Как управлять SSH-ключами на уровне предприятия |

«Такой файл очень быстро теряет свою актуальность, часть ключей не вносят, часть не удаляют, информацию вовремя не меняют, а потом забывают. Это приводит к колоссальному расхождению с реальной картиной, — говорит начальник отдела развития проекта 1cloud Сергей Белкин. — Более того, сразу возникает соблазн организовать удаленный доступ к такому файлу. Были случаи, когда пользователи выкладывали его, например, в Dropbox. А за последние годы подобные сервисы не раз страдали от масштабных утечек данных».

|
Метки: author 1cloud системное администрирование серверное администрирование блог компании 1cloud.ru 1cloud ssh администрирование |
В гостях у сказки: патентные тролли |






|
Метки: author LKulakova патентование законодательство и it-бизнес блог компании parallels parallels патентные тролли интеллектуальная собственность право ит рунет |
[Перевод] Kotlin в продакшене, что мы получили, и что мы потеряли? |
 С того времени, как Google сделал Koltin новой любимой женой уже прошло достаточно времени. И сразу же после этого объявления наша команда начала новый проект полностью на Котлине. Проясню: не тестовый или просто внутренний проект, а новый модуль для живого приложения с 600+ тысячами активных пользователей в месяц. Какой опыт мы из этого извлекли? Что мы выиграли и что потеряли?
С того времени, как Google сделал Koltin новой любимой женой уже прошло достаточно времени. И сразу же после этого объявления наша команда начала новый проект полностью на Котлине. Проясню: не тестовый или просто внутренний проект, а новый модуль для живого приложения с 600+ тысячами активных пользователей в месяц. Какой опыт мы из этого извлекли? Что мы выиграли и что потеряли?|
Метки: author fo2rist разработка под android android android development kotlin |
Байки поддержки первой линии: отличная работа, если у вас крепкие нервы |

|
Метки: author MVitoslavskiy системное администрирование it- инфраструктура блог компании крок техподдержка |
Наша методика расчета стека печатных плат |
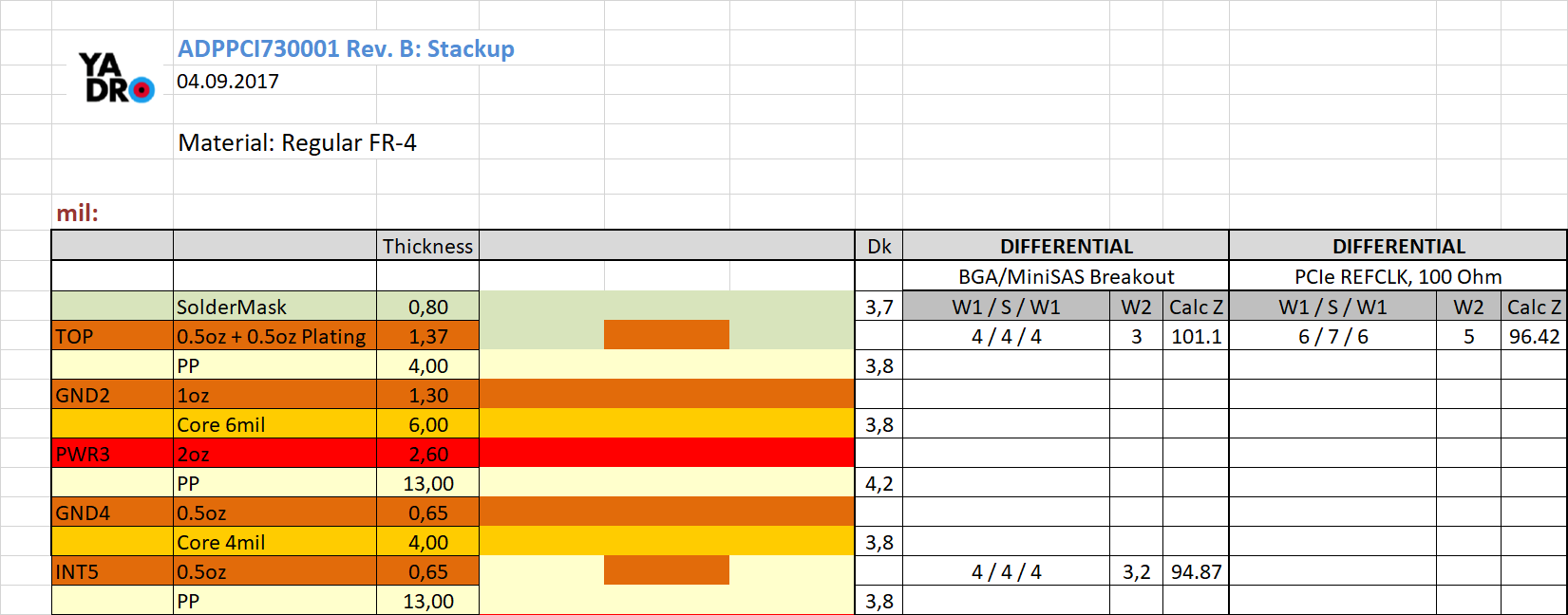


| Условия | Изменение толщины препрега при начальном значении | |
|---|---|---|
| Не более 2.3 mil | Более 2.3 mil | |
| Прилегание к меди 0.5 oz с 30% заполнением | 0.4 mil | 0.4 mil |
| Прилегание к меди 0.5 oz с 70% заполнением | 0.1 mil | 0.2 mil |
| Прилегание к меди 1 oz с 30% заполнением | 0.8 mil | 0.9 mil |
| Прилегание к меди 1 oz с 70% заполнением | 0.3 mil | 0.4 mil |
| Прилегание к меди 2 oz с 30% заполнением | 1.8 mil | 1.9 mil |
| Прилегание к меди 2 oz с 70% заполнением | 0.8 mil | 0.8 mil |
| Расположен между двумя слоями препрега | 9% | 10% |
| Прилегание к внешнему слою | не изменяется | не изменяется |


| Тип слоя | Начальная толщина | Изменение толщины | Финишная толщина |
|---|---|---|---|
| Внешний | 1.35 mil | — | 1.35 mil |
| Слой 2116 | 5.1 mil | — | 5.1 mil |
| Слой 2116 | 5.1 mill | 0.9 mil | 4.2 mil |
| Внутренний сигнальный | 1.35 mil | — | 1.35 mil |
| Core | 39 mil | — | 39 mil |
| Внутренний Plane | 1.35 mil | — | 1.35 mil |
| Слой 2116 | 5.1 mil | 0.4 mil | 4.7 mil |
| Слой 2116 | 5.1 mil | — | 5.1 mil |
| Внешний | 1.35 mil | — | 1.35 mil |
| Итого: | 63.5 mil ± 10% |

| Тип слоя | Фабрика 1 | Фабрика 2 | Фабрика 3 | Фабрика 4 | ||||
|---|---|---|---|---|---|---|---|---|
| EF | W2-W1 | EF | W2-W1 | EF | W2-W1 | EF | W2-W1 | |
| Внешний 0.5 oz | 3.4 — 4 | 1 mil | 3.4 — 4 | 1 mi | 3.4 — 2 | 1.5 mil | 2.6 | — |
| Внешний 1 oz | — | — | — | — | 1.66 | 2.4 mil | 2.6 | — |
| Внутренний 0.5 oz | 1.75 | 0.8 mil | 4.33 | 0.3 mil | 1.73 | 1.75 mil | 3 | — |
| Внутренний 1 oz | 2.4 | 1 mil | 4.33 | 0.6 mil | 2.6 | 1 mil | 3 | — |
| Внутренний 2 oz | — | 1.5 — 2 mil | 4.33 | 1.2 mil | 2.6 | 2 mil | 3 | — |
| Внутренний 3 oz | — | — | — | — | 2.6 | 3 mil | 3 | — |
| Внутренний 4 oz | — | — | — | — | 2.3 | 4.5 mil | 3 | — |
| Base copper | Plating copper | ||
|---|---|---|---|
| 0.7oz | 1oz | 2oz | |
| 0.5oz | 1.644 mil | 2.055 mil | 3.425 mil |
| 1oz | 2.329 mil | 2.74 mil | 4.11 mil |
| 2oz | 3.699 mil | 4.11 mil | 5.48 mil |
| 3oz | 5.069 mil | 5.48 mil | 6.85 mil |

|
Метки: author asmolenskiy анализ и проектирование систем блог компании yadro pcb design pcb production печатные платы проектирование |
Зачем нужен БЭМ |

Следуете ли вы БЭМу, и насколько он востребован вне Яндекса?
БЭМ расшифровывается как: блок, элемент, модификатор. Это такой набор абстракций, на который можно разбить интерфейс и разрабатывать всё в одних и тех же терминах. Как говорит сайт bem.info, БЭМ предлагает единые правила написания кода, помогает его масштабировать и повторно использовать, а также увеличивает производительность и упрощает командную работу.
Круто, да? Но зачем вам масштабируемость и командная работа, если вы один верстальщик на проекте, который не претендует на популярность Яндекса? Чтобы ответить на этот вопрос, нужно отмотать историю лет на 10 назад, когда это подход только начали формулировать.
В основу того, что мы сейчас называем БЭМом, легла идея независимых блоков, которую Виталий Харисов сформулировал и презентовал в 2007 году на первой российской конференции по фронтенду. Это было настолько давно, что тогда даже слова «фронтенд» ещё не было, тогда это называлось клиент-сайд.
Идея была в том, чтобы ограничить возможности CSS для более предсказуемых результатов. Использовать минимум глобальных стилей и каждый отдельный элемент страницы делать блоком со своим уникальным классом и стилями, которые полностью его описывают. Селекторы по элементам и ID, хрупкие связки вложенности — всё это заменялось на простые селекторы по классам. Каждый класс в стилях — это блок. Благодаря этому блоки можно легко менять местами, вкладывать друг в друга и не бояться конфликтов или влияния.
#menu ul > li {
color: old;
}
.menu-item {
color: bem;
}Потом появились абсолютно независимые блоки (АНБ), где у элементов внутри есть свой префикс с именем родителя, а состояния блоков снова дублируют класс, но уже с постфиксом. Подход обрёл черты современного БЭМа, одна из которых — многословность классов.
.block {}
.block_mod {}
.block__element {}
.block__element_mod {}Эта многословность гарантирует уникальность элементов и модификаторов в рамках одного проекта. За уникальностью имён блоков вы следите сами, но это довольно просто, если каждый блок описан в отдельном файле. Глядя на такой класс в HTML или CSS, можно легко сказать, что это, и к чему оно относится.
Изначально АНБ, а потом и БЭМ, решали задачу важную для вёрстки любых масштабов: предсказуемое поведение и создание надёжного конструктора. Вы же хотите, чтобы ваша вёрстка была предсказуемой? Вот и Яндекс тоже. Ещё это называется «модульность» — о ней хорошо написал Филип Уолтон в «Архитектуре CSS», ссылка на перевод в описании.
Через пару лет в Яндексе окончательно сформулировали нотацию БЭМ. Любой интерфейс предлагалось разделять на блоки. Неотделимые части блоков — элементы. У тех и других есть модификаторы.
Например, блок поиска по сайту. Он может быть в шапке и в подвале — значит это блок. В нём есть обязательные части: поле поиска и кнопка «найти» — это его элементы. Если поле нужно растянуть на всю ширину, но только в шапке, то блоку или элементу, который отвечает за это растягивание, даётся модификатор.
Для полной независимости блоков мало назвать классы правильно или изолировать стили, нужно собрать всё, что к нему относится. В проекте по БЭМу нет общего script.js или папки images со всеми картинками сайта. В одной папке с каждым блоком лежит всё, что нужно для его работы. Это позволяет удобно добавлять, удалять и переносить блоки между проектами. Потом, конечно, все ресурсы блоков при сборке объединяются в зависимости от задач проекта.
Когда БЭМ вышел за пределы Яндекса, сначала его воспринимали как магию и старались воспроизводить дословно, вплоть до префиксов b- у каждого блока. Такой смешной карго-культ.
.b-block {}
.b-block--mod {}
.b-block__element {}
.b-block__element--mod {}Некоторые неверно понимали идею и появлялись даже элементы элементов. Потом за нотацию взялись энтузиасты и появилась одна из самых популярных: блок отделяется двумя подчёркиваниями, а модификатор — двумя дефисами. Наглядно и просто — сам так пишу.
.block {}
.block--mod {}
.block__element {}
.block__element--mod {}А зачем вообще все эти нотации — я ведь один верстальщик на проекте, помните? Помню. А ещё помню, как сам верстал до БЭМа: в каждом проекте придумывал что-нибудь такое новенькое. А потом открывал код годичной давности и удивлялся — какой идиот это написал?
Возьмём, к примеру, русский язык. Мы же пишем с прописной имена людей, названия и прочее такое? Пишем. Чтобы легко потом считывалось: это Надя или надежда на лучшее? Уж не говоря про знаки препинания и другие полезные договорённости. Вот буква «ё», например, смягчает… так, о чём мы? Да, БЭМ.
До БЭМа были проекты с портянками стилей, которые нельзя трогать. Они копились годами, слой за слоем, как обои в древней коммуналке. Их просто подключали первыми, а потом перезаписывали что мешало. Когда у вас есть div { font-size: 80% } — это даже уже не смешно.
/* Не смешно */
div {
font-size: 80%;
}БЭМ продолжил развиваться в Яндексе и вырос за пределы вёрстки: появились уровни переопределения, богатый инструментарий, JS-библиотека для работы с БЭМ-классами, шаблонизаторы и целый БЭМ-стэк. БЭМу даже жест придумали, но это совсем другая история, специфичная для Яндекса.
Были и другие методологии: OOCSS Николь Салливан, SMACSS Джонатана Снука, вариации БЭМа и целые фреймворки. Даже у нас на продвинутом интенсиве можно было выбрать любую методологию для вёрстки учебного проекта.
Но выжил только БЭМ и его вполне можно назвать стандартом де-факто современной разработки интерфейсов. И что — это финальная ступень эволюции? Нет конечно. Как ни автоматизируй, многое в БЭМе приходится делать руками, и возможны конфликты.
Модульность и изоляцию стилей блока можно решить ещё лучше. Есть веб-компоненты, CSS-модули, куча решений CSS-в-JS и даже, прости господи, атомарный CSS. Но нет единого решения накопившихся проблем на следующие 10 лет, каким когда-то стал БЭМ. Что это будет? Посмотрим. Я ставлю на веб-компоненты.
А пока, если вы опишете интерфейс по БЭМу — код будет организован, предсказуем, расширяем и готов для повторного использования. Не только для вас, но и для других.
Вопросы можно задавать здесь.
|
Метки: author htmlacademy разработка веб-сайтов css блог компании html academy бэм для начинающих методологии разработки для новичков новичкам верстка |
[Из песочницы] Искусство создания диаграмм процессов |


