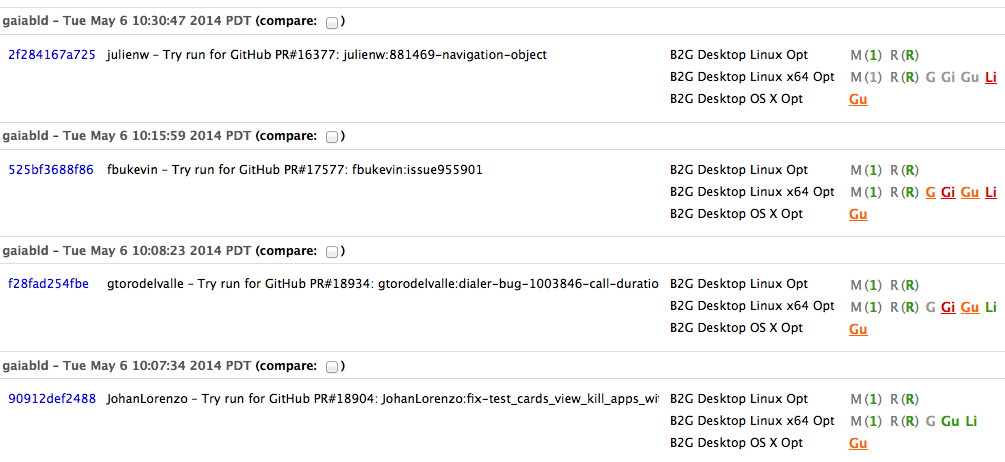
Aki Sasaki: Gaia Try |
We're now running Gaia tests on TBPL against Gaia pull requests.
John Ford wrote a commit hook in bug 989131 to push an update to the gaia-try repo that looks like this. The buildbot test scheduler master is polling this repo; when it sees a change, it triggers tests against the latest b2g desktop builds. The test jobs download the pre-built desktop binaries, and clone the appropriate pull-request Gaia repo and revision on top, then run the tests. The buildbot work was completed in bug 986209.
This should allow us to verify our code doesn't break anything before it's merged to Gaia proper, saving human time and reducing code churn.
Armen pointed out how gaia code changes currently show up in the push count via bumper processes, but that only reflects merged pull requests, not these un-reviewed pull requests. Now that we've turned on gaia-try, this is equivalent to another mozilla-inbound (an additional 10% of our push load, iirc). Our May pushes should see a significant bump.
|
|
Michael Verdi: Talking about Customer Experience on The Web Ahead podcast |
Two weeks ago I was on The Web Ahead with Jen Simmons. I talked about Customer Experience, the tour we created for the new Firefox, a theater performance Jen and I worked on in the 90s and more. Check it out.
https://blog.mozilla.org/verdi/414/talking-about-customer-experience-on-the-web-ahead-podcast/
|
|
Kumar McMillan: Some Tips On Working Remotely |
I've been working remotely from a home office with Mozilla since about 2010 (4 years so far) and although it has challenges I still enjoy it. You have to have some discipline and a routine. Matt Gemmell's article on this has excellent pointers on routines and setting up an isolated work space at home. I wanted to add a few things to his post...
http://farmdev.com/thoughts/105/some-tips-on-working-remotely/
|
|
Nathan Froyd: my code search engine |
Christian Legnitto wrote a blog post where he mentioned Firefox developers being forced to deal with “crufty code-search tools” (and many other perceived suboptimalities in the development process). I’m looking forward to reading his followup, but I also thought it was worth blogging about what I use for my day-to-day code search needs.
I use Emacs’s rgrep. rgrep (and its cousin commands grep and lgrep) executes grep on a group of files in a given directory, recursively. The grep results are then displayed in a hyperlinked format for easy browsing between matches. Well, being Emacs, I use it with a few modifications of my own. Here’s my setup.
First, a small utility I wrote for making quick selections with a single keypress:
(defun character-prompt (alist description)
(message "Select [%s]: "
(apply #'string (mapcar #'car alist)))
(let* ((ch (save-window-excursion
(select-window (minibuffer-window))
(read-char)))
(x (find ch alist :key #'car)))
(cond
((null x)
(message (format "No %s for character: %s" description ch))
(sleep-for 1)
(discard-input)
(character-prompt alist description))
(t (cdr x)))))
This function gets used in the small wrapper I wrote around rgrep. Some preliminaries first, like where the Firefox tree lives, files that contain overly long lines and therefore mess with Emacs’s hyperlinking, and directories that I generally don’t deal with in my day-to-day work.
(defvar froydnj-mozilla-srcdir (expand-file-name "~/src/gecko-dev.git/"))
(defvar froydnj-mozilla-ignored-files
(list "searchindex.js"
"jquery.js"
"jquery.min.js"
"interfaces.js"
"socket.io.min.js"
"jquery-ui-1.7.1.custom-min.js"
"edit_area_full.js"
"php.js"
"packed.js"
"socket.io.min.js"
"named-character-references.html"
"edit_area_full_with_plugins.js"
"string-tagcloud.js"
"string-unpack-code.js"
"check-string-tagcloud.js"
"check-string-unpack-code.js"
"string-unpack-code.html"))
(defvar froydnj-mozilla-ignored-directories
(list "nss" "nsprpub" "js/src/tests" "intl/icu"))
Next, the way I select subsets of files to search in. I learned after writing all this that rgrep already has built-in functionality for this (see the grep-files-aliases variable), but I like my setup better.
(defvar froydnj-mozilla-files
'((?a . "*") ; All of it
(?c . "*.[cm]*") ; C/C++/Obj-C
(?C . "*.[cmh]*") ; Same, plus headers (and HTML, sadly)
(?h . "*.h")
(?H . "*.html")
(?i . "*.idl")
(?j . "*.js*")
(?l . "*.lisp")
(?m . "Makefile.in")
(?p . "*.py")
(?v . "*.java")
(?w . "*.webidl")))
Finally, the wrapper itself, which prompts for the search pattern, the filename pattern, makes sure the directories and files above are ignored, and executes the search.
