Mozilla B-Team: happy bmo push day! |
Bugfixes + enabling the new security feature for API keys.
the following changes have been pushed to bugzilla.mozilla.org:
- [1541303] Default component bug type is not set as expected; enhancement severity is still used for existing bugs
- [1543760] When cloning a bug, the bug is added to ‘Regressed by’ of the new bug
- [1543718] Obsolete attachments should have a strikethrough
- [1543798] Do not treat email addresses with invalid.bugs as unassigned…
|
|
Daniel Stenberg: curl + hackerone = TRUE |
There seems to be no end to updated posts about bug bounties in the curl project these days. Not long ago I mentioned the then new program that sadly enough was cancelled only a few months after its birth.
Now we are back with a new and refreshed bug bounty program! The curl bug bounty program reborn.
This new program, which hopefully will manage to survive a while, is setup in cooperation with the major bug bounty player out there: hackerone.
If you find or suspect a security related issue in curl or libcurl, report it! (and don’t speak about it in public at all until an agreed future date.)
You’re entitled to ask for a bounty for all and every valid and confirmed security problem that wasn’t already reported and that exists in the latest public release.
The curl security team will then assess the report and the problem and will then reward money depending on bug severity and other details.
We intend to use funds and money from wherever we can. The Hackerone Internet Bug Bounty program helps us, donations collected over at opencollective will be used as well as dedicated company sponsorships.
We will of course also greatly appreciate any direct sponsorships from companies for this program. You can help curl getting even better by adding funds to the bounty program and help us reward hard-working researchers.
We compete for the security researchers’ time and attention with other projects, both open and proprietary. The projects that can help put food on these researchers’ tables might have a better chance of getting them to use their tools, time, skills and fingers to find our problems instead of someone else’s.
Finding and disclosing security problems can be very time and resource consuming. We want to make it less likely that people give up their attempts before they find anything. We can help full and part time security engineers sustain their livelihood by paying for the fruits of their labor. At least a little bit.
The state of the code repository in git is not subject for bounties. We need to allow developers to do mistakes and to experiment a little in the git repository, while we expect and want every actual public release to be free from security vulnerabilities.
So yes, the obvious downside with this is that someone could spot an issue in git and decide not to report it since it doesn’t give any money and hope that the flaw will linger around and ship in the release – and then reported it and claim reward money. I think we just have to trust that this will not be a standard practice and if we in fact notice that someone tries to exploit the bounty in this manner, we can consider counter-measures then.

There’s of course always a discussion as to why we should pay anyone for bugs and then why just pay for reported security problems and not for heroes who authored the code in the first place and neither for the good people who write the patches to fix the reported issues. Those are valid questions and we would of course rather pay every contributor a lot of money, but we don’t have the funds for that. And getting funding for this kind of dedicated bug bounties seem to be doable, where as a generic pay contributors fund is trickier both to attract money but it is also really hard to distribute in an open project of curl’s nature.
At the start of this program the award amounts are as following. We reward up to this amount of money for vulnerabilities of the following security levels:
Critical: 2,000 USD
High: 1,500 USD
Medium: 1,000 USD
Low: 500 USD
Depending on how things go, how fast we drain the fund and how much companies help us refill, the amounts may change over time.
|
|
Christopher Arnold |




https://ncubeeight.blogspot.com/2018/12/at-last-years-game-developers.html
|
|
Christopher Arnold: How a speech-based internet will change our perceptions |
 |
| https://en.wikipedia.org/wiki/Beowulf |
https://ncubeeight.blogspot.com/2019/01/how-speech-based-internet-will-change.html
|
|
Christopher Arnold: My 20 years of web |
 The amazing thing about the Internet is the creativity it brings out of the people who engage with it. Back when I started telling the story of the web to people, I realized I needed to have my own web page. So I needed to figure out what I wanted to amplify to the world. Because I admired folk percussion that I'd seen while I was living in Japan, I decided to make my website about the drums of the world. I used a web editor called Geocities to create this web page you see at right. I decided to leave in its original 1999 Geocities template design for posterity's sake. Since then my drum pursuits have expanded to include various other web projects including a YouTube channel dedicated to traditional folk percussion. A flickr channel dedicated to drum photos. Subsequently I launched a Soundcloud channel and a Mixcloud DJ channel for sharing music I'd composed or discovered over the decades.