|
Метки: author Shortki управление проектами бизнес-модели gtd ecm/ сэд agile бизнесс-процессы управление задачами диаграммы диаграмма состояний |
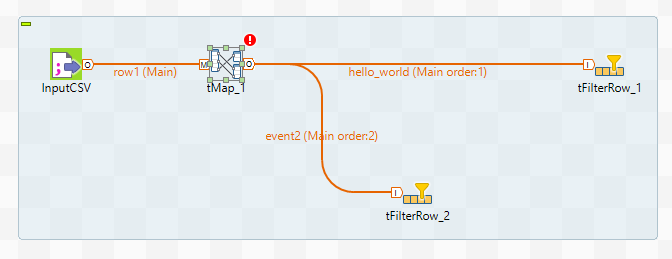
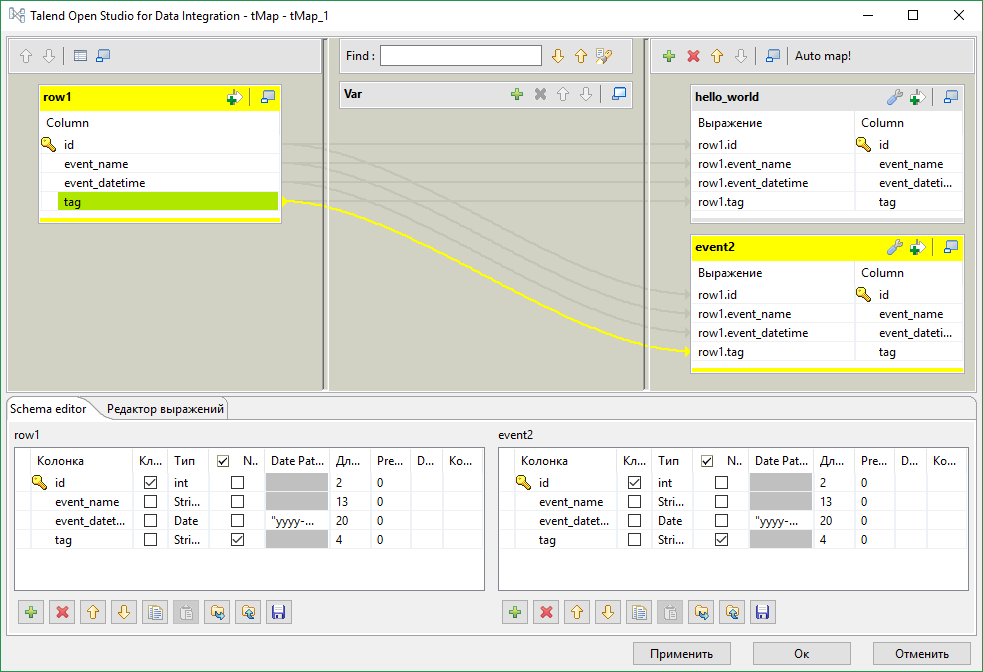
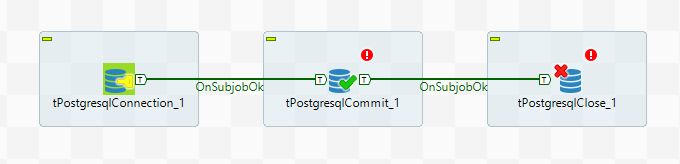
[Из песочницы] Работа c Talend Open Studio на примере парсинга CSV файла |
id,event_name,event_datetime,tag
1,"Hello, world!",2017-01-10T18:00:00Z,
2,"Event2",2017-01-10T19:00:00Z,tag1=q
3,Event3,2017-01-10T20:00:00Z,
4,"Hello, world!",2017-01-10T21:00:00Z,tag2=a
5,Event2,2017-01-10T22:00:00Z,
...

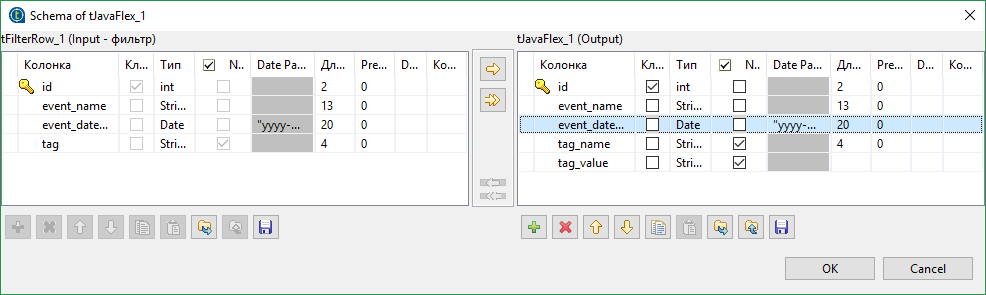
row4.tag_name = "";
row4.tag_value = "";
if(row2.tag.contains("="))
{
String[] parts = row2.tag.split("=");
row4.tag_name = parts[0];
row4.tag_value = parts[1];
}

String.format("
INSERT INTO tag(tag_name, tag_value)
SELECT '%s', '%s'
WHERE NOT EXISTS
(SELECT * FROM tag
WHERE tag_name = '%s'
AND tag_value = '%s');",
input_row.tag_name, input_row.tag_value,
input_row.tag_name, input_row.tag_value)
String.format("
WITH T1 AS (
SELECT *
FROM tag
WHERE tag_name = '%s'
AND tag_value = '%s'
), T2 AS (
INSERT INTO tag(tag_name, tag_value)
SELECT '%s', '%s'
WHERE NOT EXISTS (SELECT * FROM T1)
RETURNING tag_id
)
SELECT tag_id FROM T1
UNION ALL
SELECT tag_id FROM T2;",
input_row.tag_name, input_row.tag_value,
input_row.tag_name, input_row.tag_value)

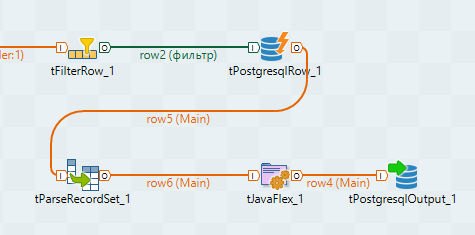
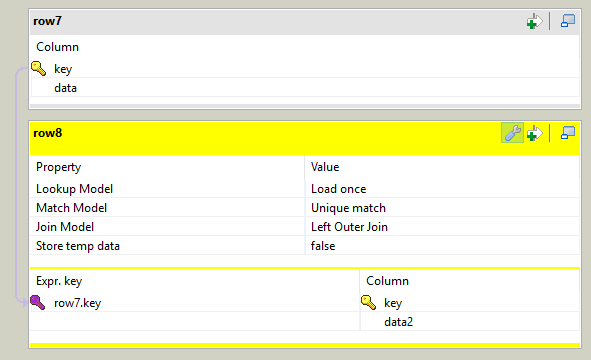
|
Метки: author railmisaka data mining talend java open source |
Как я создавал прибыльный глобальный SaaS проект, от разработки до продаж |
Consider the following:
— Alex Moskovski (@mskvsk) July 12, 2017
1. Go to Fiverr
2. Research the most popular gigs
3. Read their reviews from customers
4. Automatizing them.
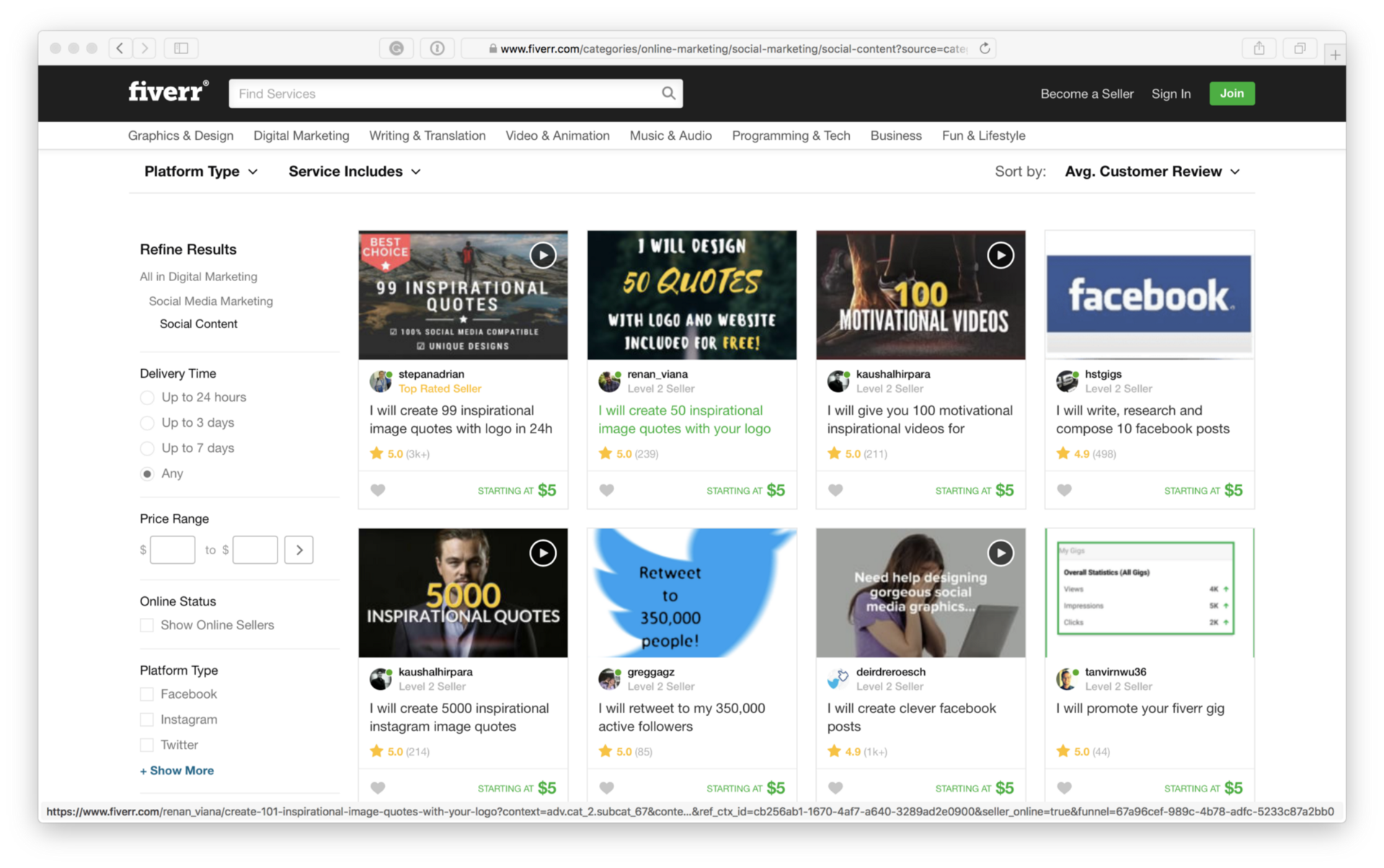
Немного отступлю от темы и скажу, что несмотря на то, что в Рунете идея подобного проекта вызвала бы смех, то на Западе, где авторское право — не пустой звук, все гораздо более интересно. Цитаты там — это доступный и популярный формат, который используют небольшие (а иногда и крупные) компании, которые не могут позволить себе более дорогой тип контента. Поэтому такая популярность услуг по созданию уникальных картинок-цитат — не случайность.


function autoWrap($text, $maxWidth, $maxHeight, $lineMargin, $fontName) {
$image = new Imagick();
$draw = new ImagickDraw();
$startFontSize = round($this->height / 4);
$fontSize = $startFontSize;
$draw->setFont($fontName);
$lineWidth = 10;
$custom = false;
$text = preg_replace('/\s+/', ' ', $text);
while (true) {
$draw->setFontSize($fontSize);
$fit = false;
while (true) {
if ($custom == false) {
$lines = explode("\n", wordwrap($text, $lineWidth, "\n", false));
}
$longestLine = 0;
$longestLineIndex = 0;
// Search for the longest line for the current font size
foreach ($lines as $i => $line) {
$fontMetrics = $image->QueryFontMetrics($draw, $line);
if ($fontMetrics['textWidth'] > $longestLine) {
$longestLine = $fontMetrics['textWidth'];
$longestLineIndex = $i;
/*
if the longest line is longer than the width then get out
of the outer loop without $fit = true
*/
if ($longestLine > $maxWidth) {
break 2;
}
}
}
$fit = true;
$resultLines = $lines;
$resultLineHeight = $fontMetrics['textHeight'];
if (count($lines) == 1) {
break;
}
$lineWidth++;
}
if ($fit) {
$totalHeight = count($resultLines) * ($resultLineHeight + $lineMargin) - $lineMargin;
if ($totalHeight <= $maxHeight) {
break;
}
}
$fontSize--;
}
return array($resultLines, $fontSize);
}




My activity the last two weeks. pic.twitter.com/KuW7xT3mA4
— Alex Moskovski (@mskvsk) April 19, 2017
A perfect landing page check list:
— Alex Moskovski (@mskvsk) September 5, 2017
Quick explanation
Demo
Major advantages
Pricing
Testimonials
Call-To-Action

The fastest way to implement at least some stats in your app (and you should ALWAYS collect as much data as you can) is scattering GA events pic.twitter.com/vmQogPN7Rb
— Alex Moskovski (@mskvsk) August 25, 2017

|
Метки: author mskvsk разработка веб-сайтов программирование php laravel стартап saas product development продуктовая разработка разработка full stack |
[Перевод] Kali Linux: политика безопасности, защита компьютеров и сетевых служб |
|
Метки: author ru_vds системное администрирование настройка linux блог компании ruvds.com администрирование linux безопасность |
Руководство по выживанию в Steam для мобильных разработчиков |

