Patrick McManus: Proxy Connections over TLS - Firefox 33 |
http://bitsup.blogspot.com/2014/11/proxy-connecitons-over-tls-firefox-33.html
|
|
Gregory Szorc: Test Drive the New Headless Try Repository |
Mercurial and Git both experience scaling pains as the number of heads in a repository approaches infinity. Operations like push and pull slow to a crawl and everyone gets frustrated.
This is the problem Mozilla's Try repository has been dealing with for years. We know the solution doesn't scale. But we've been content kicking the can by resetting the repository (blowing away data) to make the symptoms temporarily go away.
One of my official goals is to ship a scalable Try solution by the end of 2014.
Today, I believe I finally have enough code cobbled together to produce a working concept. And I could use your help testing it.
I would like people to push their Try, code review, and other miscellaneous heads to a special repository. To do this:
$ hg push -r . -f ssh://hg@hg.gregoryszorc.com/gecko-headless
That is:
Here's what happening.
I have deployed a special repository to my personal server that I believe will behave very similarly to the final solution.
When you push to this repository, instead of your changesets being applied directly to the repository, it siphons them off to a Mercurial bundle. It then saves this bundle somewhere along with some metadata describing what is inside.
When you run hg pull -r on that repository and ask for a changeset that exists in the bundle, the server does some magic and returns data from the bundle file.
Things this repository doesn't do:
hg pull or hg clone the repository and get all of the
commits from bundles. This isn't a goal. It will likely never be
supported.The purpose of this experiment is to expose the repository to some actual traffic patterns so I can see what's going on and get a feel for real-world performance, variability, bugs, etc. I plan to do all of this in the testing environment. But I'd like some real-world use on the actual Firefox repository to give me peace of mind.
Please report any issues directly to me. Leave a comment here. Ping me on IRC. Send me an email. etc.
Update 2014-11-21: People discovered a bug with pushed changesets accidentally being advanced to the public phase, despite the repository being non-publishing. I have fixed the issue. But you must now push to the repository over SSH, not HTTP.
http://gregoryszorc.com/blog/2014/11/20/test-drive-the-new-headless-try-repository
|
|
Asa Dotzler: Flame Distribution Update |
About three weeks ago, I ran out of Flame inventory for Mozilla employees and key volunteer contributors. The new order of Flames is arriving in Mountain View late today (Friday) and I’ll be working some over the weekend, but mostly Monday to deliver on the various orders you all have placed with me through email and other arrangements.
If you contacted me for a Flame or a batch of Flames, expect an email update in the next few days with information about shipping or pick-up locations and times. Thanks for your patience these last few weeks. We should not face any more Flame shortages like this going forward.
|
|
Jennie Rose Halperin: Townhall, not Shopping Mall! Community, making, and the future of the Internet |
I presented a version of this talk at the 2014 Futurebook Conference in London, England. They also kindly featured me in the program. Thank you to The Bookseller for a wonderful conference filled with innovation and intelligent people!
A few days ago, I was in the Bodleian Library at Oxford University, often considered the most beautiful library in the world. My enthusiastic guide told the following story:
After the Reformation (when all the books in Oxford were burned), Sir Thomas Bodley decided to create a place where people could go and access all the world’s information at their fingertips, for free.
“What does that sound like?” she asked. “…the Internet?”
While this is a lovely conceit, the part of the story that resonated with me for this talk is the other big change that Bodley made, which was to work with publishers, who were largely a monopoly at that point, to fill his library for free by turning the library into a copyright library. While this seemed antithetical to the ways that publishers worked, in giving a copy of their very expensive books away, they left an indelible and permanent mark on the face of human knowledge. It was not only preservation, but self-preservation.
Bodley was what people nowadays would probably call “an innovator” and maybe even in the parlance of my field, a “community manager.”
By thinking outside of the scheme of how publishing works, he joined together with a group of skeptics and created one of the greatest knowledge repositories in the world, one that still exists 700 years later. This speaks to a few issues:
Sharing economies, community, and publishing should and do go hand in hand and have since the birth of libraries. By stepping outside of traditional models, you are creating a world filled with limitless knowledge and crafting it in new and unexpected ways.
The bound manuscript is one of the most enduring technologies. This story remains relevant because books are still books and people are still reading them.
As the same time, things are definitely changing. For the most part, books and manuscripts were pretty much identifiable as books and manuscripts for the past 1000 years.
But what if I were to give Google Maps to a 16th Century Map Maker? Or what if I were to show Joseph Pulitzer Medium? Or what if I were to hand Gutenberg a Kindle? Or Project Gutenberg for that matter? What if I were to explain to Thomas Bodley how I shared the new Lena Dunham book with a friend by sending her the file instead of actually handing her the physical book? What if I were to try to explain Lena Dunham?
These innovations have all taken place within the last twenty years, and I would argue that we haven’t even scratched the surface in terms of the innovations that are to come.
We need to accept that the future of the printed word may vary from words on paper to an ereader or computer in 500 years, but I want to emphasize that in the 500 years to come, it will more likely vary from the ereader to a giant question mark.
International literacy rates have risen rapidly over the past 100 years and companies are scrambling to be the first to reach what they call “developing markets” in terms of connectivity. In the vein of Mark Surman’s talk at the Mozilla Festival this year, I will instead call these economies post-colonial economies.
