В сеть утекли исходные коды операционной системы Windows 10 [маленькая часть] |



|
Метки: author Jeditobe информационная безопасность windows 10 утечка информации |
Грех администратора или восстановление данных из стучащего HDD Western Digital WD5000AAKX |






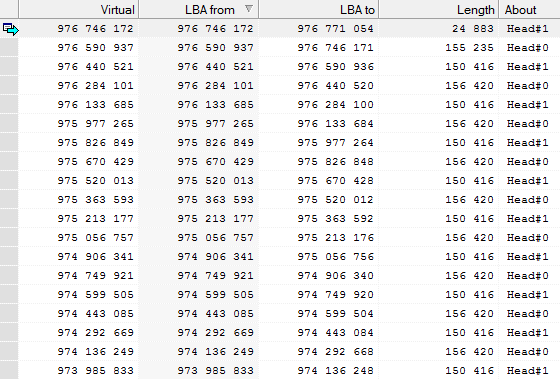
|
|
Security Week 25: В *NIX реанимировали древнюю уязвимость, WannaCry оказался не доделан, ЦРУ прослушивает наши роутеры |
 Земля, 2005 год. По всей планете происходят загадочные события: Nokia выводит на рынок планшет на Linux, в глубокой тайне идет разработка игры с участниками группы Metallica в главных ролях, Джобс объявил о переходе Маков на платформу Intel.
Земля, 2005 год. По всей планете происходят загадочные события: Nokia выводит на рынок планшет на Linux, в глубокой тайне идет разработка игры с участниками группы Metallica в главных ролях, Джобс объявил о переходе Маков на платформу Intel. 
 Это чертовски похоже на правду, хотя не очень понятно, что помешало создателям вовремя дернуть за рубильник, зарегав стоп-домен, пока распространение троянца не успело принять характер эпидемии. И еще – забавно будет, если окажется, что захардкоденный биткойн-адрес представляет собой лишь плейсхолдер, и не соответствует никакому реальному кошельку. По крайней мере, списаний с известных кошельков WannaCry пока не было.
Это чертовски похоже на правду, хотя не очень понятно, что помешало создателям вовремя дернуть за рубильник, зарегав стоп-домен, пока распространение троянца не успело принять характер эпидемии. И еще – забавно будет, если окажется, что захардкоденный биткойн-адрес представляет собой лишь плейсхолдер, и не соответствует никакому реальному кошельку. По крайней мере, списаний с известных кошельков WannaCry пока не было.

|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw linux freebsd wannacry cherry blossom |
Результаты внедрения Zextras для SaaS провайдера |


|
Метки: author KaterinaZextras хранение данных резервное копирование it- инфраструктура блог компании zimbra zimbra zextras open-source saas |
Как держать 20 тысяч VPN клиентов на серверах за $5 |
|
Метки: author zhovner сетевые технологии ipv6 openvpn блокировки сайтов украина vpn bgp dns |
CocoaHeads Russia. Прямая трансляция |

|
Метки: author 0xy разработка под ios objective c cocoa блог компании туту.ру митап ios tuturu tutu туту тутуру |
Борьба со спамом на хостинге. Настройка EFA Project Free Spam/antivirus filter |

В этой статье, как и обещали, хотим поделиться нашим опытом борьбы со спамом. Известно, что у любой причины есть следствие. Эта фраза выражает одну из философских форм связи явлений.
Нашей причиной стали многократные жалобы на спам, исходящий от наших клиентов хостинга и VPS. Не всегда можно с уверенностью сказать, были ли это умышленные действия клиентов или они сами не подозревали, что стали жертвой спам-ботов. Что бы там ни было, проблему пришлось решать.
Спам не любят. Спам оставляет «чёрное пятно» на лице провайдера, когда его IP адреса вносят в блеклисты, от чего страдают все клиенты. Удалить IP из блеклистов — особый разговор. Но это одна сторона медали. Если вернуть репутацию IP адресу можно, то вернуть репутацию компании и доверие — намного сложнее.
Мы решили найти решение и внедрить в структуру Unihost комплекс по защите и предотвращению нежелательных рассылок. После мозговых штурмов и обсуждений, начали проверять и сравнивать, что может предложить сообщество SPAM/AV.
Вариантов на рынке много. Однако, большинство качественных решений платные с тарификацией 1 лицензия на 1 сервер или даже на количество исходящих/входящих писем, что привело бы к удорожанию тарифов. Поэтому выбирали только среди opensource.
Он подходит для систем различного масштаба. Умеет интегрироваться в различные MTA (в документации описаны Exim, Postfix, Sendmail и Haraka) или работать в режиме SMTP-прокси.
Система оценки сообщений такая же, как в SpamAssassin, в частности на основании разных факторов: регулярных выражений, блок-листов DNS, белых, серых, черных списков, SPF, DKIM, статистики, хешей (fuzzy hashes) и прочего — только в работе используются другие алгоритмы.
В Rspamd поддерживается расширение при помощи плагинов.
Известность SA получил благодаря использованию технологии байесовской фильтрации. Каждое сообщение при прохождении тестов получает определенный балл и при достижении порога помещается в спам.
Легко интегрируется практически с любым почтовым сервисом. В SA доступны популярные технологии, которые подключаются как плагины: DNSBL, SPF, DKIM, URIBL, SURBL, PSBL, Razor, RelayCountry, автоматическое ведение белого списка (AWL) и другие.
Установка в общем не сложна. После установки SpamAssassin требует тонкой настройки параметров и обучения на спам-письмах.
Платформно-зависимый SMTP-прокси-сервер, принимающий сообщения до MTA и анализирующий его на спам.
Поддерживаются все популярные технологии: белые и серые списки, байесовский фильтр, DNSBL, DNSWL, URIBL, SPF, DKIM, SRS, проверка на вирусы (с ClamAV), блокировка или замена вложений и многое другое. Обнаруживается кодированный MIME-спам и картинки (при помощи Tesseract). Возможности расширяются при помощи модулей.
Документация проекта не всегда внятная, а инструкции нередко уже устаревшие, но при наличии некоторого опыта разобраться можно.
MailScanner представляет собой решение «все включено» для борьбы с фишинговыми письмами и проверки почты на наличие вирусов и спама. Он анализирует содержание письма, блокируя атаки, направленные на email-клиентов и HTML-теги, проверяет вложения (запрещенные расширения, двойные расширения, зашифрованные архивы и прочее), контролирует подмену адреса в письме и многое другое.
MailScanner легко интегрируется с любым МТА, в поставке есть готовые конфигурационные файлы. Помимо собственных наработок, он может использовать сторонние решения. Для проверки на спам может использоваться SpamAssassin.
Есть еще один Open Source проект — «eFa-project» — Email Filter Appliance. EFA изначально разработан как виртуальное устройство для работы на Vmware или HyperV. Программа использует готовые пакеты MailScanner, Postfix, SpamAssasin (весь список ниже) для остановки спама и вирусов и они уже установлены и настроены для правильной работы в vm. Это значит, что костыли не нужны — все работает «из коробки».
В EFA входят такие компоненты:
В качестве MTA (mail transfer agent) выступает Postfix — надежный, быстрый, проверенный годами;
Ядро спам фильтра — MailScanner — плечом к плечу с антивирусом принимают на себя весь удар;
Спам фильтр — SpamAssassin — определяет письма-спам. В основу включено множество оценочных систем, MTA и наборы регулярных выражений;
ClamAV — антивирус, который работает с MailScanner;
MailWatch — удобный веб-интерфейс для работы с MailScanner и другими приложениями;
Фильтр контента — DCC — определяет массовую рассылку через отправку хеш-сумм тела писем на специальный сервер, который в свою очередь предоставляет ответ в виде числа полученных хешей. Если число превышает порог score=6, письмо считается спамом;
Pyzor и Razor — помогают SpamAssassin точнее распознавать спам, используя сети по обнаружению спама;
Для grey-листинга используется SQLgrey — служба политики postfix, позволяющая снизить количество спама, которое может быть принято получателями;
Для распознавания изображений используется модуль ImageCeberus — определяет порно изображения и т.д.
Мы выбрали EFA, поскольку проект включает в себя все лучшие характеристики вышеперечисленных. К тому же наши администраторы уже имели некоторый опыт работы с ним, поэтому выбор остановили именно на EFA. Приступим к описанию установки.
Устанавливать решили на VPS с чистой CentOS 6.8 x64, который выступает в качестве relay-сервера. Первым делом, необходимо обновить все системные утилиты и компоненты до последних версий, которые доступны в репозиториях. Для этого используем команду:
yum -y updateЗатем устанавливаем утилиты wget и screen, если они не были установлены:
yum -y install wget screenПосле чего, скачаем скрипт, который выполнит установку EFA:
wget https://raw.githubusercontent.com/E-F-A/v3/master/build/prepare-build-without-ks.bashДаем скрипту права на исполнение:
chmod +x ./prepare-build-without-ks.bashЗапускаем screen:
screenИ запускаем скрипт:
./prepare-build-without-ks.bashТеперь можно свернуть наш скрин используя комбинацию Ctrl + A + D.
После установки нужно заново войти на сервер через ssh, используя данные для первого входа. Это нужно для запуска скрипта инициализации и первичной настройки EFA.
После входа, система предлагает ответить на несколько вопросов, чтобы настроить EFA.
Список вопросов выглядит следующим образом:
| Функция | Свойство |
|---|---|
| Hostname | Указывается хостнейм машины |
| Domainname | Домен, к которому относится машина. В сумме с хостнеймом, получится полный FQDN сервера |
| Adminemail | Ящик администратора, который будет получать письма от самой системы (доступные обновления, различные отчеты и т.д.) |
| Postmasteremail | Ящик человека, который будет получать письма, которые имеют отношение к MTA |
| IP address | IP адрес машины |
| Netmask | Маска |
| Default Gateway | Шлюз |
| Primary DNS | Первичный DNS сервер |
| Secondary DNS | Вторичный DNS сервер |
| Local User | Логин локального администратора. Используется для входа в систему и в веб-интерфейс MailWatch |
| Local User Password | Пароль |
| Root Password | Пароль для пользователя root |
| VMware tools | Будет отображаться только, если установка происходит на виртуальную машину под управлением VMware. Она необходима для установки инструментов по работе с VMware |
| UTC Time | Если Ваша машина находится в часовом поясе UTC, необходимо выбрать Yes |
| Timezone | Тут можно выбрать другой часовой пояс, отличный от UTC |
| Keyboard Layout | Раскладка клавиатуры, которая будет использоваться в системе |
| IANA Code | Тут указывается код страны, в которой находится машина. Это необходимо для того, чтобы определить, с каких зеркал в будущем будут скачиваться обновления |
| Your mailserver | Индивидуальный параметр. Используется в случае если EFA работает и на приём писем |
| Your organization name | Название организации. Используется для заголовков в письмах |
| Auto Updates | Задается политика автообновлений. По умолчанию установлено disabled. В этом случае, автообновлений не будет, но на емейл админа будут приходить уведомления о доступных обновлениях |
После такой анкеты, отображается весь список ответов. Если что-то нужно изменить, набираем номер вопроса и вводим новые данные. Когда готовы двигаться дальше, набираем ОК и жмем Enter. Система начнет процесс автонастройки.

