Daniel Stenberg: no more global dns cache in curl |
In January 2002, we added support for a global DNS cache in libcurl. All transfers set to use it would share and use the same global cache.
We rather quickly realized that having a global cache without locking was error-prone and not really advisable, so already in March 2004 we added comments in the header file suggesting that users should not use this option.
It remained in the code and time passed.
In the autumn of 2018, another fourteen years later, we finally addressed the issue when we announced a plan for this options deprecation. We announced a date for when it would become deprecated and disabled in code (7.62.0), and then six months later if no major incidents or outcries would occur, we said we would delete the code completely.
That time has now arrived. All code supporting a global DNS cache in curl has been removed. Any libcurl-using program that sets this option from now on will simply not get a global cache and instead proceed with the default handle-oriented cache, and the documentation is updated to clearly indicate that this is the case. This change will ship in curl 7.65.0 due to be released in May 2019 (merged in this commit).
If a program still uses this option, the only really noticeable effect should be a slightly worse name resolving performance, assuming the global cache had any point previously.
Programs that want to continue to have a DNS cache shared between multiple handles should use the share interface, which allows shared DNS cache and more – with locking. This API has been offered by libcurl since 2003.

https://daniel.haxx.se/blog/2019/04/11/no-more-global-dns-cache-in-curl/
|
|
Hacks.Mozilla.Org: Developer Roadshow 2019 returns with VR, IoT and all things web |
Mozilla Developer Roadshow is a meetup-style, Mozilla-focused event series for people who build the web. In 2017, the Roadshow reached more than 50 cities around the world. We shared highlights of the latest and greatest Mozilla and Firefox technologies. Now, we’re back to tell the story of how the web continues to democratize opportunities for developers and digital creators.
To open our 2019 series, Mozilla presents two events with VR visionary Nonny de la Pe~na and the Emblematic Group in Los Angeles (April 23) and in New York (May 20-23). de la Pe~na’s pioneering work in virtual reality, widely credited with helping create the genre of immersive journalism, has been featured in Wired, Inc., The New York Times, and on the cover of The Wall Street Journal. Emblematic will present their latest project, REACH in WebVR. Their presentation will include a short demo of their product. During the social hour, the team will be available to answer questions and share their learnings and challenges of developing for the web.
Funding and resource scarcity continue to be key obstacles in helping the creative community turn their ideas into viable products. Within the realm of cutting edge emerging technologies, such as mixed reality, it’s especially challenging for women. Because women receive less than 2% of total venture funding, the open distribution model of the web becomes a viable and affordable option to build, test, and deploy their projects.
The DevRoadshow continues on the road with eight more upcoming sessions in Europe and the Asia Pacific regions throughout 2019. Locations and dates will be announced soon. We’re eager to invite coders and creators around the world to join us this year. The Mozilla Dev Roadshow is a great way to make new friends and stay up to date on new products. Come learn about services and opportunities that extend the power of the web as the most accessible and inclusive platform for immersive experiences.
Check back to this post for updates, visit our DevRoadshow site for up to date registration opportunities, and follow along our journey on @mozhacks or sign up for the weekly Mozilla Developer Newsletter. We’ll keep you posted!
The post Developer Roadshow 2019 returns with VR, IoT and all things web appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/04/mozilla-developer-roadshow/
|
|
Mozilla Future Releases Blog: Firefox Beta for Windows 10 on Qualcomm Snapdragon Always Connected PCs Now Available |
Whether it’s checking the weather forecast or movie times, you can always count on the web to give you the information you’re seeking. Your choice of operating system and computer shouldn’t change your online experience. As part of Mozilla’s mission, we built Firefox as a trusted user agent for people on the web and it’s one of the reasons why we’re always looking to work with companies to optimize Firefox Quantum for their devices.
Last December, we announced our collaboration with Qualcomm, to create an ARM64-native build of Firefox for Snapdragon-powered Windows 10 Always Connected PCs. Today, we’re excited to report its availability in our beta release channel, a channel aimed at developers or early tech adopters to test upcoming features before they’re released to consumers.
Today’s release builds on the performance work done for Firefox Quantum, which uses multiple processes as efficiently as possible. Working with Qualcomm’s Snapdragon compute platform, we’re able to push the multi-core paradigm one step further, offering octa-core CPUs. We’re also taking advantage of Rust’s fearless concurrency to intelligently divide browsing tasks across those cores to deliver a fast, personal, and convenient experience.
Snapdragon powered Always Connected PCs are ideal for the road warrior because they are thin, fanless, lightweight with a long battery life and lightening fast cellular connectivity, and built to seamlessly perform daily work tasks on-the-go. We’re no stranger to optimizing the Firefox browser for any device. From Fire TV to the new iPad, we’ve custom tailored Firefox browsers for a number of different devices, because it shouldn’t matter what device you use.
Your feedback is valuable for us to fine-tune this experience for a future release. If you have an ARM64 device running Windows 10, you can help by reporting bugs or submitting crash reports or simply sharing feedback. If you have any questions about your experience you can visit here for assistance.
