Planet Mozilla Interns: Mihnea Dobrescu-Balaur: Start using your GitHub data |
GitHub is the home of Open Source software. Not only that, but both individuals and companies host their private code there. It started out as a hosted git solution, but it has evolved way beyond that. You can now track issues, keep wikis, host web pages, run tests for every commit and more.
While collaboration is indeed easy, I feel that GitHub lacks some of the features that are basic with dedicated issue trackers, like Bugzilla, JIRA and others. With GitHub, it's hard to keep track of lagging issues. Pull requests get forgotten all the time. Getting a quick overview of what are the most active issues is not trivial. If you want to make sure the issues are fairly distributed across team members in order to avoid burnout, good luck. There's no built-in way of specifying issue dependencies.
The good news is that there are possible workarounds - for example, we can simulate issues dependencies with issue mentions. For other shortcomings, there are no workarounds using just GitHub's UI. Fortunately, there is also an API which provides us with tons of data. Using it, we can start to address whatever shortcomings we feel GitHub has for our use cases - want to get a list of all the pull requests that can't be merged? Write a filter. Are you curious what bug is burning your users the most? Aggregate some counts.
You get the idea: all the data is there. You just have to use it.
Trying to solve this problem of getting more insights than GitHub's UI provides, I started working on a tool called Elasticboard. It provides a data-rich dashboard that helps you keep track of a GitHub repository, addressing most of the shortcomings described above. The code is hosted on GitHub, of course, and you are welcome to check out one of the demo dashboards.
Such a tool is helpful both to repo collaborators and new contributors. The repo collabs can keep track of what's going on and make sure that no issues slip through the cracks, while new contributors have their life made easier because now they can tell which of two issues is more important (there was more activity surrounding it), what issues are not assigned to anybody and so on.
Try Elasticboard out, add a repository that interests you in the hosted demo dashboard. It will only include recent events, because of GitHub's API limitations, but I think it's enough to make an idea. If the demo sparked your interest, deploying your own instance is easy - you can use the provided Docker container, or even serve it yourself. Either way, the README has all the info you need.
If feel like exploring the available data, I suggest you use Kibana and the Elasticsearch GitHub river. I wrote a short guide about it here.
The code is fully open source and it's designed to be extensible, making it easy to add new queries and data visualisations. If you are interested in contributing, again, the README will help you get started.
Happy hacking!
|
|
Stephen Horlander: (Re)Designing Firefox |
So, last Monday we launched a thing. You may have noticed it. We called it Australis. Now it’s just called Firefox.
We spent a lot of time on it.
Dedicating yourself to a project can become an intense experience. You think about it all the time: in the morning, at dinner, when you are trying to watch a movie, in the shower, in your sleep, when you should be sleeping…
But then you set it free, because it’s finally mature enough for that. It’s exciting. But it’s also really scary. You are never sure if you made the right decisions along the way. I like to take some time in the post release glow for some reflection.

So how did we get from there to here?
We launched Firefox 4 in March 2011. It was a big change from Firefox 3. It introduced the Firefox button, revamped the add-ons manager, removed the status bar, combined the stop, go and reload buttons and included a comprehensive visual update—all while still having time to prototype and discard some other features along the way.
And yet it wasn’t perfect. It had a lot of the rough edges that projects accumulate in the process of going from being designed and built to being shipped.
Firefox 4 was our last monolithic release before we moved to a rapid release cycle. Six week cycles seemed like the perfect timeframe to iteratively smooth out the rough edges. So I created a project to do just that.
The project that I had created for iterative refinement however quickly transformed into a significant overhaul.

At the beginning of June the UX team met up for its first post Firefox 4 team offsite. On the agenda was figuring out “What’s next?”. The entire team gathered in a room to pitch ideas and talk about problems unresolved—or that had been introduced—during the development of Firefox 4.
One theme that had been floating around for a while rose to the surface— Firefox is about customization, it should feel like it’s yours.
What would this mean for the interface we had just shipped? A lot of ideas were tossed around. Eventually one guiding principal stuck—make the best core experience we can and allow users to add and change the things that matter the most to them.
Building a fun easy to use Customization Mode—along with a more flexible Firefox Menu—would become the foundation of the new Firefox.
The offsite also sparked a set of other ideas that would make up what became known as Australis. Primarily: unifying the disparate bookmarking elements in the main window, refining the visual design, consolidating related or redundant features and streamlining the tabstrip.
While the redesigned customization mode would be core to the experience—the redesigned tabstrip would change the entire profile of Firefox.

We had explored the idea of adding visual cues to Firefox to make it feel faster and smoother before. Yet some of the ideas were a little over the top.

This sketch from the design session—inspired by a previous mockup from Trond—had a curvy tab shape that immediately resonated with everyone.
It also had one important additional design tweak—only render the tab shape for the active tab. Highlighting the active tab reduces visual noise and makes it easier to keep your place in the tabstrip.
The early curve shape tried on a few looks. At first it was too angular, then it was too curvy, then it was too short, then it was too tall and then (finally) it was just right.
.jpg)
It turns out that designing background tabs without a tab shape is a lot easier if you have a stable background to work with. Windows 7 has translucent windows of variable tints and Windows 8 has flat windows of variable color. This meant we needed to create our own stable background.
We went through several variations to ensure that the background tabs would be legible. First we tried creating a unified background block, but it seemed too heavy. We even thought about keeping background tab shapes and highlighting the active tab in some other way.
Eventually we decided on a background “fog” that would sit behind the tabs and in front of the window. Think of it as an interface sandwich—glass back, curvy-tab front with a delicious foggy center.
.jpg)
We also made sure that adding curves didn’t increase the width of the tabs taking up precious tabstrip real estate. And we removed the blank favicon placeholder for sites without favicons. A small tweak that frees up some extra room for the title.
One size really doesn’t fit all with something as complex and personal as your web browser. Add-ons have always made Firefox a thoroughly customizable browser, however arranging things has never been a great experience out of the box.
But before we could tackle the customization behavior, we had to rethink the Firefox Menu.
The main toolbar is the primary surface for frequently used actions; while the menu is the secondary surface for stuff you only use some of the time. We wanted users to be able to move things between these surfaces so they could tailor Firefox to their needs.

