Fr'ed'eric Harper: Firefox OS love in the Python world |

https://flic.kr/p/9dShG3
Yesterday, I was the Mozilla guy, talking about Firefox OS at Python Montreal in the Google office. Even if our hockey team was playing yesterday, since my talk was just before the beginning of the game, I was lucky enough to have a full room. I was excited to spoke at this user group as it was one of the rare group in Montreal I never had a chance to attend or speak at. Knowing the main organizer, Mathieu Leduc-Hamel, I know it would be amazing, and it was. I was happily surprise by the enthusiast, and receptivity of those Python developers about Firefox OS. After all, my talk was not about their favorite language at all!
As usual when talking about Firefox OS, my goal is to educate people about this platform. I want developers to know it is there, that they can port their applications to reach a new audience. Even more important, to know that there are API that exist to give them the power they need to create amazing mobile applications. I did not record my talk this time as the Montreal Video Man himself, Christian Aubry, was there to do the recording with his expert setup. I’ll let you know once the video will be available. Python developer, hope you enjoyed some Firefox OS awesomesauce!
--
Firefox OS love in the Python world is a post on Out of Comfort Zone from Fr'ed'eric Harper
Related posts:
|
|
Armen Zambrano: Do you need a used Mac Mini for your Mozilla team? or your non-for-profit project? |
 |
| From http://en.wikipedia.org/wiki/Mac_Mini |

|
|
Doug Belshaw: Digital Literacy: why? (a reply to Tim Klapdor) |
Tim Klapdor directed my attention a post he’d written entitled Question about Digital Literacy: How?
In it, Tim wonders out loud:
I’m keenly interested in the topic of Digital Literacy as it seems to overlap so much of my professional practice. One observation I’ve had is that while a lot has been written to define digital literacies and the need to develop them – there seems to be a lack of constructive information about how they are actually developed. What do we teach and need to learn to develop these digital literacies? In essence – how we become “digital literate”?
This, on the face of it, seems like a reasonable question to ask. If we can be ‘literate’ in a traditional sense, then why not in a digital sense? And if we can be digitally literate, how does one go about doing it?
I spent many years grappling with this question while writing my doctoral thesis. You can find that thesis online: What is digital literacy: a Pragmatic investigation. I approached the question of what constitutes digital literacy from a similar angle to William James. In other words is the belief in, and use of, the term ‘digital literacy’ good in the way of belief? Does it lead to productive outcomes?
The trouble is that the answers I’ve got to questions like Tim’s aren’t the type that people want to hear. People don’t like being answered with a question - and one I’ve got here would be why do you want to use the term ‘digital literacy’?
Let’s look at the specific questions Tim asks in his blog post:
I keep coming back to traditional literacy (the reading and writing variety) – as something that has a history, established tools and theory, even proven success – and it’s lead me to a lot of questions, but not a lot of answers:
- If we use the example of traditional literacy, reading/writing, it is inseparably paired with language – so what accompanies digital literacy? Code? Markup? Programming Logic?
- What are the equivalents of Grammar, Vocabulary, Text and Visual knowledge? Have these even been defined?
- If we want to teach digital literacy how do we go about it? Where do you start? What’s the foundational equivalent of an alphabet or dictionary or the kind of kindergarten level “learn to read” resources?
I agree with the established idea that to gain literacy it must come through practice and experience – but I’m actually curious about what are the fundamental things that people should be doing in this space?
I don’t want this to turn into an epic blog post. After all, people are welcome to read my thesis, peruse my slide decks and buy into my book. What I will say, however, is that we haven’t actually got a good handle on what it means to be traditionally ‘literate’. As I’ve quoted Martin (2006) numerous times as saying, digital literacy - and any form of literacy - is a condition, not a threshold. Even UNESCO in the 1950s found defining literacy problematic.
Digital literacy is particularly tricky because there are multiple things to which it refers. Although we assume that ‘literacy’ pertains to the tools (i.e. making marks on paper) what we’re actually doing is becoming part of a community of literate practices.
The best we can hope for with new ‘literacies’ (and we’re using that in a metaphorical way) is to define forms of literacy in particular context. In other words, a community comes together to decide what constitutes literate practices within their given domain. This can be done through consensus or through authority.
Consensus-building, takes time and presupposes a certain type of organisational/sector transparency. In the long-run it will produce better results as the people involved have a sense of ownership and agency. If you’re going down that road, I recommend using the 8 elements of digital literacy I identified in Chapter 9 of my thesis. Asking what these look like in your context is a great start.
Imposing a definition and approach to digital/new literacies through authority is easier, but can be problematic. Basically, you take an off-the-shelf definition and approach and apply it to your context. If there’s no feedback loop then the lived experience and the theory can be vastly different.
It’s not all doom and gloom. Although digital literacy is an unproductive term fraught with difficulties, there are other terms that are more useful. For example, with web literacy things are a bit easier. I’ve been working with the Mozilla community to create a Web Literacy Map which charts a middle route between consensus-building and authority. We’re using the Mozilla branding for the authority, but doing the work via consensus-building. The Web Literacy Map will evolve as the web evolves, takes account of community feedback, and thankfully, it has a single referent (the web!)