(defun froydnj-mozilla-rgrep ()
(interactive)
(let ((regexp (grep-read-regexp))
(files (character-prompt froydnj-mozilla-files "filename pattern"))
(grep-find-ignored-files (append grep-find-ignored-files
froydnj-mozilla-ignored-files))
(grep-find-ignored-directories (append grep-find-ignored-directories
froydnj-mozilla-ignored-directories)))
(rgrep regexp files froydnj-mozilla-srcdir)))
One other bit that I find useful is a custom name for each buffer. By default, the rgrep results are deposited in a buffer named *grep* (likewise for grep and lgrep; the following advice applies to them automatically), and future greps overwrite this buffer. Having records of your greps lying around is occasionally useful, so I’ve changed the hook that determines the buffer name for rgrep. The comments that refer to compilation are from a previous job where it was useful to launch compilation jobs from within Emacs. I keep meaning to tweak those bits to launch mach in various configurations instead, but I haven’t done so yet.
(defun froydnj-compilation-buffer-name (major-mode-name)
(let ((cfg-regexp "\\([-0-9_.a-z/+]+\\.cfg\\)"))
(cond
;; We're doing local compilation, stick the name of the release
;; configuration in the buffer name.
((or (string-match "^cd /scratch/froydnj/\\([^ ;]+\\)" command)
(string-match "^build-config" command))
(string-match cfg-regexp command)
(concat "*compilation " (match-string 1 command) "*"))
;; We're doing remote compilation, note the machine name and
;; the release configuration name.
((string-match "^ssh \\([^ ]+\\)" command)
(let ((machine (match-string 1 command)))
(string-match cfg-regexp command)
(concat "*compilation@" machine " " (match-string 1 command) "*")))
;; grep.el invokes compile, we might as well take advantage of that.
((string-equal major-mode-name "grep")
(if (boundp 'regexp)
(concat "*grep for " regexp "*")
"*grep*"))
;; We have no idea, just use the default.
(t
"*compilation*"))))
(setq compilation-buffer-name-function 'froydnj-compilation-buffer-name)
Search times are comparable to web-based tools, and browsing results is more convenient. It has its shortcomings (overloaded C++ method names can be a pain to deal with, for instance), but it works well enough for 95%+ of my searching needs.
https://blog.mozilla.org/nfroyd/2014/05/06/my-code-search-engine/
|
|
Daniel Stenberg: licensed to get shared |
As my http2 presentation is about to get its 16,000th viewer over at Slideshare I just have to take a moment and reflect over that fact.
Sixteen thousand viewers. I’ve uploaded slides there before over the years but no other presentation has gotten even close to this amount of attention even though some of them have been collecting views for years by now.

I wrote my http2 explained document largely due to the popularity of my presentation and the stream of questions and curiosity that brought to life. Within just a couple of days, that 27 page document had been downloaded more than 2,000 times and by now over 5000 times. This is almost 7MB of PDF which I believe raises the bar for the ordinary casual browser to not download it without having an interest and intention to at least glance through it. Of course I realize a large portion of said downloads are never really read.
Someone suggested to me (possibly in jest) that I should convert these into ebooks and “charge 1 USD a piece to get some profit out of them”. I really won’t and I would have a struggle to do that. It has been said before but in my case it is indeed true: I stand on the shoulders of giants. I’ve just collected information and written down texts that mostly are ideas, suggestions and conclusions others have already made in various other forums, lists or documents. I wouldn’t feel right charging for that nor depriving anyone the rights and freedoms to create derivatives and continue building on what I’ve done. I’m just the curator and janitor here. Besides, I already have an awesome job at an awesome company that allows me to work full time on open source – every day.
The next phase started thanks to the open license. A friendly volunteer named Vladimir Lettiev showed up and translated the entire document into Russian and now suddenly the reach of the text is vastly expanded into a territory where it previously just couldn’t penetrate. With using people’s native languages, information can really trickle down to a much larger audience. Especially in regions that aren’t very Englishified.
http://daniel.haxx.se/blog/2014/05/06/licensed-to-get-shared/
|
|
Nick Cameron: Rust for C++ programmers - part 5: borrowed references |
fn foo() {The `&` operator does not allocate memory (we can only create a borrowed reference to an existing value) and if a borrowed reference goes out of scope, no memory gets deleted.
let x = &3; // type: &int
let y = *x; // 3, type: int
bar(x, *x);
bar(&y, y);
}
fn bar(z: &int, i: int) {
// ...
