Selena Deckelmann: Release Engineering: A draft of an architecture diagram |
One of the things that I like to do is create architecture diagrams of complicated systems.
We had Release Engineering and Release Operations in the Portland Mozilla office this week, providing a perfect opportunity to pick everyone’s brains about what the current state of our release infrastructure is like.
Behold: 
And here’s a version that includes some “tree closure reasons” in magenta:

A tree closure is defined as an hg hook that prevents people from committing to a tree (like mozilla-central). It looks up status at treestatus.mozilla.org to figure out whether or not the tree is closed, and this value is updated manually by “sheriffs” who track tree status.
And the an initial key to the tree closure reasons (the numbers on the magenta blobs), is documented on the Mozilla wiki.
The goal of this document was to take brain dump information from everyone in the meeting, and create a relationship diagram of all the systems that everyone here supports. As you can see, it is pretty complex.
What I took away from creating this was:
There’s a lot more work to do to link in documentation and create some related diagrams, which I’ll tackle next week. The kinds of questions I’d like to try to answer based on the information that I’ve gathered include:
I really enjoyed identifying sources of tree closure and the kinds of failures that cause it. These are the kinds of problems I love working on solving — complicated, often unpredictable and largely driven by the normal work that people need to do to get their jobs done. There’s rarely a simple solution to things like experimental patches taking down large portions of a build infrastructure, and how we solve, or at least mitigate, these problems is fascinating.
|
|
Jonathan Protzenko: Shutting down my (now redundant) comm-central clone on github |
This is just a public service announcement: I'm shutting down the comm-central repository on github I've been maintaining since 2011. Please use the official version: they share the same hashes so it's just a matter of modifying the url in your .git/config. Plus, the official repo has all the cool tags baked in.
(Turns out that due to yet-another hg repository corruption, the repo has been broken since early March. Since no one complained, I suspect no one's really using this anymore. I'm pretty sure the folks at Mozilla are much better at avoiding hg repository corruptions than I am, so here's the end of it!).
|
|
Benjamin Kerensa: Unboxing The First Firefox OS Tablet |
This is the clean little box the tablet comes in
 And let’s open the lid and see what’s inside… Look at that nice large display
And let’s open the lid and see what’s inside… Look at that nice large display
The back of the tablet is a soft matte feel so not slippery and has a camera

This device comes with a special boot animation since its not a publicly available device yet.

Second boot animation
 The familiar Firefox OS first boot screen
The familiar Firefox OS first boot screen Let’s get on the Wifi
Let’s get on the Wifi
 Setup the timezone
Setup the timezone  Let’s begin the tablet tour
Let’s begin the tablet tour
 Swipe lessons
Swipe lessons More swipe lessons
More swipe lessons
 And more swiping
And more swiping
 And tutorial complete now to play
And tutorial complete now to play
 And that concludes this unboxing!
And that concludes this unboxing!
 Want to play with this? Find me at one of the many conferences I’m attending or speaking at this summer.
Want to play with this? Find me at one of the many conferences I’m attending or speaking at this summer.
|
|
David Boswell: Sharing Mozilla love with new contributors |
I just got two of the Mozilla Love shirts earlier this week—one to keep for myself and one to give away. I’m going to try to use my second shirt to connect someone new to a project at Mozilla.

Giving out two shirts to everyone is a great opportunity for all of us to go out and bring more people in to the project.
If you’ve never done that before, or would like some tips about how to do that, we have a 3-step guide that can help. The steps are:
The guide is short. It takes just a couple minutes to read and the suggestions are things you can make use of in a short conversation with a friend, family member or someone who asks you about your Mozilla shirt.
Read the guide for more details and good luck with bringing in new contributors. Also feel free to add other tips and suggestions to the document so other people can learn from your experience.

http://davidwboswell.wordpress.com/2014/05/02/sharing-mozilla-love-with-new-contributors/
|
|
Gervase Markham: Who We Are |
Two weeks ago, I posted about Who We Are and How We Should Be. I wrote:
But before we figure out how to be, we need to figure out who we are. What is the mission around which we are uniting? What’s included, and what’s excluded? Does Mozilla have a strict or expansive interpretation of the Mozilla Manifesto?
Here is my answer.
I think Mozilla needs to have a strict/close/tight/limited (whichever word you prefer) interpretation of the Mozilla Manifesto. To quote that document: we need to focus on “the health of the Internet”. We need to work on “making the Internet experience better”. We need to make sure “the Internet … continue[s] to benefit the public good”. As well as the 10 principles, the Manifesto also has a Mozilla Foundation Pledge:
The Mozilla Foundation pledges to support the Mozilla Manifesto in its activities. Specifically, we will:
- build and enable open-source technologies and communities that support the Manifesto’s principles;
- build and deliver great consumer products that support the Manifesto’s principles;
- use the Mozilla assets (intellectual property such as copyrights and trademarks, infrastructure, funds, and reputation) to keep the Internet an open platform;
- promote models for creating economic value for the public benefit; and
- promote the Mozilla Manifesto principles in public discourse and within the Internet industry.
Some Foundation activities—currently the creation, delivery and promotion of consumer products—are conducted primarily through the Mozilla Foundation’s wholly owned subsidiary, the Mozilla Corporation.
I think that’s an awesome summary of what we should be doing, and I think we should view activities outside that scope with healthy suspicion.
It seems to me that this logical fallacy is common:
It can also appear as:
Given the diversity of Mozillians, these cannot be good logic if applied equally and fairly. Mozilla would end up supporting many mutually-contradictory positions.
Some people believe so strongly in their non-open-web cause that they want to use the power of Mozilla to attain victory in that other cause. I can see the temptation – Mozilla is a powerful weapon. But doing that damages Mozilla – both by blurring our focus and message, and by distancing and discouraging Mozillians and potential Mozillians who take a different view. Those who care about Mozilla’s cause and about other causes deeply may find it hard to resist advocating that we give in to the temptation, but I assert that we as an organization should actively avoid promoting, or letting anyone use the Mozilla name to promote, non-open-web causes, because it will be at the expense of Mozilla’s inclusiveness and focus.
We are Mozillians. We need to agree on the Mozilla Manifesto, and agree to disagree on everything else.
http://feedproxy.google.com/~r/HackingForChrist/~3/2z_xIytBnPE/
|
|
Jess Klein: Appmaker User Interface - Mockups |



http://jessicaklein.blogspot.com/2014/05/appmaker-user-interface-mockups.html
|
|
Jess Klein: Making History in Appmaker |
Appmaker history will enable users to raise the value of their (collaborative) making process and learn from their design choices by integrating annotation into a users “save” workflow.



http://jessicaklein.blogspot.com/2014/05/making-history-in-appmaker.html
|
|
David Burns: Wanting to do some open source work but not sure what this weekend? |
The Automation and Tools team at Mozilla has been working tirelessly to find some bugs that everyone can work on if you are stuck at home with rain. Our collection of good first bugs has been curated and has a number of really great mentors that can help get you started on the path to submitting a patch.
Wondering if it is worthwhile? My post last week asking for people to help on Marionette Good First Bugs has had 2 patches landed in Mozilla-Central and people looking at another 3 bugs. The list only had 9 bugs so that is more than half that are being picked up.
The best way to do things is look at our New Contributor page and get all the necessary things setup. Unfortunately some items might take a little work but its just something you need to do once.
Want to work on some bugs? We have a great list that you can choose from.
I look forward to seeing some great patches from you all!
|
|
Chris Cooper: Dispatches from the releng team week: Portland |
 Releng has been much more diligent during our current team week about preparing presentations and, more importantly, recording sessions for posterity.