For the updated layout we started with the idea of a visual icon grid. This grid nicely mapped to the icons already found on the toolbar and would ideally make moving things back and forth feel cohesive.

The first grid we designed was wider, with smaller icons and no labels. This quickly changed to a three column grid with larger labeled icons. The updated layout served the same goal but was more clear and also less cramped.
Not everything we currently had in the Firefox Menu would translate directly to the new layout. We had to add special conjoined widgets—also known as “Wide Widgets”—for Cut/Copy/Paste and the Page Zoom controls. We also added a footer for persistent items that can’t be customized away. We did this to prevent users from getting into a broken layout with no escape hatch.

We had some serious debates about whether to use a an icon grid or a traditional menu list. The visual grid has some drawbacks: it isn’t as easy to scan and doesn’t scale as well with a lot of items. But the icon grid won this round because it was more visual, more inline with what we wanted out of drag-and-drop customization and had the side benefit of being touch friendly.

Some items from the Firefox Menu had submenus that could’t be easily reduced to a single action: Developer Tools, History, Bookmarks, Help and Character Encoding. Nested submenus hanging off of a panel felt pretty awkward. We had several ideas on how to handle this: inline expando-tray™, a drawer(interactive mockup—click History) and in-panel navigation.
We settled on what we call subviews(interactive mockup—click History). Subviews are partial overlays containing lists that slide in over the menu. Click anywhere in the partially visible menu layer to get back to the main menu—or close the entire menu and reopen it.
With the new menu layout Firefox should hopefully work just fine for most people out of the box. But by using the new Customization Mode you can really tailor Firefox to your needs. If you are interested in knowing more about why what is where Zhenshuo Fang wrote a great post about it.
Now we needed to figure out how update Firefox’s aging customization experience. Things started off a little ambitious with the idea that we could combine toolbar customization, themes and add-ons into the same UI. This led to an early interactive demo (it does some stuff, hint: tools icon –> plus sign) to try and see if this would work.
This demo surfaced a few issues: 1) including add-ons was going to be complicated 2) we needed a direct representation of the menu panel instead of a proxy. This led to a bunch of mockups for a flatter interface sans add-ons integration. Eventually I made a second demo without the theme selector that is closer to what we ended up shipping. Then Blake Winton turned that into an awesome prototype that actually did something.

