Andrew Halberstadt: Understanding Mach Try |
There is a lot of confusion around mach try. People frequently ask “How do I get task X in mach
try fuzzy?” or “How can I avoid getting backed out?”. This post is not so much a tip, rather an
explanation around how mach try works and its relationship to the CI system (taskgraph). Armed
with this knowledge, I hope you’ll be able to use mach try a little more effectively.
|
|
Mozilla Accessibility: VoiceOver Support for macOS in Firefox 87 |
Screen readers, an assistive technology that allows people to engage with computers through synthesized speech or a braille display, are available on all of the platforms where Firefox runs. However, until today we’ve had a gap in our support for this important technology. Firefox for Windows, Linux, Android, and iOS all work with the popular and included screen readers on those platforms, but macOS screen reader support has been absent.
For over a year the Firefox accessibility team has worked to bring high quality VoiceOver support to Firefox on macOS. Last August we delivered a developer preview of Firefox working with VoiceOver and in December we expanded that preview to all Firefox consumers. With Firefox 87, we think it’s complete enough for everyday use. Firefox 87 supports all the most common VoiceOver features and with plenty of performance. Users should be able to easily navigate through web content and all of the browser’s primary interface without problems.
If you’re a Mac user, and you rely on a screen reader, now’s the time to give Firefox another try. We think you’ll enjoy the experience and look forward to your feedback. You can learn more about Firefox 87 and download a copy at the Firefox release notes.
The post VoiceOver Support for macOS in Firefox 87 appeared first on Mozilla Accessibility.
https://blog.mozilla.org/accessibility/voiceover-support-for-macos-in-firefox-87/
|
|
Mozilla Security Blog: Firefox 87 introduces SmartBlock for Private Browsing |
Today, with the launch of Firefox 87, we are excited to introduce SmartBlock, a new intelligent tracker blocking mechanism for Firefox Private Browsing and Strict Mode. SmartBlock ensures that strong privacy protections in Firefox are accompanied by a great web browsing experience.
At Mozilla, we believe that privacy is a fundamental right and that everyone deserves to have their privacy protected while they browse the web. Since 2015, as part of the effort to provide a strong privacy option, Firefox has included the built-in Content Blocking feature that operates in Private Browsing windows and Strict Tracking Protection Mode. This feature automatically blocks third-party scripts, images, and other content from being loaded from cross-site tracking companies reported by Disconnect. By blocking these tracking components, Firefox Private Browsing windows prevent them from watching you as you browse.
In building these extra-strong privacy protections in Private Browsing windows and Strict Mode, we have been confronted with a fundamental problem: introducing a policy that outright blocks trackers on the web inevitably risks blocking components that are essential for some websites to function properly. This can result in images not appearing, features not working, poor performance, or even the entire page not loading at all.
To reduce this breakage, Firefox 87 is now introducing a new privacy feature we are calling SmartBlock. SmartBlock intelligently fixes up web pages that are broken by our tracking protections, without compromising user privacy.
SmartBlock does this by providing local stand-ins for blocked third-party tracking scripts. These stand-in scripts behave just enough like the original ones to make sure that the website works properly. They allow broken sites relying on the original scripts to load with their functionality intact.
The SmartBlock stand-ins are bundled with Firefox: no actual third-party content from the trackers are loaded at all, so there is no chance for them to track you this way. And, of course, the stand-ins themselves do not contain any code that would support tracking functionality.
In Firefox 87, SmartBlock will silently stand in for a number of common scripts classified as trackers on the Disconnect Tracking Protection List. Here’s an example of a performance improvement:

An example of SmartBlock in action. Previously (left), the website tiny.cloud had poor loading performance in Private Browsing windows in Firefox because of an incompatibility with strong Tracking Protection. With SmartBlock (right), the website loads properly again, while you are still fully protected from trackers found on the page.
We believe the SmartBlock approach provides the best of both worlds: strong protection of your privacy with a great browsing experience as well.
These new protections in Firefox 87 are just the start! Stay tuned for more SmartBlock innovations in upcoming versions of Firefox.
This work was carried out in a collaboration between the Firefox webcompat and anti-tracking teams, including Thomas Wisniewski, Paul Z"uhlcke and Dimi Lee with support from many Mozillians including Johann Hofmann, Rob Wu, Wennie Leung, Mikal Lewis, Tim Huang, Ethan Tseng, Selena Deckelmann, Prangya Basu, Arturo Marmol, Tanvi Vyas, Karl Dubost, Oana Arbuzov, Sergiu Logigan, Cipriani Ciocan, Mike Taylor, Arthur Edelstein, and Steven Englehardt.
We also want to acknowledge the NoScript and uBlock Origin teams for helping to pioneer this approach.
The post Firefox 87 introduces SmartBlock for Private Browsing appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2021/03/23/introducing-smartblock/
|
|
About:Community: Contributors To Firefox 87 |
With the release of Firefox 87 we are delighted to introduce the contributors who’ve shipped their first code changes to Firefox in this release, all of whom were brand new volunteers! Please join us in thanking each of these diligent, committed individuals, and take a look at their contributions:
https://blog.mozilla.org/community/2021/03/22/contributors-to-firefox-87/
|
|
Hacks.Mozilla.Org: How MDN’s site-search works |
tl;dr: Periodically, the whole of MDN is built, by our Node code, in a GitHub Action. A Python script bulk-publishes this to Elasticsearch. Our Django server queries the same Elasticsearch via /api/v1/search. The site-search page is a static single-page app that sends XHR requests to the /api/v1/search endpoint. Search results’ sort-order is determined by match and “popularity”.
The challenge with “Jamstack” websites is with data that is too vast and dynamic that it doesn’t make sense to build statically. Search is one of those. For the record, as of Feb 2021, MDN consists of 11,619 documents (aka. articles) in English. Roughly another 40,000 translated documents. In English alone, there are 5.3 million words. So to build a good search experience we need to, as a static site build side-effect, index all of this in a full-text search database. And Elasticsearch is one such database and it’s good. In particular, Elasticsearch is something MDN is already quite familiar with because it’s what was used from within the Django app when MDN was a wiki.
Note: MDN gets about 20k site-searches per day from within the site.
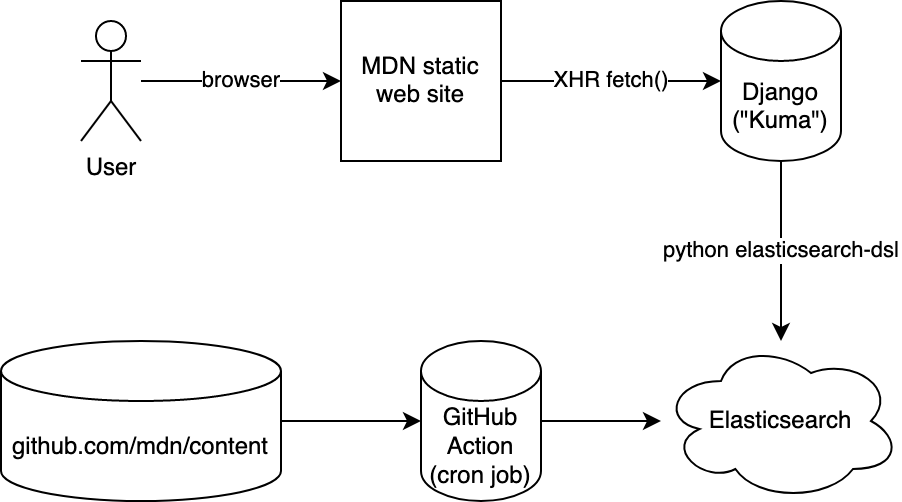
When we build the whole site, it’s a script that basically loops over all the raw content, applies macros and fixes, dumps one index.html (via React server-side rendering) and one index.json. The index.json contains all the fully rendered text (as HTML!) in blocks of “prose”. It looks something like this:
{
"doc": {
"title": "DOCUMENT TITLE",
"summary": "DOCUMENT SUMMARY",
"body": [
{
"type": "prose",
"value": {
"id": "introduction",
"title": "INTRODUCTION",
"content": "FIRST BLOCK OF TEXTS
"
}
},
...
],
"popularity": 0.12345,
...
}0
You can see one here: /en-US/docs/Web/index.json
Next, after all the index.json files have been produced, a Python script takes over and it traverses all the index.json files and based on that structure it figures out the, title, summary, and the whole body (as HTML).
