Mozilla Open Policy & Advocacy Blog: Thank you, Mr. President. |
Today, Mozilla joined with dozens of advocacy organizations and companies to urge President Obama to take action on net neutrality in response to his recent vocal support for fair and meaningful net neutrality rules. Expressing views echoed by millions of Americans, the groups urged the FCC to stand against fast lanes for those who can afford it and slow lanes for the rest of us. Below find the full text of the letter.
***
Mr. President:
Earlier this week, you made a strong statement in support of net neutrality by saying:
“One of the issues around net neutrality is whether you are creating different rates or charges for different content providers. That’s the big controversy here. So you have big, wealthy media companies who might be willing to pay more and also charge more for spectrum, more bandwidth on the Internet so they can stream movies faster.
I personally, the position of my administration, as well as a lot of the companies here, is that you don’t want to start getting a differentiation in how accessible the Internet is to different users. You want to leave it open so the next Google and the next Facebook can succeed.”
We want to thank you for making your support for net neutrality clear and we are counting on you to take action to ensure equality on the Internet. A level playing field has been vital for innovation, opportunity and freedom of expression, and we agree that the next big thing will not succeed without it. We need to avoid a future with Internet slow lanes for everybody except for a few large corporations who can pay for faster service.
Like you, we believe in preserving an open Internet, where Internet service providers treat data equally, regardless of who is creating it and who is receiving it. Your vision of net neutrality is fundamentally incompatible with FCC’s plan, which would explicitly allow for paid prioritization. The only way for the FCC to truly protect an open Internet is by using its clear Title II authority. Over the next few months, we need your continued and vocal support for fair and meaningful net neutrality rules. Our organizations will continue to pressure the FCC to put forth solidly based rules, and will continue to encourage you and other elected officials to join us in doing so.
Thank you again for standing up for the open Internet so that small businesses and people everywhere have a fair shot.
Signed,
ACLU, 18 Million Rising, Center for Media Justice, Center for Rural Strategies, ColorOfChange, Common Cause, Consumers Union, CREDO, Daily Kos, Demand Progress, Democracy for America, EFF, Engine, Enjambre Digital, Etsy, EveryLibrary, Fandor, Fight for the Future, Free Press, Future of Music Coalition, Greenpeace, Kickstarter, Louder, Media Action Grassroots Network, Media Alliance, Media Literacy Project, Media Mobilizing Project, MoveOn.org, Mozilla, Museums and the Web, National Alliance for Media Arts and Culture, National Hispanic Media Coalition, Open Technology Institute, OpenMedia International, Presente.org, Progressive Change Campaign Committee, Progressives United, Public Knowledge, Reddit, Rural Broadband Policy Group, SumOfUs, The Student Net Alliance, ThoughtWorks, United Church of Christ, OC Inc., Women’s Institute for Freedom of the Press, Women’s Media Center, Y Combinator
https://blog.mozilla.org/netpolicy/2014/08/08/thank-you-mr-president/
|
|
Matt Brubeck: Let's build a browser engine! |
I’m building a toy HTML rendering engine, and I think you should too. This is the first in a series of articles describing my project and how you can make your own. But first, let me explain why.
Let’s talk terminology. A browser engine is the portion of a web browser that works “under the hood” to fetch a web page from the internet, and translate its contents into forms you can read, watch, hear, etc. Blink, Gecko, WebKit, and Trident are browser engines. In contrast, the the browser’s own UI—tabs, toolbar, menu and such—is called the chrome. Firefox and SeaMonkey are two browsers with different chrome but the same Gecko engine.
A browser engine includes many sub-components: an HTTP client, an HTML parser, a CSS parser, a JavaScript engine (itself composed of parsers, interpreters, and compilers), and much more. The many components involved in parsing web formats like HTML and CSS and translating them into what you see on-screen are sometimes called the layout engine or rendering engine.
A full-featured browser engine is hugely complex. Blink, Gecko, WebKit—these are millions of lines of code each. Even younger, simpler rendering engines like Servo and WeasyPrint are each tens of thousands of lines. Not the easiest thing for a newcomer to comprehend!
Speaking of hugely complex software: If you take a class on compilers or operating systems, at some point you will probably create or modify a “toy” compiler or kernel. This is a simple model designed for learning; it may never be run by anyone besides the person who wrote it. But making a toy system is a useful tool for learning how the real thing works. Even if you never build a real-world compiler or kernel, understanding how they work can help you make better use of them when writing your own programs.
So, if you want to become a browser developer, or just to understand what happens inside a browser engine, why not build a toy one? Like a toy compiler that implements a subset of a “real” programming language, a toy rendering engine could implement a small subset of HTML and CSS. It won’t replace the engine in your everyday browser, but should nonetheless illustrate the basic steps needed for rendering a simple HTML document.
I hope I’ve convinced you to give it a try. This series will be easiest to follow if you already have some solid programming experience and know some high-level HTML and CSS concepts. However, if you’re just getting started with this stuff, or run into things you don’t understand, feel free to ask questions and I’ll try to make it clearer.