So, in conclusion, I see ‘digital literacy’ as a bit of a unicorn. It can be a useful conversation-starter, and perhaps a trojan horse for wider changes you want to see. But if you want real change and progress, try a different term - even if it’s just co-defining ‘digital literacies’ (plural) in your particular context!
Questions? Comments? Reply on your own blog and/or get in touch via Twitter. I’m @dajbelshaw
|
|
Will Kahn-Greene: Input: changed query syntax across the site |
Yesterday I landed the changes for bug 986589 which affects all the search boxes and search feeds on Input. Now they use the Elasticsearch simple-query-search query instead of the hand-rolled query parser I wrote.
This was only made possible in the last month after we were updated from Elasticsearch 0.20.6 (or whatever it was) to 0.90.10.
I'm pretty psyched! It's pretty much the minimum required syntax for useful searching. It's kind of lame it took a year to get to this point, but so it goes.
To quote the Elasticsearch 0.90 documentation:
+ signifies AND operation | signifies OR operation - negates a single token " wraps a number of tokens to signify a phrase for searching * at the end of a term signifies a prefix query ( and ) signify precedence
Negation and prefix were the two operators my hand-rolled query parser didn't have.
It means that you need to use the new syntax for searches on the dashboard and other parts of the site.
Further, this affects feeds, so if you're using the Atom feed, you'll probably need to update the search query there, too.
Also, we added a ? next to search boxes which links to a wiki page that documents the syntax with examples. It's a wiki page, so if the documentation is subpar or it's missing examples, feel free to let me know or fix it yourself.
http://bluesock.org/~willkg/blog/mozilla/input_query_syntax_change
|
|
Chris AtLee: Limiting coalescing on the build/test farm |
tl;dr - as of yesterday we've limited coalescing on all builds/tests to merge at most 3 pending jobs together
Coalescing (aka queue collapsing aka merging) has been part of Mozilla's build/test CI for a long, long time. Back in the days of Tinderbox, a single machine would do a checkout/build/upload loop. If there were more checkins while the build was taking place, well, they would get built on the next iteration through the loop.
Fast forward a few years later to our move to buildbot, and having pools of machines all able to do the same builds. Now we create separate jobs in the queue for each build for each push. However, we didn't always have capacity to do all these builds in a reasonable amount of time, so we left buildbot's default behaviour (merging all pending jobs together) enabled for the majority of jobs. This means that if there are pending jobs for a particular build type, the first free machine skips all but the most recent item on the queue. The skipped jobs are "merged" into the job that was actually run.
In the case that all builds and tests are green, coalescing is actually a good thing most of the time. It saves you from doing a bunch of extra useless work.
However, not all pushes are perfect (just see how often the tree is closed due to build/test failures), and coalescing makes bisecting the failure very painful and time consuming, especially in the case that we've coalesced away intermediate build jobs.
To try and find a balance between capacity and sane results, we've recently added a limit to how many jobs can be coalesced at once.
By rigorous statistical analysis:
@catlee so it's easiest to pick a single upper bound for coalescing and go with that at first @catlee did you have any ideas for what that should be? @catlee I was thinking 3 edmorley|sheriffduty catlee: that sounds good to me as a first go :-) mshal chosen by fair dice roll? :) @catlee 1d4 bhearsum Saving throw failed. You are dead. philor wfm
we've chosen 3 as the upper bound on the number of jobs we'll coalesce, and we can tweak this as necessary.
I hope this makes the trees a bit more manageable! Please let us know what you think!
As always, all our work is done in the open. See the bug with the patch here: https://bugzilla.mozilla.org/show_bug.cgi?id=1008213
http://atlee.ca/blog/posts/limiting-coalescing-on-the-buildtest-farm.html
|
|
Soledad Penades: What does the Battery API report on a desktop computer? |
I was discussing with Chris Mills how to build an example for Web APIs that was clear enough yet showed some sort of API usage in action. He had chosen the Battery API which is, effectively, simple enough. But I had a question: what does this API report when you run it in a device without battery?
Nothing better than building an example, so that’s what I did.
It reports the battery level and discharging / charging, plus the time left, if not at the maximum level already.

It reports battery level at 100%, charging, and 0 seconds to charge.
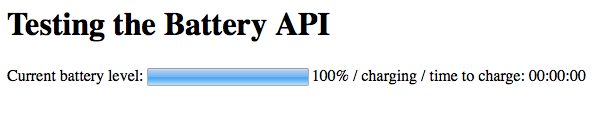
Mystery solved!
A final note/remark: while going through the API docs I found it so very synchronous and unpromise-y! If this API was written nowadays it would probably be done with Promises or some sort of asynchronicity by default. I wonder if that will be retrofitted.
![]()
http://soledadpenades.com/2014/05/13/what-does-the-battery-api-report-on-a-desktop-computer/
|
|
Doug Belshaw: Why the Web Literacy Map will remain at v1.1 until MozFest |
Mozilla’s Web Literacy Map is a map of competencies and skills that Mozilla and our community of stakeholders believe are important to pay attention to when getting better at reading, writing and participating on the web.