Releng has been much more diligent during our current team week about preparing presentations and, more importantly, recording sessions for posterity.
Sessions are still ongoing, but the list of presentations is in the wiki. We will continue to add links there.
Special thanks to Armen for helping remoties get dialed-in and for getting everything recorded.
http://coop.deadsquid.com/2014/05/dispatches-for-the-releng-team-week-portland/
|
|
Fr'ed'eric Harper: Entrevue Firefox OS de Savoir Faire Linux `a Pycon 2014 |

Je ne suis pas un d'eveloppeur Python, mais j’ai tout de m^eme 'et'e faire un petit tour `a Pycon 2014 qui avait lieu il y a quelques jours. Comme cela se passait `a Montr'eal, je voulais aller voir ce qu’avait l’air une gang de Pythoneux et surtout, dire salut `a plusieurs gens en ville pour l’'ev'enement. Je n’ai 'et'e que dans la salle des exposants, mais le retour des participants `a qui j’ai parl'e 'etait super: tous ont appr'eci'e leur conf'erence. Pour ma part, ma visite a 'et'e fructueuse, car j’ai 'et'e abord'e par Savoir Faire Linux pour faire une entrevue sur Firefox OS.
Je suis bien content de cette opportunit'e, car je n’ai pas souvent la chance de parler de Firefox OS en francais. Merci `a Christian Aubry, l’homme derri`ere la cam'era, Jonathan Le Lous et Savoir Faire Linux pour cette entrevue.
--
Entrevue Firefox OS de Savoir Faire Linux `a Pycon 2014 is a post on Out of Comfort Zone from Fr'ed'eric Harper
Related posts:
|
|
Gijs Kruitbosch: Run mochitests against an arbitrary build, or against the distribution directory |
I’ve had problems before where it would have been useful to easily run mochitests against other versions of the browser than those in my $OBJDIR. I’m pleased to say I just landed a small patch for the mochitests runner’s mach commands that lets you do:
./mach mochitest-browser --app-override /usr/bin/firefox path/to/test
and also has a special shortcut for the application as built for distribution (using omni.jar rather than a flat directory structure):
./mach mochitest-browser --app-override dist path/to/test
Happy testing!
|
|
David Clarke: The fresh and furiously fast Firefox |
Originally posted on JAWS:
The new Firefox introduces a new tab shape that is consistent with Firefox for Android, FirefoxOS, Thunderbird, as well as the web properties of Mozilla.
Firefox for Android
Firefox
As the Firefox team was implementing this new design, performance was a key metric that was measured and focused on. We wanted to not only bring a beautiful design to users, but one that matched the new sleek shape with an equally speedy outcome.
Each time a change was made to our source control repository, a fresh build of the browser was created and run against a suite of automated tests that measure the performance of the build. These results are then compared against the results of prior builds, allowing the team to track…
View original 297 more words

http://onecyrenus.wordpress.com/2014/05/01/the-fresh-and-furiously-fast-firefox/
|
|
Mitchell Baker: NetMundial |
Last week I attended the NETmundial Global Multistakeholder Meeting on the Future of Internet Governance in Sao Paulo. It was a 2 day event, following a multi-month process. A web search for NetMundial outcome will provide a range of evaluations, including one from fellow Mozillian Chris Riley. Here I’ll provide a (somewhat idiosyncratic) description of what it was like to be at the event that led to these articles.
Internet Governance and NetMundial
Internet Governance has become a much more active topic of discussion recently, spurred in part by an increased level of scrutiny of the US Government’s involvement following the Snowden revelations. I should start by saying that there is some confusion over the meaning of “Internet Governance.” It’s sometimes used to refer to development process for technical decisions affecting the Internet, and is sometimes used more broadly to mean decisions regarding public policy issues that touch life through the Internet. Here is a nice infographic about the topics, attendees and goals of the event from the folks at Access Now.
I attended NetMundial as a representative of Mozilla and as a member of the Panel on Global Internet Cooperation and Governance Mechanisms. This is a panel spurred by Fadi Chehad'e,the president of ICANN, and organized late in 2013 as this press release describes.
The NetMundial organizing committees prepared a draft “final outcome” document. There have been a number of comments, questions and criticisms submitted in written form in the months leading up to the event. Both the Panel on which I participated and Mozilla made submissions to the drafting committee, as did many, many other organizations. A good part of the event was spent hearing comments from the floor. The final version of the document was published at the end of the NetMundial event.
Multi-stakeholderism, or Who is Able to Make Decisions About the Internet
One key issue is the nature of the group that should address Internet-related issues. Boiled down to the simplest possible formulation, the question can be seen as: should the Internet be regulated by governments, in a multi-government process (such as the UN); or (b) should civil society, technologies and / or business interests be able to participate in how the Internet is developed? The first of these is known as “multi-lateral” and the latter as “multi-stakeholder”. The multi-lateral approach is of course what the government ministers and other representatives are used to. The multi-stakeholder models is closer to what much of the technical community is accustomed to. NetMundial was designed as a multi-stakeholder event.
Like many of those involved technically with the Internet, I find it impossible to imagine how a government-only process can result in anything other than big trouble for Internet development. During this event I came to realize how many people view “multi-stakeholderism” as a way for big U.S. Internet corporations to have a controlling voice in policy and Internet development. Some civil society organizations seem to prefer a government-only approach as better than one that involves the commercial players. NetMundial brought me a much better understanding of this perspective. There were also speakers who commented that governments are the legitimate actors here and multi-stakeholder resolutions are inappropriate. One speaker from China noted that each country should be able to build its own infrastructure in line with its own needs.
The relationship of national sovereignty to multi-stakeholderism was raised but (to my knowledge) not thoroughly discussed. As just noted, a few people advocated that each country should make its own laws as it thinks best. Even within groups interested in pursuing the multi-stakeholder approach there remains a question of the correct role for government. Brazil President Dilma Rousseff raised the topic of national sovereignty explicitly within a multi-stakeholder context in her address as well.
One thing that was clear at the event however — the avenues of participation open to many high level government representatives were the same as the rest of us. During the comment section there were 5 or 6 microphones for different types of participants — civil society, business, technical community, government. Government ministers who wanted to comment were given a chance to get in line behind the government microphone and participate in the round robin of comments. The same 2 minute limit applied to them as well, though not to comments or responses from the organizing committee I was particularly struck by the comments of a minister from Argentina. Argentina was one of the 12 co-hosts of the event, which one might think would give the minister some particular influence. When her turn came she noted that her government had submitted written comments earlier in the process but those comments had not been included in the draft outcome documents, so she would make them again in this public forum in the hopes that they would be accepted. As noted earlier, representatives from China, Russia, and I’m told from Iran and Saudi Arabia, rose to raise their concerns. The Canadian minister used his turn to stay that Canada supports the outcome document, understanding it is imperfect, and believing it is well worth supporting.
I was told by a few seasoned political representatives that to their knowledge this aspect of the event was unique. They at least could not remember another meeting where government representatives of this level participated but did not control the final outcome.
This strikes me as a significant success, quite separate from the content of the document. Whatever the scope of national governments, it is good to have all representatives in Internet Governance see themselves as equal as human beings, and to experience what life is like for individual citizens.
The organizers also arranged for people to participate from a number of “Remote Hubs” around the world. When I first arrived at the event venue I ran into a Free Software and Mozilla advocate I’ve known since my first trip to Brazil some years ago. (Hello Felipe!) He was part of the staff arranging the Remote Hubs, and focusing on using Free Software to do so. I heard many people comment on how effective the Hubs were. At Mozilla we’re pretty used to people participating in our meetings all using the Internet as the communications channel. (This is another reason why I <3 the web.) For many however, NetMundial seems to be the first experience with such a thing and a number of people mentioned it to me as a new and powerful element.