The amazing thing about the Internet is the creativity it brings out of the people who engage with it. Back when I started telling the story of the web to people, I realized I needed to have my own web page. So I needed to figure out what I wanted to amplify to the world. Because I admired folk percussion that I'd seen while I was living in Japan, I decided to make my website about the drums of the world. I used a web editor called Geocities to create this web page you see at right. I decided to leave in its original 1999 Geocities template design for posterity's sake. Since then my drum pursuits have expanded to include various other web projects including a YouTube channel dedicated to traditional folk percussion. A flickr channel dedicated to drum photos. Subsequently I launched a Soundcloud channel and a Mixcloud DJ channel for sharing music I'd composed or discovered over the decades.https://ncubeeight.blogspot.com/2019/04/my-20-years-of-web.html
|
|
Mozilla Localization (L10N): L10n report: April edition |
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
New localizers
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
The deadline to ship localization updates in Firefox 67 is quickly approaching (April 30). Firefox 68 is going to be an ESR version, so it’s particularly important to ship the best localization possible. The deadline for that will be June 25.
The migration to Fluent is progressing steadily, and we are approaching two important milestones:
Lot’s of things have been happening on the mobile front, and much more is going to follow shortly.
One of the first things we’d like to call out if that Fenix browser strings have arrived for localization! While work has been opened up to only a small subset of locales, you can expect us to add more progressively, quite soon. More details around this can be found here and here.
We’ve also exposed strings for Firefox Reality, Mozilla’s mixed-reality browser! Also open to only a subset of locales, we expect to be able to add more locales once the in-app locale switcher is in place. Read more about this here.
There are more new and exciting projects coming up in the next few weeks, so as usual, stay tuned to the Dev.l10n mailing list for more announcements!
Concerning existing projects: Firefox iOS v17 l10n cycle is going to start within the next days, so keep an eye out on your Pontoon folder.
And concerning Fennec, just like for Firefox desktop, the deadline to ship localization updates in Firefox 67 is quickly approaching (April 30). Please read the section above for more details.
Fluent Syntax 1.0 has been published! The syntax is now stable. Thanks to everyone who shared their feedback about Fluent in the past; you have made Fluent better for everyone. We published a blog post on Mozilla Hacks with more details about this release and about Fluent in general.
Fluent is already used in over 3000 messages in Firefox, as well as in Firefox Send and Common Voice. If you localize these projects, chances are you already localized Fluent messages. Thanks to the efforts of Matjaz and Adrian, Fluent is already well-supported in Pontoon. We continue to improve the Fluent experience in Pontoon and we’re open to your feedback about how to make it best-in-class.
You can learn more about the Fluent Syntax on the project’s website, through the Syntax Guide, and in the Mozilla localizer documentation. If you want to quickly see it in action, try the Fluent Playground—an online editor with shareable Fluent snippets.

Know someone in your l10n community who’s been doing a great job and should appear here? Contact on of the l10n-drivers and we’ll make sure they get a shout-out (see list at the bottom)!
Did you enjoy reading this report? Let us know how we can improve by reaching out to any one of the l10n-drivers listed above.
https://blog.mozilla.org/l10n/2019/04/19/l10n-report-april-edition-2/
|
|
The Mozilla Blog: Android Browser Choice Screen in Europe |
Today, Google announced a new browser choice screen in Europe. We love an opportunity to show more people our products, like Firefox for Android. Independent browsers that put privacy and security first (like Firefox) are great for consumers and an important part of the Android ecosystem.
There are open questions, though, about how well this implementation of a choice screen will enable people to easily adopt options other than Chrome as their default browser. The details matter, and the true measure will be the impact on competition and ultimately consumers. As we assess the results of this launch on Mozilla’s Firefox for Android, we’ll share our impressions and the impact we see.
The post Android Browser Choice Screen in Europe appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2019/04/18/android-browser-choice-screen-in-europe/
|
|
Mark Surman: Getting crisper about ‘better AI’ |
As I wrote a few weeks back, Mozilla is increasingly coming to the conclusion that making sure AI serves humanity rather than harms it is a key internet health issue. Our internet health movement building efforts will be focused in this area in the coming years.
In 2019, this means focusing a big part of our investment in fellowships, awards, campaigns and the Internet Health Report on AI topics. It also means taking the time to get crisper on what we mean by ‘better’ and defining a specific set of things we’d like to see happen around the politics, technology and use of AI. Thinking this through now will tee up work in the years to come.
We started this thinking in an ‘issue brief’ that looks at AI issues through the lens of internet health and the Mozilla Manifesto. It builds from the idea that intelligent systems are ultimately designed and shaped by humans — and then looks at areas where we need to collectively figure out how we want these systems used, who should control them and how we should mitigate their risks. The purpose of this brief is to spark discussions in and around Mozilla that will help us come up with more specific goals and plans of action.
As we dig into this thinking, one thing is starting to become clear: the most likely way for Mozilla to to push the future of AI in a good direction is to focus on the how automated decision making is being used in consumer products and services. The big tech companies in the US and China that provide the bulk of the internet products we use everyday are also the biggest creators and users of AI technology. The ways they deploy AI — from home assistants to ad targeting to navigation and delivery to content recommendation– also impact a growing majority of people on the planet. They are also major vendors of AI tools — like facial recognition software — used by governments and other companies. As we look around, it feels like not enough people are investigating how AI is playing out in big tech companies — and in the products and services they create. Also, consumer tech has always been the place where Mozilla has focused. It makes sense to stay focused here as we look at AI.
