This Week In Rust: This Week in Rust 377 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's crate is threadIO, a crate that makes disk IO in a background thread easy and elegant.
Thanks to David Andersen for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Fuchsia has several issues available:
If you are a Rust project owner and are looking for contributors, please submit tasks here.
384 pull requests were merged in the last week
Box the biggest ast::ItemKind variantsassert!() calling the wrong edition of panic!()Allocator object-safeVec::extend_from_within method under vec_extend_from_within feature gateBTreeMap: make Ord bound explicit, compile-test its absenceTrustedLen for FuseIterator::fold_first to reduce and stabilize itWake traitpeekable_next_ifOnce, rename poisoned()const fnonce_cell in static wakersFrom> for HashSetcargo test and cargo run--error-format short in doctestslet_underscore_drop false positivelet_and_return false positiveexhaustive_structs for structs with private fieldsmissing_panics_docNo triage report this week
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
impl PartialEq for char ; symmetry for #78636Arc.NotSupported to std::io::ErrorKindOption::expect_none(msg) and unwrap_none()If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
The main theme of Rust is not systems programming, speed, or memory safety - it's moving runtime problems to compile time. Everything else is incidental. This is an invaluable quality of any language, and is something Rust greatly excels at.
– /u/OS6aDohpegavod4 on /r/rust
Thanks to Chris for the suggestion.
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, and cdmistman.
https://this-week-in-rust.org/blog/2021/02/10/this-week-in-rust-377/
|
|
Data@Mozilla: This Week in Glean: Backfilling rejected GPUActive Telemetry data |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla uses to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as Glean inspires it. You can find an index of all TWiG posts online.)
Data ingestion is a process that involves decompressing, validating, and transforming millions of documents every hour. The schemas of data coming into our systems are ever-evolving, sometimes causing partial outages of data availability when the conditions are ripe. Once the outage has been resolved, we run a backfill to fill in the gaps for all the missing data. In this post, I’ll discuss the error discovery and recovery processes through a recent bug.
Every Monday, a group of data engineers pours over a set of dashboards and plots indicating data ingestion health. On 2020-08-04, we filed a bug where we observed an elevated rate of schema validation errors coming from environment/system/gfx/adapters/N/GPUActive. For mistakes like these that are small fractions of our overall volume, partial outages are typically not urgent (as in not “we need to drop everything right now and resolve this stat!” critical). We called the subject experts and found out that the code responsible for reporting multiple GPUs in the environment had changed.
An intern reached out to me about a DNS study running a few weeks after filing the bug about GPUActive. I helped figure out that his external monitor setup with his Macbook was causing rejections like the ones that we had seen weeks before. One PR and one deploy later, I watched the error rates for the GPUActive field abruptly drop to zero.
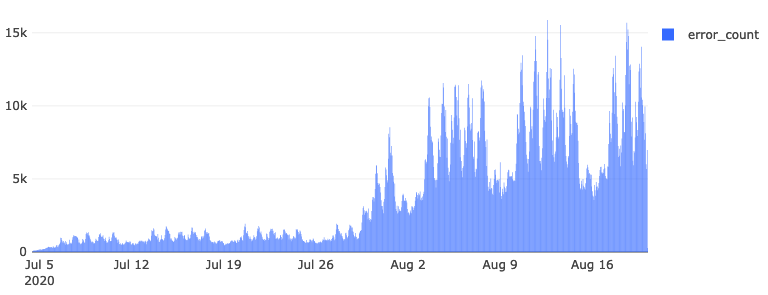
Figure: Error counts for environment/system/gfx/adapters/N/GPUActive
The schema’s misspecification resulted in 4.1 million documents between 2020-07-04 and 2020-08-20 to be sent to our error stream, awaiting reprocessing.
In January of 2021, we ran the backfill of the GPUActive rejects. First, we determined the backfill range by querying the relevant error table:
SELECT DATE(submission_timestamp) AS dt, COUNT(*)FROM `moz-fx-data-shared-prod.payload_bytes_error.telemetry`WHERE submission_timestamp < '2020-08-21' AND submission_timestamp > '2020-07-03' AND exception_class = 'org.everit.json.schema.ValidationException' AND error_message LIKE '%GPUActive%'GROUP BY 1ORDER BY 1 |
The query helped verify the date range of the errors and their counts: 2020-07-04 through 2020-08-20. The following tables were affected:
crashdnssec-study-v1eventfirst-shutdownheartbeatmainmodulesnew-profileupdatevoice |
We isolated the error documents into a backfill project named moz-fx-data-backfill-7 and mirrored our production BigQuery datasets and tables into it.
SELECT *FROM `moz-fx-data-shared-prod.payload_bytes_error.telemetry`WHERE DATE(submission_timestamp) BETWEEN "2020-07-04" AND "2020-08-20" AND exception_class = 'org.everit.json.schema.ValidationException' AND error_message LIKE '%GPUActive%' |
Then we ran a suitable Dataflow job to populate our tables using the same ingestion code as the production jobs. It took about 31 minutes to run to completion. We copied and deduplicated the data into a dataset that mirrored our production environment.
gcloud config set project moz-fx-data-backfill-7dates=$(python3 -c 'from datetime import datetime as dt, timedelta; start=dt.fromisoformat("2020-07-04"); end=dt.fromisoformat("2020-08-21"); days=(end-start).days; print(" ".join([(start + timedelta(i)).isoformat()[:10] for i in range(days)]))')./script/copy_deduplicate --project-id moz-fx-data-backfill-7 --dates $(echo $dates) |
This query took hours because it iterated over all tables for ~50 days, regardless of whether it contained data. Future backfills should probably remove empty tables before kicking off this script.
Now that tables were populated, we handled data deletion requests since the time of the initial error. A module named Shredder serves the self-service deletion requests in BigQuery ETL. We ran Shredder from the bigquery-etl root.
script/shredder_delete --billing-projects moz-fx-data-backfill-7 --source-project moz-fx-data-shared-prod --target-project moz-fx-data-backfill-7 --start_date 2020-06-01 --only 'telemetry_stable.*' --dry_run |
This removed relevant rows from our final tables.
INFO:root:Scanned 515495784 bytes and deleted 1280 rows from moz-fx-data-backfill-7.telemetry_stable.crash_v4INFO:root:Scanned 35301644397 bytes and deleted 45159 rows from moz-fx-data-backfill-7.telemetry_stable.event_v4INFO:root:Scanned 1059770786 bytes and deleted 169 rows from moz-fx-data-backfill-7.telemetry_stable.first_shutdown_v4INFO:root:Scanned 286322673 bytes and deleted 2 rows from moz-fx-data-backfill-7.telemetry_stable.heartbeat_v4INFO:root:Scanned 134028021311 bytes and deleted 13872 rows from moz-fx-data-backfill-7.telemetry_stable.main_v4INFO:root:Scanned 2795691020 bytes and deleted 1071 rows from moz-fx-data-backfill-7.telemetry_stable.modules_v4INFO:root:Scanned 302643221 bytes and deleted 163 rows from moz-fx-data-backfill-7.telemetry_stable.new_profile_v4INFO:root:Scanned 1245911143 bytes and deleted 6477 rows from moz-fx-data-backfill-7.telemetry_stable.update_v4INFO:root:Scanned 286924248 bytes and deleted 10 rows from moz-fx-data-backfill-7.telemetry_stable.voice_v4INFO:root:Scanned 175822424583 and deleted 68203 rows in total |
After this is all done, we append each of these tables to the production tables. Appends requires superuser permissions, so it was handed off to another engineer to finalize the deed. Afterward, we deleted the rows in the error table corresponding to the backfilled pings from the backfill-7 project.
DELETEFROM `moz-fx-data-shared-prod.payload_bytes_error.telemetry`WHERE DATE(submission_timestamp) BETWEEN "2020-07-04" AND "2020-08-20" AND exception_class = 'org.everit.json.schema.ValidationException' AND error_message LIKE '%GPUActive%' |
Finally, we updated the production errors with new errors generated from the backfill process.
bq cp --append_table moz-fx-data-backfill-7:payload_bytes_error.telemetry moz-fx-data-shared-prod:payload_bytes_error.telemetry |
Now those rejected pings are available for analysis down the line. For the unadulterated backfill logs, see this PR to bigquery-backfill.
No system is perfect, but the processes we have in place allow us to systematically understand the surface area of issues and systematically address failures. Our health check meeting improves our situational awareness of changes upstream in applications like Firefox, while our backfill logs in bigquery-backfill allow us to practice dealing with the complexities of recovering from partial outages. These underlying processes and systems are the same ones that facilitate the broader Glean ecosystem at Mozilla and will continue to exist as long as the data flows.
|
|
Mozilla Addons Blog: Extensions in Firefox 86 |
Firefox 86 will be released on February 23, 2021. We’d like to call out two highlights and several bug fixes for the WebExtensions API that will ship with this release.
manifest_version, which is not currently supported in Firefox. If you would like to test the new CSP for extension pages and content scripts, you must change your extension’s manifest_version to 3 and set extensions.manifestv3.enabled to true in about:config. Because this is a highly experimental and evolving feature, we want developers to be aware that extensions that work with the new CSP may break tomorrow as more changes are implemented. identity.launchWebAuthFlow API. This fix makes it possible for extensions to successfully integrate with OAuth authentication for some common web services like Google and Facebook. This will also be uplifted to Firefox Extended Support Release (ESR) 78.extensions.webextensions.tabhide.enabled preference is no longer displayed and references to it have been removed.As a quick note, going forward we’ll be publishing release updates in the Firefox developer release notes on MDN. We will still announce major changes to the WebExtensions API, like new APIs, significant enhancements, and deprecation notices, on this blog as they become available.
Many thanks to community members Sonia Singla, Tilden Windsor, robbendebiene, and Brenda Natalia for their contributions to this release!
The post Extensions in Firefox 86 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2021/02/09/extensions-in-firefox-86/
|
|
Hacks.Mozilla.Org: Browser fuzzing at Mozilla |
Mozilla has been fuzzing Firefox and its underlying components for a while. It has proven to be one of the most efficient ways to identify quality and security issues. In general, we apply fuzzing on different levels: there is fuzzing the browser as a whole, but a significant amount of time is also spent on fuzzing isolated code (e.g. with libFuzzer) or whole components such as the JS engine using separate shells. In this blog post, we will talk specifically about browser fuzzing only, and go into detail on the pipeline we’ve developed. This single pipeline is the result of years of work that the fuzzing team has put into aggregating our browser fuzzing efforts to provide consistently actionable issues to developers and to ease integration of internal and external fuzzing tools as they become available.

