Gervase Markham: Bugzilla for Humans, II |
In 2010, johnath did a very popular video introducing people to Bugzilla, called “Bugzilla for Humans“. While age has been kind to johnath, it has been less kind to his video, which now contains several screenshots and bits of dialogue which are out of date. And, being a video featuring a single presenter, it is somewhat difficult to “patch” it.
Enter Popcorn Maker, the Mozilla Foundation’s multimedia presentation creation tool. I have written a script for a replacement presentation, voiced it up, and used Popcorn Maker to put it together. It’s branded as being in the “Understanding Mozilla” series, as a sequel to “Understanding Mozilla: Communications” which I made last year.
So, I present “Understanding Mozilla: Bugzilla“, an 8.5 minute introduction to Bugzilla as we use it here in the Mozilla project:
Because it’s a Popcorn presentation, it can be remixed. So if the instructions ever change, or Bugzilla looks different, new screenshots can be patched in or erroneous sections removed. It’s not trivial to seamlessly patch my voiceover unless you get me to do it, but it’s still much more possible than patching a video. (In fact, the current version contains a voice patch.) It can also be localized – the script is available, and someone could translate it into another language, voice it up, and then remix the presentation and adjust the transitions accordingly.
Props go to the Popcorn team for making such a great tool, and the Developer Tools team for Responsive Design View and the Screenshot button, which makes it trivial to reel off a series of screenshots of a website in a particular custom size/shape format without any need for editing.
http://feedproxy.google.com/~r/HackingForChrist/~3/3pgZXXVgboc/
|
|
Doug Belshaw: On the denotative nature of programming |
This is just a quick post almost as a placeholder for further thinking. I was listening to the latest episode of Spark! on CBC Radio about Cracking the code of beauty to find the beauty of code. Vikram Chandra is a fiction author as well as a programmer and was talking about the difference between the two mediums.
It’s definitely worth a listen [MP3]
The thing that struck me was the (perhaps obvious) insight that when writing code you have to be as denotative as possible. That is to say ambiguity is a bad thing leading to imprecision, bugs, and hard-to-read code. That’s not the case with fiction, which relies on connotation.
This reminded me of a paper I wrote a couple of years ago with my thesis supervisor about a ‘continuum of ambiguity’. In it, we talk about the overlap between the denotative and connotative aspects of a word, term, or phrase being the space in which ambiguity occurs. For everything other than code, it would appear, this is the interesting and creative space.
I’ve recently updated the paper to merge comments from the 'peer review’ I did with people in my network. I also tidied it up a bit and made it look a bit nicer.
Read it here: Digital literacy, digital natives, and the continuum of ambiguity
Comments? Questions? Email me: doug@mozillafoundation.org
|
|
Soledad Penades: Publishing a Firefox add-on without using addons.mozilla.org |
A couple of days ago Tom Dale published a post detailing the issues the Ember team are having with getting the Ember Inspector add-on reviewed and approved.
It left me wondering if there would not be any other way to publish add-ons on a different site. Knowing Mozilla, it would be very weird if add-ons were “hardcoded” and tied only and exclusively to a mozilla.org property.
So I asked. And I got answers. The answer is: yes, you can publish your add-on anywhere, and yes your add-on can get the benefit of automatic updates too. There are a couple of things you need to do, but it is entirely feasible.
First, you need to host your add-on using HTTPS or “all sorts of problems will happen”.
Second: the manifest inside the add-on must have a field pointing to an update file. This field is called the updateURL, and here’s an example from the very own Firefox OS simulator source code. Snippet for posterity:
>@ADDON_UPDATE_URL@>You could have some sort of “template” file to generate the actual manifest at build time–you already have some build step that creates the xpi file for the add-on anyway, so it’s a matter of creating this little file.
And you also have to create the update.rdf file which is what the browser will be looking at somewhat periodically to see if there’s an update. Think of that as an RSS feed that the browser subscribes to ![]()
Here’s, again, an example of how an update.rdf file looks like, taken from one of the Firefox OS simulators:
span> xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:em="http://www.mozilla.org/2004/em-rdf#">
span> about="urn:mozilla:extension:fxos_2_2_simulator@mozilla.org">
>
>>
>
>2.2.20141123>
>
>
>{ec8030f7-c20a-464f-9b0e-13a3a9e97384}>
>19.0>
>40.*>
>https://ftp.mozilla.org/pub/mozilla.org/labs/fxos-simulator/2.2/mac64/fxos-simulator-2.2.20141123-mac64.xpi>
>
>
>
>>
>
>
>And again this file could be generated at build time and perhaps checked in the repo along with the xpi file containing the add-on itself, and served using github pages which do allow serving https.
The Firefox OS simulators are a fine example of add-ons that you can install, get automatic updates for, and are not hosted in addons.mozilla.org.
Hope this helps.
Thanks to Ryan Stinnett and Alex Poirot for their information-rich answers to my questions–they made this post possible!
![]()
http://soledadpenades.com/2014/11/28/publishing-a-firefox-add-on-without-using-addons-mozilla-org/
|
|
Carsten Book: Vortrag ueber Mozilla Sheriffs heute beim OpenSource Treffen in Muenchen |
Hi,
ich werde heute ab 18 Uhr wieder beim OpenSource Treffen in Muenchen dabei sein und dabei etwas erzaehlen ueber Mozilla Code Sheriffs.
Natuerlich werde ich auch fuer allgemeine Fragen rund um Mozilla zur Verfuegung stehen.
Dann bis heute abend!
Viele Gruesse
Carsten
|
|
Benoit Girard: Improving Layer Dump Visualization |
I’ve blogged before about adding a feature to visualize platforms log dumps including the layer tree. This week while working on bug 1097941 I had no idea which module the bug was coming from. I used this opportunity to improve the layer visualization features hoping that it would help me identify the bug. Here are the results (working for both desktop and mobile):

This tools works by parsing the output of layers.dump and layers.dump-texture (not yet landed). I reconstruct the data as DOM nodes which can quite trivially support the features of a layers tree because layers tree are designed to be mapped from CSS. From there some javascript or the browser devtools can be used to inspect the tree. In my case all I had to do was locat from which layer my bad texture data was coming from: 0xAC5F2C00.
If you want to give it a spin just copy this pastebin and paste it here and hit ‘Parse’. Note: I don’t intend to keep backwards compatibility with this format so this pastebin may break after I go through the review for the new layers.dump-texture format.

https://benoitgirard.wordpress.com/2014/11/28/improving-layer-dump-visualization/
|
|
Kevin Ngo: Adelheid, an Interactive Photocentric Storybook |
 Photos scroll along the bottom, pages slide left and right.
Photos scroll along the bottom, pages slide left and right.
Half a year ago, I built an interactive photocentric storybook as a gift to my girlfriend for our anniversary. It binds photos, writing, music, and animation together into an experential walk down memory lane. I named it Adelheid, a long-form version of my girlfriend's name. And it took me about a month of my after-work free time whenever she wasn't around. Adelheid is an amalgamation of my thoughts as it molds my joy of photography, writing, and web development into an elegantly-bound package.

