The Firefox Frontier: Mozilla Explains: SIM swapping |
These days, smartphones are in just about everyone’s pocket. We use them for entertainment, sending messages, storing notes, taking photos, transferring money and even making the odd phone call. Our … Read more
The post Mozilla Explains: SIM swapping appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/mozilla-explains-sim-swapping/
|
|
Luis Villa: Governing Values-Centered Tech Non-Profits; or, The Route Not Taken by FSF |
|
|
Beatriz Rizental: This Week in Glean: Publishing Glean.js or How I configured an npm package that has multiple entry points |
|
|
Data@Mozilla: This Week in Glean: Publishing Glean.js or “How I configured an npm package that has multiple entry points” |
|
|
Daniel Stenberg: steps to release curl |
I have a lot of different hats and roles in the curl project. One of them is “release manager” and in this post I’ve tried to write down pretty much all the steps I do to prepare and ship a curl release at the end of every release cycle in the project.
I’ve handled every curl release so far. All 198 of them. While the process certainly wasn’t this formal or extensive in the beginning, we’ve established a set of steps that have worked fine for us, that have been mostly unchanged for maybe ten years by now.
There’s nothing strange or magic about it. Just a process.
A typical cycle between two releases starts on a Wednesday when we do a release. We always release on Wednesdays. A complete and undisturbed release cycle is always exactly 8 weeks (56 days).
The cycle starts with us taking the remainder of the release week to observe the incoming reports to judge if there’s a need for a follow-up patch release or if we can open up for merging features again.
If there was no significant enough problems found in the first few days, we open the “feature window” again on the Monday following the release. Having the feature window open means that we accept new changes and new features getting merged – if anyone submits such a pull-request in a shape ready for merge.
If there was an issue found to be important enough to a warrant a patch release, we instead schedule a new release date and make the coming cycle really short and without opening the feature window. There aren’t any set rules or guidelines to help us judge this. We play this by ear and go with what feels like the right action for our users.

When there’s exactly 4 weeks left to the pending release we close the feature window. This gives us a period where we only merge bug-fixes and all features are put on hold until the window opens again. 28 days to polish off all sharp corners and fix as many problems we can for the coming release.
Contributors can still submit pull-requests for new stuff and we can review them and polish them, but they will not be merged until the window is reopened. This period is for focusing on bug-fixes.
We have a web page that shows the feature window’s status and I email the mailing list when the status changes.
A few days before the pending release we try to slow down and only merge important bug-fixes and maybe hold off the less important ones to reduce risk.
This is a good time to run our copyright.pl script that checks copyright ranges of all files in the git repository and makes sure they are in sync with recent changes. We only update the copyright year ranges of files that we actually changed this year.
If we have pending security fixes to announce in the coming release, those have been worked on in private by the curl security team. Since all our test infrastructure is public we merge our security fixes into the main source code and push them approximately 48 hours before the planned release.
These 48 hours are necessary for CI and automatic build jobs to verify the fixes and still give us time to react to problems this process reveals and the subsequent updates and rinse-repeats etc until everyone is happy. All this testing is done using public code and open infrastructure, which is why we need the code to be pushed for this to work.
At this time we also have detailed security advisories written for each vulnerability that are ready to get published. The advisories are stored in the website repository and have been polished by the curl security team and the reporters of the issues.
The release notes for the pending release is a document that we keep in sync and updated at a regular interval so that users have a decent idea of what to expect in the coming release – at all times.
It is basically a matter of running the release-notes.pl script, clean up the list of bug-fixes, then the run contributors.sh script and update the list of contributors to the release so far and then commit it with the proper commit message.
At release-time, the work on the release notes is no different than the regular maintenance of it. Make sure it reflects what’s been done in the code since the previous release.
When everything is committed to git for the release, I tag the repository. The name and format of the tag is set in stone for historical reasons to be curl-[version] where [version] is the version number with underscores instead of periods. Like curl-7_76_0 for curl 7.76.0. I sign and annotate the tag using git.
Make sure everything is pushed. Git needs the --tags option to push the new tag.
Our script that builds a full release tarball is called mktgz. This script is also used to produce the daily snapshots of curl that we provide and we verify that builds using such tarballs work in the CI.
The output from mktgz is four tarballs. They’re all the exact same content, just different compressions and archive formats: gzip, bz2, xz and zip.
The output from this script is the generated release at the point in time of the git tag. All the tarballs contents are then not found (identically) in git (or GitHub). The release is the output of this script.
I GPG sign the four tarballs and upload them to the curl site’s download directory. Uploading them takes just a few seconds.
The actual upload of the packages doesn’t actually update anything on the site and they will not be published just because of this. It needs a little more on the website end.
Lots of users get their release off GitHub directly so I make sure to edit the tag there to make it a release and I upload the tarballs there. By providing the release tarballs there I hope that I lower the frequency of users downloading the state of the git repo from the tag assuming that’s the same thing as a release.
As mentioned above: a true curl release is a signed tarball made with maketgz.
The curl website at curl.se is managed with the curl-www git repository. The site automatically updates and syncs with the latest git contents.
To get a release done and appear on the website, I update three files on the site. They’re fairly easy to handle:
dev/release-notes.gen to insert into the changelog. It’s mostly a copy and paste. That generated file is built from the RELEASE-NOTES that’s present in the source code repo.If there are security advisories for this release, they are also committed to the docs/ directory using their CVE names according to our established standard.
I tag the website repository as well, using the exact same tag name as I did in the source code repository, just to allow us to later get an idea of the shape of the site at the time of this particular release. Even if we don’t really “release” the website.
Using the --tags option again I push the updates to the website with git.
The website, being automatically synced with the git repository, will then very soon get the news about the release and rebuild the necessary pages on the site and the new release is then out and shown to the world. At least those who saw the git activity and visitors of the website. See also the curl website infrastructure.
Now it’s time to share the news to the world via some more channels.
I start working on the release blog post perhaps a week before the release. I then work on it on and off and when the release is getting closer I make sure to tie all loose ends and finalize it.
Recently I’ve also created a new “release image” for the particular curl release I do so if I feel inspired I do that too. I’m not really skilled or talented enough for that, but I like the idea of having a picture for this unique release – to use in the blog post and elsewhere when talking about this version. Even if that’s a very ephemeral thing as this specific version very soon appears in my rear view mirror only…
Perhaps the most important release announcement is done per email. I inform curl-users, curl-library and curl-announce about it.
If there are security advisories to announce in association with the release, those are also sent individually to the same mailing lists and the oss-security mailing list.

I’m fortunate enough to have a lot of twitter friends and followers so I also make sure they get to know about the new release. Follow me there to get future tweets.
At the day of the release I do a live-streamed presentation of it on twitch.
I create a small slide set and go through basically the same things I mention in my release blog post: security issues, new features and a look at some bug-fixes we did for this release that I find interesting or note-worthy.
Once streamed, recorded and published on YouTube. I update my release blog post and embed the presentation there and I add a link to the presentation on the changelog page on the curl website.

Immediately after having done all the steps for a release. When its uploaded, published, announced, discussed and presented I can take a moment to lean back and enjoy the moment.
I then often experience a sense of calmness and relaxation. I get an extra cup of coffee, put my feet up and just go… aaaah. Before any new bugs has arrived, when the slate is still clean so to speak. That’s a mighty fine moment and I cherish it.
It never lasts very long. I finish that coffee, get my feet down again and get back to work. There are pull requests to review that might soon be ready for merge when the feature window opens and there are things left to fix that we didn’t get to in this past release that would be awesome to have done in the next!
Can we open the feature window again on the coming Monday?
Coffee Image by Karolina Grabowska from Pixabay
https://daniel.haxx.se/blog/2021/04/07/steps-to-release-curl/
|
|
Niko Matsakis: Async Vision Doc Writing Sessions IV |
My week is very scheduled, so I am not able to host any public drafting sessions this week – however, Ryan Levick will be hosting two sessions!
| When | Who | Topic |
|---|---|---|
| Thu at 07:00 ET | Ryan | The need for Async Traits |
| Fri at 07:00 ET | Ryan | Challenges from cancellation |
If you’re available and those stories sound like something that interests you, please join him! Just ping me or Ryan on Discord or Zulip and we’ll send you the Zoom link. If you’ve already joined a previous session, the link is the same as before.
Next week, we will be holding more vision doc writing sessions. We are now going to expand the scope to go beyond “status quo” stories and cover “shiny future” stories as well. Keep your eyes peeled for a post on the Rust blog and further updates!
Never heard of the async vision doc? It’s a new thing we’re trying as part of the Async Foundations Working Group:
We are launching a collaborative effort to build a shared vision document for Async Rust. Our goal is to engage the entire community in a collective act of the imagination: how can we make the end-to-end experience of using Async I/O not only a pragmatic choice, but a joyful one?
Read the full blog post for more.
http://smallcultfollowing.com/babysteps/blog/2021/04/07/async-vision-doc-writing-sessions-iv/
|
|
Luis Villa: Protected: Governing Values-Centered Tech Non-Profits; or, The Route Not Taken by FSF |
|
|
Daniel Stenberg: 20,000 github stars |
In September 2018 I celebrated 10,000 stars, up from 5,000 back in May 2017. We made 1,000 stars on August 12, 2014.
Today I’m cheering for the 20,000 stars curl has received on GitHub.
It is worth repeating that this is just a number without any particular meaning or importance. It just means 20,000 GitHub users clicked the star symbol for the curl project over at curl/curl.
At exactly 08:15:23 UTC today we reached this milestone. Checked with a curl command line like this:
$ curl -s https://api.github.com/repos/curl/curl | jq '.stargazers_count' 20000
(By the time I get around to finalize this post, the count has already gone up to 20087…)
To celebrate this occasion, I decided I was worth a beer and this time I went with a hand-written note. The beer was a Swedish hazy IPA called Amazing Haze from the brewery Stigbergets. One of my current favorites.

