Sean Martell: Firefox Behind the Scenes: Australis Tab |
With the launch of our latest version of Firefox yesterday, an all new updated interface was brought to the browser. The UX team here at Mozilla was hard at work for over two years dreaming up, building and refining the final product. Here’s a 3-part GIFtastic cinematic glimpse into that process.

http://blog.seanmartell.com/2014/04/30/firefox-behind-the-scenes-australis-tab/
|
|
Matej Cepl: Current State of the Distributed Issue Tracking |
While listening to the old issue of The Git Minutes podcast, I was again reminded about the possibility of the distributed issue tracking. Albeit I have grown to be persuaded that the issue tracking has to have available web input (because “normals” won’t file bugs via git) and tried to work with normal Bugzilla (and found it surprisingly simple), I am still intrigued by the idea of the issues data (or metadata?) stored in the repository itself and followed with the git branches. Therefore, I have decided to write this brief overview of the current state (i.e., summer 2013) of the distributed issue trackers (mostly limited to those working with git), and to evaluate whether it would be possible to use some of them.
Generally to introduce whole landscape of the distributed issue trackers let me present you this very old photograph of the landscape after the Battle of Verdun

Unfortunately, this image really well represents the current situation of the distributed issue trackers. Most of the projects mentioned below are defunct and abandoned even by its original authors.
Generally I would say that the thinking in this area ended up in one of the two camps:
Seems like alive project (which is rare), the latest commit on master was just in the October last year (by me, true ;)). Also, written in Python, which is a plus (for me).
gitissius is another rare example of the project which is not completely dead yet. Also, I have been working on some improvements , but nothing has been merged in the upstream yet (perhaps, because it is broken?)
Rubyforge homesite, also some bugs are listed on Launchpad, and there is (dead) email list
Python clone ... pitz https://github.com/mw44118/pitz
Ditz commander https://code.google.com/p/ditz-commander/
There is also ditz-trac to sync ditz database with Trac. Not working ATM.
Presentation and code
http://www.ditrack.org/ ... SVN based
https://github.com/schacon/ticgit/wiki declares project as dead and suggests https://github.com/jeffWelling/ticgit
This is the granddaddy of all issues-in-separate-branch systems.
https://github.com/jwiegley/git-issues
I have my own version with an attempt to bring a little bit of sanity to the code on http://luther.ceplovi.cz/git/git-issues.git but truly, one should use gitissius instead.
http://dist-bugs.branchable.com/people/bartman/git-case/ and https://github.com/bartman/git-case
Looks like yet another bugs-stored-in-hidden-directory issue tracker. Also, it is dead (last commit is four years old).
http://www.eharning.us/wiki/stick/, unfortunately the link to the code gives 404.
https://lwn.net/Articles/434922/ and http://syncwith.us/sd/
Not part of any DVCS, distributed only the meaning that it is based on the distributed database Prophet. There is a nice discussion by Lars Wirzenius why he believes that’s The Right Thing™ to do, and why bugs shouldn’t be stored in the repository itself.
http://www.mrzv.org/software/artemis/ ... Mercurial extension, doesn’t work with git.
DisTract Linuxmafia article has this to say about it:
We're all now familiar with working with distributed software control systems, such as Monotone, Git, Darcs, Mercurial and others, but bug trackers still seem to be fully stuck in the centralised model: Bugzilla and Trac both have single centralised servers. This is clearly wrong, as if you're able to work on the Train, off the network and still perform local commits of code then surely you should also be able to locally close bugs too.
DisTract allows you to manage bugs in a distributed manner through your Web browser. Currently only Firefox is supported. The reason for this is that there is no local server used, and so the Web browser must directly (via Javascript) call programs on your local system. I only know how to do this in Firefox. The distribution is achieved by making use of a distributed software control system, Monotone. Thus Monotone is used to move files across the network, perform merging operations and track the development of every bug. Finally, the glue in the middle that generates the HTML summaries and modifies the bugs is written in Haskell.
Other features include the use of Markdown markup syntax for bug descriptions and comments, with live preview via a Javascript implementation of Markdown.
Code is Haskell and Javascript. New BSD licence.
Just to acknowledge that there also other reviews of this area:
https://luther.ceplovi.cz/blog/2014/04/30/current-state-distributed-issue-tracking/
|
|
Jared Wein: Refinements to the Linux theme in the new Firefox |
Firefox on GTK Linux now matches the look of Firefox on Windows and Mac OS X. The new Firefox brings interactions and visual designs that were present previously only on Windows and Mac OS X to Linux to provide a more familiar user experience to Firefox users regardless of platform.


Firefox on Linux now has the familiar “keyhole” design. This design is an immediately recognizable feature of Firefox, and is shown by the shape of the back button connected to the forward button and location bar.
