William Quiviger: Exploring volunteer-run community spaces |

As a follow-up to my blog post last month, I wanted to introduce the second component of the Community Building partnership I’ve been shepherding with WPR. This component focuses on Mozilla Community Spaces ie. work spaces that are 100% managed by Mozilla volunteers and funded by WPR.
Since I joined Mozilla, a bit more than 6 years ago, I’ve traveled to more than 50 countries to meet and work with dozens of Mozilla communities and hundreds upon hundreds of passionate contributors. If there is one recurrent topic brought up by Mozillians during my trips, it’s the importance of face-to-face interaction and collaboration. While we Mozillians love hacking, sharing, chatting, debating together remotely online (ie. the power of the web in all its splendor!), we also love being together and seeing each other’s faces. And this goes beyond natural social interaction (ie. hanging out with people who share a common passion and interests). As awesome as IRC, email or video conferencing may be, the virtual cross-pollination of ideas has its limits. There is real tangible value in spending time working on a project together, brainstorming, discussing and debating, all under the same roof. That’s why events at Mozilla have always been so important. Historically, events have been, for many Mozillians, the only opportunity they had to meet their fellow Mozillians in person. And to be sure, one of the big rationales of launching the Mozilla Reps programs was precisely to enable more Mozillians to organize more events in more places around the world. Since the launch of the Mozilla Reps program, there has been a surge in the number of Mozilla happening in more than 80 countries. Predictably, this increase in the number of events has resulted in not only the growth and consolidation of existing Mozilla communities, but also in the birth of new ones.
And it's precisely because Mozilla’s most established communities have grown so much and that the concentration of contributors in a given city is such that having a dedicated physical work space appears to be the logical next step to sustain this growth. Having a dedicated work space Mozillians can run on their own is much more practical, productive and cost efficient than running weekly community events to meet in a rented venue. Last but not least, those Mozillians in countries where broadband is still a rare and expensive commodity (eg. Kenya) can greatly benefit from working from a well-connected space. It is clear, community spaces can help more Mozillians do more, together.
And this is where the Community Space initiative comes in. Over the past couple of months, I’ve been gathering feedback from different communities who have expressed a strong interest in having a community space to work from. I’ve also gathered lots of feedback and ideas as to how these community spaces could be run by volunteers while being funded by WPR. This led Rob Middleton (Director of WPR) and I to kick off several “pilots” around the world over the next 12 months, specifically in Athens, Bogota, Bangalore, Madrid, Manila, Nairobi and Taipei.
The selection criteria for these pilot cities include: - level of interest expressed by community - level of the community's preparedeness to manage a space - located in a strategic market for Firefox OS
These pilots will, hopefully, help us test out different sizes of spaces, gather important learnings and best practices to enable us to eventually roll-out a global community space initiative next year, which will support *all* communities who wish to run their own community spaces.
For more details on the initiative, make sure to peruse through the official wiki page which I'll be updating regularly: https://wiki.mozilla.org/Contribute/WPR/Community_Space_Initiative
In the next few months, I’ll be sharing regular progress reports for each space on this blog and also on the Grow Mozilla calls. Feedback and ideas are, as always, more than welcome. These pilots will be critical in the planning and design of the official community space initiative next year.
The first pilot we’re running is with the Taiwanese community in Taipei, which officially inaugurated its community space a few weeks ago. This will be the focus of my next blog post. Stay tuned!
http://somethin-else.org/index.php?post/2014/08/02/Exploring-community-spaces
|
|
Eric Shepherd: The Sheppy Report: Week of July 28, 2014 |
It’s been a while since my last Sheppy Report; there several good(ish) reasons for that. I won’t rehash all that today, though.
My intent is to resume these weekly reports; they were well-received back then, and I hope they’ll help improve my ability to keep people apprised of what I’m doing and about what’s new on MDN.
My primary mission this week was to work on the MDN documentation project plans, getting them prepared for use by moving them to MDN, building any necessary content and macros to support their presence, and so forth. This has gone pretty well, although it’s not quite finished yet. I plan to work on Saturday to complete this project.
Next week, I intend to tackle integration of the project plans with doc status pages and to write the WebGL documentation project plan. This will let us get started with the job of finding someone to write that important content.
There’s plenty more on my to-do list, and it’s possible priorities could shift, but finishing the current work is pretty much my Most Important Thing right now.
non-standardGeneric macro
string.repeat() documentation.MakeColumnsForDL macro on MDN; this macro, which breaks up a
There’s lots not covered here, such as email catch-up from my vacation a week or two ago, and all sorts of non-meeting discussions about MDN features, ideas for improving articles, etc. But you’re likely not interested. In fact, I bet you didn’t actually read this far anyway. :)
Unfortunately, a personal meeting ran very long on Friday, causing me to miss several scheduled meetings. Repeat apologies to everyone affected.
In general, a pretty productive week. A lot got done, and I’m making definite progress.
http://www.bitstampede.com/2014/08/01/the-sheppy-report-week-of-july-28-2014/
|
|
Margaret Leibovic: Firefox for Android: Search Experiments |
Search is a large part of mobile browser usage, so we (the Firefox for Android team) decided to experiment with ways to improve our search experience for users. As an initial goal, we decided to look into how we can make search faster. To explore this space, we’re about to enable two new features in Nightly: a search activity and a home screen widget.
Android allows apps to register to handle an “assist” intent, which is triggered by the swipe-up gesture on Nexus devices. We decided to hook into this intent to launch a quick, lightweight search experience for Firefox for Android users.