To be as effective as possible we make use of different methods of detecting errors. These include sanitizers such as AddressSanitizer (with LeakSanitizer), ThreadSanitizer, and UndefinedBehaviorSanitizer, as well as using debug builds that enable assertions and other runtime checks. We also make use of debuggers such as rr and Valgrind. Each of these tools provides a different lens to help uncover specific bug types, but many are incompatible with each other or require their own custom build to function or provide optimal results. Besides providing debugging and error detection, some tools cannot work without build instrumentation, such as code coverage and libFuzzer. Each operating system and architecture combination requires a unique build and may only support a subset of these tools.
Last, each variation has multiple active branches including Release, Beta, Nightly, and Extended Support Release (ESR). The Firefox CI Taskcluster instance builds each of these periodically.
Taskcluster makes it easy to find and download the latest build to test. We discussed above the number of variants created by different instrumentation types, and we need to fuzz them in automation. Because of the large number of combinations of builds, artifacts, architectures, operating systems, and unpacking each, downloading is a non-trivial task.
To help reduce the complexity of build management, we developed a tool called fuzzfetch. Fuzzfetch makes it easy to specify the required build parameters and it will download and unpack the build. It also supports downloading specified revisions to make it useful with bisection tools.
As the goal of this blog post is to explain the whole pipeline, we won’t spend much time explaining fuzzers. If you are interested, please read “Fuzzing Firefox with WebIDL” and the in-tree documentation. We use a combination of publicly available and custom-built fuzzers to generate test cases.
For fuzzers that target the browser, Grizzly manages and runs test cases and monitors for results. Creating an adapter allows us to easily run existing fuzzers in Grizzly.

To make full use of available resources on any given machine, we run multiple instances of Grizzly in parallel.
For each fuzzer, we create containers to encapsulate the configuration required to run it. These exist in the Orion monorepo. Each fuzzer has a configuration with deployment specifics and resource allocation depending on the priority of the fuzzer. Taskcluster continuously deploys these configurations to distribute work and manage fuzzing nodes.
Grizzly Target handles the detection of issues such as hangs, crashes, and other defects. Target is an interface between Grizzly and the browser. Detected issues are automatically packaged and reported to a FuzzManager server. The FuzzManager server provides automation and a UI for triaging the results.
Other more targeted fuzzers use JS shell and libFuzzer based targets use the fuzzing interface. Many third-party libraries are also fuzzed in OSS-Fuzz. These deserve mention but are outside of the scope of this post.
Running multiple fuzzers against various targets at scale generates a large amount of data. These crashes are not suitable for direct entry into a bug tracking system like Bugzilla. We have tools to manage this data and get it ready to report.
The FuzzManager client library filters out crash variations and duplicate results before they leave the fuzzing node. Unique results are reported to a FuzzManager server. The FuzzManager web interface allows for the creation of signatures that help group reports together in buckets to aid the client in detecting duplicate results.
Fuzzers commonly generate test cases that are hundreds or even thousands of lines long. FuzzManager buckets are automatically scanned to queue reduction tasks in Taskcluster. These reduction tasks use Grizzly Reduce and Lithium to apply different reduction strategies, often removing the majority of the unnecessary data. Each bucket is continually processed until a successful reduction is complete. Then an engineer can do a final inspection of the minimized test case and attach it to a bug report. The final result is often used as a crash test in the Firefox test suite.