Next up, before sending this into the bulk-publisher in Elasticsearch it strips the HTML. It’s a bit more than just turning
Some cool text.
toSome cool text. because it also cleans up things like One thing worth noting is that this whole thing runs roughly every 24 hours and then it builds everything. But what if, between two runs, a certain page has been removed (or moved), how do you remove what was previously added to Elasticsearch? The solution is simple: it deletes and re-creates the index from scratch every day. The whole bulk-publish takes a while so right after the index has been deleted, the searches won’t be that great. Someone could be unlucky in that they’re searching MDN a couple of seconds after the index was deleted and now waiting for it to build up again.
It’s an unfortunate reality but it’s a risk worth taking for the sake of simplicity. Also, most people are searching for things in English and specifically the Web/ tree so the bulk-publishing is done in a way the most popular content is bulk-published first and the rest was done after. Here’s what the build output logs:
Found 50,461 (potential) documents to index
Deleting any possible existing index and creating a new one called mdn_docs
Took 3m 35s to index 50,362 documents. Approximately 234.1 docs/second
Counts per priority prefixes:
en-us/docs/web 9,056
*rest* 41,306
So, yes, for 3m 35s there’s stuff missing from the index and some unlucky few will get fewer search results than they should. But we can optimize this in the future.
The way you connect to Elasticsearch is simply by a URL it looks something like this:
https://USER:PASSWD@HASH.us-west-2.aws.found.io:9243
It’s an Elasticsearch cluster managed by Elastic running inside AWS. Our job is to make sure that we put the exact same URL in our GitHub Action (“the writer”) as we put it into our Django server (“the reader”).
In fact, we have 3 Elastic clusters: Prod, Stage, Dev.
And we have 2 Django servers: Prod, Stage.
So we just need to carefully make sure the secrets are set correctly to match the right environment.
Now, in the Django server, we just need to convert a request like GET /api/v1/search?q=foo&locale=fr (for example) to a query to send to Elasticsearch. We have a simple Django view function that validates the query string parameters, does some rate-limiting, creates a query (using elasticsearch-dsl) and packages the Elasticsearch results back to JSON.
How we make that query is important. In here lies the most important feature of the search; how it sorts results.
In one simple explanation, the sort order is a combination of popularity and “matchness”. The assumption is that most people want the popular content. I.e. they search for foreach and mean to go to /en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/forEach not /en-US/docs/Web/API/NodeList/forEach both of which contains forEach in the title. The “popularity” is based on Google Analytics pageviews which we download periodically, normalize into a floating-point number between 1 and 0. At the time of writing the scoring function does something like this:
rank = doc.popularity * 10 + search.score
This seems to produce pretty reasonable results.
But there’s more to the “matchness” too. Elasticsearch has its own API for defining boosting and the way we apply is:
title: Boost = 10.0body: Boost = 5.0title: Boost = 2.0body: Boost = 1.0This is then applied on top of whatever else Elasticsearch does such as “Term Frequency” and “Inverse Document Frequency” (tf and if). This article is a helpful introduction.
We’re most likely not done with this. There’s probably a lot more we can do to tune this myriad of knobs and sliders to get the best possible ranking of documents that match.
The last piece of the puzzle is how we display all of this to the user. The way it works is that developer.mozilla.org/$locale/search returns a static page that is blank. As soon as the page has loaded, it lazy-loads JavaScript that can actually issue the XHR request to get and display search results. The code looks something like this:
function SearchResults() { const [searchParams] = useSearchParams(); const sp = createSearchParams(searchParams); // add defaults and stuff here const fetchURL = `/api/v1/search?${sp.toString()}`; const { data, error } = useSWR( fetchURL, async (url) => { const response = await fetch(URL); // various checks on the response.statusCode here return await response.json(); } ); // render 'data' or 'error' accordingly here
A lot of interesting details are omitted from this code snippet. You have to check it out for yourself to get a more up-to-date insight into how it actually works. But basically, the window.location (and pushState) query string drives the fetch() call and then all the component has to do is display the search results with some highlighting.
The /api/v1/search endpoint also runs a suggestion query as part of the main search query. This extracts out interest alternative search queries. These are filtered and scored and we issue “sub-queries” just to get a count for each. Now we can do one of those “Did you mean…”. For example: search for intersections.
There are a lot of interesting, important, and careful details that are glossed over here in this blog post. It’s a constantly evolving system and we’re constantly trying to improve and perfect the system in a way that it fits what users expect.
A lot of people reach MDN via a Google search (e.g. mdn array foreach) but despite that, nearly 5% of all traffic on MDN is the site-search functionality. The /$locale/search?... endpoint is the most frequently viewed page of all of MDN. And having a good search engine that’s reliable is nevertheless important. By owning and controlling the whole pipeline allows us to do specific things that are unique to MDN that other websites don’t need. For example, we index a lot of raw HTML (e.g. ) and we have code snippets that needs to be searchable.
Hopefully, the MDN site-search will elevate from being known to be very limited to something now that can genuinely help people get to the exact page better than Google can. Yes, it’s worth aiming high!
(Originally posted on personal blog)
The post How MDN’s site-search works appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/03/how-mdns-site-search-works/
|
|
Wladimir Palant: Follow-up on Amazon Assistant’s data collection |
In my previous article on Amazon Assistant, one sentence caused considerable irritation:
Mind you, I’m not saying that Amazon is currently doing any of this.
Yes, when I wrote that article I didn’t actually know how Amazon was using the power they’ve given themselves. The mere potential here, what they could do with a minimal and undetectable change on one of their servers, that was scary enough for me. I can see that other people might prefer something more tangible however.
So this article now analyzes what data Amazon actually collects. Not the kind of data that necessarily flows to Amazon servers to make the product work. No, we’ll look at a component dedicated exclusively to “analytics,” collecting data without providing any functionality to the user.

The logic explained here applies to Amazon Assistant browser extension for Mozilla Firefox, Google Chrome and Microsoft Edge. It is also used by Amazon Assistant for Android, to a slightly limited extent however: Amazon Assistant can only access information from the Google Chrome browser here, and it has less information available to it. Since this logic resides on an Amazon web server, I can only show what is happening for me right now. It could change any time in either direction, for all Amazon Assistant users or only a selected few.
The “TitanClient” process in Amazon Assistant is its data collection component. While it’s hard to determine which websites it is active on, it’s definitely active on Google search pages as well as shopping websites such as eBay, AliExpress, Zalando, Apple, Best Buy, Barnes & Noble. And not just the big US or international brands, German building supplies stores like Hornbach and Hagebau are on its list as well, just like the Italian book shop IBS. You can get a rough idea of Amazon’s interests here. While belonging to a different Amazon Assistant feature, this list appears to be a subset of all affected websites.
When active on a website, the TitanClient process transmits the following data for each page loaded:
In addition, the following data is dependent on website configuration. Any or all of these data pieces can be present:
This is sufficient to get a very thorough look at your browsing behavior on the targeted websites. In particular, Amazon knows what you search for, what articles you look at and how much competition wants to have for these.
As mentioned in the previous article, Amazon Assistant loads eight remote “processes” and gives them considerable privileges. The code driving these processes is very complicated, and at that point I couldn’t quite tell what these are responsible for. So why am I now singling out the TitanClient process as the one responsible for analytics? Couldn’t it be implementing some required extension functionality?
The consumed APIs of the process as currently defined in FeatureManifest.js file are a good hint:
"consumedAPIs" : {
"Platform" : [
"getPageDimensionData", "getPageLocationData", "getPagePerformanceTimingData",
"getPageReferrer", "scrape", "getPlatformInfo", "getStorageValue",
"putStorageValue", "deleteStorageValue", "publish"
],
"Reporter" : [ "appendMetricData" ],
"Storage" : [ "get", "put", "delete" ],
"Dossier" : [ "buildURLs" ],
"Identity" : [
"getCohortToken", "getPseudoIdToken", "getAllWeblabTreatments",
"getRTBFStatus", "confirmRTBFExecution"
]
},If you ignore extension storage access and event publishing, it’s all data retrieval functionality such as the scrape function. There are other processes also using the scrape API, for example one named PComp. This one also needs various website manipulation functions such as createSandbox however: PComp is the component actually implementing functionality on third-party websites, so it needs to display overlays with Amazon suggestions there. TitanClient does not need that, it is limited to data extraction.
So while processes like PComp and AAWishlistProcess collect data as a side-effect of doing their job, with TitanClient it isn’t a side-effect but the only purpose. The data collected here shows what Amazon is really interested in. So let’s take a closer look at its inner workings.
Luckily, Amazon made this job easier by providing an unminified version of TitanClient code. A comment in function BITTitanProcess.prototype._handlePageTurnEvent explains when a tab change notification (called “page turn” in Amazon Assistant) is ignored:
/**
* Ignore page turn event if any of the following conditions:
* 1. Page state is not {@link PageState.Loading} or {@link PageState.Loaded} then
* 2. Data collection is disabled i.e. All comparison toggles are turned off in AA
* settings.