Photos from previous GitHub-star celebrations :


|
|
Hacks.Mozilla.Org: Eliminating Data Races in Firefox – A Technical Report |
We successfully deployed ThreadSanitizer in the Firefox project to eliminate data races in our remaining C/C++ components. In the process, we found several impactful bugs and can safely say that data races are often underestimated in terms of their impact on program correctness. We recommend that all multithreaded C/C++ projects adopt the ThreadSanitizer tool to enhance code quality.
ThreadSanitizer (TSan) is compile-time instrumentation to detect data races according to the C/C++ memory model on Linux. It is important to note that these data races are considered undefined behavior within the C/C++ specification. As such, the compiler is free to assume that data races do not happen and perform optimizations under that assumption. Detecting bugs resulting from such optimizations can be hard, and data races often have an intermittent nature due to thread scheduling.
Without a tool like ThreadSanitizer, even the most experienced developers can spend hours on locating such a bug. With ThreadSanitizer, you get a comprehensive data race report that often contains all of the information needed to fix the problem.
 ThreadSanitizer Output for this example program (shortened for article)
ThreadSanitizer Output for this example program (shortened for article)
One important property of TSan is that, when properly deployed, the data race detection does not produce false positives. This is incredibly important for tool adoption, as developers quickly lose faith in tools that produce uncertain results.
Like other sanitizers, TSan is built into Clang and can be used with any recent Clang/LLVM toolchain. If your C/C++ project already uses e.g. AddressSanitizer (which we also highly recommend), deploying ThreadSanitizer will be very straightforward from a toolchain perspective.
Despite ThreadSanitizer being a very well designed tool, we had to overcome a variety of challenges at Mozilla during the deployment phase. The most significant issue we faced was that it is really difficult to prove that data races are actually harmful at all and that they impact the everyday use of Firefox. In particular, the term “benign” came up often. Benign data races acknowledge that a particular data race is actually a race, but assume that it does not have any negative side effects.
While benign data races do exist, we found (in agreement with previous work on this subject [1] [2]) that data races are very easily misclassified as benign. The reasons for this are clear: It is hard to reason about what compilers can and will optimize, and confirmation for certain “benign” data races requires you to look at the assembler code that the compiler finally produces.
Needless to say, this procedure is often much more time consuming than fixing the actual data race and also not future-proof. As a result, we decided that the ultimate goal should be a “no data races” policy that declares even benign data races as undesirable due to their risk of misclassification, the required time for investigation and the potential risk from future compilers (with better optimizations) or future platforms (e.g. ARM).
However, it was clear that establishing such a policy would require a lot of work, both on the technical side as well as in convincing developers and management. In particular, we could not expect a large amount of resources to be dedicated to fixing data races with no clear product impact. This is where TSan’s suppression list came in handy:
We knew we had to stop the influx of new data races but at the same time get the tool usable without fixing all legacy issues. The suppression list (in particular the version compiled into Firefox) allowed us to temporarily ignore data races once we had them on file and ultimately bring up a TSan build of Firefox in CI that would automatically avoid further regressions. Of course, security bugs required specialized handling, but were usually easy to recognize (e.g. racing on non-thread safe pointers) and were fixed quickly without suppressions.
To help us understand the impact of our work, we maintained an internal list of all the most serious races that TSan detected (ones that had side-effects or could cause crashes). This data helped convince developers that the tool was making their lives easier while also clearly justifying the work to management.
In addition to this qualitative data, we also decided for a more quantitative approach: We looked at all the bugs we found over a year and how they were classified. Of the 64 bugs we looked at, 34% were classified as “benign” and 22% were “impactful” (the rest hadn’t been classified).
We knew there was a certain amount of misclassified benign issues to be expected, but what we really wanted to know was: Do benign issues pose a risk to the project? Assuming that all of these issues truly had no impact on the product, are we wasting a lot of resources on fixing them? Thankfully, we found that the majority of these fixes were trivial and/or improved code quality.
The trivial fixes were mostly turning non-atomic variables into atomics (20%), adding permanent suppressions for upstream issues that we couldn’t address immediately (15%), or removing overly complicated code (20%). Only 45% of the benign fixes actually required some sort of more elaborate patch (as in, the diff was larger than just a few lines of code and did not just remove code).
We concluded that the risk of benign issues being a major resource sink was not an issue and well acceptable for the overall gains that the project provided.
As mentioned in the beginning, TSan does not produce false positive data race reports when properly deployed, which includes instrumenting all code that is loaded into the process and avoiding primitives that TSan doesn’t understand (such as atomic fences). For most projects these conditions are trivial, but larger projects like Firefox require a bit more work. Thankfully this work largely amounted to a few lines in TSan’s robust suppression system.
Instrumenting all code in Firefox isn’t currently possible because it needs to use shared system libraries like GTK and X11. Fortunately, TSan offers the “called_from_lib” feature that can be used in the suppression list to ignore any calls originating from those shared libraries. Our other major source of uninstrumented code was build flags not being properly passed around, which was especially problematic for Rust code (see the Rust section below).
As for unsupported primitives, the only issue we ran into was the lack of support for fences. Most fences were the result of a standard atomic reference counting idiom which could be trivially replaced with an atomic load in TSan builds. Unfortunately, fences are fundamental to the design of the crossbeam crate (a foundational concurrency library in Rust), and the only solution for this was a suppression.
We also found that there is a (well known) false positive in deadlock detection that is however very easy to spot and also does not affect data race detection/reporting at all. In a nutshell, any deadlock report that only involves a single thread is likely this false positive.
The only true false positive we found so far turned out to be a rare bug in TSan and was fixed in the tool itself. However, developers claimed on various occasions that a particular report must be a false positive. In all of these cases, it turned out that TSan was indeed right and the problem was just very subtle and hard to understand. This is again confirming that we need tools like TSan to help us eliminate this class of bugs.
Currently, the TSan bug-o-rama contains around 20 bugs. We’re still working on fixes for some of these bugs and would like to point out several particularly interesting/impactful ones.
Bitfields are a handy little convenience to save space for storing lots of different small values. For instance, rather than having 30 bools taking up 240 bytes, they can all be packed into 4 bytes. For the most part this works fine, but it has one nasty consequence: different pieces of data now alias. This means that accessing “neighboring” bitfields is actually accessing the same memory, and therefore a potential data race.
In practical terms, this means that if two threads are writing to two neighboring bitfields, one of the writes can get lost, as both of those writes are actually read-modify-write operations of all the bitfields:
If you’re familiar with bitfields and actively thinking about them, this might be obvious, but when you’re just saying myVal.isInitialized = true you may not think about or even realize that you’re accessing a bitfield.
We have had many instances of this problem, but let’s look at bug 1601940 and its (trimmed) race report:
When we first saw this report, it was puzzling because the two threads in question touch different fields (mAsyncTransformAppliedToContent vs. mTestAttributeAppliers). However, as it turns out, these two fields are both adjacent bitfields in the class.
This was causing intermittent failures in our CI and cost a maintainer of this code valuable time. We find this bug particularly interesting because it demonstrates how hard it is to diagnose data races without appropriate tooling and we found more instances of this type of bug (racy bitfield write/write) in our codebase. One of the other instances even had the potential to cause network loads to supply invalid cache content, another hard-to-debug situation, especially when it is intermittent and therefore not easily reproducible.
We encountered this enough that we eventually introduced a MOZ_ATOMIC_BITFIELDS macro that generates bitfields with atomic load/store methods. This allowed us to quickly fix problematic bitfields for the maintainers of each component without having to redesign their types.
We also found several instances of components which were explicitly designed to be single-threaded accidentally being used by multiple threads, such as bug 1681950:
The race itself here is rather simple, we are racing on the same file through stat64 and understanding the report was not the problem this time. However, as can be seen from frame 10, this call originates from the PreferencesWriter, which is responsible for writing changes to the prefs.js file, the central storage for Firefox preferences.
It was never intended for this to be called on multiple threads at the same time and we believe that this had the potential to corrupt the prefs.js file. As a result, during the next startup the file would fail to load and be discarded (reset to default prefs). Over the years, we’ve had quite a few bug reports related to this file magically losing its custom preferences but we were never able to find the root cause. We now believe that this bug is at least partially responsible for these losses.
We think this is a particularly good example of a failure for two reasons: it was a race that had more harmful effects than just a crash, and it caught a larger logic error of something being used outside of its original design parameters.
On several occasions we encountered a pattern that lies on the boundary of benign that we think merits some extra attention: intentionally racily reading a value, but then later doing checks that properly validate it. For instance, code like:
See for example, this instance we encountered in SQLite.
Please Don’t Do This. These patterns are really fragile and they’re ultimately undefined behavior, even if they generally work right. Just write proper atomic code — you’ll usually find that the performance is perfectly fine.
Another difficulty that we had to solve during TSan deployment was due to part of our codebase now being written in Rust, which has much less mature support for sanitizers. This meant that we spent a significant portion of our bringup with all Rust code suppressed while that tooling was still being developed.
We weren’t particularly concerned with our Rust code having a lot of races, but rather races in C++ code being obfuscated by passing through Rust. In fact, we strongly recommend writing new projects entirely in Rust to avoid data races altogether.
The hardest part in particular is the need to rebuild the Rust standard library with TSan instrumentation. On nightly there is an unstable feature, -Zbuild-std, that lets us do exactly that, but it still has a lot of rough edges.
Our biggest hurdle with build-std was that it’s currently incompatible with vendored build environments, which Firefox uses. Fixing this isn’t simple because cargo’s tools for patching in dependencies aren’t designed for affecting only a subgraph (i.e. just std and not your own code). So far, we have mitigated this by maintaining a small set of patches on top of rustc/cargo which implement this well-enough for Firefox but need further work to go upstream.