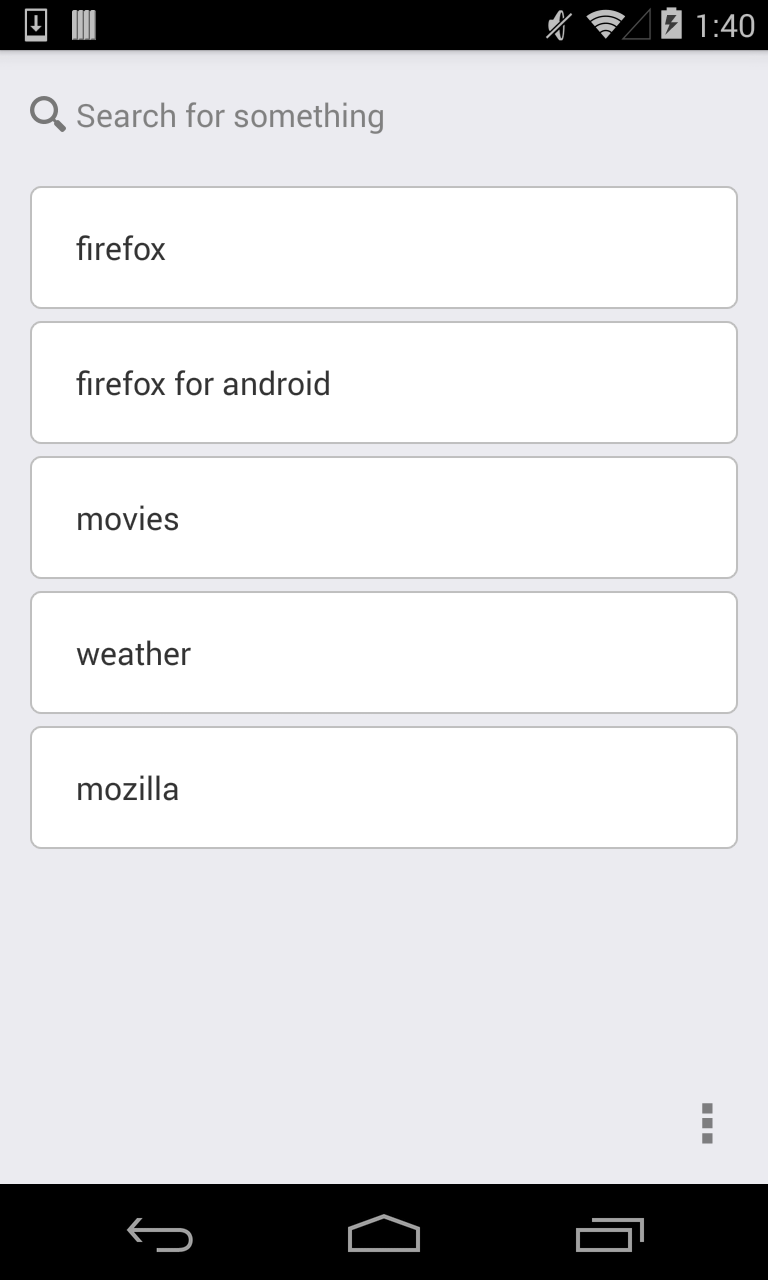
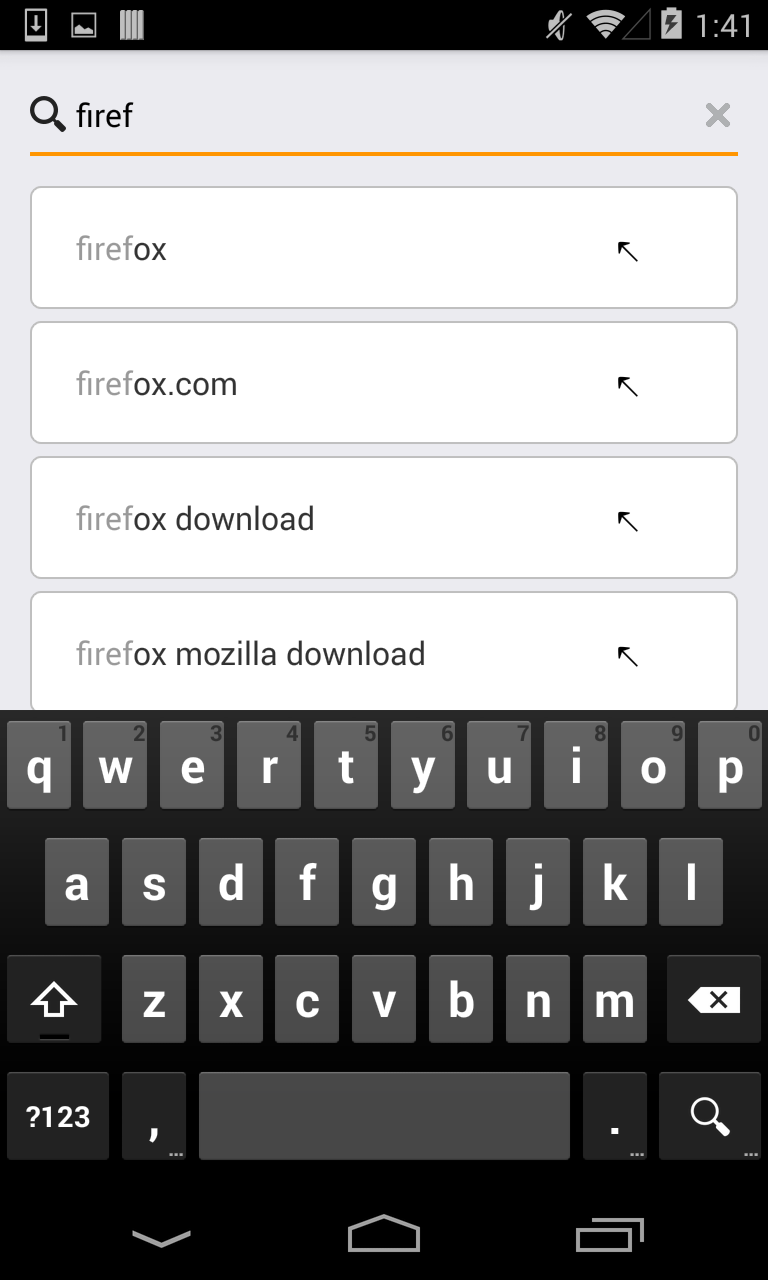
Right now we’re using Yahoo! to power search suggestions and results, but we have patches in the works to let users choose their own search engine. Tapping on results will launch users back into their normal Firefox for Android experience.
We also created a simple home screen widget to help users quickly launch this search activity even if they’re not using a Nexus device. As a bonus, this widget also lets users quickly open a new tab in Firefox for Android.