To try the ARM64-native build of Firefox on Windows beta version, you can download it here.
The post Firefox Beta for Windows 10 on Qualcomm Snapdragon Always Connected PCs Now Available appeared first on Future Releases.
|
|
Mozilla Localization (L10N): Implementing Fluent in a localization tool |
|
|
Wladimir Palant: Bogus security mechanisms: Encrypting localhost traffic |
Nowadays it is common for locally installed applications to also offer installing browser extensions that will take care of browser integration. Securing the communication between extensions and the application is not entirely trivial, something that Logitech had to discover recently for example. I’ve also found a bunch of applications with security issues in this area. In this context, one has to appreciate RememBear password manager going to great lengths to secure this communication channel. Unfortunately, while their approach isn’t strictly wrong, it seems to be based on a wrong threat assessment and ends up investing far more effort into this than necessary.
It is pretty typical for browser extensions and applications to communicate via WebSockets. In case of RememBear the application listens on port 8734, so the extension creates a connection to ws://localhost:8734. After that, messages can be exchanged in both directions. So far it’s all pretty typical. The untypical part is RememBear using TLS to communicate on top of an unencrypted connection.
So the browser extension contains a complete TLS client implemented in JavaScript. It generates a client key, and on first connection the user has to confirm that this client key is allowed to connect to the application. It also remembers the server’s public key and will reject connecting to another server.
Why use an own TLS implementation instead of letting the browser establish an encrypted connection? The browser would verify TLS certificates, whereas the scheme here is based on self-signed certificates. Also, browsers never managed to solve authentication via client keys without degrading user experience.
Now I could maybe find flaws in the forge TLS client they are using. Or criticize them for using 1024 bit RSA keys which are deprecated. But that would be pointless, because the whole construct addresses the wrong threat.
According to RememBear, the threat here is a malicious application disguising as RememBear app towards the extension. So they encrypt the communication in order to protect the extension, making sure that it only talks to the real application.
Now the sad reality of password managers is: once there is a malicious application on the computer, you’ve lost already. Malware does things like logging keyboard input and should be able to steal your master password this way. Even if malware is “merely” running with user’s privileges, it can go as far as letting a trojanized version of RememBear run instead of the original.
But hey, isn’t all this setting the bar higher? Like, messing with local communication would have been easier than installing a modified application? One could accept this line argumentation of course. The trouble is: messing with that WebSocket connection is still trivial. If you check your Firefox profile directory, there will be a file called browser-extension-data/ff@remembear.com/storage.js. Part of this file: the extension’s client key and RememBear application’s public key, in plain text. A malware can easily read out (if it wants to connect to the application) or modify these (if to wants to fake the application towards the extension). With Chrome the data format is somewhat more complicated but equally unprotected.

Image by Joybot
It’s weird how the focus is on protecting the browser extension. Yet the browser extension has no data that a malicious application could steal. If anything, malware might be able to trick the extension into compromising websites. Usually however, malware applications manage to do this on their own, without help.
In fact, the by far more interesting target is the RememBear application, the one with the passwords data. Yet protecting it against malware is a lost cause, whatever a browser extension running in the browser sandbox can do – malware can easily do the same.
The realistic threat here are actually regular websites. You see, same-origin policy isn’t enforced for WebSockets. Any website can establish a connection to any WebSocket server. It’s up to the WebSocket server to check the Origin HTTP header and reject connections from untrusted origins. If the connection is being established by a browser extension however, the different browsers are very inconsistent about setting the Origin header, so that recognizing legitimate connections is difficult.
In the worst case, the WebSocket server doesn’t do any checks and accepts any connection. That was the case with the Logitech application mentioned earlier, it could be reconfigured by any website.
If the usual mechanisms to ensure connection integrity don’t work, what do you do? You can establish a shared secret between the extension and the application. I’ve seen extensions requiring you to copy a secret key from the application into the extension. Another option would be the extension generating a secret and requiring users to approve it in the application, much like RememBear does it right now with the extension’s client key. Add that shared secret to every request made by the extension and the application will be able to identify it as legitimate.
Wait, no encryption? After all, somebody called out 1Password for sending passwords in cleartext on a localhost connection (article has been removed since). That’s your typical bogus vulnerability report however. Data sent to localhost never leaves your computer. It can only be seen on your computer and only with administrator privileges. So we would again be either protecting against malware or a user with administrator privileges. Both could easily log your master password when you enter it and decrypt your password database, “protecting” localhost traffic wouldn’t achieve anything.
But there is actually an even easier solution. Using WebSockets is unnecessary, browsers implement native messaging API which is meant specifically to let extensions and their applications communicate. Unlike WebSockets, this API cannot be used by websites, so the application can be certain: any request coming in originates from the browser extension.
There is no reasonable way to protect a password manager against malware. With some luck, the malware functionality will be too generic to compromise your application. Once you expect it to have code targeting your specific application, there is really nothing you can do any more. Any protective measures on your end are easily circumvented.