Privacy
Another key topic was privacy, with a particular emphasis on protection from mass surveillance. President Rousseff has been outspoken on this issue, making a clear connection between privacy and democracy, and privacy and state-to-state relationships:
In the absence of the right to privacy, there can be no true freedom of expression and opinion, and therefore no effective democracy. In the absence of the respect for sovereignty, there is no basis for the relationship among nations.
(Sept. 2013 speech to the United Nations General Assembly: http://www.theguardian.com/world/2013/sep/24/brazil-president-un-speech-nsa-surveillance.)
There were many, many comments on this topic at NetMundial. The reaction to US mass surveillance globally is deep and seems to be ongoing in a way that’s not nearly as apparent from inside the US. The NetMundial outcome document includes a condemnation of mass surveillance, but many, many people felt this is inadequate, and that a stronger and more specific response is required.
Net Neutrality
Another contentious topic was net neutrality. In ironic timing, the event took place at the same time as the US Federal Communications Commission announced that it is contemplating rules that allow business discretion in how content is delivered to people. The rules themselves are not yet known. There was an immediate and deep concern that this will dramatically change the rules in the US, and thus deepen problems on a global basis. The FCC chairman Mr. Wheeler asserts that “The proposal would establish that behavior harmful to consumers or competition by limiting the openness of the Internet will not be permitted.” But many believe the changes will end up providing enhanced opportunity for those with extra financial resources, and limit opportunity for anyone else. Net neutrality language did not end up in the final document, which is another source of disappointment for many.
Overall
NetMundial’s big innovation was in the range of participants, not the particular format. For me, accustomed as I am to hack-a-thons and un-conferences and self-organizing work groups, the event was a bit traditional. However, I talked to enough other people to know it was wildly different from most events government officials and diplomats attend.
I’m very happy I was a participant, I’m very pleased the event occurred, and I see it as a positive step forward in Internet Governance. The challenges to a healthy Internet and healthy online life are deep and varied. There’s still a reasonable chance that the wildly democratizing and hopeful nature of the Internet will deteriorate into yet another centralized technology for the big organizations of the world. NetMundial was also an opportunity for citizens and civic groups to participate along with the big players — government and business. NetMundial showed the range of people everywhere who look to the Internet with hope and energy.
|
|
Robert Kaiser: Finding an Openly Licensed JS Graph Library |
http://home.kairo.at/blog/2014-05/finding_an_openly_licensed_js_graph_lib
|
|
Jess Klein: Prototype: Evaluating Prototypes that we make at Mozilla |





http://jessicaklein.blogspot.com/2014/04/prototype-evaluating-prototypes-that-we.html
|
|
Zack Weinberg: Redesigning Income Tax |
Here is an opinionated proposal, having no chance whatsoever of adoption, for how taxes ought to be levied on income. This post was originally scheduled for Income Tax Day here in the good old U.S.A., but I was having trouble with the algebra and then I was on vacation. So instead you get it for Canadian tax day. Everything is calculated in US dollars and compared to existing US systems, but I don’t see any great difficulty translating it to other countries.
Premises for this redesign:
Read on for concrete details of the proposal.
The first thing we do is institute an unconditional basic income. (Just to poke David Weber in the eye, let’s call it the Basic Living Stipend.) Every adult gets \(B\) dollars every year, in monthly installments, unconditionally and untaxed. The value of \(B\) is set by statute when the reforms go into effect and automatically adjusted for inflation thereafter. In this hypothetical I’m setting \(B\) to $24,000 for concreteness; this is a nice round number—$2000 a month—that happens to be a little more than 200% of the (USA) Federal poverty line for a one-person household in 2014, according to http://familiesusa.org/product/federal-poverty-guidelines.
We also institute a unified national pension. It works hand in hand with the tax scheme, so I’ll explain that first and come back to this, but you need to know the pension exists. It differs from existing pensions in one important way: it starts paying immediately upon your having made any amount of contribution; there is no age or disability requirement. (It may not pay out very much, though, as I’ll explain below.) Income from the pension is not taxed either, but it raises your marginal tax rate as if it had been taxed. The combination of the BLS and the pension are intended to replace all existing government-administered pension plans (Social Security, the Railroad Retirement Board, etc.), disability benefits, unemployment insurance, etc.
All income from other sources is taxed according to the same formula. This tax replaces all income and payroll taxes collected by the IRS. There are no deductions, exemptions, credits, special categories, or anything else. Congress gets one and only one adjustment knob: the set point, \((s,r)\). A marginal tax rate of \(r\%\) is charged on the \(s\)’th dollar of income above \(B\). The marginal tax rate \(M\) on the \(i\)’th dollar of income is
and one’s after-tax income, \(A\), if one earns \(I\) dollars in total (of which \(B\) are from the BLS and \(P\) the pension), is
These functions look messy, and possibly I am out of my mind to even suggest them to such a pack of know-nothings as we have presently in Congress, but they have exactly the mathematical properties we want. \(M\) is continuous, increases monotonically, and converges to 1 at positive infinity, but \(A\) diverges at positive infinity, so there is no upper limit in principle on after-tax income. (As we shall see, though, in practice that next after-tax dollar gets very, very expensive past a certain point.) Also, the equations get a lot less messy if we substitute in numbers for some of the parameters. For instance, setting \(B = 24000\), \(s = 500000\), and \(r = 40\%\) (corresponding to the blue line below) gives us \(A = 24000 + P + 774000 \bigl( \ln\,(0.4I + 300000) - \ln\,(0.4P + 309600) \bigr)\) for the formula that taxpayers would actually have to wrestle with.
Below is a chart of the marginal tax rate and the after-tax income for several choices of \(r\), with \(s\) fixed to $500,000. For comparison, the jagged gray line is the real marginal tax rate for the USA for 2013 (for individuals under the age of 65, all income wages, taking the standard deduction and one exemption, with no other adjustments or credits—this is a gross oversimplification, but attempting to factor in things like the EITC and the AMT was too complicated for me; if someone wants to provide me with a more realistic comparison curve I am happy to update the chart). Do keep in mind that after the reform, everyone has at least $24,000 of yearly income. The x-axis in both charts, and the y-axis in the right-hand chart, are on a log10 scale. Click to embiggen.

You can see that regardless of the choice of set point, this is likely to be a modest tax cut for people earning less than $100,000 a year, and a hefty tax hike for people earning more than that. That’s by design. It should be almost unheard of for anyone to earn more than $500,000 or so a year after taxes. This is what makes this a Pigovian correction to the negative externalities involved in high income inequality. (For instance, an expected consequence of this reform is that corporations will stop throwing money away on their executives.)
Now, remember that pension scheme? That’s automatically funded for each individual by the taxes they pay in. This obeys a similar formula to the taxation itself. There are two control points: the first dollar paid in taxes returns a pension of \(p_0\) dollars per year, and the \(s\)’th dollar paid in taxes returns a pension of \(p_r\) dollars per year, where \(p_rp>
and the cumulative payout on \(T\) dollars paid in is
The amount paid into the pension scheme accumulates year over year, but every year it’s multiplied by a decay factor, \(d < 1\). The next two charts show three hypothetical yearly pretax incomes (not including BLS or pension), pension accumulation, and the resulting after-tax income, all as a function of time, for plausible choices of the parameters: \(s = 500000,\: r = 40\%,\: p_0 = 0.50,\: p_r = 0.05,\: d = 0.99\).