As before, I wanted it to a representation of myself: photography, writing, web development. I spent time sketching it out on a notebook and came up with this. The storybook is divided into chapters. Chapters consist of a song, summary text, a key photo, other photos, and moments. Moments are like subchapters; they consist of text and a key photo. Chapters slide left and right like pages in a book, photos roll through the bottom like an image reel, moments lie behind the chapters like the back of a notecard, all while music plays in the background. Then I put in a title page at the beginning that lifts like a stage curtain.
It took a month of work to bring it to fruition, and it was at last unveiled as a surprise on a quiet night at Picnic Island Park in Tampa, Florida.
With all of the large image and audio files, it becomes quite a large app. My private storybook contains about 110MB, as a single-page app! Well, that's quite ludicrous. However, I made it easy for myself and had it intended to only be used as a packaged app. This means I don't have to worry about load times over a web server since all assets can be downloaded and installed as a desktop app.
Unfortunately, it currently only works well in Firefox. Chrome was targeted initially but was soon dropped to decrease maintenance time and hit my deadline. There's a lot of fancy animation going on, and it was difficult to get it working properly in both browsers. Not only for CSS compatability, but it currently only works as a packaged app for Firefox. Packaged apps have not been standardized, and I only configured packaged app manifests for Firefox's specifications.
After the whole thing, I became a bit more adept at CSS3 animations. This included the chapter turns, image reels, and moment flips. Some nice touches were parallaxed images so the key images transitioned a bit slower to give off a three-dimensional effect. Also the audio faded in and out between chapter turns using a web audio library.
You can install the demo app at adelheid.ngokevin.com.
|
|
Yura Zenevich: Resources For Contributing to Firefox OS Accessibility. |
28 Nov 2014 - Toronto, ON
I believe when contributing to Firefox OS and Gaia, just like with most open source projects, a lot of attention should be given to reducing the barrier for entry for new contributors. It is even more vital for Gaia since it is an extremely fast moving project and the number of things to keep track of is overwhelming. In an attempt to make it easier to start contributing to Firefox OS Accessibility I compiled the following list of resources, that I will try keeping up to date. It should be helpful for a successful entry into the project:
Firstly, links to high level documentation:
Gaia project is hosted on Github and the version control that is used is Git. Here's a link to the project source code:
https://github.com/mozilla-b2g/gaia/
One of my coworkers (James Burke) proposed the following workflow that you might find useful (link to source):
yzen as an example) git clone --recursive git@github.com:yzen/gaia.git gaia-yzen
cd gaia-yzen
git remote add upstream git@github.com:mozilla-b2g/gaia.git
# this updates your local master to match mozilla-b2g's latest master
# you should always do this to give better odds your change will work
# with the latest master state for when the pull request is merged
git pull upstream master
# this updates your fork on github's master to match
git push origin master
# Create bug-specific branch based on current state of master
git checkout -b bug-123
Now you will be in the bug-123 branch locally, and its contents will look the same as the master branch. The idea with bug-specific branches is that you keep your master branch pristine and only matching what is in the official mozilla-b2g branch. No other local changes. This can be useful for comparisons or rebasing.
Do the changes in relation to the bug you are working on.
Commit the change to the branch and then push the branch to your fork. For the commit message, you can just copy in the title of the bug:
git commit -am "Bug 123 - this is the summary of changes."
git push origin bug-123
Now you can go to https://github.com/yzen/gaia and do the pull request.
In the course of the review, if you need to do other commits to the branch for review feedback, once it is all reviewed, you can flatten all the commits into one commit, then force push the change to your branch. I normally use rebase -i for this. So, in the gaia-yzen directory, while you are in the bug-123, you can run:
git rebase -i upstream/master
At this point, git gives you a way to edit all the commits. I normally 'pick' the first one, then choose 's' for squash for the rest, so the rest of the commits are squashed to the first picked commit.
Once that is done and git is happy, you can the force push the new state of the branch back to GitHub:
git push -f origin bug-123
More resources at:
All apps are located in apps/ directory. Each up is located within its own directory. So for example if you are working on a Calendar app you would be making your changes in the apps/calendar directory.
The way we want to make sure that the improvements that we work on actually help Firefox OS accessibility and do not regress we have a policy of adding gaia-ui python Marionette tests for all new accessible functionality. You can find tests in the tests/python/gaia-ui-tests/gaiatest/tests/accessibility/ directory.
More resources at:
Localization is very relevant to accessibility especially because one of the tasks that we perform when making something accessible is ensuring that all elements in the applications are labeled for the user of assistive technologies. Please see Localization best practices for guidelines on how to add new text to applications.
Using a device or navigating a web application is different with the screen reader. Screen reader introduces a concept of virtual cursor (or focus) that represents screen reader's current position inside the app or web page. For mode information and example videos please see: Screen Reader
Here are some of the basic resources to help you get to know what mobile accessibility (and accessibility) is:
yzen
http://feedproxy.google.com/~r/yura-zenevich/~3/b2D4BWGsSSQ/resources-for-contributing.html
|
|
Christian Heilmann: What if everything is awesome? |

These are the notes for my talk at Codemotion Madrid this year.
You can watch the screencast on YouTube and you can check out the slides at Slideshare.
The other day I watched Pacific Rim and was baffled by the awesomeness and the awesome inanity of this movie.
Let’s recap a bit:
All in all the movie is borderline insane as if we had a rift like that under water, all we’d need is mine it. Or have some massive ships and submarines where the rift is ready to shoot and bomb anything that comes through. Which, of course, beats trying to communicate with it.
The issue is that this solution would not make for a good blockbuster 3D movie aimed at 13 year olds. Nothing fights or breaks in a fantastic manner and you can’t show crumbling buildings. We’d be stuck with mundane tasks. Like writing a coherent script, proper acting or even manual camera work and settings instead of green screen. We can’t have that.
What does all that have to do with web development? Well, I get the feeling we got to a world where we try to be awesome for the sake of being awesome. And at the same time we seem to be missing out on the fact that what we have is pretty incredible as it is.
One thing I blame is the tech press. We still get weekly Cinderella stories of the lonely humble developer making it big with his first app (yes, HIS first app). We hear about companies buying each other for billions and everything being incredibly exciting.
In stark contrast to that, our daily lives as developers are full of frustrations. People not knowing what we do and thus not really giving us feedback on what we do, for example. We only appear on the scene when things break.
Our users can also be a bit of an annoyance as they do not upgrade the way we want them to and keep using things differently than we anticipated.
And even when we mess up, not much happens. We put our hearts and lots of efforts into our work. When we see something obviously broken or in dire need of improvement we want to fix it. The people above us in the hierarchy, however, are happy to see it as a glitch to fix later.
Instead of working on the obvious broken communication between us and those who use our products and us and those who sell them (or even us and those who maintain our products) I hear a louder and louder call for “professional development”. This involves many abstractions and intelligent package managers and build scripts that automate a lot of the annoying cruft of our craft. Cruft in the form of extraneous code. Code that got there because of mistakes that our awesome new solutions make go away. But isn’t the real question why we still make so many mistakes in the first place?