Security design needs to be guided by a realistic threat assessment. Here, by far the most important threat is communication channels being taken over by a malicious website. This threat is easily addressed by authenticating the client via a shared secret, or simply using native messaging which doesn’t require additional authentication. Everything else is merely security theater that doesn’t add any value.
This isn’t the only scenario where bogus vulnerability reports prompted an overreaction however. Eventually, I want to deconstruct research scolding password managers for leaving passwords in memory when locked. Here as well, a threat scenario has been blown out of proportion.
https://palant.de/2019/04/11/bogus-security-mechanisms-encrypting-localhost-traffic/
|
|
The Firefox Frontier: First photo of a black hole or cosmic cousin of the Firefox logo? |
A photo of a small, fiery circular shape floating in blackness will go down in history as the first photo of a black hole. It might not look like much, … Read more
The post First photo of a black hole or cosmic cousin of the Firefox logo? appeared first on The Firefox Frontier.
|
|
Mozilla GFX: WebRender newsletter #43 |
WebRender is a GPU based 2D rendering engine for the web written in Rust, currently powering Mozilla’s research web browser servo and on its way to becoming Firefox‘s rendering engine.
The gfx team got together in Mozilla’s Toronto office last week. These gatherings are very valuable since the team is spread over many timezones (in no particular order, there are graphics folks in Canada, Japan, France, various parts of the US, Germany, England, Australia and New Zealand).
It was an intense week, filled with technical discussions and planning. I’ll go over some of them below:
Nical continues investigating a more powerful and expressive render task graph for WebRender. The work is happening in the toy render-graph repository and during the week a lot task scheduling and texture memory allocation strategies were discussed. It’s an interesting and open problem space where various trade-offs will play out differently on different platforms.
One of the things that came out of these discussions is the need for tools to understand the effects of the different graph scheduling and allocation strategies, and help debugging their effects and bugs once we get to integrating a new system into WebRender. As a result, Nical started building a standalone command-line interface for the experimental task graph and generate SVG visualizations.

So far our experimentation has showed that energy consumption in WebRender (as well as Firefox’s painting and compositing architecture) is strongly correlated with the amount of pixels that are manipulated. In other word, it is dominated by memory bandwidth which is stressed by high screen resolutions. This is perhaps no surprise for someone having worked with graphics rendering systems, but what’s nice with this observation is that it gives us a very simple metric to measure and build optimizations and heuristics around.
Avenues for improvements in power consumption therefore include Doug’s work with document splitting and Markus’s work on better integration with MacOS’s compositing window manager with the Core Animation API. No need to tell the window manager to redraw the whole window when only the upper part changed (the document containing the browser’s UI for example).
The browser can break the window up into several surfaces and let the window manager composite them together which saves some work and potentially substantial amounts of memory bandwidth.
On Windows the same can be achieved with the Direct Composition API. On Linux with Wayland we could use sub-surfaces although in our preliminary investigation we couldn’t find a reliable/portable way to obtain the composited content for the whole browser window which is important for our testing infrastructure and other browser functionalities. Only recently did Android introduce similar functionalities with the SurfaceControl API.
We made some short and long term plans around the theme of better integration with the various window manager APIs. This is an area where I hope to see WebRender improve a lot this year.
Ryan gave us an overview of the architecture and progress of project Fission, which he has been involved with for some time. The goal of the project is to further isolate content from different origins by dramatically increasing the amount of content processes. There are several challenging aspects to this. Reducing the per-process memory overhead is an important one as we really want to remain better than Chrome overall memory usage. WebRender actually helps in this area as it moves most of the rendering out of content processes. There are also fun (with some notion of “fun”) edge cases to deal with such as page from domain A nested into iframe of domain B nested into iframe of domain A, and what this type of sandwichery implies in terms of processes, communication and what should happen when a CSS filter is applied to that kind of stack.
Fun stuff.
There will always be hardware and driver configurations that are too old, too buggy, or both, for us to support with WebRender using the GPU. For some time Firefox will fall back to the pre-WebRender architecture, but we’ll eventually want to get to a point where we phase out this legacy code while still work for all of our users. So WebRender needs some way to work when GPU doesn’t.
We discussed several avenues for this, one of which being to leverage WebRender’s OpenGL implementation with a software emulation such as SwiftShader. It’s unclear at his point whether or not we’ll be able to get acceptable performance this way, but Glenn’s early experiments show that there are a lot of low hanging fruits to pick and optimize such a software implementation, hopefully to the point where it provides a good user experience.
Other options include dedicated CPU rendering backend which we could safely expect to get to at least Firefox’s current software rendering performance, at the expense of more engineering resources.
As WebRender replaces Firefox’s current rendering architecture, we’ll be able to remove large amounts of fairly complex code in the gfx and layout modules, which is an exciting prospect. We discussed how much we can simplify and at which stages of WebRender’s progressive rollout.
