Все, что вы хотели знать о компонуемой инфраструктуре HPE Synergy, в вопросах и ответах |

|
Метки: author tonyafilonenko it- инфраструктура блог компании hewlett packard enterprise hpe hpe synergy вебинар компонуемая инфраструктура composable infrastructure |
Зачем нужен Kubernetes и почему он больше, чем PaaS? |


Что должно быть в стандартной библиотеке C++? Идеалом для программиста является возможность найти каждый интересный, значимый и разумно обобщённый класс, функцию, шаблон и т.п. в библиотеке. Однако вопрос не в том, «что должно быть в какой-то библиотеке», а в том, «что должно быть в стандартной библиотеке». И ответ «Всё!» — первое разумное приближение к ответу на первый вопрос, но не последний. Стандартная библиотека — то, что должен предоставлять каждый автор и делать это так, чтобы каждый программист мог на это положиться [т.е. действительно нуждался в этом — прим. перев.].

|
Метки: author distol анализ и проектирование систем open source it- стандарты блог компании флант kubernetes devops облачные сервисы микросервисы контейнеры paas |
«База знаний»: 100 практических материалов по безопасности, экономике и инструментарию IaaS |
 / фото Leonardo Rizzi CC
/ фото Leonardo Rizzi CC
|
Метки: author it_man информационная безопасность блог компании ит-град ит-град iaas мегадайджест iaas- кейсы |
Платформа ServiceNow: Искусственный интеллект автоматизирует рабочие процессы |
 Изображение Matthew Hurst CC
Изображение Matthew Hurst CC«Сферы обслуживания клиентов и управления персоналом хорошо поддаются автоматизации, — отмечает технический директор ServiceNow Аллан Лейнволд. — Но бизнес тратит большое количество времени на решение типовых, рутинных задач, например на запросы информации об отгулах к отделу кадров».
«Покупая компанию, мы первым делом переписываем ее продукты под свою платформу, — рассказывает директор по стратегии ServiceNow Дэйв Райт (Dave Wright). — Такой подход исключает неразбериху с ворохом плохо интегрированных продуктов».
|
Метки: author it-guild help desk software блог компании ит гильдия ит гильдия servicenow |
Spark-in.me. Часть 4 — Базовое админство для обычных человеков |

У слова backup есть несколько значений, как и у других похожих слов, например setup — это еще и «прикид», а не только набор настроек, устройств и еще бог весть чего.
Бекап — это своего рода снимок или слепок вашей системы в некоторый момент времени, который позволяет в случае возникновения над вами купола сияющего медного таза вернуть все к тому состоянию, которое запомнил бекап. Обычно это то желанное состояние, в котором все хорошо и тазиков не предвидится.

Сами медные тазики бывают разными. Тазики, которые накрывают вас не по вашей воле или из-за вашей тупой ошибки, материализуясь прямо из воздуха; тазики, которые бренчат где-то, не пойми где, а потом вы дергаете ручку кладовки, в которую не заходили давно, и они засыпают вас с ног до головы, попутно оставляя добротные синяки — это далеко не полная классификация, но это самые отстойные из них. Второй вид отстойнее, потому что может оказаться, что копиться тазы начали сильно давно, и даже логи не помнят эти времена, не то что бекапы. И нельзя не только сдуть всю эту тазобратию одной командой, но и после ручного перетаскивания сияющего великолепия на помойку придется искать его источник и чинить. Ну или искать источник сначала, а потом уже таскать, — в зависимости от скорости генерации тазов в кладовке или предпочтений.

Я уже успела упомянуть логи. Логи — это такие летописи всякой ерунды, происходящей в вашей системе. Ведут эти летописи как сама система, так и разного рода приложения. Приложения могут писать в отдельные файлы, а могут и в системные. Зачем нужны логи? Логи позволяют «найти все» — найти ошибку и подробности ее возникновения, что здорово помогает затем ее локализовать и устранить. Логи незаменимы, когда ошибку трудно воспроизвести и кажется, что условием возникновения ошибки является святой рандом. Есть целые энтерпрайз решения для хранения, структуризации и анализа логов it-систем, и, надо сказать, это очень удобно, здорово и дорого.
Данные, особенно если их собирали долго и упорно — с каждого клиента и его заказа, или из открытых источников при помощи чьих-то глаз и рук, парсинга и последующей чистки, терять очень больно. Данные — это информация, это клиенты, это месяцы и даже годы работы, это закономерности — скрытые или уже найденные. Всякий админ, даже не понимая всю значимость данных, имеет все-таки представление об этом и чахнет над базой словно царь Кащей над златом.
Мы не админы, мы обычные человеки, которые поставили себе прекрасную СУБД. Но данные терять не хотим и не хотим предоставить воле случая возможность испепелить наше детище. Что же делать? Настраивать бекапы и логи, конечно же. В самом простом и неказистом виде.
Расскажу, как делаю я. Как вы понимаете, правильнее открыть документацию, прочитать пару статей и сделать выбор. Но можно обойтись и так. Потом можно осознать, что вам нужно что-то другое, что у этого подхода есть свои минусы и перейти на что-то более соответсвующее именно вам.
Положим, я создала в кластере две базы данных. Я делаю бекап каждой из них и складываю бекапы в папку, папку называю текущей датой. Делается это так:
TIME=`date '+%m-%d-%Y'`
mkdir -p /path/to-your-db-backups/$TIME
pg_dump mydb1 > /path/to-your-db-backups/$TIME/mydb1.sql
pg_dump mydb2 > /path/to-your-db-backups/$TIME/mydb2.sql
Если у вас бекапы хранятся на отдельном диске, на котором рейд массив, это приемлемо. В противном случае бекапы лучше утащить куда-нибудь в более стабильное место. Если у вас есть такое стабильное место (например, отдельная помойка или сервер, на котором ничего потенциально деструктивного не происходит, потому что там торчит необновляющийся контент вашего древнего сайта) и туда есть доступ по ssh, то лучше перенести бекапы туда. Иначе тазик накроет вместе с системой и ваши бекапы тоже, и вы ничего не спасете.
Чтобы делать это автоматически, лучше настроить ssh без пассфразы (кому интересно, почитайте про Алису и Боба и RSA, стандартная штука). Хороший и простой гайд, который я периодически навещаю, — тут. Нужно только определиться, где вы будете выполнять скрипт бекапа. Делать это можно как на системе, которую вы бекапите, так и на системе, в которую вы складываете бекап. Для переноса файлов используйте secure copy — scp. После переноса не забудьте удалить файл из системы, которую бекапили, чтобы не захламлять. И будьте осторожны с удалением.
Вот пример скрипта, который бекапит одну из наших удаленных баз. Скрипт запускается по крону на домашнем сервере, выполняя ssh-команды на удаленном сервере.
TIME=`date '+%m-%d-%Y'`
mkdir -p /path/to/your/backups/local/backup-$TIME
ssh sshuser@remote "pg_dump mydb > /etc/postgresql/x.y/backups/backup-$TIME.sql"
scp sshuser@remote:/etc/postgresql/x.y/backups/backup-$TIME.sql /path/to/you/backups/local/backup-$TIME
sleep 2m
ssh rsshuser@remote "rm /etc/postgresql/x.y/backups/backup-$TIME.sql"
Вот пример скрипта, который бекапит одну из наших систем целиком. Скрипт запускается по крону на домашнем сервере, выполняя ssh-команды на удаленном сервере.
#START
# This Command will add date in Backup File Name.
TIME=`date +%b-%d-%y`
# Here i define Backup file name format.
FILENAME=some-system-backup-$TIME.tar.gz
# Backed up folder (system root) location
SRCDIR=/
# Destination of backup file
DESDIR=/home/backups
# exclude folder list
EXCLUDE='--exclude /home/backups --exclude=/another'
# Do not include files on a different filesystem
ONEFSYSPARAM='--one-file-system'
ssh sshuser@remote "tar -cpzf $DESDIR/$FILENAME $EXCLUDE $ONEFSYSPARAM $SRCDIR"
scp sshuser@remote:$DESDIR/$FILENAME /place/backup/here/
ssh sshuser@remote "echo 'WHOLE_SYSTEM_BACKUP is successful: $(date)' >> /home/bash-scripts/cron_log.log"
ssh sshuser@remote "rm $DESDIR/$FILENAME"
#ENDНемного о выборе системы, на которой выполнять скрипт. Я предпочитаю использовать систему, которая хранит бекапы. Во-первых, вы настроите порядок всех бекапов в кроне так, чтобы процессы не мешали друг другу (а системные бекапы жрут много и выполняются долго). Во-вторых, обязательно настраивайте ssh так, чтобы в случае, если система перестанет вам принадлежать, у нее не было безпарольного доступа на ваши сервера. То есть, если помойка всегда будет вашей, настройте безпарольный доступ с нее на условно чужую систему (арендованный сервер), не наоборот.
Ну и наконец не забывайте о порядке. Лучше всего делать бекапы автоматически и так же автоматически их удалять. Закиньте скрипты в крон (crontab -e). Храните не один последний бекап, храните несколько. Пример команды для автоматической чистки, которая удаляет все кроме последних 4 файлов в директории (настоятельно рекомендую прочесть, почему не надо парсить ответ ls и почему эта команда не подходит для бекапов с названиями, содержащими пробел):
DIR=/path/to-your-backups/somesystem/somedate
ls -dt $DIR/* | tail -n +5 | xargs rm -r --
И, конечно же, не забывайте просматривать свои бекапы вручную время от времени. Они могут перестать создаваться — смотрите на даты. Заглядывайте в папки на предмет отсутсвия содержимого. Еще рекомендую чекать размер бекапов. Если бекап три дня назад весил 14 гб, а сегодня 9 гб, при этом вы не помните масштабной чистки в системе, это повод задуматься. Если бекап маленький, можно даже заглянуть внутрь архива.
Я ни разу не восстанавливала систему из архива файлов, не пробовала. Знаю только, что для этого нужен загрузочный диск и физический доступ к серверу) Тут я ничего особо не смогу рассказать. Вероятно, cтоит как-нибудь научиться этому на примере распберри. Статьи, обязательные к прочтению, на эту тему — раз, два, три.
Сервер мы бекапим как раз созданием архива файлов, исключая из него совсем ненужные (файлы помойки, к примеру). Про параметры можно подробно прочесть документацию.
tar -cpzf /destination/directory/filename --exclude /exclude/directory1 --exclude /exclude/directory2 --one-file-system /source/directoryМне эти бекапы нужны в одном случае — когда мои бекапы (то есть бекапы базы данных) утеряны или не существовали никогда (было такое).
Обычные sql дампы разворачиваются очень легко. Надо заметить, что сначала нужно дропнуть остатки старой базы, чтобы не возникло конфликтов. Затем создать ее заново и развернуть в нее дамп:
psql mydb1 < /path/to-your-db-backup/mydb1.sqlЧто касается разворачивания базы из архива, то это можно сделать, надо лишь учесть несколько нюансов. Восстановите данные из /var/lib/postgresql, а настройки из /etc/postgresql (если ваши директории нестандартные — восстанавливайте оттуда). Если настройки утеряны — восстановите вручную, по сути, просто нужно поправить конфиг. Юзеров в моем случае приходится пересоздавать. Все файлы должны иметь соответсвующие настройки доступа (chmod в помощь) и оунером, конечно же, должен быть юзер postgres (поможет команда chown).
Как я уже успела заметить, логирование — это полезно. Поэтому иметь логи бд не помешает.
В постгрес логи настраиваются очень просто, через postgresql.conf в разделе error reporting and logging. Вам просто нужно задать удобные для вас настройки. Лучше всего в таком случае открыть документацию и выбрать нужные настройки. Рекомендую настроить логи по дням, хранить неделю (в документации есть пример того, как это сделать), а дальше в зависмости от уровня паранойи и уровня загрузки базы: можно логировать любые входы, любые запросы, а можно логировать только запросы, которые выполняются долго. Еще можно логировать дедлоки (почитайте про взаимные блокировки). Такие штуки постгрес разруливает сам, но в общем, не забывайте про их существование.
Ну вот и все. Можно еще рассказать немного про юзеров, о том, как их настроить, чтобы не ломали в общем случае ничего. Ну и убийство зомби-коннектов.
Рано или поздно нужно делиться данными и работой с ними с кем-то еще. Приходится создавать новых пользователей в базе (никогда не шарьте одного и того же юзера на всех, потом не узнаете, кто это грохнул все и почему. Один человек = 1 или больше юзеров, 1 юзер = 1 человек). Есть много хороших статей, которые расскажут вам, как все сделать по канону. С группами, наследованием ролей, доступом в конкретную схему или конкретные таблицы. Все это можно сделать, если нужно.
Я расскажу про самый простой вариант, когда мы выдаем доступ на чтение пользователю и ограничиваем его так, чтобы не возникло кошмара. Для этого создаем пользователя без прав создания баз данных, ролей и т.д., ограничиваем количество коннектов к базе, которые он может создать, ограничиваем его по времени выполнения запроса (чтобы он не гонял запросы, которые выполняются по полчаса и роняют базу).
create role somerole nocreaterole nocreateuser nocreatedb noinherit login noreplication connection limit 5 password 'somepassword';
alter role somerole set statement_timeout=30000;
grant select on all tables in schema public to somerole;
Зачастую так бывает, что коннект был создан, но не был закрыт. Такие коннекты продолжают висеть некоторое время, потом постгрес сам их находит и предает праведному огню. Чтобы такие коннекты не плодились почем зря, мы и задали нашему юзеру ограничение по количеству коннектов. Тем не менее, может случиться так, что нужно все-таки вручную запустить чистку зомбаков. Я использую решение отсюда, его можно подредактировать под ваши нужды.
WITH inactive_connections AS (
SELECT
pid,
rank() over (partition by client_addr order by backend_start ASC) as rank
FROM
pg_stat_activity
WHERE
-- Exclude the thread owned connection (ie no auto-kill)
pid <> pg_backend_pid( )
AND
-- Exclude known applications connections
application_name !~ '(?:psql)|(?:pgAdmin.+)'
AND
-- Include connections to the same database the thread is connected to
datname = current_database()
AND
-- Include connections using the same thread username connection
usename = current_user
AND
-- Include inactive connections only
state in ('idle', 'idle in transaction', 'idle in transaction (aborted)', 'disabled')
AND
-- Include old connections (found with the state_change field)
current_timestamp - state_change > interval '5 minutes'
)
SELECT
pg_terminate_backend(pid)
FROM
inactive_connections
WHERE
rank > 1 -- Leave one connection for each application connected to the database
Остается только пожелать удачи и поменьше тазиков =)
|
Метки: author snakers4 серверное администрирование восстановление данных администрирование баз данных *nix postgresql tar администрирование бекапы |
Spark-in.me. Часть 1 — зачем и почему? |
| Список основых фич | Что в итоге с ними стало |
| База, структура |
|
| АПИ, проверки, логирование | Написал сам + взял свой код из прошлых проектов для АПИ |
| Сессии и запоминание юзера PHP, управление юзерами, права сессий | Написал сам + взял свой код из прошлых проектов для АПИ |
| Клиентская часть админки, CMS | Сделал через одно место сам (я ноль в JS и фронтенде) используя свои прошлые наработки и этот фреймворк |
| Шаблон блога | Взял отсюда |
| Морда на react.js | Заказал у этого разработчика . Был на 95% доволен работой. |
Фичи:
|
Все сделал сам сочетанием тулзов
|
| Интеграция с телеграмом |
|
| Комментарии, подписка, аналитика |
|
|
Метки: author snakers4 разработка веб-сайтов анализ и проектирование систем веб-сайт блогосфера разработка сайтов |
Spark-in.me. Часть 2 — Архитектура приложения и структура БД |