Before you start, a few remarks on some choices you can make:
You can build a toy layout engine in any programming language. Really! Go ahead and use a language you know and love. Or use this as an excuse to learn a new language if that sounds like fun.
If you want to start contributing to major browser engines like Gecko or WebKit, you might want to work in C++ because it’s the main language used in those engines, and using it will make it easier to compare your code to theirs. My own toy project, robinson, is written in Rust. I’m part of the Servo team at Mozilla, so I’ve become very fond of Rust programming. Plus, one of my goals with this project is to understand more of Servo’s implementation. (I’ve written a lot of browser chrome code, and a few small patches for Gecko, but before joining the Servo project I knew nothing about many areas of the browser engine.) Robinson sometimes uses simplified versions of Servo’s data structures and code. If you too want to start contributing to Servo, try some of the exercises in Rust!
In a learning exercise like this, you have to decide whether it’s “cheating” to use someone else’s code instead of writing your own from scratch. My advice is to write your own code for the parts that you really want to understand, but don’t be shy about using libraries for everything else. Learning how to use a particular library can be a worthwhile exercise in itself.
I’m writing robinson not just for myself, but also to serve as example code for these articles and exercises. For this and other reasons, I want it to be as tiny and self-contained as possible. So far I’ve used no external code except for the Rust standard library. (This also side-steps the minor hassle of getting multiple dependencies to build with the same version of Rust while the language is still in development.) This rule isn’t set in stone, though. For example, I may decide later to use a graphics library rather than write my own low-level drawing code.
Another way to avoid writing code is to just leave things out. For example, robinson has no networking code yet; it can only read local files. In a toy program, it’s fine to just skip things if you feel like it. I’ll point out potential shortcuts like this as I go along, so you can bypass steps that don’t interest you and jump straight to the good stuff. You can always fill in the gaps later if you change your mind.
Are you ready to write some code? We’ll start with something small: data structures for the DOM. Let’s look at robinson’s dom module.
The DOM is a tree of nodes. A node has zero or more children. (It also has various other attributes and methods, but we can ignore most of those for now.)
struct Node {
// data common to all nodes:
children: Vec<Node>,
// data specific to each node type:
node_type: NodeType,
}
There are several node types, but for now we will ignore most of them
and say that a node is either an Element or a Text node. In a language with
inheritance these would be subtypes of Node. In Rust they can be an enum
(Rust’s keyword for a “tagged union” or “sum type”):
enum NodeType {
Text(String),
Element(ElementData),
}
An element includes a tag name and any number of attributes, which can be stored as a map from names to values. Robinson doesn’t support namespaces, so it just stores tag and attribute names as simple strings.
struct ElementData {
tag_name: String,
attributes: AttrMap,
}
type AttrMap = HashMap<String, String>;
Finally, some constructor functions to make it easy to create new nodes:
fn text(data: String) -> Node {
Node { children: vec![], node_type: Text(data) }
}
fn elem(name: String, attrs: AttrMap, children: Vec<Node>) -> Node {
Node {
children: children,
node_type: Element(ElementData {
tag_name: name,
attributes: attrs,
})
}
}
And that’s it! A full-blown DOM implementation would include a lot more data and dozens of methods, but this is all we need to get started. In the next article, we’ll add a parser that turns HTML source code into a tree of these DOM nodes.
These are just a few suggested ways to follow along at home. Do the exercises that interest you and skip any that don’t.
Start a new program in the language of your choice, and write code to represent a tree of DOM text nodes and elements.
Install the latest version of Rust, then download and build
robinson. Open up dom.rs and extend NodeType to include
additional types like comment nodes.
Write code to pretty-print a tree of DOM nodes.
Here’s a short list of “small” open source web rendering engines. Most of them are many times bigger than robinson, but still way smaller than Gecko or WebKit. WebWhirr, at 2000 lines of code, is the only other one I would call a “toy” engine.
You may find these useful for inspiration or reference. If you know of any other similar projects—or if you start your own—please let me know!
- Part 1: Getting started
- Part 2: Parsing HTML
http://limpet.net/mbrubeck/2014/08/08/toy-layout-engine-1.html
|
|
Irving Reid: Telemetry Results for Add-on Compatibility Check |
Earlier this year (in Firefox 32), we landed a fix for bug 760356, to reduce how often we delay starting up the browser in order to check whether all your add-ons are compatible. We landed the related bug 1010449 in Firefox 31 to gather telemetry about the compatibility check, so that we could to before/after analysis.
When you upgrade to a new version of Firefox, changes to the core browser can break add-ons. For this reason, every add-on comes with metadata that says which versions of Firefox it works with. There are a couple of straightforward cases, and quite a few tricky corners…
We want to keep as many add-ons as possible enabled, because our users love (most of) their add-ons, while protecting users from incompatible add-ons that break Firefox. To do this, we implemented a very conservative check every time you update to a new version. On the first run with a new Firefox version, before we load any add-ons we ask addons.mozilla.org *and* each add-on’s update server whether there is a metadata update available, and whether there is a newer version of the add-on compatible with the new Firefox version. We then enable/disable based on that updated metadata, and offer the user the chance to upgrade those add-ons that have new versions available. Once this is done, we can load up the add-ons and finish starting up the browser.