Beyond this constraint, the universe of possible goals for this work is quite broad. Some of the options that we are batting around include:
These are the sorts of questions we’re starting to debate — and will invite you to debate with us — over the coming months.
It’s worth noting that of these possible goals are focused on outcomes for users and society, and not on core AI technology. Mozilla is doing important and interesting technology work with things like Deep Speech and Common Voice, showing that collaborative, inclusionary, open source AI approaches are possible. However, Mozilla’s work on AI technology is modest at this point. This is one of the reasons that we decided to make ‘better machine decision making’ a focus of our movement building work right now. AI represents the next wave of computing and will shape what the internet looks like — how things work out with AI will have a huge impact on whether we live in a healthy digital environment, or not. It is critical that Mozilla weigh in on this early and strongly, and this includes going beyond what we’re able to do directly through writing code. The internet health movement building work we’ve been doing over the last few years gives us a way to do this, working with allies around the world who are also trying to nudge the future of AI in a good direction.
If you have thoughts on where this work is going — or should go — I’d love to hear them. You can comment on this blog, tweet or send me an email. There is also a wiki where you can track this work. And, there will be more specific opportunities for feedback on potential goals for our working coming over the next couple of months.
PS. I will write more about the topic of consumer tech and why we should focus on this area in an upcoming post.
The post Getting crisper about ‘better AI’ appeared first on Mark Surman.
https://marksurman.commons.ca/2019/04/17/getting-crisper-about-better-ai/
|
|
Mozilla B-Team: happy bmo push day! |
Note that I’ve missed the last two push announcements, you’ll want to check https://wiki.mozilla.org/BMO/Recent_Changes#Recent_Changes to be fully up-to date. That said, we’ve been very busy. In the past 30 days.
6 authors have pushed 76 commits to master and 81 commits to all branches.
On master, 213 files have changed and there have been 2,852 additions
and 850 deletions.Below the fold are all…
|
|
Chris H-C: Distributed Teams: A Test Failing Because It’s Run West of Newfoundland and Labrador |
(( Not quite 500 mile email-level of nonsense, but might be the closest I get. ))
A test was failing.
Not really unusual, that. Tests fail all the time. It’s how we know they’re good tests: protecting us developers from ourselves.
But this one was failing unusually. Y’see, it was failing on my machine.
(Yes, har har, it is a common-enough occurrence given my obvious lack of quality as a developer how did you guess.)
The unusual part was that it was failing only for me… and I hadn’t even touched anything yet. It wasn’t failing on our test infrastructure “try”, and it wasn’t failing on the machine of :raphael, the fellow responsible for the integration test harness itself. We were building Firefox the same way, running telemetry-tests-client the same way… but I was getting different results.
I fairly quickly locked down the problem to be an extra “main” ping with reason “environment-change” being sent during the initial phases of the test. By dumping some logging into Firefox, rebuilding it, and then routing its logs to console with --gecko-log "-" I learned that we were sending a ping because a monitored user preference had been changed: browser.search.region.
When Firefox starts up the first time, it doesn’t know where it is. And it needs to know where it is to properly make a first guess at what language you want and what search engines would work best. Google’s results are pretty bad in Canada unless you use “google.ca”, after all.
But while Firefox doesn’t know where it is, it does know is what timezone it’s in from the settings in your OS’s clock. On top of that it knows what language your OS is set to. So we make a first guess at which search region we’re in based on whether or not the timezone overlaps a US timezone and if your OS’ locale is `en-US` (United States English).
What this fails to take into account is that United States English is the “default” locale reported by many OSes even if you aren’t in the US. And how even if you are in a timezone that overlaps with the US, you might not be there.
So to account for that, Mozilla operates a location service to double-check that the search region is appropriately set. This takes a little time to get back with the correct information, if it gets back to us at all. So if you happen to be in a US-overlapping timezone with an English-language OS Firefox assumes you’re in the US. Then if the location service request gets back with something that isn’t “US”, browser.search.region has to be updated.
And when it updates, it changes the Telemetry Environment.
And when the Environment changes, we send a “main” ping.
And when we send a “main” ping, the test breaks.
…all because my timezone overlaps the OS and my language is “Default” English.
I feel a bit persecuted, but this shows another strength of Distributed Teams. No one else on my team would be able to find this failure. They’re in Germany, Italy, and the US. None of them have that combination of “Not in the US, but in a US timezone” needed to manifest the bug.
So on one hand this sucks. I’m going to have to find a way around this.
