOTP (например, Google Authenticator) или USB-ключа типа U2F.
Оба подхода требуют ручных манипуляций, поэтому почти никто их использует.
Работать с ними очень неудобно. В первом случае приходится записывать резервные коды на бумаге (что я никогда не делал), а второй вариант мало кем поддерживается. Поэтому их уровень проникновения крайне мал.
Пришло время поговорить о втором принципе, на котором основан SecureLogin.
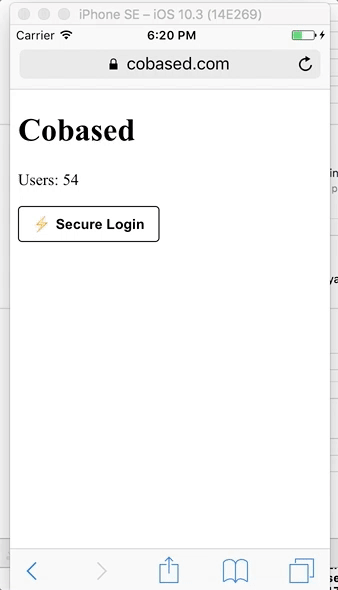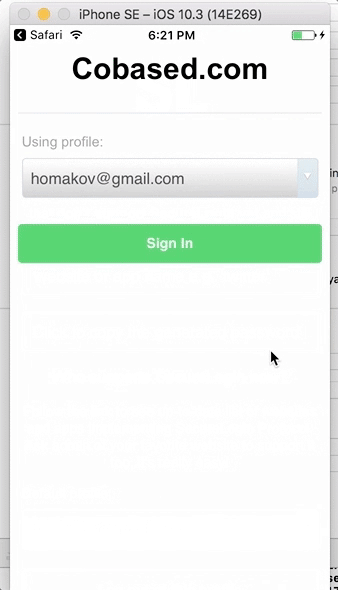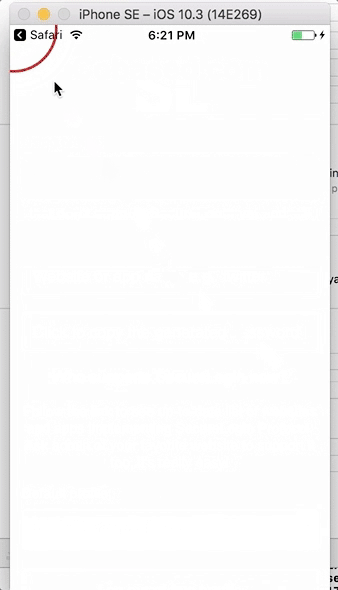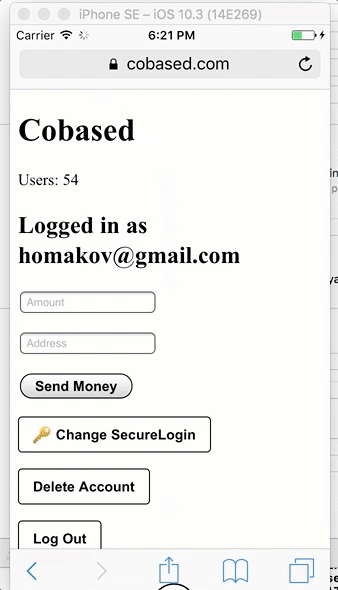
Демонстрация пользовательского интерфейса десктопного и мобильного приложений
Это очень похоже на Facebook Connect (исключая зависимость от серверов Facebook): вы нажимаете кнопку Login, приложение открывается, вы подтверждаете запрос, и это все.
Никакой возни с аппаратными ключами, одноразовыми паролями, ожидания электронных писем или SMS, доставания телефона из кармана, сканирования QR-кодов и т. д.
Это настолько просто, насколько вообще возможно для аутентификации.
Для соответствия этому принципу SecureLogin сделан детерминированным и реализован на программной основе. Он готов к обслуживанию четырех миллиардов людей уже завтра утром, и не существует единой точки отказа, которая могла бы этому помешать.
О резервных копиях беспокоиться не стоит, так как их не существует: ваш закрытый ключ генерируется на основе вашего же мастер-пароля. Серверы SecureLogin не смогут испортить production-базу, так как этой базы не существует. Система работает в автономном режиме (offline).
Никакого аппаратного обеспечения покупать не нужно. Написаны приложения для iOS, Android, macOS, Windows, Linux, и при этом вы всегда можете воспользоваться веб-клиентом.
Протокол полностью свободен (entirely free), и код всех клиентов открыт. За использование системы никогда ничего не придется платить.
API протокола настолько прост, что даже нет необходимости в SDK-библиотеках: 20 строк JS-кода на клиенте, 50 строк на сервере.
Если вы ищете идею для open-source-проекта, рассмотрите реализацию SecureLogin-плагина для вашей любимой CMS. Напишите мне письмо, чтобы присоединиться к нашему Slack.
Кстати, первопроходцы SecureLogin могут получить бесплатный аудит безопасности.
Буду рад ответить на них в Twitter! Но сначала поищите ответ в FAQ — 90% вопросов повторяют друг друга.
Прошу заметить, что SecureLogin не задумывался как самое безопасное решение, которое покрывало бы все граничные случаи (однако для версии 2.0 планируется функциональность Doublesign), или самое комфортное решение (тут вряд ли удастся переплюнуть Facebook Connect — он слишком удобен). Здесь весь смысл в балансе.
Ссылки:
|
Метки: author olemskoi информационная безопасность блог компании southbridge securelogin homakov |
От Oracle Database 12c EE к PostgreSQL, или основные отличия PostgreSQL при разработке под IEM-платформу Ultimate |
-- current search_path = my_schema
create or replace function my_func(my_arg text) returns void as $$
declare v_id bigint;
begin
perform another_func(my_arg); -- same as perform my_schema.another_func(my_arg);
select id into v_id from kernel.users -- table name is qualified with kernel schema name where login = my_arg; -- the rest is skipped...
end $$ language plpgsql set search_path to my_schema;
create or replace function my_secure_func() returns void as $$
begin -- call here any functions available to the superuser
end $$ language plpgsql security definer; -- default is security invoker
create_permanent_temp_table(table_name [, schema_name]);
drop_permanent_temp_table(table_name [, schema_name]);
create temporary table if not exists another_temp_table ( first_name varchar, last_name varchar, date timestamp(0) with time zone, primary key(first_name, last_name) ) on commit drop;
-- create my_schema.another_temp_table select pack_temp.create_permanent_temp_table('another_temp_table', 'my_schema');
-- or create another_temp_table in the current schema -- select create_permanent_temp_table('another_temp_table');
-- don't forget to commit: PostgreSQL DDL is transactional commit;
// было
var query = from a in DataContext.GetTable()
where a.ID = Constants.TestAgentID select a;
// стало
var testAgentId = Constants.TestAgentID;
var query = from a in DataContext.GetTable()
where a.ID = testAgentId select a;
// было
foreach (var langId in DataContext.GetTable().Select(x => x.ID))
{
using (LanguageService.UseLanguage(langId))
{
// do something language-specific
}
}
// стало
foreach (var langId in DataContext.GetTable().Select(x => x.ID).ToIDList())
{
using (LanguageService.UseLanguage(langId))
{
// do something language-specific
}
}
// было
var dictionary = DataContext.GetTable().Where(d => dates.Contains(d.DT)) .GroupBy(g => g.DT, e => e.StatusID) .ToDictionary(k => k.Key, e => e.ToIDList());
// стало
var dictionary = DataContext.GetTable() .Where(d => dates.Contains(d.DT)) .GroupBy(g => g.DT, e => e.StatusID) .ToDictionary(p => p.Key);
var dict = dictionary.ToDictionary(p => p.Key, p => p.Value.ToIDList());
|
Метки: author Rupper postgresql oracle c# .net блог компании ultima erp iem sql migration solid |
Новые возможности C#, которые можно ожидать в ближайшее время |

public static Task Main();
public static Task Main();
public static Task Main(string[] args);
public static Task Main(string[] args); async Task Main(string[] args) {
// здесь какой-то ваш код
}
// этот метод сгенерируется «за кулисами» автоматически
int $GeneratedMain(string[] args) {
return Main(args).GetAwaiter().GetResult();
} void SomeMethod(string[] args)
{
}SomeMethod(default(string[]));void SomeMethod(string[] args = default)
{
}int i = default;int i = 1;
if (i == default) { } // значением по умолчанию типа int является 0
if (i is default) { } // точно такая же проверка
const int? y = default;
if (default == default)
if (default is T) // оператор is нельзя использовать с default
var i = default
throw default
default as int; // 'as' может быть только reference тип static Vector3 Add (ref readonly Vector3 v1, ref readonly Vector3 v2)
{
// так нельзя!
v1 = default(Vector3);
// и так нельзя!
v1.X = 0;
// так тоже нельзя!
foo(ref v1.X);
// а вот теперь нормально
return new Vector3(v1.X +v2.X, v1.Y + v2.Y, v1.Z + v2.Z);
} static Vector3 Add (in Vector3 v1, in Vector3 v2)
{
return new Vector3(v1.X +v2.X, v1.Y + v2.Y, v1.Z + v2.Z);
}interface IA
{
void SomeMethod() { WriteLine("Вызван SomeMethod интерфейса IA"); }
}class C : IA { }IA i = new C();i.SomeMethod(); // выведет на экран "Вызван SomeMethod интерфейса IA"// c и result содержат в себе элементы с именами f1 и f2
var result = list.Select(c => (c.f1, c.f2)).Where(t => t.f2 == 1);Action y = () => M();
var t = (x: x, y);
t.y(); // ранее был бы выбран extension method y(), а сейчас будет вызвана лямбдаTuple element name 'y' is inferred. Please use language version 7.1 or greater to access an element by its inferred name.
class Program
{
static void Main(string[] args)
{
string x = "demo";
Action y = () => M();
var t = (x: x, y);
t.y(); // ранее был бы выбран extension method y(), а сейчас будет вызвана лямбда
}
private static void M()
{
Console.WriteLine("M");
}
}
public static class MyExtensions
{
public static void y(this (string s, Action a) tu)
{
Console.WriteLine("extension method");
}
}|
Метки: author asommer программирование c# 7.0 новые функции фичи default async main readonly ref |
Интеграция сценарного тестирования в процесс разработки решений на базе платформы 1С |
| Последние обновления | https://github.com/grumagargler/tester |
| Депо общих тестов | https://github.com/grumagargler/CommonTests |
| Депо демо тестов для ERP2 (демо) | https://github.com/grumagargler/ERP2 |
| Сайт проекта | http://www.test1c.com |
| Язык | Интерфейс: Английский, Русский Справка: Английский (частично), Русский |
| Пользователи | Задачи |
|---|---|
| Программисты | Использование системы в процессе разработки. Эволюция процесса ручного тестирования |
| Тестировщики с базовыми знаниями программирования на языке 1С | Написание сценариев, максимально приближенных к сценариям работы пользователей. Эти сценарии, обычно не такие глубокие, как у программистов, но более выраженные с точки зрения бизнес-процесса |
| Бизнес аналитики. Консультанты | Запуск тестов, анализ результатов. Через чтение тестов, понимание работы функционала системы |




Подключить (); // Подключаем БСП к Тестеру
Меню ( "Справочники / Демо: Партнеры" ); // Открываем в БСП форму списка// Подключаем БСП к Тестеру
Подключить ();
// Закроем все окна в БСП
ЗакрытьВсё ();
// Открываем в БСП форму списка
Меню ( "Справочники / Демо: Партнеры" );
// Говорим Тестеру, что мы будем сейчас работать с этим окном
Здесь ( "Демо: Партнеры" );
// Нажмем кнопку Создать
Нажать ( "Создать" );
// Говорим Тестеру, что мы будем сейчас работать с этим окном
Здесь ( "Демо: Партнер (создание)" );
// Установим наименование партнера
Установить ( "Наименование", "Мой тестовый партнер" );
// Кликнем на флажок Поставщик
Нажать ( "Поставщик" );
// Нажмем кнопку Записать и закрыть
Нажать ( "Записать и закрыть" );14: Поле "Создать" найдено в нескольких местах: ФормаСоздать (Тестируемая кнопка формы / Кнопка командной панели), СписокКонтекстноеМенюСоздать (Тестируемая кнопка формы / Кнопка командной панели) {Тест1[14]}// Вариант 1
Нажать ( "!ФормаСоздать" );
// Вариант 2
Нажать ( "!КоманднаяПанель / Создать" );

Вызвать ( "Общее.ПроверитьОшибкуЗаписи", "Не заполнен контрагент" );


При запуске теста по кнопке F5 (или командe Запустить) Тестер всегда запускает сценарий, установленный как основной. Таким образом, вне зависимости от кого, какой сценарий вы в данный момент редактируете, запускаться будет только основной.Такой подход позволяет редактировать группу взаимосвязанных тестов, и быстро запускать весь сценарий на выполнение, без ненужных переключений вкладок. Кроме запуска основного сценария, имеется возможность запуска текущего сценария. Полный набор функций см. в контекстных меню Тестера.