Many brands have identifiable shapes such as the Mickey Mouse ears that Disney uses, and the curvy bottle shape of Coke. These shapes are immediately recognizable as part of their respective brands, and bringing Linux in to the mix is something that has been on the Firefox front-end team’s backlog for a while now.
I’m really happy to see the keyhole shape now present on all of our tier-1 platforms: Windows, Mac OS X, and now Linux (GTK).
 Another large refinement that has been brought to Linux is new toolbar icons for buttons such as the Home, Back/Forward, and tab close buttons. The iconography of our Linux version now matches that of Windows and Mac OS X.
Another large refinement that has been brought to Linux is new toolbar icons for buttons such as the Home, Back/Forward, and tab close buttons. The iconography of our Linux version now matches that of Windows and Mac OS X.
These changes help unify the experience of Firefox users independent of platform, while also allowing for a faster pace of development for the people working on making Firefox.
If you’re already running Firefox, it will automatically update to the latest version. If not, you can download Firefox now, always free and always open.

http://msujaws.wordpress.com/2014/04/30/refinements-to-the-linux-theme-in-the-new-firefox/
|
|
Hub Figui`ere: Fixing deprecations |
Also, I updated the PHP version on the hosting side (the hosting company did, I just clicked on the button in the panel). This cause some glitches with the antispam and the rest when commenting. Sorry about that.
I addressed the known issues, related to deprecated PHP functions. This is still easier than upgrading to the newer version of Dotclear that break the URLs.
http://www.figuiere.net/hub/blog/?2014/04/29/848-fixing-deprecations
|
|
Hub Figui`ere: Crazy idea: Decentralised bug tracker |
Last week, over a nice diner in a nice Portuguese restaurant on "the main", I had a discussion with @pphaneuf about decentralised bug tracking. He had the idea first.
Since you have decentralised version control in the name of git (there are others), couldn't we have the same for a bug tracker? Using sha1 instead of bug name isn't much different as you could use the abbreviated form. After all, Mozilla has reached the 7 digits bug numbers now.
The idea I proposed was something like carrying that metadata in a secondary repository inside that would be linked - or even better, in a different branch. Also there would be an equivalent to cgit to serve this data in a web interface and probably a few new git commands. The bug repository could be skipped on check out for those who don't want it.
And here goes bug fixing and triaging in a European airport or luxurious hotel wifi with proper access to the whole history.
The idea sounds crazy, but I think it can work. Let's call it buggit.
And no I'm not coding it. This is just small talk. And I haven't done due diligence in searching if something already existed but I like crazy ideas.
http://www.figuiere.net/hub/blog/?2014/04/29/847-crazy-idea-decentralised-bug-tracker
|
|
Daniel Stenberg: #MeraKrypto |
A whole range of significant Swedish network organizations (ISOC, SNUS, DFRI and SUNET) organized a full-day event today, managed by the great mr Olle E Johansson. The event, called “MeraKrypto” (MoreCrypto would be the exact translation), was a day with introductions to TLS and a lot of talks around TLS and other encryption and security related topics.
I was there and held a talk on the topic of “curl and TLS” and I basically talked some basics around what curl and libcurl are, how we do TLS, some common problems and hwo verifying the server cert is a common usage mistake and then I continued on to quickly mention how http2 and TLS relate..See my slides below, but please be aware that as usual you may not grasp the whole thing only by the (English) slides. The event was fully booked so there was around one hundred peeps in the audience and there were a lot of interested minds that asked good questions proving they really understood the topics.
The discussion almost got heated during the talk about how companies do MITMing of SSL sessions and this guy from Bluecoat pretty much single-handedly argued for the need for this and how “it fills a useful purpose”.
It was a great afternoon!
The event was streamed live and recorded on video. I’ll post a link as soon as it gets available to me.
|
|
Christie Koehler: Community Building Education Update – 29 April 2014 |
Note: This is the first in what I plan to be weekly updates about the work we’re doing as part of the Education and Wiki Working Groups, part of the community building team at Mozilla. I’ll tag these updates with mozilla as well as cbt-education and wwg when appropriate.
On Tuesday of last week we help our twice-monthly Wiki Working Group meeting (notes). Key takeaways:
During our next meeting we’ll continue work on both the short- and long-term roadmaps. If you’re interested in contributing, please get involved!
Later in the week, a few of us fixed the following bugs:
Last week a handful of contributors gathered at the San Francisco office to plan MozCamps 2014, the next phase of what we’re still calling “MozCamps” but which we plan to evolve into a new kind of event.
