Дайджест свежих материалов из мира фронтенда за последнюю неделю №267 (12 — 18 июня 2017) |

| Веб-разработка |
| CSS |
| Javascript |
| Браузеры |
| Занимательное |
 Веб-разработка
Веб-разработка
 Все записи докладов с с JSConf EU 2017 Grab Front End Guide — введение в стек современного фронтенда Готовимся к Web Bluetooth! Использование Workbox + Webpack для предварительного кеширования с помощью Service Worker Люди с ограниченными возможностями отвечают, что же для них самое сложное в вебе A11ycasts #19: доступные модальные окна PWA Directory — каталог прогрессивных веб приложений Что такое Accelerated Mobile Pages и чем они отличаются от отзывчивого веб-дизайна Пожалуйста, сделайте Google AMP опциональным topol.io — удобный генератор шаблонов писем, в том числе и отзывчивых Network Monitor в Firefox: Подробно о новых возможностях инструмента, работа с внутренним сервером и удаленным отладчиком Введение в FuseBox — более быструю и легкрую альтернативу Webpack Введение в Webpack: Entry, Output, загрузчики и плагины Представление Bonsai: open source анализатор Webpack от Pinterest Желейный эффект для фигур в canvas — Юрий Артюх пишет код в прямом эфире с комментариями и пояснениями Улучшаем SVG анимацию с помощью GSAP CSS Animations vs Web Animations API Эффектный анимированный морской пейзаж на HTML/CSS
Все записи докладов с с JSConf EU 2017 Grab Front End Guide — введение в стек современного фронтенда Готовимся к Web Bluetooth! Использование Workbox + Webpack для предварительного кеширования с помощью Service Worker Люди с ограниченными возможностями отвечают, что же для них самое сложное в вебе A11ycasts #19: доступные модальные окна PWA Directory — каталог прогрессивных веб приложений Что такое Accelerated Mobile Pages и чем они отличаются от отзывчивого веб-дизайна Пожалуйста, сделайте Google AMP опциональным topol.io — удобный генератор шаблонов писем, в том числе и отзывчивых Network Monitor в Firefox: Подробно о новых возможностях инструмента, работа с внутренним сервером и удаленным отладчиком Введение в FuseBox — более быструю и легкрую альтернативу Webpack Введение в Webpack: Entry, Output, загрузчики и плагины Представление Bonsai: open source анализатор Webpack от Pinterest Желейный эффект для фигур в canvas — Юрий Артюх пишет код в прямом эфире с комментариями и пояснениями Улучшаем SVG анимацию с помощью GSAP CSS Animations vs Web Animations API Эффектный анимированный морской пейзаж на HTML/CSS  CSS
CSS 5 возможностей LESS, о которых вы могли не знать Используем CSS Grid Layouts на продакшене уже сегодня Введение в единицу CSS `fr` Масштабирование отзывчивой типографики в CSS Типографический потенциал вариабельных шрифтов Практическое руководство по CSS переменным (пользовательские свойства) Мысли по поводу самодокументированного CSS Создание минималистичной HTML карточки всего в 53 строки кода (с Flexbox) Обработка длинного и неожиданного контента в CSS Результаты глобального CSS опроса 2017 От CSS препроцессоров до CSS в JS Better-Less — кросс-совместимая подсветка синтаксиса для Less кода
5 возможностей LESS, о которых вы могли не знать Используем CSS Grid Layouts на продакшене уже сегодня Введение в единицу CSS `fr` Масштабирование отзывчивой типографики в CSS Типографический потенциал вариабельных шрифтов Практическое руководство по CSS переменным (пользовательские свойства) Мысли по поводу самодокументированного CSS Создание минималистичной HTML карточки всего в 53 строки кода (с Flexbox) Обработка длинного и неожиданного контента в CSS Результаты глобального CSS опроса 2017 От CSS препроцессоров до CSS в JS Better-Less — кросс-совместимая подсветка синтаксиса для Less кода  JavaScript New releases: ESLint v4.0.0, V8 Release 6.0, Node 8 и npm5 Книга заклинаний современного веб-разработчика: большая картинка, тезаурус и таксономия современного веб-разработки JavaScript Реактивное программирование, блин. Это не о ReactJS Почему вы должны ограничить JavaScript — и как это сделать Выбор Jest вместо Mocha Как отслеживать изменения в DOM-е с использованием Mutation Observer Коллбэк в JavaScript… Что за зверь? Декораторы в JavaScript В чем разница между Null и Undefined? Работа с периферией из JavaScript: от теории к практике 19+ методов сокращённого написания кода в JavaScript Как я разработал и создал Fullstack JavaScript клон Trello Использование HTML5 canvas для добавления водяных знаков на изображения Машинное обучение с JavaScript: часть 1 Детальный курс по управлению памятью История о производительности JavaScript, часть 3: Рендереры всех форм и размеров vue-styleguidist — стайлгайд для vue-компонентов XSS в Vue.js Создание приложения на Vue JS (webpack, axios, bootstrap 4, reddit и бесконечный скроллинг на vanilla javascript) Станет ли Vue.js таким же гигантом, как Angular или React? Расширение компонентов VueJS PWAs с Angular: Being Reliable, Being Fast, Being Engaging Angular 1.0 исполнилось пять лет Релиз Angular 4.2 Сокращаем использование Redux кода с помощью React Apollo Видеокурс Начало работы с Preact Что такое React? Термины React на простом английском и в рисунках Почему я выбрал React вместо Vue Релиз Is-React 1.0.0 — Утилитарные методы для React React State или Redux State: когда что использовать? Сделать React снова быстрым [часть 1]: временная шкала производительности Подсветка текста в Textarea v2 spected — низкоуровневая библиотека для валидации js-joda — библиотека для работы с неизменяемыми временем и датой dutier — небольшое (1Кб), асинхронное и простое решение для управления состоянием приложения Vivaldi 1.10 — маленькие радости широких возможностей Вышел Firefox 54, который наконец получил поддержку многопроцессного режима. Подробности для разработчиков в блоге Марата Таналина Chrome 60 Beta: Paint Timing API, CSS font-display, и улучшения Credential Management API Как написать расширение для Chrome
JavaScript New releases: ESLint v4.0.0, V8 Release 6.0, Node 8 и npm5 Книга заклинаний современного веб-разработчика: большая картинка, тезаурус и таксономия современного веб-разработки JavaScript Реактивное программирование, блин. Это не о ReactJS Почему вы должны ограничить JavaScript — и как это сделать Выбор Jest вместо Mocha Как отслеживать изменения в DOM-е с использованием Mutation Observer Коллбэк в JavaScript… Что за зверь? Декораторы в JavaScript В чем разница между Null и Undefined? Работа с периферией из JavaScript: от теории к практике 19+ методов сокращённого написания кода в JavaScript Как я разработал и создал Fullstack JavaScript клон Trello Использование HTML5 canvas для добавления водяных знаков на изображения Машинное обучение с JavaScript: часть 1 Детальный курс по управлению памятью История о производительности JavaScript, часть 3: Рендереры всех форм и размеров vue-styleguidist — стайлгайд для vue-компонентов XSS в Vue.js Создание приложения на Vue JS (webpack, axios, bootstrap 4, reddit и бесконечный скроллинг на vanilla javascript) Станет ли Vue.js таким же гигантом, как Angular или React? Расширение компонентов VueJS PWAs с Angular: Being Reliable, Being Fast, Being Engaging Angular 1.0 исполнилось пять лет Релиз Angular 4.2 Сокращаем использование Redux кода с помощью React Apollo Видеокурс Начало работы с Preact Что такое React? Термины React на простом английском и в рисунках Почему я выбрал React вместо Vue Релиз Is-React 1.0.0 — Утилитарные методы для React React State или Redux State: когда что использовать? Сделать React снова быстрым [часть 1]: временная шкала производительности Подсветка текста в Textarea v2 spected — низкоуровневая библиотека для валидации js-joda — библиотека для работы с неизменяемыми временем и датой dutier — небольшое (1Кб), асинхронное и простое решение для управления состоянием приложения Vivaldi 1.10 — маленькие радости широких возможностей Вышел Firefox 54, который наконец получил поддержку многопроцессного режима. Подробности для разработчиков в блоге Марата Таналина Chrome 60 Beta: Paint Timing API, CSS font-display, и улучшения Credential Management API Как написать расширение для Chrome Занимательное Разработчики, использующие пробелы, зарабатывают больше денег, чем те, кто используют табы
Занимательное Разработчики, использующие пробелы, зарабатывают больше денег, чем те, кто используют табыПросим прощения за возможные опечатки или неработающие/дублирующиеся ссылки. Если вы заметили проблему — напишите пожалуйста в личку, мы стараемся оперативно их исправлять.
|
|
Технологии больших данных в работе с бактериями микробиоты. Лекция в Яндексе |
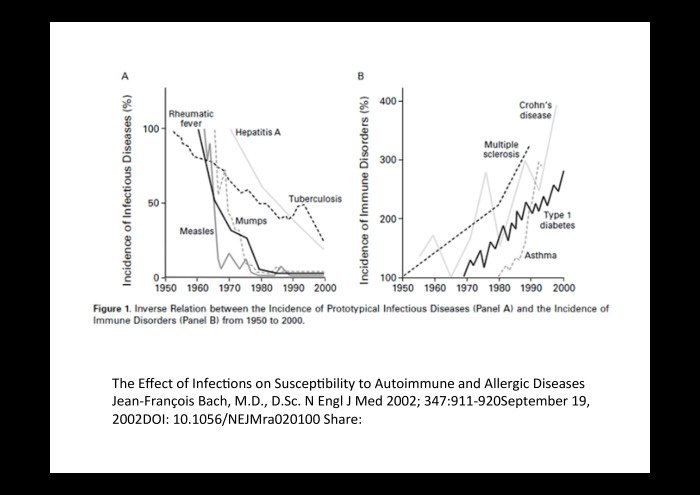




