Daniel Stenberg: Please select your TLS |
tldr: starting now, you need to select which TLS to use when you run curl’s configure script.
In June 1998, three months after the first release of curl, we added support for HTTPS. We decided that we would use an external library for this purpose – for providing SSL support – and therefore the first dependency was added. The build would optionally use SSLeay. If you wanted HTTPS support enabled, we would use that external library.
SSLeay ended development at the end of that same year, and OpenSSL rose as a new project and library from its ashes. Of course, even later the term “SSL” would also be replaced by “TLS” but the entire world has kept using them interchangeably.

The initial configure script we wrote and provided back then (it appeared for the first time in November 1998) would look for OpenSSL and use it if found present.
In the spring of 2005, we merged support for an alternative TLS library, GnuTLS, and now you would have to tell the configure script to not use OpenSSL but instead use GnuTLS if you wanted that in your build. That was the humble beginning of the explosion of TLS libraries supported by curl.
As time went on we added support for more and more TLS libraries, giving the users the choice to select exactly which particular one they wanted their curl build to use. At the time of this writing, we support 14 different TLS libraries.

The original logic from when we added GnuTLS back in 2005 was however still kept so whatever library you wanted to use, you would have to tell configure to not use OpenSSL and instead use your preferred library.
Also, as the default configure script would try to find and use OpenSSL it would result in some surprises to users who maybe didn’t want TLS in their build or even when something was just not correctly setup and configure unexpectedly didn’t find OpenSSL and the build then went on and was made completely without TLS support! Sometimes even without getting noticed for a long time.
Starting now, curl’s configure will not select TLS backend by default.
It will not decide for you which one you use, as there are many decisions involved when selecting TLS backend and there are many users who prefer something else than OpenSSL. We will no longer give any special treatment to that library at build time. We will not impose our bias onto others anymore.
Not selecting any TLS backend at all will just make configure exit quickly with a help message prompting you to make a decision, as shown below. Notice that going completely without a TLS library is still fine but similarly also requires an active decision (--without-ssl).
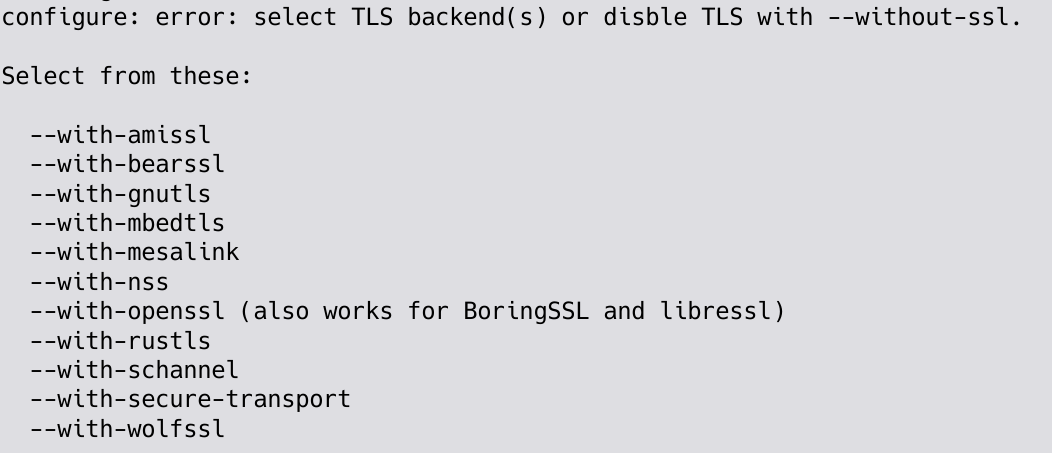
With this change, every configure invoke needs to clearly state which TLS library or even libraries (in plural since curl supports building with support for more than one library) to use.
The biggest change is of course for everyone who invokes configure and wants to build with OpenSSL since they now need to add an option and say that explicitly. For virtually everyone else life can just go on like before.
Everyone who builds curl automatically from source code might need to update their build scripts.
The first release shipping with this change will be curl 7.77.0.
Image by Free-Photos from Pixabay
https://daniel.haxx.se/blog/2021/04/23/please-select-your-tls/
|
|
Spidermonkey Development Blog: SpiderMonkey Newsletter 10 (Firefox 88-89) |
|
|
The Mozilla Blog: Notes on Implementing Vaccine Passports |
|
|
Hacks.Mozilla.Org: Pyodide Spin Out and 0.17 Release |
We are happy to announce that Pyodide has become an independent and community-driven project. We are also pleased to announce the 0.17 release for Pyodide with many new features and improvements.
Pyodide consists of the CPython 3.8 interpreter compiled to WebAssembly which allows Python to run in the browser. Many popular scientific Python packages have also been compiled and made available. In addition, Pyodide can install any Python package with a pure Python wheel from the Python Package Index (PyPi). Pyodide also includes a comprehensive foreign function interface which exposes the ecosystem of Python packages to Javascript and the browser user interface, including the DOM, to Python.
You can try out the latest version of Pyodide in a REPL directly in your browser.
We are happy to announce that Pyodide now has a new home in a separate GitHub organisation (github.com/pyodide) and is maintained by a volunteer team of contributors. The project documentation is available on pyodide.org.
Pyodide was originally developed inside Mozilla to allow the use of Python in Iodide, an experimental effort to build an interactive scientific computing environment for the web. Since its initial release and announcement, Pyodide has attracted a large amount of interest from the community, remains actively developed, and is used in many projects outside of Mozilla.
The core team has approved a transparent governance document and has a roadmap for future developments. Pyodide also has a Code of Conduct which we expect all contributors and core members to adhere to.
New contributors are welcome to participate in the project development on Github. There are many ways to contribute, including code contributions, documentation improvements, adding packages, and using Pyodide for your applications and providing feedback.
Pyodide 0.17.0 is a major step forward from previous versions. It includes:
The type translations module was significantly reworked in v0.17 with the goal that round trip translations of objects between Python and Javascript produces an identical object.
In other words, Python -> JS -> Python translation and JS -> Python -> JS translation now produce objects that are equal to the original object. (A couple of exceptions to this remain due to unavoidable design tradeoffs.)
One of Pyodide’s strengths is the foreign function interface between Python and Javascript, which at its best can practically erase the mental overhead of working with two different languages. All I/O must pass through the usual web APIs, so in order for Python code to take advantage of the browser’s strengths , we need to be able to support use cases like generating image data in Python and rendering the data to an HTML5 Canvas, or implementing event handlers in Python.
In the past we found that one of the major pain points in using Pyodide occurs when an object makes a round trip from Python to Javascript and back to Python and comes back different. This violated the expectations of the user and forced inelegant workarounds.
The issues with round trip translations were primarily caused by implicit conversion of Python types to Javascript. The implicit conversions were intended to be convenient, but the system was inflexible and surprising to users. We still implicitly convert strings, numbers, booleans, and None. Most other objects are shared between languages using proxies that allow methods and some operations to be called on the object from the other language. The proxies can be converted to native types with new explicit converter methods called .toJs and to_py.
For instance, given an Array in JavaScript,
window.x = ["a", "b", "c"];
We can access it in Python as,
>>> from js import x # import x from global Javascript scope >>> type(x)>>> x[0] # can index x directly 'a' >>> x[1] = 'c' # modify x >>> x.to_py() # convert x to a Python list ['a', 'c']
Several other conversion methods have been added for more complicated use cases. This gives the user much finer control over type conversions than was previously possible.
For example, suppose we have a Python list and want to use it as an argument to a Javascript function that expects an Array. Either the caller or the callee needs to take care of the conversion. This allows us to directly call functions that are unaware of Pyodide.
Here is an example of calling a Javascript function from Python with argument conversion on the Python side:
function jsfunc(array) {
array.push(2);
return array.length;
}
pyodide.runPython(`
from js import jsfunc
from pyodide import to_js
def pyfunc():
mylist = [1,2,3]
jslist = to_js(mylist)
return jsfunc(jslist) # returns 4
`)
This would work well in the case that jsfunc is a Javascript built-in and pyfunc is part of our codebase. If pyfunc is part of a Python package, we can handle the conversion in Javascript instead:
function jsfunc(pylist) {
let array = pylist.toJs();
array.push(2);
return array.length;
}
See the type translation documentation for more information.
Another major new feature is the implementation of a Python event loop that schedules coroutines to run on the browser event loop. This makes it possible to use asyncio in Pyodide.
Additionally, it is now possible to await Javascript Promises in Python and to await Python awaitables in Javascript. This allows for seamless interoperability between asyncio in Python and Javascript (though memory management issues may arise in complex use cases).
Here is an example where we define a Python async function that awaits the Javascript async function “fetch” and then we await the Python async function from Javascript.
pyodide.runPython(`
async def test():
from js import fetch
# Fetch the Pyodide packages list
r = await fetch("packages.json")
data = await r.json()
# return all available packages
return data.dependencies.object_keys()
`);
let test = pyodide.globals.get("test");
// we can await the test() coroutine from Javascript
result = await test();
console.log(result);
// logs ["asciitree", "parso", "scikit-learn", ...]
Errors can now be thrown in Python and caught in Javascript or thrown in Javascript and caught in Python. Support for this is integrated at the lowest level, so calls between Javascript and C functions behave as expected. The error translation code is generated by C macros which makes implementing and debugging new logic dramatically simpler.
For example:
function jserror() {
throw new Error("ooops!");
}
pyodide.runPython(`
from js import jserror
from pyodide import JsException
try:
jserror()
except JsException as e:
print(str(e)) # prints "TypeError: ooops!"
`);
Pyodide uses the Emscripten compiler toolchain to compile the CPython 3.8 interpreter and Python packages with C extensions to WebAssembly. In this release we finally completed the migration to the latest version of Emscripten that uses the upstream LLVM backend. This allows us to take advantage of recent improvements to the toolchain, including significant reductions in package size and execution time.
For instance, the SciPy package shrank dramatically from 92 MB to 15 MB so Scipy is now cached by browsers. This greatly improves the usability of scientific Python packages that depend on scipy, such as scikit-image and scikit-learn. The size of the base Pyodide environment with only the CPython standard library shrank from 8.1 MB to 6.4 MB.
On the performance side, the latest toolchain comes with a 25% to 30% run time improvement:

