Mozilla Addons Blog: addons.mozilla.org API v3 Deprecation |
The addons.mozilla.org (AMO) external API can be used by users and developers to get information about add-ons available on AMO, and to submit new add-on versions for signing. It’s also used by Firefox for recommendations, among other things, by the web-ext tool, and internally within the addons.mozilla.org website.
We plan to shut down Version 3 (v3) of the AMO API on December 31, 2021. If you have any personal scripts that rely on v3 of the API, or if you interact with the API through other means, we recommend that you switch to the stable v4. You don’t need to take any action if you don’t use the AMO API directly. The AMO API v3 is entirely unconnected to manifest v3 for the WebExtensions API, which is the umbrella project for major changes to the extensions platform itself.
Roughly five years ago, we introduced v3 of the AMO API for add-on signing. Since then, we have continued developing additional versions of the API to fulfill new requirements, but have maintained v3 to preserve backwards compatibility. However, having to maintain multiple different versions has become a burden. This is why we’re planning to update dependent projects to use v4 of the API soon and shut down v3 at the end of the year.
You can find more information about v3 and v4 on our API documentation site. When updating your scripts, we suggest just making the change from “/v3/” to “/v4” and seeing if everything still works – in most cases it will.
Feel free to contact us if you have any difficulties.
The post addons.mozilla.org API v3 Deprecation appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2021/02/01/addons-mozilla-org-api-v3-deprecation/
|
|
Tiger Oakes: Turning junk phones into an art display |

What do you do with your old phone when you get a new one? It probably goes to a pile in the back of the closest, or to the dump. I help my family with tech support and end up with any of their old devices, so my pile of junk phones got bigger and bigger.
I didn’t want to leave the phones lying around and collecting dust. One day I had the idea to stick them on the wall like digital photo frames. After some time with Velcro, paint, and programming, I had all the phones up and running.
These phones can do anything a normal phone does, but I’ve tweaked the use cases since they’re meant to be viewed and not touched.

Each of these phones has a story of its own. Some have cracked screens, some can’t connect to the internet, and one I found in the woods. To build Cell Wall, I needed a physical board, software for the phones, and a way to mount the phones on the board. You might have some of this lying around already!
First off: there needs to be a panel for the phones to sit on top of. You could choose to stick phones directly on your wall, but I live in an apartment and I wanted to make something I could remove. I previously tried using a foam board but decided to “upgrade” to a wood panel with paint.
I started off arranging the phones on the floor and figuring out how much space was needed. I took some measurements and estimated that the board needed to be 2 feet by 1 1/2 feet to comfortably fit all the phones and wires.
Once I had some rough measurements, I took a trip to Home Depot. Home Depot sells precut 2 feet by 2 feet wood panels, so I found a sturdy light piece. You can get wood cut for free inside the store by an employee or at a DIY station, so I took out a saw and cut off the extra 6-inch piece.
The edges can be a little sharp afterwards. Use a block of sandpaper to smooth them out.
I wanted the wood board to blend in with my wall and not look like…wood. At a craft store, I picked up a small bottle of white paint and a paintbrush. At home, on top of some trash bags, I started painting a few coats of white.
To keep the phones from falling off, I use Velcro. It’s perfect for securely attaching the phones to the board while allowing them to be removed if needed.
Before sticking them on, I also double-checked that the phones turn on at all. Most do, and the ones that are busted make a nice extra decoration.
If the phone does turn on, enable developer mode. Open settings, open the System section, and go to “About phone”. Developer mode is hidden here - by tapping on “Build number” many times, you eventually get a prompt indicating you are now a true Android developer.
The wires are laid out with a bunch of tiny wire clips. $7 will get you 100 of these clips in a bag, and I’ve laid them out so each clip only contains 1 or 2 wires. The wires themselves are all standard phone USB cables you probably have lying around for charging. You can also buy extra cables for less than a dollar each at Monoprice.
All the wires feed into a USB hub. This hub lets me connect all the phones to a computer just using a single wire. I had one lying around, but similar hubs are on Amazon for $20. The hub needs a second cable that plugs directly into an outlet and provides extra power, since it needs to charge so many phones.
With all the phones hooked up to the USB hub, I can connect them all to a single computer server. All of these phones are running Android, and I’ll use this computer to send commands to them.
Usually, phones communicate to a server through the internet over WiFi. But, some of the phones don’t have working WiFi, so I need to connect over the USB cable instead. The computer communicates with the phones using a program from Google called the Android Debug Bridge. This program, called ADB for short, lets you control an Android phone by sending commands, such as installing a new app, simulating a button, or starting an app.
You can check if ADB can connect to your devices by running the command adb devices. The first time this runs, each phone gets a prompt to check if you trust this computer. Check the “remember” box and hit OK.
Android uses a system called “intents” to open an app. The simplest example is tapping an icon on the home screen, which sends a “launch” intent. However, you can also send intents with additional data, such as an email subject and body when opening an email app, or the address of a website when opening a web browser. Using this system, I can send some data to a custom Android app over ADB that tells it which screen to display.
# Command to send an intent using ADB
adb shell am start
# The intent action type, such as viewing a website
-a android.intent.action.VIEW
# Data URI to pass in the intent
-d https://example.com
Each phone is running a custom Android app that interprets intents then displays one of 3 screens.
This doesn’t sound like a lot, but when all the devices are connected together to a single source, you can achieve complicated functionality.
The core logic doesn’t run on the phones but instead runs on the computer all the phones are connected to. Any computer with a USB port can work as the server that the phones connect to, but the Raspberry Pi is nice and small and uses less power.
This computer runs server software that acts as the manager for all the connected devices, sending them different data. It will take a large photo to crop into little photos, then send them to each phone. It can also take a list of text, then send individual lines to each cell. A grocery list can be shown by spreading the text across multiple phones. Larger images can be displayed by cutting them up on the server and sending a cropped version to each cell.
The server software is written in TypeScript and creates an HTTP server to expose functionality through different web addresses. This allows other programs to communicate with the server and lets me make a bridge with a Google Home or smart home software.
To control CellWall, I wrote a small JavaScript app served by the Node server. It includes a few buttons to turn each display on, controls for specific screens, and presets to display. These input elements all send HTTP requests to the server, which then converts them into ADB commands sent to the cells.
