The Mozilla Blog: Why getting voting right is hard, Part IV: Absentee Voting and Vote By Mail |
|
|
The Firefox Frontier: Think you don’t need a VPN? Here are five times you just might. |
As more of daily life takes place across internet connections, privacy and security issues become even more important. A VPN — Virtual Private Network — can help anyone create a … Read more
The post Think you don’t need a VPN? Here are five times you just might. appeared first on The Firefox Frontier.
|
|
Mozilla Attack & Defense: Guest Blog Post: Leaking silhouettes of cross-origin images |
This blog post is one of several guest blog posts, where we invite participants of our bug bounty program to write about bugs they’ve reported to us.
This is a writeup of a vulnerability I found in Chromium and Firefox that could allow a malicious page to read some parts of an image located on an origin it is not supposed to be able to access. Although technically interesting, it is quite limited in scope—I am not aware of any major websites it could’ve been used against. As of November 17th, 2020, the vulnerability has been fixed in the most recent versions of both browsers.
The time that it takes CanvasRenderingContext2D.drawImage to draw a pixel depends on whether it is fully transparent, opaque, or semi-transparent. By timing a bunch of calls to drawImage, we can reliably infer the transparency of each pixel in a cross-origin image, which is enough to, for example, read text on a transparent background, like this:
JavaScript running on a website is not allowed to read the contents of documents located on other websites. For example, your bank might have a page https://mybank.com/get_balance/ that the application at https://mybank.com/accounts/ should be able to read, but this blog certainly shouldn’t. This is formalized by the Same-Origin Policy, which allows resources that are located on a different origin from the current page to be embedded in it, but does not allow them to be read.
The embedding/reading distinction means that while I can, for example, include an image from a different origin on this page and your browser will display it for you, the page—and any JavaScript running on it—shouldn’t be allowed to learn the image’s contents. Unfortunately, there are side channels for the page to learn the existence or non-existence of an image at a URL, its size and dimensions, but if the contents of an image served from a well-known URL contain an authenticated user’s private information, the contents should remain private because any third-party page will only be able to display it back to the user—not read them.
Canvas is an HTML feature that makes implementing this distinction tricky. A element is kind of like an image, but it can be manipulated from JavaScript—you can draw shapes, text, and other images onto it and, importantly, access individual pixels of the canvas for both reading and writing. Using the function CanvasRenderingContext2D.drawImage, any image that can be embedded onto a page can also be drawn onto a canvas, and this includes cross-origin images as well. In order to prevent an attacker from drawing a cross-origin image onto a canvas then reading the canvas to learn what the image looks like, a canvas that has ever had a cross-origin image drawn to it is marked as tainted and can no longer be read from.
Pixels in an image can have varying levels of transparency, and a well-optimized image drawing library might use different code to draw an image depending on what kind of pixels it contains. There are three cases that arise naturally:
Conveniently for us, drawImage lets us both crop and resize the image that will be drawn, so we can make a call like drawImage(img, x, y, 1, 1, 0, 0, 1024, 1024) to take just the one pixel located at coordinates (x, y) in img, scale it up to 1024x1024, and draw that onto our canvas.
If there’s any difference in performance between the three cases above, doing this will take a different amount of time depending on whether the given pixel is transparent, opaque, or semi-transparent, so by measuring the time the operation takes we can figure out which one it is. Repeat this for every pixel in img and you’ll have a “silhouette” of the image, which might be enough to figure out what the image contains, especially if it’s an image of text or a drawing on a transparent background.
Indeed, both Firefox and Chromium use Google’s Skia Graphics Library, which used to handle the three cases separately in the function blit_row_s32a_opaque. A quick benchmark I wrote confirmed that the performance of drawImage varied depending on the alpha-value of the pixels being drawn1:
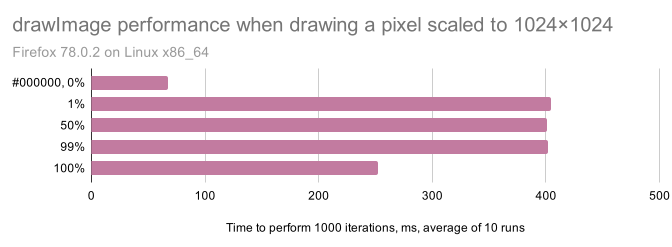
All of the above only applies when image’s operations are performed using the CPU. When they are performed using GPU acceleration, no observable differences in performance seem to exist.