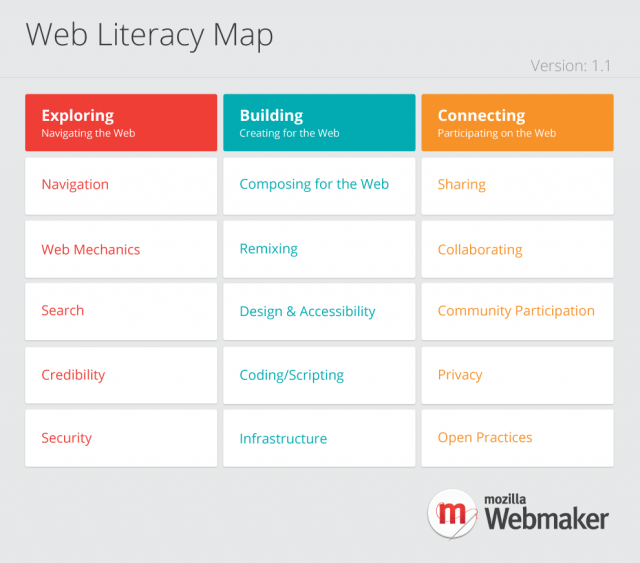
The Webmaker Product and Community teams are currently building out all sorts of things that use the current version of Web Literacy Map. Witness the WebLitMapper, Webmaker Textbook (visual sample: Credibility), and (of course!) badges.
While the competency layer (that you see in the grid above) is relatively mature and stable, at some point we could do with another pass at the skills underpinning these. The initial plan was to review these in parallel to the current work. However, after some consideration and thought, we should wait until after the Mozilla Festival at the end of October 2014 to do so.
Re-invigorating the community that initially help build the Web Literacy Map will be easier to do once we have examples of how it is being used in practice. We can also use the process to surface any skills listed that seem problematic.
Note: the plan is to use the wiki for development work and the Webmaker site for point releases. We’ll stick to that, so please link to webmaker.org/literacy when discussing this work!*
Questions? Comments? Direct them to @dajbelshaw or doug@mozillafoundation.org
|
|
Byron Jones: happy bmo push day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
http://globau.wordpress.com/2014/05/13/happy-bmo-push-day-93/
|
|
Paul Rouget: A quick, simple and not perfect guide to start hacking on Firefox |
This is how I work: https://gist.github.com/paulrouget/11294094 (based on @ednapiranha's gist).
|
|
Selena Deckelmann: Monitorama 2014 wrapup |
I’m just settling back into the daily routine after RelEng/RelOps’ workweek and then Monitorama back-to-back.
Videos will eventually be posted here.
I thought it was awesome the conference started with some #hugops.
Here are my highlights:
I gave a talk about crontabber! I have my speakers notes if you’re interested!
Dan Slimmons gave a nice talk about basic probability and how understanding the difference between sensitivity and specificity can help you choose more useful alerts. It was super basic stats stuff, but a good foundation for building up stats competency in teams.
James Mickens gave a hilarious talk about the cloud that is well-worth finding when it goes up.
Ashe Dryden gave a talk about gender issues and “our most wicked problem”. It was very well-received by the audience, which was gratifying for me personally. I think the audience walked away with some very practical things to do: speak up among peers when someone says things that make you uncomfortable and ask questions about equal treatment in your company for things like salary, perks and benefits.
Several talks were given about monitoring and managing ops inside companies. My favorite was from Daniel Schauenberg (contributor to statsd) of Etsy. and Scott Sanders spoke about similar topics in this presentaton on Github’s outage lifecycle. And related, but not at the conference, Heroku just published an incident response runbook.
There was a hilarious lightning talk about the failure of the Swedish ship Vasa as an object lesson for massive project failure. Here’s a link to the case study the lightning talk was based on.
Larry Price (@laprice) gave a 5-minute talk about Postgres autovacuum tuning, which was awesome, and I hope he posts the slides. It reminded me that I should do a couple brownbags about Postgres config this summer!
I was struck by how many people said they used Postgres in production. Someone else asked the question during a talk, and nearly half the audience raised their hands.
InfluxDB, a new timeseries database emphasizing an HTTP API (remind anyone of CouchDB? :D), seemed interesting, although maybe rough around the edges when it came to documenting useful features/best practices. When I mentioned it on Twitter, I found a few folks already trying to use it in production and got at least one bug filed. ![]()
I also saw an amazing demo of Kibana, which seems like a very interesting dashboard/investigation/querying interface to Elastic Search. I watched a friend deploy it in about an hour to look at their ES systems last Wednesday.
Dashing from Shopify was also very interesting, although a rubyist project, so not easy to integrate with our Pythonic world. However, putting on a contributor relations hat — it could be a wonderful and beautiful way for contributors to interact with our many APIs.
I’m looking forward to the videos coming out and a list of slide decks, as I missed a few talks during hallway track conversations. I met several people who are managing similar or larger event loads than we do with Socorro, so it was fun swapping stories and seeing how their software stacks are evolving. RabbitMQ was a weapon of choice for reporting environments, along with Storm. Lots of love for Kafka was out there for the people dealing with real-time customer response.