}
fn foo() {Like values, borrowed references are immutable by default. You can also use `&mut` to take a mutable reference, or to denote mutable reference types. Mutable borrowed references are unique (you can only take a single mutable reference to a value, and you can only have a mutable reference if there are no immutable references). You can use mutable reference where an immutable one is wanted, but not vice versa. Putting all that together in an example:
let x = 5; // type: int
let y = &x; // type: &int
let z = y; // type: &int
let w = y; // type: &int
println!("These should all 5: {} {} {}", *w, *y, *z);
}
fn bar(x: &int) { ... }Note that the reference may be mutable (or not) independently of the mutableness of the variable holding the reference. This is similar to C++ where pointers can be const (or not) independently of the data they point to. This is in contrast to unique pointers, where the mutableness of the pointer is linked to the mutableness of the data. For example,
fn bar_mut(x: &mut int) { ... } // &mut int is a reference to an int which
// can be mutated
fn foo() {
let x = 5;
//let xr = &mut x; // Error - can't make a mutable reference to an
// immutable variable
let xr = &x; // Ok (creates an immutable ref)
bar(xr);
//bar_mut(xr); // Error - expects a mutable ref
let mut x = 5;
let xr = &x; // Ok (creates an immutable ref)
//*xr = 4; // Error - mutating immutable ref
//let xr = &mut x; // Error - there is already an immutable ref, so we
// can't make a mutable one
let mut x = 5;
let xr = &mut x; // Ok (creates a mutable ref)
*xr = 4; // Ok
//let xr = &x; // Error - there is already a mutable ref, so we
// can't make an immutable one
//let xr = &mut x; // Error - can only have one immutable ref at a time
bar(xr); // Ok
bar_mut(xr); // Ok
}
fn foo() {If a mutable value is borrowed, it becomes immutable for the duration of the borrow. Once the borrowed pointer goes out of scope, the value can be mutated again. This is in contrast to unique pointers, which once moved can never be used again. For example,
let mut x = 5;
let mut y = 6;
let xr = &mut x;
//xr = &mut y; // Error xr is immutable
let mut x = 5;
let mut y = 6;
let mut xr = &mut x;
xr = &mut y; // Ok
let mut x = 5;
let mut y = 6;
let mut xr = &x;
xr = &y; // Ok - xr is mut, even though the referenced data is not
}
fn foo() {The same thing happens if we take a mutable reference to a value - the value still cannot be modified. In general in Rust, data can only ever be modified via one variable or pointer. Furthermore, since we have a mutable reference, we can't take an immutable reference. That limits how we can use the underlying value:
let mut x = 5; // type: int
{
let y = &x; // type: &int
//x = 4; // Error - x has been borrowed
println!("{}", x); // Ok - x can be read
}
x = 4; // OK - y no longer exists
}
fn foo() {Unlike C++, Rust won't automatically reference a value for you. So if a function takes a parameter by reference, the caller must reference the actual parameter. However, pointer types will automatically be converted to a reference:
let mut x = 5; // type: int
{
let y = &mut x; // type: &mut int
//x = 4; // Error - x has been borrowed
//println!("{}", x); // Error - requires borrowing x
let z = *y + x; // Ok - doesn't require borrowing
}
x = 4; // OK - y no longer exists
}
fn foo(x: &int) { ... }
fn bar(x: int, y: ~int) {
foo(&x);
// foo(x); // Error - expected &int, found int
foo(y); // Ok
foo(&*y); // Also ok, and more explicit, but not good style
}
fn foo() {In the above example, x and xr don't have the same lifetime because xr starts later than x, but it's the end of lifetimes which is more interesting, since you can't reference a variable before it exists in any case - something else which Rust enforces and which makes it safer than C++.
let x = 5;
let mut xr = &x; // Ok - x and xr have the same lifetime
{
let y = 6;
//xr = &y // Error - xr will outlive y
} // y is released here
} // x and xr are released here
http://featherweightmusings.blogspot.com/2014/05/rust-for-c-programmers-part-5-borrowed.html
|
|
Byron Jones: happy bmo push day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
http://globau.wordpress.com/2014/05/06/happy-bmo-push-day-92/
|
|
Eitan Isaacson: Look what I did to fix Mozilla |
When you have a hammer, every problem looks like a nail. In my case, I have a 3D printer, and every problem is an opportunity to stare at the hypnotic movements of the extruder.
It has a nifty hinge/magnet mechanism, here is a video:
You could download and print this via the thingiverse page, or you could check out the github repo and hack on it.
Some lucky duck has me as a Secret Dino, and will be getting this in the mail soon!

http://blog.monotonous.org/2014/05/05/look-what-i-did-to-fix-mozilla/
|
|
Christie Koehler: Community Building Education Update – 5 May 2014 |
This doesn’t fit specifically in either category below, but I still wanted to call attention to it: Last Tuesday we launched Firefox 29 “Australis,” our biggest redesign of Firefox since version 4!
As always, you are welcome to join me in any of these projects. Look at my mozillians profile for the best way to get in touch with me.
Calendar file for both meetings: ics or html.
http://subfictional.com/2014/05/05/community-building-education-update-5-may-2014/
|
|
Armen Zambrano Gasparnian: Releng goodies from Portlandia! |
 |
| The Releng dreams are alive in Portland |

http://armenzg.blogspot.com/2014/05/releng-goodies-from-portlandia.html
|
|
Joel Maher: Performance Alerts – by the numbers |
If you have ever received an automated mail about a performance regression, and then 10 more, you probably are frustrated by the volume of alerts. 6 months ago, I started looking at the alerts and filing bugs, and 10 weeks ago a little tool was written to help out.
What have I seen in 10 weeks:
1926 alerts on mozilla.dev.tree-management for Talos resulting in 58 bugs filed (or 1 bug/33 alerts):

*keep in mind that many alerts are improvements, as well as duplicated between trees and pgo/nonpgo
Now for some numbers as we uplift. How are we doing from one release to another? Are we regressing, Improving? These are all questions I would like to answer in the coming weeks.
Firefox 30 uplift, m-c -> Aurora:
Firefox 31 uplift, m-c -> Aurora (tracking bug 990085):
Is this useful information?
Are there questions you would rather I answer with this data?

http://elvis314.wordpress.com/2014/05/05/performance-alerts-by-the-numbers/
|
|
K Lars Lohn: Crouching Argparse, Hidden Configman |
from configman import ArgumentParser
parser = ArgumentParser(description='Process some integers.')
parser.add_argument('integers', metavar='N', type=int, nargs='+',
help='an integer for the accumulator')
parser.add_argument('--sum', dest='accumulate', action='store_const',
const=sum, default=max,
help='sum the integers (default: find the max)')
args = parser.parse_args()
print(args.accumulate(args.integers))
$ ./x1.py 0 0 --help
usage: x1.py [-h] [--sum] [--admin.print_conf ADMIN.PRINT_CONF]
[--admin.dump_conf ADMIN.DUMP_CONF] [--admin.strict]
[--admin.conf ADMIN.CONF]
N [N ...]