I’m still synthesizing everything we covered during the planning session, but the most relevant takeaway in terms of the education working group was this list of community building skills that the group generating during a brainstorming session about what content should be included in the new MozCamps. This week I’m working to integrate that list into the existing community building curriculum roadmap.
http://subfictional.com/2014/04/29/community-building-education-update-29-april-2014/
|
|
Eitan Isaacson: Make pita like a pro |
Anyone who comes from a pita-rich country to North America knows that you really can’t get your hands on good pita here. I came across a recipe in Hebrew that is really good, and makes fantastic doughy pitas with nice pockets.
You need:
In a large bowl, sift in the flour and mix all the dry ingredients (salt, sugar, yeast) until it is all evenly distributed. Add the olive oil, and half the the warm water. Start mixing with a spoon, and add the rest of the water slowly.
Now it’s time to get dirty (if you haven’t gotten flower on everything already). With a wet hand, reach into the bowl, and knead the dough in a twisting fashion, as if you were screwing a light bulb. If the business gets sticky, re-wet your hand as many times as needed. Does your arm hurt yet? Good. Keep twist-kneading, and switch directions every once in a while. Do this for 10 minutes.
Set the bowl aside, and let the dough rise for an hour and a half until it doubles in size.
Put pizza stone in oven and preheat it to its max temperature, my oven goes to 550 degrees F. The dough, once risen should be very airy and wet. This is good! Spill it out to a floured work surface and get control over it with flour. Now use a knife to split the dough into 16 balls. Flatten each ball with a rolling pin to create flat circles.
Baking time! Each pita will need about 2 or 3 minutes, not more. If you are seeing any browning you are a few seconds late. You should see the pita puff up and get a pocket. I managed to bake two at a time, and have a huge basket filled with fresh pita in about 15 minutes.

|
|
Arky: The Web We Want: An Open Letter (Video) |
The Web is our largest shared resource. Let's keep it free and open for us, and for the next generation.
What kind of Web do you want? Tell us: http://mzl.la/1hHyqBq
Learn more about at webwewant.mozilla.org and WebWeWant.org global movement to defend, claim and change the future of the Web.
http://playingwithsid.blogspot.com/2014/04/the-web-we-want-open-letter-video.html
|
|
Mark Coggins: Find the Movie, the ultimate movie quiz game for Firefox OS,... |

Find the Movie, the ultimate movie quiz game for Firefox OS, brought to the Firefox Marketplace as part of the Phones for Cordova/PhoneGap ports program.
|
|
Jared Wein: The fresh and furiously fast Firefox |
One of the less covered parts of this week’s Firefox release is high attention that was placed on the performance of the redesign of the tab shape.
The new Firefox introduces a new tab shape that is consistent with Firefox for Android, FirefoxOS, Thunderbird, as well as the web properties of Mozilla.

Firefox for Android

Firefox
As the Firefox team was implementing this new design, performance was a key metric that was measured and focused on. We wanted to not only bring a beautiful design to users, but one that matched the new sleek shape with an equally speedy outcome.
Each time a change was made to our source control repository, a fresh build of the browser was created and run against a suite of automated tests that measure the performance of the build. These results are then compared against the results of prior builds, allowing the team to track improvements and regressions.
One such test that was used is called TART, short for Tab Animation Regression Test. The test works by opening and closing tabs and measuring the amount of time needed to paint each frame of the animation. Normally Firefox only attempts to paint one frame every 16ms (equivalent to 60fps) but during TART that limit is disabled.
Users of Firefox can have infinite variations of hardware setup, some of which are much slower than our testing infrastructure. By trying to paint as fast as possible, we can get a number that will represent the maximum bound for our graphics performance on our fixed-setup testing infrastructure. By tracking this number, we project that the full Firefox user-base will on average see proportional performance gains.

 In the previous version of Firefox on Windows 7, Firefox took an average of 3.52ms to paint each frame of the tab opening animation [1]. With the new version of Firefox, we have gotten this number down to 2.81ms, which is a 20% speed up!
In the previous version of Firefox on Windows 7, Firefox took an average of 3.52ms to paint each frame of the tab opening animation [1]. With the new version of Firefox, we have gotten this number down to 2.81ms, which is a 20% speed up!
When it comes to closing tabs, we saw a shift from 2.72ms to 1.88ms [2], an amazing 31% speed up!
Gains like the above only happen when a solid testing framework is in place and an equally solid team keeps performance as a top priority. Cheers to everyone that has helped make the new release of Firefox the fastest yet.
If you’re already running Firefox, it will automatically update to the latest version. If not, you can download Firefox now, always free and always open.