One of the things we seem to be craving is to match the state of affairs of native platforms, especially the form factor of apps. Apps seem to be the new, modern form factor of software delivery. Fact is that they are a questionable success (and may even be a step back in software evolution as I put it in a TEDx talk. If you look at who earns something with them and how long they are in use on average it is hard to shout “hooray for apps”. On the web, there is a problem that there are so far no standards that define an app that are working across platforms. If you wonder how far that is going along, the current state of mobile apps on the web describes this in meticulous detail at the W3C.
A lot of what we crave as developers is generic. We don’t want to write code that does one job well, we want to write code that can take any input and does something intelligent with it. This is feel good code. We are not only clever enough to be programmers We also write solutions that prevent people from making mistakes by predicting them.
Fredrik Noren wrote a brilliant piece on this called “On Generalisation“. In it he argues that writing generic code means trying to predict the future and that we are bad at that. He calls out for simpler, more modular and documented code that people can extend instead of catch-all solutions to simple problems.
I found myself nodding along reading this. There seems to be a general tendency to re-invent instead of improving existing solutions. This comes natural for developers – we want to create instead of read and understand. I also blame sites like hacker news which are a beauty pageant of small, quick and super intelligent technical solutions for every conceivable problem out there.
Want some proof? How about Static Site Generators listing 295 different ways to create static HTML pages? Let’s think about that: static HTML pages!
We try to fix our world by stacking abstractions and creating generic solutions for small issues. The common development process and especially the maintenance process looks different, though.
People using Content Management Systems to upload lots of un-optimised photos are a problem. People using too many of our sleak and clever solutions also add to the fact that that web performance is still a big issue. According to the HTTP Archive the average web site is 2 MB in data delivered in 100(!) HTTP requests. And that years after we told people that each request is a massive cause of a slow and sluggish web experience. How can anyone explain things like the new LG G Watch site clocking in at 54 MB on the first loadLG G Watch site clocking in at 54 MB on the first load whilst being a responsive design?
There are no excuses. We have incredible tools that give us massive insight into our work. What we do is not black art any longer, we don’t hope that browsers do good things with our code. We can peek under the hood and see the parts moving.
Webpagetest.org is incredible. It gives us detailed insight into what is going right and wrong in our web sites right in the browser. You can test the performance of a site simulating different speeds and load it from servers all over the world. You get a page optimisation checklist, graphs about what got loaded when and when things started rendering. You even get a video of your page loading and getting ready for users to play with.
There are many resources how to use this tool and others that help us with fixing performance issues. Addy Osmani gave a great talk at CSS Conf in Berlin re-writing the JSConf web site live on stage using many of these tools.
Browsers have evolved from simple web consumption tools to full-on development environments. Almost all browsers have some developer tools built in that not only allow you to see the code in the current page but also to debug. You have step-by-step debugging of JavaScript, CSS debugging and live previews of colours, animations, element dimensions, transforms and fonts. You have insight into what was loaded in what sequence, you can see what is in localStorage and you can do performance analysis and see the memory consumption.
The innovation in development tools of browsers is incredible and moves at an amazing speed. You can now even debug on devices connected via USB or wireless and Chrome allows you to simulate various devices and network/connectivity conditions.
Sooner or later this might mean that we won’t any other editors any more. Any user downloading a browser could also become a developer. And that is incredible. But what about older browsers?
A lot of bloat on the web happens because of us trying to give new, cool effects to old, tired browsers. We do this because of a wrong understanding of the web. It is not about giving the same functionality to everybody, but instead to give a working experience to everybody.
The idea of a polyfill is genius: write a solution for an older environment to play with new functionality and get our UX ready for the time browsers support it. It fails to be genius when we never, ever remove the polyfills from our solutions. The Financial Times development team now had a great idea to offer polyfill as a service. This means you include one JavaScript file.
span> src="//cdn.polyfill.io/v1/polyfill.min.js"
async defer>
> |