The intent here is that you can build up a pension sufficient for a “comfortable” retirement either by earning relatively small amounts of money over a long time, or by earning large amounts of money over a relatively short time. That way, the system acts to smooth out the take-home pay of people whose income comes in bursts, which is characteristic of a lot of ‘creative’ jobs (that people generally prefer over ‘day’ jobs, if given the choice). Unfortunately this did not work out as well as I was hoping it would; I think the “decay” mechanism needs to be more sophisticated, possibly with \(T\) initially earning interest rather than decaying. But I’ve spent enough time messing with this. More fully baked ideas solicited.
It is probably a good idea for the BLS to phase in starting at age 12 give or take, and it is probably also a good idea to have pension contributions at least partially transfer to one’s heirs upon death (if only to reduce people’s need for life insurance), but I haven’t thought these bits through carefully.
One final consideration is that in the USA, lots of people have tax-advantaged ‘retirement accounts’ holding much of their savings. It probably makes sense to preserve these, if only to smooth the transition. In keeping with the general no-questions-asked principle behind this proposal, something like this might work: A ‘long-term investment account’ is defined as a bank or brokerage account intended to accumulate capital over the long term. It must invest the money according to a fixed algorithm (“this list of stocks” is a valid choice); the algorithm and/or its parameters may be changed no more than once a month, and all earnings from the investments must be reinvested according to the same algorithm. You can stick as much of your pretax income in one of these as you want. If you’re content to live on the BLS despite earning $10,000,000 a year, your tax obligation can be zero. You can also withdraw money from the account whenever you want. Withdrawals count as regular income; there is no calculation of cost basis, length of holding, or anything like that.
If this were actually going to be implemented, existing pension plans would need to be converted to the new system (providing an equivalent benefit at the time of the conversion, ideally), it would need to come along with a sane national health insurance scheme (read “single payer of some variety”), and it might be a good idea to manipulate the states into scrapping their own income taxes in favor of some sort of share in the national income tax. While we’re at it it would make sense to make property taxes Georgian and replace sales taxes with an at-source carbon tax, but that would be the pony to go along with the impossible wish.
In case anyone wants to play with the numbers, the R script that generated the graphs is available here.
|
|
Mike Conley: Electrolysis Code Spelunking: How links open new windows in Firefox |
Hey. I’ve started hacking on Electrolysis bugs. I’m normally a front-end engineer working on Firefox desktop, but I’ve been temporarily loaned out to help get Electrolysis ready to be enabled by default on Nightly.
I’m working on bug 989501. Basically, when you click on a link that targets “_blank” or uses window.open, we open a new tab instead. That’s no good – assuming the user’s profile is set to allow it, we should open the link in a new window.
In order to fix this, I need a clearer picture on what happens in the Firefox platform when we click on one of these links.
This isn’t really a tutorial – I’m not going to go out of my way to explain much here. Think of this more as a public posting of my notes during my exploration.
So, here goes.
(Note that the code in this post was current as of revision 400a31da59a9 of mozilla-central, so if you’re reading this in the future, it’s possible that some stuff has greatly changed).
I know for a fact that once the link is clicked, we eventually call mozilla::dom::TabChild::ProvideWindow. I know this because of conversations I’ve had with smaug, billm and jdm in and out of Bugzilla, IRC, and meatspace.
Because I know this, I can hook up gdb to see how I get to that call. I have some notes here on how to hook up gdb to the content process of an e10s window.
Once that’s hooked up, I set a breakpoint on mozilla::dom::TabChild::ProvideWindow, and click on a link somewhere with target=”_blank”.
I hit my breakpoint, and I get a backtrace. Ready for it? Here we go:
#0 mozilla::dom::TabChild::ProvideWindow (this=0x109afb400, aParent=0x10b098820, aChromeFlags=4094, aCalledFromJS=false, aPositionSpecified=false, aSizeSpecified=false, aURI=0xffe, aName=@0x0, aFeatures=@0x0, aWindowIsNew=0x10b098820, aReturn=0x7fff5fbfb648) at TabChild.cpp:1201 #1 0x00000001018682e4 in nsWindowWatcher::OpenWindowInternal (this=0x10b05b540, aParent=0x10b098820, aUrl=, aName= , aFeatures= , aCalledFromJS=false, aDialog= , aNavigate= , _retval= ) at nsWindowWatcher.cpp:601 #2 0x0000000101869544 in non-virtual thunk to nsWindowWatcher::OpenWindow2(nsIDOMWindow*, char const*, char const*, char const*, bool, bool, bool, nsISupports*, nsIDOMWindow**) () at nsWindowWatcher.cpp:417 #3 0x0000000100e5dc63 in nsGlobalWindow::OpenInternal (this=0x10b098800, aUrl=@0x7fff5fbfbf90, aName=@0x7fff5fbfc038, aOptions=@0x103d77320, aDialog=false, aContentModal=false, aCalleePrincipal= , aJSCallerContext= , aReturn= ) at /Users/mikeconley/Projects/mozilla-central/dom/base/nsGlobalWindow.cpp:11498 #4 0x0000000100e5e3a4 in non-virtual thunk to nsGlobalWindow::OpenNoNavigate(nsAString_internal const&, nsAString_internal const&, nsAString_internal const&, nsIDOMWindow**) () at /Users/mikeconley/Projects/mozilla-central/dom/base/nsGlobalWindow.cpp:7463 #5 0x000000010184d99d in nsDocShell::InternalLoad (this= , aURI=0x113eed200, aReferrer=0x1134c0fe0, aOwner=0x114a69070, aFlags=0, aWindowTarget=0x10b098820, aLoadType= , aSHEntry= , aSourceDocShell= , aDocShell= , aRequest= ) at /Users/mikeconley/Projects/mozilla-central/docshell/base/nsDocShell.cpp:9079 #6 0x0000000101855758 in nsDocShell::OnLinkClickSync (this=0x10b075000, aContent=0x112865eb0, aURI=0x113eed3c0, aTargetSpec= , aFileName=@0x106f27f10, aPostDataStream=0x0, aDocShell= , aRequest= ) at /Users/mikeconley/Projects/mozilla-central/docshell/base/nsDocShell.cpp:12699 #7 0x0000000101857f85 in mozilla::Maybe::~Maybe () at /Users/mikeconley/Projects/mozilla-central/obj-x86_64-apple-darwin12.5.0/dist/include/nsCxPusher.h:12499 #8 0x0000000101857f85 in nsCxPusher::~nsCxPusher () at /Users/mikeconley/Projects/mozilla-central/docshell/base/nsDocShell.cpp:41 #9 0x0000000101857f85 in nsCxPusher::~nsCxPusher () at /Users/mikeconley/Projects/mozilla-central/obj-x86_64-apple-darwin12.5.0/dist/include/nsCxPusher.h:66 #10 0x0000000101857f85 in OnLinkClickEvent::Run (this= ) at /Users/mikeconley/Projects/mozilla-central/docshell/base/nsDocShell.cpp:12502 #11 0x0000000100084f60 in nsThread::ProcessNextEvent (this=0x106f245e0, mayWait=false, result=0x7fff5fbfc947) at nsThread.cpp:715 #12 0x0000000100023241 in NS_ProcessPendingEvents (thread= , timeout=20) at nsThreadUtils.cpp:210 #13 0x0000000100d41c47 in