Firefox UX: Who Gets to Define Success? Listening to Stories of How People Value Firefox to Redefine Metrics |
|
|
Karl Dubost: Site interventions and automated testing |
Sometimes, a website is broken with a webcompat issue. In the best case, the webcompat team is able to diagnose it. (You can help). The team has been keeping a regular pace for diagnosis for the last year.
But after diagnosis what should we do?

There are a couple of possibilities:
We follow a strict release process tied to the release cycle of Firefox. You can discover our CSS interventions and JavaScript Interventions. The calendar for the upcoming releases is defined in advance.
Before each release cycle for site interventions, the Softvision Webcompat team (Oana and Cipri) makes sure to test the site without the patch to discover if the site intervention is still necessary. This takes time and requires a lot of manual work. Time that could be used for more introspective work.
To activate deactivate site interventions, you can play with extensions.webcompat.perform_injections in about:config.
So we started to discuss again the prospect of automating the site interventions patches verification. We often discussed about it, but we often wanted it to be too perfect. Opera Software had for browser.js a very neat system. Each time a patch was not valid anymore it was sending an alert telling us that we should fix or remove it.
We should probably target something simpler by using webdriver at least for the simple bugs. By the way you should read Improving Cross-Browser Testing, Part 1: Web Application Testing Today if you want to know a bit more about the landscape of testing in browsers these days. We need to make it simple enough so that people who are checking the validity of a patch can create a simple webdriver script replicating the task done by hand. Then we could aim for a very simple solution where someone run the script and see if something is broken. It is still not fully automated but it's a good first step.
Keeping things simple even if a bit hackish at the beginning help other people in your community to grow, to engage in the process, and to evolve from there. It's an opportunity to acquire new skills.
Histography is working in Firefox, but only if we fake the user agent string (The bug, the patch).
A webdriver script here would be.
The content of the page is
<div id="about">
<h2>SORRY!span>h2> WE ARE CURRENTLY NOT SUPPORTING YOUR BROWSER <br>(BUT WE WILL SOON) <br>
<br>
<br>
<br>TRY <a href="https://www.google.com/chrome/">CHROMEspan>a> OR <a href="https://www.apple.com/safari/">SAFARIspan>a>
span>div>
In Python that would roughly translate to:
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
# Here usually you may define a profile
browser = Firefox()
# The meat of the code
# Go the site
browser.get('http://histography.io/')
# find the element with an id having the value about
el = browser.find_element_by_id('about')
# extract the needed text
message = el.text
# test the message.
assert "NOT SUPPORTING YOUR BROWSER" in message
That would make it a lot easier and more systematic for testing and remove the burden of manually testing every steps for every releases.
Otsukare!
https://www.otsukare.info/2021/01/22/site-interventions-and-webdriver
|
|
Mike Taylor: The Mike Taylor method™ of naming git branches |
I thought I would document how I do branching in git because it’s clearly the best a perfectly acceptable way to do it, especially if you use GitHub.
Step 1: git checkout -b /
(That’s it.)
maps to the GitHub (or Bugzilla, or Chromium, or Roblox customer support, etc.) issue number.
1 for me. But if, for whatever reason, you want to get wild and pivot off into a totally different direction, or set a new , you just increment that integer and still have some kind of transparent relationship with the bug task at hand.
For example:
git checkout -b parsing_html_with_regex_in_the_year_2021/2
As a side benefit, when you go to write a commit message you don’t have to go hunting for the bug number in your N^2 + 1 open tabs (where N is the number of hours you’ve been working on the patches), because it’s in the branch name.
(For no good reason, for GitHub issues I like to prefix it with issues/, I guess I just like the symmetry with the GitHub URL.)
I started doing this about 10 years ago when I worked at Opera. I don’t know if it was a widely used convention, or I just copied it off someone, but it’s pretty good, IMHO.
https://miketaylr.com/posts/2021/01/how-i-do-git-branches.html
|
|
Mozilla Addons Blog: Promoted Add-ons Pilot Wrap-up |
A few months ago, we launched a pilot for a new program to help developers promote their extensions on addons.mozilla.org (AMO). The main goal of this program was to increase the number of add-ons that our staff can review and verify as compliant with Mozilla policies and provide developers with options for boosting their discoverability on AMO.
For the pilot, we tested one iteration of how this type of program might work. Pilot developers would have their add-ons manually reviewed for policy compliance. After successfully passing manual review, the pilot add-ons received a Verified badge on their AMO listing page and in the Firefox Add-ons Manager (about:addons), while we removed the standard warning label about the risks of installing third party software.

Pilot developers could also promote their Verified add-ons on the AMO homepage.

During the pilot, developers participated at no cost. However, the intent of the experimentation was to determine if the Promoted Add-ons program made sense to graduate into a paid service for developers.
After reviewing the pilot results, we have decided not to move forward with this iteration of the program. Later this month the Verified badges for pilot participants will be deactivated and the Sponsored shelf on the AMO homepage removed. This was a difficult decision, but we believe there are other, more impactful ways we can help add-on developers be successful; and we’ve turned our attention to exploring new experimental programs. As we chart new developer focused efforts in 2021, we’ll be sure to post updates here.
The post Promoted Add-ons Pilot Wrap-up appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2021/01/21/promoted-add-ons-pilot-wrap-up/
|
|
Daniel Stenberg: More on less curl memory |
tldr: curl uses 30K of dynamic memory for downloading a large HTTP file, plus the size of the download buffer.
Back in September 2020 I wrote about my work to trim curl allocations done for FTP transfers. Now I’m back again on the memory use in curl topic, from a different angle.
This time, I learned about the awesome tool pahole, which can (among other things) show structs and their sizes from a built library – and when embracing this fun toy, I ran some scripts on a range of historic curl releases to get a sense of how we’re doing over time – memory size and memory allocations wise.
The task I set out to myself was: figure out how the sizes of key structs in curl have changed over time, and correlate that with the number and size of allocations done at run-time. To make sure that trimming down the size of a specific struct doesn’t just get allocated by another one instead, thus nullifying the gain. I want to make sure we’re not slowly degrading – and if we do, we should at least know about it!
Also: we keep developing curl at a fairly good pace and we’re adding features in almost every release. Some growth is to expected and should be tolerated I think. We also keep the build process very configurable so users with particular needs and requirements can switch off features and thus also gain memory.
Of course systems are growing every year and machines ship with more and more ram, which also goes for the smallest machines. But there are still a vast amount of systems out there with limited memory capabilities that want good Internet transfers as well. Also, by keeping sizes down, it allows applications and systems to scale better: a 10% decrease in size can imply a 10% increase in number of possible parallel transfers. curl, and especially libcurl, is still today in 2021 frequently used on machines with limited amounts of available memory. Sometimes in the few megabytes of ram range.
In my tests I did for this I used the exact same configuration and build config for all versions tested. The sizes and behavior will vary greatly depending on config, but I tried to use a fairly complete and typical build to see how code and memory use is for “most” users. I ran everything on my x86_64 Debian Linux dev machine. My focus is on curl versions from the last 3-4 years. I figured going back to ancient times won’t help here.
struct Curl_easy – this is the “easy handle”, what is allocated by curl_easy_init() and is the anchor for every transfer done with libcurl, no matter which API you’re using. An application creates one of these for each concurrent transfer it wants to do or keep around. Some applications allocate hundreds or even thousands of these.
struct Curl_multi – this is the “multi handle”, allocated with curl_multi_init(). This handle is created by applications as a holder of many concurrent transfers so applications typically do not have a very large amount of these.
struct connectdata – this is an internal struct that isn’t visible externally to applications. It is the holder of connection related data for a connection to a specific server. The connection pool curl uses to handle persistent connections will hold a number of these structs in memory after the transfer has completed, to allow subsequent reuse. The size of the connection pool is customizable. A busy application doing lots of transfers might end up with a sizeable number of connections in the pool, so the size of this struct adds up.
In early curl history, the download and upload buffers for transfers were part of the Curl_easy struct, which made it fairly large.