But with build-std hacked into working for us we were able to instrument our Rust code and were happy to find that there were very few problems! Most of the things we discovered were C++ races that happened to pass through some Rust code and had therefore been hidden by our blanket suppressions.
We did however find two pure Rust races:
The first was bug 1674770, which was a bug in the parking_lot library. This Rust library provides synchronization primitives and other concurrency tools and is written and maintained by experts. We did not investigate the impact but the issue was a couple atomic orderings being too weak and was fixed quickly by the authors. This is yet another example that proves how difficult it is to write bug-free concurrent code.
The second was bug 1686158, which was some code in WebRender’s software OpenGL shim. They were maintaining some hand-rolled shared-mutable state using raw atomics for part of the implementation but forgot to make one of the fields atomic. This was easy enough to fix.
Overall Rust appears to be fulfilling one of its original design goals: allowing us to write more concurrent code safely. Both WebRender and Stylo are very large and pervasively multi-threaded, but have had minimal threading issues. What issues we did find were mistakes in the implementations of low-level and explicitly unsafe multithreading abstractions — and those mistakes were simple to fix.
This is in contrast to many of our C++ races, which often involved things being randomly accessed on different threads with unclear semantics, necessitating non-trivial refactorings of the code.
Data races are an underestimated problem. Due to their complexity and intermittency, we often struggle to identify them, locate their cause and judge their impact correctly. In many cases, this is also a time-consuming process, wasting valuable resources. ThreadSanitizer has proven to be not just effective in locating data races and providing adequate debug information, but also to be practical even on a project as large as Firefox.
We would like to thank the authors of ThreadSanitizer for providing the tool and in particular Dmitry Vyukov (Google) for helping us with some complex, Firefox-specific edge cases during deployment.
The post Eliminating Data Races in Firefox – A Technical Report appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/04/eliminating-data-races-in-firefox-a-technical-report/
|
|
Andrew Halberstadt: A Better Replacement for ls |
If it ain’t broke don’t fix it.
This old addage is valuable advice that has been passed down through generations. But it hasn’t stopped these people from rewriting command line tools perfected 30+ years ago in Rust.
This week we’ll take a quick look at exa, a replacement for ls. So why
should you ignore the wise advice from the addage and replace ls? Because there are marginal
improvements to be had, duh! Although the improvements in this case are far from marginal.
|
|
The Mozilla Blog: Software Innovation Prevails in Landmark Supreme Court Ruling in Google v. Oracle |
In an important victory for software developers, the Supreme Court ruled today that reimplementing an API is fair use under US copyright law. The Court’s reasoning should apply to all cases where developers reimplement an API, to enable interoperability, or to allow developers to use familiar commands. This resolves years of uncertainty, and will enable more competition and follow-on innovation in software.

Yes you would – Credit: Parker Higgins (https://twitter.com/XOR)
This ruling arrives after more than ten years of litigation, including two trials and two appellate rulings from the Federal Circuit. Mozilla, together with other amici, filed several briefs throughout this time because we believed the rulings were at odds with how software is developed, and could hinder the industry. Fortunately, in a 6-2 decision authored by Justice Breyer, the Supreme Court overturned the Federal Circuit’s error.
When the case reached the Supreme Court, Mozilla filed an amicus brief arguing that APIs should not be copyrightable or, alternatively, reimplementation of APIs should be covered by fair use. The Court took the second of these options:
We reach the conclusion that in this case, where Google reimplemented a user interface, taking only what was needed to allow users to put their accrued talents to work in a new and transformative program, Google’s copying of the Sun Java API was a fair use of that material as a matter of law.
In reaching his conclusion, Justice Breyer noted that reimplementing an API “can further the development of computer programs.” This is because it enables programmers to use their knowledge and skills to build new software. The value of APIs is not so much in the creative content of the API itself (e.g. whether a particular API is “Java.lang.Math.max” or, as the Federal Circuit once suggested as an alternative, ““Java.lang.Arith.Larger”) but in the acquired experience of the developer community that uses it.
We are pleased that the Supreme Court has reached this decision and that copyright will no longer stand in the way of software developers reimplementing APIs in socially, technologically, and economically beneficial ways.
The post Software Innovation Prevails in Landmark Supreme Court Ruling in Google v. Oracle appeared first on The Mozilla Blog.
|
|
The Firefox Frontier: Mozilla Explains: Cookies and supercookies |
Every time you visit a website and it seems to remember you, that’s a cookie at work. You might have heard that all cookies are bad, but reality is a … Read more
The post Mozilla Explains: Cookies and supercookies appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/mozilla-explains-cookies-and-supercookies/
|
|
Manish Goregaokar: A Tour of Safe Tracing GC Designs in Rust |
|
|
Cameron Kaiser: TenFourFox FPR32b1 available |
Anyway, the beta for the final TenFourFox Feature Parity Release, FPR32, is now available (downloads, hashes, release notes). This release adds another special preference dialogue for auto reader view, allowing you to automatically jump to reader view for subpages or all pages of domains you enter. I also updated Readability, the underlying Reader View library, to the current tip and also refreshed the ATSUI font blocklist. It will become final on or about April 20 parallel to Firefox 88.
I received lots of kind messages which I have been replying to. Many people appreciated that they could use their hardware for longer, even if they themselves are no longer using their Power Macs, and I even heard about a iMac G4 that is currently a TenFourFox-powered kiosk. I'm willing to bet there are actually a number of these systems hauled out of the closet easily serving such purposes by displaying a ticker or dashboard that can be tweaked to render quickly.
Don't forget, though, that even after September 7 I will still make intermittent updates (primarily security-based) for my own use which will be public and you can use them too. However, as I mentioned, you'll need to build the browser yourself, and since it will only be on a rolling basis (I won't be doing specific versions or tags), you can decide how often you want to update your own local copy. I'll make a note here on the blog when I've done a new batch so that your feedreader can alert you if you aren't watching the Github repository already. The first such batch is a near certainty since it will be me changing the certificate roots to 91ESR.
If you come up with simpler or better build instructions, I'm all ears.
I'm also willing to point people to third-party builds. If you're able to do it and want to take on the task, and don't mind others downloading it, post in the comments. You declare how often you want to do it and which set of systems you want to do it for. The more builders the merrier so that the load can be shared and people can specialize in the systems they most care about.
As a last comment, a few people have asked what it would take to get later versions (52ESR, etc.) to run on Power Macs. Fine, here's a summarized to-do list. None of them are (probably) technically impossible; the real issue is the amount of time required and the ongoing burden needed, plus any unexpected regressions you'd incur. (See also the flap over the sudden Rust requirement for the Python cryptography library, an analogous situation which broke a number of other platforms of similar vintage.)
If you think I'm wrong about all this, rather than argue with me in the comments, today's your chance to prove it :)
http://tenfourfox.blogspot.com/2021/04/tenfourfox-fpr32b1-available.html
|
|
Daniel Stenberg: Where is HTTP/3 right now? |
tldr: the level of HTTP/3 support in servers are surprisingly high considering very few clients enable it by default.
The specifications are all done. They’re now waiting in queues to get their final edits and approvals before they will get assigned RFC numbers and get published as such – they will not change any further. That’s a set of RFCs (six I believe) for various aspects of this new stack. The HTTP/3 spec is just one of those. Remember: HTTP/3 is the application protocol done over the new transport QUIC. (See http3 explained for a high-level description.)
The HTTP/3 spec was written to refer to, and thus depend on, two other HTTP specs that are in the works: httpbis-cache and https-semantics. Those two are mostly clarifications and cleanups of older HTTP specs, but this forces the HTTP/3 spec to have to get published after the other two, which might introduce a small delay compared to the other QUIC documents.
The working group has started to take on work on new specifications for extensions and improvements beyond QUIC version 1.
In early April 2021, the usage of QUIC and HTTP/3 in the world is measured by a few different companies.
netray.io scans the IPv4 address space weekly and checks how many hosts that speak QUIC. Their latest scan found 2.1 million such hosts.
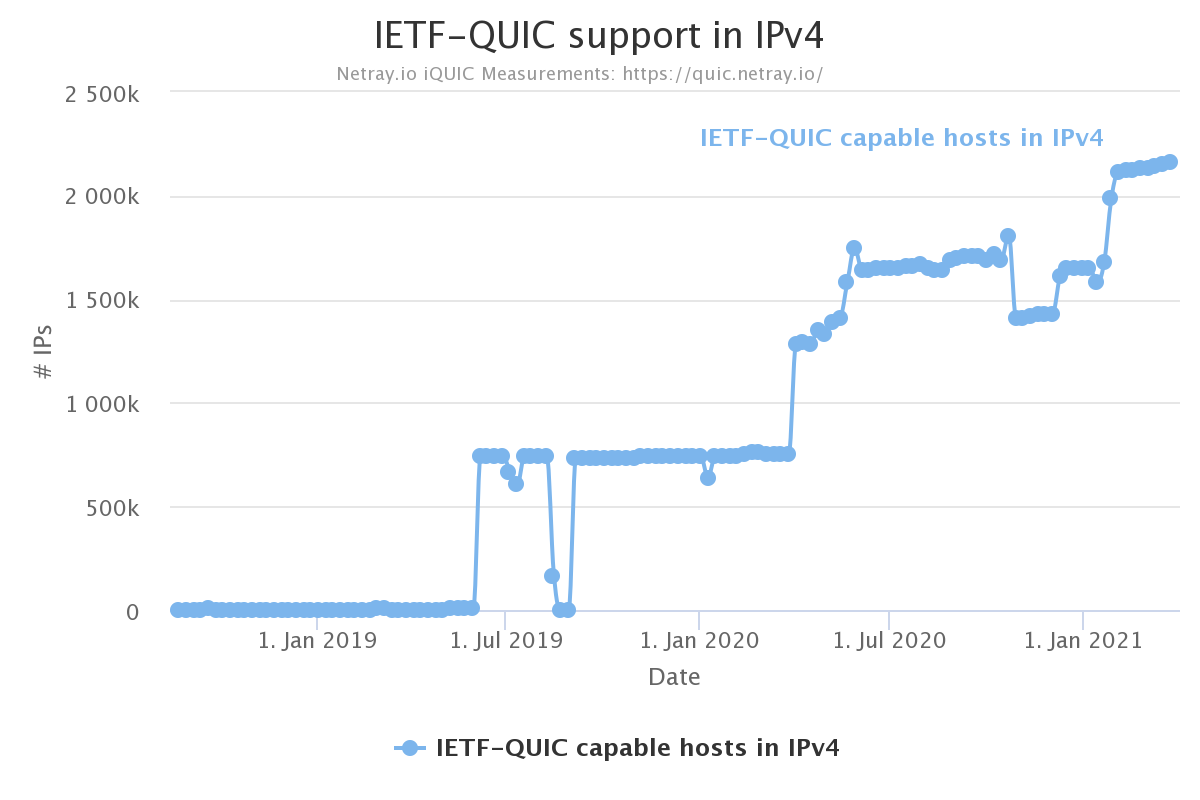
Arguably, the netray number doesn’t say much. Those two million hosts could be very well used or barely used machines.