* 3. Location is not supported by titan client.
*/
The first one is obvious: TitanClient will wait for a page to be ready. For the second one we have to take a look at TitanDataCollectionToggles.prototype.isTitanDataCollectionDisabled function:
return !(this._isPCompEnabled || this._isRSCompEnabled || this._isSCompEnabled);
This refers to extension settings that can be found in the “Comparison Settings” section: “Product,” “Retail Searches” and “Search engines” respectively. If all of these are switched off, the data collection will be disabled. Is the data collection related to these settings in any way? No, these settings normally apply to the PComp process which is a completely separate component. The logic is rather: if Amazon Assistant is allowed to mess with third-party websites in some way, it will collect data there.
Finally, there is a third point: which locations are supported by TitanClient? When it starts up, it will make a request to aascraperservice.prod.us-east-1.scraper.assistant.a2z.com. The response contains a spaceReferenceMap value: an address pointing to aa-scraper-supported-prod-us-east-1.s3.amazonaws.com, some binary data. This binary data is a Bloom filter, a data structure telling TitanService which websites it should be active on. Obfuscation bonus: it’s impossible to tell which websites this data structure contains, one can only try some guesses.
What happens when you visit a “supported” website such as www.google.com? First, aascraperservice.prod.us-east-1.scraper.assistant.a2z.com will be contacted again for instructions:
POST / HTTP/1.1
Host: aascraperservice.prod.us-east-1.scraper.assistant.a2z.com
Content-Type: application/json; charset=UTF-8
Content-Length: 73
{"originURL":"https://www.google.com:443","isolationZones":["ANALYTICS"]}
It’s exactly the same request that PComp process is sending, except that the latter sets isolationZones value to "FEDERATION". The response contains lots of JSON data with scraping instructions. I’ll quote some interesting parts only, e.g. the instructions for extracting the search query:
{
"cleanUpRules": [],
"constraint": [{
"type": "None"
}],
"contentType": "SearchQuery",
"expression": ".*[?#&]q=([^&]+).*\n$1",
"expressionType": "UrlJsRegex",
"isolationZones": ["ANALYTICS"],
"scraperSource": "Alexa",
"signature": "E8F21AE75595619F581DA3589B92CD2B"
}The extracted value will sometimes be passed through MD5 hash function before being sent. This isn’t a reason to relax however. While technically speaking a hash function cannot be reversed, some web services have huge databases of pre-calculated MD5 hashes, so MD5 hashes of typical search queries can all be found there. Even worse: an additional result with type FreudSearchQuery will be sent where the query is never hashed. A comment in the source code explains:
// TODO: Temporary experiment to collect search query only blessed by Freud filter.
Any bets on how long this “temporary” experiment has been there? There are comments referring to the Freud filter dated 2019 in the codebase.
The following will extract links to search results:
{
"attributeSource": "href",
"cleanUpRules": [],
"constraint": [{
"type": "None"
}],
"contentType": "SearchResult",
"expression": "//div[@class='g' and (not(ancestor::div/@class = 'g kno-kp mnr-c g-blk') and not(ancestor::div/@class = 'dfiEbb'))] // div[@class='yuRUbf'] /a",
"expressionType": "Xpath",
"isolationZones": ["ANALYTICS"],
"scraperSource": "Alexa",
"signature": "88719EAF6FD7BE959B447CDF39BCCA5D"
}These will also sometimes be hashed using MD5. Again, in theory MD5 cannot be reversed. However, you can probably guess that Amazon wouldn’t collect useless data. So they certainly have a huge database with pre-calculated MD5 hashes of all the various links they are interested in, watching these pop up in your search results.
Another interesting instruction is extracting advertised products:
{
"attributeSource": "href",
"cleanUpRules": [],
"constraint": [{
"type": "None"
}],
"contentType": "ProductLevelAdvertising",
"expression": "#tvcap .commercial-unit ._PD div.pla-unit-title a",
"expressionType": "Css",
"isolationZones": ["ANALYTICS"],
"scraperSource": "Alexa",
"signature": "E796BF66B6D2BDC3B5F48429E065FE6F"
}No hashing here, this is sent as plain text.
Once the data is extracted from a page, TitanClient generates an event and adds it to the queue. You likely won’t see it send out data immediately, the queue is flushed only every 15 minutes. When this happens, you will typically see three requests to titan.service.amazonbrowserapp.com with data like:
{
"clientToken": "gQGAA3ikWuk…",
"isolationZoneId": "FARADAY",
"clientContext": {
"marketplace": "US",
"region": "NA",
"partnerTag": "amz-mkt-chr-us-20|1ba00-01000-org00-linux-other-nomod-de000-tclnt",
"aaVersion": "10.2102.26.11554",
"cohortToken": {
"value": "30656463…"
},
"pseudoIdToken": {
"value": "018003…"
}
},
"events": [{
"sequenceNumber": 43736904,
"eventTime": 1616413248927,
"eventType": "View",
"location": "https://www.google.com:443/06a943c59f33a34bb5924aaf72cd2995",
"content": [{
"contentListenerId": "D61A4C…",
"contentType": "SearchResult",
"scraperSignature": "88719EAF6FD7BE959B447CDF39BCCA5D",
"properties": {
"searchResult": "[\"391ed66ea64ce5f38304130d483da00f\",…]"
}
}, {
"contentListenerId": "D61A4C…",
"contentType": "PageType",
"scraperSignature": "E732516A4317117BCF139DE1D4A89E20",
"properties": {
"pageType": "Search"
}
}, {
"contentListenerId": "D61A4C…",
"contentType": "SearchQuery",
"scraperSignature": "E8F21AE75595619F581DA3589B92CD2B",
"properties": {
"searchQuery": "098f6bcd4621d373cade4e832627b4f6",
"isObfuscated": "true"
}
}, {
"contentListenerId": "D61A4C…",
"contentType": "FreudSearchQuery",
"scraperSignature": "E8F21AE75595619F581DA3589B92CD2B",
"properties": {
"searchQuery": "test",
"isObfuscated": "false"
}
}],
"listenerId": "D61A4C…",
"context": "59",
"properties": {
"referrer": "https://www.google.com:443/d41d8cd98f00b204e9800998ecf8427e"
},
"userTrustLevel": "Unknown",
"customerProperties": {}
}],
"clientTimeStamp": 1616413302828,
"oldClientTimeStamp": 1616413302887
}The three requests differ by isolationZoneId: the values are ANALYTICS, HERMES and FARADAY. Judging by the configuration, browser extensions always send data to all three, with different clientToken values. Amazon Assistant for Android however only messages ANALYTICS. Code comments give slight hints towards the difference between these zones, e.g. ANALYTICS:
* {@link IsolationZoneId#ANALYTICS} is tied to a Titan Isolation Zone used
* for association with business analytics data
* Such data include off-Amazon prices, domains, search queries, etc.
HERMES is harder to understand:
* {@link IsolationZoneId#HERMES} is tied to a Titan Isolation Zone used for
* P&C purpose.
If anybody can guess what P&C means: let me know. Should it mean “Privacy & Compliance,” this seems to be the wrong way to approach it. As to FARADAY, the comment is self-referring here:
* {@link IsolationZoneId#FARADAY} is tied to a Titan Isolation Zone used for
* collect data for Titan Faraday integration.
An important note: FARADAY is the only zone where pseudoIdToken is sent along. This one is generated by the Identity service for the given Amazon account and session identifier. So here Amazon can easily say “Hello” to you personally.
The remaining tokens are fairly unspectacular. The cohortToken appears to be a user-independent value used for A/B testing. When decoded, it contains some UUIDs, cryptographic keys and encrypted data. partnerTag contains information about this specific Android Assistant build and the platform it is running on.
As to the actual event data, location has the path part of the address “obfuscated,” yet it’s easy to find out that 06a943c59f33a34bb5924aaf72cd2995 is the MD5 hash of the word search. So the location is actually https://www.google.com:443/search. At least query parameters and anchor are being stripped here. referrer is similarly “obfuscated”: d41d8cd98f00b204e9800998ecf8427e is the MD5 hash of an empty string. So I came here from https://www.google.com:443/. And context indicates that this is all about tab 59, allowing to distinguish actions performed in different tabs.
The values under content are results of scraping the page according to the rules mentioned above. SearchResult lists ten MD5 hashes representing the results of my search, and it is fairly easy to find out what they represent. For example, 391ed66ea64ce5f38304130d483da00f is the MD5 hash of https://www.test.de/.
Page type has been recognized as Search, so there are two more results indicating my search query. Here, the “regular” SearchQuery result contains yet another MD5 hash: a quick search will quickly tell that 098f6bcd4621d373cade4e832627b4f6 means test. But in case anybody still has doubts, the “experimental” FreudSearchQuery result confirms that this is indeed what I searched for. Same query string as plain text here.