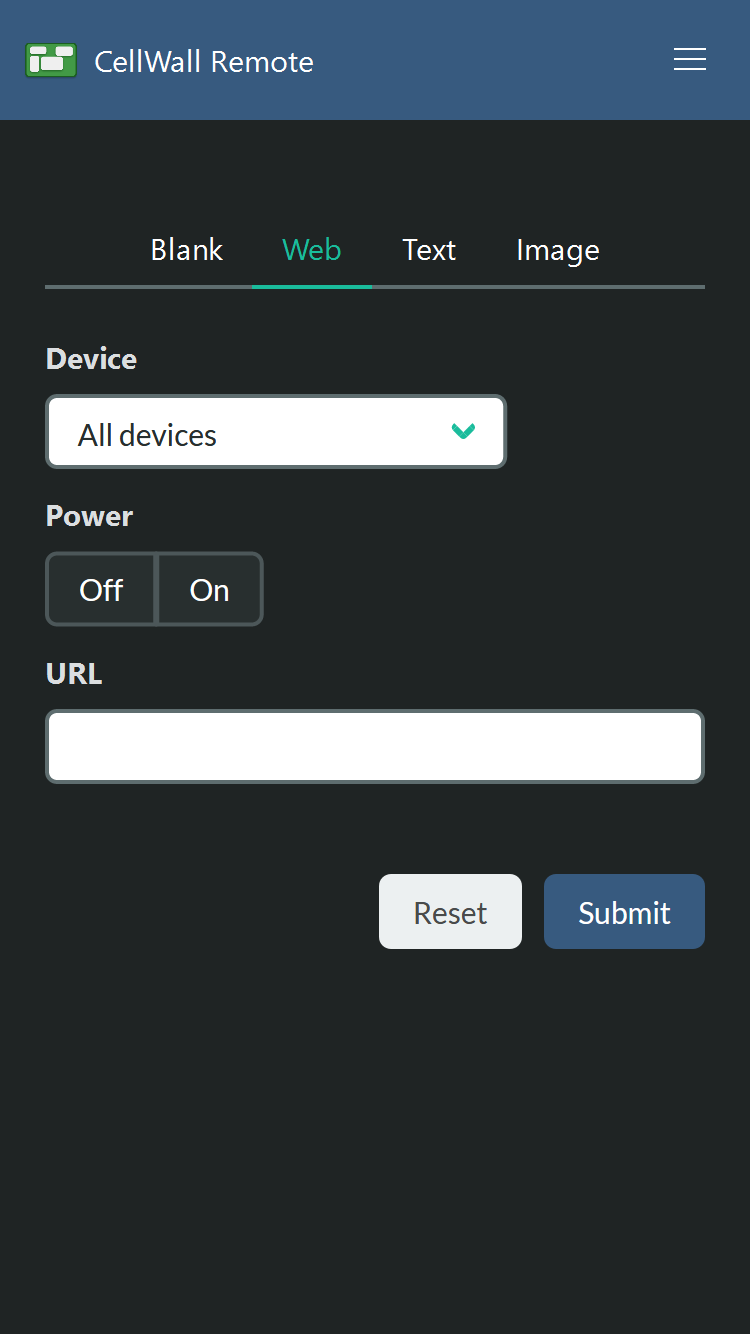
As a nice final touch, I put some black masking tape to resemble wires coming out of the board. While this is optional, it makes a nice Zoom background for meetings. My partner’s desk is across the room, and I frequently hear her coworkers comment on the display behind her.
I hope you’re inspired to try something similar yourself. All of my project code is available on GitHub. Let me know how yours turns out! I’m happy to answer any questions on Twitter @Not_Woods.
|
|
Cameron Kaiser: Floodgap.com down due to domain squatter attack on Network Solutions |
Update: Looks like it was a social engineering attack. I spoke with a very helpful person in their security department (Beth) and she walked me through it. On the 26th someone initiated a webchat with their account representatives and presented official-looking but fraudulent identity documents (a photo ID, a business license and a utility bill), then got control of the account and logged in and changed everything. NetSol is in the process of reversing the damage and restoring the DNS entries. They will be following up with me for a post-mortem. I do want to say I appreciate how quickly and seriously they are taking this whole issue.
If you are on Network Solutions, check your domains this morning, please. I'm just a "little" site, and I bet a lot of them were attacked in a similar fashion.
Update the second: Domains should be back up, but it may take a while for them to propagate. The servers themselves were unaffected, and I don't store any user data anyway.
http://tenfourfox.blogspot.com/2021/01/floodgapcom-down-due-to-domain-squatter.html
|
|
The Firefox Frontier: Four ways to protect your data privacy and still be online |
Today is Data Privacy Day, which is a good reminder that data privacy is a thing, and you’re in charge of it. The simple truth: your personal data is very … Read more
The post Four ways to protect your data privacy and still be online appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/four-ways-to-protect-your-data-privacy/
|
|
Daniel Stenberg: What if GitHub is the devil? |
Some critics think the curl project shouldn’t use GitHub. The reasons for being against GitHub hosting tend to be one or more of:
Some have insisted on craziness like “we let GitHub hold our source code hostage”.
The curl project switched to GitHub (from Sourceforge) almost eleven years ago and it’s been a smooth ride ever since.
We’re on GitHub not only because it provides a myriad of practical features and is a stable and snappy service for hosting and managing source code. GitHub is also a developer hub for millions of developers who already have accounts and are familiar with the GitHub style of developing, the terms and the tools. By being on GitHub, we reduce friction from the contribution process and we maximize the ability for others to join in and help. We lower the bar. This is good for us.
I like GitHub.
Providing even close to the same uptime and snappy response times with a self-hosted service is a challenge, and it would take someone time and energy to volunteer that work – time and energy we now instead can spend of developing the project instead. As a small independent open source project, we don’t have any “infrastructure department” that would do it for us. And trust me: we already have enough infrastructure management to deal with without having to add to that pile.
… and by running our own hosted version, we would lose the “network effect” and convenience for people that already are on and know the platform. We would also lose the easy integration with cool services like the many different CI and code analyzer jobs we run.
While git is open source, GitHub is a proprietary system. But the thing is that even if we would go with a competitor and get our code hosting done elsewhere, our code would still be stored on a machine somewhere in a remote server park we cannot physically access – ever. It doesn’t matter if that hosting company uses open source or proprietary code. If they decide to switch off the servers one day, or even just selectively block our project, there’s nothing we can do to get our stuff back out from there.
We have to work so that we minimize the risk for it and the effects from it if it still happens.
A proprietary software platform holds our code just as much hostage as any free or open source software platform would, simply by the fact that we let someone else host it. They run the servers our code is stored on.