w3techs.com has been in the game of scanning web sites for stats purposes for a long time. They scan the top ten million sites and count how large share that runs/supports what technologies and they also check for HTTP/3. In their data they call the old Google QUIC for just “QUIC” which is confusing but that should be seen as the precursor to HTTP/3.
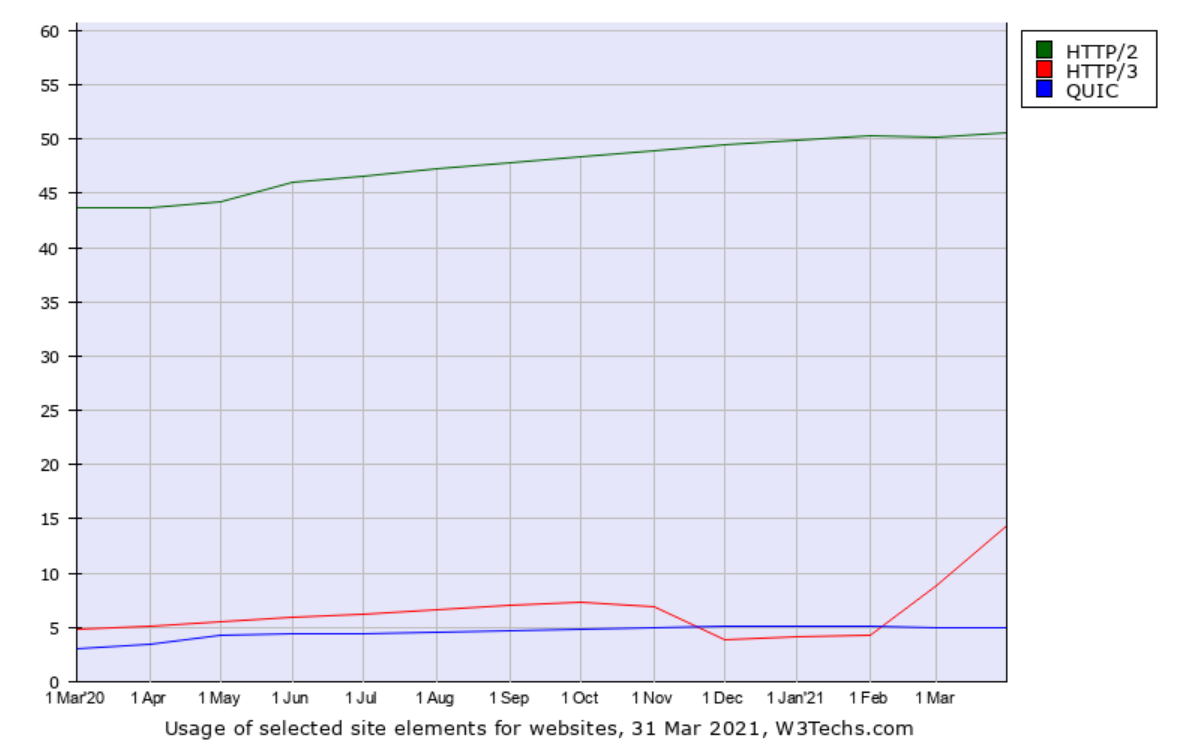
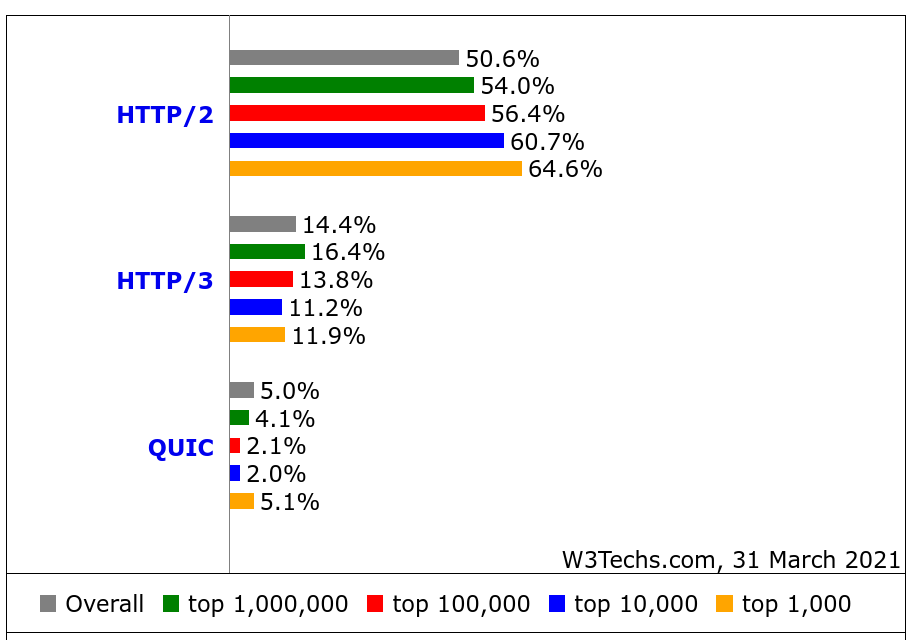
What stands out to me in this data except that the HTTP/3 usage seems very high: the top one-million sites are claimed to have a higher share of HTTP/3 support (16.4%) than the top one-thousand (11.9%)! That’s the reversed for HTTP/2 and not how stats like this tend to look.
It has been suggested that the growth starting at Feb 2021 might be explained by Cloudflare’s enabling of HTTP/3 for users also in their free plan.
On radar.cloudflare.com we can see Cloudflare’s view of a lot of Internet and protocol trends over the world.
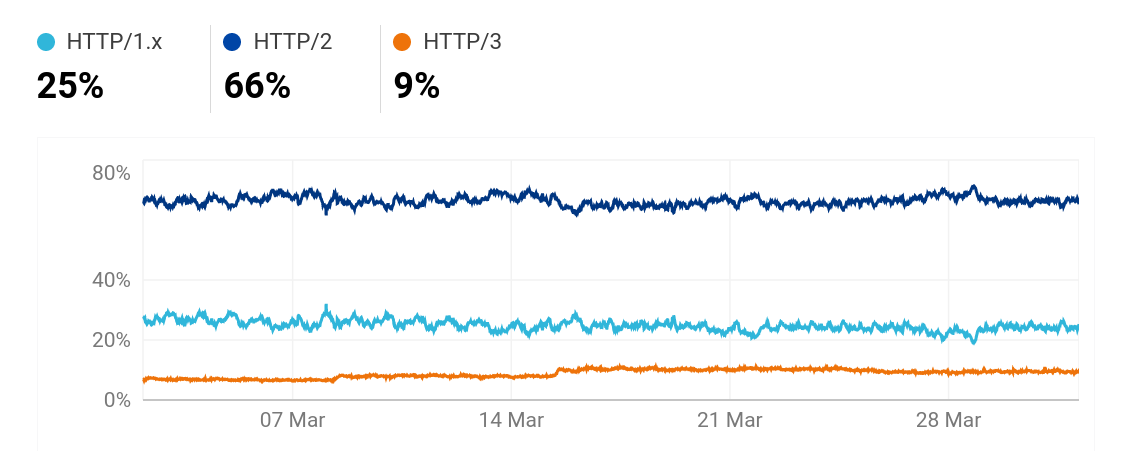
This HTTP/3 number is significantly lower than w3techs’. Presumably because of the differences in how they measure.
All the major browsers have HTTP/3 implementations and most of them allow you to manually enable it if it isn’t already done so. Chrome and Edge have it enabled by default and Firefox will so very soon. The caniuse.com site shows it like this (updated on April 4):

(Earlier versions of this blog post showed the previous and inaccurate data from caniuse.com. Not anymore.)

curl supports HTTP/3 since a while back, but you need to explicitly enable it at build-time. It needs to use third party libraries for the HTTP/3 layer and it needs a QUIC capable TLS library. The QUIC/h3 libraries are still beta versions. See below for the TLS library situation.
curl’s HTTP/3 support is not even complete. There are still unsupported areas and it’s not considered stable yet.
Facebook has previously talked about how they use HTTP/3 in their app, and presumably others do as well. There are of course also other implementations available.
curl supports 14 different TLS libraries at this time. Two of them have QUIC support landed: BoringSSL and GnuTLS. And a third would be the quictls OpenSSL fork. (There are also a few other smaller TLS libraries that support QUIC.)