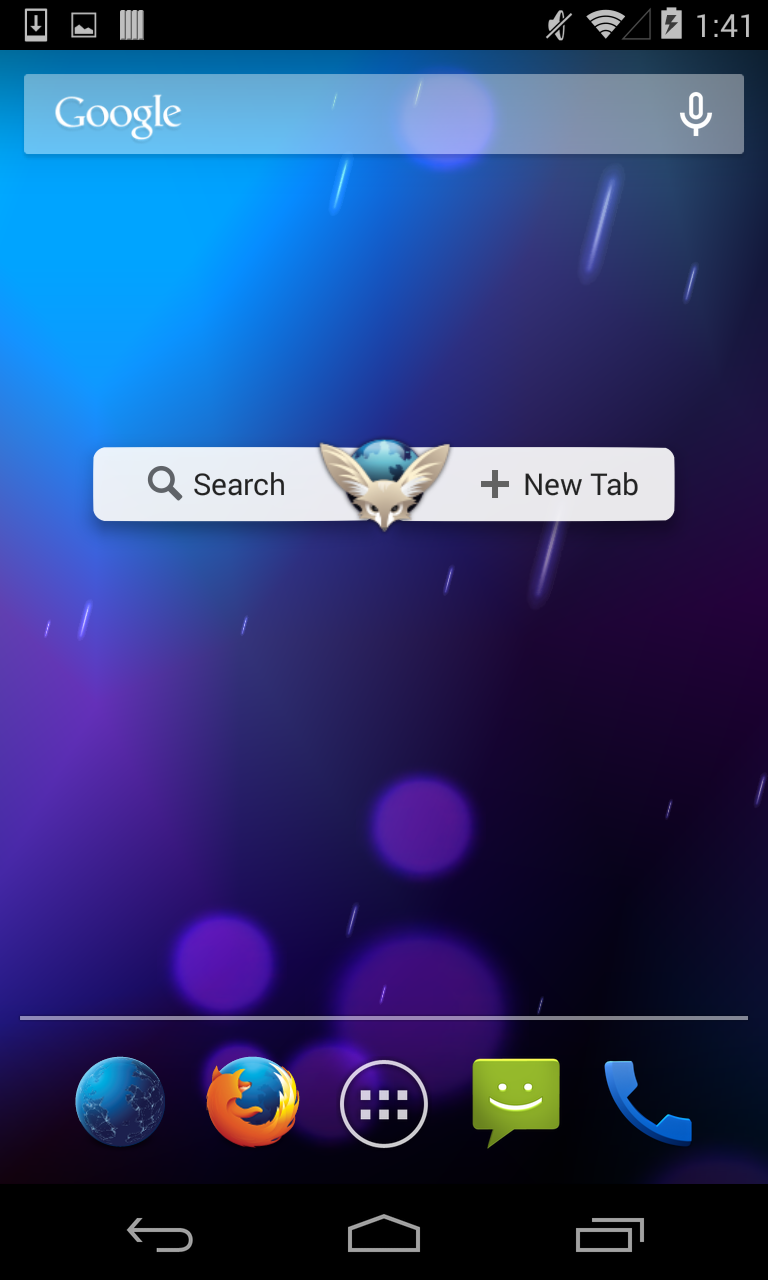
We are still in the early phases of design and development, so be prepared to see changes as we iterate to improve this search experience. We have a few telemetry probes in place to let us gather data on how people are using these new search features, but we’d also love to hear your feedback!
You can find links to relevant bugs on our project wiki page. As always, discussion about Firefox for Android development happens on the mobile-firefox-dev mailing list and in #mobile on IRC. And we’re always looking for new contributors if you’d like to get involved!
Special shout-out to our awesome intern Eric for leading the initial search activity development, as well as Wes for implementing the home screen widget.
|
|
Michael Kaply: New Certificate Verification Library in Firefox 31 |
I just learned that Firefox 31 contains a new Certificate Verification Library.
If you are running into certificate errors with Firefox 31 that were not happening before, it is important that you report them as soon as possible.
It's also important that you test your infrastructure as soon as possible.
More information about this change can be found in this blog post and this Wiki article.
More information about testing can be found in this Wiki article.
If you run into problems you can change the preference security.use_mozillapkix_verification to false and this will turn off the new verification.
This is not recommended, though, because the old code will be removed in Firefox 33, so we need to make sure we get any problems worked out.
http://mike.kaply.com/2014/08/01/new-certificate-verification-library-in-firefox-31/
|
|
Jared Wein: Faster and snappier searches now in Firefox Aurora |
 In case you haven’t noticed yet, Firefox Aurora contains some great speed ups when searching from the location bar. For far too long, searches that consisted of a single-word or arithmetic expressions would either result in errors or long delays before a search results page was presented.
In case you haven’t noticed yet, Firefox Aurora contains some great speed ups when searching from the location bar. For far too long, searches that consisted of a single-word or arithmetic expressions would either result in errors or long delays before a search results page was presented.
This has all changed starting in Firefox Aurora. Take for example, a search for “867-5309'':
Previously when a single word was typed in to the location bar and Enter was pressed (or the Go button clicked), Firefox would look for a website at http://867-5309/. After the lookup timed out, Firefox would redirect to a search for “867-5309“. If the hyphen was removed and “8675309” was entered, Firefox would immediately go to an error page saying that it was unable to connect to the server at 8675309.
Some people may have become accustomed to placing a `?` at the beginning of the location bar to subvert this behavior. With the new Firefox Aurora, this is no longer necessary.

Slow and broken search behavior seen in Firefox 32 and older
Now, in both of these cases Firefox will kick off the search request immediately. In the background, Firefox will look for locally-hosted sites that have a hostname matching the value that was typed in. Most people will see search results on average 5 seconds quicker!
In cases where there is a potential match, Firefox will show a notification bar asking if the locally-hosted site was the intended destination. Clicking “Yes, take me to 8675309'' will navigate to the matched site and whitelist it for future.

Screenshot of new behavior coming in Firefox 33
 If you’d like to proactively whitelist a site, you can go to
If you’d like to proactively whitelist a site, you can go to about:config and create a new Boolean pref with the name of `browser.fixup.domainwhitelist.` followed by the single word that you would like whitelisted. Set the pref to true, and the search will be skipped. localhost is already whitelisted.
Firefox continues to gain speed, customizability, and security with each release. This feature will find its way to the Release population with Firefox 33. In the meantime, you can install Firefox Aurora or Firefox Nightly and begin using it today.