Тестер позволяет в одной базе вести работу с тестами для неограниченного числа приложений (конфигураций). Не стоит создавать отдельную базу с Тестером под каждый проект/конфигурацию/клиента. В Тестере возможна настройка ограничения доступа пользователей к приложениям.
Примечание: в качестве решения проблемы загрязнения рабочей базы я не рассматриваю откат транзакций в сценарном цикле, что вы можете найти как подход в некоторых авторитетных источниках. По моему опыту, используя такой подход говорить о сколь-нибудь серьёзном тестировании не приходится.Начальную базу нужно подключить к хранилищу, куда сливаются финальные обновления конфигурации. Это необходимо для оперативного обновления начальной базы новым функционалом, обновления и/или заполнения базы новыми начальными данными.
| Плюсы | Минусы |
|---|---|
| Очевидность подхода | Сложность поддержки согласованности данных в развивающемся функционале приложения, проблемы загрузки данных при измененной структуре метаданных, смене владельцев, появлению полей обязательных для заполнения, переименованию или удалению объектов и их реквизитов. |
| Быстрый старт в подготовке данных | Потенциальная опасность получения не консистентных данных и ложного положительного прохождения теста. Такие тестовые данные как правило загружаются в специальном режиме, без дополнительных проверок и срабатывания обработчиков форм. Фактически, тестовые данные готовятся не так, как это бы сделал пользователь. |
| Сложность логистики хранения, взаимосвязанности наборов файлов, данных и тестов. | |
| Статичность. Данные загружаются как есть и их сложно менять под вариативность тестов в случае необходимости. | |
| Проблемы с удалением тестовых данных для повторных запусков сценариев. |
| Плюсы | Минусы |
|---|---|
| Гибкость создания требуемого окружения тестовых данных под различные вариации тестов. Возможность разработки сложных взаимосвязанных тестов. | Сложно без опыта выстроить структуру библиотечных тестов для создания тестовых данных |
| Высокое качество тестов за счет дополнительного тестирование всего стека используемых объектов при подготовке данных. Это очень важный нюанс, потому что создание тестовых данных таким образом, выполняется для разных видов целевых сценариев, что автоматически покрывает тестами разнообразие условий создания объектов. Например, у нас может быть тест-метод создания поставщика. Но поставщик может создаваться из разных контекстов: из формы списка контрагентов или из поля ввода на форме документа. И если тестовые данные загружать “извне”, можно не отловить ошибку создания контрагента из документа. Тест проверки документа пройдет успешно, хотя фактически, пользователь документ ввести не сможет (потому что не сможет создать для документа поставщика). |
Требуется первоначальная инвестиция времени в разработку тестов-методов |
| Консистентность полученного тестового окружения, заполненность реквизитов, отработка возможных событий и программных оповещений об изменении данных, другими словами — полная штатная эмуляция работы приложения. | |
| Слабая связанность с изменчивостью структуры метаданных. Если изменяется структура данных объекта, достаточно изменить (если необходимо) один тест-метод, при этом все остальные тестовые данные менять не придётся. | |
| Простота хранения. Все тест-методы хранятся в одной среде, и не являются внешними по отношению к системе тестирования. | |
| Использование одних и тех же тестовых данных даже в случае, когда их версии метаданных отличаются. В этом случае, в тест-методах можно организовывать условия по обработке/заполнению полей в зависимости от версии используемой программистом конфигурации (см. функцию МояВерсия ()) |
Дело не только в том, когда мы обнаружим проблему, сейчас, после ночного тестирования, или тестирования тестировщиками, а в том, что когда мы находимся глубоко в коде, нередко нужно здесь и сейчас проверить механизмы, чтобы определиться с выбранным направлением, понять, что наращиваемый функционал не конфликтует и не искажает другие алгоритмы.Я хотел бы обратить внимание, что даже при условии, когда тесты программиста проходят, они могут содержать методологические ошибки или ошибки понимания задачи. Такие ошибки может выловить отдельный департамент, специальные тестировщики или в конце концов заказчик. Но это отнюдь не означает, что вся история с тестированием программистами не имеет смысла. Наоборот, на основе готовых тестов, программисту достаточно будет скорректировать целевую часть (третья часть сценария), а всю остальную работу по подготовке данные и их проверке выполнит система.
| Программирование | Тестирование |
|---|---|
В Конфигураторе:
|
В Тестере : Создадим тест ПроверкаДатыСогласования, где:
|



// Сценарий:
// - Вводим новый документ Реализация
// - Устанавливаем неправильную дату согласования, проверяем наличие ошибки
// - Устанавливаем правильную дату, проверяем отсутствие ошибки
Подключить ();
ЗакрытьВсё ();
// Вводим новый документ
Коммандос ( "e1cib/data/Document.РеализацияТоваровУслуг" );
Здесь ( "Реализация *" );
// Определяем даты
дата = Дата ( Взять ( "!Дата" ) );
плохая = Формат ( дата - 86400, "DLF=D" );
хорошая = Формат ( дата + 86400, "DLF=D" );
// Вводим плохую дату
Нажать ( "!ТоварыДобавить" );
Установить ( "!ТоварыДатаСогласования", плохая );
// Проводим документ
Нажать ( "!ФормаПровести" );
если ( НайтиСообщения ( "Дата согласования*" ).Количество () = 0 ) тогда
Стоп ( "Должна быть ошибка неверной установки даты согласования" );
конецесли;
// Вводим хорошую дату
товары = Получить ( "!Товары" );
Установить ( "!ТоварыДатаСогласования [1]", хорошая, товары );
// Проводим документ
Нажать ( "!ФормаПровести" );
если ( НайтиСообщения ( "Дата согласования*" ).Количество () > 0 ) тогда
Стоп ( "Не должно быть ошибок неверной установки даты согласования" );
конецесли
|
Метки: author grumegargler тестирование it-систем программирование 1c bdd tdd автоматизация тестирования сценарное тестирование |
Перевод книги Appium Essentials. Глава 3 |

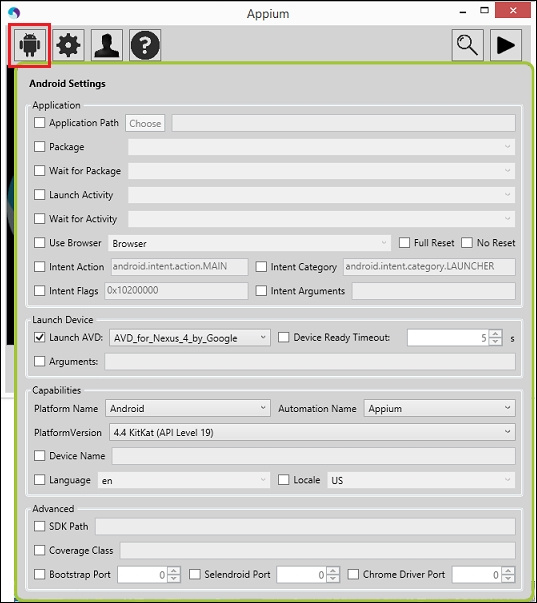
| Поле | Описание |
| Здесь указывается путь до файла .apk, который хотите протестировать. | |
| Указывает пакет для запуска. Например, com.android.calculator2. | |
| Эта возможность ожидает запуска пакета, который указан в поле Package. | |
| Можно указать активити, которую вы хотите запустить в приложении. Например, MainActivity. | |
| Позволяет выбрать из списка браузер для запуска | |
| Удаление приложения в конце сессии | |
| Предотвращает сброс устройства. | |
| Используется для запуска активити | |
| Категория интента | |
| Выставляет флаги старта активити. [Про флаги можно почитать здесь.] | |
| Здесь можно задать дополнительные аргументы при старте активити |
| Поле | Описание |
| Здесь указывается имя AVD для запуска | |
| Таймаут (в секундах) ожидания готовности устройства | |
| Аргументы запуска эмулятора |
| Поле | Описание |
| Задает имя платформы, на которой будет запущено приложение | |
| Имя инструмента автоматизации (можно выбрать из списка) | |
| Здесь указывается версия Android, на которой будет тестироваться приложение. | |
| Имя девайса. | |
| Язык, который будет задан на устройстве Android. | |
| Локаль, которая будет задана на Android. |
| Поле | Описание |
| Путь к Android SDK. | |
| Здесь задается класс инструментов [подробнее позже]. | |
| Порт, на котором будет «висеть» Appium. | |
| Порт для Selendroid. | |
| Порт для ChromeDriver [если нужен]. |
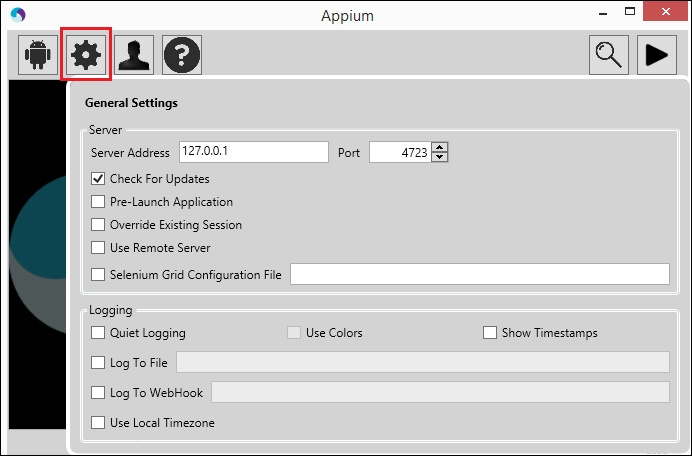
| Поле | Описание |
| IP-адрес, где запущен Appium-сервер. | |
| Порт, по которому Appium-сервер будет передавать команды. По дефолту: 4723. | |
| Если выбрать, Appium будет автоматически проверять наличие обновлений. | |
| Позволяет запустить приложение на девайсе до того, как начнет слушать команды от WebDriver. | |
| Если активно, текущие сессии будут пересозданы, если они есть. | |
| Если Appium-сервер запущен на другой машине, вы можете использовать эту опцию, чтобы задействовать Appium Inspector. | |
| Вы можете задать путь до конфиг файла для Selenium Grid. |
| Поле | Описание |
| Задает уровень логирования. | |
| Вывод в консоль будет сопровождаться датой-временем записи. | |
| Выведенный лог будет сохранен в указанном файле (например, C:\\appium\\abc.log). | |
| Лог будет отправлен по HTTP слушателю. | |
| Если выберете эту опцию, будет использоваться местная тайм-зону, иначе будет использоваться тайм-зона node-сервера. |
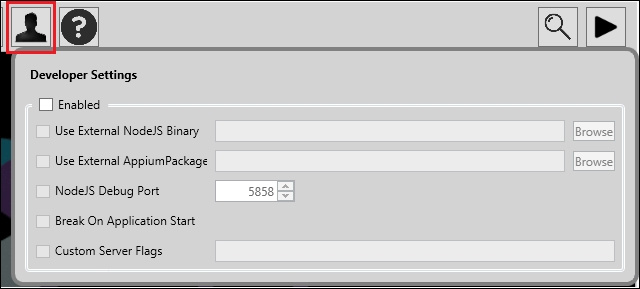
| Поле | Описание |
| Настройки разработчика будут доступны, если выбран чек-бокс. | |
| Если у вас другая версия Node.js, отличная от установленного с Appium, то можно использовать ее. Нужно задать путь. | |
| Здесь можно задать пакет Appium, если у вас есть свой [все-таки open source]. | |
| Порт, на котором будет запущен дебаггер Node.js. | |
| Как только приложение на девайсе запуститься, дебаггер Node.js остановится. | |
| Здесь можно передать серверу флаги для запуска (например, --device-name Nexus 5). [Я так понимаю, речь идет об этих флагах] |



