[Из песочницы] Мой опыт проведения курсов по Java для новых сотрудников |

|
Метки: author nzeshka java обучение программированию |
Как я проходил собеседования на позицию Junior .Net Developer |
|
Метки: author JosefDzeranov алгоритмы c# .net собеседование вопросы с# net |
Управление фермой Android-устройств. Лекция в Яндексе |




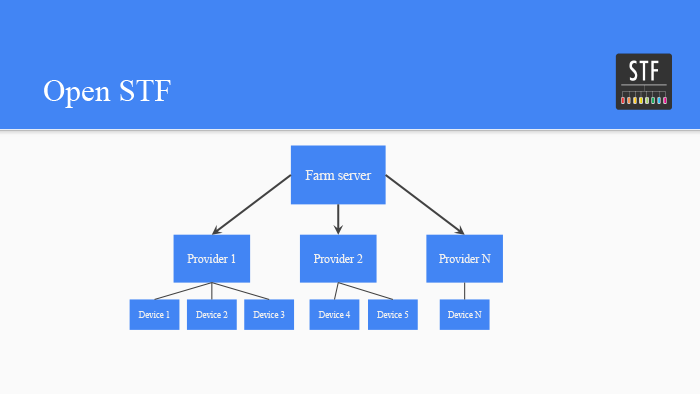


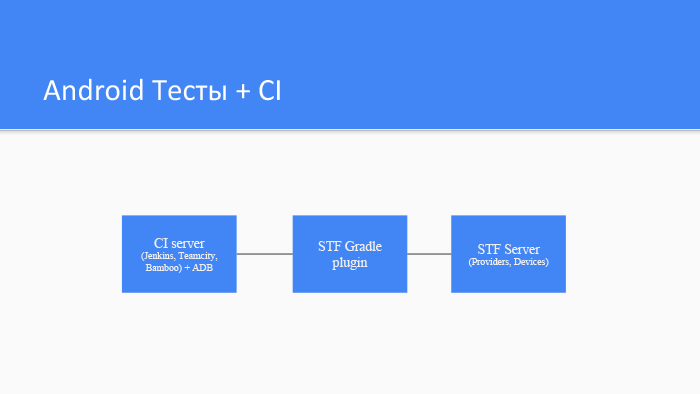



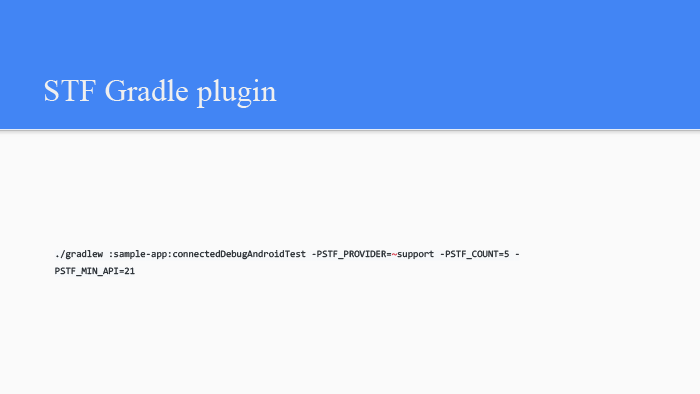





|
|
[recovery mode] Немного о доморощенном |
|
Метки: author PennyLane хабрахабр api разработка |
ASO: ранжирование в App Store и Google Play (найди 10 отличий в алгоритмах) |
|
Метки: author belltane аналитика мобильных приложений aso app store google play ranking |
Смарт контракты Ethereum: пишем простой контракт для ICO |

/*
This file is part of the EasyCrowdsale Contract.
The EasyCrowdsale Contract is free software: you can redistribute it and/or
modify it under the terms of the GNU lesser General Public License as published
by the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
The EasyCrowdsale Contract is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU lesser General Public License for more details.
You should have received a copy of the GNU lesser General Public License
along with the EasyCrowdsale Contract. If not, see /www.gnu.org/licenses/>.
@author Ilya Svirin <i.svirin@prover.io>
*/
pragma solidity ^0.4.0;
contract owned {
address public owner;
function owned() payable {
owner = msg.sender;
}
modifier onlyOwner {
require(owner == msg.sender);
_;
}
function changeOwner(address _owner) onlyOwner public {
owner = _owner;
}
}
contract Crowdsale is owned {
uint256 public totalSupply;
mapping (address => uint256) public balanceOf;
event Transfer(address indexed from, address indexed to, uint256 value);
function Crowdsale() payable owned() {
totalSupply = 21000000;
balanceOf[this] = 20000000;
balanceOf[owner] = totalSupply - balanceOf[this];
Transfer(this, owner, balanceOf[owner]);
}
function () payable {
require(balanceOf[this] > 0);
uint256 tokensPerOneEther = 5000;
uint256 tokens = tokensPerOneEther * msg.value / 1000000000000000000;
if (tokens > balanceOf[this]) {
tokens = balanceOf[this];
uint valueWei = tokens * 1000000000000000000 / tokensPerOneEther;
msg.sender.transfer(msg.value - valueWei);
}
require(tokens > 0);
balanceOf[msg.sender] += tokens;
balanceOf[this] -= tokens;
Transfer(this, msg.sender, tokens);
}
}
contract EasyToken is Crowdsale {
string public standard = 'Token 0.1';
string public name = 'EasyTokens';
string public symbol = "ETN";
uint8 public decimals = 0;
function EasyToken() payable Crowdsale() {}
function transfer(address _to, uint256 _value) public {
require(balanceOf[msg.sender] >= _value);
balanceOf[msg.sender] -= _value;
balanceOf[_to] += _value;
Transfer(msg.sender, _to, _value);
}
}
contract EasyCrowdsale is EasyToken {
function EasyCrowdsale() payable EasyToken() {}
function withdraw() public onlyOwner {
owner.transfer(this.balance);
}
}
|
Метки: author isvirin платежные системы биллинговые системы javascript блокчейн смарт-контракты solidity ethereum |
Мои 5 копеек про Highload Cup 2017 или история 9го места |