This check involves multiple network requests, so it can be rather slow. Not surprisingly, our users would rather not have to wait for these checks, so in bug 760356 we implemented a less conservative approach:
Yes! On the Aurora channel, we went from interrupting 92.7% of the time on the 30 -> 31 upgrade (378091 out of
407710 first runs reported to telemetry) to 74.8% of the time (84930 out of 113488) on the 31 -> 32 upgrade, to only interrupting 16.4% (10158 out of 61946) so far on the 32 -> 33 upgrade.
The change took effect over two release cycles; the new implementation was in 32, so the change from “interrupt if there are *any* add-ons the user could possibly update” to “interrupt if there is a *newly disabled* add-on the user could update” is in effect for the 31 -> 32 upgrade. However, since we didn’t start tracking the metadata update time until 32, the “don’t interrupt if the metadata is fresh” change wasn’t effective until the 32 -> 33 upgrade. I wish I had thought of that at the time; I would have added the code to remember the update time into the telemetry patch that landed in 31.
On Aurora 33, the distribution of metadata age was:
| Age (days) | Sessions |
|---|---|
| < 1 | 37207 |
| 1 | 9656 |
| 2 | 2538 |
| 3 | 997 |
| 4 | 535 |
| 5 | 319 |
| 6 – 10 | 565 |
| 11 – 15 | 163 |
| 16 – 20 | 94 |
| 21 – 25 | 69 |
| 26 – 30 | 82 |
| 31 – 35 | 50 |
| 36 – 40 | 48 |
| 41 – 45 | 53 |
| 46 – 50 | 6 |
so about 88% of profiles had fresh metadata when they upgraded. The tail is longer than I expected, though it’s not too thick. We could improve this by forcing a metadata ping (or a full add-on background update) when we download a new Firefox version, but we may need to be careful to do it in a way that doesn’t affect usage statistics on the AMO side.
We also started gathering detailed information about how many add-ons are enabled or disabled during various parts of the upgrade process. The measures are all shown as histograms in the telemetry dashboard at http://telemetry.mozilla.org;
For these values, we got good telemetry data from the Beta 32 upgrade. The counts represent the number of Firefox sessions that reported that number of affected add-ons (e.g. 3170 Telemetry session reports said that 2 add-ons were XPIDB_DISABLED by the upgrade):
| Add-ons affected | XPIDB DISABLED | APPUPDATE DISABLED | METADATA ENABLED | METADATA DISABLED | UPGRADED | DECLINED | FAILED |
|---|---|---|---|---|---|---|---|
| 0 | 2.6M | 2.6M | 2.6M | 2.6M | 2.6M | 2.6M | 2.6M |
| 1 | 36230 | 7360 | 59240 | 14780 | 824 | 121 | 98 |
| 2 | 3170 | 1570 | 2 | 703 | 5 | 1 | 0 |
| 3 | 648 | 35 | 0 | 43 | 1 | 0 | 0 |
| 4 | 1070 | 14 | 1 | 6 | 0 | 0 | 0 |
| 5 | 53 | 20 | 0 | 0 | 0 | 0 | 0 |
| 6 | 157 | 194 | 0 | 0 | 0 | 0 | 0 |
| 7+ | 55 | 9 | 0 | 1 | 0 | 0 | 0 |
The things I find interesting here are:
http://www.controlledflight.ca/2014/08/08/telemetry-results-for-add-on-compatibility-check/
|
|
Mozilla WebDev Community: Webdev Extravaganza – August 2014 |
Once a month, web developers from across Mozilla gather to summon cyber phantoms and techno-ghouls in order to learn their secrets. It’s also a good opportunity for us to talk about what we’ve shipped, share what libraries we’re working on, meet newcomers, and just chill. It’s the Webdev Extravaganza! Despite the danger of being possessed, the meeting is open to the public; you should stop by!
You can check out the wiki page that we use to organize the meeting, check out the Air Mozilla recording, or amuse yourself with the wild ramblings that constitute the meeting notes. Or, even better, read on for a more PG-13 account of the meeting.
The shipping celebration is for anything we finished and deployed in the past month, whether it be a brand new site, an upgrade to an existing one, or even a release of a library.
There’s a new release of ErikRose‘s peep out! Peep is essentially pip, which installs Python packages, but with the ability to check downloaded packages against cryptographic hashes to ensure you’re receiving the same code each time you install. The latest version now passes through most arguments for pip install, supports Python 3.4, and installs a secondary script tied to the active Python version.
Here we talk about libraries we’re maintaining and what, if anything, we need help with for them.
pmac and peterbe, with feedback from the rest of Mozilla Webdev, have created contribute.json, a JSON schema for open-source project contribution data. The idea is to make contribute.json available at the root of every Mozilla site to make it easier for potential contributors and for third-party services to find details on how to contribute to that site. The schema is still a proposal, and feedback or suggestions are very welcome!