| Поле | Описание |
| Здесь задается путь до iOS-приложения (.app, .zip, or .ipa), которое мы хотим протестировать. | |
| Задает ID бандла. | |
| Если тестируется мобильное веб-приложение, то можно выбрать эту опцию, чтобы запустить Safari. Убедитесь, что BundleID и App Path не выбраны. |
| Поле | Описание |
| Можете выбрать iPhone или iPad симулятор. | |
| Используется для выбора версии платформы. | |
| Указывается ориентация экрана на симуляторе. | |
| Задается язык на симуляторе. | |
| Формат календаря на симуляторе. | |
| Локаль симулятора. | |
| Если чекбокс UDID выбран, Appium запустит приложение на подключенном устройстве iOS; нужно убедиться, что bundleID поставлен, а App Path не выбран. | |
| Удаляет всю папку симулятора. | |
| Указывает, на то. что симулятор не должен перезапускаться между сессиями. | |
| Логи симулятора будут записываться в консоль. |
| Поле | Описание |
| Если выбрано, Appium будет отдавать предпочтение нативной библиотеке инструментов. | |
| Мы можем определить количество попыток запуска инструментов перед тем, как репортить крэш или таймаут. | |
| В миллисекундах определяет, сколько инструменты должны ждать запуска. | |
| Файл шаблона, который будет использоваться инструментами. | |
| Путь до XCode. |
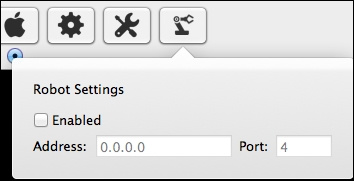
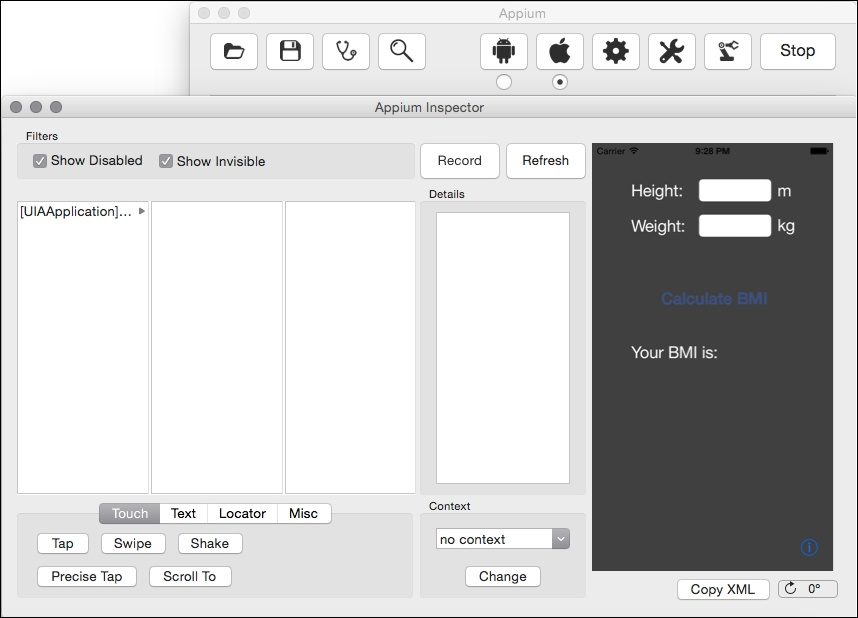
| Поле | Описание |
| Содержит кнопки для имитации действий: тап, свайп, скрол и шейк [трясем девайсом]. | |
| Здесь работа с текстом: ввод текста и выполнение JavaScript. | |
| Полезная опция от Appium. Используя ее, мы можем проверить, что наш локатор возвращает элемент. | |
| Кнопки для обработки разных предупреждений. |
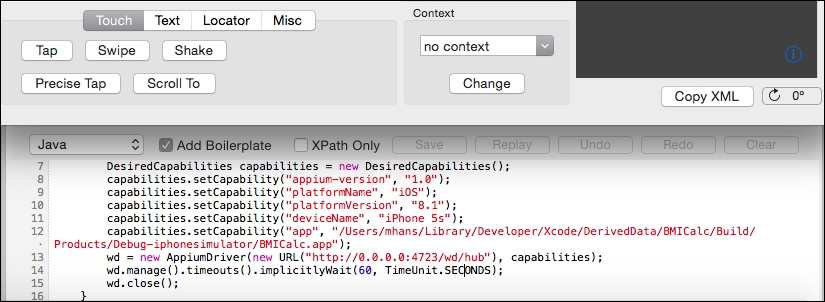
| Поле | Описание |
| Можно выбрать ЯП, на котором хотим получить тестовый скрипт (на скриншоте выбран Java). | |
| Если выбрано, скрипт будет содержать код, отвечающий за поднятие инстанса Selenium. Если нет — то только сами записанные шаги | |
| Воспроизводит записанный скрипт. | |
| Кнопки для обработки разных предупреждений. |
|
Метки: author EreminD читальный зал appium automation testing тестирование тестирование мобильных приложений |
Регистрация с помощью telegram бота |
/project/
/conf/
settings.go
/src/
database.go
telegramBot.go
main.go
const (
TELEGRAM_BOT_API_KEY = "paste your key here" // API ключ, который мы получили у BotFather
MONGODB_CONNECTION_URL = "localhost" // Адрес сервера MongoDB
MONGODB_DATABASE_NAME = "regbot" // Название базы данных
MONGODB_COLLECTION_USERS = "users" // Название таблицы
)
type User struct {
Chat_ID int64
Phone_Number string
}
type DatabaseConnection struct {
Session *mgo.Session // Соединение с сервером
DB *mgo.Database // Соединение с базой данных
}
type TelegramBot struct {
API *tgbotapi.BotAPI // API телеграмма
Updates tgbotapi.UpdatesChannel // Канал обновлений
ActiveContactRequests []int64 // ID чатов, от которых мы ожидаем номер
}
func (connection *DatabaseConnection) Init() {
session, err := mgo.Dial(conf.MONGODB_CONNECTION_URL) // Подключение к серверу
if err != nil {
log.Fatal(err) // При ошибке прерываем выполнение программы
}
connection.Session = session
db := session.DB(conf.MONGODB_DATABASE_NAME) // Подключение к базе данных
connection.DB = db
}
func (telegramBot *TelegramBot) Init() {
botAPI, err := tgbotapi.NewBotAPI(conf.TELEGRAM_BOT_API_KEY) // Инициализация API
if err != nil {
log.Fatal(err)
}
telegramBot.API = botAPI
botUpdate := tgbotapi.NewUpdate(0) // Инициализация канала обновлений
botUpdate.Timeout = 64
botUpdates, err := telegramBot.API.GetUpdatesChan(botUpdate)
if err != nil {
log.Fatal(err)
}
telegramBot.Updates = botUpdates
}
func (telegramBot *TelegramBot) Start() {
for update := range telegramBot.Updates {
if update.Message != nil {
// Если сообщение есть -> начинаем обработку
telegramBot.analyzeUpdate(update)
}
}
}
// Начало обработки сообщения
func (telegramBot *TelegramBot) analyzeUpdate(update tgbotapi.Update) {
chatID := update.Message.Chat.ID
if telegramBot.findUser(chatID) { // Есть ли пользователь в БД?
telegramBot.analyzeUser(update)
} else {
telegramBot.createUser(User{chatID, ""}) // Создаём пользователя
telegramBot.requestContact(chatID) // Запрашиваем номер
}
}
func (telegramBot *TelegramBot) findUser(chatID int64) bool {
find, err := Connection.Find(chatID)
if err != nil {
msg := tgbotapi.NewMessage(chatID, "Произошла ошибка! Бот может работать неправильно!")
telegramBot.API.Send(msg)
}
return find
}
func (telegramBot *TelegramBot) createUser(user User) {
err := Connection.CreateUser(user)
if err != nil {
msg := tgbotapi.NewMessage(user.Chat_ID, "Произошла ошибка! Бот может работать неправильно!")
telegramBot.API.Send(msg)
}
}
func (telegramBot *TelegramBot) requestContact(chatID int64) {
// Создаём сообщение
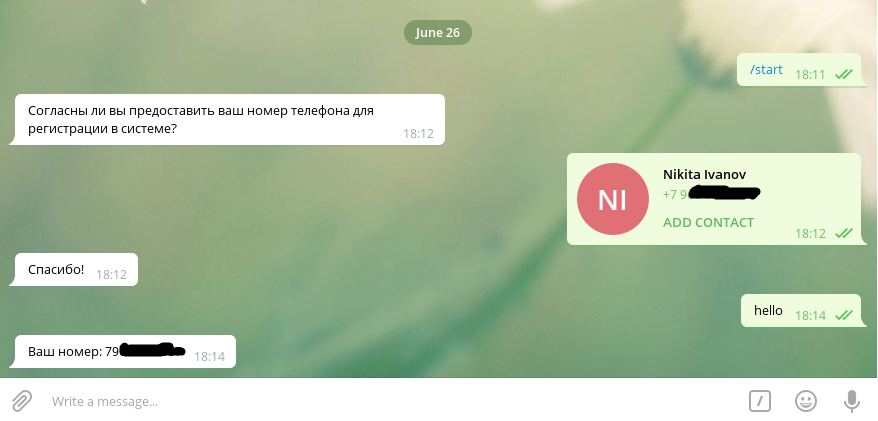
requestContactMessage := tgbotapi.NewMessage(chatID, "Согласны ли вы предоставить ваш номер телефона для регистрации в системе?")
// Создаём кнопку отправки контакта
acceptButton := tgbotapi.NewKeyboardButtonContact("Да")
declineButton := tgbotapi.NewKeyboardButton("Нет")
// Создаём клавиатуру
requestContactReplyKeyboard := tgbotapi.NewReplyKeyboard([]tgbotapi.KeyboardButton{acceptButton, declineButton})
requestContactMessage.ReplyMarkup = requestContactReplyKeyboard
telegramBot.API.Send(requestContactMessage) // Отправляем сообщение
telegramBot.addContactRequestID(chatID) // Добавляем ChatID в лист ожидания
}
func (telegramBot *TelegramBot) addContactRequestID(chatID int64) {
telegramBot.ActiveContactRequests = append(telegramBot.ActiveContactRequests, chatID)
}
var Connection DatabaseConnection // Переменная, через которую бот будет обращаться к БД
// Проверка на существование пользователя
func (connection *DatabaseConnection) Find(chatID int64) (bool, error) {
collection := connection.DB.C(conf.MONGODB_COLLECTION_USERS) // Получаем коллекцию "users"
count, err := collection.Find(bson.M{"chat_id": chatID}).Count() // Считаем количество записей с заданным ChatID
if err != nil || count == 0 {
return false, err
} else {
return true, err
}
}
// Получение пользователя
func (connection *DatabaseConnection) GetUser(chatID int64) (User, error) {
var result User
find, err := connection.Find(chatID) // Сначала проверяем, существует ли он
if err != nil {
return result, err
}
if find { // Если да -> получаем
collection := connection.DB.C(conf.MONGODB_COLLECTION_USERS)
err = collection.Find(bson.M{"chat_id": chatID}).One(&result)
return result, err
} else { // Нет -> возвращаем NotFound
return result, mgo.ErrNotFound
}
}
// Создание пользователя
func (connection *DatabaseConnection) CreateUser(user User) error {
collection := connection.DB.C(conf.MONGODB_COLLECTION_USERS)
err := collection.Insert(user)
return err
}
// Обновление номера мобильного телефона
func (connection *DatabaseConnection) UpdateUser(user User) error {
collection := connection.DB.C(conf.MONGODB_COLLECTION_USERS)
err := collection.Update(bson.M{"chat_id": user.Chat_ID}, &user)
return err
}
func (telegramBot *TelegramBot) analyzeUser(update tgbotapi.Update) {
chatID := update.Message.Chat.ID
user, err := Connection.GetUser(chatID) // Вытаскиваем данные из БД для проверки номера
if err != nil {
msg := tgbotapi.NewMessage(chatID, "Произошла ошибка! Бот может работать неправильно!")
telegramBot.API.Send(msg)
return
}
if len(user.Phone_Number) > 0 {
msg := tgbotapi.NewMessage(chatID, "Ваш номер: " + user.Phone_Number) // Если номер у нас уже есть, то пишем его
telegramBot.API.Send(msg)
return
} else {
// Если номера нет, то проверяем ждём ли мы контакт от этого ChatID
if telegramBot.findContactRequestID(chatID) {
telegramBot.checkRequestContactReply(update) // Если да -> проверяем
return
} else {
telegramBot.requestContact(chatID) // Если нет -> запрашиваем его
return
}
}
}
// Проверка принятого контакта
func (telegramBot *TelegramBot) checkRequestContactReply(update tgbotapi.Update) {
if update.Message.Contact != nil { // Проверяем, содержит ли сообщение контакт
if update.Message.Contact.UserID == update.Message.From.ID { // Проверяем действительно ли это контакт отправителя
telegramBot.updateUser(User{update.Message.Chat.ID, update.Message.Contact.PhoneNumber}, update.Message.Chat.ID) // Обновляем номер
telegramBot.deleteContactRequestID(update.Message.Chat.ID) // Удаляем ChatID из списка ожидания
msg := tgbotapi.NewMessage(update.Message.Chat.ID, "Спасибо!")
msg.ReplyMarkup = tgbotapi.NewRemoveKeyboard(false) // Убираем клавиатуру
telegramBot.API.Send(msg)
} else {
msg := tgbotapi.NewMessage(update.Message.Chat.ID, "Номер телефона, который вы предоставили, принадлежит не вам!")
telegramBot.API.Send(msg)
telegramBot.requestContact(update.Message.Chat.ID)
}
} else {
msg := tgbotapi.NewMessage(update.Message.Chat.ID, "Если вы не предоставите ваш номер телефона, вы не сможете пользоваться системой!")
telegramBot.API.Send(msg)
telegramBot.requestContact(update.Message.Chat.ID)
}
}
// Обновление номера мобильного телефона пользователя
func (telegramBot *TelegramBot) updateUser(user User, chatID int64) {
err := Connection.UpdateUser(user)
if err != nil {
msg := tgbotapi.NewMessage(chatID, "Произошла ошибка! Бот может работать неправильно!")
telegramBot.API.Send(msg)
return
}
}
// Есть ChatID в листе ожидания?
func (telegramBot *TelegramBot) findContactRequestID(chatID int64) bool {
for _, v := range telegramBot.ActiveContactRequests {
if v == chatID {
return true
}
}
return false
}
// Удаление ChatID из листа ожидания
func (telegramBot *TelegramBot) deleteContactRequestID(chatID int64) {
for i, v := range telegramBot.ActiveContactRequests {
if v == chatID {
copy(telegramBot.ActiveContactRequests[i:], telegramBot.ActiveContactRequests[i + 1:])
telegramBot.ActiveContactRequests[len(telegramBot.ActiveContactRequests) - 1] = 0
telegramBot.ActiveContactRequests = telegramBot.ActiveContactRequests[:len(telegramBot.ActiveContactRequests) - 1]
}
}
}
var telegramBot src.TelegramBot
func main() {
src.Connection.Init() // Инициализация соединения с БД
telegramBot.Init() // Инициализация бота
telegramBot.Start()
}
|
Метки: author De1aY разработка веб-сайтов go api telegram bot golang bot |
Эффективная DI библиотека на Swift в 200 строк кода |
var apiClient: IAPIClient {
return define(init: APIClient()) {
$0.baseURl = self.baseURL
}
}
Зависимости для объектов надо закрыть протоколами и передать в объект снаружи.
class OrderViewController {
func didClickShopButton(_ sender: UIButton?) {
APIClient.sharedInstance.purchase(...)
}
}
protocol IPurchaseService {
func perform(...)
}
class OrderViewController {
var purchaseService: IPurchaseService?
func didClickShopButton(_ sender: UIButton?) {
self.purchaseService?.perform(...)
}
}
protocol IPurchaseService {
func perform(with objectId: String, then completion: (success: Bool)->Void)
}
class PurchaseService: IPurchaseService {
var baseURL: URL?
var apiPath = "/purchase/"
var apiClient: IAPIClient?
func perform(with objectId: String, then completion: (_ success: Bool) -> Void) {
guard let apiClient = self.apiClient, let url = self.baseURL else {
fatalError("Trying to do something with uninitialized purchase service")
}
let purchaseURL = baseURL.appendingPathComponent(self.apiPath).appendingPathComponent(objectId)
let urlRequest = URLRequest(url: purchaseURL)
self.apiClient.post(urlRequest) { (_, error) in
let success: Bool = (error == nil)
completion( success )
}
}
}
class OrderViewController {
var purchaseService: IPurchaseService?
var purchaseId: String?
func didClickShopButton(_ sender: UIButton?) {
guard let purchaseService = self.purchaseService, let purchaseId = self.purchaseId else {
fatalError("Trying to do something with uninitialized order view controller")
}
self.purchaseService.perform(with: self.purchaseId) { (success) in
self.presenter(showOrderResult: success)
}
}
}
class ServiceAssembly: Assembly {
var purchaseService: IPurchaseService {
return define(init: PurchaseService()) {
$0.baseURL = self.apiV1BaseURL
$0.apiClient = self.apiClient
}
}
var apiClient: IAPIClient {
return define(init: APIClient())
}
var apiV1BaseURL: URL {
return define(init: URL("http://someapi.com/")!)
}
}
var orderViewAssembly: Assembly {
var serviceAssembly: ServiceAssembly = self.context.assembly()
func inject(into controller: OrderViewController, purchaseId: String) {
define(init: controller) {
$0.purchaseService = self.serviceAssembly.purchaseService
$0.purchaseId = purchaseId
}
}
}
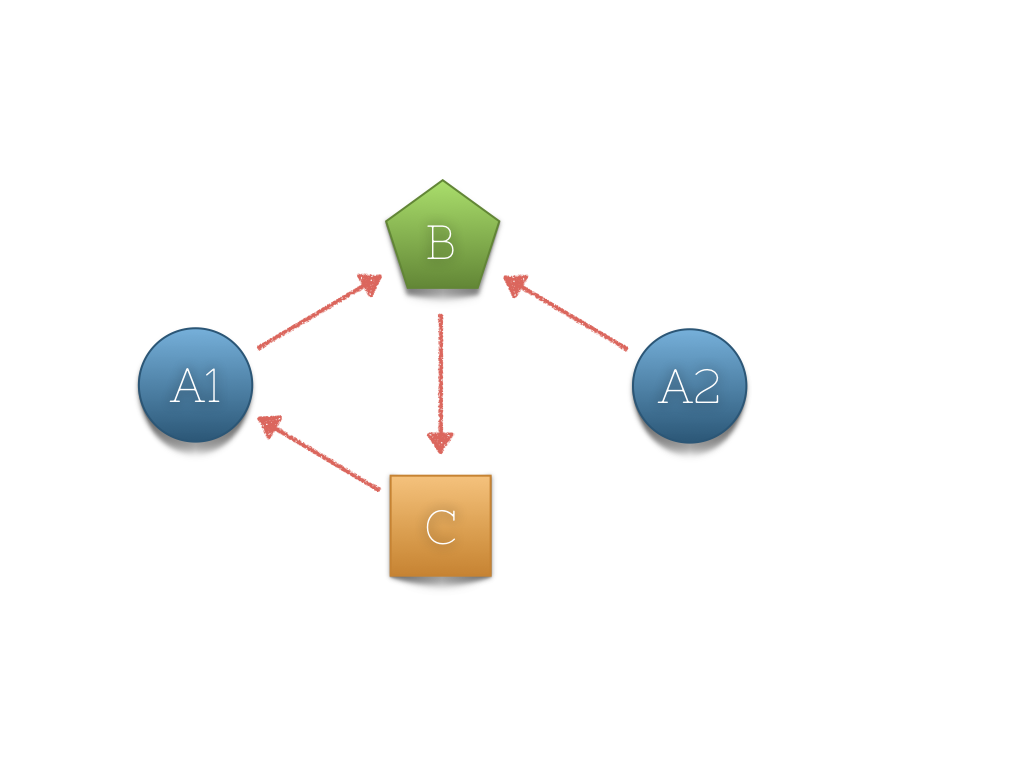
class A {
var b: B?
}
class B {
var c: C?
}
class C {
var a: A?
}
class ABCAssembly: Assembly {
var a:A {
return define(init: A()) {
$0.b = self.B()
}
}
var b:B {
return define(init: B()) {
$0.c = self.C()
}
}
var c:C {
return define(init: C()) {
$0.a = self.A()
}
}
}
var a1 = ABCAssembly.instance().a
var a2 = ABCAssembly.instance().a