{
"key": "very_secret_key",
"method": {
"name": "getTagByAlias",
"version": 1
},
"params": {
"targetId": 2,
"tagAlias": "not-buying-bs",
"getFullArticles": 1
}
}/*
{"params":{"targetId":"integer"}}
*/
function getTagByAlias($params){
/*
Check necessary param consistency
*/
if ( !isset($params['targetId']) ) {
try {
$erLogData = new ErLogData(
'API_INTERNAL_PARAM_TRANSMISSION_ERROR',
57,
get_class($e),
__FILE__,
__CLASS__,
__FUNCTION__,
__LINE__,
date('Y-m-d H:i:s')
);
$erLog = ErLogFactory::create($erLogData, $e);
$response = json_encode(array('response' => array('error' => ['message' => $erLog->_user_message, 'code' => $erlog->_code])), JSON_UNESCAPED_UNICODE);
throw $erLog;
}
catch (ErLog $ee) {
ErLog::full_log_v1($ee);
return $response;
}
}
if ( !isset($params['tagAlias']) ) {
try {
$erLogData = new ErLogData(
'API_INTERNAL_PARAM_TRANSMISSION_ERROR',
57,
get_class($e),
__FILE__,
__CLASS__,
__FUNCTION__,
__LINE__,
date('Y-m-d H:i:s')
);
$erLog = ErLogFactory::create($erLogData, $e);
$response = json_encode(array('response' => array('error' => ['message' => $erLog->_user_message, 'code' => $erlog->_code])), JSON_UNESCAPED_UNICODE);
throw $erLog;
}
catch (ErLog $ee) {
ErLog::full_log_v1($ee);
return $response;
}
}
if ( !isset($params['getFullArticles']) ) {
try {
$erLogData = new ErLogData(
'API_INTERNAL_PARAM_TRANSMISSION_ERROR',
57,
get_class($e),
__FILE__,
__CLASS__,
__FUNCTION__,
__LINE__,
date('Y-m-d H:i:s')
);
$erLog = ErLogFactory::create($erLogData, $e);
$response = json_encode(array('response' => array('error' => ['message' => $erLog->_user_message, 'code' => $erlog->_code])), JSON_UNESCAPED_UNICODE);
throw $erLog;
}
catch (ErLog $ee) {
ErLog::full_log_v1($ee);
return $response;
}
}
if ($params['tagAlias']=='all-tags') {
$whereClause = '';
} else {
$params['tagAlias'] = "'" . $params['tagAlias'] . "'";
$whereClause = 'AND at.alias =' . $params['tagAlias'];
}
if ($params['getFullArticles']==0) {
$fullClause = '';
} else {
$fullClause = '
,article.creation_date as created,
article.html_text as content,
article.main_picture as main_picture,
article.feed_picture as feed_picture,
article.title as title,
article.subtitle as subtitle,
article."alias" as "slug",
article.creation_date as published,
article.author_id as author_id
';
}
/*
Language - setting param by default
*/
if (!isset($params['language']) ) {
$params['language'] = 1;
}
if ( !is_int($params['language']) ) {
try {
$erLogData = new ErLogData(
'LANGUAGE IS NOT INT',
58,
get_class($e),
__FILE__,
__CLASS__,
__FUNCTION__,
__LINE__,
date('Y-m-d H:i:s')
);
$erLog = ErLogFactory::create($erLogData, $e);
$response = json_encode(array('response' => array('error' => ['message' => $erLog->_user_message, 'code' => $erlog->_code])), JSON_UNESCAPED_UNICODE);
throw $erLog;
}
catch (ErLog $ee) {
ErLog::full_log_v1($ee);
return $response;
}
}
if (is_file('../Credentials/db_credentials.php')){
include '../Credentials/db_credentials.php';
}
else {
exit("No ../Credentials/db_credentials.php credentials available");
}
$credentials =
[
'host' => $host,
'db' => $db,
'user' => $user,
'pass' => $pass,
];
/*
Create a new article
*/
try {
$queryString =
"
SELECT
to_json((a)) as tag_info
FROM
(
SELECT
to_json(\"array_agg\"(b)) as tag_data,
(SELECT publication_targets.title FROM publication_targets WHERE publication_targets.\"id\" = ".$params['targetId'].") as publication_target_title,
(SELECT publication_targets.\"id\" FROM publication_targets WHERE publication_targets.\"id\" = ".$params['targetId'].") as publication_target_id
FROM
(
SELECT
raw_data.*,
(SELECT to_json(array_agg(f)) FROM (
SELECT
article_list.*,
(SELECT to_json(array_agg(e)) FROM (
SELECT
author.\"id\" as author_id,
author.alias as author_alias,
author.contact_json as author_contacts,
author.description as author_description,
author.header_picture as main_picture
FROM
author
WHERE
author.\"id\" = article_list.article_author_id
) e) as author_info
FROM
(
SELECT DISTINCT
article.\"id\" as article_id,
article.author_id as article_author_id
".$fullClause."
FROM
article_tags
JOIN article_publication ON article_tags.\"id\" = raw_data.tag_id AND article_tags.\"id\" = article_publication.tag_id AND article_publication.is_actual = 't' AND article_publication.language_id = ".$params['language']."
JOIN article ON article.\"id\" = article_publication.article_id
) as article_list
) f) as article_list,
(
SELECT
count(article.\"id\") as article_count
FROM
article_tags
JOIN article_publication ON article_tags.\"id\" = raw_data.tag_id AND article_tags.\"id\" = article_publication.tag_id AND article_publication.is_actual = 't' AND article_publication.language_id = ".$params['language']."
JOIN article ON article.\"id\" = article_publication.article_id
) as article_count,
(SELECT to_json(array_agg(f)) FROM (
SELECT DISTINCT
article.author_id as author_id,
author.alias as author_alias,
author.contact_json::TEXT as author_contacts,
author.description as author_description,
author.header_picture as main_picture
FROM
article_tags
JOIN article_publication ON article_tags.\"id\" = raw_data.tag_id AND article_tags.\"id\" = article_publication.tag_id AND article_publication.is_actual = 't' AND article_publication.language_id = ".$params['language']."
JOIN article ON article.\"id\" = article_publication.article_id
JOIN author ON author.id = article.author_id
) f) as author_list,
array_to_json(
array[
json_build_object (
'type',
'rel',
'key',
'canonical',
'content',
'spark-in.me/tag/'||raw_data.tag_alias
),
json_build_object (
'type',
'name',
'key',
'title',
'content',
raw_data.tag_title
),
json_build_object (
'type',
'name',
'key',
'description',
'content',
raw_data.tag_description
),
json_build_object (
'type',
'property',
'key',
'og:site_name',
'content',
'Spark in me'
),
json_build_object (
'type',
'property',
'key',
'og:title',
'content',
raw_data.tag_title
),
json_build_object (
'type',
'property',
'key',
'og:url',
'content',
'spark-in.me/tag/'||raw_data.tag_alias
),
json_build_object (
'type',
'property',
'key',
'og:description',
'content',
raw_data.tag_description
)
]
) as tag_meta
FROM
(
SELECT DISTINCT
\"at\".\"id\" as tag_id,
at.\"alias\" as tag_alias,
at.title as tag_title,
at.header_picture as main_picture,
at.description as tag_description,
att.title as att_title,
att.colour as att_colour,
att.description as att_description,
att.sort_order as att_sort_order
FROM
article_tags at
JOIN article_tag_types att ON at.tag_type_id = att.id
JOIN article_publication ap ON at.\"id\" = ap.tag_id AND ap.language_id = ".$params['language']."
JOIN publication_targets pt ON pt.\"id\" = ap.target_id
WHERE 1=1
AND pt.\"id\" = ".$params['targetId']."
".$whereClause."
) raw_data
ORDER BY
7 DESC
) b
) a
";
} catch (Exception $e){
try {
$erLogData = new ErLogData(
'API_QUERY_CONSTRUCTION_ERROR',
59,
get_class($e),
__FILE__,
__CLASS__,
__FUNCTION__,
__LINE__,
date('Y-m-d H:i:s')
);
$erLog = ErLogFactory::create($erLogData, $e);
$response = json_encode(array('response' => array('error' => ['message' => $erLog->_user_message, 'code' => $erlog->_code])), JSON_UNESCAPED_UNICODE);
throw $erLog;
}
catch (ErLog $ee) {
ErLog::full_log_v1($ee);
return $response;
}
}
$result = queryWrapper ($credentials, $queryString);
return $result;
} 
if (!$dbconn) {
$errorString = $appName . "\r\n". date('m/d/Y h:i:s a', time()) . "\r\n". $credentials['db'] . "\r\n". $queryString . "\r\n". implode(",", $queryParamArray);
error_log($errorString, 1, "aveysov@gmail.com");
$ret = file_put_contents('offline-errors.log', $errorString);
die('Could not connect (logged)');
} else {
/*
Continue executing code
*/
}

|
Метки: author snakers4 разработка веб-сайтов анализ и проектирование систем postgresql php веб-сайт react.js |
Spark-in.me. Часть 3 — DIY поддержка и админство сайта |

# installation of the key software
sudo apt-get update
# server monitoring tool
sudo apt-get install glances
# just invoke glances to monitor the system