Because we (as people of the book) are fundamentally idealists who believe that the printed word can change lives, we need to be engaged with rethinking the printed word in a way that recognizes power structures and does not settle for the limited choices that the corporate Internet provides (think Facebook vs WhatsApp). This is not as a panacea to fix the world’s ills.
In the Atlantic last year, Phil Nichols wrote an excellent piece that paralleled Web literacy and early 20th century literacy movements. The dualities between “connected” and “non-connected,” he writes, impose the same kinds of binaries and blind cure-all for social ills that the “literacy” movement imposed in the early 20th century. In equating “connectedness” with opportunity, we are “hiding an ideology that is rooted in social control.”
Surman, who is director of the Mozilla Foundation, claims that the Web, which had so much potential to become a free and open virtual meeting place for communities, has started to resemble a shopping mall. While I can go there and meet with my friends, it’s still controlled by cameras that are watching my every move and its sole motive is to get me to buy things.
85 percent of North America is connected to the Internet and 40 percent of the world is connected. Connectivity increased at a rate of 676% in the past 13 years. Studies show that literacy and connectivity go hand in hand.
How do you envision a fully connected world? How do you envision a fully literate world? How can we empower a new generation of connected communities to become learners rather than consumers?
I’m not one of these technology nuts who’s going to argue that books are going to somehow leave their containers and become networked floating apparatuses, and I’m not going to argue that the ereader is a significantly different vessel than the physical book.
I’m also not going to argue that we’re going to have a world of people who are only Web literate and not reading books in twenty years. To make any kind of future prediction would be a false prophesy, elitist, and perhaps dangerous.
Although I don’t know what the printed word will look like in the next 500 years,
I want to take a moment to think outside the book,
to think outside traditional publishing models, and to embrace the instantaneousness, randomness, and spontaneity of the Internet as it could be, not as it is now.
One way I want you to embrace the wonderful wide Web is to try to at least partially decouple your social media followers from your community.
Twitter and other forms of social media are certainly a delightful and fun way for communities to communicate and get involved, but your viral campaign, if you have it, is not your community.
True communities of practice are groups of people who come together to think beyond traditional models and innovate within a domain. For a touchstone, a community of practice is something like the Penguin Labs internal innovation center that Tom Weldon spoke about this morning and not like Penguin’s 600,000 followers on Twitter. How can we bring people together to allow for innovation, communication, and creation?
The Internet provides new and unlimited opportunities for community and innovation, but we have to start managing communities and embracing the people we touch as makers rather than simply followers or consumers.
The maker economy is here— participatory content creation has become the norm rather than the exception. You have the potential to reach and mobilize 2.1 billion people and let them tell you what they want, but you have to identify leaders and early adopters and you have to empower them.
How do you recognize the people who create content for you? I don’t mean authors, but instead the ambassadors who want to get involved and stay involved with your brand.
I want to ask you, in the spirit of innovation from the edges
What is your next platform for radical participation? How are you enabling your community to bring you to the next level? How can you differentiate your brand and make every single person you touch psyched to read your content, together? How can you create a community of practice?
Community is conversation. Your users are not your community.
Ask yourself the question Rachel Fershleiser asked when building a community on Tumblr: Are you reaching out to the people who want to hear from you and encouraging them or are you just letting your community be unplanned and organic?
There reaches a point where we reach the limit of unplanned organic growth. Know when you reach this limit.
Target, plan, be upbeat, and encourage people to talk to one another without your help and stretch the creativity of your work to the upper limit.
Does this model look different from when you started working in publishing? Good.
As the story of the Bodelian Library illustrated, sometimes a totally crazy idea can be the beginning of an enduring institution.
To repeat, the book is one of the most durable technologies and publishing is one of the most durable industries in history. Its durability has been put to the test more than once, and it will surely be put to the test again. Think of your current concerns as a minor stumbling block in a history filled with success, a history that has documented and shaped the world.
Don’t be afraid of the person who calls you up and says, “I have this crazy idea that may just change the way you work…” While the industry may shift, the printed word will always prevail.
Publishing has been around in some shape or form for 1000 years. Here’s hoping that it’s around for another 1000 more.
|
|
Mozilla Reps Community: Reps Weekly Call – November 20th 2014 |
Last Thursday we had our regular weekly call about the Reps program, where we talk about what’s going on in the program and what Reps have been doing during the last week.

Don’t forget to comment about this call on Discourse and we hope to see you next week!
https://blog.mozilla.org/mozillareps/2014/11/21/reps-weekly-call-november-20th-2014/
|
|
Pascal Finette: Introduction to Exponential Thinking and Technology |
A few weeks ago I had the privilege to deliver the closing keynote at GroupM’s What’s Next Illuminate conference in New York City. I gave a short introduction to exponential thinking (the stuff we teach at Singularity University) and then walked the audience through a whole bunch of examples (focussed on media).
The talk was a shortened and more media-related version of my “Technology Trends” talk I give here at SU to groups from all over the world quite often.
Here’s the video:
http://blog.finette.com/introduction-to-exponential-thinking-and-technology/
|
|
Mike Taylor: document.body.scrollTop vs document.documentElement.scrollTop |
Here's a track from Web Compatibility's Greatest Hits Album (Volume I) that just doesn't want to go away—with the latest club remix titled "scrolling to sections from the menu in the mobile Google News site doesn't work due to setting scrollTop position on document.body in Firefox for Android".
Here's some background for those with less refined musical tastes.
(Why yes I can do this bad metaphor stuff all day long, why do you ask?)