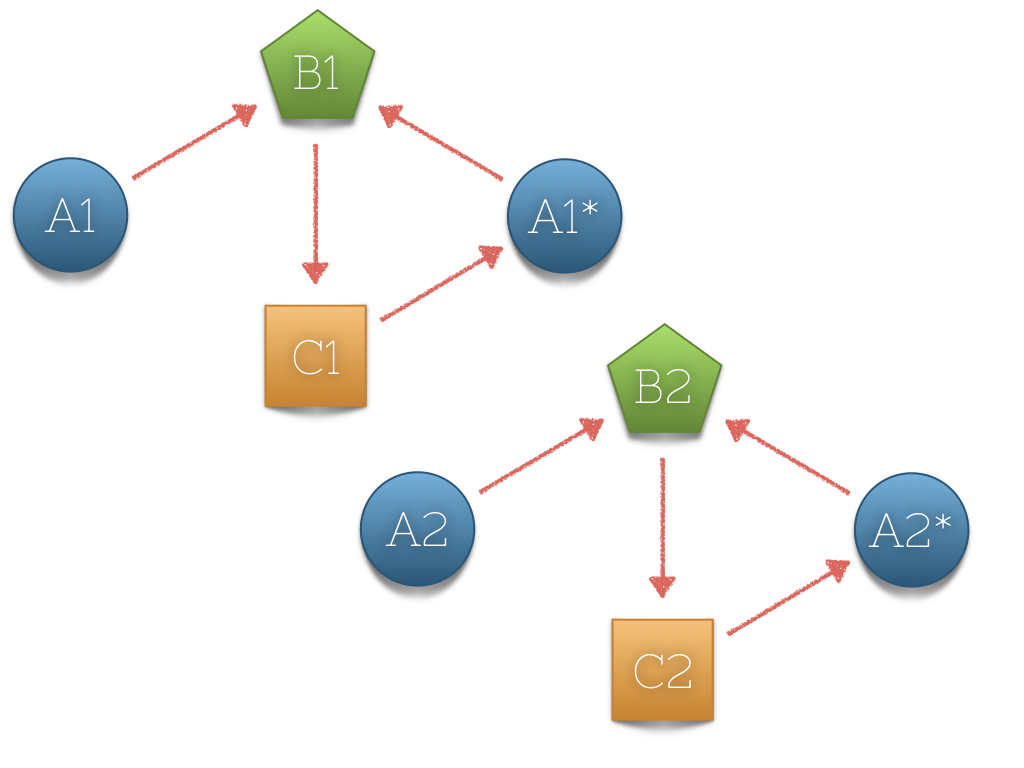
class ABCAssembly: Assembly {
var a:A {
return define(init: A()) {
$0.b = self.B()
}
}
var b:B {
return define(scope: .lazySingleton, init: B()) {
$0.c = self.C()
}
}
var c:C {
return define(init: C()) {
$0.a = self.A()
}
}
}
var a1 = ABCAssembly.instance().a
var a2 = ABCAssembly.instance().a
class ABCAssembly: Assembly {
var a:A {
return define(scope: .prototype, init: A()) {
$0.b = self.B()
}
}
var b:B {
return define(init: B()) {
$0.c = self.C()
}
}
var c:C {
return define(init: C()) {
$0.a = self.A()
}
}
}
var a1 = ABCAssembly.instance().a
var a2 = ABCAssembly.instance().a
let context: DIContext = DIContext()
let assemblyInstance2 = TestAssembly.instance(from: context)
class FeedViewAssembly: Assembly {
lazy var serviceAssembly:ServiceAssembly = self.context.assembly()
}
protocol ITheObject {
var intParameter: Int { get }
}
class MyAssembly: Assembly {
var theObject: ITheObject {
return define(init: TheObject()) {
$0.intParameter = 10
}
}
}
let myAssembly = MyAssembly.instance()
myAssembly.addSubstitution(for: "theObject") { () -> ITheObject in
let result = FakeTheObject()
result.intParameter = 30
return result
}
let FeatureAssembly: Assembly {
var feature: IFeature {
return define(init: Feature) {
...
}
}
}
let FeatureABTestAssembly: Assembly {
lazy var featureAssembly: FeatureAssembly = self.context.assembly()
var feature: IFeature {
return define(init: FeatureV2) {
...
}
}
func activate(firstTest: Bool) {
if (firstTest) {
self.featureAssembly.addSubstitution(for: "feature") {
return self.feature
}
} else {
self.featureAssembly.removeSubstitution(for: "feature")
}
}
}
сlass ModuleAssembly: Assembly {
func inject(into view: ModuleViewController) {
return define(key: "view", init: view) {
$0.presenter = self.presenter
}
}
var view: IModuleViewController {
return definePlaceholder()
}
var presenter: IModulePresenter {
return define(init: ModulePresenter()) {
$0.view = self.view
$0.interactor = self.interactor
}
}
var interaction: IModuleInteractor {
return define(init: ModuleInteractor()) {
$0.presenter = self.presenter
...
}
}
}
pod 'EasyDi', '~>1.1'|
Метки: author shadow_of_irbis разработка под ios swift dependency injection cocoapods easydi a/b тестирование viper |
[Из песочницы] Альтернативы блокчейну для ведения защищённых реестров |