Here we introduce any newcomers to the Webdev group, including new employees, interns, volunteers, or any other form of contributor.
| Name | IRC Nick | Project |
|---|---|---|
| John Whitlock | jwhitlock | Web Platform Compatibility API |
| Mark Lavin | mlavin | Mobile Partners |
The Roundtable is the home for discussions that don’t fit anywhere else.
peterbe brought up the question of what to do about Playdoh, Mozilla’s Django-based project template for new sites. Many sites that used to be based on Playdoh are removing the components that tie them to the semi-out-of-date library, such as depending on playdoh-lib for library updates. The general conclusion was that many people want Playdoh to be rewritten or updated to address long-standing issues, such as:
pmac has taken responsibility as a peer on the Playdoh module to spend some time extracting improvements from Bedrock into Playdoh.
jgmize shared his experience making Bedrock run on the Cloud9 platform. The goal is to make it easy for contributors to spin up an instance of Bedrock using a free Cloud9 account, allowing them to edit and submit pull requests without having to go through the complex setup instructions for the site. jgmize has been dogfooding using Cloud9 as his main development environment for a few weeks and has had positive results using it.
If you’re interested in this approach, check out Cloud9 or ask jgmize for more information.
Unfortunately, we were unable to learn any mystic secrets from the ghosts that we were able to summon, but hey: there’s always next month!
If you’re interested in web development at Mozilla, or want to attend next month’s Extravaganza, subscribe to the dev-webdev@lists.mozilla.org mailing list to be notified of the next meeting, and maybe send a message introducing yourself. We’d love to meet you!
See you next month!
https://blog.mozilla.org/webdev/2014/08/08/webdev-extravaganza-august-2014/
|
|
Frederic Plourde: Gecko on Wayland |
![]() At Collabora, we’re always on the lookout for cool opportunities involving Wayland and we noticed recently that Mozilla had started to show some interest in porting Firefox to Wayland. In short, the Wayland display server is becoming very popular for being lightweight, versatile yet powerful and is designed to be a replacement for X11. Chrome and Webkit already got Wayland ports and we think that Firefox should have that too.
At Collabora, we’re always on the lookout for cool opportunities involving Wayland and we noticed recently that Mozilla had started to show some interest in porting Firefox to Wayland. In short, the Wayland display server is becoming very popular for being lightweight, versatile yet powerful and is designed to be a replacement for X11. Chrome and Webkit already got Wayland ports and we think that Firefox should have that too.
Some months ago, we wrote a simple proof-of-concept basically starting from actual Gecko’s GTK3 paths and stripping all the MOZ_X11 ifdefs out of the way. We did a bunch of quick hacks fixing broken stuff but rather easily and quickly (couple days), we got Firefox to run on Weston (Wayland official reference compositor). Ok, because of hard X11 dependencies, keyboard input was broken and decorations suffered a little, but that’s a very good start! Take a look at the below screenshot :)


http://fredinfinite23.wordpress.com/2014/08/08/gecko-on-wayland/
|
|
Christian Heilmann: Microsoft’s first web page and what it can teach us |
Today Microsoft released a re-creation of their first web site, 20 years ago complete with a readme.html explaining how it was done and why some things are the way they are.
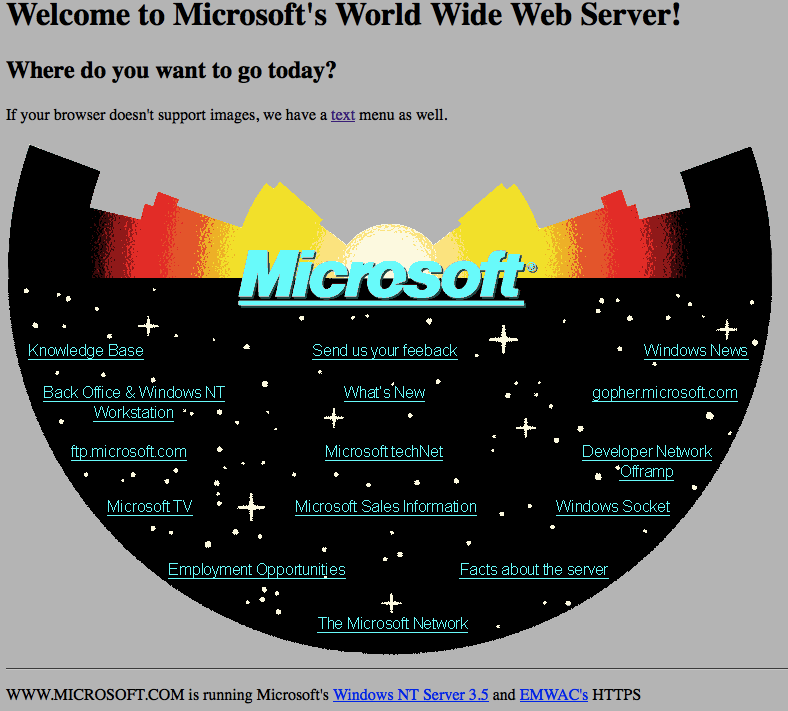
I found this very interesting. First of all because it took me back to my beginnings – I built my first page in 1996 or so. Secondly this is an interesting reminder how creating things for the web changed over time whilst our mistakes or misconceptions stayed the same.