You can define which functionality you want to polyfill and it’ll be done that way. When the browser supports what you want, the stop-gap solution never gets included at all. How good is that?
Another thing of awesome I saw the other day at CSS tricks. Chris Coyier uses Flexbox to create a toolbar that has fixed elements and others using up the rest of the space. It extends semantic HTML and does a great job being responsive.
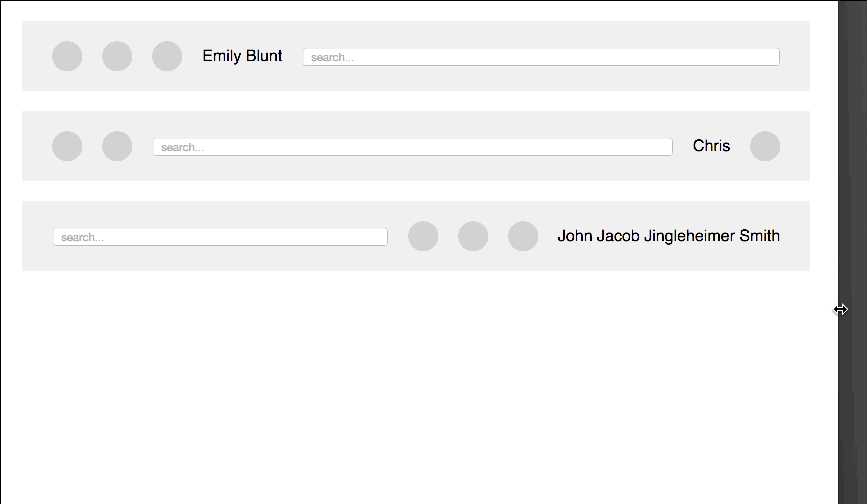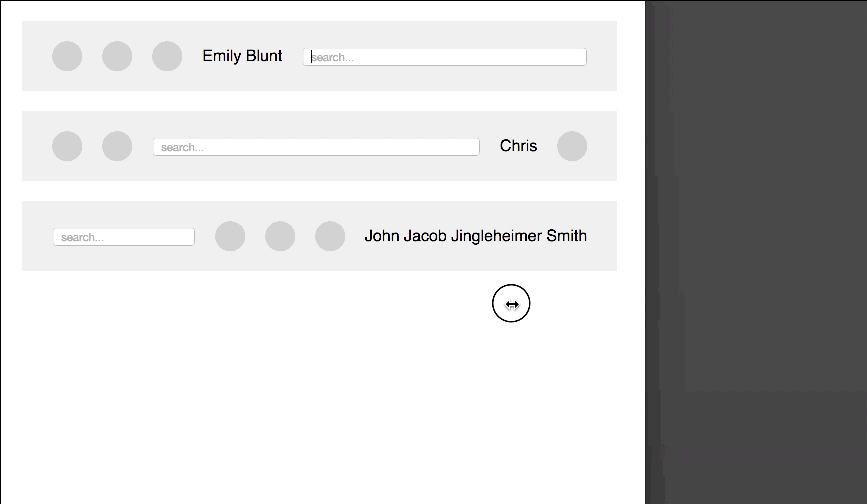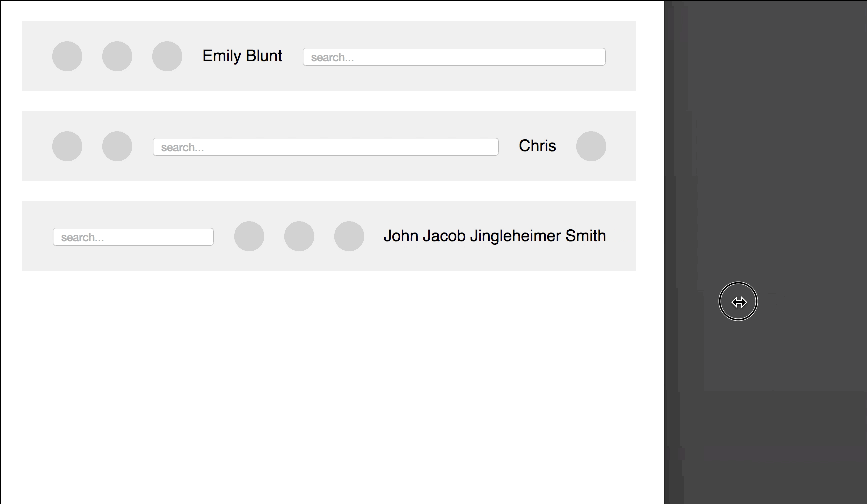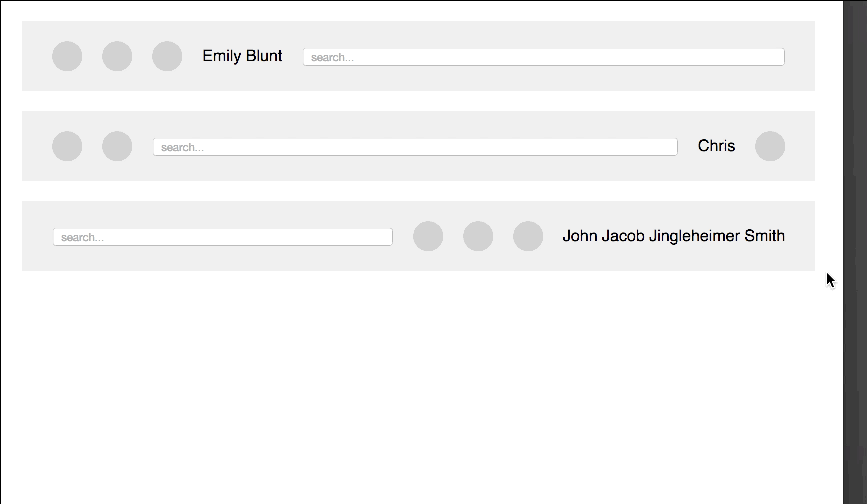
All the CSS code needed for it is this:
*, *:before, *:after { -moz-box-sizing: inherit; box-sizing: inherit; } html { -moz-box-sizing: border-box; box-sizing: border-box; } body { padding: 20px; font: 100% sans-serif; } .bar { display: -webkit-flex; display: -ms-flexbox; display: flex; -webkit-align-items: center; -ms-flex-align: center; align-items: center; width: 100%; background: #eee; padding: 20px; margin: 0 0 20px 0; } .bar > * { margin: 0 10px; } .icon { width: 30px; height: 30px; background: #ccc; border-radius: 50%; } .search { -webkit-flex: 1; -ms-flex: 1; flex: 1; } .search input { width: 100%; } .bar-2 .username { -webkit-order: 2; -ms-flex-order: 2; order: 2; } .bar-2 .icon-3 { -webkit-order: 3; -ms-flex-order: 3; order: 3; } .bar-3 .search { -webkit-order: -1; -ms-flex-order: -1; order: -1; } .bar-3 .username { -webkit-order: 1; -ms-flex-order: 1; order: 1; } .no-flexbox .bar { display: table; border-spacing: 15px; padding: 0; } .no-flexbox .bar > * { display: table-cell; vertical-align: middle; white-space: nowrap; } .no-flexbox .username { width: 1px; } @media (max-width: 650px) { .bar { -webkit-flex-wrap: wrap; -ms-flex-wrap: wrap; flex-wrap: wrap; } .icon { -webkit-order: 0 !important; -ms-flex-order: 0 !important; order: 0 !important; } .username { -webkit-order: 1 !important; -ms-flex-order: 1 !important; order: 1 !important; width: 100%; margin: 15px; } .search { -webkit-order: 2 !important; -ms-flex-order: 2 !important; order: 2 !important; width: 100%; } } |
That is pretty incredible, isn’t it?
Other things that are brewing get me equally excited. WebRTC, WebGL, Web Audio and many more things are pointing to a high fidelity web. A web that allows for rich gaming experiences and productivity tools built right into the browser. We can video and audio chat with each other and send data in a peer-to-peer fashion without relying or burning up a server between us.
Service Workers will allow us to build a real offline experience. With AppCahse we’re hoping users will get something and not aggressively cache outdated information. If you want to know more about that watch these two amazing videos by Jake Archibald: The Service Worker: The Network layer that is yours to own and The Service worker is coming, look busy!
Web Components have been the near future for quite a while now and seem to be in a bit of a “let’s build a framework instead” rut. Phil Legetter has done and incredible job collecting what that looks like. It is true: the support of Shadow DOM across the board is still not quite there. But a lot of these frameworks offer incredible client-side functionality to go into the standard.
I think it is time to stop chasing the awesome of “soon we will be able to use that” and instead be more fearless about using what we have now. We love to write about just how broken things are when they are in their infancy. We tend to forget to re-visit them when they’ve matured more. Many things that were a fever dream a year ago are now ready for you to roll out – if you work with progressive enhancement. In general, this is a safe bet as the web will never be in a finished state. Even native platforms are only in a fixed state between major releases. Mattias Petter Johansson of Spotify put it quite succinctly in a thread why JavaScript is the only client side language:
Hating JavaScript is like hating the Internet.
The Internet is a cobweb of different technologies cobbled together with duct tape, string and chewing gum. It’s not elegantly designed in any way, because it’s more of a growing organism than it is a machine constructed with intent.
The web is chaotic, so much for sure, but it also aims to be longer lasting than other platforms. The in-built backwards compatibility of its technologies makes it a beautiful investment. As Paul Bakaus of Google put it:
If you build a web app today, it will run in browsers 10 years from now. Good luck trying the same with your favorite mobile OS (excluding Firefox OS).
The other issue we have to overcome is the dogma associated with some of our decisions. Yes, it would be excellent if we could use open web standards to build everything. It would be great if all solutions had their principles of distribution, readability and easy sharing. But we live in a world that has changed. In many ways in the mobile space we have to count our blessings. We can and should allow some closed technology take its course before we go back to these principles. We’ve done it with Flash, we can do it with others, too. My mantra these days is the following:
If you enable people world-wide to get a good experience and solve a problem they have, I like it. The technology you use is not the important part. How much you lock them in is. Don’t lock people in.