But on the other hand… I feel like my Canadianness is a bit of a bug-finding superpower. I’m no Brok Windsor or Captain Canuck, but I can get the job done in a way no one else on my team can.
Not too bad, eh?
:chutten
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla reacts to European Parliament plenary vote on EU Terrorist Content regulation |
This evening lawmakers in the European Parliament voted to adopt the institution’s negotiating position on the EU Terrorist Content regulation.
Here is a statement from Owen Bennett, Internet Policy Manager, reacting to the vote –
As the recent atrocities in Christchurch underscored, terrorism remains a serious threat to citizens and society, and it is essential that we implement effective strategies to combat it. But the Terrorist Content regulation passed today in the European Parliament is not that. This legislation does little but chip away at the rights of European citizens and further entrench the same companies the legislation was aimed at regulating. By demanding that companies of all sizes take down ‘terrorist content’ within one hour the EU has set a compliance bar that only the most powerful can meet.
Our calls for targeted, proportionate and evidence-driven policy responses to combat the evolving threat, were not accepted by the majority, but we will continue to push for a more effective regulation in the next phase of this legislative process. The issue is simply too important to get wrong, and the present shortfalls in the proposal are too serious to let stand.
The post Mozilla reacts to European Parliament plenary vote on EU Terrorist Content regulation appeared first on Open Policy & Advocacy.
|
|
Nicholas Nethercote: A better DHAT |
DHAT is a heap profiler that comes with Valgrind. (The name is short for “Dynamic Heap Analysis Tool”.) It tells your where all your heap allocations come from, and can help you find the following: places that cause excessive numbers of allocations; leaks; unused and under-used allocations; short-lived allocations; and allocations with inefficient data layouts. This old blog post goes into some detail.
In the new Valgrind 3.15 release I have given DHAT a thorough overhaul.
The old DHAT was very useful and I have used it a lot while profiling the Rust compiler. But it had some rather annoying limitations, which the new DHAT overcomes.
First, the old DHAT dumped its data as text at program termination. The new DHAT collects its data in a file which is read by a graphical viewer that runs in a web browser. This gives several advantages.
Second, the old DHAT divided its output into records, where each record consisted of all the heap allocations that have the same allocation stack trace. The choice of stack trace depth could greatly affect the output.
In contrast, the new DHAT is based around trees of stack traces that avoid the need to choose stack trace depth. This avoids both the problem of not enough depth (when records that should be distinct are combined, and may not contain enough information to be actionable) and the problem of too much depth (when records that should be combined are separated, making them seem less important than they really are).
Third, the new DHAT also collects and/or shows data that the old DHAT did not.
Finally, the new DHAT has a better handling of realloc. The sequence p = malloc(100); realloc(p, 200); now increases the total block count by 2 and the total byte count by 300. In the old DHAT it increased them by 1 and 200. The new handling is a more operational view that better reflects the effect of allocations on performance. It makes a significant difference in the results, giving paths involving reallocation (e.g. repeated pushing to a growing vector) more prominence.
Overall these changes make DHAT more powerful and easier to use.
The following screenshot gives an idea of what the new graphical viewer looks like.

The new DHAT can be run using the --tool=dhat flag, in contrast with the old DHAT, which was an “experimental” tool and so used the --tool=exp-dhat flag. For more details see the documentation.
https://blog.mozilla.org/nnethercote/2019/04/17/a-better-dhat/
|
|
Hacks.Mozilla.Org: Fluent 1.0: a localization system for natural-sounding translations |
Fluent is a family of localization specifications, implementations and good practices developed by Mozilla. It is currently used in Firefox. With Fluent, translators can create expressive translations that sound great in their language. Today we’re announcing version 1.0 of the Fluent file format specification. We’re inviting translation tool authors to try it out and provide feedback.
With almost 100 supported languages, Firefox faces many localization challenges. Using traditional localization solutions, these are difficult to overcome. Software localization has been dominated by an outdated paradigm: translations that map one-to-one to the source language. The grammar of the source language, which at Mozilla is English, imposes limits on the expressiveness of the translation.
Consider the following message which appears in Firefox when the user tries to close a window with more than one tab.
tabs-close-warning-multiple =
You are about to close {$count} tabs.
Are you sure you want to continue?
The message is only displayed when the tab count is 2 or more. In English, the word tab will always appear as plural tabs. An English-speaking developer may be content with this message. It sounds great for all possible values of $count.
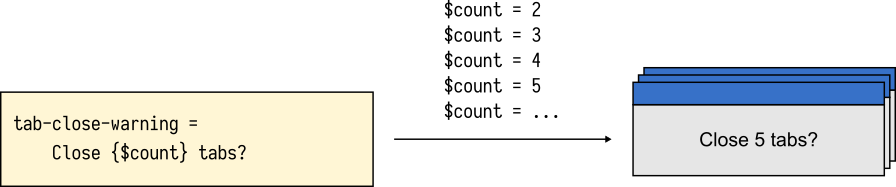
$count.Many translators, however, will quickly point out that the word tab will take different forms depending on the exact value of the $count variable.