std::set, где visitsCmp позволяет хранить id визитов в отсортированном по дате визита порядке. Т.е. при выводе не нужно копировать визиты в отдельный массив и сортировать, а можно сразу выводить в сериализованном виде в буфер. Выглядит он так:struct visitsCmp {
Visit* visits;
bool operator()(const uint32_t &i, const uint32_t &j) const {
if (visits[i].VisitedAt == visits[j].VisitedAt) {
return visits[i].Id < visits[j].Id;
} else {
return visits[i].VisitedAt < visits[j].VisitedAt;
}
}
std::unordered_set, в котором содержатся в визиты конкретного location'а.bool DB::UpdateVisit(Visit& visit, bool add) {
if (add) {
memcpy(&visits[visit.Id], &visit, sizeof(Visit));
// Добвляем визит в индексы
users[visit.User].visits->insert(visit.Id);
locations[visit.Location].visits->insert(visit.Id);
return true;
}
// Если изменилась дата визита, то надо пересортировать визиты пользователя
if (visit.Fields & Visit::FIELD_VISITED_AT) {
users[visits[visit.Id].User].visits->erase(visit.Id);
visits[visit.Id].VisitedAt = visit.VisitedAt;
users[visits[visit.Id].User].visits->insert(visit.Id);
}
if (visit.Fields & Visit::FIELD_MARK) {
visits[visit.Id].Mark = visit.Mark;
}
// Если изменилась пользователь то надо удалить у старого пользователя из индекса и добавить новому
if (visit.Fields & Visit::FIELD_USER) {
users[visits[visit.Id].User].visits->erase(visit.Id);
users[visit.User].visits->insert(visit.Id);
visits[visit.Id].User = visit.User;
}
// Аналогично, если изменился location
if (visit.Fields & Visit::FIELD_LOCATION) {
locations[visits[visit.Id].Location].visits->erase(visit.Id);
locations[visit.Location].visits->insert(visit.Id);
visits[visit.Id].Location = visit.Location;
}
return true;
}
{
"id": 1,
"email": "robosen@icloud.com",
"first_name": "Данила",
"last_name": "Стамленский",
"gender": "m",
"birth_date": 345081600
}
bool User::UmnarshalJSON(const char* data, int len) {
JSON_SKIP_SPACES()
JSON_START_OBJECT()
while (true) {
JSON_SKIP_SPACES()
// Конец объекта
if (data[0] == '}') {
return true;
// Разделитель полей
} else if (data[0] == ',') {
data++;
continue;
// Поле "id"
} else if (strncmp(data, "\"id\"", 4) == 0) {
data += 4;
JSON_SKIP_SPACES()
JSON_FIELDS_SEPARATOR()
JSON_SKIP_SPACES()
// Прочитать и сохранить значение в поле Id
JSON_LONG(Id)
// Выставить флаг, что поле Id было в JSON
Fields |= FIELD_ID;
// Поле "lastname"
} else if (strncmp(data, "\"last_name\"", 11) == 0) {
data += 11;
JSON_SKIP_SPACES()
JSON_FIELDS_SEPARATOR();
JSON_SKIP_SPACES()
// Прочитать и сохранить значение в поле Id
JSON_STRING(LastName)
// Выставить флаг, что поле LastName было в JSON
Fields |= FIELD_LAST_NAME;
} else if (strncmp(data, "\"first_name\"", 12) == 0) {
data += 12;
JSON_SKIP_SPACES()
JSON_FIELDS_SEPARATOR()
JSON_SKIP_SPACES()
JSON_STRING(FirstName)
Fields |= FIELD_FIRST_NAME;
} else if (strncmp(data, "\"email\"", 7) == 0) {
data += 7;
JSON_SKIP_SPACES()
JSON_FIELDS_SEPARATOR()
JSON_SKIP_SPACES()
JSON_STRING(EMail)
Fields |= FIELD_EMAIL;
} else if (strncmp(data, "\"birth_date\"", 12) == 0) {
data += 12;
JSON_SKIP_SPACES()
JSON_FIELDS_SEPARATOR()
JSON_SKIP_SPACES()
JSON_LONG(BirthDate)
Fields |= FIELD_BIRTH_DATE;
} else if (strncmp(data, "\"gender\"", 8) == 0) {
data += 8;
JSON_SKIP_SPACES()
JSON_FIELDS_SEPARATOR()
JSON_SKIP_SPACES()
JSON_CHAR(Gender)
Fields |= FIELD_GENDER;
} else {
JSON_ERROR(Unknow field)
}
}
return true;
}
#define JSON_ERROR(t) fprintf(stderr, "%s (%s:%d)\n", #t, __FILE__, __LINE__); return false;
#define JSON_SKIP_SPACES() data += strspn(data, " \t\r\n")
#define JSON_START_OBJECT() if (data[0] != '{') { \
JSON_ERROR(Need {}) \
} \
data++;
#define JSON_FIELDS_SEPARATOR() if (data[0] != ':') { \
JSON_ERROR(Need :) \
} \
data++;
#define JSON_LONG(field) char *endptr; \
field = strtol(data, &endptr, 10); \
if (data == endptr) { \
JSON_ERROR(Invalid ## field ## value); \
} \
data = endptr;
#define JSON_STRING(field) if (data[0] != '"') {\
JSON_ERROR(Need dquote); \
} \
auto strend = strchr(data+1, '"'); \
if (strend == NULL) { \
JSON_ERROR(Need dquote); \
} \
field = strndup(data+1, strend - data - 1); \
data = strend + 1;
#define JSON_CHAR(field) if (data[0] != '"') {\
JSON_ERROR(Need dquote); \
} \
if (data[2] != '"') {\
JSON_ERROR(Need dquote); \
} \
field = data[1]; \
data += 3;
/users/1/visits?country=%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D1%8F. Для декодинга на StackOverflow было найдено замечательное решение, в которое я дописал поддержку замены + на пробел:int percent_decode(char* out, char* in) {
static const char tbl[256] = { -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, -1, -1, -1, -1, -1, -1,
-1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 10,
11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1 };
char c, v1, v2;
if (in != NULL) {
while ((c = *in++) != '\0') {
switch (c) {
case '%':
if (!(v1 = *in++) || (v1 = tbl[(unsigned char) v1]) < 0
|| !(v2 = *in++)
|| (v2 = tbl[(unsigned char) v2]) < 0) {
return -1;
}
c = (v1 << 4) | v2;
break;
case '+':
c = ' ';
break;
}
*out++ = c;
}
}
*out = '\0';
return 0;
}
"\u0420\u043E\u0441\u0441\u0438\u044F". В общем случае это не страшно, но у нас есть сравнение со страной, поэтому одно поле нужно уметь декодировать. За основу я взял percent_decode, только в случае с Unicode не достаточно превратить \u0420 в 2 байта 0x0420, этому числу надо поставить в соответствие UTF символ. К счастью у нас только символы кириллицы и пробелы, поэтому если посмотреть на таблицу, то можно заметить, что есть всего один разрыв последовательностей между буквами «п» и «р», так что для преобразования можно использовать смещение:void utf_decode(char* in) {
static const char tbl[256] = { -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, -1, -1, -1, -1, -1, -1,
-1, 10, 11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 10,
11, 12, 13, 14, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1 };
char *out = in;
while (in[0] != 0) {
if (in[0] == '\' && in[1] == 'u') {
uint16_t u = tbl[in[2]] << 12 | tbl[in[3]] << 8 | tbl[in[4]] << 4 | tbl[in[5]];