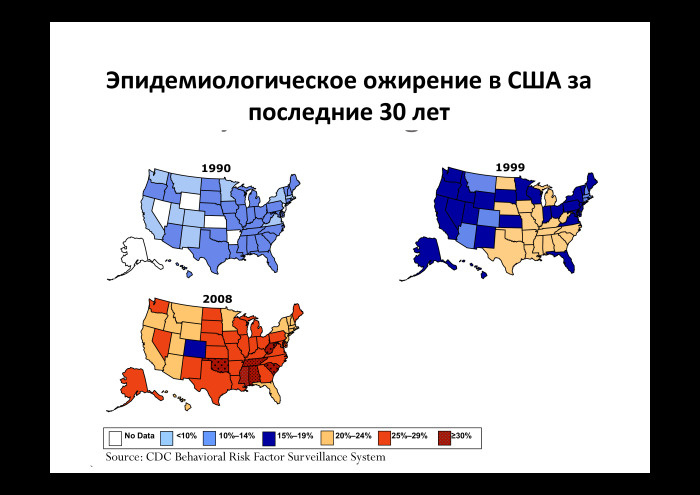






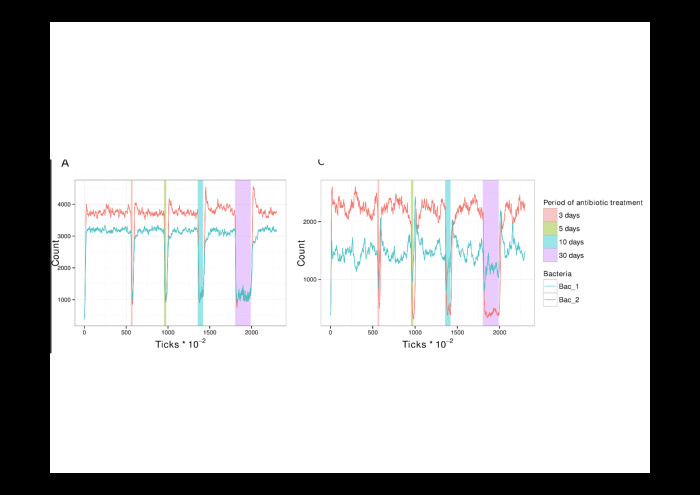





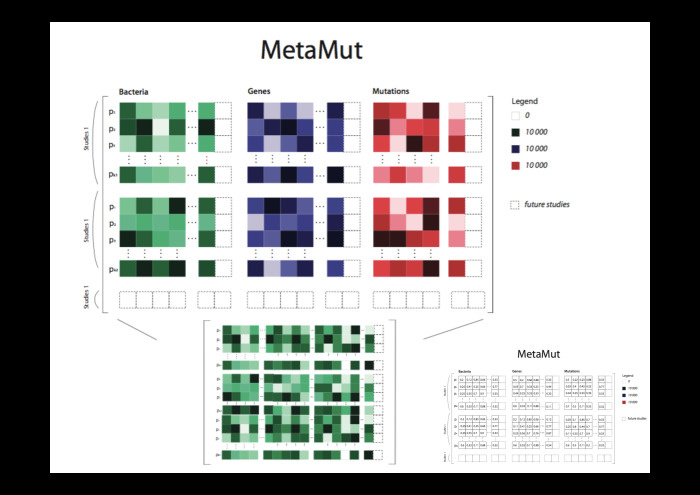




|
|
[Из песочницы] Рисование толстых линий в WebGL |





 (рис. 6)
(рис. 6)


var vb = this._verticesBuffer;
gl.bindBuffer(gl.ARRAY_BUFFER, vb);
gl.vertexAttribPointer(sha.prev._pName, vb.itemSize, gl.FLOAT, false, 8, 0);
gl.vertexAttribPointer(sha.current._pName, vb.itemSize, gl.FLOAT, false, 8, 32);
gl.vertexAttribPointer(sha.next._pName, vb.itemSize, gl.FLOAT, false, 8, 64);
gl.bindBuffer(gl.ARRAY_BUFFER, this._ordersBuffer);
gl.vertexAttribPointer(sha.order._pName, this._ordersBuffer.itemSize, gl.FLOAT, false, 4, 0);
Polyline2d.createLineData = function (pathArr, outVertices, outOrders, outIndexes) {
var index = 0;
outIndexes.push(0, 0);
for ( var j = 0; j < pathArr.length; j++ ) {
path = pathArr[j];
var startIndex = index;
var last = [path[0][0] + path[0][0] - path[1][0], path[0][1] + path[0][1] - path[1][1]];
outVertices.push(last[0], last[1], last[0], last[1], last[0], last[1], last[0], last[1]);
outOrders.push(1, -1, 2, -2);
//На каждую вершину приходится по 4 элемента
for ( var i = 0; i < path.length; i++ ) {
var cur = path[i];
outVertices.push(cur[0], cur[1], cur[0], cur[1], cur[0], cur[1], cur[0], cur[1]);
outOrders.push(1, -1, 2, -2);
outIndexes.push(index++, index++, index++, index++);
}
var first = [path[path.length - 1][0] + path[path.length - 1][0] - path[path.length - 2][0], path[path.length - 1][1] + path[path.length - 1][1] - path[path.length - 2][1]];
outVertices.push(first[0], first[1], first[0], first[1], first[0], first[1], first[0], first[1]);
outOrders.push(1, -1, 2, -2);
outIndexes.push(index - 1, index - 1, index - 1, index - 1);
if ( j < pathArr.length - 1 ) {
index += 8;
outIndexes.push(index, index);
}
}
};
var path = [[[-100, -50], [1, 2], [200, 15]]];
var vertices = [],
orders = [],
indexes = [];
Polyline2d.createLineData(path, vertices, orders, indexes);
attribute vec2 prev; //предыдущая координата
attribute vec2 current; //текущая координата
attribute vec2 next; //следующая координата
attribute float order; //порядок
uniform float thickness; //толщина
uniform vec2 viewport; //размеры экрана
//Функция проецирование на экран
vec2 proj(vec2 coordinates){
return coordinates / viewport;
}
void main() {
vec2 _next = next;
vec2 _prev = prev;
//Блок проверок для случаев, когда координаты точек равны
if( prev == current ) {
if( next == current ){
_next = current + vec2(1.0, 0.0);
_prev = current - next;
} else {
_prev = current + normalize(current - next);
}
}
if( next == current ) {
_next = current + normalize(current - _prev);
}
vec2 sNext = _next,
sCurrent = current,
sPrev = _prev;
//Направляющие от текущей точки, до следующей и предыдущей координаты
vec2 dirNext = normalize(sNext - sCurrent);
vec2 dirPrev = normalize(sPrev - sCurrent);
float dotNP = dot(dirNext, dirPrev);
//Нормали относительно направляющих
vec2 normalNext = normalize(vec2(-dirNext.y, dirNext.x));
vec2 normalPrev = normalize(vec2(dirPrev.y, -dirPrev.x));
float d = thickness * 0.5 * sign(order);
vec2 m; //m - точка сопряжения, от которой зависит будет угол обрезанным или нет
if( dotNP >= 0.99991 ) {
m = sCurrent - normalPrev * d;
} else {
vec2 dir = normalPrev + normalNext;
// Таким образом ищется пересечение односторонних граней линии (рис. 2)
m = sCurrent + dir * d / (dirNext.x * dir.y - dirNext.y * dir.x);
//Проверка на пороговое значение остроты угла
if( dotNP > 0.5 && dot(dirNext + dirPrev, m - sCurrent) < 0.0 ) {
float occw = order * sign(dirNext.x * dirPrev.y - dirNext.y * dirPrev.x);
//Блок решения для правильного построения цепочки LINE_STRING
if( occw == -1.0 ) {
m = sCurrent + normalPrev * d;
} else if ( occw == 1.0 ) {
m = sCurrent + normalNext * d;
} else if ( occw == -2.0 ) {
m = sCurrent + normalNext * d;
} else if ( occw == 2.0 ) {
m = sCurrent + normalPrev * d;
}
//Проверка "внутренней" точки пересечения, чтобы она не убегала за границы сопряженных сегментов
} else if ( distance(sCurrent, m) > min(distance(sCurrent, sNext), distance(sCurrent, sPrev)) ) {
m = sCurrent + normalNext * d;
}
}
m = proj(m);
gl_Position = vec4(m.x, m.y, 0.0, 1.0);
}
|
Метки: author mgevlich webgl javascript glsl |
Игры на Scheme(Lisp) в среде DrRacket |
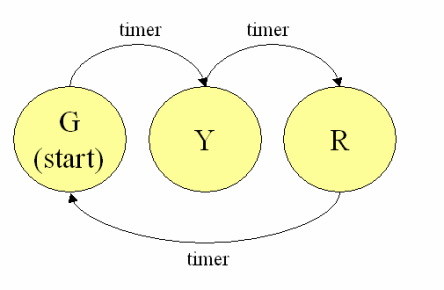
#lang racket
(require picturing-programs)
(define (DOT s) (circle 100 "solid" s))
(define (traffic-light-next s)
(cond
[(string=? "red" s) "green"]
[(string=? "green" s) "yellow"]
[(string=? "yellow" s) "red"]))
(big-bang "red"
[on-tick traffic-light-next 1]
[to-draw DOT])
[(> (+ x DELTA) WIDTH) 0]
(cond
[(> (+ x dx) WIDTH) 0]
[else (+ x dx)] )
#lang racket
(require 2htdp/image)
(require 2htdp/universe)
(define WIDTH 100)
(define DELTA 1)
(define BALL (circle 5 "solid" "red"))
(define MT (empty-scene WIDTH 10))
(define (main x0)
(big-bang x0
[to-draw render]
[on-tick bounce]))
(define (bounce x)
(cond
[(> (+ x DELTA) WIDTH) 0]
[else (+ x DELTA)] ))
(define (render x)
(place-image BALL x 5 MT))
(main 50)
#lang racket
(require 2htdp/image)
(require 2htdp/universe)
(define BACKGROUND (empty-scene 100 100))
(define DOT (circle 10 "solid" "red"))
(define (place-dot-at x)
(place-image DOT x 50 BACKGROUND))
(define (change-func p k) ; обработка клавиш
(cond
[(string=? "left" k)
(- p 5)]
[(string=? "right" k)
(+ p 5)]
[else p]))
( big-bang 50
[to-draw place-dot-at]
[on-key change-func] )
(define-struct posn (x y))
(define INIT-WORLD (make-posn 100 100))
#lang racket
(require picturing-programs)
(define WIDTH 200)
(define HEIGHT 200)
(define BACKGROUND (empty-scene WIDTH HEIGHT))
(define obj1 (circle 10 "solid" "red"))
(define-struct posn (x y)) ;объявляем структуру
(define INIT-WORLD (make-posn 100 100) )
(define (change-current-world-key current-world a-key-event) ;обработка "событий" клавиатуры
(cond
[(key=? a-key-event "up")
(make-posn (posn-x current-world) (- (posn-y current-world) 5))]
[(key=? a-key-event "down")
(make-posn (posn-x current-world) (+ (posn-y current-world) 5))]
[(key=? a-key-event "left")
(make-posn (-(posn-x current-world)5) (posn-y current-world) )]
[(key=? a-key-event "right")
(make-posn (+(posn-x current-world)5) (posn-y current-world) )]
[else current-world]))
(define (redraw current-world)
(place-image obj1
(posn-x current-world)
(posn-y current-world)
BACKGROUND))
(big-bang INIT-WORLD
(on-key change-current-world-key)
(on-draw redraw) )
#lang racket
(require picturing-programs)
(define WIDTH 300)
(define HEIGHT 300)
(define BACKGROUND (empty-scene WIDTH HEIGHT))
(define obj1 (circle 10 "solid" "red"))
(define obj2 (circle 10 "solid" "green"))
(define-struct posn (x y))
(define-struct world [obj1 obj2])
; Инициализация параметров в структуре world
(define INIT-WORLD (make-world (make-posn 100 100) (make-posn 200 100)))
(define (draw-game world)
(place-image
obj1
(posn-x (world-obj1 world))
(posn-y (world-obj1 world))
(place-image
obj2
(posn-x (world-obj2 world))
(posn-y (world-obj2 world))
BACKGROUND)))
(big-bang INIT-WORLD
[to-draw draw-game])
#lang racket
(require picturing-programs)
(define WIDTH 300)
(define HEIGHT 300)
(define BACKGROUND (empty-scene WIDTH HEIGHT))
(define obj1 (circle 10 "solid" "red"))
(define obj2 (circle 10 "solid" "green"))
(define-struct posn (x y))
(define-struct world [obj1 obj2])
(define INIT-WORLD (make-world (make-posn 50 150) (make-posn 250 150)))
(define (change-current-world-key current-world a-key-event)
(make-world (change-obj1 (world-obj1 current-world) a-key-event)
(world-obj2 current-world)))
(define (change-obj1 a-posn a-key-event)
(cond
[(key=? a-key-event "up")
(make-posn (posn-x a-posn) (- (posn-y a-posn) 5))]
[(key=? a-key-event "down")
(make-posn (posn-x a-posn) (+ (posn-y a-posn) 5))]
[(key=? a-key-event "left")
(make-posn (-(posn-x a-posn) 5) (posn-y a-posn) )]
[(key=? a-key-event "right")
(make-posn (+(posn-x a-posn)5) (posn-y a-posn) )]
[else a-posn]))
(define (draw-game world)
(place-image
obj1
(posn-x (world-obj1 world))
(posn-y (world-obj1 world))
(place-image
obj2
(posn-x (world-obj2 world))
(posn-y (world-obj2 world))
BACKGROUND)))
(big-bang INIT-WORLD
(on-key change-current-world-key)
[to-draw draw-game] )
|
Метки: author demser функциональное программирование программирование lisp создание игр scheme drracket htdp htdw |
[recovery mode] Пользовательские типы в PHP |