The demos and prototypes helped us quickly get feedback from people on the idea. One of the complaints we heard was that it wasn’t obvious that you were entering a mode. We mocked up a lot of ideas for various ways to give visual feedback that you were in a mode and could now rearrange your stuff. We eventually settled on a subtle blueprint pattern and Madhava suggested we add some kind of animation with padding.
Thank you to everyone who dedicated so much time and effort into making this happen.
If you want to know more about the people and process behind Firefox 29, Madhava has a good post with an overview.
I think the post-release glow is over now. Time to get back to making Firefox better.
http://www.stephenhorlander.com/2014/05/redesigning-firefox/
|
|
Henrik Skupin: Firefox Automation report – week 13/14 2014 |
In this post you can find an overview about the work happened in the Firefox Automation team during week 13 and 14.
Finally we were able to upgrade our mozmill-ci production system to Mozmill 2.0.6. The only caveat is that we had to disable one test for cleaning history to prevent the always occurring Flash crash on Windows.
This week Henrik was able to land the first fixes for broken TPS tests. Together with Andrei we were able to fix 4 of them.
Also we had our first Automation Training days. The first one on Monday was a huge success, and we have seen lots of new faces. Sadly the second one on the following Wednesday we haven’t announced separately, so lesser people joined our training. In the future we will make sure, to announce each Automation Training day separately. Also there will be only a single one in a full week, so it will allow people to do some homework until the next session.
In week 14 we released version 2.0.6.1 of our mozmill-automation package. It was necessary to allow QA to run the Mozmill update tests with overriding the update channel, so update tests from a release candidate to the next beta build can be performed.
After we discovered even more Flash crashes of the same type, we decided to use the debug version of Flash on our Windows systems. Main reason is that those builds don’t crash. Sadly, given that they would give us way more information. But Adobe should at least know where the crash is happening. Also given that we do not have any private data on our test machines, we decided to actually upload a minidump from one of those crashes to Bugzilla. This information actually helped Adobe a lot! So we will continue doing that.
Last but not least Henrik was able to fix another 7 bugs for TPS. Those were broken tests, a broken behavior of the TPS test extension, or enhancements.
For more granular updates of each individual team member please visit our weekly team etherpad for week 13 and week 14.
If you are interested in further details and discussions you might also want to have a look at the meeting agenda, the video recording, and notes from the Firefox Automation meetings of week 13 and week 14.
http://www.hskupin.info/2014/05/09/firefox-automation-report-week-13-14-2014/
|
|
Doug Belshaw: Mozilla Webmaker training starts Monday 12th May! |
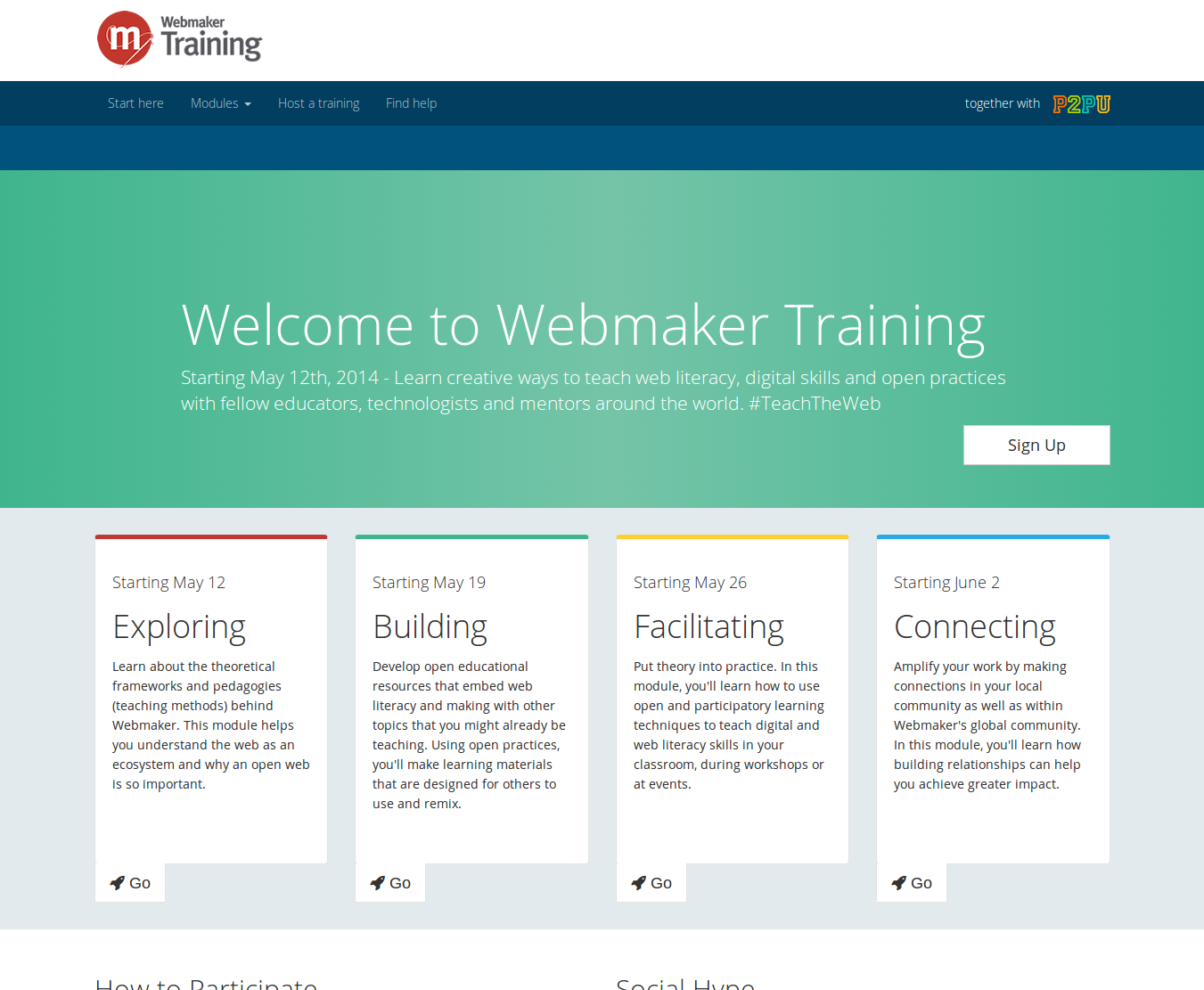
Excitingly, Mozilla’s Webmaker training starts on Monday. Join us (free!) to learn creative ways to teach web literacy, digital skills and open practices with fellow educators, technologists and mentors around the world.
Sign up here: http://training.webmakerprototypes.org
Each of the four weeks is a separate topic, but if you decide to do all of them, they build upon one another:
The brains behind the operation is Laura Hilliger, our Training & Curriculum Lead. Several of us from the Webmaker Community team are going to be helping out with running sessions.
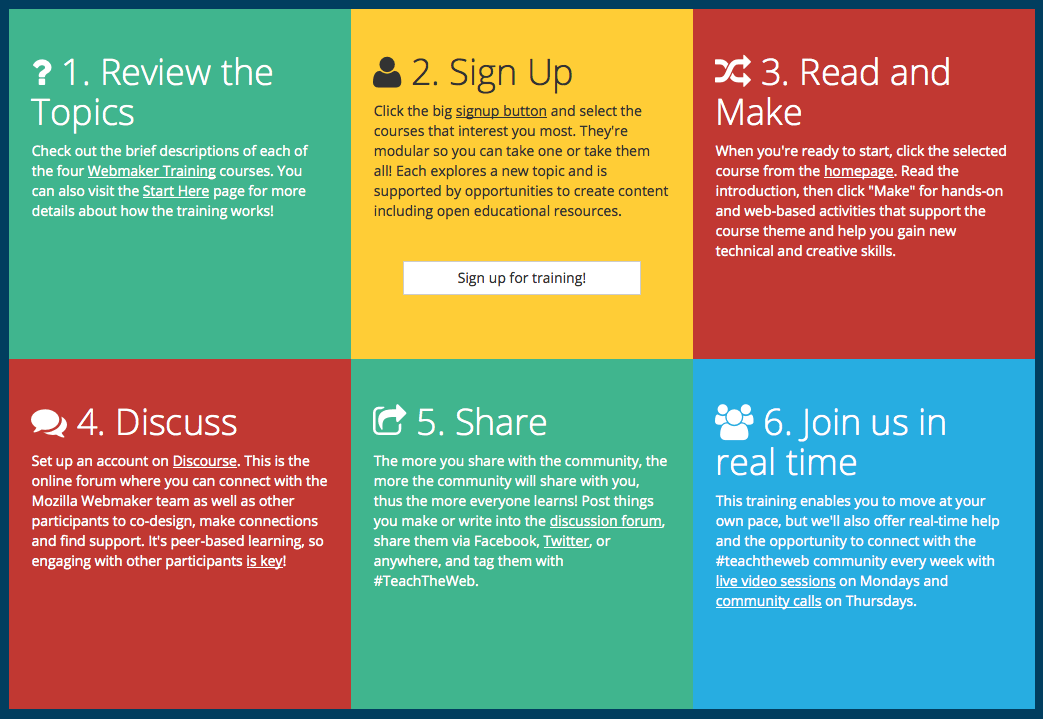