No matter which service we use, there’s always a risk that they will turn off the light one day and not come back – or just change the rules or licensing terms that would prevent us from staying there. We cannot avoid that risk. But we can make sure that we’re smart about it, have a contingency plan or at least an idea of what to do when that day comes.
If GitHub shuts down immediately and we get zero warning to rescue anything at all from them, what would be the result for the curl project?
Code. We would still have the entire git repository with all code, all source history and all existing branches up until that point. We’re hundreds of developers who pull that repository frequently, and many automatically, so there’s a very distributed backup all over the world.
CI. Most of our CI setup is done with yaml config files in the source repo. If we transition to another hosting platform, we could reuse them.
Issues. Bug reports and pull requests are stored on GitHub and a sudden exit would definitely make us lose some of them. We do daily “extractions” of all issues and pull-requests so a lot of meta-data could still be saved and preserved. I don’t think this would be a terribly hard blow either: we move long-standing bugs and ideas over to documents in the repository, so the currently open ones are likely possible to get resubmitted again within the nearest future.
There’s no doubt that it would be a significant speed bump for the project, but it would not be worse than that. We could bounce back on a new platform and development would go on within days.
It’s a rare thing, that a service just suddenly with no warning and no heads up would just go black and leave projects completely stranded. In most cases, we get alerts, notifications and get a chance to transition cleanly and orderly.
Sure there are alternatives. Both pure GitHub alternatives that look similar and provide similar services, and projects that would allow us to run similar things ourselves and host locally. There are many options.
I’m not looking for alternatives. I’m not planning to switch hosting anytime soon! As mentioned above, I think GitHub is a net positive for the curl project.
We’ve switched services several times before and I’m expecting that we will change again in the future, for all sorts of hosting and related project offerings that we provide to the work and to the developers and participators within the project. Nothing lasts forever.
When a service we use goes down or just turns sour, we will figure out the best possible replacement and take the jump. Then we patch up all the cracks the jump may have caused and continue the race into the future. Onward and upward. The way we know and the way we’ve done for over twenty years already.
Image by Elias Sch. from Pixabay
After this blog post went live, some users remarked than I’m “disingenuous” in the list of reasons at the top, that people have presented to me. This, because I don’t mention the moral issues staying on GitHub present – like for example previously reported workplace conflicts and their association with hideous American immigration authorities.
This is rather the opposite of disingenuous. This is the truth. Not a single person have ever asked me to leave GitHub for those reasons. Not me personally, and nobody has asked it out to the wider project either.
These are good reasons to discuss and consider if a service should be used. Have there been violations of “decency” significant enough that should make us leave? Have we crossed that line in the sand? I’m leaning to “no” now, but I’m always listening to what curl users and developers say. Where do you think the line is drawn?
https://daniel.haxx.se/blog/2021/01/28/what-if-github-is-the-devil/
|
|
The Talospace Project: Firefox 85 on POWER |
|
|
Data@Mozilla: This Week in Glean: The Glean Dictionary |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
On behalf of Mozilla’s Data group, I’m happy to announce the availability of the first milestone of the Glean Dictionary, a project to provide a comprehensive “data dictionary” of the data Mozilla collects inside its products and how it makes use of it. You can access it via this development URL:
https://dictionary.protosaur.dev/

The goal of this first milestone was to provide an equivalent to the popular “probe” dictionary for newer applications which use the Glean SDK, such as Firefox for Android. As Firefox on Glean (FoG) comes together, this will also serve as an index of what data is available for Firefox and how to access it.
Part of the vision of this project is to act as a showcase for Mozilla’s practices around lean data and data governance: you’ll note that every metric and ping in the Glean Dictionary has a data review associated with it — giving the general public a window into what we’re collecting and why.
In addition to displaying a browsable inventory of the low-level metrics which these applications collect, the Glean Dictionary also provides:
Over the next few months, we’ll be expanding the Glean Dictionary to include derived datasets and dashboards / reports built using this data, as well as allow users to add their own annotations on metric behaviour via a GitHub-based documentation system. For more information, see the project proposal.
The Glean Dictionary is the result of the efforts of many contributors, both inside and outside Mozilla Data. Special shout-out to Linh Nguyen, who has been moving mountains inside the codebase as part of an Outreachy internship with us. We welcome your feedback and involvement! For more information, see our project repository and Matrix channel (#glean-dictionary on chat.mozilla.org).
https://blog.mozilla.org/data/2021/01/27/this-week-in-glean-the-glean-dictionary/
|
|
Mozilla Privacy Blog: Five issues shaping data, tech and privacy in the African region in 2021 |
The COVID 19 crisis increased our reliance on technology and accelerated tech disruption and innovation, as we innovated to fight the virus and cushion the impact. Nowhere was this felt more keenly than in the African region, where the number of people with internet access continued to increase and the corresponding risks to their privacy and data protection rose in tandem. On the eve of 2021 Data Privacy Day, we take stock of the key issues that will shape data and privacy in the Africa region in the coming year.
As we move through 2021, the African region will continue to see Big Tech’s unencumbered rise, with vulnerable peoples’ data being used to enhance companies’ innovations, entrench their economic and political power, while impacting the social lives of billions of people. Ahead of Data Privacy Day, we must remember that our work to ensure data protection and data privacy will not be complete until all individuals, no matter where they are located in the world, enjoy the same rights and protections.
The post Five issues shaping data, tech and privacy in the African region in 2021 appeared first on Open Policy & Advocacy.
|
|
Daniel Stenberg: curl your own error message |
The --write-out (or -w for short) curl command line option is a gem for shell script authors looking for more information from a curl transfer. Experienced users know that this option lets you extract things such as detailed timings, the response code, transfer speeds and sizes of various kinds. A while ago we even made it possible to output JSON.
Maybe the best resource to learn more about it, is the dedication section in Everything curl. You’ll like it!
In curl 7.75.0 (coming on February 3, 2021) we introduce five new variables for this option, and I’ll elaborate on some of the fun new things you can do with these!
These new variables were invented when we received a bug report that pointed out that when a user transfers many URLs in parallel and one or some of them fail – the error message isn’t identifying exactly which of the URLs that failed. We should improve the error messages to fix this!
Or wait a minute. What if we provide enough details for --write-out to let the user customize the error message completely by themselves and thus get exactly the info they want?
Using this, you can specify a message only to get written if the transfer ends in error. That is a non-zero exit code. An example could look like this:
curl -w '%{onerror}failed\n' $URL -o saved -s
…. if the transfer is OK, it says nothing. If it fails, the text on the right side of the “onerror” variable gets output. And that text can of course contain other variables!