# postgresql
# installing contrib version via ppa
sudo apt-get install postgresql postgresql-contrib
# installing apache2
sudo apt-get install apache2
# checking syntax of apache2 config files
sudo apache2ctl configtest
sudo systemctl status apache2
# restarting apache2
sudo systemctl restart apache2
# apache2 specific mods
sudo a2enmod proxy # for reverse proxy
# checking ufw
sudo ufw app list
# disable apache2 directory listing mod
sudo a2dismod autoindex -f
# install php
# https://www.digitalocean.com/community/tutorials/how-to-install-linux-apache-mysql-php-lamp-stack-on-ubuntu-16-04
sudo apt-get install php libapache2-mod-php php-mcrypt
# install postgresql driver
sudo apt-get install php-pgsql
# install curl
sudo apt-get install php-curl
# locate the php.ini file ans set
# memory to 256m, time to 60s and error reporting to on
# installing node js and npm
sudo apt-get install nodejs
# this actually installs node 4.3
# do this to install 6.9+
wget -qO- https://deb.nodesource.com/setup_7.x | sudo bash -
sudo apt-get install -y nodejs
sudo apt-get install npm
# install yarn
# https://yarnpkg.com/lang/en/docs/install/#linux-tab
curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
echo "deb https://dl.yarnpkg.com/debian/ stable main" | sudo tee /etc/apt/sources.list.d/yarn.list
sudo apt-get update && sudo apt-get install yarn
# disable the apache2 default conf
sudo a2dissite 000-default.conf
sudo systemctl restart apache2
# vsftpd installation and config
sudo apt-get install vsftpd
sudo cp /etc/vsftpd.conf /etc/vsftpd.conf.original
sudo nano /etc/vsftpd.conf
# key changes
# uncomment local_umask=022
# local_enable=YES
# write_enable=YES
# anonymous_enable=NO
# chroot_local_user=YES
sudo adduser spark-in-me
sudo chown spark-in-me:spark-in-me /var/www/spark-in-me/
sudo usermod -d /var/www/spark-in-me spark-in-me
sudo chmod a-w /var/www/spark-in-me
sudo service vsftpd restart
chown spark-in-me:spark-in-me /var/www/spark-in-me/blog/
chown spark-in-me:spark-in-me /var/www/spark-in-me/admin/
# after this commands vsftpd should start properly working
# crontab setup and usage
crontab -e
# CRONTAB CONTENTS START HERE
# Borrowed from anacron
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=aveysov@gmail.com
#End borrowed from anacron
# 0 1 * * * /home/snakers41/bash-scripts/WHOLE_SYSTEM_BACKUP.sh
# CRONTAB CONTENTS END HERE
# backups
# plain backup script
mkdir /home/bash-scripts
mkdir /media/backups
sudo nano /home/bash-scripts/WHOLE-SYSTEM-BACKUP.sh
# SCRIPT STARTS HERE
# http://help.ubuntu.ru/wiki/backup#восстановление_из_архива
#/bin/bash
#Purpose = Whole system backup
#Created on 25-08-2016
#Last modified on 29-08-2016
#Author = aveysov@gmail.com
#Version 1.1
#START
# This Command will add date in Backup File Name.
TIME=`date +%b-%d-%y`
# Here i define Backup file name format.
FILENAME=test-system-backup-$TIME.tar.gz
# Backed up folder (system root) location
SRCDIR=/
# Destination of backup file
DESDIR=/media/backups
# exclude folder list
EXCLUDE='--exclude=/media/server --exclude=/media/ext_storage --exclude=/media --exclude=/proc --exclude=/lost+found --exclude=/backup.tgz --exclude=/mnt --exclude=/sys'
# Do not include files on a different filesystem
ONEFSYSPARAM='--one-file-system'
# test command validity
# echo -e tar -cvpzf $DESDIR/$FILENAME $EXCLUDE $ONEFSYSPARAM $SRCDIR
sudo tar -cpzf $DESDIR/$FILENAME $EXCLUDE $ONEFSYSPARAM $SRCDIR
echo "WHOLE_SYSTEM_BACKUP is successful: $(date)" >> /home/bash-scripts/cron_log.log
#END
# SCRIPT ENDS HERE
# email alerts set-up - useful for cron
sudo apt-get install ssmtp
# START CONFIG
# Config file for sSMTP sendmail
# The person who gets all mail for userids < 1000
# Make this empty to disable rewriting.
# root=postmaster
root=gmail-addresscom
# The place where the mail goes. The actual machine name is required no
# MX records are consulted. Commonly mailhosts are named mail.domain.com
# mailhub=mail
mailhub=smtp.gmail.com:587
AuthUser=gmail-addresscom
AuthPass=your_pass
UseTLS=YES
UseSTARTTLS=YES
# Where will the mail seem to come from?
rewriteDomain=gmail.com
# The full hostname
# hostname=snakers41-ubuntu
hostname=localhost
# Are users allowed to set their own From: address?
# YES - Allow the user to specify their own From: address
# NO - Use the system generated From: address
FromLineOverride=YES
# END CONFIG
# IMPORTANT - turn on less secure apps in google account settings
# https://support.google.com/accounts/answer/6010255
# test email
# echo "Test message from Linux server using ssmtp" | sudo ssmtp -vvv destination-email-address@some-domain.com
# database setup
#
mkdir -p /etc/postgresql/dumps
root@ubuntu-512mb-fra1-01:~# scp -P 8023 snakers41@77.37.164.97:'/media/server/04_BACKUP/localdbrestore/03-20-2017/news.sql' /etc/postgresql/dumps
root@ubuntu-512mb-fra1-01:~# passwd postgres
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
root@ubuntu-512mb-fra1-01:~# su postgres
postgres@ubuntu-512mb-fra1-01:/root$ psql
could not change directory to "/root": Permission denied
psql (9.5.6)
Type "help" for help.
postgres=# create database news
postgres-# ;
CREATE DATABASE
postgres=# create role aveysov login superuser password 'yourpassword';
postgres=# \q
postgres@ubuntu-512mb-fra1-01:/root$ psql news < /etc/postgresql/dumps/news.sql
postgres@ubuntu-512mb-fra1-01:/root$ nano /etc/postgresql/9.5/main/postgresql.conf
#?????? ???????? ??: listen_addresses = *
postgres@ubuntu-512mb-fra1-01:/root$ nano /etc/postgresql/9.5/main/pg_hba.conf
#?????? ???????? ??????
#host news aveysov 0.0.0.0/0 md5
postgres@ubuntu-512mb-fra1-01:/root$ exit
exit
root@ubuntu-512mb-fra1-01:~# service postgresql restart
Доступ к репозиторию делается через SSH-ключ.
# redeploy script
rm -rf /var/www/spark-in-me/blog/*
rm -rf /var/www/spark-in-me/blog/.*
eval $(ssh-agent -s)
ssh-add ~/.ssh/git
cd /var/www/spark-in-me/blog
git clone git@github.com:snakers4/spark-in-me-vds .
sudo yarn install
sudo yarn run build --release
touch /var/www/spark-in-me/blog/build/public/sitemap.xml
touch /var/www/spark-in-me/blog/build/public/main.rss
chmod 777 /var/www/spark-in-me/blog/build/public/sitemap.xml
chmod 777 /var/www/spark-in-me/blog/build/public/robots.txt
chmod 777 /var/www/spark-in-me/blog/build/public/main.rss
echo "# www.robotstxt.org/
Sitemap: http://www.spark-in.me/sitemap.xml
# Allow crawling of all content
User-agent: *
Disallow:" > /var/www/spark-in-me/blog/build/public/robots.txt
php /var/www/spark-in-me/admin/Api/Rss/rssMakerBash.php
#/bin/bash
#Purpose = Start node js webserver via yarn
#Created on 21-03-2017
#Last modified on 21-03-2017
#Author = aveysov@gmail.com
#Version 1.1
#START
# This Command will add date in Backup File Name.
cd /var/www/spark-in-me/blog/build
yarn start
#END
|
Метки: author snakers4 восстановление данных администрирование доменных имен администрирование баз данных devops *nix ubuntu postgresql bash php cron vsftpd веб-сайт |
Spark-in.me. Часть 5 — переход на HTTPS |


$ sudo apt-get install software-properties-common
$ sudo add-apt-repository ppa:certbot/certbot
$ sudo apt-get update
$ sudo apt-get install python-certbot-nginx
$ sudo certbot --nginx# http://nginx.org/en/docs/varindex.html
# https://serverfault.com/questions/638097/passing-ssl-protocol-info-to-backend-via-http-header
# https://serverfault.com/questions/213185/how-to-restart-nginx
# https://serverfault.com/questions/527780/nginx-detect-https-connection-using-a-header
# https://stackoverflow.com/questions/17483641/nginx-to-node-js-pass-params
server {
listen 80;
server_name spark-in.me www.spark-in.me;
root /var/www/spark-in-me/blog;
location / {
proxy_pass http://127.0.0.1:3000;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
proxy_set_header X_SPARK_SSL 0;
}
location ~ /\.(ht|git) {
deny all;
}
}
server {
listen 443 ssl; # managed by Certbot
server_name spark-in.me www.spark-in.me;
ssl_certificate /etc/letsencrypt/live/spark-in.me/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/spark-in.me/privkey.pem; # managed by Certbot
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
root /var/www/spark-in-me/blog;
location / {
proxy_pass http://127.0.0.1:3000;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
proxy_set_header X_SPARK_SSL 1;
}
location ~ /\.(ht|git) {
deny all;
}
}
/*Protections against CSRF attacks*/
if ("POST" == $_SERVER["REQUEST_METHOD"]) {
if (isset($_SERVER["HTTP_ORIGIN"])) {
$http_origin = $_SERVER['HTTP_ORIGIN'];
$address = "http://".$_SERVER["SERVER_NAME"];
/*
Uncomment the protection bit during deploy
if (strpos($address, $_SERVER["HTTP_ORIGIN"]) !== 0) {
exit("CSRF protection in POST request: detected invalid Origin header: ".$_SERVER["HTTP_ORIGIN"]);
}
*/
} else {
if(!isset($http_origin)) {
$http_origin = '';
}
}
}
/*Headers for modern http-request libraries*/
if (
$http_origin == "http://spark-in.me"
|| $http_origin == "http://api.spark-in.me"
|| $http_origin == "http://admin.spark-in.me"
|| $http_origin == "http://pics.spark-in.me"
|| $http_origin == "http://author.spark-in.me"
|| $http_origin == "https://spark-in.me"
|| $http_origin == "https://api.spark-in.me"
|| $http_origin == "https://admin.spark-in.me"
|| $http_origin == "https://pics.spark-in.me"
|| $http_origin == "https://author.spark-in.me"
|| $http_origin == "http://www.spark-in.me"
|| $http_origin == "http://www.api.spark-in.me"
|| $http_origin == "http://www.admin.spark-in.me"
|| $http_origin == "http://www.pics.spark-in.me"
|| $http_origin == "http://www.author.spark-in.me"
|| $http_origin == "https://www.spark-in.me"
|| $http_origin == "https://www.api.spark-in.me"
|| $http_origin == "https://www.admin.spark-in.me"
|| $http_origin == "https://www.pics.spark-in.me"
|| $http_origin == "https://www.author.spark-in.me"
) {
header("Access-Control-Allow-Origin: $http_origin");
}
else {
// Do nothing
}
header("Access-Control-Allow-Headers: X-Requested-With");UPDATE file SET host = replace(host, 'https://pics.spark-in.me/', 'https://pics.spark-in.me/')return 301 https://$server_name$request_uri;
|
Метки: author snakers4 серверное администрирование настройка linux nginx *nix https certbot google search console seo php |
Быстрый анализ сайтов конкурентов через сайтмапы. Часть 1 — парсинг |


from __future__ import print_function
import os.path
from collections import defaultdict
import string
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
from sklearn.feature_extraction.text import CountVectorizer
import wordcloud
%matplotlib inline