Kvark gave us an update on the status of the WebGPU specification effort. Things are coming along in a lot of areas, although the binding model and shader format are still very much under debate. Apple proposes to introduce a brand new shading language called WebHLSL while Mozilla and Google want a bytecode format based on a safe subset of SPIRV (the Khronos group’s shader bytecode standard used in Vulkan OpenCL, and OpenGL through an extension). Having both a bytecode and high-level language is also on the table although fierce debates continue around the merits of introducing a new language instead of using and/or extending GLSL, already used in WebGL.
From what I have seen of the already-agreed-upon areas so far, WebGPU’s specification is shaping up to be a very nice and modern API, leaning towards Metal in terms of level of abstraction. I’m hopeful that it’ll eventually be extended into providing some of Vulkan’s lower level controls for performance.
Display lists can be quite large and costly to process. Gankro is working on compression opportunities to reduce the IPC overhead, and Glenn presented plans to move some of the interning infrastructure to the API endpoints so as to to send deltas instead of the entire display lists at each layout update, further reducing IPC cost.
Kvark presented his approach to investigating WebRender bugs and shared clever tricks around manipulating and simplifying frame recordings.
Glenn presented his Android development and debugging workflow and shared his observations about WebRender’s performance characteristics on mobile GPUs so far.
We’ve covered about half of the week’s topics and it’s already a lot for a single newsletter. We will go over the rest in the next episode.
In about:config, enable the pref gfx.webrender.all and restart the browser.
The best place to report bugs related to WebRender in Firefox is the Graphics :: WebRender component in bugzilla.
Note that it is possible to log in with a github account.
WebRender is available as a standalone crate on crates.io (documentation)
https://mozillagfx.wordpress.com/2019/04/10/webrender-newsletter-43/
|
|
Mozilla Open Policy & Advocacy Blog: US House Votes to Save the Internet |
Today, the House took a firm stand on behalf of internet users across the country. By passing the Save the Internet Act, members have made it clear that Americans have a fundamental right to access the open internet. Without these protections in place, big corporations like Comcast, Verizon, and AT&T could block, slow, or levy tolls on content at the expense of users and small businesses. We hope that the Senate will recognize the need for strong net neutrality protections and pass this legislation into law. In the meantime, we will continue to fight in the courts as the DC Circuit considers Mozilla v. FCC, our effort to restore essential net neutrality protections for consumers through litigation.
The post US House Votes to Save the Internet appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2019/04/10/us-house-votes-to-save-the-internet/
|
|
Mozilla Open Policy & Advocacy Blog: What we think about the UK government’s ‘Online Harms’ white paper |
The UK government has just outlined its plans for sweeping new laws aimed at tackling illegal and harmful content and activity online, described by the government as ‘the toughest internet laws in the world’. While the UK proposal has some promising ideas for what the next generation of content regulation should look like, there are several aspects that would have a worrying impact on individuals’ rights and the competitive ecosystem. Here we provide our preliminary assessment of the proposal, and offer some guidance on how it could be improved.
According to the UK white paper, companies of all sizes would be under a ‘duty of care’ to protect their users from a broad class of so-called ‘online harms’, and a new independent regulator would be established to police them. The proposal responds to legitimate public policy concerns around how platforms deal with illegal and harmful content online, as well as the general public demand for tech companies to ‘do more’. We understand that in many respects the current regulatory paradigm is not fit for purpose, and we support an exploration of what codified content ‘responsibility’ might look like.
The UK government’s proposed regulatory architecture (a duty of care overseen by an independent regulator) has some promising potential. It could shift focus to regulating systems and instilling procedural accountability, rather than a focus on individual pieces of content and the liability/no liability binary. If implemented properly, its principles-based approach could allow for scalability, fine tailoring, and future-proofing; features that are presently lacking in the European content regulation paradigm (see for instance the EU Copyright directive and the EU Terrorist Content regulation).
Yet while the high-level architecture has promise, the UK government’s vision for how this new regulatory model could be realised in practice contains serious flaws. These must be addressed if this proposal is to reduce rather than encourage online harms.
Yet as we noted earlier, the UK government’s approach holds some promise, and many of the above issues could be addressed if the government is willing. There’s some crucial changes that we’ll be encouraging the UK government to adopt when it brings forward the relevant legislation. These relate to:
We look forward to engaging with the UK government as it enters into a consultation period on the new white paper. Our approach to the UK government will mirror the one that we are taking vis-`a-vis the EU – that is, building out a vision for a new content regulation paradigm that addresses lawmakers’ legitimate concerns, but in a way which is rights and ecosystem protective. Stay tuned for our consultation response in late June.
The post What we think about the UK government’s ‘Online Harms’ white paper appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2019/04/10/uk_online-harms/
|
|
Hacks.Mozilla.Org: Teaching machines to triage Firefox bugs |
Mozilla receives hundreds of bug reports and feature requests from Firefox users every day. Getting bugs to the right eyes as soon as possible is essential in order to fix them quickly. This is where bug triage comes in: until a developer knows a bug exists, they won’t be able to fix it.