nsBaseAppShell::NativeEventCallback (this=0x1096e8660) at nsBaseAppShell.cpp:98 #14 0x0000000100cfdba1 in nsAppShell::ProcessGeckoEvents (aInfo=0x1096e8660) at nsAppShell.mm:388 #15 0x00007fff86adeb31 in __CFRUNLOOP_IS_CALLING_OUT_TO_A_SOURCE0_PERFORM_FUNCTION__ () #16 0x00007fff86ade455 in __CFRunLoopDoSources0 () #17 0x00007fff86b017f5 in __CFRunLoopRun () #18 0x00007fff86b010e2 in CFRunLoopRunSpecific () #19 0x00007fff8ad65eb4 in RunCurrentEventLoopInMode () #20 0x00007fff8ad65c52 in ReceiveNextEventCommon () #21 0x00007fff8ad65ae3 in BlockUntilNextEventMatchingListInMode () #22 0x00007fff8cce1533 in _DPSNextEvent () #23 0x00007fff8cce0df2 in -[NSApplication nextEventMatchingMask:untilDate:inMode:dequeue:] () #24 0x0000000100cfd266 in -[GeckoNSApplication nextEventMatchingMask:untilDate:inMode:dequeue:] (self=0x106f801a0, _cmd= , mask=18446744073709551615, expiration=0x422d63c37f00000d, mode=0x7fff7205e1c0, flag=1 '\001') at nsAppShell.mm:165 #25 0x00007fff8ccd81a3 in -[NSApplication run] () #26 0x0000000100cfe32b in nsAppShell::Run (this= ) at nsAppShell.mm:746 #27 0x000000010199b3dc in XRE_RunAppShell () at /Users/mikeconley/Projects/mozilla-central/toolkit/xre/nsEmbedFunctions.cpp:679 #28 0x00000001002a0dae in MessageLoop::AutoRunState::~AutoRunState () at message_loop.cc:229 #29 0x00000001002a0dae in MessageLoop::AutoRunState::~AutoRunState () at /Users/mikeconley/Projects/mozilla-central/ipc/chromium/src/base/message_loop.h:197 #30 0x00000001002a0dae in MessageLoop::Run (this=0x0) at message_loop.cc:503 #31 0x000000010199b0cd in XRE_InitChildProcess (aArgc= , aArgv= , aProcess= ) at /Users/mikeconley/Projects/mozilla-central/toolkit/xre/nsEmbedFunctions.cpp:516 #32 0x0000000100000f1d in main (argc= , argv=0x7fff5fbff4d8) at /Users/mikeconley/Projects/mozilla-central/ipc/app/MozillaRuntimeMain.cpp:149
Oh my. Well, the good news is, we can chop off a good chunk of the lower half because that’s all message / event loop stuff. That’s going to be in every single backtrace ever, pretty much, so I can just ignore it. Here’s the more important stuff:
#0 mozilla::dom::TabChild::ProvideWindow (this=0x109afb400, aParent=0x10b098820, aChromeFlags=4094, aCalledFromJS=false, aPositionSpecified=false, aSizeSpecified=false, aURI=0xffe, aName=@0x0, aFeatures=@0x0, aWindowIsNew=0x10b098820, aReturn=0x7fff5fbfb648) at TabChild.cpp:1201 #1 0x00000001018682e4 in nsWindowWatcher::OpenWindowInternal (this=0x10b05b540, aParent=0x10b098820, aUrl=, aName= , aFeatures= , aCalledFromJS=false, aDialog= , aNavigate= , _retval= ) at nsWindowWatcher.cpp:601 #2 0x0000000101869544 in non-virtual thunk to nsWindowWatcher::OpenWindow2(nsIDOMWindow*, char const*, char const*, char const*, bool, bool, bool, nsISupports*, nsIDOMWindow**) () at nsWindowWatcher.cpp:417 #3 0x0000000100e5dc63 in nsGlobalWindow::OpenInternal (this=0x10b098800, aUrl=@0x7fff5fbfbf90, aName=@0x7fff5fbfc038, aOptions=@0x103d77320, aDialog=false, aContentModal=false, aCalleePrincipal= , aJSCallerContext= , aReturn= ) at /Users/mikeconley/Projects/mozilla-central/dom/base/nsGlobalWindow.cpp:11498 #4 0x0000000100e5e3a4 in non-virtual thunk to nsGlobalWindow::OpenNoNavigate(nsAString_internal const&, nsAString_internal const&, nsAString_internal const&, nsIDOMWindow**) () at /Users/mikeconley/Projects/mozilla-central/dom/base/nsGlobalWindow.cpp:7463 #5 0x000000010184d99d in nsDocShell::InternalLoad (this= , aURI=0x113eed200, aReferrer=0x1134c0fe0, aOwner=0x114a69070, aFlags=0, aWindowTarget=0x10b098820, aLoadType= , aSHEntry= , aSourceDocShell= , aDocShell= , aRequest= ) at /Users/mikeconley/Projects/mozilla-central/docshell/base/nsDocShell.cpp:9079 #6 0x0000000101855758 in nsDocShell::OnLinkClickSync (this=0x10b075000, aContent=0x112865eb0, aURI=0x113eed3c0, aTargetSpec= , aFileName=@0x106f27f10, aPostDataStream=0x0, aDocShell= , aRequest= ) at /Users/mikeconley/Projects/mozilla-central/docshell/base/nsDocShell.cpp:12699 #7 0x0000000101857f85 in mozilla::Maybe::~Maybe () at /Users/mikeconley/Projects/mozilla-central/obj-x86_64-apple-darwin12.5.0/dist/include/nsCxPusher.h:12499 #8 0x0000000101857f85 in nsCxPusher::~nsCxPusher () at /Users/mikeconley/Projects/mozilla-central/docshell/base/nsDocShell.cpp:41 #9 0x0000000101857f85 in nsCxPusher::~nsCxPusher () at /Users/mikeconley/Projects/mozilla-central/obj-x86_64-apple-darwin12.5.0/dist/include/nsCxPusher.h:66 #10 0x0000000101857f85 in OnLinkClickEvent::Run (this= ) at /Users/mikeconley/Projects/mozilla-central/docshell/base/nsDocShell.cpp:12502
That’s a bit more manageable.
So we start inside something called a docshell. I’ve heard that term bandied about a lot, and I can’t say I’ve ever been too sure what it means, or what a docshell does, or why I should care.
I found some documents that make things a little bit clearer.
Basically, my understanding is that a docshell is the thing that connects incoming stuff from some URI (this could be web content, or it might be a XUL document that’s loading the browser UI…), and connects it to the things that make stuff show up on your screen.
So, pretty important.
It seems to be a place where some utility methods and functions go as well, so it’s kind of this abstract thing that seems to have multiple purposes.
But the most important thing for the purposes of this post is this: every time you load a document, you have a docshell taking care of it. All of these docshells are structured in a tree which is rooted with a docshell owner. This will come into play later.
So one thing that a docshell does, is that it notices when a link was clicked inside of its content. That’s nsDocShell.cpp’d OnLinkClickEvent::Run, and that eventually makes its way over to nsDocShell::OnLinkClickSync.
After some initial checks and balances to ensure that this thing really is a link we want to travel to, we get sent off to nsDocShell::InternalLoad.
Inside there, there’s some more checking… there’s a policy check to make sure we’re allowed to open a link. Lots of security going on. Eventually I see this:
if (aWindowTarget && *aWindowTarget)
That’s good. aWindowTarget maps to the target=”_blank” attribute in the anchor. So we’ll be entering this block.
if (aWindowTarget && *aWindowTarget) {
// Locate the target DocShell.
nsCOMPtr targetItem;
rv = FindItemWithName(aWindowTarget, nullptr, this,
getter_AddRefs(targetItem));
So now we’re looking for the right docshell to load this new document in. That makes sense – if you have a link where target=”foo”, subsequent links from the same origin targeted at “foo” will open in the same window or tab or what have you. So we’re checking to see if we’ve opened something with the name inside aWindowTarget already.
So now we’re in nsDocShell::FindItemWithName, and I see this:
else if (name.LowerCaseEqualsLiteral("_blank"))
{
// Just return null. Caller must handle creating a new window with
// a blank name himself.
return NS_OK;
}
Ah hah, so target=”_blank”, as we already knew, is special-cased – and this is where it happens. There’s no existing docshell for _blank because we know we’re going to be opening a new window (or tab if the user has preffed it that way). So we don’t return a pre-existing docshell.