In curl 7.53.0 (February 2017) the download buffer was turned dynamically sized and is since then allocated separately. Before that transition, curl 7.52.0 had a Curl_easy struct that was 36584 bytes, which included both the download and the upload buffers. In 7.58.0 the size was down to 21264 bytes since the download buffer was then allocated separately and was then also allowed to be done much larger than the previously set 16KB fixed size.
The 16KB upload buffer was moved out of the Curl_easy handle in the 7.62.0 release (October 2018) to be done on demand – which of course especially benefits everyone who doesn’t do uploads at all… The size of this struct was then down to 6208 bytes.
In curl 7.71.0 we also made the download buffer allocated on demand, and immediately freed after the transfer completes. This makes applications that keep handles around for reuse use significantly less memory. Applications are generally encouraged to keep the handles around to better facilitate connection reuse.
The size in bytes of struct Curl_easy the last few years:
7.52.0 36584 7.58.0 21264 7.61.0 21344 7.62.0 6208 7.63.0 6216 7.64.0 6312 7.65.0 5976 7.66.0 6024 7.67.0 6040 7.68.0 6040 7.69.0 6040 7.70.0 6080 7.71.0 6448 7.72.0 6472 7.73.0 6464 7.74.0 6512
Current git: 5312 bytes (-18% from last release). With this, the struct is smaller than it has ever been before.
How we made this extra reduction? Primarily I noticed how we had a DoH related struct in the handle by default, which was turned into on-demand allocation. DoH is still rare and that data only needs to be allocated during the name resolving phase.
The size in bytes of struct Curl_multi the last few years has remained very stable and it keeps being very small. Notable is that when we removed pipelining support in 7.65.0 it took away 96 bytes from this struct.
7.50.0 384
7.52.0 384
7.58.0 480
7.59.0 488
7.60.0 488
7.61.0 512
7.62.0 512
7.63.0 512
7.64.0 512
7.65.0 416
7.66.0 416
7.67.0 424
7.68.0 432
7.69.0 416
7.70.0 416
7.71.0 416
7.72.0 416
7.73.0 416
7.74.0 416
Current git: 416 bytes.
With this, we’re smaller than we were in the beginning of 2018.
The size in bytes of struct connectdata. It’s been both up and down.
7.50.0 1904
7.52.0 2104
7.58.0 2112
7.59.0 2112
7.60.0 2112
7.61.0 2128
7.62.0 2152
7.63.0 2160
7.64.0 2160
7.65.0 1944
7.66.0 1960
7.67.0 1976
7.68.0 1976
7.69.0 2600
7.70.0 2608
7.71.0 2608
7.72.0 2624
7.73.0 2640
7.74.0 2656
Current git: 2008 bytes (-24% from last release)
The size bump in 7.69.0 was the insertion of a new struct for state data when doing SOCKS connections non-blocking, and the corresponding decrease again for the pending release is the removal of the buffer from that struct. With this, we’re back to the size we had at the end of 2016.
To make sure that we don’t just move memory to other on-demand buffers that we need to allocate anyway, I ran a script with a lot of curl versions and counted the number of allocations needed and the peak amount of memory allocated. For a plain 512MB download over HTTP from localhost. The counted allocations were only the ones done by curl code (malloc, calloc, realloc, strdup etc).
There are many reasons to allocate memory and while we want to keep the number down, lots of factors of course needs to be taken into account.
In the list below you’ll see that clearly we had some mistake in 7.52.0 and perhaps some more versions, as it did over 32,000 allocations. The situation was fixed in or before 7.58.0 and I haven’t bothered to go back to check exactly what it was.
7.52.0 32883
7.58.0 82
7.59.0 82
7.60.0 82
7.61.0 82
7.62.0 86
7.63.0 87
7.64.0 87
7.65.0 82
7.66.0 101
7.67.0 107
7.68.0 111
7.69.0 113
7.70.0 113
7.71.0 99
7.72.0 99
7.73.0 96
7.74.0 96
Current git: 96 allocations.
We do more allocations than some years back, but I think it is still within a reasonable growth.
Here’s some developments to look closer at!
If we start out looking at the oldest versions in my test, we can see that they’re sub 100KB allocated – but we need to take into account the fact that back then we used a fixed 16KB download buffer. In curl 7.54.1 we bumped the default buffer size the curl tool uses to 100K which in the table below is visible in the 7.58.0 allocation.
7.50.0 84473 7.52.0 85329 7.58.0 174243 7.59.0 174315 7.60.0 174339 7.61.0 174531 7.62.0 143886 7.63.0 143928 7.64.0 144128 7.65.0 143152 7.66.0 168188 7.67.0 173365 7.68.0 168575 7.69.0 169167 7.70.0 169303 7.71.0 136573 7.72.0 136765 7.73.0 136875 7.74.0 137043
Current git: 132827 bytes.
The gain in 7.62.0 was mostly the removal of the default allocation of the upload buffer, which isn’t used in this test…
The current size tells me several things. We’re at a memory consumption level that is probably at its lowest point in the last decade – while at the same time having more features and being better than ever before. If we deduct the download buffer we have 30427 additional bytes allocated. Compare this to 7.50.0 which allocated 68089 bytes on top of the download buffer!
If I change my curl to use the smallest download buffer size allowed by libcurl (1KB) instead of the default 100KB, it ends up peaking at: 31451 bytes. That’s 37% of the memory needed by 7.50.0.
In my opinion, this is very good.
It might also be worth to reiterate that this is with a full featured libcurl build. We can shrink even further if we switch off undesired features or just go tiny-curl.
I hope this goes without saying, but of course all of this work has been done with the API and ABI still intact.
You know I like graphs, but for now I decided this blog post and analysis was enough. I’m going to think about how we can perhaps get this info somehow floated on a more regular and automated way in the future. Not sure it is worth spending a lot of effort on though.
--enable-debug option to configure. Don’t use the threaded resolver – I use the c-ares one, because it otherwise breaks the memdebug system.#!/bin/sh export CURL_MEMDEBUG=/tmp/curlmem.log ./src/curl -v localhost/512M -o /dev/null ./tests/memanalyze.pl -v /tmp/curlmem.log
To get the struct sizes, just run pahole on the static libcurl lib after the build:
pahole -s lib/.libs/libcurl.a > sizes.txt
The photo was taken by me, in Siem Reap, Combodia. “A smaller transport”
https://daniel.haxx.se/blog/2021/01/21/more-on-less-curl-memory/
|
|
Hacks.Mozilla.Org: Analyzing Bugzilla Testcases with Bugmon |

As a member of Mozilla’s fuzzing team, our job is not only to find bugs, but to do what we can to help get those bugs fixed as quickly as possible. Some of the many ways we can do that is by:
To further reduce the delay in getting these bugs fixed, we wanted to automate as much of this process as possible. This effort resulted in the development of Bugmon; a tool that automates these basic triage tasks for Firefox and SpiderMonkey bugs directly in Bugzilla.
Bugmon analysis is opt-in and only applies to crash or assertion bugs with a testcase. If you work on Firefox and are interested in having bugmon analyze your bugs, it’s as simple as adding the “bugmon” keyword.
Fuzzing is, in its most basic form, the process of supplying random bits of data to an application in the hopes of triggering unexpected behavior. In relation to Mozilla and those of us fuzzing Firefox, this random data often comes in the form of JavaScript, HTML, CSS, etc., and the unexpected behavior we’re looking for, often presents itself in the form of application crashes or fatal assertions.
When we identify issues like these, our first step is to notify the team which maintains the problematic code via a bug in Bugzilla. When we file these bugs, we include as much relevant data as possible such as:
For a recent example of what this looks like, take a look at bug 1682612.
Many people would consider that at this point, our job is done. The bug is in the hands of the developer and we can move on to breaking more code. Unfortunately for us, that’s not the case.
There are many reasons why, during the course of a bug’s life, we may be required to provide further information. Oftentimes, the exact cause of a bug may not be clear. Further, the owner of the problematic code may be equally unclear. In order to get our bug in the hands of those best able to fix it, we need to provide more information.
One useful technique that we can leverage is bisection. Bisection is the process of identifying the specific changeset that introduced the problematic behavior (i.e. the crash or the assertion). By identifying the changeset that introduced the bug, we can likely pinpoint not only the area which is responsible for the bug, but also the individual who last modified that code. Both of which can help us to get the bug fixed quicker.