The by far most popular TLS library to use with curl, OpenSSL, has postponed their QUIC work:
At the same time they have delayed the OpenSSL 3.0 release significantly. Their release schedule page still today speaks of a planned release of 3.0.0 in “early Q4 2020”. That plan expects a few months from the beta to final release and we have not yet seen a beta release, only alphas.
Realistically, this makes QUIC in OpenSSL many months off until it can appear even in a first alpha. Maybe even 2022 material?
The Google powered OpenSSL fork BoringSSL has supported QUIC for a long time and provides the OpenSSL API, but they don’t do releases and mostly focus on getting a library done for Google. People outside the company are generally reluctant to use and depend on this library for those reasons.
The quiche QUIC/h3 library from Cloudflare uses BoringSSL and curl can be built to use quiche (as well as BoringSSL).
Microsoft and Akamai have made a fork of OpenSSL available that is based on OpenSSL 1.1.1 and has the QUIC pull-request applied in order to offer a QUIC capable OpenSSL flavor to the world before the official OpenSSL gets their act together. This fork is called quictls. This should be compatible with OpenSSL in all other regards and provide QUIC with an API that is similar to BoringSSL’s.
The ngtcp2 QUIC library uses quictls. curl can be built to use ngtcp2 as well as with quictls,
I realize I can’t blog about this topic without at least touching this question. The main reason for adding support for HTTP/3 on your site is probably that it makes it faster for users, so does it?
According to cloudflare’s tests, it does, but the difference is not huge.
We’ve seen other numbers say h3 is faster shown before but it’s hard to find up-to-date performance measurements published for the current version of HTTP/3 vs HTTP/2 in real world scenarios. Partly of course because people have hesitated to compare before there are proper implementations to compare with, and not just development versions not really made and tweaked to perform optimally.
I think there are reasons to expect h3 to be faster in several situations, but for people with high bandwidth low latency connections in the western world, maybe the difference won’t be noticeable?
I’ve previously shown the slide below to illustrate what needs to be done for curl to ship with HTTP/3 support enabled in distros and “widely” and I think the same works for a lot of other projects and clients who don’t control their TLS implementation and don’t write their own QUIC/h3 layer code.
This house of cards of h3 is slowly getting some stable components, but there are still too many moving parts for most of us to ship.

I assume that the rest of the browsers will also enable HTTP/3 by default soon, and the specs will be released not too long into the future. That will make HTTP/3 traffic on the web increase significantly.
The QUIC and h3 libraries will ship their first non-beta versions once the specs are out.
The TLS library situation will continue to hamper wider adoption among non-browsers and smaller players.
The big players already deploy HTTP/3.
I’ve updated this post after the initial publication, and the biggest corrections are in the Chrome/Edge details. Thanks to immediate feedback from Eric Lawrence. Remaining errors are still all mine! Thanks also to Barry Pollard who filed the PR to update the previously flawed caniuse.com data.
https://daniel.haxx.se/blog/2021/04/02/where-is-http-3-right-now/
|
|
Hacks.Mozilla.Org: A web testing deep dive: The MDN web testing report |
For the last couple of years, we’ve run the MDN Web Developer Needs Assessment (DNA) Report, which aims to highlight the key issues faced by developers building web sites and applications. This has proved to be an invaluable source of data for browser vendors and other organizations to prioritize improvements to the web platform. This year we did a deep dive into web testing, and we are delighted to be able to announce the publication of this follow-on work, available at our insights.developer.mozilla.org site along with our other Web DNA publications.
In the Web DNA studies for 2019 and 2020, developers ranked the need “Having to support specific browsers, (e.g., IE11)” as the most frustrating aspect of web development, among 28 needs. The 2nd and 3rd rankings were also related to browser compatibility:
In 2020, we released our browser compatibility research results — a deeper dive into identifying specific issues around browser compatibility and pinpointing what can be done to mitigate these issues.
This year we decided to follow up with another deep dive focused on the 4th most frustrating aspect of developing for the web, “Testing across browsers.” It follows on nicely from the previous deep dive, and also concerns much-sought-after information.
You can download this report directly — see the Web Testing Report (PDF, 0.6MB).
Based on the 2019 ranking of “testing across browsers”, we introduced a new question to the DNA survey in 2020: “What are the biggest pain points for you when it comes to web testing?” We wanted to understand more about this need and what some of the underlying issues are.
Respondents could choose one or more of the following answers:
7.5% of respondents (out of 6,645) said they don’t have pain points with web testing. For those who did, the biggest pain point is the time spent on manual testing.
To better understand the nuances behind these results, we ran a qualitative study on web testing. The study consisted of twenty one-hour interviews with web developers who took the 2020 DNA survey and agreed to participate in follow-up research.
The results will help browser vendors understand whether to accelerate work on WebDriver Bidirectional Protocol (BiDi) or if the unmet needs lie elsewhere. Our analysis on WebDriver BiDi is based on the assumption that the feature gap between single-browser test tooling and cross-browser test tooling is a source of pain. Future research on the struggles developers have will be able to focus the priorities and technical design of that specification to address the pain points.
The post A web testing deep dive: The MDN web testing report appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/04/a-web-testing-deep-dive-the-mdn-web-testing-report/
|
|
Mike Hommey: Announcing git-cinnabar 0.5.7 |
Git-cinnabar is a git remote helper to interact with mercurial repositories. It allows to clone, pull and push from/to mercurial remote repositories, using git.
These release notes are also available on the git-cinnabar wiki.
git -c config=value ... works again.|
|
Robert Kaiser: Is Mozilla Still Needed Nowadays? |
 The text of this post is licensed under Creative Commons BY-SA 4.0.
The text of this post is licensed under Creative Commons BY-SA 4.0. https://home.kairo.at/blog/2021-03/is_mozilla_still_needed_nowadays
|
|
Henri Sivonen: A Look at Encoding Detection and Encoding Menu Telemetry from Firefox 86 |
Firefox gained a way to trigger chardetng from the Text Encoding menu in Firefox 86. In this post, I examine both telemetry from Firefox 86 related to the Text Encoding menu and telemetry related to chardetng running automatically (without the menu).
The questions I’d like to answer are:
Can we replace the Text Encoding menu with a single menu item that performs the function currently performed by the item Automatic in the Text Encoding menu?
Does chardetng have to revise its guess often? (That is, is the guess made at one kilobyte typically the same as the guess made at the end of the stream? If not, there’s a reload.)
Does the top-level domain affect the guess often? (If yes, maybe it’s worthwhile to tune this area.)
Is unlabeled UTF-8 so common as to warrant further action to support it?
Is the unlabeled UTF-8 situation different enough for text/html and text/plain to warrant different treatment of text/plain?
The failure mode of decoding according to the wrong encoding is very different for the Latin script and for non-Latin scripts. Also, there are historical differences in UTF-8 adoption and encoding labeling in different language contexts. For example, UTF-8 adoption happened sooner for the Arabic script and for Vietnamese while Web developers in Poland and Japan had different attitudes towards encoding labeling early on. For this reason, it’s not enough to look at the global aggregation of data alone.
Since Firefox’s encoding behavior no longer depends on the UI locale and a substantial number of users use the en-US localization in non-U.S. contexts, I use geographic location rather than the UI locale as a proxy for the legacy encoding family of the Web content primary being read.
The geographical breakdown of telemetry is presented in the tables by ISO 3166-1 alpha-2 code. The code is deduced from the source IP addresses of the telemetry submissions at the time of ingestion after which the IP address itself is discarded. As another point relevant to make about privacy, the measurements below referring to the .jp, .in, and .lk TLDs is not an indication of URL collection. The split into four coarse categories, .jp, .in+.lk, other ccTLD, and non-ccTLD, was done on the client side as a side effect of these four TLD categories getting technically different detection treatment: .jp has a dedicated detector, .in and .lk don’t run detection at all, for other ccTLDs the TLD is one signal taken into account, and for other TLDs the detection is based on the content only. (It’s imaginable that there could be regional differences in how willing users are to participate in telemetry collection, but I don’t know if there actually are regional differences.)
Starting with 86, Firefox has a probe that measures if the item “Automatic” in the Text Encoding menu has been used at least once in a given subsession. It also has another probe measuring whether any of the other (manual) items in the Text Encoding menu has been used at least once in a given subsession.
Both the manual selection and the automatic selection are used at the highest rate in Japan. The places with the next-highest usage rates are Hong Kong and Taiwan. The manual selection is still used in more sessions that the automatic selection. In Japan and Hong Kong, the factor is less than 2. In Taiwan, it’s less than 3. In places where the dominant script is the Cyrillic script, manual selection is relatively even more popular. This is understandable, considering that the automatic option is a new piece of UI that users probably haven’t gotten used to, yet.
All in all, the menu is used rarely relative to the total number of subsessions, but I assume the usage rate in Japan still makes the menu worth keeping considering how speedy feedback from Japan is whenever I break something in this area. Even though the menu usage seems very rare, with a large number of users, a notable number of users daily still find the need to use the menu.
Japan is a special case, though, since we have have a dedicated detector that runs on the .jp TLD. The menu usage rates in Hong Kong and Taiwan are pretty close to the rate in Japan, though.