Firefox does not support GPU acceleration in all configurations yet: the majority of Windows users are accelerated in the common case, but other platforms are likely affected. Chromium will use GPU acceleration on most hardware, so it is only affected when GPU rendering is disabled, either because the user is using a known-bad GPU or driver, or because GPU acceleration has been explicitly disabled2.
To exploit this, let’s write a function that takes one pixel of an image and measures how long it takes to draw it, blown up to 1024x1024 pixels, a hundred times:
const Iters = 100
let ScratchContext = document.createElement('canvas').getContext('2d')
function zeroDelay() {
return new Promise(resolve => setTimeout(resolve, 0))
}
async function timePixel(image, x, y) {
let startTime = performance.now()
for (let j = 0; j < Iters; j++) {
ScratchContext.drawImage(image, x, y, 1, 1, 0, 0, 1024, 1024)
}
/* in Chromium, the draw operations aren't actually performed
immediately, but only after the JavaScript thread stops. we wait
on a timeout with a duration of zero to give the browser a chance
to do the drawing, as otherwise we'd just be measuring the time
taken to enqueue all of the draw operations. */
await zeroDelay()
let endTime = performance.now()
return endTime - startTime
}
Looking at the performance chart above, we know that, in an image where all pixels are either fully transparent or fully opaque, timePixel will return a much higher value for the opaque ones. Now we can measure all of the pixels one-by-one and render the timings on a heatmap, obtaining the Hollywood hacker movie-worthy reconstruction we saw in the video at the beginning of the post.
The full source code for the exploit is available on my Github.
I reported this bug to Mozilla on May 29th, 2020 through the Mozilla Security Bug Bounty program and to Google through the Chrome Vulnerability Reward the next day. It took some time to figure out which graphics backend is used in Firefox by default these days. With the help of a Google engineer and some profiling tools, we identified that the same piece of Skia code was responsible for this behavior in both browsers.
Google updated Skia to remove branching on alpha value in blit_row_s32a_opaque completely on August 29th, 2020 and merged that change into Chromium on the same day. Mozilla merged the change on October 6th, 2020.
Google has issued CVE-2020-16012 to notify users about this bug.
Both vendors offered very generous bounties for my reports. It’s been a pleasure working with Mozilla and Google to get this fixed, and I would like to take this opportunity to thank Mike Klein from Google and Lee Salzman from Mozilla for their work on diagnosing and fixing the bug. I would also like to thank Tom Ritter and Lee Salzman from Mozilla for their helpful feedback on drafts of this blog post.
1 Although the behavior in Chromium is nearly identical, if you’re not careful about how you set up the benchmark, you might get a surprising result there: while the performance for fully and semi-transparent pixels is the same as in Firefox, fully solid pixels are drawn much faster. This is caused by an additional optimization that is only hit in Chromium, where Skia detects that an opaque 1024x1024 image is being drawn onto a canvas that’s exactly the same size, so instead of doing it pixel-by-pixel it just moves the whole buffer over, which turns out to be even faster than doing nothing 10242 times. It appears that this optimization is only triggered when the entire source image is opaque, not just the pixel we crop out of it. If you use a source image that has pixels with different alpha-values, Chromium performs exactly the same as Firefox.