Process some integers.
positional arguments:
N an integer for the accumulator
optional arguments:
-h, --help show this help message and exit
--sum sum the integers (default: find the max)
--admin.print_conf ADMIN.PRINT_CONF
write current config to stdout (json, py, ini, conf)
--admin.dump_conf ADMIN.DUMP_CONF
a file system pathname for new config file (types:
json, py, ini, conf)
--admin.strict mismatched options generate exceptions rather than
just warnings
--admin.conf ADMIN.CONF
the pathname of the config file (path/filename)
$ ./x1.py --admin.dump_conf=x1.iniThen we'll edit that file and make it automatically use the sum function instead of the max function. Uncomment the "accumulate" line and replace the "max" with "sum". Configman will associate an ini file with the same base name as a program file to trigger automatic loading. From that point on, invoking the program means loading the ini file. That means the command line arguments aren't necessary. Rather not have a secret automatically loaded config file? Give it a different name.
$ cat x1.ini
# sum the integers (default: find the max)
#accumulate=max
# an integer for the accumulator
#integers=
$ ./x1.py 1 2 3I can even make the integer arguments get loaded from the ini file. Revert the "sum" line change and instead change the "integers" line to be a list of numbers of your own choice.
6
$ ./x1.py 4 5 6
15
$ cat x1.ini
# sum the integers (default: find the max)
#accumulate=max
# an integer for the accumulator
integers=1 2 3 4 5 6
$ ./x1.py
6
$ ./x1.py --sum
21
$ export accumulate=sum
$ ./x1.py 1 2 3
6
$ ./x1.py 1 2 3 4 5 6
21
http://www.twobraids.com/2014/05/crouching-argparse-hidden-configman.html
|
|
Benoit Girard: Profiler: Frame performance and debugging! |
When we designed the platform profiler our goal was to expose internal information to answer performance questions that other tools could never practically answer without. I’m very excited to show off these prototypes because I feel that we are without a doubt finally there.
NOTE: We’re still missing at least two un-landed platform patches before this is ready in Nightly; Bug 926922 and Bug 1004899. Feel free to apply these patches locally and give me feedback! They should work on any platform when running with OMTCompositing.
I’ve redesigned how frame markers work to expose more details. Painting in Gecko is triggered off a refresh timer. When that timer fires we will execute scripts that are listening for the refresh like pending requestAnimationFrame() callbacks for the document. This is denoted by the Scripts phase. If any changes were made to the styles or flow of the document we will show a marker for each, if applicable, as Styles and Reflow markers. Next we will need to build a display list and a layer tree to prepare for painting denoted by DisplayList marker. The next phase is rasterizing, the process of turning the display list into pixels, any changed region of the page. This is denoted by the, you guessed it, Rasterize phase. And finally, on the compositor thread, we will take the results and composite them to the phase under the Composite phase.
This further break down was necessary to facilitate exposing more information about each of these phases. Note that I’m exposing internal gecko decisions. The primary use should be to debug and optimize the platform. It’s not meant for web developers to micro optimize their pages to implementation details of our rendering engine.

New Frame Markers
As platform engineers we’re often asked to look into performance problems of complex web applications. It’s difficult to pin point what’s causing excessive style and reflow flushes in an app we’re not familiar with. Careful breakpoints may get you this information for simple performance problems but in my experience that’s not enough to diagnose the hard problems. One frame tends to have a disproportionately longer style or reflow flush and finding which exactly can be very tricky. With flush causes in the profiler we can now find what code in the past triggered the flush that’s taking so long to execute now.
Here’s a real world example of the b2g homescreen as of the current master tip. See Style #0? We’re spending 35ms in there so understanding why we’re flushing is critical to fixing it. Now it’s a pain free process with a simple mouse-over the problematic Styles block:

B2G Homescreen Style Flush Cause
Here the flush is triggered by handleEvent() in grid.js. A closer inspection will point out several style changes that are occurring from that function. After taking a closer look at grid.js, we can pinpoint the problem to a CSS transform.
Sometimes the display list and layer tree is the key to the performance problem. It can point to rendering bugs, severe platform performance problems, an overly complicated page to paint and many more problems. The visualization is still an early implementation. In the future I’m hoping to display a preview of the display items themselves but we need to extend how they are dumped from gecko. This information is logged for each frame so it’s useful to track the evolution and how it corresponds with other things like slow paths being hit.
NOTE: This feature is only enabled if you’ve flipped a preference to dump the display list and/or layer tree for each frame. This will slow down your build and skew profiling sample but will still serve as a great debugging tool.

DisplayList Preview
And to finish off, the profiler now has a simple feature to visualize how consistent our frame rate is. Each dot represents the time between frames. If everything is working as expected, during scrolling each dot should be near 16ms. Below is a graph of fairly smooth scrolling.

Profiler Composite Uniformity Graph

http://benoitgirard.wordpress.com/2014/05/05/profiler-frame-performance-and-debugging/
|
|
Christian Heilmann: Presentation tips: using videos in presentations |
I am currently doing a survey amongst people who speak for Mozilla or want to become speakers. As a result of this, I am recording short videos and write guidelines on how to deal with various parts of presenting.

Photo Credit: Carbon Arc via Compfight cc
A lot of the questions in the “Presenting tips for Mozilla Reps” survey this time revolved around videos in presentations. Let’s take a look at that topic.