Performance ranges between near native to up to 3 to 5 times slower, depending on the benchmark. The above benchmarks were created with Firefox 87.
Other notable features include:
We also did a large amount of maintenance work and code quality improvements:
See the changelog for more details.
Mozilla has made the difficult decision to wind down the Iodide project. While alpha.iodide.io will continue to be available for now (in part to provide a demonstration of Pyodide’s capabilities), we do not recommend using it for important work as it may shut down in the future. Since iodide’s release, there have been many efforts at creating interactive notebook environments based on Pyodide which are in active development and offer a similar environment for creating interactive visualizations in the browser using python.
While many issues were addressed in this release, a number of other major steps remain on the roadmap. We can mention
For additional information see the project roadmap.
Lots of thanks to:
We are also grateful to all Pyodide contributors.
The post Pyodide Spin Out and 0.17 Release appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/04/pyodide-spin-out-and-0-17-release/
|
|
Daniel Stenberg: “So what exactly is curl?” |
You know that question you can get asked casually by a person you’ve never met before or even by someone you’ve known for a long time but haven’t really talked to about this before. Perhaps at a social event. Perhaps at a family dinner.
– So what do you do?
The implication is of course what you work with. Or as. Perhaps a title.
In my case I typically start out by saying I’m a software engineer. (And no, I don’t use a title.)
If the person who asked the question is a non-techie, this can then take off in basically any direction. From questions about the Internet, how their printer acts up sometimes to finicky details about Wifi installations or their parents’ problems to install anti-virus. In other words: into areas that have virtually nothing to do with software engineering but is related to computers.
If the person is somewhat knowledgeable or interested in technology or computers they know both what software and engineering are. Then the question can get deepened.
Alternatively they ask for what company I work for, but it usually ends up on the same point anyway, just via this extra step.
I work on curl. (Saying I work for wolfSSL rarely helps.)

curl is a command line tool used but a small set of people (possibly several thousands or even millions), and the library libcurl that is installed in billions of places.
I often try to compare libcurl with how companies build for example cars out of many components from different manufacturers and companies. They use different pieces from many separate sources put together into a single machine to produce the end product.

libcurl is like one of those little components that a car manufacturer needs. It isn’t the only choice, but it is a well known, well tested and familiar one. It’s a safe choice.
Lots of people, even many with experience, knowledge or even jobs in the IT industry I’ve realized don’t know what an Internet transfer is. Me describing curl as doing such, doesn’t really help in those cases.
An internet transfer is the bridge between “the cloud” and your devices or applications. curl is a bridge.

In general, anything today that has power goes towards becoming networked. Everything that can, will connect to the Internet sooner or later. Maybe not always because it’s a good idea, but because it gives your thing a (perceived) advantage to your competitors.
Things that a while ago you wouldn’t dream would do that, now do Internet transfers. Tooth brushes, ovens, washing machines etc.
If you want to build a new device or application today and you want it to be successful and more popular than your competitors, you will probably have to make it Internet-connected.
You need a “bridge”.
Everyone who makes devices or applications today have a wide variety of different components and pieces of the big “puzzle” to select from.
You can opt to write many pieces yourself, but virtually nobody today creates anything digital entirely on their own. We lean on others. We stand on other’s shoulders. In particular open source software has grown up to become or maybe provide a vast ocean of puzzle pieces to use and leverage.
One of the little pieces in your device puzzle is probably Internet transfers, because you want your thing to get updates, upload telemetry and who knows what else.
The picture then needs a piece inserted in the right spot to get complete. The Internet transfers piece. That piece can be curl. We’ve made curl to be a good such piece.

Lots have been said about the fact that companies, organizations and entire ecosystems rely on pieces and components written, maintained and provided by someone else. Some of them are open source components written by developers on their spare time, but are still used by thousands of companies shipping commercial products.
curl is one such component. It’s not “just” a spare time project anymore of course, but the point remains. We estimate that curl runs in some ten billion installations these days, so quite a lot of current Internet infrastructure uses our little puzzle piece in their pictures.

I rarely get to this point in any conversation because I would have already bored my company into a coma by now.
The concept of giving away a component like this as open source under a liberal license is a very weird concept to general people. Maybe also because I say that I work on this and I created it, but I’m not at all the only contributor and we wouldn’t have gotten to this point without the help of several hundred other developers.
“- No, I give it away for free. Yes really, entirely and totally free for anyone and everyone to use. Correct, even the largest and richest mega-corporations of the world.”
The ten billion installations work as marketing for getting companies to understand that curl is a solid puzzle piece so that more will use it and some of those will end up discovering they need help or assistance and they purchase support for curl from me!
I’m not rich, but I do perfectly fine. I consider myself very lucky and fortunate who get to work on curl for a living.
There are about 5 billion Internet using humans in the world. There are about 10 billion curl installations.
The puzzle piece curl is there in the middle.
This is how they’re connected. This is the curl world map 2021.