But what happens if the bug is low priority and several weeks or months pass before a developer has a chance to review the bug?
In these cases, it’s often helpful to determine if a bug still exists. To answer this, we will attempt to trigger the same issue using the original testcase attached to a bug. If the bug no longer reproduces, it’s likely that the bug has already been fixed. We can once again leverage bisection to identify the specific changeset responsible for fixing our bug.
At this stage, the bug has been fixed. Success! Or, at least it appears to be. It’s important for us to verify that the original test case no longer triggers the problematic behavior. In these cases, we will once again attempt to trigger the same issue using the original test case. If the bug no longer reproduces, we can safely mark the bug as verified.
After repeating many of these tasks by hand, we quickly realized that we could automate much of the process to provide greater support to the developers tasked with fixing our bugs.
Bugmon is specifically designed to automate many of these basic triage tasks. Originally conceived by Christian Holler nearly 8 years ago as JSBugMon for the analysis of bugs affecting SpiderMonkey; Bugmon is a complete redesign of Christian’s efforts. This new approach leverages several additional tools developed by the fuzzing team such as autobisect, fuzzfetch, and grizzly to quickly and effectively apply this concept to both SpiderMonkey and Firefox bugs.

A demo of bugmon processing a bug.

Bugmon will perform several automated tasks based on the current status of the bug.
Occasionally you may want to trigger specific actions to be performed outside of the timeline described above. This may be because the original testcase no longer reproduces, or you think that the status of the bug may have changed since a prior Bugmon analysis.
In addition to it’s automatic parsing capabilities, bugmon actions can also be requested for immediate processing via the bug whiteboard.
While the information provided by Bugmon is certainly helpful in getting bugs fixed quicker, there are a number of features we’d still like to implement.
Improvements to the bisection analysis stages may allow us to identify regressions down to a single code change. In these cases, we can automatically update the relevant regression fields which can then be leveraged by other Mozilla bots such as autonag. Additionally, we can automate requests for review by the author of the previously identified code change as they may likely be the best candidate to fix it.
Finally, one often requested feature is to include support for recording bugs with rr. For those unfamiliar with rr; it is a timeless debugger which allows us to record application failures and replay them deterministically. In combination with pernosco, a web-based rr session browser, we can get these recordings into the hands of developers instantly and without any required setup on their part. Thus, reducing the overhead associated with hard to reproduce or intermittent bugs.
We certainly hope that Bugmon helps reduce the time required to triage new bugs and effectively get bugs fixed faster. If there are specific use cases you have that are not currently supported by Bugmon we’d love to hear from you.
The post Analyzing Bugzilla Testcases with Bugmon appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/01/analyzing-bugzilla-testcases-with-bugmon/
|
|
The Mozilla Blog: Mozilla’s Climate Commitments |
Assuming responsibility for our emissions
“In these disruptive, crises-ridden times, our attention is often captured by the immediate political and technical challenges right in front of us. Facing the climate crisis and ensuring that there is a habitable planet for us and future generations to continue fighting these fights is not something that can be pushed to the back seat. I, and Mozilla, are committed to protecting the environment.” — Mitchell Baker, CEO
We can’t save the planet without people, and we understand that the internet is an incredibly powerful tool to help us draw the attention to what needs to happen.
The first line of order is that Mozilla assumes responsibility for its greenhouse gas emissions: We will reduce our emissions significantly and mitigate what we can’t avoid. We will share what we learn and lead transparently, supporting others on their journeys and continuously exploring ways to increase the resiliency of our communities.
Four Climate Commitments
To that end, we pledge:
Mitigation and Carbon Offsets
Doing right by the environment cannot be about simply paying off your emissions. In order to be carbon-neutral today, we invested in high quality carbon offsets to mitigate our 2019 impact for business services and operations. While these offsets are an important tool to mitigate emissions that we are not yet able to avoid, they do not provide or stimulate the sort of transformation that our societies need in order to truly be sustainable.
The most effective climate mitigation strategy is avoiding emissions, and Mozilla will continue to reduce its share while working with allies and partners to amplify our ambitions.
Such a transformation requires new mindsets and a high degree of organisational and cultural change. Training our staff and providing a range of different incentives to improve our environmental impact will be integral to achieving this.
Supported Sequestration Projects
We interviewed a range of offsets retailers and providers, assessing each project with a view to: level of certification with a preference for Gold Standard or Verified Carbon Standard (VCS), human rights compliance, focus on sequestration rather than avoidance, additionality and permanence of projects, social impact and community resilience.
On the basis of these criteria, we decided to work with EcoAct and invest in three sequestration projects: Madre de Dios REDD project, Peru; Darkwoods carbon forestry project, Canada; and Rimba Raya Reserve project, Indonesia.
In addition, we purchased renewable energy certificates (RECs) for our offices and co-locations in North America, Europe and Taiwan starting with our 2019 impact.
Next steps
In 2021, we will double down on our reduction efforts and develop implementation plans with each part of our organisation.
This will include switching more of our offices to renewable energy, reviewing our travel policies, exploring options for cloud optimisation, developing toolkits for product integrity and design principles, and more. We will share details on our process and targets as we refine them.
And for anyone pondering their options, I’d love to hear what you think about these ideas:
The post Mozilla’s Climate Commitments appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2021/01/21/mozillas-climate-commitments/
|
|
Daniel Stenberg: everything.curl.dev |
The online version of the curl book “everything curl” has been moved to the address shown in the title:
This, after I did a very unscientific and highly self-selective poll on twitter on January 18 2020
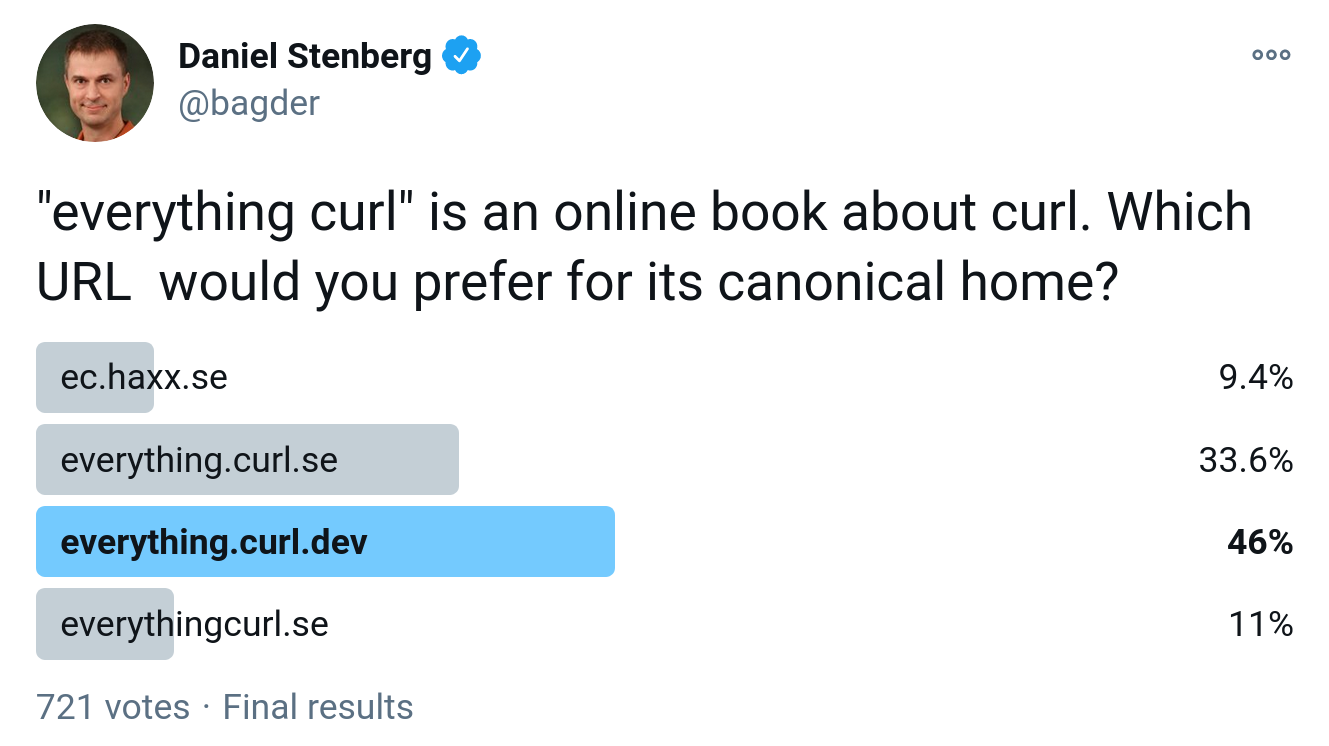
The old name (which you can see what the least selected in the poll) will now redirect to the new host name and so will everything.curl.se .