In retrospect, it’s unfortunate that the new probes for menu usage frequency can’t be directly compared with the old probe, because we now have distinct probes for the automatic option being used at least once per subsession and a manual option being used at least once per subsession and both a manual option and the automatic option could be used in the same Firefox subsession. We can calculate changes assuming the extreme cases: the case where the automatic option is always used in a subsession together with a manual option and the case where they are always used in distinct subsessions. This gives us worst case and best case percentages of 86 menu use rate compared to 71 menu use rate. (E.g. 89% means than the menu was used 11% less in 86 than in 71.) The table is sorted by the relative frequency of use of the automatic option in Firefox 86. The table is not exhaustive. It is filtered both to objectively exclude rows by low number of distinct telemetry submitters and semi-subjectively to exclude encoding-wise similar places or places whose results seemed noisy. Also, Germany, India, and Italy are taken as counter-examples of places that are notably apart from the others in terms of menu usage frequency and India being encoding-wise treated specially.
| Worst case | Best case | |
|---|---|---|
| JP | 89% | 58% |
| TW | 63% | 46% |
| HK | 61% | 40% |
| CN | 80% | 54% |
| TH | 82% | 66% |
| KR | 72% | 53% |
| UA | 206% | 167% |
| BG | 112% | 99% |
| RU | 112% | 82% |
| SG | 59% | 46% |
| GR | 91% | 69% |
| IL | 92% | 80% |
| IQ | 24% | 13% |
| TN | 15% | 10% |
| EE | 63% | 43% |
| TR | 102% | 61% |
| HU | 109% | 77% |
| LV | 88% | 72% |
| LT | 67% | 53% |
| EG | 39% | 28% |
| VN | 41% | 35% |
| DE | 90% | 65% |
| IN | 108% | 77% |
| IT | 83% | 55% |
The result is a bit concerning. According to the best case numbers, things got better everywhere except in Ukraine. The worst case numbers suggest that things might have gotten worse also in other places where the Cyrillic script is the dominant script as well as in Turkey and Hungary where the dominant legacy encoding is known to be tricky to distinguish from windows-1252, and in India, whose domestic ccTLD is excluded from autodetection. Still, the numbers for Russia, Hungary, Turkey, and India look like things might have stayed the same or gotten a bit better.
At least in the case of the Turkish and Hungarian languages, the misdetection of the encoding is going to be another Latin-script encoding anyway, so the result is not catastrophic in terms of user experience. You can still figure out what the text is meant to say. For any non-Latin script, including the Cyrillic script, misdetection makes the page completely unreadable. In that sense, the numbers for Ukraine are concerning.
In the case of India, the domestic ccTLD, .in, is excluded from autodetection and simply falls back to windows-1252 like it used to. Therefore, for users in India, the added autodetection applies only on other TLDs, including to content published from within India on generic TLDs. We can’t really conclude anything in particular about changes to the browser user experience in India itself. However, we can observe that with the exception of Ukraine, the other case where the worst case was over 100%, the worst case was within the same ballpark as the worst case for India, where the worst case may not be meaningful, so maybe the other similar worst case results don’t really indicate things getting substantially worse.
To understand how much menu usage in Ukraine has previously changed from version to version, I looked at the old numbers from Firefox 69, 70, 71, 74, 75, and 75. chardetng landed in Firefox 73 and settled down by Firefox 78. The old telemetry probe expired, which is why we don’t have data from Firefox 85 to compare with.
| 69 | 70 | 71 | 74 | 75 | 76 | |
|---|---|---|---|---|---|---|
| 69 | 100% | 87% | 70% | 75% | 75% | 73% |
| 70 | 115% | 100% | 81% | 87% | 86% | 83% |
| 71 | 143% | 124% | 100% | 107% | 106% | 103% |
| 74 | 133% | 115% | 93% | 100% | 99% | 96% |
| 75 | 134% | 117% | 94% | 101% | 100% | 97% |
| 76 | 138% | 120% | 97% | 104% | 103% | 100% |
In the table, the percentage in the cell is the usage rate in the version from the column relative to the version from the row. E.g. in version 70, the usage was 87% of the usage in version 69 and, therefore, decreased by 13%.
This does make even the best-case change from 71 to 86 for Ukraine look like a possible signal and not noise. However, the change from 71 to 74, 75, and 76, representing the original landing of chardetng, was substantially milder. Furthermore, the difference between 69 and 71 was larger, which suggests that the fluctuation between versions may be rather large.
It’s worth noting that with the legacy encoded data synthesized from the Ukrainian Wikipedia, chardetng is 100% accurate with document-length inputs and 98% accurate with title-length inputs. This suggests that the problem might be something that cannot be remedied by tweaking chardetng. Boosting Ukrainian detection without a non-Wikipedia corpus to evaluate with would risk breaking Greek detection (the other non-Latin bicameral script) without any clear metric of how much to boost Ukrainian detection.
Let’s look at what the situation where the menu (either the automatic option or a manual option) was used was like. This is recorded relative to the top-level page, so this may be misleading if the content that motivate the user to use the menu was actually in a frame.
First, let’s describe the situations. Note that Firefox 86 did not honor bogo-XML declarations in text/html, so documents whose only label was in a bogo-XML declaration count as unlabeled.
| ManuallyOverridden | AutoOverridden | UnlabeledNonUtf8TLD | UnlabeledNonUtf8 | LocalUnlabeled | UnlabeledAscii | UnlabeledInLk | UnlabeledJp | UnlabeledUtf8 | ChannelNonUtf8 | ChannelUtf8 | MetaNonUtf8 | MetaUtf8 | LocalLabeled | Bug | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Global | 8.7% | 2.3% | 0.3% | 2.6% | 2.1% | 6.7% | 0.4% | 6.3% | 30.0% | 12.6% | 16.4% | 4.4% | 0.8% | 4.8% | 1.6% |
| JP | 6.5% | 2.7% | 0.1% | 3.5% | 1.4% | 4.7% | 0.7% | 22.7% | 15.8% | 9.5% | 19.7% | 3.0% | 0.7% | 6.5% | 2.4% |
| HK | 15.9% | 5.5% | 0.5% | 2.9% | 4.8% | 6.0% | 0.0% | 0.0% | 34.8% | 7.1% | 14.0% | 4.2% | 0.7% | 1.3% | 2.3% |
| TW | 14.2% | 4.4% | 0.4% | 2.1% | 6.3% | 7.9% | 0.0% | 0.1% | 30.2% | 7.9% | 16.6% | 4.8% | 1.0% | 3.3% | 1.0% |
| CN | 7.0% | 1.7% | 0.4% | 2.0% | 0.9% | 5.9% | 0.0% | 0.0% | 56.8% | 7.2% | 7.5% | 4.4% | 0.9% | 2.6% | 2.4% |
| TH | 7.9% | 3.1% | 0.6% | 1.6% | 2.3% | 9.3% | 0.0% | 0.4% | 17.7% | 25.8% | 15.8% | 10.3% | 1.0% | 3.5% | 0.7% |
| KR | 8.8% | 3.1% | 0.1% | 1.2% | 3.2% | 6.7% | 0.6% | 0.0% | 39.7% | 11.6% | 15.8% | 3.2% | 1.1% | 3.2% | 1.8% |
| UA | 11.5% | 2.3% | 0.6% | 0.4% | 2.0% | 7.7% | 0.0% | 0.0% | 32.9% | 14.8% | 17.0% | 2.9% | 0.0% | 6.7% | 1.3% |
| BG | 8.1% | 2.8% | 0.0% | 2.0% | 2.4% | 4.9% | 0.0% | 0.0% | 22.9% | 14.8% | 26.9% | 4.5% | 0.0% | 3.4% | 7.3% |
| RU | 11.1% | 1.3% | 0.4% | 1.2% | 1.6% | 3.8% | 0.0% | 0.0% | 33.3% | 21.3% | 17.1% | 1.6% | 0.4% | 6.0% | 0.8% |
| BY | 10.9% | 1.2% | 1.6% | 1.4% | 0.4% | 4.5% | 0.0% | 0.0% | 27.8% | 23.6% | 15.1% | 5.1% | 1.5% | 6.2% | 0.8% |
| SG | 12.5% | 3.2% | 0.0% | 1.6% | 6.9% | 7.5% | 0.0% | 0.0% | 38.1% | 13.1% | 12.3% | 2.5% | 0.0% | 1.7% | 0.6% |
| GR | 14.6% | 1.5% | 0.3% | 2.7% | 8.3% | 6.1% | 0.0% | 0.0% | 25.5% | 7.4% | 22.6% | 3.0% | 0.9% | 6.3% | 0.9% |
| IL | 16.7% | 2.0% | 0.0% | 1.2% | 4.5% | 16.5% | 0.0% | 0.0% | 24.7% | 13.3% | 14.1% | 4.8% | 0.0% | 2.4% | 0.0% |
| BR | 5.6% | 2.5% | 0.3% | 1.8% | 0.3% | 4.3% | 0.0% | 0.0% | 7.1% | 38.7% | 26.1% | 5.9% | 0.7% | 5.6% | 1.0% |
| HU | 9.0% | 2.4% | 1.0% | 2.4% | 1.6% | 3.4% | 0.0% | 0.0% | 26.8% | 4.6% | 28.9% | 6.7% | 4.6% | 5.9% | 2.8% |
| CZ | 10.0% | 3.8% | 0.0% | 1.1% | 3.0% | 3.2% | 0.0% | 0.0% | 25.5% | 11.3% | 27.3% | 3.2% | 1.3% | 9.4% | 0.9% |
| DE | 8.3% | 2.9% | 0.4% | 2.2% | 1.8% | 5.6% | 0.0% | 0.2% | 17.8% | 18.9% | 24.5% | 8.5% | 1.5% | 5.2% | 2.2% |
| IN | 7.2% | 2.0% | 0.0% | 0.6% | 1.8% | 7.6% | 12.7% | 0.0% | 6.7% | 40.6% | 5.2% | 9.2% | 0.4% | 3.4% | 2.6% |
The cases AutoOverridden, UnlabeledNonUtf8TLD, UnlabeledNonUtf8, and LocalUnlabeled represent cases that are suggestive of chardetng having been wrong (or the user misdiagnosing the situation). These cases together are in the minority relative to the other cases. Notably, their total share is very near the share of UnlabeledAscii, which is probably more indicative of how often users misdiagnose what they see as remedyable via the Text Encoding menu than as indicative of sites using frames. However, I have no proof either way of whether this represents misdiagnosis by the user more often or frames more often. In any case, having potential detector errors be in the same ballbark as cases where the top-level page is actually all-ASCII is a sign of the detector probably being pretty good.