|
Метки: author maslyaev анализ и проектирование систем блокчейн альтернатива |
[Из песочницы] Что будет если скрестить React и Angular? |

import Akili from 'akili';
class MyComponent extends Akili.Component {
constructor(el, scope) {
super(el, scope);
scope.example = 'Hello World';
}
}
Akili.component('my-component', MyComponent); // регистрируем компонент
document.addEventListener('DOMContentLoaded', () => {
Akili.init(); // инициализируем фреймворк
});
${ this.example }
class MySecondComponent extends MyComponent {
constructor(...args) {
super(...args);
this.scope.example = 'Goodbye World';
}
myOwnMethod() {}
}
Akili.component('my-second-component', MySecondComponent)
${ this.example }
${ this.example }
${ this.example }, где this и есть этот самый scope. На самом деле в скобках может быть любое javascript выражение.class MyComponent extends Akili.Component {
constructor(el, scope) {
super(el, scope);
scope.example = 'Hello World';
scope.test = 'Test';
}
}
${ this.example }
${ this.example } - ${ this.test }
Hello World
Goodbye World - Test
class MyComponent extends Akili.Component {
constructor(...args) {
super(...args);
this.scope.example = 'Hello World';
setTimeout(() => {
this.scope.example = 'Goodbye World';
}, 1000);
}
}
class MyComponent extends Akili.Component {
static templateUrl = '/my-component.html';
constructor(...args) {
super(...args);
this.scope.example = 'Hello World';
}
}
class MyComponent extends Akili.Component {
static templateUrl = '/my-component.html';
constructor(...args) {
super(...args);
this.scope.example = 'Hello World';
}
compiled() {
return new Promise((res) => setTimeout(res, 1000));
}
}
import Akili from 'akili';
class NineComponent extends Akili.Component {
static template = '${ this.str }';
static define() {
Akili.component('nine', NineComponent);
}
constructor(...args) {
super(...args);
this.scope.str = '';
}
compiled() {
this.attrs.hasOwnProperty('str') && this.addNine(this.attrs.str);
}
changed(key, value) {
if(key == 'str') {
this.addNine(value);
}
}
addNine(value) {
this.scope.str = value + '9';
}
}
import NineComponent from './nine-component';
NineComponent.define();
Akili.component('my-component', MyComponent);
document.addEventListener('DOMContentLoaded', () => {
Akili.init();
});
Hello World9
this.attrs => this.props. Они выполняют одну и туже роль, но есть мелкие различия: class NineComponent extends Akili.Component {
changed(key, value) {
if(key == 'str') {
this.addNine(value);
}
}
}
class NineComponent extends Akili.Component {
changedStr(value) {
this.addNine(value);
}
}
class MyComponent extends Akili.Component {
static events = ['timeout'];
constructor(...args) {
super(...args);
this.scope.example = 'HelloWorld';
this.scope.sayGoodbye = this.sayGoodbye;
}
compiled() {
setTimeout(() => this.attrs.onTimeout.trigger(9), 5000);
}
sayGoodbye(event) {
console.log(event instanceof Event); // true
this.scope.example = 'Goodbye World';
}
}
${ this.example }
class MyComponent extends Akili.Component {
constructor(...args) {
super(...args);
this.scope.data = [];
for (let i = 1; i <= 10; i++) {
this.scope.data.push({ title: 'value' + i });
}
}
}
${ this.loopIndex } => ${ this.loopKey} => ${ this.loopValue.title }
- ${ this.loopValue }
|
Метки: author IsOrtex разработка веб-сайтов javascript akiil framework spa react angular angularjs aurelia |
Выпуск#4: ITренировка — актуальные вопросы и задачи от ведущих компаний |
$str1 = 'yabadabadoo';
$str2 = 'yaba';
if (strpos($str1,$str2)) {
echo "\"" . $str1 . "\" contains \"" . $str2 . "\"";
} else {
echo "\"" . $str1 . "\" does not contain \"" . $str2 . "\"";
}
"yabadabadoo" does not contain "yaba"
echo и print в PHP?$a = '1';
$b = &$a;
$b = "2$b";
|
Метки: author SpiceIT программирование занимательные задачки php блог компании spice it recruitment spiceit it ренировка собеседование |
Таблицы! Таблицы? Таблицы… |
В статье я покажу стандартную табличную разметку, какие у неё есть альтернативы. Дам пример собственной таблицы и разметки, а также опишу общие моменты её реализации.
Когда появилась необходимость в HTML разметке показывать таблицы — изобрели тег
| Header 1 | Header 2 |
|---|---|
| 1.1 | 1.2 |
| 2.1 | 2.2 |
Однако можно использовать "каноничную" разметку:
Header 1
Header 2
1.1
1.2
2.1
2.2
Если нужна таблица без шапки и в то же время нам необходимо контроллировать ширину столбцов:
1.1
1.2
2.1
2.2
Чаще всего нам в разметке необходимо получить следующее. У нас есть некий контейнер с заданной шириной или с заданной максимальной шириной. Внутри него мы хотим вписать таблицу.
Если ширина таблицы больше чем контейнер, тогда необходимо показывать скролл для контейнера. Если ширина таблицы меньше чем контейнер, тогда необходимо расширять таблицу до ширины контейнера.
Но ни в коем случае мы не хотим, чтобы таблица сделала наш контейнер шире чем мы задали.
По этой ссылке можно уведеть контейнер с таблицей в действии. Если мы будем сужать контейнер, то в тот момент, когда таблица уже больше не сможет сужаться — появиться скролл.
Первая дилемма с которой сталкиваются фронт-энд разработчики — это задавать или не задавать ширину столбцов.
Если не задавать, тогда ширина каждого столбца будет вычисляться в зависимости от содержимого.
Исходя из логики, можно понять, что в этом случае браузеру нужно два прохода. На первом он просто отображает все в таблице, подсчитывает ширину столбцов (мин, макс). На втором подстраивает ширину столбцов в зависимости от ширины таблицы.
Со временем вам скажут что таблица выглядит некрасиво, т.к. один из столбцов слишком широкий и
вот в этом столбце нам надо показать больше текста чем в этом, а у нас наоборотИ самая распространенная "фича":
...Т.е. если текст в ячейке вылазит за ширину колонки, то его необходимо сокращать и в конце добавлять ....
Первое разочарование, что если не задавать ширину столбцов, то сокращение не работает. В этом есть своя логика, т.к. на первом проходе браузер высчитывает мин/макс ширину колонки без сокращения, а тут мы пытаемся сократить текст. Необходимо либо все пересчитать повторно, либо игнорировать сокращение.
Сокращение реализуется просто, необходимо указать CSS свойства для ячейки:
td {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis;
}И соответственно задать ширину колонки. По этой ссылке можно увидеть, что все настроено, но сокращение не работает.
В спецификации есть заметка, немного объясняющая, почему сокращение не работает:
If column widths prove to be too narrow for the contents of a particular table cell, user agents may choose to reflow the tableОпять же сужаться таблица будет до минимальной ширины содержимого. Но если применить свойство table-layout: fixed то таблица начнёт "слушаться" и сокращение заработает. Но автоподстройка ширины столбцов уже не работает.
Вышеприведенный пример будет работать со скроллом и пользоваться этим можно. Однако возникает следующее требование:
здесь нам надо сделать, чтобы шапка таблицы оставалась на месте, а тело прокручивалосьВторая дилемма с которой сталкиваются фронт-энд разработчики:
В спецификации таблицы есть прямое указание, что тело таблицы может быть с шапкой и подвалом. Т.е. шапка и подвал всегда видимы.
User agents may exploit the head/body/foot division to support scrolling of body sections independently of the head and foot sections. When long tables are printed, the head and foot information may be repeated on each page that contains table dataА есть и указание о том, что тело таблицы можно скроллить, а шапка и подвал будут оставаться на месте:
Table rows may be grouped into a table head, table foot, and one or more table body sections, using the THEAD, TFOOT and TBODY elements, respectively. This division enables user agents to support scrolling of table bodies independently of the table head and footА по факту браузеры этого не делают и скролл для таблицы необходимо придумывать/настраивать вручную.
Есть много способов это сделать, но все они сводяться к тому, что:
Можно задать ограниченную высоту телу таблицы. Следующий пример показывает, что можно попробовать задать высоту тела таблицы.
В результате мы ломаем табличное отображение тела таблицы CSS свойством display: block, и при этом необходимо синхронизировать прокрутку шапки с телом таблицы.
Этот вариант, где все предлагают/строят решения.
Если нам необходима прокрутка тела таблицы, то без составных разметок не обойтись. Все примеры составных таблиц используют свои пользовательские разметки.
Одна из самых известных таблиц Data Tables использует следующую разметку:
Я намеренно сокращаю разметку, чтобы можно было составить общую картину, как выглядит разметка.
Мы видим в разметке две таблицы, хотя для пользователя это "видится" как одна.
Следующий пример React Bootstrap Table, если посмотреть в разметку, использует тоже две таблицы:
Верхняя таблица отображает шапку, нижняя — тело. Хотя для пользователя кажется как будто бы это одна таблица.
Опять же пример использует синхронизацию прокрутки, если прокрутить тело таблицы, то произойдет синхронизация шапки.