So we’re back in nsDocShell::InternalLoad.
rv = FindItemWithName(aWindowTarget, nullptr, this, getter_AddRefs(targetItem)); NS_ENSURE_SUCCESS(rv, rv); targetDocShell = do_QueryInterface(targetItem); // If the targetDocShell doesn't exist, then this is a new docShell // and we should consider this a TYPE_DOCUMENT load isNewDocShell = !targetDocShell;
Ok, so now targetItem is nullptr, targetDocShell is also nullptr, and so isNewDocShell is true.
There seems to be more policy checking going on in InternalLoad after this… but eventually, I see this:
if (aWindowTarget && *aWindowTarget) {
// We've already done our owner-inheriting. Mask out that bit, so we
// don't try inheriting an owner from the target window if we came up
// with a null owner above.
aFlags = aFlags & ~INTERNAL_LOAD_FLAGS_INHERIT_OWNER;
bool isNewWindow = false;
if (!targetDocShell) {
// If the docshell's document is sandboxed, only open a new window
// if the document's SANDBOXED_AUXILLARY_NAVIGATION flag is not set.
// (i.e. if allow-popups is specified)
NS_ENSURE_TRUE(mContentViewer, NS_ERROR_FAILURE);
nsIDocument* doc = mContentViewer->GetDocument();
uint32_t sandboxFlags = 0;
if (doc) {
sandboxFlags = doc->GetSandboxFlags();
if (sandboxFlags & SANDBOXED_AUXILIARY_NAVIGATION) {
return NS_ERROR_DOM_INVALID_ACCESS_ERR;
}
}
nsCOMPtr win =
do_GetInterface(GetAsSupports(this));
NS_ENSURE_TRUE(win, NS_ERROR_NOT_AVAILABLE);
nsDependentString name(aWindowTarget);
nsCOMPtr newWin;
nsAutoCString spec;
if (aURI)
aURI->GetSpec(spec);
rv = win->OpenNoNavigate(NS_ConvertUTF8toUTF16(spec),
name, // window name
EmptyString(), // Features
getter_AddRefs(newWin));
So we check again to see if we’re targeted at something, and check if we’ve found a target docshell for it. We hadn’t, so we do some security checks, and then … what the hell is nsPIDOMWindow? I’m used to things being called nsIBlahBlah, but now nsPIBlahBlah… what does the P mean?
It took some asking around, but I eventually found out that the P is supposed to be for Private – as in, this is a private XPIDL interface, and non-core embedders should stay away from it.
Ok, and we also see do_GetInterface. This is not the same as QueryInterface, believe it or not. The difference is subtle, but basically it’s this: QueryInterface says “you implement X, but I think you also implement Y. If you do, please return a pointer to yourself that makes you seem like a Y.” GetInterface is different – GetInterface says “I know you know about something that implements Y. It might be you, or more likely, it’s something you’re holding a reference to. Can I get a reference to that please?”. And if successful, it returns it. Here’s more documentation about GetInterface.
It’s a subtle but important difference.
So this docshell knows about a window, and we’ve now got a handle on that window using the private interface nsPIDOMWindow. Neat.
So eventually, we call OpenNoNavigate on that nsPIDOMWindow. That method is pretty much like nsIDOMWindow::Open, except that OpenNoNavigate doesn’t send the window anywhere – it just returns it so that the caller can send it to a URI.
Through the magic of do_GetInterface, nsDocShell::GetInterface, EnsureScriptEnvironment, and NS_NewScriptGlobalObject, I know that the nsPIDOMWindow is being implemented by nsGlobalWindow, and that’s where I should go to to find the OpenNoNavigate implementation.
So off we go!
nsGlobalWindow::OpenNoNavigate just seems to forward the call, after some argument setting, to nsGlobalWindow::OpenInternal, like this:
return OpenInternal(aUrl, aName, aOptions, false, // aDialog false, // aContentModal true, // aCalledNoScript false, // aDoJSFixups false, // aNavigate nullptr, nullptr, // No args GetPrincipal(), // aCalleePrincipal nullptr, // aJSCallerContext _retval);
Having a glance around at the rest of the nsGlobalWindow::Open[foo] methods, it looks like they all call into OpenInternal. It’s the big-mamma opening method.
This method does a few things, including making sure that we’re not being abused by web content that’s trying to spam the user with popups.
Eventually, we get to this:
rv = pwwatch->OpenWindow2(this, url.get(), name_ptr, options_ptr, /* aCalledFromScript = */ false, aDialog, aNavigate, aExtraArgument, getter_AddRefs(domReturn));
and return the domReturn pointer back after a few more checks to our caller. Remember that the caller is going to take this new window, and navigate it to some URI.
Ok, so, pwwatch. What is that? Well, that appears to be a private interface to nsWindowWatcher, which gives us access to the OpenWindow2 method.
After prepping some arguments, much like nsGlobalWindow::OpenNoNavigate did, we forward the call over to nsWindowWatcher::OpenWindowInternal.
And now we’re almost done – we’re almost at the point where we’re actually going to open a window!
Some key things need to happen though. First, we do this:
nsCOMPtrparentTreeOwner; // from the parent window, if any ... GetWindowTreeOwner(aParent, getter_AddRefs(parentTreeOwner));
So what that does is it tries to get the docshell owner of the docshell that’s attempting to open the window (and that’d be the docshell that we clicked the link in).
After a few more things, we check to see if there’s an existing window with that target name which we can re-use:
// try to find an extant window with the given name nsCOMPtrfoundWindow = SafeGetWindowByName(name, aParent); GetWindowTreeItem(foundWindow, getter_AddRefs(newDocShellItem));
And if so, we set it to newDocShellItem.
After some more security stuff, we check to see if newDocShellItem exists. Because name is nullptr (since we had target=”_blank”, and nsDocShell::FindItemWithName returned nullptr), newDocShellItem is null.
Because it doesn’t exist, we know we’re opening a brand new window!
More security things seem to happen, and then we get to the part that I’m starting to focus on:
nsCOMPtrprovider = do_GetInterface(parentTreeOwner); if (provider) { NS_ASSERTION(aParent, "We've _got_ to have a parent here!"); nsCOMPtr newWindow; rv = provider->ProvideWindow(aParent, chromeFlags, aCalledFromJS, sizeSpec.PositionSpecified(), sizeSpec.SizeSpecified(), uriToLoad, name, features, &windowIsNew, getter_AddRefs(newWindow));
We ask the parentTreeOwner to get us something that it knows about that implements nsIWindowProvider. In the Electrolysis / content process case, that’d be TabChild. In the normal, non-Electrolysis case, that’s nsContentTreeOwner.
The nsIWindowProvider is the thing that we’ll use to get a new window from! So we call ProvideWindow on it, to give us a pointer to new nsIDOMWindow window, assigned to newWindow.
Here’s TabChild::ProvideWindow:
NS_IMETHODIMP
TabChild::ProvideWindow(nsIDOMWindow* aParent, uint32_t aChromeFlags,
bool aCalledFromJS,
bool aPositionSpecified, bool aSizeSpecified,
nsIURI* aURI, const nsAString& aName,
const nsACString& aFeatures, bool* aWindowIsNew,
nsIDOMWindow** aReturn)
{
*aReturn = nullptr;
// If aParent is inside an or and this
// isn't a request to open a modal-type window, we're going to create a new
// and return its window here.
nsCOMPtr docshell = do_GetInterface(aParent);
if (docshell && docshell->GetIsInBrowserOrApp() &&
!(aChromeFlags & (nsIWebBrowserChrome::CHROME_MODAL |
nsIWebBrowserChrome::CHROME_OPENAS_DIALOG |
nsIWebBrowserChrome::CHROME_OPENAS_CHROME))) {
// Note that BrowserFrameProvideWindow may return NS_ERROR_ABORT if the
// open window call was canceled. It's important that we pass this error
// code back to our caller.
return BrowserFrameProvideWindow(aParent, aURI, aName, aFeatures,
aWindowIsNew, aReturn);
}
// Otherwise, create a new top-level window.