// Все ASCII символы оставляем как есть
if (u < 255) {
out[0] = u;
out++;
} else {
uint16_t w;
// < 'р'
if (u >= 0x0410 && u <= 0x043f) {
w = u - 0x0410 + 0xd090;
// >= 'р'
} else {
w = u - 0x0440 + 0xd180;
}
out[0] = w >> 8;
out[1] = w;
out += 2;
}
in += 6;
} else {
out[0] = in[0];
in++;
out++;
}
}
out[0] = 0;
}
...
auto body = inBuf.Data;
const char *cendptr;
char *endptr;
while (true) {
switch (state) {
case METHOD:
body += strspn(body, " \r\n");
if (strncmp(body, "GET ", 4) == 0) {
method = GET;
body += 4;
} else if (strncmp(body, "POST ", 5) == 0) {
body += 5;
method = POST;
} else {
state = DONE;
WriteBadRequest();
return;
}
body += strspn(body, " ");
cendptr = strchr(body, ' ');
if (cendptr == NULL) {
WriteBadRequest();
return;
}
strncpy(path.End, body, cendptr - body);
path.AddLen(cendptr - body);
cendptr = strchr(cendptr + 1, '\n');
if (cendptr == NULL) {
WriteBadRequest();
return;
}
state = HEADER;
body = (char*) cendptr + 1;
break;
case HEADER:
cendptr = strchr(body, '\n');
if (cendptr == NULL) {
WriteBadRequest();
return;
}
if (cendptr - body < 2) {
if (method == GET) {
doRequest();
return;
}
state = BODY;
}
body = (char*) cendptr + 1;
case BODY:
requst_body = body;
doRequest();
return;
}
...
...
switch (method) {
case GET:
if (strncmp(path.Data, "/users", 6) == 0) {
handlerGetUser();
} else if (strncmp(path.Data, "/locations", 10) == 0) {
handlerGetLocation();
} else if (strncmp(path.Data, "/visits", 7) == 0) {
handlerGetVisit();
} else {
WriteNotFound();
}
break;
case POST:
if (strncmp(path.Data, "/users", 6) == 0) {
handlerPostUser();
} else if (strncmp(path.Data, "/locations", 10) == 0) {
handlerPostLocation();
} else if (strncmp(path.Data, "/visits", 7) == 0) {
handlerPostVisit();
} else {
WriteNotFound();
}
break;
default:
WriteBadRequest();
}
...
void Worker::Run() {
int efd = epoll_create1(0);
if (efd == -1) {
FATAL("epoll_create1");
}
connPool = new ConnectionsPool(db);
// Регистрируем серверный сокет в epoll
auto srvConn = new Connection(sfd, defaultDb);
struct epoll_event event;
event.data.ptr = srvConn;
event.events = EPOLLIN;
if (epoll_ctl(efd, EPOLL_CTL_ADD, sfd, &event) == -1) {
perror("epoll_ctl");
abort();
}
struct epoll_event *events;
events = (epoll_event*) calloc(MAXEVENTS, sizeof event);
while (true) {
auto n = epoll_wait()(efd, events, MAXEVENTS, -1);
for (auto i = 0; i < n; i++) {
auto conn = (Connection*) events[i].data.ptr;
if ((events[i].events & EPOLLERR) || (events[i].events & EPOLLHUP)
|| (!(events[i].events & EPOLLIN))) {
/* An error has occured on this fd, or the socket is not
ready for reading (why were we notified then?) */
fprintf(stderr, "epoll error\n");
close(conn->fd);
if (conn != srvConn) {
connPool->PutConnection(conn);
}
continue;
// Если событие пришло для серверного сокета, то нужно сделать accept
} else if (conn == srvConn) {
/* We have a notification on the listening socket, which
means one or more incoming connections. */
struct sockaddr in_addr;
socklen_t in_len;
in_len = sizeof in_addr;
int infd = accept4(sfd, &in_addr, &in_len, SOCK_NONBLOCK);
if (infd == -1) {
if ((errno == EAGAIN) || (errno == EWOULDBLOCK)) {
continue;
} else {
perror("accept");
continue;;
}
}
int val = true;
if (setsockopt(infd, IPPROTO_TCP, TCP_NODELAY, &val,
sizeof(val)) == -1) {
perror("TCP_NODELAY");
}
event.data.ptr = connPool->GetConnection(infd);
event.events = EPOLLIN | EPOLLET;
if (epoll_ctl(efd, EPOLL_CTL_ADD, infd, &event) == -1) {
perror("epoll_ctl");
abort();
}
continue;
// Событие для клиентского сокета, надо подготовить и отправить ответ
} else {
bool done = false;
bool closeFd = false;
while (true) {
ssize_t count;
count = read(conn->fd, conn->inBuf.Data, conn->inBuf.Capacity);
conn->inBuf.AddLen(count);
if (count == -1) {
/* If errno == EAGAIN, that means we have read all
data. So go back to the main loop. */
if (errno != EAGAIN) {
perror("read");
done = true;
} else {
continue;
}
break;
} else if (count == 0) {
/* End of file. The remote has closed the connection. */
done = true;
closeFd = true;
break;
}
if (!done) {
done = conn->ProcessEvent();
break;
}
}
if (done) {
if (closeFd) {
close(conn->fd);
connPool->PutConnection(conn);
} else {
conn->Reset(conn->fd);
}
}
}
}
}
}
pthread_attr_setstacksize. Минимальный размер стека — 16KB. Т.к. внутри потоков у меня ничего большого в стек не кладётся я выбрал размер стека 32KB: pthread_attr_t attr;
pthread_attr_init(&attr);
if (pthread_attr_setstacksize(&attr, 32 * 1024) != 0) {
perror("pthread_attr_setstacksize");
}
pthread_create(&thr, &attr, &runInThread, (void*) this);
std::to_string. Это было довольно быстро исправлено, но теперь основное время было в операциях epoll_wait, write и writev. На первое я не обратил внимания, что, возможно, стоило попадания в призёры, а что делать с write начал изучать, попутно находя ускорения для accept int val = 1;
if (setsockopt(sfd, IPPROTO_TCP, TCP_NODELAY, &val, sizeof(val)) == -1) {
perror("TCP_NODELAY");
}
int val = 1;
if (setsockopt(sfd, IPPROTO_TCP, TCP_DEFER_ACCEPT, &val, sizeof(val)) == -1) {
perror("TCP_DEFER_ACCEPT");
}
int val = 1;
if (setsockopt(sfd, IPPROTO_TCP, TCP_QUICKACK, &val, sizeof(val)) == -1) {
perror("TCP_QUICKACK");
}
int sndsize = 2 * 1024 * 1024;
if (setsockopt(sfd, SOL_SOCKET, SO_SNDBUF, &sndsize, (int) sizeof(sndsize)) == -1) {
perror("SO_SNDBUF");
}
if (setsockopt(sfd, SOL_SOCKET, SO_RCVBUF, &sndsize, (int) sizeof(sndsize)) == -1) {
perror("SO_RCVBUF");
}
accept для получения клиентского сокета и 2 вызова fcntl для выставления флага fcntl. Вместо 3 системных вызова нужно использовать accept4, которая позволяет сделать тоже самое передав последним аргументом флаг SOCK_NONBLOCK за 1 системный вызов: int infd = accept4(sfd, &in_addr, &in_len, SOCK_NONBLOCK);
lio_listio, позволяющая объединить в 1 системный вызов несколько write/read, что должно уменьшить задержки на переключение в пространство ядра.|
Метки: author svistunov ненормальное программирование высокая производительность c++ |
[Из песочницы] По следам кибер детектива |