Videos are a great format to bring a message across:
As part of a presentation, videos can be supportive or very destructive. The problem with videos is that they are very engaging. As a presenter, it is up to you to carry the talk: you are the main attraction. That’s why playing a video with sound in the middle of your talk is awkward; you lose the audience and become one of them. You are just another spectator and you need to be very good to get people’s attention back to you after the video played.
The rule of thumb of videos with sound is either to start with it and thus ease people into your talk or to end with it. In Mozilla we got a lot of very cool and inspirational short videos you can start with and then introduce yourself as a Mozillian followed by what you do and what you want to talk about today. You can also end with it: “And that’s what I got. I am part of Mozilla, and here are some other things we do and why it would be fun for you to join us”.
Screencasts are a superb format to use in your presentation to narrate over. Using a screencast instead of a live demo has a lot of benefits:
Of course screencasts have a few pitfalls:
Videos in presentations should make a point and have a purpose. In the end, a talk is a show and you are the star. You are the centre of attention. That’s why videos are good to make things more engaging but don’t lose the audience to them – after all they will have to look at them instead of you. One minute is to me a good time, less is better. Anything above 5 minutes should be a screenshot of the video, the URL to see it and you telling people why they should watch it. This works, I keep seeing people tweet the URL of a video I covered in my talks and thanking me that I flagged it up as something worth watching.
http://christianheilmann.com/2014/05/04/presentation-tips-using-videos-in-presentations/
|
|
Robert O'Callahan: Introducing rr |
Bugs that reproduce intermittently are hard to debug with traditional techniques because single stepping, setting breakpoints, inspecting program state, etc, is all a waste of time if the program execution you're debugging ends up not even exhibiting the bug. Even when you can reproduce a bug consistently, important information such as the addresses of suspect objects is unpredictable from run to run. Given that software developers like me spend the majority of their time finding and fixing bugs (either in new code or existing code), nondeterminism has a major impact on my productivity.
Many, many people have noticed that if we had a way to reliably record program execution and replay it later, with the ability to debug the replay, we could largely tame the nondeterminism problem. This would also allow us to deliberately introduce nondeterminism so tests can explore more of the possible execution space, without impacting debuggability. Many record and replay systems have been built in pursuit of this vision. (I built one myself.) For various reasons these systems have not seen wide adoption. So, a few years ago we at Mozilla started a project to create a new record-and-replay tool that would overcome the obstacles blocking adoption. We call this tool rr.
Here are some of our key design parameters:
I believe we've achieved those goals with our 1.0 release.
There's a lot to say about how rr works, and I'll probably write some followup blog posts about that. In this post I focus on what rr can do.
rr records and replays a Linux process tree, i.e. an initial process and the threads and subprocesses (indirectly) spawned by that process. The replay is exact in the sense that the contents of memory and registers during replay are identical to their values during recording. rr provides a gdbserver interface allowing gdb to debug the state of replayed processes.
Here are performance results for some Firefox testsuite workloads: ") These represent the ratio of wall-clock run-time of rr recording and replay over the wall-clock run-time of normal execution (except for Octane, where it's the ratio of the normal execution's Octane score over the record/replay Octane scores ... which, of course, are the same). It turns out that reftests are slow under rr because Gecko's current default Linux configuration draws with X11, hence the rendered pixmap of every test and reference page has to be slurped back from the X server over the X socket for comparison, and rr has to record all of that data. So I also show overhead for reftests with Xrender disabled, which causes Gecko to draw locally and avoid the problem.
These represent the ratio of wall-clock run-time of rr recording and replay over the wall-clock run-time of normal execution (except for Octane, where it's the ratio of the normal execution's Octane score over the record/replay Octane scores ... which, of course, are the same). It turns out that reftests are slow under rr because Gecko's current default Linux configuration draws with X11, hence the rendered pixmap of every test and reference page has to be slurped back from the X server over the X socket for comparison, and rr has to record all of that data. So I also show overhead for reftests with Xrender disabled, which causes Gecko to draw locally and avoid the problem.
I should also point out that we stopped focusing on rr performance a while ago because we felt it was already good enough, not because we couldn't make it any faster. It can probably be improved further without much work.
The rr project landing page has a screencast illustrating the rr debugging experience. rr lets you use gdb to debug during replay. It's difficult to communicate the feeling of debugging with rr, but if you've ever done something wrong during debugging (e.g. stepped too far) and had that "crap! Now I have to start all over again" sinking feeling --- rr does away with that. Everything you already learned about the execution --- e.g. the addresses of the objects that matter --- remains valid when you start the next replay. Your understanding of the execution increases monotonically.
rr has limitations. Some are inherent to its design, and some are fixable with more work.
We believe rr is already a useful tool. I like to use it myself to debug Gecko bugs; in fact, it's the first "research" tool I've ever built that I like to use myself. If you debug Firefox at the C/C++ level on Linux you should probably try it out. We would love to have feedback --- or better still, contributions!
If you try to debug other large applications with rr, you will probably encounter rr bugs. Therefore we are not yet recommending rr for general-purpose C/C++ debugging. However, if rr interests you, please consider trying it out and reporting/fixing any bugs that you find.
We hope rr is a useful tool in itself, but we also see it as just a first step. rr+gdb is not the ultimate debugging experience (even if gdb's backtracing features get an rr-based backend, which I hope happens!). We have a lot of ideas for making vast improvements to the debugging experience by building on rr. I hope other people find rr useful as a building block for their ideas too.
I'd like to thank the people who've contributed to rr so far: Albert Noll, Nimrod Partush, Thomas Anderegg and Chris Jones --- and to Mozilla Research, especially Andreas Gal, for supporting this project.
|
|
Justin Dolske: Shredding Fail |
A few years ago I blogged about the importance of using a good paper shredder. A crappy shredder is just (bad) security through obscurity, and easily leaks all kinds of info. So I was delighted and horrified to find this package show up in the mail, using shreds as packing protection for the item I had ordered.