libcurl is a library for doing transfers specified with a URL, using one of the supported protocols. It is fast, reliable, very portable, well documented and feature rich. A de-facto standard API available for everyone.
The original island image is by Julius Silver from Pixabay. xkcd strip edits were done by @tsjost.
https://daniel.haxx.se/blog/2021/04/22/so-what-exactly-is-curl/
|
|
Mozilla Privacy Blog: Mozilla reacts to publication of EU’s draft regulation on AI |
Today, the European Commission published its draft for a regulatory framework for artificial intelligence (AI). The proposal lays out comprehensive new rules for AI systems deployed in the EU. Mozilla welcomes the initiative to rein in the potential harms caused by AI, but much remains to be clarified.
Reacting to the European Commission’s proposal, Raegan MacDonald, Mozilla’s Director of Global Public Policy, said:
“AI is a transformational technology that has the potential to create value and enable progress in so many ways, but we cannot lose sight of the real harms that can come if we fail to protect the rights and safety of people living in the EU. Mozilla is committed to ensuring that AI is trustworthy, that it helps people instead of harming them. The European Commission’s push to set ground rules is a step in the right direction and it is good to see that several of our recommendations to the Commission are reflected in the proposal – but there is more work to be done to ensure these principles can be meaningfully implemented, as some of the safeguards and red lines envisioned in the text leave a lot to be desired.
Systemic transparency is a critical enabler of accountability, which is crucial to advancing more trustworthy AI. We are therefore encouraged by the introduction of user-facing transparency obligations – for example for chatbots or so-called deepfakes – as well as a public register for high-risk AI systems in the European Commission’s proposal. But as always, details matter, and it will be important what information exactly this database will encompass. We look forward to contributing to this important debate.”
The post Mozilla reacts to publication of EU’s draft regulation on AI appeared first on Open Policy & Advocacy.
|
|
Cameron Kaiser: Coloured iMacs? We got your coloured iMacs right here |

Plus, these coloured iMacs can build and run TenFourFox: Chris T proved it on his 400MHz G3. It took 34 hours to compile from source. I always did like slow-cooked meals better.
http://tenfourfox.blogspot.com/2021/04/coloured-imacs-we-got-your-coloured.html
|
|
This Week In Rust: This Week in Rust 387 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
No papers/research projects this week.
std in embedded RustThis week's crate is deltoid, another crate for delta-compressing Rust data structures.
Thanks to Joey Ezechi"els for the nomination
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
No calls for participation this week
If you are a Rust project owner and are looking for contributors, please submit tasks here.
292 pull requests were merged in the last week
deref_nullptr detecting when a null ptr is dereferencedT to *const/mut Tnon-ascii-identsis_subnormalduration_zerononzero_leading_trailing_zerosbufreader_seek_relativeBTree{Map, Set}::retainthread_local_const_initjoin_paths error displayspec_extendvecdeque_binary_searchInstRUSTC_WRAPPER changesis_diagnostic_assoc_itemsingle_matchneedless_returnmissing_const_for_fnwrong_self_convention lintredundant_pattern_matching drop orderreturn on try_errAnother quiet week with very small changes to compiler performance.
Triage done by @rylev. Revision range: 5258a74..6df26f
1 Regressions, 0 Improvements, 1 Mixed
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
impl From<[(K, V); N]> for HashMap`target_family to multiple values, and implement target_family="wasm":pat_param but leave :pat2021 gatedNo new RFCs were proposed this week.
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Grover GmbH
Massa Labs
Instaclustr
Subspace Labs
Senior Software Engineer, Visualization
Luminovo
Tweet us at @ThisWeekInRust to get your job offers listed here!
We feel that Rust is now ready to join C as a practical language for implementing the [Linux] kernel. It can help us reduce the number of potential bugs and security vulnerabilities in privileged code while playing nicely with the core kernel and preserving its performance characteristics.
– Wedson Almeida Filho on the Google Security Blog
Thanks to Jacob Pratt for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, and cdmistman.
https://this-week-in-rust.org/blog/2021/04/21/this-week-in-rust-387/
|
|
The Talospace Project: Firefox 88 on POWER |
Fortunately Fx88 builds uneventually as usual on OpenPOWER, though our PGO-LTO patches (apply to the tree with patch -p1) required a slight tweak to nsTerminator.cpp. Debug and optimized .mozconfigs are unchanged.
Also, an early milestone in the Firefox JavaScript JIT for OpenPOWER: Justin Hibbits merged my earlier jitpower work to a later tree (right now based on Firefox 86) and filled in the gaps with code from TenFourFox, and after some polishing up I did over the weekend, a JIT-enabled JavaScript shell now compiles on Fedora ppc64le. However, it immediately asserts due to probably some missing defintions for register sets, and I'm sure there are many other assertions and lurking bugs to be fixed, but this is much further along than before. The fork is on Github for others who wish to contribute; I will probably decommission the old jitpower project soon since it is now superfluous. More to come.
|
|
The Mozilla Blog: Mark Surman joins the Mozilla Foundation Board of Directors |
In early 2020, I outlined our efforts to expand Mozilla’s boards. Over the past year, we’ve added three new external Mozilla board members: Navrina Singh and Wambui Kinya to the Mozilla Foundation board and Laura Chambers to the Mozilla Corporation board.
Today, I’m excited to welcome Mark Surman, Executive Director of the Mozilla Foundation, to the Foundation board.
As I said to staff prior to his appointment, when I think about who should hold the keys to Mozilla, Mark is high on that list. Mark has unique qualifications in terms of the overall direction of Mozilla, how our organizations interoperate, and if and how we create programs, structures or organizations. Mark is joining the Mozilla Foundation board as an individual based on these qualifications; we have not made the decision that the Executive Director is automatically a member of the Board.
Mark has demonstrated his commitment to Mozilla as a whole, over and over. The whole of Mozilla figures into his strategic thinking. He’s got a good sense of how Mozilla Foundation and Mozilla Corporation can magnify or reduce the effectiveness of Mozilla overall. Mark has a hunger for Mozilla to grow in impact. He has demonstrated an ability to think big, and to dive into the work that is in front of us today.
For those of you who don’t know Mark already, he brings over two decades of experience leading projects and organizations focused on the public interest side of the internet. In the 12 years since Mark joined Mozilla, he has built the Foundation into a leading philanthropic and advocacy voice championing the health of the internet. Prior to Mozilla, Mark spent 15 years working on everything from a non-profit internet provider to an early open source content management system to a global network of community-run cybercafes. Currently, Mark spends most of his time on Mozilla’s efforts to promote trustworthy AI in the tech industry, a major focus of the Foundation’s current efforts.
Please join me in welcoming Mark Surman to the Mozilla Foundation Board of Directors.
You can read Mark’s message about why he’s joining Mozilla here.
PS. As always, we continue to look for new members for both boards, with the goal of adding the skills, networks and diversity Mozilla will need to succeed in the future.
LinkedIn: https://www.linkedin.com/in/msurman/
The post Mark Surman joins the Mozilla Foundation Board of Directors appeared first on The Mozilla Blog.
|
|
The Mozilla Blog: Wearing more (Mozilla) hats |