А как же так получается, что тело таблицы (одна таблица) и шапка (другая таблица) подстраиваются под ширину контейнера и они никак не разъезжаются по ширине и совпадают друг с другом?
Тут кто как умеет так и синхронизирует, например, вот функция синхронизации ширины из вышеприведенной библиотеки:
componentDidUpdate() {
...
this._adjustHeaderWidth();
...
}
_adjustHeaderWidth() {
...
// берем ширину столбцов из тела таблицы если есть хоть один ряд, или берем ширину Возникает вполне логичный вопрос, а зачем тогда вообще использовать тег
разработчик должен будет писать:
render() {
const
descriptions = getColumnDescriptions(this.getTableColumns()),
filteredData = filterBy([], []),
sortedData = sortBy(filteredData, []);
return (
Разработчик должен сам прописывать шаги: вычислить описание колонок, отфильтровать, отсортировать.
Все функции/конструкторы getColumnDescriptions, filterBy, sortBy, TableHeader, TableBody, TableColumn будут импортироваться из моей таблицы.
В качестве данных будет использоваться массив объектов:
[
{ "Company": "Alfreds Futterkiste", "Cost": "0.25632" },
{ "Company": "Francisco Chang", "Cost": "44.5347645745" },
{ "Company": "Ernst Handel", "Cost": "100.0" },
{ "Company": "Roland Mendel", "Cost": "0.456676" },
{ "Company": "Island Trading Island Trading Island Trading Island Trading Island Trading", "Cost": "0.5" },
]Мне понравился подход создания описания колонок в jsx в качестве элементов.
Будем использовать ту же идею, однако, чтобы сделать независимыми шапку и тело таблицы, будем вычислять описание один раз и передавать его и в шапку и в тело:
getTableColumns() {
return [
first header row ,
Company
,
Cost
,
];
}
render() {
const
descriptions = getColumnDescriptions(this.getTableColumns());
return (
В функции getTableColumns мы создаем описание колонок.
Все обязательные свойства я могу описать через propTypes, но после того как их вынесли в отдельную библиотеку — это решение кажется сомнительным.
Обязательно указываем row — число, которое показывает индекс строки в шапке (если шапка будет группироваться).
Параметр dataField, определяет какой ключ из объекта использовать для получения значения.
Ширина width тоже обязательный параметр, может задаватся как числом или как массивом ключей от которых зависит ширина.
В примере верхняя строка в таблице row={0} зависит от ширины двух колонок ["Company", "Cost"].
Элемент TableColumn "фейковый", он никогда не будет отображаться, а вот его содержимое this.props.children — отображается в ячейке шапки.
На основе описаний колонок сделаем функцию, которая будет разбивать описания по рядам и по ключам, а также будет сортировать описания по рядам в результирующем массиве:
function getColumnDescriptions(children) {
let byRows = {}, byDataField = {};
React.Children.forEach(children, (column) => {
const {row, hidden, dataField} = column.props;
if (column === null || column === undefined || typeof row !== 'number' || hidden) { return; }
if (!byRows[row]) { byRows[row] = [] }
byRows[row].push(column);
if (dataField) { byDataField[dataField] = column }
});
let descriptions = Object.keys(byRows).sort().map(row => {
byRows[row].key = row;
return byRows[row];
});
descriptions.byRows = byRows;
descriptions.byDataField = byDataField;
return descriptions;
}Теперь обработанные описания передаём в шапку и в тело для отображения ячеек. Шапка будет строить ячейки так:
getFloor(width, factor) {
return Math.floor(width * factor);
}
renderChildren(descriptions) {
const {widthFactor} = this.props;
return descriptions.map(rowDescription => {
return
{rowDescription.map((cellDescription, index) => {
const {props} = cellDescription;
const {width, dataField} = props;
const _width = Array.isArray(width) ?
width.reduce((total, next) => {
total += this.getFloor(descriptions.byDataField[next].props.width, widthFactor);
return total;
}, 0) :
this.getFloor(width, widthFactor);
return
{cellDescription.props.children}
})}
})
}
render() {
const {className, descriptions} = this.props;
return (
{this.renderChildren(descriptions)}
)
}Тело таблицы будет строить ячейки тоже на основе обработанных описаний колонок:
renderDivRows(cellDescriptions, data, keyField) {
const {rowClassName, widthFactor} = this.props;
return data.map((row, index) => {
return
{cellDescriptions.map(cellDescription => {
const {props} = cellDescription;
const {dataField, dataFormat, cellClassName, width} = props;
const value = row[dataField];
const resultValue = dataFormat ? dataFormat(value, row) : value;
return
{resultValue ? resultValue : '\u00A0'}
})}
});
}
getCellDescriptions(descriptions) {
let cellDescriptions = [];
descriptions.forEach(rowDescription => {
rowDescription.forEach((cellDescription) => {
if (cellDescription.props.dataField) {
cellDescriptions.push(cellDescription);
}
})
});
return cellDescriptions;
}
render() {
const {className, descriptions, data, keyField} = this.props;
const cellDescriptions = this.getCellDescriptions(descriptions);
return (
{this.renderDivRows(cellDescriptions, data, keyField)}
)
}Тело таблицы использует описания у которых есть свойство dataField, поэтому описания фильтруются используя функцию getCellDescriptions.
Тело таблицы будет слушать события изменения размеров экрана, а также прокрутки самого тела таблицы:
componentDidMount() {
this.adjustBody();
window.addEventListener('resize', this.adjustBody);
if (this.tb) {
this.tb.addEventListener('scroll', this.adjustScroll);
}
}
componentWillUnmount() {
window.removeEventListener('resize', this.adjustBody);
if (this.tb) {
this.tb.removeEventListener('scroll', this.adjustScroll);
}
}Подстройка ширины таблицы происходит следующим образом.
После отображения берётся ширина контейнера, сравнивается с шириной всех ячеек, если ширина контейнера больше, увеличивается ширина всех ячеек.
Для этого разработчик должен хранить состояние коэффициента ширины (который будет меняться).
Следующие функции реализованы в таблице, однако разработчик может использовать свои. Чтобы использовать уже реализованные, необходимо их импортировать и прилинковать к текущему компоненту:
constructor(props, context) {
super(props, context);
this.state = {
activeSorts: [],
activeFilters: [],
columnsWidth: {
Company: 300, Cost: 300
},
widthFactor: 1
};
this.handleFiltersChange = handleFiltersChange.bind(this);
this.handleSortsChange = handleSortsChange.bind(this);
this.handleAdjustBody = handleAdjustBody.bind(this);
this.getHeaderRef = getHeaderRef.bind(this, 'th');
this.getBodyRef = getBodyRef.bind(this, 'tb');
this.syncHeaderScroll = syncScroll.bind(this, 'th');
}Функция подстройки ширины:
adjustBody() {
const {descriptions, handleAdjustBody} = this.props;
if (handleAdjustBody) {
const cellDescriptions = this.getCellDescriptions(descriptions);
let initialCellsWidth = 0;
cellDescriptions.forEach(cd => {
initialCellsWidth += cd.props.width;
});
handleAdjustBody(this.tb.offsetWidth, initialCellsWidth);
}
}Функция синхронизация шапки:
adjustScroll(e) {
const {handleAdjustScroll} = this.props;
if (typeof handleAdjustScroll === 'function') {
handleAdjustScroll(e);
}
}Ключевая особенность таблицы для redux — это то, что она не имеет своего внутреннего состояния (она должна иметь состояние, но только в том месте, где укажет разработчик).
И подстройка ширины adjustBody и синхронизация скролла adjustScroll — это функции которые изменяют состояние у прилинкованного компонента.
Внутрь TableColumn можно вставлять любую jsx разметку. Зачастую используются такие варианты: текст, кнопка сортировки и кнопка фильтрации.
Для массива активных сортировок/фильтраций разработчик должен создать состояние и передавать его в таблицу.
this.state = {
activeSorts: [],
activeFilters: [],
};Передаем в таблицу массив активных сортировок/фильтраций:
getTableColumns() {
const {activeFilters, activeSorts, columnsWidth} = this.state;
return [
first header row ,
,
,
];
}Компонент сортировки SortButton и компонент фильтрации MultiselectDropdown при изменении "выбрасывают" новые активные фильтры/сортировки, которые разработчик должен заменить в состоянии. Массивы activeSorts и activeFilters как раз и предполагают, что возможна множественная сортировка и множественная фильтрация по каждой колонке.
К сожалению, формат статьи не позволяет описать всех тонкостей, поэтому предлагаю сразу посмотреть результат.
Итого разработчику в таблице необходимо:
Все это я реализовал в примере. Надеюсь теперь, при переходе на новый фреймворк, у вас как минимум появился выбор — брать готовую или сделать свою таблицу.
Исходники находятся здесь.
|
Метки: author volodalexey reactjs javascript html table react |
Чипы Intel Skylake и Kaby Lake — обнаружена проблема при активном Hyper-Threading |
 / фото Ultra Mendoza PD
/ фото Ultra Mendoza PD
|
Метки: author it_man информационная безопасность блог компании ит-град ит-град skylake hyper-threading |
Комплексный подход по защите от направленных атак и вымогательского ПО типа Ransomware |


|
|
Интеграция инструментов статистического анализа кода для OpenStack на Jenkins CI |
pip install pylinttouch pylint.cfg
pylint --generate-rcfile > pylint.cfgfind /var/lib/jenkins/workspace/$JOB_NAME/
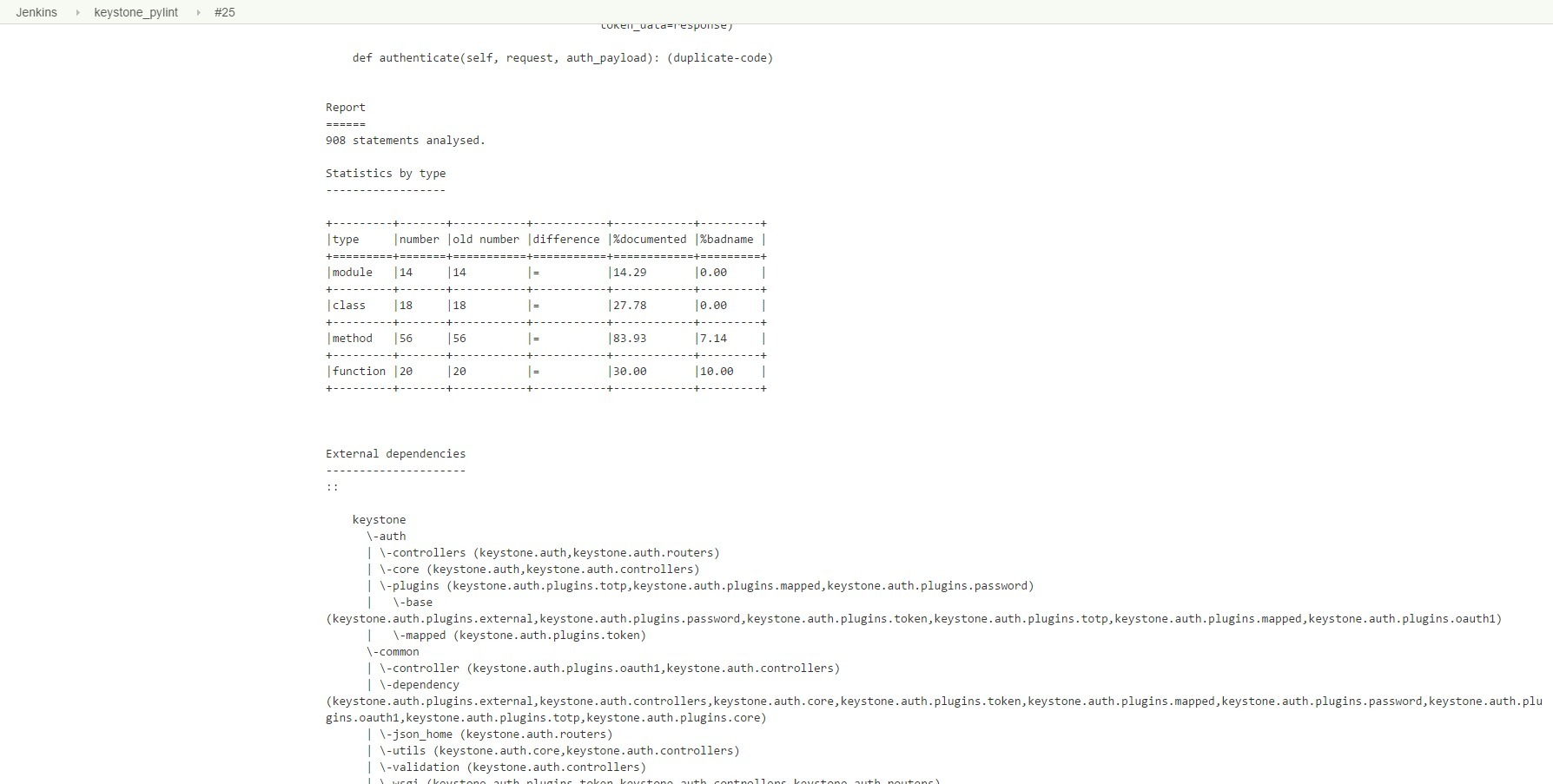