Overall, highly recommend attending Monitorama to dip a toe into the state of the art with regard to system operations, monitoring and ops management.
|
|
Ludovic Hirlimann: The next major release of Thunderbird is around the corner and needs some love |
We just released the first beta of Thunderbird 30. There will be two betas for 30 and probably 2 or more for 31. We need to start uncovering bugs nows so that developers have time to fix things.
Now is the time to get the betas and use them as you do with the current release and file bugs. Makes these bugs block our tracking bug : 1008543.
For the next beta we will need more people to do formal testing - we will use moztrap and eventbrite to track this. The more participants to this (and other during the 31 beta period), the higher the quality. Follow this blog or subscribe to the Thunderbird-tester mailing list if you wish to make 31 a great release.
Ludo for the QA team
|
|
Christian Heilmann: TEDx Thessaloniki – The web is dead? |
OMG OMG OMG I am speaking at TEDx! Sorry, just had to get this out of the way…
I am currently in the sunny Thessaloniki in Greece at TEDx and waiting for things to kick off. My own talk is in the afternoon and I wanted to share my notes and slides here for those who can’t wait for the video.
The, slightly cryptic overall theme of the event is “every end is a beginning” and thus I chose to talk about the perceived end of the web at the hand of native apps and how apps are already collapsing in on themselves. Here are the slides and notes which – as usual – might end up just being a reminder for myself what I want to cover.
Hello, I am here today to tell you that the web is dead. Which is unfortunate, as I am a web developer. I remember when the web was the cool new revolution and people flocked to it. It was the future. What killed it?
The main factor in the death of the web is the form factor of the smart phone. This is how people consume the web right now. And as typing web addresses in it isn’t fun, people wanted something different.
We got rather desperate in our attempt to make things easier. QR codes were the cool thing to do. Instead of typing in an address in a minute it is much easier to scan them with your phone – and most of the time the camera does focus correctly in a few minutes and only drains 30% of your battery.
This is when the app revolution kicked in. Instead of going to web sites, you can have one app each for all your needs. Apps are great. They perform well, they are beautiful, they are easy to find and easy to install and use.
Apps are also focused. They do one thing and one thing well, and you really use them. You don’t have a browser open with several windows. You keep your attention to the one thing you wanted to do.
So, in order to keep my job, I came up with an idea for an app myself.In my research, I found that apps are primarily used in moments of leisure. Downtime, so to say.
This goes so far that one could say that most apps are actually used in moments historically used for reflection and silence. Like being in the bathroom. My research showed that there is a direct correlation between apps released and time spent in facilities.
And this is where my app idea comes in. Instead of just using a random app in these moments, use WhatsOut!
WhatsOut is a location based checkin app much like Foursquare but focused at public facilities. You can check-in, become the mayor, leave reviews, win badges like “3 stall buddies” when checking in with friends.
The app is based on principles of other markets, like the canine one where it’s been very successful for years. There are many opportunities to enhance the app. You can link photos of food on Instagram with the checkin (as an immediate result), and with enough funding and image recognition it could even become a health app.
Seriously though: this is my problem with apps. Whilst technically superior on a mobile device they are not an innovation.
The reason is their economic model: everything is a numbers game. For app markets to succeed, they need millions of apps. For apps to succeed, they need thousands of users. What the app does is not important – how many eyeballs it gets is.
This is why every app needs to lock you in. It needs for you to stay and do things. Add content, buy upgrades, connect to friends and follow people.
In essence, for apps to succeed they have to be super annoying Tamagotchi. They want you to care for them all the time and be there only for them. And we all know what happened to Tamagotchi – people were super excited about them and now they all collect dust.
The web was software evolved – you get your content and functionality on demand and independent of hardware. Apps, as they are now, are a step back in that regard. We’re back to waiting for software to be delivered to us as a packaged format dependent on hardware.
That’s why the web is far from dead. It is not a consumable product. Its very nature is distributed. And you can’t shut down or replace that. Software should enrich and empower our lives, our lives should not be the content that makes software successful.
http://christianheilmann.com/2014/05/10/tedx-thessaloniki-the-web-is-dead/
|
|
Code Simplicity: Test-Driven Development and the Cycle of Observation |
Today there was an interesting discussion between Kent Beck, Martin Fowler, and David Heinemeier Hansson on the nature and use of Test-Driven Development (TDD), where one writes tests first and then writes code.
Each participant in the conversation had different personal preferences for how they write code, which makes sense. However, from each participant’s personal preference you could extract an identical principle: “I need to observe something before I can make a decision.” Kent often (though not always) liked writing tests first so that he could observe their behavior while coding. David often (though not always) wanted to write some initial code, observe that to decide on how to write more code, and so on. Even when they talked about their alternative methods (Kent talking about times he doesn’t use TDD, for example) they still always talked about having something to look at as an inherent part of the development process.
It’s possible to minimize this point and say it’s only relevant to debugging or testing. It’s true that it’s useful in those areas, but when you talk to many senior developers you find that this idea is actually a fundamental basis of their whole development workflow. They want to see something that will help them make decisions about their code. It’s not something that only happens when code is complete or when there’s an bug—it’s something that happens at every moment of the software lifecycle.