There are a few details worth mentioning in this page:
And this, to me, is the most interesting part here: one of the first web sites created by a large corporation makes the most basic mistake in web design – starting with a fixed design created in a graphical tool and trying to create the HTML to make it work. In other words: putting print on the web.
The web was meant to be consumed on any device capable of HTTP and text display (or voice, or whatever you want to turn the incoming text into). Text browsers like Lynx were not uncommon back then. And here is Microsoft creating a web page that is a big image with no text alternative. Also interesting to mention is that the image is 767px x 513px big. Back then I had a computer capable of 640 x 480 pixels resolution and browsers didn’t scale pictures automatically. This means that I would have had quite horrible scrollbars.
If you had a text browser, of course there is something for you:
If your browser doesn’t support images, we have a text menu as well.
This means that this page is also the first example of graceful degradation – years before JavaScript, Flash or DHTML. It means that the navigation menu of the page had to be maintained in two places (or with a CGI script on the server). Granted, the concept of progressive enhancement wasn’t even spoken of and with the technology of the day almost impossible (could you detect if images are supported and then load the image version and hide the text menu? Probably with a beacon…).
And this haunts us until now: the first demos of web technology already tried to be pretty and shiny instead of embracing the unknown that is the web. Fixed layouts were a problem then and still are. Trying to make them work meant a lot of effort and maintainability debt. This gets worse the more technologies you rely on and the more steps you put into between what you code and what the browser is meant to display for you.
It is the right of the user to resize a font. It is completely impossible to make assumptions of ability, screen size, connection speed or technical setup of the people we serve our content to. As Brad Frost put it, we have to Embrace the Squishiness of the web and leave breathing room in our designs.
One thing, however, is very cool: this page is 20 years old, the technology it is recreated in is the same age. Yet I can consume the page right now on the newest technology, in browsers Microsoft never dreamed of existing (not that they didn’t try to prevent that, mind you) and even on my shiny mobile device or TV set.
Let’s see if we can do the same with Apps created right now for iOS or Android.
This is the power of the web: what you build now in a sensible, thought-out and progressively enhanced manner will always stay consumable. Things you force into a more defined and controlled format will not. Something to think about. Nobody stops you from building an amazing app for one platform only. But don’t pretend what you did there is better or even comparable to a product based on open web technologies. They are different beasts with different goals. And they can exist together.
http://christianheilmann.com/2014/08/08/microsofts-first-web-page-and-what-it-can-teach-us/
|
|
Robert O'Callahan: Choose Firefox Now, Or Later You Won't Get A Choice |
I know it's not the greatest marketing pitch, but it's the truth.
Google is bent on establishing platform domination unlike anything we've ever seen, even from late-1990s Microsoft. Google controls Android, which is winning; Chrome, which is winning; and key Web properties in Search, Youtube, Gmail and Docs, which are all winning. The potential for lock-in is vast and they're already exploiting it, for example by restricting certain Google Docs features (e.g. offline support) to Chrome users, and by writing contracts with Android OEMs forcing them to make Chrome the default browser. Other bad things are happening that I can't even talk about. Individual people and groups want to do the right thing but the corporation routes around them. (E.g. PNaCl and Chromecast avoided Blink's Web standards commitments by declaring themselves not part of Blink.) If Google achieves a state where the Internet is really only accessible through Chrome (or Android apps), that situation will be very difficult to escape from, and it will give Google more power than any company has ever had.
Microsoft and Apple will try to stop Google but even if they were to succeed, their goal is only to replace one victor with another.
So if you want an Internet --- which means, in many ways, a world --- that isn't controlled by Google, you must stop using Chrome now and encourage others to do the same. If you don't, and Google wins, then in years to come you'll wish you had a choice and have only yourself to blame for spurning it now.
Of course, Firefox is the best alternative :-). We have a good browser, and lots of dedicated and brilliant people improving it. Unlike Apple and Microsoft, Mozilla is totally committed to the standards-based Web platform as a long-term strategy against lock-in. And one thing I can say for certain is that of all the contenders, Mozilla is least likely to establish world domination :-).
http://robert.ocallahan.org/2014/08/choose-firefox-now-or-later-you-wont.html
|
|
Michael Verdi: Lightspeed – a browser experiment |
Planet Mozilla viewers – you can watch this video on YouTube.
This is a presentation that Philipp Sackl and I put together for the Firefox UX team. It’s a browser experiment called Lightspeed. If you want the short version you can download this pdf version of the presentation. Let me know what you think!