Code coverage of the fuzzer is also measured periodically. FuzzManager is used again to collect code coverage data and generate coverage reports.
Our goal is to create actionable bug reports to get issues fixed as soon as possible while minimizing overhead for developers.
We do this by providing:
Grizzly Replay is a tool that forms the basic execution engine for Bugmon and Grizzly Reduce, and makes it easy to collect rr traces to submit to Pernosco. It makes re-running browser test cases easy both in automation and for manual use. It simplifies working with stubborn test cases and test cases that trigger multiple results.
As mentioned, we have also been making use of Pernosco. Pernosco is a tool that provides a web interface for rr traces and makes them available to developers without the need for direct access to the execution environment. It is an amazing tool developed by a company of the same name which significantly helps to debug massively parallel applications. It is also very helpful when test cases are too unreliable to reduce or attach to bug reports. Creating an rr trace and uploading it can make stalled bug reports actionable.
The combination of Grizzly and Pernosco have had the added benefit of making infrequent, hard to reproduce issues, actionable. A test case for a very inconsistent issue can be run hundreds or thousands of times until the desired crash occurs under rr. The trace is automatically collected and ready to be submitted to Pernosco and fixed by a developer, instead of being passed over because it was not actionable.
To request new features get a proper assessment, the fuzzing team can be reached at fuzzing@mozilla.com or on Matrix. This is also a great way to get in touch for any reason. We are happy to help you with any fuzzing related questions or ideas. We will also reach out when we receive information about new initiatives and features that we think will require attention. Once fuzzing of a component begins, we communicate mainly via Bugzilla. As mentioned, we strive to open actionable issues or enhance existing issues logged by others.
Bugmon is used to automatically bisect regression ranges. This notifies the appropriate people as quickly as possible and verifies bugs once they are marked as FIXED. Closing a bug automatically removes it from FuzzManager, so if a similar bug finds its way into the code base, it can be identified again.
Some issues found during fuzzing will prevent us from effectively fuzzing a feature or build variant. These are known as fuzz-blockers, and they come in a few different forms. These issues may seem benign from a product perspective, but they can block fuzzers from targeting important code paths or even prevent fuzzing a target altogether. Prioritizing these issues appropriately and getting them fixed quickly is very helpful and much appreciated by the fuzzing team.
PrefPicker manages the set of Firefox preferences used for fuzzing. When adding features behind a pref, consider adding it to the PrefPicker fuzzing template to have it enabled during fuzzing. Periodic audits of the PrefPicker fuzzing template can help ensure areas are not missed and resources are used as effectively as possible.
As in other fields, measurement is a key part of evaluating success. We leverage the meta bug feature of Bugzilla to help us keep track of the issues identified by fuzzers. We strive to have a meta bug per fuzzer and for each new component fuzzed.
For example, the meta bug for Domino lists all the issues (over 1100!) identified by this tool. Using this Bugzilla data, we are able to show the impact over the years of our various fuzzers.

Number of bugs reported by Domino over time
These dashboards help evaluate the return on investment of a fuzzer.
There are many components in the fuzzing pipeline. These components are constantly evolving to keep up with changes in debugging tools, execution environments, and browser internals. Developers are always adding, removing, and updating browser features. Bugs are being detected, triaged, and logged. Keeping everything running continuously and targeting as much code as possible requires constant and ongoing efforts.
If you work on Firefox, you can help by keeping us informed of new features and initiatives that may affect or require fuzzing, by prioritizing fuzz-blockers, and by curating fuzzing preferences in PrefPicker. If fuzzing interests you, please take part in the bug bounty program. Our tools are available publicly, and we encourage bug hunting.
The post Browser fuzzing at Mozilla appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/02/browser-fuzzing-at-mozilla/
|
|
Mozilla Attack & Defense: Guest Blog Post: Good First Steps to Find Security Bugs in Fenix (Part 2) |
This blog post is one of several guest blog posts, where we invite participants of our bug bounty program to write about bugs they’ve reported to us.
Continuing with Part 1, this article introduces some practices for finding security bugs in Fenix.
Fenix’s architecture is unique. Many of the browser features are not implemented in Fenix itself – they come from independent and reusable libraries such as GeckoView and Mozilla Android Components (known as Mozac). Fenix as a browser application combines these libraries as building parts for the internals, and the fenix project itself is primarily a User Interface. Mozac is noteworthy because it connects web contents rendered in GeckoView into the native Android world.
There are common pitfalls that lead to security bugs in the connection between web content and native apps. In this post, we’ll take a look at one of the pitfalls: private browsing mode bypasses. While looking for this class of bug, I discovered three separate but similar issues (Bugs 1657251, 1658231, and 1663261.)
Take a look at the following two lines of HTML.

Although these two HTML tags look similar in that they both fetch and render PNG images from the server, their internal processing is very different. In the former tag identifies a favicon for the page, and code in Mozac fetches the image and renders it as a part of a view of Android. When I discovered these vulnerabilities in the fall of 2020, a HTTP request sent from showed the string “MozacFetch”.
Like other browsers, GeckoView has a separated context for normal mode and private browsing mode. So the cookies and local storage areas in private browsing mode are completely separated from the normal mode, and these values are not shared. On the other hand, the URL fetch class that Mozac has – written in Kotlin – has only a single cookie store. If a favicon request responded with a Set-Cookie header; it would be stored in that cookie store and a later fetch of the favicon in private browsing mode would respond with the same cookie and vice versa. (Bug 1657251).

This same type of bug appears not only in Favicon, but also in other features that have a similar mechanism. One example is the Web Notification API. Web Notifications is a feature that shows an OS-level notification through JavaScript. Similar to favicons, an icon image can appear in the notification dialog – and it had a bug that shared private browsing mode cookies with the normal mode in the exact same way (Bug 1658231).

These bugs do not only occur when loading icon images. Bug 1663261 points out that a similar bypass occurs when downloading linked files via . File downloads are also handled by Mozac’s Downloads feature, which satisfies the same conditions to cause a similar flaw.
As you can see, Mozac’s URL fetch is one of the places that creates inconsistencies with web content. Other than private browsing mode, there are various other security protection mechanisms in the web world, such as port blocks, HSTS, CSP, Mixed-Content Block, etc. These protections are sometimes overlooked when issuing HTTP requests from another component. By focusing on these common pitfalls, you’ll likely be able to find new security bugs continuously into the future.
Using the difference in User-Agent to distinguish the initiator of the request was a useful technique for finding these kinds of bugs, but it’s no longer available in today’s Fenix. If you can build Fenix yourself, you can still use this technique by setting a custom request header indicating the request from Mozac like below.
private fun WebRequest.Builder.addHeadersFrom(request: Request): WebRequest.Builder {
request.headers?.forEach { header ->
addHeader(header.name, header.value)
}
+ addHeader("X-REQUESTED-BY", "MozacFetch") // add
return this
}
For monitoring HTTP requests, the Remote Debugging is useful. Requests sent from MozacFetch will be output to the Network tab of the Multiprocess Toolbox process in Remote Debug window.You can find requests from Mozac by filtering by the string “MozacFetch”.