The UnlabeledAscii number for Israel stands out. I have no idea why. Are frames more common there? Is it a common pattern to programmatically convert content to numeric character references? If the input to such conversion has been previously misdecoded, the result looks like an encoding error to the user but cannot be remedied from the menu.
Globally, the dominant case is UnlabeledUtf8. This is sad in the sense that we could automatically fix this case for users if there wasn’t a feedback loop to Web author behavior. See a separate write-up on this topic. Also, this metric stands out for mainland China. We’ll also come back to other metrics related to unlabeled UTF-8 standing out in the case of mainland China.
Mislabeled content is a very substantial reason for overriding the encoding. For the ChannelNonUtf8, MetaNonUtf8, and LocalLabeled the label was either actually wrong or the user misdiagnosed the situation. For the UnlabeledUtf8 and MetaUtf8, we can very confident that there was an actual authoring-side error. Unsurprisingly, overriding an encoding labeled on the HTTP layer is much more common that overriding the encoding labeled within the file. This supports the notion that Ruby’s Postulate is correct.
Note that number for UnlabeledJp in Japan does not indicate that the dedicated Japanese detector is broken. The number could represent unlabeled UTF-8 on the .jp TLD, since the .jp TLD is excluded from the other columns.
The relatively high numbers for ManuallyOverridden indicate that users are rather bad at figuring out on the first attempt what they should choose from the menu. When chardetng would guess right, not giving users the manual option would be an usability improvement. However, in cases where nothing in the menu solves the problem, there’s a cohort of users who are unhappy about software deciding for them that there is no solution and are happier by manually coming to the conclusion that there is no solution. For them, an objective usability improvement could feel patronizing. Obviously, when chardetng would guess wrong, not providing manual recourse would make things substiantially worse.
It’s unclear what one should conclude from the AutoOverridden and LocalUnlabeled numbers. They can represent case where chardetng actually guesses wrong or it could also represent cases where the manual items don’t provide a remedy, either. E.g. none of the menu items remedies UTF-8 having been decoded as windows-1252 and the result having been encoded as UTF-8. The higher numbers for Hong Kong and Taiwan look like a signal of a problem. Because mainland China and Singapore don’t show a similar issue, it’s more likely that the signal for Hong Kong and Taiwan is about Big5 rather than GBK. I find this strange, because Big5 should be structurally distinctive enough for the guess to be right if there is an entire document of data to make the decision from. One possibility is that Big5 extensions, such as Big5-UAO, whose character allocations the Encoding Standard treats as unmapped are more common in legacy content than previously thought. Even one such extension character causes chardetng to reject the document as not Big5. I have previously identified this as a potential risk. Also, it is strange that LocalUnlabeled is notably higher than global also for Singapore, Greece, and Israel, but these don’t show a similar difference on the AutoOverridden side.
The Bug category is concerningly high. What have I missed when writing the collection code? Also, how is it so much higher in Bulgaria?
Next, let’s look an non-menu detection scenarios: What’s the relative frequency of non-file: non-menu non-ASCII chardetng outcomes? (Note that this excludes the .jp, .in, and .lk TLDs. .jp runs a dedicated detector instead of chardetng and no detector runs on .in and .lk.)
Here are the outcomes (note that ASCII-only outcomes are excluded):
The rows are grouped by the most detection-relevant legacy encoding family (e.g. Singapore is grouped according to Simplified Chinese) sorted by Windows code page number and the rows within a group are sorted by the ISO 3166 code. The places selected for display are either exhaustive exemplars of a given legacy encoding family or, when not exhaustive, either large-population exemplars or detection-wise remarkable cases. (E.g. Icelandic is detection-wise remarkable, which is why Iceland is shown.)
| UtfInitial | UtfFinal | TldInitial | TldFinal | ContentInitial | ContentFinal | GenericInitial | GenericFinal | ||
|---|---|---|---|---|---|---|---|---|---|
| Global | 12.7% | 66.6% | 1.0% | 0.0% | 9.3% | 0.1% | 9.0% | 1.3% | |
| Thai | TH | 17.0% | 68.2% | 0.4% | 0.0% | 5.8% | 0.1% | 7.0% | 1.5% |
| Japanese | JP | 13.0% | 72.4% | 0.0% | 0.0% | 0.8% | 0.0% | 13.1% | 0.5% |
| Simplified Chinese | CN | 13.7% | 17.3% | 0.2% | 0.0% | 7.0% | 0.1% | 61.1% | 0.6% |
| SG | 14.7% | 69.5% | 0.9% | 0.0% | 1.8% | 0.3% | 11.2% | 1.6% | |
| Korean | KR | 23.8% | 30.2% | 0.4% | 0.0% | 22.2% | 0.1% | 21.6% | 1.8% |
| Traditional Chinese | HK | 13.5% | 56.3% | 0.5% | 0.0% | 3.6% | 0.1% | 24.4% | 1.6% |
| MO | 27.9% | 46.5% | 0.4% | 0.0% | 2.8% | 0.0% | 21.4% | 0.9% | |
| TW | 9.3% | 75.8% | 0.3% | 0.0% | 6.3% | 0.1% | 7.7% | 0.5% | |
| Central European | CZ | 12.6% | 49.6% | 0.7% | 0.0% | 33.6% | 0.1% | 2.5% | 0.9% |
| HU | 15.1% | 48.0% | 18.4% | 0.3% | 1.4% | 1.2% | 13.4% | 2.2% | |
| PL | 15.8% | 72.5% | 3.7% | 0.1% | 3.1% | 0.4% | 3.0% | 1.5% | |
| SK | 23.6% | 61.5% | 1.2% | 0.0% | 8.7% | 0.1% | 3.7% | 1.2% | |
| Cyrillic | BG | 9.7% | 81.8% | 0.4% | 0.0% | 2.3% | 0.1% | 4.4% | 1.4% |
| RU | 6.2% | 91.0% | 0.1% | 0.0% | 1.7% | 0.0% | 0.8% | 0.2% | |
| UA | 6.4% | 86.0% | 0.2% | 0.0% | 4.0% | 0.1% | 2.6% | 0.6% | |
| Western | BR | 22.9% | 44.8% | 2.9% | 0.0% | 26.7% | 0.0% | 2.3% | 0.4% |
| CA | 19.6% | 61.4% | 0.8% | 0.0% | 3.9% | 0.0% | 11.3% | 2.9% | |
| DE | 14.0% | 65.6% | 0.5% | 0.0% | 15.1% | 0.0% | 4.1% | 0.7% | |
| ES | 4.2% | 75.1% | 1.4% | 0.0% | 7.3% | 0.0% | 11.1% | 0.9% | |
| FR | 6.4% | 70.5% | 0.3% | 0.0% | 14.5% | 0.0% | 7.7% | 0.6% | |
| GB | 10.5% | 84.5% | 0.7% | 0.0% | 1.1% | 0.0% | 2.2% | 0.9% | |
| IS | 46.2% | 39.3% | 0.3% | 0.0% | 5.5% | 0.0% | 7.8% | 0.8% | |
| IT | 8.8% | 73.1% | 0.6% | 0.0% | 11.3% | 0.1% | 5.3% | 1.0% | |
| US | 12.8% | 72.1% | 0.4% | 0.0% | 1.4% | 0.0% | 10.5% | 2.7% | |
| Greek | GR | 12.0% | 71.4% | 5.8% | 0.0% | 2.3% | 0.8% | 4.5% | 3.2% |
| Turkic | AZ | 7.3% | 86.3% | 0.3% | 0.0% | 1.8% | 0.1% | 3.2% | 1.1% |
| TR | 19.5% | 59.4% | 1.6% | 0.0% | 8.8% | 0.2% | 7.9% | 2.6% | |
| Hebrew | IL | 6.9% | 79.9% | 0.6% | 0.0% | 6.8% | 0.1% | 4.3% | 1.5% |
| Arabic-script | EG | 5.5% | 75.9% | 0.3% | 0.0% | 1.3% | 0.1% | 5.0% | 11.8% |
| PK | 2.2% | 86.4% | 4.0% | 1.6% | 0.8% | 0.1% | 3.4% | 1.4% | |
| SA | 9.1% | 80.2% | 0.6% | 0.0% | 1.2% | 0.1% | 4.8% | 4.1% | |
| Baltic | EE | 21.6% | 67.2% | 0.4% | 0.0% | 6.5% | 0.1% | 3.2% | 1.0% |
| LT | 48.6% | 47.1% | 0.8% | 0.1% | 1.3% | 0.1% | 1.4% | 0.6% | |
| LV | 6.4% | 87.2% | 0.4% | 0.0% | 3.0% | 0.1% | 2.1% | 0.7% | |
| Vietnamese | VN | 19.7% | 67.4% | 1.1% | 0.0% | 1.5% | 0.2% | 7.9% | 2.1% |
| Other | AM | 7.9% | 85.2% | 0.4% | 0.0% | 2.5% | 0.0% | 3.0% | 0.9% |
| ET | 2.8% | 85.2% | 1.1% | 0.0% | 2.6% | 0.1% | 6.2% | 2.0% | |
| GE | 10.7% | 82.9% | 0.3% | 0.0% | 1.8% | 0.1% | 3.2% | 1.0% | |
| IN | 11.6% | 69.7% | 0.6% | 0.0% | 1.5% | 0.1% | 12.6% | 3.9% | |
| LK | 3.4% | 89.6% | 0.2% | 0.0% | 0.5% | 0.1% | 4.7% | 1.4% | |
| UtfInitial | UtfFinal | TldInitial | TldFinal | ContentInitial | ContentFinal | GenericInitial | GenericFinal | ||
|---|---|---|---|---|---|---|---|---|---|
| Global | 15.8% | 71.5% | 0.6% | 0.0% | 4.1% | 0.2% | 6.9% | 0.8% | |
| Thai | TH | 12.2% | 54.9% | 5.6% | 0.0% | 3.6% | 0.1% | 22.1% | 1.6% |
| Japanese | JP | 15.7% | 28.7% | 0.1% | 0.0% | 1.5% | 0.1% | 51.6% | 2.4% |