If you want to get or set the vertical scroll position of a document, you can use element.scrollTop. According to the CSSOM View Module spec, if you're in standards mode you need to operate on the document's root element (the element—or document.documentElement in DOM land). In quirks mode you would use the element, via document.body.
This works in IE and Firefox and the late Presto Opera.
In Blink and WebKit browsers, it's the exact opposite. Both have attempted to implement the standard (safari, chrome), but both have had to back out their patches due to sites breaking (some Google properties and webkit.org among them, as luck would have it).
The bug that was filed against WebKit for Facebook breaking as a result of changing to the standard is especially interesting because it shows the tension between following standards (and other browsers) and breaking sites for their own users.
It's also a good example of how user-agent-string-based development can sometimes make it hard, if not impossible, to remove some of the crappier stuff from the web platform.
Here's some excerpts, but the whole bug is a good read.
It really doesn't matter how faithfully you implemented the spec. If it causes a major backward compatibility with the Web, we can't have it.
Yes, the regression doesn't reproduce if we fake the UA string as I mentioned in the comment #31.
Maybe sites will update one day and let other browsers do the right thing™. (Not that I'm holding my breath over here.)
Until then I guess we get to have fun writing stuff like this (found on apple.com a few weeks back):
(document.documentElement ||
document.body.parentNode ||
document.body).scrollTop;
https://miketaylr.com/posts/2014/11/document-body-scrollTop.html
|
|
Yunier Jos'e Sosa V'azquez: Nueva estrategia de b'usqueda para Firefox promueve la elecci'on y la innovaci'on |
Google dejar'a de ser el buscador por defecto en Firefox a partir de diciembre para Estados Unidos, seg'un el anuncio oficial publicado por Chris Beard en el blog de Mozilla. En otras regiones del planeta tambi'en Google ser'a reemplazado por otros “competidores” en aras de promover la elecci'on en la Web. Las b'usquedas son una parte esencial en la experiencia en Internet para todos, solamente los usuarios de Firefox realizan m'as de 100 millones de b'usquedas por a~no.
Las b'usquedas son una parte esencial en la experiencia en Internet para todos, solamente los usuarios de Firefox realizan m'as de 100 millones de b'usquedas por a~no.
Con Firefox, Mozilla populariz'o la integraci'on del buscador en el navegador ali'andose con compa~n'ias de Internet como Google, Yahoo y otras m'as para generar remuneraci'on y avanzar en su misi'on. Google ha sido el buscador por defecto globalmente en Firefox desde el 2004 y al vencerse este a~no el contrato, Mozilla ha tomado esto como una oportunidad para revisar su estrategia y explorar otras opciones.
Seg'un Beard, al evaluar los socios, para Mozilla la primera consideraci'on fue asegurar una estrategia alineada a los valores de elecci'on e independencia, capaz de posicionarlos y avanzar en su misi'on para brindar un mejor servicio a los usuarios y a la Web. Al final, cada opci'on disponible por los socios era fuerte, mejorando los t'erminos econ'omicos y reflejando los valores que Firefox brinda al ecosistema. Pero una opci'on sobresali'o por encima de las dem'as.
Mozilla ha finalizado su pr'actica de tener un 'unico buscador global en Firefox y en su lugar han adoptado una forma flexible que permitir'a tener buscadores por pa'is:

 Rusia
Rusia China
China Resto de los pa'ises
Resto de los pa'ises
Por eso la independencia importa. Al no perseguir el lucro, nos permite crear opciones diferentes. Opciones que mantienen la Web abierta, por todos lados e independiente. Pensamos que hoy se da un gran paso hacia esa direcci'on.
Cabe destacar que Google se mantendr'a disponible como buscador por defecto para los dem'as pa'ises pero la oferta est'a abierta para que otros socios interesados se sumen a esta estrategia.
Fuente: The Mozilla Blog
Fuente: Google System
|
|
Mozilla Fundraising: Mozilla Now Accepts Bitcoin |
|
|
Lukas Blakk: Artisinal Contributors |
Ascend had very few ‘rules’ but there was one which was non-negotiable: it’s an in-person program. We didn’t do distance learning, online coursework, or video-based classes. We did bring in a couple of speakers virtually to speak to the room of 20 participants but the opposite was never true.
This was super important in how we were going to build a strong cohort. Don’t get me wrong, I’m a fan of remote work and global contribution as well as with people working from wherever they are. This was a 6 week intensive program though and in order to build the inter-dependent cohort I was hoping to[0], it had to be in person at first. Those cruicial early stages where someone is more likely to ‘disappear’ if things were hard, confusing, or if they couldn’t get someone’s attention to ask a question.
It’s been over 5 years since I graduated from my software development program and over 8 years since I started lurking in IRC channels[0] and getting to know Mozillians in digital space first. I wouldn’t have stuck with it, or gotten so deeply involved without my coursework with Dave Humphrey though. That was a once a week class, but it meant the world to be in the same room as other people who were learning and struggling with the same or similar problems. It was an all-important thread connecting what I was trying to do in my self-directed time with actual people who could show more caring about me and my ability to participate.
Even as an experienced open source contributor I can jump into IRC channels for projects I’m trying to work on – most recently dd-wrt for my home server setup – and when I ask a question (with lots of evidence for what I’ve already tried and an awareness of what the manual has to say) I get no response, aka: Crickets. There are a host of reasons, and I know more than a beginner might about what those could be: timezones, family comitments, no one with the expertise currently in the channel, and more. None of that matters when you’re new to this type of environment. Silence is interpreted as a big “GO AWAY YOU DON’T BELONG HERE” despite the best intentions of any community.