This command line uses -s for “silent” to make it inhibit the regular built-in error message.
To help craft a good error message, maybe you want the URL included that was used in the transfer?
curl -w '%{onerror}%{url} failed\n' $URL
If you get more than one URL in the command line, it might be helpful to get the index number of the used URL. This is of course especially useful if you for example work with the same URL multiple times in the same command line and just one of them fails!
curl -w '%{onerror}URL %{urlnum} failed\n' $URL $URL
The regular built-in curl error message shows the exit code, as it helps diagnose exactly what the problem was. Include that in the error message like:
curl -w '%{onerror}%{url} got %{exitcode}\n' $URL
This is the human readable explanation for the problem. The error message. Mimic the default curl error message like this:
curl -w '%{onerror}curl: %{exitcode} %{errormsg}\n' $URL
We already provide this “variable” from before, which allows you to make sure the output message is sent to stderr instead of stdout, which then makes it even more like a real error message:
url -w '%{onerror}%{stderr}curl: %{exitcode} %{errormsg}\n' $URL
These new variables work fine after %{onerror}, but they also of course work just as fine to output even when there was no error, and they work perfectly fine whether you use -Z for parallel transfers or doing them serially, one after the other.
https://daniel.haxx.se/blog/2021/01/27/curl-your-own-error-message/
|
|
William Lachance: The Glean Dictionary |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
On behalf of Mozilla’s Data group, I’m happy to announce the availability of the first milestone of the Glean Dictionary, a project to provide a comprehensive “data dictionary” of the data Mozilla collects inside its products and how it makes use of it. You can access it via this development URL:
https://dictionary.protosaur.dev/
The goal of this first milestone was to provide an equivalent to the popular “probe” dictionary for newer applications which use the Glean SDK, such as Firefox for Android. As Firefox on Glean (FoG) comes together, this will also serve as an index of what data is available for Firefox and how to access it.
Part of the vision of this project is to act as a showcase for Mozilla’s practices around lean data and data governance: you’ll note that every metric and ping in the Glean Dictionary has a data review associated with it — giving the general public a window into what we’re collecting and why.
In addition to displaying a browsable inventory of the low-level metrics which these applications collect, the Glean Dictionary also provides:
Over the next few months, we’ll be expanding the Glean Dictionary to include derived datasets and dashboards / reports built using this data, as well as allow users to add their own annotations on metric behaviour via a GitHub-based documentation system. For more information, see the project proposal.
The Glean Dictionary is the result of the efforts of many contributors, both inside and outside Mozilla Data. Special shout-out to Linh Nguyen, who has been moving mountains inside the codebase as part of an Outreachy internship with us. We welcome your feedback and involvement! For more information, see our project repository and Matrix channel (#glean-dictionary on chat.mozilla.org).
https://wlach.github.io/blog/2021/01/the-glean-dictionary/?utm_source=Mozilla&utm_medium=RSS
|
|
Mozilla Attack & Defense: Effectively Fuzzing the IPC Layer in Firefox |
The Inter-Process Communication (IPC) Layer within Firefox provides a cornerstone in Firefox’ multi-process Security Architecture. Thus, eliminating security vulnerabilities within the IPC Layer remains critical. Within this blogpost we survey and describe the different communication methods Firefox uses to perform inter-process communication which hopefully provide logical entry points to effectively fuzz the IPC Layer in Firefox.
When starting the Firefox web browser it internally spawns one privileged process (also known as the parent process) which then launches and coordinates activities of multiple content processes. This multi process architecture allows Firefox to separate more complicated or less trustworthy code into processes, most of which have reduced access to operating system resources or user files. (Entering about:processes into the address bar shows detailed information about all of the running processes). As a consequence, less privileged code will need to ask more privileged code to perform operations which it itself cannot. That request for delegation of operations or in general any communication between content and parent process happens through the IPC Layer.
From a security perspective the Inter-Process Communication (IPC) is of particular interest because it spans several security boundaries in Firefox. The most obvious one is the PARENT <-> CONTENT process boundary. The content (or child process), which hosts one or more tabs containing web content, is unprivileged and sandboxed and in threat modeling scenarios often considered to be compromised and running arbitrary attacker code. The parent process on the other hand has full access to the host machine. While this parent-child relationship is not the only security boundary (see e.g. this documentation on process privileges), it is the most critical one from a security perspective because any violation will result in a sandbox escape.
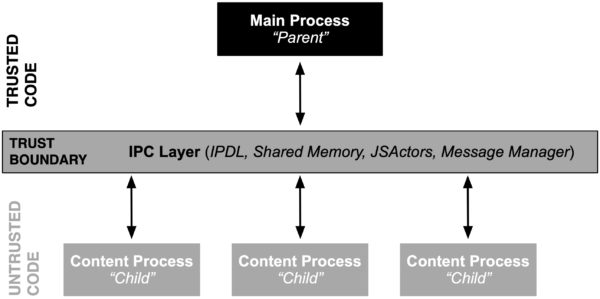
Firefox internally uses three main communication methods (plus an obsolete one) through which content processes can communicate with the main process. In more detail, inter process communication within processes in Firefox happen through either: (1) IPDL protocols, (2) Shared Memory, (3) JS Actors and sometimes through (4) the obsolete and outdated process communication mechanism of Message Manager. Please note that (3) and (4) internally are built on top of (1) and hence are IPDL aware.
For automated testing, in particular fuzzing, isolating the components to be tested has proven to be effective many times. For IPC, unfortunately this approach has not been successful because the interesting classes, such as the ContentParent IPC endpoint, have very complex runtime contracts with their surrounding environment. Using them in isolation results in a lot of false positive crashes. As an example, compare the libFuzzer target for ContentParent, which has found some security bugs, but also an even larger number of (mostly nullptr) crashes that are related to missing initialization steps. Reporting false positives not only lowers the confidence in the tool’s results and requires additional maintenance but also indicates some missing parts of the attack surface because of an improper set up. Hence, we believe that a system testing approach is the only viable solution for comprehensive IPC testing.
One potential approach to fuzz such scenarios effectively could be to start Firefox with a new tab, navigate to a dummy page, then perform a snapshot of the parent (process- or VM-based snapshot fuzzing) and then replace the regular child messages with coverage-guided fuzzing. The snapshot approach would further allow to reset the parent to a defined state from time to time without suffering the major performance bottleneck of restarting the process. As described above in the IPDL section, it is crucial to have multiple messages going back and forth to ensure that we can reach deep into the protocol tree. And finally, the reproducibility of the crashes is crucial, since bugs without reliable steps to reproduce usually receive a lot less traction. Put differently, vulnerabilities with reliable steps to reproduce can be isolated, addressed and fixed a lot faster.