sitemap_list = [
{'url': 'https://www.ig.com/sitemap.xml', 'recursive': 1},
{'url': 'https://www.home.saxo/sitemap.xml', 'recursive': 0},
{'url': 'https://www.fxcm.com/sitemap.xml', 'recursive': 1},
{'url': 'https://www.icmarkets.com/sitemap_index.xml', 'recursive': 1},
{'url': 'https://www.cmcmarkets.com/en/sitemap.xml', 'recursive': 0},
{'url': 'https://www.oanda.com/sitemap.xml', 'recursive': 0},
{'url': 'http://www.fxpro.co.uk/en_sitemap.xml', 'recursive': 0},
{'url': 'https://en.swissquote.com/sitemap.xml', 'recursive': 0},
{'url': 'https://admiralmarkets.com/sitemap.xml', 'recursive': 0},
{'url': 'https://www.xtb.com/sitemap.xml', 'recursive': 1},
{'url': 'https://www.ufx.com/en-GB/sitemap.xml', 'recursive': 0},
{'url': 'https://www.markets.com/sitemap.xml', 'recursive': 0},
{'url': 'https://www.fxclub.org/sitemap.xml', 'recursive': 1},
{'url': 'https://www.teletrade.eu/sitemap.xml', 'recursive': 1},
{'url': 'https://bmfn.com/sitemap.xml', 'recursive': 0},
{'url': 'https://www.thinkmarkets.com/en/sitemap.xml', 'recursive': 0},
{'url': 'https://www.etoro.com/sitemap.xml', 'recursive': 1},
{'url': 'https://www.activtrades.com/en/sitemap_index.xml', 'recursive': 1},
{'url': 'http://www.fxprimus.com/sitemap.xml', 'recursive': 0}
]
from fake_useragent import UserAgent
ua = UserAgent()
headers = ua.chrome
headers = {'User-Agent': headers}
result = requests.get(sitemap_list[3]['url'])
c = result.content
c = c.decode("utf-8-sig")
c'\n\n\t\n\t\thttps://www.icmarkets.com/post-sitemap.xml \n\t\t2016-12-16T07:13:32-01:00 \n\t \n\t\n\t\thttps://www.icmarkets.com/page-sitemap.xml \n\t\t2017-06-20T07:11:01+00:00 \n\t \n\t\n\t\thttps://www.icmarkets.com/attachment-sitemap1.xml \n\t\t2014-07-01T15:44:46+00:00 \n\t \n\t\n\t\thttps://www.icmarkets.com/attachment-sitemap2.xml \n\t\t2014-10-29T02:36:07-01:00 \n\t \n\t\n\t\thttps://www.icmarkets.com/attachment-sitemap3.xml \n\t\t2015-03-15T18:41:51-01:00 \n\t \n\t\n\t\thttps://www.icmarkets.com/attachment-sitemap4.xml \n\t\t2017-05-30T12:33:34+00:00 \n\t \n\t\n\t\thttps://www.icmarkets.com/category-sitemap.xml \n\t\t2016-12-16T07:13:32-01:00 \n\t \n\t\n\t\thttps://www.icmarkets.com/post_tag-sitemap.xml \n\t\t2014-03-27T01:14:54-01:00 \n\t \n\t\n\t\thttps://www.icmarkets.com/csscategory-sitemap.xml \n\t\t2013-06-11T00:02:10+00:00 \n\t \n\t\n\t\thttps://www.icmarkets.com/author-sitemap.xml \n\t\t2017-05-05T06:44:19+00:00 \n\t \n \n'# xml tree parsing
import xml.etree.ElementTree as ET
def xml2df(xml_data):
root = ET.XML(xml_data) # element tree
all_records = []
for i, child in enumerate(root):
record = {}
for subchild in child:
record[subchild.tag] = subchild.text
all_records.append(record)
return pd.DataFrame(all_records)end_sitemap_list = []
for sitemap in log_progress(sitemap_list, every=1):
if(sitemap['recursive']==1):
try:
result = requests.get(sitemap['url'], headers=headers)
c = result.content
c = c.decode("utf-8-sig")
df = xml2df(c)
end_sitemap_list.extend(list(df['{http://www.sitemaps.org/schemas/sitemap/0.9}loc'].values))
except:
print(sitemap)
else:
end_sitemap_list.extend([sitemap['url']])
result_df = pd.DataFrame(columns=['changefreq','loc','priority'])
for sitemap in log_progress(end_sitemap_list, every=1):
result = requests.get(sitemap, headers=headers)
c = result.content
try:
c = c.decode("utf-8-sig")
df = xml2df(c)
columns = [
'{http://www.sitemaps.org/schemas/sitemap/0.9}changefreq',
'{http://www.sitemaps.org/schemas/sitemap/0.9}loc',
'{http://www.sitemaps.org/schemas/sitemap/0.9}priority'
]
try:
df2 = df[columns]
df2['source'] = sitemap
df2.columns = ['changefreq','loc','priority','source']
except:
df2['loc'] = df['{http://www.sitemaps.org/schemas/sitemap/0.9}loc']
df2['changefreq'] = ''
df2['priority'] = ''
df2['source'] = sitemap
result_df = result_df.append(df2)
except:
print(sitemap)
|
|
Z-order в 8D |
|
Метки: author zzeng алгоритмы postgresql open source spatial index zorder субд olap olap- кубы |
Phoenix Framework – Webpack вместо Brunch, деплой с помощью Distillery и немного systemd |