[1] icon-open-DPI1.all.TART (Fx28 1b8f6597b67f vs Fx29 f1c211a4714d)
[2] icon-close-DPI1.all.TART (Fx28 1b8f6597b67f vs Fx29 f1c211a4714d)

[Update: Thank you to Benedikt who in the comments below corrected a math error that I made with the percentage of improvements]

http://msujaws.wordpress.com/2014/04/29/the-fresh-and-furiously-fast-firefox/
|
|
Gervase Markham: bugzilla.mozilla.org Stats At 1,000,000 |
Thanks to glob, we’ve got some interesting stats from BMO as it crosses the 1M bug mark.
UNCONFIRMED 23745 NEW 103655 ASSIGNED 8826 REOPENED 3598 RESOLVED 640326 VERIFIED 220235 CLOSED 1628
DUPLICATE 119242 EXPIRED 10677 FIXED 303099 INCOMPLETE 30569 INVALID 58096 MOVED 27 WONTFIX 36179 WORKSFORME 82437
DUPLICATE 64702 EXPIRED 27 FIXED 108935 INCOMPLETE 1746 INVALID 17099 MOVED 150 WONTFIX 6105 WORKSFORME 21471
2014-04-01 519 2014-04-02 531 2014-04-03 620 2014-04-04 373 2014-04-05 133 2014-04-06 132 2014-04-07 544 2014-04-08 622 2014-04-09 597 2014-04-10 571 2014-04-11 467 2014-04-12 156 2014-04-13 170 2014-04-14 573 2014-04-15 580 2014-04-16 574 2014-04-17 619 2014-04-18 356 2014-04-19 168 2014-04-20 118 2014-04-21 445 2014-04-22 635 2014-04-23 787 2014-04-24 562 2014-04-25 498 2014-04-26 173
2013-12-30 1360 (bulk import from another tracker) 2013-12-29 1081 (bulk import from another tracker) 2008-07-22 1037 (automated security scanner filing bugs) 2012-10-01 1013 (Gaia bugs import) 2014-02-11 805 2014-04-23 787 2014-02-04 678 2013-01-09 675 2013-11-19 647 2014-04-22 635
Bugs filed 4351 Comments made 148493 Assigned to 4029 Commented on 56138 QA-Contact 8 Patches submitted 8080 Patches reviewed 14872 Bugs poked 66215
(You can find these stats about yourself by going to your own user profile. If you are logged in, you can search for other users and see their stats.)
nobody@mozilla.org 349671 mscott@mozilla.org 16385 bugzilla@blakeross.com 15056 asa@mozilla.org 13350 sspitzer@mozilla.org 11974 bugs@bengoodger.com 10995 justdave@mozilla.com 4768 sean@mozilla.com 4697 oremj@mozilla.com 4672 mozilla@davidbienvenu.org 4273
jruderman@gmail.com 8037 timeless@bemail.org 6129 krupa.mozbugs@gmail.com 5032 pascalc@gmail.com 4789 bzbarsky@mit.edu 4351 philringnalda@gmail.com 4348 stephen.donner@gmail.com 4038 dbaron@dbaron.org 3680 cbook@mozilla.com 3651 bhearsum@mozilla.com 3528
tbplbot@gmail.com 347695 bzbarsky@mit.edu 148481 philringnalda@gmail.com 65552 dbaron@dbaron.org 58588 ryanvm@gmail.com 50560 bugzilla@mversen.de 48840 gerv@mozilla.org 48704 roc@ocallahan.org 47453 hskupin@gmail.com 43596 timeless@bemail.org 42885
bzbarsky@mit.edu 8080 dbaron@dbaron.org 4879 ehsan@mozilla.com 4502 roc@ocallahan.org 4397 masayuki@d-toybox.com 4079 neil@httl.net 3930 mozilla@davidbienvenu.org 3890 timeless@bemail.org 3739 brendan@mozilla.org 3659 bugs@pettay.fi 3530 wtc@google.com 3411
roc@ocallahan.org 15581 bzbarsky@mit.edu 14869 neil@httl.net 9424 jst@mozilla.org 8352 dbaron@dbaron.org 8103 benjamin@smedbergs.us 7272 mozilla@davidbienvenu.org 6198 dveditz@mozilla.com 5983 asa@mozilla.org 5499 mark.finkle@gmail.com 5346 gavin.sharp@gmail.com 5126
http://feedproxy.google.com/~r/HackingForChrist/~3/uIHa4l_20J4/
|
|
Panos Astithas: My 3 year mozversary |
http://feedproxy.google.com/~r/PastMidnight/~3/PLOvihF0oiw/my-3-year-mozversary.html
|
|
David Burns: Do you trust a test that you have never seen fail? |
Recently David Heinemeier Hansson (dhh) wrote a blog post called "TDD is dead, long live testing". He describes how the TDD world has got mean spirited and perhaps the use of the technique was to break down the barriers of automated testing and regression testing but that is no longer the case. (I agree with this a little but there are a lot of angry people out there)
He then declares that he has had enough and declares that he does not write tests first and is proud of it.