function typedef(string $aName, IType $aType): IType;function type(string $aName): IType;function is($aValue, IType $aType): bool;function IType::validate($aValue): bool;function bool(): BoolType;function number(float $aMin = null, float $aMax = null): NumericType;
function int(int $aMin = null, int $aMax = null): IntType;
function uint(int $aMax = null): UIntType;function string(int $aLength = null): StringType;function regexp(string $aRegularExpression): RegExpType;function enum(...$aValues): EnumType;function object(string $aClass = null): ObjectType;function nullable(IType $aType): NullableType;function any(IType ...$aTypes): MultiType;function lot(int $aLength = null): ArrayType;function struct(IField ...$aFields): StructType;function field(string $aName, IType $aType = null): Field;function optional(IField $aField): OptionalField;function union(IField ...$aFields): Union;typedef('input', struct(
field('name', string()),
field('authors', any(
string(),
lot()->of(string())
)),
optional(union(
field('text', string()),
field('content', struct(
field('title', string(255)),
optional(field('annotation', string(65535))),
field('text', string()),
optional(field('pages', nullable(uint(5000))))
))
)),
field('read', enum(false, true, 0, 1, 'yes', 'no'))
));
if (PHP_SAPI === 'cli') {
$input = [];
parse_str(implode('&', array_slice($argv, 1)), $input);
} else {
$input = $_GET;
}
echo "Validation: " . (is($input, type('input')) ? 'success' : 'failed') . "\n";name="The Lord of the Rings"
authors[]="J. R. R. Tolkien"
content[title]="The Return of the King"
content[text]=...
read=yesname="The Lord of the Rings"
authors[]="J. R. R. Tolkien"
text=...
content[title]="The Return of the King"
content[text]=...
read=yesTea\Generics\IndexedArray(array $aValues = null, callable $aValueConstraintCallback = null);function ($aValue): bool;Tea\Generics\AssocArray(array $aValues = null, callable $aKeyConstraintCallback = null, callable $aValueConstraintCallback = null);function values(...$aValues): IndexedArray;function numbers(float ...$aValues): NumericArray;
function integers(int ...$aValues): IntArray;
function cardinals(int ...$aValues): UIntArrayfunction strings(string ...$aValues): StringArrayfunction objects(string $aClass, array $aValues = null): ObjectArray;function map(array $aItems = null): AssocArray;function dict(array $aItems = null): Dictionary;function hash(array $aItems = null): StringDictionary;function collection(IType $aType, array $aValues = null): Collection;
|
Метки: author altgamer php типы данных массивы дженерики |
Дайджест интересных материалов для мобильного разработчика #208 (13 июня — 18 июня) |
 |
Тестируем возможности ARKit. Создаем игру с дополненной реальностью |
 |
May the Code Review be with you |
 |
Как технологии Яндекс.Такси приближают будущее личного и общественного транспорта |
 iOS
iOS Как расширить свое приложение SiriKit Создаем нормальные пуш-уведомления Портирование iOS-приложения на macOS Руководство по быстродействию скрола от OkCupid
Как расширить свое приложение SiriKit Создаем нормальные пуш-уведомления Портирование iOS-приложения на macOS Руководство по быстродействию скрола от OkCupid YapImageManager: быстрый загрузчик картинок Gagat: библиотека для красивого переключения между темами
YapImageManager: быстрый загрузчик картинок Gagat: библиотека для красивого переключения между темами Android Android Instant Apps шаг за шагом: как Vimeo использует их Android Dialogs: App Shortcuts Пользовательское тестирование Android приложений Исследуем Android O: бейджи уведомлений Анимация меню Просто Android Things Обеспечиваем качественный код для Android Как применить Kotlin на существующем Java коде
Android Android Instant Apps шаг за шагом: как Vimeo использует их Android Dialogs: App Shortcuts Пользовательское тестирование Android приложений Исследуем Android O: бейджи уведомлений Анимация меню Просто Android Things Обеспечиваем качественный код для Android Как применить Kotlin на существующем Java коде Windows
Windows Разработка Лучшие конференции Июня-Августа 2017 Чему я научился за 2 года разработки и продвижения мобильных игр Видео конференции Facebook Data @Scale 2017
Разработка Лучшие конференции Июня-Августа 2017 Чему я научился за 2 года разработки и продвижения мобильных игр Видео конференции Facebook Data @Scale 2017 Аналитика, маркетинг и монетизация Геймификация в мобильных приложений: 5 вещей, которые надо помнить
Аналитика, маркетинг и монетизация Геймификация в мобильных приложений: 5 вещей, которые надо помнить Устройства, IoT, AI
Устройства, IoT, AI|
Метки: author EverydayTools разработка под ios разработка под android разработка мобильных приложений разработка игр блог компании everyday tools app store ark firebase яндекс |
Список доменов в зоне ru/su/tatar/рф/дети утек в публичный доступ из-за некорректной настройки DNS |
$ dig axfr su. @a.dns.ripn.net
; <<>> DiG 9.10.4-P8-RedHat-9.10.4-5.P8.fc25 <<>> axfr su. @a.dns.ripn.net
;; global options: +cmd
SU. 345600 IN SOA a.dns.ripn.net. hostmaster.ripn.net. 650170097 86400 14400 2592000 3600
SU. 345600 IN RRSIG SOA 8 1 345600 20170728095315 20170618085528 12810 su. AMqjxdOOp9rIVMk9gvH6TiXEB8FAWZn0xbqxxYxsQMYrqCUE49AXSUQ1 nESJ//bPE8g7mNa/KCqrt21icAOG6+gzwes+TZ2nu62dwbwH3IeEoxry GZ+uEIGlQfjPC6AxRuPELnaKRpLUy+Ir28ScJDLjIBewVs3J7zAHXw/K bYU=
SU. 345600 IN NS a.dns.ripn.net.
SU. 345600 IN NS b.dns.ripn.net.
SU. 345600 IN NS d.dns.ripn.net.
SU. 345600 IN NS e.dns.ripn.net.
SU. 345600 IN NS f.dns.ripn.net.
…
0--0.SU. 345600 IN NS ns1.shop.reg.ru.
0--0.SU. 345600 IN NS ns2.shop.reg.ru.
0--GDE-KUPIT-DOMEN-DESHEVO--RU--SU--COM--NET--ORG--INFO--ME--TV.SU. 345600 IN NS ns1.hostmonster.com.
0--GDE-KUPIT-DOMEN-DESHEVO--RU--SU--COM--NET--ORG--INFO--ME--TV.SU. 345600 IN NS ns2.hostmonster.com.
0-0.SU. 345600 IN NS dns1.yandex.net.
0-0.SU. 345600 IN NS dns2.yandex.net.
0-0-0.SU. 345600 IN NS ns1.shop.reg.ru.
0-0-0.SU. 345600 IN NS ns2.shop.reg.ru.
0-1.SU. 345600 IN NS dns1.elasticweb.org.
0-1.SU. 345600 IN NS dns2.elasticweb.org.
0-3.SU. 345600 IN NS ns1.timeweb.ru.
0-3.SU. 345600 IN NS ns2.timeweb.ru.
0-4.SU. 345600 IN NS ns.hostland.ru.
0-4.SU. 345600 IN NS ns3.hostland.ru.
…| Зона | Количество доменов |
|---|---|
| .ru | 5325898 |
| .su | 109719 |
| .tatar | 869 |
| .рф | 796707 |
| .дети | 1066 |
magnet:?xt=urn:btih:3457106ce62b2707639978d802e20567e278aa39&dn=Russian%20domain%20zones&tr=udp%3a%2f%2ftracker.leechers-paradise.org%3a6969&tr=udp%3a%2f%2ftracker.coppersurfer.tk%3a6969%2fannounce&tr=udp%3a%2f%2fp4p.arenabg.com%3a1337%2fannounce&tr=udp%3a%2f%2ftracker.zer0day.to%3a1337%2fannounce|
Метки: author ValdikSS администрирование доменных имен dns домены axfr |
[Из песочницы] Система синтеза самосинхронных схем Petrify: проблемы и их решение |



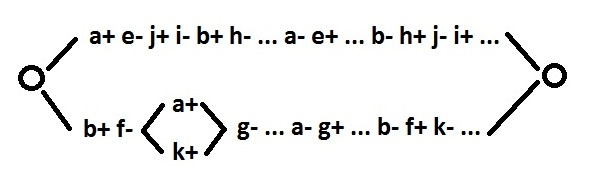
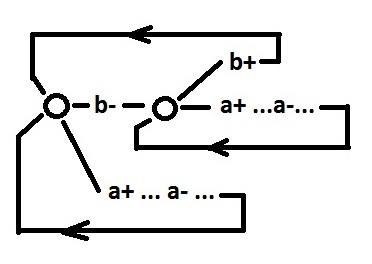
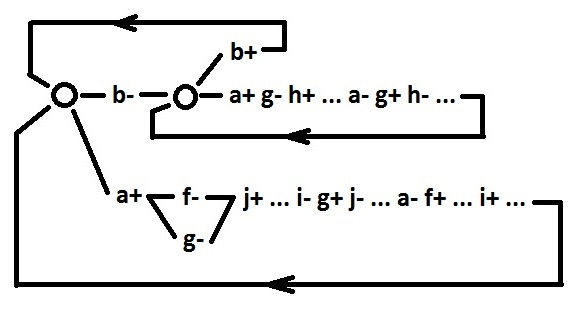
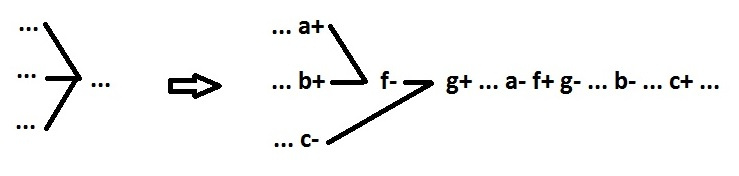


|
Метки: author ajrec fpga самосинхронные схемы |
[Из песочницы] История создания одной игры, или Все, что нас не убивает, делает нас сильнее |