One thing is for sure: we never had a more amazing environment to learn and share. Services like GitHub, JSFiddle, JSBin and Codepen make it easy to distribute and explain code. You can show instead of describe and you can fix instead of telling people that they are doing wrong. There is no better way to learn than to show and if you set out to teach you end up learning.
A great demo of this is together.js. Using this WebRTC based tool (or its implementation in JSFiddle by hitting the collaborate button) you can code together, with several cursors, audio chat or a text chat client directly in the browser. You explain in context and collaborate live. And you make each other learn something and get better. And this is what is really awesome.
http://christianheilmann.com/2014/11/27/what-if-everything-is-awesome/
|
|
Allison Naaktgeboren: Applying Privacy Series: The 2nd meeting |
The day after the first meeting…
Engineering Manager: Welcome DBA, Operations Engineer, and Privacy Officer. Did you all get a chance to look over the project wiki? What do you think?
Operations Engineer: I did.
DBA: Yup, and I have some questions.
Privacy Officer: Sounds really cool, as long as we’re careful.
Engineer: We’re always careful!
DBA: There are a lot of pages on the web, Keeping that much data is going to be expensive. I didn’t see anything on the wiki about evicting entries and for a table that big, we’ll need to do that regularly.
Privacy Officer: Also, when will we delete the device ids? Those are like a fingerprint for someone’s phone, so keeping them around longer than absolutely necessary increases risk for the user & the company’s risk.
Operations Engineer: The less we keep around, the less it costs to maintain.
Engineer: We know that most mobile users have only 1-3 pages open at any given time and we estimate no more than 50,000 users will be eligible for the service.
DBA: Well that does suggest a manageable load, but that doesn’t answer my question.
Engineer: Want to say if a page hasn’t been accessed in 48 hours we evict it from the server? And we can tune that knob as necessary?
Operations Engineer: As long as I can tune it in prod if something goes haywire.
Privacy Officer:: And device ids?
Engineer: Apply the same rule to them?
Engineering Manager: 48 hours would be too short. Not everyone uses their mobile browser every day. I’d be more comfortable with 90 days to start.
DBA: I imagine you’d want secure destruction for the ids.
Privacy Officer:: You got it!
DBA: what about the backup tapes? We back up the dbs regularly?
Privacy Officer:: are the backups online?
DBA: No, like I said, they’re on tape. Someone has to physically run ‘em through a machine. You’d need physical access to the backup storage facility.
Privacy Officer:: Then it’s probably fine if we don’t delete from the tapes.
Operations Engineer: What is the current timeline?
Engineer: End of the quarter, 8 weeks or so.
Operations Engineer: We’re under water right now, so it might be tight getting the hardware in & set up. New hardware orders usually take 6 weeks to arrive. I can’t promise the hardware will be ready in time.
Engineering Manager: We understand, please do your best and if we have to, Product Manager won’t be happy, but we’ll delay the feature if we need to.
Privacy Officer:: Who’s going to be responsible for the data on the stage & production servers?
Engineering Manager: Product Manager has final say.
DBA: thanks. good to know!
Engineer: I’ll draw up a plan and send it around for feedback tomorrow.
Who brought up user data safety & privacy concerns in this conversation?
Privacy Officer is obvious. The DBA & Operations Engineer also raised privacy concerns.
http://www.allisonnaaktgeboren.com/applying-privacy-series-the-2nd-meeting/
|
|
Robert Helmer: Better Source Code Browsing With FreeBSD and Mozilla DXR |
Lately I've been reading about the design and implementation of the FreeBSD Operating System (great book, you should read it).
However I find browsing the source code quite painful. Using vim or emacs is fine for editing invidual files, but when you are trying to understand and browse around a large codebase, dropping to a shell and grepping/finding around gets old fast. I know about ctags and similar, but I also find editors uncomfortable for browsing large codebases for an extended amount of time - web pages tend to be easier on the eyes.
There's an LXR fork called FXR available, which is way better and I am very grateful for it - however it has all the same shortcomings LXR that we've become very familiar with on the Mozilla LXR fork (MXR):
I've been an admirer of Mozilla's next gen code browsing tool, DXR, for a long time now. DXR uses a clang plugin to do static analysis of the code, so it produces the real call graph - this means it doesn't need to guess at the definition of types or where a variable is used, it knows.
A good example is to contrast a file on MXR with the same file on DXR. Let's say you wanted to know where this macro was first defined, that's easy in DXR - just click on the word "NS_WARNING" and select "Jump to definition".
Now try that on MXR - clicking on "NS_WARNING" instead yields a search which is not particularly helpful, since it shows every place in the codebase that the word "NS_WARNING" appears (note that DXR has the ability to do this same type of search, in case that's really what you're after).
So that's what DXR is and why it's useful. I got frustrated enough with the status quo trying to grok the FreeBSD sources that I took a few days and the with help of folks in the #static channel on irc.mozilla.org (particularly Erik Rose) to get DXR running on FreeBSD and indexed a tiny part of the source tree as a proof-of-concept (the source for "/bin/cat"):
This is running on a FreeBSD instance in AWS.
DXR is currently undergoing major changes, SQLite to ElasticSearch transition being the central one. I am tracking how to get the "es" branch of DXR going in this gist.
Currently I am able to get a LINT kernel build indexed on DXR master branch, but still working through issues on the "es" branch.
Overall, I feel like I've learned way more about static analysis, how DXR works, FreeBSD source code and produced some useful patches for the Mozilla and the DXR project and hopefully will provide a useful resource for the FreeBSD project, all along the way. Totally worth it, I highly recommended working with all of the aforementioned :)
http://rhelmer.org/blog/better-source-code-browsing-with-freebsd-and-mozilla-dxr
|
|
Brian R. Bondy: Developing and releasing the Khan Academy Firefox OS app |
I'm happy to announce that the Khan Academy Firefox OS app is now available in the Firefox Marketplace!

Khan Academy’s mission is to provide a free world-class education for anyone anywhere. The goal of the Firefox OS app is to help with the “anyone anywhere” part of the KA mission.
There's something exciting about being able to hold a world class education in your pocket for the cheap price of a Firefox OS phone. Firefox OS devices are mostly deployed in countries where the cost of an iPhone or Android based smart phone is out of reach for most people.
The app enables developing countries, lower income families, and anyone else to take advantage of the Khan Academy content. A persistent internet connection is not required.
What's that.... you say you want another use case? Well OK, here goes: A parent wanting each of their kids to have access to Khan Academy at the same time could be very expensive in device costs. Not anymore.






Technologies used to develop the app include:
The app is fully localized for English, Portuguese, French, and Spanish, and will use those locales automatically depending on the system locale. The content (videos, articles, subtitles) that the app hosts will also automatically change.
I was lucky enough to have several amazing and kind translators for the app volunteer their time.
The translations are hosted and managed on Transifex.
The Khan Academy Firefox OS app source is hosted in one of my github repositories and periodically mirrored on the Khan Academy github page.