Эта статья является попыткой автора свести воедино в виде небольшого руководства несколько тем, с которыми, так или иначе, сталкиваются практически все разработчики веб-приложений, а именно – работа со статическими файлами, конфигурациями и доставкой приложений на сервер. На момент написания этого текста, последней стабильной веткой Phoenix Framework была ветка 1.2.х.
Кому интересно, почему не Brunch и как совместить миграции с Distillery – прошу под кат.
Phoenix для работы с JS-кодом и ассетами по-умолчанию использует Brunch – возможно, очень простой и быстрый бандлер, но уж точно не самый распространенный и не самый мощный по возможностям и размеру экосистемы (и ответам на StackOverflow, конечно же). Поэтому и произошла замена Brunch на Webpack, де-факто – бандлер номер один в текущем мире фронт-энда.
А вот для решения вопросов деплоя, фреймворк не предоставляет практически ничего, кроме возможности подложить разные конфигурации для разных окружений. Судя по ответам разных разработчиков на форумах и прочих площадках, многие из них разворачивают свои приложения путем установки инструментов разработки прямо на боевом сервере и компилируя и запуская приложение с помощью Mix. По ряду причин, считаю такой подход неприемлемым, потому, перепробовав несколько вариантов упаковки приложения в self-contained пакет, я остановился на Distillery.
Т.к. статья является туториалом, то в качестве примера будет разработано абсолютно ненужное приложение, отображающее некий список неких пользователей. Весь код доступен на GitHub, каждый шаг зафиксирован в виде отдельного коммита, потому рекомендую смотреть историю изменений. Также, я буду давать ссылки на коммиты на определенных шагах, чтобы, с одной стороны, хорошо было видно по diff'у, какие изменения были сделаны, а с другой – чтобы не загромождать текст листингами.
Итак, создадим шаблон нашего проекта, с указанием того, что Brunch мы использовать не будем:
$ mix phoenix.new userlist --no-brunchТут ничего интересного не происходит. Надо зайти внутрь нового проекта, поправить настройки базы данных в файле config/dev.exs, запустить создание репозитория Ecto и миграций (коммит):
$ mix ecto.create && mix ecto.migrateДля того, чтобы сделать пример хоть немного нагляднее, я добавил модель сущности User, содержащую два поля – имя и бинарный признак, активен ли пользователь или нет (коммит):
$ mix phoenix.gen.model User users name active:booleanДалее, чтобы наполнить БД хоть какими-то данными, я добавил три экземпляра "пользователей" в файл priv/repo/seeds.exs, который и служит для таких целей. После этого можно выполнить миграцию и вставить данные в БД:
$ mix ecto.migrate && mix run priv/repo/seeds.exsТеперь у нас есть миграция в priv/repo/migrations/ – она нам пригодится в дальнейшем, а пока, надо еще добавить http API, по которому приложение сможет забрать список пользователей в формате JSON-объекта (коммит). Не буду загромождать текст листингами, diff на ГитХабе будет более нагляден, скажу лишь, что был добавлен контроллер, вью и изменен роутинг так, что у нас появилась "http-ручка" по пути /api/users, которая будет возвращать JSON с пользователями.
На этом все с приготовлениями, и на данном этапе приложение можно запустить командой
$ mix phoenix.serverи убедится, что все работает, как задумано.
Теперь обратим внимание на структуру каталогов проекта, а именно, на два из них – priv/static/ и web/static/. В первом из них уже лежат файлы, которые нужны для отображения фениксовской "Hello, World!" страницы, и именно этот каталог используется приложением, когда оно запущенно, для отдачи статических файлов. Второй каталог, web/static/, по-умолчанию задействован при разработке, и Brunch (в проектах с ним), грубо говоря, перекладывает файлы из него в priv/static, попутно обрабатывая их (статья в официальной документации об этом).
Оба вышеозначенных каталога находятся под управлением системы контроля версий, в оба из них можно добавлять файлы, вот только если вы добавите файлы сразу в priv/static/, то Brunch'ем они обработаны не будут, а если в web/static/, то будут, но если вы положите файл в web/static/assets/, то снова не будут… Мне кажется, что тут что-то пошло не так, потому я предлагаю более строгий подход, а именно:
Итак, следующим шагом я почистил priv/static от ненужных файлов, а robots.txt и favicon.ico перенес в web/static/ – вернемся к ним позже. Также, почистил html разметку главной страницы и ее шаблона (коммит).
Перед тем, как добавлять Webpack, надо инициализировать сам NPM:
$ npm initПолучившийся package.json я почистил, оставив в нем только самое главное (коммит):
{
"name": "userlist",
"version": "1.0.0",
"description": "Phoenix example application",
"scripts": {
},
"license": "MIT"
}И после этого добавляем сам Webpack (коммит):
$ npm install --save-dev webpackТеперь давайте добавим какой-то минимально возможный JS код к проекту, например, такой:
console.log("App js loaded.");Для JS-файлов я создал каталог web/js/, куда и положил файл app.js с кодом выше. Подключим его в шаблоне web/templates/layout/app.html.eex, вставив перед закрывающим тегом :
js/app.js") %>">Очень важно использовать макрос static_path, иначе вы потеряете возможность загружать ресурсы с digest-меткой, что приведет к проблемам с инвалидацией кешей у клиентов и вообще, так не по правилам.
Создаем конфигурацию Webpack'а – файл webpack.config.js в корне проекта:
module.exports = {
entry: __dirname + "/web/js/app.js",
output: {
path: __dirname + "/priv/static",
filename: "js/app.js"
}
};Из кода видно, что результирующий файл app.js будет находится в каталоге priv/static/js/ как и задумывалось. На данном этапе можно запустить Webpack вручную, но это не очень удобно, так что добавим автоматизации, благо фреймворк это позволяет. Первое, что надо сделать, это добавить шорткат watch в секцию scripts файла package.json:
"scripts": {
"watch": "webpack --watch-stdin --progress --color"
},Теперь Webpack можно запускать командой
$ npm run watchНо и этого делать не надо, пускай этим занимается Phoenix, тем более, что у эндпоинта вашего приложения есть опция watchers, как раз и предназначенная для запуска подобных внешних утилит. Изменим файл config/dev.exs, добавив вызов npm:
watchers: [npm: ["run", "watch"]]После этого, Webpack в режиме слежения за изменениями в каталогах и файлах будет запускаться каждый раз вместе с основным приложением командой
$ mix phoenix.serverКоммит со всеми вышеозначенными изменениями тут.
C JS кодом немного разобрались, но еще остаются файлы в web/static/. Задачу по их копированию я тоже возложил на Webpack, добавив в него расширение copy:
$ npm install --save-dev copy-webpack-pluginСконфигурируем плагин в в файле webpack.config.js(коммит):
var CopyWebpackPlugin = require("copy-webpack-plugin");
module.exports = {
entry: __dirname + "/web/js/app.js",
output: {
path: __dirname + "/priv/static",
filename: "js/app.js"
},
plugins: [
new CopyWebpackPlugin([{ from: __dirname + "/web/static" }])
]
};После данных манипуляций, наш каталог priv/static/ начнет наполнятся двумя пайплайнами – обработанным JS и статическими файлами, не требующих таковой. В довершение данного этапа, я добавил отображение списка пользователей с помощью JS (коммит), визуальным стилем для неактивных пользователей (коммит) и картинкой-логотипом для пущей наглядности работы пайплайна (коммит).
Может возникнуть вопрос – что делать, если надо производить пред-обработку, например, CSS. Ответ банален – выносить CSS в отдельный каталог, добавлять в Webpack соответствующие плагины и настраивать пайплайн, аналогичный используемому для JS. Либо использовать css-loader'ы, но это отдельная история.
Distillery это второй заход автора Exrm в попытке сделать хороший инструмент для пакетирования и создания релизных пакетов для проектов на Elixir. Ошибки первого были учтены, многое исправлено, пользоваться Distillery удобно. Добавим его в проект, указав как зависимость в mix.exs:
{:distillery, "~> 1.4"}Обновим зависимости и создадим шаблон релизной конфигурации (коммит):
$ mix deps.get && mix release.initПоследняя команда создаст файл rel/config.exs примерно такого содержания:
Path.join(["rel", "plugins", "*.exs"])
|> Path.wildcard()
|> Enum.map(&Code.eval_file(&1))
use Mix.Releases.Config,
# This sets the default release built by `mix release`
default_release: :default,
# This sets the default environment used by `mix release`
default_environment: Mix.env()
environment :dev do
set dev_mode: true
set include_erts: false
set cookie: :"Mp@oK==RSu$@QW.`F9(oYks&xDCzAWCpS*?jkSC?Zo{p5m9Qq!pKD8!;Cl~gTC?k"
end
environment :prod do
set include_erts: true
set include_src: false
set cookie: :"/s[5Vq9hW(*IA>grelN4p*NjBHTH~[gfl;vD;:kc}qAShL$MtAI1es!VzyYFcC%p"
end
release :userlist do
set version: current_version(:userlist)
set applications: [
:runtime_tools
]
endПредлагаю оставить его пока таким, как он есть. Указанного в конфигурации вполне достаточно: один релиз :userlist, он же :default, т.к. первый и единственный в списке релизов, а так же два окружения :dev и :prod. Под релизом здесь понимается OTP Release – набор приложений, который войдет в результирующий пакет, версию ERTS. В данном случае, наш релиз соответствует приложению :userlist, чего нам достаточно. Но, мы можем иметь несколько релизов и несколько окружений и комбинировать их по необходимости.
Distillery расширяется с помощью плагинов, так что можно организовать любой дополнительный пайплайн при сборке. Больше о плагинах тут.
Подготовим приложение к релизу. В первую очередь, надо отредактировать файл config/prod.secret.exs, поправим в нем настройки БД. Этот файл не добавляется в VCS, потому, в случае его отсутствия, его надо создать самому с примерно следующий содержанием:
use Mix.Config
config :userlist, Userlist.Endpoint,
secret_key_base: "uE1oi7t7E/mH1OWo/vpYf0JLqwnBa7bTztVPZvEarv9VTbPMALRnqXKykzaESfMo"
# Configure your database
config :userlist, Userlist.Repo,
adapter: Ecto.Adapters.Postgres,
username: "phoenix",
password: "",
database: "userlist_prod",
pool_size: 20Следующим важным этапом будет поправить конфигурацию Userlist.Endpoint в файле config/prod.exs. Прежде всего, заменить хост на нужный, а порт с 80 на читаемый из окружения параметр PORT и добавить важнейшую опцию server, которая является признаком того, что именно этот эндпоинт запустит Cowboy:
url: [host: "localhost", port: {:system, "PORT"}],
...
server: trueДалее, я добавил Babel к пайплайну обработки JS кода, т.к. UglifyJS, используемый по-умолчанию в Webpack, не обучен обращению с ES6:
$ npm install --save-dev babel-loader babel-core babel-preset-es2015И секция настройки Babel в webpack.config.js после plugins:
module: {
loaders: [
{
test: /\.js$/,
exclude: /node_modules/,
loader: "babel-loader",
query: {
presets: ["es2015"]
}
}
]
}И последнее – добавляем шорткат deploy в конфигурацию NPM (коммит):
"scripts": {
"watch": "webpack --watch-stdin --progress --color",
"deploy": "webpack -p"
},На данном этапе можно попробовать собрать и запустить релиз:
$ npm run deploy
$ MIX_ENV=prod mix phoenix.digest
$ MIX_ENV=prod mix release
$ PORT=8080 _build/prod/rel/userlist/bin/userlist consoleПервой командой мы подготавливаем JS (минификация и т.п.), копируем static-файлы; вторая генерирует для всех файлов дайджест; третья непосредственно собирает релиз для соответствующего окружения. Ну и в конце – запуск приложения в интерактивном режиме, с консолью.
После релиза в каталоге _build будет находится распакованная (exploded) версия пакета, а архив будет лежать по пути _build/prod/rel/userlist/releases/0.0.1/userlist.tar.gz.
Приложение запустится, но при попытке получить список пользователей будет вызвана ошибка, т.к. миграции для этой БД мы не применили. В документации к Distillery этот момент описан, я же немного упростил его.
После сборки, исполняемый файл приложения предоставляет нам одну из опций, которая называется command:
command [] # execute the given MFA Это очень похоже на rpc, с разницей в том, что command выполнится и на не запущенном приложении – что нам и надо. Создадим модуль с функцией миграции, помня о том, что приложение запущенно не будет. Я разместил этот файл по пути lib/userlist/release_tasks.ex (коммит):
defmodule Release.Tasks do
alias Userlist.Repo
def migrate do
Application.load(:userlist)
{:ok, _} = Application.ensure_all_started(:ecto)
{:ok, _} = Repo.__adapter__.ensure_all_started(Repo, :temporary)
{:ok, _} = Repo.start_link(pool_size: 1)
path = Application.app_dir(:userlist, "priv/repo/migrations")
Ecto.Migrator.run(Repo, path, :up, all: true)
:init.stop()
end
endКак видно из кода, мы загружаем, а потом запускаем не все приложения, а ровно необходимые – в данном случае, это только Ecto. Теперь все, что осталось, это пересобрать релиз (только Elixir, т.к. остальное не менялось):
$ MIX_ENV=prod mix releaseзапустить миграции:
$ _build/prod/rel/userlist/bin/userlist command 'Elixir.Release.Tasks' migrateи запустить приложение:
$ PORT=8080 _build/prod/rel/userlist/bin/userlist consoleВот, собственно, и все, но осталась еще пара мелочей. Например, запускать миграции таким способом, указывая полное имя модуля, функцию, не очень удобно. Для этого Distillery предоставляет хуки и команды (теперь другие).
Концепция хуков и команд проста – это обычные shell-скрипты, которые вызываются на определенном этапе жизни приложения (хуки), либо вручную (команды) и которые являются расширением главного исполняемого boot-скрипта. Хуки могут быть четырех видов: pre/post_start и pre/post_stop.
Я добавил пример двух хуков в проект, смотрите код, он лучше всего объяснит, как это сделать.
В свою очередь, команды помогут скрыть ненужные подробности, чтобы, например, миграции выглядели как:
$ _build/prod/rel/userlist/bin/userlist migrateПри сборке релиза, после выполнения команды phoenix.digest, все статические файлы получают хеш-сумму в свое имя (плюс добавляются сжатые версии), и генерируется таблица соответствия между исходным именем файла и новым, которая находится в файле priv/static/manifest.json, если вы не меняли его положение в конфигурации. Если вдруг вам понадобится информация из него во время выполнения приложения, то у вас два варианта:
добавить его в список файлов, которые отдаются из каталога со статикой в lib/userlist/endpoint.ex:
only: ~w(css fonts images js favicon.ico robots.txt manifest.json)после чего, его можно будет забрать Ajax'ом, например;
если он нужен на бекенде, или если вы хотите рендерить его в шаблоне (я не знаю, зачем, но вдруг надо), то можно расширить LayoutView до такого:
defmodule Userlist.LayoutView do
use Userlist.Web, :view
def digest do
manifest =
Application.get_env(:userlist, Userlist.Endpoint, %{})[:cache_static_manifest]
|| "priv/static/manifest.json"
manifest_file = Application.app_dir(:userlist, manifest)
if File.exists?(manifest_file) do
manifest_file
|> File.read!
else
%{}
end
end
endчтобы потом, где-то в шаблоне, написать следующее:
Коммит с эти безумием тут.
Последнее, о чем хотелось бы упомянуть, это запуск приложения на боевом сервере. С тех пор, как у нас появился systemd, написание init-скриптов не то, что улучшилось, а стало просто элементарным.
Допустим, что мы будем разворачивать архив с приложением в /opt/userlist/ и запускать от имени пользователя userlist. Создадим файл userlist.service следующего содержания (коммит):
# Userlis is a Phoenix, Webpack and Distillery demo application
[Unit]
Description=Userlist application
After=network.target
[Service]
Type=simple
User=userlist
RemainAfterExit=yes
Environment=PORT=8080
WorkingDirectory=/opt/userlist
ExecStart=/opt/userlist/bin/userlist start
ExecStop=/opt/userlist/bin/userlist stop
Restart=on-failure
TimeoutSec=300
[Install]
WantedBy=multi-user.targetПосле чего, все, что надо сделать, это скопировать его в /etc/systemd/system/:
$ sudo cp userlist.service /etc/systemd/systemВключить в "автозагрузку":
$ sudo systemctl enable userlist.serviceИ запустить приложение:
$ sudo systemctl start userlistЦелью данной статьи была попытка собрать воедино разрозненную информацию по разным темам, касающуюся Phoenix'а и дать какое-то более-менее цельное представление о жизненном цикле приложений, написанных на этом замечательном фреймворке. Очень много осталось за кадром, есть куча тем, достойная отдельных статей, например, способы доставки релизных пакетов на сервер и т.п.
Я, как автор, прекрасно понимаю, что могу ошибаться, потому заранее извиняюсь за ошибки или неточности и прошу писать о таковых в комментариях.
|
Метки: author helions8 разработка веб-сайтов elixir/phoenix elixir phoenix phoenix framework erlang webpack deployment npm |
Перевод отрывков из книги Роберта Хайнлайна «Заберите себе правительство» — часть 25 |
За время кампании ваш кандидат посетил дома более 3 000 избирателей, а, возможно даже до 5 000. (Скажете, фантастика? Вовсе нет: в свое время, в одной из своих кампаний, я посетил 8 000 избирателей). Ваши агитаторы посетили еще 25 000 человек, и вы, конечно же, тоже участвовали в обходе избирателей. Говорите, у вас не было времени? Мои дорогие леди или сэр, на это у вас должно найтись время! Советую выделить для посещений избирателей вторую половину дня вторника и четверга, с часу дня до пяти вечера. И не назначайте никаких дел на это время.
Пусть ваша кампания не была идеальной, но все же ваши 20 000 прицельных выстрелов оказались удачными – они нашли тех, кто проголосует за вас. Ваши меткие попадания были подкреплены массированной артподготовкой – массовым охватом избирателей рекламой и митингами. Однако, многие из ваших попаданий совершены довольно давно, и теперь нужно напомнить избирателям о том, что пришел час проголосовать. Для этого вы используете напоминания, рассылаемые в последнюю неделю перед выборами. Советую вам, либо массово рассылать открытки по центу штука, либо направлять персональные письма, адресованные лично каждому избирателю, а не выбирать какой-то промежуточный вариант. Потому что традиционная политическая реклама, напечатанная по трафарету, адресованная всем сразу, и посланная третьим почтовым классом в пухлом незаклеенном конверте, набитом кучей листовок с пространным текстом, окажется в мусорной корзине еще до прочтения. Открытка же будет прочитана, потому что ее текст краток, и есть шанс что она не будет выброшена сразу, а будет сохранена в течение нескольких дней, как напоминание. Личное письмо, посланное первым почтовым классом, еще более вероятно будет прочтено и запомнено избирателем.
Однако, ваши почтовые расходы даже на одни открытки составят не менее двухсот долларов, не считая стоимости печати текста на них, и (естественно волонтерского) труда по заполнению адреса и проставлению подписи на них. Открытки всегда должны быть кем-то подписаны, хотя, и не обязательно от вашего имени. Подписание и адресация открыток займут много часов, так что эту работу надо начинать делать задолго до даты рассылки. Рассылка напоминаний в последнюю неделю перед выборами станет вашей самой большой тратой за всю кампанию, и может достичь до трети величины всех ваших расходов на кампанию. Возможно, исходя из имеющихся у временных и денежных ресурсов, вам придется использовать открытки, а не личные письма избирателям. Но и в этом случае, я бы посоветовал вам, все же, рассмотреть возможность рассылки личных писем тем из избирателей, которых кандидат посетил лично: они – ваши фавориты.
«Пять тысяч личных писем?» — скажете вы – «Да ведь даже профессиональная машинистка потратит на их печать не менее четырех месяцев!» И это действительно так. Но не все так плохо: существует механизм, изобретенный человеком по имени Гувен, способный с введенного текста, отпечатать много его копий – штука наподобие механического пианино. В образец текста можно даже вставить команды, встретив которые механизм делает паузу, позволяя оператору впечатать имя, дату, личное обращение, и любые другие добавления в исходный текст, никак не влияя на печать остального текста. Письмо, отпечатанное этим механизмом, не отличить от напечатанного человеком вручную. Службы печати, использующие механизм Гувена, существуют во всех больших городах. Если в вашем городе такой нет, вы можете воспользоваться их услугами по почте. Этот способ печати дороже, чем типографская печать, но намного дешевле услуг профессиональной машинистки («Когда-нибудь» – размечтался он – «и наш окружной комитет обзаведется этой замечательной машиной»)
Текст письма старайтесь сделать кратким и ёмким – для эффективности и экономии средств. Вот примерный образец такого письма:
Заголовок письма
Дата
Уважаемый мистер Богглз,
Я надеюсь, вы помните мой визит к вам 3 апреля этого года, и нашу с Вами дискуссию по поводу предварительных выборов. Праймериз состоятся в следующий вторник. Выдвигаясь на номинацию кандидата в Конгресс от Демпубликанской партии, я надеюсь, что могу рассчитывать на ваш голос. Прилагаю краткое описание своей персоны и свою политическую программу.
Вне зависимости от того, поддержите ли вы меня, или другого кандидата, я прошу вас и вашу семью в следующий вторник обязательно сходить проголосовать. Право голоса и гражданский долг для блага нашей страны гораздо важнее, чем амбиции кандидатов.
Искренне вам,
Джонатан Честняга
В этом письме, имя избирателя и дата визита к нему – единственные поля, требующие остановки автомата Гувена, чтобы можно было вписать конкретные данные. Если же вы используете открытки с напечатанным в типографии текстом, тогда вам придется ограничиться общими формулировками, вроде «Уважаемый Демпубликанец» и «недавний визит». Но все же, лучше разослать такие открытки всем избирателям из вашего списка, чем разослать личные письма, только части избирателей. Только не поддавайтесь искушению разослать напоминания поголовно всем зарегистрированным в округе избирателям: такая рассылка не оправдает ваших затрат.
Вашему кандидату желательно пролистать уже готовые открытки, чтобы снабдить хотя бы часть из них постскриптумами, обращенными к избирателю лично. Эти постскриптумы могут быть приписаны от руки тем же человеком, который будет открытки подписывать. Например: «P.S.Привет вашему щеночку – Дж.Ч.», или «Ваш сын совсем взрослый, надеюсь на его голос на выборах 1960 года» «Кстати, напишите мне ваше мнение по поводу того предложения, которое мы обсуждали», и «Надеюсь, ваш муж уже полностью выздоровел».
Возможно, некоторые из ваших агитаторов в своем избирательном участке могут себе позволить сами воспользоваться службой печати Гувена, или же оказаться настолько усердными, что смогут подготовить личные письма вручную – от руки, или на печатной машинке. Это большая работа, но в масштабах одного избирательного участка она выполнима. Или же, вы можете снабдить своих агитаторов открытками с отпечатанной на них вашей «торговой маркой» – портретом мистера Честняги, занимающим примерно треть открытки, обращением: «Уважаемый избиратель», и основным текстом вашего напоминания избирателям. Используйте шрифт, имитирующий шрифт печатной машинки и оставьте место для подписи агитатора.
Возможно, вам придется попросить тех из своих сотрудников, кто может себе позволить, скинуться на почтовые расходы. Собрав всего по несколько долларов с человека, вы соберете в фонд кампании, как минимум, несколько сотен долларов. Одно из замечательных свойств волонтеров – это то, насколько самозабвенно они готовы выкладываться, работая на кампанию перед самыми выборами. В то время, как наемные сотрудники ждут, что им все принесут на блюдечке, включая их зарплату.
Особое внимание надо уделить незарегистрированным избирателям, которых в ходе кампании нашли мистер Честняга и ваши агитаторы, и которые могут за вас проголосовать. Ведь вы регулярно получали отчеты от своих сотрудников о найденных ими незарегистрированных избирателях, имена которых вы передавали имена регистратору избирателей, с которым, конечно же, поддерживаете дружеские отношения. Эти голоса – ваши, если вы хорошенько попросите их обладателей проголосовать. Их может набраться до нескольких тысяч, чего достаточно для превращения досадного поражения в трудную победу. Это те самые голоса, которых Томасу Дьюи не хватило на выборах 1944 года – голоса «спящих» избирателей. Уделите особое внимание посланным им напоминаниям, и опекайте их в день выборов. Можно в напоминаниях для них использовать более индивидуализированные тексты, чем ваш основной текст напоминания.
Всю пачку рассылаемых напоминаний необходимо рассортировать по отдельным избирательным округам, и отдать их на почту не позже второй половины дня пятницы перед выборами (которые будут проходить во вторник).
Избирательная кампания почти закончилась, остался только финальный рывок, который требует тщательной подготовки. Идеальный вариант организации выборов выглядит так: каждый квартал города опекает отдельный сотрудник предвыборного штаба, группой сотрудников руководит командир группы, над которым стоит командир подразделения. Наготове у вас имеется отряд автомобилей, направляемых из штаб-квартиры на избирательные участки, по телефону осуществляется умелая координация их действий, на пунктах голосования находятся ваши сотрудники. На случай грубых провокаций со стороны оппозиции, наготове имеется отряд физически крепких людей и групп юристов – для более сложных ситуаций. Все это организовано и работает так же четко, как команда военного корабля, идущего в бой.
Но такой идеальной организации у вас не будет. И ничего похожего вы нигде не увидите, за исключением некоторых организаций в больших городах на Миссисипи, но и там они не будут настолько идеальными. Идеал вашей организации, которого вы в лучшем случае, достигнете на 80% – это три полевых сотрудника на каждом избирательном участке, по одному – на каждом пункте голосования, один человек на телефоне, один – с автомобилем наготове, командиры групп, доступные по телефону, в случае необходимости, выезжающие в нужное место вверенной им территории, телефон, группа ваших личных помощников, и два юриста на связи, немедленно выезжающие на место в случае возникновения проблем. Для силового давления вы обходитесь своей группой помощников, надеясь на то, что, даже самые бессовестные полицейские не допустят беззакония, если им известно, что за их действиями наблюдает юрист. Мистер Честняга проведет этот день, разъезжая по участкам, и воодушевляя сотрудников на местах.
Чтобы в день выборов создать такую организацию, вам понадобится в несколько раз больше сотрудников, чем у вас имеется в клубе агитаторов. Но создать такую организацию на один день не так уж трудно, при условии, что все ваши командиры отрядов работают активно и энергично. О некоторых из них сказать этого нельзя, поэтому грамотно расставьте приоритеты, и, в первую очередь, займитесь следующими важнейшими задачами:
Цель вашей работы в день выборов заключается в том, чтобы накопленные вами потенциальные голоса превратить в отданные за вас реальные голоса избирателей, обеспечив всем вашим сторонникам возможность проголосовать. Нередко выборы, в исходе которых вы заинтересованы, проводятся для голосования по достаточно несущественным вопросам, или по кандидатам на достаточно невысокую должность. На таких выборах избиратели могут проголосовать в вашу пользу только потому, что ваши сотрудники оказали им услугу, доставив их на пункт голосования. Многие избиратели сами приходят голосовать только на выборы уровня президентских, губернаторских, и выборов в сенат. Если сторонники мистера Честняги доставят таких избирателей на пункт голосования, то есть большая вероятность, что голоса привезенных будут отданы именно этому кандидату.
-> Часть 1, где есть ссылки на все остальные части
|
Метки: author sunman читальный зал хайнлайн политика |
Дайджест свежих материалов из мира фронтенда за последнюю неделю №268 (19 — 25 июня 2017) |