There are two minor cases left to fix:

http://msujaws.wordpress.com/2014/08/01/faster-and-snappier-searches-now-in-firefox-aurora/
|
|
Mozilla Reps Community: Arjun and Rahid |

Arjun – Picture by Mozilla India

Rahid
https://blog.mozilla.org/mozillareps/2014/08/01/arjun-and-rahid/
|
|
Pascal Finette: A Personal Update |
Last year, on November 11th I joined Google.org. Exactly 90 days later I quit.
My plan for 2014 was to take some time off and focus on the things I love doing most - which is the magic which happens at the intersection of entrepreneurship, technology and impact.
I founded/co-founded two non-profits: POWERUP and The Coaching Fellowship. I did a ton of public speaking and mentored a whole bunch of entrepreneurs. I spent a week in Boulder, CO, working with the incredible Unreasonable Institute. I worked with a couple of very large companies on their innovation strategy. I became an executive coach working with some of the most inspiring individuals I’ve ever met.
And then everything changed.
For a long time I’ve been a huge fan of the work being done at Singularity University. Their mission of leveraging bleeding edge technologies to solve for the most intractable problems in the world is what I live and breath. It feels like we have been circling each other for a long time now - I have spoken a whole bunch of people there for years; and every conversation ended with “we should do something together”.
That “something” is now here!
Today I joined Singularity University to head up their Startup Lab.
We grow startups solving the world’s most intractable problems. We support, convene, collaborate and innovate. We bring the support of the world’s biggest companies to the table. We work together with the leading impact organizations worldwide.
I am at home. Let’s get cranking!
|
|
Karl Dubost: IE is aliasing some WebKit properties |
DOUBLE RAINBOW. Microsoft Internet Explorer is aliasing some of the WebKit properties. Read their blog post The Mobile Web should just work for everyone.

A little while ago I was working for Opera in the Open The Web (aka Web Compatibility) team when Opera decided an experiment for Opera on Mobile. A version of the browser was released with aliases for popular CSS WebKit prefixes which were often forgotten by Web developers and name_here_your_popular framework. I can tell you that it didn't please anyone in particular at Opera, but as Bruce is mentionning in his blog post:
It’s difficult to argue for ideological purity when a simple aliasing makes the user experience so demonstrably better – and one thing I’ve learned at Opera is most users don’t care two hoots for ideology if their favourite site works better in another browser.
Any Web professional who is shocked by IE announcement has first to go through a serious introspection assessment about his/her own Web practices. What is the browser you are using on Desktop, on Mobile? Do you even know what is it to use a Web browser which is not Webkit compatible as your main browser, not just for testing? Go use Firefox for Android for one year or IE on mobile and then talk about the issues at stake. Mike on his blog, Hallvord on his and here myself are regularly talking about these issues. We specifically started Webcompat.com because of these issues. IE Team is participating to this. We hope to get wider participation from Chrome and Opera teams too.
No, what IE has announced is not surprising or even shocking. What really surprises me is that they didn't in fact fully switch to Blink or implemented a dual rendering engine. I'm not in the known, but I would not be surprised it happens one day. That would left Mozilla in a pretty nasty place of the Web and would probably force Mozilla to switch to Blink.
After wiping out all our tears if this was announced that would raise an interesting set of questions on Web governance around some projects. For example, you could imagine that Blink becomes a real opensource library not mainly controlled by Google. You may be too young for remembering, but at the very beginning of the Web most Web clients were using a single common opensource library: LibWWW.
The common code library is the basis for most browers. It contains the network access code and format handling.
Note that I'm not wishing a Blink world, because in the current situation, we don't really have an equilibrium of powers around the Blink project. Libwww was not driven by one company with a few participants. The work for standard organizations like W3C and IETF around Web technology would be dramatically be shifted from specifications to managing issues and pull requests. It would be another social dynamics.
Otsukare.
|
|
Jeff Walden: mfbt now has UniquePtr and MakeUnique for managing singly-owned resources |
C++ supports dynamic allocation of objects using new. For new objects to not leak, they must be deleted. This is quite difficult to do correctly in complex code. Smart pointers are the canonical solution. Mozilla has historically used nsAutoPtr, and C++98 provided std::auto_ptr, to manage singly-owned new objects. But nsAutoPtr and std::auto_ptr have a bug: they can be “copied.”
The following code allocates an int. When is that int destroyed? Does destroying ptr1 or ptr2 handle the task? What does ptr1 contain after ptr2‘s gone out of scope?
typedef auto_ptrauto_int; { auto_int ptr1(new int(17)); { auto_int ptr2 = ptr1; // destroy ptr2 } // destroy ptr1 }
Copying or assigning an auto_ptr implicitly moves the new object, mutating the input. When ptr2 = ptr1 happens, ptr1 is set to nullptr and ptr2 has a pointer to the allocated int. When ptr2 goes out of scope, it destroys the allocated int. ptr1 is nullptr when it goes out of scope, so destroying it does nothing.
auto_ptrImplicit-move semantics are safe but very unclear. And because these operations mutate their input, they can’t take a const reference. For example, auto_ptr has an auto_ptr::auto_ptr(auto_ptr&) constructor but not an auto_ptr::auto_ptr(const auto_ptr&) copy constructor. This breaks algorithms requiring copyability.
We can solve these problems with a smart pointer that prohibits copying/assignment unless the input is a temporary value. (C++11 calls these rvalue references, but I’ll use “temporary value” for readability.) If the input’s a temporary value, we can move the resource out of it without disrupting anyone else’s view of it: as a temporary it’ll die before anyone could observe it. (The rvalue reference concept is incredibly subtle. Read that article series a dozen times, and maybe you’ll understand half of it. I’ve spent multiple full days digesting it and still won’t claim full understanding.)
mozilla::UniquePtrI’ve implemented mozilla::UniquePtr in #include "mozilla/UniquePtr.h" to fit the bill. It’s based on C++11's std::unique_ptr (not always available right now). UniquePtr provides auto_ptr‘s safety while providing movability but not copyability.
UniquePtr template parametersUsing UniquePtr requires the type being owned and what will ultimately be done to generically delete it. The type is the first template argument; the deleter is the (optional) second. The default deleter performs delete for non-array types and delete[] for array types. (This latter improves upon auto_ptr and nsAutoPtr [and the derivative nsAutoArrayPtr], which fail horribly when used with new[].)