Have a good bug hunt!
|
|
Mozilla Performance Blog: Performance Sheriff Newsletter (January 2021) |
|
|
Daniel Stenberg: curl supports rustls |
curl is an internet transfer engine. A rather modular one too. Parts of curl’s functionality is provided by selectable alternative implementations that we call backends. You select what backends to enable at build-time and in many cases the backends are enabled and powered by different 3rd party libraries.
curl has a range of such alternative backends for various features:
Maintaining a stable API and ABI is key to libcurl. As long as those promises are kept, changing internals such as switching between backends is perfectly fine.
The API is the armored front door that we don’t change. The backends is the garden on the back of the house that we can dig up and replant every year if we want, without us having to change the front door.
Already back in 2005 we added support for using an alternative TLS library in curl when we added support for GnuTLS in addition to OpenSSL, and since then we’ve added many more. We do this by having an internal API through which we do all the TLS related things and for each third party library we support we have code that does the necessary logic to connect the internal API with the corresponding TLS library.
Today, we merged support for yet another TLS library: rustls. This is a TLS library written in rust and it has a C API provided in a separate project called crustls. Strictly speaking, curl is built to use crustls.
This is still early days for the rustls backend and it is not yet feature complete. There’s more work to do and polish to apply before we can think of it as a proper competitor to the already established and well-used TLS backends, but with this merge it makes it much easier for more people to help out and test it out. Feel free and encouraged to join in!
We count this addition as the 14th concurrently supported TLS library in curl. I’m not aware of any other project, anywhere, that supports more or even this many TLS libraries.

The TLS library named mesalink is actually already using rustls, but under an OpenSSL API disguise and we support that since a few years back…
The TLS backend code for rustls was written and contributed by Jacob Hoffman-Andrews.
https://daniel.haxx.se/blog/2021/02/09/curl-supports-rustls/
|
|
The Mozilla Blog: Mozilla Welcomes the Rust Foundation |
Today Mozilla is thrilled to join the Rust community in announcing the formation of the Rust Foundation. The Rust Foundation will be the home of the popular Rust programming language that began within Mozilla. Rust has long been bigger than just a Mozilla project and today’s announcement is the culmination of many years of community building and collaboration. Mozilla is pleased to be a founding Platinum Sponsor of the Rust Foundation and looks forward to working with it to help Rust continue to grow and prosper.
Rust is an open-source programming language focused on safety, speed and concurrency. It started life as a side project in Mozilla Research. Back in 2010, Graydon Hoare presented work on something he hoped would become a “slightly less annoying” programming language that could deliver better memory safety and more concurrency. Within a few years, Rust had grown into a project with an independent governance structure and contributions from inside and outside Mozilla. In 2015, the Rust project announced the first stable release, Rust 1.0.
Success quickly followed. Rust is so popular that it has been voted the most “most-loved” programming language in Stack Overflow’s developer survey for five years in a row. Adoption is increasing as companies big and small, scientists, and many others discover its power and usability. Mozilla used Rust to build Stylo, the CSS engine in Firefox (replacing approximately 160,000 lines of C++ with 85,000 lines of Rust).
It takes a lot for a new programming language to be successful. Rust’s growth is thanks to literally thousands of contributors and a strong culture of inclusion. The wide range of contributors and adopters has made Rust a better language for everyone.
Mozilla is proud of its role in Rust’s creation and we are happy to see it outgrow its origins and secure a dedicated organization to support its continued evolution. Given its reach and impact, Rust will benefit from an organization that is 100% focused on the project.
The new Rust Foundation will have board representation from a wide set of stakeholders to help set a path to its own future. Other entities will be able to provide direct financial resources to Rust beyond in-kind contributions. The Rust Foundation will not replace the existing community and technical governance for Rust. Rather, it will be the organization that hosts Rust infrastructure, supports the community, and stewards the language for the benefit of all users.
Mozilla joins all Rustaceans in welcoming the new Rust Foundation.
The post Mozilla Welcomes the Rust Foundation appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2021/02/08/mozilla-welcomes-the-rust-foundation/
|
|
Mike Taylor: Obsolete RFCs and obsolete Cookie Path checking comments |
|
|
Will Kahn-Greene: Markus v3.0.0 released! Better metrics API for Python projects. |
Markus is a Python library for generating metrics.
Markus makes it easier to generate metrics in your program by:
providing multiple backends (Datadog statsd, statsd, logging, logging roll-up, and so on) for sending metrics data to different places
sending metrics to multiple backends at the same time
providing testing helpers for easy verification of metrics generation
providing a decoupled architecture making it easier to write code to generate metrics without having to worry about making sure creating and configuring a metrics client has been done--similar to the Python logging module in this way
We use it at Mozilla on many projects.
I released v3.0.0 just now. Changes:
Features
Added support for Python 3.9 (#79). Thank you, Brady!
Changed assert_* helper methods on markus.testing.MetricsMock
to print the records to stdout if the assertion fails. This can save some
time debugging failing tests. (#74)
Backwards incompatible changes
Dropped support for Python 3.5 (#78). Thank you, Brady!
markus.testing.MetricsMock.get_records and
markus.testing.MetricsMock.filter_records return
markus.main.MetricsRecord instances now.
This might require you to rewrite/update tests that use the MetricsMock.
Changes for this release: https://markus.readthedocs.io/en/latest/history.html#february-5th-2021
Documentation and quickstart here: https://markus.readthedocs.io/en/latest/index.html
Source code and issue tracker here: https://github.com/willkg/markus/
Let me know how this helps you!
|
|
Firefox Nightly: These Weeks in Firefox: Issue 87 |
https://blog.nightly.mozilla.org/2021/02/05/these-weeks-in-firefox-issue-86-2/
|
|
Daniel Stenberg: Webinar: curl, Hyper and Rust |
On February 11th, 2021 18:00 UTC (10am Pacific time, 19:00 Central Europe) we invite you to participate in a webinar we call “curl, Hyper and Rust”. To join us at the live event, please register via the link below:
https://www.wolfssl.com/isrg-partner-webinar/
What is the project about, how will this improve curl and Hyper, how was it done, what lessons can be learned, what more can we expect in the future and how can newcomers join in and help?
Participating speakers in this webinar are:
Daniel Stenberg. Founder of and lead developer of curl.
Josh Aas, Executive Director at ISRG / Let’s Encrypt.
Sean McArthur, Lead developer of Hyper.
The event will be about 30 minutes long with a following Q&A session.
The webinar will be recorded and made available after the fact. This post will get updated with a link once the video is ready.
If you already have a question you want to ask, please let us know ahead of time. Either in a reply here on the blog, or as a reply on one of the many tweets that you will see about about this event from me and my fellow “webinarees”.
https://daniel.haxx.se/blog/2021/02/04/webinar-curl-hyper-and-rust/
|
|
Mozilla GFX: Improving texture atlas allocation in WebRender |
This is going to be a rather technical dive into a recent improvement that went into WebRender.
In order to submit work to the GPU efficiently, WebRender groups as many drawing primitives as it can into what we call batches. A batch is submitted to the GPU as a single drawing command and has a few constraints. for example a batch can only reference a fixed set of resources (such as GPU buffers and textures). So in order to group as many drawing primitives as possible in a single batch we need to place as many drawing parameters as possible in few resources. When rendering text, WebRender pre-renders the glyphs before compositing them on the screen so this means packing as many pre-rendered glyphs as possible into a single texture, and the same applies for rendering images and various other things.
For a moment let’s simplify the case of images and text and assume that it is the same problem: input images (rectangles) of various rectangular sizes that we need to pack into a larger textures. This is the job of the texture atlas allocator. Another common name for this is rectangle bin packing.