| Статус | Дата | Событие |
|---|---|---|
| - | 5.8.2016 | Понимаем, что игра нам обойдется намного дороже, чем мы изначально планировали. Оно и понятно, запросы и желания по игре тоже выросли. |
| - | 8.8.2016 | Из проекта уходит программист, который работал над браузерной версией игры. |
| + | 9.8.2016 | У нас появляется страничка в магазине Steam. |
| + | 11.8.2016 | Меняем дизайн игры практически на 90%. |
| + | 16.8.2016 | На фрилансе находим звукорежисера и заказываем первые треки (меню и боевка). |
| - | 18.8.2016 | Команду покидает один из двух механиков. |
| - | 22.8.2016 | Отменяем Альфа-тест. |
| + | 27.8.2016 | Первый розыгрыш среди подписчиков группы ВКонтакте. |
| + | 5.9.2016 | Открываем регистрацию на альфа-тест. |
| + | 9.9.2016 | Сообщаем о том, что Альфа-тест проходит внутри команды и вместо него будет сразу бета-тест. |
| + | 7.9.2016 | Решаем ввести в игре двойные показатели на картах. «Прочность» — «Броня» и «Урон» — «Бронебойность». |
| + | 15.9.2016 | Первое видео обновленного дизайна игры. |
| + | 17.9.2016 | Презентуем музыкальный трек (Главная тема/меню) для игры. |
| Статус | Дата | Событие |
|---|---|---|
| + | 19.9.2016 | В преддверии ЗБТ рассылаем пресс-релизы. |
| + | 21.9.2016 | Нас начинают публиковать на различных порталах, в числе которых несколько крупных и известных игровых сайтов. |
| - | 27.9.2016 | Первый стрим/интервью. |
| + | 3.10.2016 | В нашей группе ВКонтакте 500 подписчиков. |
| + | 5.10.2016 | Презентуем первую сувенирную продукцию (кружки). |
| + | 6.10.2016 | Презентуем музыкальный трек (боевка) для игры |
| + | 11.10.2016 | Презентуем коллекционные карточки для Steam. |
| Статус | Дата | Событие |
|---|---|---|
| + | 25.10.2016 | Открытие нового сайта/форума. |
| - | 27.10.2016 | Сообщаем о том, что в связи с подставой предыдущего программиста ЗБТ отменяется. |
| - | 1.11.2016 | Начинаем рубрику «Дневник разработчика» с отчетами о процессе создания игры. |
| + | 11.11.2016 | Проводим конкурс на лучшую «обзывалку» исходя из названия Heroes of Card War. |
| + | 13.11.2016 | Отказываемся от полного названия игры (перестаем его публиковать) в пользу «обзывалки» аббревиатуры HoCWar, легко запомнить и красиво звучит:-) |
| + | 13.11.2016 | Вводим пакеты доступа. |
| - | 3.11.2016 | Команду покидает второй механик. |
| + | 5.11.2016 | Находим новых механиков, два человека, не любители, а профессионалы в играх жанра ККИ. Они знакомятся с наследством предыдущих механиков и вносят свои корректировки, в лучшую сторону. Первым делом отменяют двойные показатели на картах и возвращают это дело в привычный и простой для всех вариант «Урон/Здоровье» |
| + | 5.11.2016 | Переезд сайта на международный домен, .NET |
| - | 8.11.2016 | В Steam выходит обновление которое по сути отменяет стартовую рекламу новым играм. Мы понимаем, что из-за подставы предыдущего программиста, который кинул нас с игрой — мы опоздали и теперь рекламы нам не будет. |
| Статус | Дата | Событие |
|---|---|---|
| + | 11.1.2017 | Вводим в игру бота. |
| + | 13.1.2017 | Частичное обновление интерфейса. |
| + | 17.1.2016 | БОЛЬШАЯ раздача ключей доступа, 303 ключа. |
| + | 19.1.2017 | Презентуем дизайн «Простых карт». |
| + | 25.1.2017 | Заказываем шевроны в виде логотипа игры. |
| + | 3.2.2016 | В игре появляется внутриигровой магазин, это означает, что мы можем перевести игру в бесплатный доступ и начать ОБТ. |
| - | 11.2.2017 | Понимаем, что один программист не справляется, слишком много багов и другой работы. Начинаем поиски второго программиста. |
| + | 15.2.2017 | Возвращаемся к вопросу о переводах и локализации. Договариваемся с механиком который временно этим занимался, что теперь он будет постоянно работать по этому направлению. Не пришлось бежать снова на фриланс и искать еще одного сотрудника. |
| - | 15.2.2017 | Наш дизайнер пытается нас кинуть, путем шантажа получить с нас денег. Мы не идем на поводу. |
| - | 18.2.2017 | Дизайнер покидает нашу команду и подает жалобу в Steam, в которой указывает, что мы используем его работу без его разрешения. |
| + | 19.2.2017 | Идем на фриланс на поиски второго программиста. Люди начинают отзываться, но посмотрев код — отказываются. |
| - | 21.2.2017 | Нам временно блокируют игру в Steam. Необходимо заменить в игре практически всю графику. |
| + | 21.2.2017 | Принимаем решение, что от ныне даже не значительную мелочь заказанную у сторонних исполнителей — будем фиксировать через договор, дабы избежать потом претензий или шантажа от непорядочных исполнителей. |
| + | 23.2.2017 | Находим на фрилансе дизайнеров, не хотим терять много времени, в связи с этим берем не 1, а 5 человек. Начинается процесс создания и замены 95% графики в игре. |
| + | 26.2.2017 | По поискам второго программиста появляются результаты. Из более 15 желающих — несколько человек соглашаются взяться за наш проект. Выбираем на наш взгляд самого толкового (как показала практика, не прогадали, до сих пор с нами). |
| +- | 27.2.2017 | Нас покидает предыдущий (основной) программист. |
| - | 29.2.2017 | Мы узнаем, почему нас покинул предыдущий программист (в коде косяк на косяке). |
| Статус | Дата | Событие |
|---|---|---|
| - | 26.4.2017 | Предыдущий дизайнер снова подает жалобу в Steam и нам повторно блокируют игру. |
| + | 27.4.2017 | Мы грозим предыдущему дизайнеру судом за клевету, и он отзывает свою претензию в Steam. |
| + | 28.4.2017 | Нам снимают блокировку в Steam. |
| + | 29.4.2017 | Начинаем активную работу над способностями карт. |
| + | 3.5.2017 | Steam переводит игру в бесплатное распространение. Начало ОБТ. (Перевод на бесплатку решен. Модераторы Steam сперва предложили нам вернуть деньги уже тем кто купил игру, потом договорились на том, что всем кто приобрел игру за деньги, мы в качестве компенсации перед игроками, которые будут получать игру бесплатно — предоставить им в будущем одно из платных DLС — бесплатно. Что делать, наверное, это справедливо.) |
| + | 6.5.2017 | Презентуем еще один тип карт, самые простые — солдатские, изображение на которых стилизовано под рисунок карандашом, в черно-белом варианте. |
| - | 13.5.2017 | Мы понимаем, что пролетели с краудфандинг-проектом на бумстартере. |

|
Метки: author Psychoanalytic разработка под windows разработка игр unity3d карточные игры кки онлайн игры |
Ловись Data большая и маленькая! (Краткий обзор курсов по Data Science от Cognitive Class) |
В последнее время все чаще натыкаюсь на упоминание о «Data Science» или по-нашему «Наука о данных». Не являюсь специалистом в области IT и на протяжении всей жизни не дружу с мат. анализом и статистикой, поэтому я достаточно долго проходил мимо этого вопроса и наверное, продолжал бы проходить стороной, но в какой-то момент любопытство взяло верх.
Итак Cognitive Class он же Big Data University от IBM (иногда сокращенно BDU) – портал с бесплатными курсами по тематике близкой к BIG Data и соответственно Data Science.
Хотите узнать, чему он может или не может Вас научить, тогда милости прошу под кат.