In traditional localization solutions, the onus of fixing this message is on developers. They need to account for the fact that other languages distinguish between more than one plural form, even if English doesn’t. As the number of languages supported in the application grows, this problem scales up quickly—and not well.
There are many grammatical and stylistic variations that don’t map one-to-one between languages. Supporting all of them using traditional localization solutions isn’t straightforward. Some language features require trade-offs in order to support them, or aren’t possible at all.
Fluent turns the localization landscape on its head. Rather than require developers to predict all possible permutations of complexity in all supported languages, Fluent keeps the source language as simple as it can be.
We make it possible to cater to the grammar and style of other languages, independently of the source language. All of this happens in isolation; the fact that one language benefits from more advanced logic doesn’t require any other localization to apply it. Each localization is in control of how complex the translation becomes.
Consider the Czech translation of the “tab close” message discussed above. The word panel (tab) must take one of two plural forms: panely for counts of 2, 3, and 4, and panelu for all other numbers.
tabs-close-warning-multiple = {$count ->
[few] Chyst'ate se zavr'it {$count} panely. Opravdu chcete pokracovat?
*[other] Chyst'ate se zavr'it {$count} panelu. Opravdu chcete pokracovat?
}
Fluent empowers translators to create grammatically correct translations and leverage the expressive power of their language. With Fluent, the Czech translation can now benefit from correct plural forms for all possible values of the $count variable.
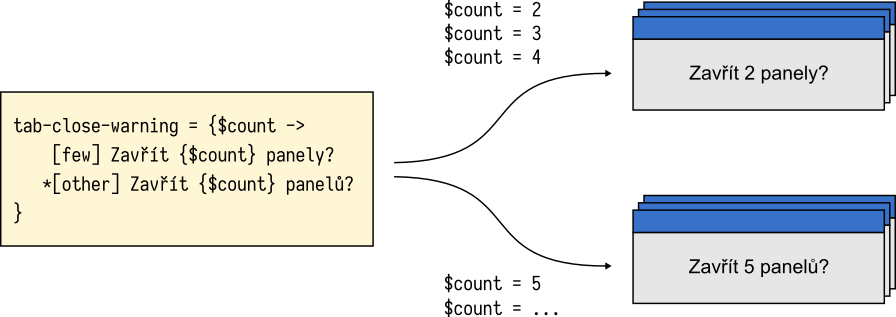
$count values of 2, 3, and 4 require a special plural form of the noun.At the same time, no changes are required to the source code nor the source copy. In fact, the logic added by the Czech translator to the Czech translation doesn’t affect any other language. The same message in French is a simple sentence, similar to the English one:
tabs-close-warning-multiple =
Vous ^etes sur le point de fermer {$count} onglets.
Voulez-vous vraiment continuer ?
The concept of asymmetric localization is the key innovation of Fluent, built upon 20 years of Mozilla’s history of successfully shipping localized software. Many key ideas in Fluent have also been inspired by XLIFF and ICU’s MessageFormat.
At first glance, Fluent looks similar to other localization solutions that allow translations to use plurals and grammatical genders. What sets Fluent apart is the holistic approach to localization. Fluent takes these ideas further by defining the syntax for the entire text file in which multiple translations can be stored, and by allowing messages to reference other messages.
A Fluent file may consist of many messages, each translated into the translator’s language. Messages can refer to other messages in the same file, or even to messages from other files. In the runtime, Fluent combines files into bundles, and references are resolved in the scope of the current bundle.
Referencing messages is a powerful tool for ensuring consistency. Once defined, a translation can be reused in other translations. Fluent even has a special kind of message, called a term, which is best suited for reuse. Term identifiers always start with a dash.
-sync-brand-name = Firefox Account
Once defined, the -sync-brand-name term can be referenced from other messages, and it will always resolve to the same value. Terms help enforce style guidelines; they can also be swapped in and out to modify the branding in unofficial builds and on beta release channels.
sync-dialog-title = {-sync-brand-name}
sync-headline-title =
{-sync-brand-name}: The best way to bring
your data always with you
sync-signedout-account-title =
Connect with your {-sync-brand-name}
Using terms verbatim in the middle of a sentence may cause trouble for inflected languages or for languages with different capitalization rules than English. Terms can define multiple facets of their value, suitable for use in different contexts. Consider the following definition of the -sync-brand-name term in Italian.