For VM-based snapshot fuzzing, we are aware of certain requirements that need to be fulfilled for successful Fuzzing. In particular:
We have found (security) bugs through various means, including static analysis, manual audits, and libFuzzer targets on isolated parts (which has the problems described above). Looking through the reports of those bugs might additionally provide some useful information:
The following resources are not specifically for IPC fuzzing but might provide additional background information and are widely used at Mozilla for fuzzing Firefox in various ways:
Providing architectural insights into the security design of a system is crucial for truly working in the open and ultimately allows contributors, hackers, and bug bounty hunters to verify and challenge our design decisions. We would like to point out that bugs in the IPC Layer are eligible for a bug bounty — you can report potential vulnerabilities simply by filing a bug on Bugzilla. Thank you!
https://blog.mozilla.org/attack-and-defense/2021/01/27/effectively-fuzzing-the-ipc-layer-in-firefox/
|
|
About:Community: New contributors to Firefox 85 |
With Firefox 85 fresh out of the oven, we are delighted to welcome the developers who contributed their first code change to Firefox in this release, 13 of whom are new volunteers! Please join us in thanking each of them, and take a look at their contributions:
https://blog.mozilla.org/community/2021/01/26/new-contributors-to-firefox-85/
|
|
The Firefox Frontier: Jessica Rosenworcel’s appointment is good for the internet |
With a new year comes change, and one change we’re glad to see in 2021 is new leadership at the Federal Communications Commission (FCC). On Thursday, Jan. 21, Jessica Rosenworcel, … Read more
The post Jessica Rosenworcel’s appointment is good for the internet appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/jessica-rosenworcel-appointment-is-good-for-the-internet/
|
|
Hacks.Mozilla.Org: January brings us Firefox 85 |
To wrap up January, we are proud to bring you the release of Firefox 85. In this version we are bringing you support for the :focus-visible pseudo-class in CSS and associated devtools, , and the complete removal of Flash support from Firefox. We’d also like to invite you to preview two exciting new JavaScript features in the current Firefox Nightly — top-level await and relative indexing via the .at() method. Have fun!
This blog post provides merely a set of highlights; for all the details, check out the following:
The :focus-visible pseudo-class, previously supported in Firefox via the proprietary :-moz-focusring pseudo-class, allows the developer to apply styling to elements in cases where browsers use heuristics to determine that focus should be made evident on the element.
The most obvious case is when you use the keyboard to focus an element such as a button or link. There are often cases where designers will want to get rid of the ugly focus-ring, commonly achieved using something like :focus { outline: none }, but this causes problems for keyboard users, for whom the focus-ring is an essential accessibility aid.
:focus-visible allows you to apply a focus-ring alternative style only when the element is focused using the mouse, and not when it is clicked.
For example, this HTML:
Could be styled like this:
/* remove the default focus outline only on browsers that support :focus-visible */
a:not(:focus-visible), button:not(:focus-visible), button:not(:focus-visible) {
outline: none;
}
/* Add a strong indication on browsers that support :focus-visible */
a:focus-visible, button:focus-visible, input:focus-visible {
outline: 4px dashed orange;
}And as another nice addition, the Firefox DevTools’ Page Inspector now allows you to toggle :focus-visible styles in its Rules View. See Viewing common pseudo-classes for more details.
After a couple of false starts in previous versions, we are now proud to announce support for , which allows developers to instruct the browser to preemptively fetch and cache high-importance resources ahead of time. This ensures they are available earlier and are less likely to block page rendering, improving performance.
This done by including rel="preload" on your link element, and an as attribute containing the type of resource that is being preloaded, for example:
You can also include a type attribute containing the MIME type of the resource, so a browser can quickly see what resources are on offer, and ignore ones that it doesn’t support:
See Preloading content with rel=”preload” for more information.
Firefox 85 sees the complete removal of Flash support from the browser, with no means to turn it back on. This is a coordinated effort across browsers, and as our plugin roadmap shows, it has been on the cards for a long time.
For some like myself — who have many nostalgic memories of the early days of the web, and all the creativity, innovation, and just plain fun that Flash brought us — this is a bittersweet day. It is sad to say goodbye to it, but at the same time the advantages of doing so are clear. Rest well, dear Flash.
There are a couple of upcoming additions to Gecko that are currently available only in our Nightly Preview. We thought you’d like to get a chance to test them early and give us feedback, so please let us know what you think in the comments below!
async/await has been around for a while now, and is proving popular with JavaScript developers because it allows us to write promise-based async code more cleanly and logically. This following trivial example illustrates the idea of using the await keyword inside an async function to turn a returned value into a resolved promise.
async function hello() {
return greeting = await Promise.resolve("Hello");
};
hello().then(alert);The trouble here is that await was originally only allowed inside async functions, and not in the global scope. The experimental top-level await proposal addresses this, by allowing global awaits. This has many advantages in situations like wanting to await the loading of modules in your JS application. Check out the proposal for some useful examples.
Currently an ECMAScript stage 3 draft proposal, the relative indexing method .at() has been added to Array, String, and TypedArray instances to provide an easy way of returning specific index values in a relative manner. You can use a positive index to count forwards from position 0, or a negative value to count backwards from the highest index position.
Try these, for example:
let myString = 'Hello, how are you?';
myString.at(4);
myString.at(-3);
let myArray = [0, 10, 35, 70, 100, 300];
myArray.at(1);
myArray.at(-2);Last but not least, let’s look at what has changed in our WebExtensions implementation in Fx 85.
browsingData API is now available on Firefox for Android.And finally, we want to remind you about upcoming site isolation changes with Project Fission. As we previously mentioned, the drawWindow() method is being deprecated as part of this work. If you use this API, we recommend that you switch to using the captureTab() method instead.
The post January brings us Firefox 85 appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/01/january-brings-us-firefox-85/
|
|
The Mozilla Blog: Why getting voting right is hard, Part V: DREs (spoiler: they’re bad) |
|
|
Mozilla Security Blog: Firefox 85 Cracks Down on Supercookies |
Trackers and adtech companies have long abused browser features to follow people around the web. Since 2018, we have been dedicated to reducing the number of ways our users can be tracked. As a first line of defense, we’ve blocked cookies from known trackers and scripts from known fingerprinting companies.