UniquePtri1(new int(8)); UniquePtr arr1(new int[17]());
Deleters are callable values, that are called whenever a UniquePtr‘s object should be destroyed. If a custom deleter is used, it’s a really good idea for it to be empty (per mozilla::IsEmpty) so that UniquePtr is as space-efficient as a raw pointer.
struct FreePolicy
{
void operator()(void* ptr) {
free(ptr);
}
};
{
void* m = malloc(4096);
UniquePtr mem(m);
int* i = static_cast(malloc(sizeof(int)));
UniquePtr integer(i);
// integer.getDeleter()(i) is called
// mem.getDeleter()(m) is called
}
UniquePtr construction and assignmentAs you’d expect, no-argument construction initializes to nullptr, a single pointer initializes to that pointer, and a pointer and a deleter initialize embedded pointer and deleter both.
UniquePtri1; assert(i1 == nullptr); UniquePtr i2(new int(8)); assert(i2 != nullptr); UniquePtr i3(nullptr, FreePolicy());
All remaining constructors and assignment operators accept only nullptr or compatible, temporary UniquePtr values. These values have well-defined ownership, in marked contrast to raw pointers.
class B
{
int i;
public:
B(int i) : i(i) {}
virtual ~B() {} // virtual required so delete (B*)(pointer to D) calls ~D()
};
class D : public B
{
public:
D(int i) : B(i) {}
};
UniquePtr MakeB(int i)
{
typedef UniquePtr::DeleterType BDeleter;
// OK to convert UniquePtr to UniquePtr:
// Note: For UniquePtr interconversion, both pointer and deleter
// types must be compatible! Thus BDeleter here.
return UniquePtr(new D(i));
}
UniquePtr b1(MakeB(66)); // OK: temporary value moved into b1
UniquePtr b2(b1); // ERROR: b1 not a temporary, would confuse
// single ownership, forbidden
UniquePtr b3;
b3 = b1; // ERROR: b1 not a temporary, would confuse
// single ownership, forbidden
b3 = MakeB(76); // OK: return value moved into b3
b3 = nullptr; // OK: can't confuse ownership of nullptr
What if you really do want to move a resource from one UniquePtr to another? You can explicitly request a move using mozilla::Move() from #include "mozilla/Move.h".
int* i = new int(37); UniquePtri1(i); UniquePtr i2(Move(i1)); assert(i1 == nullptr); assert(i2.get() == i); i1 = Move(i2); assert(i1.get() == i); assert(i2 == nullptr);
Move transforms the type of its argument into a temporary value type. Move doesn’t have any effects of its own. Rather, it’s the job of users such as UniquePtr to ascribe special semantics to operations accepting temporary values. (If no special semantics are provided, temporary values match only const reference types as in C++98.)
UniquePtr‘s valueThe dereferencing operators (-> and *) and conversion to bool behave as expected for any smart pointer. The raw pointer value can be accessed using get() if absolutely needed. (This should be uncommon, as the only pointer to the resource should live in the UniquePtr.) UniquePtr may also be compared against nullptr (but not against raw pointers).
int* i = new int(8); UniquePtrp(i); if (p) *p = 42; assert(p != nullptr); assert(p.get() == i); assert(*p == 42);
UniquePtr‘s valueThree mutation methods beyond assignment are available. A UniquePtr may be reset() to a raw pointer or to nullptr. The raw pointer may be extracted, and the UniquePtr cleared, using release(). Finally, UniquePtrs may be swapped.
int* i = new int(42); int* i2; UniquePtri3, i4; { UniquePtr integer(i); assert(i == integer.get()); i2 = integer.release(); assert(integer == nullptr); integer.reset(i2); assert(integer.get() == i2); integer.reset(new int(93)); // deletes i2 i3 = Move(integer); // better than release() i3.swap(i4); Swap(i3, i4); // mozilla::Swap, that is }
When a UniquePtr loses ownership of its resource, the embedded deleter will dispose of the managed pointer, in accord with the single-ownership concept. release() is the sole exception: it clears the UniquePtr and returns the raw pointer previously in it, without calling the deleter. This is a somewhat dangerous idiom. (Mozilla’s smart pointers typically call this forget(), and WebKit’s WTF calls this leak(). UniquePtr uses release() only for consistency with unique_ptr.) It’s generally much better to make the user take a UniquePtr, then transfer ownership using Move().
UniquePtr and UniquePtr share the same interface, with a few substantial differences. UniquePtr defines an operator[] to permit indexing. As mentioned earlier, UniquePtr by default will delete[] its resource, rather than delete it. As a corollary, UniquePtr requires an exact type match when constructed or mutated using a pointer. (It’s an error to delete[] an array through a pointer to the wrong array element type, because delete[] has to know the element size to destruct each element. Not accepting other pointer types thus eliminates this class of errors.)
struct B {};
struct D : B {};
UniquePtr bs;
// bs.reset(new D[17]()); // ERROR: requires B*, not D*
bs.reset(new B[5]());
bs[1] = B();
mozilla::MakeUnique helper functionTyping out new T every time a UniquePtr is created or initialized can get old. We’ve added a helper function, MakeUnique, that combines new object (or array) creation with creation of a corresponding UniquePtr. The nice thing about MakeUnique is that it’s in some sense foolproof: if you only create new objects in UniquePtrs, you can’t leak or double-delete unless you leak the UniquePtr‘s owner, misuse a get(), or drop the result of release() on the floor. I recommend always using MakeUnique instead of new for single-ownership objects.
struct S { S(int i, double d) {} };
UniquePtr s1 = MakeUnique(17, 42.0); // new S(17, 42.0)
UniquePtr i1 = MakeUnique(42); // new int(42)
UniquePtr i2 = MakeUnique(17); // new int[17]()
// Given familiarity with UniquePtr, these work particularly
// well with C++11 auto: just recognize MakeUnique means new,
// T means single object, and T[] means array.
auto s2 = MakeUnique(17, 42.0); // new S(17, 42.0)
auto i3 = MakeUnique(42); // new int(42)
auto i4 = MakeUnique(17); // new int[17]()
MakeUnique computes new T(...args). MakeUnique of an array takes an array length and constructs the correspondingly-sized array.