Добрый вечер!Адрес узнать удалось. Но пришлось потом перезванивать, так как адрес немного не разобрал, и якобы сейчас уточняю по карте адрес для составления маршрута. Уже в процессе разговора понял, что подаю многовато информации, нужно было больше общения. Тем не менее, как позже признались разработчики, это была лучшая попытка из всех, кто получил и не получил адрес. До Кевина Митника мне конечно же далеко, да и кардингом не занимаюсь, но для первого раза сойдет. Хочу отметить, что именно с этого задания начал решать CTF, привлек необычный и очень интересный формат получения ответа. Думаю, админы не спали сутками, так как участников много, и решают они круглые 24 часа. Как потом мне подсказали, можно было еще в телеграмме написать этому номеру, и так же ответили бы, это сделано, думаю, для иностранцев. Хотя конечно же тут совсем не тот драйв, риск, эмоции. По телефону нужно отвечать быстро на вопросы, которые не мог предусмотреть, и качество ответов зависело от грамотности и продуманности легенды. Получив классный опыт, новые впечатления еще больше хотел продолжать решать. Однако такое интересное задание оценивалось в 100 очков, что не порадовало, не справедливо выделили баллы для этого задания на мой взгляд. До игроков в топе скорборда было далеко, но две бессонные ночи это исправили.
Меня зовут Андрей.
Я представляю движение студентов под названием «World Frendship». Мы занимаемся тем, что объединяем людей, основываясь на взаимопомощи. Помогая в разных жизненных и бытовых вопросах, мы заводим новых знакомых, друзей, а также хотим подарить хоть немного хорошего настроения людям. Хотите поучаствовать?
— (ответ)
Тогда я немножко расскажу о нашем движении и о том, что мы, собственно, делаем.
Наше движение организовывает многие проекты. Например, не так давно мы запустили один проект, суть которого в том, чтобы помочь иностранцам найти жилье бесплатно. Идея в том, чтобы завести новые знакомства, иностранных друзей, так же иметь возможность узнать немного о культуре других людей, попрактиковать иностранный язык, ну и так далее. Возможно вы слышали о подобных таких проектах, проводящихся в Англии и США. Вот.
Вам же я хочу предложить поучаствовать в другом проекте под названием «Теплый ужин».
Суть в том, что мы готовим вместе с вами еду и проводим время в веселой обстановке. Как вам предложение?
— (ответ)
Смотрите. Вы готовите продукты, а также рецепты блюд, которые хотели бы попробовать. Двое наших студентов, как правило парень и девушка, приезжают к вам и готовят. Затем можно поиграть в какие-то настольные игры, или же пойти на прогулку. Ну как, вы согласны?
— (ответ)
Тогда нужно уточнить еще пару моментов. Подскажите, как вас зовут?
— …
И скажите ваш адрес




