In person learning is the best way to counter that. Being able to turn to a colleague or a mentor and say what’s happening helps get you both reassurance that it’s not you, but also someone who can help you get unstuck on what to do next. While you wait for a response, check out this other topic we’re studying. Perhaps you can try other methods of communication too, like in a bug or an email.
Over the course of our first pilot I also discovered that removing myself from the primary workroom the Ascend participants were in helped the cohort to rapidly built up strengths in helping each other first[0]. The workflow looked more like: have a question/problem, ask a cohort member (or several), if you still can’t figure it out ask on IRC, and if then if you’re still stuck find your course leader. This put me at the end of the escalation path[0] and meant that people were learning to rely both on in-person communications as well as IRC but more importantly were building up the muscle of “don’t stop asking for help until you get it” which is really where open source becomes such a great space to work in.
Back to my recent dd-wrt experience, I didn’t hear anything back in IRC and I felt I had exhausted the forums & wikis their community provided. I started asking in other IRC channels where tech-minded people hung out (thanks womenwhohack!) and then I tried yet another search with slightly different terms. In the end I found what I needed in a YouTube tutorial. I hope that sufficiently demonstrates that a combination of tactics are what culminate in an ability to be persistent when learning in open source projects.
Never underestimate the importance of removing isolation for new contributors to a project. In person help, even just at first, can be huge.
[0] Because the ultimate goal of Ascend was to give people skills for long-term contribution and participation and a local cohort of support and fellow learners seemed like a good bet for that to be possible once the barrier-removing help of the 6 week intensive was no longer in place.
[0] By the way, I’m such a huge fan of IRC that I wrote the tutorial for it at Mozilla in order to help get more non-engineering folks using it, in my perfect world everyone is in IRC all the time with scrollback options and logging.
[0] Only after the first three weeks when we moved to the more independent work, working on bugs, stage.
[0] Which is awesome because I was always struggling to keep up with the course creation as we were running it, I didn’t realize that teaching 9–5 was asking for disaster and next time we’ll do 10–4 for the participants to give the mentors pre and post prep time.
|
|
Lukas Blakk: Release Management Tooling: Past, Present, and Future |
As I was interviewing a potential intern for the summer of 2015 I realized I had outlined all our major tools and what the next enhancement for each could be but that this wasn’t well documented anywhere else yet.
By coming to Release Management from my beginnings as a Release Engineer, I’ve been a part of seeing our overall release automation improve across the whole spectrum of what it takes to put out packaged software for multiple platforms and we’ve come a long way so this post is also intended to capture how the main tools we use have gotten to their current state as well as share where they are heading.
Past: Release Manager on point for a release sent an email to the Release-Drivers mailing list with an hg changeset, a version, build number, and this was the “go” to build for Release Engineering to take over and execute a combination of automated/manual steps (there was even a time when it was only said in IRC, email became the constant when Joduinn pushed for consistency and a traceable trail of events). Release Engineers would update a config files & locale changes, get them attached to a bug, approved, uplifted, then go reconfigure the build machines so they could kick off the release build automation.
Present: Ship-It is an app developed by Release Engineering (bhearsum) that allows a Release Manager to input the configurations needed (changeset, version, build number, partials to be created, l10n changesets) all in one place, and on submit the build automation picks up this change from a db, reconfigures the build machine, and triggers builds. When all goes well, there are zero human hands between the “go” and the availability of builds to QA.
Future: In two parts:
1. To have a simple app that can take a list of bug numbers and check them for landing to {branch} (where branch is Beta, Release, or ESR), once all the bug numbers listed have landed, check tree herder for green status on that last changeset, submit to Ship-It if builds are successful. Benefits: hands off even sooner, knowing that all the important fixes are on the branch in question, and that the tree is totally green prior to build (sometimes we “go” without all the results because of human timing needs).
2. Complete End-To-End Release Checklist, dynamically updated to show what stage a release job is at and who’s got the ball in their court. This should track from buglist added (for the final landings a RM is waiting on) all the way until the release notes are live and QA signs off on updates for the general release being in the wild.
Past: Oh dear, you probably don’t even want to know how our release notes used to be made. It’s worse than sausage. There was a sqlite db file, a script that pulled from that db and generated html based on templates and then the Release Manager had to manually re-order the html to get the desired appearance on final pages, all this was then committed to SVN and with that comes the power to completely break mozilla.org properties. Fun stuff. Really. Also once Release Management was more than just one person we shared this sqlite db over Dropbox which had some fun quirks, like clobbering your changes if two people had the file open at the same time. Nowhere to go but up from here!
Present: Thanks to the web production team (jgmize, hoosteeno, craigcook, jbertsch) we got a new Django app in place that gives us a proper databse that’s redundant, production quality, and not in our hands. We add in release notes as well as releases and can publish notes to both staging and production without any more commits to SVN. There’s also an API that can be scripted to.