This is such a broad principle that you could say the cycle of all software development is:
Observation -> Decision -> Action -> Observation -> Decision -> Action -> etc.
If you want a term for this, you could call it the “Cycle of Observation” or “ODA.”
What do I mean by all of this? Well, let’s take some examples to make it clearer. When doing TDD, the cycle looks like:
Another valid way to go about this would be to write the code first. The difference from the above sequence is that Step 3 would be “write some code” rather than “write a test.” Then you observe the code itself to make further decisions, or you write tests after the code and observe those.
There are many valid processes.
What’s interesting is that, as far as I know, every valid development process follows this cycle as its primary guiding principle. Even large-scale processes like Agile that cover a whole team have this built into them. In fact, Agile is to some degree an attempt to have shorter Observation-Decision-Action cycles (every few weeks) for a team than previous broken models (Waterfall, aka “Big Design Up Front) which took months or years to get through a single cycle.
So, shorter cycles seem to be better than longer cycles. In fact, it’s possible that most of the goal of developer productivity could be accomplished simply by shortening the ODA cycle down to the smallest reasonable time period for the developer, the team, or the organization.
Usually you can accomplish these shorter cycles just by focusing on the Observation step. Once you’ve done that, the other two parts of the cycle tend to speed up on their own. (If they don’t, there are other remedies, but that’s another post.)
There are three key factors to address in Observation:
This helps us understand the reasons behind the success of certain development tools in recent decades. Continuous Integration, production monitoring systems, profilers, debuggers, better error messages in compilers, IDEs that highlight bad code—almost everything that’s “worked” has done so because it made Observation faster, more accurate, or more complete.
There is one catch—you have to deliver the information in such a way that it can actually be received by people. If you dump a huge sea of information on people without making it easy for them to find the specific data they care about, the data becomes useless. If nobody ever receives a production alert, then it doesn’t matter. If a developer is never sure of the accuracy of information received, then they may start to ignore it. You must successfully communicate the information, not just generate it.
There is a “big ODA cycle” that represents the whole process of software development—seeing a problem, deciding on a solution, and delivering it as software. Within that big cycle there are many smaller ones (see the need for a feature, decide on how the feature should work, and then write the feature). There are even smaller cycles within that (observe the requirements for a single change, decide on an implementation, write some code), and so on.
The trickiest part is the first ODA cycle in any of these sequences, because you have to make an observation with no previous decision or action.
For the “big” cycle, it may seem like you start off with nothing to observe. There’s no code or computer output to see yet! But in reality, you start off with at least yourself to observe. You have your environment around you. You have other people to talk to, a world to explore. Your first observations are often not of code, but of something to solve in the real world that will help people somehow.
Then when you’re doing development, sometimes you’ll come to a point where you have to decide “what do I work on next?” This is where knowing the laws of software design can help, because you can apply them to the code you’ve written and the problem you observed, which lets you decide on the sequence to work in. You can think of these principles as a form of observation that comes second-hand—the experience of thousands of person-years compressed into laws and rules that can help you make decisions now. Second-hand observation is completely valid observation, as long as it’s accurate.
You can even view even the process of Observation as its own little ODA cycle: look at the world, decide to put your attention on something, put your attention on that thing, observe it, decide based on that to observe something else, etc.
There are likely infinite ways to use this principle; all of the above represents just a few examples.
-Max
|
|
Taras Glek: How Mozilla Amazon EC2 Usage Got 15X Cheaper in 8 Months |
I started getting familiar with Mozilla continuous integration infrastructure in September. I’ve been particularly focused on the cloud part of that.
Thinking was that Amazon can take care of buying, managing hw so we can focus on higher level workloads. In theory this allows us to move faster and possibly lets us do more with less people. We have a lot of improvements to make to our C-I process, API-driven nature of Amazon EC2 was the obvious way to iterate quickly.
Our September Amazon bill was $136K. About $84K was that was spent on 150K hours of m3.xlarge virtual machines used for compilation. This did not feel cheap. We paid ondemand rates due to a combination of difficulty of forecasting the perfect mix of Amazon reserved instances and pain of getting over 1 million dollars for upfront reservations approved. Then the following happened:
September: $0.450/hour m3.xlarge was the most cost-effective instance Amazon had to offer.
October: I’m pushing for us to start using spot instances, as they seem to be 5x cheaper. Downside is that spot nodes get terminated by Amazon if there is insufficient capacity vs our bid price. Investigations into spot & some work to switch starts. There is a lot of uncertainty about how often our jobs will get killed.
December: Amazon starts offering $0.300 c3.xlarge instances, but these require upgrading our ami images. Work to switch to c3.xlarge starts.
February: We start switching to c3.xlarge, pocketing a 33% ondemand reduction vs m3.xlarge. We also start running m3.xlarge on spot. We end up paying around $0.15 for the mix of c3/m3 nodes we are running on spot. Turns out Amazon spot bidding API does not try to pick the cheapest AvailabilityZone for us. We also see about 3-4% of our spot jobs get killed.