Mark Surman
For many years now — and well before I sought out the job I have today — I thought: the world needs more organizations like Mozilla. Given the state of the internet, it needs them now. And, it will likely need them for a very long time to come.
Why? In part because the internet was founded with public benefit in mind. And, as the Mozilla Manifesto declared back in 2007, “… (m)agnifying the public benefit aspects of the internet is an important goal, worthy of time, attention and commitment.”
Today, this sort of ‘time and attention’ is more important — and urgent — than ever. We live in an era where the biggest companies in the world are internet companies. Much of what they have created is good, even delightful. Yet, as the last few years have shown, leaving things to commercial actors alone can leave the internet — and society — in a bit of a mess. We need organizations like Mozilla — and many more like it — if we are to find our way out of this mess. And we need these organizations to think big!
It’s for this reason that I’m excited to add another ‘hat’ to my work: I am joining the Mozilla Foundation board today. This is something I will take on in addition to my role as executive director.
Why am I assuming this additional role? I believe Mozilla can play a bigger role in the world than it does today. And, I also believe we can inspire and support the growth of more organizations that share Mozilla’s commitment to the public benefit side of the internet. Wearing a board member hat — and working with other Foundation and Corporation board members — I will be in a better position to turn more of my attention to Mozilla’s long term impact and sustainability.
What does this mean in practice? It means spending some of my time on big picture ‘Pan Mozilla’ questions. How can Mozilla connect to more startups, developers, designers and activists who are trying to build a better, more humane internet? What might Mozilla develop or do to support these people? How can we work with policy makers who are trying to write regulations to ensure the internet benefits the public interest? And, how do we shift our attention and resources outside of the US and Europe, where we have traditionally focused? While I don’t have answers to all these questions, I do know we urgently need to ask them — and that we need to do so in an expansive way that goes beyond the current scope of our operating organizations. That’s something I’ll be well positioned to do wearing my new board member hat.
Of course, I still have much to do wearing my executive director hat. We set out a few years ago to evolve the Foundation into a ‘movement building arm’ for Mozilla. Concretely, this has meant building up teams with skills in philanthropy and advocacy who can rally more people around the cause of a healthy internet. And, it has meant picking a topic to focus on: trustworthy AI. Our movement building approach — and our trustworthy AI agenda — is getting traction. Yet, there is still a way to go to unlock the kind of sustained action and impact that we want. Leading the day to day side of this work remains my main focus at Mozilla.
As I said at the start of this post: I think the world will need organizations like Mozilla for a long time to come. As all corners of our lives become digital, we will increasingly need to stand firm for public interest principles like keeping the internet open and accessible to all. While we can all do this as individuals, we also need strong, long lasting organizations that can take this stand in many places and over many decades. Whatever hat I’m wearing, I continue to be deeply committed to building Mozilla into a vast, diverse and sustainable institution to do exactly this.
The post Wearing more (Mozilla) hats appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2021/04/20/wearing-more-mozilla-hats/
|
|
Karl Dubost: Get Ready For Three Digits User Agent Strings |
In 2022, Firefox and Chrome will reach a version number with three digits: 100.
It's time to get ready and extensively test your code, so your code doesn't return null or worse 10 instead of 100.