Future: The future’s so bright in this area, let me get my shades. We have a flag in Bugzilla for relnote-firefox where it can get set to ? when something is nominated and then when we decide to take on that bug as a release note we can set it to {versionNum}+. With a little tweaking on the Bugzilla side of things we could either have a dedicated field for “release-note text” or we could parse it out of a syntax in a comment (though that’s gonna be more prone to user error, so I prefer the former) and then automatically grab all the release notes for a version, create the release in Nucleus, add the notes, publish to staging, and email the link around for feedback without any manual interference. This also means we can dynamically adjust release notes using Bugzilla (and yes, this will need to be really cautiously done), and it makes sure that our recent convention of having every release note connect to a bug persist and become the standard.
Past: Our only way to visualize the work we were doing was a spreadsheet, and graphs generated from it, of how many crasher bugs were tracked for a version, how many bugs tracked/fixed over the course of 18 weeks for a version, and not much else. We also pay attention to the crash rate at ship time, whether we had to do a dot release or chemspill, and any other release-version-specific issues are sort of lost in the fray after we’re a couple of weeks out from a release. This means we don’t have a great sense of our own history, what we’re doing that works in generating a more stable/successful release, and whether a release is in fact ready to go out the door. It’s a gamble, and we take it every 6 weeks.
Present: We have in place a dashboard that is supposed to allow us to view the current crash data, select Talos (performance) data, custom bug queries, and be able to compare a current release coming down the pipe to previous releases. We do not use this dashboard yet because it’s been a side project for the past year and a half, primarily being created and improved upon by fabulous – yet short-term – interns at Mozilla. The dashboard relies on Elastic Search for Bugzilla data and the cluster it points to is not always up. The dash is written in php and that’s no one’s strong suit on our current team, our last intern did his work by creating a Python Flask app that would work into the current dash. The present situation is basically: we need to work on this.
Future: In the future, this dashboard will be robust, reliable, production-quality (and supported), and it will be able to go up on Mozilla office screens in the dashboard rotation where it will make clear to any viewer:
* Where we are in the current release cycle
* What blockers remain for releas
* How our stability is (over/under acceptable rates)
* If we’re meeting performance expectations
And hopefully more. We have to find more ways to get visibility into issues a release might hit once it’s with the larger population. I’d love to see us get more of our Beta user’s feedback by asking for it on specific features/fixes, get a broader Beta audience that is more reflective of our overall release population (by hardware, location, language, user types) and then grow their ability to report issues well. Then we can find ways to get that front and center too – including to developers because they are great at confirming if something unusual is happening.
Well, we used to have an automated script that reminded teams of their open & tracked bugs on Beta/Aurora/Nightly in order to provide a priority order that was visible to devs & their managers. It’s a finicky script that breaks often. I’d like to see that replaced with something that’s not just a cronjob on my personal VPS. We’re also this close to not needed to update product-details (still in SVN) on every release. The fact that the Release Management team has the ability to accidentally take down all mozilla.org properties when a mistake is made submitting svn propedits is not desireable or necessary. We should get the heck away from that asap.
We’ll have more discussions of this in Portland, especially with the teams we work closely with and Sylvestre and I will be talking up our process & future goals at FOSDEM in 2015 as well as following it with a work week in Paris where we can put our heads down and code. Next summer we get an intern again and so we’ll have another set of skilled hands to put on tooling & web service improvements.
Always improving. Always automating. These are the things that make me excited for the next year of Release Management.
http://lukasblakk.com/release-management-tooling-past-present-and-future/
|
|
Mozilla Open Policy & Advocacy Blog: Spotlight on the Open Technology Institute: A Ford-Mozilla Open Web Fellow Host |
{This is the third installment in our series highlighting the 2015 Host Organizations for the Ford-Mozilla Open Web Fellows program. We are now accepting applications to be a 2015 fellow. We are thrilled to feature the New America Foundation’s Open Technology Institute as a host. Over the years, OTI has been a meaningful change agent, helping to protect the free and open Web. Working at OTI, the Open Web Fellow will be developing tools that lead to greater transparency, enabling all stakeholders to better understand how public policy and business practices impact the Web experience.}
Spotlight on the Open Technology Institute: A Ford-Mozilla Open Web Fellow Host Organization
By Kevin Bankston, Policy Director, and Georgia Bullen, Senior Data Analyst; Open Technology Institute
Last month’s MozFest 2014 provided us a welcome opportunity to think about what we at New America’s Open Technology Institute hope to do over the next year as one of the few organizations lucky enough to host a Ford-Mozilla Open Web Fellow during that fellowship program’s inaugural year. At OTI, we are committed to freedom and social justice in the digital age. To achieve these goals, we engage in policy debates, build technology, and work with communities to understand needs, test tools and build alternative models of infrastructure. And we are looking for a passionate maker to help us with our work in 2015. In particular, to help make more transparent the workings of the Internet and the companies that offer services over it.
![OTI-Institute-CMYK [Converted]-01](http://www.liveinternet.ru/journal_proc.php?action=redirect&url=http://blog.mozilla.org/netpolicy/files/2014/11/OTI-Institute-CMYK-Converted-01.png)
So much of what impacts our online experience happens without us seeing it, making it easy to overlook.
For example, look at the Net Neutrality debate, where decisions made at interconnection points deep in the network have both business and policy implications. At OTI, we have tools that allow us to dig into the technical depths of the issue through our Measurement Lab platform, and we recently published a major report laying out much of that data. But we need help figuring out how to make this information more available and more clear so that policy experts, advocates, industry professionals and everyday Internet users can understand what interconnection is, how it works, and how it affects the online experience. We’ve started on one of these efforts by working on a visualization tool that we’re calling the Measurement Lab Observatory, but there’s so much more we can do with the Measurement Lab data, as well as the platform and tools to make it more accessible to everyone–if only we can find the right fellow.