| Веб-разработка |
| CSS |
| Javascript |
| Браузеры |
| Занимательное |
 Веб-разработка
Веб-разработка Connect: советы по современному фронтенду HTTP/2 Server Push не так прост, как я думал
Connect: советы по современному фронтенду HTTP/2 Server Push не так прост, как я думал Выбираем фронтенд фреймворк в 2017 Интересная техника реализации иконочной системы на SVG HTML imports — это лучший веб-компонент Bojler — заготовка для создания рассылочных писем, которые будут отображаться корректно в наиболее популярных email-клиентах.
Выбираем фронтенд фреймворк в 2017 Интересная техника реализации иконочной системы на SVG HTML imports — это лучший веб-компонент Bojler — заготовка для создания рассылочных писем, которые будут отображаться корректно в наиболее популярных email-клиентах.  Addy Osmani: Руководство для хакеров для мгновенной загрузки в бразуер чего угодно (доклад с JSConf EU 2017) webpack 3: официальный релиз Уязвимость Webpack и Preact-CLI Hacker-box — автоматизация работы с фронтендом благодаря манипуляциям с JSON Accelerated Mobile Pages (AMP): чем вы готовы пожертвовать ради скорости? AMP: мысли о проекте с двумя миллиардами страниц Иллюзия скорости Обзор анимации с codepen для страниц загрузки сайта Fluent Design: Calendar Юрий Артюх опять верстает в прямом эфире: #4 ALL YOUR HTML, различные анимации лендинга с помощью GSAP
Addy Osmani: Руководство для хакеров для мгновенной загрузки в бразуер чего угодно (доклад с JSConf EU 2017) webpack 3: официальный релиз Уязвимость Webpack и Preact-CLI Hacker-box — автоматизация работы с фронтендом благодаря манипуляциям с JSON Accelerated Mobile Pages (AMP): чем вы готовы пожертвовать ради скорости? AMP: мысли о проекте с двумя миллиардами страниц Иллюзия скорости Обзор анимации с codepen для страниц загрузки сайта Fluent Design: Calendar Юрий Артюх опять верстает в прямом эфире: #4 ALL YOUR HTML, различные анимации лендинга с помощью GSAP  CSS Занимательная вёрстка с единицами измерения области просмотра CSS: введение в единицу длины 'fr' Кому нужны флексы — HTML Шорты Spectral — первый шрифт от Google с параметрической технологией, позволяющей работать с отзывчивыми символами О нет! Наши таблицы стилей только растут и растут! (Проблемы стилей, которые только добавляются) Используйте CSS переменные правильно Как выглядит хорошо задокументированная кодовая база CSS? Как применить CSS3 Transforms к Background Images Соотношение сторон в CSS — это хак CSS vs. JavaScript: доверие vs. контроль Как я создал кроссворд на чистом CSS Мощное улучшение CSS Grid Inspector в Firefox Nightly CSS фреймворки для использования с Angular 2+ Less-Grid-Boilerplate — легковесная двенадцатиколоночная сетка с CSS Grid и LESS Visual Component Library “VCL“. Модульный, расширяемый CSS
CSS Занимательная вёрстка с единицами измерения области просмотра CSS: введение в единицу длины 'fr' Кому нужны флексы — HTML Шорты Spectral — первый шрифт от Google с параметрической технологией, позволяющей работать с отзывчивыми символами О нет! Наши таблицы стилей только растут и растут! (Проблемы стилей, которые только добавляются) Используйте CSS переменные правильно Как выглядит хорошо задокументированная кодовая база CSS? Как применить CSS3 Transforms к Background Images Соотношение сторон в CSS — это хак CSS vs. JavaScript: доверие vs. контроль Как я создал кроссворд на чистом CSS Мощное улучшение CSS Grid Inspector в Firefox Nightly CSS фреймворки для использования с Angular 2+ Less-Grid-Boilerplate — легковесная двенадцатиколоночная сетка с CSS Grid и LESS Visual Component Library “VCL“. Модульный, расширяемый CSS JavaScript ArrayBuffer и SharedArrayBuffer в JavaScript, часть 1: краткий курс по управлению памятью sonar — инструмент для линтинга, новейший проект JS Foundation Почему всегда стоит использовать Linter Шаблоны оптимизации JavaScript (часть 1) Функциональное программирование в Javascript — это антипаттерн Руководство для начинающих по тестированию функционального JavaScript Создание прогрессивных веб приложений с Ember Подводные камни Service Worker Как создать интерактивные JavaScript графики и диаграммы из задаваемых наборов данных Lodash это не (только) для манипуляций со списками! Машинное обучение с JavaScript: часть 2 JavaScript для микроконтроллеров и IoT: часть 1 async/await из ES2017 — лучшее что происходило в JavaScript ES6 Katas — Изучайте ES6 практикуясь. Чините падающие тесты. Сохраняйте изучаемое. Давайте изучим ES6 Generators p-iteration — утилиты, делающие итерации по массиву более простыми с async/await или промисами Excel-подобная таблица в 25 строк ES6 Динамический рендеринг компонентов в Angular 2 От новичка до героя Angular Состояние Angular и срок 5й версии ng-annotate устарел: что это означает для ваших проектов flight — ультра-простые анимационные композиции для React React Express — полное руководство по современной разработке React приложений Создание мини-Netflix на React за 10 минут fbox — Flexbox компонент для Reactjs Vataxia — Open source социальная сеть, написанная на React и Redux Учишь React? Начни с малого. Первое приложение Reason React для Javascript разработчиков Техники для декомпозиции компонентов React Почему VueJS внедряется так медленно? (на самом деле нет) Четыре способа ускорения приложения Vue.js c Webpack Vue vs React: битва Javascript фреймворков Миграция с KnockoutJS на VueJS Начинаем работать с Vue Router Vue.js: трехминутное интерактивное введение Зачем выбирать Vue.js 5 отличных докладов с VueConf 2017, первой конференции по Vue.js Использование Vue, Vuex, Immutable для программирования Tetris Pasition — маленькая библиотека для плавного морфинга Path gpotter-gradient — Библиотека выдаёт rgb-цвет из линейного градиента на определённом участке от 0 до 100 с шагом в 1. Поддерживает на входе нотации #rrggbb, #rgb и названия цветов. graphql-js — имплементация GraphQL для JavaScript lazy-arr — «Ленивые» (Lazy) массивы в JavaScript Советы для разработчиков по DevTools: как снять полностраничный скриншот без расширений браузера
JavaScript ArrayBuffer и SharedArrayBuffer в JavaScript, часть 1: краткий курс по управлению памятью sonar — инструмент для линтинга, новейший проект JS Foundation Почему всегда стоит использовать Linter Шаблоны оптимизации JavaScript (часть 1) Функциональное программирование в Javascript — это антипаттерн Руководство для начинающих по тестированию функционального JavaScript Создание прогрессивных веб приложений с Ember Подводные камни Service Worker Как создать интерактивные JavaScript графики и диаграммы из задаваемых наборов данных Lodash это не (только) для манипуляций со списками! Машинное обучение с JavaScript: часть 2 JavaScript для микроконтроллеров и IoT: часть 1 async/await из ES2017 — лучшее что происходило в JavaScript ES6 Katas — Изучайте ES6 практикуясь. Чините падающие тесты. Сохраняйте изучаемое. Давайте изучим ES6 Generators p-iteration — утилиты, делающие итерации по массиву более простыми с async/await или промисами Excel-подобная таблица в 25 строк ES6 Динамический рендеринг компонентов в Angular 2 От новичка до героя Angular Состояние Angular и срок 5й версии ng-annotate устарел: что это означает для ваших проектов flight — ультра-простые анимационные композиции для React React Express — полное руководство по современной разработке React приложений Создание мини-Netflix на React за 10 минут fbox — Flexbox компонент для Reactjs Vataxia — Open source социальная сеть, написанная на React и Redux Учишь React? Начни с малого. Первое приложение Reason React для Javascript разработчиков Техники для декомпозиции компонентов React Почему VueJS внедряется так медленно? (на самом деле нет) Четыре способа ускорения приложения Vue.js c Webpack Vue vs React: битва Javascript фреймворков Миграция с KnockoutJS на VueJS Начинаем работать с Vue Router Vue.js: трехминутное интерактивное введение Зачем выбирать Vue.js 5 отличных докладов с VueConf 2017, первой конференции по Vue.js Использование Vue, Vuex, Immutable для программирования Tetris Pasition — маленькая библиотека для плавного морфинга Path gpotter-gradient — Библиотека выдаёт rgb-цвет из линейного градиента на определённом участке от 0 до 100 с шагом в 1. Поддерживает на входе нотации #rrggbb, #rgb и названия цветов. graphql-js — имплементация GraphQL для JavaScript lazy-arr — «Ленивые» (Lazy) массивы в JavaScript Советы для разработчиков по DevTools: как снять полностраничный скриншот без расширений браузера Занимательное
ЗанимательноеПросим прощения за возможные опечатки или неработающие/дублирующиеся ссылки. Если вы заметили проблему — напишите пожалуйста в личку, мы стараемся оперативно их исправлять.
|
|
PHP-Дайджест № 111 – свежие новости, материалы и инструменты (12 – 25 июня 2017) |

Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 7.2.0 Alpha 2, пара новых RFC, материалы с YiiConf и FWDays, PHP руткит, и многое другое.
Приятного чтения!
try {
somethingSketchy();
} retry 3 (RecoverableException $e, $attempt) {
echo "Failed doing sketchy thing on try #{$attempt}. Retrying...";
sleep(1);
} catch (RecoverableException $e) {
echo $e->getMessage();
}
try {
somethingSketchy();
} catch (RecoverableException $e)
retry; // Go to top of try block
}
??, добавленного в PHP 7.0:if ($_POST["action"]?? === "submit") {
// Form submission logic
} else {
// Form display logic
}
 Symfony 4: структура приложения Symfony 4: Тестируем плагин Symfony Flex Создание быстрых и более оптимизированных сайтов на WordPress Создаем свой кастомный плагин Style – Темизация Views в Drupal 8
Symfony 4: структура приложения Symfony 4: Тестируем плагин Symfony Flex Создание быстрых и более оптимизированных сайтов на WordPress Создаем свой кастомный плагин Style – Темизация Views в Drupal 8 Разворачиваем PHP-приложение с помощью Docker Пользовательские типы в PHP
Разворачиваем PHP-приложение с помощью Docker Пользовательские типы в PHP PHP fwdays '17: Как все прошло и видео докладов
PHP fwdays '17: Как все прошло и видео докладовСпасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в личку.
Вопросы и предложения пишите на почту или в твиттер.
Прислать ссылку
Быстрый поиск по всем дайджестам
<- Предыдущий выпуск: PHP-Дайджест № 110
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author pronskiy разработка веб-сайтов php блог компании zfort group дайджест php- ссылки symfony yii laravel zend |
[Из песочницы] Сглаживание изображений фильтром анизотропной диффузии Перона и Малика |
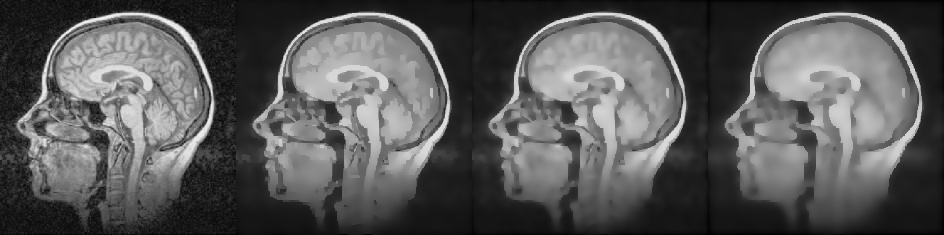
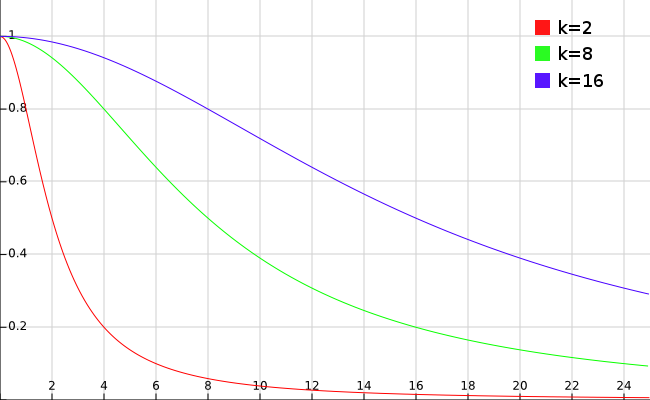
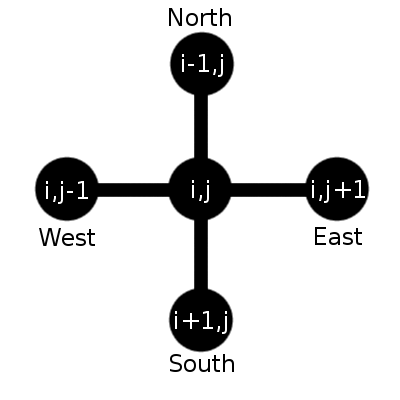

program blur
use pgmio
implicit none
double precision, parameter :: t=10.0d0, deltaT=0.2d0, k=10.0d0
character*(*), parameter :: input='dif_tomography.pgm', output='output.pgm'
double precision, allocatable :: u(:,:), nu(:,:)
double precision :: north, south, east, west, level
integer :: w, h, offset, n, i, j
end program blur
t — это уровень размытия, на котором мы хотим прекратить работу алгоритма, deltaT — шаг по времени, k — параметр для пока еще не описанной функции g. Input и output — файл с исходным изображением и выходной файл соответственно.w и h.call pgmsize(input, w, h, offset)
Offset определяет количество байт, отведенных на заголовок изображения.input.allocate(u(0:w+1,0:h+1))
u=0
allocate(nu(w,h))
call pgmread(input, offset, w, h, u, 0, 0)
0 до w+1 по первому измерения, и от 0 до h+1 по второму. Это позволит при дальнейшем пересчете использовать естественную индексацию без смещения.pgmread считываем w*h байт, пропуская offset байт (занимаемых заголовком PGM) в массив u. Последние два параметра сообщают процедуре, что отсчет в матрице u начинается с нуля по каждому измерению. level = 0 !счетчик уровня сглаживания
do while (levelcode>j идет раньше цикла по i. Все, опять же, из-за того, что фортран хранит двумерные массивы в памяти как последовательности столбцов. Если помять циклы местами, программа также будет работать, но значительно медленнее — программа будет обходить память не последовательно, а перебегать из разных ячеек «туда-сюда». deallocate(u)
call pgmwriteheader(output, w, h)
call pgmappendbytes(output, nu, 1, 1)
deallocate(nu)
pgmwriteheader создает файл output и записывает в него заголовок PGM P5. Процедура pgmappendbytes записывает в конец файла output последовательность байт из nu, учитывая, что индексы nu начинаются с 1 по обоим измерениям. Замечу, что pgmappendbytes записывает байты из двумерного массива опять же в порядке столбцов, поэтому, хотя в памяти и находилось транспонированная версия изображения, при записи изображение транспонируется обратно.g. Например, реализуем функцию по формуле 3. contains
function g(x) result(v)
implicit none
double precision, intent(in) :: x
double precision :: v
v = 1/(1+(x/k)**2)
end function g
gfortran pgmio.f90 blur.f90
t.

t=10).
t=10, k=8).
k при одинаковых t и deltaT (t=10, deltaT=0.2).
k. Но более мелкие области постепенно начинают сливаться. При достаточно большом k фактически получим гауссово размытие, так как условие на границу не пройдет ни одна точка.t=10,k=5).
deltaT=10 они уже заполняют все изображение.|
|
[Перевод] Сжатие фотографий без видимой потери качества: опыт Yelp |
# do a typical thumbnail, preserving aspect ratio
new_photo = photo.copy()
new_photo.thumbnail(
(width, height),
resample=PIL.Image.ANTIALIAS,
)
thumbfile = cStringIO.StringIO()
save_args = {'format': format}
if format == 'JPEG':
save_args['quality'] = 85
new_photo.save(thumbfile, **save_args)optimize=True). По определению, это никак не отразится на качестве фотографий.gzip -9 вместо gzip -6.progressive=True). В результате, качество субъективно повышается (так и есть, легче заметить частичное отсутствие изображения, чем его неидеальную резкость)