2/ Though my Intel GPU is not on the blocklist, during my experiments I found that hammering it with thousands of draw commands will crash the driver and force Chromium to revert to CPU rendering, so this might be one way of exploiting the vulnerability on some hardware/OS combinations.
https://blog.mozilla.org/attack-and-defense/2021/01/11/leaking-silhouettes-of-cross-origin-images/
|
|
Cameron Kaiser: Another way social media is bad |
But relevant to this blog and this audience is social media's impact on trying to get the most bang for your buck out of your old devices and computers. Full-fat Twitter and Facebook (and others) are computationally expensive: the bells and whistles cost in terms of JavaScript, and there is no shortage of other client-side analytics to feed you the posts to keep you engaged and to monitor your actions to construct ad profiles. A number of our outstanding bugs in TenFourFox are directly due to this, and some can't be fixed without terrible consequences (such as Facebook's asm.js draw code using little-endian floats, which would be a nightmare to constantly byteswap, which is why the reaction icons don't show up), and pretty much none of them are easy to diagnose because all of their code is minified to hell. As they track changes in hardware and the browser base and rely on them, these problems continuously get worse. Most of TenFourFox's development is done by me and me alone and a single developer simply can't keep up with all the Web platform changes anymore.
Moreover, whatever features are available still have to contend with what the hardware is capable of. As our base is overwhelmingly Power Macs, I expect people to realize they are using computers which are no less than 15 years old and often more. We support operating systems with inadequate GPU support and we have to use Carbon APIs, so we will never be 64-bit, even on G5. Built-in basic adblock cuts a lot of fat, and we have a JIT and the fastest JavaScript on any 32-bit PowerPC platform, but it's still not enough. No one at these sites cares about our systems; I've never had any luck with trying to contact developers other than autoreply contact forms and unhelpful support desks which cater to users instead of other devs. Sometimes the sites offer light versions, such as basic Facebook. Some of you use this, some of you won't. However, sometimes the sites offer light versions, but only through mobile-specific apps (like Twitter Lite), so it doesn't help us. Sometimes user agent twiddling can help but many users don't know how or can't be bothered. And their continued availability is always subject to whether the home site wants to continue to supporting them or not because they probably do have impacts in terms of what browsing and activity information they can aggregate.
Many people effectively rate a computer today on how well it can access social media, and a computer that can't is therefore useless. This means you permit these companies to determine when the computer you spent your hard-earned money on should go in the trash. That decision probably won't be made maliciously, but it certainly won't be made to benefit you.
These are private companies and they get to decide how they will spend their money and time. But we, in turn, shouldn't depend on them for anything nor expect anything from them, and we should think about finding ways to extricate ourselves from them and maintain contact with the people we care about in other fashions. On our systems in particular this will only get worse and it doesn't have to. The power they have over our wallets and our public discourse is only — and entirely — because collectively we gave it to them.
http://tenfourfox.blogspot.com/2021/01/another-way-social-media-is-bad.html
|
|
The Mozilla Blog: We need more than deplatforming |
There is no question that social media played a role in the siege and take-over of the US Capitol on January 6.
Since then there has been significant focus on the deplatforming of President Donald Trump. By all means the question of when to deplatform a head of state is a critical one, among many that must be addressed. When should platforms make these decisions? Is that decision-making power theirs alone?
But as reprehensible as the actions of Donald Trump are, the rampant use of the internet to foment violence and hate, and reinforce white supremacy is about more than any one personality. Donald Trump is certainly not the first politician to exploit the architecture of the internet in this way, and he won’t be the last. We need solutions that don’t start after untold damage has been done.
Changing these dangerous dynamics requires more than just the temporary silencing or permanent removal of bad actors from social media platforms.
Additional precise and specific actions must also be taken:
Reveal who is paying for advertisements, how much they are paying and who is being targeted.
Commit to meaningful transparency of platform algorithms so we know how and what content is being amplified, to whom, and the associated impact.
Turn on by default the tools to amplify factual voices over disinformation.
Work with independent researchers to facilitate in-depth studies of the platforms’ impact on people and our societies, and what we can do to improve things.
These are actions the platforms can and should commit to today. The answer is not to do away with the internet, but to build a better one that can withstand and gird against these types of challenges. This is how we can begin to do that.