-sync-brand-name = {$capitalization ->
*[uppercase] Account Firefox
[lowercase] account Firefox
}
Thanks to the asymmetric nature of Fluent, the Italian translator is free to define two facets of the brand name. The default one (uppercase) is suitable for standalone appearances as well as for use at the beginning of sentences. The lowercase version can be explicitly requested by passing the capitalization parameter, when the brand name is used inside a larger sentence.
sync-dialog-title = {-sync-brand-name}
sync-headline-title =
{-sync-brand-name}: il modo migliore
per avere i tuoi dati sempre con te
# Explicitly request the lowercase variant of the brand name.
sync-signedout-account-title =
Connetti il tuo {-sync-brand-name(capitalization: "lowercase")}
Defining multiple term variants is a versatile technique which allows the localization to cater to the grammatical needs of many languages. In the following example, the Polish translation can use declensions to construct a grammatically correct sentence in the sync-signedout-account-title message.
-sync-brand-name = {$case ->
*[nominative] Konto Firefox
[genitive] Konta Firefox
[accusative] Kontem Firefox
}
sync-signedout-account-title =
Zaloguj do {-sync-brand-name(case: "genitive")}
Fluent makes it possible to express linguistic complexities when necessary. At the same time, simple translations remain simple. Fluent doesn’t impose complexity unless it’s required to create a correct translation.
sync-signedout-caption = Take Your Web With You
sync-signedout-caption = Il tuo Web, sempre con te
sync-signedout-caption = Zabierz swoja sie'c ze soba
sync-signedout-caption = So haben Sie das Web "uberall dabei.
Today, we’re announcing the first stable release of the Fluent Syntax. It’s a formal specification of the file format for storing translations, accompanied by beta releases of parser implementations in JavaScript, Python, and Rust.
You’ve already seen a taste of Fluent Syntax in the examples above. It has been designed with non-technical people in mind, and to make the task of reviewing and editing translations easy and error-proof. Error recovery is a strong focus: it’s impossible for a single broken translation to break the entire file, or even the translations adjacent to it. Comments may be used to communicate contextual information about the purpose of a message or a group of messages. Translations can span multiple lines, which helps when working with longer text or markup.
Fluent files can be opened and edited in any text editor, lowering the barrier to entry for developers and localizers alike. The file format is also well supported by Pontoon, Mozilla’s open-source translation management system.
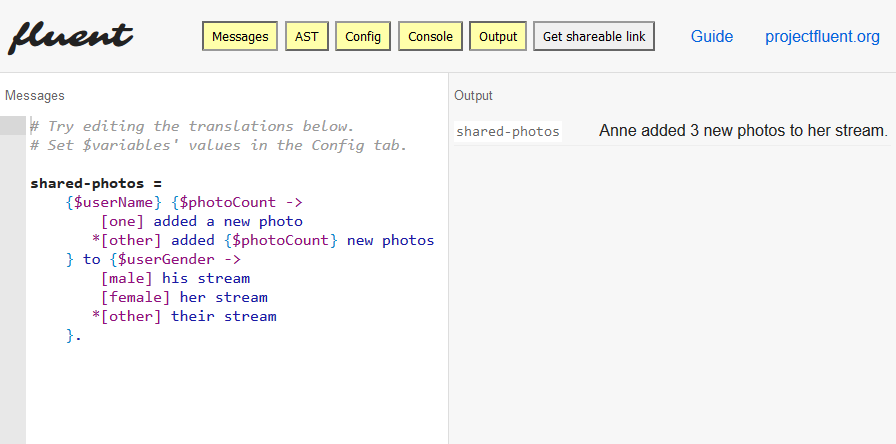
You can learn more about the syntax by reading the Fluent Syntax Guide. The formal definition can be found in the Fluent Syntax specification. And if you just want to quickly see it in action, try the Fluent Playground—an online editor with shareable Fluent snippets.
Firefox has been the main driver behind the development of Fluent so far. Today, there are over 3000 Fluent messages in Firefox. The migration from legacy localization formats started early last year and is now in full swing. Fluent has proven to be a stable and flexible solution for building complex interfaces, such as the UI of Firefox Preferences. It is also used in a number of Mozilla websites, such as Firefox Send and Common Voice.
We think Fluent is a great choice for applications that value simplicity and a lean runtime, and at the same time require that elements of the interface depend on multiple variables. In particular, Fluent can help create natural-sounding translations in size-constrained UIs of mobile apps; in information-rich layouts of social media platforms; and in games, to communicate gameplay statistics and mechanics to the player.
We’d love to hear from projects and localization vendors outside of Mozilla. Because we’re developing Fluent with a future standard in mind, we invite you to try it out and let us know if it addresses your challenges. With your help, we can iterate and improve Fluent to address the needs of many platforms, use cases, and industries.
We’re open to your constructive feedback. Learn more about Fluent on the project’s website and please get in touch on Fluent’s Discourse.