If you'd like to contribute there's a lot of future tasks posted as issues on github.
By default, apps on the Firefox marketplace are only served to devices with at least 500MB of RAM. To get them on 256MB devices, you need to do a low memory review.
One of the major enhancements I'd like to add next, is to add an option to use the YouTube player instead of HTML5 video. This may use less memory and may be a way onto 256MB devices.
They're coming in a future release.
It's possible to request to get pre-installed on devices and I'll be looking into that in the near future after getting some more initial feedback.
Projects like Matchstick also seem like a great opportunity for this app.
|
|
Hannah Kane: We are very engaging |
Yesterday someone asked me what the engagement team is up to, and it made me sad because I realized I need to do a waaaaay better job of broadcasting my team’s work. This team is dope and you need to know about it.
As a refresher, our work encompasses these areas:
In short, we aim to support the Webmaker product and programs and our leadership pipelines any time we need to engage individuals or institutions.
What’s currently on our plate:
Pro-tip: You can always see what we’re up to by checking out the Engagement Team Workbench.
These days we’re spending our time on the following:

|
|
Niko Matsakis: Purging proc |
The so-called “unboxed closure” implementation in Rust has reached the
point where it is time to start using it in the standard library. As
a starting point, I have a
pull request that removes proc from the language. I started
on this because I thought it’d be easier than replacing closures, but
it turns out that there are a few subtle points to this transition.
I am writing this blog post to explain what changes are in store and
give guidance on how people can port existing code to stop using
proc. This post is basically targeted Rust devs who want to adapt
existing code, though it also covers the closure design in general.
To some extent, the advice in this post is a snapshot of the current Rust master. Some of it is specifically targeting temporary limitations in the compiler that we aim to lift by 1.0 or shortly thereafter. I have tried to mention when that is the case.
For those who haven’t been following, Rust is moving to a powerful new closure design (sometimes called unboxed closures). This part of the post covers the highlight of the new design. If you’re already familiar, you may wish to skip ahead to the “Transitioning away from proc” section.
The basic idea of the new design is to unify closures and traits. The
first part of the design is that function calls become an overloadable
operator. There are three possible traits that one can use to overload
():
1 2 3 | |
As you can see, these traits differ only in their “self” parameter. In fact, they correspond directly to the three “modes” of Rust operation:
Fn trait is analogous to a “shared reference” – it means that
the closure can be aliased and called freely, but in turn the
closure cannot mutate its environment.FnMut trait is analogous to a “mutable reference” – it means
that the closure cannot be aliased, but in turn the closure is
permitted to mutate its environment. This is how || closures work
in the language today.FnOnce trait is analogous to “ownership” – it means that the
closure can only be called once. This allows the closure to move out
of its environment. This is how proc closures work today.One downside of the older Rust closure design is that closures and procs always implied virtual dispatch. In the case of procs, there was also an implied allocation. By using traits, the newer design allows the user to choose between static and virtual dispatch. Generic types use static dispatch but require monomorphization, and object types use dynamic dispatch and hence avoid monomorphization and grant somewhat more flexibility.
As an example, whereas before I might write a function that takes a closure argument as follows:
1 2 3 4 5 | |
I can now choose to write that function in one of two ways. I can use a generic type parameter to avoid virtual dispatch:
1 2 3 4 5 6 7 | |
Note that we write the type parameters to FnMut using parentheses
syntax (FnMut(&String) -> uint). This is a convenient syntactic
sugar that winds up mapping to a traditional trait reference
(currently, for<'a> FnMut<(&'a String,), uint>). At the moment,
though, you are required to use the parentheses form, because we
wish to retain the liberty to change precisely how the Fn trait type
parameters work.
A caller of foo() might write:
1 2 | |
You can see that the || expression still denotes a closure. In fact,
the best way to think of it is that a || expression generates a
fresh structure that has one field for each of the variables it
touches. It is as if the user wrote:
1 2 3 | |
where ClosureEnvironment is a struct like the following:
1 2 3 4 5 6 7 8 9 | |
Obviously the || form is quite a bit shorter.
The downside of using generic type parameters for closures is that you will get a distinct copy of the fn being called for every callsite. This is a great boon to inlining (at least sometimes), but it can also lead to a lot of code bloat. It’s also often just not practical: many times we want to combine different kinds of closures together into a single vector. None of these concerns are specific to closures. The same things arise when using traits in general. The nice thing about the new closure design is that it lets us use the same tool – object types – in both cases.
If I wanted to write my foo() function to avoid monomorphization,
I might change it from:
1 2 3 | |
to:
1 2 | |
Note that the argument is now a &mut FnMut(&String) -> uint, rather
than being of some type F where F : FnMut(&String) -> uint.
One downside of changing the signature of foo() as I showed is that
the caller has to change as well. Instead of writing:
1
| |
the caller must now write:
1
| |
Therefore, what I expect to be a very common pattern is to have a “wrapper” that is generic which calls into a non-generic inner function:
1 2 3 4 5 6 7 8 | |
This way, the caller does not have to change, and only this outer wrapper is monomorphized, and it will likely be inlined away, and the “guts” of the function remain using virtual dispatch.
In the future, I’d like to make it possible to pass object types (and other
“unsized” types) by value, so that one could write a function that just
takes a FnMut() and not a &mut FnMut():
1 2 | |
Among other things, this makes it possible to transition simply between static and virtual dispatch without altering callers and without creating a wrapper fn. However, it would compile down to roughly the same thing as the wrapper fn in the end, though with guaranteed inlining. This change requires somewhat more design and will almost surely not occur by 1.0, however.
We just said that every closure expression like || expr generates a
fresh type that implements one of the three traits (Fn, FnMut, or
FnOnce). But how does the compiler decide which of the three traits
to use?
Currently, the compiler is able to do this inference based on the
surrouding context – basically, the closure was an argument to a
function, and that function requested a specific kind of closure, so
the compiler assumes that’s the one you want. (In our example, the
function foo() required an argument of type F where F implements
FnMut.) In the future, I hope to improve the inference to a more
general scheme.
Because the current inference scheme is limited, you will sometimes
need to specify which of the three fn traits you want
explicitly. (Some people also just prefer to do that.) The current
syntax is to use a leading &:, &mut:, or :, kind of like an
“anonymous parameter”:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
The main time you need to use an explicit fn type annotation is when
there is no context. For example, if you were just to create a closure
and assign it to a local variable, then a fn type annotation is
required:
1
| |
Caveat: It is still possible we’ll change the &:/&mut:/:
syntax before 1.0; if we can improve inference enough, we might even
get rid of it altogether.
There is one final aspect of closures that is worth covering. We gave the
example of a closure |str| myhashfn(str.as_slice(), &some_salt)
that expands to something like:
1 2 3 | |
Note that the variable some_salt that is used from the surrounding
environment is borrowed (that is, the struct stores a reference to
the string, not the string itself). This is frequently what you want,
because it means that the closure just references things from the
enclosing stack frame. This also allows closures to modify local
variables in place.