quality. Многие приложения, способные сохранять в формате JPEG, определяют quality в виде числа.quality = 85, показаны синим цветом.quality = 80, показан красным цветом.SSIM 80-85, показан оранжевым цветом. Здесь качество выбирается из диапазона от 80 до 85 (включительно), в зависимости от совпадения или превышения соотношения SSIM: предварительно вычисляемого статической величины, которая совершает этот переход где-то посредине диапазона изображений. Это позволяет нам снизить средний размер файла без понижения качества плохо выглядящих изображений.
import cStringIO
import PIL.Image
from ssim import compute_ssim
def get_ssim_at_quality(photo, quality):
"""Return the ssim for this JPEG image saved at the specified quality"""
ssim_photo = cStringIO.StringIO()
# optimize is omitted here as it doesn't affect
# quality but requires additional memory and cpu
photo.save(ssim_photo, format="JPEG", quality=quality, progressive=True)
ssim_photo.seek(0)
ssim_score = compute_ssim(photo, PIL.Image.open(ssim_photo))
return ssim_score
def _ssim_iteration_count(lo, hi):
"""Return the depth of the binary search tree for this range"""
if lo >= hi:
return 0
else:
return int(log(hi - lo, 2)) + 1
def jpeg_dynamic_quality(original_photo):
"""Return an integer representing the quality that this JPEG image should be
saved at to attain the quality threshold specified for this photo class.
Args:
original_photo - a prepared PIL JPEG image (only JPEG is supported)
"""
ssim_goal = 0.95
hi = 85
lo = 80
# working on a smaller size image doesn't give worse results but is faster
# changing this value requires updating the calculated thresholds
photo = original_photo.resize((400, 400))
if not _should_use_dynamic_quality():
default_ssim = get_ssim_at_quality(photo, hi)
return hi, default_ssim
# 95 is the highest useful value for JPEG. Higher values cause different behavior
# Used to establish the image's intrinsic ssim without encoder artifacts
normalized_ssim = get_ssim_at_quality(photo, 95)
selected_quality = selected_ssim = None
# loop bisection. ssim function increases monotonically so this will converge
for i in xrange(_ssim_iteration_count(lo, hi)):
curr_quality = (lo + hi) // 2
curr_ssim = get_ssim_at_quality(photo, curr_quality)
ssim_ratio = curr_ssim / normalized_ssim
if ssim_ratio >= ssim_goal:
# continue to check whether a lower quality level also exceeds the goal
selected_quality = curr_quality
selected_ssim = curr_ssim
hi = curr_quality
else:
lo = curr_quality
if selected_quality:
return selected_quality, selected_ssim
else:
default_ssim = get_ssim_at_quality(photo, hi)
return hi, default_ssimЭти таблицы приводятся только как примеры и необязательно подходят для какого-то конкретного приложения.
--with-jpeg8 и убедитесь, что он может быть залинкован с Pillow. Если вы используете Docker, то можно сделать такой Dockerfile:FROM ubuntu:xenial
RUN apt-get update \
&& DEBIAN_FRONTEND=noninteractive apt-get -y --no-install-recommends install \
# build tools
nasm \
build-essential \
autoconf \
automake \
libtool \
pkg-config \
# python tools
python \
python-dev \
python-pip \
python-setuptools \
# cleanup
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
# Download and compile mozjpeg
ADD https://github.com/mozilla/mozjpeg/archive/v3.2-pre.tar.gz /mozjpeg-src/v3.2-pre.tar.gz
RUN tar -xzf /mozjpeg-src/v3.2-pre.tar.gz -C /mozjpeg-src/
WORKDIR /mozjpeg-src/mozjpeg-3.2-pre
RUN autoreconf -fiv \
&& ./configure --with-jpeg8 \
&& make install prefix=/usr libdir=/usr/lib64
RUN echo "/usr/lib64\n" > /etc/ld.so.conf.d/mozjpeg.conf
RUN ldconfig
# Build Pillow
RUN pip install virtualenv \
&& virtualenv /virtualenv_run \
&& /virtualenv_run/bin/pip install --upgrade pip \
&& /virtualenv_run/bin/pip install --no-binary=:all: Pillow==4.0.0
4:1:1 (это настройки по умолчанию Pillow, если не указать другие настройки), так что мы вряд ли получим какой-то выигрыш при дальнейшей оптимизации.|
Метки: author m1rko хранение данных сжатие данных серверная оптимизация yelp jpeg квантование оптимизация компрессия pillow mozjpeg |
Скрипт статического коллтрекинга |
Описание работы скрипта для подмены на сайте номеров любых операторов. Конструктор для визуальной настройки скрипта. Подмена заголовков, для разных источников трафика.
Скрипт для подмены номеров телефона на сайте помогает настроить условия, когда должен появится тот или иной номер. Номера могут быть любых операторов, важно лишь, чтобы вы могли получить статистику звонков на эти номера.
Скрипт также запоминает откуда пришел посетитель. Если в первый раз он пришел из Яндекс, а затем, повторно из закладок, ему показывается номер телефона, связанный с Яндекс.
Предположим, нужно определить сколько звонков от пользоватлей, пришедших из рекламы Яндекс Директ и статей на сайтах. Для отслеживания двух источников трафика потребуется 3 номера. Один номер будет подсчитывать звонки со всех остальных источников.
Для этого на сайте нужно установить скрипт, который определяет откуда пришел посетитель и показывает ему нужный номер телефона.
Скачайте скрипт и подключите на сайте.
Добавьте CSS класс ct_phone в элементах, где будет происходить подмена номеров. Если номер есть в шапке и в подвале сайта, то для всех номеров нужно добавить класс.
+7 888 888-88-88Вставьте код подмены. Его можно вставить в любом месте страницы, главное, чтобы он был после элементов, в которых происходит подмена.
Если подмена требуется только в шапке сайта, то код можно вставить прямо под номерами. В этом случае подмена номеров почти незаметна.
Без особой причины не рекомендую выполнять код в событии готовности DOM модели или в Google Tag Manager, потому что подмена номеров становится заметнее.
Для упрощения настройки мы создали конструктор. Для работы с конструктором советую прочитать всю статью, чтобы понимать значения параметров.
В первой секции нужно создать источники трафика и условия как их определить. Ниже, вы задаете соответсвие источников трафика и номеров телефона. Готовый скрипт внизу страницы.
В конструкторе есть примеры определения источников трафика. Их можно использовать как основу, и расширить если требуется.
Когда все настроили готовый код можно скопировать внизу страницы.
В массиве sources задаются источники трафика.
'articles':{'ref': /(habrahabr|oborot.ru)/ig}В этом примере, articles это название источника. Это название используется в массиве phones. Ключ ref означает искать в адресе источника, а значение — регулярное выражение, с помощью которого выполянть поиск.
Поддерживаются следующие места поиска:
В этом примере, в utm_medium будет искаться подстрока email.
'email': {'utm_medium': 'email'}Заменив подстроку на регулярное выражение можно использовать более сложные правила поиска.
'email': {'utm_medium': /(email|eml)/ig }Если поиска подстроки или регулярного выражения недостаточно, есть возможность задать функцию. В параметр функции подается значение места поиска, а вернуть функция должна true или false.
'ydirect_openstat': {'dst': function(subject){
var o = query.getRawParam(subject, '_openstat');
return (o && a2b(o).indexOf('direct.yandex.ru')>-1);
}
}В этой функции распаковывается параметр _openstat из адреса страницы и проверяется, что он от Яндекс Директ.
После настройки источников трафика, нужно задать соответсвие номеров и источников.
phones: [
{'src':'yadirect', 'phone':['+74951111114']},
{'src':'articles', 'phone':['+74952222224']}
],Если на сайте одновременно отображаются несколько номеров, их нужно перечислить в массиве phone.
targets: ['.phone1', '.phone2'],
phones: [
{'src':'yadirect', 'phone':['+74951111114', '+78121111114']},
{'src':'articles', 'phone':['+74952222224', '+78122222224']}
],Параметр targets задает селекторы для элементов, в которых заменять номера. Количество в targets должно соответсвовать количеству телефонов в параметре phone
HTML будет выглядеть так:
+7 495 888-88-88
+7 812 888-88-88 По умолчанию в targets задан один селектор — .ct_phone
Номера отображаются в соответствтии с параметром pattern. По умолчанию он равен
+# (###) ###-##-## Вместо символов # будут подставлены цифры из номера.
Шаблон нужно задавать под конкретные номера. Шаблон по умолчанию позволяет отображать 11-ти значные российские номера, но не сможет правильно показать белорусский номер, потому что в нем 12 цифр.
В шаблоне можно использовать HTML тэги. Например, если нужно отделить номер от кода города.
+# (###) ###-##-## Если параметр pattern сделать пустым, номер будет выводится как он записан в секции phones.
Если шаблона недостаточно, отображение номера можно сделать при помощи callback функции. В параметр функции подается массив из списка phones.
function substCallback(p){
if(p){
document.getElementById('top_phone').innerText=someComplexModification(p.phone[0]);
}
}
sipuniCalltracking({
callback: substCallback,
sources: {
...
},
phones: [
{'src':'yadirect', 'phone':['+74951111114']},
{'src':'articles', 'phone':['+74952222224']}
],
}, window);Скрипт можно использовать для подмены любого содержимого страницы в зависимости от источников трафика.
Простой вариант подмены, когда вместо номеров телефона указывается заголовок.
sipuniCalltracking({
pattern: '',
sources: {
'yadirect_ustanovka':{'utm_keyword': 'установка'},
'yadirect_rassrochka':{'utm_keyword': 'рассрочку'}
},
phones: [
{'src':'yadirect_ustanovka', 'phone':['Газовые котлы с установкой']},
{'src':'yadirect_rassrochka', 'phone':['Газовые котлы в рассрочку']}
]
}, window);Теперь нужно добавить CSS класс в тэге заголовка.
Газовые котлы
Если посетитель пришел по объявлению о газовых котлах с установкой, ему покажется заголовок “Газовые котлы с установкой”. Поскольку скрипт запоминает, откуда пришел посетитель в первый раз, то при повторном заходе на сайт он все равно увидит “Газовые котлы с установкой”.
В параметр pattern подаем пустую строку, чтобы шаблон не применялся к строкам при выводе.
Можно менять заголовок и подзаголовок, и сделать CSS классы понятнее при помощи настройки targets.
pattern:'',
targets: ['.title', '.subtitle'],
phones: [
{'src':'yadirect_ustanovka', 'phone':[
'Газовые котлы с установкой',
'Доставим и установим газовый котел в вашем доме']},
{'src':'yadirect_rassrochka', 'phone':[
'Газовые котлы в рассрочку',
'Безпроцентная рассрочка до 6 месяцев']}
],Размечаем CSS классами title и subtitle элементы, в которых будем менять содержимое.
Газовые котлы
Доставка и установка газовых котлов
Для более сложного варианта подмены, можно использовать функцию. Такой вариант подойтет, если нужно заменить изображение. В функцию передается словарь из списка phones или null если источник не найден.
function substCallback(p){
if(p){
document.getElementById('header_img').src=p.phone[1];
}else{
document.getElementById('header_img').src = '/default.png';
}
}
sipuniCalltracking({
pattern:'',
targets:['.title'],
callback: substCallback,
sources:{
...
},
phones:[
{src:'yadirect_dostavka', phone:['Котлы с доставкой', '/kotel_dostavka.png']},
{src:'yadirect_ras', phone:['Котлы в рассрочку', '/kotel_ras.png']}
]
}, window);Проверить работу скрипта можно в jsFiddle. Для того чтобы подключить файл скрипта используйте эту ссылку. Напрямую jsFiddle не позволяет подключить файлы из GitHub поэтому ссылка преобразована при помощи сервиса rawgit.com
В обычном режиме вторым параметром скрипта подается объект window. Для отладки вместо него используйте словарь, в котором укажите referrer и посадочную страницу.
var wnd = {
document:{referrer:'http://yandex.ru'},
location:{href:'http://mysite.com/?utm_keyword=dostavka'}
};
sipuniCalltracking({
…
}, wnd);При отладке важно отключить механизм сохранения в куках источника посетителя. Для этого добавьте два параметра:
cookie_ttl_days: 0,
cookie_key: 'test1',Пример jsFiddle для проверки работы скрипта: https://jsfiddle.net/xndmnydj/1/
После отладки не забудьте убрать cookie_ttl_days и cookie_key и заменить параметр wnd на window.
У статического коллтрекинга есть ряд преимуществ по сравнению с динамическим: не возникает нехватки номеров при увеличении трафика, не возникает коллизий, когда номер показан другому человеку, а по нему звонит предыдущий посетитель.
Статический коллтрекинг подходит для оценки работы каналов рекламы, например, органика, социальные сети, контекстная реклама. В этом поможет скрипт, описанный в статье.
Скрипт мы создавали для наших клиентов, но поскольку он работает с номерами любых операторов, решили, сделать его открытым, лицензия — MIT.
В планах добавить установку через менеджер пакетов, например Browserify или Webpack.
|
Метки: author harabchuk разработка веб-сайтов open source javascript html блог компании sipuni коллтрекинг интернет маркетинг веб-аналитика |
Еще один пример синтеза асинхронных схем: VME bus controller |

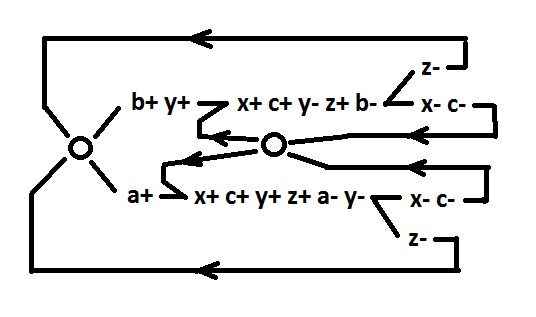
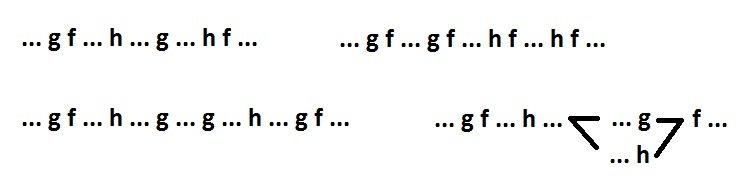
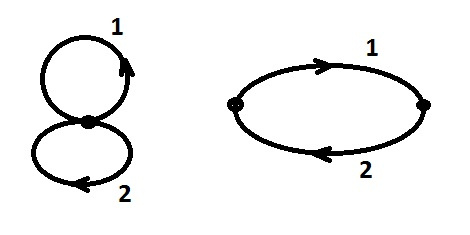
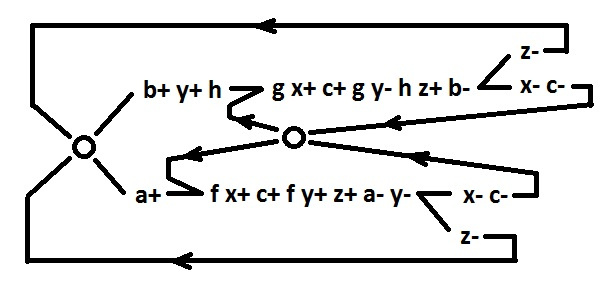






|
Метки: author ajrec fpga асинхронные схемы |
Ограничение количества выполнений метода в секунду |

|
Метки: author MoreBeauty c# .net нагруженные системы |