I am the owner of this domain since a little while back but we haven’t yet figured out what to do with the domain – this is the first use of curl.dev for real content.
If you have ideas of how we can improve curl’s web presence with this domain, please let me know! I do not want to move the official curl web site again from its new home at curl.se, that’s not what I would call a productive idea.
|
|
Mozilla Addons Blog: Extensions in Firefox for Android Update |
Starting with Firefox 85, which will be released January 25, 2021, Firefox for Android users will be able to install supported Recommended Extensions directly from addons.mozilla.org (AMO). Previously, extensions for mobile devices could only be installed from the Add-ons Manager, which caused some confusion for people accustomed to the desktop installation flow. We hope this update provides a smoother installation experience for mobile users.
As a quick note, we plan to enable the installation buttons on AMO during our regularly scheduled site update on Thursday, January 21. These buttons will only work if you are using a pre-release version of Firefox for Android until version 85 is released on Tuesday, January 25.
This wraps up our initial plans to enable extension support for Firefox for Android. In the upcoming months, we’ll continue to work on optimizing add-on performance on mobile. As a reminder, you can use an override setting to install other extensions listed on AMO on Firefox for Android Nightly.
We’ll be sure to provide more updates on this blog about extensions in Fenix as they become available.
The post Extensions in Firefox for Android Update appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2021/01/20/extensions-in-firefox-for-android-update/
|
|
Hacks.Mozilla.Org: Porting Firefox to Apple Silicon |
The release of Apple Silicon-based Macs at the end of last year generated a flurry of news coverage and some surprises at the machine’s performance. This post details some background information on the experience of porting Firefox to run natively on these CPUs.
We’ll start with some background on the Mac transition and give an overview of Firefox internals that needed to know about the new architecture, before moving on to the concept of Universal Binaries.
We’ll then explain how DRM/EME works on the new platform, talk about our experience with macOS Big Sur, and discuss various updater problems we had to deal with. We’ll conclude with the release and an overview of various other improvements that are in the pipeline.
Speculation that Apple would switch its Mac lineup to use ARM CPUs had been ongoing in the industry for several years. As early as 2013, Apple had referred to the custom ARM chips they were putting in the iPhone as “desktop-class” designs.
While the claim initially met some scepticism, near the end of 2018 computer hardware magazine AnandTech published the results of running the industry-standard SPEC benchmark on the iPhone XS, showing that even workloads that reflect real-world desktop use cases reached desktop chip performance, and were doing so at significantly better power efficiency. This provided us with some warning that Apple might be ready to start the transition to the ARM architecture in the near future.
From the perspective of Mozillla’s platform team, an area of particular interest for such an architecture change on macOS is Firefox’s use of macOS APIs. Firefox and Gecko’s roots go back to the Netscape codebase, which already supported the Mac as it was in 1994.
Although continuously updated, Firefox still uses a wide range of macOS APIs that followed the Mac’s evolution over the years (Carbon, Cocoa, HITheme, Quartz, …).
Apple has generally kept them — the code is there and working, after all — and has even added compatibility shims in some places where behavior has changed. But they’re not willing to keep compatibility forever, and in fact had removed 32-bit support in the previous macOS Catalina which had an impact on applications that were relying on this, among them many games.
As such, we were concerned that not all APIs would still be supported on the new architecture and we’d have to go in and rewrite some amount of widget, toolkit or theming code in short order.
Based on the performance from the aforementioned benchmarks and Apple’s historical release schedule, the platform team estimated in March that “macOS 10.16” was likely to appear around September or October 2020 and that there was a significant risk it could involve API changes in order to add ARM support, which we took into account in our planning.
On the 22nd of June 2020, Apple confirmed it would begin moving its Mac hardware to their own ARM chips – referred to as Apple Silicon. They also confirmed that the machines would ship with an Intel x64 emulator (Rosetta 2) and would support iOS apps.
The latter led to some guessing within Mozilla’s platform team as to whether the new Macs would have a touchscreen. While we were — and still are — quite ready to support it, at least the eventual first Apple Silicon-based Macs didn’t end up having one.
Together with the announcement of the transition, Apple also announced the availability of Developer Transition Kits (DTK), essentially containing the iPad Pro’s chip in a Mac Mini housing. What Apple didn’t share was when exactly the final machines were coming to market.
Based on the timing of the DTK availability and Apple’s hint that it would be “by the end of the year”, we guessed this was likely to be somewhat before the Christmas holidays.
Looking back, we noticed that Apple has very consistently been able to make hardware available near immediately after announcing it, so we figured that any next planned announcement should be taken as a release date.
When another announcement was planned for November 10th – about a month before our original estimate – we took it as the shipping date. And indeed, Apple did end up shipping the first hardware one week later on November 17th.
Of all the work needed to support the new hardware, porting Firefox to the 64-bit ARM architecture was not actually something we needed to do: we’ve supported 64-bit ARM on Android and Linux for years.
We refrained from publishing the 64-bit Android builds until late 2019 because before that point our JavaScript JIT was not fully optimized for 64-bit ARM, and the resulting 64-bit version would have been slower than the 32-bit one. There wasn’t much demand for the browser to be able to use over 4GB of memory on phones either! In 2019, we released the first Firefox version for Windows on 64 bit ARM which gave us some additional experience in exactly the kind of effort we were facing now.
While Windows on ARM hardware has failed to catch on with our users so far, expectations were for the Apple transition to be very different. Not only was there a good reason to expect hardware performance to be groundbreaking as explained in the first section. Apple made it clear they were switching their entire lineup and not releasing a single device as a “feeler”. To top it off, they had a proven track record of successful architecture transitions on the Mac.
So with 64-bit ARM support already in the codebase, the first pass of work was to go through all the Firefox code, dependencies, and various third-party build systems to see if they correctly dealt with the novel idea that a Mac could have an ARM chip inside.
Secondly, we needed to adapt and fix the various parts of the Firefox codebase that deal with low-level calling conventions and particularly the interfaces between the JavaScript and C++ (and nowadays Rust) parts of the code.
Rust in particular was a concern. Firefox depends on Rust code, and we require a working Rust compiler to build the browser. Although Apple Silicon support for Rust was underway, it took until mid-August for there to be functional compiler builds, which limited the amount of progress possible for Firefox.
Once the compiler was working, a similar exercise needed to be done with all the Rust crates we depend on. The need to update the compiler and the reliance of some crates on the exact compiler version, especially parts dealing with SIMD support, would end up biting us later on as it made it hard to push Apple Silicon support forward to an earlier release of Firefox without potentially affecting other platforms.
An important decision to be made was whether to produce separate builds for Intel- and ARM-based Macs, or to generate Universal Binaries which bundle both builds and select the correct version at runtime. Producing Universal Binaries is a bit more complicated, but we had existing tooling in place dating back to the time when Apple supported both 32-bit and 64-bit binaries, which could be adapted.
It greatly simplifies things for the user — there is no risk of downloading the wrong version — and also meant that our download pages and some infrastructure like localization could remain unchanged.
The main downside is the installer significantly increasing in size, not just for ARM users but also for Intel ones. As this only affects the initial install, and users typically receive new versions through updates that are much smaller, we felt that this was an acceptable downside and proceeded along this route.
While we can port the open-source parts of Firefox to 64-bit ARM ourselves, Netflix and some other video streaming services such as Hulu, Disney+, or Amazon Prime require their video to be decoded with closed source, proprietary DRM software.