Photo by Cameron Smith on Unsplash
The post We need more than deplatforming appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2021/01/08/we-need-more-than-deplatforming/
|
|
Mozilla Security Blog: Encrypted Client Hello: the future of ESNI in Firefox |
Two years ago, we announced experimental support for the privacy-protecting Encrypted Server Name Indication (ESNI) extension in Firefox Nightly. The Server Name Indication (SNI) TLS extension enables server and certificate selection by transmitting a cleartext copy of the server hostname in the TLS Client Hello message. This represents a privacy leak similar to that of DNS, and just as DNS-over-HTTPS prevents DNS queries from exposing the hostname to on-path observers, ESNI attempts to prevent hostname leaks from the TLS handshake itself.
Since publication of the ESNI draft specification at the IETF, analysis has shown that encrypting only the SNI extension provides incomplete protection. As just one example: during session resumption, the Pre-Shared Key extension could, legally, contain a cleartext copy of exactly the same server name that is encrypted by ESNI. The ESNI approach would require an encrypted variant of every extension with potential privacy implications, and even that exposes the set of extensions advertised. Lastly, real-world use of ESNI has exposed interoperability and deployment challenges that prevented it from being enabled at a wider scale.
To address the shortcomings of ESNI, recent versions of the specification no longer encrypt only the SNI extension and instead encrypt an entire Client Hello message (thus the name change from “ESNI” to “ECH”). Any extensions with privacy implications can now be relegated to an encrypted “ClientHelloInner”, which is itself advertised as an extension to an unencrypted “ClientHelloOuter”. Should a server support ECH and successfully decrypt, the “Inner” Client Hello is then used as the basis for the TLS connection. This is explained in more detail in Cloudflare’s excellent blog post on ECH.
ECH also changes the key distribution and encryption stories: A TLS server supporting ECH now advertises its public key via an HTTPSSVC DNS record, whereas ESNI used TXT records for this purpose. Key derivation and encryption are made more robust, as ECH employs the Hybrid Public Key Encryption specification rather than defining its own scheme. Importantly, ECH also adds a retry mechanism to increase reliability with respect to server key rotation and DNS caching. Where ESNI may currently fail after receiving stale keys from DNS, ECH can securely recover, as the client receives updated keys directly from the server.
In keeping with our mission of protecting your privacy online, Mozilla is actively working with Cloudflare and others on standardizing the Encrypted Client Hello specification at the IETF. Firefox 85 replaces ESNI with ECH draft-08, and another update to draft-09 (which is targeted for wider interoperability testing and deployment) is forthcoming.
Users that have previously enabled ESNI in Firefox may notice that the about:config option for ESNI is no longer present. Though we recommend that users wait for ECH to be enabled by default, some may want to enable this functionality earlier. This can be done in about:config by setting network.dns.echconfig.enabled and network.dns.use_https_rr_as_altsvc to true, which will allow Firefox to use ECH with servers that support it. While ECH is under active development, its availability may be intermittent as it requires both the client and server to support the same version. As always, settings exposed only under about:config are considered experimental and subject to change. For now, Firefox ESR will continue to support the previous ESNI functionality.
In conclusion, ECH is an exciting and robust evolution of ESNI, and support for the protocol is coming to Firefox. We’re working hard to make sure that it is interoperable and deployable at scale, and we’re eager for users to realize the privacy benefits of this feature.
The post Encrypted Client Hello: the future of ESNI in Firefox appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2021/01/07/encrypted-client-hello-the-future-of-esni-in-firefox/
|
|
The Mozilla Blog: Why getting voting right is hard, Part III: Optical Scan |
|
|
Aaron Klotz: 2018 Roundup: Q2, Part 3 |
This is the fourth post in my “2018 Roundup” series. For an index of all entries, please see my blog entry for Q1.
Yes, you are reading the dates correctly: I am posting this nearly two years after I began this series. I am trying to get caught up on documenting my past work!
Once I had landed the skeletal implementation of the launcher process, it was time to start making it do useful things.
[For an overview of Windows integrity levels, check out this MSDN page – Aaron]
Since Windows Vista, security tokens for standard users have declared a medium integrity level by default.