30 seconds of searching turned up a number of interesting bits (plus a few more with full names which I have kindly omitted):

Let’s count a few of the obvious mistakes here:
And of course it would have been better security to use a microcut shredder.
Now, to be fair, even this poor shredding has technically done its job. Other than a few alluring snippets, it’s not worth my time to assemble the rest to see the full details of these banking, business, and health care records. But then I’m a nice guy who isn’t interested in committing fraud or identity theft, which is an unreasonable risk to assume of every customer.

|
|
Nick Cameron: A thought on language design |
http://featherweightmusings.blogspot.com/2014/05/a-thought-on-language-design.html
|
|
Gervase Markham: Bugzilla 1,000,000 Bug Sweepstake Results |
Milestone bugzilla.mozilla.org bug 1,000,000 was filed on 2014-04-23 at 01:10 ZST by Archaeopteryx (although rumour has it he used a script, as he also filed the 12 previous bugs in quick succession). The title of the bug was initially “Long word suggestions can move/shift keyboard partially off screen so it overflows” (a Firefox OS Gaia::Keyboard bug, now bug 1000025), but has since been changed to “Celebrate 1000000 bugs, bring your own drinks.”
The winner of the sweepstake to guess the date and time is Gijs Kruitbosch, who guessed 2014-04-25 05:43:21 – which is 2 days, 4 hours, 33 minutes and 5 seconds out. This is a rather wider error, measured in seconds, than the previous sweepstake, but this one had a much longer time horizon – it was instituted 9 months ago. So that’s an error of about 0.95%. The 800,000 bug winner had an error of about 1.55% using the same calculation, so in those terms Gijs’ effort is actually better.
Gijs writes:
I’m Dutch, recently moved to Britain, and I’ll be celebrating my 10th “mozversary” sometime later this year (for those who are counting, bugs had 6 digits and started with “2'' when I got going). Back in 2004, I got started by working on ChatZilla, later the Venkman JS debugger and a bit of Firefox, and last year I started working on Firefox as my day job. Outside of Mozilla, I play the piano every now and then, and try to adjust to living in a nation that puts phone booths in its cycle paths.
The two runners-up are Havard Mork (2d 14h 50m 52s out) and Mark Banner (8d 8h 24m 36s out). Havard writes:
My name is Havard Mork. I’m a Java software developer, working with Firefox and web localization to Norwegian. I’ve been involved with localization since 2003. I think localization is rewarding, because it is a process of understanding the mindset of the users, and their perception of IT.
I’m surprised that my estimate came that close. I spent almost an hour trying to figure out how much bug numbers grow, and estimate the exponential components. Unfortunately I lost the equation, so need to start over for the 2,000,000 sweepstakes…
Mark writes:
I’m Mark Banner, also known as Standard8 on irc, I work from home in the UK. I came to Mozilla through volunteering on Thunderbird, and then working at Mozilla Messaging. I still manage Thunderbird releases. Alongside those, I am working on the Loop project (formally Talkilla), which is aiming to provide a real time communications service for Mozilla products, built on top of WebRTC.
Gijs will get a Most Splendid Package, and also a knitted thing from Sheeri as a special bonus prize! The other winners will receive something a little less splendid, but I’m sure it’ll be worth having nevertheless.
http://feedproxy.google.com/~r/HackingForChrist/~3/IdpbLl5cqaQ/
|
|
Marco Zehe: WAI-ARIA for screen reader users: An overview of things you can find in some mainstream web apps today |
After my recent post about WAI-ARIA, which was mostly geared towards web developers, I was approached by more than one person on Twitter and elsewhere suggesting I’d do a blog post on what it means for screen reader users.
Well, I’ve got news for all my blind and visually impaired readers: You’re not getting one blog post, you’re getting a whole series instead! ![]()
This blog post will kick it off, and I will cover some general uses where you will find that WAI-ARIA improves your user experience. These examples are most useful when using modern screen reader/browser combinations, as is the case with most web stuff today anyway. So if you’re using NVDA or JAWS on Windows, Orca on Linux, or VoiceOver on the Mac, most, if not all, example uses below should work for you in one way or another. Browsers on Windows are Firefox and Internet Explorer, on Linux it’s also Firefox, and on OS X most likely Safari. Chrome and ChromeVox may or may not work in a similar way, but I’ll leave that to those using that combination to test it.
WAI-ARIA stands for Web Accessibility Initiative – Accessible Rich Internet Applications. It is a World Wide Web Consortium (W3C) standard. It allows web authors to tell assistive technologies that certain constructs of HTML markup — the stuff that makes up web pages — mean something that is not actually available in normal HTML, but maps to some desktop control that users are probably familiar with.
WAI-ARIA has three pillars: Roles, States and Properties, and Live Regions. I will briefly cover each of them below, but not extensively, since this is mostly for end users.
Roles tell the screen reader that a particular element of a web page is actually meant to be something else. For example, if assigning a role of “button” to a fancy looking clickable element made up of one or more generic HTML elements, screen readers will simply read it as a button in virtual buffer. If the author did a good job of providing keyboard accessibility, you can even tab to it and press Space to activate. All examples below do that.
Roles are oriented along known control types from the desktop. Using WAI-ARIA, you can mark up even fancy stuff like whole tree views, similar to what the folder tree in Windows Explorer is. In a later article, we’ll see such a tree view in action.
States and Properties tell the screen reader something more about a particular control than normal HTML can. For example, even in older web pages, they can tell the screen reader that a field is required or invalid. They can tell whether a button opens a popup or sub menu, if something has an auto-complete, if a fancy checkbox is checked or not, etc. We’ll see a lot of these in action in this and other articles.