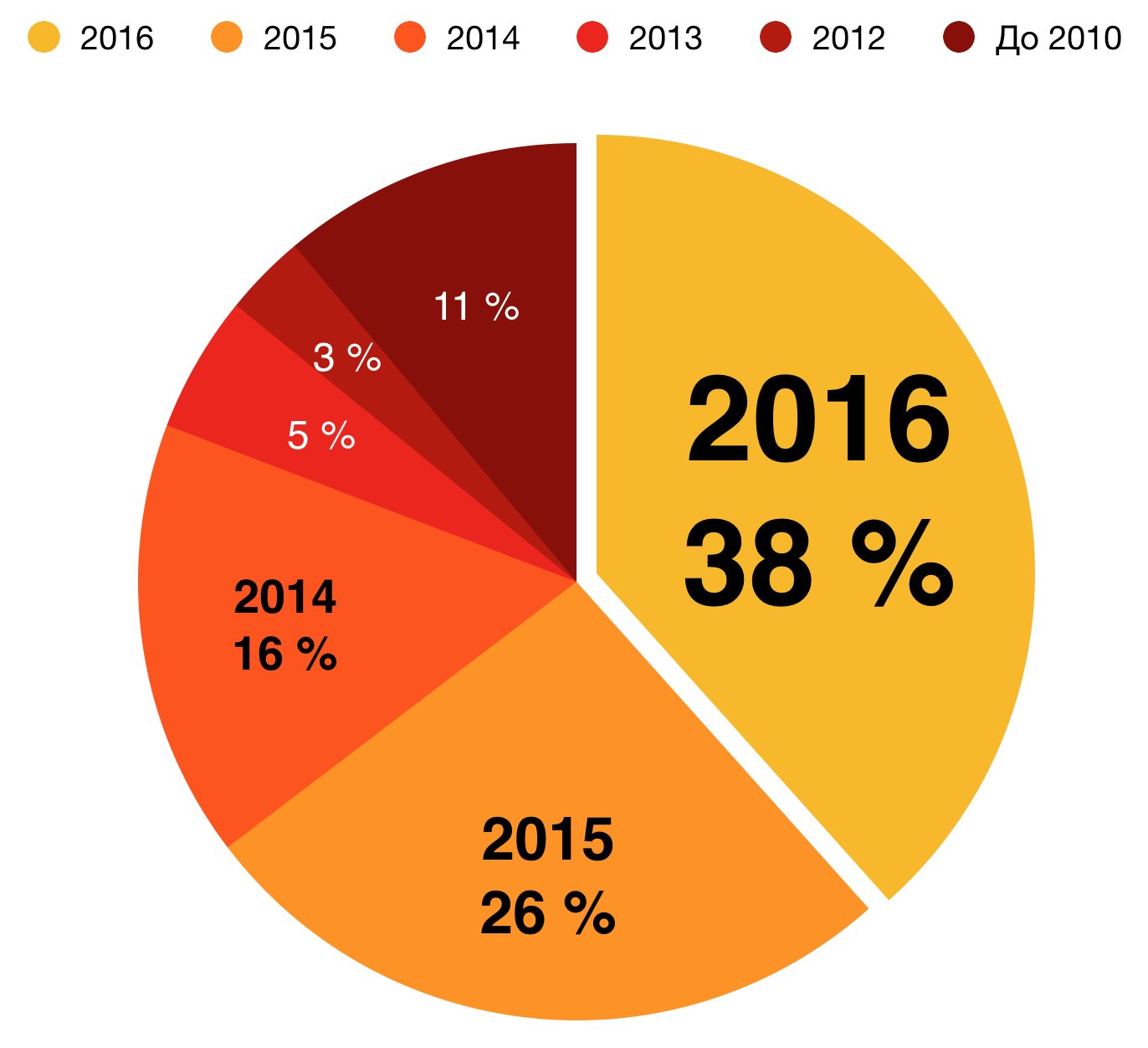
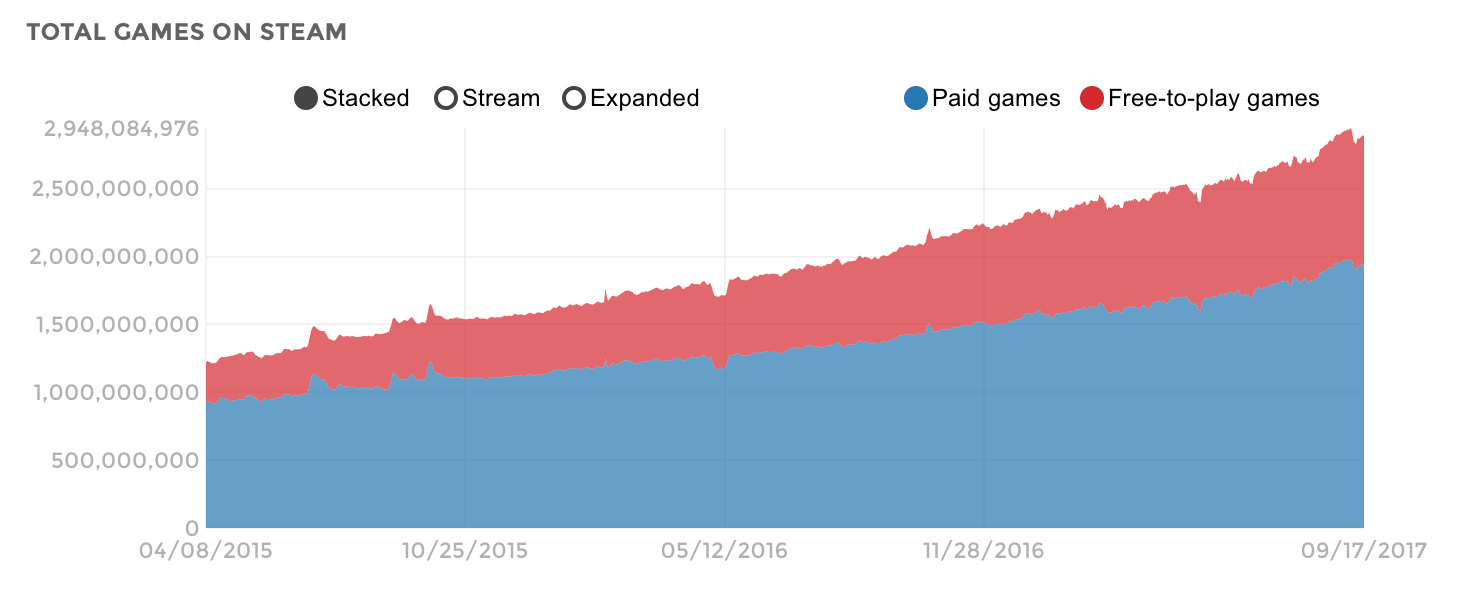


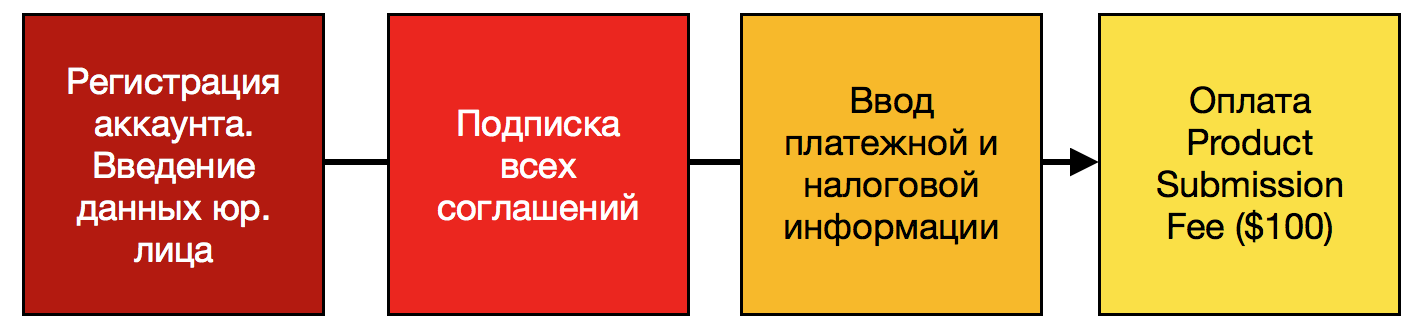
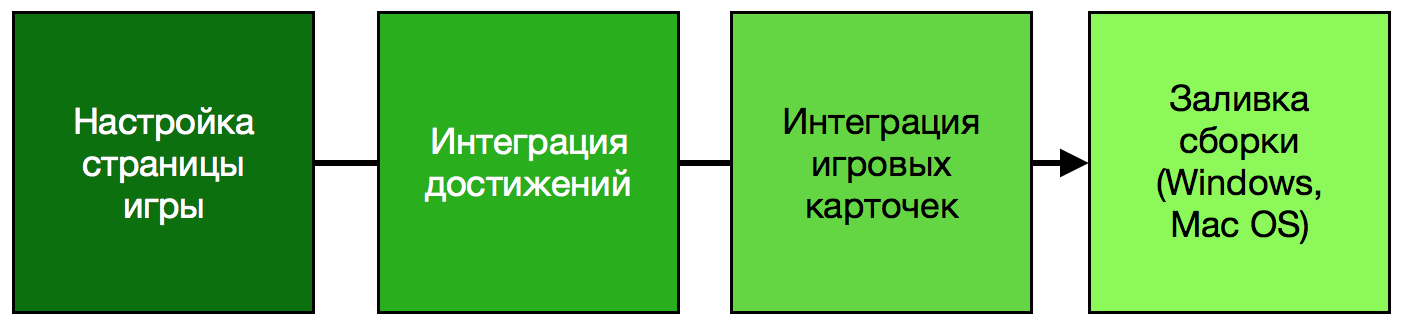