If the user visits such a site, Firefox will automatically download and install such a proprietary EME/CDM module. This presented a problem to us as we would be dependent on those third-party vendors to publish ARM64 versions of those decoders.
We did not manage to get a commitment to a release date for such updates, and even if we did, there was no guarantee that they would be before the unknown release date of the Apple Silicon hardware. As a significant number of our users use the browser to watch video online, this presented a potential showstopper for a native Apple Silicon release.
We ended up leveraging a technique that we are also using for the Windows on ARM version of Firefox. The DRM video decoder already executes in a separate process so we can sandbox the proprietary code from the user’s system.
If we force this decoding process to run under emulation, we would be able to use the existing Intel x64 decoder modules and have them communicate with the main browser that was running natively.
There were a few catches to getting this to work: because the process that loads the Google Widevine DRM module itself depends on some runtime libraries, we needed Intel x64 copies of those as well.
Luckily, due to the Universal Binary containing both versions of Firefox, we were able to pick them up directly from the Application Bundle.
Secondly, Apple did not actually ship their Rosetta 2 emulator preinstalled on the Apple Silicon machines but its installation is triggered when the user tries to run an Intel application.
So while it is very likely in practice that Rosetta is installed on the user’s system, we could not rely on this always being the case. Triggering the installation of Rosetta programmatically works, but some of our colleagues found out the hard way it is not very reliable, so we backed off on doing this in our first release and fell back to referring people that hit the relevant error to a support article.
The macOS Big Sur betas arrived independently of the Apple Silicon hardware and allowed us to get an early look at the compatibility story. To our relief, no APIs we depended on were deprecated and any backwards compatibility problems or missing shims were limited to small cosmetic issues, which we typically managed to fix quickly. Other open-source projects with a similarly old codebase were not as lucky.
Bumping the version numbers from 10.x to 11.0 – somewhat predictably – produced errors both in our code and in external websites relying on UA sniffing, despite Apple’s attempts to mitigate the problem by returning the old version number in apps built with older SDKs.
Pushing the updated Firefox application bundle to users – which was now a Universal Binary supporting both types of Apple hardware, instead of only Intel x64 as before – revealed some further complications.
During an update, after updating the files on disk, Firefox will relaunch the updated version of itself. Any application on Apple Silicon that is running under Intel x64 emulation and launches another process will also cause that process to be launched under emulation.
So when the old Firefox 83 – running under emulation – launches the new Firefox 84 with native support, it would not launch the new native binary but end up forcing it to be run under emulation as well, at least until the application was fully restarted.
While we developed a workaround for this, we didn’t feel it was sufficiently tested by the release date for the marginal benefit it gave and ended up simply adding a release note to cover this case.
More of a concern was user reports that some antivirus software was flagging all our Universal Binaries as malware, and corrupting the Firefox installation the moment the update arrived.
The software was using machine learning techniques and presumably observed that our combined Universal Binaries didn’t quite look like any other legitimate software it had ever seen before.
Attempts to contact the vendor through regular support channels were unsuccessful so we ended up searching LinkedIn and managed to find an engineer working on the core antivirus detection.
They immediately understood the seriousness of the problem and took prompt action to get a fix shipped, thus preventing quite the disaster for the users of this product. It’s notable that without this last-ditch effort we would have been effectively blocked from releasing a native Apple Silicon version for an indefinite period.
This wouldn’t be the first time that browser makers are exasperated at the misaligned incentives for anti-virus vendors when anti-virus software and browsers don’t get along.
Comparing the Firefox release schedule with the predicted release date from Apple meant that our Firefox 83 – scheduled for November 17th – aligned with the availability of release hardware.
While it would have been nice to announce native support in the stable version as soon as the first production machines arrived to customers, this would also have meant that it would be completely untested on the real hardware.
We decided to be conservative here and keep our initial support to the Firefox 84 beta, which was released the same day as Firefox 83, giving both us and our users a window of time to evaluate the stability of the product on the actual Apple Silicon hardware.
Though somewhat disappointed that after being one of the first to announce native support in Nightly we ended up delaying a stable release slightly, the difficulties experienced by other browser vendors with shipping a working version supported our decision. Firefox with native Apple Silicon support went into the wider world when 84 beta rolled into the Firefox 84 release, on December 15th, 2020.
While most benchmarking of Apple Silicon indicated that the performance impact of Rosetta emulation was typically low and that applications could be expected to run at about 70-80% of native performance, we saw much larger gains when testing the native Firefox build, including doubled performance on some key benchmarks and a spectacular 2.5 times faster startup.
One reasonable explanation for this faster startup could be that many parts of Firefox itself are written in the web’s own languages – JavaScript, CSS, and HTML – and thus use a JavaScript JIT for much of its own functionality.
On startup, the JIT has to translate the JavaScript to machine code and while this is typically a very fast operation when running under emulation Rosetta has to then translate this JIT-generated machine code to machine code for another architecture.
Apple introduced a translation cache that likely removes this overhead completely for most applications but it does not work for code that is output by a JIT. With the native build, this second translation is avoided completely and we’re back to having a snappy browser.
With the initial release out, there are a number of further improvements that we can and will make to the Apple Silicon version, some of which will already be available in Firefox 85.
First of all, we had to disable WebRender in the initial version because it triggered graphics driver bugs in the first Big Sur releases for Apple Silicon. Now that these have been addressed and we’ve validated WebRender on the final hardware, we have re-enabled it and it will ship in 85.
Secondly, Firefox currently uses the baseline compiler for WebAssembly on 64-bit ARM. There is a faster optimizing compiler called Cranelift available for testing on Firefox Nightly, and in a few weeks, we expect to finish the 64-bit ARM port of our own optimizing compiler, Ion, which is likely to become the new default.
The Apple Silicon chips are one of the first desktop chips that are a heterogeneous design with distinct performance and efficiency cores. We’re revising much of our core threading and thread pooling architecture to handle the distinction better, improve efficiency, and eventually be able to schedule less performance-critical tasks on the efficiency cores.
Finally, we’re cleaning up and modernizing our usage of legacy macOS drawing APIs, and in some cases, removing our custom drawing code entirely. This is expected to help with some of the outstanding glitches in dark mode support, as the legacy macOS APIs simply don’t support it and the color values must be obtained via newer APIs. It will also remove some of our deprecation worries!
We hope you enjoyed this inside view of how the Firefox team experienced the Apple Silicon transition and we’re looking forward to pushing the Firefox experience on macOS to even higher levels in the year to come.
Thanks to Mike Hommey and Haik Aftandilian for their substantial input to this post. They also did a lot of the engineering work described here. Further editorial suggestions were provided by Andrew Overholt, Sylvestre Ledru, and Selena Deckelmann.
The post Porting Firefox to Apple Silicon appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/01/porting-firefox-to-apple-silicon/
|
|
Daniel Stenberg: bye bye svn.haxx.se |
It isn’t actually going away. It’s just been thrown over the fence to the Apache project and Subversion itself to host and maintain going forward.
When the Subversion project started in the early year 2000, I was there. I joined the project and participated in the early days of its development as I really believed in creating an “improved CVS” and I thought I could contribute to it.
While I was involved with the project, I noticed the lack of a decent mailing list archive for the discussions and set one up under the name svn.haxx.se as a service for myself and for the entire community. I had the server and the means to do it, so why not?
After some years I drifted away from the project. It was doing excellently and I was never any significant contributor. Then git and some of the other distributed version control systems came along and in my mind they truly showed the world how version control should be done…
The mailing list archive however I left, and I had even added more subversion related lists to it over time. It kept chugging along without me having to do much. Mails flew in, got archived and were made available for the world to search for and link to. Today it has over 390,000 emails archived from over twenty years of rather active open source development on multiple mailing lists. It is fascinating that no less than 46 persons have written more than a thousand emails each on those lists during these two decades.
The physical machine that runs the website is going to be shut down and taken out of service soon, and instead of just shutting down this service I’ve worked with the good people in the Subversion project and the hosting of that site and archive has now been taken over by the Apache project instead. It is no longer running on my machine. If you discover any issues with it, you need to talk to them.