Notes:
https://blog.mozilla.org/verdi/463/lightspeed-a-browser-experiment/
|
|
Mozilla Open Policy & Advocacy Blog: MozFest 2014 – Calling All Policy & Advocacy Session Proposals |
Planning for MozFest 2014 (October 24-26 in London) is in full swing! This year, ‘Policy & Advocacy’ has its own track and we invite you to submit session proposals by the August 22nd deadline.
If you’ve never been to MozFest, here’s a bit about the conference: MozFest is a hands-on festival dedicated to forging the future of this open, global Web. Thousands of passionate makers, builders, educators, thinkers and creators from across the world come together as a community to dream at scale: exploring the Web, learning together, and making things that can change the world.
The Policy & Advocacy Track
MozFest is built on 11 core tracks, which are clusters of topics and sessions that have the greatest potential for innovation and empowerment with the Web. The Policy & Advocacy track will explore the current state of global Internet public policy and how to mobilize people to hold their leaders accountable to stronger privacy, security, net neutrality, free expression, digital citizenship, and access to the Web. Successful proposals are participatory, purposeful, productive, and flexible.
This is a critical time for the Internet, and you are all the heroes fighting everyday to protect and advance the free and open web. The Policy & Advocacy community is engaged in groundbreaking, vital efforts throughout the world. Let’s bring the community together to share ideas, passion, and expertise at MozFest.
We hope that you submit a session proposal today. We would love to hear from you.
|
|
Karl Dubost: Lightspeed and Blackhole |
It's 5AM. And I watched the small talk, Lightspeed a browser experiment, by Michael Verdi, who's doing UX at Mozilla. The proposal is about improving the user experience for people who don't want to have to configure anything. This is a topic I have at heart for two reasons. I think browsers are not helping me to manage information (I'm a very advanced user) and they are difficult to use by some people close to me (users with no technical knowledge).
When watching the talk, I was often along "yes, but we could push further this thing". I left a comment on Michael Verdi with this following content. I put it here too so I can keep a memory of it and I'm sure it will not disappear in the future. Here we go:
Search: Awesome bar matches the keywords in the title and the URI. Enlarge the scope by indexing the content of the full page instead. Rationale: We often remember things we have read more than their title which is invisible.
Heart: There are things I want to remember (the current heart), there are things I want to put on my ignore list or that I think are useless, disgusting, etc. Putting things on a list for ignoring will help to make it better. Hearts need to be page related and not domain related.
Bayesian: Now that you have indexed the full page, that you have chosen good and bad (heart/yirk), you can do bayesian filtering in the search results when you start styping, showing things which matters the most. Bayesian filtering is often used for removing spam, you can do the same by promoting content that is indexed.
BrowserTimeMachine: ok we indexed the full content of a page… hmm what about keeping a local copy of this page, be automatically or dynamically. Something that would work ala Time Machine, a kind of backup of my browsing. Something that would be a dated organization of my browsing or if you prefer an enhanced history. When you start searching you might have different versions in time of a Web page. I went there in October 2013, in February 2012. etc. When you are on a Webpage you could have a time slider timemachine and or ala Google streetview with the views from the past. (Additional benefit it can help you understand your self consumption of information). It could be everything you browse, or just the thing you put an heart. Which means you can put an heart multiple times on the same page.
In the end you get something which is becoming a very convenient tool for browsing (through local search) AND remembering (many tabs without managing them).
Otsukare!
|
|
Frederic Plourde: Firefox/Gecko : Getting rid of Xlib surfaces |
Over the past few months, working at Collabora, I have helped Mozilla get rid of Xlib surfaces for content on Linux platform. This task was the primary problem keeping Mozilla from turning OpenGL layers on by default on Linux, which is one of their long-term goals. I’ll briefly explain this long-term goal and will thereafter give details about how I got rid of Xlib surfaces.
LONG-TERM GOAL – Enabling Skia layers by default on Linux
My work integrated into a wider, long-term goal that Mozilla currently has : To enable Skia layers by default on Linux (Bug 1038800). And for a glimpse into how Mozilla initially made Skia layers work on linux, see bug 740200. At the time of writing this article, Skia layers are still not enabled by default because there are some open bugs about failing Skia reftests and OMTC (off-main-thread compositing) not being fully stable on linux at the moment (Bug 722012). Why is OMTC needed to get Skia layers on by default on linux ? Simply because by design, users that choose OpenGL layers are being grandfathered OMTC on Linux… and since the MTC (main-thread compositing) path has been dropped lately, we must tackle the OMTC bugs before we can dream about turning Skia layers on by default on Linux.
For a more detailed explanation of issues and design considerations pertaining turning Skia layers on by default on Linux, see this wiki page.