Чтобы у Вас было понимание какими глазами я смотрел на этот курс пара тезисов обо мне:
Надеюсь, что вы не зря прочитали мою краткую биографию и она все же пригодится.
Будем исходить из того, что люди с разным «бэкграундом» будут смотреть на этот курс по-разному, поэтому не претендуя на объективность, начну:
По нелепой случайности, я глубоко убежден, что наверняка есть много другого качественного и полезного материала по данной теме, просто это была одна из ссылок и я по ней перешел.
Надо заметить, что в русскоязычном Интернет пространстве ни под новым брендом (Cognitive Class) ни под старым (Big Data University) портал особо не «светится». Скорее всего главная причина – он не переведен на русский язык.
Тем не менее, то что все материалы бесплатные, большая часть курсов базируется на open-source ПО, а по окончании выдают какие-то сертификаты и «бейджи»(о них позже), в сочетании с любопытством сделали свое дело. Ну и как плюс можно потренировать английский.
На сайте после регистрации открывается доступ к множеству курсов. Все курсы, что мне попадались можно было начинать в любой момент, ограничений по времени не было, взаимодействие с преподавателями или студентами тоже не требовалось.
Каждый курс можно пройти по отдельности, а можно в составе учебной программы (learning path). За прохождение каждого учебного курса выдается электронный сертификат, за выполнение требований учебной программы — бейдж
Интерфейс сайта напоминает любую другую систему дистанционного обучения, так что думаю сам процесс не должен вызывать проблем у опытных пользователей.
Поскольку о Data Science на момент регистрации я не знал вообще ничего, сам бог велел начать с программы обучения Data Science Fundamentals, в принципе это же мне подтвердил местный «Скайнет». На сайте есть бот (Student Advisor), если ему написать: «Data Science», то он как раз присоветует эту учебную программу. Для каких-либо более сложных и душевных бесед бот не подходит, потому что он понимает похоже только ключевые слова из тем курсов.
Приступим. На странице учебной программы, видно, что она состоит из нескольких курсов, ранжированных в рекомендуемом порядке прохождения (хотя никто не запрещает проходить в любом порядке).
При этом, для получения бейджика первой степени, как правило необходимо освоить самый первый курс учебной программы, для получения бейджика второй степени необходимо, как правило пройти все курсы программы. Рассмотрим её подробней.
Программа состоит из следующих курсов в рекомендуемом порядке прохождения
По окончанию всех — второй бейдж
Кратко о концепции «среднестатистического курса» на платформе.
Каждый курс из тех что мне попался обладает следующими свойствами:
Основной материал разбит на модули (похоже их всегда 5)
Есть вспомогательные разделы типа введения, экзамена, отзывов.
В каждом из учебных модулей, как правило есть одно видео (чаще больше) и почти всегда набор тестовых вопросов по пройденному материалу, также обычно есть лабораторные и иногда попадаются статьи.
Схема оценки обычно 50%/50%. Первая половина за итоговые тесты модулей, вторая за итоговый экзамен. Порог прохождения обычно 70%. В некоторых курсах значения могут меняться, не поленитесь заглянуть в раздел Grading Scheme.
Смотреть все видео или выполнять все лабораторные не обязательно, главное, чтобы вы сдали все тесты и сдали финальный экзамен.
Сами по себе тесты довольно простые, на любые вопросы, кроме тех, где надо ткнуть true/false дается 2 попытки без штрафа (в true/false – как у сапера нет права на ошибку). Обычно в конце модуля 3-4 вопроса, большинство из них с одним вариантом ответа из 3-5 значений, иногда попадаются вопросы с галочкой, иногда с полем для ввода, вопросы обычно по материалу и простые до ужаса. Время на сдачу теста не ограничено, «тыкать» в ответы можно в любой момент.
Экзамен в отличии от тестов надо сдать ровно за 60 минут (но можно и раньше), в остальном похож на тесты, только вопросов побольше (10-20).
По окончании каждого курса дадут сертификат и если предусмотрено бейдж (о них ближе к концу)
Давайте кратко разберем каждый курс программы, ну и я поделюсь впечатлениями о нем:
Data Science 101 – Полезный, воодушевляющий курс, чем-то напоминает курсы «Как стать программистом за 2 часа от известных школ программирования». В первом же видео, почтенный ученый из Канады, и молодые ребята расскажут Вам, кто такой Data Scientist и с чем его едят.
Еще раз напомню, что все курсы что мне попались были только на английском, но в большинстве случаев говорят понятно и субтитры есть (хотя есть и исключения)
После просмотра всех видео в модуле по идее должна быть лабораторная, но в этом курсе ее по сути нет, вместо нее в модулях будет 1 страничка из книги, в тестах к модулю как раз будут вопросы из этой странички, вопросы простые, достаточно просто пробежать глазами текст.
Собственно, финальный экзамен, тоже не блещет сложностью и по сути является проверкой знаний по чудо-книге из лабораторных.
С другой стороны, это же вводный курс, не будем хотеть от него чудес.
По окончанию курса вы в лучшем случае поймете, зачем вообще нужно было выдумывать этот Data Science. Практических навыков не дадут никаких.
Но зато вы получите бейдж который с гордостью подтвердит то что вы: «This badge earner has an understanding of the possibilities and opportunities that data science, analytics and big data bring to new applications in any industry.» Ценность его примерно, такая же как у «зайчиков», которые вместо оценок в моем детстве ставили в тетрадку первоклассникам
О других буду писать еще более сжато:
Data Science Methodology – Для меня этот курс как ни странно оказался сложным, причем в первую очередь из-за языкового барьера, если специфика английского для IT, глазу привычна, то более научная специфика языка, вызывала затруднения. Сам по себе курс реальной практики по сути не дает, но описывает основные концепции, рассказывает, как примерно должен думать Data Scientist (буду называть его так, потому что «ученый по данным» как-то не так круто звучит)
В отличии от прошлого курса, в этом уже есть некоторое подобие лабораторных, вы будете скачивать pdf тетрадку и если захотите, то даже отвечать на поставленные там вопросы (что не обязательно). Пару лабораторных вы сделать не сможете, потому что «пока не умете», авторы предлагают вам если захотите вернуться к ним позже (я не захотел).
Data Science Hands-on with Open Source Tools – Было бы странно если бы IBM в рамках своих курсов не продвигало бы свои разработки, данный курс познакомит вас с их инструментарием datascientistworkbench.com. Штука бесплатная, висит в облаке, один минус модули не очень быстро инициализируются. В рамках курса Вас научат пользоваться по всей видимости основными open-source инструментами, которые применяются для обработки данных (а может и нет, я профан в этом вопросе, поэтому буду верить IBM). Помимо вводной части основной упор будет сделан на следующие приложения: Jupyter Notebooks, Zeppelin Notebooks, RStudio IDE, Seahorse. Еще раз повторюсь все висит в облаке ставить ничего не надо.
В отличии от прошлых курсов, этот хоть уже предлагает небольшую практику, в рамках лабораторных, можно будет хоть чуть-чуть побаловаться инструментами, но уровень задач — для совсем начинающих. В принципе надо будет, просто посмотреть, как всё работает.
R 101 – тут мы подробней изучим основы языка R и их версию RStudio. Лабораторные уже приобретают хоть какой-то смысл, местами даже надо будет, чуть-чуть подправить их код, чтобы получить нужные для ответов в тестах цифры (если память меня не подвела). Но опять курс – для совсем новичков, чуть сложнее чем «Hello world», так что не питайте иллюзий программировать на R вы тут вряд ли так сразу научитесь.
Итак, по завершении всех курсов вы получает сертификаты и обещанный бейдж и тут у вас могут возникнуть проблемы.
Не то что бы бесплатный сыр был только в мышеловке, но дареному коню мы явно в зубы смотреть не будем.
Я думаю внимательный читатель уже догадался, что ценность сертификатов и бейджев стремится к нулю.
Сертификат он такой же, как и везде, можно им по ссылке поделиться, можно распечатать и в рамочку вставить.
Подавляющее большинство сертификатов и бейджев не требует верификации, а значит получить их может кто угодно.
Теперь про бейджи. Бейджи размещаются на сайте партнере https://www.youracclaim.com. (придется создавать еще 1 профиль), там вы можете в публичный доступ выставить все свои достижения и потом делиться ссылкой на профиль сразу со всеми, например в соц. сетях или резюме.
Проблемы. Представьте вы мужественно прошли все курсы на вторую ступеньку, получили все сертификаты, а бейджик вам не дали. Не расстраивайтесь если он вам очень нужен можете устроится в ритейл :). Будем считать, что зачеркнутый путь нам не подходит и начнем разбираться в чем же дело.
Если бейджа нет, первое на что стоит обратить внимание так это на вкладку Progress. Программа выдаст Вам сертификат, как только вы перевалите за пороговую планку (обычно 70%), а вот с бейджем сложнее. Обязательно убедитесь, что вы ответили на все вопросы в тестах (нажали Final Check там, где требуют). Если будет хоть 1 незачтенный вопрос в одном из курсов, учебную программу вам до конца не закроют.
Итак, вы пробежались по вкладе «прогресс» у всех курсов и убедились, что везде написано «ноу проблем», а бейджа все равно нет. Дальше начинается шаманизм, рекомендую открыть каждый курс еще раз и нажать на кнопку «Courseware». Если текст отличается по смыслу от:
«You were most recently in Get your completion certificate and badge. If you're done with that, choose another section on the left»
или от:
«You were most recently in Download your completion certificate. If you're done with that, choose another section on the left»,
то есть смысл перейти в те пункты куда он советует. Обязательно рекомендую запрашивать сертификат именно внизу вкладки «прогресс» по ссылке типа «Download your completion certificate» и там во все потыкать, заметил, что когда запрашиваешь сертификат на вкладке прогресс сверху он возможно не фиксирует тот факт, что обучение совсем закончилось.
Итак, мы разобрали стартовую учебную программу по Data science на площадке Cognitive class, для тех, кто уже устал от большого текста предлагаю перейти к заключению в конце статьи, для остальных бонус — краткое описание еще нескольких курсов.
Поскольку первая учебная программа была пройдена за день, а особых знаний не прибавилось, логично было продвинуться дальше, тем более сами разработчики учебных программ советуют перейти к Data Science for Business, ну и еще я решил посмотреть в сторону курса Statistics 101, с него и начну.
Statistics 101 – Похоже к этому курсу ребята «сдулись», потому, что после определенного момента к видео не сделали субтитры, конечно есть автоматический перевод Youtube, но по мне это не очень удобно. С моим плохим английским курс кажется сложным, по крайней мере если вам раньше в ВУЗе не давалась статистика, сложно ожидать, что вот на «басурманском» языке к вам придет озарение. И тем не менее курс несложный и что-то полезное сообщает (средне квадратичное отклонение, медиана, дисперсия и т.д.). Может быть есть смысл посмотреть его перед курсами по Data Science, а может и нет, вам решать.
Важно отметить, что для этого курса надо регистрироваться качать триал версию программы SPSS Statistics. Триал всего 14 дней, так что хоть формально время курса и не ограничено, лучше совсем не затягивать. Программа сама по себе дорогая, а курс завязан во многом на нее, поэтому в конечном счете курс мне не понравился =)
Data Science for Business
Состоит из:
К первым двум курсам нет субтитров для видео (вроде).
Кратко про каждый:
Data Privacy Fundamentals – курс на примере канадского законодательства говорит о том, как важно соблюдать информационную безопасность. Кроме текста и видео в курсе будет одно упражнение, где нам с помощью заготовок на R, подскажут как легко взломать ненадежные пароли. Ну а на экзамене придется «хакнуть» пароль для бедолаги Джастина (можно не «хакать», а просто «включить голову»)
Digital Analytics & Regression – курс наконец-то дает хоть немножечко адекватной практики и демонстрации анализа «небольших» данных на R. Не абы что, но все же полезно.
Predictive Modeling Fundamentals I – ужасный курс, на видео мужик часто шипит в микрофон и говорит так как будто у него во рту … леденец, причем не знаю глюк или нет, но на youtube видео не выложено, а в плеере на сайте нельзя включить субтитры так, чтобы они вылезали как нормальные субтитры (получается только сбоку) в итоге просмотр видео превращается в пытку.
Курс заточен под еще одно творенье от IBM — SPSS Modeler, так что надо опять скачивать триал (в этот раз на 30 дней)