In Firefox 85, we’re introducing a fundamental change in the browser’s network architecture to make all of our users safer: we now partition network connections and caches by the website being visited. Trackers can abuse caches to create supercookies and can use connection identifiers to track users. But by isolating caches and network connections to the website they were created on, we make them useless for cross-site tracking.
In short, supercookies can be used in place of ordinary cookies to store user identifiers, but they are much more difficult to delete and block. This makes it nearly impossible for users to protect their privacy as they browse the web. Over the years, trackers have been found storing user identifiers as supercookies in increasingly obscure parts of the browser, including in Flash storage, ETags, and HSTS flags.
The changes we’re making in Firefox 85 greatly reduce the effectiveness of cache-based supercookies by eliminating a tracker’s ability to use them across websites.
Like all web browsers, Firefox shares some internal resources between websites to reduce overhead. Firefox’s image cache is a good example: if the same image is embedded on multiple websites, Firefox will load the image from the network during a visit to the first website and on subsequent websites would traditionally load the image from the browser’s local image cache (rather than reloading from the network). Similarly, Firefox would reuse a single network connection when loading resources from the same party embedded on multiple websites. These techniques are intended to save a user bandwidth and time.
Unfortunately, some trackers have found ways to abuse these shared resources to follow users around the web. In the case of Firefox’s image cache, a tracker can create a supercookie by “encoding” an identifier for the user in a cached image on one website, and then “retrieving” that identifier on a different website by embedding the same image. To prevent this possibility, Firefox 85 uses a different image cache for every website a user visits. That means we still load cached images when a user revisits the same site, but we don’t share those caches across sites.
In fact, there are many different caches trackers can abuse to build supercookies. Firefox 85 partitions all of the following caches by the top-level site being visited: HTTP cache, image cache, favicon cache, HSTS cache, OCSP cache, style sheet cache, font cache, DNS cache, HTTP Authentication cache, Alt-Svc cache, and TLS certificate cache.
To further protect users from connection-based tracking, Firefox 85 also partitions pooled connections, prefetch connections, preconnect connections, speculative connections, and TLS session identifiers.
This partitioning applies to all third-party resources embedded on a website, regardless of whether Firefox considers that resource to have loaded from a tracking domain. Our metrics show a very modest impact on page load time: between a 0.09% and 0.75% increase at the 80th percentile and below, and a maximum increase of 1.32% at the 85th percentile. These impacts are similar to those reported by the Chrome team for similar cache protections they are planning to roll out.
Systematic network partitioning makes it harder for trackers to circumvent Firefox’s anti-tracking features, but we still have more work to do to continue to strengthen our protections. Stay tuned for more privacy protections in the coming months!
Re-architecting how Firefox handles network connections and caches was no small task, and would not have been possible without the tireless work of our engineering team: Andrea Marchesini, Tim Huang, Gary Chen, Johann Hofmann, Tanvi Vyas, Anne van Kesteren, Ethan Tseng, Prangya Basu, Wennie Leung, Ehsan Akhgari, and Dimi Lee.
We wish to express our gratitude to the many Mozillians who contributed to and supported this work, including: Selena Deckelmann, Mikal Lewis, Tom Ritter, Eric Rescorla, Olli Pettay, Kim Moir, Gregory Mierzwinski, Doug Thayer, and Vicky Chin.
We also want to acknowledge past and ongoing efforts carried out by colleagues in the Brave, Chrome, Safari and Tor Browser teams to combat supercookies in their own browsers.
The post Firefox 85 Cracks Down on Supercookies appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2021/01/26/supercookie-protections/
|
|
Hacks.Mozilla.Org: Welcoming Open Web Docs to the MDN family |
Collaborating with the community has always been at the heart of MDN Web Docs content work — individual community members constantly make small (and not so small) fixes to help incrementally improve the content, and our partner orgs regularly come on board to help with strategy and documenting web platform features that they have an interest in.
At the end of the 2020, we launched our new Yari platform, which exposes our content in a GitHub repo and therefore opens up many more valuable contribution opportunities than before.
And today, we wanted to spread the word about another fantastic event for enabling more collaboration on MDN — the launch of the Open Web Docs organization.
Open Web Docs (OWD) is an open collective, created in collaboration between several key MDN partner organizations to ensure the long-term health of open web platform documentation on de facto standard resources like MDN Web Docs, independently of any single vendor or organization. It will do this by collecting funding to finance writing staff and helping manage the communities and processes that will deliver on present and future documentation needs.
You will hear more about OWD, MDN, and opportunities to collaborate on web standards documentation very soon — a future post will outline exactly how the MDN collaborative content process will work going forward.
Until then, we are proud to join our partners in welcoming OWD into the world.