PBrowserChild* newChild;
if (!CallCreateWindow(&newChild)) {
return NS_ERROR_NOT_AVAILABLE;
}
*aWindowIsNew = true;
nsCOMPtr win =
do_GetInterface(static_cast(newChild)->WebNavigation());
win.forget(aReturn);
return NS_OK;
}
The docshell->GetIsInBrowserOrApp() is basically asking “are we b2g?”, to which the answer is “no”, so we skip that block, and go right for CallCreateWindow.
CallCreateWindow is using the IPC library to communicate with TabParent in the UI process, which has a corresponding function called AnswerCreateWindow. Here it is:
bool
TabParent::AnswerCreateWindow(PBrowserParent** retval)
{
if (!mBrowserDOMWindow) {
return false;
}
// Only non-app, non-browser processes may call CreateWindow.
if (IsBrowserOrApp()) {
return false;
}
// Get a new rendering area from the browserDOMWin. We don't want
// to be starting any loads here, so get it with a null URI.
nsCOMPtr frameLoaderOwner;
mBrowserDOMWindow->OpenURIInFrame(nullptr, nullptr,
nsIBrowserDOMWindow::OPEN_NEWTAB,
nsIBrowserDOMWindow::OPEN_NEW,
getter_AddRefs(frameLoaderOwner));
if (!frameLoaderOwner) {
return false;
}
nsRefPtr frameLoader = frameLoaderOwner->GetFrameLoader();
if (!frameLoader) {
return false;
}
*retval = frameLoader->GetRemoteBrowser();
return true;
}
So after some checks, we call mBrowserDOMWindow’s OpenURIInFrame, with (among other things), nsIBrowserDOMWindow::OPEN_NEWTAB. So that’s why we’ve got a new tab opening instead of a new window.
mBrowserDOMWindow is a reference to this thing implemented in browser.js:
function nsBrowserAccess() { }
nsBrowserAccess.prototype = {
QueryInterface: XPCOMUtils.generateQI([Ci.nsIBrowserDOMWindow, Ci.nsISupports]),
_openURIInNewTab: function(aURI, aOpener, aIsExternal) {
let win, needToFocusWin;
// try the current window. if we're in a popup, fall back on the most recent browser window
if (window.toolbar.visible)
win = window;
else {
let isPrivate = PrivateBrowsingUtils.isWindowPrivate(aOpener || window);
win = RecentWindow.getMostRecentBrowserWindow({private: isPrivate});
needToFocusWin = true;
}
if (!win) {
// we couldn't find a suitable window, a new one needs to be opened.
return null;
}
if (aIsExternal && (!aURI || aURI.spec == "about:blank")) {
win.BrowserOpenTab(); // this also focuses the location bar
win.focus();
return win.gBrowser.selectedBrowser;
}
let loadInBackground = gPrefService.getBoolPref("browser.tabs.loadDivertedInBackground");
let referrer = aOpener ? makeURI(aOpener.location.href) : null;
let tab = win.gBrowser.loadOneTab(aURI ? aURI.spec : "about:blank", {
referrerURI: referrer,
fromExternal: aIsExternal,
inBackground: loadInBackground});
let browser = win.gBrowser.getBrowserForTab(tab);
if (needToFocusWin || (!loadInBackground && aIsExternal))
win.focus();
return browser;
},
openURI: function (aURI, aOpener, aWhere, aContext) {
... (removed for brevity)
},
openURIInFrame: function browser_openURIInFrame(aURI, aOpener, aWhere, aContext) {
if (aWhere != Ci.nsIBrowserDOMWindow.OPEN_NEWTAB) {
dump("Error: openURIInFrame can only open in new tabs");
return null;
}
var isExternal = (aContext == Ci.nsIBrowserDOMWindow.OPEN_EXTERNAL);
let browser = this._openURIInNewTab(aURI, aOpener, isExternal);
if (browser)
return browser.QueryInterface(Ci.nsIFrameLoaderOwner);
return null;
},
isTabContentWindow: function (aWindow) {
return gBrowser.browsers.some(function (browser) browser.contentWindow == aWindow);
},
get contentWindow() {
return gBrowser.contentWindow;
}
}
So nsBrowserAccess’s openURIInFrame only supports opening things in new tabs, and then it just calls _openURIInNewTab on itself, which does the job of returning the tab’s remote browser after the tab is opened.
I might follow this up with a post about how nsContentTreeOwner opens a window in the non-Electrolysis case, and how we might abstract some of that out for re-use here. We’ll see.
And that’s about it. Hopefully this is useful to future spelunkers.
|
|
Tantek Celik: Markup For People Focused Mobile Communication |
All functionality on web pages and applications starts with markup. The previous post in this series, URLs For People Focused Mobile Communication, documented the various URL schemes for launching the communication apps shown in the mockups, as well as results of testing them on mobile devices. Those tests used minimal markup.
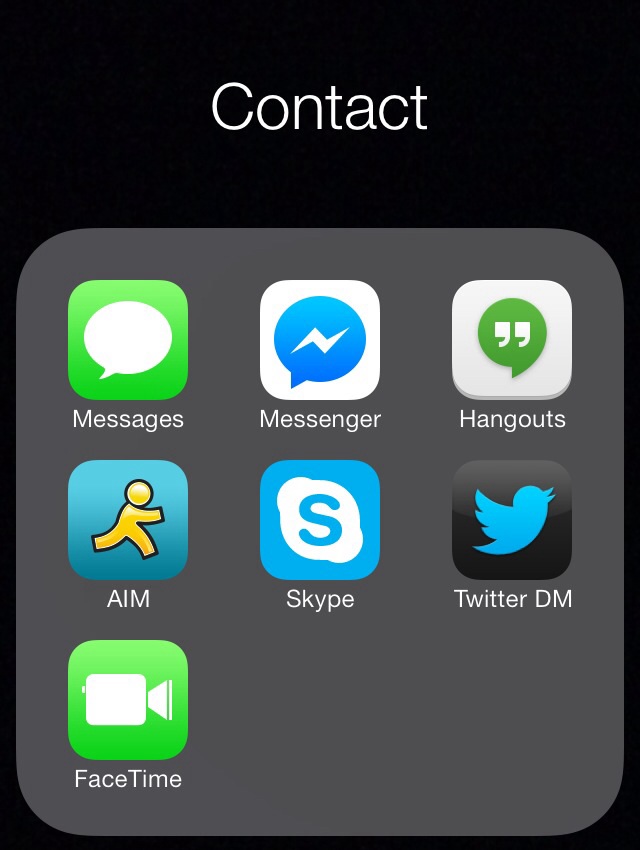
This post documents and explains that markup, building up element by element from a simple hyperlink to the structure implied by this mockup:
Or if you want, you may jump directly to the complete markup example.
A hyperlink provides a way for the user to navigate to other web pages. Using a URL scheme for a communication app, a hyperlink can start a message, resume a conversation, or start an audio/video call. Here's a simple hyperlink that uses the first URL scheme documented in the previous post, sms:
txt message
Live example: txt message
Activating that live example likely won't do much, as user@example.com does not belong to anyone. Example.com is a domain registered purely for the purpose of examples like this one. To make this hyperlink work, you'd have to use a registered AppleID email address, which would send a txt on iOS, and fallback to email via phone provider on Android.