The browser user agent string is used in many circumstances, on the server side with the User-Agent HTTP header and on the client side with navigator.userAgent. Browsers lie about it. Web apps and websites detection do not cover all cases. So browsers have to modify the user agent string on a site by site case.
According to the Firefox release calendar, during the first quarter of 2022 (probably February), Firefox will reach version 100.
And Chrome release calendar sets a current date of March 29, 2022.
Dennis Schubert started to test JavaScript Libraries, but this tests only the libraries which are up to date. And we know it, the Web is a legacy machine full of history.
The webcompat team will probably automatically test the top 1000 websites. But this is very rudimentary. It will not cover everything. Sites always break in strange ways.
100 UA stringMozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:89.0) Gecko/20100101 Firefox/89.0, change it to be Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:100.0) Gecko/20100101 Firefox/100.0If your web app has a JavaScript Test suite, add a profile with a browser having 100 for its version number and check if it breaks. Test both Firefox and Chrome (mobile and desktop) because the libraries have different code paths depending on the user agent. Watch out for code like:
const ua_string = "Firefox/100.0";
ua_string.match(/Firefox\/(\d\d)/); // ["Firefox/10", "10"]
ua_string.match(/Firefox\/(\d{2})/); // ["Firefox/10", "10"]
ua_string.match(/Firefox\/(\d\d)\./); // null
Compare integer, not string when you have decided to have a minimum version for supporting a browser, because
"80" < "99" // true
"80" < "100" // false
parseInt("80", 10) < parseInt("99", 10) // true
parseInt("80", 10) < parseInt("100", 10) // true
If you have more questions, things I may have missed, different take on them. Feel free to comment…. Be mindful.
Otsukare!
https://www.otsukare.info/2021/04/20/ua-three-digits-get-ready
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla Mornings on the DSA: Setting the standard for third-party platform auditing |
 On 11 May, Mozilla will host the next instalment of Mozilla Mornings – our regular event series that brings together policy experts, policymakers and practitioners for insight and discussion on the latest EU digital policy developments.
On 11 May, Mozilla will host the next instalment of Mozilla Mornings – our regular event series that brings together policy experts, policymakers and practitioners for insight and discussion on the latest EU digital policy developments.
This instalment will focus on the DSA’s provisions on third-party platform auditing, one of the stand-out features of its next-generation regulatory approach. We’re bringing together a panel of experts to unpack the provisions’ strengths and shortcomings; and to provide recommendations for how the DSA can build a standard-setting auditing regime for Very Large Online Platforms.
Speakers
Alexandra Geese MEP
IMCO DSA shadow rapporteur
Group of the Greens/European Free Alliance
Amba Kak
Director of Global Programs and Policy
AI Now Institute
Dr Ben Wagner
Assistant Professor, Faculty of Technology, Policy and Management
TU Delft
With opening remarks by Raegan MacDonald
Director of Global Public Policy
Mozilla
Moderated by Jennifer Baker
EU technology journalist
Logistical details
Tuesday 11 May, 14:00 – 15:00 CEST
Zoom Webinar
Register *here*
Webinar login details to be shared on day of event
The post Mozilla Mornings on the DSA: Setting the standard for third-party platform auditing appeared first on Open Policy & Advocacy.
|
|
Mozilla Addons Blog: Changes to themeable areas of Firefox in version 89 |
Firefox’s visual appearance will be updated in version 89 to provide a cleaner, modernized interface. Since some of the changes will affect themeable areas of the browser, we wanted to give theme artists a preview of what to expect as the appearance of their themes may change when applied to version 89.
tab_background_separator, which controls the appearance of the vertical lines that separate tabs, will no longer be supported.tab_line property can set the color of an active tab’s thick top border. In Firefox 89, this property will set a color for all borders of an active tab, and the borders will be thinner.
toolbar_field_separator, which controls the color of the vertical line that separates the URL bar from the three-dot “meatball menu,” will no longer be supported.
toolbar_vertical_separator, which controls the vertical lines near the three-line “hamburger menu” and the line separating items in the bookmarks toolbar, will no longer appear next to the hamburger menu. You can still use this property to control the separators in the bookmarks toolbar. (Note: users will need to enable the separator by right clicking on the bookmarks toolbar and selecting “Add Separator.”)
You can use the Nightly pre-release channel to start testing how your themes will look with Firefox 89. If you’d like to get more involved testing other changes planned for this release, please check out our foxfooding campaign, which runs until May 3, 2021.
Firefox 89 is currently set available on the Beta pre-release channel by April 23, 2021, and released on June 1, 2021.
As always, please post on our community forum if there are any questions.
The post Changes to themeable areas of Firefox in version 89 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2021/04/19/changes-to-themeable-areas-of-firefox-in-version-89/
|
|
Daniel Stenberg: Mars 2020 Helicopter Contributor |
Friends of mine know that I’ve tried for a long time to get confirmation that curl is used in space. We’ve believed it to be likely but I’ve wanted to get a clear confirmation that this is indeed the fact.
Today GitHub posted their article about open source in the Mars mission, and they now provide a badge on their site for contributors of projects that are used in that mission.
I have one of those badges now. Only a few other of the current 879 recorded curl authors got it. Which seems to be due to them using a very old curl release (curl 7.19, released in September 2008) and they couldn’t match all contributors with emails or the authors didn’t have their emails verified on GitHub etc.
According to that GitHub blog post, we are “almost 12,000” developers who got it.