| Simplified Chinese | CN | 14.1% | 70.6% | 1.1% | 0.1% | 2.7% | 0.1% | 10.8% | 0.6% |
| SG | 10.3% | 73.7% | 0.7% | 0.0% | 1.9% | 0.1% | 12.0% | 1.2% | |
| Korean | KR | 2.8% | 5.1% | 0.3% | 0.1% | 89.8% | 0.0% | 1.7% | 0.2% |
| Traditional Chinese | HK | 14.0% | 70.6% | 0.5% | 0.1% | 2.7% | 0.1% | 10.8% | 1.2% |
| MO | 13.8% | 69.7% | 0.6% | 0.0% | 3.4% | 0.0% | 12.6% | 0.0% | |
| TW | 20.4% | 45.6% | 3.9% | 0.1% | 11.8% | 0.1% | 16.7% | 1.5% | |
| Central European | CZ | 25.7% | 69.7% | 0.9% | 0.1% | 1.3% | 0.0% | 2.1% | 0.2% |
| HU | 19.9% | 53.8% | 12.8% | 0.2% | 2.5% | 1.0% | 8.4% | 1.5% | |
| PL | 28.5% | 61.4% | 2.2% | 0.1% | 2.3% | 0.3% | 4.6% | 0.6% | |
| SK | 28.6% | 46.4% | 3.2% | 0.1% | 8.1% | 0.5% | 11.2% | 1.8% | |
| Cyrillic | BG | 14.4% | 47.2% | 1.8% | 0.3% | 17.5% | 0.1% | 17.0% | 1.8% |
| RU | 25.8% | 58.2% | 2.5% | 0.0% | 4.1% | 0.3% | 8.1% | 1.0% | |
| UA | 22.6% | 46.4% | 3.1% | 0.0% | 6.9% | 0.1% | 19.3% | 1.5% | |
| Western | BR | 21.6% | 53.8% | 0.6% | 0.0% | 15.0% | 0.2% | 6.9% | 1.9% |
| CA | 75.3% | 20.9% | 0.1% | 0.0% | 0.6% | 0.0% | 2.7% | 0.5% | |
| DE | 13.8% | 62.4% | 0.3% | 0.0% | 13.6% | 1.0% | 7.8% | 1.1% | |
| ES | 17.5% | 60.3% | 0.4% | 0.0% | 5.9% | 0.2% | 14.6% | 1.1% | |
| FR | 24.2% | 61.5% | 0.2% | 0.0% | 4.7% | 0.1% | 8.5% | 0.7% | |
| GB | 2.2% | 92.5% | 0.1% | 0.0% | 1.6% | 0.1% | 3.0% | 0.5% | |
| IS | 13.2% | 65.7% | 0.5% | 0.0% | 11.6% | 0.0% | 8.1% | 0.8% | |
| IT | 9.7% | 73.6% | 0.5% | 0.0% | 7.2% | 0.2% | 7.9% | 0.9% | |
| US | 6.0% | 83.5% | 0.1% | 0.0% | 1.0% | 0.3% | 7.7% | 1.3% | |
| Greek | GR | 25.6% | 52.9% | 6.9% | 0.1% | 1.6% | 1.3% | 10.1% | 1.4% |
| Turkic | AZ | 17.6% | 58.3% | 1.6% | 0.5% | 2.6% | 0.0% | 18.6% | 0.9% |
| TR | 7.3% | 80.7% | 1.0% | 0.0% | 1.7% | 0.0% | 8.2% | 1.1% | |
| Hebrew | IL | 14.1% | 67.0% | 1.6% | 0.1% | 1.7% | 0.1% | 13.0% | 2.4% |
| Arabic-script | EG | 13.1% | 47.1% | 1.8% | 0.0% | 1.5% | 0.3% | 33.8% | 2.4% |
| PK | 10.2% | 68.2% | 2.2% | 0.0% | 1.2% | 0.1% | 16.5% | 1.7% | |
| SA | 14.7% | 58.7% | 16.5% | 0.0% | 1.2% | 0.1% | 7.5% | 1.4% | |
| Baltic | EE | 49.9% | 37.7% | 0.4% | 0.0% | 3.7% | 0.0% | 7.1% | 1.1% |
| LT | 26.5% | 59.9% | 3.7% | 0.2% | 1.9% | 0.1% | 6.7% | 0.9% | |
| LV | 15.2% | 58.2% | 9.8% | 0.2% | 3.5% | 0.2% | 11.6% | 1.4% | |
| Vietnamese | VN | 12.8% | 60.5% | 2.1% | 0.2% | 1.7% | 0.5% | 20.9% | 1.3% |
| Other | AM | 16.6% | 59.7% | 0.7% | 0.0% | 5.9% | 0.2% | 15.6% | 1.2% |
| ET | 15.2% | 61.6% | 0.3% | 0.0% | 3.9% | 0.3% | 15.2% | 3.5% | |
| GE | 12.6% | 56.8% | 1.4% | 0.0% | 14.5% | 0.0% | 12.4% | 2.3% | |
| IN | 9.6% | 67.7% | 0.3% | 0.0% | 1.4% | 0.1% | 18.8% | 2.2% | |
| LK | 9.0% | 63.3% | 0.2% | 0.0% | 1.2% | 0.0% | 23.1% | 3.2% | |
Recall that for Japan, India, and Sri Lanka, the domestic ccTLDs (.jp, .in, and .lk, respectively) don’t run chardetng, and the table above covers only chardetng outcomes. Armenia, Ethiopia, and Georgia are included as examples where, despite chardetng running on the domestic ccTLD, the primary domestic script has no Web Platform-supported legacy encoding.
When the content is not actually UTF-8, the decision is almost always made from the first kilobyte. We can conclude that the chardetng doesn’t reload too much.
GenericFinal for HTML in Egypt is the notable exception. We know from testing with synthetic data that chardetng doesn’t perform well for short inputs of windows-1256. This looks like a real-world confirmation.
The TLD seems to have the most effect in Hungary, which is unsuprising, because it’s hard to make the detector detect Hungarian from the content every time without causing misdetection of other Latin-script encodings.
The most surprising thing in these results is that unlabeled UTF-8 is encountered relatively more commonly than unlabeled legacy encodings, but this is so often detected only after the first kilobyte. If this content was mostly in the primary language of the places listed in the table, UTF-8 should be detected from the first kilobyte. I even re-checked the telemetry collection code on this point to see that the collection works as expected.
Yet, the result of most unlabeled UTF-8 HTML being detected after the first kilobyte repeats all over the world. The notably different case that stands out is mainland China, where the total of unlabeled UTF-8 is lower than elsewhere even if the late detection is still a bit more common than early detection. Since the phenomenon occurs in places where the primary script is not the Latin script but mainland China is different, my current guess is that unlabeled UTF-8 might be dominated by an ad network that operates globally with the exception of mainland China. This result could be caused by ads that have more than a kilobyte of ASCII code and a copyright notice at the end of the file. (Same-origin iframes inherit the encoding from their parent instead of running chardetng. Different-origin iframes, such as ads, could be represented in these numbers, though.)
I think the next step is to limit these probes to top-level navigations only to avoid the participation of ad iframes in these numbers.
Curiously, the late-detected unlabeled UTF-8 phenomenon extends to plain text, too. Advertising doesn’t plausibly explain plain text. This suggest that plain-text loads are dominanted by something other than local-language textual content. To the extent scripts and stylesheets are viewed as documents that are navigated to, one would expect copyright legends to typically appear at the top. Could plain text be dominated by mostly-ASCII English regardless of where in the world users are? The text/plain UTF-8 result for the United Kingdom looks exactly like one would expect for English. But why is the UTF-8 text/plain situation so different from everywhere else in South Korea?
Let’s go back to the questions:
Most likely yes, but before doing so, it’s probably a good idea to make chardetng tolerate Big5 byte pairs that conform to the Big5 byte pattern but that are unmapped in terms of the Encoding Standard.
Replacing the Text Encoding menu would probably improve usability considering how the telemetry suggests that users are bad at making the right choice from the menu and bad at diagnosing whether the problem they are seeing can be addressed by the menu. (If the menu had only the one item, we’d be able to disable the menu more often, since we’d be able to better conclude ahead of time that it won’t have an effect.)
No. For legacy encodings, one kilobyte is most often enough. It’s not worthwhile to make adjustments here.
It affects the results often in Hungary, which is expected, but not otherwise. Even though the TLD-based adjustments to detection are embarrassingly ad hoc, the result seems to work well enough that it doesn’t make sense to put effort into tuning this area better.
There is a lot of unlabeled UTF-8 encountered relative to unlabeled non-UTF-8, but the unlabeled UTF-8 doesn’t appear to be normal text in the local language. In particular, the early vs. late detection telemetry doesn’t vary in the expected way when the primary local language is near-ASCII-only and when the primary local language uses a non-Latin script.
More understanding is needed before drawing more conclusions.
More understanding is needed before drawing conclusions. The text/plain and text/html cases look strangely similar even though the text/plain cases are unlikely to be explainable as advertising iframes.
Keep an eye on the menu usage telemetry for Ukraine over the next releases.
Limit the (non-menu) text/html and text/plain outcome probes to top-level navigations only. Then take another look at the UTF-8 issues.
Bonus: Consider tolerating, for detection purposes only, other legacy CJK extensions that diverge from the Encoding Standard (unclear if these are worthwhile):
|
|