По завершению конфигурирования, система перезагрузится и будет в полной боевой готовности.
В следующий раз, авторизуясь по ssh, сразу отобразится конфигурационное меню EFA. В этом меню доступно множество полезных действий:
Это список основных опций EFA, которые недоступны для редактирования через веб-интерфейс MailWatch. Поэтому, хорошо знать, где их найти.
Мы же пошли сложным путем, но более гибким. Настройку EFA под себя делали не через интерактивное меню, а правили конфигурационные файлы. Мы хотели не просто всё настроить, а еще и разобраться во всех компонентах и понять, что и как работает.
Первым делом в файле main.cf настроек postfix добавили mynetworks, с которых принимались соединения по SMTP. Затем прописали ограничения по helo запросам, отправителям, получателям, и указали пути к картам с политиками ACCEPT или REJECT при соблюдении определенных условий. Также, inet_protocols был изменен на ipv4, чтобы исключить соединения по ipv6.
Затем изменили политику Spam Actions на Store в конфигурационном файле /etc/MailScanner/MailScanner.conf. Это значит, что если письмо будет определено как спам, оно уйдет в карантин. Это помогает дополнительно обучать SpamAssassin.
После таких настроек мы столкнулись с первой проблемой. На нас обрушились тысячи писем от адресатов you@example.com, fail2ban@example.com, root@localhost.localdomain и т.д. Получатели были схожие. Также получили письма, отправленные MAILER-DAEMON, то есть фактически без отправителя.
В итоге получили забитую очередь без возможности найти среди «красного полотна» нормальные, письма не-спам. Решили делать REJECT подобных писем, используя стандартный функционал Postfix карт: helo_access, recipient_access, sender_access. Теперь вредные адресаты и подобные стали успешно REJECT’иться. А те письма, которые отправлялись MAILER-DAEMON отфильтровываются по helo запросам.
Когда очередь вычистили, а наши нервы успокоились, начали настраивать SpamAssassin.
Обучение SpamAssassin делается на письмах, которые уже попали в спам. Делать это можно двумя способами.
Первый способ — через веб-интерфейс MailWatch. В каждом письме можно увидеть заголовки, тело, а также оценку по алгоритму Байеса и других показателях. Выглядит это так:
| Score | Matching Rule | Description |
|---|---|---|
| -0.02 | AWL | Adjusted score from AWL reputation of From: address |
| 0.80 | BAYES_50 | Bayes spam probability is 40 to 60% |
| 0.90 | DKIM_ADSP_NXDOMAIN | No valid author signature and domain not in DNS |
| 0.00 | HTML_MESSAGE | HTML included in message |
| 1.00 | KAM_LAZY_DOMAIN_SECURITY | Sending domain does not have any anti-forgery methods |
| 0.00 | NO_DNS_FOR_FROM | Envelope sender has no MX or A DNS records |
| 0.79 | RDNS_NONE | Delivered to internal network by a host with no rDNS |
| 2.00 | TO_NO_BRKTS_HTML_IMG | To: lacks brackets and HTML and one image |
| 0.00 | WEIRD_PORT | Uses non-standard port number for HTTP |
Открыв письмо, можно поставить галку в чекбоксе «SA Learn» и выбрать одно из нескольких действий:
Делается это просто. Команда выглядит следующим образом:
sa-learn --ham /20170224/spam/0DC5B48D4.A739DВ этой команде письмо с ID: 0DC5B48D4.A739D, которое находится в архиве спам писем за определенную дату /20170224/spam/, помечается как чистое (не спам) bash--ham.
Бытует мнение, что достаточно обучать SpamAssassin только для эффективной фильтрации почты. Мы решили тренировать SpamAssassin, скармливая ему абсолютно все письма, как чистые, так и спам. В дополнение, мы нашли базу спам-писем и отдали SA на растерзание.
Такая тренировка помогла более точно откалибровать Байесовский алгоритм. В результате фильтрация происходит гораздо эффективнее. Такие тренировки мы проводим тогда, когда почтовый трафик не очень высок, чтобы успеть проанализировать и захватить максимальное количество писем.
Для того, чтобы SpamAssassin начал работать на полную мощность, на старте ему необходимо скормить около 1000 различных писем. Поэтому наберитесь терпения и приступайте к тренировке.
Пока еще рано говорить о полной победе над спамом. Однако, сейчас количество жалоб на спам с наших серверов равно нулю. Более детально рассказывать о самом процессе обучения сейчас не будем— не хочется раскрывать все фишки. Хотя, если поковыряться в настройках, разобраться не сложно.
P.S.: Эта статья не является панацеей. Мы просто решили поделиться с вами одним из наших методов борьбы со спамом.
Всем добра и may the ham be with you! :)
|
Метки: author Ukr2net хостинг спам и антиспам системное администрирование серверное администрирование настройка linux администирование спам efa |
Как нам помогают нейронные сети в технической поддержке |




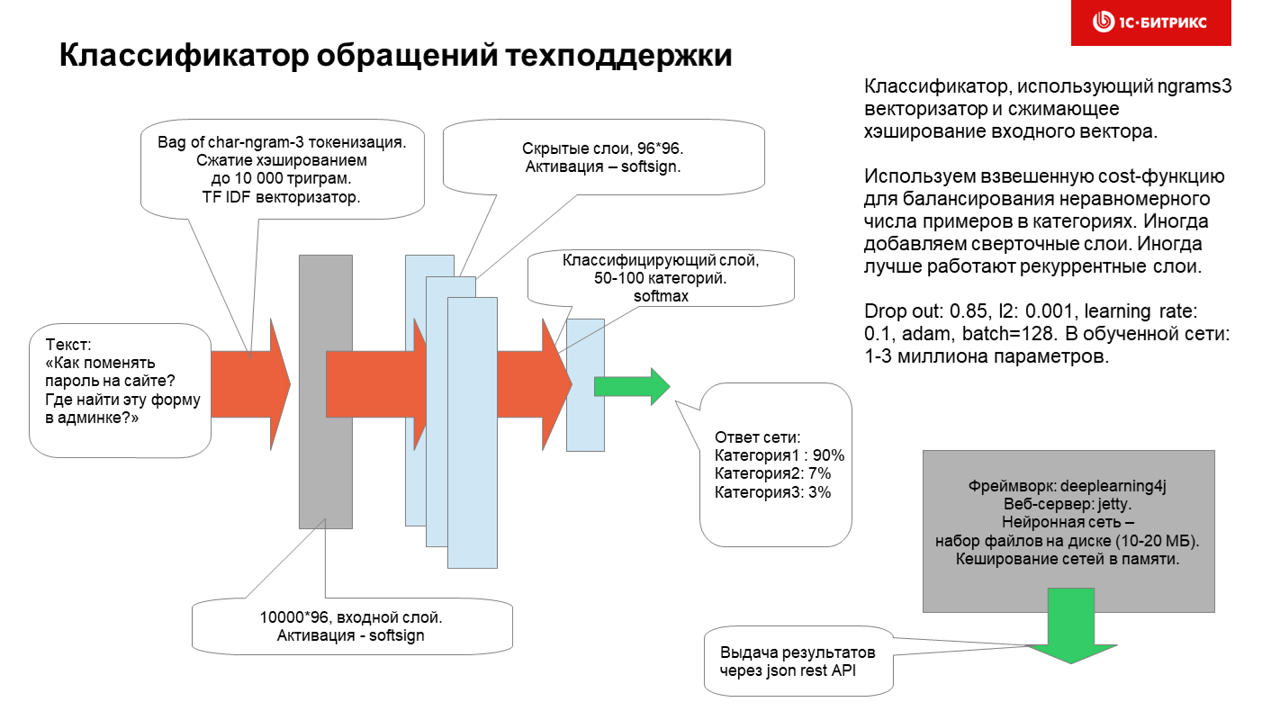
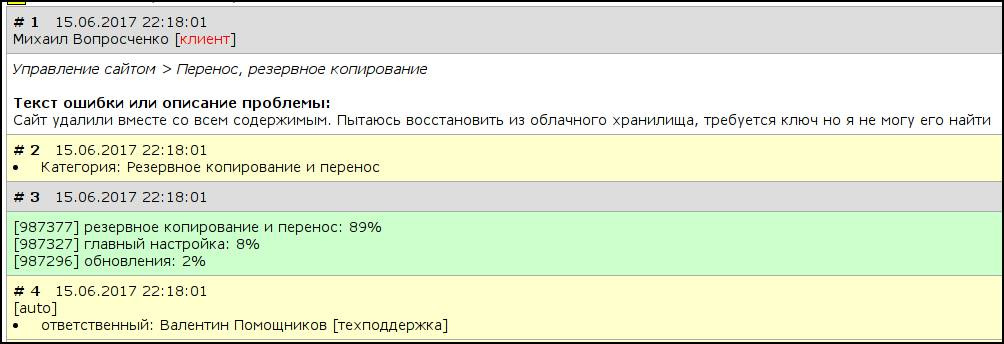

|
Метки: author AlexSerbul машинное обучение блог компании 1с-битрикс нейронные сети классификатор текстов с-битрикс техническая поддержка |
[Из песочницы] Symfony 4: структура приложения |
{
"autoload": {
"psr-4": {
"App\\": "src/"
}
},
"autoload-dev": {
"psr-4": {
"App\\Tests\\": "tests/"
}
}
}
//bundles.php
|
Метки: author shude symfony php symfony 4 |
[Перевод] Как мы собрали 1500 звезд на Гитхабе, соединив проверенную временем технологию и новый интерфейс |

Недавно мы выпустили инструмент с открытым исходным кодом GraphQL Voyager. Удивительно, но он попал на первую страницу новостей Hacker News и GitHub, и в первые несколько дней получил 1000+ звезд. Сейчас у него уже более 1600 звезд.*
Людям понравился гладкий интерфейс, интерактивные функции и анимация. Мы использовали TypeScript, React, Redux, webpack и даже PostCSS, но это НЕ еще одна статья об этом. Давайте заглянем под капот...
Все началось несколько месяцев назад. Мой друг и я (мы называем себя APIs.guru) искали идею для проекта вокруг GraphQL (язык запросов для API, разработанных Facebook). После некоторых исследований нам попался на глаза один интересный инструмент — GraphQL Visualizer.
Вот что мы получили на выходе из GraphQL Visualizer:
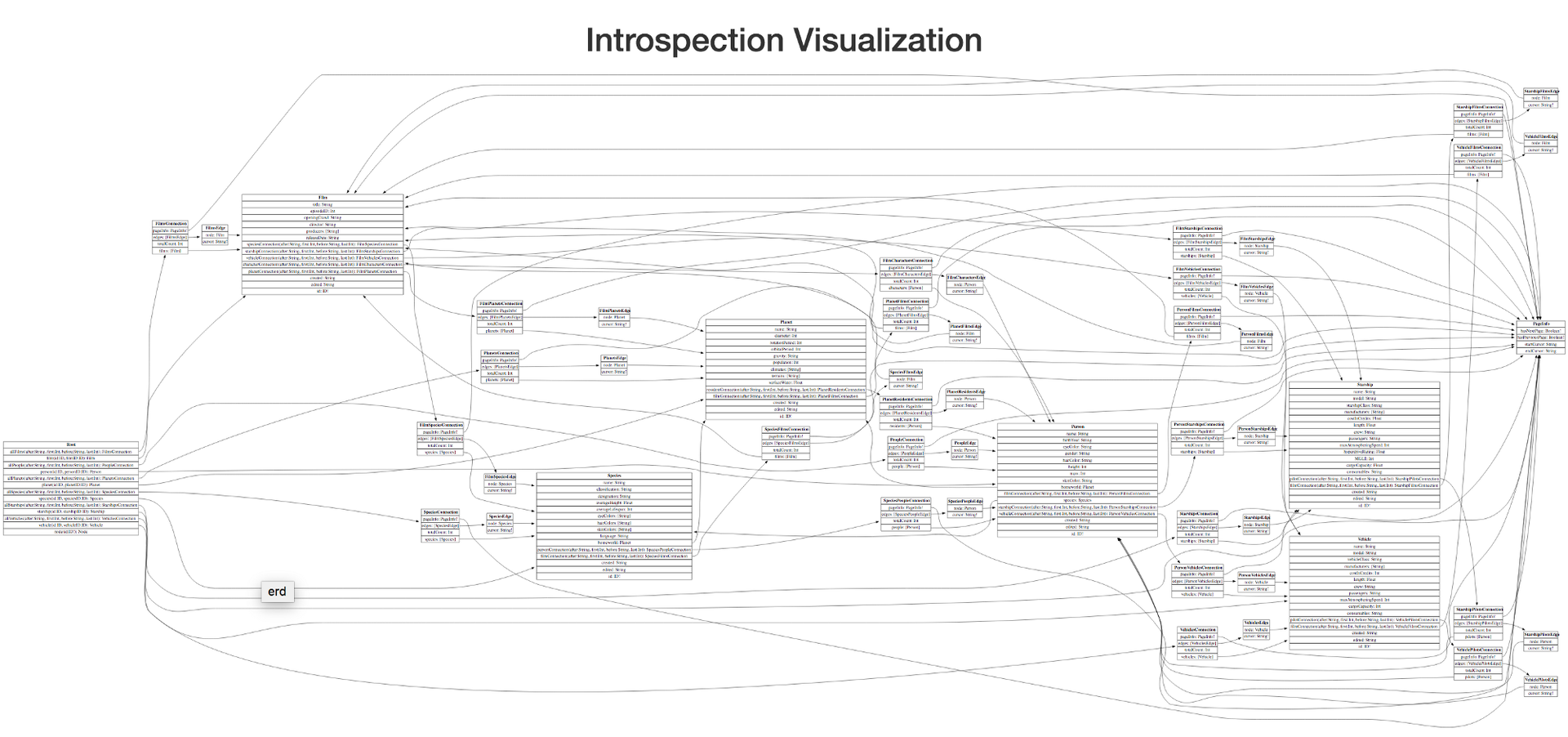
Нам захотелось в него добавить:
Но, посмотрев исходный код, мы обнаружили фатальный недостаток этой штуки: там использовался Graphviz — инструмент, разработанный десятки лет назад, написанный на обычном C и скомпилированный в нечитабельный JavaScript с использованием Emscripten.
Выглядит даже хуже, чем то, что вылазит обычно из Uglify.js:

Как мы можем использовать что-то из 2000-го года? Мы же хипстеры, в конце концов! ReactJS, D3, webpack, TypeScript, PostCSS — вот с чем мы работаем! Не с инструментами, написанными на старомодном C ![]() .
.
Немного покопав, мы нашли самую лучшую библиотеку для решения этой задачи — Cytoscape.js. Она написана на прекрасном JavaScript и даже позволяет применять CSS-подобные селекторы прямо к самому графу. Отличный результат!
Но после недели напряженного программирования он показался нам не таким уж хорошим.
Посудите сами, вот как выглядит визуализация графа с использованием Cytoscape.js:

И это мы даже не отобразили на этом графике все детали! Что за мешанина!
Хотя код был гораздо чище, конечный результат оказался намного хуже по сравнению с оригинальным инструментом. Совершенно неюзабельно.
Оказалось, что в cytoscape.js нельзя сделать так, чтобы ребра не пересекались с вершинами графа. Мы перепробовали все варианты. Мы гуглили. Мы задавали вопросы на StackOverflow. Мы даже побеспокоили нескольких знакомых гуру SVG. Безуспешно :(
От безысходности я даже попытался хакнуть cytoscape.js, чтобы добиться читабельного результата. Ещё немного изучив этот вопрос, я вынужден был сдаться: видимо, визуализация графов — это и в самом деле rocket science (даже для магистра по прикладной математике).
Мы были побеждены...
И тогда нас осенило. А что, если мы возьмём результат работы Graphviz (это ведь просто SVG) и причешем его при помощи CSS и JS?
И это сработало ![]()
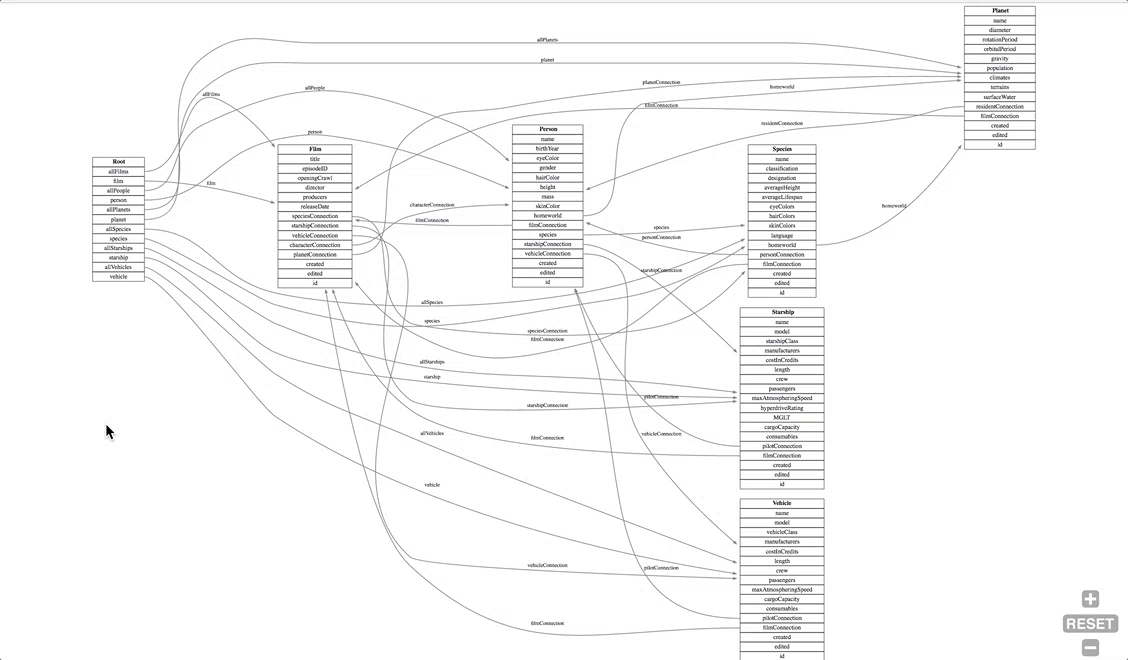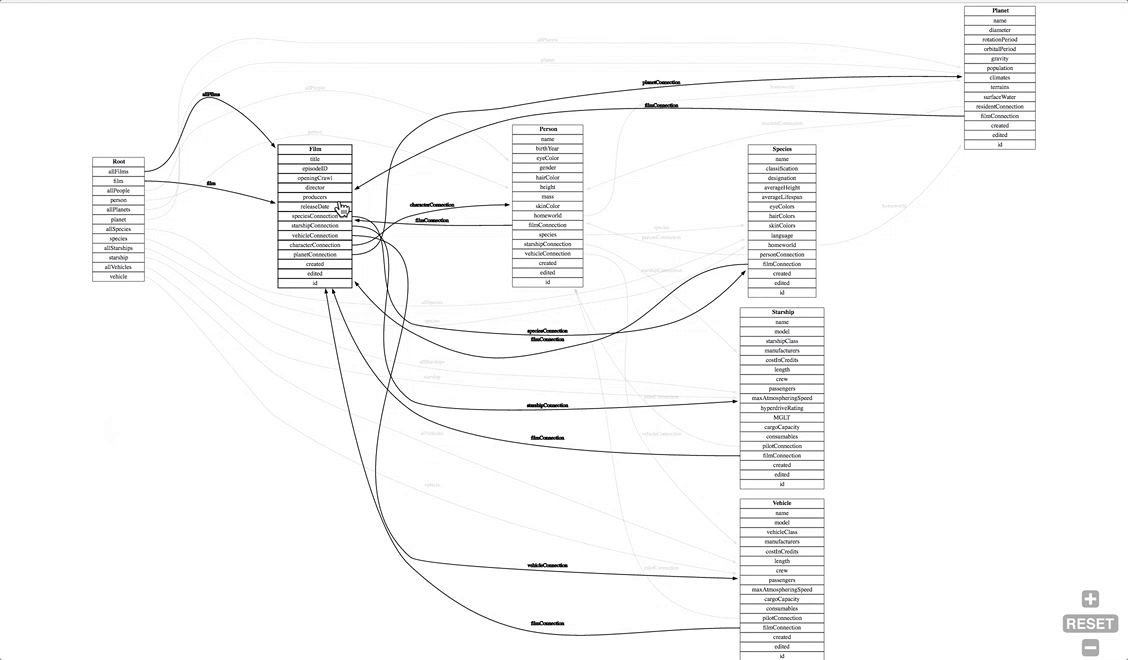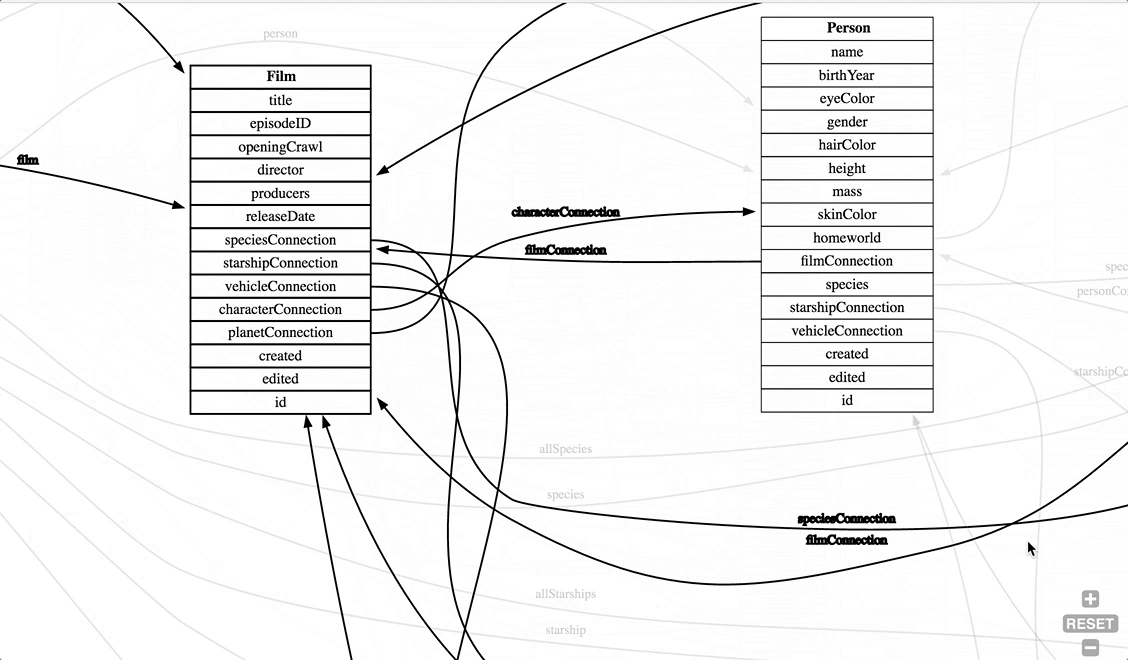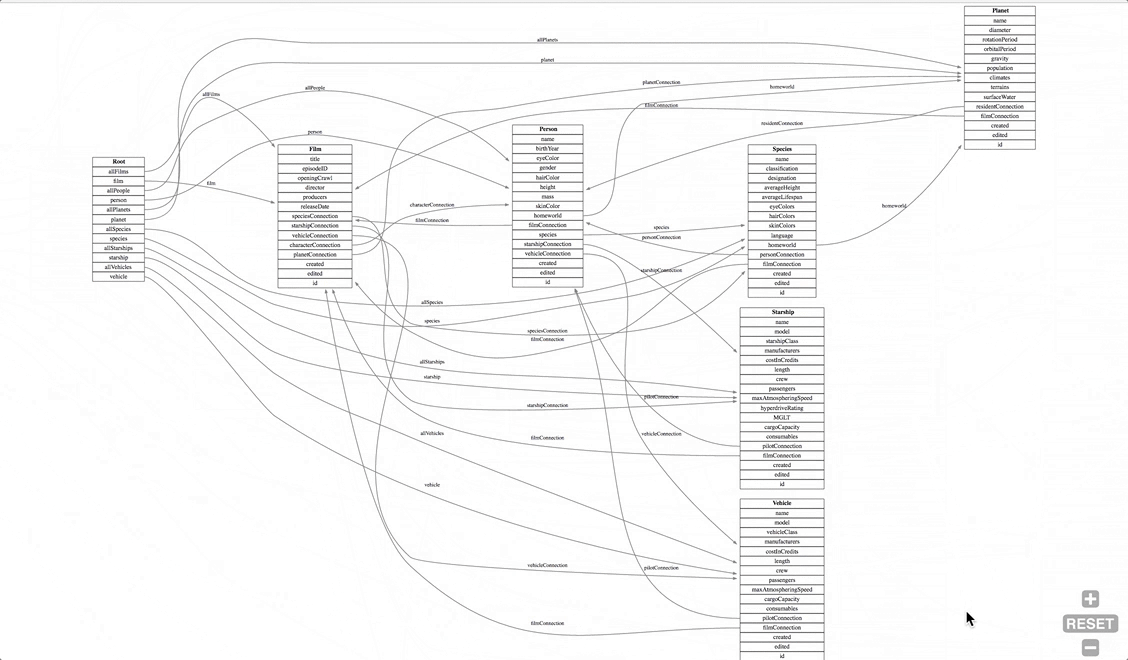
Намного лучше! И код написан меньше, чем за день ![]() .
.
Добавляем немного цвета, логотип, загружаем анимацию, еще несколько полезных функций, и вот конечный результат, то, что нам нужно:
Да, мы написали несколько сотен строк уродливых манипуляций с DOM. Да, мы упаковали весь этот бардак НЕ в виде чистого ![]() компонента React / Redux. И да, код Graphviz настолько большой, что мы выделили его в отдельный файл размером 2 МБ. Но это работает, и всем пофигу. Что подтверждается 1600 звездами на GitHub.
компонента React / Redux. И да, код Graphviz настолько большой, что мы выделили его в отдельный файл размером 2 МБ. Но это работает, и всем пофигу. Что подтверждается 1600 звездами на GitHub.
Апдейт: с момента представления статьи времени нашу разработку взяли на вооружение компании в этой области (например, Graphcool, Neo4j), и её показали на GraphQL Europe, так что уже не только 1600 звезд подтверждают это :)
«Если я видел дальше других, то потому, что стоял на плечах гигантов». — Исаак Ньютон
Не судите код по его возрасту. Особенно, если он был написан такими технологическими гигантами, как AT&T Labs (где родилась ОС Unix и языки C и C++).
К сожалению, мы оказались жертвами когнитивного искажения: старый код — это плохой код. Но истина может быть противоположной. Старый код проверен в бою тысячами пользователей в сотнях различных проектов. Большинство критических ошибок были исправлены, документация завершена, есть много вопросов и ответов на StackOverflow и Quora.
Мы живем в 2017 году, и пользовательский интерфейс из 2000-х определенно не приемлем. Но графики и математика, которые стоят за ними, не сильно меняются.
Эта идея применима во многих других областях. Так что мы должны дать шанс старому коду, особенно потому, что его всегда можно обернуть в современный интерфейс.
Вот почему мы видим огромный потенциал в Web Assembly. Этот формат позволяет соединить проверенные временем алгоритмы с современными пользовательскими интерфейсами. Мы очень хотим увидеть потрясающие вещи, которые люди будут на нем делать.
Упс… Ладно. И правда. Я хотел сделать заголовок достаточно запоминающимся.
Ниже приведен список самых важных советов и трюков, которые мы используем для нашего проекта с открытым исходным кодом:

Есть еще несколько статей о том, как продвигать проекты с открытым исходным кодом: здесь, здесь и здесь.
На этом все, ребятки. Если вы когда-либо завернули старый код в новый блестящий интерфейс, расскажите свою историю в комментариях ниже.
* Примечание переводчика: спустя неделю после оригинальной публикации у проекта уже 2000+ звезд.
** Заглавная картинка, как и в исходном посте, взята с сайта www.k3projektwheels.com.
|
Метки: author mngr визуализация данных open source github css graphql graphviz визуализация графов документация api |
ECS (Elastic Cloud Storage) - облачная платформа хранения Dell EMC |


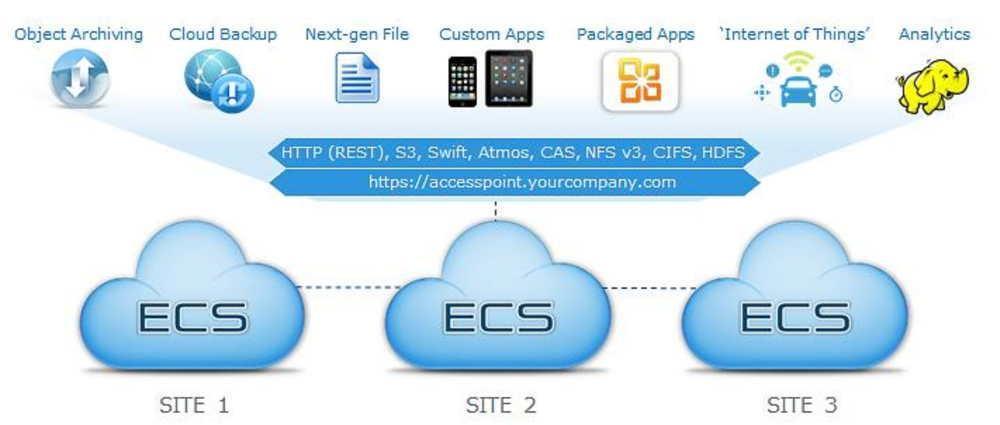
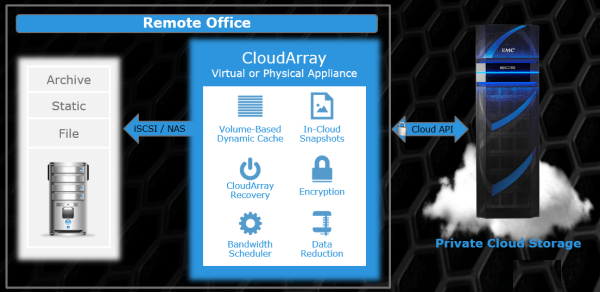

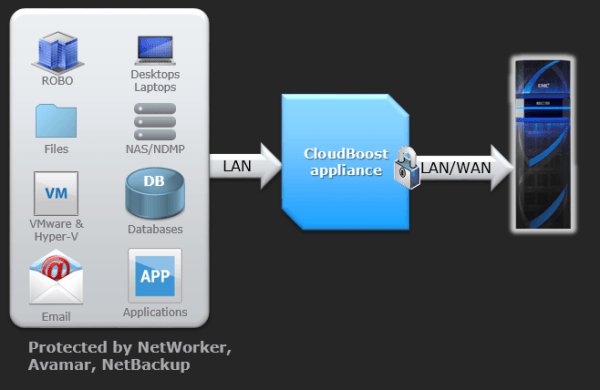
|
Метки: author DellEMCTeam хранилища данных хранение данных it- инфраструктура блог компании dell emc dell emc ecs elastic cloud storage |
13 вопросов, чтобы узнать, готовы ли вы нанимать команду мобильной разработки |

|
|
Автоэнкодеры в Keras, Часть 2: Manifold learning и скрытые (latent) переменные |
# Импорт необходимых библиотек
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
# Создание датасета
x1 = np.linspace(-2.2, 2.2, 1000)
fx = np.sin(x1)
dots = np.vstack([x1, fx]).T
noise = 0.06 * np.random.randn(*dots.shape)
dots += noise
# Цветные точки для отдельной визуализации позже
from itertools import cycle
size = 25
colors = ["r", "g", "c", "y", "m"]
idxs = range(0, x1.shape[0], x1.shape[0]//size)
vx1 = x1[idxs]
vdots = dots[idxs]
# Визуализация
plt.figure(figsize=(12, 10))
plt.xlim([-2.5, 2.5])
plt.scatter(dots[:, 0], dots[:, 1])
plt.plot(x1, fx, color="red", linewidth=4)
plt.grid(False)

from keras.layers import Input, Dense
from keras.models import Model
from keras.optimizers import Adam
def linear_ae():
input_dots = Input((2,))
code = Dense(1, activation='linear')(input_dots)
out = Dense(2, activation='linear')(code)
ae = Model(input_dots, out)
return ae
ae = linear_ae()
ae.compile(Adam(0.01), 'mse')
ae.fit(dots, dots, epochs=15, batch_size=30, verbose=0)
# Применение линейного автоэнкодера
pdots = ae.predict(dots, batch_size=30)
vpdots = pdots[idxs]
# Применение PCA
from sklearn.decomposition import PCA
pca = PCA(1)
pdots_pca = pca.inverse_transform(pca.fit_transform(dots))
# Визуализация
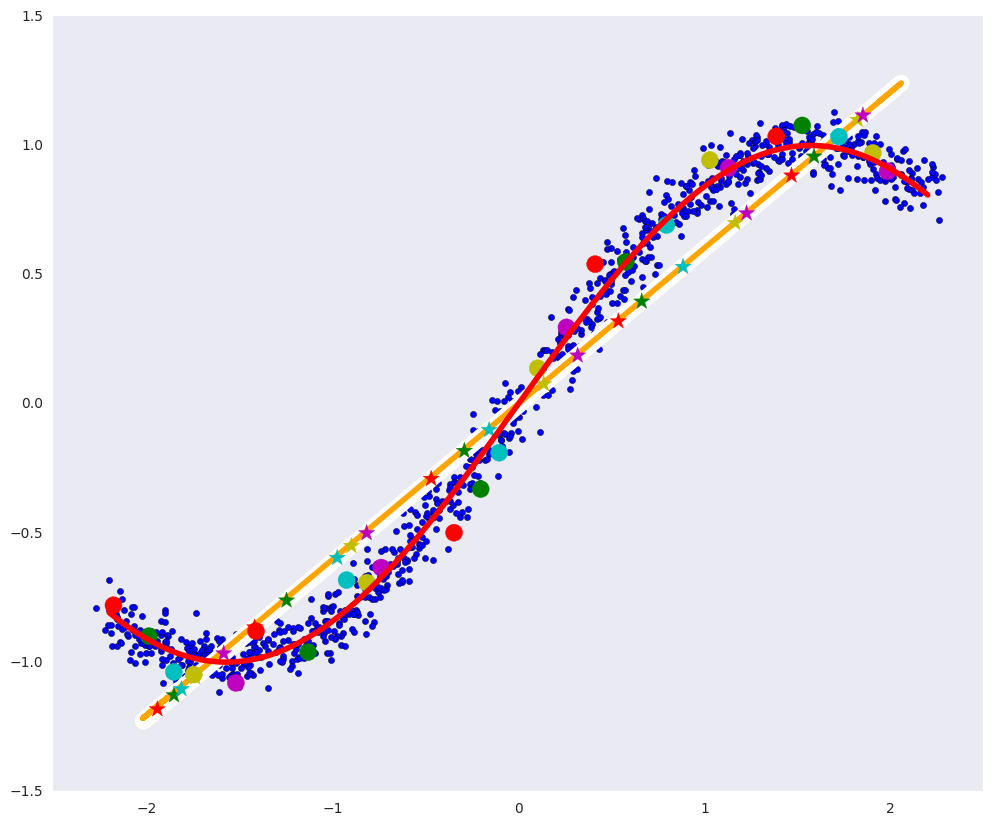
plt.figure(figsize=(12, 10))
plt.xlim([-2.5, 2.5])
plt.scatter(dots[:, 0], dots[:, 1], zorder=1)
plt.plot(x1, fx, color="red", linewidth=4, zorder=10)
plt.plot(pdots[:,0], pdots[:,1], color='white', linewidth=12, zorder=3)
plt.plot(pdots_pca[:,0], pdots_pca[:,1], color='orange', linewidth=4, zorder=4)
plt.scatter(vpdots[:,0], vpdots[:,1], color=colors*5, marker='*', s=150, zorder=5)
plt.scatter(vdots[:,0], vdots[:,1], color=colors*5, s=150, zorder=6)
plt.grid(False)
def deep_ae():
input_dots = Input((2,))
x = Dense(64, activation='elu')(input_dots)
x = Dense(64, activation='elu')(x)
code = Dense(1, activation='linear')(x)
x = Dense(64, activation='elu')(code)
x = Dense(64, activation='elu')(x)
out = Dense(2, activation='linear')(x)
ae = Model(input_dots, out)
return ae
dae = deep_ae()
dae.compile(Adam(0.003), 'mse')
dae.fit(dots, dots, epochs=200, batch_size=30, verbose=0)
pdots_d = dae.predict(dots, batch_size=30)
vpdots_d = pdots_d[idxs]
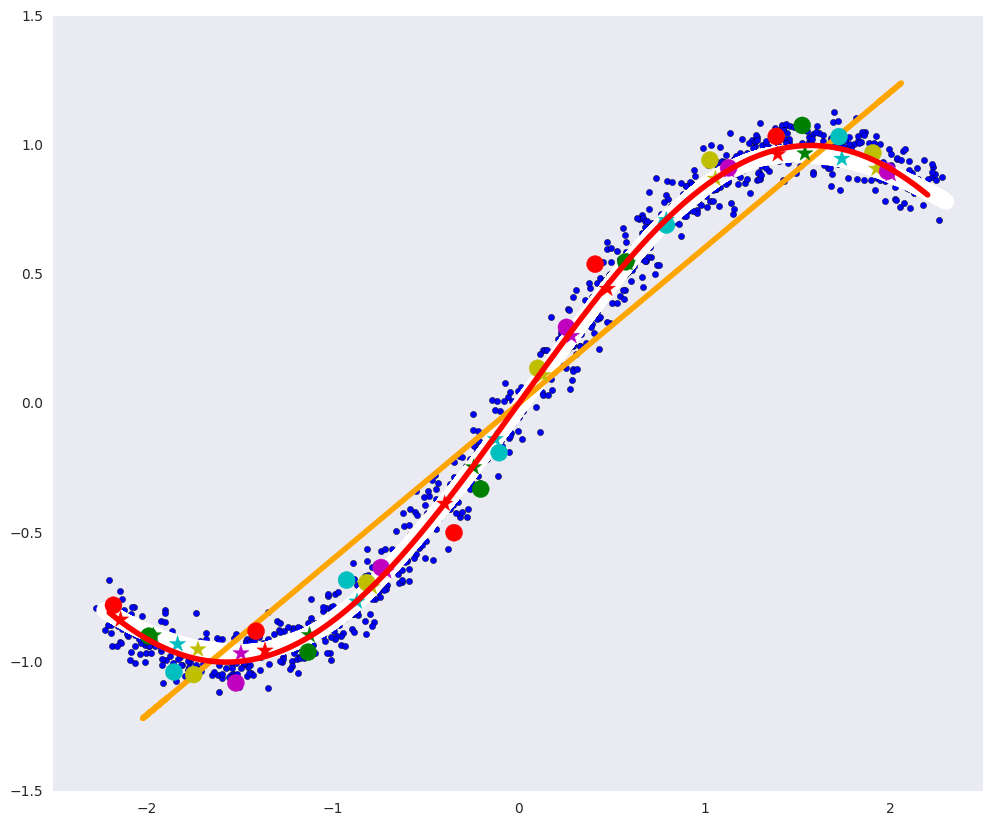
# Визуализация
plt.figure(figsize=(12, 10))
plt.xlim([-2.5, 2.5])
plt.scatter(dots[:, 0], dots[:, 1], zorder=1)
plt.plot(x1, fx, color="red", linewidth=4, zorder=10)
plt.plot(pdots_d[:,0], pdots_d[:,1], color='white', linewidth=12, zorder=3)
plt.plot(pdots_pca[:,0], pdots_pca[:,1], color='orange', linewidth=4, zorder=4)
plt.scatter(vpdots_d[:,0], vpdots_d[:,1], color=colors*5, marker='*', s=150, zorder=5)
plt.scatter(vdots[:,0], vdots[:,1], color=colors*5, s=150, zorder=6)
plt.grid(False)
from keras.layers import Conv2D, MaxPooling2D, UpSampling2D
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test .astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
# Сверточный автоэнкодер
def create_deep_conv_ae():
input_img = Input(shape=(28, 28, 1))
x = Conv2D(128, (7, 7), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (2, 2), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
encoded = Conv2D(1, (7, 7), activation='relu', padding='same')(x)
# На этом моменте представление (7, 7, 1) т.е. 49-размерное
input_encoded = Input(shape=(7, 7, 1))
x = Conv2D(32, (7, 7), activation='relu', padding='same')(input_encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(128, (2, 2), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (7, 7), activation='sigmoid', padding='same')(x)
# Модели
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
c_encoder, c_decoder, c_autoencoder = create_deep_conv_ae()
c_autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
c_autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
def plot_digits(*args):
args = [x.squeeze() for x in args]
n = min([x.shape[0] for x in args])
plt.figure(figsize=(2*n, 2*len(args)))
for j in range(n):
for i in range(len(args)):
ax = plt.subplot(len(args), n, i*n + j + 1)
plt.imshow(args[i][j])
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
# Гомотопия по прямой между объектами или между кодами
def plot_homotopy(frm, to, n=10, decoder=None):
z = np.zeros(([n] + list(frm.shape)))
for i, t in enumerate(np.linspace(0., 1., n)):
z[i] = frm * (1-t) + to * t
if decoder:
plot_digits(decoder.predict(z, batch_size=n))
else:
plot_digits(z)
# Гомотопия между первыми двумя восьмерками
frm, to = x_test[y_test == 8][1:3]
plot_homotopy(frm, to)