With the help of the participants at our MozFest usability workshop, we thought about other ways to get people involved in Internet measurement, such as building a network troubleshooting tool that could generate new M-Lab data while also testing your connection. We also talked about developing out our Firefox Browser extension to have different themes depending on a user’s needs, such as a journalist or advocate dashboard which includes recent news about Internet policy issues, or a “notebook” app with which Internet citizen scientists can run and annotate tests as part of the M-Lab research team.
These are just the types of ideas that we’re hoping our incoming Ford-Mozilla Fellow can run with.
On the policy and governance side, there’s also a lot more that we could be doing to reveal what happens behind the scenes between governments and Internet companies. Many companies now publish “Transparency Reports” that include information about how and when governments ask for user’s data. However, there’s no standardization in how companies report, making it hard to meaningfully combine or compare the data from different companies — and hard for new companies to get into the reporting game. Building on some of our previous research and education efforts around transparency reporting, in 2015 we will be launching a project called the Transparency Reporting Toolkit. We’re going to build a Web portal filled with best practices information and tools to help companies create and upload reports in a standardized way, and tools for others to mash up and visualize the data from multiple companies’ reports. OTI’s technologists and data visualization experts are gearing up to build those tools, but it’s a big project and we could use some help — possibly yours.
Ultimately, we can only make good policy with good information, and we can only get good information – and, crucially, understand that information – with good tools. We’re ready to move forward on all of these projects in 2015, full steam ahead. All we need now is the right technologist to help us make those tools. If that sounds exciting to you, apply to be a 2015 Ford-Mozilla Open Web Fellow and work with us and the Mozilla community to help build new windows into the technical and political depths of the Internet.
Apply to be a 2015 Ford-Mozilla Open Web Fellow. Visit www.mozilla.org/advocacy.
|
|
Soledad Penades: Using the Firefox Developer Edition dark theme with Nightly |
With a recent version of Nightly, go to about:config and set browser.devedition.theme.enabled to true.
Open DevTools (I use alt + cmd + i, or you can also go to the Tools -> Web Developer -> Toggle tools menu). Then open DevTools preferences by clicking on the gear icon, and select “Dark Theme” on the top right, underneath the Themes.
Screenshot for clarification:
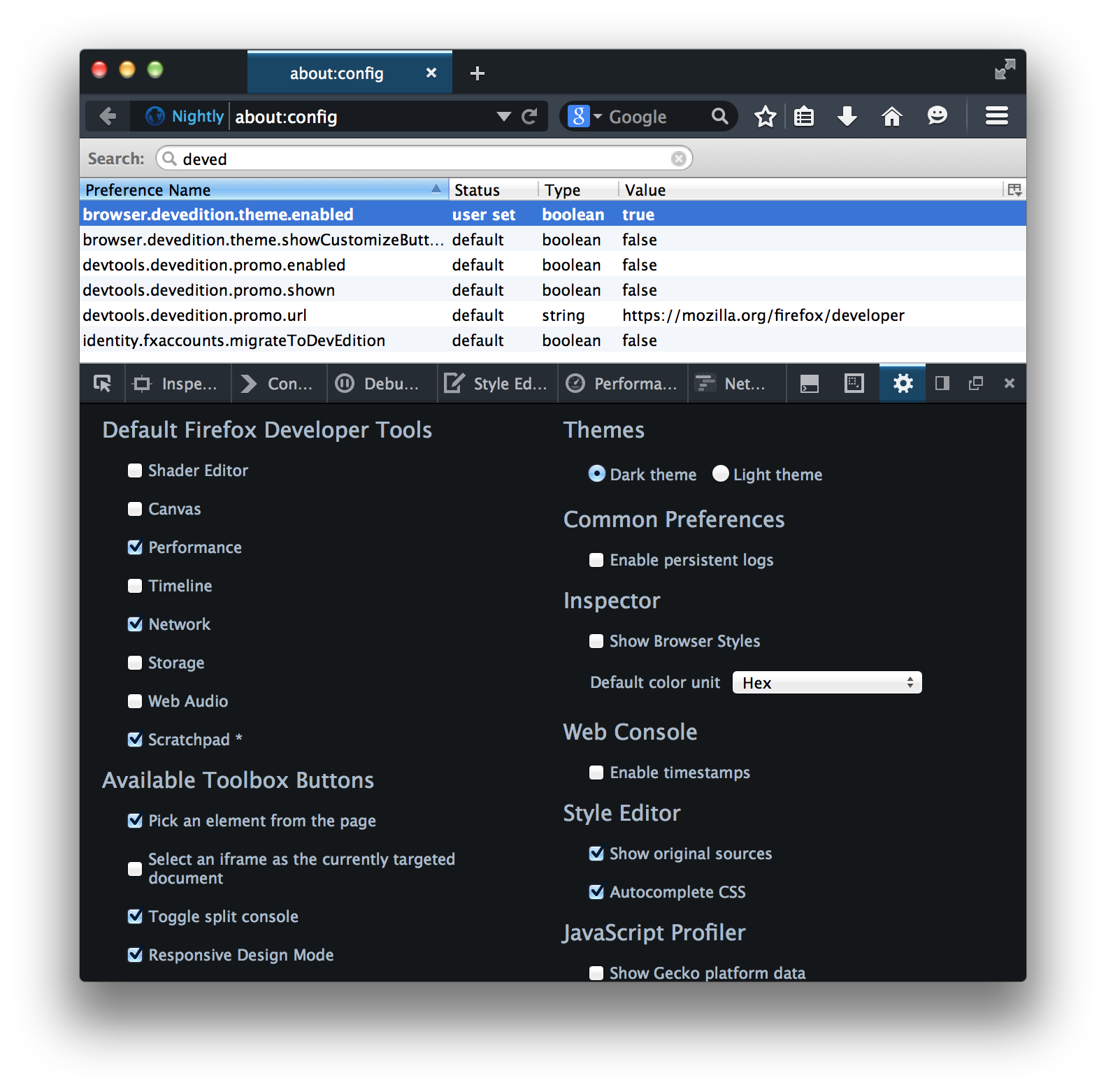
Note: you might not get the full effect if there is “legacy stuff” in your profile. If it doesn’t look as you expect… your best option might be to just create a new profile when you start the browser.