Many in game and web development are used to packing many images into fewer assets. In most cases this can be achieved at build time Which means that the texture atlas allocator isn’t constrained by allocation performance and only needs to find a good layout for a fixed set of rectangles without supporting dynamic allocation/deallocation within the atlas at run time. I call this “static” atlas allocation as opposed to “dynamic” atlas allocation.
There’s a lot more literature out there about static than dynamic atlas allocation. I recommend reading A thousand ways to pack the bin which is a very good survey of various static packing algorithms. Dynamic atlas allocation is unfortunately more difficult to implement while keeping good run-time performance. WebRender needs to maintain texture atlases into which items are added and removed over time. In other words we don’t have a way around needing dynamic atlas allocation.
A while back, WebRender used a simple implementation of the guillotine algorithm (explained in A thousand ways to pack the bin). This algorithm strikes a good compromise between packing quality and implementation complexity.
The main idea behind it can be explained simply: “Maintain a list of free rectangles, find one that can hold your allocation, split the requested allocation size out of it, creating up to two additional rectangles that are added back to the free list.”. There is subtlety in which free rectangle to choose and how to split it, but the overall, the algorithm is built upon reassuringly understandable concepts.

Deallocation could simply consist of adding the deallocated rectangle back to the free list, but without some way to merge back neighbor free rectangles, the atlas would quickly get into a fragmented stated with a lot of small free rectangles and can’t allocate larger ones anymore.

To address that, WebRender’s implementation would regularly do a O(n^2) complexity search to find and merge neighbor free rectangles, which was very slow when dealing with thousands of items. Eventually we stopped using the guillotine allocator in systems that needed support for deallocation, replacing it with a very simple slab allocator which I’ll get back to further down this post.
Moving to a worse allocator because of the run-time defragmentation issue was rubbing me the wrong way, so as a side project I wrote a guillotine allocator that tracks rectangle splits in a tree in order to find and merge neighbor free rectangle in constant instead of quadratic time. I published it in the guillotiere crate. I wrote about how it works in details in the documentation so I won’t go over it here. I’m quite happy about how it turned out, although I haven’t pushed to use it in WebRender, mostly because I wanted to first see evidence that this type of change was needed and I already had evidence for many other things that needed to be worked on.
What replaced WebRender’s guillotine allocator in the texture cache was a very simple one based on fixed power-of-two square slabs, with a few special-cased rectangular slab sizes for tall and narrow items to avoid wasting too much space. The texture is split into 512 by 512 regions, each region is split into a grid of slabs with a fixed slab size per region.

This is a very simple scheme with very fast allocation and deallocation, however it tends to waste a lot of texture memory. For example allocating an 8x10 pixels glyph occupies a 16x16 slot, wasting more than twice the requested space. Ouch!
In addition, since regions can allocate a single slab size, space can be wasted by having a region with few allocations because the slab size happens to be uncommon.

Images and glyphs used to be cached in the same textures. However we render images and glyphs with different shaders, so currently they can never be used in the same rendering batches. I changed image and glyphs to be cached into a separate set of textures which provided with a few opportunities.
Not mixing images and glyphs means the glyph textures get more room for glyphs which reduces the number of textures containing glyphs overall. In other words, less chances to break batches. The same naturally applies to images. This is of course at the expense of allocating more textures on average, but it is a good trade-off for us and we are about to compensate the memory increase by using tighter packing.
In addition, glyphs and images are different types of workloads: we usually have a few hundred images of all sizes in the cache, while we have thousands of glyphs most of which have similar small sizes. Separating them allows us to introduce some simple workload-specific optimizations.
The first optimization came from noticing that glyphs are almost never larger than 128px. Having more and smaller regions, reduces the amount of atlas space that is wasted by partially empty regions, and allows us to hold more slab sizes at a given time so I reduced the region size from 512x512 to 128x128 in the glyph atlases. In the unlikely event that a glyph is larger than 128x128, it will go into the image atlas.
Next, I recorded the allocations and deallocations browsing different pages, gathered some statistics about most common glyph sizes and noticed that on a low-dpi screen, a quarter of the glyphs would land in a 16x16 slab but would have fit in a 8x16 slab. In latin scripts at least, glyphs are usually taller than wide. Adding 8x16 and 16x32 slab sizes that take advantage of this helps a lot.
I could have further optimized specific slab sizes by looking at the data I had collected, but the more slab sizes I would add, the higher the risk of regressing different workloads. This problem is called over-fitting. I don’t know enough about the many non-latin scripts used around the world to trust that my testing workloads were representative enough, so I decided that I should stick to safe bets (such as “glyphs are usually small”) and avoid piling up optimizations that might penalize some languages. Adding two slab sizes was fine (and worth it!) but I wouldn’t add ten more of them.

At this point, I had nice improvements to glyph allocation using the slab allocator, but I had a clear picture of the ceiling I would hit from the fixed slab allocation approach.
I already had guillotiere in my toolbelt, in addition to which I experimented with two algorithms derived from the shelf packing allocation strategy, both of them released in the Rust crate etagere. The general idea behind shelf packing is to separate the 2-dimensional allocation problem into a 1D vertical allocator for the shelves and within each shelf, 1D horizontal allocation for the items.
The atlas is initialized with no shelf. When allocating an item, we first find the shelf that is the best fit for the item vertically, if there is none or the best fit wastes too much vertical space, we add a shelf. Once we have found or added a suitable shelf, an horizontal slice of it is used to host the allocation.