March: We switch the majority of our workload to spot, come up with a trivial spot bidding algo. c3.xlarge now costs $0.068, but we can also bid on m3.xlarge, m3.2xlarge, c3.2xlarge depending on market prices. Our kill rates drop closer to 0.3%
April: Amazon spot prices drop by 50%, c3.xlarge/m3.xlarge now cost around $0.035. Amazon seems to have increased capacity, spot instances are almost never killed. There are still inefficiencies to deal with (EBS costs us as much as EC2), but cost is no longer our primary concern.
In September, we paid for ~150,000 hours of m3.xlarge. In April we paid for 190,000(even though our builds got about 2x faster) hours of a mix of compilation-friendly instance types(4-8Xeon cores, 8-16GB of RAM). 190000hours/730.5hours-per-month=260machines. We have around to 100-400 Amazon builders operating at any given time depending on how many Mozilla developers are awake.
This is interesting because $0.035 x 730.5hours = $25.57. According to the Dell website that’s identical to a 36month lease of a $900 quadcore Xeon server. At $0.035/hour we could still buy some types of hardware for less than we are paying to Amazon, but we’d have no money left to provision & power the machines on.
Releng engineers did a great job retrofitting our infra to save Mozilla money, it was nice of Amazon to help out by repeatedly droppping prices during the same period. I’m now confident that using Amazon spot instances is the most operationally efficient way to do C-I. I doubt Amazon will let us cut our price by 15x over 8month period again, but I hope they keep up the regular 30-50% price cuts :)
Amazon cost explorer provides for a dramatic visualization:

http://taras.glek.net/blog/2014/05/09/how-amazon-ec2-got-15x-cheaper-in-6-months/
|
|
Michael Verdi: Help answer Firefox users’ questions |
Planet Mozilla viewers – you can watch this video on YouTube.
Firefox 29 is out! Help answer users’ questions. If you need help helping people, talk to us in #sumo on IRC.
https://blog.mozilla.org/verdi/424/help-answer-firefox-users-questions/
|
|
Christie Koehler: Scope and Mission of wiki.mozilla.org — feedback wanted |
One issue to emerge for last December’s Community Building meet-up was how important the Mozilla Wiki is to the project and also how neglected a resource it is. The Wiki Working Group was formed to address this issue. Since then, the Mozilla Wiki has become an official sub-module of Websites, we’ve fixed a handful of long-standing bugs, and we’re working on short- and long-term roadmaps for the wiki.
During our discussions about the wiki, we discovered the need for a clear statement about the purpose of the wiki, its role and importance to the project, what content belongs on the wiki (vs MDN, vs SUMO, etc.), and its governance structure. As such, we have drafted an About page that attempts to do those things.
We’d like for as many Mozillians as possible to read our draft and comment on it. When reviewing, we ask you to consider the following questions:
The comment period is open until 26 May 2014 at 14:00 UTC. Those comments will be considered and incorporated and this page adopted into the wiki by 15 June 2014.
Please make comments directly on the draft About wiki.mozilla.org.
Thank you to everyone from the Wiki Working Group who contributed to this document, especially: Lyre Calliope, Gordon Hemsley, Justin Crawford, Larissa Shapiro, Jennie Rose Halperin, Mark A. Hershberger, and Jason Crowe.
http://subfictional.com/2014/05/09/scope-and-mission-of-wiki-mozilla-org-feedback-wanted/
|
|
Sylvestre Ledru: Changes Firefox 29.0 to 29.0.1 |
29.0.1 fixes the PDF.js bug, a session storage error and a few other issues on Desktop. For mobile, this release fixes an encoding issue, bring back the "Send to tab" feature and a few other minor issues.
| Extension | Occurrences |
| js | 7 |
| txt | 2 |
| ini | 2 |
| cpp | 2 |
| xml | 1 |
| mn | 1 |
| java | 1 |
| in | 1 |
| Module | Occurrences |
| browser | 6 |
| mobile | 5 |
| widget | 1 |
| netwerk | 1 |
| modules | 1 |
| intl | 1 |
| gfx | 1 |
| config | 1 |
List of changesets:
| Matt Woodrow | Backout Bug 991767 for causing Bug 1003707. a=lsblakk - 07e9f010bf08 |
| Ryan VanderMeulen | Backed out changeset b84e23f32f81 (Bug 943262) for causing Bug 1003897. a=lsblakk - 6b14de55b252 |
| Richard Marti | Bug 907373 - Fix -moz-os-version media query on Windows 8.1. r=jimm, a=lsblakk - b14554c010ad |
| Tim Taubert | Bug 1001167 - Don't let invalid sessionstore.js files break sessionstore. r=smacleod, a=lsblakk - 67b273f17641 |
| Richard Newman | Bug 1005074 - Part 1: Rename Send Tab activity. r=mfinkle, a=lsblakk - 2d371f067965 |
| Richard Newman | Bug 1005074 - Part 2: Re-enable Send Tab on Beta. r=mfinkle, a=lsblakk - fad6e80495ba |
| Richard Newman | Bug 987867 - JB & KK crash in java.util.ConcurrentModificationException: at java.util.LinkedList.next(LinkedList.java). r=mfinkle,ckitching, a=lsblakk - 5f238cb34fe7 |
| Nicholas Hurley | Bug 1005958 - Disable seer. r=mcmanus a=lsblakk - bebd4af02d88 |
Original post blogged on b2evolution.