When UAC is enabled, members of the Administrators group also run as a standard user with a medium IL, with
the additional ability of being able to “elevate” themselves to a high IL. An administrator who disables UAC
has a token that is always high integrity.
Running a process at a high IL is something that is not to be taken lightly: at that level, the process may alter system settings and access files that would otherwise be restricted by the OS.
While our sandboxed content processes always run at a low IL, I believed that defense-in-depth called for ensuring that the browser process did not run at a high IL. In particular, I was concerned about cases where elevation might be accidental. Consider, for example, a hypothetical scenario where a system administrator is running two open command prompts, one elevated and one not, and they accidentally start Firefox from the one that is elevated.
This was a perfect use case for the launcher process: it detects whether it is running at high IL, and if so, it launches the browser with medium integrity.
Unfortunately some users prefer to configure their accounts to run at all times as Administrator with high integrity!
This is terrible idea from a security perspective, but it is what it is; in my experience, most users who
run with this configuration do so deliberately, and they have no interest in being lectured about it.
Unfortunately, users running under this account configuration will experience side-effects of the Firefox browser process running at medium IL. Specifically, a medium IL process is unable to initiate IPC connections with a process running at a higher IL. This will break features such as drag-and-drop, since even the user’s shell processes are running at a higher IL than Firefox.
Being acutely aware of this issue, I included an escape hatch for these users: I implemented a command line option that prevents the launcher process from de-elevating when running with a high IL. I hate that I needed to do this, but moral suasion was not going to be effective technique for solving this problem.
Another tool that the launcher process enables us to utilize is process mitigation options. Introduced in Windows 8, the kernel provides several opt-in flags that allows us to add prophylactic policies to our processes in an effort to harden them against attacks.
Additional flags have been added over time, so we must be careful to only set flags that are supported by the version of Windows on which we’re running.
We could have set some of these policies by calling the
SetProcessMitigationPolicy API.
Unfortunately this API is designed for a process to use on itself once it is already running. This implies that there
is a window of time between process creation and the time that the process enables its mitigations where an attack could occur.
Fortunately, Windows provides a second avenue for setting process mitigation flags: These flags may be set as part of
an attribute list in the STARTUPINFOEX
structure that we pass into CreateProcess.
Perhaps you can now see where I am going with this: The launcher process enables us to specify process mitigation flags for the browser process at the time of browser process creation, thus preventing the aforementioned window of opportunity for attacks to occur!
While there are other flags that we could support in the future, the initial mitigation policy that I added was the
PROCESS_CREATION_MITIGATION_POLICY_IMAGE_LOAD_PREFER_SYSTEM32_ALWAYS_ON
flag. Note that I am only discussing flags applied to the browser process; sandboxed processes receive additional mitigations.
This flag forces the Windows loader to always use the Windows system32 directory as the first directory in its search path,
which prevents library preload attacks. Using this mitigation also gave us an unexpected performance gain on devices with
magnetic hard drives: most of our DLL dependencies are either loaded using absolute paths, or reside in system32. With
system32 at the front of the loader’s search path, the resulting reduction in hard disk seek times produced a slight but
meaningful decrease in browser startup time! How I made these measurements is addressed in a future post.
This concludes the Q2 topics that I wanted to discuss. Thanks for reading! Coming up in Q3: Preparing to Enable the Launcher Process by Default.
|
|
Aaron Klotz: 2018 Roundup: Q2, Part 2 |
This is the third post in my “2018 Roundup” series. For an index of all entries, please see my blog entry for Q1.
Yes, you are reading the dates correctly: I am posting this nearly two years after I began this series. I am trying to get caught up on documenting my past work!
One of the things I added to Firefox for Windows was a new process called the “launcher process.” “Bootstrap process” would be a better name, but we already used the term “bootstrap” for our XPCOM initialization code. Instead of overloading that term and adding potential confusion, I opted for using “launcher process” instead.
The launcher process is intended to be the first process that runs when the user starts Firefox. Its sole purpose is to create the “real” browser process in a suspended state, set various attributes on the browser process, resume the browser process, and then self-terminate.