MY TASK – Getting rig of Xlib surfaces for content
Xlib surfaces for content rendering have been used extensively for a long time now, but when OpenGL got attention as a means to accelerate layers, we quickly ran into interoperability issues between XRender and Texture_From_Pixmap OpenGL extension… issues that were assumed insurmountable after initial analysis. Also, and I quote Roc here, “We [had] lots of problems with X fallbacks, crappy X servers, pixmap usage, weird performance problems in certain setups, etc. In particular we [seemed] to be more sensitive to Xrender implementation quality that say Opera or Webkit/GTK+.” (Bug 496204)
So for all those reasons, someone had to get rid of Xlib surfaces, and that someone was… me ;)
The Problem
So problem was to get rid of Xlib surfaces (gfxXlibSurface) for content under Linux/GTK platform and implicitly, of course, replace them with Image surfaces (gfxImageSurface) so they become regular memory buffers in which we can render with GL/gles and from which we can composite using GPU. Now, it’s pretty easy to force creation of Image surfaces (instead of Xlib ones) for just all content layers in gecko gfx/layers framework, just force gfxPlatformGTK::CreateOffscreenSurfaces(…) to create gfxImageSurfaces in any case.
Problem is, naively doing so gives rise to a series of perf. regressions and sub-optimal paths being taken, for example, to copy image buffers around when passing them across process boundaries, or unnecessary copying when compositing under X11 with Xrender support. So the real work was to fix everything after having pulled the gfxXlibSurface plug ;)
The Solution
First glitch on the way was that GTK2 theme rendering, per design, *had* to happen on Xlib surfaces. We didn’t have much choice as to narrow down our efforts to the GTK3 branch alone. What’s nice with GTK3 on that front is that it makes integral use of cairo, thus letting theme rendering happen on any type of cairo_surface_t. For more detail on that decision, read this.
Upfront, we noticed that the already implemented GL compositor was properly managing and buffering image layer contents, which is a good thing, but on the way, we saw that the ‘basic’ compositor did not. So we started streamlining basic compositor under OMTC for GTK3.
The core of the solution here was about implementing server-side buffering of layer contents that were using image backends. Since targetted platform was Linux/GTK3 and since Xrender support is rather frequent, the most intuitive thing to do was to subclass BasicCompositor into a new X11BasicCompositor and make it use a new specialized DataTextureSource (that we called X11DataTextureSourceBasic) that basically buffers upcoming layer content in ::Update() to an gfxXlibSurface that we keep alive for the TextureSource lifetime (unless surface changes size and/or format).
Performance results were satisfying. For 64 bit systems, we had around 75% boost in tp5o_shutdown_paint, 6% perf gain for ‘cart’, 14% for ‘tresize’, 33% for tscrollx and 12% perf gain on tcanvasmark.
For complete details about this effort, design decisions and resulting performance numbers, please read the corresponding bugzilla ticket.
To see the code that we checked-in to solve this, look at those 2 patches :
https://hg.mozilla.org/mozilla-central/rev/a500c62330d4
https://hg.mozilla.org/mozilla-central/rev/6e532c9826e7
Cheers !

http://fredinfinite23.wordpress.com/2014/08/07/firefoxgecko-getting-rid-of-xlib-surfaces/
|
|
Kim Moir: Scaling mobile testing on AWS |
 |
| Do Android's Dream of Electric Sheep? ©Bill McIntyre, Creative Commons by-nc-sa 2.0 |
 | |
|


http://relengofthenerds.blogspot.com/2014/08/scaling-mobile-testing-on-aws.html
|
|
Armen Zambrano Gasparnian: mozdevice now mozlogs thanks to mozprocess! |
jgraham: armenzg_brb: This new logging in mozdevice is awesome!We recently changed the way that mozdevice works. mozdevice is a python package used to talk to Firefox OS or Android devices either through ADB or SUT.
armenzg: jgraham, really? why you say that?
jgraham: armenzg: I can see what's going on!
DeviceManagerADB(logLevel=mozlog.DEBUG)As part of this change, we also switched to use structured logging instead of the basic mozlog logging.
 |
| At least with mozdevice you can know what is going on! |

http://armenzg.blogspot.com/2014/08/mozdevice-now-mozlogs-thanks-to.html
|
|
Gervase Markham: Laziness |
Dear world,
This week, I ordered Haribo Jelly Rings on eBay and had them posted to me. My son brought them from the front door to my office and I am now eating them.
That is all.
http://feedproxy.google.com/~r/HackingForChrist/~3/CBmHSwJ-BTU/
|
|
Nick Fitzgerald: Wu.Js 2.0 |
On May 21st, 2010, I started experimenting with lazy, functional streams in JavaScript with a library I named after the Wu-Tang Clan.
commit 9d3c5b19a088f6e33888c215f44ab59da4ece302
Author: Nick Fitzgerald <fitzgen@gmail.com>
Date: Fri May 21 22:56:49 2010 -0700
First commit
Four years later, the feature-complete, partially-implemented, and soon-to-be-finalized ECMAScript 6 supports lazy streams in the form of generators and its iterator protocol. Unfortunately, ES6 iterators are missing the higher order functions you expect: map, filter, reduce, etc.