http://sylvestre.ledru.info/blog/2014/05/09/changes-firefox-29-0-to-29-0-1
|
|
Nathan Froyd: the compiler is always right |
I think everybody who programs has had a bug in one of their programs that they were positive was the compiler’s fault. (Perhaps “it’s the operating system’s fault” or “it’s the hardware’s fault”, though these are less common.) At this point, you learn the rules of programming:
The corollary, of course, is that it is your program that has the bug, not the compiler. (The third through sixth laws are restatements of these two with the operating system and the hardware, respectively.)
Yesterday was one of those occasions where I thought the compiler might be wrong and spent a little time remembering the First Rule. It’s instructive to look at the example and understand why the compiler is always right. I was looking at bug 611781, reducing the size of the NSS library shipped with Firefox, and ran across this Linux x86-64 assembly code, compiled with gcc -Os:
0000000000000000 : 0: 41 51 push %r9 2: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax 5: R_X86_64_GOTPCREL NSS_ERROR_NOT_FOUND+0xfffffffffffffffc 9: 8b 38 mov (%rax),%edi b: e8 00 00 00 00 callq 10 c: R_X86_64_PLT32 nss_SetError+0xfffffffffffffffc 10: 31 c0 xor %eax,%eax 12: 41 5a pop %r10 14: c3 retq
You can find a lot of these small functions in lib/pki/trustdomain.c in an NSS source tree. Looking over this, you notice two things if you know a little bit about x86-64 assembler:
push and pop instructions are suspiciously mismatched; if I save a register to the stack with push, I ought to restore the same register from the stack with a pop. The compiler must have a bug!%r9 in the body of the function, so we shouldn’t need to save it at all.What is the compiler doing here? It’s easiest to explain away the second issue first. If you look at the x86-64 ABI document, you’ll see that in section 3.2.2, the stack must be kept 16-byte aligned before calling other functions. Since our function calls another function, our function must ensure that the stack is properly aligned when that other function begins execution. And since the call instruction on x86-64 (which is how we would have arrived at our function) adjusts the stack pointer by 8 bytes (in addition to all the other work it does), our function must adjust by an additional 8 bytes to maintain 16-byte alignment. The compiler has chosen to use a push instruction to manipulate the stack pointer in this case. This instruction subtracts 8 bytes from the stack pointer and stores the indicated register into the memory at the new stack pointer.
Another way to do this would be to subtract 8 bytes from the stack pointer (sub $0x8, %rsp), which avoids writing the register to memory at all. If you compile with -O2, optimizing for speed, instead of -Os, you would indeed see the compiler using sub $0x8, %rsp. But since we compiled this code with -Os, optimizing for size, the compiler knows that the instruction for pushing a register onto the stack (2 bytes) is smaller than the instruction for subtracting 8 bytes from the stack pointer (4 bytes). Likewise, the instruction for popping a register from the stack (2 bytes) is smaller than the instruction for adding 8 bytes to the stack pointer (4 bytes).
These “useless” instructions are therefore doing real work, which is maintaining the contract of the ABI.
OK, so the efficiency claim has been addressed. What about the correctness claim with mismatched registers? Again, if you look at the aforementioned ABI document, section 3.2.3 describes how registers are used for function calls. The registers %r9 and %r10 are caller-saved registers, which means that a called function is free to overwrite any values stored in those registers. It doesn’t matter what value, if any, our function stores in %r10, because we know that if the caller had cared about the value, the caller would have stored that value away somewhere. Since we need spare registers for maintaining stack alignment via push and pop, caller-saved registers are ideal for pushing and popping with abandon.
In this case, it turned out that my understanding of what the program was doing had the bug, not the compiler. It’s also worth pointing out that if the compiler really was mismatching register saves and restores, lots and lots of things would be broken. The likelihood of the code produced in this instance being wrong—but the same problem not occurring in the millions of lines of code the compiler has compiled to produce the system on your computer—is vanishingly small. The next time you see the compiler doing something weird, remember that the compiler is always right and try to figure out why it’s doing that.
(I should say, of course, that compilers, just like many other computer programs, do have bugs; GCC’s bugzilla or LLVM’s bugzilla would not exist otherwise, nor would bugfix releases continue to come out for your favorite compiler. But in the vast, vast majority of cases, you have a bug to fix, not the compiler.)
https://blog.mozilla.org/nfroyd/2014/05/09/the-compiler-is-always-right/
|
|
Ben Hearsum: This week in Mozilla RelEng – May 9th, 2014 |
This was a quieter week than most. With everybody flying home from Portland on Friday/Saturday, it took some time for most of us to get back into the swing of things.
Major highlights:
Completed work (resolution is ‘FIXED’):
In progress work (unresolved and not assigned to nobody):
http://hearsum.ca/blog/this-week-in-mozilla-releng-may-9th-2014/
|
|
Kyle Huey: DOM Object Reflection: How does it work? |
I started writing a bug comment and it turned out to be generally useful, so I turned it into this blog post.