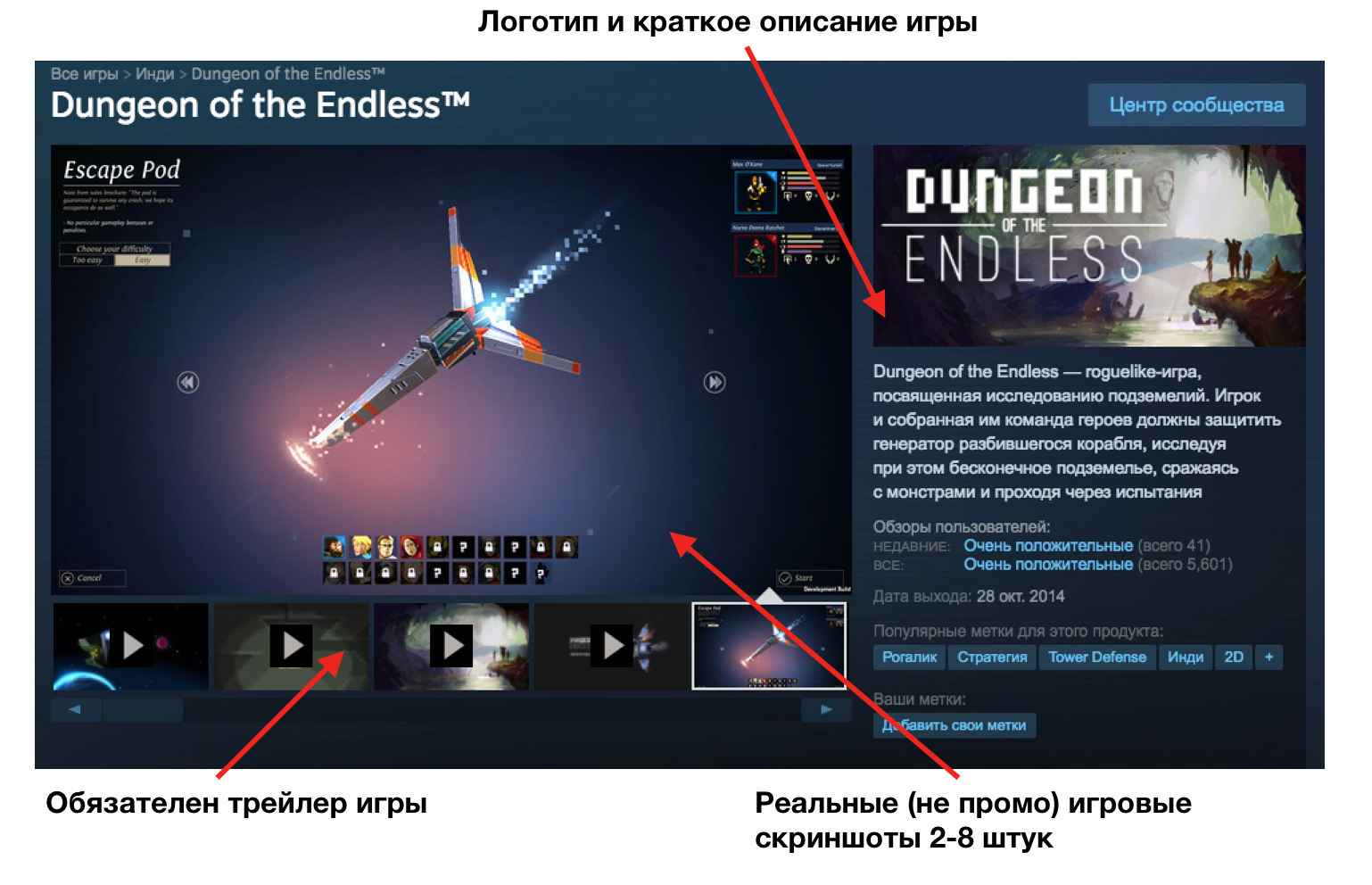

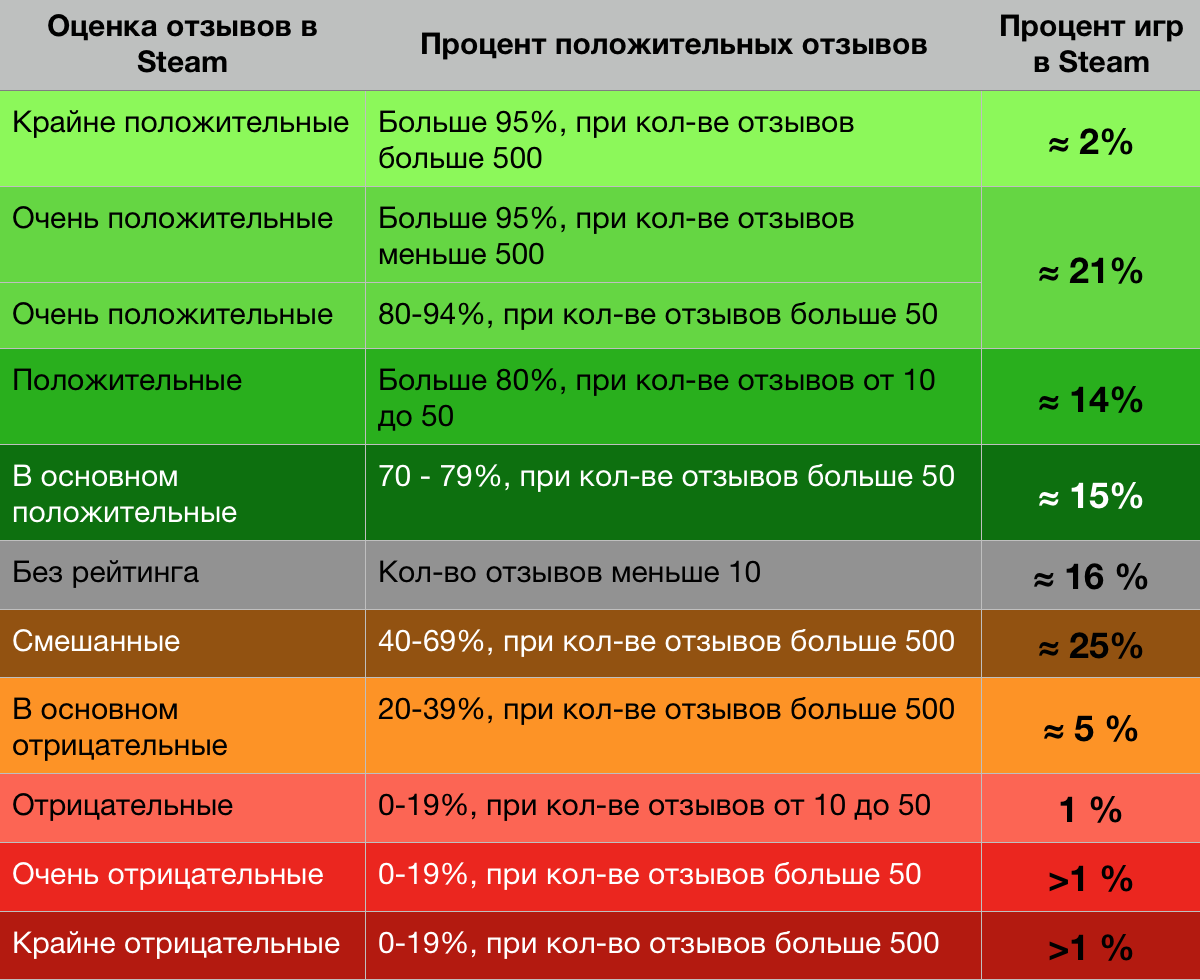
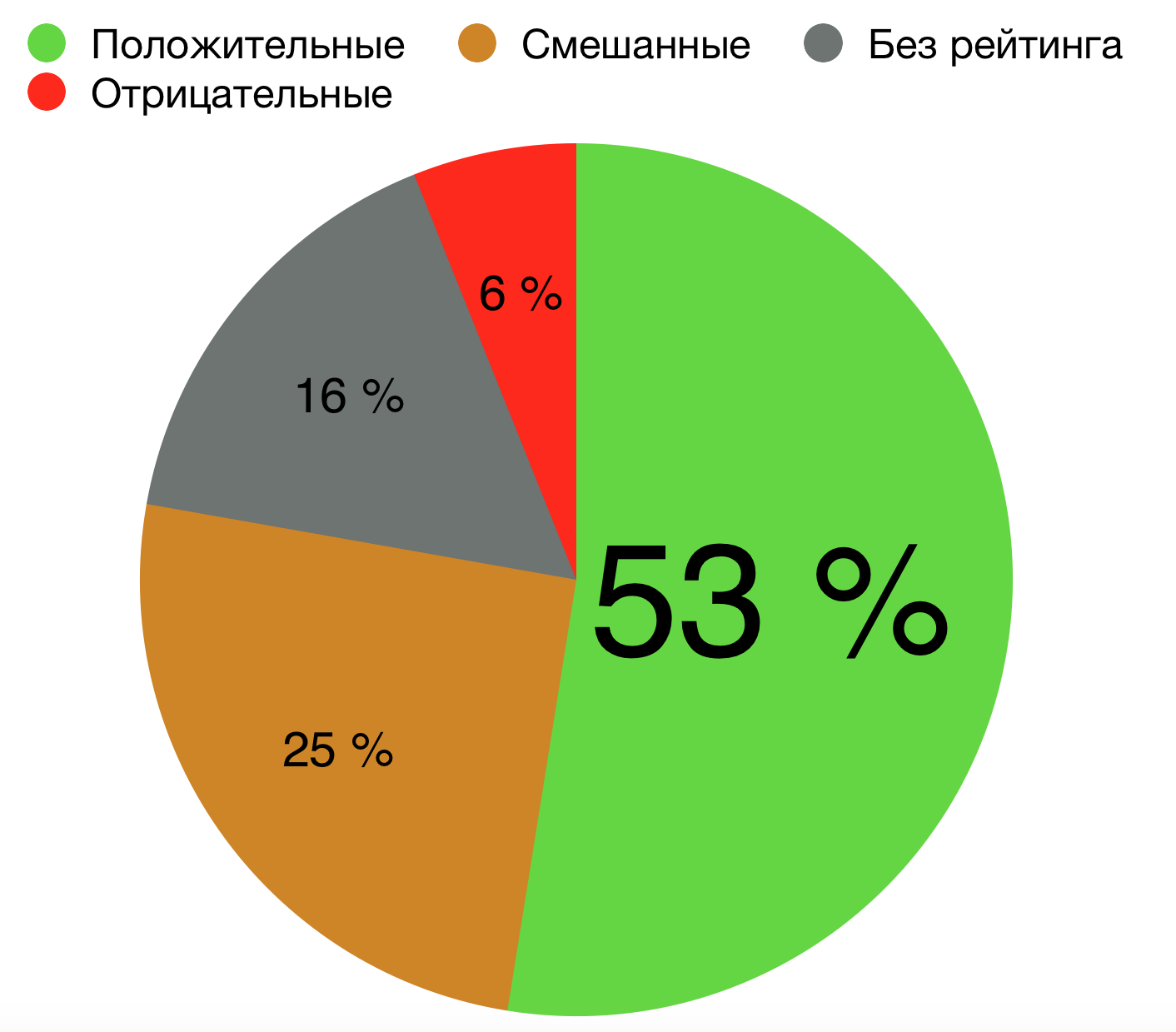
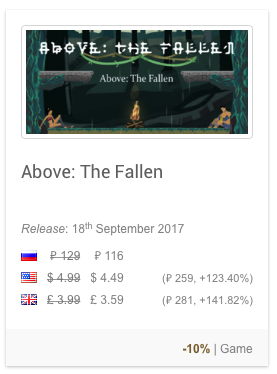
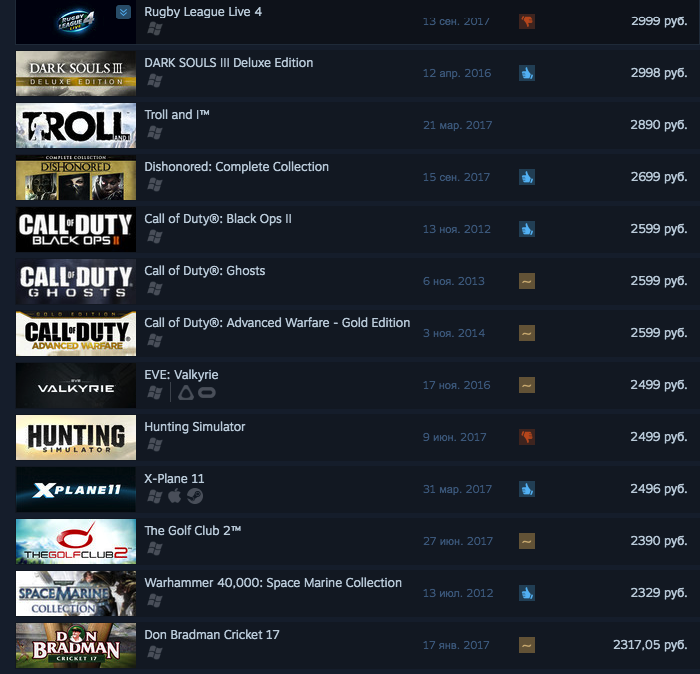
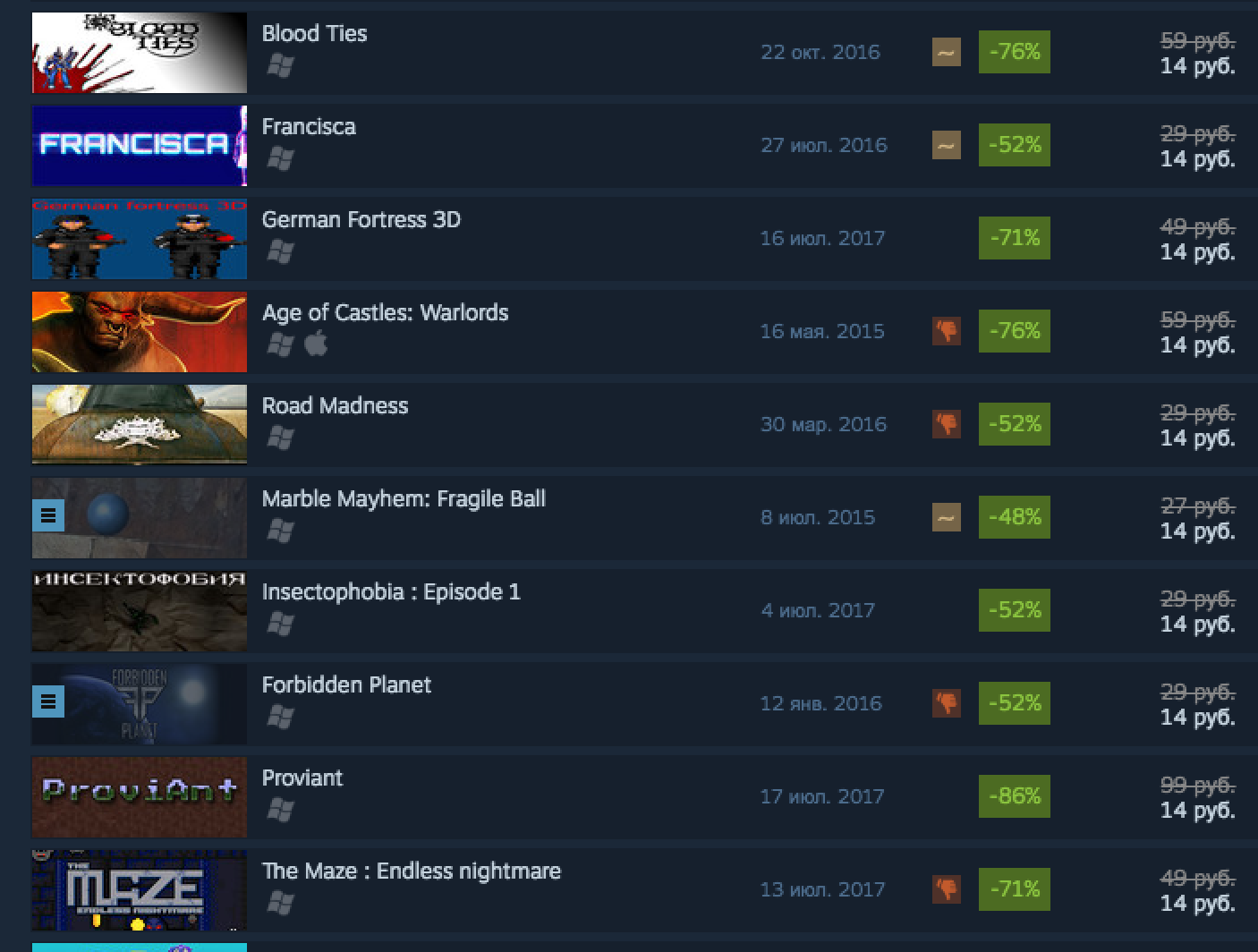


|
Метки: author TimTim разработка игр блог компании everyday tools steam продвижение игр десктопные приложения |
Как работает Android, часть 2 |

В этой статье я расскажу о некоторых идеях, на которых построены высокоуровневые части Android, о нескольких его предшественниках и о базовых механизмах обеспечения безопасности.
Статьи серии:
Говоря про Unix- и Linux-корни Android, нужно вспомнить и о других проектах операционных систем, влияние которых можно проследить в Android, хотя они и не являются его прямыми предками.
Я уже упомянул про BeOS, в наследство от которой Android достался Binder.
Plan 9 — потомок Unix, логическое продолжение, развитие его идей и доведение их до совершенства. Plan 9 был разработан в Bell Labs той же командой, которая создала Unix и C — над ним работали такие люди, как Ken Thompson, Rob Pike, Dennis Ritchie, Brian Kernighan, Tom Duff, Doug McIlroy, Bjarne Stroustrup, Bruce Ellis и другие.
В Plan 9 взаимодействие процессов между собой и с ядром системы реализовано не через многочисленные системные вызовы и механизмы IPC, а через виртуальные текстовые файлы и файловые системы (развитие принципа Unix «всё — это файл»). При этом каждая группа процессов «видит» файловую систему по-своему (пространства имён, namespaces), что позволяет запускать разные части системы в разном окружении.
Например, чтобы получить позицию курсора мыши, приложения читают текстовый файл /dev/mouse. Оконная система rio предоставляет каждому приложению свою версию этого файла, в которой видны только события, относящиеся к окну этого приложения, и используются локальные по отношению к окну координаты. Сама rio читает события «настоящей» мыши через такой же файл /dev/mouse — в том виде, в котором его видит она. Если она запущена напрямую, этот файл предоставляется ядром и действительно описывает движения настоящей мыши, но она может быть совершенно прозрачно запущена в качестве приложения под другой копией rio, без какой-то специальной поддержки с её стороны.
Plan 9 полностью поддерживает доступ к удалённым файловым системам (используется собственный протокол 9P, кроме того, поддерживаются FTP и SFTP), что позволяет программам совершенно прозрачно получать доступ к удалённым файлам, интерфейсам и ресурсам. Такая «родная» сетевая прозрачность превращает Plan 9 в распределённую операционную систему — пользователь может физически находиться за одним компьютером, на котором запущена rio, запускать приложения на нескольких других, использовать в них файлы, хранящиеся на файловом сервере и выполнять вычисления на CPU-сервере — всё это полностью прозрачно и без специальной поддержки со стороны каждой из частей системы.
За счёт красиво спроектированной архитектуры Plan 9 значительно проще и меньше, чем Unix — на самом деле ядро Plan 9 даже в несколько раз меньше известного микроядра Mach.
Perfection is achieved not when there is nothing more to add, but when there is nothing left to take away.
Несмотря на техническое превосходство и наличие слоя совместимости с Unix, Plan 9 не получил широкого распространения. Тем не менее, многие идеи и технологии из Plan 9 получили распространение и были реализованы в других системах. Самая известная из них — кодировка
Больше всего идей и технологий из Plan 9 реализовано в Linux:
/proc (procfs)clone (аналог rfork из Plan 9)Многое из этого используется, в том числе, и в Android. Кроме того, в Android реализован механизм intent’ов, похожий на plumber из Plan 9; о нём я расскажу в следующей статье.
Про Plan 9 можно узнать подробнее на сайте plan9.bell-labs.com (сохранённая копия в Wayback Machine), или его зеркале 9p.io
Plan 9 получил продолжение в виде проекта Inferno, тоже разработанного в Bell Labs. К таким свойствам Plan 9, как простота и распределённость, Inferno добавляет переносимость. Программы для Inferno пишутся на высокоуровневом языке Limbo и выполняются — с использованием just-in-time компиляции — встроенной в ядро Inferno виртуальной машиной.
Inferno настолько переносим, что может запускаться
При этом приложениям, запущенным внутри Inferno, предоставляется совершенно одинаковое окружение.
Inferno получил ещё меньше распространения и известности, чем Plan 9. С другой стороны, Inferno во многом предвосхитил Android, самую популярную операционную систему на свете.
Компания Danger Research Inc. была сооснована Энди Рубином (Andy Rubin) в 1999 году, за 4 года до сооснования им же Android Inc. в 2004 году.
В 2002 году Danger выпустили свой смартфон Danger Hiptop. Многие из разработчиков Danger впоследствии работали над Android, поэтому неудивительно, что его операционная система была во многом похожа на Android. Например, в ней были реализованы:

Подробнее о Danger можно прочитать в статье Chris DeSalvo, одного из разработчиков, под названием The future that everyone forgot.
Хотя использование высокоуровневых языков для серьёзной разработки сейчас уже никого не удивляет, из популярных операционных систем только у Android «родной» язык — высокоуровневая Java (с другой стороны, здесь можно вспомнить веб с его JavaScript, .NET для Windows и относительно высокоуровневый — но полностью компилируемый в нативный код и не использующий сборку мусора — Swift).
Несмотря на кажущиеся недостатки («Java сочетает в себе красоту синтаксиса C++ со скоростью выполнения питона»), Java обладает множеством преимуществ.
Во-первых, Java — самый популярный (с большим отрывом) язык программирования. У Java огромная экосистема библиотек и инструментов разработки (в том числе систем сборки и IDE). Про Java написано множество статей, книг и документации. Наконец, существует множество квалифицированных Java-разработчиков.
Программы на Java, как и на многих других высокоуровневых языках, переносимы между операционными системами и архитектурами процессора («Write once, run anywhere»). Практически это проявляется, например, в том, что приложения для Android работают без перекомпиляции на устройствах любой архитектуры (Android поддерживает ARM, ARM64, x86, x86–64 и MIPS).
В отличие от низкоуровневых языков вроде C и C++, использующих ручное управление памятью, в Java память автоматически управляется средой времени выполнения (runtime environment). Программа на Java даже не имеет прямого доступа к памяти, что автоматически предотвращает несколько классов ошибок, часто приводящих к падениям и уязвимостям в программах, написанных на низкоуровневых языках — невозможны «висячие ссылки» (из-за которых происходит NullPointerException), чтение неинициализированной памяти и выход за границы массива.
Использование полноценной сборки мусора (по сравнению с automatic reference counting) избавляет программиста от всех проблем и сложностей с циклическими ссылками и позволяет реализовывать ещё более продвинутые (advanced) зависимости между объектами.
Это делает разработку под Android более приятной, чем разработку с использованием низкоуровневых языков, а приложения под Android гораздо более надёжными, в том числе и точки зрения безопасности.
В отличие от большинства других высокоуровневых языков, программы на Java не распространяются в виде исходного кода, а компилируются в промежуточный формат (байткод, bytecode), который представляет собой исполняемый бинарный код для специального процессора.
Хотя делаются попытки создать физический процессор, который исполнял бы Java-байткод напрямую, в подавляющем большинстве случаев в качестве такого процессора используется эмулятор — Java virtual machine (JVM). Обычно используется реализация от Oracle/OpenJDK под названием HotSpot.
В Android используется собственная реализация под названием Android Runtime (ART), специально оптимизированная для работы на мобильных устройствах. В старых версиях Android (до 5.0 Lollipop) вместо ART использовалась другая реализация под названием Dalvik.
И в Dalvik, и в ART используется собственный формат байткода и собственный формат файлов, в которых хранится байткод — DEX (Dalvik executable). В отличие от classes.dex. При сборке Android-приложения Java-код сначала компилируется обычным компилятором Java в
И HotSpot, и Dalvik, и ART дополнительно оптимизируют выполняемый код. Все три используют just-in-time compilation (JIT), то есть во время выполнения компилируют байткод в куски полностью нативного кода, который выполняется напрямую. Кроме очевидного выигрыша в скорости, это позволяет оптимизировать код для выполнения на конкретном процессоре, не отказываясь от полной переносимости байткода.
Кроме того, ART может компилировать байткод в нативный код заранее, а не во время выполнения (ahead-of-time compilation) — причём система автоматически планирует эту компиляцию на то время, когда устройство не используется и подключено к зарядке (например, ночью). При этом ART учитывает данные, собранные профилировщиком во время предыдущих запусков этого кода (profile-guided optimization). Такой подход позволяет дополнительно оптимизировать код под специфику работы конкретного приложения и даже под особенности использования этого приложения именно этим пользователем.
В результате всех этих оптимизаций производительность Java-кода на Android не сильно уступает производительности низкоуровневого кода (на C/C++), а в некоторых случаях и превосходит её.
Java-байткод, в отличие от обычного исполняемого кода, использует объектную модель Java — то есть в байткоде явно записываются такие вещи, как классы, методы и сигнатуры. Это делает возможным компиляцию других языков в Java-байткод, что позволяет написанным на них программам исполняться на виртуальной машине Java и быть в той или иной степени совместимыми (interoperable) с Java.
Существуют как JVM-реализации независимых языков — например, Jython для Python, JRuby для Ruby, Rhino для JavaScript и диалект Lisp Clojure — так и языки, исходно разработанные для компиляции в Java-байткод и выполнения на JVM, самые известные из которых — Groovy, Scala и Kotlin.
Самый новый из них, Kotlin, специально разработанный для идеальной совместимости с Java и обладающий гораздо более приятным синтаксисом (похожим на Swift), поддерживается Google как официальный язык разработки под Android наравне с Java.