Laura’s put together a really nice ‘how to participate’ Thimble resource that’s worth checking out:
Week beginning 12th May. Learn about the theoretical frameworks and pedagogies (teaching methods) behind Webmaker. This module helps you understand the web as an ecosystem and why an open web is so important.
Week beginning 19th May. Develop open educational resources that embed web literacy and making with other topics that you might already be teaching. Using open practices, you’ll make learning materials that are designed for others to use and remix.
Week beginning 26th May. Put theory into practice. In this module, you’ll learn how to use open and participatory learning techniques to teach digital and web literacy skills in your classroom, during workshops or at events.
Week beginning 2nd June. Amplify your work by making connections in your local community as well as within Webmaker’s global community. In this module, you’ll learn how building relationships can help you achieve greater impact.
There’ll be three main places to pay attention to:
If you’ve always wanted to improve your web skills so that you can teach the web to others, this is your perfect opportunity – so sign up!
|
|
John Zeller: MySQL databases are all setup in BuildAPI-app docker container! |
As I stated in the previous post, the next step here was to setup databases. I spent time attempting to have sqlite work in this situation, but ran into issues with buildapi connecting to the sqlite databases. Rather than chase that rabbithole, I doublechecked the configuration in production buildapi and was reminded by the configs that production is running mysql. So I went ahead and did so. This setup required adding the following to the Dockerfile:
RUN apt-get install -y mysql-server
RUN chown mysql.mysql /var/run/mysqld/
RUN mysql_install_db # Installs mysql database schemas
RUN /usr/bin/mysqld_safe &
After this, everything was peachy except for the sql schemas available in the current buildapi repo. Those schemas are for sqlite, so I dumped my own mysql schemas for use here, and loaded them with the following commands:
mysql < status_schema.mysql
mysql < scheduler_schema.mysql
I went ahead and submitted a patch to add the mysql specific schemas to the buildapi repo in Bug 1007994, but for now I added the schemas in with the files in the buildapi-app directory.
I uploaded the current contents of the buildapi-app docker container and it launches with schemas all loaded and running well.
I am still having some issues verifying that selfserve-agent can execute commands from data sent to it over the amqp by buildapi. Further testing is needed to fix this issue. I am currently getting 404 error with my tests, but that might be a peripheral problem rather than selfserve-agent not getting data from the amqp.
Left to do on buildapi-app is to:
Links I found useful for this:
http://ijonas.com/devops-2/building-a-docker-based-mysql-server/
http://johnzeller.com/blog/2014/05/08/mysql-databases-are-all-setup-in-buildapi-docker-container/
|
|
Matthew Gregan: Testing MSE in Firefox Nightly |
Firefox's implementation of Media Source Extensions took a step forward recently. With last week's landing of the patch sets from bug 881512 and bug 1000608, along with a handful of minor follow-ups, videos are now playable in YouTube's HTML5 DASH player. The functionality in these patches extends Firefox's general Media Source Extensions implementation for all users, but the current focus for this iteration of development has been playback with YouTube's player.
It's now at a point that wider testing and technical feedback would be useful, so if you're feeling brave and need a good excuse to watch cats on treadmills and file bugs, please try it out. For now, MSE is hidden behind a preference, so first you'll need to set the preference to true:

Next, make sure YouTube detects MSE support by visiting YouTube's HTML5 feature test page, which should look like this:

Now your Firefox is ready to test MSE. To verify that you're using MSE on a YouTube video, right-click on the video area and select "Stats for nerds" from the pop-up menu, which will indicate "DASH: yes" if MSE being used with the current video. Note any unusual behaviour that you haven't seen with the HTML5 player, bearing in mind the caveats listed below.

Not all videos have DASH versions, so here's a video I've been testing:
Before filing new bugs, please be aware of the following known bugs and limitations:
Seeking in adaptive videos is limited to buffered ranges. Support for seeking in unbuffered ranges is happening in bug 1002297,
Quality isn't automatically adapted to the player size or available bandwidth, and MSE videos always use the lowest quality available. You can seamlessly switch resolutions manually using the video settings button (with the gear icon). Automatic quality adaptation will start working when bug 238041 is fixed. The same bug also causes the bandwidth estimation and graph in "Stats for nerds" to read low.
Firefox's MSE support (via MediaSource isTypeSupported(DOMString type))
is intentionally restricted to WebM. MP4 will be added in the near
future.
Not all content on YouTube is available with adaptive streaming and/or in WebM/VP9 format yet.
If you find a bug, please file it in Bugzilla against Core::Video/Audio, add "mediasource" (aka bug 778617) to the "Blocks" field, and include me (:kinetik) in the CC list.
Once the first two of the issues listed above have been fixed, along with any other blocking bugs that may be found during testing, MSE will be enabled by default (for WebM only) in Nightly builds for further testing. That change is tracked by bug 1000686.
http://blog.mjg.im/2014/05/08/testing-media-source-extensions/
|
|
William Lachance: mozregression: New maintainer, issues tracked in bugzilla |
Just wanted to give some quick updates on mozregression, your favorite regression-finding tool for Firefox:
If you’re interested in contributing to Mozilla and are somewhat familiar with python, mozregression is a great place to start. The codebase is quite approachable and the impact will be high — as I’ve found out over the last few months, people all over the Mozilla organization (managers, developers, QA …) use it in the course of their work and it saves tons of their time. A list of currently open bugs is here.
|
|
Pascal Finette: On Happiness |
This morning I had the great pleasure and honor to hold the closing keynote at the Symposium Oeconomicum in M"unster, Germany.
The theme of the day was “the leap into the unknown”. The organizers asked me to wrap up the day with an inspiring message. And what better way to send off 600 students, than to talk about happiness?
Here’s the video:
|
|
Byron Jones: a tale of bugzilla performance |
a high-level goal across multiple teams this year is to improve bugzilla.mozilla.org’s performance, specifically focusing on the time it takes to load a bug (show_bug.cgi).
towards this end, in q1 2014 i focused primarily on two things: implementing a framework for bugzilla to use memcached, and deep instrumentation of bmo in our production environment to help identify areas which require optimisation and could leverage memcached.
i’ll talk more about memcached in a later blog post. today i’ll talk about a single little query.
the data gathered quickly identified a single query used to determine a user’s group membership was by far the slowest query, averaging more than 200 ms to complete, and was executed on every page:
SELECT DISTINCT groups.id
FROM groups,
user_group_map,
group_group_map
WHERE user_group_map.user_id = 3881
AND (
(user_group_map.isbless = 1 AND groups.id=user_group_map.group_id)
OR (groups.id = group_group_map.grantor_id
AND group_group_map.grant_type = 1
AND group_group_map.member_id IN (20,19,10,9,94,23,49,2,119,..))
)
in bug 993894 i rewrote this query to:
SELECT DISTINCT group_id
FROM user_group_map
WHERE user_id = 3881
AND isbless = 1
UNION
SELECT DISTINCT grantor_id
FROM group_group_map
WHERE grant_type = 1
AND member_id IN (20,19,10,9,94,23,49,2,119,..)
which executes almost instantly.
the yellow bar on the following graph shows when this fix was deployed to bugzilla.mozilla.org:

http://globau.wordpress.com/2014/05/09/a-tale-of-bugzilla-performance/
|
|
Fr'ed'eric Harper: Thinking about different devices viewport with Responsive Web Design at Devoxx UK |

On the 12th, and 13th of June, I’ll be in London, United Kingdom to speak at Devoxx UK. I’m happy to present at this event as I know it will be amazing, and it will be my first time in this country. My talk will be about Responsive Web Design, and how to get the best of your design.
There is no mobile Web, there is no desktop Web, and there is no tablet Web. We view the same Web just in different ways. So how do we do it? By getting rid of our fixed-width, device-specific approaches and use Responsive Web Design techniques. This session will focus on what is Responsive Web Design and how you can use his 3-pronged approach on your current apps today which will also adapt to new devices in the future.
It will be quite interesting to talk about responsive web design again: I’ve always been a big believer in making sure you give a good experience to your users, no matter their screen size or platform, and I think it’s even more important in today’s world. For developers, using such a technique not only give them the opportunity to reach more people, and give a great experience to their users, but also make it so much easier to port to different web platforms like Firefox OS. If you want to join us, buy your ticket now, and use my promotion code SPK10E4 to save some bucks… See you in June London!
--
Thinking about different devices viewport with Responsive Web Design at Devoxx UK is a post on Out of Comfort Zone from Fr'ed'eric Harper
Related posts:
|
|
Joel Maher: The lifecycle of a Talos performance regression |