Let’s start by defining some vocabulary:
DOM object - any object (not just nodes!) exposed to JS code running in a web page. This includes things that are actually part of the Document Object Model, such as the document, nodes, etc, and many other things such as XHR, IndexedDB, the CSSOM, etc. When I use this term I mean all of the pieces required to make it work (the C++ implementation, the JS wrapper, etc).
wrapper - the JS representation of a DOM object
native object - the underlying C++ implementation of a DOM object
wrap - the process of taking a native object and retrieving or creating a wrapper for it to give to JS
IDL property - a property on a wrapper that is “built-in”. e.g. ‘nodeType’ on nodes, ‘responseXML’ on XHR, etc. These properties are automatically defined on a wrapper by the browser.
expando property - a property on a wrapper that is not part of the set of “built-in” properties that are automatically reflected. e.g. if I say “document.khueyIsAwesome = true” ‘khueyIsAwesome’ is now an expando property on ‘document’. (sadly khueyIsAwesome is not built into web browsers yet)
I’m going to ignore JS-implemented DOM objects here, but they work in much the same way: with an underlying C++ object that is automatically generated by the WebIDL code generator.
A DOM object consists of one or two pieces: the native object and potentially a wrapper that reflects it into JS. Not all DOM objects have a wrapper. Wrappers are created lazily in Gecko, so if a DOM object has not been accessed from JS it may not have a wrapper. But the native object is always present: it is impossible to have a wrapper without a native object.
If the native object has a wrapper, the wrapper has a “strong” reference to the native. That means that the wrapper exerts ownership over the native somehow. If the native is reference counted then the wrapper holds a reference to it. If the native is newed and deleted then the wrapper is responsible for deleting it. This latter case corresponds to “nativeOwnership=’owned’” in Bindings.conf. In both cases this means that as long as the wrapper is alive, the native will remain alive too.
For some DOM objects, the lifetimes of the wrapper and of the native are inextricably linked. This is certainly true for all “nativeOwnership=’owned’” objects, where the destruction of the wrapper causes the deletion of the native. It is also true for certain reference counted objects such as NodeIterator. What these objects have in common is that they have to be created by JS (as opposed to, say, the HTML parser) and that there is no way to “get” an existing instance of the object from JS. Things such as NodeIterator and TextDecoder fall into this category.
But many objects do not. An HTMLImageElement can be created from JS, but can also be created by the HTML parser, and it can be retrieved at some point later via getElementById. XMLHttpRequest is only created from JS, but you can get an existing XHR via event.target of events fired on it.
In these cases Gecko needs a way to create a wrapper for a native object. We can’t even rely on knowing the concrete type. Unlike constructors, where the concrete type is obviously known, we can’t require functions like getElementById or getters like event.target to know the concrete type of the thing they return.
Gecko also needs to be able to return wrappers that are indistinguishable from JS for the underlying native object. Calling getElementById twice with the same id should return two things that === each other.
We solve these problems with nsWrapperCache. This is an interface that we can get to via QueryInterface that exposes the ability to create and retrieve wrappers even if the caller doesn’t know the concrete type of the DOM object. Overriding the WrapObject function allows the derived class to create wrappers of the correct type. Most implementations of WrapObject just call into a generated binding function that does all the real work. The bindings layer calls WrapObject and/or GetWrapper when it receives a native object and needs to hand a wrapper back to a JS caller.
This solves the two problems mentioned above: the need to create wrappers for objects that we don’t know the concrete type of and the need to make object identity work for DOM objects. Gecko actually takes the latter a step further though. By default, nsWrapperCache merely caches the wrapper stored in it. It still allows that wrapper to be GCd. GCing wrappers can save large amounts of memory, so we want to do it when we can avoid breaking object identity. If JS does not have a reference to the wrapper then recreating it later after a GC does not break a === comparison because there is nothing to compare it to. The internal state of the object all lives in the C++ implementation, not in JS, so don’t need to worry about the values of any IDL properties changing.
But we do need to be concerned about expando properties. If a web page adds properties to a wrapper then if we later GC it we won’t be able to recreate the wrapper exactly as it was before and the difference will be visible for that page. For that reason, setting expando properties on a wrapper triggers “wrapper preservation”. This establishes a strong edge from the native object to the wrapper, ensuring that the wrapper cannot be GCd until the native object is garbage. Because there is always an edge from the wrapper to the native object the two now participate in a cycle that will ultimately be broken by the cycle collector. Wrapper preservation is also handled in nsWrapperCache.
tl;dr
DOM objects consist of two pieces, native objects and JS wrappers. JS wrappers are lazily created and potentially garbage collected in certain situations. nsWrapperCache provides an interface to handle the three aspects of working with wrappers:
And certain types of DOM objects, such as those with native objects that are not reference counted or those that can only be constructed, and never accessed through a getter or a function’s return value, do not need to be wrapper cached because the wrapper cannot outlive the native object.
|
|