The post Welcoming Open Web Docs to the MDN family appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/01/welcoming-open-web-docs-to-the-mdn-family/
|
|
Mozilla VR Blog: A New Year, A New Hubs |
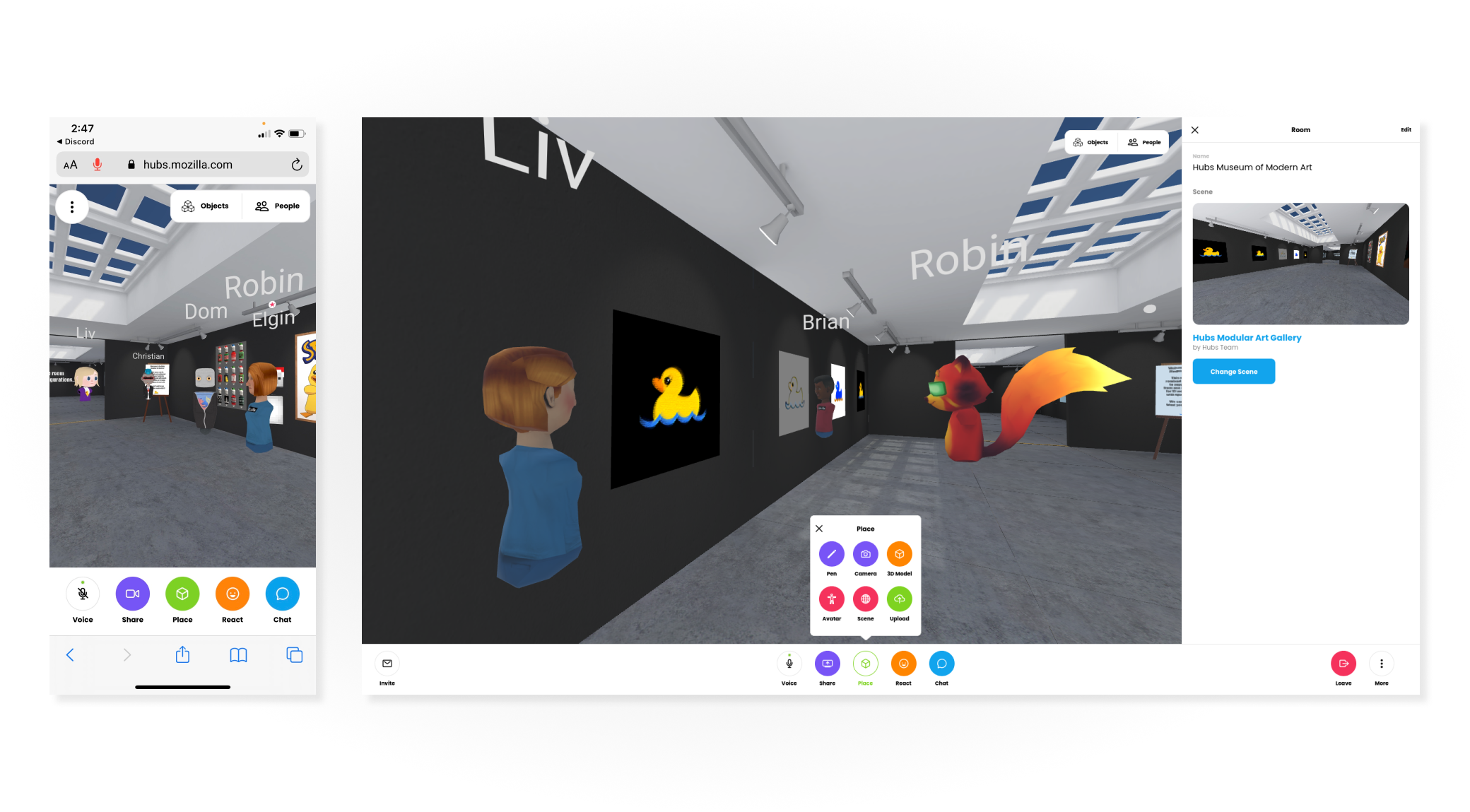
An updated look & feel for Hubs, with an all-new user interface, is now live.
Just over two years ago, we introduced a preview release of Hubs. Our hope was to bring people together to create, socialize and collaborate around the world in a new and fun way. Since then, we’ve watched our community grow and use Hubs in ways we could only imagine. We’ve seen students use Hubs to celebrate their graduations last May, educational organizations use Hubs to help educators adapt to this new world we’re in, and heck, even NASA has used Hubs to feature new ways of working. In today’s world where we’re spending more time online, Hubs has been the go-to online place to have fun and try new experiences.
Today’s update brings new features including a chat sidebar, a new streamlined design for desktop and mobile devices, and a support forum to help our community get the most out of their Hubs experience.
Chat scroll back has been a highly requested feature in Hubs. Before today’s update, messages sent in Hubs were ephemeral and disappeared after just a few seconds. The chat messages were also displayed drawn over the room UI, which could prevent scene content from being viewed. With the new chat sidebar, you’ll be able to see chat from the moment you join the lobby, and choose when to show or hide the panel. On desktop, if the chat panel is closed, you’ll still get the quick text notifications, which have moved from the center of the screen to the bottom-left.
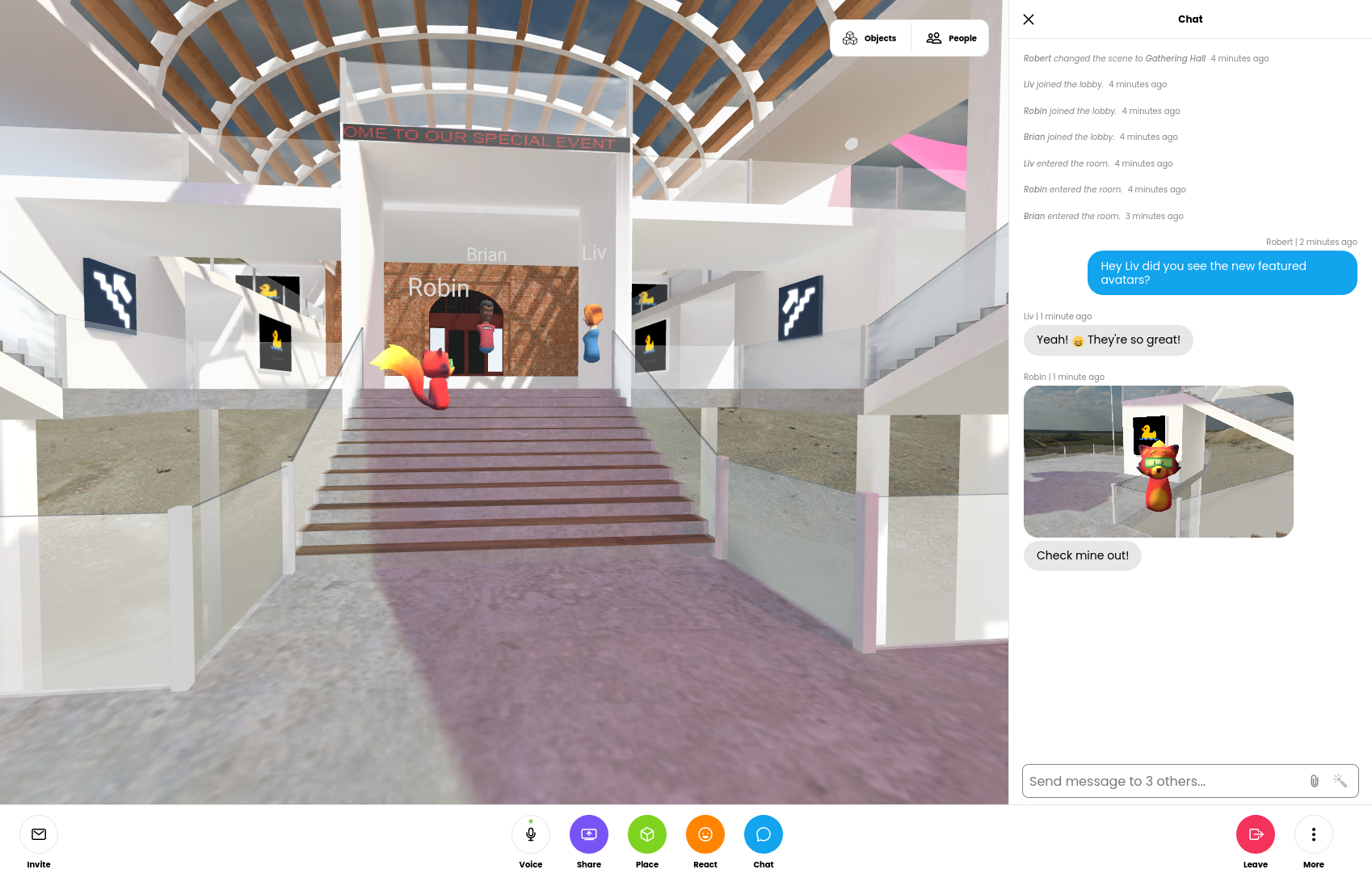
In the past, our team took a design approach that kept the desktop, mobile, and virtual reality interfaces tightly coupled. This often meant that the application’s interactions were tailored primarily to virtual reality devices, but in practice, the vast majority of Hubs users are visiting rooms on non-VR devices. This update separates the desktop and mobile interfaces to align more to industry-standard best practices, and makes the experience of being in a Hubs room more tailored to the device you’re using at any given time. We’ve improved menu navigation by making these full-screen on mobile devices, and by consolidating options and preferences for personalizing your experience.