Live Regions allow the web author to make the screen reader tell the user about some dynamic updates. For example, a live region can be used to make the screen reader say information like “auto-complete results are available”, or “Your message has been sent successfully”. Status information that is good to know at a particular moment, but not important enough to stick around for long, or even be exposed in a dialog form.
Live regions can be either polite, meaning they speak once your screen reader has finished speaking what it’s currently speaking, or assertive, meaning they will interrupt whatever the screen reader is currently speaking, to immediately make you aware of a certain status change.
OK, now that we’ve got these pillars of WAI-ARIA laid out a bit, let’s get started looking at some examples! it is important that you have JavaScript in your browser turned on. Yes: On, not off! Modern web apps live only because of JavaScript, and turning it off nowadays is like cutting off an arm or foot, it will leave you mostly immobilized on most modern web sites. So throw away those old beliefs that javaScript is no good for accessibility, and turn it back on or uninstall that NoJS add-on you’ve been keeping around!
Each of the below examples will open in a new tab or window on purpose, so you can play around with them a bit and return to the article when you’re done.
Twitter got a huge accessibility boast over the last year to a year and a half. Twitter even has a dedicated accessibility team now making sure their web site and mobile apps are becoming more accessible, and stay that way.
When you open Twitter and log in — assuming you have an account –, you can do several things to try out its accessibility.
First, focus on the Tweet Text edit field and invoke focus or forms mode, or whatever that mode is called in your preferred screen reader. Even that alone will give you several bits of information. It will tell you that the edit field is collapsed, that it has a sub menu, that it has an auto-complete, and that it is multi-line. The bits about having a sub menu and being collapsed are coming from WAI-ARIA markup. The other info could be encountered in just any multi-line edit field on the web.
Next, start typing some text. Notice that on occasion, Twitter will speak numbers as the number of available characters that you have left in the tweet decreases. Twitter has a limit of 140 characters per tweet.
Now, let’s add a user name. Type the @ sign. My Twitter handle is MarcoInEnglish (in one word, capitalization is not important). So after the @ sign, type the letter m. If you’re following me, at least one result should come up. The first thing you’ll hear now is that the edit field changes state from “collapsed” to “expanded”. After a moment, depending on your internet connection, you will also hear something like “3 results available” (number may vary). This means that Twitter has found matching handles that start with, or contain, the letter m.
Now, press DownArrow. You will now hear that you are in a list, that a certain list item is selected and what it contains, and that it’s item 1 of 3 (or whichever number of results are being displayed). All this is WAI-ARIA magic. You can press Up and Down to select an entry, Tab or Enter to insert that into your tweet, or Escape to dismiss the AutoComplete and return focus to the edit field without inserting anything, and resume typing.
If you decided to press Enter or Tab, you’ll hear that focus returns to the edit field, and that it is now collapsed again. Your cursor is positioned after the Twitter handle you just inserted, and a space has been added for you so you can continue typing uninterrupted.
Next, let’s look at something else on the Twitter page. Press Escape or whichever hotkey gets you out of forms or focus mode back into browse mode/virtual cursor mode. Find the heading level 2 that says “Tweets”, then DownArrow to the first tweet. After the tweet text and possible links, you’ll find a list of 4 items. The first three items are normal buttons named Reply, Retweet and Favorite. The fourth, however, is a menu button that has a sub menu. Screen readers will announce it as such. Press it. Focus will now shift to a menu, and you have 3 items: Share via E-Mail, Embed, and Report. These are announced as menu items within a menu. Press Escape to dismiss this menu without selecting anything.
These are also WAI-ARIA menus. Menu items, or menu buttons with attached sub menus are normally not available in HTML. However, through WAI-ARIA markup and some focus/keyboard handling via JavaScript, these widgets can be made fully keyboard accessible and expose all relevant information to screen readers, including menus.
Want to get even more app-like? If you’re on Windows, which probably most of you are, turn off your virtual cursor. With NVDA, you do this by pressing NVDA+SpaceBar. JAWS’s shortcut is Insert+Z. You may have to press it twice to also prevent JAWS from reinvoking virtual PC cursor when a new page loads. Once you’ve turned off your browse mode or virtual cursor, start pressing J and K (yes, the letters) to move through tweets. You’re now moving the actual keyboard focus, and through WAI-ARIA labeling, and some live regions on occasion, you are getting a fully accessible experience. Press your Question Mark key to hear which other keyboard shortcuts you have available. You can reply, favorite, retweet tweets, expand conversations and jump to the new tweets that might, in the meantime, have been added while you were browsing your timeline. You can also quickly jump to the compose edit we were in earlier, to write a new fresh tweet. In essence, you might hardly ever need virtual cursor at all on Twitter, because the app-like experience is so good!
On Mac OS X, you don’t even have to worry about switching modes, because there is no virtual cursor, and you can use those Twitter shortcuts right away. In fact, this might be a much more efficient way to navigate the Twitter experience than the VoiceOver commands for web browsing.
All the while, keyboard focus will make sure that pressing Tab will actually move into the tweet you’re currently reading.
Facebook has made similar advancements in making their regular web presence more accessible in the last 18 to 24 months. If you log in with your Facebook account and start exploring from the top, you’ll immediately encounter a few menu buttons that have popups attached to them. These are the Friend Requests, Messages, and Notifications buttons. If you have the newest design, the Privacy and Account Settings buttons will also be there.
A bit further below, you will find the Search field. It is announced as a combo edit field, one of those edits that you can either type in or choose from a list. Focus it, and start typing, for example the name of the Facebook Accessibility page. You will automatically hear announcements as results become available. Like you would expect, you can arrow up and down through the results, and if you found the one you were looking for, press Enter to go to that page.