At a glance we can see that this scheme is likely to provide much better packing than the slab allocator. For one, items are tightly packed horizontally within the shelves. That alone saves a lot of space compared to the power-of-two slab widths. A bit of waste happens vertically, between an item and the top of its shelf. How much the shelf allocator wastes vertically depends on how the shelve heights are chosen. Since we aren’t constrained to power-of-two size, we can also do much better than the slab allocator vertically.
The first shelf allocator I implemented was inspired from Mapbox’s shelf-pack allocator written in JavaScript. It has an interesting bucketing strategy: items are accumulated into fixed size “buckets” that behave like a small bump allocators. Shelves are divided into a certain number of buckets and buckets are only freed when all elements are freed. The trade-off here is to keep atlas space occupied for longer in order to reduce the CPU cost of allocating and deallocating. Only the top-most shelf is removed when empty so consecutive empty shelves in the middle aren’t merged until they become the top-most shelves, which can cause a bit of vertical fragmentation for long running sessions. When the atlas is full of (potentially empty) shelves the chance that a new item is too tall to fit into one of the existing shelves depends on how common the item height is. Glyphs tend to be of similar (small) heights so it works out well enough.
I added very limited support for merging neighbor empty shelves. When an allocation fails, the atlas iterates over the shelves and checks if there is a sequence of empty shelves that in total would be able to fit the requested allocation. If so, the first shelf of the sequence becomes the size of the sum, and the other shelves are squashed to zero height. It sounds like a band aid (it is) but the code is simple and it is working within the constraints that make the rest of the allocator very simple and fast. It’s only a limited form of support for merging empty shelves but it was an improvement for workloads that contain both small and large items.

This allocator worked quite well for the glyph texture (unsurprisingly, as Mapbox’s implementation it was inspired from is used with their glyph cache). The bucketing strategy was problematic, however, with large images. The relative cost of keeping allocated space longer was higher with larger items. Especially with long running sessions, this allocator was good candidate for the glyph cache but not for the image cache.
The guillotine allocator was working rather well with images. I was close to just using it for the image cache and move on. However, having spent a lot of time looking at various allocations patterns, my intuition was that we could do better. This is largely thanks to being able to visualize the algorithms via our integrated debugging tool that could generate nice SVG visualizations.
It motivated experimenting with a second shelf allocator. This one is conceptually even simpler: A basic vertical 1D allocator for shelves with a basic horizontal 1D allocator per shelf. Since all items are managed individually, they are deallocated eagerly which is the main advantage over the bucketed implementation. It is also why it is slower than the bucketed allocator, especially when the number of items is high. This allocator also has full support for merging/splitting empty shelves wherever they are in the atlas.

Unlike the Bucketed allocator, this one worked very well for the image workloads. For short sessions (visiting only a handful of web pages) it was not packing as tightly as the guillotine allocator, but after browsing for longer period of time, it had a tendency to better deal with fragmentation.

The implementation is very simple, scanning shelves linearly and then within the selected shelf another linear scan to find a spot for the allocation. I expected performance to scale somewhat poorly with high number of glyphs (we are dealing in the thousands of glyphs which arguably isn’t that high), but the performance hit wasn’t as bad I had anticipated, probably helped by mostly cache friendly underlying data-structure.
For both allocators I implemented the ability to split the atlas into a fixed number of columns. Adding columns means more (smaller) shelves in the atlas, which further reduces vertical fragmentation issues, at the cost of wasting some space at the end of the shelves. Good results were obtained on 2048x2048 atlases with two columns. You can see in the previous two images that the shelf allocator was configured to use two columns.
The shelf allocators support arranging items in vertical shelves instead of horizontal ones. It can have an impact depending on the type of workload, for example if there is more variation in width than height for the requested allocations. As far as my testing went, it did not make a significant difference with workloads recorded in Firefox so I kept the default horizontal shelves.
The allocators also support enforcing specific alignments in x and y (effectively, rounding up the size of allocated items to a multiple of the x and y alignment). This introduces a bit of wasted space but avoids leaving tiny holes in some cases. Some platforms also require a certain alignment for various texture transfer operations so it is useful to have this knob to tweak at our disposal. In the Firefox integration, we use different alignments for each type of atlas, favoring small alignments for atlases that mostly contain small items to keep the relative wasted space small.

The guillotine allocator is the best at keeping track of all available space and can provide the best packing of the algorithms I tried. The shelf allocators waste a bit of space by simplifying the arrangement into shelves, and the slab allocator wastes a lot of space for the sake of simplicity. On the other hand the guillotine allocator is the slowest when dealing with multiple thousands of items and can suffer from fragmentations in some of the workloads I recorded. Overall the best compromise was the simple shelf allocator which I ended up integrating in Firefox for both glyph and image textures in the cache (in both cases configured to have two columns per texture). The bucketed allocator is still a very reasonable option for glyphs and we could switch to it in the future if we feel we should trade some packing efficiency for allocation/deallocation performance. In other parts of WebRender, for short lived atlases (a single frame), the guillotine allocation algorithm is used.
These observations are mostly workload-dependent, though. Workloads are rarely completely random so results may vary.
There are other algorithms I could have explored (and maybe will someday, who knows), but I had found a satisfying compromise between simplicity, packing efficiency, and performance. I wasn’t aiming for state of the art packing efficiency. Simplicity was a very important parameter and whatever solutions I came up with would have to be simple enough to ship it in a web browser without risks.
To recap, my goals were to:
This was achieved by improving atlas packing to the point that we more rarely have to allocate multiple textures for each item type . The results look pretty good so far. Before the changes in Firefox, glyphs would often be spread over a number of textures after having visited a couple of websites, Currently the cache eviction is set so that we rarely need more than than one or two textures with the new allocator and I am planning to crank it up so we only use a single texture. For images, the shelf allocator is pretty big win as well. what used to fit into five textures now fits into two or three. Today this translates into fewer draw calls and less CPU-to-GPU transfers which has a noticeable impact on performance on low end Intel GPUs, in addition to reducing GPU memory usage.
The slab allocator improvements landed in bug 1674443 and shipped in Firefox 85, while the shelf allocator integration work went in bug 1679751 and will make it hit the release channel in Firefox 86. The interesting parts of this work are packaged in a couple of rust crates under permissive MIT OR Apache-2.0 license:
https://mozillagfx.wordpress.com/2021/02/04/improving-texture-atlas-allocation-in-webrender/
|
|
Armen Zambrano: Making Big Sur and pyenv play nicely |
Soon after Big Sur came out, I received my new work laptop. I decided to upgrade to it. Unfortunately, I quickly discovered that the Python set up needed for Sentry required some changes. Since it took me a bit of time to figure it out I decided to document it for anyone trying to solve the same problem.
If you are curious about all that I went through and see references to upstream issues you can visit this issue. It’s a bit raw. Most important notes are in the first comment.
On Big Sur, if you try to install older versions of Python you will need to tell pyenv to patch the code. For instance, you can install Python 3.8.7 the typical way ( pyenv install 3.8.7 ), however, if you try to install 3.8.0, or earlier, you will have to patch the code before building Python.
pyenv install --patch 3.6.10 < \
<(curl -sSL https://github.com/python/cpython/commit/8ea6353.patch\?full_index\=1)
If your pyenv version is lesser than 1.2.22 you will also need to specify LDFLAGS. You can read more about it here.
LDFLAGS="-L$(xcrun --show-sdk-path)/usr/lib ${LDFLAGS}" \
pyenv install --patch 3.6.10 < \
<(curl -sSL https://github.com/python/cpython/commit/8ea6353.patch\?full_index\=1)It seems very simple, however, it took me a lot of work to figure it out. I hope I saved you some time!
|
|
Martin Giger: Sunsetting Stream Notifier |