Добрый вечер!
Почему не работает сайт shop.cyber-detective.hackit.ua?








































|
Метки: author Jarvis7 хакатоны исследования и прогнозы в it разведка компьютерная безопасность ctf сбор данных google |
[Перевод] Моки и явные контракты |
Наверное каждый, кто начинал писать юнит и интеграционные тесты, сталкивался с проблемой злоупотребления моками, которая приводит к хрупким тестам. Последние, в свою очередь, создают у программиста неверное убеждение в том, что тесты только мешают работать.
Ниже представлен вольный перевод статьи, в которой Jos'e Valim — создатель языка Elixir — высказал своё мнение на проблему использования моков, с которым я полностью согласен.
Несколько дней назад я поделился своими мыслями по поводу моков в Twitter:
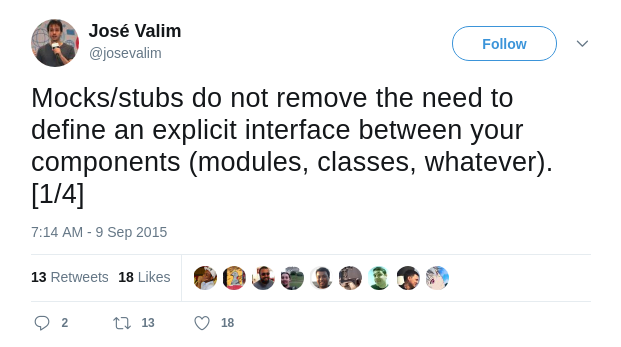
Мок — полезный инструмент в тестировании, но имеющиеся тестовые библиотеки и фреймворки зачастую приводят к злоупотреблению этим инструментом. Ниже мы рассмотрим лучший способ использования моков.
Воспользуемся определением из англоязычной википедии: мок — настраиваемый объект, который имитирует поведение реального объекта. Я сделаю акцент на этом позже, но для меня мок — это всегда существительное, а не глагол [для наглядности, глагол mock везде будет переводиться как "замокать" — прим. перев.].
Давайте рассмотрим стандартный пример из реальной жизни: внешнее API.
Представьте, что вы хотите использовать Twitter API в веб-приложении на фреймворке Phoenix или Rails. В приложение приходит запрос, который перенаправляется в контроллер, который, в свою очередь, делает запрос к внешнему API. Вызов внешнего API происходит прямо в контроллере:
defmodule MyApp.MyController do
def show(conn, %{"username" => username}) do
# ...
MyApp.TwitterClient.get_username(username)
# ...
end
endСтандартным подходом при тестирования такого кода будет замокать (опасно! замокать в данном случае является глаголом!) HTTPClient, которым пользуется MyApp.TwitterClien:
mock(HTTPClient, :get, to_return: %{..., "username" => "josevalim", ...})Далее вы используете такой же подхода в других частях приложения и добиваетесь прохождения юнит и интеграционных тестов. Время двигаться дальше?
Не так быстро. Основная проблема при моке HTTPClient заключается в создании сильной внешней зависимости [англ. coupling везде переведена как "зависимость" — прим. перев.] к конкретному HTTPClient. Например, если вы решите использовать новый более быстрый HTTP-клиент, не изменяя поведение приложения, большая часть ваших интеграционных тестов упадет, потому что все они зависят от конкретного замоканного HTTPClient. Другими словами, изменение реализации без изменения поведения системы все равно приводит к падению тестов. Это плохой знак.
Кроме того, так как мок, показанный выше, изменяет модуль глобально, вы больше не сможете запустить эти тесты в Elixir параллельно.
Вместо того, чтобы мокать HTTPClient, мы можем заменить MyApp.TwitterClient чем-нибудь другим во время тестов. Давайте посмотрим, как решение может выглядеть на Elixir.
В Elixir все приложения имеют конфигурационные файлы и механизм для их чтения. Используем этот механизм, чтобы настроить клиент Twitter'a для различных окружений. Код контроллера теперь будет выглядеть следующим образом:
defmodule MyApp.MyController do
@twitter_api Application.get_env(:my_app, :twitter_api)
def show(conn, %{"username" => username}) do
# ...
@twitter_api.get_username(username)
# ...
end
endСоответствующие настройки для различных окружений:
# config/dev.exs
config :my_app, :twitter_api, MyApp.Twitter.Sandbox
# config/test.exs
config :my_app, :twitter_api, MyApp.Twitter.InMemory
# config/prod.exs
config :my_app, :twitter_api, MyApp.Twitter.HTTPClientСейчас мы можем выбрать лучшую стратегию получения данных из Twitter для каждого из окружений. Sandbox может быть полезен, если Twitter предоставляет какой-нибудь sandbox для разработки. Наша замоканная версия HTTPClient позволяла избежать реальных HTTP-запросов. Реализация этой же функциональности в данном случае:
defmodule MyApp.Twitter.InMemory do
def get_username("josevalim") do
%MyApp.Twitter.User{
username: "josevalim"
}
end
endКод получился простым и чистым, а сильной внешней зависимости от HTTPClient больше нет. MyApp.Twitter.InMemory является моком, то есть существительным, и для его создания вам не нужны никакие библиотеки!
Мок предназначен для замены реального объекта, а значит будет эффективен только в том случае, когда поведение реального объекта определено явно. Иначе, вы можете оказаться в ситуации, когда мок начнет становиться все сложнее, увеличивая зависимость между тестируемыми компонентами. Без явного контракта заметить это будет сложно.
Мы уже имеем три реализации Twitter API и лучше сделать их контракты явными. В Elixir описать явный контракт можно с помощью behaviour:
defmodule MyApp.Twitter do
@doc "..."
@callback get_username(username :: String.t) :: %MyApp.Twitter.User{}
@doc "..."
@callback followers_for(username :: String.t) :: [%MyApp.Twitter.User{}]
endТеперь добавьте @behaviour MyApp.Twitter в каждый модуль, который реализует этот контракт, и Elixir поможет вам создать ожидаемый API.
В Elixir мы полагаемся на такие behaviours постоянно: когда используем Plug, когда работаем с базой данных в Ecto, когда тестируем Phoenix channels и так далее.
Сначала, когда явные контракты отсутствовали, границы приложения выглядели так:
[MyApp] -> [HTTPClient] -> [Twitter API]
Поэтому изменение HTTPClient могло приводить к падению интеграционных тестов. Сейчас приложение зависит от контракта и только одна реализация этого контракта работает с HTTP:
[MyApp] -> [MyApp.Twitter (contract)]
[MyApp.Twitter.HTTP (contract impl)] -> [HTTPClient] -> [Twitter API]
Тесты такого приложения изолированы от HTTPClient и от Twitter API. Но как нам протестировать MyApp.Twitter.HTTP?
Сложность тестирования больших систем заключается в определение четких границ между компонентами. Слишком высокий уровень изоляции при отсутствии интеграционных тестов сделает тесты хрупкими, а большинство проблем будут обнаруживаться только на production. С другой стороны, низкий уровень изоляции увеличит время прохождения тестов и сделает тесты сложными в сопровождении. Единственного верного решения нет, и уровень изоляции будет изменяться в зависимости от уверенности команды и прочих факторов.
Лично я бы протестировал MyApp.Twitter.HTTP на реальном Twitter API, запуская эти тесты по-необходимости во время разработки и каждый раз при сборке проекта. Система тегов в ExUnit — библиотеке для тестирования в Elixir — реализует такое поведение:
defmodule MyApp.Twitter.HTTPTest do
use ExUnit.Case, async: true
# Эти тесты будут работать с Twitter API
@moduletag :twitter_api
# ...
endИсключим тесты с Twitter API:
ExUnit.configure exclude: [:twitter_api]При необходимости включим их в общий тестовый прогон:
mix test --include twitter_api
Также можно запустить их отдельно:
mix test --only twitter_api
Хотя я предпочитаю такой подход, внешние ограничения, вроде максимального количества запросов к API, могут сделать его бесполезным. В таком случае, возможно, действительно нужно использовать мок HTTPClient, если его использование не нарушает определенных ранее правил:
HTTPClient приводит только к падению тестов на MyApp.Twitter.HTTPHTTPClient. Вместо этого, вы передаете его как зависимость через файл конфигурации, подобно тому, как мы делали для Twitter APIВместо создания мока HTTPClient можно поднять dummy-сервер, который будет эмулировать Twitter API. bypass — один из проектов, который может в этом помочь. Все возможные варианты вы должны обсудить со своей командой.
Я бы хотел закончить эту статью разбором нескольких общих проблем, которые всплывают практически в каждом обсуждении моков.
Цитата из elixir-talk mailing list:
Получается, предложенное решение делает production-код более "тестируемым", но создает необходимость ходить в конфигурацию приложения на каждый вызов функции? Наличие ненужного оверхэда, чтобы сделать что-то "тестируемым", не похоже на хорошее решение.
Я бы сказал, что речь идет не о создании "тестируемого" кода, а об улучшении дизайна [от англ. design of your code — прим. перев.].
Тест — это пользователь вашего API, как и любой другой код, который вы пишите. Одна из идей TDD заключается в том, что тесты — это код и ничем не отличаются от кода. Если вы говорите: "Я не хочу делать мой код тестируемым", это означает "Я не хочу уменьшать зависимость между компонентами" или "Я не хочу думать о контракте (интерфейсе) этих компонентов".
Нет ничего плохого в нежелании уменьшать зависимость между компонентами. Например, если речь идет о модуле работы с URI [имеется ввиду модуль URI для Elixir — прим. перев.]. Но если мы говорим о чем-то таком же сложном, как внешнее API, определение явного контракта и наличие возможности заменять реализацию этого контракта сделает ваш код удобным и простым в сопровождении.
Кроме того, оверхэд минимален, так как конфигурация Elixir-приложения хранится в ETS, а значит вычитывается прямо из памяти.
Хотя мы и использовали конфигурацию приложения для решения проблемы с внешним API, иногда проще передать зависимость как аргумент. Например, некоторая функция выполняет долгие вычисления, которые вы хотите изолировать в тестах:
defmodule MyModule do
def my_function do
# ...
SomeDependency.heavy_work(arg1, arg2)
# ...
end
endМожно избавиться от зависимости, передав её как аргумент. В данном случае будет достаточно передачи анонимной функции:
defmodule MyModule do
def my_function(heavy_work \\ &SomeDependency.heavy_work/2) do
# ...
heavy_work.(arg1, arg2)
# ...
end
endТест будет выглядеть следующим образом:
test "my function performs heavy work" do
# Симулируем долгое вычисление с помощью отправки сообщения тесту
heavy_work = fn(_, _) ->
send(self(), :heavy_work)
end
MyModule.my_function(heavy_work)
assert_received :heavy_work
endИли, как было описано ранее, можно определить контракт и передать модуль целиком:
defmodule MyModule do
def my_function(dependency \\ SomeDependency)
# ...
dependency.heavy_work(arg1, arg2)
# ...
end
endИзменим тест:
test "my function performs heavy work" do
# Симулируем долгое вычисление с помощью отправки сообщения тесту
defmodule TestDependency do
def heavy_work(_arg1, _arg2) do
send self(), :heavy_work
end
end
MyModule.my_function(TestDependency)
assert_received :heavy_work
endВы также можете представить зависимость в виде data structure и определить контракт с помощью protocol.
Передать зависимость как аргумент намного проще, поэтому, если возможно, такой способ должен быть предпочтительнее использования конфигурационного файла и Application.get_env/3.
Лучше думать о моках как о существительных. Вместо того, чтобы мокать API (мокать — глагол), нужно создать мок (мок — существительное), который реализует необходимый API.
Большинство проблем от использования моков возникают, когда они используются как глаголы. Если вы мокаете что-то, вы изменяете уже существующие объекты, и зачастую эти изменения являются глобальными. Например, когда мы мокаем модуль SomeDependency, он изменится глобально:
mock(SomeDependency, :heavy_work, to_return: true)При использовании мока как существительного, вам необходимо создать что-то новое, и, естественно, это не может быть уже существующий модуль SomeDependency. Правило "мок — это существительное, а не глагол" помогает находить "плохие" моки. Но ваш опыт может отличаться от моего.
После прочитанного у вас может возникнуть вопрос: "Нужно ли отказываться от библиотек для создания моков?"
Все зависит от ситуации. Если библиотека подталкивает вас на подмену глобальных объектов (или на использование моков в качестве глаголов), изменение статических методов в объектно-ориентированном или замену модулей в функциональном программировании, то есть на нарушение описанных выше правил создания моков, то вам лучше отказаться от неё.
Однако, есть библиотеки для создания моков, которые не подталкивают вас на использование описанных выше анти-паттернов. Такие библиотеки предоставляют "мок-объекты" или "мок-модули", которые передаются в тестируемую систему в качестве аргумента и собирают информацию о количестве вызовов мока и о том, с какими аргументами он был вызван.
Одна из задач тестирования системы — нахождение правильных контрактов и границ между компонентами. Использование моков только в случае наличия явного контракта позволит вам:
URI и Enum за контрактом.@callback в Elixir). Бесконечный рост @callback укажет на зависимость, которая берет на себя слишком много ответственности, и вы сможете раньше расправиться с проблемой.Явные контракты позволяют увидеть сложность зависимостей в вашем приложении. Сложность присутствует в каждом приложении, поэтому всегда старайтесь делать её настолько явной, насколько это возможно.
|
Метки: author Telichkin тестирование it-систем совершенный код elixir/phoenix elixir mock stub testing тестирование |
[Из песочницы] Классический 2д квест или как прошли наши два года разработки. Часть 1 |