But let’s stay on the main page for now, and find the edit field that alllows you to post a status update. This is not only a normal edit field. It, too, has the possibility to auto-complete names or locations as you type them. If you start typing the name of a friend, a list will pop up that allows you to select from the available auto-complete results, and press Tab to insert that name into the text field, including tagging that person once you post the status update. Unlike we’ve seen on Twitter, the list comes up automatically, but you can continue typing without the danger of selecting something. You will only insert a search result via the Tab key.
Again, listen to what your screen reader tells you about the results, the list items, etc. Also, the widget to post a status update has a few buttons at the top that allow you to switch whether you’re posting a news item, a photo or video. These are called toggle buttons. They are a bit similar to radio buttons, but because they will immediately perform an action once you press them, they’re buttons. Radio buttons normally only change a selection, but don’t cause whole widget environments to change. You will hear the announcement that one, by default the Story item, is pressed, meaning this is the button that is currently active. An analogous construct could be in your word processing toolbar where you have Left, Center, Right, and Justified buttons. Only one of them can be active — or pressed — at a particular time. If one is pressed, the pressed state of another goes away. Same here in this Facebook widget.
All of this is, again, WAI-ARIA. In earlier years, you would not have known which item was the active one, or that these were toggle buttons at all. The auto-complete results would not have spoken as such, either.
There’s one more thing I would like you to try: Find a friend who will be your guineapig and send them a private message. After you send it, leave your focus in the edit field and wait for their reply. Ideally, you’d choose a friend who is currently showing as online. Once she or he replies, you should automatically hear the message and can start replying right away. This is again a live region at work. Once new messages come in, even those that you just sent, they’ll be read out aloud.
Microsoft also has made some great strides in making their online services more accessible. Their cloud storage is called OneDrive, and it is a web frontend to the files and folders you have stored in their cloud.
If you have an account at Microsoft OneDrive, log in and look at the list that is available on that page. It will list all your files and folders. Here, you can see a not yet fully complete implementation (as of this writing) of WAI-ARIA. For one, the list items are in multiple columns, so you can not only use up and down, but also left and right to move to items. Second, when pressing Enter, screen readers are not yet notified of changes. You have to press an arrow key again to hear that the contents has actually changed. Now, select a file, and press the context menu key. This is also called the windows key and is located to the left of the right control key on most keyboards. You should now hear a context menu open, and when you press up and down, you should hear the selected menu item. Yes, you should, but you won’t. ![]() Because this is currently still a bug in the implementation. The context menu appears, you can move up and down, but the newly focused item is not yet being communicated to screen readers. Yup, it’s a bug, and I let Microsoft know about it when I found it just now.
Because this is currently still a bug in the implementation. The context menu appears, you can move up and down, but the newly focused item is not yet being communicated to screen readers. Yup, it’s a bug, and I let Microsoft know about it when I found it just now. ![]()
As a workaround, you can turn virtual mode back on manually (NVDA+Space or for JAWS the NUMPAD PLUS key), move to the end of the virtual document, and find the menu items there. Arrow to the one you want and press Enter to select and activate it.
The Word document, if you selected one, will now open in Office Online. I wrote a more detailed review of Office Online already, so I strongly suggest you read that for an in-depth look at what Word in the browser has to offer! And it’s all done through a combination of modern web technologies, including WAI-ARIA. The tool bars and ribbons etc. are all rich internet application stuff.
The use of WAI-ARIA is spreading. Since many web sites use re-usable components such as jQueryUI and others nowadays, making these accessible will bring better accessibility to many web sites automatically. Other components, such as the TinyMCE and CKEditor rich web editors, have also made great strides in accessibility in the last year or two, and sites using these will get that accessibility for free. If you have a WordPress blog on version 3.9, try using the visual editor for a change, and from the edit area, press Alt+F10, for example! ![]()
Sometimes, as shown in the Microsoft OneDrive case above, things may not be fully implemented yet. Yes, these things can happen, and they happened on the desktop before, too. The best is to provide constructive feedback to the site owners and point out where the problems lie exactly. That way, they can be fixed most easily.
In the next few blog posts on this series, I will take an in-depth look at Google apps like GMail, Contacts and calendar, Google Drive, Docs, Sheets and Slides, etc. These have become more and more important in many work as well as educational environments, and Google has made great progress in the last 6 to 9 months alone making their offerings much more accessible than they were before. Their documentation is also generally pretty good, but I’d like to provide my own perspective nevertheless, and provide a few tips and tricks and point out possible caveats. So stay tuned!
I hope this article helped you get a bit of a glimpse into what WAI-ARIA is and what good it can do for you as a blind or visually impaired user when used properly. More and more web sites, components and companies are using it.
And if anyone tries to tell you that WAI-ARIA is not important or its importance is greatly overstated, ask them if they can do what you can do, without using WAI-ARIA, and without offering any 3rd party app, just the web browser and assistive technology. WAI-ARIA is important, and it is being enhanced to provide even richer and more accessible experiences in the future. More and more apps are moving to a web-based user interface for both desktop and mobile operating systems, and it is important to have a technology that can make these rich applications as accessible as their native counterparts or legacy offerings. The technology is there, it’s working, so let’s use it!
So keep your JavaScript turned on, fear not, and embrace the future of web apps!
![]()
|
|
Alan Starr: Enough Privacy? |
I'm trying to debug by Candy Crush is slow to load in the latest Firefox. It seems to go faster in Safe-Mode, so that's good. The next step, of course is disabling all add-ons. If I didn't know better, then I'd be asking why "Restart with add-ons disabled" isn't the same. For those of you that don't know, it is because that invokes Safe mode which also eases up on some other restrictions.
But that is something for another post. As I was re-instating my add-ons, I realized that while I care about my privacy, I don't know the best way to achieve that. I have at least 5 add-ons related to that. I know I'll keep NoScript, but which of the others do I also need? The Add-Ons website lists more than 1100 extensions to choose from. How is someone supposed to choose?
|
|