Today, January 20 2021, I updated the DNS to instead have the host name svn.haxx.se point to Apache’s web server. I believe the plan is to keep the site as an archive of past emails and not add any new emails to it as of now.
I hereby sign off my twenty years of service as an svn email archive janitor. It was a pleasure to serve you.
|
|
Armen Zambrano: Joining Sentry |
I’m happy to announce that at the end of 2020 I joined Sentry.io as their second Developer Productivity engineer \o/

I’m excited to say that it’s been a great fit and that I can make use of most of the knowledge I’ve gained in the last few years. I like the ambition of the company and that they like to make work fun.
So far, I have been able to help to migrate to Python 3, enabled engineers to bootstrap their Python installation on Big Sur, migrated some CI from Travis to Github actions amongst many other projects.
If you ship software, I highly recommend you trying Sentry as part of your arsenal of tools to track errors and app performance. I used Sentry for many years at Mozilla and it was of great help!
If you are interested in joining Sentry please visit the careers page.
http://feedproxy.google.com/~r/armenzg_mozilla/~3/KA2EZU6oD9E/joining-sentry-cc0f37b6dda7
|
|
Chris H-C: Doubling the Speed of Windows Firefox Builds using sccache-dist |
I’m one of the many users but few developers of Firefox on Windows. One of the biggest obstacles stopping me from doing more development on Windows instead of this beefy Linux desktop I have sitting under my table is how slow builds are.
Luckily, distributed compilation (and caching) using sccache is here to help. This post is a step-by-step version of the rather-more-scattered docs I found on the github repo and in Firefox’s documentation. Those guides are excellent and have all of the same information (though they forgot to remind me to put the ports on the url config variables), but they have to satisfy many audiences with many platforms and many use cases so I found myself having to switch between all three to get myself set up.
To synthesize what I learned all in one place, I’m writing my Home Office Version to be specific to “using a Linux machine to help your Windows machine compile Firefox on a local network”. Here’s how it goes:
# Don't forget the port, and don't use an internal iface address like 127.0.0.1. # This is where the Clients and Servers should find the Scheduler public_addr = "192.168.1.1:10600" [client_auth] type = "token" # You can use whatever source of random, long, hard-to-guess token you'd like. # But chances are you have openssl anyway, and it's good enough unless you're in # a VM or other restrained-entropy situation. token = "" [server_auth] type = "jwt_hs256" secret_key = " "
# Toolchains are how a Linux Server can build for a Windows Client. # The Server needs a place to cache these so Clients don’t have to send them along each time. cache_dir = "/tmp/toolchains" # You can also config the cache size with toolchain_cache_size, but the default of 10GB is fine. # This is where the Scheduler can find the Server. Don’t forget the port. public_addr = "192.168.1.1:10501" # This is where the Server can find the Scheduler. Don’t forget http. Don’t forget the port. # Ideally you’d have an https server in front that’d add a layer of TLS and # redirect to the port for you, but this is Home Office Edition. scheduler_url = "http://192.168.1.1:10600" [builder] type = "overlay" # I don’t know what this means build_dir = "/tmp/build" # Where on the fs you want that sandbox of build jobs to live bwrap_path = "/usr/bin/bwrap" # Where the bubblewrap 0.3.0+ binary lives [scheduler_auth] type = "jwt_token" token = "--server "
[dist] scheduler_url = "http://192.168.1.1:10600" # Don’t forget the protocol or port toolchain_cache_size = 5368709120 # The default of 10GB is at least twice as big as you need. # Gonna need two toolchains, one for C++ and one for Rust # Remember to replace allwith your user name on disk [[dist.toolchains]] type = "path_override" compiler_executable = "C:/Users/ /.mozbuild/clang/bin/clang-cl.exe" archive = "C:/Users/ /.mozbuild/clang-dist-toolchain.tar.xz" archive_compiler_executable = "/builds/worker/toolchains/clang/bin/clang" [[dist.toolchains]] type = "path_override" compiler_executable = "C:/Users/ /.rustup/toolchains/stable-x86_64-pc-windows-msvc/bin/rustc.exe" archive = "C:/Users/ /.mozbuild/rustc-dist-toolchain.tar.xz" archive_compiler_executable = "/builds/worker/toolchains/rustc/bin/rustc" # Near as I can tell, these dist.toolchains blocks tell sccache # that if a job requires a tool at `compiler_executable` then it should instead # distribute the job to be compiled using the tool present in `archive` at # the path within the archive of `archive_compiler_executable`. # You’ll notice that the `archive_compiler_executable` binaries do not end in `.exe`. [dist.auth] type = "token" token = " "
# Remember to replace allwith your user name on disk ac_add_options CCACHE="C:/Users/ /.mozbuild/sccache/sccache.exe" export CC="C:/Users/ /.mozbuild/clang/bin/clang-cl.exe --driver-mode=cl" export CXX="C:/Users/ /.mozbuild/clang/bin/clang-cl.exe --driver-mode=cl" export HOST_CC="C:/Users/ /.mozbuild/clang/bin/clang-cl.exe --driver-mode=cl" export HOST_CXX="C:/Users/ /.mozbuild/clang/bin/clang-cl.exe --driver-mode=cl"
Oh, dang, I should manufacture a final step so it’s How To Speed Up Windows Firefox Builds In Ten Easy Steps (if you have a fast Linux machine and network). Oh well.
Anyhoo, I’m not sure if this is useful to anyone else, but I hope it is. No doubt your setup is less weird than mine somehow so you’ll be better off reading the general docs instead. Happy Firefox developing!
:chutten
|
|
Henri Sivonen: Text Encoding Menu in 2021 |
Back in December 2014, I wrote a post called Character Encoding Menu in 2014. Now seems like a good time to take a new snapshot for the record. Copypaste from the old intro still applies: This post is about a UI feature that I wish no one would have to use. Happily, it is indeed almost unused. Still, I made it more usable in the case when it is used.
To recap, at the end of 2014 the Character Encoding menu looked like this:
In mid-January 2021, the Text Encoding menu looks like this:
There are four differences made as four distinct steps over time:
Does it make sense to have items other than “Automatic”? Probably not. After all, Chrome and Firefox for Android don’t have the menu at all.
For users who have telemetry enabled, we collect data about whether the item “Automatic” was used at least once in given Firefox subsession, whether an item other than “Automatic” was used at least once in a given Firefox subsession, and a characterization of how the encoding that is being overridden was determined (from HTTP, from meta, from chardetng running without the user triggering it, from chardetng as triggered by the user by having chosen “Automatic” previously, etc.). If things go well, the telemetry can be analyzed when Firefox 87 is released (i.e. when 86 has spent its time on the release channel). The current expectation for this is 2021-03-23.
Additionally, the intent is to start honoring the encoding declaration in an XML declaration in text/html soon. The spec says not to do this, which is why Firefox does not do this at present, but the plan is to change the spec. This will eliminate a reason for Firefox to differ from Chrome and Safari on the encoding topic.
The expectation is that the telemetry will show that the single menu item “Automatic” can replace the whole menu. Obviously, that would involve renaming the item to something like “Override Text Encoding”. Hopefully, there won’t be a Text Encoding menu in 2022.
|
|
Data@Mozilla: This Week in Glean: Proposals for Asynchronous Design |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
At last count there are 14 proposals for Firefox on Glean, the effort that, last year, brought the Glean SDK to Firefox Desktop. What in the world is a small, scrappy team in a small, scrappy company like Mozilla doing wasting so much time with old-school Waterfall Model overhead?!
Because it’s cheaper than the alternative.
Design is crucial before tackling difficult technological problems that affect multiple teams. At the very least you’re writing an API and you need to know what people want to do with it. So how do you get agreement? How do you reach the least bad design in the shortest time?
We in the Data Org use a Proposal Process. It’s a very lightweight thing. You write down in a (sigh) Google Doc what it is you’re proposing (we have a snazzy template), attach it to a bug, then needinfo folks who should look at it. They use Google Docs’ commenting and suggested changes features to improve the proposal in small ways and discuss it, and use Bugzilla’s comments and flags to provide overall feedback on the proposal itself (like, should it even exist) and to ensure they keep getting reminded to look at the proposal until the reviewer’s done reviewing. All in all, it’ll take a week or two of part-time effort to write the proposal, find the right people to review it, and then incorporate the feedback and consider it approved.