The cycle of landing a change to Firefox that affects performance

http://elvis314.wordpress.com/2014/05/08/the-lifecycle-of-a-talos-performance-regression/
|
|
Mike Hommey: Faster compilations for everyone? |
If you’re following this blog, you may be aware of the recent work on shared compilation cache. This has been deployed with great results on Mozilla’s try server for all platforms (except a few build types, like ASAN or valgrind), and is being tested for Linux/Android builds on b2g-inbound (more on that in subsequent posts).
A side effect of the work to make it run on all platforms is that it now works to build Firefox on Windows, although it requires a specific setup. And since recently, it’s also possible to use it with local storage instead of S3. This means we now have a (basic) ccache for Windows that works to build Firefox.
If you wish to try it, here is what you need to do:
$ git clone https://github.com/glandium/sccache
mozconfig:
ac_add_options "--with-compiler-wrapper=python2.7 path/to/sccache/sccache.py"
export _DEPEND_CFLAGS='-deps$(MDDEPDIR)/$(@F).pp'
mk_add_options "export CC_WRAPPER="
mk_add_options "export CXX_WRAPPER="
mk_add_options "export COMPILE_PDB_FLAG="
mk_add_options "export HOST_PDB_FLAG="
mk_add_options "export MOZ_DEBUG_FLAGS=-Z7"
Update: Currently, path/to/sccache/sccache.py needs to be a windows-like path (as opposed to msys/cygwin path) with forward slashes.
SCCACHE_DIR environment variable to some local directory.A few things to note:
mozconfig changes, except for the --with-compiler-wrapper line.Play with it and feel free to fork it on github, and improve it. Pull requests encouraged.
|
|
Aki Sasaki: brainstorm: splitting mozharness |
Mozharness currently handles a lot of complexity. (It was designed to be able to, but the ideal is still elegantly simple scripts and configs.)
Our production-oriented scripts take (and sometimes expect) config inputs from multiple locations, some of them dynamic; and they contain infrastructure-oriented behavior like clobberer, mock, and tooltool, which don't apply to standalone users.
We want mozharness to be able to handle the complexity of our infrastructure, but make it elegantly simple for the standalone user. These are currently conflicting goals, and automating jobs in infrastructure often wins out over making the scripts user friendly. We've brainstormed some ideas on how to fix this, but first, some more details:
[complex configs]
A lot of the current complexity involves config inputs from many places:
We want to lock the running config at the beginning of the script run, but we also don't want to have to clone a repo or make external calls to web resources during __init__(). Our current solution has been to populate runtime configs during one of our script actions, but then to support those runtime configs we have to check multiple config locations for our script logic. (self.buildbot_config, self.test_config, self.config, ...)
We're able to handle this complexity in mozharness, and we end up with a single config dict that we then dump to the log + to a json file on disk, which can then be reused to replicate that job's config. However, this has a negative effect on humans who need to either change something in the running configs, or who want to simplify the config to work locally.
[in-tree vs out-of-tree]
We also want some of mozharness' config and logic to ride the trains, but other portions need to be able to handle outside-of-tree processes and config, for various reasons:
Part of the solution is to move logic out of mozharness. Desktop Firefox builds and repacks moving to mach makes sense, since they're
However, Andrew Halberstadt wanted to write the in-tree test harnesses in mozharness, and have mach call the mozharness scripts. This broke some of the above assumptions, until we started thinking along the lines of splitting mozharness: a portion in-tree running the test harnesses, and a portion out-of-tree doing the pre-test-run machine setup.
(I'm leaning towards both splitting mozharness and using helper objects, but am open to other brainstorms at this point...)
[splitting mozharness]
In effect, the wrapper, out-of-tree portion of mozharness would be taking all of the complex inputs, simplifying them for the in-tree portion, and setting up the environment (mock, tooltool, downloads+installs, etc.); the in-tree portion would take a relatively simple config and run the tests.
We could do this by having one mozharness script call another. We'd have to fix the logging bug that causes us to double-log lines when we instantiate a second BaseScript, but that's not an insurmountable problem. We could also try execing the second script, though I'd want to verify how that works on Windows. We could also modify our buildbot ScriptFactory to be able to call two scripts consecutively, after the first script dynamically generates the simplified config for the second script.
We could land the portions of mozharness needed to run test harnesses in-tree, and leave the others out-of-tree. There will be some duplication, especially in the mozharness.base code, but that's changing less than the scripts and mozharness.mozilla modules.
We would be able to present a user-friendly "inner" script with limited inputs that rides the trains, while also allowing for complex inputs and automation-oriented setup beforehand in the "outer" script. We'd most likely still have to allow for automation support in the inner script, if there's some reporting or error checking or other automation task that's needed after the handoff, but we'd still be able to limit the complexity of that inner script. And we could wrap that inner script in a mach command for easy developer use.
[helper objects]
Currently, most of mozharness' logic is encapsulated in self. We do have helper objects: the BaseConfig and the ReadOnlyDict self.config for config; the MultiFileLogger self.log_obj that handles all logging; MercurialVCS for cloning, ADBDeviceHandler and SUTDeviceHandler for mobile device wrangling. But a lot of what we do is handled by mixins inherited by self.
A while back I filed a bug to create a LocalLogger and BaseHelper to enable parallelization in mozharness scripts. Instead of cloning 90 locale repos serially, we could create 10 helper objects that each clone a repo in parallel, and launch new ones as the previous ones finish. This would have simplified Armen's parallel emulator testing code. But even if we're not planning on running parallel processes, creating a helper object allows us to simplify the config and logic in that object, similar to the "inner" script if we split mozharness into in-tree and out-of-tree instances, which could potentially also be instantiated by other non-mozharness scripts.
Essentially, as long as the object has a self.log_obj, it will use that for logging. The LocalLogger would log to memory or disk, outside of the main script log, to avoid parallel log interleaving; we would use this if we were going to run the helper objects in parallel. If we wanted the helper object to stream to the main log, we could set its log_obj to our self.log_obj. Similarly with its config. We could set its config to our self.config, or limit what config we pass to simplify.
(Mozharness' config locking is a feature that promotes easier debugging and predictability, but in practice we often find ourselves trying to get around it somehow. Other config dicts, self.variables, editing self.config in _pre_config_lock() ... Creating helper objects lets us create dynamic config at runtime without violating this central principle, as long as it's logged properly.)
Because this "helper object" solution overlaps considerably with the "splitting mozharness" solution, we could use a combination of the two to great efficacy.
[functions and globals]
This idea completely alters our implementation of mozharness, by moving self.config to a global config, directly calling logging methods (or wrapped logging methods). By making each method a standalone function that's only slightly different from a standard python function, it lowers the bar for contribution or re-use of mozharness code. It does away with both the downsides and benefits of objects.
The first, large downside I see is this solution appears incompatible with the "helper objects" solution. By relying on a global config and logging in our functions, it's difficult to create standalone helpers that use minimized configs or alternate logging configurations. I also think the global logging may make the double-logging bug more prevalent.
It's quite possible I'm downplaying the benefit of importing individual functions like a standard python script. There are decorators to transform functions into class methods and vice versa, which might allow for both standalone functions and object-based methods with the same code.