Note 2: for some reason the tabs weren’t rendering correctly on my normal nightly profile because the about:config browser.tabs.drawInTitlebar entry was set to false instead of true—I set it to true and now everything looks fine for me.
Or just use the standard Firefox Developer Edition if you’re not an impatient person like me ![]()
![]()
http://soledadpenades.com/2014/11/20/using-the-firefox-developer-edition-dark-theme-with-nightly/
|
|
David Rajchenbach Teller: RFC: We deserve better than runtime warnings |
Consider the following scenario:
How often has this happened to everyone of us?
This scenario has many variants (e.g. module A changed and nobody realized that module B is now in a situation it misuses module A), but they all boil down to the same thing: runtime warnings are designed to be lost, not fixed. To make things worse, many of our warnings are not actionable, simply because we have no way of knowing where they come from – I’m looking at you, Cu.reportError.
We would certainly save considerable amounts of time if warnings caused immediate assertion failures, or alternatively test failures (i.e. fail, but only when running the unit tests). Unfortunately, we can do neither, as we have a number of tests that trigger the warnings either
However, I believe that causing test failures is still the solution. We just need a mechanism that supports a form of whitelisting to cope with the aforementioned cases.
RuntimeAssert is an experiment at provoding a standard mechanism to replace warnings. I have a prototype implemented as part of bug 1080457. Feedback would be appreciated.
The key features are the following:
RuntimeAssert.fail(keyword, string or Error) from production code;MOZ_RUNTIME_ASSERT(keyword, string);Assert.whitelist.expected(keyword, regexp) or Assert.whitelist.FIXME(keyword, regexp).
//
// Module
//
let MyModule = {
oldAPI: function(foo) {
RuntimeAssert.fail(“Deprecation”, “Please use MyModule.newAPI instead of MyModule.oldAPI”);
// ...
},
newAPI: function(foo) {
// ...
},
};
let MyModule2 = {
api: function() {
return somePromise().then(null, error => {
RuntimeAssert.fail(“MyModule2.api”, error);
// Rather than leaving this error uncaught, let’s make it actionable.
});
},
api2: function(date) {
if (typeof date == “number”) {
RuntimeAssert.fail(“MyModule2.api2”, “Passing a number has been deprecated, please pass a Date”);
date = new Date(date);
}
// ...
}
}
//
// Whitelisting a RuntimeAssert in a test.
//
// This entire test is about MyModule.oldAPI, warnings are normal.
Assert.whitelist.expected(“Deprecation”, /Please use MyModule.newAPI/);
// We haven’t fixed all calls to MyModule2.api2, so they should still warn, but not cause an orange.
Assert.whitelist.FIXME(“MyModule2.api2”, /please pass a Date/);
Assert.whitelist.expected(“MyModule2.api”, /TypeError/, function() {
// In this test, we will trigger a TypeError in MyModule2.api, that’s entirely expected.
// Ignore such errors within the (async) scope of this function.
});
In the long-term, I believe that RuntimeAssert (or some other mechanism) should replace almost all our calls to Cu.reportError.
In the short-term, I plan to use this for reporting

![]()
|
|
Doug Belshaw: Firefox Interest Dashboard: privacy-respecting analytics for your web browsing history |
On a recent Mozilla project call I heard about the new Firefox Interest Dashboard. As someone who loves self-tracking, but stopped using my Fitbit due to privacy concerns, this is awesome.

Some of the numbers may be a bit off, and the categorisation certainly is in some cases, but it’s a promising start! The great thing is that if you use Firefox Sync it uses your data from other installations you use, too!
From the Content Services team:
This is an early version of interest categorization we’re working on. We invite you to test out this experimental beta add-on and help us out with the misclassified results. We would love to hear from you on suggestions on improvement or any feedback through the flag icon on the interest timeline.
Unlike other analytics services, the FAQ assures users that “all of the interest analysis and categorization is done on the client-side of your browser. No personal data is stored on Mozilla’s servers.”
Download the add-on (Firefox only)
Questions? Comments? Direct them to doug@mozillafoundation.org or discuss in the #TeachTheWeb discussion forum.
|
|
Julien Vehent: SSL/TLS for the Pragmatic |
Tonight I had the pleasure to present "SSL/TLS for the Pragmatic" to the fine folks of Bucks County Devops. It was a fun evening, and I want to thank the organizers, Mike Smalley & Ben Krein, for the invitation.