(( Full disclosure, the parts involving Bugzilla are my spin on the Proposal Process. It just says you should get feedback, not how. ))
Why not use a meeting? Wouldn’t that be faster?
Think about who gets to review things in a meeting as a series of filters. First and foremost, only those who attend can review. I’ve talked before about how distributed across the globe my org is, and a lot of the proposals in Project FOG also needed feedback from subject matter experts across Mozilla as a whole (we are not jumping into the XPIDL swamp without a guide). No way could I find a space in all those calendars, assuming that any of them even overlap due to time zones.
Secondly, with a defensive Proposer, feedback will be limited to those reviewers they can’t overpower in a meeting. So if someone wants to voice a subtle flaw in the C++ Metrics API Design (like how I forgot to include any details about how to handle Labeled Metrics), they have to first get me to stop talking. And even though I’m getting better at that (still a ways to go), if you are someone who doesn’t feel comfortable providing feedback in a meeting (perhaps you’re new and hesitant, or you only kinda know about the topic and are worried about looking foolish, or you are generally averse to speaking in front of others) it won’t matter how quiet I am. The proposal won’t be able to benefit from your input.
Thirdly, some feedback can’t be thought of in a meeting. There’s a rough-and-readiness, an immediacy, to feedback in a meeting setting. You’re thinking on your feet, even if the Proposal and meeting agenda are set well in advance. Some critiques need time to percolate, or additional critical voices to bounce off of. Meetings aren’t great for that unless you can get everyone in a room for a day. Pandemic aside, when was the last time you all had that much time?
Proposal documents are just so much more inclusive than design meetings. You probably still want to have a meeting for early prototyping with a small group of insiders, and another at the end to coax out any lingering doubts… but having the main review stages be done asynchronously to your reviewers’ schedules allows you to include a wider variety of voices. You wouldn’t feel comfortable asking a VP to an hour-long design meeting, but you might feel comfortable sending the doc in an email for visibility.
On top of being more inclusive, proposals are also more respectful. I don’t know what your schedule is today. I don’t know what life you’re living. But I can safely assume that, unless you’re on vacation, you’ll have enough time between now and, say, next Friday to skim a doc and see if there’s anything foolish in it you need to stop me from doing. Or think of someone else who I didn’t think of who should really take a look.
And by setting a feedback deadline, you the Proposer are setting yourself free. You’ll be getting emails as feedback comes in. You’ll be responding to questions, accepting and rejecting changes, and having short little chats. But you can handle that in bite sized chunks on your own schedule, asynchronously, and give yourself the freedom to schedule synchronous work and meetings in the meantime.
Name a Design that was implemented exactly as written. Go on, I’ll wait.
No? Can’t think of one? Neither can I.
Designs (and thus Proposals) are always incomplete. They can’t take into consideration everything. They’re necessarily at a higher level than the implementation. So in some way, the implementation is the evolution of the Design. But implementations lose the valuable information about Why and How that was so important to set down in the Design. When someone new comes to the project and asks you why we implemented it this way, will you have to rely on the foggy remembrance of oral organizational history? Or will you find some way of keeping an objective record?
Only now have we started to develop the habit of indexing and archiving Proposals internally. That’s how I know there’s been fourteen Project FOG proposals (so far). But I don’t think a dusty wiki is the correct place for them.
I think, once accepted, Proposals should evolve into Documentation. Documentation is a Design adjusted by the realities encountered during implementation and maintained by users asking questions. Documentation is a living document explaining Why and How, kept in sync with the implementation’s explanation of What.
But Documentation is a discussion for another time. Reference Documentation vs User Guides vs Design Documentation vs Marketing Copy vs… so much variety, so little time. And I’ve already written too much.
:chutten
(( This post is a syndicated version of the original. ))
https://blog.mozilla.org/data/2021/01/15/this-week-in-glean-proposals-for-asynchronous-design/
|
|
Mozilla Performance Blog: Performance Sheriff Newsletter (December 2020) |
|
|
Daniel Stenberg: Food on the table while giving away code |
I founded the curl project early 1998 but had already then been working on the code since November 1996. The source code was always open, free and available to the world. The term “open source” actually wasn’t even coined until early 1998, just weeks before curl was born.

In the beginning of course, the first few years or so, this project wasn’t seen or discovered by many and just grew slowly and silently in a dusty corner of the Internet.
Already when I shipped the first versions I wanted the code to be open and freely available. For years I had seen the cool free software put out the in the world by others and I wanted my work to help build this communal treasure trove.
When I started this journey I didn’t really know what I wanted with curl’s license and exactly what rights and freedoms I wanted to give away and it took a few years and attempts before it landed.
The early versions were GPL licensed, but as I learned about resistance from proprietary companies and thought about it further, I changed the license to be more commercially friendly and to match my conviction better. I ended up with MIT after a brief experimental time using MPL. (It was easy to change the license back then because I owned all the copyrights at that point.)
To be exact: we actually have a slightly modified MIT license with some very subtle differences. The reason for the changes have been forgotten and we didn’t get those commits logged in the “big transition” to Sourceforge that we did in late 1999… The end result is that this is now often recognized as “the curl license”, even though it is in effect the MIT license.
The license says everyone can use the code for whatever purpose and nobody is required to ship any source code to anyone, but they cannot claim they wrote it themselves and the license/use of the code should be mentioned in documentation or another relevant location.
As licenses go, this has to be one of the most frictionless ones there is.
Open source relies on a solid copyright law and the copyright owners of the code are the only ones who can license it away. For a long time I was the sole copyright owner in the project. But as I had decided to stick to the license, I saw no particular downsides with allowing code and contributors (of significant contributions) to retain their copyrights on the parts they brought. To not use that as a fence to make contributions harder.
Today, in early 2021, I count 1441 copyright strings in the curl source code git repository. 94.9% of them have my name.
I never liked how some projects require copyright assignments or license agreements etc to be able to submit code or patches. Partly because of the huge administrative burden it adds to the project, but also for the significant friction and barrier to entry they create for new contributors and the unbalance it creates; some get more rights than others. I’ve always worked on making it easy and smooth for newcomers to start contributing to curl. It doesn’t happen by accident.
In many ways, running a spare time open source project is easy. You just need a steady income from a “real” job and sufficient spare time, and maybe a server to host stuff on for the online presence.
The challenge is of course to keep developing it, adding things people want, to help users with problems and to address issues timely. Especially if you happen to be lucky and the user amount increases and the project grows in popularity.
I ran curl as a spare time project for decades. Over the years it became more and more common that users who submitted bug reports or asked for help about things were actually doing that during their paid work hours because they used curl in a commercial surrounding – which sometimes made the situation almost absurd. The ones who actually got paid to work with curl were asking the unpaid developers to help them out.
I changed employers several times. I started my own company and worked as my own boss for a while. I worked for Mozilla on network stuff in Firefox for five years. But curl remained a spare time project because I couldn’t figure out how to turn it into a job without risking the project or my economy.
For many years it was a pipe dream for me to be able to work on curl as a real job. But how do I actually take the step from a spare time project to doing it full time? I give away all the code for free, and it is a solid and reliable product.
The initial seeds were planted when I met and got to know Larry (wolfSSL CEO) and some of the other good people at wolfSSL back in the early 2010s. This, because wolfSSL is a company that write open source libraries and offer commercial support for them – proving that it can work as a business model. Larry always told me he thought there was a possibility waiting here for me with curl.
Apart from the business angle, if I would be able to work more on curl it could really benefit the curl project, and then of course indirectly everyone who uses it.
It was still a step to take. When I gave up on Mozilla in 2018, it just took a little thinking before I decided to try it. I joined wolfSSL to work on curl full time. A dream came true and finally curl was not just something I did “on the side”. It only took 21 years from first curl release to reach that point…
I’m living the open source dream, working on the project I created myself.