In bug 1454745 I implemented an initial skeletal (and opt-in) implementation of the launcher process.
This seems like pretty straightforward code, right? Na"ively, one could just rip a CreateProcess
sample off of MSDN and call it day. The actual launcher process implmentation is more complicated than
that, for reasons that I will outline in the following sections.
firefox.exeI wanted the launcher process to exist as a special “mode” of firefox.exe, as opposed to a distinct
executable.
By definition, the launcher process lies on the critical path to browser startup. I needed to be very conscious of how we affect overall browser startup time.
Since the launcher process is built into firefox.exe, I needed to examine that executable’s existing
dependencies to ensure that it is not loading any dependent libraries that are not actually needed
by the launcher process. Other than the essential Win32 DLLs kernel32.dll, advapi32.dll (and their
dependencies), I did not want anything else to load. In particular, I wanted to avoid loading user32.dll
and/or gdi32.dll, as this would trigger the initialization of Windows’ GUI facilities, which would be a
huge performance killer. For that reason, most browser-mode library dependencies of firefox.exe
are either delay-loaded or are explicitly loaded via LoadLibrary.
We wanted the launcher process to both respect Firefox’s safe mode, as well as alter its behaviour as necessary when safe mode is requested.
There are multiple mechanisms used by Firefox to detect safe mode. The launcher process detects
all of them except for one: Testing whether the user is holding the shift key. Retrieving keyboard
state would trigger loading of user32.dll, which would harm performance as I described above.
This is not too severe an issue in practice: The browser process itself would still detect the shift key. Furthermore, while the launcher process may in theory alter its behaviour depending on whether or not safe mode is requested, none of its behaviour changes are significant enough to materially affect the browser’s ability to start in safe mode.
Also note that, for serious cases where the browser is repeatedly unable to start, the browser triggers a restart in safe mode via environment variable, which is a mechanism that the launcher process honours.
We wanted the launcher process to behave well with respect to automated testing.
The skeletal launcher process that I landed in Q2 included code to pass its console handles on to the browser process, but there was more work necessary to completely handle this case. These capabilities were not yet an issue because the launcher process was opt-in at the time.
We wanted the launcher process to gracefully handle failures even though, also by definition, it does not have access to facilities that internal Gecko code has, such as telemetry and the crash reporter.
The skeletal launcher process that I landed in Q2 did not yet utilize any special error handling code, but this was also not yet an issue because the launcher process was opt-in at this point.
Thanks for reading! Coming up in Q2, Part 3: Fleshing Out the Launcher Process
|
|
The Rust Programming Language Blog: mdBook security advisory |
This is a cross-post of the official security advisory. The official post contains a signed version with our PGP key, as well.
The Rust Security Response Working Group was recently notified of a security issue affecting the search feature of mdBook, which could allow an attacker to execute arbitrary JavaScript code on the page.
The CVE for this vulnerability is CVE-2020-26297.
The search feature of mdBook (introduced in version 0.1.4) was affected by a cross site scripting vulnerability that allowed an attacker to execute arbitrary JavaScript code on an user's browser by tricking the user into typing a malicious search query, or tricking the user into clicking a link to the search page with the malicious search query prefilled.
mdBook 0.4.5 fixes the vulnerability by properly escaping the search query.
Owners of websites built with mdBook have to upgrade to mdBook 0.4.5 or greater and rebuild their website contents with it. It's possible to install mdBook 0.4.5 on the local system with:
cargo install mdbook --version 0.4.5 --force
Thanks to Kamil Vavra for responsibly disclosing the vulnerability to us according to our security policy.
All times are listed in UTC.
https://blog.rust-lang.org/2021/01/04/mdbook-security-advisory.html
|
|
Daniel Stenberg: Age is just a number or two |
Kjell, a friend of mine, mailed me a zip file this morning saying he’d found an earlier version of “urlget” lying around. Meaning: an older version than what we provide on the curl download page. urlget was the name we used for the command line tool before we changed the name to curl in March 1998.