You might have wondered why Amazon would invoke the name of Sigmund Freud. As it appears, Freud has the deciding power over which searches should be private and which can just be shared with Amazon without any obfuscation.
TitanClient will break up each search query into words, removing English stop words like “each” or “but.” The remaining words will be hashed individually using SHA-256 hash and the hashes sent to aafreudservice.prod.us-east-1.freud.titan.assistant.a2z.com. As with MD5, SHA-256 cannot technically be reversed but one can easily build a database of hashes for every English word. The Freud service uses this database to decide for each word whether it is “blessed” or not.
And if TitanClient receives Freud’s blessing for a particular search query, it considers it fine to be sent in plain text. And: no, Freud does not seem to object to sex of whatever kind. He appears to object to any word when used together with “test” however.
That might be the reason why Amazon doesn’t quite seem to trust Freud at this point. Most of the decisions are made by a simpler classifier which works like this:
* We say page is blessed if
* 1. At least one PLA is present in scrapped content. OR
* 2. If amazon url is there in organic search results.
For reference: PLA means “Product-Level Advertising.” So if your Google search displays product ads or if there is a link to Amazon in the results, all moderately effective MD5-based obfuscation will be switched off. The search query, search results and everything else will be sent as plain text.
The privacy policy for Amazon Assistant currently says:
Information We Collect Automatically. Amazon Assistant automatically collects information about websites you view where we may have relevant product or service recommendations when you are not interacting with Amazon Assistant. … You can also control collection of “Information We Collect Automatically” by disabling the Configure Comparison Settings.
This explains why TitanClient is only enabled on search sites and web shops, these are websites where Amazon Assistant might recommend something. It also explains why TitanClient is disabled if all features under “Comparison Settings” settings are disabled. It has been designed to fit in with this privacy policy without having to add anything too suspicious here. Albeit not quite:
We do not connect this information to your Amazon account, except when you interact with Amazon Assistant
As we’ve seen above, this isn’t true for data going to the FARADAY isolation zone. The pseudoIdToken value sent here is definitely connected to the user’s Amazon account.
For example, we collect and process the URL, page metadata, and limited page content of the website you are visiting to find a comparable Amazon product or service for you
This formulation carefully avoids mentioning search queries, even though it is vague enough that it doesn’t really exclude them either. And it seems to implicate that the purpose is only suggesting Amazon products, even though that’s clearly not the only purpose. As the previous sentence admits:
This information is used to operate, provide, and improve … Amazon’s marketing, products, and services (including for business analytics and fraud detection).
I’m not a lawyer, so I cannot tell whether sending conflicting messages like that is legit. But Amazon clearly goes for “we use this for anything we like.” Now does the data at least stay within Amazon?
Amazon shares this information with Amazon.com, Inc. and subsidiaries that Amazon.com, Inc. controls
This sounds like P&C above doesn’t mean “Peek & Cloppenburg,” since sharing data with this company (clearly not controlled by Amazon) would violate this privacy policy. Let’s hope that this is true and the data indeed stays within Amazon. It’s not like I have a way of verifying that.
https://palant.info/2021/03/22/follow-up-on-amazon-assistants-data-collection/
|
|
Mozilla Security Blog: Firefox 87 trims HTTP Referrers by default to protect user privacy |
We are pleased to announce that Firefox 87 will introduce a stricter, more privacy-preserving default Referrer Policy. From now on, by default, Firefox will trim path and query string information from referrer headers to prevent sites from accidentally leaking sensitive user data.
Browsers send the HTTP Referrer header (note: original specification name is ‘HTTP Referer’) to signal to a website which location “referred” the user to that website’s server. More precisely, browsers have traditionally sent the full URL of the referring document (typically the URL in the address bar) in the HTTP Referrer header with virtually every navigation or subresource (image, style, script) request. Websites can use referrer information for many fairly innocent uses, including analytics, logging, or for optimizing caching.
Unfortunately, the HTTP Referrer header often contains private user data: it can reveal which articles a user is reading on the referring website, or even include information on a user’s account on a website.
The introduction of the Referrer Policy in browsers in 2016-2018 allowed websites to gain more control over the referrer values on their site, and hence provided a mechanism to protect the privacy of their users. However, if a website does not set any kind of referrer policy, then web browsers have traditionally defaulted to using a policy of ‘no-referrer-when-downgrade’, which trims the referrer when navigating to a less secure destination (e.g., navigating from https: to http:) but otherwise sends the full URL including path, and query information of the originating document as the referrer.
The ‘no-referrer-when-downgrade’ policy is a relic of the past web, when sensitive web browsing was thought to occur over HTTPS connections and as such should not leak information in HTTP requests. Today’s web looks much different: the web is on a path to becoming HTTPS-only, and browsers are taking steps to curtail information leakage across websites. It is time we change our default Referrer Policy in line with these new goals.

Firefox 87 new default Referrer Policy ‘strict-origin-when-cross-origin’ trimming user sensitive information like path and query string to protect privacy.
Starting with Firefox 87, we set the default Referrer Policy to ‘strict-origin-when-cross-origin’ which will trim user sensitive information accessible in the URL. As illustrated in the example above, this new stricter referrer policy will not only trim information for requests going from HTTPS to HTTP, but will also trim path and query information for all cross-origin requests. With that update Firefox will apply the new default Referrer Policy to all navigational requests, redirected requests, and subresource (image, style, script) requests, thereby providing a significantly more private browsing experience.
If you are a Firefox user, you don’t have to do anything to benefit from this change. As soon as your Firefox auto-updates to version 87, the new default policy will be in effect for every website you visit. If you aren’t a Firefox user yet, you can download it here to start taking advantage of all the ways Firefox works to improve your privacy step by step with every new release.”
The post Firefox 87 trims HTTP Referrers by default to protect user privacy appeared first on Mozilla Security Blog.
|
|
William Lachance: Blog moving back to wrla.ch |
House keeping news: I’m moving this blog back to the wrla.ch domain from wlach.github.io. This domain sorta kinda worked before (I set up a netlify deploy a couple years ago), but the software used to generate this blog referenced github all over the place in its output, so it didn’t really work as you’d expect. Anyway, this will be the last entry published on wlach.github.io: my plan is to turn that domain into a set of redirects in the future.
I don’t know how many of you are out there who still use RSS, but please update your feeds. I have filed a bug to update my Planet Mozilla entry, so hopefully the change there will be seamless.
Why? Recent events have made me not want to tie my public web presence to a particular company (especially a larger one, like Microsoft). I don’t have any immediate plans to move this blog off of github, but this gives me that option in the future. For those wondering, the original rationale for moving to github is in this post. Looking back, the idea of moving away from a VPS and WordPress made sense, the move away from my own domain less so. I think it may have been harder to set up static hosting (esp. with HTTPS) at that time, though I might also have just been ignorant.
In related news, I decided to reactivate my twitter account: you can once again find me there as @wrlach (my old username got taken in my absence). I’m not totally thrilled about this (I basically stand by what I wrote a few years ago, except maybe the concession I made to Facebook being “ok”), but it seems to be where my industry peers are. As someone who doesn’t have a large organic following, I’ve come to really value forums where I can share my work. That said, I’m going to be very selective about what I engage with on that site: I appreciate your understanding.
https://wlach.github.io/blog/2021/03/blog-moving-back-to-wrla-ch/?utm_source=Mozilla&utm_medium=RSS
|
|
Daniel Stenberg: curl is 23 years old today |
curl’s official birthday was March 20, 1998. That was the day the first ever tarball was made available that could build a tool named curl. I put it together and I called it curl 4.0 since I kept the version numbering from the previous names I had used for the tool. Or rather, I bumped it up from 3.12 which was the last version I used under the previous name: urlget.

Of course curl wasn’t created out of thin air exactly that day. The history can be traced back a little over a year earlier: On November 11, 1996 there was a tool named httpget released. It was developed by Rafael Sagula and this was the project I found and started contributing to. httpget 0.1 was less than 300 lines of a single C file. (The earliest code I still have source to is httpget 1.3, found here.)
I’ve said it many times before but I started poking on this project because I wanted to have a small tool to download currency rates regularly from a web site site so that I could offer them in my IRC bot’s currency exchange.
Small and quick decisions done back then, that would later make a serious impact on and shape my life. curl has been one of my main hobbies ever since – and of course also a full-time job since a few years back now.
On that exact same November day in 1996, the first Wget release shipped (1.4.0). That project also existed under another name prior to its release – and remembering back I don’t think I knew about it and I went with httpget for my task. Possibly I found it and dismissed it because of its size. The Wget 1.4.0 tarball was 171 KB.