Given the large number of bugs filed, it is unworkable to make each developer look at every bug (at the time of writing, we’d reached bug number 1536796!). This is why, on Bugzilla, we group bugs by product (e.g. Firefox, Firefox for Android, Thunderbird, etc.) and component (a subset of a product, e.g. Firefox::PDF Viewer).
Historically, the product/component assignment has been mostly done manually by volunteers and some developers. Unfortunately, this process fails to scale, and it is effort that would be better spent elsewhere.
To help get bugs in front of the right Firefox engineers quickly, we developed BugBug, a machine learning tool that automatically assigns a product and component for each new untriaged bug. By presenting new bugs quickly to triage owners, we hope to decrease the turnaround time to fix new issues. The tool is based on another technique that we have implemented recently, to differentiate between bug reports and feature requests. (You can read more about this at https://marco-c.github.io/2019/01/18/bugbug.html).

High-level architecture of BugBug training and operation
We have a large training set of data for this model: two decades worth of bugs which have been reviewed by Mozillians and assigned to products and components.
Clearly we can’t use the bug data as-is: any change to the bug after triage has been completed would be inaccessible to the tool during real operation. So, we “roll back” the bug to the time it was originally filed. (This sounds easy in practice, but there are a lot of corner cases to take into account!).
Also, although we have thousands of components, we only really care about a subset of these. In the past ~2 years, out of 396 components, only 225 components had more than 49 bugs filed. Thus, we restrict the tool to only look at components with a number of bugs that is at least 1% of the number of bugs of the largest component.
We use features collected from the title, the first comment, and the keywords/flags associated with each bug to train an XGBoost model.

High-level overview of the BugBug model
During operation, we only perform the assignment when the model is confident enough of its decision: at the moment, we are using a 60% confidence threshold. With this threshold, we are able to assign the right component with a very low false positive ratio (> 80% precision, measured using a validation set of bugs that were triaged between December 2018 and March 2019).
Training the model on 2+ years of data (around 100,000 bugs) takes ~40 minutes on a 6-core machine with 32 GB of RAM. The evaluation time is in the order of milliseconds. Given that the tool does not pause and is always ready to act, the tool’s assignment speed is much faster than manual assignment (which, on average, takes around a week).
Since we deployed BugBug in production at the end of February 2019, we’ve triaged around 350 bugs. The median time for a developer to act on triaged bugs is 2 days. (9 days is the average time to act, but it’s only 4 days when we remove outliers.)

BugBug in action
We have plans to use machine learning to assist in other software development processes, for example:
Right now our tool only assigns components for Firefox-related products. We would like to extend BugBug to automatically assign components for other Mozilla products.
We also encourage other organizations to adopt BugBug. If you use Bugzilla, adopting it will be very easy; otherwise, we’ll need to add support for your bug tracking system. File an issue on https://github.com/mozilla/bugbug and we’ll figure it out. We are willing to help!
The post Teaching machines to triage Firefox bugs appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/04/teaching-machines-to-triage-firefox-bugs/
|
|
Mozilla Security Blog: DNS-over-HTTPS Policy Requirements for Resolvers |
Over the past few months, we’ve been experimenting with DNS-over-HTTPS (DoH), a protocol which uses encryption to protect DNS requests and responses, with the goal of deploying DoH by default for our users. Our plan is to select a set of Trusted Recursive Resolvers (TRRs) that we will use for DoH resolution in Firefox. Those resolvers will be required to conform to a specific set of policies that put privacy first.
To that end, today we are releasing a list of DOH requirements, available on the Mozilla wiki, that we will use to vet potential resolvers for Firefox. The requirements focus on three areas: 1) limiting data collection and retention from the resolver, 2) ensuring transparency for any data retention that does occur, and 3) limiting any potential use of the resolver to block access or modify content. This is intended to cover resolvers that Firefox will offer by default and resolvers that Firefox might discover in the local network.
In publishing this policy, our goal is to encourage adherence to practices for DNS that respect modern standards for privacy and security. Not just for our potential DoH partners, but for all DNS resolvers.
The post DNS-over-HTTPS Policy Requirements for Resolvers appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2019/04/09/dns-over-https-policy-requirements-for-resolvers/
|
|
Mozilla Future Releases Blog: Protections Against Fingerprinting and Cryptocurrency Mining Available in Firefox Nightly and Beta |
At Mozilla, we have been working hard to protect you from threats and annoyances on the web, so you can live your online life with less to worry about. Last year, we told you about adapting our approach to anti-tracking given the added importance of keeping people’s information on the web private in today’s climate. We talked about blocking tracking while also offering a clear set of controls to give our users more choice over what information they share with sites. One of the three key initiatives we listed was mitigating harmful practices like fingerprinting and cryptomining. We have added a feature to block fingerprinting and cryptomining in Firefox Nightly as an option for users to turn on.