I have decided to halt any plans to maintain the extension and focus on other spare time open source projects instead. I should have probably made this decision about seven months ago, when Twitch integration broke, however this extension means a lot to me. It was my first browser extension that still exists and went …
Continue reading "Sunsetting Stream Notifier"
The post Sunsetting Stream Notifier appeared first on Humanoids beLog.
|
|
Will Kahn-Greene: Socorro: This Period in Crash Stats: Volume 2021.1 |
In 2020q3, Roger and I worked out a new Breadcrumbs crash annotation for
crash reports generated by the android-components crash reporter. It's a
JSON-encoded field with a structure just like the one that the sentry-sdk
sends. Incoming crash reports that have this annotation will show the data on
the crash report view page to people who have protected data access.

Figure 1: Screenshot of Breadcrumbs data in Details tab of crash report view on Crash Stats.
I implemented it based on what we get in the structure and what's in the Sentry interface.
Breadcrumbs information is not searchable with Supersearch. Currently, it's
only shown in the crash report view in the Details tab.
Does this help your work? Are there ways to improve this? If so, let me know!
This work was done in [bug 1671276].
For the longest of long times, crash reports from a Java process included a
JavaStackTrace annotation which was a big unstructured string of problematic
parseability and I couldn't do much with it.
In 2020q4, Roger and I worked out a new JavaException crash annotation which
was a JSON-encoded structured string containing the exception information. Not
only does it have the final exception, but it also has cascading exceptions if
there are any! With a structured form of the exception, we can suddenly do a
lot of interesting things.
As a first step, I added display of the Java exception information to the crash report view page in the Display tab. It's in the same place that you would see the crashing thread stack if this were a C++/Rust crash.
Just like JavaStackTrace, the JavaException annotation has some data in
it that can have PII in it. Because of that, the Socorro processor generates
two versions of the data: one that's sanitized (no java exception message
values) and one that's raw. If you have protected data access, you can see the
raw one.
The interface is pretty wide and exceeds the screenshot. Sorry about that.

Figure 2: Screenshot of Java exception data in Details tab of crash report view in Crash Stats.
My next step is to use the structured exception information to improve Java crash report signatures. I'm doing that work in [bug 1541120] and hoping to land that in 2021q1. More on that later.
Does this help your work? Are there ways to improve this? If so, let me know!
This work was done in [bug 1675560].
One of the things I don't like about the crash report view is that it's impossible to intuit where the data you're looking at is from. Further, some of the tabs were unclear about what bits of data were protected data and what bits weren't. I've been improving that over time.
The most recent step involved the following changes:
The "Metadata" tab was renamed to "Crash Annotations". This tab holds the crash annotation data from the raw crash before processing as well as a few fields that the collector adds when accepting a crash report from the client. Most of the fields are defined in the CrashAnnotations.yaml file in mozilla-central. The ones that aren't, yet, should get added. I have that on my list of things to get to.
The "Crash Annotations" tab is now split into public and protected data sections. I hope this makes it a little clearer which is which.
I removed some unneeded fields that the collector adds at ingestion.
Does this help your work? Are there ways to improve this? If so, let me know!
In addition to the day-to-day stuff, I'm working on the following big projects in 2021q1.
Last year, I looked into who's using the Email field and for what, whether the data was any good, and in what circumstances do we even get Email data. That work was done in [bug 1626277].
The consensus is that since not all of the crash reporter clients let a user enter in an email address, it doesn't seem like we use the data, and it's pretty toxic data to have, we should remove it.
The first step of that is to delete the field from the crash report at ingestion. I'll be doing that work in [bug 1688905].
The second step is to remove it from the webapp. I'll be doing that work in [bug 1688907].
Once that's done, I'll write up some bugs to remove it from the crash reporter clients and wherever else it is in products.
Does this affect you? If so, let me know!
Currently, signature generation for Java crashes is pretty basic and it's not flexible in the ways we need it. Now we can fix that.
I need some Java crash expertise to bounce ideas off of and to help me verify "goodness" of signatures. If you're interested in helping in any capacity or if you have opinions on how it should work or what you need out of it, please let me know.
I'm hoping to do this work in 2021q1.
The tracker bug is [bug 1541120].
Thank you to Roger Yang who implemented Breadcrumbs and JavaException
reporting and Gabriele Svelto who advised on new annotations and how things
should work! Thank you to everyone who submits signature generation changes--I
really appreciate your efforts!
https://bluesock.org/~willkg/blog/mozilla/socorro_tpics_2021_1.html
|
|
Daniel Stenberg: curl 7.75.0 is smaller |
There’s been another 56 day release cycle and here’s another curl release to chew on!
the 197th release
6 changes
56 days (total: 8,357)
113 bug fixes (total: 6,682)
268 commits (total: 26,752)
0 new public libcurl function (total: 85)
1 new curl_easy_setopt() option (total: 285)
2 new curl command line option (total: 237)
58 contributors, 30 new (total: 2,322)
31 authors, 17 new (total: 860)
0 security fixes (total: 98)
0 USD paid in Bug Bounties (total: 4,400 USD)
No new security advisories this time!
We added --create-file-mode to the command line tool. To be used for the protocols where curl needs to tell the remote server what “mode” to use for the file when created. libcurl already supported this, but now we expose the functionality to the tool users as well.
The --write-out option got five new “variables” to use. Detailed in this separate blog post.
The CURLOPT_RESOLVE option got an extended format that now allows entries to be inserted to get timed-out after the standard DNS cache expiry time-out.
gophers:// – the protocol GOPHER done over TLS – is now supported by curl.
As a new experimentally supported HTTP backend, you can now build curl to use Hyper. It is not quite up to 100% parity in features just yet.
AWS HTTP v4 Signature support. This is an authentication method for HTTP used by AWS and some other services. See CURLOPT_AWS_SIGV4 for libcurl and --aws-sigv4 for the curl tool.
Some of the notable things we’ve fixed this time around…
In my ongoing struggles to remove “dead weight” and ensure that curl can run on as small devices as possible, I’ve trimmed down the size of several key structs in curl. The memory foot-print of libcurl is now smaller than it has been for a very long time.
While itself not exactly a bug-fix, this is a step in a larger refactor of libcurl where we work on removing all references back from connections to the transfer. The grand idea is that transfers can point to connections, but since a connection can be owned and used by many transfers, we should remove all code that reference back to a transfer from the connection. To simplify internals. We’re not quite there yet.
Many users found out that when asking the curl tool to output timing information with -w, I accidentally made it show microseconds instead of seconds in 7.74.0! This is fixed and we’re back to the way it always was now…
The option that lets the user set the “request target” of a HTTP request to something custom (like for example “*” when you want to issue a request using the OPTIONS method) didn’t work over proxy!
Often used with the tools --fail flag, this is feature that makes libcurl stop and return error if the HTTP response code is 400 or larger. Starting in this version, curl will still read and parse all the response headers before it stops and exists. This then allows curl to act on and store contents from the other headers that can be used for features in combination with --fail.
In some circumstances, providing a custom “Proxy-Connection:” header for a HTTP request would still get curl’s own added header in the request as well, making the request get sent with a duplicate set!
There was a bug in the code that handles proxy responses, when the body of the CONNECT responses was using chunked-encoding. curl could end up thinking the response had ended before it actually had…
Back in 7.71.0 we fixed a problem with the user-agent header and made it get stored correctly in the transfer struct, from previously having been stored in the connection struct.
That cause a regression that we fixed now. The previous code had a mistake that caused the user-agent header to not get used when a connection was re-used or multiplexed, which from an outside perspective made it appear go missing in a random fashion…
Thanks to the new preprocessor we added for test cases some releases ago, we could now take the next step and offer conditionals in the test cases so that we can now better allow tests to run and behave differently depending on features and parameters. Previously, we have resorted to only make tests require a certain feature set to be able to run and otherwise skip the tests completely if the feature set could be satisfied, but with this new ability we can make tests more flexible and thus work with a wider variety of features.
A user reported that that curl failed to get the data when given a funny URL, while it worked fine in browsers (and wget):