codes = c_encoder.predict(x_test[y_test == 8][1:3])
plot_homotopy(codes[0], codes[1], n=10, decoder=c_decoder)

dae = deep_ae()
dae.compile(Adam(0.0003), 'mse')
x_train_oft = np.vstack([dots[idxs]]*4000)
dae.fit(x_train_oft, x_train_oft, epochs=200, batch_size=15, verbose=1)
pdots_d = dae.predict(dots, batch_size=30)
vpdots_d = pdots_d[idxs]
plt.figure(figsize=(12, 10))
plt.xlim([-2.5, 2.5])
plt.scatter(dots[:, 0], dots[:, 1], zorder=1)
plt.plot(x1, fx, color="red", linewidth=4, zorder=10)
plt.plot(pdots_d[:,0], pdots_d[:,1], color='white', linewidth=6, zorder=3)
plt.plot(pdots_pca[:,0], pdots_pca[:,1], color='orange', linewidth=4, zorder=4)
plt.scatter(vpdots_d[:,0], vpdots_d[:,1], color=colors*5, marker='*', s=150, zorder=5)
plt.scatter(vdots[:,0], vdots[:,1], color=colors*5, s=150, zorder=6)
plt.grid(False)

from keras.layers import Flatten, Reshape
from keras.regularizers import L1L2
def create_deep_sparse_ae(lambda_l1):
# Размерность кодированного представления
encoding_dim = 16
# Энкодер
input_img = Input(shape=(28, 28, 1))
flat_img = Flatten()(input_img)
x = Dense(encoding_dim*4, activation='relu')(flat_img)
x = Dense(encoding_dim*3, activation='relu')(x)
x = Dense(encoding_dim*2, activation='relu')(x)
encoded = Dense(encoding_dim, activation='linear', activity_regularizer=L1L2(lambda_l1, 0))(x)
# Декодер
input_encoded = Input(shape=(encoding_dim,))
x = Dense(encoding_dim*2, activation='relu')(input_encoded)
x = Dense(encoding_dim*3, activation='relu')(x)
x = Dense(encoding_dim*4, activation='relu')(x)
flat_decoded = Dense(28*28, activation='sigmoid')(x)
decoded = Reshape((28, 28, 1))(flat_decoded)
# Модели
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
encoder, decoder, autoencoder = create_deep_sparse_ae(0.)
autoencoder.compile(optimizer=Adam(0.0003), loss='binary_crossentropy')
autoencoder.fit(x_train, x_train,
epochs=100,
batch_size=64,
shuffle=True,
validation_data=(x_test, x_test))
n = 10
imgs = x_test[:n]
decoded_imgs = autoencoder.predict(imgs, batch_size=n)
plot_digits(imgs, decoded_imgs)

codes = encoder.predict(x_test)
sns.jointplot(codes[:,1], codes[:,3])

s_encoder, s_decoder, s_autoencoder = create_deep_sparse_ae(0.00001)
s_autoencoder.compile(optimizer=Adam(0.0003), loss='binary_crossentropy')
s_autoencoder.fit(x_train, x_train, epochs=200, batch_size=256, shuffle=True,
validation_data=(x_test, x_test))
imgs = x_test[:n]
decoded_imgs = s_autoencoder.predict(imgs, batch_size=n)
plot_digits(imgs, decoded_imgs)
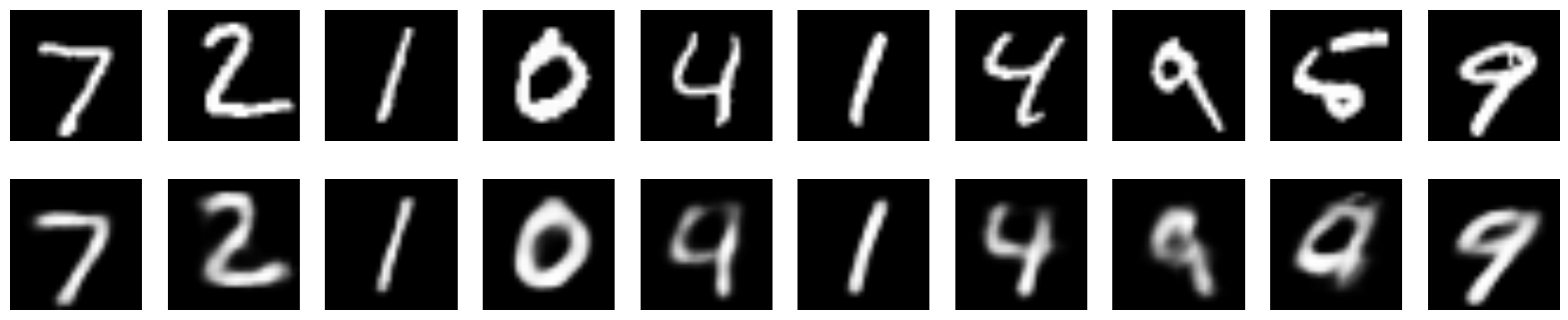
codes = s_encoder.predict(x_test)
snt.jointplot(codes[:,1], codes[:,3])

|
Метки: author iphysic python big data autoencoder machine learning deep learning keras |
Автоэнкодеры в Keras, Часть 1: Введение |
from keras.datasets import mnist
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test .astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
from keras.layers import Input, Dense, Flatten, Reshape
from keras.models import Model
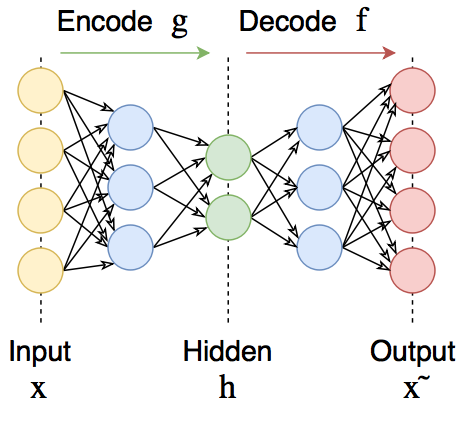
def create_dense_ae():
# Размерность кодированного представления
encoding_dim = 49
# Энкодер
# Входной плейсхолдер
input_img = Input(shape=(28, 28, 1)) # 28, 28, 1 - размерности строк, столбцов, фильтров одной картинки, без батч-размерности
# Вспомогательный слой решейпинга
flat_img = Flatten()(input_img)
# Кодированное полносвязным слоем представление
encoded = Dense(encoding_dim, activation='relu')(flat_img)
# Декодер
# Раскодированное другим полносвязным слоем изображение
input_encoded = Input(shape=(encoding_dim,))
flat_decoded = Dense(28*28, activation='sigmoid')(input_encoded)
decoded = Reshape((28, 28, 1))(flat_decoded)
# Модели, в конструктор первым аргументом передаются входные слои, а вторым выходные слои
# Другие модели можно так же использовать как и слои
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
encoder, decoder, autoencoder = create_dense_ae()
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
autoencoder.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
encoder (Model) (None, 49) 38465
_________________________________________________________________
decoder (Model) (None, 28, 28, 1) 39200
=================================================================
Total params: 77,665.0
Trainable params: 77,665.0
Non-trainable params: 0.0
_________________________________________________________________
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
Epoch 46/50
60000/60000 [==============================] - 3s - loss: 0.0785 - val_loss: 0.0777
Epoch 47/50
60000/60000 [==============================] - 2s - loss: 0.0784 - val_loss: 0.0777
Epoch 48/50
60000/60000 [==============================] - 3s - loss: 0.0784 - val_loss: 0.0777
Epoch 49/50
60000/60000 [==============================] - 2s - loss: 0.0784 - val_loss: 0.0777
Epoch 50/50
60000/60000 [==============================] - 3s - loss: 0.0784 - val_loss: 0.0777
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
def plot_digits(*args):
args = [x.squeeze() for x in args]
n = min([x.shape[0] for x in args])
plt.figure(figsize=(2*n, 2*len(args)))
for j in range(n):
for i in range(len(args)):
ax = plt.subplot(len(args), n, i*n + j + 1)
plt.imshow(args[i][j])
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
n = 10
imgs = x_test[:n]
encoded_imgs = encoder.predict(imgs, batch_size=n)
encoded_imgs[0]
array([ 6.64665604, 7.53528595, 3.81508064, 4.66803837,
1.50886345, 5.41063929, 9.28293324, 10.79530716,
0.39599913, 4.20529413, 6.53982353, 5.64758158,
5.25313473, 1.37336707, 9.37590599, 6.00672245,
4.39552879, 5.39900637, 4.11449528, 7.490417 ,
10.89267063, 7.74325705, 13.35806847, 3.59005809,
9.75185394, 2.87570286, 3.64097357, 7.86691713,
5.93383646, 5.52847338, 3.45317888, 1.88125253,
7.471385 , 7.29820824, 10.02830505, 10.5430584 ,
3.2561543 , 8.24713707, 2.2687614 , 6.60069561,
7.58116722, 4.48140812, 6.13670635, 2.9162209 ,
8.05503941, 10.78182602, 4.26916027, 5.17175484, 6.18108797], dtype=float32)
decoded_imgs = decoder.predict(encoded_imgs, batch_size=n)
plot_digits(imgs, decoded_imgs)

def create_deep_dense_ae():
# Размерность кодированного представления
encoding_dim = 49
# Энкодер
input_img = Input(shape=(28, 28, 1))
flat_img = Flatten()(input_img)
x = Dense(encoding_dim*3, activation='relu')(flat_img)
x = Dense(encoding_dim*2, activation='relu')(x)
encoded = Dense(encoding_dim, activation='linear')(x)
# Декодер
input_encoded = Input(shape=(encoding_dim,))
x = Dense(encoding_dim*2, activation='relu')(input_encoded)
x = Dense(encoding_dim*3, activation='relu')(x)
flat_decoded = Dense(28*28, activation='sigmoid')(x)
decoded = Reshape((28, 28, 1))(flat_decoded)
# Модели
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
d_encoder, d_decoder, d_autoencoder = create_deep_dense_ae()
d_autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
d_autoencoder.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
encoder (Model) (None, 49) 134750
_________________________________________________________________
decoder (Model) (None, 28, 28, 1) 135485
=================================================================
Total params: 270,235.0
Trainable params: 270,235.0
Non-trainable params: 0.0
d_autoencoder.fit(x_train, x_train,
epochs=100,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
Epoch 96/100
60000/60000 [==============================] - 3s - loss: 0.0722 - val_loss: 0.0724
Epoch 97/100
60000/60000 [==============================] - 3s - loss: 0.0722 - val_loss: 0.0719
Epoch 98/100
60000/60000 [==============================] - 3s - loss: 0.0721 - val_loss: 0.0722
Epoch 99/100
60000/60000 [==============================] - 3s - loss: 0.0721 - val_loss: 0.0720
Epoch 100/100
60000/60000 [==============================] - 3s - loss: 0.0721 - val_loss: 0.0720
n = 10
imgs = x_test[:n]
encoded_imgs = d_encoder.predict(imgs, batch_size=n)
encoded_imgs[0]
decoded_imgs = d_decoder.predict(encoded_imgs, batch_size=n)
plot_digits(imgs, decoded_imgs)