After a short while, I took over as maintainer of httpget and expanded its functionality further. It subsequently was renamed to urlget when I added support for Gopher and FTP (driven by the fact that I found currency rates hosted on such servers as well). In the spring of 1998 I added support for FTP upload as well and the name of the tool was again misleading and I needed to rename it once more.
Naming things is really hard. I wanted a short word in classic Unix style. I didn’t spend an awful lot of time, as I thought of a fun word pretty soon. The tool works on URLs and it is an Internet client-side tool. ‘c’ for client and URL made ‘cURL’ seem pretty apt and fun. And short. Very “unixy”.
I already then wanted curl to be a citizen in the Unix tradition of using pipes and stdout etc. I wanted curl to work mostly like the cat command but for URLs so it would by default send the URL to stdout in the terminal. Just like cat does. It would then let us “see” the contents of that URL. The letter C is pronounced as see, so “see URL” also worked. In my pun-liking mind I didn’t need more. (but I still pronounce it “kurl”!)
I packaged curl 4.0 and made it available to the world on that Friday. Then at 2,200 lines of code. In the curl 4.8 release that I did a few months later, the THANKS file mentions 7 contributors who had helped out. It took us almost seven years to reach a hundred contributors. Today, that file lists over 2,300 names and we add a few hundred new entries every year. This is not a solo project!
curl was not a massive success or hit. A few people found it and 14 days after that first release I uploaded 4.1 with a few bug-fixes and a multi-decade tradition had started: keep on shipping updates with bug-fixes. “ship early and often” is a mantra we’ve stuck with.
Later in 1998 when we had done more than 15 releases, the web page featured this excellent statement:

I never had any world-conquering ideas or blue sky visions for the project and tool. I just wanted it to do Internet transfers good, fast and reliably and that’s what I worked on making reality.
To better provide good Internet transfers to the world, we introduced the library libcurl, shipped for the first time in the summer of 2000 and that then enabled the project to take off at another level. libcurl has over time developed into a de-facto internet transfer API.
Today, at its 23rd birthday that is still mostly how I view the main focus of my work on curl and what I’m here to do. I believe that if I’ve managed to reach some level of success with curl over time, it is primarily because of one particular quality. A single word:

We hold out. We endure and keep polishing. We’re here for the long run. It took me two years (counting from the precursors) to reach 300 downloads. It took another ten or so until it was really widely available and used.
In 2008, the curl website served about 100 GB data every month. This months it serves 15,600 GB – which interestingly is 156 times more data over 156 months! But most users of course never download anything from our site but they get curl from their distro or operating system provider.
curl was adopted in Red Hat Linux in late 1998, became a Debian package in May 1999, shipped in Mac OS X 10.1 in August 2001. Today, it is also shipped by default in Windows 10 and in iOS and Android devices. Not to mention the game consoles, Nintendo Switch, Xbox and Sony PS5.
Amusingly, libcurl is used by the two major mobile OSes but not provided as an API by them, so lots of apps, including many extremely large volume apps bundle their own libcurl build: YouTube, Skype, Instagram, Spotify, Google Photos, Netflix etc. Meaning that most smartphone users today have many separate curl installations in their phones.
Further, libcurl is used by some of the most played computer games of all times: GTA V, Fortnite, PUBG mobile, Red Dead Redemption 2 etc.
libcurl powers media players and set-top boxes such as Roku, Apple TV by maybe half a billion TVs.
curl and libcurl ships in virtually every Internet server and is the default transfer engine in PHP, which is found in almost 80% of the world’s almost two billion websites.
Cars are Internet-connected now. libcurl is used in virtually every modern car these days to transfer data to and from the vehicles.
Then add media players, kitchen and medical devices, printers, smart watches and lots of “smart” IoT things. Practically speaking, just about every Internet-connected device in existence runs curl.
I’m convinced I’m not exaggerating when I claim that curl exists in over ten billion installations world-wide

A few times over the years I’ve tried to see if curl could join an umbrella organization, but none has accepted us and I think it has all been for the best in the end. We are completely alone and independent, from organizations and companies. We do exactly as we please and we’re not following anyone else’s rules. Over the last few years, sponsorships and donations have really accelerated and we’re in a good position to pay large rewards for bug-bounties and more.
The fact that I and wolfSSL offer commercial curl support has only made curl stronger I believe: it lets me spend even more time working on curl and it makes more companies feel safer with going with curl, which in the end makes it better for all of us.
Those 300 lines of code in late 1996 have grown to 172,000 lines in March 2021.
Our most important job is to “not rock the boat”. To provide the best and most solid Internet transfer library you can find, on as many platforms as possible.
But to remain attractive we also need to follow with the times and adapt to new protocols and new habits as they emerge. Support new protocol versions, enable better ways to do things and over time deprecate the bad things in responsible ways to not hurt users.
In the short term I think we want to work on making sure HTTP/3 works, make the Hyper backend really good and see where the rustls backend goes.
After 23 years we still don’t have any grand blue sky vision or road map items to guide us much. We go where Internet and our users lead us. Onward and upward!

Over the last few days ahead of this birthday, I’ve tweeted 23 “curl numbers” from the project using the #curl23 hashtag. Those twenty-three numbers and facts are included below.
2,200 lines of code by March 1998 have grown to 170,000 lines in 2021 as curl is about to turn 23 years old
14 different TLS libraries are supported by curl as it turns 23 years old
2,348 contributors have helped out making curl to what it is as it turns 23 years old
197 releases done so far as curl turns 23 years
6,787 bug-fixes have been logged as curl turns 23 years old
10,000,000,000 installations world-wide make curl one of the world’s most widely distributed 23 year-olds
871 committers have provided code to make curl a 23 year old project
935,000,000 is the official curl docker image pull-counter at (83 pulls/second rate) as curl turns 23 years old
22 car brands – at least – run curl in their vehicles when curl turns 23 years old
100 CI jobs run for every commit and pull-request in curl project as it turns 23 years old
15,000 spare time hours have been spent by Daniel on the curl project as it turns 23 years old
2 of the top-2 mobile operating systems bundle and use curl in their device operating systems as curl turns 23
86 different operating systems are known to have run curl as it turns 23 years old
250,000,000 TVs run curl as it turns 23 years old
26 transport protocols are supported as curl turns 23 years old
36 different third party libraries can optionally be built to get used by curl as it turns 23 years old
22 different CPU architectures have run curl as it turns 23 years old
4,400 USD have been paid out in total for bug-bounties as curl turns 23 years old
240 command line options when curl turns 23 years
15,600 GB data is downloaded monthly from the curl web site as curl turns 23 years old
60 libcurl bindings exist to let programmers transfer data easily using any language as curl turns 23 years old
1,327,449 is the total word count for all the relevant RFCs to read for curl’s operations as curl turns 23 years old
1 founder and lead developer has stuck around in the project as curl turns 23 years old
https://daniel.haxx.se/blog/2021/03/20/curl-is-23-years-old-today/
|
|
Cameron Kaiser: TenFourFox FPR31 available |
http://tenfourfox.blogspot.com/2021/03/tenfourfox-fpr31-available.html
|
|
The Mozilla Blog: Reinstating net neutrality in the US |
Today, Mozilla together with other internet companies ADT, Dropbox, Eventbrite, Reddit, Vimeo, Wikimedia, sent a letter to the FCC asking the agency to reinstate net neutrality as a matter of urgency.
For almost a decade, Mozilla has defended user access to the internet, in the US and around the world. Our work to preserve net neutrality has been a critical part of that effort, including our lawsuit against the Federal Communications Commission (FCC) to keep these protections in place for users in the US.
With the recent appointment of Acting Chairwoman Jessica Rosenworcel to lead the agency, there will be a new opportunity to establish net neutrality rules at the federal level in the near future, ensuring that families and businesses across the country can enjoy these fundamental rights.
Net neutrality preserves the environment that allowed the internet to become an engine for economic growth. In a marketplace where users frequently do not have access to more than one internet service provider (ISP), these rules ensure that data is treated equally across the network by gatekeepers. More specifically, net neutrality prevents ISPs from leveraging their market power to slow, block, or prioritize content–ensuring that users can freely access ideas and services without unnecessary roadblocks. Without these rules in place, ISPs can make it more difficult for new ideas or applications to succeed, potentially stifling innovation across the internet.
The need for net neutrality protections has become even more apparent during the pandemic. In a moment where classrooms and offices have moved online by necessity, it is critically important to have rules paired with strong government oversight and enforcement to protect families and businesses from predatory practices. In California, residents will have the benefit of these fundamental safeguards as a result of a recent court decision that will allow the state to enforce its state net neutrality law. However, we believe that users nationwide deserve the same ability to control their own online experiences.