I’ve been reckless with some of the source code and keeping track of early history so this made me curios and when I glanced through the source code for urlget 2.4, shipped in October 1997. Kjell had found a project of his own where he’d imported the urlget sources as that was from before the days curl was also a library.
In this source code I also found the original URL to the home page for urlget and its predecessor, httpget: http://www.inf.ufrgs.br/~sagula/urlget.html
I don’t know if I have this info stored somewhere else too, but the important thing here is that it then struck me that I hadn’t checked the Internet Archive for what it has archived for this URL!
The earliest archived version of the urlget page is from February 16 1998. I checked, but there’s no archived version from slightly earlier when the tool was named just httpget. I did however find source code from httpget that was older than I had saved from before: httpget 1.3! 320 lines of hopelessly naive code. From April 14, 1997.
That date is also the only one that has content as the next archived one is just a redirect to the first curl web site over at http://www.fts.frontec.se/~dast/curl/
I used this newly found gem to update the curl history page with exact dates for some of the earliest releases and events, as it was previously not very specific there as I hadn’t kept notes.
I could now also once and for all note that the first release of HttpGet (version 0.1) was done on November 11, 1996. My personal participation in the project began at some days/weeks after that, as it is recorded that I provided improvements in the HttpGet 0.2 release that was done on December 17 the same year.
I’ve always counted the age of curl from March 20, 1998 which is when I first released something under the name “curl”, but since we released it as curl 4.0 that is certainly a sign that the time up to that point could possibly also be counted into its age.
It’s not terribly important of when to start the count.
What’s more fun with the particular HttpGet 0.1 release date, is that it is the exact same date Wget was released the first time under that name! It had previously been developed and released under a different name (“geturl”) and exactly on November 11, 1996 Hrvoje Niksi? released Wget 1.4.0 to the world.
People sometimes ask me why I didn’t use wget to get currencies that winter day back in 1996 when I found HttpGet and started to work on that HTTP client, but the fact is then that not only was the search engines and software hosting alternatives clearly inferior back in those days so finding software could be difficult, wget was also very new to the world. I didn’t learn about the existence of wget until many months later – although I can’t recall exactly when or how.
I also think, looking back at myself in that time, that if I would’ve found wget then, I would probably have thought it to be overkill for my use case and opted to use something else anyway. I mean, I was “just getting a HTTP page” and the wget package was 171KB compressed, while HttpGet 1.3 was still less than 8K in a single source code file… I’m not saying that way of thinking was right!
https://daniel.haxx.se/blog/2021/01/03/age-is-just-a-number-or-two/
|
|
Armen Zambrano: Farewell, Mozilla |
The summer of 2020 marked the end of 12 years of working for Mozilla. My career with Mozilla began with an internship during the summer of 2008 when I worked from Building K in 1981 Landings Drive, Mountain View, CA.

Writing this post is hard since Mozilla was such a great place to work at, not only for its altruistic mission, but mostly because of the fantastic people I met during my time there.
I’m eternally grateful to my Lord Jesus Christ, Who placed me in a workplace where I could grow so much, both as a person and as an engineer.

I can count dozens of Mozillians I’ve talked and laughed with over the years. I could try unsuccessfully to list each and every one, however I believe it’s better to simply say that I’ve enjoyed every moment with each one of you.
It’s been a long time since I’ve spoken with many of you and some of you I may never get the chance to talk with again. Nevertheless, if you ever see me somewhere online, please be sure to say hi. I would love to hear from you.

Mozilla, thank you for the opportunity to help further your mission. I wish you success in 2021 and beyond.
http://feedproxy.google.com/~r/armenzg_mozilla/~3/1zfwHIXQdYY/farewell-mozilla-5d52b7110194
|
|
The Rust Programming Language Blog: Announcing Rust 1.49.0 |
|
|
This Week In Rust: This Week in Rust 371 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
No newsletters this week.
matches macro! in RustThis week's crate is autograd, a library of differentiable operations and tensors for machine learning applications.