This post has obviously had mixed reviews from people. A lot of the consultant types that I follow on twitter who are rather large advocates of TDD have said dhh shouldn't really be saying things like this. Their arguments have been around how hard it is to test rails applications because the underlying architecture doesn't allow it (Which distracts from the argument in my opinion!). The thing that David describes briefly is that we should not follow things dogmatically which is sound advice that everyone should follow. It's the same with best practises, don't follow them unless they make sense.
The amount of people who then started shouting from the roof tops that they don't test first and were proud of it grew quite quickly. I find this sentiment quite worrying. Why?
If you have hundreds of thousands of tests that are run when you commit code you want there to be a very high probability that any regression will be caught. Writing tests after you have written the code can lead to a lot of tests that may never fail which take up huge amounts of resource that costs money. At the beginning of the year Mozilla would use ~200 computing hours per push to Mozilla Inbound (the main tree that holds the Firefox code). Thats A LOT of resource to be wasting on a test that you are not sure will ever catch anything. For what it is worth there a lot of tests in the Mozilla tree that may never catch anything but its hard to find them :(.
I know that you can't always write a test first, there are times where it is quite hard to do that, but making sure you have faith in your tests so that they actually do what you expect is the most important thing you can do.
dhh does say that not everything can be unit tested and I think this is the crux of his issue. He is, and a lot of other people, are getting hung up on labels for tests in my opinion. This then puts them off writing tests first. I have been a big fan of the way that Google labels their tests. This removes the dogmatic beliefs in TDD and describes them in how much work they are doing. This is the way we should be doing it!!!
So if you are going to not write a test first make sure that you are writing tests that you can trust and that your colleagues can trust too!
http://www.theautomatedtester.co.uk/blog/2014/do-you-trust-a-test-that-you-have-never-seen-fail.html
|
|
Francois Marier: Settings v. Prefs in Gaia Development |
Jed and I got confused the other day when trying to add hidden prefs for a
small Firefox OS application. We wanted to make a few advanced options
configurable via preferences (like those found in about:config in Firefox)
but couldn't figure out why it wasn't possible to access them from within
our certified application.
The answer is that settings and prefs are entirely different things in FxOS land.
This is how you set prefs in Gaia:
pref("devtools.debugger.forbid-certified-apps", false);
pref("dom.inter-app-communication-api.enabled", true);
from build/config/custom-prefs.js.
These will be used by the Gecko layer like this:
if (!Preferences::GetBool("dom.inter-app-communication-api.enabled", false)) {
return false;
}
from within C++ code, and like this:
let restrictPrivileges = Services.prefs.getBoolPref("devtools.debugger.forbid-certified-apps");
from JavaScript code.
Preferences can be strings, integers or booleans.
Settings on the other hand are JSON objects which can be set like this:
"alarm.enabled": false,
in build/config/common-settings.json and can then be read like this:
var req = navigator.mozSettings.createLock().get('alarm.enabled');
req.onsuccess = function() {
marionetteScriptFinished(req.result['alarm.enabled']);
};
as long as you have the following in your application manifest:
"permissions": {
...
"settings":{ "access": "readwrite" },
...
}
In other words, if you set something in build/config/custom-prefs.js,
don't expect to be able to read it using navigator.mozSettings or the
SettingsHelper!
http://feeding.cloud.geek.nz/posts/settings_v_prefs_in_gaia_development/
|
|
Patrick Cloke: Extending JavaScript Maps (or other built-in objects) |
// Similar to Object.hasOwnProperty, but doesn't fail if the objectReplacing these custom objects with a Map would alleviate this funky dance.
// has a hasOwnProperty property set.
function hasOwnProperty(aObject, aPropertyName)
Object.prototype.hasOwnProperty.call(aObject, aPropertyName)
function NormalizedMap() { }
NormalizedMap.prototype = {
__proto__: Map.prototype,
_normalize: function(aStr) aStr.toLowerCase(),
get: function(aStr) Map.prototype.get.call(this, this._normalize(aStr)),
set: function(aStr, aVal) Map.prototype.set.call(this, this._normalize(aStr), aVal)
};
let m = new NormalizedMap();
m.set("foo", 1) // Throws TypeError: set method called on incompatible Object
m instanceof Map; // true . . . wat . . .