BaseConfig, but Argparse requires python 2.7 and mozharness locks the config.|
|
Pascal Finette: An Entrepreneur's Call to Arms |
We are living in incredible times. Incredibly scary and incredibly exciting: On one hand we face issues such as three billion people living in poverty, 2.5 billion people without access to sanitation and 800 million people who don’t have access to clean drinking water. On the other hand we experience innovation happening at an ever increasing pace, allowing us to touch more people in less time. There are now seven billion mobile phone connections on a planet with 7.1 billion people; we grow human tissue in a petri dish; we program DNA and 3D print complete houses out of concrete in less than 24 hours.
The American psychologist Abraham Maslow (who created the famous “hierarchy of needs”) once said: “Everyone I know who is happy is working well at something they consider important.”
You have an incredible opportunity. You, more than any generation before you, can change the world, rewrite the course of human history. You have the tools, the education, the network. You are growing up in the most exciting times ever. All it takes is to allow yourself to go where your heart tells you to go, to make the leap into the unknown and trust in yourself and the process. You have little to lose and much to gain.
The future is a renewable resource: Every morning you get a new chance to do something which is important to you, something which will make you happy.
This is your world. Start. Now.
(This Call to Arms was originally published as a contribution to the Symposium Oeconomicum 2014 in M"unster, Germany)
|
|
Gervase Markham: Software Project “Politics” |
Speaking of politics, this is as good a time as any to drag that much-maligned word out for a closer look. Many engineers like to think of politics as something other people engage in. “I’m just advocating the best course for the project, but she’s raising objections for political reasons.” I believe this distaste for politics (or for what is imagined to be politics) is especially strong in engineers because engineers are bought into the idea that some solutions are objectively superior to others. Thus, when someone acts in a way that seems motivated by outside considerations—say, the maintenance of his own position of influence, the lessening of someone else’s influence, outright horse-trading, or avoiding hurting someone’s feelings—other participants in the project may get annoyed. Of course, this rarely prevents them from behaving in the same way when their own vital interests are at stake.
If you consider “politics” a dirty word, and hope to keep your project free of it, give up right now. Politics are inevitable whenever people have to cooperatively manage a shared resource. It is absolutely rational that one of the considerations going into each person’s decision-making process is the question of how a given action might affect his own future influence in the project. After all, if you trust your own judgement and skills, as most programmers do, then the potential loss of future influence has to be considered a technical result, in a sense. Similar reasoning applies to other behaviors that might seem, on their face, like “pure” politics. In fact, there is no such thing as pure politics: it is precisely because actions have multiple real-world consequences that people become politically conscious in the first place. Politics is, in the end, simply an acknowledgment that all consequences of decisions must be taken into account. If a particular decision leads to a result that most participants find technically satisfying, but involves a change in power relationships that leaves key people feeling isolated, the latter is just as important a result as the former. To ignore it would not be high-minded, but shortsighted.
– Karl Fogel, Producing Open Source Software
http://feedproxy.google.com/~r/HackingForChrist/~3/0fRlHgRv7eE/
|
|
Sylvestre Ledru: Changes Firefox 30 beta1 to beta2 |
| Extension | Occurrences |
| js | 22 |
| cpp | 10 |
| java | 5 |
| html | 4 |
| xml | 3 |
| jsm | 3 |
| ini | 3 |
| py | 2 |
| xul | 1 |
| list | 1 |
| in | 1 |
| h | 1 |
| css | 1 |
| Module | Occurrences |
| browser | 24 |
| mobile | 8 |
| layout | 6 |
| js | 6 |
| toolkit | 3 |
| testing | 2 |
| mozglue | 2 |
| content | 2 |
| xpcom | 1 |
| intl | 1 |
| dom | 1 |
List of changesets:
| Richard Newman | Bug 987867 - JB & KK crash in java.util.ConcurrentModificationException: at java.util.LinkedList.next(LinkedList.java). r=mfinkle,ckitching, a=lsblakk - 69fcc2d9c81b |
| Nathan Froyd | Bug 997820 - Disable telemetry in tests. r=ted, a=test-only - a7ab7384526e |
| JW Wang | Bug 916399 - Autoplay fails to activate due to Bug 1001317, call play() instead. r=cpearce, a=test-only - 5dfe868c0bea |
| Bill McCloskey | Back out 4f2f5c15e065 (Bug 652510) for regressions - 30a4e7382829 |
| Mike de Boer | Bug 1000744: re-introduce a checked state for panel-menu buttons. r=MattN, a=lsblakk - 6c2ea428e1f8 |
| Mike de Boer | Bug 966723: exit Customize Mode on menu-button click, not mouse-down. r=mconley, feedback=dao, a=lsblakk - 23481585e2e5 |
| Tim Taubert | Bug 1001167 - Don't let invalid sessionstore.js files break sessionstore r=smacleod a=sylvestre - 63a8f593b292 |
| Bill McCloskey | Bug 994291 - Avoid calling SimpleTest.finish more than once. r=dougt, a=test-only - 3136f0462a23 |
| James Graham | Bug 1002267 - Stop trying to compare times in the mozlog unit tests. r=wlach, a=test-only - 461e1c788403 |
| Gabor Krizsanits | Bug 999585 - wantExportHelpers for all content-script. r=Mossop, a=sledru - 5c955e3d64b6 |
| James Willcox | Bug 966154 - Don't use __fork, it's gone in newer bionic. r=glandium, a=sledru - ae9db69edde3 |
| Lucas Rocha | Bug 975091 - Use wrap_content height params in PanelArticleItem (r=margaret) a=lsblakk - bd20a12260ea |
| Margaret Leibovic | Bug 999760 - Apply padding to entire article item view. r=liuche a=lsblakk - d9336eebf796 |
| Simon Montagu | Follow up the parent chain when making continuations non-fluid at the end of a directional run. Bug 989994, r=roc, a=lsblakk - 3c6892869d25 |
| David Rajchenbach-Teller | Bug 995162 - Rewrite the mechanism that (re)starts the OS.File worker. r=froydnj, a=lsblakk - 0678e5469636 |
| Tim Taubert | Bug 1000198 - Fix sessionstore tests that remove the original tab. r=smacleod, a=test-only - e078f53fd234 |
| Tim Taubert | Bug 1001521 - Fix tabview tests that remove the original tab. r=smacleod, a=test-only - d20b23d033e4 |
| Tim Taubert | Bug 1003096 - Make browser_tabview_bug595601.js wait until the test session is restored. r=smacleod, a=test-only - 66518d59cdbd |
| Richard Newman | Bug 1003911 - Part 1: Don't try to extract null favicons from the database. r=margaret, a=sledru - 97392de21322 |
| Richard Newman | Bug 1003911 - Part 2: Don't write null favicons or thumbnails into the DB. r=margaret, a=sledru - e03ba68c6044 |
| Jonathan Watt | Bug 1004327 - Don't limit the number of significant fractional digits for . r=bz, a=sylvestre - 8c9e76ede410 |
| Gabor Krizsanits | Bug 985472 - Name fixup in ExportFunction. r=bholley, a=lsblakk - b955f950df88 |
| Gabor Krizsanits | Bug 985472 - cloneInto for sandbox. r=bholley, a=test-only - 4c244576343b |
| James Kitchener | Bug 1000030 - Don't let Windows overwrite length 0 strings. r=dmajor, a=lsblakk - c66942faa3b2 |
| David Major | Bug 1001759 - Record total RAM and pagefile size in crash reports. r=bsmedberg, a=sledru - 4ee9435a9863 |
| David Major | Bug 973138 - Block DLLs that match the MovieMode pattern. r=bsmedberg, a=sledru - 743afab610fa |
| Tim Nguyen | Bug 989751 - Some items in the Web Developer and Sidebar widgets have the wrong styling. r=Gijs, a=sledru - 5ad3f17e39d2 |
| Richard Newman | Bug 1005074 - Part 1: Rename Send Tab activity. r=mfinkle, a=sledru - d41eb0c5c169 |
| Richard Newman | Bug 1005074 - Part 2: Re-enable Send Tab on Beta. r=mfinkle, a=sledru - dfe6e2beb722 |
| Ms2ger | Bug 1004202 - Stop calling PrepareToStartLoad in nsDocumentViewer::LoadStart. r=smaug, a=lsblakk - c219fc2b4cc2 |
| Steve Singer | Bug 997992 - Fix build error on non ion builds. r=jandem, a=lsblakk - 5958a9259d6a |
r= means reviewed by
a= means uplift approved by
Original post blogged on b2evolution.
http://sylvestre.ledru.info/blog/2014/05/07/changes-firefox-30-beta1-to-beta2
|
|
Yura Zenevich: Building and Flashing a Firefox OS device |
07 May 2014 - Toronto, ON
Yesterday I found a mystery box sitting on my table. I was super excited to discover that I finally got the new "Flame" reference Firefox OS device (MDN). So let the testing begin!