However, capturing upvars by reference has the downside that the closure is tied to the stack frame that created it. This is a problem if you would like to return the closure, or use it to spawn another thread, etc.
For this reason, closures can also take ownership of the things that
they close over. This is indicated by using the move keyword before
the closure itself (because the closure “moves” things out of the
surrounding environment and into the closure). Hence if we change
that same closure expression we saw before to use move:
1
| |
then it would generate a closure type where the some_salt variable
is owned, rather than being a reference:
1 2 3 | |
This is the same behavior that proc has. Hence, whenever we replace
a proc expression, we generally want a moving closure.
Currently we never infer whether a closure should be move or not.
In the future, we may be able to infer the move keyword in some
cases, but it will never be 100% (specifically, it should be possible
to infer that the closure passed to spawn should always take
ownership of its environment, since it must meet the 'static bound,
which is not possible any other way).
This section covers what you need to do to modify code that was using
proc so that it works once proc is removed.
For users of the standard library, the transition away from proc is
fairly straightforward. Mostly it means that code which used to write
proc() { ... } to create a “procedure” should now use move|| {
... }, to create a “moving closure”. The idea of a moving closure
is that it is a closure which takes ownership of the variables in its
environment. (Eventually, we expect to be able to infer whether or not
a closure must be moving in many, though not all, cases, but for now
you must write it explicitly.)
Hence converting calls to libstd APIs is mostly a matter of search-and-replace:
1 2 3 4 5 | |
One non-obvious case is when you are creating a “free-standing” proc:
1
| |
In that case, if you simply write move||, you will get some strange errors:
1
| |
The problem is that, as discussed before, the compiler needs context
to determine what sort of closure you want (that is, Fn vs FnMut
vs FnOnce). Therefore it is necessary to explicitly declare the sort
of closure using the : syntax:
1 2 | |
Note also that it is precisely when there is no context that you must also specify the types of any parameters. Hence something like:
1 2 3 4 5 6 7 8 | |
might become:
1 2 3 4 5 6 7 8 | |
The transition story for a library author is somewhat more
complicated. The complication is that the equivalent of a type like
proc():Send ought to be Box – that is, a boxed
FnOnce object that is also sendable. However, we don’t currently
have support for invoking fn(self) methods through an object, which
means that if you have a Box object, you can’t call it’s
call_once method (put another way, the FnOnce trait is not object
safe). We plan to fix this – possibly by 1.0, but possibly shortly
thereafter – but in the interim, there are workarounds you can use.
In the standard library, we use a trait called Invoke (and, for
convenience, a type called Thunk). You’ll note that although these
two types are publicly available (under std::thunk), these types do
not appear in the public interface any other stable APIs. That is,
Thunk and Invoke are essentially implementation details that end
users do not have to know about. We recommend you follow the same
practice. This is for two reasons:
Thread::spawn(move|| ...) and not
Thread::spawn(Thunk::new(move|| ...)) (etc).Box works properly, Thunk and
Invoke may be come deprecated. If this were to happen, your
public API would be unaffected.Basically, the idea is to follow the “thin wrapper” pattern that I
showed earlier for hiding virtual dispatch. If you recall, I gave the
example of a function foo that wished to use virtual dispatch
internally but to hide that fact from its clients. It did do by creating
a thin wrapper API that just called into another API, performing the
object coercion:
1 2 3 4 5 6 7 8 | |
The idea with Invoke is similar. The public APIs are generic APIs
that accept any FnOnce value. These just turnaround and wrap that
value up into an object. Here the problem is that while we would
probably prefer to use a Box object, we can’t because
FnOnce is not (currently) object-safe. Therefore, we use the trait
Invoke (I’ll show you how Invoke is defined shortly, just let me
finish this example):
1 2 3 4 5 6 7 8 9 10 | |
The Invoke trait in the standard library is defined as:
1 2 3 | |
This is basically the same as FnOnce, except that the self type is
Box, and not Self. This means that Invoke requires
allocation to use; it is really tailed for object types, unlike
FnOnce.
Finally, we can provide a bridge impl for the Invoke trait as
follows:
1 2 3 4 5 6 7 8 | |
This impl allows any type that implements FnOnce to use the Invoke
trait.
Here are the points I want you to take away from this post:
proc() with move|| (sometimes move|:| if there
is no surrounding context).Fn traits. You can then convert
to an object internally to use virtual dispatch.Box doesn’t currently work, library authors may
want to use another trait internally, such as std::thunk::Invoke.I also want to emphasize that a lot of the nitty gritty details in this post are transitionary. Eventually, I believe we can reach a point where:
Fn vs FnMut vs FnOnce explicitly.move.Box works, so Invoke and friends are not needed.I expect the improvements in inference before 1.0. Fixing the final two points is harder and so we will have to see where it falls on the schedule, but if it cannot be done for 1.0 then I would expect to see those changes shortly thereafter.
http://smallcultfollowing.com/babysteps/blog/2014/11/26/purging-proc/
|
|
Jared Wein: The Bugs Blocking In-Content Prefs, part 2 |
 At the beginning of November I published a blog post with the list of bugs that are blocking in-content prefs from shipping. Since that post, quite a few bugs have been fixed and we figured out an approach for fixing most of the high-contrast bugs.
At the beginning of November I published a blog post with the list of bugs that are blocking in-content prefs from shipping. Since that post, quite a few bugs have been fixed and we figured out an approach for fixing most of the high-contrast bugs.
As in the last post, bugs that should be easy to fix for a newcomer are highlighted in yellow.
Here is the new list of bugs that are blocking the release:
The list is now down to 16 bugs (from 20). In the meantime, the following bugs have been fixed:
Big thanks goes out to Richard Marti and Tim Nguyen for fixing the above mentioned bugs as well as their continued focus on helping to bring the In-Content Preferences to to the Beta and Release channels.

http://msujaws.wordpress.com/2014/11/26/the-bugs-blocking-in-content-prefs-part-2/
|
|
Lucas Rocha: Leaving Mozilla |
I joined Mozilla 3 years, 4 months, and 6 days ago. Time flies!
I was very lucky to join the company a few months before the Firefox Mobile team decided to rewrite the product from scratch to make it more competitive on Android. And we made it: Firefox for Android is now one of the highest rated mobile browsers on Android!
This has been the best team I’ve ever worked with. The talent, energy, and trust within the Firefox for Android group are simply amazing.
I’ve thoroughly enjoyed my time here but an exciting opportunity outside Mozilla came up and decided to take it.
What’s next? That’s a topic for another post ;-)
|
|
Will Kahn-Greene: Input: New feedback form |
Since the beginning of 2014, I've been laying the groundwork to rewrite the feedback form that we use on Input.
Today, after a lot of work, we pushed out the new form! Just in time for Firefox 34 release.
This blog post covers the circumstances of the rewrite.
In 2011, James, Mike and I rewrote Input from the ground up. In order to reduce the amount of time it took to do that rewrite, we copied a lot of the existing forms and styles including the feedback forms. At that time, there were two: one for desktop and one for mobile. In order to avoid a translation round, we kept all the original strings of the two forms. The word "Firefox" was hardcoded in the strings, but that was fine since at the time Input only collected feedback for Firefox.