We sell commercial support for curl and libcurl. Companies and users that need a helping hand or swift assistance with their problems can get it from us – and with me here I dare to claim that there’s no company anywhere else with the same ability. We can offload engineering teams with their curl issues. Up to 24/7 level!
We also offer custom curl development, debugging help, porting to new platforms and basically any other curl related activity you need. See more on the curl product page on the wolfSSL site.
curl (mostly in the shape of libcurl) runs in ten billion installations: some five, six billion mobile phones and tablets – used by several of the most downloaded apps in existence, in virtually every website and Internet server. In a billion computer games, a billion Windows machines, half a billion TVs, half a billion game consoles and in a few hundred million cars… curl has been made to run on 82 operating systems on 22 CPU architectures. Very few software components can claim a wider use.
“Isn’t it easier to list companies that are not using curl?”
Wide use and being recognized does not bring food on the table. curl is also totally free to download, build and use. It is very solid and stable. It performs well, is documented, well tested and “battle hardened”. It “just works” for most users.
How to convince companies that they should get a curl support contract with me?
Paying customers get to influence what I work on next. Not only distant road-mapping but also how to prioritize short term bug-fixes etc. We have a guaranteed response-time.
You get your issues first in line to get fixed. Customers also won’t risk getting their issues added the known bugs document and put in the attic to be forgotten. We can help customers make sure their application use libcurl correctly and in the best possible way.
I try to emphasize that by getting support from us, customers can take away some of those tasks from their own engineers and because we are faster and better on curl related issues, that is a pure net gain economically. For all of us.
This is not an easy sell.
Sure, curl is used by thousands of companies everywhere, but most of them do it because it’s free (in all meanings of the word), functional and available. There’s a real challenge in identifying those that actually use it enough and value the functionality enough that they realize they want to improve their curl foo.
Most of our curl customers purchased support first when they faced a complicated issue or problem they couldn’t fix themselves – this fact gives me this weird (to the wider curl community) incentive to not fix some problems too fast, because it then makes it work against my ability to gain new customers!
We need paying customers for this to be sustainable. When wolfSSL has a sustainable curl business, I get paid and the work I do in curl benefits all the curl users; paying as well as non-paying.
There’s clearly business in releasing open source under a strong copyleft license such as GPL, and as long as you keep the copyrights, offer customers to purchase that same code under another more proprietary- friendly license. The code is still open source and anyone doing totally open things can still use it freely and at no cost.
We’ve shipped tiny-curl to the world licensed under GPLv3. Tiny-curl is a curl branch with a strong focus on the tiny part: the idea is to provide a libcurl more suitable for smaller systems, the ones that can’t even run a full Linux but rather use an RTOS.
Consider it a sort of experiment. Are users interested in getting a smaller curl onto their products and are they interested in paying for licensing. So far, tiny-curl supports two separate RTOSes for which we haven’t ported the “normal” curl to.
Maybe you don’t realize this, but I work hard to keep separate things compartmentalized. I am not curl, curl is not wolfSSL and wolfSSL is not me. But we all overlap greatly!

I work for wolfSSL. I work on curl. wolfSSL offers commercial curl support.
One idea that we haven’t explored much yet is the ability to make and offer “reserved features” to paying customers only. This of course as another motivation for companies to become curl support customers.
Such reserved features would still have to be sensible for the curl project and most likely we would provide them as specials for paying customers for a period of time and then merge them into the “real” open source curl project. It is very important to note that this will not in any way make the “regular curl” worse or a lesser citizen in any way. It would rather be a like a separate product, a curl+ with extra stuff on top of vanilla curl.
Since we haven’t ventured into this area yet, we haven’t worked out all the details. Chances are we will wander into this territory soon.
I do occasional speaking gigs on curl and HTTP related topics but even if I charge for them this activity never brings much more than some extra pocket money. I do it because it’s fun and educational.
It has been suggested that I should create a web shop to sell curl branded merchandise in, like t-shirts, mugs, etc but I think that grossly over-estimates the user interest and how much margin I could put on mundane things just because they’d have a curl logo glued on them. Also, I would have a difficult time mentally to sell curl things and claim the profit personally. I rather keep giving away curl stash (mostly stickers) for free as a means to market the project and long term encourage users into buying support.
We receive money to the curl project through donations, most of them via our opencollective account. It is important to note that even if I’m a key figure in the project, this is not my money and it’s not my project. Donated money is spent on project related expenses, which so far primarily is our bug bounty program. We’ve avoided to spend donated money on direct curl development, and especially such that I could provide or benefit from myself, as that would totally blur the boundaries. I’m not ruling out taking that route in a future though. As long as and only if it is to the project’s benefit.
Donations via GitHub to me personally sponsors me personally and ends up in my pockets. That’s not curl money but I spend it mostly on curl development, equipment etc and it makes me able to not have to think twice when sending curl stickers to fans and friends all over the world. It contributes to food on my table and I like to think that an occasional beer I drink is sponsored by friends out there!
We get a steady number of companies paying for support at a level that allows us to also pay for a few more curl engineers than myself.
Image by Khusen Rustamov from Pixabay
https://daniel.haxx.se/blog/2021/01/15/food-on-the-table-while-giving-away-code/
|
|
The Mozilla Blog: Reimagine Open: Building a Healthier Internet |
Does the “openness” that made the internet so successful also inevitably lead to harms online? Is an open internet inherently a haven for illegal speech, for eroding privacy and security, or for inequitable access? Is “open” still a useful concept as we chart a future path for the internet?
A new paper from Mozilla seeks to answer these questions. Reimagine Open: Building Better Internet Experiences explores the evolution of the open internet and the challenges it faces today. The report catalogs findings from a year-long project of outreach led by Mozilla’s Chairwoman and CEO, Mitchell Baker. Its conclusion: We need not break faith with the values embedded in the open internet. But we do need to return to the original conceptions of openness, now eroded online. And we do need to reimagine the open internet, to address today’s need for accountability and online health.
As the paper outlines, the internet’s success is often attributed to a set of technical design choices commonly labelled as “the open internet.” These features – such as decentralized architectures, end-to-end networks, open standards, and open source software – powered the internet’s growth. They also supported values of access, opportunity, and empowerment for the network’s users. And they were aided by accountability mechanisms that checked bad behavior online.
Today’s internet has moved away from these values. The term “open” itself has been watered down, with open standards and open source software now supplanted by closed platforms and proprietary systems. Companies pursuing centralization and walled gardens claim to support “openness.” And tools for online accountability have failed to scale with the incredible diversity of online life. The result is an internet that we know can be better.
Reimagine Open concludes with a set of ideas about how society can take on the challenges of today’s internet, while retaining the best of openness. These include new technical designs and a recommitment to open standards and open software; stronger user demand for healthier open products online; tougher, smarter government regulation; and better online governance mechanisms. Short case studies demonstrate how reimagine open can offer practical insights into tough policy problems.
Our hope is that Reimagine Open is a jumping-off point for the continuing conversation about the internet’s future. Open values still offer powerful insights to address policy challenges, like platform accountability, or digital identity. Openness can be an essential tool in building a new conception of local, open innovation to better serve the Global South. For a deeper look at these ideas and more, please visit the Reimagine Open Project Wiki, and send us your thoughts. Together we can build a reimagined open internet that will act as a powerful force for human progress online.
The post Reimagine Open: Building a Healthier Internet appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2021/01/14/reimagine-open-building-a-healthier-internet/
|
|
Will Kahn-Greene: Socorro Engineering: Half in Review 2020 h2 and 2020 retrospective |
2020h1 was rough. 2020h2 was also rough: more layoffs, 2 re-orgs, Covid-19.
I (and Socorro and Tecken) got re-orged into the Data Org. Data Org manages the Telemetry ingestion pipeline as well as all the things related to it. There's a lot of overlap between Socorro and Telemetry and being in the Data Org might help reduce that overlap and ease maintenance.
But this post isn't about the future--it's about the past! Let's talk about what happened in 2020h2 and then a brief retrospective of 2020.
Prepare to dive in!
Read more… (8 min remaining to read)
https://bluesock.org/~willkg/blog/mozilla/socorro_2020_h2.html
|
|