В отличии от прошлых курсов материал к лабораторным нормально не подготовлен и если где-то ошибся, то решение надо искать самому, сверится не с чем, контрольного файла нет.
В рамках курса разбирают задачку про Титаник (как я понял тема, избитая до жути)
Я его до конца не осилил, после второго модуля сдался, просто бегло просмотрел видео, в трудных местах залез в Википедию, ответил на тесты + экзамен и успешно сдал этот курс (что еще раз говорит о низкой ценности сертификатов).
Предполагая, что в момент «развилки» не все прочитали часть 5, поэтому поделю свои впечатления на две части.
Пройдена только Data Science Fundamentals:
Ну в целом достаточно, для того, чтобы в самых общих чертах понять, что такое Data Science. Подготовки никакой не требуется, ни мат. анализом ни статистикой, ни программированием можно не владеть, главное «шпрейхать по-аглицки».
Думаю, итак очевидно, что за один день вы ничего толком не выучите и на 1500000 млн. рублей зарплату рассчитывать не стоит (я надеюсь вы еще не успели открыть «Хантер» и создать резюме?)
По идее этот курс должен развить у вас интерес к предмету и не напугать, в принципе разработчикам это удалось.
Пройдена Data Science Fundamentals + Data Science for Business + Statistics 101:
Рушит все надежды, потому что по-настоящему толковая практика так и не попалась, а курсы Data Science for Business + Statistics 101 выполнены несколько хуже по качеству чем Data Science Fundamentals, да еще и требуют установки триал версий программ от IBM.
Примеры в задачках не абы какие и оторваны во многом от реальности.
Наверное, пройдя все это, вы возможно, сдлаете для себя вывод — Data Science это ваше или нет, было ли вам до ужаса скучно или вы в восторге от колдовства над данными.
Подводя итог: Представленные курсы по пользе напоминают ситуацию, как если бы вас не умеющего водить машину, посадили бы за руль нормального автомобиля с автоматической коробкой передач, показали бы вам где газ и тормоз, как заводить машину и заливать бензин, как включить фары и дворники, ну и в конце под контролем дали бы проехать пару километров по проселочной дороге. С одной стороны водителем вы точно после этого не станете, с другой стороны если вы будете спасаться от маньяка с бензопилой возможно эти знания сохранят вашу жизнь. Ровно также и с этими курсами.
В любом случае, всем кто потратил время на обучение по программе от Cognitive class, советую не останавливаться на достигнутом. В конце концов даже у них там еще много чего интересного (Big Data, Hadoop, Scala и т.п.)
Если коллеги в комментариях порекомендуют, по-настоящему годные бесплатные ресурсы размещу их в обновлении к статье.
Спасибо за внимание, всем удачной недели!
|
Метки: author BosonBeard учебный процесс в it data science курсы обучение онлайн статистика ibm |
[Перевод] Не используйте return в Scala |
Сегодня я бы хотел представить вашему вниманию перевод небольшой статьи Роберта Норриса, возможно, знакомого вам под никнеймом tpolecat. Этот человек достаточно хорошо известен в Scala-сообществе как автор бибилиотеки doobie и участник проекта cats.
В своей публикации Роберт рассказывает о том, что использование return может негативно повлиять на семантику вашего кода, а также проливает свет на пару интересных особенностей реализации return в Scala. Оригинал статьи вы можете найти в блоге автора по ссылке.
Итак, каждый раз, когда на Coursera запускают курс Мартина, у нас на #scala появляются люди, вопрошающие, почему за return с них снимают очки стиля. Поэтому, вот вам ценный совет:
Ключевое слово return не является «необязательным» или «подразумевающимся» по контексту — оно меняет смысл вашей программы, и вам никогда не следует его использовать.Взглянем на этот небольшой пример:
// Сложим в методе два инта и затем используем его,
// чтобы просуммировать список.
def add(n: Int, m: Int): Int = n + m
def sum(ns: Int*): Int = ns.foldLeft(0)(add)
scala> sum(33, 42, 99)
res0: Int = 174
// То же самое, но при помощи return.
def addR(n:Int, m:Int): Int = return n + m
def sumR(ns: Int*): Int = ns.foldLeft(0)(addR)
scala> sumR(33, 42, 99)
res1: Int = 174Пока что все в порядке. Между sum и sumR нет очевидной разницы, что может навести вас на мысль о том, что return является просто необязательным ключевым словом. Но давайте слегка отрефакторим оба метода, вручную заинлайнив add и addR:
// Заинлайнили add.
def sum(ns: Int*): Int = ns.foldLeft(0)((n, m) => n + m)
scala> sum(33, 42, 99)
res2: Int = 174 // Вполне норм.
// Заинлайнили addR.
def sumR(ns: Int*): Int = ns.foldLeft(0)((n, m) => return n + m)
scala> sumR(33, 42, 99)
res3: Int = 33 // Хм...Если кратко, то:
Когда поток управления доходит до выражения return, текущее вычисление прекращается и происходит немедленный возврат из того метода, в теле которого находится return.В нашем втором примере оператор return не возвращает значение из анонимной функции — он возвращает значение из метода, внутри которого находится. Еще пример:
def foo: Int = {
val sumR: List[Int] => Int = _.foldLeft(0)((n, m) => return n + m)
sumR(List(1,2,3)) + sumR(List(4,5,6))
}
scala> foo
res4: Int = 1Когда функциональный объект, содержащий вызов return, выполняется нелокально, прекращение вычисления и возврат результата из него происходит путём возбуждения исключения NonLocalReturnControl[A]. Эта деталь реализации легко и без особых церемоний просачивается наружу:
def lazily(s: => String): String =
try s catch { case t: Throwable => t.toString }
def foo: String = lazily("foo")
def bar: String = lazily(return "bar")
scala> foo
res5: String = foo
scala> bar
res6: String = scala.runtime.NonLocalReturnControlЕсли кто-нибудь мне сейчас возразит, что перехватывать Throwable — дурной тон, я могу ему ответить, что дурной тон — использовать исключения для управления потоком исполнения. Глупость под названием breakable из стандартной библиотеки устроена аналогичным образом и, подобно return, не должна никогда использоваться.
Ещё пример. Что, если оператор return оказывается замкнут в лямбда-выражение, которое остаётся живым даже после того, как его родной метод отработал? Возрадуйтесь, в вашем распоряжении бомба замедленного действия, которая рванет при первой же попытке использования.
scala> def foo: () => Int = () => return () => 1
foo: () => Int
scala> val x = foo
x: () => Int =
scala> x()
scala.runtime.NonLocalReturnControl Дополнительным бонусом прилагается тот факт, что NonLocalReturnControl наследуется от NoStackTrace, поэтому у вас не будет никаких улик относительно того, где эта бомба была изготовлена. Классная штука.
return?В конструкции return a возвращаемое выражение a должно соответствовать по типу результату метода, в котором находится return, однако выражение return a и само по себе имеет тип. Исходя из его смысла «прекратить дальнейшие вычисления», вы, должно быть, догадались какой тип оно имеет. Если нет, вот вам чутка просвещения:
def x: Int = { val a: Int = return 2; 1 } // результат 2Видите, анализатор типов не ругается, так что можем предположить, что тип выражения return a всегда совпадает с типом a. Давайте теперь проверим эту теорию, попробовав написать что-то, что не должно работать:
def x: Int = { val a: String = return 2; 1 }Хм, тоже не ругается. Что вообще происходит? Каким бы ни был тип у return 2, он должен быть приводимым к Int и String одновременно. А так как оба эти класса являются final, а Int — еще и AnyVal, вы знаете, к чему всё идёт.
def x: Int = { val a: Nothing = return 2; 1 }Именно так, к Nothing. А всякий раз, сталкиваясь с Nothing, вам было бы благоразумнее развернуться и пойти другой дорогой. Так как Nothing — необитаем (не существует ни одного значения этого типа), то и результат return не имеет никакой нормального представления в программе. Любое выражение, имеющее тип Nothing, при попытке его вычислить обязано либо войти в бесконечный цикл, либо завершить виртуальную машину, либо (методом исключения) передать управление куда-либо еще, что мы и можем тут наблюдать.
Если вы сейчас подумали: «Вообще-то, в этом примере мы, по-логике, всего-лишь вызываем продолжение, мы постоянно так делаем в Scheme, и я совершенно не вижу тут проблемы», хорошо. Вот вам печенька. Но все, кроме вас, тут думают, что это безумие.
Это, как бы, очевидно. Но вдруг вы не совсем в курсе, что эти слова означают. Так вот, если у меня есть такой код:
def foo(n:Int): Int = {
if (n < 100) n else return 100
}то, будь он ссылочно прозрачным, я был бы вправе переписать его без изменения смысла вот так:
def foo(n: Int): Int = {
val a = return 100
if (n < 100) n else a
}Конечно, он не будет работать: выполнение return порождает побочный эффект.
Не нужно. Если вы окажетесь в ситуации, когда вам, по вашему мнению, нужно досрочно покинуть метод, на самом деле вам нужно переделать структуру кода. Например, вот это
// Складываем числа из списка до тех пор,
// пока их сумма меньше ста.
def max100(ns: List[Int]): Int =
ns.foldLeft(0) { (n, m) =>
if (n + m > 100)
return 100
else
n + m
}может быть переписано с использованием простой хвостовой рекурсии:
def max100(ns: List[Int]): Int = {
def go(ns: List[Int], a: Int): Int =
if (a >= 100) 100
else ns match {
case n :: ns => go(ns, n + a)
case Nil => a
}
go(ns, 0)
}Это преобразование возможно всегда. Даже полное устранение оператора return из языка не увеличит количество программ, которые невозможно написать на Scala, и на единицу. Вам может потребоваться немного усилий над собой, чтобы принять бесполезность return, но в результате вы поймёте, что куда проще писать код без внезапных возвратов, чем ломать голову в попытках предсказать побочные эффекты, вызванные нелокальными переходами потока управления.
От переводчика:
Большое спасибо Бортниковой Евгении за вычитку. Отдельная благодарность firegurafiku за уточнения в переводе. Спасибо Владу Ледовских, за пару дельных советов которые сделали перевод немного точнее.
|
Метки: author ppopoff функциональное программирование программирование scala return goto |
[Из песочницы] В чем сущность дизайна? Нахожу ответ на вопрос рассматривая UI и UX, новые термины в области веб-дизайна |
|
Метки: author Iwan_Terkin77 графический дизайн веб-дизайн ui ux дизайн инженерная психология альтамира дубна архитектор домостроительство домострой дом |
[Из песочницы] Альтернатива Emacs Lisp'у |
![]()
Вы когда-нибудь искали альтернативу Emacs Lisp'у? Давайте попробуем добавить в Emacs ещё один язык программирования.
В этой статье:
Статья может заинтересовать пользователей Emacs'а, а также тех, кому небезразличны все эти бесчисленные реализации бесчисленных языков программирования.
В самом конце статьи представлена ссылка на work in progress проект, который позволяет конвертировать Go в Emacs Lisp.
Как и любой другой язык программирования, Emacs Lisp имеет ряд "недостатков", которые мы будем политкорректно назвать "design tradeoffs". Говорить "лучше" или "хуже" о тех или иных свойствах языка программирования на объективном уровне достаточно сложно, потому что почти всегда найдутся защитники противоположных позиций. Нам же, как пользователям языков программирования, можно стараться выбрать тот язык, чьи компромиссы нам принять проще в силу наших задач или личных предпочтений. Ключевой момент — возможность выбора.
Предположим, что мы выбрали Go. Как вы будете использовать Go для взаимодействия с редактором?
Ваши варианты:
Способов может быть больше, но ни один из них не будет ближе к "нативному" лиспу, чем (3). Он позволяет на уровне исполнения иметь ту же виртуальную машину, что и обычный Emacs Lisp.
Это, в свою очередь, означает, что:
Если вы в первый раз слышите о байт-коде Emacs'а, ознакомьтесь со статьёй Chris Wellons.
На месте Go потенциально мог бы быть любой другой язык программирования.
Есть несколько причин из-за которых сделанный выбор становится более обоснованным. Основные из них:
Есть также те свойства, которые могли бы быть аргументами в пользу выбора, но конкретно для меня они были менее значимыми:
Пакеты go/* значительно упрощают написание инструментов для Go.
Не нужно писать parser, typechecker и прочие прелести frontend'а компилятора. За 20 строк кода мы можем получить AST и информацию о типах для целого пакета.
Документация, по большей части, хороша. А для go/types на мой взгляд — образцовая.
Изначально для меня это было убийственным аргументом. Задача казалась на 90% решённой благодаря этому секретному оружию: "осталось только преобразовать AST в байт-код Emacs'а".
На практике возникали сложности с теми или иными нюансами.