While there are many challenges that need to be resolved to fix the internet, reinstating net neutrality is a crucial down payment on the much broader internet reform that we need. Net neutrality is good for people and for personal expression. It is good for business, for innovation, for our economic recovery. It is good for the internet. It has long enjoyed bipartisan support among the American public. There is no reason to further delay its reinstatement once the FCC is in working order.
The post Reinstating net neutrality in the US appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2021/03/19/reinstating-net-neutrality-in-the-us/
|
|
The Rust Programming Language Blog: Building a shared vision for Async Rust |
The Async Foundations Working Group believes Rust can become one of the most popular choices for building distributed systems, ranging from embedded devices to foundational cloud services. Whatever they're using it for, we want all developers to love using Async Rust. For that to happen, we need to move Async Rust beyond the "MVP" state it's in today and make it accessible to everyone.
We are launching a collaborative effort to build a shared vision document for Async Rust. Our goal is to engage the entire community in a collective act of the imagination: how can we make the end-to-end experience of using Async I/O not only a pragmatic choice, but a joyful one?
The "vision document" starts with a cast of characters. Each character is tied to a particular Rust value (e.g., performance, productivity, etc) determined by their background; this background also informs the expectations they bring when using Rust.
Let me introduce you to one character, Grace. As an experienced C developer, Grace is used to high performance and control, but she likes the idea of using Rust to get memory safety. Here is her biography:
Grace has been writing C and C++ for a number of years. She's accustomed to hacking lots of low-level details to coax the most performance she can from her code. She's also experienced her share of epic debugging sessions resulting from memory errors in C. She's intrigued by Rust: she likes the idea of getting the same control and performance she gets from C but with the productivity benefits she gets from memory safety. She's currently experimenting with introducing Rust into some of the systems she works on, and she's considering Rust for a few greenfield projects as well.
For each character, we will write a series of "status quo" stories that describe the challenges they face as they try to achieve their goals (and typically fail in dramatic fashion!) These stories are not fiction. They are an amalgamation of the real experiences of people using Async Rust, as reported to us by interviews, blog posts, and tweets. To give you the idea, we currently have two examples: one where Grace has to debug a custom future that she wrote, and another where Alan -- a programmer coming from a GC'd language -- encounters a stack overflow and has to debug the cause.
Writing the "status quo" stories helps us to compensate for the curse of knowledge: the folks working on Async Rust tend to be experts in Async Rust. We've gotten used to the workarounds required to be productive, and we know the little tips and tricks that can get you out of a jam. The stories help us gauge the cumulative impact all the paper cuts can have on someone still learning their way around. This gives us the data we need to prioritize.
The ultimate goal of the vision doc, of course, is not just to tell us where we are now, but where we are going and how we will get there. Once we've made good progress on the status quo stories, the next step will be start brainstorming stories about the "shiny future".
Shiny future stories talk about what the world of async could look like 2 or 3 years in the future. Typically, they will replay the same scenario as a "status quo" story, but with a happier ending. For example, maybe Grace has access to a debugging tool that is able to diagnose her stuck tasks and tell her what kind of future they are blocked on, so she doesn't have to grep through the logs. Maybe the compiler could warn Alan about a likely stack overflow, or (better yet) we can tweak the design of select to avoid the problem in the first place. The idea is to be ambitious and focus first and foremost on the user experience we want to create; we'll figure out the steps along the way (and maybe adjust the goal, if we have to).
The async vision document provides a forum where the Async Rust community can plan a great overall experience for Async Rust users. Async Rust was intentionally designed not to have a "one size fits all" mindset, and we don't want to change that. Our goal is to build a shared vision for the end-to-end experience while retaining the loosely coupled, exploration-oriented ecosystem we have built.
The process we are using to write the vision doc encourages active collaboration and "positive sum" thinking. It starts with a brainstorming period, during which we aim to collect as many "status quo" and "shiny future" stories as we can. This brainstorming period runs for six weeks, until the end of April. For the first two weeks (until 2021-04-02), we are collecting "status quo" stories only. After that, we will accept both "status quo" and "shiny future" stories until the end of the brainstorming period. Finally, to cap off the brainstorming period, we will select winners for awards like "Most Humorous Story" or "Must Supportive Contributor".
Once the brainstorming period is complete, the working group leads will begin work on assembling the various stories and shiny futures into a coherent draft. This draft will be reviewed by the community and the Rust teams and adjusted based on feedback.
If you'd like to help us to write the vision document, we'd love for you to contribute your experiences and vision! Right now, we are focused on creating status quo stories. We are looking for people to author PRs or to talk about their experiences on issues or elsewhere. If you'd like to get started, check out the template for status quo stories -- it has all the information you need to open a PR. Alternatively, you can view the How To Vision page, which covers the whole vision document process in detail.
|
|
Robert Kaiser: Crypto stamp Collections - An Overview |
safeTransferFrom() function) - which is the normal way that those are transferred between owners - does actually test if the new owner is a simple account or a contract, and if it actually is a contract, it "asks" if that contract can receive tokens via a contract function call. The collection contract does use that function call to register any such transfer into the collection and puts such received assets into a list. As for transferring away an asset, you need to make a function call on the collection contract anyhow, removing from that list can be done there. So, this list can be made available for querying and will always be accurate - as long as "safe" transfers are used. Unfortunately, ERC-721 allows "unsafe" transfers via transferFrom() even though it warns that NFTs "MAY BE PERMANENTLY LOST" when that function is used. This was probably added into the standard mostly for compatibility with CryptoKitties, which predate this standard and only supported "unsafe" transfers. To deal with that, the collections contract has a function to "sync" ownership, which is given a contract address and token ID, and it adjusts it assets list accordingly by either adding or removing it from there. Note that there is a theoretical possibility to also lose an assets without being able to track it there, that's why both directions are supported there. (Note: OpenSea has used "unsafe" transfers in their "gift" functionality at least in the past, but that hopefully has been fixed by now.)externalCall() function, to which the caller needs to hand over a contract address to call and an encoded payload (which can relatively easily be generated e.g. via the web3.js library). The result is that the Collection can e.g. call the function for Crypto stamps sold via the OnChain shop to have their physical versions sent to a postage address, which is a function that only the owner of a Crypto stamp can call - as the Collection is that owner and its own owner can call this "external" function, things like this can still be achieved.https://home.kairo.at/blog/2021-03/crypto_stamp_collections_an_overview
|
|
Andrew Halberstadt: Managing Multiple Mozconfigs |
Mozilla developers often need to juggle multiple build configurations in their day to day work.
Strategies to manage this sometimes include complex shell scripting built into their mozconfig, or a
topsrcdir littered with mozconfig-* files and then calls to the build system like
MOZCONFIG=mozconfig-debug ./mach build. But there’s another method (which is basically just a
variant on the latter), that might help make managing mozconfigs a teensy bit easier:
mozconfigwrapper.
In the interest of not documenting things in blog posts (and because I’m short on time this morning), I invite you to read the README file of the repo for installation and usage instructions. Please file issues and don’t hesitate to reach out if the README is not clear or you have any problems.
|
|
Data@Mozilla: This Week in Glean: Reducing Release Friction |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
One thing that I feel less confident in myself about is the build and release process behind the software components I have been working on recently. That’s why I was excited to take on prototyping a “Better Build” in order to get a better understanding of how the build and release process works and hopefully make it a little better in the process. What is a “Better Build”? Well that’s what we have been calling the investigation into how to reduce the overall pain of releasing our Rust based components to consumers on Android, iOS, and desktop platforms.
Getting changes out the door from a Rust component like Glean all the way into Firefox for iOS is somewhat non-trivial right now and requires multiple steps in multiple repositories, each of which has its own different procedures and ownership. Glean in Firefox for iOS currently ships via the Application Services iOS megazord, mostly because that allows us to compile most of the Rust code together to make a smaller impact on the app. That means, if we need to ship a bug fix in Glean on iOS we need to:
That’s a process that can take multiple days to accomplish and requires the involvement of multiple members of multiple teams. Even then, we can run into unexpected hiccups that slow the process down, like breaking changes in the other components that we have bundled together. Getting things into Fenix isn’t much easier, especially because there is yet another repository and release process involved with Android Components in the mix.
This creates a situation where we hold back on the frequency of releases and try to bundle as many fixes and changes as possible to reduce the number of times we have to subject ourselves to the release process. This same situation makes errors and bugs harder to find, because, once they have been introduced into a component it may be days or weeks before they show up. Once the errors do show up, we hope that they register as test failures and get caught before going live, but sometimes we see the results in crash reports or in data analysis. It is then not a simple task to determine what you are looking for when there is a Glean release that’s in an Application Services release that’s in an Android Components release that’s in a Fenix release… all of which have different versions.