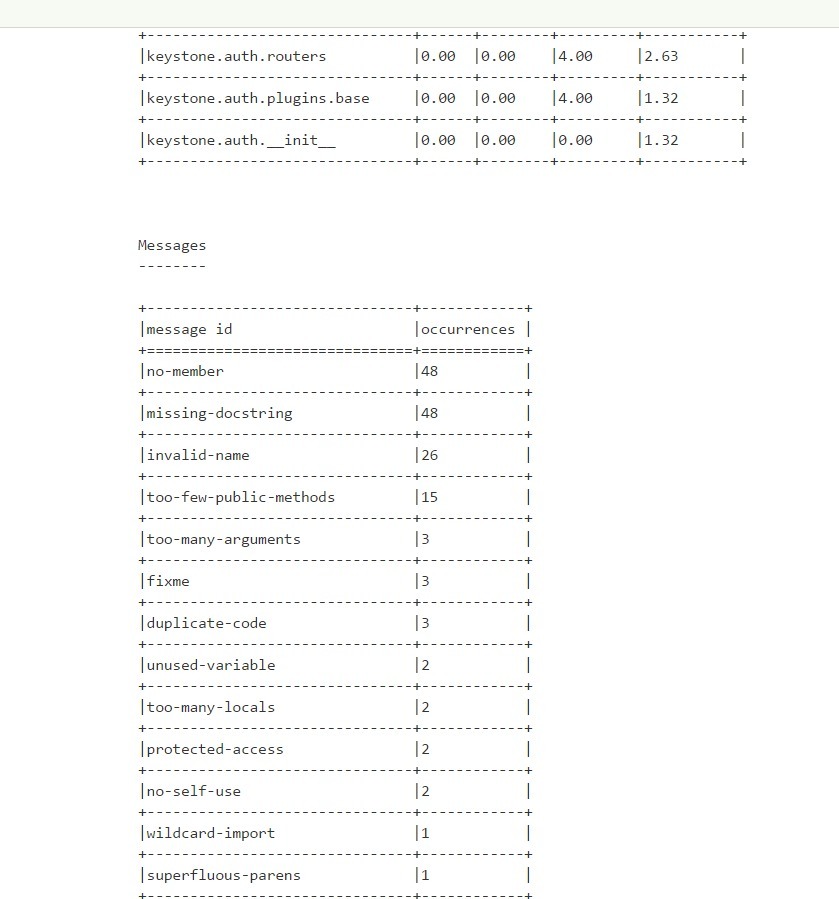
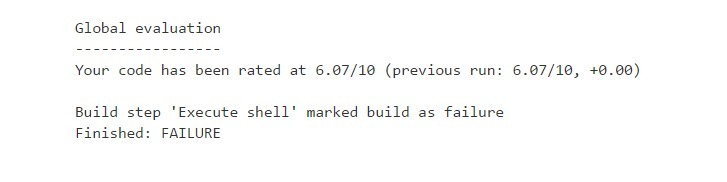
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
sudo rpm -ivh mysql-community-release-el7-5.noarch.rpm
sudo yum update -y
sudo yum install mysql-server
sudo systemctl start mysqld
sudo mysql_secure_installation - нажать enter если пароль по умолчанию отсутствует
mysql -u root -p
CREATE DATABASE sonar CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE USER 'sonar' IDENTIFIED BY 'sonar';
GRANT ALL ON sonar.* TO 'sonar'@'%' IDENTIFIED BY 'sonar';
GRANT ALL ON sonar.* TO 'sonar'@'localhost' IDENTIFIED BY 'sonar';
Скачивание установочного файла в /opt
cd /opt
sudo wget https://sonarsource.bintray.com/Distribution/sonarqube/sonarqube-6.0.zip
Установка unzip и java
sudo yum install unzip -y
sudo yum install java-1.8.0-openjdk -y
Разархивирование sonarqube
sudo unzip sonarqube-6.0.zip
mv sonarqube-6.0 sonarqube
Настройка конфигурационного файла
vi /opt/sonarqube/conf/sonar.properties
sonar.jdbc.username=sonar
sonar.jdbc.password=sonar
sonar.jdbc.url=jdbc:mysql://localhost:3306/sonar?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true&useConfigs=maxPerformance
sonar.web.host=localhost
sonar.web.context=/sonar
sonar.web.port=9000
По ссылке http://localhost:9000 будет находиться сервер sonarqube
Запуск SonarQube:
cd /opt/sonar/bin/linux-x86-64/
sudo ./sonar.sh start
Настройка SonarQube как сервиса:
Создать файл
/etc/init.d/sonar
Скопировать в содержимое файла
#!/bin/sh
#
# rc file for SonarQube
#
# chkconfig: 345 96 10
# description: SonarQube system (www.sonarsource.org)
#
### BEGIN INIT INFO
# Provides: sonar
# Required-Start: $network
# Required-Stop: $network
# Default-Start: 3 4 5
# Default-Stop: 0 1 2 6
# Short-Description: SonarQube system (www.sonarsource.org)
# Description: SonarQube system (www.sonarsource.org)
### END INIT INFO
/usr/bin/sonar $*
Создание ссылки на SonarQube
sudo ln -s /opt/sonarqube/bin/linux-x86-64/sonar.sh /usr/bin/sonar
Настройка прав и добавление в boot
sudo chmod 755 /etc/init.d/sonar
sudo chkconfig --add sonar
Запуск sonar
sudo service sonar start
Установка sonar runner:
yum install sonar-runner
wget http://repo1.maven.org/maven2/org/codehaus/sonar/runner/sonar-runner-dist/2.4/sonar-runner-dist-2.4.zip
unzip sonar-runner-dist-2.4.zip
mv sonar-runner-2.4 /opt/sonar-runner
export SONAR_RUNNER_HOME=/opt/sonar-runner
export PATH=$PATH:$SONAR_RUNNER_HOME/bin
Необходимо в корне проекта создать файл sonar-project.properties. Пример содержания файла

Запуск в Jenkins:
1. В настройках Jenkins - управление плагинами установить плагины “SonarQube Scanner for Jenkins” для генерации наглядного отчета
2. Перейти в “Настройки Jenkins” - “Конфигурирование системы” - “SonarQube servers” (если данной конфигурации не будет, то необходимо перезагрузить Jenkins). Далее нужно заполнить поля конфигурации:
Рис.8. Настройка SonarQube сервера в системе непрерывной интеграции Jenkins

3. Перейти в “Настройки Jenkins” - “Global Tool Configuration” - “SonarQube Scanner”. Заполнить поля конфигурации
Рис.9. Настройка SonarQube сканера в системе непрерывной интеграции Jenkins

4. Создать проект (job) со свободной конфигурацией
5. В пункте управления исходным кодом вставить ссылку до репозитория
6. В пункте сборки выбрать “Execute SonarQube Scanner”
В поле “Analysis properties” ввести параметры из файла sonar-project.properties или указать путь до данного файла
7. Сохранить проект и запустить
Рис.10. Результат выполнения работы SonarQube

Рис.11. Результат выполнения работы SonarQube - продолжение 1

Перейдя по ссылке из результата выполнения проекта localhost:9000/sonar/dashboard/index/keystone можно детально рассмотреть отчет по проверке качества кода keystone
Рис.12. Пример сгенерированного отчета SonarQube

Рис.13. Пример сгенерированного отчета SonarQube - продолжение 1

|
Метки: author Ilusa тестирование it-систем open source openstack itis |
«Когда управление идёт не сверху, а появляется внутри тебя»: о JS-разработке в SEMrush |

 — Над чем лично вы работаете в SEMrush?
— Над чем лично вы работаете в SEMrush?|
Метки: author phillennium javascript блог компании jug.ru group semrush holyjs |
Пример построения процесса тестирования OpenStack на Jenkins CI |
node{
stage 'Deploy'
build 'Deploy_CHECK'
stage 'Sonar_analysis'
build job: 'Sonar_analysis', parameters: [string(name: 'STAND', value: 'CHECK')]
stage 'Unit tests'
build job: 'Unit_tests', parameters: [string(name: 'STAND', value: 'CHECK')]
stage 'Deploy DEV'
build 'Deploy_DEV'
stage 'Unit tests'
build job: 'Unit_tests', parameters: [string(name: 'STAND', value: 'DEV')]
stage 'Acceptance_test'
build 'Acceptance_test'
stage 'Smoke_tests'
build job: 'Smoke_tests', parameters: [string(name: '', value: 'DEV')]
}