Несмотря на все преимущества Java, в некоторых случаях всё-таки желательно использовать низкоуровневый язык — например, для реализации критичного по производительности компонента, такого как браузерный движок, или чтобы использовать существующую нативную библиотеку. Java позволяет вызывать нативный код через Java Native Interface (JNI), и Android предоставляет специальные средства для нативной разработки — Native Development Kit (NDK), в который входят в том числе заголовочные файлы, компилятор (Clang), отладчик (LLDB) и система сборки.
Хотя NDK в основном ориентирован на использование C/C++, с его помощью можно писать под Android и на других языках — в том числе Rust, Swift, Python, JavaScript и даже Haskell. Больше того, есть даже возможность портировать iOS-приложения (написанные на
Модель безопасности в классическом Unix основана на системе UID/GID — специальных номеров, которые ядро хранит для каждого процесса. Процессам с одинаковым UID разрешён доступ друг к другу, процессы с разным UID защищены друг от друга. Аналогично ограничивается доступ к файлам.
По смыслу каждый UID (user ID) соответствует своему пользователю — во времена создания Unix была нормальной ситуация, когда один компьютер одновременно использовался множеством людей. Таким образом, в Unix процессы и файлы разных людей были защищены друг от друга. Чтобы разрешить общий доступ к некоторым файлам, пользователи объединялись в группы, которым и соответствовал GID (group ID).
При этом всем программам, запускаемым пользователем, даётся полный доступ ко всему, к чему есть доступ у этого пользователя. Собственно, поскольку пользователь не может общаться с ядром напрямую, а взаимодействует с компьютером через shell и другие процессы — права пользователя и есть права программ, запущенных от его имени.
Такая модель подразумевает, что пользователь полностью доверяет всем программам, которые использует. В то время это было логично, потому что программы чаще всего либо были частью системы, либо создавались (писались и компилировались) самим пользователем.
В Unix есть и исключение из ограничений доступа — UID 0, который принято называть root. У него есть доступ ко всему в системе, и никакие ограничения на него не распространяются. Этот аккаунт использовался системным администратором; кроме того, под UID 0 запускаются многие системные сервисы.
В современном Linux эта модель была значительно расширена и обобщена, в том числе появились capabilities, позволяющие «получить часть root-прав», и реализующая мандатное управление доступом (mandatory access control, MAC) подсистема SELinux, которая позволяет дополнительно ограничить права (в том числе права root-процессов).
За несколько десятков лет, прошедших с создания Unix до создания Android, практика использования компьютеров («вычислителей») значительно изменилась.
Вместо машин, рассчитанных на параллельное использование многими пользователями (через терминалы — то, что сейчас эмулируют эмуляторы терминалов), появились персональные компьютеры, рассчитанные на использование одним человеком. Компьютеры перестали быть лишь рабочим инструментом и стали центром нашей цифровой жизни. С появлением мобильных устройств — сначала КПК, потом смартфонов, планшетов, умных часов и т.п. — эта тенденция только усилилась (потому что заниматься рабочими вопросами на мобильных устройствах относительно неудобно).
На таких устройствах хранятся гигабайты персональной информации, доступ к которой должен быть защищён и ограничен. В то же время расцвёл рынок сторонних приложений, которым у пользователя нет никаких оснований доверять.
Таким образом, в современных условиях вместо защиты разных пользователей друг от друга необходимо защищать от приложений другие приложения, пользовательские данные и саму систему. Кроме того, широкое распространение получили вирусы, которые обычно используют уязвимости в системе — для защиты от них нужно дополнительно защищать части системы друг от друга, чтобы использование одной уязвимости не давало злоумышленнику доступ ко всей системе.
Хотя часть Android-приложений поставляется с системой — например, такие стандартные приложения, как Калькулятор, Часы и Камера — большинство приложений пользователи устанавливают из сторонних источников. Самый известный из них — Google Play Store, но есть и другие, например, F-Droid, Amazon Appstore, Яндекс.Store, китайские Baidu App Store, Xiaomi App Store, Huawei App Store и т.д. Кроме того, Android позволяет вручную устанавливать произвольные приложения из APK-файлов (это называют sideloading).
Как и другие Unix-подобные системы, Android использует для ограничения доступа существующий механизм UID/GID. При этом — в отличие от традиционного использования, когда UID соответствуют пользователям — в Android разные UID соответствуют разным приложениям. Поскольку процессы разных приложений запускаются с разными UID, уже на уровне ядра приложения защищены и изолированы друг от друга и не имеют доступа к системе и данным пользователя. Это образует песочницу (Application Sandbox) и позволяет пользователю устанавливать любые приложения без необходимости доверять им.
Чтобы всё-таки получить доступ к пользовательским данным, камере, совершению звонков и т.п., приложение должно получить от пользователя разрешение (permission). Некоторые из разрешений существуют в виде GID, в которые приложение добавляется, когда получает это разрешение — например, получение разрешения ACCESS_FM_RADIO помещает приложение в группу media, что позволяет ему получить доступ к файлу /dev/fm. Остальные существуют только на более высоком уровне (в виде записей в файле packages.xml) и проверяются другими компонентами системы при обращении к высокоуровневому API через Binder.

Небольшая часть системных сервисов в Android запускается под UID 0, то есть root, но большинство используют специально выделенные номера UID, повышая при необходимости свои права с помощью Linux capabilities. Кроме того, Android использует SELinux — использование SELinux в Android называют SEAndroid — для ещё большего ограничения того, какие действия разрешено выполнять приложениям и системным сервисам.
Обычно Android не предоставляет пользователю прямой доступ к root-аккаунту, но в некоторых случаях у него есть возможность этот доступ получить. Как это происходит, зачем это нужно и какими опасностями это грозит я расскажу позднее.
В следующей статье (которая выходит уже через неделю) я расскажу о компонентах, из которых состоят приложения под Android, и об идеях, которые стоят за этой архитектурой.
|
|
Как работает Android, часть 2 |
В этой статье я расскажу о некоторых идеях, на которых построены высокоуровневые части Android, о нескольких его предшественниках и о базовых механизмах обеспечения безопасности.
Статьи серии:
Говоря про Unix- и Linux-корни Android, нужно вспомнить и о других проектах операционных систем, влияние которых можно проследить в Android, хотя они и не являются его прямыми предками.
Я уже упомянул про BeOS, в наследство от которой Android достался Binder.
Plan 9 — потомок Unix, логическое продолжение, развитие его идей и доведение их до совершенства. Plan 9 был разработан в Bell Labs той же командой, которая создала Unix и C — над ним работали такие люди, как Ken Thompson, Rob Pike, Dennis Ritchie, Brian Kernighan, Tom Duff, Doug McIlroy, Bjarne Stroustrup, Bruce Ellis и другие.
В Plan 9 взаимодействие процессов между собой и с ядром системы реализовано не через многочисленные системные вызовы и механизмы IPC, а через виртуальные текстовые файлы и файловые системы (развитие принципа Unix «всё — это файл»). При этом каждая группа процессов «видит» файловую систему по-своему (пространства имён, namespaces), что позволяет запускать разные части системы в разном окружении.
Например, чтобы получить позицию курсора мыши, приложения читают текстовый файл /dev/mouse. Оконная система rio предоставляет каждому приложению свою версию этого файла, в которой видны только события, относящиеся к окну этого приложения, и используются локальные по отношению к окну координаты. Сама rio читает события «настоящей» мыши через такой же файл /dev/mouse — в том виде, в котором его видит она. Если она запущена напрямую, этот файл предоставляется ядром и действительно описывает движения настоящей мыши, но она может быть совершенно прозрачно запущена в качестве приложения под другой копией rio, без какой-то специальной поддержки с её стороны.
Plan 9 полностью поддерживает доступ к удалённым файловым системам (используется собственный протокол 9P, кроме того, поддерживаются FTP и SFTP), что позволяет программам совершенно прозрачно получать доступ к удалённым файлам, интерфейсам и ресурсам. Такая «родная» сетевая прозрачность превращает Plan 9 в распределённую операционную систему — пользователь может физически находиться за одним компьютером, на котором запущена rio, запускать приложения на нескольких других, использовать в них файлы, хранящиеся на файловом сервере и выполнять вычисления на CPU-сервере — всё это полностью прозрачно и без специальной поддержки со стороны каждой из частей системы.
За счёт красиво спроектированной архитектуры Plan 9 значительно проще и меньше, чем Unix — на самом деле ядро Plan 9 даже в несколько раз меньше известного микроядра Mach.
Perfection is achieved not when there is nothing more to add, but when there is nothing left to take away.
Несмотря на техническое превосходство и наличие слоя совместимости с Unix, Plan 9 не получил широкого распространения. Тем не менее, многие идеи и технологии из Plan 9 получили распространение и были реализованы в других системах. Самая известная из них — кодировка
Больше всего идей и технологий из Plan 9 реализовано в Linux:
/proc (procfs)clone (аналог rfork из Plan 9)Многое из этого используется, в том числе, и в Android. Кроме того, в Android реализован механизм intent’ов, похожий на plumber из Plan 9; о нём я расскажу в следующей статье.
Про Plan 9 можно узнать подробнее на сайте plan9.bell-labs.com (сохранённая копия в Wayback Machine), или его зеркале 9p.io
Plan 9 получил продолжение в виде проекта Inferno, тоже разработанного в Bell Labs. К таким свойствам Plan 9, как простота и распределённость, Inferno добавляет переносимость. Программы для Inferno пишутся на высокоуровневом языке Limbo и выполняются — с использованием just-in-time компиляции — встроенной в ядро Inferno виртуальной машиной.
Inferno настолько переносим, что может запускаться
При этом приложениям, запущенным внутри Inferno, предоставляется совершенно одинаковое окружение.
Inferno получил ещё меньше распространения и известности, чем Plan 9. С другой стороны, Inferno во многом предвосхитил Android, самую популярную операционную систему на свете.
Компания Danger Research Inc. была сооснована Энди Рубином (Andy Rubin) в 1999 году, за 4 года до сооснования им же Android Inc. в 2004 году.
В 2002 году Danger выпустили свой смартфон Danger Hiptop. Многие из разработчиков Danger впоследствии работали над Android, поэтому неудивительно, что его операционная система была во многом похожа на Android. Например, в ней были реализованы:
Подробнее о Danger можно прочитать в статье Chris DeSalvo, одного из разработчиков, под названием The future that everyone forgot.
Хотя использование высокоуровневых языков для серьёзной разработки сейчас уже никого не удивляет, из популярных операционных систем только у Android «родной» язык — высокоуровневая Java (с другой стороны, здесь можно вспомнить веб с его JavaScript, .NET для Windows и относительно высокоуровневый — но полностью компилируемый в нативный код и не использующий сборку мусора — Swift).
Несмотря на кажущиеся недостатки («Java сочетает в себе красоту синтаксиса C++ со скоростью выполнения питона»), Java обладает множеством преимуществ.
Во-первых, Java — самый популярный (с большим отрывом) язык программирования. У Java огромная экосистема библиотек и инструментов разработки (в том числе систем сборки и IDE). Про Java написано множество статей, книг и документации. Наконец, существует множество квалифицированных Java-разработчиков.
Программы на Java, как и на многих других высокоуровневых языках, переносимы между операционными системами и архитектурами процессора («Write once, run anywhere»). Практически это проявляется, например, в том, что приложения для Android работают без перекомпиляции на устройствах любой архитектуры (Android поддерживает ARM, ARM64, x86, x86–64 и MIPS).
В отличие от низкоуровневых языков вроде C и C++, использующих ручное управление памятью, в Java память автоматически управляется средой времени выполнения (runtime environment). Программа на Java даже не имеет прямого доступа к памяти, что автоматически предотвращает несколько классов ошибок, часто приводящих к падениям и уязвимостям в программах, написанных на низкоуровневых языках — невозможны «висячие ссылки» (из-за которых происходит NullPointerException), чтение неинициализированной памяти и выход за границы массива.
Использование полноценной сборки мусора (по сравнению с automatic reference counting) избавляет программиста от всех проблем и сложностей с циклическими ссылками и позволяет реализовывать ещё более продвинутые (advanced) зависимости между объектами.
Это делает разработку под Android более приятной, чем разработку с использованием низкоуровневых языков, а приложения под Android гораздо более надёжными, в том числе и точки зрения безопасности.
В отличие от большинства других высокоуровневых языков, программы на Java не распространяются в виде исходного кода, а компилируются в промежуточный формат (байткод, bytecode), который представляет собой исполняемый бинарный код для специального процессора.
Хотя делаются попытки создать физический процессор, который исполнял бы Java-байткод напрямую, в подавляющем большинстве случаев в качестве такого процессора используется эмулятор — Java virtual machine (JVM). Обычно используется реализация от Oracle/OpenJDK под названием HotSpot.
В Android используется собственная реализация под названием Android Runtime (ART), специально оптимизированная для работы на мобильных устройствах. В старых версиях Android (до 5.0 Lollipop) вместо ART использовалась другая реализация под названием Dalvik.
И в Dalvik, и в ART используется собственный формат байткода и собственный формат файлов, в которых хранится байткод — DEX (Dalvik executable). В отличие от classes.dex. При сборке Android-приложения Java-код сначала компилируется обычным компилятором Java в
И HotSpot, и Dalvik, и ART дополнительно оптимизируют выполняемый код. Все три используют just-in-time compilation (JIT), то есть во время выполнения компилируют байткод в куски полностью нативного кода, который выполняется напрямую. Кроме очевидного выигрыша в скорости, это позволяет оптимизировать код для выполнения на конкретном процессоре, не отказываясь от полной переносимости байткода.
Кроме того, ART может компилировать байткод в нативный код заранее, а не во время выполнения (ahead-of-time compilation) — причём система автоматически планирует эту компиляцию на то время, когда устройство не используется и подключено к зарядке (например, ночью). При этом ART учитывает данные, собранные профилировщиком во время предыдущих запусков этого кода (profile-guided optimization). Такой подход позволяет дополнительно оптимизировать код под специфику работы конкретного приложения и даже под особенности использования этого приложения именно этим пользователем.
В результате всех этих оптимизаций производительность Java-кода на Android не сильно уступает производительности низкоуровневого кода (на C/C++), а в некоторых случаях и превосходит её.
Java-байткод, в отличие от обычного исполняемого кода, использует объектную модель Java — то есть в байткоде явно записываются такие вещи, как классы, методы и сигнатуры. Это делает возможным компиляцию других языков в Java-байткод, что позволяет написанным на них программам исполняться на виртуальной машине Java и быть в той или иной степени совместимыми (interoperable) с Java.
Существуют как JVM-реализации независимых языков — например, Jython для Python, JRuby для Ruby, Rhino для JavaScript и диалект Lisp Clojure — так и языки, исходно разработанные для компиляции в Java-байткод и выполнения на JVM, самые известные из которых — Groovy, Scala и Kotlin.
Самый новый из них, Kotlin, специально разработанный для идеальной совместимости с Java и обладающий гораздо более приятным синтаксисом (похожим на Swift), поддерживается Google как официальный язык разработки под Android наравне с Java.
Несмотря на все преимущества Java, в некоторых случаях всё-таки желательно использовать низкоуровневый язык — например, для реализации критичного по производительности компонента, такого как браузерный движок, или чтобы использовать существующую нативную библиотеку. Java позволяет вызывать нативный код через Java Native Interface (JNI), и Android предоставляет специальные средства для нативной разработки — Native Development Kit (NDK), в который входят в том числе заголовочные файлы, компилятор (Clang), отладчик (LLDB) и система сборки.
Хотя NDK в основном ориентирован на использование C/C++, с его помощью можно писать под Android и на других языках — в том числе Rust, Swift, Python, JavaScript и даже Haskell. Больше того, есть даже возможность портировать iOS-приложения (написанные на
Модель безопасности в классическом Unix основана на системе UID/GID — специальных номеров, которые ядро хранит для каждого процесса. Процессам с одинаковым UID разрешён доступ друг к другу, процессы с разным UID защищены друг от друга. Аналогично ограничивается доступ к файлам.
По смыслу каждый UID (user ID) соответствует своему пользователю — во времена создания Unix была нормальной ситуация, когда один компьютер одновременно использовался множеством людей. Таким образом, в Unix процессы и файлы разных людей были защищены друг от друга. Чтобы разрешить общий доступ к некоторым файлам, пользователи объединялись в группы, которым и соответствовал GID (group ID).
При этом всем программам, запускаемым пользователем, даётся полный доступ ко всему, к чему есть доступ у этого пользователя. Собственно, поскольку пользователь не может общаться с ядром напрямую, а взаимодействует с компьютером через shell и другие процессы — права пользователя и есть права программ, запущенных от его имени.
Такая модель подразумевает, что пользователь полностью доверяет всем программам, которые использует. В то время это было логично, потому что программы чаще всего либо были частью системы, либо создавались (писались и компилировались) самим пользователем.
В Unix есть и исключение из ограничений доступа — UID 0, который принято называть root. У него есть доступ ко всему в системе, и никакие ограничения на него не распространяются. Этот аккаунт использовался системным администратором; кроме того, под UID 0 запускаются многие системные сервисы.
В современном Linux эта модель была значительно расширена и обобщена, в том числе появились capabilities, позволяющие «получить часть root-прав», и реализующая мандатное управление доступом (mandatory access control, MAC) подсистема SELinux, которая позволяет дополнительно ограничить права (в том числе права root-процессов).
За несколько десятков лет, прошедших с создания Unix до создания Android, практика использования компьютеров («вычислителей») значительно изменилась.
Вместо машин, рассчитанных на параллельное использование многими пользователями (через терминалы — то, что сейчас эмулируют эмуляторы терминалов), появились персональные компьютеры, рассчитанные на использование одним человеком. Компьютеры перестали быть лишь рабочим инструментом и стали центром нашей цифровой жизни. С появлением мобильных устройств — сначала КПК, потом смартфонов, планшетов, умных часов и т.п. — эта тенденция только усилилась (потому что заниматься рабочими вопросами на мобильных устройствах относительно неудобно).
На таких устройствах хранятся гигабайты персональной информации, доступ к которой должен быть защищён и ограничен. В то же время расцвёл рынок сторонних приложений, которым у пользователя нет никаких оснований доверять.
Таким образом, в современных условиях вместо защиты разных пользователей друг от друга необходимо защищать от приложений другие приложения, пользовательские данные и саму систему. Кроме того, широкое распространение получили вирусы, которые обычно используют уязвимости в системе — для защиты от них нужно дополнительно защищать части системы друг от друга, чтобы использование одной уязвимости не давало злоумышленнику доступ ко всей системе.
Хотя часть Android-приложений поставляется с системой — например, такие стандартные приложения, как Калькулятор, Часы и Камера — большинство приложений пользователи устанавливают из сторонних источников. Самый известный из них — Google Play Store, но есть и другие, например, F-Droid, Amazon Appstore, Яндекс.Store, китайские Baidu App Store, Xiaomi App Store, Huawei App Store и т.д. Кроме того, Android позволяет вручную устанавливать произвольные приложения из APK-файлов (это называют sideloading).
Как и другие Unix-подобные системы, Android использует для ограничения доступа существующий механизм UID/GID. При этом — в отличие от традиционного использования, когда UID соответствуют пользователям — в Android разные UID соответствуют разным приложениям. Поскольку процессы разных приложений запускаются с разными UID, уже на уровне ядра приложения защищены и изолированы друг от друга и не имеют доступа к системе и данным пользователя. Это образует песочницу (Application Sandbox) и позволяет пользователю устанавливать любые приложения без необходимости доверять им.
Чтобы всё-таки получить доступ к пользовательским данным, камере, совершению звонков и т.п., приложение должно получить от пользователя разрешение (permission). Некоторые из разрешений существуют в виде GID, в которые приложение добавляется, когда получает это разрешение — например, получение разрешения ACCESS_FM_RADIO помещает приложение в группу media, что позволяет ему получить доступ к файлу /dev/fm. Остальные существуют только на более высоком уровне (в виде записей в файле packages.xml) и проверяются другими компонентами системы при обращении к высокоуровневому API через Binder.
Небольшая часть системных сервисов в Android запускается под UID 0, то есть root, но большинство используют специально выделенные номера UID, повышая при необходимости свои права с помощью Linux capabilities. Кроме того, Android использует SELinux — использование SELinux в Android называют SEAndroid — для ещё большего ограничения того, какие действия разрешено выполнять приложениям и системным сервисам.
Обычно Android не предоставляет пользователю прямой доступ к root-аккаунту, но в некоторых случаях у него есть возможность этот доступ получить. Как это происходит, зачем это нужно и какими опасностями это грозит я расскажу позднее.
В следующей статье (которая выходит уже через неделю) я расскажу о компонентах, из которых состоят приложения под Android, и об идеях, которые стоят за этой архитектурой.
|
|
Вы купили CRM. Как с этим жить? |