A variety of popular “fingerprinting” scripts are invisibly embedded on many web pages, harvesting a snapshot of your computer’s configuration to build a digital fingerprint that can be used to track you across the web, even if you clear your cookies. Fingerprinting violates Firefox’s anti-tracking policy.
Another category of scripts called “cryptominers” run costly operations on your web browser without your knowledge or consent, using the power of your computer’s CPU to generate cryptocurrency for someone else’s benefit. These scripts slow down your computer, drain your battery and rack up your electric bill.
To combat these threats, we are pleased to announce new protections against fingerprinters and cryptominers. In collaboration with Disconnect, we have compiled lists of domains that serve fingerprinting and cryptomining scripts. Now in the latest Firefox Nightly and Beta versions, we give users the option to block both kinds of scripts as part of our Content Blocking suite of protections.
In Firefox Nightly 68 and Beta 67, these new protections against fingerprinting and cryptomining are currently disabled by default. You can enable them with the following steps:





Once enabled, Firefox will block any scripts that have been identified by Disconnect to participate in cryptomining or fingerprinting. (These protections will be turned on by default in Nightly in the coming weeks.)
In the coming months, we will start testing these protections with small groups of users and will continue to work with Disconnect to improve and expand the set of domains blocked by Firefox. We plan to enable these protections by default for all Firefox users in a future release.
As always, we welcome your reports of any broken websites you may encounter. Just click on the Tracking Protection “shield” in the address bar and click “Report a Problem”:

Help us by reporting broken websites
We invite you to check out this feature to keep users safe on the current Nightly and Beta releases.
The post Protections Against Fingerprinting and Cryptocurrency Mining Available in Firefox Nightly and Beta appeared first on Future Releases.
|
|
The Firefox Frontier: 10 unicorn themes for Firefox to make Unicorn Day extra magical. |
If today feels a little extra magical, that’s because it’s Unicorn Day! That’s right, a whole day devoted to these enchanting fairytale creatures. Unicorn Day is a new holiday created … Read more
The post 10 unicorn themes for Firefox to make Unicorn Day extra magical. appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/unicorn-themes-for-firefox/
|
|
Mike Conley: Firefox Front-End Performance Update #16 |
With Firefox 67 only a few short weeks away, I thought it might be interesting to take a step back and talk about some of the work that the Firefox Front-end Performance team is shipping to users in that particular release.
To be clear, this is not an exhaustive list of the great performance work that’s gone into Firefox 67 – but I picked a few things that the front-end team has been focused on to talk about.
The fastest code is the code that doesn’t run at all. Sometimes, as the browser evolves, we realize that there are components that don’t need to be loaded right away during start-up, and can instead of deferred until sometime after start-up. Sometimes, that means we can wait until the very last moment to initialize some component – that’s called loading something lazily.
Here’s a list of things that either got deferred until sometime after start-up, or made lazy:
These are modules that support, you guessed it, Form Autofill – that part of the browser that helps you fill in web forms, and makes sure forms are passing validation. We were loading these modules too early, and now we load them only when there are forms to auto-fill or validate on a page.
The Hidden Window is a mysterious chunk of code that manages the state of the global menu bar on macOS when there are no open windows. The Hidden Window is also sometimes used as a singleton DOM window where various operations can take place. On Linux and Windows, it turns out we were creating this Hidden Window far early than needs be, and now it’s quite a bit lazier.
Page Style is a menu you can find under View in the main menu bar, and it’s used to switch between alternative style sheets on a page. It’s a pretty rarely used feature from what we can tell, but we were scanning pages for their alternative stylesheets far earlier than we needed to. We were also scanning pages that we know don’t have alternative stylesheets, like the about:home / about:newtab page. Now we only scan normal web pages, and we do so only after we service the idle event queue.
The Startup Cache is an important part of Firefox startup performance. It’s primary job is to cache computations that occur during each startup so that they only have to happen every once in a while. For example, the mark-up of the browser UI often doesn’t change from startup to startup, so we can cache a version of the mark-up that’s faster to read from disk, and only invalidate that during upgrades.
We were invalidating the whole startup cache every time a WebExtension was installed or uninstalled. This used to be necessary for old-style XUL add-ons (since those could cause changes to the UI that would need to go into the cache), but with those add-ons no longer available, we were able to remove the invalidation. This means faster startups more often.
The disk is almost always the slowest part of the system. Reading and writing to the disk can take a long time, especially on spinning magnetic drives. The less we can read and write, the better. And if we’re going to read, best to do it off of the main thread so that the UI remains responsive.
We were reading from the disk on the main thread to search for window-specific icons to display in the window titlebar.
Firefox doesn’t use window-specific icons, so we made it so that we skip these checks. This means less disk activity, which is great for responsiveness and start-up!
We noticed that when we were checking that a directory exists on Windows (to write a file to it), we were using the CreateDirectoryW Windows API. This API checks each folder on the way down to the last one to see if they exist. That’s a lot of disk IO! We can avoid this if we assume that the parent directories exist, and only fall into the slow path if we fail to write our file. This means that we hit the faster path with less IO more often, which is good for responsiveness and start-up time.