|
Метки: author MaikShamrock разработка игр java продвижение игр steam greenlight corona sdk libgdx android google play |
[Из песочницы] ASO в iOS 11: сводная таблица изменений |




|
Метки: author belltane аналитика мобильных приложений aso ios development |
Пишем «Тир» на JavaScript для рекламы на сайте |



// объявляем движок
var pjs = new PointJS(640, 480, {
backgroundColor : 'white' // optional
});
// растягиваем игру на всю страницу
pjs.system.initFullPage(); // for Full Page mode
// системные функции для сокращения
var log = pjs.system.log; // log = console.log;
var game = pjs.game; // Game Manager
var point = pjs.vector.point; // Constructor for Point
var camera = pjs.camera; // Camera Manager
var brush = pjs.brush; // Brush, used for simple drawing
var OOP = pjs.OOP; // Objects manager
var math = pjs.math; // More Math-methods
var levels = pjs.levels; // Levels manager
// включим мышь
var mouse = pjs.mouseControl.initControl();
// получим новые ширину и высоту экрана
var width = game.getWH().w; // width of scene viewport
var height = game.getWH().h; // height of scene viewport
// заголовок
pjs.system.setTitle('Tir'); // Set Title for Tab or Window
// отключим показ кусора (заменим своим)
mouse.setVisible(false);
// переменная для счета
var score = 0;
// при изменении размера перезагрузим игру
window.onresize = function () {
location.reload();
};
// этой функцией будем прогонять зависимые от высоты экрана значения
var i = function (num) {
return num * (height/260);
};
// Объявляем игровой цикл
game.newLoopFromConstructor('Menu', function () {
// Для меню мне требуется создать красивый фон в стиле DNS
var bg = game.newImageObject({
x : 0, y : 0, // позиция
file : 'dns_logo.jpeg', // файл фона
w : width, // ширину установим, высота подгонится сама
alpha : 0.8 // немного блеклый
});
this.update = function () {
// запомним на всякий случай позицию курсора
var mp = mouse.getPosition();
// при наведении мыши сделаем ярче
if (mp.x > 10 && mp.x < width - 10 && mp.y > 10 && mp.y < height - 10) bg.setAlpha(1);
else bg.setAlpha(0.5);
// по клику перейдем в игру
if (mouse.isPress('LEFT')) {
game.setLoop('Game');
}
// отрисуем фон
bg.draw();
// отрисуем свой курсор
brush.drawImage({
x : mp.x - 10, y : mp.y - 10, // 10 - смещение картинки из-за обрамления
file : 'menu_cursor.png'
});
};
});
// Запускаем игру на текущем игровом цикле
game.startLoop('Menu');