function NormalizedMap() {
let m = new Map();
m.__proto__ = NormalizedMap.prototype;
return m;
}
NormalizedMap.prototype = {
__proto__: Map.prototype,
_normalize: function(aStr) aStr.toLowerCase(),
get: function(aStr) Map.prototype.get.call(this, this._normalize(aStr)),
set: function(aStr, aVal) Map.prototype.set.call(this, this._normalize(aStr), aVal)
};
let m = new NormalizedMap();
m.set("foo", 1)
m.get("FOO"); // 1
m instanceof Map; // true
// A Map that automatically normalizes keys before accessing the values.
function NormalizedMap(aNormalizeFunction, aIt = []) {
if (typeof(aNormalizeFunction) != "function")
throw "NormalizedMap must have a normalize function!";
this._normalize = aNormalizeFunction;
this._map = new Map([[this._normalize(key), val] for ([key, val] of aIt)]);
}
NormalizedMap.prototype = {
_map: null,
// The function to apply to all keys.
_normalize: null,
// Anything that accepts a key as an input needs to be manually overridden.
delete: function(aKey) this._map.delete(this._normalize(aKey)),
get: function(aKey) this._map.get(this._normalize(aKey)),
has: function(aKey) this._map.has(this._normalize(aKey)),
set: function(aKey, aValue) this._map.set(this._normalize(aKey), aValue),
// Properties must be manually forwarded.
get size() this._map.size,
// Here's where the magic happens. If a method is called that isn't defined
// here, just pass it to the internal _map object.
__noSuchMethod__: function(aId, aArgs) this._map[aId].apply(this._map, aArgs)
}
http://clokep.blogspot.com/2014/04/extending-javascript-maps-or-other.html
|
|
Tantek Celik: Remembering BostonStrong, Meeting PavementRunner & Sam, Learning About NovemberProject |
One year and five days ago I bicycled from work to Crissy Field because my friend Julie Logan invited me out to #BostonStrongSF, a run in support of the Boston community, and runners in particular, one week after last year's Boston Marathon attack.
I had stress-fractured my left ankle two months before, and having originally misdiagnosed it as a sprain, was still recovering and unable to run. I went anyway, to fastwalk (you know that goofy looking walk) the 3-4 miles solidarity run. My podiatrist had cleared me to fastwalk as fast as I wanted, as long as it didn't hurt.
I didn't care if I was the last person to finish. My injury was trivial compared to what so many had suffered a week before. I knew I would fully recover, I couldn't stop thinking about the runners and others who had lost a limb, or their lives.
I fastwalked as quick as I could, almost keeping up with the tail end of runners, and returned to the finishing area where I found my friend Julie. She was literally the only person I knew there. But she was very happy to see me, and introduced me to her crowd of Nike Ambassador friends.
Julie also introduced me to Brian AKA PavementRunner, who had proposed the Boston Strong series of runs across cities, and organized #BostonStrongSF in particular. Brian is an amazing person: kind, understated, and warm-hearted. I was reminded of this when I got to catchup with Brian this past Monday night at Chipotle, having dinner with him and few NovemberProject friends after this year's Nike #StrongerEveryRun run.
Get to know Brian and you'll learn he's passionate and bold as well, just the type of individual to not only come up with a powerful idea like #BostonStrong

Julie introduced me to a lot of people, but one in particular stood out. If you've met her you know what I mean. She introduced me to Sam Livermore, who is one of the most enthusiastically kind people I've ever met. You know how some people instantly make you feel worthy and appreciated? That's Sam.
Sam encouraged me to friend her on Facebook so I did and didn't think much of it. I think we started following each others' Instagrams also. We didn't really cross paths but occassionally her posts would pop up when I checked the Facebook home page and they always reminded me just how warm and welcoming she had been that Monday evening.
I don't remember if I first saw the chalkmarks in Golden Gate park ("NovemberProject 6:30am Kezar!" - back when it was there), or if I first saw postings from Sam & Julie about it. But it was seeing them talk about it that stuck in my head.
I point this out because it was meeting Sam, then seeing her & Julie enthusiastically mention NovemberProject in their posts that somehow made it click six months later. Last October I looked up the details, and last Wednesday of last October I managed to wake up at 6am and jog over to Alamo Square and made it in time for my first NovemberProject workout, not knowing anyone there except Sam. But that experience is a different story.
A year ago I don't think I could have predicted where I would be now. That I would have finished two half marathons and would be considering running two more by year's end.
Looking back on the #BostonStrongSF event & photos I'm amazed how many now familiar faces I see. I am grateful for meeting PavementRunner and Sam just over a year ago.

Sam and PavementRunner after a recent NovemberProjectSF workout.
Oh, and little Barnum too.