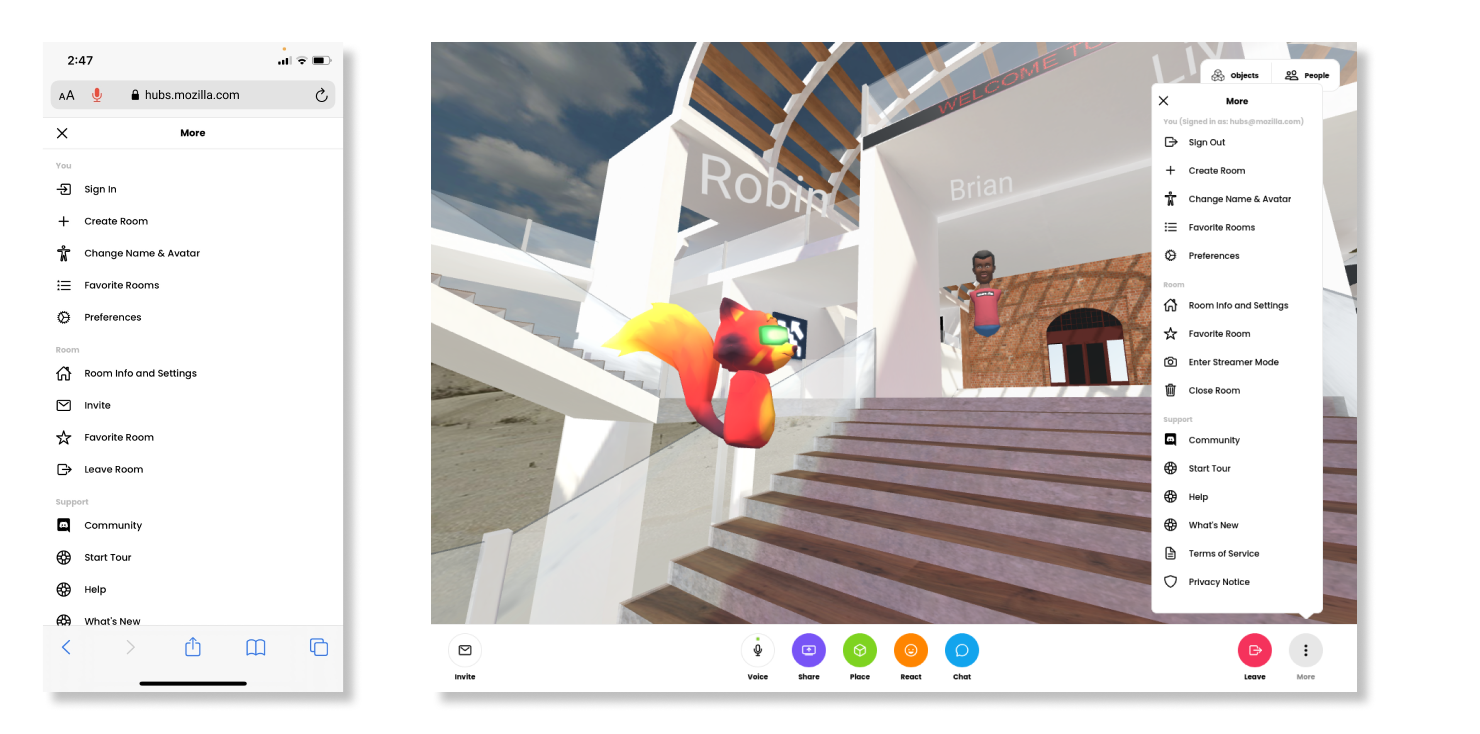
For our Hubs Cloud customers, we’re planning to release the UI changes after March 25th, 2021. If you’re running Hubs Cloud out of the box on AWS, no manual updates will be required. If you have a custom fork, you will need to pull the changes into your client manually. We’ve created a guide here to explain what changes need to be made. For help with updates to Hubs Cloud or custom clients, you can connect with us on GitHub. We will be releasing an update to Hubs Cloud next week that does not include the UI redesign.
We’re excited to share that you can now get answers to questions about Hubs using support.mozilla.org. In addition to articles to help with basic Hubs setup and troubleshooting, the ‘Ask a Question’ forum is now available. This is a new place for the community and team to help answer questions about Hubs. If you’re an active Hubs user, you can contribute by answering questions and flagging information for the team. If you’re new to Hubs and find yourself needing some help getting up and running, pop over and let us know how we can help.
In the coming months, we’ll have additional detail to share about accessibility and localization in the new Hubs client. In the meantime, we invite you to check out the new Hubs experience on either your mobile or desktop device and let us know what you think!
Thank you to the following community members for letting us include clips of their scenes and events in our promo video: Paradowski, XP Portal, Narratify, REM5 For Good, Innovaci'on Educativa del Tecnol'ogico de Monterrey, Jordan Elevons, and Brendan Bradley. For more information, see the video description on Vimeo.
|
|
Cameron Kaiser: TenFourFox FPR30 SPR1 available |
http://tenfourfox.blogspot.com/2021/01/tenfourfox-fpr30-spr1-available.html
|
|