It might be easier if each of our components were a stand-alone dependency of the consuming application, but our Rust components want and need to call each other. So there is some interdependence between them which requires us to build them together if we want to take the best advantage of calling things in other crates in Rust. Building things together also helps to minimize the size impact of the library on consuming applications, which is especially important for mobile.
So how was I going to make any of this part of a “Better Build”? The first thing I needed to do was to create a new git repository that combined Application Services, Glean, Nimbus, and Uniffi. There were a couple of different ways to accomplish this and I chose to go with git submodules as that seemed to be the simplest path to getting everything in one place so I could start trying to build things together. The first thing that complicated this approach was that Application Services already pulls in Glean and Nimbus as submodules, so I spent some time hacking around removing those so that all I had was the versions in the submodules I had added. Upon reflecting on this later, I probably should have just worked off of a fork of Application Services since it basically already had everything I needed in it, just lacking all the things in the Android and iOS builds. Git submodules didn’t seem to make things too terribly difficult to update, and should be possible to automate as part of a build script. I do foresee each component repository needing something like a release branch that would always track the latest release so that we don’t have to go in and update the tag that the submodule in the Better Builds repo points at. The idea being that the combined repo wouldn’t need to know about the releases or release schedule of the submodules, pushing that responsibility to the submodule’s original repo to advertise releases in a standardized way like with a release branch. This would allow us to have a regular release schedule for the Better Build that could in turn be picked up by automation in downstream consumers.
Now that I had everything in one place, the next step was to build the Rusty parts together so there was something to link the Android and iOS builds to, because some of the platform bindings of the components we build have Kotlin and Swift stuff that needs to be packaged on top of the Rust stuff, or at least need repackaged in a format suitable for consumers on the platform. Let me just say right here, Cargo made this very easy for me to figure out. It took only a little while to set up the build dependencies. With each project already having a “root” workspace Cargo.toml, I learned that I couldn’t nest workspaces. Not to fear, I just needed to exclude those directories from my root workspace Cargo.toml and it just worked. Finally, a few patch directives were needed to ensure that everyone was using the correct local copies of things like viaduct, Uniffi, and Glean. After a few tweaks, I was able to build all the Rust components in under 2 minutes from cargo build to done.
Armed with these newly built libs, I next set off to tackle an Android build using Gradle. I had the most prior art to see how to do this so I figured it wouldn’t be too terrible. In fact, it was here that I ran into a bit of a brick wall. My first approach was to try and build everything as subprojects of the new repo, but unfortunately, there was a lot of references to rootProject that meant “the root project I think I am in, not this new root project” and so I found myself changing more and more build.gradle files embedded in the components. After struggling with this for a day or so, I then switched to trying a composite build of the Android bits of all the components. This allowed me to at least build, once I had everything set up right. It was also at this point that I realized that having the embedded submodules for Nimbus and Glean inside of Application Services was causing me some problems, and so I ended up dropping Nimbus from the base Better Build repo and just using the one pulled into Application Services. Once I had done this, the gradle composite build was just a matter of including the Glean build and the Application Services build in the settings.gradle file. Along with a simple build.gradle file, I was able to build a JAR file which appeared to have all the right things in it, and was approximately the size I would expect when combining everything. I was now definitely at the end of my Gradle knowledge, and I wasn’t sure how to set up the publishing to get the AAR file that would be consumed by downstream applications.
I was starting to run out of time in my timebox, so I decided to tinker around with the iOS side of things and see how unforgiving Xcode might be. Part of the challenge here was that Nimbus didn’t really have iOS bindings yet, and we have already shown that this can be done with Application Services and Glean via the iOS megazord, so I started by trying to get Xcode to generate the Uniffi bindings in Swift for Nimbus. Knowing that a build phase was probably the best bet, I started by writing a script that would invoke the call to uniffi-bindgen with the proper flags to give me the Swift bindings, and then added the output file. But, no matter what I tried, I couldn’t get Xcode to invoke Cargo within a build phase script execution to run uniffi-bindgen. Since I was now out of time in my investigation, I couldn’t dig any deeper into this and I hope that it’s just some configuration problem in my local environment or something.
I took some time to consolidate and share my notes about what I had learned, and I did learn a lot, especially about Cargo and Gradle. At least I know that learning more about Gradle would be useful, but I was still disappointed that I couldn’t have made it a little further along to try and answer more of the questions about automation which is ultimately the real key to solving the pain I mentioned earlier. I was hoping to have a couple of prototype GitHub actions that I could demo, but I didn’t quite get there without being able to generate the proper artifacts.
The final lesson I learned was that this was definitely something that was outside of my comfort zone. And you know what? That was okay. I identified an area of my knowledge that I wanted to and could improve. While it was a little scary to go out and dive into something that was both important to the project and the team as well as something that I wasn’t really sure I could do, there were a lot of people who helped me through answering the questions I had.
https://blog.mozilla.org/data/2021/03/16/this-week-in-glean-reducing-release-friction/
|
|
Karl Dubost: Working With A Remote Distributed Team (Mozilla Edition) |
The Mozilla Webcompat team has always been an internationally distributed team from the start (7+ years). I have been working this way for the last 20 years with episodes of in-office life.

When sending messages to talk about something, always choose the most open forum first.
It's always easier to restrict a part of a message to a more private discussion. Once a discussion starts in private, making its content available to a larger sphere extends the intimacy, privacy, secrecy. It becomes increasingly harder to know if we can share it more broadly.
Everything you say, write, think might be interesting for someone out there in another Mozilla team, someone in Mozilla contributors community, someone out there in the world. I can't count the number of times I have been happy to learn through people discussing in the open, sharing what they do internally. It's inspiring. It extends your community. It solidifies the existence of your organization.
When the scope is broad, the information becomes more resilient. More people know the information. You probably had to use a publishing system involving the persistence of the information.
Give it a URI, so it exists! or in the famous words of Descartes: "URI, ergo sum".
URI is this thing which starts with http or https that you are currently using to read this content. Once you gave a URI to a piece of content, you access to plenty of features:
You may want to create a URI persistence policy at the organization level.
Context is everything!
This applies to basically all messaging style (chat, email, etc.)
If you send a message addressing someone, think about this:
note: I have written, a long time ago, a special guide for working with emails in French and it has been translated in English
Mozilla is a distributed community with a lot of different cultures (social, country, education, beliefs) and across all timezones. At Flickr, Heather Champ had a good reminder for the community: "Don't be a creep."
You may (will probably) do terrible blunders with regards to someone else. Address them right away when the person is making a comment about them. And if necessary, apologize in the same context, you made the mistake. When you are on the receiving part of the offensive message, address them with the person who made them right away in private. Seek for clarification and explain how it can have been hurtful. If it repeats, bring it up to the hierarchy ladder and/or follow the community guidelines.
When sending messages to share things about your work at Mozilla, use matrix over slack. It will be more accessible to the community and it will allow more participation.
That said be mindful. These systems do not have built-in web archives. That's a strength and a weakness. The strength part is that it allows a more casual tone on discussing stuff without realizing that you are saying today could become embarassing in 10 years. The weakness part is that there is valuable work discussions going on sometimes in chat. So if you think a discussion on chat was important enough that it deserves a permanent record, publish it in a more permanent and open space. (Exactly this blog post which started by a discussion on slack about someone inquiring about Team communications at Mozilla.)
Read Only Emails Sent To You.
Ah emails… the most loved hating subject. I understand that mail clients can be infuriating, but mails are really an easy task. Probably the issue with emails is not that much the emails themselves, but the way we treat them. Again see my guide for working with emails.
I end up all my working days with all messages marked as read. I don't understand what INBOX 0 means. So here my recipes:
/2021/03 mailbox.Cc:. This is bad. It encourages top replies to keep context. There is always someone missing who needs to be added later. It doesn't resist time at all. Information belongs to the organization/context you are working on, not the people. You will be leaving one day the organization. New people will join. The information needs to be accessible.With these, you will greatly reduce your burden. And one last thing, probably which is conter-intuitive. For work, do not use emails on your mobile phone. Mail clients on mobile are not practical. Typing on a virtual keyboard on a small screen for emails is useless. Mails require space.
Meetings are for discussions
If it's about information sharing, there are many ways of doing it in a better way. Publish a blog post, write it on a wiki, send it to the mailing-list of the context of your information. But do not create a meeting to just have one person talking all the time. Meetings are here for the interactions and picking ideas.
Here some recommendations for good meetings:
In a distributed team, the shape of Earth comes to crash into the fixed time reality of a meeting. You will not be able to satisfy everyone, but there are things to avoid the usual grumpiness, frustrations.