|
Метки: author Axelus управление проектами управление персоналом erp- системы crm- блог компании regionsoft developer studio crm внедрение crm regionsoft |
Вы купили CRM. Как с этим жить? |
|
Метки: author Axelus управление проектами управление персоналом erp- системы crm- блог компании regionsoft developer studio crm внедрение crm regionsoft |
Создаем уязвимые виртуальные машины в два счета с SecGen |

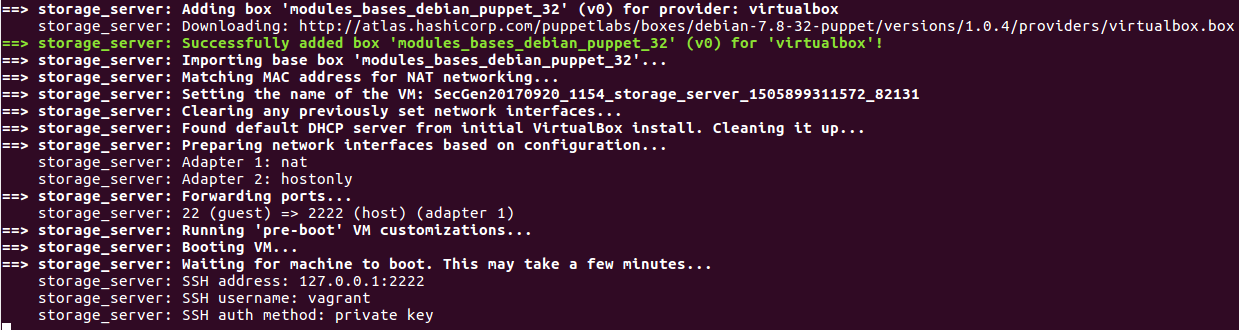
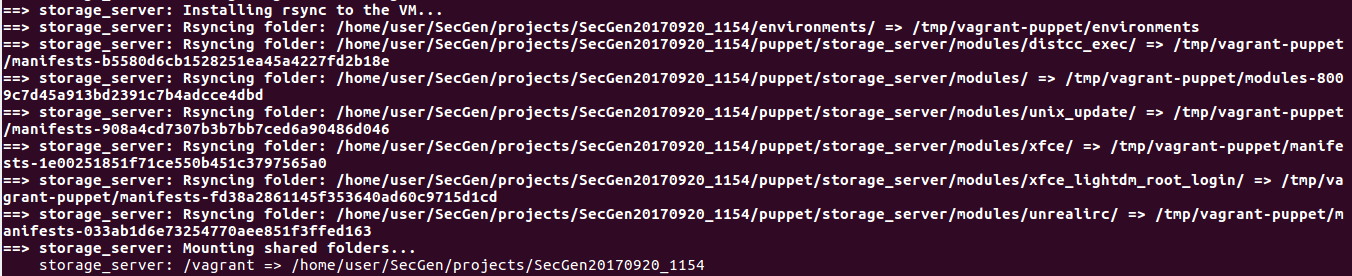
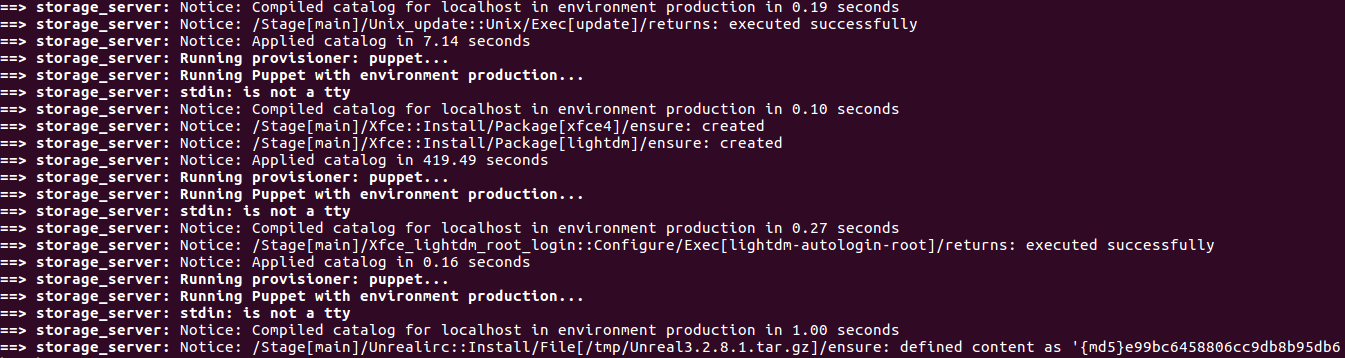
sudo apt-get install ruby-dev zlib1g-dev liblzma-dev build-essential patch virtualbox ruby-bundler vagrant imagemagick libmagickwand-dev exiftoolsudo apt-get install libpq-devgit clone https://github.com/cliffe/SecGen.gitcd SecGen
bundle install
ruby secgen.rb --help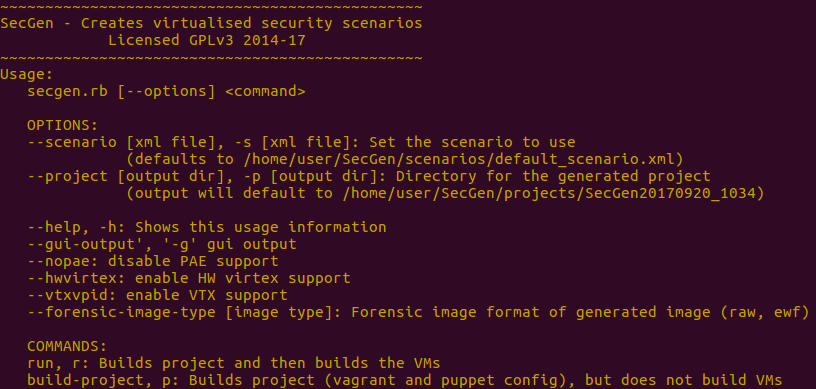
ruby secgen.rb run


ruby secgen.rb --project home/user/SecGen/projects/SecGen20170920_1154 build-vmsruby secgen.rb list-projects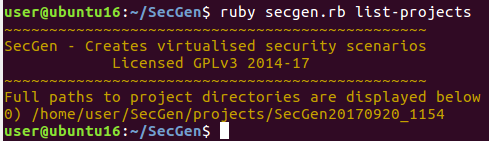
storage_server

chkrootkit 0.49 privilege escalation
Thomas Shaw
MIT
chkrootkit 0.49 and earlier contain a local privilege escalation vulnerability allowing a non-root user to place a
script in /tmp that will be executed as root when chkrootkit is run. This module adds a cronjob to run chkrootkit
periodically for exploitability.
privilege_escalation
root_rwx
local
linux
... ssh vagrant@127.0.0.1 -p 2222 -i private_key
eth0 Link encap:Ethernet HWaddr 08:00:27:86:1c:fb
inet addr:10.0.2.15 Bcast:10.0.2.255 Mask:255.255.255.0
inet6 addr: fe80::a00:27ff:fe86:1cfb/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:125254 errors:0 dropped:0 overruns:0 frame:0
TX packets:13570 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:177651061 (169.4 MiB) TX bytes:1034124 (1009.8 KiB)
eth1 Link encap:Ethernet HWaddr 08:00:27:83:ea:5e
inet addr:172.28.128.3 Bcast:172.28.128.255 Mask:255.255.255.0
inet6 addr: fe80::a00:27ff:fe83:ea5e/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:14 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:3130 (3.0 KiB) TX bytes:2304 (2.2 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
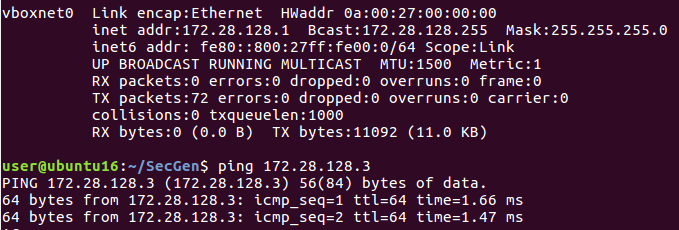
sudo nmap -n -Pn -p- 172.28.128.3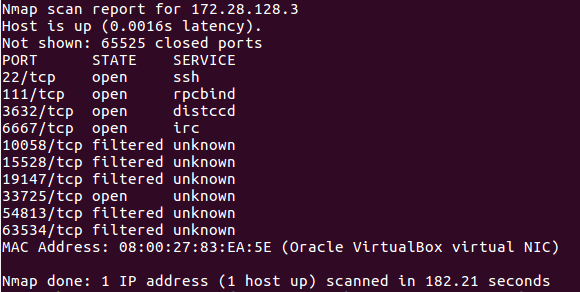
|
Метки: author antgorka информационная безопасность блог компании pentestit secgen metasploitable damn vulnerable linux puppet vagrant |
Создаем уязвимые виртуальные машины в два счета с SecGen |
sudo apt-get install ruby-dev zlib1g-dev liblzma-dev build-essential patch virtualbox ruby-bundler vagrant imagemagick libmagickwand-dev exiftoolsudo apt-get install libpq-devgit clone https://github.com/cliffe/SecGen.gitcd SecGen
bundle installruby secgen.rb --helpruby secgen.rb runruby secgen.rb --project home/user/SecGen/projects/SecGen20170920_1154 build-vmsruby secgen.rb list-projects
storage_server
chkrootkit 0.49 privilege escalation
Thomas Shaw
MIT
chkrootkit 0.49 and earlier contain a local privilege escalation vulnerability allowing a non-root user to place a
script in /tmp that will be executed as root when chkrootkit is run. This module adds a cronjob to run chkrootkit
periodically for exploitability.
privilege_escalation
root_rwx
local
linux
... ssh vagrant@127.0.0.1 -p 2222 -i private_keyeth0 Link encap:Ethernet HWaddr 08:00:27:86:1c:fb
inet addr:10.0.2.15 Bcast:10.0.2.255 Mask:255.255.255.0
inet6 addr: fe80::a00:27ff:fe86:1cfb/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:125254 errors:0 dropped:0 overruns:0 frame:0
TX packets:13570 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:177651061 (169.4 MiB) TX bytes:1034124 (1009.8 KiB)
eth1 Link encap:Ethernet HWaddr 08:00:27:83:ea:5e
inet addr:172.28.128.3 Bcast:172.28.128.255 Mask:255.255.255.0
inet6 addr: fe80::a00:27ff:fe83:ea5e/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:14 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:3130 (3.0 KiB) TX bytes:2304 (2.2 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
sudo nmap -n -Pn -p- 172.28.128.3|
Метки: author antgorka информационная безопасность блог компании pentestit secgen metasploitable damn vulnerable linux puppet vagrant |
Как поделить одного инструктора на всех, чтобы каждому досталось по два. Best practice в обучении ИТ |