game.newLoopFromConstructor('Game', function () {
// создадим полки, по которым будут плыть компьютеры
var bg = game.newImageObject({
x : 0, y : 0, // позиция
file : 'bg_game.jpg', // файл фона
w : width, // ширину установим, высота подгонится сама,
h : height
});
// массив с количеством компьютеров на полочках (для инициализации)
var cntShelf;
var cntRIP = 0;
// уровни полок по оси Y
var shelf = {
1 : i(15), // верхняя полка
2 : i(86), // средняя
3 : i(160) // нижняя
};
// скорости движения на полках
var shelfSpeed = {
1 : math.random(2, 8),
2 : math.random(2, 8),
3 : math.random(2, 8)
};
var createLaptop = function (s) { // агрументом передаем полку
var rnd = s ? s : math.random(1, 3); // выбираем полку (случайно) или из агрумента
var rip = math.random(1, 5) == 5; // выберем тип компьютера (случайно)
// увеличим количество компьютеров, которые надо убрать (для инициализации)
if (!s && rip) cntRIP++;
return game.newImageObject({
y : shelf[rnd], // установим на выбранную полку
h : i(50), // выота компьютера
file : !rip ? 'laptop.png' : 'laptop_rip.png', // выбираем нужный спрайт
userData : { // дополнительные данные (нестандартные)
shelf : rnd, // полка
rip : rip // тип компьютера
},
onload : function () { // отпозиционируем после загрузки по оси X
var dist = 10; // дистанция между компьютерами
this.x = -cntShelf[rnd] * (this.w + dist); // рссчитываем позицию
cntShelf[rnd]++; // увеличиваем количество на выбранной полке
}
});
};
// объекты для "отстрела"
var cells = []; // это массив
var fog = 0; // степень прозрачности после тумана после выстрела
var scale = 1; // степень деформации прицела
// при входе в игровой цикл установим первичные данные
this.entry = function () {
score = 0; // сбросим счет
// сбросим количества компьютеров
cntShelf = {
1 : 0,
2 : 0,
3 : 0
};
// заполнение массива
OOP.fillArr(cells, math.random(20, 90), function () {
return createLaptop(); // вернем в массив только что созданный объект
});
};
this.update = function () {
var dt = game.getDT(30); // для плавного движения возьмем дельту и поделим на 100
// запомним на всякий случай позицию курсора
var mp = mouse.getPosition();
// запомним так же скорость мыши
var mps = Math.max(mouse.getSpeed().x, mouse.getSpeed().y);
// запомним состояние нажатия (true/false) для текущего кадра
var fire = mouse.isPress('LEFT');
// имитируем выстрел
if (fire) {
fog = 1;
scale = 1.5;
}
// рисуем полочки
bg.draw();
// рисуем объекты
OOP.forArr(cells, function (c, i) {
var rnd;
c.draw();
c.move(point(shelfSpeed[c.shelf] * dt, 0)); // двигаем по оси X
// если объект ушел за пределы видимости, меняем его позицию по X
if (c.x > width) {
c.x = -c.w * cntShelf[c.shelf];
}
// если выстрел, проверим попадание
if (fire) {
// если курсор попадает в статический бокс объекта BBOX
if (mouse.isInStatic(c.getStaticBox())) {
// если компьютер с синим экраном - то увеличиваем счет
if (c.rip) {
score++;
// если мы набрали нужное количество очков
if (score >= cntRIP) {
score = 1;
game.setLoop('Menu');
}
} else { // а иначе выкидываем в меню из-за неправильного выбора
score = -1;
game.setLoop('Menu');
return;
}
cells.splice(i, 1);
cells.push(createLaptop()); // добавляем еще новый компьютер
return;
}
}
});
// рисуем прицел
brush.drawImage({
x : mp.x - i(50) * scale, y : mp.y - i(50) * scale, // 10 - смещение картинки из-за обрамления
w : i(100) * scale, h : i(100) * scale, // размеры установим фактические
file : 'cell.png'
});
// рисуем счет
brush.drawText({
text : 'Убрано: ' + score + '/' + cntRIP,
color : 'black',
size : i(15),
font : 'serif'
});
// если есть туман, рисуем его и меняем прозрачность
if (fog > 0) {
brush.drawRect({
w : width, h : height, // закрываем всё
fillColor : 'rgba(255, 255, 255, '+fog+')'
});
fog -= 0.1; // прозрачность
scale -= 0.05; // степень деформации прицела
}
};
});

// Объявляем игровой цикл
game.newLoopFromConstructor('Menu', function () {
// Для меню мне требуется создать красивый фон в стиле DNS
var bg = game.newImageObject({
x : 0, y : 0, // позиция
file : 'dns_logo.jpeg', // файл фона
w : width, // ширину установим
h : height,
alpha : 0.8 // немного блеклый
});
// объявим функция входа в игровой цикл
this.entry = function () {
var div, _s;
if (score) {
div = pjs.system.newDOM('div', true);
_s = div.style; // ссылка на стили
_s.height = _s.width = '100%'; // установили ширину и высоту HTML блока
_s.backgroundColor = 'white'; // заливка
_s.cursor = 'default'; // курсор
if (score == 1) { // если выиграл
div.innerHTML = `
Вот так мы оставляем на прилавках только качественный продукт!
Перейти в магазин и попробовать лично
Сыграть еще раз
`;
} else if (score == -1) { // если проиграл
div.innerHTML = `
Задача - убрать только сломанные компьютеры!
Я понял, запускай!
Перейти в магазин и попробовать лично
`;
}
}
};
this.update = function () {
// запомним на всякий случай позицию курсора
var mp = mouse.getPosition();
// при наведении мыши сделаем ярче
if (mp.x > 10 && mp.x < width - 10 && mp.y > 10 && mp.y < height - 10) bg.setAlpha(1);
else bg.setAlpha(0.5);
// по клику перейдем в игру
if (mouse.isPress('LEFT')) {
game.setLoop('Game');
}
// отрисуем фон
bg.draw();
// отрисуем свой курсор
brush.drawImage({
x : mp.x - 10, y : mp.y - 10, // 10 - смещение картинки из-за обрамления
file : 'menu_cursor.png'
});
};
});
// Запускаем игру на текущем игровом цикле
game.startLoop('Menu');
|
Метки: author Skaner разработка игр программирование javascript html причем тут linux? game development gamedev |
Приглашаем на Android Devs Meetup 22 сентября |
|
Метки: author meetup_vero разработка под android kotlin блог компании mail.ru group android mail.ru android devs meetup |
Стриминговый сервис Roku собрался на IPO: что может пойти не так |

|
Метки: author itinvest финансы в it блог компании itinvest roku стриминг ipo биржа |
[Перевод] Твой софт никому не нужен. Или почему разработка ПО требует свежего подхода |
|
Метки: author vsabadazh интерфейсы usability ux |
Обновления Magento, Защита от вредных администраторов, утечки данных, исполнения кода |