Thanks to Zicklag for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
275 pull requests were merged in the last week
min_const_generics (Huzzah!)Fn trait bounds rather than the unique closure typeDefPath from Visibility and calculate it on demandimpl Divcode>> for u`* which cannot paniccompare_and_swap methodcore::slice::filldeque_rangeclone_from from hashbrown::{HashMap, HashSet}RUSTC_WORKSPACE_WRAPPER--default-theme command line optionTriage done by @simulacrum.
See the full report for more.
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
No RFCs are currently in the final comment period.
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
This is a common theme in Rust’s design: To reduce breakage as code evolves, you’re only allowed to rely on features that have been intentionally declared by the author.
Thanks to Kornel for the suggestion.
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, and cdmistman.
https://this-week-in-rust.org/blog/2020/12/30/this-week-in-rust-371/
|
|
Tiger Oakes: Deploy a site to GitHub Pages from multiple branches using GitHub Actions |
I’ve been moving many repositories over to GitHub Actions to automate deployment and testing. One of my projects uses GitHub Pages, but includes data from two different branches:
main branch contains the bulk of the websiteapp-challenge branch contains a second site that appears under a /heleon/ pathUsing GitHub Actions, I set up the site pull from both branches before deploying. The script looks like this:
name: Deploy from two branches
on:
push:
branches: [main]
jobs:
build:
runs-on: ubuntu-latest
steps:
# Checkout the `main` branch
- uses: actions/checkout@v2
# Install Node.js
- uses: actions/setup-node@v2-beta
with:
node-version: '14'
# Install npm dependencies
# (similar to npm install)
- run: npm ci
# Run code to build the site files inside the `big-island-buses` folder
- run: npm run build
# Checkout the `app-challenge` branch
- uses: actions/checkout@v2
with:
ref: app-challenge
# Put the checked out files inside the `big-island-buses/heleon` folder
path: big-island-buses/heleon
clean: false
# Delete the .git folder from `big-island-buses/heleon`
# This turns the files into a plain folder instead of a git repository
- run: rm -rf big-island-buses/heleon/.git
# Deploy the `big-island-buses` folder to GitHub Pages
- uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: "./big-island-buses"
user_name: 'github-actions[bot]'
user_email: 'github-actions[bot]@users.noreply.github.com'
The first sequence of steps checks out the main branch, installs Node.js and npm dependencies, then runs the build script. The files created by the build script end up in a folder named big-island-buses.
The second sequence checks out the app-challenge branch, and places the files inside a folder named heleon, which is a subfolder of big-island-buses. These files are static so they don’t have a separate build script.
However, putting one git repository inside another like this creates problems for the GitHub Pages script. Deleting the .git folder turns the git repository into a plain folder.
https://tigeroakes.com/posts/til-github-pages-two-branches-github-actions/
|
|
Daniel Stenberg: The curl year 2020 |
As we’re approaching the end of the year, I just want to sum up the curl year with a few words.
2020 has been another glorious year in the curl project. We’ve seen a series of accomplishments and introductions of new things during this the year of the plague.
I personally have done more commits in the git repository since any year after 2004 (890 so far).
The total number of commits done in git is the largest since 2014 (1445 plus some).
The number of published curl related CVEs is the lowest since 2013 (6). For the ones we announced, we could reward record amounts in our bug bounty program!
139 authors wrote commits that were merged (so far).
We did nine curl releases, out of which two unfortunately were quicker “panic releases” that patched up problems in the previous release.
We’ve logged no less than 905 bug-fixes and 30 changes in the releases of this year, but the seven perhaps most memorable things we’ve introduced in 2020 are…
--help refinedThis year I’ve introduced the concept of doing a “release presentation” for every release. Those are videos where I go through and discuss the changes, the security releases and some interesting bug-fixes. Each release links to those from the changelog page on the website.
This is the year when we finally got ourselves a curl domain. curl.se is our new home.
We cancelled curl up 2020 due to Covid-19. It was planned to happen in Berlin. We did it purely online instead. We’re not planning any new physical curl up for 2021 either. Let’s just wait and see what happens with the pandemic next year and hope that we might be able to go back and have a physical meetup in 2022…

|
|