In the long run we probably should expect everyone to recognize the MakeUnique idiom so that we can use auto here and cut down on redundant typing. In the short run, feel free to do whichever you prefer.
UniquePtr was a free-time hacking project last Christmas week, that I mostly finished but ran out of steam on when work resumed. Only recently have I found time to finish it up and land it, yet we already have a couple hundred uses of it and MakeUnique. Please add more uses, and make our existing new code safer!
A final note: please use UniquePtr instead of mozilla::Scoped. UniquePtr is more standard, better-tested, and better-documented (particularly on the vast expanses of the web, where most unique_ptr documentation also suffices for UniquePtr). Scoped is now deprecated — don’t use it in new code!
|
|
Fr'ed'eric Harper: HTML5 to the next level, the recording of my presentation at Montreal Python |

Last month I spoke at the monthly Python Montr'eal meetup about, guess what, Firefox OS. I already uploaded the slides online, and now the recording of my talk.
Thanks again to the friend Christian Aubry, who, like always, did an amazing job with the recording. Thanks also to Python Montr'eal for having me and Google Montr'eal for sponsoring the event.
--
HTML5 to the next level, the recording of my presentation at Montreal Python is a post on Out of Comfort Zone from Fr'ed'eric Harper
Related posts:
|
|
Kent James: Thunderbird’s Future: the TL;DR Version |
In the next few months I hope to do a series of blog posts that talk about Mozilla’s Thunderbird email client and its future. Here’s the TL;DR version (though still pretty long). These are my personal views, I have no authority to speak for Mozilla or for the Thunderbird project.
The Thunderbird team is currently planning to get together in Toronto in October 2014, and Mozilla staff are trying to plan an all-hands meeting sometimes soon. Let’s discussion the future in conjunction with those events, to make sure that in 2015 we have a sustainable plan for the future.
|
|
Vladimir Vuki'cevi'c: VR and CSS Integration in Firefox |
It’s taken a little longer than expected, but he second Firefox build with VR support and preliminary CSS content rendering support is ready. It is extremely early, and the details of interactions with CSS have not yet been worked out. I’m hoping that experimentation from the community will lead to some interesting results that can help us define what the interaction should be.
These builds support both the Oculus Rift DK1 and DK2 (see DK2 instructions towards the end of the post). No support for other devices is available yet.
The API for accessing the VR devices has changed, and is now using Promises. Additionally, the “moz” prefix was removed from all methods. Querying VR devices now should look like:
function vrDeviceCallback(devices) {
...
}
navigator.getVRDevices().then(vrDeviceCallback);
This build includes experimental integration of CSS 3D transforms and VR fullscreen mode. It also allows for mixing WebGL content along with browser-rendered CSS content. Within a block element that is made full screen with a VR HMD device, any children that have the transform-style: preserve-3d CSS property will cause the browser to render the content twice from different viewpoints. Any elements that don’t have preserve-3d will cause those elements to be stretched across the full display of the output device. For example:
Hello World
Will cause the css-square element to be rendered by the browser in the 3D space, but the WebGL canvas will be rendered only once, in this case underneath all content. No depth buffering is done between elements at this time.
The interaction between CSS transformed elements and the VR 3D space is poorly defined at the moment. CSS defines a coordinate space where 0,0 starts at the top left of the page, with Y increasing downwards, X increasing to the right, and Z increasing towards the viewer (i.e. out of the screen). For 3D content creation using CSS, “camera” and “modelview” elements could be used to provide transforms for getting a normal scene origin (based on the page’s dimensions) and camera position. It should also take care of applying orientation and position information from the HMD.
The browser itself will take care of applying the per-eye projection matrices and distortion shaders. Everything else is currently up to content. (I’ll go into detail exactly what’s done in a followup blog post.) So, a suggested structure could be:
...
...
One issue is that there currently is no way to specify the min and max depth of the scene. Normally, these would be specified as part of the projection, but that is inaccessible. For regular CSS 3D transforms, the perspective property provides some of this information, but it’s not appropriate for VR because the browser itself will define the projection transform. In this particular build, the depth will range from -(max(width,height) / 2) * 10 .. +(max(width,height) / 2) * 10. This is a complete hack, and will likely be replaced with an explicit CSS depth range property very soon. Alternatively, it might be replaced by an explicit setDepthRange call on the VR HMD device object (much like the FOV can be changed there).
I have not yet worked out the full best practices here. Some combination of transform-origin and transform will be needed to set up a useful coordinate space. A simple demo/test is available here.
As before, issues are welcome via GitHub issues on my gecko-dev repo. Additionally, discussion is welcome on the web-vr-discuss mailing list.
These builds can support the DK2 when it is run in legacy/extended desktop mode. The following steps should enable rendering to the DK2, with orientation/position data:
http://blog.bitops.com/blog/2014/07/31/css-and-vr-integration/
|
|
Bogomil Shopov: Optimize your GitHub Issues and 4 tricks and facts you should know about GitHub |
I wrote an article, that can be found here about the new GitHub Issues, web development processes, using visual feedback and some facts about GitHub:['bigdata','github stats','xkcd comic ban','more''].
Actually I am using one old bug from input.mozilla.org project (a.k.a) Fjord. It’s a good 4 mins read full of useful stuff and fun.
If you are interested in the tool I am using to optimize your GitHub Issues processes, it is available for free for F(L)OSS projects from here, but you should read the article first.
Any thoughts?
http://talkweb.eu/optimize-your-github-issues-and-4-tricks-and-facts-you-should-know-about-github/
|
|
Lucas Rocha: The new TwoWayView |
What if writing custom view recycling layouts was a lot simpler? This question stuck in my mind since I started writing Android apps a few years ago.
The lack of proper extension hooks in the AbsListView API has been one of my biggest pain points on Android. The community has come up with different layout implementations that were largely based on AbsListView‘s code but none of them really solved the framework problem.
So a few months ago, I finally set to work on a new API for TwoWayView that would provide a framework for custom view recycling layouts. I had made some good progress but then Google announced RecyclerView at I/O and everything changed.
At first sight, RecyclerView seemed to be an exact overlap with the new TwoWayView API. After some digging though, it became clear that RecyclerView was a superset of what I was working on. So I decided to embrace RecyclerView and rebuild TwoWayView on top of it.