|
Метки: author kirmorozov разработка под e-commerce информационная безопасность open source magento magento 2 безопасность веб-приложений xss csrf |
Анализ статьи «Начальник, хочу работать из дома» |
|
Метки: author ARadzishevskiy управление разработкой управление персоналом удаленная работа процесс разработки |
Security Week 37: Дружно выключаем Bluetooth, дыра в Tor на миллион, ботнеты на серверах Elasticsearch |
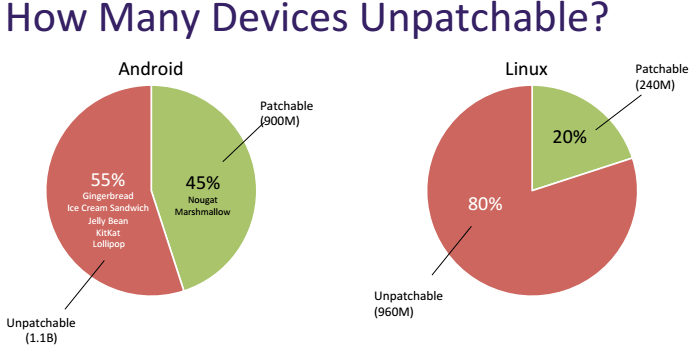
 BlueBorne. Запомните это название. Это даже не уязвимость, это — целая пачка дыр в реализациях Bluetooth в Windows, Linux, Android и даже немножко в iOS. Вскрыли этот нарыв исследователи из Armis Labs, они же и оценили число потенциальных жертв в… 5,3 миллиарда устройств.
BlueBorne. Запомните это название. Это даже не уязвимость, это — целая пачка дыр в реализациях Bluetooth в Windows, Linux, Android и даже немножко в iOS. Вскрыли этот нарыв исследователи из Armis Labs, они же и оценили число потенциальных жертв в… 5,3 миллиарда устройств.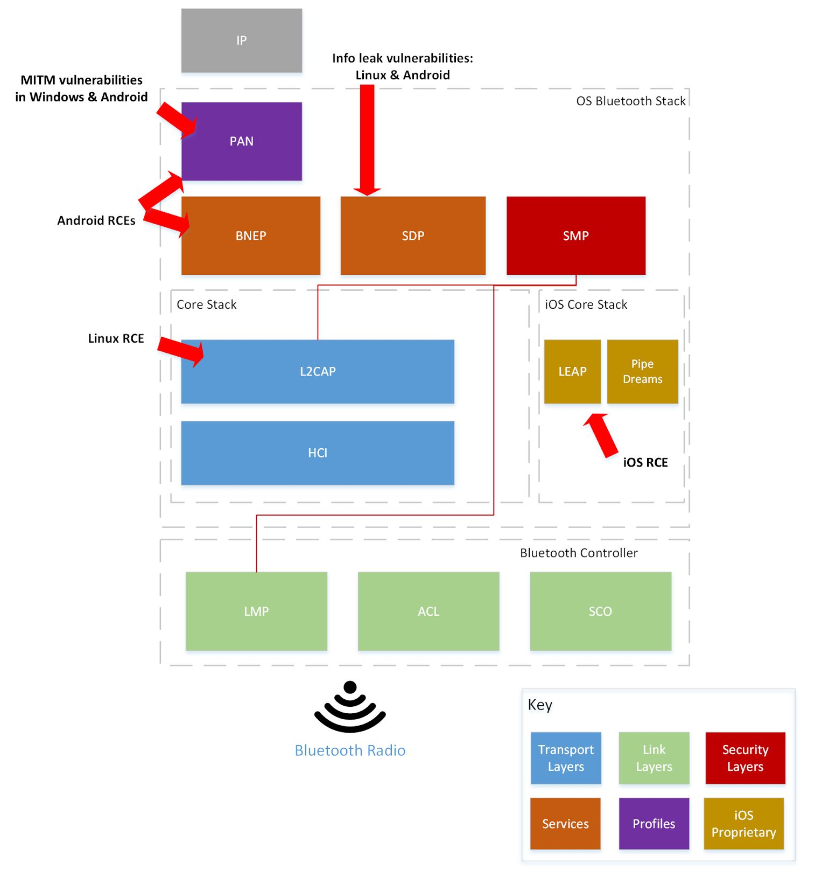
 Новость. Поставщик эксплойтов Zerodium снова объявил красивую семизначную награду за эксплойт нулевого дня – на этот раз в браузере Tor. Полностью функциональный эксплойт для доселе неизвестной уязвимости в Tor под Tails Linux и Windows обойдется конторе в миллион долларов.
Новость. Поставщик эксплойтов Zerodium снова объявил красивую семизначную награду за эксплойт нулевого дня – на этот раз в браузере Tor. Полностью функциональный эксплойт для доселе неизвестной уязвимости в Tor под Tails Linux и Windows обойдется конторе в миллион долларов.

|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw bluetooth blueborne elasticsearch pos malware zerodium tor project |
Как правильно вставлять SVG |
|
Метки: author htmlacademy разработка веб-сайтов html блог компании html academy svg html5 для начинающих верстка сайтов html- верстка графика |
Приглашаем на mini ai cups |

Вот уже пять лет мы проводим russian ai cup, крупнейший в СНГ ежегодный чемпионат по искусственному интеллекту (а если проще — по написанию ботов для игр). И вот уже семь лет участники этого чемпионата просят либо оставлять песочницу работать весь год, либо запустить площадку, где можно было бы весь год играться в подобные же конкурсы, только чуть меньше размером.
Мы подумали и решили опробовать второй вариант — открыли новую площадку с мини-конкурсами, связанными с искусственным интеллектом и написанием ботов для игр. Встречайте новый для нас класс чемпионатов — http://aicups.ru/.
И сразу же предлагаем принять участие в первом, тестовом чемпионате.
И не бейте нас, пожалуйста, за дизайн площадки. Мы очень упарывались в качество самого соревнования, поэтому в дизайн мы просто не успели. Сделаем вид, что мы так видим ;)
Поскольку это первый чемпионат на новой площадке, мы особо не упарывались в сложность задачи и взяли довольно простую тематику — развоз пассажиров по этажам с помощью лифта. Чтобы разнообразить задачу, в неё добавлено несколько факторов, влияющих на алгоритм развоза пассажиров:
Кроме того, задачу мультиплеерная. То есть, у нас есть две группы лифтов и каждый игрок управляет своей группой. Сами же пассажиры делятся на “своих” и “чужих” — чужого сложнее забрать с этажа. Но если смог, получил 2x очков ;)
Подробнее обо всем этом можно прочитать ниже, в разделе “Правила”
Чемпионат открывается сегодня, 15-сентября, и продлится до 9-го октября.
Пока что наш план таков:
15-го сентября открывается площадка с песочницей, и у участников появляется возможность загружать свои стратегии и играть не-рейтинговые игры “на интерес” с другими своими стратегиями, с другими игроками или с бейзлайном — в песочнице живут два фейковых пользователя (“good baseline” — забирает всегда только своих пассажиров и “evil baseline” — забирает только чужих).
В сутки можно загрузить не более 6 новых решений, и сыграть не более 30 не-рейтинговых игр.
18 сентября в песочнице начинают работать рейтинговые игры (их система создает сама). Время от времени псевдослучайно выбирается два участника (для подбора мы используем TrueSkill, спасибо Microsoft за этот прекрасный алгоритм!). От каждого из них мы берем стратегию, которую он до этого выбрал для участия в рейтинге. Две эти стратегии играют друг с другом, победившая передвигается в лидерборде вверх, проигравшая вниз. Таким образом строится рейтинг песочницы.
9-го октября мы планируем провести финал. Некоторое количество топовых участников из песочницы будет отобрано в отдельный рейтинг, после чего мы запустим несколько волн игр “каждый с каждым” и таким образом выясним, чья же стратегия самая крутая, раздадим призы, учтем пожелания и пойдем готовиться к следующему подобному чемпионату!
Как уже давно принято в наших чемпионатах, мы награждаем TOP6. Расклад призов такой же, как и в прошедшем недавно highloadcup:
Кроме того, маечки! Не будем нарушать и эту добрую традицию — TOP20 получат от нас майки с символикой чемпионата. Возможно маек будет больше — в highloadcup мы тоже начали с 20-ти штук, в результате дарим 116 :)
Итак, подробнее о задаче.

Место появления пассажиров
Лестница
Кол-во пассажиров в группе
Кол-во пассажиров на этаже
Кол-во пассажиров в лифте
Тики
Описание здания:
Лифты:
Пассажиры:
Подсчет очков:
Побеждает игрок, набравший большее кол-во очков.
API и Baseline мы выложили в официальном репозитории с документацией, здесь. В этом же репозитории принимаются новые issue, мы обязательно будем их просматривать.
Сейчас у нас есть API для следующих языков:
Возможно, этот список будет пополняться. Прямо сейчас пытаемся подключить C#.
Участвовать могут все, без ограничений! Заходите, пробуйте! Поучаствовать можно здесь, а обсудить чемпионат можно в VK и в Telegram. Удачи в чемпионате!
|
Метки: author sat2707 разработка игр блог компании mail.ru group russian ai cup ai algorithms ненормальное программирование |