Firefox 67 is slated to ship with these improvements on May 14th – just a little over a month away. Enjoy!
https://mikeconley.ca/blog/2019/04/08/firefox-front-end-performance-update-16/
|
|
Firefox UX: Designing Better Security Warnings |
Security messages are very hard to get right, but it’s very important that you do. The world of internet security is increasingly complex and scary for the layperson. While in-house security experts play a key role in identifying the threats, it’s up to UX designers and writers to communicate those threats in ways that enlighten and empower users to make more informed decisions.
We’re still learning what works and what doesn’t in the world of security messages, but there are some key insights from recent studies from the field at large. We had a chance to implement some of those recommendations, as well as learnings from our own in-house research, in a recent project to overhaul Firefox’s most common security certificate warning messages.
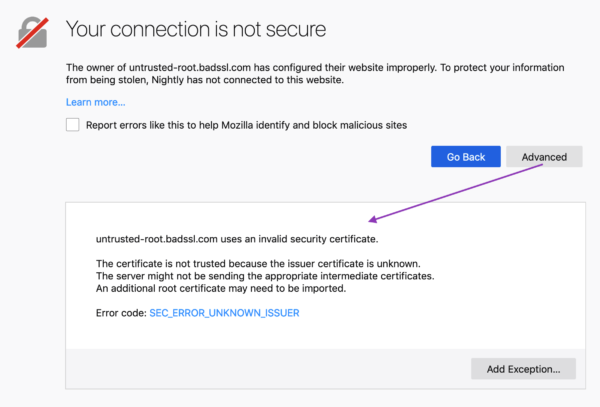
Websites prove their identity via security certificates (i.e., www.example.com is in fact www.example.com, and here’s the documentation to show it). When you try to visit any website, your browser will review the certificate’s authenticity. If everything checks out, you can safely proceed to the site.
If something doesn’t check out, you’ll see a security warning. 3% of Firefox users encounter a security certificate message on a daily basis. Nearly all users who see a security message see one of five different message types. So, it’s important that these messages are clear, accurate, and effective in educating and empowering users to make the informed (ideally, safer) choice.
These error messages previously included some vague, technical jargon nestled within a dated design. Given their prevalence, and Firefox’s commitment to user agency and safety, the UX and security team partnered up to make improvements. Using findings from external and in-house research, UX Designer Bram Pitoyo and I collaborated on new copy and design.
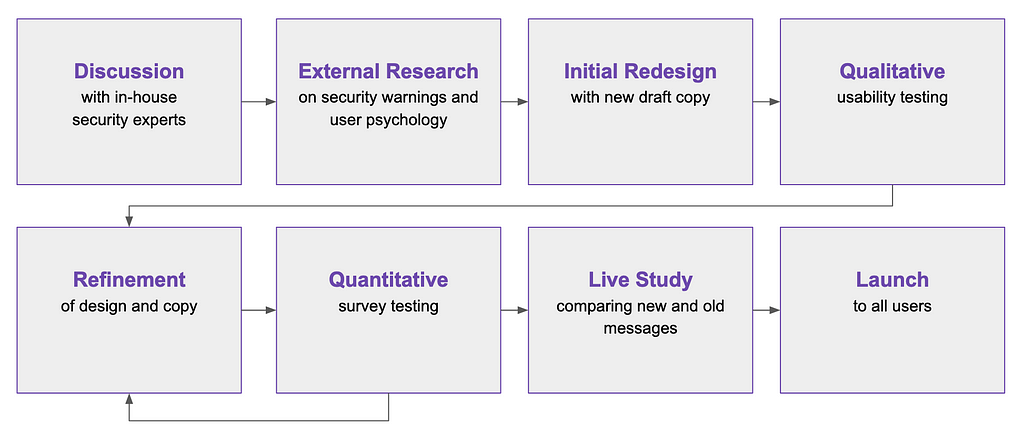
We met our goals, as illustrated by three different studies:
1. A qualitative usability study (remote, unmoderated on usertesting.com) of a first draft of redesigned and re-written error pages. The study evaluated the comprehensibility, utility, and tone of the new pages. Our internal user researcher, Francis Djabri, tested those messages with eight participants and we made adjustments based on the results.
2. A quantitative survey comparing Firefox’s new error pages, Firefox’s current error pages, and Chrome’s current comparative pages. This was a paid panel study that asked users about the source of message, how they felt about the message, and what actions they would take as a result of the message. Here’s a snapshot of the results:
When presented with the redesigned error message, we saw a 22–50% decrease in users stating they would attempt to ignore the warning message.
When presented with the redesigned error message, we saw a 29–60% decrease in users stating they would attempt to access the website via another browser. (Only 4.7–8.5 % of users who saw the new Firefox message said they would try another browser, in contrast to 10–11.3% of users who saw a Chrome message).