The new TwoWayView is functional enough now. Time to get some early feedback. This post covers the upcoming API and the general-purpose layout managers that will ship with it.
RecyclerView itself doesn’t actually do much. It implements the fundamental state handling around child views, touch events and adapter changes, then delegates the actual behaviour to separate components—LayoutManager, ItemDecoration, ItemAnimator, etc. This means that you still have to write some non-trivial code to create your own layouts.
LayoutManager is a low-level API. It simply gives you extension points to handle scrolling and layout. For most layouts, the general structure of a LayoutManager implementation is going to be very similar—recycle views out of parent bounds, add new views as the user scrolls, layout scrap list items, etc.
Wouldn’t it be nice if you could implement LayoutManagers with a higher-level API that was more focused on the layout itself? Enter the new TwoWayView API.
TWAbsLayoutManagercode is a simple API on top of LayoutManager that does all the laborious work for you so that you can focus on how the child views are measured, placed, and detached from the RecyclerView.
To get a better idea of what the API looks like, have a look at these sample layouts: SimpleListLayout is a list layout and GridAndListLayout is a more complex example where the first N items are laid out as a grid and the remaining ones behave like a list. As you can see you only need to override a couple of simple methods to create your own layouts.
The new API is pretty nice but I also wanted to create a space for collaboration around general-purpose layout managers. So far, Google has only provided LinearLayoutManager. They might end up releasing a few more layouts later this year but, for now, that is all we got.
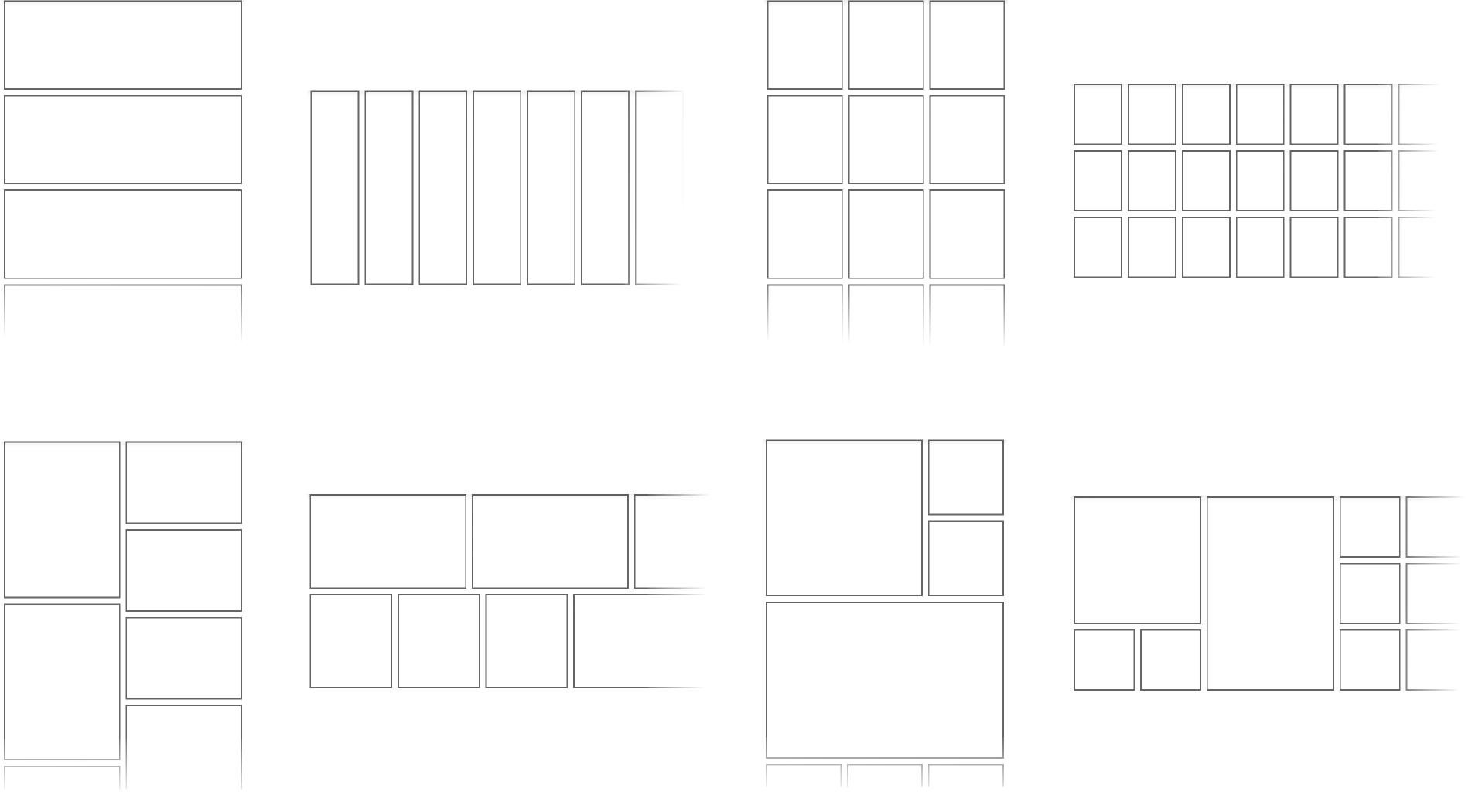
The new TwoWayView ships with a collection of four built-in layouts: List, Grid, Staggered Grid, and Spannable Grid.
These layouts support all RecyclerView features: item animations, decorations, scroll to position, smooth scroll to position, view state saving, etc. They can all be scrolled vertically and horizontally—this is the TwoWayView project after all ;-)
You probably know how the List and Grid layouts work. Staggered Grid arranges items with variable heights or widths into different columns or rows according to its orientation.
Spannable Grid is a grid layout with fixed-size cells that allows items to span multiple columns and rows. You can define the column and row spans as attributes in the child views as shown below.
...
The new TwoWayView API will ship with a convenience view (TWView) that can take a layoutManager XML attribute that points to a layout manager class.
This way you can leverage the resource system to set layout manager depending on device features and configuration via styles.
You can also use TWItemClickListener to use ListView-style item (long) click listeners. You can easily plug-in support for those in any RecyclerView (see sample).
I’m also planning to create pluggable item decorations for dividers, item spacing, list selectors, and more.