The post Fluent 1.0: a localization system for natural-sounding translations appeared first on Mozilla Hacks - the Web developer blog.
|
|
Daniel Stenberg: One year in still no visa |
One year ago today. On the sunny Tuesday of April 17th 2018 I visited the US embassy in Stockholm Sweden and applied for a visa. I’m still waiting for them to respond.
My days-since-my-visa-application counter page is still counting. Technically speaking, I had already applied but that was the day of the actual physical in-person interview that served as the last formal step in the application process. Most people are then getting their visa application confirmed within weeks.
Initially I emailed them a few times after that interview since the process took so long (little did I know back then), but now I haven’t done it for many months. Their last response assured me that they are “working on it”.
Lots of things have happened in my life since last April. I quit my job at Mozilla and started a new job at wolfSSL, again working for a US based company. One that I cannot go visit.
During this year I missed out on a Mozilla all-hands, I’ve been invited to the US several times to talk at conferences that I had to decline and a friend is getting married there this summer and I can’t go. And more.
Going forward I will miss more interesting meetings and speaking opportunities and I have many friends whom I cannot visit. This is a mild blocker to things I would want to do and it is an obstacle to my profession and career.
I guess I might get my rejection notice before my counter reaches two full years, based on stories I’ve heard from other people in similar situations such as mine. I don’t know yet what I’ll do when it eventually happens. I don’t think there are any rules that prevent me from reapplying, other than the fact that I need to pay more money and I can’t think of any particular reason why they would change their minds just by me trying again. I will probably give it a rest a while first.
I’m lucky and fortunate that people and organizations have adopted to my situation – a situation I of course I share with many others so it’s not uniquely mine – so lots of meetings and events have been held outside of the US at least partially to accommodate me. I’m most grateful for this and I understand that at times it won’t work and I then can’t attend. These days most things are at least partly accessible via video streams etc, repairing the harm a little. (And yes, this is a first-world problem and I’m fortunate that I can still travel to most other parts of the world without much trouble.)
Finally: no, I still have no clue as to why they act like this and I don’t have any hope of ever finding out.

https://daniel.haxx.se/blog/2019/04/17/one-year-in-still-no-visa/
|
|
The Mozilla Blog: Latest Firefox for iOS Now Available |
Today’s Firefox for iPhone and iPad users offers enhancements that will make it easier to get you to what you want faster, from new links within your library and managing your logins and passwords, plus deleting your history as recent as the last hour.
With today’s release, we made it easier to clear your web history with one tap on the history page. In the menu or on the Firefox Home page, tap ‘Your Library’, then ‘History’, and ‘Clear Recent History’. You’ll be able to quickly delete browsing data from the last hour, that day, or that day and the day before.
Because we all make wrong turns on the web from time to time, you can now choose to delete your history from only the last hour, that specific day, the day and the one before or, as it has always been, your full browsing history.
Clear your web history with one tap
Everyone likes a shortcut that gets you quickly to the place you need to go. We created links in your library to get you to your bookmarks, history, reading list and downloads all from the Firefox Home screen.
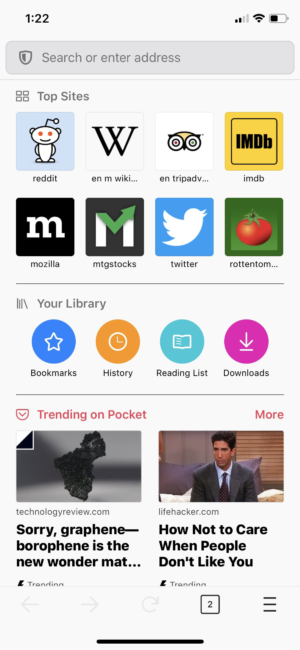
Get you to your bookmarks, history, reading list and downloads all from the Firefox Home screen
We simplified the place where you can find your logins and passwords in the menu. Go to the menu and tap ‘Logins & Passwords’. Also, from there you can enable Face ID or password authentication in Settings to keep your passwords even more secure. It’s located under in the Face ID & Passcode option.
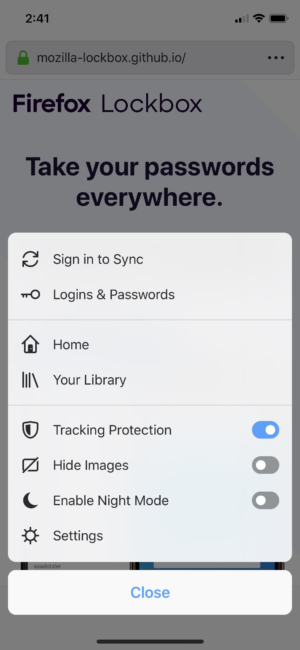
Find your logins and passwords easily
To get the latest version of Firefox for iOS, visit the App Store.