from keras.layers import Conv2D, MaxPooling2D, UpSampling2D
def create_deep_conv_ae():
input_img = Input(shape=(28, 28, 1))
x = Conv2D(128, (7, 7), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (2, 2), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
encoded = Conv2D(1, (7, 7), activation='relu', padding='same')(x)
# На этом моменте представление (7, 7, 1) т.е. 49-размерное
input_encoded = Input(shape=(7, 7, 1))
x = Conv2D(32, (7, 7), activation='relu', padding='same')(input_encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(128, (2, 2), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (7, 7), activation='sigmoid', padding='same')(x)
# Модели
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
c_encoder, c_decoder, c_autoencoder = create_deep_conv_ae()
c_autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
c_autoencoder.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_5 (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
encoder (Model) (None, 7, 7, 1) 24385
_________________________________________________________________
decoder (Model) (None, 28, 28, 1) 24385
=================================================================
Total params: 48,770.0
Trainable params: 48,770.0
Non-trainable params: 0.0
c_autoencoder.fit(x_train, x_train,
epochs=64,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
Epoch 60/64
60000/60000 [==============================] - 24s - loss: 0.0698 - val_loss: 0.0695
Epoch 61/64
60000/60000 [==============================] - 24s - loss: 0.0699 - val_loss: 0.0705
Epoch 62/64
60000/60000 [==============================] - 24s - loss: 0.0699 - val_loss: 0.0694
Epoch 63/64
60000/60000 [==============================] - 24s - loss: 0.0698 - val_loss: 0.0691
Epoch 64/64
60000/60000 [==============================] - 24s - loss: 0.0697 - val_loss: 0.0693
n = 10
imgs = x_test[:n]
encoded_imgs = c_encoder.predict(imgs, batch_size=n)
decoded_imgs = c_decoder.predict(encoded_imgs, batch_size=n)
plot_digits(imgs, decoded_imgs)

import keras.backend as K
from keras.layers import Lambda
batch_size = 16
def create_denoising_model(autoencoder):
def add_noise(x):
noise_factor = 0.5
x = x + K.random_normal(x.get_shape(), 0.5, noise_factor)
x = K.clip(x, 0., 1.)
return x
input_img = Input(batch_shape=(batch_size, 28, 28, 1))
noised_img = Lambda(add_noise)(input_img)
noiser = Model(input_img, noised_img, name="noiser")
denoiser_model = Model(input_img, autoencoder(noiser(input_img)), name="denoiser")
return noiser, denoiser_model
noiser, denoiser_model = create_denoising_model(autoencoder)
denoiser_model.compile(optimizer='adam', loss='binary_crossentropy')
denoiser_model.fit(x_train, x_train,
epochs=200,
batch_size=batch_size,
shuffle=True,
validation_data=(x_test, x_test))
n = 10
imgs = x_test[:batch_size]
noised_imgs = noiser.predict(imgs, batch_size=batch_size)
encoded_imgs = encoder.predict(noised_imgs[:n], batch_size=n)
decoded_imgs = decoder.predict(encoded_imgs[:n], batch_size=n)
plot_digits(imgs[:n], noised_imgs, decoded_imgs)

from keras.regularizers import L1L2
def create_sparse_ae():
encoding_dim = 16
lambda_l1 = 0.00001
# Энкодер
input_img = Input(shape=(28, 28, 1))
flat_img = Flatten()(input_img)
x = Dense(encoding_dim*3, activation='relu')(flat_img)
x = Dense(encoding_dim*2, activation='relu')(x)
encoded = Dense(encoding_dim, activation='linear', activity_regularizer=L1L2(lambda_l1))(x)
# Декодер
input_encoded = Input(shape=(encoding_dim,))
x = Dense(encoding_dim*2, activation='relu')(input_encoded)
x = Dense(encoding_dim*3, activation='relu')(x)
flat_decoded = Dense(28*28, activation='sigmoid')(x)
decoded = Reshape((28, 28, 1))(flat_decoded)
# Модели
encoder = Model(input_img, encoded, name="encoder")
decoder = Model(input_encoded, decoded, name="decoder")
autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder")
return encoder, decoder, autoencoder
s_encoder, s_decoder, s_autoencoder = create_sparse_ae()
s_autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
s_autoencoder.fit(x_train, x_train,
epochs=400,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
n = 10
imgs = x_test[:n]
encoded_imgs = s_encoder.predict(imgs, batch_size=n)
encoded_imgs[1]
array([ 7.13531828, -0.61532277, -5.95510817, 12.0058918 ,
-1.29253936, -8.56000137, -7.48944521, -0.05415952,
-2.81205249, -8.4289856 , -0.67815018, -11.19531345,
-3.4353714 , 3.18580866, -0.21041733, 4.13229799], dtype=float32)
decoded_imgs = s_decoder.predict(encoded_imgs, batch_size=n)
plot_digits(imgs, decoded_imgs)

imgs = x_test
encoded_imgs = s_encoder.predict(imgs, batch_size=16)
codes = np.vstack([encoded_imgs.mean(axis=0)]*10)
np.fill_diagonal(codes, encoded_imgs.max(axis=0))
decoded_features = s_decoder.predict(codes, batch_size=16)
plot_digits(decoded_features)

|
Метки: author iphysic python big data autoencoder machine learning deep learning keras |
[Перевод] Вехи истории шифрования и борьбы с ним |











|
Метки: author ru_vds криптография информационная безопасность блог компании ruvds.com защита данных шифрование |
Расставляем точки над микросервисами. Секция Avito на РИТ++ 2017 (Видео) |