В первую очередь — запутанность API и дублирование разными пакетами похожих сущностей, да ещё и под одинаковыми именами. Часто одно и то же можно сделать через go/ast и go/types; не редко вам нужно перемешивать сущности из обоих пакетов (да-да, в том числе те, что с одинаковыми именами).
Ещё на удивление неудобной оказалась работа с import'ами и декларациями (ох уж этот ast.GenDecl).
Многие решения, с помощью которых вы можете решить эти проблемы, выглядят как "грязные хаки". Детальное описание этих хаков — это, возможно, материал для отдельной статьи (тем более я не проверял обилие информации на эту тему в интернете, наверняка уже всё успели разжевать и не раз).
Создать реализацию, которая в большей степени (~80%) конформна спецификации — вполне посильная задача для одного человека. Спецификацию Go легко читать, её можно осилить за вечер.
Особенности спецификации:
Чем больше в языке фич, которые реализуются в библиотеке времени выполнения, тем сложнее их будет транскомпилировать.
Если хотя бы временно выбросить за борт горутины и каналы, то останется компактное ядро, которое вполне можно реализовать в терминах Emacs Lisp без потери производительности.
Это чертовски приятно, когда многие привычные фичи работают в нескольких твоих любимых редакторах, причём единообразно.
Для Go многие функции, которые обычно переизобретаются для каждой IDE отдельно, реализованы в виде отдельных утилит. Самый простой пример, известный каждому Go разработчику — gofmt. В немалой степени этому способствуют упомянутые выше go/types,
go/build и остальные пакеты из группы go/*.
Sublime text, Emacs, Visual Studio Code — выбираешь любой из них, ставишь плагин(ы), и наслаждаешься рефакторингом через gorename, множеством линтеров и автоматическими import'ами. А автодополнение… превосходит company-elisp во многих аспектах.
Рефакторить и поддерживать проект на Emacs Lisp уже после 1000 строк кода лично мне уже некомфортно. Программировать Emacs на Go чуть ли не удобнее, чем на Emacs Lisp.
Пофантазируем на тему того, как мог бы выглядеть Go для Emacs'а. Насколько он был бы удобен и функционален?
Перед тем как говорить непосредственно о вызовах Lisp функций, нужно продумать мост, который соединяет два языка программирования, работающих на одной и той же вычислительной модели.
С примитивными типами вроде int, float64, string и другими всё более-менее просто. И в Go, и в Emacs Lisp эти типы присутствуют.
Интерес представляют слайсы, символьные типы (symbol) и беззнаковые целочисленные типы фиксированной разрядности (uintX).
Тип, который может выразить "объект произвольного типа", который возвращается Emacs Lisp функцией, назовём lisp.Object. Его определение дано под спойлером lisp.Object: детали реализации.
Для аналогии: слайсы в Go по своему "интерфейсу" — это std::vector из C++, но с возможностью брать полноценный subslice без копирования элементов.
Начнём с интуитивного представления {data, len, cap}.
data будет вектором, len и cap — числами. Чтобы хранить атрибуты выбираем improper list, где у нас нет финального nil, чтобы немного экономить память:
(cons data (cons len cap))
Если вкратце, то: выбор между списком и вектором здесь не особо критичен, так что можно было взять вектор.
Более развёрнутый ответ на этот вопрос поможет найти дизассемблер (или таблица опкодов). Доступ к спискам из 2-3 элементов — очень эффективный. Чем ближе к голове списка, тем более ощутима разница. Атрибут data используется чаще всего, поэтому он в самом начале списка.
При N=4 можно считать, что список начинает уступать по эффективности в случае считывания последнего элемента, но остальные три атрибута всё так же более эффективны в доступе => даже для объектов из четырёх атрибутов я склонен полагать, что список является более удачной структурой, чем вектор.
Оговорка: это всё справедливо для виртуальной машины Emacs'а, её набора инструкций. Вырывать из контекста не стоит.
Операции slice-get/slice-set будут очень эффективными. У нас будет тот же aset/aget, но с одной дополнительной инструкцией car для извлечения атрибута data.
Но что будет, когда нам нужен subslice?
В C можно было бы data сделать указателем и сместить его, куда нужно. Адресация была бы такой же, 0-based. В нашем случае это невозможно, что приводит к необходимости хранить ещё и offset:
(cons data (cons offset (cons len cap)))
Для каждого slice-get/slice-set теперь нужно к индексу прибавлять offset.
Сравним байт-код для операции slice-get.
;; Обычный вектор
;; [vector]
;; [vector index]
aref ;; [elem]
;; Slice без offset (не поддерживаем subslice)
;; [slice]
car ;; [data]
;; [data index]
aref ;; [elem]
;; Slice с поддержкой subslice
;; [slice]
dup ;; [slice slice] (1)
car ;; [slice data]
stack-ref 1 ;; [slice data slice]
cdr ;; [slice data slice.cdr]
car ;; [slice data offset]
;; [slice data offset index]
plus ;; [slice data real-index]
aref ;; [slice elem]
stack-set 1 ;; [elem] (2)
;; (1) Поскольку может быть дорогим выражением, мы
;; вычисляем его единожды.
;; (2) Нам требуется восстановить инвариант стека и удалить
;; лишний slice со стека. С помощью нотации stack-ref, до call со множеством аргументов). Справа от кода отображено состояние стека данных.
Некоторые типы мы не захотим/не сможем выразить как Go структуры. К таким типам относятся lisp.Object, lisp.Symbol и lisp.Number.
Главной целью opaque типа для нас является запрет на произвольное создание объектов через литералы. С этим отлично справляются интерфейсные типы с неэкспортируемым методом.
type Symbol interface {
symbol()
}
type Object interface {
object()
// Другие методы...
}
// Для создания объектов должна использоваться специальная функция-конструктор.
// Intern returns the canonical symbol with specified name.
func Intern(name string) SymbolФункция Intern обрабатывается компилятором по-особому. Другими словами она — intrinsic функция.
Теперь мы можем быть уверены, что у этих особых типов такое API, которое мы хотим им придать, а не то, какое возможно по законам Go.
Если lisp.Object представляет "любое значение", то почему мы не используем interface{}?
Вспомним, что такое interface{} в Go — это структура, хранящая в себе динамический тип объекта, плюс сам объект — "данные".
Это не совсем то, чего хотелось бы, потому что для Emacs'а такое представление "чего угодно" не является эффективным. lisp.Object нужен для того чтобы хранить unboxed Emacs Lisp значения,
которые легко можно передавать в функции лиспа и получать в качестве результата.
Для того, чтобы можно было получить из lisp.Object значение конкретного типа, можно добавить дополнительные методы в его интерфейс.
type Object interface {
object()
Int() int
Float() float64
String() string
// ... etc.
// Можно также предоставить следующие методы:
IsInt() bool // Предикат для проверки типа
GetInt() (val int, ok bool) // Для "comma, ok"-style извлечения
// ... аналоги для оставшихся типов.
}Каждый вызов генерирует проверку типа. Если внутри lisp.Object хранится значение отличного от запрошенного типа, должен быть вызван panic. Чем-то напоминает API reflect.Value, не так ли?
Если сигнатура функции неизвестна, то единственное, что нам остаётся — это принимать вариативное количество аргументов произвольного типа, а возвращать lisp.Object.
pair := lisp.Call("cons", 1, "2")
a, b := lisp.Call("car", pair), lisp.Call("cdr", pair)
lisp.Call("insert", "Hello, Emacs!")
sum := lisp.Call("+", 1, 2).Int()Функции, аннотированные вручную, можно вызывать более удобным способом.
part := "c"
lisp.Insert("Hello, Emacs!") // Возвращает void
s := lisp.Concat("a", "b", part) // Возвращает string, принимает ...stringDSL для аннотирования функций можно написать на макросах.
;; Пример описания функций, доступных через FFI.
(ffi-declare
(concat Concat (:string &parts) :string)
(message Message (:string format :any &args) :string)
(insert Insert (:any &args) :void)
(+ IntAdd (:int &xs) :int))
;; Разворачивается макрос, например, в Go сигнатуры.
Разворачиваться такой макрос должен в Go сигнатуры функций. Нужно оставлять комментарий-директиву для сохранения информации о том, какую Lisp функцию следует вызывать.
// IntAdd - ... <комментарий функции + из Emacs>
//$GO-ffi:+
func IntAdd(xs ...int) int
// ... Остальные функцииДокументацию можно подтягивать из Emacs'а функцией documentation. Получаем функции с известной арностью и при этом не теряем ценные docstrings.
Результатом транскомпиляции будет Emacs Lisp пакет, в котором все символы из Go имеют преобразованный вид.
Схема преобразования идентификаторов может быть, например, такой:
package "foo" func "f" => "$GO-foo.f"
package "foo/bar" func "f" => "$GO-foo/bar.g"
package "foo" func (typ) "m" => "$GO-foo.typ.m"
package "foo" var "v" => "$GO-foo.v"Соответственно для того, чтобы вызвать функцию или воспользоваться переменной, нужно знать какому Go пакету она принадлежала (и её название, разумеется). Префикс $GO позволяет избежать конфликтов с уже определёнными в Emacs именами.
В качестве выходного формата можно выбирать среди трёх вариантов:
Первый вариант сильно проигрывает остальным вариантам, потому что он не позволит эффективно транслировать return statement, а ещё в нём сложнее реализовать оператор goto (который есть в Go).
Второй и третий варианты по возможностям практически эквивалентны.
Компилятор Emacs'а умеет оптимизировать на уровне исходного кода и lapcode представления.
Если выбираем lapcode, то можем дополнительно применять низкоуровневые оптимизации,
реализованные Emacs разработчиками.
Lisp assembly program — это внутренний формат компилятора Emacs'а (IR). Документации по нему ещё меньше, чем по байт-коду.
Писать на этом "ассемблере" самостоятельно практически невозможно из-за особенностей оптимизатора, который может сломать ваш код.
Я так и не нашёл точного описания формата инструкций. Здесь помогает метод проб и ошибок, а также чтение исходников компилятора Emacs Lisp'а (вам понадобятся стальные нервы).
Go, который "бегает" внутри Emacs VM не может быть быстрее Emacs Lisp.
Или может?
В Emacs Lisp есть динамический scoping для переменных. Если вы заглянете в "emacs/lisp/emacs-lisp/byte-opt.el", то сможете найти множество отсылок к этой особенности языка; из-за неё некоторые оптимизации либо невозможны, либо значительно затруднены.
Констант в Emacs Lisp нет. Имена, объявленные с помощью defconstant менее неизменяемые, чем те, что определены через defvar. В Go константы встраиваются в место использования, что позволяет сворачивать больше константных выражений.
Оптимизировать Go код проще, поэтому можно ожидать как минимум не уступающую обычному Emacs Lisp коду производительность. Потенциально, обгон в плане быстродействия реален.
Даже без горутин есть такие возможности Go, которые не имеют очевидной и/или оптимальной реализации внутри Emacs VM.
Наиболее интересной трудностью являются указатели.
В контексте задачи мы можем выделить две категории значений в Emacs Lisp:
string, vector, list/cons)integer и float)Для ссылочных типов задача решается попроще.
Взятие адреса от переменной типа int или float требует обработки
большего количества граничных случаев.
Ещё не следует забывать, что для указателей определён оператор =,
поэтому предлагаемым решением должно соблюдаться тождество адресов объектов.
Заворачивая number в cons, пролетаем по семантике,
потому что значение, у которого взяли адрес,
не будет меняться в случае изменения данных, хранимых в cons.
Если все числа изначально создавать в boxed виде (внутри cons),
сильно повысится количество аллокаций.
Распаковка будет требовать дополнительную инструкцию car при каждом считывании значения.
У реализации указателей через cons есть значительный изъян: &x != &x,
потому что (eq (cons x nil) (cons x nil)) всегда ложно.
Корректная эмуляция семантики указателей — это открытый для обсуждения вопрос.
Буду рад услышать ваши идеи для их реализации.
Проект goism — это инструмент, который позволяет получать из Go пакетов близкий к оптимальному Emacs Lisp байт-код.
Библиотека времени выполнения изначально была написана на лиспе, но с недавних пор полностью переписана на транслируемом в lapcode Go.
emacs/rt на данный момент — один из самых крупных пакетов, написанных с помощью goism.
На данный момент goism не особо дружелюбен по отношению к конечному пользователю,
придётся работать руками, чтобы правильно его собрать и настроить
(guick start guide должен упростить задачу).
Почему статья написана именно сейчас, а не когда вышла более стабильная версия? Ответ довольно прост: нет гарантий, что эта самая версия когда-либо будет готова, плюс дорабатывать можно очень и очень долго.
Хочется узнать, кажется ли членам хабра-сообщества эта идея интересной и полезной.
|
Метки: author quasilyte компиляторы go emacs emacs lisp compilers |
Вариант быстрой настройки системы управления оптовой компанией |



