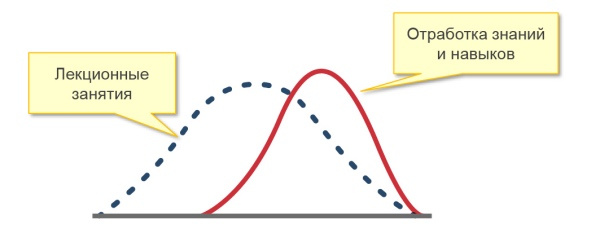
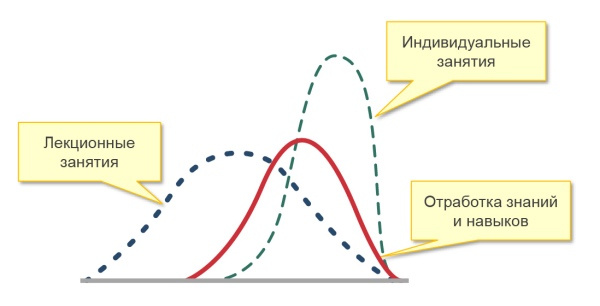

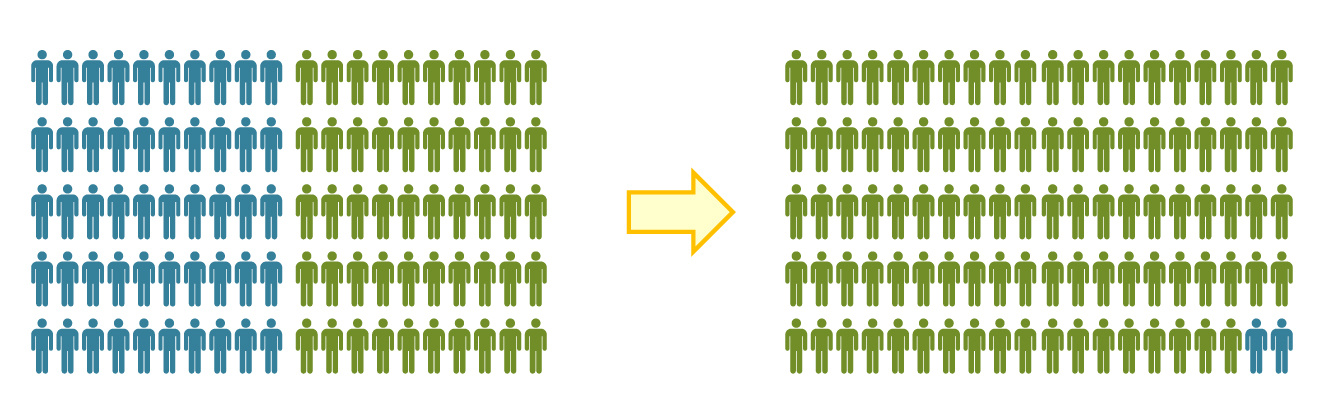
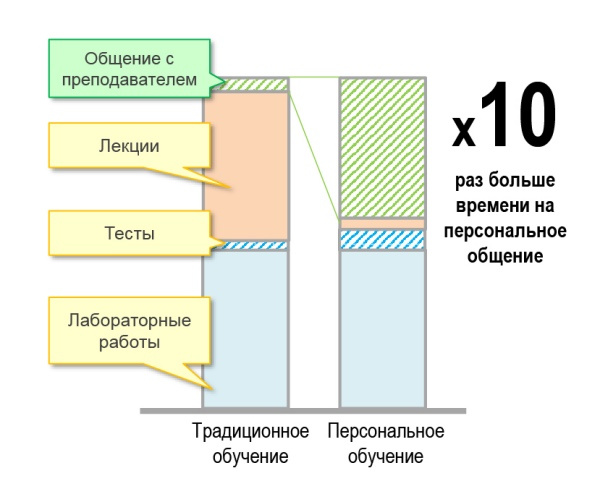


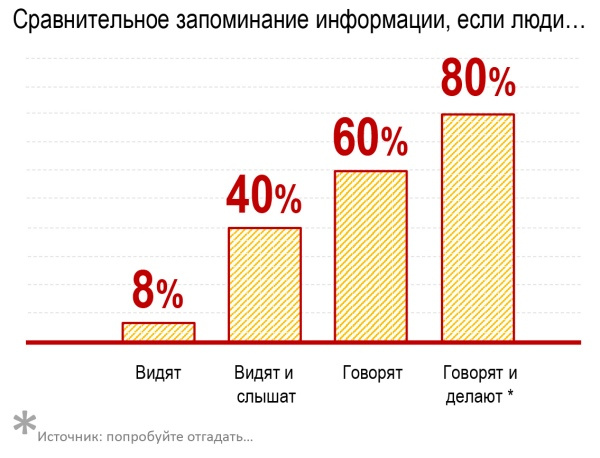




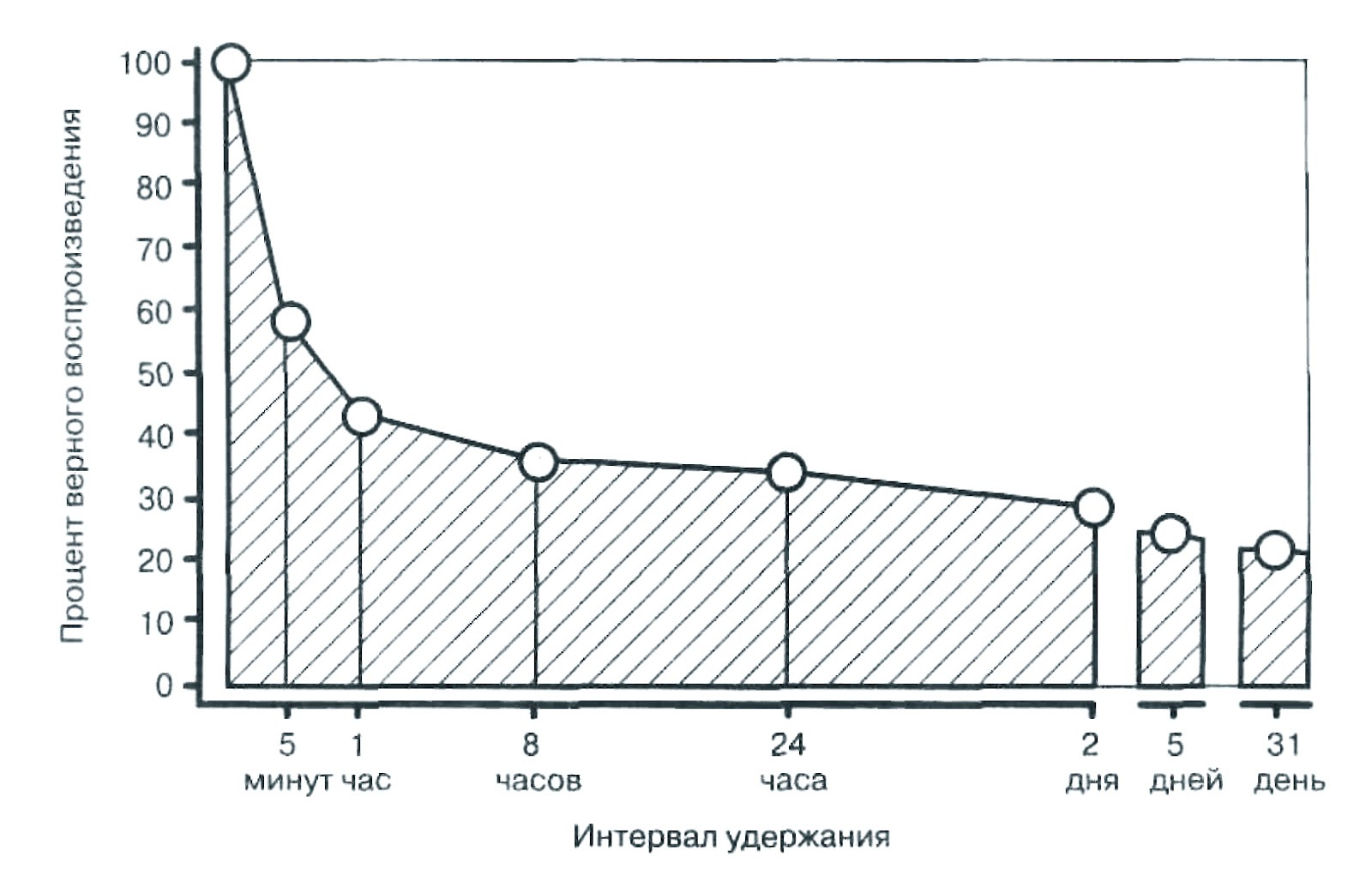

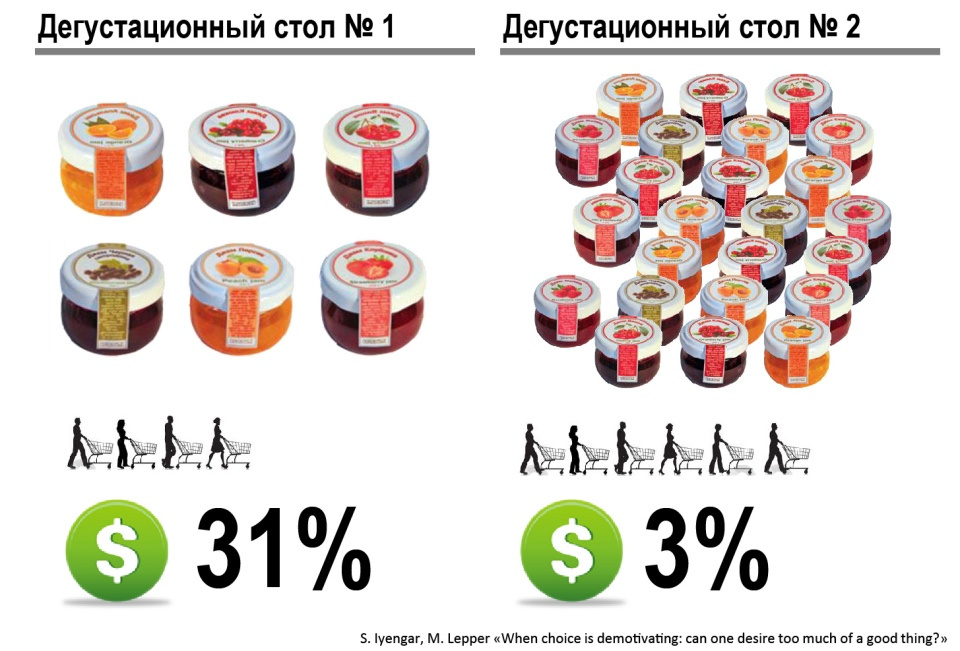
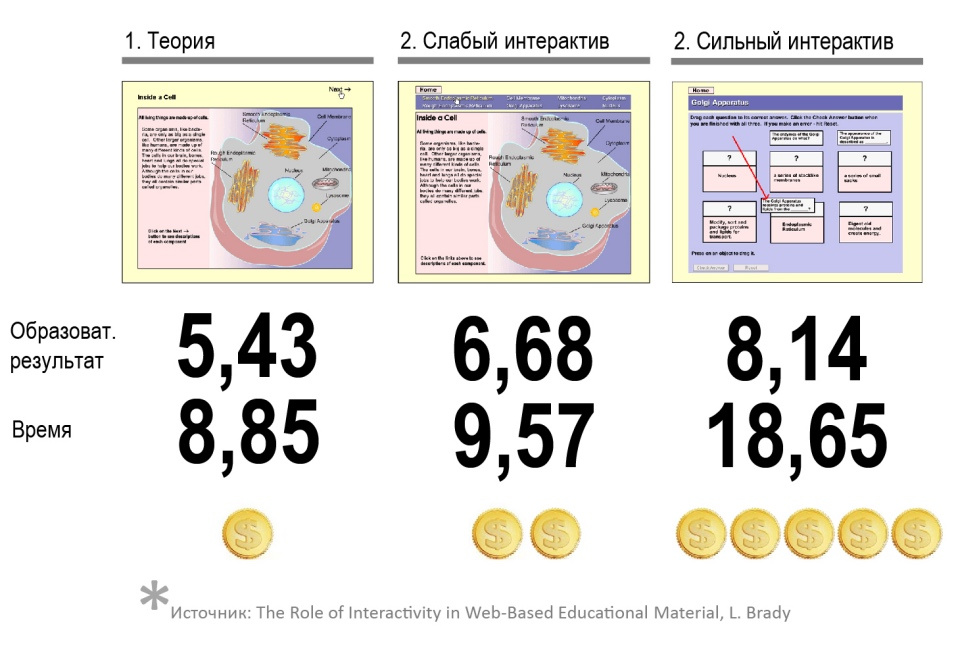



Один из учителей поясняет: «Источник жизненной силы любого класса – дискуссия, а для ее ведения необходима определенная критическая масса. В настоящее время я работаю с классами, где есть ученики, которые вообще никогда не участвуют в обсуждениях, это кошмар какой-то. Если учеников слишком мало, обсуждение тоже страдает. Кажется нелогичным, ведь я всегда считал, что робкие дети, которым неловко выступать в классе из 32 учеников, охотнее разговорятся в классе из 16 человек. Но я ошибался. Робкие дети робели вне зависимости от размера класса. А если класс слишком маленький, то среди участников не наблюдается широкого разброса мнений, необходимых, чтобы дискуссия развивалась. К тому же очень маленькая группа лишена той энергии, что возникает в результате трений между людьми».
(Гладуэлл Малкольм «Давид и Голиаф. Как аутсайдеры побеждают фаворитов» )
|
Метки: author juliashikova управление персоналом карьера в it-индустрии блог компании гк ланит обучение it карьера сетевая академия ланит формат обучения |
Как поделить одного инструктора на всех, чтобы каждому досталось по два. Best practice в обучении ИТ |
Один из учителей поясняет: «Источник жизненной силы любого класса – дискуссия, а для ее ведения необходима определенная критическая масса. В настоящее время я работаю с классами, где есть ученики, которые вообще никогда не участвуют в обсуждениях, это кошмар какой-то. Если учеников слишком мало, обсуждение тоже страдает. Кажется нелогичным, ведь я всегда считал, что робкие дети, которым неловко выступать в классе из 32 учеников, охотнее разговорятся в классе из 16 человек. Но я ошибался. Робкие дети робели вне зависимости от размера класса. А если класс слишком маленький, то среди участников не наблюдается широкого разброса мнений, необходимых, чтобы дискуссия развивалась. К тому же очень маленькая группа лишена той энергии, что возникает в результате трений между людьми».
(Гладуэлл Малкольм «Давид и Голиаф. Как аутсайдеры побеждают фаворитов» )
|
Метки: author juliashikova управление персоналом карьера в it-индустрии блог компании гк ланит обучение it карьера сетевая академия ланит формат обучения |
Автопилот своими рукам. Добавляем электронное управление steer-by-wire на обычный автомобиль |
Всем привет. Любому автопилоту, очевидно, нужно не только принимать решения по управлению, но и заставлять автомобиль этим решениям подчиняться. Сегодня увидим, как весьма доступными средствами доработать обычный автомобиль полностью электронным рулевым управлением (steer-by-wire). Оказывается, сам авто для разработки не очень и нужен, а большинство функционала можно с комфортом отлаживать дома или в офисе. В главных ролях всем известные компоненты из хобби-магазинов электроники.