I'm also very thankful for Julie & Sam's encouragement to checkout NovemberProject. I'm doing my best to pass it on. If you're any level of runner or jogger in SF, join us in the middle of Alamo Square, Wednesday morning 6:25am rain or shine. You can count on me to be there when I'm in town.
http://tantek.com/2014/117/b1/bostonstrong-pavementrunner-sam-novemberproject
|
|
Honza Bambas: NTLMv1 and Firefox |
In Firefox 30 the internal fallback implementation of the NTLM authentication schema talking only NTLMv1 has been disabled by default for security reasons.
If you are experiencing problems with authentication to NTLM or Negotiate proxies or servers since Firefox 30 you may need to switch network.negotiate-auth.allow-insecure-ntlm-v1 in about:config to true.
Firefox (Necko) knows two ways to authenticate to a proxy or a server that requires NTLM or LM authentication:
Note that if you are in an environment where the system API can be used we have no handles to influence what NTLM version is used. It’s fully up to your local system and network setting, Firefox has no control over it.
(Note: there is a similar list dedicated to the Negotiate schema)
Disclaimer: NO WARRANTY how accurate or complete this list is. I don’t know the Kerberos preferences (if there are any) at all. I am not the original author of this code, I’m only occasionally maintaining it as part of my HTTP work.
|
|
Daniel Stenberg: http2 explained |

I’m hereby offering you all the first version of my document explaining http2, the protocol. It features explanations on the background, basic fundamentals, details on the wire format and something about existing implementations and what’s to expect for the future.
The full PDF currently boasts 27 pages at version 1.0, but I plan to keep up with the http2 development going further and I’m also kind of thinking that I will get at least some user feedback, and I’ll do subsequent updates to improve and extend the document over time. Of course time will tell how good that will work.
The document is edited in libreoffice and that file is available on github, but ODT is really not a format suitable for patches and merges so I hope we can sort out changes with filing issues and sending emails.
|
|
Soledad Penades: From the city of FOMOnto |
I seriously intended to write three (three!) blog posts past week-end but I got dragged outside to experience the glorious British Spring in London, and its pubs and stuff, and I ended up not writing anything at all. But it was good because it was Easter and you’re supposed to have a break sometimes.
Then I had this very intense work week here in Toronto which was full of discussions, pair programming, presentations, hack hack hackety hack, more discussions, and even a double session of bad 80s/90s movies to top that. The Mozilla Toronto office is packed full with so many rad people that great conversations happen all the time, so I didn’t really have the time to write any of those three posts.
But I have some cool stuff to show/discuss, so there we go before I fly back to Europe:
First, just in case you’re interested – here are the slides of my presentation: our projects, in the future. Without any context you won’t actually get most of the points, but that’s to be expected. I want to get back to this in a blog post because it’s something that every open source project should be doing, so don’t worry if you don’t follow along.
My talk ended with me trying to plant two seeds in the minds of my team mates, the first one being that we should aim to be the open source developer we would like to see. So whenever you’re unsure of what to do, pretend you’re that ideal perfect developer and act as they would do. The second idea was an automatic “good open source citizen” ACID test, and hey, tofumatt and me hacked a prototype together. Here’s acidity, which you can also install with the node package maid with
npm install -g aciditythen cd to any of your projects and run acidity, and maybe you’ll get some cool emoji.
Also, not something that I took part in, but Potch came up with a nice hackxperiment which enables you to write CommonJS-style code in WebWorkers, with the notion of making it easier to move more business logic into Web Workers so that the main thread is snappy and responsive. He also happened to say “Shadow DOM” out aloud and BAM! Angelina Fabbro (from Inspector Web and the mystery of Shadow DOM fame) entered the room. Was this staged? We’ll never know.