|
Метки: author leanoffice crm- системы crm |
[Перевод] Типичные распределения вероятности: шпаргалка data scientist-а |
|
Метки: author kayan математика татистика data science теория вероятности и мат статистика |
Функциональное программирование в Scala — нужно ли оно вообще? |
object Main {
def square(v: Int): Int = v * v
def cube(v: Int): Int = v * v * v
def abs(v: Int): Int = if (v < 0) -v else v
def fun(v: Int): Int = {
4 * cube(v) + 2 * square(v) + abs(v)
}
println(fun(42))
}
object Main {
def square(v: Int): Int = v * v
def cube(v: Int): Int = v * v * v
def abs(v: Int): Int = if (v < 0) -v else v
// выносим все зависимости в аргументы функции
// сразу делаем частичное каррирование (два списка аргументов), чтобы упростить частичное применение аргументов чуть ниже
def fun(
square: Int => Int,
cube: Int => Int,
abs: Int => Int)
(v: Int): Int = {
4 * cube(v) + 2 * square(v) + abs(v)
}
// делает мемоизацию - по функции одного аргумента возвращает функцию того же типа,
// которая умеет себя кешировать
def memoize[A, B](f: A => B): A => B = new mutable.HashMap[A, B] {
override def apply(key: A): B = getOrElseUpdate(key, f(key))
}
val cachedCube = memoize(cube)
// cachedFun - это лямбда с одним аргументом, умеющая кешировать cube. Тип функции - как в первом примере
val cachedFun: Int => Int = fun(
square = square,
cube = cachedCube,
abs = abs)
println(cachedFun(42))
}
object Test3 {
trait Ops {
def square(v: Int): Int = v * v
def cube(v: Int): Int = v * v * v
def abs(v: Int): Int = if (v < 0) -v else v
}
def fun( //более симпатичная сигнатура, не так ли?
ops: Ops)
(v: Int): Int = {
4 * ops.cube(v) + 2 * ops.square(v) + ops.abs(v)
}
// мемоизация уже не нужна - мы можем просто переопределить поведение методов
// дополнительный бонус - мы управляем мутабельным состоянием явно
// т.е. можем выбирать время жизни кеша - к примеру, не создавать Map здесь,
// а использовать какую-то внешнюю реализацию. Из Guava к примеру.
val cachedOps = new Ops {
val cache = mutable.HashMap.empty[Int, Int]
override def cube(v: Int): Int = cache.getOrElseUpdate(v, super.cube(v))
}
val realFun: Int => Int = fun(cachedOps)
println(realFun(42))
}
object Main {
trait Ops {
def square(v: Int): Int = v * v
def cube(v: Int): Int = v * v * v
def abs(v: Int): Int = if (v < 0) -v else v
}
class MyFunctions(ops: Ops) {
def fun(v: Int): Int = {
4 * ops.cube(v) + 2 * ops.square(v) + ops.abs(v)
}
}
val cachedOps = new Ops {
val cache = mutable.HashMap.empty[Int, Int]
override def cube(v: Int): Int = cache.getOrElseUpdate(v, super.cube(v))
}
val myFunctions = new MyFunctions(cachedOps)
println(myFunctions.fun(42))
}
|
Метки: author Scf функциональное программирование программирование scala functional programming |
Терминология OneGet, NuGet, Chocolatey, PowerShellGet — разложим по полочкам |
chocolatey для установки приложений, nuget — для установки зависимостей разработчиком.
Install-Package <имя pip-пакета>pip install <имя pip-пакета>Install-Package <имя nupkg-пакета>nuget install <имя nupkg-пакета>PS C:\> nuget source list
Registered Sources:
1. nuget.org [Enabled]
https://api.nuget.org/v3/index.json
2. ABC [Enabled]
http://<тут_я_спрятал_IP>/artifactory/api/nuget/<имя_репо>PS C:\> gem sources
*** CURRENT SOURCES ***
https://rubygems.orgPS C:\> Get-PackageProvider
Name Version DynamicOptions
---- ------- --------------
Chocolatey 2.8.5.130 SkipDependencies, ContinueOnFailure, ExcludeVers
ChocolateyGet 1.0.0.1 AdditionalArguments
msi 3.0.0.0 AdditionalArguments
msu 3.0.0.0
NuGet 2.8.5.208 Destination, ExcludeVersion, Scope, SkipDependen
PowerShellGet 1.0.0.1 PackageManagementProvider, Type, Scope, AllowClo
Programs 3.0.0.0 IncludeWindowsInstaller, IncludeSystemComponent
PS C:\> Get-PackageSource
Name ProviderName IsTrusted Location
---- ------------ --------- --------
nuget.org NuGet False https://api.nuget.org/v3/index.json
PSGallery PowerShellGet False https://www.powershellgallery....
chocolatey Chocolatey False http://chocolatey.org/api/v2/
PS C:\> Get-PSRepository -Name "PSGallery" | Format-List * -Force
Name : PSGallery
SourceLocation : https://www.powershellgallery.com/api/v2/
Trusted : False
Registered : True
InstallationPolicy : Untrusted
PackageManagementProvider : NuGet
PublishLocation : https://www.powershellgallery.com/api/v2/package/
ScriptSourceLocation : https://www.powershellgallery.com/api/v2/items/psscript/
ScriptPublishLocation : https://www.powershellgallery.com/api/v2/package/
ProviderOptions : {}PS C:\> Get-PackageSource -Name "PSGallery" | Format-List * -Force
Name : PSGallery
Location : https://www.powershellgallery.com/api/v2/
Source : PSGallery
ProviderName : PowerShellGet
Provider : Microsoft.PackageManagement.Implementation.PackageProvider
IsTrusted : False
IsRegistered : True
IsValidated : False
Details : {[ScriptPublishLocation, https://www.powershellgallery.com/api/v2/package/], [InstallationPolicy, Untrusted], [PackageManagementProvider, NuGet],
[ScriptSourceLocation, https://www.powershellgallery.com/api/v2/items/psscript/]...}
|
Метки: author Singaporian системы сборки разработка под windows visual studio c# nuget chocolatey windows пакетный менеджер |
Android: динамически подгружаем фрагменты из сети |
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
// Inflate the layout for this fragment
//return inflater.inflate(R.layout.fragment1, container, false);
LinearLayout linearLayout = new LinearLayout(getActivity());
linearLayout.setOrientation(LinearLayout.VERTICAL);
linearLayout.setGravity(Gravity.CENTER);
LinearLayout.LayoutParams lp = new LinearLayout.LayoutParams(
ViewGroup.LayoutParams.WRAP_CONTENT, ViewGroup.LayoutParams.WRAP_CONTENT);
Button button = new Button(getActivity());
button.setText("Кнопка");
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
showFragment("jatx.networkingclassloader.dx.Fragment1", null); // рассмотрим чуть позже
}
});
linearLayout.addView(button, lp);
return linearLayout;
}
@Override
protected void onCreate(Bundle savedInstanceState) {
// ......
dataDir = getApplicationInfo().dataDir;
frameLayout = (FrameLayout) findViewById(R.id.main_frame);
progressDialog = new ProgressDialog(this);
progressDialog.setIndeterminate(true);
progressDialog.setMessage("Загружаем классы из сети");
progressDialog.show();
// Загружаем classes.dex с сервера, подробно рассматривать не будем:
DownloadTask downloadTask = new DownloadTask(this, dataDir);
downloadTask.execute(null, null, null);
// receiver нужен для того, чтобы мы могли из фрагмента открывать другие фрагменты:
BroadcastReceiver receiver = new BroadcastReceiver() {
@Override
public void onReceive(Context context, Intent intent) {
String className = intent.getStringExtra("className");
Bundle args = intent.getBundleExtra("args");
showFragment(className, args);
}
};
IntentFilter filter = new IntentFilter("jatx.networkingclassloader.ShowFragment");
registerReceiver(receiver, filter);
}
// Вызывается, когда наш AsyncTask успешно загрузил c сервера classes.dex:
public void downloadReady() {
Toast.makeText(this, "Классы из сети загружены", Toast.LENGTH_SHORT).show();
progressDialog.dismiss();
showFragment("jatx.networkingclassloader.dx.Fragment0", null);
}
public void showFragment(String className, Bundle arguments) {
// Наш загруженный файл:
File dexFile = new File(dataDir, "classes.dex");
Log.e("Networking activity", "Loading from dex: " + dexFile.getAbsolutePath());
// Каталог кэша, нужен для DexClassLoader:
File codeCacheDir = new File(getCacheDir() + File.separator + "codeCache");
codeCacheDir.mkdirs();
// Создаем ClassLoader:
DexClassLoader dexClassLoader = new DexClassLoader(
dexFile.getAbsolutePath(), codeCacheDir.getAbsolutePath(), null, getClassLoader());
try {
// Загружаем класс фрагмента по имени:
Class clazz = dexClassLoader.loadClass(className);
// Создаем объект класса:
Fragment fragment = (Fragment) clazz.newInstance();
// Передаем фрагменту аргументы и отображаем его:
fragment.setArguments(arguments);
FragmentManager fragmentManager = getFragmentManager();
FragmentTransaction fragmentTransaction = fragmentManager.beginTransaction();
fragmentTransaction.add(R.id.main_frame, fragment);
fragmentTransaction.commit();
} catch (Exception e) {
e.printStackTrace();
}
}
public void showFragment(String className, Bundle args) {
Intent intent = new Intent("jatx.networkingclassloader.ShowFragment");
intent.putExtra("className", className);
intent.putExtra("args", args);
getActivity().sendBroadcast(intent);
}
protected void loadLayoutFromURL(FrameLayout container, String url) {
this.container = container;
// загружаем файл разметки:
LayoutDownloadTask layoutDownloadTask = new LayoutDownloadTask(this, url);
layoutDownloadTask.execute(null, null, null);
}
// Вызывается, если xml-разметка успешно загружена:
public void onLayoutDownloadSuccess(String xmlAsString) {}
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
FrameLayout frameLayout = new FrameLayout(getActivity());
loadLayoutFromURL(frameLayout, "http://tabatsky.ru/testing/fragment1.xml");
return frameLayout;
}
@Override
public void onLayoutDownloadSuccess(String xmlAsString) {
LinearLayout linearLayout = (LinearLayout) DynamicLayoutInflator.inflate(getActivity(), xmlAsString, container);
FrameLayout.LayoutParams lp = new FrameLayout.LayoutParams(
ViewGroup.LayoutParams.MATCH_PARENT, ViewGroup.LayoutParams.MATCH_PARENT);
linearLayout.setLayoutParams(lp);
final EditText editText = (EditText) DynamicLayoutInflator.findViewByIdString(linearLayout, "edit_text");
Button button = (Button) DynamicLayoutInflator.findViewByIdString(linearLayout, "button");
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Bundle args = new Bundle();
args.putString("userName", editText.getText().toString());
showFragment("jatx.networkingclassloader.dx.Fragment2", args);
}
});
}
|
Метки: author jatx разработка под android java android development classloader networking |
[recovery mode] Новый плагин для гарнитур Sennheiser и бесплатное обновление до 3CX v15.5 |

|
|
Размышления на тему науки программирования |
 Программирование не является наукой на сегодняшний день. Но когда сфера пройдет некоторую критическую точку и станет наукой, то какой? Технической (точной) или гуманитарной (не точной)? Статья — свободное размышление на данную тему. Автор имеет 9 классов образования и с темой про науку, написанную за 2 часа перед сном, залезает «со свиным рылом в
Программирование не является наукой на сегодняшний день. Но когда сфера пройдет некоторую критическую точку и станет наукой, то какой? Технической (точной) или гуманитарной (не точной)? Статья — свободное размышление на данную тему. Автор имеет 9 классов образования и с темой про науку, написанную за 2 часа перед сном, залезает «со свиным рылом в Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author pistol программирование наука |