That’s all for now! The API is still in flux and will probably go through a few more iterations. The built-in layouts definitely need more testing.
You can help by filing (and fixing) bugs and giving feedback on the API. Maybe try using the built-in layouts in your apps and see what happens?
I hope TwoWayView becomes a productive collaboration space for RecyclerView extensions and layouts. Contributions are very welcome!
|
|
Daniel Stenberg: Me in numbers, today |
Number of followers on twitter: 1,302
Number of commits during the last 365 days at github: 686
Number of publicly visible open source commits counted by openhub: 36,769
Number of questions I’ve answered on stackoverflow: 403
Number of connections on LinkedIn: 608
Number of days I’ve committed something in the curl project: 2,869
Number of commits by me, merged into Mozilla Firefox: 9
Number of blog posts on daniel.haxx.se, including this: 734
Number of friends on Facebook: 150
Number of open source projects I’ve contributed to, openhub again: 35
Number of followers on Google+: 557
Number of tweets: 5,491
Number of mails sent to curl mailing lists: 21,989
TOTAL life achievement: 71,602
|
|
Brian Warner: To Infinity And Beyond! |
It’s been a great four and a half years at Mozilla, where I’ve had the privilege to work with the wonderful and brilliant people in Labs, Jetpack, Identity, and most recently Cloud Services. I’m grateful to you all.
Now it’s time for me to move on. This Friday will be my last day in the office (but certainly not as a Mozillian!), and this blog will probably be closed down or frozen at that time. You can reach me at warner@lothar.com, and my home blog lives at http://www.lothar.com/blog .
Mozilla is an amazing place, and will always be in my heart. Thank you all for everything!
https://blog.mozilla.org/warner/2014/07/30/to-infinity-and-beyond/
|
|
Zbigniew Braniecki: Reducing MozL10n+Gaia technical debt in Firefox OS 2.1 cycle |
Firefox OS is becoming a more mature platform, and one of the components that is maturing with it is the mozL10n library.
In 2.0 cycle, which is already feature complete, we introduced the codebase based on the L20n project.
The 2.1 cycle we’re currently in is a major API cleanup effort. We’re reviewing how Gaia apps use mozL10n, migrating them to the new API and minimizing the code complexity.
Simplifying the code responsible for localizability of Firefox OS is crucial for our ability to maintain and bring new features to the platform.
There are four major areas we’re working on:
We’re working on all four areas and would love to get your help.
No matter if you are a Gaia app owner, or if you’ve never wrote a patch for Gaia. If you know JavaScript, you can help us!
All of those bugs have instructions on how to start fixing, and I will be happy to mentor you.
We have time until October 13th. Let’s get Gaia ready for the next generation features we want to introduce soon! ![]()
http://diary.braniecki.net/2014/07/30/reducing-mozl10ngaia-technical-debt-in-firefox-os-2-1-cycle/
|
|
Justin Crawford: Vouched Improvements on Mozillians.org |
Back in October I wrote a few blog posts describing a significant problem with the way we admit new members into the Mozillians.org community platform. Yesterday the Mozillians.org team fixed it!
Before yesterday, everyone with a “vouched” account in Mozillians.org was empowered to vouch others. But we never explained what it meant to vouch someone: What it implied, what it granted. As a result, the standard for being vouched was arbitrary, the social significance of being vouched was diluted, and the privileges granted to vouched users were distributed more widely than they ought to be.
Yesterday the Mozillians.org development team released a major refactor of the vouching system. For the first time we have a shared definition and understanding of vouching: A vouch signals participation and contribution in Mozilla’s community, and grants access to content and systems not available to the general public.
The new vouch system includes features that…
It is much clearer now who can access non-public information using Mozillians.org (people who have been vouched because they participate and contribute to Mozilla) and how that list of people can grow (through individual judgments by people who have themselves been vouched numerous times).
When we know the composition of a network and understand how it will grow, we can make better decisions about sharing things with the network. We can confidently choose to share some things because we understand whom we’re sharing with. And we can reasonably choose to withhold some things for the very same reason. Understanding a network simultaneously encourages more sharing and reduces inadvertent disclosure.
Thanks to the Mozillians.org development team for making these excellent improvements!
|
|
Wesley Johnston: Better tiles in Fennec |
We recently reworked Firefox for Android‘s homescreen to look a little prettier on first-run by shipping “tile” icons and colors for the default sites. In Firefox 33, we’re allowing sites to designate their own tiles images by supporting msApplication-Tile and Colors in Fennec. So, for example, you might start seeing tiles that look like:
appear as you browse. Sites can add these with just a little markup in the page:
As you can see above in the Boston Globe tile, sometimes we don’t have much to work with. Firefox for Android already supports the sizes attribute on favicon links, and our fabulous intern Chris Kitching improved things even more last year. In the absence of a tile, we’ll show a screenshot. If you’ve designated that Firefox shouldn’t cache the content of your site for security reasons, we’ll use the most appropriate size we can find and pull colors out of it for the background. But if sites can provide us with this information directly its 1.) must faster and 2.) gives much better results.
AFAIK, there is no standard spec for these types of meta tags, and none in the works either. Its a bit of the wild wild west right now. For instance, Apple supports apple-mobile-web-app-status-bar-style for designating the color of the status bar in certain situations, as well as a host of images for use in different situations.
Opera at one point supported using a minimized media query to designate a stylesheet for thumbnails (sadly they’ve removed all of those docs, so instead you just get a github link to an html file there). Gecko doesn’t have view-mode media query support currently, and not many sites have implemented it anyway, but it might in the future provide a standards based alternative. That said, there are enough useful reasons to know a “color” or a few different “logos” for an app or site, that it might be useful to come up with some standards based ways to list these things in pages.

http://digdug2k.wordpress.com/2014/07/30/better-tiles-in-fennec/
|
|
Bogomil Shopov: Capture screenshots and annotate web sites in your Firefox |
Usersnap’s visual communication addon was just approved by the addon team and now we have a “green button”. Hooray!
This is a “must have” addon for every web developer who wants to solve problems with web sites faster and who wants to earn more money by shortening the communication time with the client or inside the team.
Every developer will get access and to the Usersnap Dashboard where he/she can:
http://talkweb.eu/capture-screenshots-and-annotate-web-sites-in-your-firefox/
|
|