|
|
[recovery mode] NTT Com заявили о создании первой в мире полностью программно-определяемой сети |
 / Flickr / Dennis van Zuijlekom / CC
/ Flickr / Dennis van Zuijlekom / CC
|
Метки: author VASExperts сетевые технологии блог компании vas experts vas experts sd-wan ntt communications |
[Перевод] Рассмотрим Kotlin повнимательнее |
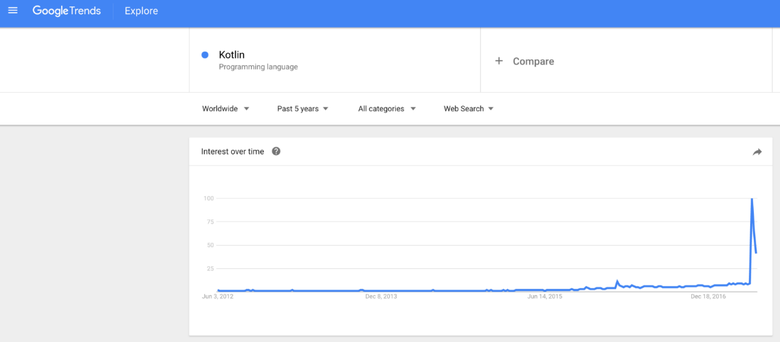
https://trends.google.com/trends/explore?q=%2Fm%2F0_lcrx4
Выше приведён скриншот Google Trends, когда я искал по слову «kotlin». Внезапный всплеск — это когда Google объявила, что Kotlin становится главным языком в Android. Произошло это на конференции Google I/O несколько недель назад. На сегодняшний день вы либо уже использовали этот язык раньше, либо заинтересовались им, потому что все вокруг вдруг начали о нём говорить.
Одно из главных свойств Kotlin — его взаимная совместимость с Java: вы можете вызывать из Java код Kotlin, а из Kotlin код Java. Это, пожалуй, важнейшая черта, благодаря которой язык широко распространяется. Вам не нужно сразу всё мигрировать: просто возьмите кусок имеющейся кодовой базы и начните добавлять код Kotlin, и это будет работать. Если вы поэкспериментируете с Kotlin и вам не понравится, то всегда можно от него отказаться (хотя я рекомендую попробовать).
Когда я впервые использовал Kotlin после пяти лет работы на Java, некоторые вещи казались мне настоящим волшебством.
«Погодите, что? Я могут просто писать data class, чтобы избежать шаблонного кода?»
«Стоп, так если я пишу apply, то мне уже не нужно определять объект каждый раз, когда я хочу вызвать метод применительно к нему?»
После первого вздоха облегчения от того, что наконец-то появился язык, который не выглядит устаревшим и громоздким, я начал ощущать некоторый дискомфорт. Если требуется взаимная совместимость с Java, то как именно в Kotlin реализованы все эти прекрасные возможности? В чём подвох?
Этому и посвящена статья. Мне было очень интересно узнать, как компилятор Kotlin преобразует конкретные конструкции, чтобы они стали взаимосовместимы с Java. Для своих исследований я выбрал четыре наиболее востребованных метода из стандартной библиотеки Kotlin:
applywithletrunКогда вы прочитаете эту статью, вам больше не надо будет опасаться. Сейчас я чувствую себя гораздо увереннее, потому что понял, как всё работает, и я знаю, что могу доверять языку и компилятору.
/**
* Вызывает определённую функцию [block] со значением `this` в качестве своего получателя и возвращает значение `this`.
*/
@kotlin.internal.InlineOnly
public inline fun T.apply(block: T.() -> Unit): T { block(); return this } apply проста: это функция-расширение, которая выполняет параметр block применительно к экземпляру расширенного типа (extended type) (он называется «получатель») и возвращает самого получателя.
Есть много способов применения этой функции. Можно привязать создание объекта к его начальной конфигурации:
val layout = LayoutStyle().apply { orientation = VERTICAL }
Как видите, мы предоставляем конфигурацию для нового LayoutStyle прямо при создании, что способствует чистоте кода и реализации, гораздо менее подверженной ошибкам. Случалось вызывать метод применительно к неправильному экземпляру, потому что он имел то же наименование? Или, ещё хуже, когда рефакторинг был полностью ошибочным? С вышеуказанным подходом будет куда сложнее столкнуться с такими неприятностями. Также обратите внимание, что необязательно определять параметр this: мы находимся в той же области видимости, что и сам класс. Это как если бы мы расширяли сам класс, поэтому this задаётся неявно.
Но как это работает? Давайте рассмотрим короткий пример.
enum class Orientation {
VERTICAL, HORIZONTAL
}
class LayoutStyle {
var orientation = HORIZONTAL
}
fun main(vararg args: Array) {
val layout = LayoutStyle().apply { orientation = VERTICAL }
} Благодаря инструменту IntelliJ IDEA «Show Kotlin bytecode» (Tools > Kotlin > Show Kotlin Bytecode) мы можем посмотреть, как компилятор преобразует наш код в JVM-байткод:
NEW kotlindeepdive/LayoutStyle
DUP
INVOKESPECIAL kotlindeepdive/LayoutStyle. ()V
ASTORE 2
ALOAD 2
ASTORE 3
ALOAD 3
GETSTATIC kotlindeepdive/Orientation.VERTICAL : Lkotlindeepdive/Orientation;
INVOKEVIRTUAL kotlindeepdive/LayoutStyle.setOrientation (Lkotlindeepdive/Orientation;)V
ALOAD 2
ASTORE 1 Если вы не слишком хорошо ориентируетесь в байткоде, то предлагаю почитать эти замечательные статьи, после них вы станете разбираться гораздо лучше (важно помнить, что при вызове каждого метода происходит обращение к стеку, так что компилятору нужно каждый раз загружать объект).
Разберём по пунктам:
LayoutStyle и дублируется в стек.Orientation.VERTICAL.setOrientation, который поднимает из стека объект и значение.Здесь отметим пару вещей. Во-первых, не задействовано никакой магии, всё происходит так, как ожидается: применительно к созданному нами экземпляру LayoutStyle вызывается метод setOrientation. Кроме того, нигде не видно функции apply, потому что компилятор инлайнит её.
Более того, байткод почти идентичен тому, который генерируется при использовании одного лишь Java! Судите сами:
// Java
enum Orientation {
VERTICAL, HORIZONTAL;
}
public class LayoutStyle {
private Orientation orientation = HORIZONTAL;
public Orientation getOrientation() {
return orientation;
}
public void setOrientation(Orientation orientation) {
this.orientation = orientation;
}
public static void main(String[] args) {
LayoutStyle layout = new LayoutStyle();
layout.setOrientation(VERTICAL);
}
}
// Bytecode
NEW kotlindeepdive/LayoutStyle
DUP
ASTORE 1
ALOAD 1
GETSTATIC kotlindeepdive/Orientation.VERTICAL : kotlindeepdive/Orientation;
INVOKEVIRTUAL kotlindeepdive/LayoutStyle.setOrientation (kotlindeepdive/Orientation;)VСовет: вы могли заметить большое количество операций ASTORE/ALOAD. Они вставлены компилятором Kotlin, так что отладчик работает и для лямбд! Об этом мы поговорим в последнем разделе статьи.
/**
* Вызывает определённую функцию [block] с данным [receiver] в качестве своего получателя и возвращает результат.
*/
@kotlin.internal.InlineOnly
public inline fun with(receiver: T, block: T.() -> R): R = receiver.block()with выглядит аналогичным apply, но есть некоторые важные отличия. Во-первых, with не является функцией-расширением типа: получатель должен явным образом передаваться в качестве параметра. Более того, with возвращает результат функции block, а apply — самого получателя.
Поскольку мы можем возвращать что угодно, этот пример выглядит очень правдоподобно:
val layout = with(contextWrapper) {
// `this` is the contextWrapper
LayoutStyle(context, attrs).apply { orientation = VERTICAL }
}Здесь можно опустить префикс contextWrapper. для context и attrs, потому что contextWrapper — получатель функции with. Но даже в этом случае способы применения вовсе не так очевидны по сравнению с apply, эта функция может оказаться полезна при определённых условиях.
Учитывая это, вернёмся к нашему примеру и посмотрим, что будет, если воспользоваться with:
enum class Orientation {
VERTICAL, HORIZONTAL
}
class LayoutStyle {
var orientation = HORIZONTAL
}
object SharedState {
val previousOrientation = VERTICAL
}
fun main() {
val layout = with(SharedState) {
LayoutStyle().apply { orientation = previousOrientation }
}
}Получатель with — синглтон SharedState, он содержит параметр ориентации (orientation parameter), который мы хотим задать для нашего макета. Внутри функции block создаём экземпляр LayoutStyle, и благодаря apply мы можем просто задать ориентацию, считав её из SharedState.
Посмотрим снова на сгенерированный байткод:
GETSTATIC kotlindeepdive/SharedState.INSTANCE : Lkotlindeepdive/SharedState;
ASTORE 1
ALOAD 1
ASTORE 2
NEW kotlindeepdive/LayoutStyle
DUP
INVOKESPECIAL kotlindeepdive/LayoutStyle. ()V
ASTORE 3
ALOAD 3
ASTORE 4
ALOAD 4
ALOAD 2
INVOKEVIRTUAL kotlindeepdive/SharedState.getPreviousOrientation ()Lkotlindeepdive/Orientation;
INVOKEVIRTUAL kotlindeepdive/LayoutStyle.setOrientation (Lkotlindeepdive/Orientation;)V
ALOAD 3
ASTORE 0
RETURN Ничего особенного. Извлечён синглтон, реализованный в виде статичного поля в классе SharedState; экземпляр LayoutStyle создаётся так же, как и раньше, вызывается конструктор, ещё одно обращение для получения значения previousOrientation внутри SharedState и последнее обращение для присвоения значения экземпляру LayoutStyle.
Совет: при использовании «Show Kotlin Bytecode» можно нажать «Decompile» и посмотреть Java-представление байткода, созданного для компилятора Kotlin. Спойлер: оно будет именно таким, как вы ожидаете!
/**
* Вызывает заданную функцию [block] со значением `this` в качестве аргумента и возвращает результат.
*/
@kotlin.internal.InlineOnly
public inline fun T.let(block: (T) -> R): R = block(this)let очень полезен при работе с объектами, которые могут принимать значение null. Вместо того чтобы создавать бесконечные цепочки выражений if-else, можно просто скомбинировать оператор ? (называется «оператор безопасного вызова») с let: в результате вы получите лямбду, у которой аргумент it является не-nullable-версией исходного объекта.
val layout = LayoutStyle()
SharedState.previousOrientation?.let { layout.orientation = it }Рассмотрим пример целиком:
enum class Orientation {
VERTICAL, HORIZONTAL
}
class LayoutStyle {
var orientation = HORIZONTAL
}
object SharedState {
val previousOrientation: Orientation? = VERTICAL
}
fun main() {
val layout = LayoutStyle()
// layout.orientation = SharedState.previousOrientation -- this would NOT work!
SharedState.previousOrientation?.let { layout.orientation = it }
}Теперь previousOrientation может быть null. Если мы попробуем напрямую присвоить его нашему макету, то компилятор возмутится, потому что nullable-тип нельзя присваивать не-nullable-типу. Конечно, можно написать выражение if, но это приведёт к двойной ссылке на выражение SharedState.previousOrientation. А если воспользоваться let, то получим не-nullable-ссылку на тот же самый параметр, которую можно безопасно присвоить нашему макету.
С точки зрения байткода всё очень просто:
NEW kotlindeepdive/let/LayoutStyle
DUP
INVOKESPECIAL kotlindeepdive/let/LayoutStyle. ()V
GETSTATIC kotlindeepdive/let/SharedState.INSTANCE : Lkotlindeepdive/let/SharedState;
INVOKEVIRTUAL kotlindeepdive/let/SharedState.getPreviousOrientation ()Lkotlindeepdive/let/Orientation;
DUP
IFNULL L2
ASTORE 1
ALOAD 1
ASTORE 2
ALOAD 0
ALOAD 2
INVOKEVIRTUAL kotlindeepdive/let/LayoutStyle.setOrientation (Lkotlindeepdive/let/Orientation;)V
GOTO L9
L2
POP
L9
RETURN Здесь используется простой условный переход IFNULL, который, по сути, вам бы пришлось делать вручную, за исключением этого раза, когда компилятор эффективно выполняет его за вас, а язык предлагает приятный способ написания такого кода. Думаю, это замечательно!
Есть две версии run: первая — простая функция, вторая — функция-расширение обобщённого типа (generic type). Поскольку первая всего лишь вызывает функцию block, которая передаётся как параметр, мы будем анализировать вторую.
/**
* Вызывает определённую функцию [block] со значением `this` в качестве получателя и возвращает результат.
*/
@kotlin.internal.InlineOnly
public inline fun T.run(block: T.() -> R): R = block()Пожалуй, run — самая простая из рассмотренных функций. Она определена как функция-расширение типа, чей экземпляр затем передаётся в качестве получателя и возвращает результат исполнения функции block. Может показаться, что run — некий гибрид let и apply, и это действительно так. Единственное отличие заключается в возвращаемом значении: в случае с apply мы возвращаем самого получателя, а в случае с run — результат функции block (как и у let).
В этом примере подчёркивается тот факт, что run возвращает результат функции block, в данном случае это присваивание (Unit):
enum class Orientation {
VERTICAL, HORIZONTAL
}
class LayoutStyle {
var orientation = HORIZONTAL
}
object SharedState {
val previousOrientation = VERTICAL
}
fun main() {
val layout = LayoutStyle()
layout.run { orientation = SharedState.previousOrientation } // returns Unit
}Эквивалентный байткод:
NEW kotlindeepdive/LayoutStyle
DUP
INVOKESPECIAL kotlindeepdive/LayoutStyle. ()V
ASTORE 0
ALOAD 0
ASTORE 1
ALOAD 1
ASTORE 2
ALOAD 2
GETSTATIC kotlindeepdive/SharedState.INSTANCE : Lkotlindeepdive/SharedState;
INVOKEVIRTUAL kotlindeepdive/SharedState.getPreviousOrientation ()Lkotlindeepdive/Orientation;
INVOKEVIRTUAL kotlindeepdive/LayoutStyle.setOrientation (Lkotlindeepdive/Orientation;)V
RETURN run была инлайнена, как и другие функции, и всё сводится к простым вызовам методов. Здесь тоже нет ничего странного!
Мы отмечали, что между функциями стандартной библиотеки есть много сходств: это сделано умышленно, чтобы покрыть как можно больше вариантов применения. С другой стороны, не так просто понять, какая из функций лучше всего подходит для конкретной задачи, учитывая незначительность отличий между ними.
Чтобы помочь вам разобраться со стандартной библиотекой, я нарисовал таблицу, в которой сведены все отличия между основными рассмотренными функциями (за исключением also):

store/loadЯ ещё кое-что не мог до конца понять при сравнении «Java-байткода» и «Kotlin-байткода». Как я уже говорил, в Kotlin, в отличие от Java, были дополнительные операции astore/aload. Я знал, что это как-то связано с лямбдами, но мог разобраться, зачем они нужны.
Похоже, эти дополнительные операции необходимы отладчику для обработки лямбд как стековых фреймов, что позволяет нам вмешиваться (step into) в их работу. Мы можем видеть, чем являются локальные переменные, кто вызывает лямбду, кто будет вызван из лямбды и т. д.
Но когда мы передаём APK в production, нас не волнуют возможности отладчика, верно? Так что можно считать эти функции избыточными и подлежащими удалению, несмотря на их небольшой размер и незначительность.
Для этого может подойти ProGuard, инструмент всем известный и всеми «любимый». Он работает на уровне байткода и, помимо запутывания и урезания, также выполняет оптимизационные проходы, чтобы сделать байткод компактнее. Я написал одинаковый кусок кода на Java и Kotlin, применил к обеим версиям ProGuard с одним набором правил и сравнил результаты. Вот что обнаружилось.
-dontobfuscate
-dontshrink
-verbose
-keep,allowoptimization class kotlindeepdive.apply.LayoutStyle
-optimizationpasses 2
-keep,allowoptimization class kotlindeepdive.LayoutStyleJJava:
package kotlindeepdive
enum OrientationJ {
VERTICAL, HORIZONTAL;
}
class LayoutStyleJ {
private OrientationJ orientation = HORIZONTAL;
public OrientationJ getOrientation() {
return orientation;
}
public LayoutStyleJ() {
if (System.currentTimeMillis() < 1) { main(); }
}
public void setOrientation(OrientationJ orientation) {
this.orientation = orientation;
}
public OrientationJ main() {
LayoutStyleJ layout = new LayoutStyleJ();
layout.setOrientation(VERTICAL);
return layout.orientation;
}
}Kotlin:
package kotlindeepdive.apply
enum class Orientation {
VERTICAL, HORIZONTAL
}
class LayoutStyle {
var orientation = Orientation.HORIZONTAL
init {
if (System.currentTimeMillis() < 1) { main() }
}
fun main() {
val layout = LayoutStyle().apply { orientation = Orientation.VERTICAL }
layout.orientation
}
}Java:
sgotti@Sebastianos-MBP ~/Desktop/proguard5.3.3/lib/PD/kotlindeepdive > javap -c LayoutStyleJ.class
Compiled from "SimpleJ.java"
final class kotlindeepdive.LayoutStyleJ {
public kotlindeepdive.LayoutStyleJ();
Code:
0: aload_0
1: invokespecial #8 // Method java/lang/Object."":()V
4: aload_0
5: getstatic #6 // Field kotlindeepdive/OrientationJ.HORIZONTAL$5c1d747f:I
8: putfield #5 // Field orientation$5c1d747f:I
11: invokestatic #9 // Method java/lang/System.currentTimeMillis:()J
14: lconst_1
15: lcmp
16: ifge 34
19: new #3 // class kotlindeepdive/LayoutStyleJ
22: dup
23: invokespecial #10 // Method "":()V
26: getstatic #7 // Field kotlindeepdive/OrientationJ.VERTICAL$5c1d747f:I
29: pop
30: iconst_1
31: putfield #5 // Field orientation$5c1d747f:I
34: return
} Kotlin:
sgotti@Sebastianos-MBP ~/Desktop/proguard5.3.3/lib/PD/kotlindeepdive > javap -c apply/LayoutStyle.class
Compiled from "Apply.kt"
public final class kotlindeepdive.apply.LayoutStyle {
public kotlindeepdive.apply.LayoutStyle();
Code:
0: aload_0
1: invokespecial #13 // Method java/lang/Object."":()V
4: aload_0
5: getstatic #11 // Field kotlindeepdive/apply/Orientation.HORIZONTAL:Lkotlindeepdive/apply/Orientation;
8: putfield #10 // Field orientation:Lkotlindeepdive/apply/Orientation;
11: invokestatic #14 // Method java/lang/System.currentTimeMillis:()J
14: lconst_1
15: lcmp
16: ifge 32
19: new #8 // class kotlindeepdive/apply/LayoutStyle
22: dup
23: invokespecial #16 // Method "":()V
26: getstatic #12 // Field kotlindeepdive/apply/Orientation.VERTICAL:Lkotlindeepdive/apply/Orientation;
29: putfield #10 // Field orientation:Lkotlindeepdive/apply/Orientation;
32: return
} Выводы после сравнения двух листингов байткода:
astore/aload в «Kotlin-байткоде» исчезли, потому что ProGuard счёл их избыточными и сразу удалил (любопытно, что для этого понадобилось сделать два оптимизационных прохода, после одного они не были удалены).Замечательно получить новый язык, предлагающий разработчикам настолько много возможностей. Но также важно знать, что мы можем полагаться на используемые инструменты, и чувствовать уверенность при работе с ними. Я рад, что могу сказать: «Я доверяю Kotlin», в том смысле, что я знаю: компилятор не делает ничего лишнего или рискованного. Он делает только то, что в Java нам нужно делать вручную, экономя нам время и ресурсы (и возвращает давно утраченную радость от кодинга для JVM). В какой-то мере это приносит пользу и конечным пользователям, потому что благодаря более строгой типобезопасности мы оставим меньше багов в приложениях.
Кроме того, компилятор Kotlin постоянно улучшается, так что генерируемый код становится всё эффективнее. Так что не нужно пытаться оптимизировать Kotlin-код с помощью компилятора, лучше сосредоточиться на том, чтобы писать более эффективный и идиоматичный код, оставляя всё остальное на откуп компилятору.
|
Метки: author AloneCoder компиляторы анализ и проектирование систем kotlin java блог компании mail.ru group никто не читает теги |
[recovery mode] Как пожизненный пользователь Windows переключился на Linux по-плохому |