The post Latest Firefox for iOS Now Available appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2019/04/16/latest-firefox-for-ios-now-available/
|
|
Mozilla Cloud Services Blog: Making Firefox Accounts more transparent in Firefox |
Over the past few months the Firefox Accounts team have been working on making users more aware of Firefox Account and the benefits of having an account. This phase had an emphasis on our desktop users because we believe that would have the highest impact.
Based on user testing and feedback, most of our users did not clearly understand all of the advantages of having a Firefox Account. Most users failed to understand the value proposition of an account and why they should create one. Additionally, if they had an account, users were not always aware of the current signed in status in the browser. This meant that users could be syncing their private data and not fully aware they were doing that.
The benefits of an account we wanted to highlight were:
Previously, users that downloaded Firefox would only see the outlined benefits at a couple touch points in the browser. Specifically these points below

First run page (New installation)

What’s New page (Firefox installation upgraded)

Browsing to preferences and clicking Firefox Account menu
If a user failed to create an account and login during the first two points, it was very unlikely that they would organically discover Firefox Accounts at point three. Having only these touch points meant that users could not always set-up a Firefox Account at their own pace.
Our team decided that we needed to make this easier and solicited input from our Growth and Marketing teams, particularly on how to best showcase and highlight our features. From these discussions, we decided to experiment with putting a top level account menu item next to the Firefox application menu. Our hypothesis was that having a top level menu would drive engagement and reinforce the benefits of Firefox Accounts.
We believed that having an account menu item at this location would give users more visibility into their account status and allow them to quickly manage it.
While most browsers have some form of a top level account menu, we decided to experiment with the feature because Firefox users are more privacy focused and might not behave as other browser users.

New Firefox Account Toolbar menu
The initial designs for this experiment had a toolbar menu left of the Firefox application menu. This menu could not be removed and was always fixed. After consulting with engineering teams, having a fixed menu could more easily be achieved as a native browser feature. However, because of the development cycle of Firefox browser (new releases every 6 weeks), we would have to wait 6 weeks to test our experiment as a native feature.

Initial toolbar design
If the requirement that the menu was not fixed was lifted then we could ship a Shield web extension experiment and get results much more quickly (2-3 weeks). Shield experiments are not tied to a specific Firefox release schedule and users can opt in and out of them. This means that Firefox can install shield experiments, run them and then uninstall them at the end of the experiment.
After discussions with product and engineering teams, we decided to develop and ship the Shield web extension experiment (with these known limitations) and while that experiment was gathering data, start development of the native browser version for the originally spec design. There was a consensus between product and engineering teams that if the experiment was successful, it should eventually live as a native feature in the browser and not as a web extension.

Account toolbar Web Extension Version
Our experiment ran for 28 days and at the end of it, users were given a survey to fill out. There was a treatment (installed web extension) and control (did not install web extension) group. Below is a summary of the results
The overall feedback for the top level menu was positive and most users were not bothered by it. Based on this we decided to update and iterate on the design for the final native browser version.
While the overall feedback was positive for the new menu item, there were a few tweaks to the final design. Most notably
Because we started working on the native feature while the experiment was running, we did not have to dedicate as many development resources to complete new requirements.

Final toolbar design
Check out the development bug here for more details.
We are currently researching ways to best surface new account security features and services for Firefox Accounts using the new toolbar menu. Additionally, there are a handful of usability tweaks that we would like to add in future versions. Stay tuned!
The Firefox Account toolbar menu will be available starting in desktop Firefox 67. If you want to experiment early with it, you can download Firefox Beta 67 or Firefox Nightly.
Big thank you for all the teams and folks that helped to make this feature happen!
https://blog.mozilla.org/services/2019/04/16/making-firefox-accounts-more-transparent-in-firefox/
|
|
Mozilla Open Policy & Advocacy Blog: Brussels Mozilla Mornings: A policy blueprint for internet health |
On 14 May, Mozilla will host the next installment of our Mozilla Mornings series – regular breakfast meetings where we bring together policy experts, policymakers and practitioners for insight and discussion on the latest EU digital policy developments.
This event will coincide with the launch of the 2019 Mozilla Foundation Internet Health Report. We’re bringing together an expert panel to discuss some of the report’s highlights, and their vision for how the next EU political mandate can enhance internet health in Europe.
Prabhat Agarwal
Deputy Head of Unit, E-Commerce & Platforms
European Commission, DG CNECT
Claudine Vliegen
Telecoms & Digital Affairs attach'e
Permanent Representation of the Netherlands to the EU
Mark Surman
Executive Director, Mozilla Foundation
Introductory remarks by Solana Larsen
Editor in Chief, Internet Health Report
Moderated by Jennifer Baker, EU tech journalist
14 May, 2019
08:00-10:00
Radisson Red, Rue d’Idalie 35, 1050 Brussels
The post Brussels Mozilla Mornings: A policy blueprint for internet health appeared first on Open Policy & Advocacy.
|
|