In 2013, in order to reduce complexity on the site because there's only one developer (me), I merged the desktop and mobile forms into one form. In order to avoid a translation round, I continued to keep the original strings. The wording became awkward and the flow through the form wasn't very smooth. Further, the form wasn't responsive at all, so it worked ok on desktop machines, but mediocre on other viewport sizes.
2014 rolled around and it was clear Input was going to need to branch out into capturing feedback for multiple products---some of which were not Firefox. The form made this difficult.
Related, the smoketest framework I wrote in 2014 struggled with testing the form accurately. I spent some time tweaking it, but a simpler form would make smoketesting a lot easier and less flakey.
Thus over the course of 3 years, we had accumulated the following problems:
Further, we were seeing many instances of people putting contact information in the description field and there was a significant amount of dropoff.
I had accrued the following theories:
Anyhow, it was due for an overhaul.
I've been working on the overhaul for most of 2014, but did the bulk of the work in October and November. It has the following changes:

The old Input feedback form.

The new Input feedback form.
Note: Showing before and after isn't particularly exciting since this is only the first card of the form in both cases.
The old and new forms were instrumented in various ways, so we'll be able to analyze differences between the two. Particularly, we'll be able to see if the new form performs worse.
Further, I'll be checking the data to see if my theories hold true especially the one regarding why people put contact data in the description.
There are a few changes in the queue that we want to make over the course of the next 6 months. Now that the new form has landed, we can start working on those.
Even if there are problems with the new form, we're in a much better position to fix them than we were before. Progress has been made!
Have you ever submitted feedback? Have you ever told Mozilla what you like and don't like about Firefox?
Take a moment and fill out the feedback form and tell us how you feel about Firefox.
I've been doing web development since 1997 or so. I did a lot of frontend work back then, but I haven't done anything serious frontend-wise in the last 5 years. Thus this was a big project for me.
I had a lot of help: Ricky, Mike and Rehan from the SUMO Engineering team were invaluable reviewing code, helping me fix issues and giving me a huge corpus of examples to learn from; Matt, Gregg, Tyler, Ilana, Robert and Cheng from the User Advocacy team who spent a lot of time smoothing out the rough edges of the new form so it captures the data we need; Schalk who wrote the product picker which I later tweaked; Matej who spent time proof-reading the strings to make sure they were consistent and felt good; the QA team which wrote the code that I copied and absorbed into the current Input smoketests; and the people who translated the user interface strings (and found a bunch of issues) making it possible for people to see this form in their language.
http://bluesock.org/~willkg/blog/mozilla/input_new_form_2014
|
|
Brian R. Bondy: SQL on Khan Academy enabled by SQLite, sqljs, asm.js and Emscripten |
Originally the computer programming section at Khan Academy only focused on learning JavaScript by using ProcessingJS. This still remains our biggest environment and still has lots of plans for further growth, but we recently generalized and abstracted the whole framework to allow for new environments.
The first environment we added was HTML/CSS which was announced here. You can try it out here. We also have a lot of content for learning how to make webpages already created.
 We recently also experimented with the ability to teach SQL on Khan Academy. This wasn't a near term priority for us, so we used our hack week as an opportunity to bring an SQL environment to Khan Academy.
We recently also experimented with the ability to teach SQL on Khan Academy. This wasn't a near term priority for us, so we used our hack week as an opportunity to bring an SQL environment to Khan Academy.
You can try out the SQL environment here.
To implement the environment, one would think of WebSQL, but there are a couple major browser vendors (Mozilla and Microsoft) who do not plan to implement it and W3C stopped working on the specification at the end of 2010,
Our implementation of SQL is based off of SQLite which is compiled down to asm.js by Emscripten packaged into sqljs.
All of these technologies I just mentioned, other than SQLite which is sponsored by Mozilla, are Mozilla based projects. In particular, largely thanks to Alon Zakai.
The environment looks like this, the entire code for creating, inserting, updating, and querying a database occur in a single editor. Behind the scenes, we re-create the entire state of the database and result sets on each code edit. Things run smoothly in the browser and you don't notice that.

Unlike many online SQL tutorials, this environment is entirely client side. It has no limitations on what you can do, and if we wanted, we could even let you export the SQL databases you create.
One of the other main highlights is that you can modify the inserts in the editor, and see the results in real time without having to run the code. This can lead to some cool insights on how changing data affects aggregate queries.
Unlike the HTML/CSS work, we don’t have a huge number of tutorials created, but we do have some videos, coding talk throughs, challenges and a project setup in a single tutorial which we’ll be using for one of our hour of code offerings: Hour of Databases.
|
|
Doug Belshaw: Toward The Development of a Web Literacy Map: Exploring, Building, and Connecting Online |
The title of this post is also the title of a presentation I’m giving at the Literacy Research Association conference next week. The conference has the theme ‘The Dialogic Construction of Literacies’ – so this session is a great fit. It’s been organised by Ian O'Byrne and Greg McVerry, both researchers and Mozilla contributors.

I’m cutting short my participation in the Mozilla work week in Portland, Oregon next week to fly to present at this conference. This is not only because I think it’s important to honour prior commitments, but because I want to encourage more literacy researchers to get involved in developing the Web Literacy Map.
I’ve drafted the talk in the style in which I’d deliver it. The idea isn’t to read it, but to use this to ensure that my presentation is backed up by slides, rather than vice-versa. I’ll then craft speaker notes to ensure I approximate what’s written here.
Click here to read the text of the draft presentation
I’d very much appreciate your feedback. Here’s the specific things I’m looking for answers to:
I’ve created a thread on the #TeachTheWeb discussion forum for your responses - or you can email me directly: doug@mozillafoundation.org
Thanks in advance! And remember, it doesn’t matter how new you are to the Web Literacy Map or the process of creating it. I’m interested in the views of newbies and veterans alike.
\(@
|
|
Andrea Marchesini: Switchy 0.9 released |
Break-news: Finally I had time to update Switchy to the latest addon-sdk 1.7 and now, version 0.9.x is restart-less!
What is Switchy? Switchy is an add-on for Firefox to better manage several profiles. This add-on allows the user to create Firefox profiles, rename, delete and open them just with a click.
By using Switchy, you can open more profiles at the same time: an important feature for those who are concerned about security and privacy. For instance, you can have a separate profile for Facebook and other social networks while browsing other websites or have a separate profile for Google so you are not always logged in.
Don’t we have some similar addons? There are other similar add-ons but Switchy has extra features. You can assign websites to be exclusive for particular profiles. This means that, when from profile X I try to open one of websites saved in a specific profile, Switchy allows me to “switch” to the correct profile with just 1 click. For example, if I open ‘Facebook’ from my default profile, Switchy immediately offers me the opportunity to open the correct profile where I am logged in on Facebook - which is nice!
What is new in version 0.9? Restart-less, and a new awesome UI for the Switchy panel.
I hope you enjoy it!
|
|