While this strictly speaking doesn’t say that curl is actually used in space, I think it can probably be assumed to be.
Here’s the interplanetary curl development displayed in a single graph:

See also: screenshotted curl credits and curl supports NASA.
Image by Aynur Zakirov from Pixabay
https://daniel.haxx.se/blog/2021/04/19/mars-2020-helicopter-contributor/
|
|
Mozilla Security Blog: Firefox 88 combats window.name privacy abuses |
We are pleased to announce that Firefox 88 is introducing a new protection against privacy leaks on the web. Under new limitations imposed by Firefox, trackers are no longer able to abuse the window.name property to track users across websites.
Since the late 1990s, web browsers have made the window.name property available to web pages as a place to store data. Unfortunately, data stored in window.name has been allowed by standard browser rules to leak between websites, enabling trackers to identify users or snoop on their browsing history. To close this leak, Firefox now confines the window.name property to the website that created it.
The window.name property of a window allows it to be able to be targeted by hyperlinks or forms to navigate the target window. The window.name property, available to any website you visit, is a “bucket” for storing any data the website may choose to place there. Historically, the data stored in window.name has been exempt from the same-origin policy enforced by browsers that prohibited some forms of data sharing between websites. Unfortunately, this meant that data stored in the window.name property was allowed by all major browsers to persist across page visits in the same tab, allowing different websites you visit to share data about you.
For example, suppose a page at https://example.com/ set the window.name property to “my-identity@email.com”. Traditionally, this information would persist even after you clicked on a link and navigated to https://malicious.com/. So the page at https://malicious.com/ would be able to read the information without your knowledge or consent:

Window.name persists across the cross-origin navigation.
Tracking companies have been abusing this property to leak information, and have effectively turned it into a communication channel for transporting data between websites. Worse, malicious sites have been able to observe the content of window.name to gather private user data that was inadvertently leaked by another website.
To prevent the potential privacy leakage of window.name, Firefox will now clear the window.name property when you navigate between websites. Here’s how it looks:

Firefox 88 clearing window.name after cross-origin navigation.
Firefox will attempt to identify likely non-harmful usage of window.name and avoid clearing the property in such cases. Specifically, Firefox only clears window.name if the link being clicked does not open a pop-up window.
To avoid unnecessary breakage, if a user navigates back to a previous website, Firefox now restores the window.name property to its previous value for that website. Together, these dual rules for clearing and restoring window.name data effectively confine that data to the website where it was originally created, similar to how Firefox’s Total Cookie Protection confines cookies to the website where they were created. This confinement is essential for preventing malicious sites from abusing window.name to gather users’ personal data.
Firefox isn’t alone in making this change: web developers relying on window.name should note that Safari is also clearing the window.name property, and Chromium-based browsers are planning to do so. Going forward, developers should expect clearing to be the new standard way that browsers handle window.name.
If you are a Firefox user, you don’t have to do anything to benefit from this new privacy protection. As soon as your Firefox auto-updates to version 88, the new default window.name data confinement will be in effect for every website you visit. If you aren’t a Firefox user yet, you can download the latest version here to start benefiting from all the ways that Firefox works to protect your privacy.
The post Firefox 88 combats window.name privacy abuses appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2021/04/19/firefox-88-combats-window-name-privacy-abuses/
|
|
Daniel Stenberg: curl those funny IPv4 addresses |
Everyone knows that on most systems you can specify IPv4 addresses just 4 decimal numbers separated with periods (dots). Example:
192.168.0.1
Useful when you for example want to ping your local wifi router and similar. “ping 192.168.0.1”
The IPv4 string is usually parsed by the inet_addr() function or at times it is passed straight into the name resolver function like getaddrinfo().
This address parser supports more ways to specify the address. You can for example specify each number using either octal or hexadecimal.
Write the numbers with zero-prefixes to have them interpreted as octal numbers:
0300.0250.0.01
Write them with 0x-prefixes to specify them in hexadecimal:
0xc0.0xa8.0x00.0x01
You will find that ping can deal with all of these.
An IPv4 address is a 32 bit number that when written as 4 separate numbers are split in 4 parts with 8 bits represented in each number. Each separate number in “a.b.c.d” is 8 bits that combined make up the whole 32 bits. Sometimes the four parts are called quads.
The typical IPv4 address parser however handles more ways than just the 4-way split. It can also deal with the address when specified as one, two or three numbers (separated with dots unless its just one).
If given as a single number, it treats it as a single unsigned 32 bit number. The top-most eight bits stores what we “normally” with write as the first number and so on. The address shown above, if we keep it as hexadecimal would then become:
0xc0a80001
And you can of course write it in octal as well:
030052000001
and plain old decimal:
3232235521
If you instead write the IP address as two numbers with a dot in between, the first number is assumed to be 8 bits and the next one a 24 bit one. And you can keep on mixing the bases as you see like. The same address again, now in a hexadecimal + octal combo:
0xc0.052000001
This allows for some fun shortcuts when the 24 bit number contains a lot of zeroes. Like you can shorten “127.0.0.1” to just “127.1” and it still works and is perfectly legal.
Now the parts are supposed to be split up in bits like this: 8.8.16. Here’s the example address again in octal, hex and decimal:
0xc0.0250.1
All of these versions shown above work with most tools that accept IPv4 addresses and sometimes you can bypass filters and protection systems by switching to another format so that you don’t match the filters. It has previously caused problems in node and perl packages and I’m guessing numerous others. It’s a feature that is often forgotten, ignored or just not known.
It begs the question why this very liberal support was once added and allowed but I’ve not been able to figure that out – maybe because of how it matches class A/B/C networks. The support for this syntax seems to have been introduced with the inet_aton() function in the 4.2BSD release in 1983.
URLs have a host name in them and it can be specified as an IPv4 address.
The RFC 3986 URL specification’s section 3.2.2 says an IPv4 address must be specified as:
dec-octet "." dec-octet "." dec-octet "." dec-octet
… but in reality very few clients that accept such URLs actually restrict the addresses to that format. I believe mostly because many programs will pass on the host name to a name resolving function that itself will handle the other formats.
The Host Parsing section of this spec allows the many variations of IPv4 addresses. (If you’re anything like me, you might need to read that spec section about three times or so before that’s clear).
Since the browsers all obey to this spec there’s no surprise that browsers thus all allow this kind of IP numbers in URLs they handle.
curl has traditionally been in the camp that mostly accidentally somewhat supported the “flexible” IPv4 address formats. It did this because if you built curl to use the system resolver functions (which it does by default) those system functions will handle these formats for curl. If curl was built to use c-ares (which is one of curl’s optional name resolver backends), using such address formats just made the transfer fail.
The drawback with allowing the system resolver functions to deal with the formats is that curl itself then works with the original formatted host name so things like HTTPS server certificate verification and sending Host: headers in HTTP don’t really work the way you’d want.
Starting in curl 7.77.0 (since this commit ) curl will “natively” understand these IPv4 formats and normalize them itself.
There are several benefits of doing this ourselves:
Fun example command line to see if it works:
curl -L 16843009
16843009 gets normalized to 1.1.1.1 which then gets used as http://1.1.1.1 (because curl will assume HTTP for this URL when no scheme is used) which returns a 301 redirect over to https://1.1.1.1/ which -L makes curl follow…
Image by Thank you for your support Donations welcome to support from Pixabay
https://daniel.haxx.se/blog/2021/04/19/curl-those-funny-ipv4-addresses/
|
|
Cameron Kaiser: TenFourFox FPR32 available, plus a two-week reprieve |
Mozilla is advancing Firefox 89 by two weeks to give them additional time to polish up the UI changes in that version. This will thus put all future release dates ahead by two weeks as well; the next ESR release and the first Security Parity Release parallel with it instead will be scheduled for June 1. Aligning with this, the testing version of FPR32 SPR1 will come out the weekend before June 1 and the final official build of TenFourFox will also move ahead two weeks, from September 7 to September 21. After that you'll have to DIY but fortunately it already looks like people are rising to the challenge of building the browser themselves: I have been pointed to an installer which neatly wraps up all the necessary build prerequisites, provides a guided Automator workflow and won't interfere with any existing installation of MacPorts. I don't have anything to do this with this effort and can't attest to or advise on its use, but it's nice to see it exists, so download it from Macintosh Garden if you want to try it out. Remember, compilation speed on G4 (and, shudder, G3) systems can be substantially slower than on a G5, and especially without multiple CPUs. Given this Quad G5 running full tilt (three cores dedicated to compiling) with a full 16GB of RAM takes about three and a half hours to kick out a single architecture build, you should plan accordingly for longer times on lesser systems.
I have already started clearing issues from Github I don't intend to address. The remaining issues may not necessarily be addressed either, and definitely won't be during the security parity period, but they are considerations for things I might need later. Don't add to this list: I will mark new issues without patches or PRs as invalid. I will also be working on revised documentation for Tenderapp and the main site so people are aware of the forthcoming plan; those changes will be posted sometime this coming week.
http://tenfourfox.blogspot.com/2021/04/tenfourfox-fpr32-available-plus-two.html
|
|
Hacks.Mozilla.Org: QUIC and HTTP/3 Support now in Firefox Nightly and Beta |
tl;dr: Support for QUIC and HTTP/3 is now enabled by default in Firefox Nightly and Firefox Beta. We are planning to start rollout on the release in Firefox Stable Release 88. HTTP/3 will be available by default by the end of May.
HTTP/3 is a new version of HTTP (the protocol that powers the Web) that is based on QUIC. HTTP/3 has three main performance improvements over HTTP/2:
QUIC also provides connection migration and other features that should improve performance and reliability. For more on QUIC, see this excellent blog post from Cloudflare.
Firefox Nightly and Firefox Beta will automatically try to use HTTP/3 if offered by the Web server (for instance, Google or Facebook). Web servers can indicate support by using the Alt-Svc response header or by advertising HTTP/3 support with a HTTPS DNS record. Both the client and server must support the same QUIC and HTTP/3 draft version to connect with each other. For example, Firefox currently supports drafts 27 to 32 of the specification, so the server must report support of one of these versions (e.g., “h3-32”) in Alt-Svc or HTTPS record for Firefox to try to use QUIC and HTTP/3 with that server. When visiting such a website, viewing the network request information in Dev Tools should show the Alt-Svc header, and also indicate that HTTP/3 was used.
If you encounter issues with these or other sites, please file a bug in Bugzilla.
The post QUIC and HTTP/3 Support now in Firefox Nightly and Beta appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/04/quic-and-http-3-support-now-in-firefox-nightly-and-beta/
|
|