I use the link text "txt message" to indicate its user-centered function: the action of creating a txt message, from one human to another.
Contrast that with the mockup above (which I "built" using an iOS7 home screen folder), which uses the label "Messages", the name of the application it launches.
This deliberate change from "Messages" (application) to "txt message" (action) reflects the larger purpose of this exercise: people-focused rather than app-focused communication. Subsequent labels follow a similar approach.
A simple text hyperlink is functional, yet does not provide the immediate association and recognition conveyed by the Messages icon in the mockup. There are two methods of providing an image hyperlink:
![]()
background-imageThe question of when to use markup for an image and when to use CSS is usually easily answered by the question: is the image meaningful content (like a photograph) or purely decorative (like a flourish)? Or by asking, is any meaning lost if the image is dropped?
The Messages image is neither content nor decorative. It's a button, and it's also a standard iOS user interface element, which means it does convey meaning to those users, above and beyond any text label. Here's the minimum markup for an image hyperlink, with the link text moved into the alt attribute as a fallback:

Live example:
![]()
There is a third option, as implied by the mockup, and that is to use both an image and a text label. That's a simple matter of moving the alt text outside the image:
txt message
Live example:
![]() txt message
txt message
The alt attribute is left deliberately empty since putting anything there would not add to the usability of the link, and could in fact detract from it.
Unlike the mockup, the link text is next to (instead of underneath) the image, and is blue & underlined. These are all presentational aspects and will be addressed in the next post on CSS for People Focused Mobile Communication.
The mockup also shows multiple communication buttons in a list laid out as a grid. We can assign meaning to the order of the buttons - the site owner's preferred order of communication methods. Thus we use an ordered list to convey that their order is significant. Here's a few image+text links wrapped in list items inside an ordered list:
Note the use of an element to abbreviate "Facebook" just to "FB" to shorten the overall "FB message" link text.
Live example:
Just as in the previous URLs post, the FB message link uses Zuck's ID, and the AIM chat link uses the same nickname I've had in the sidebar for a while.
The mockup labels the entire grid "Contact" (also deliberately chosen as an action, rather than the "Contacts" application). This makes sense as a heading, and in the context of a home page, a second level heading:
Contact
No need for a separate live example - the subheads above are all
Combining the Contact heading with the previous ordered list, and adding the remaining buttons:
Contact
In this final code example I've highlighted (using orange bold tags), the key pieces you need to change to your own identifiers on each service.
Live example once more, including heading:
I dropped the Google Hangouts icon since that application lacks support for any URL schemes (as noted in the previous post). Also I've re-ordered a bit from the mockup, having found that I prefer FaceTime over Skype. Pick your own from among the documented URL schemes, and order them to your preference.
All the essential structure is there, yet it clearly needs some CSS. There's plenty to fix from inconsistent image sizes (all but the Messages & FaceTime icons are from Apple's iTunes store web pages), to blue underlined link text. And there's plenty to clean up to approach the look of the mockup: from the clustered center-aligned image+text button layout, to the grid layout of the buttons, to white text on the gray rounded corner ordered list background.
That's all for the next post in this series.
http://tantek.com/2014/120/b1/markup-people-focused-mobile-communication
|
|
Margaret Leibovic: Firefox Hub Add-on Hackathon |
For the past few months, the Firefox for Android team has been working on Firefox Hub, a project to make your home page more customizable and extensible. At its core, this feature is a set of new APIs that allows add-ons to add new content to the Firefox for Android home page.
These APIs are new in Firefox 30, but there are even more features available in Firefox 31, which is moving to Aurora this week. As we’ve been working on these APIs, we’ve been building plenty of demo add-ons ourselves, but we’re at the point where we want more developers to get involved!
Next week (May 5-9), we’re holding a distributed add-on hackathon to encourage more people to start building things with these APIs, and I want to encourage anyone who’s interested to participate!
This hackathon has three main goals:
To kick off this hackathon, I made an etherpad that links to documentation, example add-ons, and a long list of new add-on ideas. Since our community lives all over the world, we’ll hang out in #mobile on irc.mozilla.org to ask questions, report problems, and share progress on things we’re making. In addition to building add-ons, you can also participate by testing new add-ons as they’re made!
At the end of the week, everyone who participated in the hackathon will receive a special limited-edition open badge, as well as pride in contributing to Firefox for Android. And maybe I’ll try to dig up some special prizes for anyone who makes a really cool add-on :)
|
|
Alina Mierlus: Beyond the apps – thoughts on software development |
For the last couple of months I collaborated with Telefonica Foundation for PremiosApps, a first program intended to offer support for dozens of developers aiming to build web-applications with a more social impact (apps for education, art or healthcare).
Some of the apps are already up on the Firefox Marketplace (winners had the opportunity to further develop their project through ThinkBig programme or work with Telefonica Digital on FirefoxOS). It was a really interesting experience for me, as my role was to provide support on technical, but also project management side.
So I wrote code, deployed some services, played with some tools for software project management and I had the chance to have meaningful conversation with people who build their own first web-apps. Of course, among the conversations there were questions such as whether building for a platform or another is better, whether is optimal to migrate web apps to other mobile platforms (such as iOS or Android), to go either for SQL or NoSQL databases, to use a framework or another, etc. The answer is hard in such situations and sometimes, technical decisions can play tricky when come to plan with the resources you have to dedicate to the project.
When comes to questions like “which kind of technology should I choose” – my answer has always been: choose whatever technology you find comfortable with, the technology that your tech. team colleague feels that manages it well enough, the technology that best fits with your resources and time.
In a world that changes so fast, with dozens of frameworks, APIs, programming languages and various platforms – it’s hard to make decisions, especially when you just start your project. The thing is (and we’ve had a conversation about this when discussing about databases) – software is after all an interface that connects you, as a human being, with the machine.
Databases are nothing more than conceptual representations of elements you’re working with and the relationships between them.
The Cloud Services are nothing more than infrastructure on which our code (e.g. web services) runs – a set of computers running as servers and a pipe that connects them with other parts of the internet.
One of the things I learned from this experience is that, when you start a project (like building a piece of software) that eventually will become a product (a piece a software you can actually sell or deploy) – don’t start with the “I’m going to build an app” thinking. The app is just a small, tiny part of the project, the interface between you and the user (which, of course, it’s important).
The problem today, especially in software development world, is having to cope with a constant wave of miscommunication, that is, all that marketing talk about how easy is to build an app (eventually with just a few clicks) and how easy is to be a developer (eventually in just a few days).
That was part of the experience for the group: learning that things are not easy, that building software is harder than it may look like at first and that even the most popular programming language – JavaScript – has its own secrets and tricks.
Applications on the web are a real opportunity in these moments of paradigm change. It may help us explore what could be next on software development. However, we should not forget that we are still through this platforms war ![]() .
.
Beside this, when thinking about building software with social impact, things get even harder as you have to do some “problem finding”. But on this topic, building technology within a social layer, I’ll write more soon.
Thanks to Telefonica Foundation and, above all, to the group of participants I worked with. That was inspiring and made me feel hopeful about the future of software industry in Spain.
I finish this post by sharing a recent talk by Alan Kay, software engineer and inventor from Sillicon Valley (the Sillicon Valley that used to inspire me some years ago… ): youtube.com/watch?v=gTAghAJcO1o
http://blog.alinamierlus.com/2014/04/beyond-the-apps-thoughts-on-software-development/
|
|










 FB message
FB message AIM chat
AIM chat Skype call
Skype call