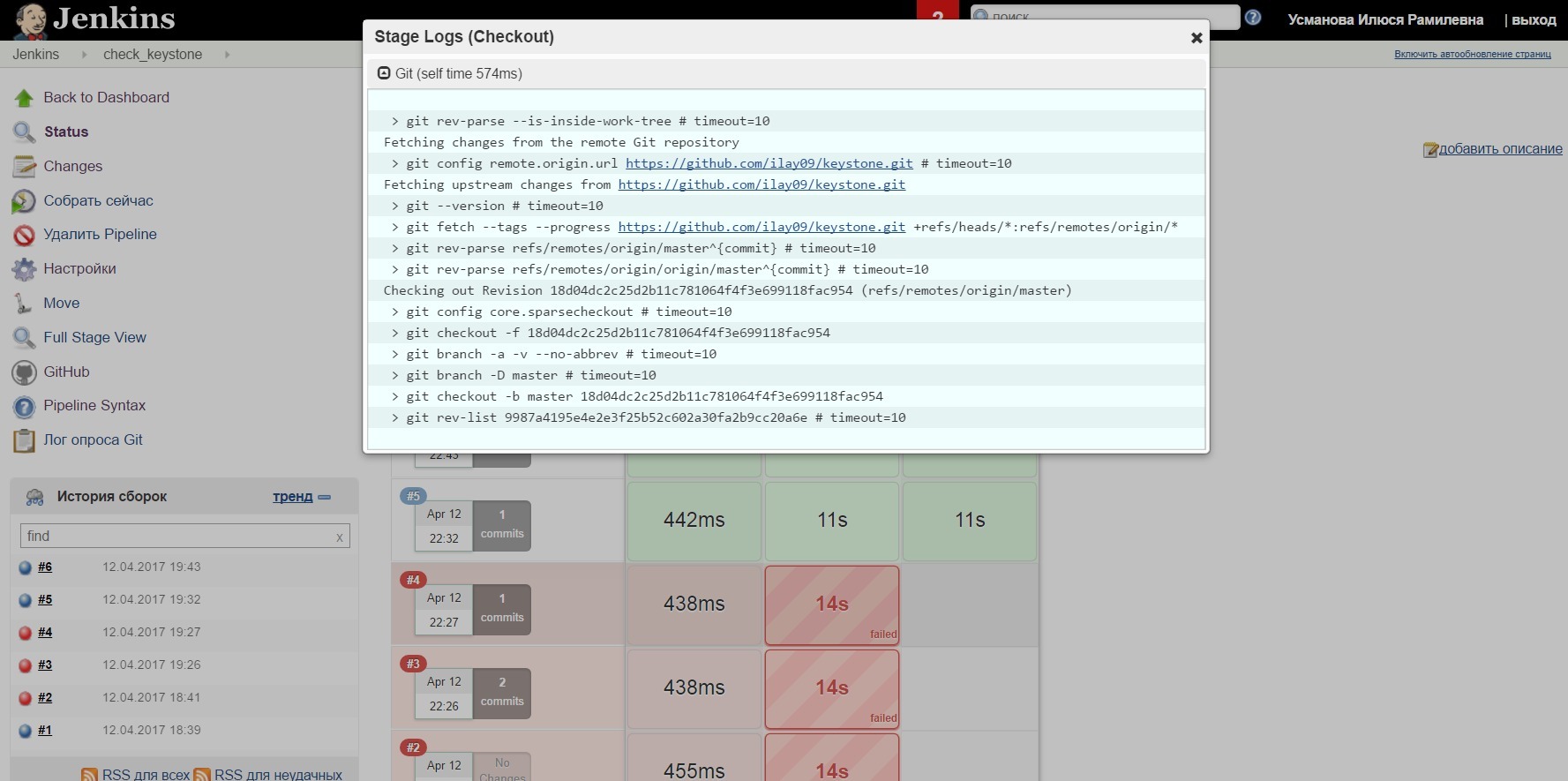
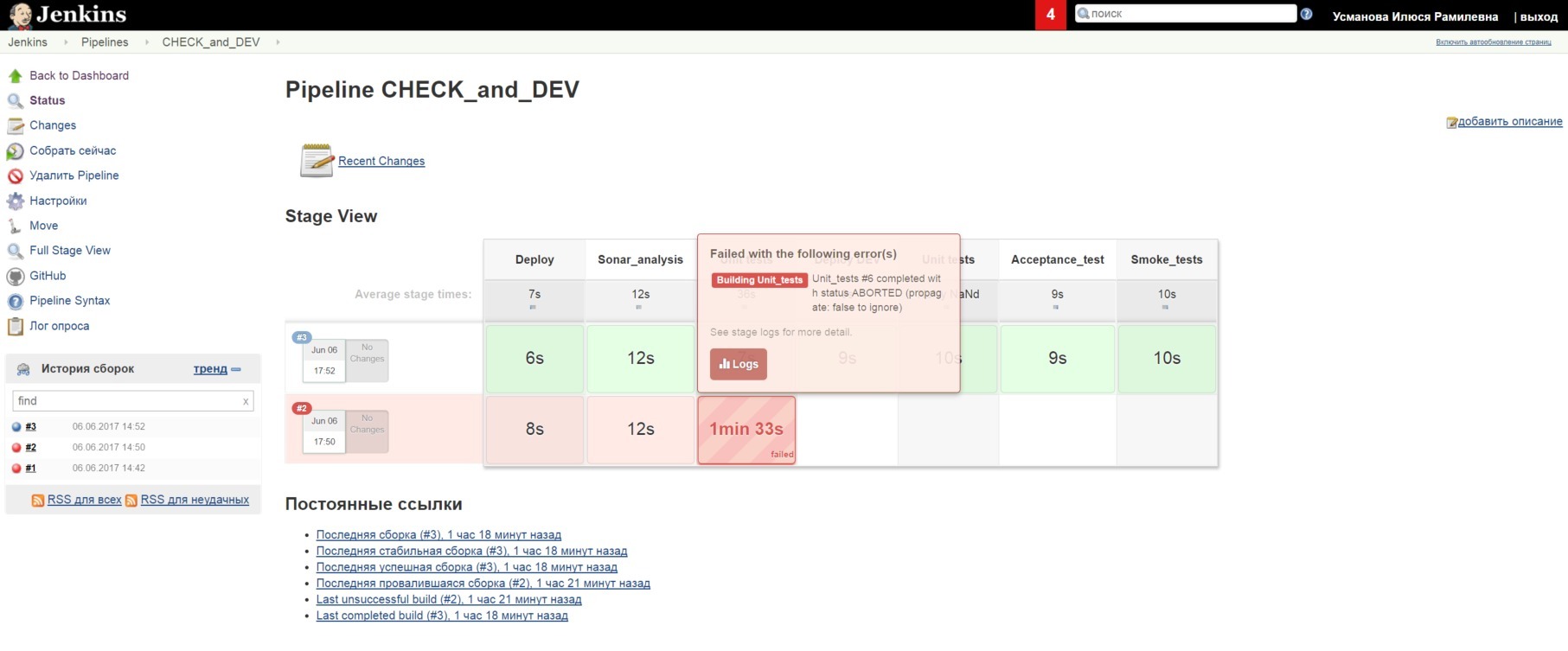
node{
stage 'Deploy QA'
build 'Deploy_QA'
stage 'Compliance tests'
build job: 'chef-compliance', parameters: [string(name: 'STAND', value: 'QA')]
stage 'Functional tests'
build job: 'Tempest', parameters: [string(name: 'STAND', value: 'QA')]
stage 'Performance tests'
build 'Rally'
stage 'Deploy PROD'
build 'Deploy_PROD'
stage 'Smoke tests PROD'
build 'Smoke_tests_PROD'
}
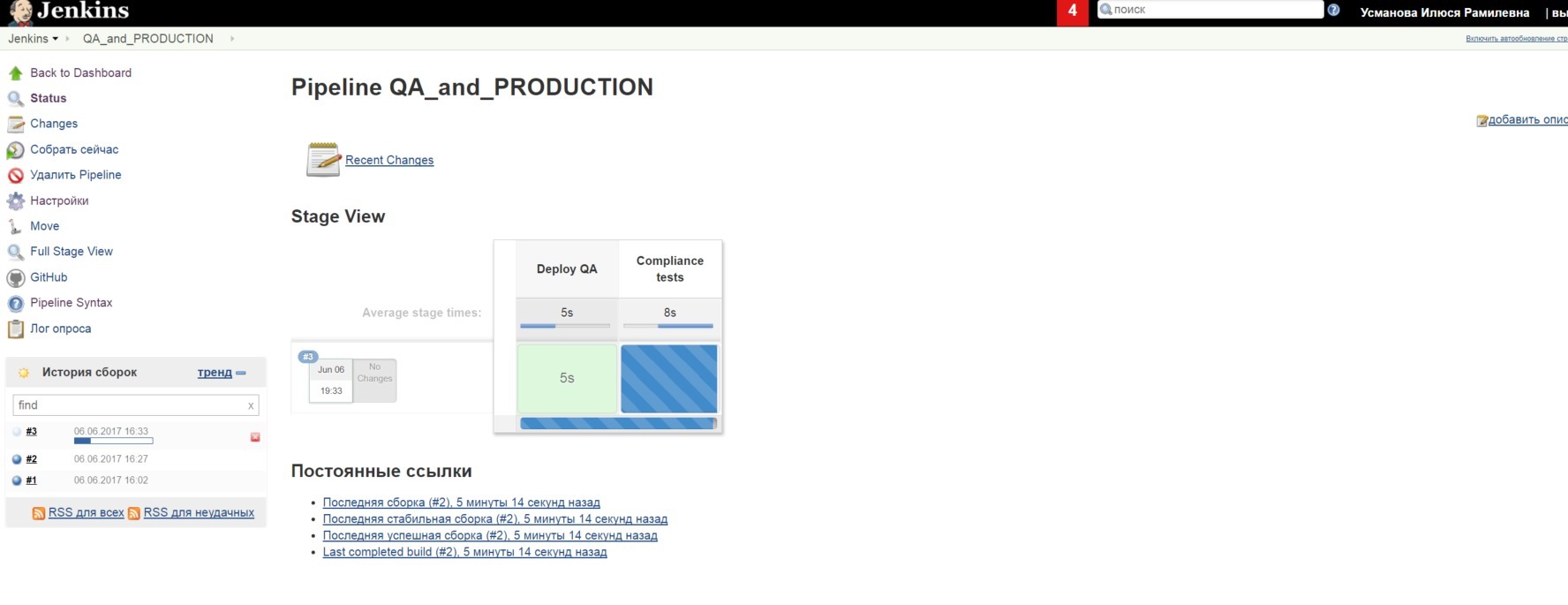

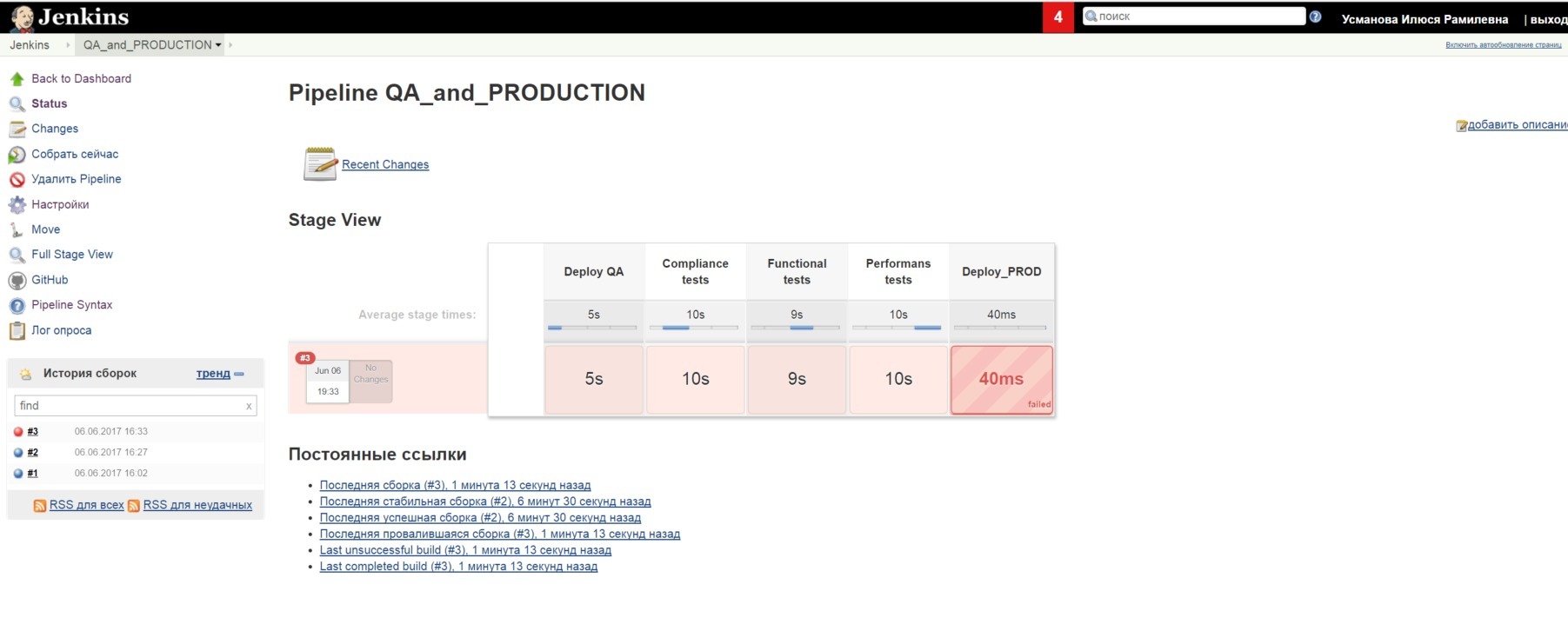
|
Метки: author Ilusa тестирование it-систем open source openstack itis fix llc |
Pure Storage: час //m настал |


|
|
Командная разработка системы на базе MS Dynamics CRM |
|
Метки: author Otkritie css api блог компании открытие dynamics crm microsoft |