Another ultraexciting thing that happened was that I finally had early access to the brand new App Manager in Firefox’s DevTools. With this version you can create new Firefox OS apps straight from its interface, edit them, open existing projects, deploy and debug them, etc. The UI is way (WAY) more streamlined now—you don’t need to switch back and forth to go from debugging to deploying, and you can simply use some natural shortcuts: CTRL+Save / CTRL+Reload. This makes developing privileged FxOS apps really webby and it feels GREAT. Here’s an early screenshot so you can drool:
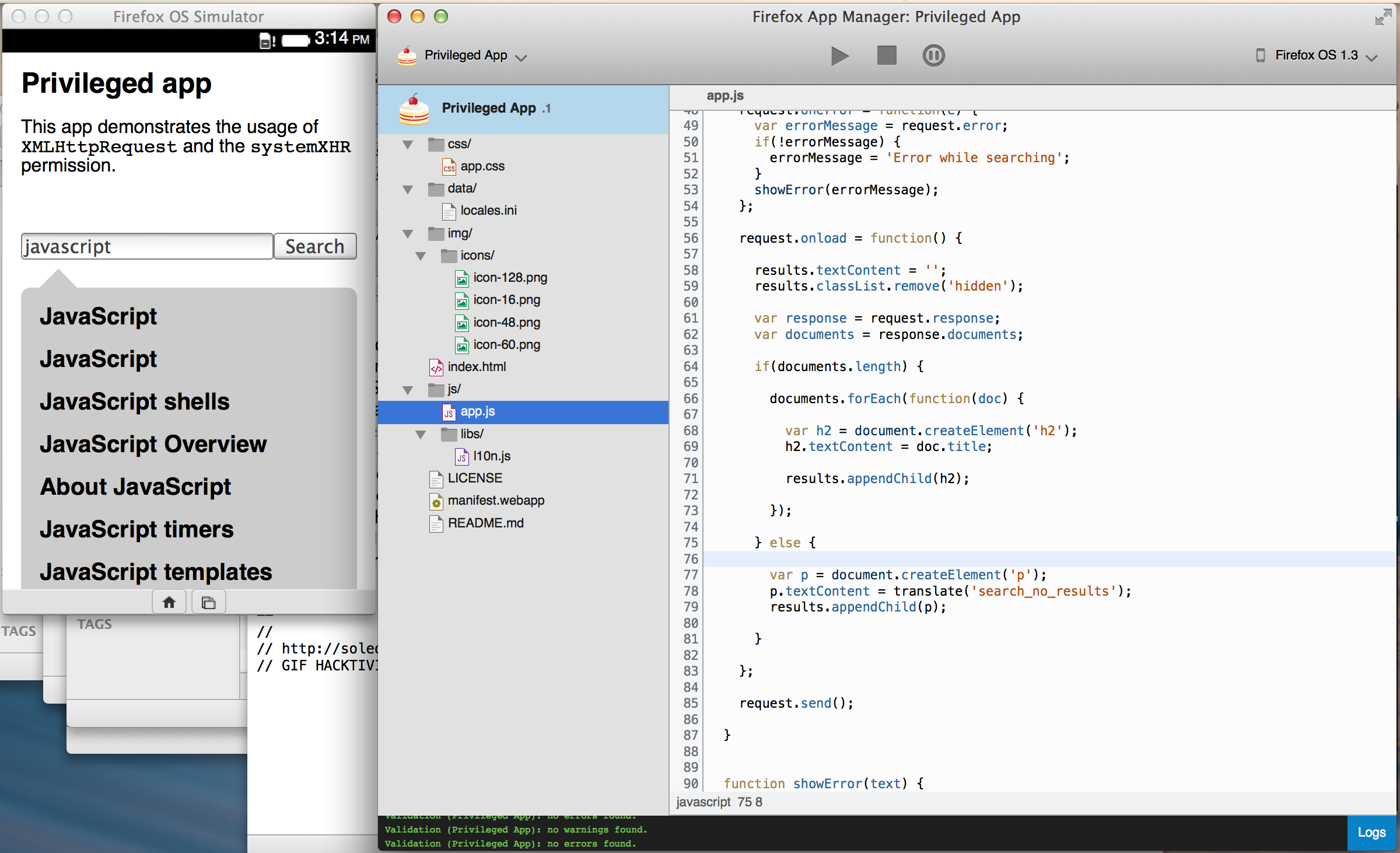
The way I got access to this version was by checking the code out of Paul Rouget‘s Firefox branch and compiling it. I’m told I was the first person that run this new AppManager apart from its own developers, so I suppose that means ACHIEVEMENT UNLOCKED. Paul warned me of some potential weirdnesses but I couldn’t reproduce them.
For those of you curious, compiling took about 30 minutes and 5 Gb of disk space, on a MacBook Pro. I’m told that subsequent compilations should be way faster but I haven’t got to that yet.
More cool things from this week: I will be mentoring a Google Summer of Code student this summer! The project is about Firefox OS games. Isn’t it exciting?!
I also got confirmation that I’ll be speaking at an awesome conference in June. I’ll be actually speaking at two awesome conferences in June but I still haven’t announced the first one as that’s one of the posts I wanted to write, with my own promo code and stuff.
We also had a mini meatspaces meatup with some great Torontonians, where it was decided in a sideway non-important comment in passing that Toronto should be renamed to City of FOMOnto. Note to non-insiders: FOMO = Fear Of Missing Out. Fun fact: I used to think that FOMO meant Fear Of Making Out for a long time.
Now if you excuse me I have to perform some ~~~magics~~~ and fit all my stuff back into the suitcase. Stay tuned!
![]()
http://soledadpenades.com/2014/04/26/from-the-city-of-fomonto/
|
|