The host name consists of a heart and a fox emoji in the .ws top-level domain. This is yet another URLs-are-weird issue and how to do International Domain Names with them is indeed a complicated matter, but starting now curl falls back and tries a more conservative approach if the first take fails and voil'a, now curl too can get the heart-fox URL just fine… Regular readers of my blog might remember the smiley URLs of 2015, which were similar.
We provide types for the most commonly used handles in the libcurl API as typedef’ed void pointers. The handles are typically declared like this:
CURL *easy;
CURLM *multi;
CURLSH *shared;
… but since they’re typedefed void-pointers, the compiler cannot helpfully point out if a user passes in the wrong handle to the wrong libcurl function and havoc can ensue.
Starting now, all these three handles have a “magic” struct field in the same relative place within their structs so that libcurl can much better detect when the wrong kind of handle is passed to a function and instead of going bananas or even crash, libcurl can more properly and friendly return an error code saying the input was wrong.
Since you’d ask: using void-pointers like that was a mistake and we regret it. There are better ways to accomplish the same thing, but the train has left. When we’ve tried to correct this situation there have been cracks in the universe and complaints have been shouted through the ether.
Turned out we didn’t support this before and it wasn’t hard to add…
The SNI (Server Name Indication) field is data set in TLS that tells the remote server which host name we want to connect to, so that it can present the client with the correct certificate etc since the server might serve multiple host names.
The spec clearly says that this field should contain the DNS name and that it is case insensitive – like DNS names are. Turns out it wasn’t even hard to find multiple servers which misbehave and return the wrong cert if the given SNI name is not sent lowercase! The popular browsers typically always send the SNI names like that… In curl we keep the host name internally exactly as it was given to us in the URL.
With a silent protest that nobody cares about, we went ahead and made curl also lowercase the host name in the SNI field when using OpenSSL.
I did not research how all the other TLS libraries curl can use behaves when setting SNI. This same change is probably going to have to be done on more places, or perhaps we need to surrender and do the lowercasing once and for all at a central place… Time will tell!
We have several pull requests in the queue suggesting changes, which means the next release is likely to be named 7.76.0 and the plan is to ship that on March 31st, 2021.
Send us your bug reports and pull requests!
https://daniel.haxx.se/blog/2021/02/03/curl-7-75-0-is-smaller/
|
|
This Week In Rust: This Week in Rust 376 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
No official blog posts this week.
This week's crate is fancy-regex a regex implementation using regex for speed and backtracking for fancy features.
Thanks to Benjamin Minixhofer for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
323 pull requests were merged in the last week
-Zrun-dsymutil as -Csplit-debuginfo_ field pattern when suggesting ..clashing_extern_declarations: use symbol interning to avoid string alloccompare_exchange_weakVec::shrink_to greater than capacity should be no-opAsMut for strio::Seek for io::Emptyio::copy reuse BufWriter buffersfordyn Any + Send + Sync`unwrap_unchecked() methods for Option and Resultcore::stream::Streamcore::slice::fill_withunsigned_abs[T; N] iterator core::array::IntoItercargo test -- --include-ignoredArc::{increment, decrement}_strong_countSeek::stream_position (feature seek_convenience)Another week dominated by rollups, most of which had relatively small changes with unclear causes embedded. Overall no major changes in performance this week.
Triage done by @simulacrum. Revision range: 1483e67addd37d9bd20ba3b4613b678ee9ad4d68.. f6cb45ad01a4518f615926f39801996622f46179
2 Regressions, 1 Improvements, 1 Mixed
3 of them in rollups
See the full report for more.
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
No RFCs are currently in the final comment period.
const fnArc.#[derive] into a regular macro attributepartition_pointIf you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
This time we had two very good quotes, I could not decide, so here are both:
What I have been learning ... was not Rust in particular, but how to write sound software in general, and that in my opinion is the largest asset that the rust community tough me, through the language and tools that you developed.
Under this prism, it was really easy for me to justify the step learning curve that Rust offers: I wanted to learn how to write sound software, writing sound software is really hard , and the Rust compiler is a really good teacher.
[...]
This ability to identify unsound code transcends Rust's language, and in my opinion is heavily under-represented in most cost-benefit analysis over learning Rust or not.
and
Having a fast language is not enough (ASM), and having a language with strong type guarantees neither (Haskell), and having a language with ease of use and portability also neither (Python/Java). Combine all of them together, and you get the best of all these worlds.
Rust is not the best option for any coding philosophy, it’s the option that is currently the best at combining all these philosophies.
– /u/CalligrapherMinute77 on /r/rust
Thanks to 2e71828 and Rusty Shell for their respective suggestions.
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, and cdmistman.
https://this-week-in-rust.org/blog/2021/02/03/this-week-in-rust-376/
|
|
The Talospace Project: Followup on Firefox 85 for POWER: new low-level fix |
This fix is now in the tree as bug 1690152; read that bug for the dirty details. You will need to apply it to Firefox 85 and rebuild, though I plan to ask to land this on beta 86 once it sticks and it will definitely be in Firefox 87. It should also be applied to ESR 78, though that older version doesn't exhibit the crashes to the frequency Fx85 does. This bug also only trips in optimized builds.
https://www.talospace.com/2021/02/followup-on-firefox-85-for-power-new.html
|
|