First of all, I wanted to comment on the great build and hardware quality that the device has! I was impressed to a point of wanting to dog-food the device as my primary smartphone. Unfortunately, none of the Firefox OS devices released to date work on Wind Mobile network (1700/2100 AWS band).
My second thought was to flash it with the latest Firefox OS build. Since I am using OSX as my primary working environment, I opted for using the current Ubuntu LTS with Virtual Box and Vagrant. I was using that setup for a while now with the Inari device without any issues. The first thing I discovered when building for "Flame" is that my build now explicitly fails because of the non-case sensitive file system (I shared the source for B2G, gecko and Gaia between the host and the guest environments).
Given that other developers that work on OSX and develop for "Flame" might face the same issues, here is a step by step guide to setting up, building and flashing the reference device:
NOTE: proceed to the next step if you have a case-sensitive file system already
To create mountable case-sensitive disk image run
hdiutil create -volname 'firefoxos' -type SPARSE -fs \
'Case-sensitive Journaled HFS+' -size 40g ~/firefoxos.sparseimage
open ~/firefoxos.sparseimage
The drive will now be located at /Volumes/firefoxos/
The disk image is the place to keep the B2G source code. In case you have a pre-existing Gaia and gecko repositories you can use symlinks to/for them.
Now is also a good time to set an environment variable that will be used to reference the path to B2G source:
export B2G_PATH="/Volumes/firefoxos/B2G"
By now you should have Virtual Box and Vagrant installed. Vagrant makes it really easy to create and configure the build environment with just one command. All of the provisioning stuff is specified in this Vagrantfile that you should save somewhere close to where you keep your other VMs.
Now navigate to the directory you saved the Vagrantfile to. And run the following command:
vagrant up
It will take some time to set everything up but once you are done your VM should be easily accessible via ssh, so type:
vagrant ssh
and you are in.
At this point you are all set up and ready to roll. Here's what you need to do:
Connect your device via USB and verify that it is visible to the VM: adb devices should list it.
cd B2G // host's B2G_PATH is synced to guest's $HOME/B2G
./config.sh flame // Will take some time to fetch everything
./build.sh // Will take a very long time to build everything
./flash.sh // Will flash the device with your new shiny build
Hopefully everything worked for you and you are ready to hack on B2G or Gaia from OSX. The changes you make will be synced to the VM. When you are ready to build again, just ssh to it and run the necessary commands (more here).
yzen
http://feedproxy.google.com/~r/yura-zenevich/~3/jHIH0W6xw2U/building-flame.html
|
|
Selena Deckelmann: The Final Crontab: an introduction to crontabber |
I gave a talk at Monitorama today about crontabber. (slides)
My coworker tells me that I left out the part of “why you should care” about crontabber from my first few slides. So here’s a list:
Those three are probably the top features sysadmins who are not happy with how cron is managing jobs wish they had.
Crontabber needs at least Python 2.6, Postgres 9.2, is FOSS and being used in production. We’ve used a version of the code since February 2013, and currently have the python module version you can install with pip install crontabber is currently running in our stage environment.
Let us know what you think!
|
|
Joel Maher: Hey, SessionRestore- you have a Talos test |
As of last Friday bug 936630 landed so we now have sessionrestore (and sessionrestore_no_auto_restore) as 2 new tests in the Talos suite (posting results under they magic ‘o’ key on tbpl). In fact we have already seen this test show improvements.
Thanks to Yoric for creating these new tests, give him some karma on irc! Please refer to the talos docs if you want more information on these tests.

http://elvis314.wordpress.com/2014/05/06/hey-sessionrestore-you-have-a-talos-test/
|
|
Kim Moir: Releng 2014 invited talks available |
http://relengofthenerds.blogspot.com/2014/05/invited-releng-2014-talks-online.html
|
|