Задумаемся на секунду, что нужно для системы электронного управления? Сервопривод, который может поворачивать колёса, и контроллер, чтобы сервоприводом управлять. Внезапно, всё это в большинстве современных автомобилей уже есть, и называется "усилитель рулевого управления". Традиционные чисто механические (как правило, гидравлические) усилители стремительно исчезают с рынка, уступая место узлам с электронным блоком управления (ЭБУ). А значит, задача сразу упрощается: нам остается только "уговорить" имеющийся ЭБУ усилителя выдать нужные команды на сервопривод.
Очень удобным для доработки оказался KIA Cee'd начиная с 2015 модельного года (скорее всего аналогично и его соплатформенники от KIA/Hyundai). Сошлись одновременно несколько факторов:
Итак, получена в распоряжение рулевая колонка в сборе:

Будем заставлять её крутиться. Для этого нужно создать у блока управления впечатление, что
Пойдем по порядку.
Нужно понять интерфейс между электронным блоком управления (ЭБУ) усилителя и остальным автомобилем. Нагуглив электрическую схему видим картинку:

Из схемы видно, что физически интерфейс очень прост:
Внешний вид и распиновки разъемов находим на том же сайте.
С питанием и зажиганием всё просто, берем 12V с обычного компьютерного блока питания. Но если просто подать питание и зажигание, усилитель полноценно не включится, и усиливать не будет. Дополнительно нужна информация от других блоков автомобиля: работает ли двигатель (чтобы не тратить энергию аккумулятора при выключенном), текущая скорость (чтобы делать руль "тяжелее" на скорости), наверняка что-то ещё.
Обмен данными между электронными блоками в современных автомобилях организован по шинам CAN (Controller Area Network). Это широковещательная (у пакетов нет адресов назначения) локальная сеть на витой паре, где каждый блок может публиковать свои данные. У каждого типа данных свой идентификатор. Например, в нашем случае усилитель руля рассылает значения угла поворота руля с ID 0x2B0. Часто бывает несколько физически разделенных шин, чтобы второстепенные блоки типа контроллеров стеклоподъемников не мешались обмену между критически важными компонентами. В Cee'd используется две шины: C-CAN и B-CAN (схема здесь, в части "Информация о канале передачи данных"). На C-CAN "висят" почти все блоки с ней и будем работать.
Первым делом понадобится CAN интерфейс для компьютера. Детальный обзор возможных решений есть например здесь, цены варьируются от десятков до сотен долларов. По устройствам у нас относительно доступны:
Софта разного тоже много (за обзором опять сюда). Самый простой вариант — Linux c can-utils из SocketCAN, за который спасибо инженерам Volkswagen. Большой плюс SocketCAN в стандартизации — любое USB устройство с поддержкой протокола LAWICEL (pdf) видится системой как обычный сетевой интерфейс. Таким образом избегаем привязки к вендор-специфическому софту конкретного устройства. У текущей версии CANHacker есть небольшая несовместимость со стоковыми can-utils по работе с USB, поэтому берём патченную версию отсюда. Raspberry Pi с CAN шилдом работает со стоковым пакетом can-utils из Raspbian OS без проблем.
С подключением к индивидуальному узлу на стенде всё просто: соединяем контакт CAN-High адаптера с CAN-High автомобильного узла, CAN-Low — c CAN-Low. По стандарту между CAN-High и CAN-Low должно быть 2 замыкающих резистора по 120 Ом, на практике обычно всё работает на довольно широком интервале сопротивлений, у меня например одно на 110 Ом.
На автомобиле замыкающий резистор не нужен (они там уже стоят, чтобы шина сама по себе работала). В зависимости от модели авто, возможно придется повозиться с физическим доступом к проводке шины. Самый удобный вариант — разъём OBD-II (on-board diagnostic), он обязателен на всех легковых автомобилях, выпущенных в Европе с начиная 2001-2004 года и находится не дальше 60 см от рулевого колеса. На Cee'd разъём слева под рулём, за пластмасовой крышкой блока предохранителей.

Распиновка OBD-II стандартизована и включает шину CAN (CANH на 6 контакте, CANL на 14). Нам повезло, корейцы пошли по пути наименьшего сопротивления и вывели C-CAN, на которой висят все важные узлы, прямо на диагностический разъём:

В результате на Cee'd можно прослушать весь внутренний трафик, ничего в авто не разбирая. Когда машина не твоя, а знакомые пустили повозиться — большой плюс. Но такая халява не везде. У Volkswagen например служебная CAN изолирована от OBD шлюзом, поэтому подключаться пришлось бы примерно так:

Подключив все контакты, поднимаем сетевой интерфейс:
$ sudo slcand -o -c -s6 -S 115200 ttyACM0 slcan0 && sleep 1 && sudo ifconfig slcan0 upПроверяем, что сеть работает и данные принимаются (включив зажигание):
$ cansniffer slcan0И наконец, если всё нормально, можно записывать лог:
$ candump -L slcan0 > real-car-can-log.txtЗдесь нужно запустить двигатель, т.к. усилитель руля включается на собственно усиление только при работающем двигателе, а нам на стенде надо, чтобы он усиливал.
С записанным логом с авто можно возвращаться на стенд и приступать к обману нашего одинокого усилителя. Первым делом вспомним, что в автомобиле стоит свой собственный усилитель, он тоже шлёт данные в CAN шину, и эти пакеты есть и в нашем логе. Отфильтруем их, чтобы избежать конфликтов. Подключаемся к усилителю на стенде, смотрим, что он выдает:
$ $ candump slcan0
slcan0 2B0 [5] 00 00 00 00 00
slcan0 2B0 [5] FF 7F FF 06 F1
slcan0 2B0 [5] FF 7F FF 06 C2
slcan0 2B0 [5] FF 7F FF 06 D3
slcan0 2B0 [5] FF 7F FF 06 A4
slcan0 2B0 [5] FF 7F FF 06 B5
slcan0 2B0 [5] FF 7F FF 06 86
slcan0 2B0 [5] FF 7F FF 06 97
slcan0 2B0 [5] FF 7F FF 06 68
slcan0 5E4 [3] 00 00 00
slcan0 2B0 [5] FF 7F FF 06 79
slcan0 2B0 [5] FF 7F FF 06 4A
....Видим, что рассылаются пакеты 2B0 (текущий угол поворота руля) и, реже, 5E4 (какой-то общий статус усилителя). Отфильтровываем их из общего лога:
$ cat real-car-can-log.txt | grep -v ' 2B0' | grep -v ' 5E4 ' > can-log-no-steering.txtФильтрованный лог можно подавать на воспроизведение:
% sudo ifconfig slcan0 txqueuelen 1000
$ canplayer -I can-log-no-steering.txtЕсли всё сработало успешно, усилитель заработает, крутить рукой рулевой вал станет гораздо легче. Итак, работать в штатном режиме мы узел заставили, можно переходить к симуляции усилий на руле.
Крутящий момент на рулевом валу и угол поворота измеряются встроенным блоком датчиков, от которого идет жгут проводов к блоку управления усилителем:

Блок управления обрабатывает сигналы датчиков и выдаёт команды сервоприводу на создание дополнительного усилия на поворот рулевого вала.
По информации PolySync, на Soul, у которого с Cee'd общая платформа, два аналоговых датчика крутящего момента. Cигнал каждого — отклонение уровня постоянного напряжения от базовых 2.5V, провода в жгуте — зеленый и синий. Проверим, что у нас то же самое:

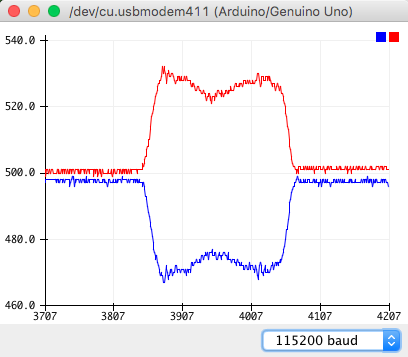
Переходим к эмуляции сигнала датчиков. Для этого поставим свой модуль в разрыв цепи между датиком и ЭБУ, будем транслировать настоящий сигнал с датчика и по команде сдвигать его на фиксированный уровень (изображая приложенное к рулевой колонке усилие). Силами одной arduino это не получится: там нет полноценного цифро-аналогового преобразователя, который мог бы выдавать постоянное напряжение. Аналоговые входы arduino нам тоже не очень подходят — хотя пинов для них целых 6, канал АЦП в контроллере только один, и его переключение между пинами занимает заметное время.
Нужно добавить к arduino внешние ЦАП/АЦП. Мне попались модули YL-40 (описание в pdf) на основе чипа PCF8591 — на каждой по 4 канала 8-бит АЦП и 1 8-бит ЦАП. Модуль может общаться с arduino по протоколу I2C. Потребуется небольшое допиливание (в буквальном смысле): китайские товарищи поставили на плату светодиод индикации напряжения на выходе ЦАП — его обязательно надо отсоединить. Иначе утекающий через диод ток не даст ЦАП поднять напряжение на выходе больше 4.2V (вместо штатных 5V). Диод отсоединяем, отковыривая резистор R4 с обратной стороны платы.

Также на входы распаяны игрушечные нагрузки (терморезистор, фоторезистор, ещё что-то), отсоединяем их, убирая перемычки, чтобы не мешались.

С интерфейсом к arduino есть нюанс — нам нужно 2 канала ЦАП, соотвественно 2 модуля, но у них одинаковые адреса I2C (зашиты в чип). Хотя чип позволяет менять свой I2C адрес, замыкая определенные ноги на +5V вместо земли, на плате эти перемычки не разведены. Вместо перепайки возьмем костыль — две разные библиотеки I2C на arduino (стандартная Wire и SoftI2CMaster), каждая на свою пару пинов. Получаем модули на разных шинах, конфликт пропадает.
Остальное прямолинейно — ставим модули в разрыв цепи от датчиков, соединяем с arduino, загружаем скетч. Подробности по распиновке подключения есть в комментариях в скетче. Остается включить всё в сборе, здесь важна последовательность:
l и r через Serial Monitor усилитель будет поворачивать рулевой вал. Объявляется победа. На сегодня всё, на очереди доработка софта (интеграция с CAN шиной, чтение оттуда текущего угла поворота и динамическое управление крутящим усилием, чтобы внешний контроллер мог задать фиксированный угол поворота руля и система его выдерживала), отработка на автомобиле (на стенде не смоделируешь сопротивление от колёс). Возможно замена 8-битных ЦАП/АЦП на 10 или 12 бит (взял первое, что под руку попалось). Рулящая нейросеть тоже в процессе, надеюсь скоро сделать пост.
Спасибо Artemka86 за ценные консультации по работе с CAN и помощь с оборудованием.
Прежде всего, внимание, CAN шилд и raspberry pi нельзя соединять напрямую, они не совместимы по напряжению. На Arduino UNO-совместимых платах напряжение логики 5V, а на raspberry pi только 3.3V, поэтому прямое соединение только сожжет задействованные пины.
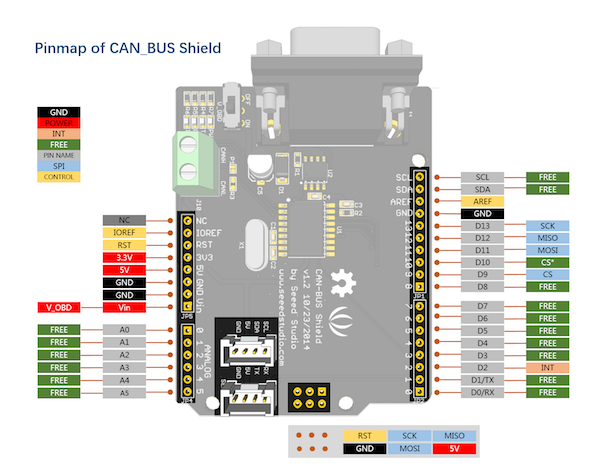
Нам понадобятся:
Нужно завести на CAN шилд питание (5V), соединения интерфейса данных SPI (4 пина: MOSI, MISO, SCLK, CS) и 1 пин сигнала прерывания. Всё, кроме питания, идет через преобразователь уровня, который в свою очередь тоже надо запитать.
На схемах ищем нужные пины.
Raspberry Pi:

CAN шилд:
Получаем результат:
Соединяем через преобразователь, заводим нужные напряжения питания на каждую сторону преобразователя, получается такая лапша:

Всё, кроме 5V питания и земли на шилд идёт через преобразователь:

Переходим к настройке софта (стандартный Raspbian).
Включаем поддержку SPI и CAN модуля. В /boot/config.txt добавляем
dtparam=spi=on
dtoverlay=mcp2515-can0,oscillator=16000000,interrupt=25,spimaxfrequency=1000000
dtoverlay=spi0-hw-csЗдесь interrupt=25 указывает пин, на который заведено прерывание с шилда. Индексация идёт по GPIO пинам, поэтому interrupt=25 это GPIO 25, он же пин 22 по сквозной индексации всех пинов. Также важно указать частоту интерфейса SPI spimaxfrequency, т.к. значение по умолчанию — 10 МГц — слишком высокое для шилда, он просто не соединится.
Перезагружаем raspberry pi, проверяем соединение с шилдом:
$ dmesg
...
[ 12.985754] CAN device driver interface
[ 13.014774] mcp251x spi0.0 can0: MCP2515 successfully initialized.
...Устанавливаем can-utils:
$ sudo apt install can-utilsЗапускаем виртуальный сетевой интерфейс:
$ sudo /sbin/ip link set can0 up type can bitrate 500000
$ sudo ifconfig can0 txqueuelen 1000Вторая команда важна при воспроизведении большого количества данных с raspberry pi, то есть когда записанный на автомобиле полный лог CAN шины воспоизводим для изолированного узла на стенде. Без увеличения буфера он скорее всего переполнится, когда в логе встретится несколько CAN пакетов с маленькими интервалами, и тогда соединение зависнет.
candump, cansniffer и всем остальным из can-utils.|
Метки: author waiwnf разработка робототехники программирование микроконтроллеров self-driving-car steer-by-wire |