Publish Online with a wide accessible scope if possible.
First rule at the start. If you create a Google docs, do not forget to set the viewing and sharing rights for the document. Think long term. For example, the wiki at Mozilla has been here for a longer time than Google Docs. Mozilla controls the URI space of the wiki, but not so much the one of Google Docs.
Having an URI for your information is key as said above.
If you have more questions, things I may have missed, different take on them. Feel free to comment…. Be mindful.
Otsukare!
https://www.otsukare.info/2021/03/16/working-tips-remote-team
|
|
The Firefox Frontier: How one business founder is brewing new ideas for her future after a rough 2020 |
After years of brewing beer at home and honing her craft, Briana Brake turned her passion into a profession by starting Spaceway Brewing Company in Rocky Mount, North Carolina. She … Read more
The post How one business founder is brewing new ideas for her future after a rough 2020 appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/briana-brake-spaceway-brewing-woman-owned-online-business/
|
|
Wladimir Palant: DuckDuckGo Privacy Essentials vulnerabilities: Insecure communication and Universal XSS |
A few months ago I looked into the inner workings of DuckDuckGo Privacy Essentials, a popular browser extension meant to protect the privacy of its users. I found some of the typical issues (mostly resolved since) but also two actual security vulnerabilities. First of all, the extension used insecure communication channels for some internal communication, which, quite ironically, caused some data leakage across domain boundaries. The second vulnerability gave a DuckDuckGo server way more privileges than intended: a Cross-site Scripting (XSS) vulnerability in the extension allowed this server to execute arbitrary JavaScript code on any domain.
Both issues are resolved in DuckDuckGo Privacy Essentials 2021.2.3 and above. At the time of writing, this version is only available for Google Chrome however. Two releases have been skipped for Mozilla Firefox and Microsoft Edge for some reason, so that the latest version available here only fixes the first issue (insecure internal communication). Update (2021-03-16): An extension version with the fix is now available for both Firefox and Edge.

These vulnerabilities are very typical, I’ve seen similar mistakes in other extensions many times. This isn’t merely extension developers being clueless. The extension platform introduced by Google Chrome simply doesn’t provide secure and convenient alternatives. So most extension developers are bound to get it wrong on the first try. Update (2021-03-16): Linked to respective Chromium issues.
Seeing window.postMessage() called in a browser extension’s content script is almost always a red flag. That’s because it is really hard to use this securely. Any communication will be visible to the web page, and it is impossible to distinguish legitimate messages from those sent by web pages. This doesn’t stop extensions from trying of course, simply because this API is so convenient compared to secure extension APIs.
In case of DuckDuckGo Privacy Essentials, the content script element-hiding.js used this to coordinate actions of different frames in a tab. When a new frame loaded, it sent a frameIdRequest message to the top frame. And the content script there would reply:
if (event.data.type === 'frameIdRequest') {
document.querySelectorAll('iframe').forEach((frame) => {
if (frame.id && !frame.className.includes('ddg-hidden') && frame.src) {
frame.contentWindow.postMessage({
frameId: frame.id,
mainFrameUrl: document.location.href,
type: 'setFrameId'
}, '*')
}
})
}
While this communication is intended for the content script loaded in a frame, the web page there can see it as well. And if that web page belongs to a different domain, this leaks two pieces of data that it isn’t supposed to know: the full address of its parent frame and the id attribute of the tag where it is loaded.
Another piece of code was responsible for hiding blocked frames to reduce visual clutter. This was done by sending a hideFrame message, and the code handling it looked like this:
if (event.data.type === 'hideFrame') {
let frame = document.getElementById(event.data.frameId)
this.collapseDomNode(frame)
}
Remember, this isn’t some private communication channel. Without any origin checks, any website could have sent this message. It could be a different frame in the same tab, it could even be the page which opened this pop-up window. And this code just accepts the message and hides some document element. Without even verifying that it is indeed an iframe tag. This certainly makes the job of anybody running a Clickjacking attack much easier.
DuckDuckGo addressed the issue by completely removing this entire content script. Good riddance!
When extensions load content scripts dynamically, the tabs.executeScript() API allows them to specify the JavaScript code as string. Sadly, using this feature is sometimes unavoidable given how this API has no other way of passing configuration data to static script files. It requires special care however, there is no Content Security Policy here to save you if you embed data from untrusted sources into the code.
The problematic code in DuckDuckGo Privacy Essentials looked like this:
var variableScript = {
'runAt': 'document_start',
'allFrames': true,
'matchAboutBlank': true,
'code': `
try {
var ddg_ext_ua='${agentSpoofer.getAgent()}'
} catch(e) {}
`
};
chrome.tabs.executeScript(details.tabId, variableScript);
Note how agentSpoofer.getAgent() is inserted into this script without any escaping or sanitization. Is that data trusted? Sort of. The data used to decide about spoofing the user agent is downloaded from staticcdn.duckduckgo.com. So the good news are: the websites you visit cannot mess with it. The bad news: this data can be manipulated by DuckDuckGo, by Microsoft (hosting provider) or by anybody else who gains access to that server (hackers or government agency).
If somebody managed to compromise that data (for individual users or for all of them), the impact would be massive. First of all, this would allow executing arbitrary JavaScript code in the context of any website the user visits (Universal XSS). But content scripts can also send messages to the extension’s background page. Here the background page will react for example to messages like {getTab: 1} (retrieving information about user’s tabs), {updateSetting: {name: "activeExperiment", value: "2"}} (changing extension settings) and many more.
Per my recommendation, the problematic code has been changed to use JSON.stringify():
'code': `
try {
var ddg_ext_ua=${JSON.stringify(agentSpoofer.getAgent())}
} catch(e) {}
`
This call will properly encode any data, so that it is safe to insert into JavaScript code. The only concern (irrelevant in this case): if you insert JSON-encoded data into a in the data. You can escape forward slashes after calling JSON.stringify() to avoid this issue.
I’ve heard that Google is implementing Manivest V3 in order to make their extension platform more secure. While these changes will surely help, may I suggest doing something about the things that extensions continuously get wrong? If there are no convenient secure APIs, extension developers will continue using insecure alternatives.
For example, extension developers keep resorting to window.postMessage() for internal communication. I understand that runtime.sendMessage() is all one needs to keep things secure. But going through the background page when you mean to message another frame is very inconvenient, doing it correctly requires lots of boilerplate code. So maybe an API to communicate between content scripts in the same tab could be added to the extension platform, even if it’s merely a wrapper for runtime.sendMessage()?
The other concern is the code parameter in tabs.executeScript(), security-wise it’s a footgun that really shouldn’t exist. It has only one legitimate use case: to pass configuration data to a content script. So how about extending the API to pass a configuration object along with the script file? Yes, same effect could also be achieved with a message exchange, but that complicates matters and introduces timing issues, which is why extension developers often go for a shortcut.
|
|
Mike Taylor: Slack is optimized for Firefox version 520 |
Last week my pal Karl sent me a link to web-bug 67866: which has the cool title “menu buttons don’t work in Firefox version 100”. It turns out that Mozilla’s Chris Peterson has been surfing the web with a spoofed UA string reporting version 100 to see what happens (because he knows the web can be a hot mess, and that history is bound to repeat itself).
The best part of the report, IMHO, is Chris’ comment:
I discovered Slack’s message popup menu’s buttons (such as “Add reaction” or “Reply in thread”) stop working for Firefox versions >= 100 and <= 519. They mysteriously start working again for versions >= 520.
(I like to imagine he manually bisected Firefox version numbers from 88 to 1000, because it feels like something wacky that I would try.)

Broken website diagnosis wizard Tom Wisniewski followed a hunch that Slack was doing string comparison on version numbers, and found the following code:
const _ = c.a.firefox && c.a.version < '52' ||
c.a.safari && c.a.version < '11'
? h
: 'button',
(We’re just going to ignore what h is, and the difference between that and button presumably solving some cross-browser interop problem; I trust it’s very clever.)
So this is totally valid JS, but someone forgot that comparison operators for strings in JS do alphanumeric comparison, comparing each character between the two strings (we’ve all been there).
So that’s how you get the following comparisons that totally work, until they totally don’t:
> "10" < "1"
false // ok
> "10" < "20"
true // sure
> "10" < "2"
true // lol, sure why not
So, how should you really be comparing stringy version numbers? Look, I don’t know, this isn’t leetcode. But maybe “search up” (as the kids say) String.prototype.localeCompare or parseInt and run with that (or don’t, I’m not in charge of you).
https://miketaylr.com/posts/2021/03/firefox-version-520-works-in-slack.html
|
|