Today, I'm happy to announce the release of wu.js version 2.0, which has been
completely rewritten for ES6.
wu.js aims to provide higher order functions for ES6 iterables. Some of them
you already know (filter, some, reduce) and some of them might be new to
you (reductions, takeWhile). wu.js works with all ES6 iterables,
including Arrays, Maps, Sets, and generators you write yourself. You don't
have to wait for ES6 to be fully implemented by every JS engine, wu.js can be
compiled to ES5 with the Tracuer compiler.
Here's a couple small examples:
const factorials = wu.count(1).reductions((last, n) => last * n);
// (1, 2, 6, 24, ...)
const isEven = x => x % 2 === 0;
const evens = wu.filter(isEven);
evens(wu.count());
// (0, 2, 4, 6, ...)
|
|
Byron Jones: happy bmo push day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
http://globau.wordpress.com/2014/08/07/happy-bmo-push-day-106/
|
|
William Reynolds: 2014 halfway point for Community Tools |
As part of Mozilla’s 2014 goal to grow the number of active contributors by 10x, we have been adding new functionality to our tools. Community Tools are the foundation for all activities that our global contributors do to help us achieve our mission. At their best, they enable us to do more and do better.
We have a comprehensive roadmap to add more improvements and features, but stepping back, this post summarizes what the Community Tools team has accomplished so far this year. Tools are an org-wide, cross-functional effort with the Community Building team working on tools such as Baloo and the Mozilla Foundation building tools to enable and measure impact (see areweamillionyet.org). We’re in the process of trying to merge our efforts and work more closely. However, this post focuses on mozillians.org and the Mozilla Reps Portal.
Our community directory, has over 6000 profiles of vouched Mozillians. This is a core way for volunteers and staff to contact each other and organize their programs, projects and interests through groups. Our efforts have a common theme of making it easier for Mozillians to get the information they need. Recently, we’ve worked on:
The portal for Reps activities and events has over 400 Reps and documents over 21,000 of their activities since the Reps program started 3 years ago. It provides tools for Reps to carry out their activities as well as public-facing information about thousands of Reps-organized events and general information about the Reps program. So far this year, we have:
We’ve made great progress this year. There’s still a lot to do. For mozillians.org we want to focus on making contributor information more accessible, recognizing contributors in a meaningful way, and creating a suite of modules. On the Reps Portal we will work on scaling operations, measuring the impact of activities and events, and creating a community leadership platform.
The roadmap describes specific projects, and we’ll continue blogging about updates and announcements.
We’d love your help with making mozillians.org and the Reps Portal better. Check out how to get involved and say hi to the team on the #commtools and #remo-dev IRC channels.
http://dailycavalier.com/2014/08/2014-halfway-point-for-community-tools/
|
|
David Boswell: People are the hook |
One of Mozilla’s goals for 2014 is to grow the number of active contributors by 10x. As we’ve been working on this, we’ve been learning a lot of interesting things. I’m going to do a series of posts with some of those insights.
The recent launch of the contributor dashboard has provided a lot of interesting information. What stands out to me is the churn — we’re able to connect new people to opportunities, but growth is slower than it could be because many people are leaving at the same time.

To really highlight this part of the data, Pierros made a chart that compares the number of new people who are joining with the number of people leaving. The results are dramatic — more people are joining, but the number of people leaving is significant.

This is understandable — the goal for this year is about connecting new people and we haven’t focused much effort on retention. As the year winds down and we look to next year, I encourage us to think about what a serious retention effort would look like.
I believe that the heart of a retention effort is to make it very easy for contributors to find new contribution opportunities as well as helping them make connections with other community members.
Stories we’ve collected from long time community members almost all share the thread of making a connection with another contributor and getting hooked. We have data from an audit that shows this too — a positive experience in the community keeps people sticking around.

There are many ways we could help create those connections. Just one example is the Kitherder mentor matching tool that the Security team is working on. They did a demo of it at the last Grow Mozilla meeting.
I don’t know what the answer is though, so I’d love to hear what other people think. What are some of the ways you would address contributor retention?

http://davidwboswell.wordpress.com/2014/08/06/people-are-the-hook/
|
|
Mike Conley: Bugnotes |
Over the past few weeks, I’ve been experimenting with taking notes on the bugs I’ve been fixing in Evernote.
I’ve always taken notes on my bugs, but usually in some disposable text file that gets tossed away once the bug is completed.
Evernote gives me more powers, like embedded images, checkboxes, etc. It’s really quite nice, and it lets me export to HTML.
Now that I have these notes, I thought it might be interesting to share them. If I have notes on a bug, here’s what I’m going to aim to do when the bug is closed:
I’ve just posted my first bugnote. It’s raw, unedited, and probably a little hard to follow if you don’t know what I’m working on. I thought maybe it’d be interesting to see what’s going on in my head as I fix a bug. And who knows, if somebody needs to re-investigate a bug or a related bug down the line, these notes might save some people some time.
Anyhow, here are my bugnotes. And if you’re interested in doing something similar, you can fork it (I’m using Jekyll for static site construction).
|
|