It was a great opportunity to summarize 18 months of work at Mozilla on building the Server Side TLS Guidelines. By the feedback I received tonight, and on several other occasions, I think we've achieved the goal of building a document that is useful to operations people, and made TLS just a little easier to understand.
We are not, however, anywhere done with the process of teaching TLS to the Internet. Stats speak for themselves, with 70% of sites still supporting SSLv3, 86% enabling RC4, and about 32% still not preferring PFS over RSA handshakes. But things are getting better every day, and ongoing efforts may bring safe defaults in Linux servers as soon as Fedora 21. We live in exciting times!
The slides from my talk are below, and on github as well. I hope you enjoy them. Feel free to share your comments at julien[at]linuxwall.info.
https://jve.linuxwall.info/blog/index.php?post/2014/11/20/SSL/TLS-for-the-Pragmatic
|
|
Giorgio Maone: s/http(:\/\/(?:noscript|flashgot|hackademix)\.net)/https\1/ |
I'm glad to announce noscript.net, flashgot.net and hackademix.net have been finally switched to full, permanent TLS with HSTS
Please do expect a sm"orgasbord of bugs and bunny funny stuff :)
https://hackademix.net/2014/11/20/shttpnoscriptflashgothackademixnethttps1/
|
|
Andreas Gal: Yahoo and Mozilla Form Strategic Partnership |
SUNNYVALE, Calif. and MOUNTAIN VIEW, Calif., Wednesday, November 19, 2014 – Yahoo Inc. (NASDAQ: YHOO) and Mozilla Corporation today announced a strategic five-year partnership that makes Yahoo the default search experience for Firefox in the United States on mobile and desktop. The agreement also provides a framework for exploring future product integrations and distribution opportunities to other markets.
The deal represents the most significant partnership for Yahoo in five years. As part of this partnership, Yahoo will introduce an enhanced search experience for U.S. Firefox users which is scheduled to launch in December 2014. It features a clean, modern and immersive design that reflects input from the Mozilla team.
“We’re thrilled to partner with Mozilla. Mozilla is an inspirational industry leader who puts users first and focuses on building forward-leaning, compelling experiences. We’re so proud that they’ve chosen us as their long-term partner in search, and I can’t wait to see what innovations we build together,” said Marissa Mayer, Yahoo CEO. “At Yahoo, we believe deeply in search – it’s an area of investment, opportunity and growth for us. This partnership helps to expand our reach in search and also gives us an opportunity to work closely with Mozilla to find ways to innovate more broadly in search, communications, and digital content.”
“Search is a core part of the online experience for everyone, with Firefox users alone searching the Web more than 100 billion times per year globally,” said Chris Beard, Mozilla CEO. “Our new search strategy doubles down on our commitment to make Firefox a browser for everyone, with more choice and opportunity for innovation. We are excited to partner with Yahoo to bring a new, re-imagined Yahoo search experience to Firefox users in the U.S. featuring the best of the Web, and to explore new innovative search and content experiences together.”
To learn more about this, please visit the Yahoo Corporate Tumblr and the Mozilla blog.
About Yahoo
Yahoo is focused on making the world’s daily habits inspiring and entertaining. By creating highly personalized experiences for our users, we keep people connected to what matters most to them, across devices and around the world. In turn, we create value for advertisers by connecting them with the audiences that build their businesses. Yahoo is headquartered in Sunnyvale, California, and has offices located throughout the Americas, Asia Pacific (APAC) and the Europe, Middle East and Africa (EMEA) regions. For more information, visit the pressroom (pressroom.yahoo.net) or the Company’s blog (yahoo.tumblr.com).
About Mozilla
Mozilla has been a pioneer and advocate for the Web for more than a decade. We create and promote open standards that enable innovation and advance the Web as a platform for all. Today, hundreds of millions of people worldwide use Mozilla Firefox to discover, experience and connect to the Web on computers, tablets and mobile phones. For more information please visit https://www.mozilla.com/press
Yahoo is registered trademark of Yahoo! Inc. All other names are trademarks and/or registered trademarks of their respective owners.







http://andreasgal.com/2014/11/19/yahoo-and-mozilla-form-strategic-partnership/
|
|
Monty Montgomery: Daala Demo 6: Perceptual Vector Quantization (by J.M. Valin) |

Jean-Marc has finished the sixth Daala demo page, this one about PVQ, the foundation of our encoding scheme in both Daala and Opus.
(I suppose this also means we've finally settled on what the acronym 'PVQ' stands for: Perceptual Vector Quantization. It's based on, and expanded from, an older technique called Pyramid Vector Quantization, and we'd kept using 'PVQ' for years even though our encoding space was actually spherical. I'd suggested we call it 'Pspherical Vector Quantization' with a silent P so that we could keep the acronym, and that name appears in some of my slide decks. Don't get confused, it's all the same thing!)
|
|
David Dahl: Encryptr: ‘zero knowledge’ essential information storage |
Encryptr is one of the first “in production” applications built on top of Crypton. Encryptr can store short pieces of text like passwords, credit card numbers and other random pieces of information privately, in the cloud. Since it uses Crypton, all data that is saved to the server is encrypted first, making even a server compromise an exercise in futility for the attacker.
A key feature is that you can run Encryptr on your phone as well as your desktop and all data is available in each place immediately. Have a look:

http://monocleglobe.wordpress.com/2014/11/19/encryptr-zero-knowledge-essential-information-storage/
|
|