systemd event handlers: /etc/systemd/logind.conf
Для URxvt: ~/.Xdefaults
Для i3wm: ~/.config/i3/config
Для i3bar: ~/.config/i3status/config/i3status.conf
Для dunst: ~/.config/dunst/dunstrc
Для Compton: ~/.config/compton.conf$ killall -u oldusername
$ id oldusername
>>> uid=1000(oldusername) gid=1000(oldusername) groups=1000(oldusername),24(cdrom),25(floppy),27(sudo),29(audio),30(dip),44(video),46(plugdev),108(netdev)
# изменение логина
$ usermod -l newusername oldusername
# изменение имени группы
$ groupmod -n newusername oldusername
# изменение директории home
$ usermod -d /home/newusername -m newusername
# добавление комментария с полным именем
$ usermod -c "New Full Name" newusername
# проверяем что "newusername" заменил "oldusername" во всех полях
$ id newusername
>>> uid=1000(newusername) gid=1000(newusername) groups=1000(newusername),24(cdrom),25(floppy),27(sudo),29(audio),30(dip),44(video),46(plugdev),108(netdev)# автозапуск приложений
exec --no-startup-id /usr/bin/nm-applet
exec --no-startup-id dropbox startapt-get install network-manager-openvpn
run_watch VPN {
pidfile = "sys/class/net/yoursetting"
}# настройки яркости (brightness adjustment)
bindsym $mod+Shift+F6 exec xrandr --output eDP-1 --brightness 1
bindsym $mod+F6 exec xrandr --output eDP-1 --brightness 0.8
bindsym $mod+F5 exec xrandr --output eDP-1 --brightness 0.5
bindsym $mod+F7 exec xrandr --output eDP-1 --brightness 0.1
# настройки звука (volume control)
bindsym $mod+F12 exec amixer -q sset Master 3%+
bindsym $mod+F11 exec amixer -q sset Master 3%-
bindsym $mod+F10 exec amixer -q sset Master toggle|
Метки: author Grinzzly разработка под linux linux debian tutorial |
Марафонский раунд Яндекс.Алгоритма 2017 |
И вновь, как и в прошлые годы, приближается финал конкурса Яндекс.Алгоритм. В этом году мы ввели новый раунд — марафонский. Он представляет из себя одну оптимизационную задачу без точного решения, которую участникам предлагалось «покрутить» в течение 48 часов. Такой формат похож на решение практических задач больше, чем популярные соревнования по спортивному программированию.

Особенностью большинства практических задач является отсутствие точного решения — или же алгоритмы его нахождения оказываются слишком медленными. Команде и отдельному разработчику нужно сделать хороший прототип решения, который будет внедряться в окончательный алгоритм. Задачи подобного рода давно встречаются в соревнованиях TopCoder, ежегодных соревнованиях Marathon24, Deadline24, Google Hash Code и других. Конкурс длится больше стандартных алгоритмических раундов, так что участники могут в спокойной обстановке и в удобное для себя время реализовать придуманный метод.
Мы, организаторы Алгоритма, очень хотим, чтобы разноплановые участники могли успешно себя проявить. Поэтому добавление марафонского раунда рассматриваем как путь к расширению аудитории и популяризации таких соревнований.
Мы попросили участников, показавших лучший результат, объяснить, как они его достигли.
Предлагаем и вам попробовать порешать задачу! Тому, кто покажет лучший результат до финала Алгоритма, мы подарим футболку с символикой конкурса. Финал состоится 18 июля. К участию приглашаются и те, кто решал раунд в рамках Алгоритма, и новые участники.
| Ограничение времени: | Ограничение памяти: | Ввод: | Вывод: |
|---|---|---|---|
| 2 с | 256 МБ | стандартный ввод | стандартный вывод |
В одной эльфийской стране назрел раскол. Как это часто бывает, после смерти короля его сыновья долго не могли решить, кто из них будет править страной, и в итоге не придумали ничего лучше, чем разделить её на отдельные области.
Эльфийская страна представлена клетчатым прямоугольником из n строк и m столбцов. В k клетках находятся источники жизни, ещё в k клетках находятся источники магии, при этом все источники находятся в различных клетках. По счастливому совпадению, у умершего короля было ровно k сыновей, поэтому они хотят разделить страну на k связных областей таким образом, чтобы каждая область содержала ровно один источник жизни и ровно один источник магии. Область называется связной, если из любой её клетки можно попасть в любую другую клетку этой области, переходя только по клеткам, принадлежащим области и имеющим общую сторону. Каждая клетка должна относиться ровно к одной области. Области могут содержать «дырки», то есть одна из областей может быть со всех сторон окружена другой.
Выведите n строк по m латинских букв в каждой: разбиение страны на области. Участки, содержащие одинаковые буквы, будут отнесены к одной области. В качестве символов разрешается использовать строчные и прописные английские буквы. Всего должно быть использовано в точности k различных букв. Клетки с одинаковыми буквами должны образовывать связную область. Каждая область должна содержать ровно один источник жизни и ровно один источник магии.
Предоставленное разбиение будет оценено по следующей системе:
При отсылке во время соревнования ваше решение будет проверено на наборе из 50 предварительных тестов. Ваш предварительный результат будет равен среднему количеству баллов за все тесты. Обратите внимание на ссылку «отчёт» рядом с отосланным решением: она позволяет увидеть, на каких тестах ваша программа успешно отработала, а на каких выдала некорректный ответ или же не выдала его вовсе. Увидеть как входные, так и выходные данные для конкретного теста нельзя.
После окончания соревнования ваше последнее отосланное и скомпилированное решение будет проверено на полном наборе из 250 тестов (50 предварительных тестов не входят в полный набор). Среднее количество баллов по всем тестам из полного набора и будет вашим окончательным результатом.
Если на очередном шаге генерации в любом из алгоритмов дальнейшие действия произвести невозможно, то весь процесс генерации начинается сначала.
| ввод | вывод |
4 6 3 0 0 1 3 3 0 3 5 2 4 2 2 |
aaabbc aaabbc aaabbc cccccc |
В примере имеются три области:
Тогда средняя «выпуклость» равна 0.048(3), а количество баллов за этот тест — 7733.
Вы можете отправлять решения не чаще одного раза в 5 минут.

Сначала найдём какие-нибудь пути от одних источников к другим. Это стандартная задача на потоки. Некоторые участники здесь использовали min-cost max-flow, но в моём решении он не дал никакого прироста, и в последней версии я оставил алгоритм Диница.
Дальше надо как-то раздать все остальные клетки. Это я делал совсем примитивно. Проходимся по всем нераспределённым клеткам, выбираем случайного соседа. Если сосед отдан какому-то сыну, отдаём эту клетку ему же. Иначе оставляем неопределённой. И так итерируемся, пока не раздадим все клетки. Небольшая оптимизация: если три соседа отданы одному и тому же сыну, обязательно отдаём клетку ему.
Конечно, на оба предыдущих шага можно добавить случайности. Перемешать вершины для Диница, итерироваться по клеткам в случайном порядке.
Дальше у нас есть какая-то карта, будем её локально оптимизировать.
Тут у меня есть три случая:
- У клетки есть лишь один сосед с той же территории, что и она, и хотя бы два соседа с другой. Тогда её стоит передать туда, с кем у неё два соседа.
- У клетки есть два соседа с той же территории и два с какой-то другой. Тогда полезность передачи зависит от площадей этих территорий.
- У клетки есть один сосед с той же территории и по одному соседу с ещё трёх.
Чтобы быстро понимать, что выгоднее делать в случаях 2 и 3, нужно поддерживать площади и периметры всех территорий. Но каждый случай давал довольно заметный прирост.
Ну и всё это можно делать много раз, пока есть время, и выбирать лучшее.
В таком виде решение уже набирает довольно много баллов, но часто скатывается в локальные минимумы. Возможный способ с этим бороться: в случаях 2 и 3, даже если изменение не приносит пользы, всё равно с некоторой вероятностью делать его, причём эта вероятность уменьшается с каждой итерацией. Это изменение увеличило результат почти на 200 баллов.
И про обратную связь:
Не понравилось, что с VK Cup'ом пересекается. Кстати, следующего раунда это тоже касается — он в один день с Russian code cup и Distributed code jam, я три контеста в один день точно не потяну. А задача очень приятная, да.
Спасибо за отличный конкурс и очень интересную задачу. Работать над ней было сплошным удовольствием. Единственное, что мне не понравилось, — немного непонятное описание генерации тестовых данных («некое случайное распределение» — но какое?). Возможно, стоило добавить «официальный» генератор данных (без начального значения), а нам оставить нетривиальную часть, где нужно «убедиться, что решение существует».
Версию моего решения с комментариями можно найти здесь:
https://www.mimuw.edu.pl/~erykk/yandex/solution.cpp
Я вижу, что часть финальных тестов упала (хотя с публичными тестами всё было нормально). У меня не возникло идеи использовать min-cost max-flow для построения путей. Думаю, если бы я задействовал это в качестве альтернативного подхода, то получил бы корректные ответы на указанных тестах, а возможно и улучшил бы другие результаты.
Thanks for the great contest and the very interesting task! It was a pleasure to work on it. The only thing I did not like was a bit unclear
statement of the test case generation («some random distribution» — but what distribution?), possibly a 'official' test generator could be even included (with no seeds), with the non-trivial part «make sure that a solution exists» left for us to implement (or solve manually).
The commented version of my solution can be found at:
https://www.mimuw.edu.pl/~erykk/yandex/solution.cpp
I see that I have failed some final tests (the public tests were all okay). I did not get the idea to use min-cost-max-flow to generate paths; I think using this as an alternative approach could help me get positive scores on these few tests, and possibly improve the results on other tests.
Я уже что-то написал в http://codeforces.com/blog/entry/51858?#comment-358766
Задача понравилась, по модулю тормозов Java. Решение устроено следующим образом:
- Сначала min-cost-max-flow ищет пути, соединяющие истоки и стоки.
- Потом пути расширяются жадно, пока поле не будет заполнено. Жадные шаги пробуют добавлять по одной клетке, а также по отрезку столбца/строки к существующей компоненте. Целевая функция — изменение скора / (количество добавленных клеток + 10).
- Полученное решение жадно оптимизируется, перекидывая клетки или отрезки столбцов/строк между компонентами (с той же целевой функцией).
- Описанный процесс запускается много раз, выбирается лучшее решение. В процесс добавлен рандом: рёбра в графе для потока перемешиваются, скоры в жадности умножаются на случайное число от 1 до 1,2.
Больше всего очков принесло переписывание решения с Java на C++ (~+150). Помимо этого, жадные улучшения после того как решение сгенерировалось — видимо, полезная идея. Из нереализованного — пробовать больше изменений в жадности (например, отрезать «углы» — пары сторон) и вместо потока сделать что-нибудь, что лучше приспособлено к целевой метрике (т. к. для потока длинный горизонтальный путь — сильно лучше, чем путь по диагонали с таким же горизонтальным смещением, а с точки зрения целевой метрики — сильно хуже). Ещё была идея попробовать simulated annealing вместо жадности, но на это не осталось времени.
|
Метки: author altolstikov спортивное программирование программирование алгоритмы блог компании яндекс яндекс.алгоритм соревнование программирования марафон |