(Source: Firefox Strategy & Insights, Tyler Downer, November 2018 Survey Highlights)
3. A live study comparing the new and old security messages with Firefox users confirmed that the new messages did not significantly impact usage or retention in a negative way. This gave us the green light to go-live with the redesigned pages for all users.
In this blog post, I identify the eight design and content tips — based on outside research and our own — for creating more successful security warning messages.
Unless your particular users are more technical, it’s generally good practice to avoid technical terms — they aren’t helpful or accessible for the general population. Words like “security credentials,” “encrypted,” and even “certificate” are too abstract and thus ineffective in achieving user understanding.(2)
It’s hard to avoid some of these terms entirely, but when you do use them, explain what they mean. In our new messages, we don’t use the technical term, “security certificates,” but we do use the term “certificates.” On first usage, however, we explain what “certificate” means in plain language:

Some seemingly common terms can also be problematic. Our own user study showed that the term, “connection,” confused people. They thought, mistakenly, that the cause of the issue was a bad internet connection, rather than a bad certificate.(3) So, we avoid the term in our final heading copy:

When confronted with decisions online, we all tend to be “cognitive misers.” To minimize mental effort, we make “quick decisions based on learned rules and heuristics.” This efficiency-driven decision making isn’t foolproof, but it gets the job done. It means, however, that we cut corners when consuming content and considering outcomes.(4)
Knowing this, we kept our messages short and scannable.

We also streamlined the decision-making process with opinionated design and progressive disclosure (read on below).
“Safety is an abstract concept. When evaluating alternatives in making a decision, outcomes that are abstract in nature tend to be less persuasive than outcomes that are concrete.” — Ryan West, “The Psychology of Security”
When users encounter a security warning, they can’t immediately access content or complete a task. Between the two options — proceed and access the desired content, or retreat to avoid some potential and ambiguous threat — the former provides a more immediate and tangible award. And people like rewards.(5)
Knowing that safety may be the less appealing option, we employed opinionated design. We encourage users to make the safer choice by giving it a design advantage as the “clear default choice.”(6) At the same time, we have to be careful that we aren’t being a big brother browser. If users want to proceed, and take the risk, that’s their choice (and in some cases, the informed user can do so knowing they are actually safe from the particular certificate error at hand). It might be tempting to add ten click-throughs and obscure the unsafe choice, but we don’t want to frustrate people in the process. And, the efficacy of additional hurdles depends on how difficult those hurdles are.(7)
Striving for balance, we:

In addition to “safety” being an abstract concept, users tend to believe that they won’t be the ones to fall prey to the potential threat (i.e., those kind of things happen to other people…they won’t happen to me).(8) And, save for our more tech-savvy users, the general population might not care what particular certificate error is taking place and its associated details.
So, we needed to make the risk as concrete as possible, and communicate it in more personal terms. We did the following:

While the general population might not need or want to know the technical details, you should provide them for the users that do…in the right place.
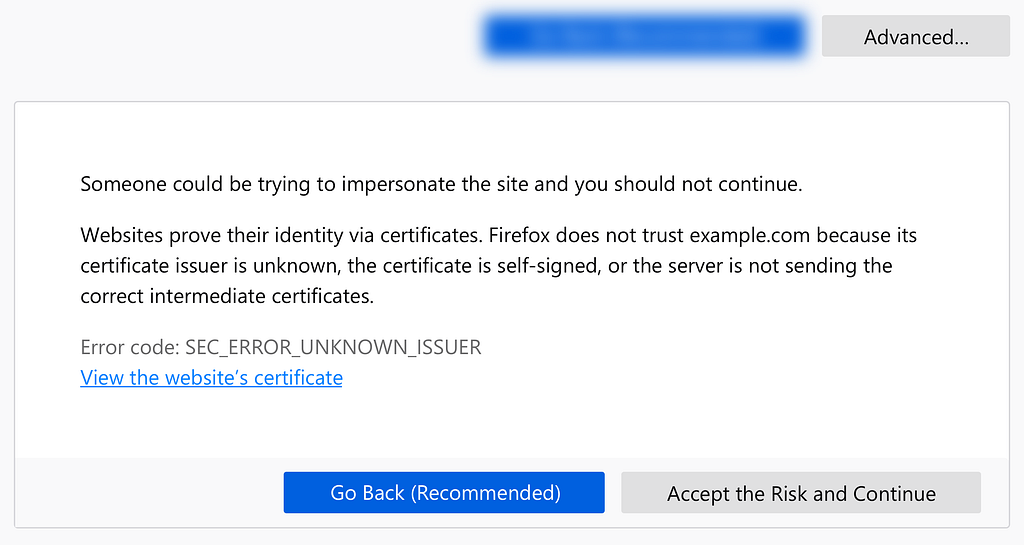
Users rarely click on links like “Learn more” and “More Information.”(9) Our own usability study confirmed this, as half of the participants did not notice or feel compelled to select the “Advanced” button.(10) So, we privileged content that is more broadly accessible and immediately important on our first screen, but provided more detail and technical information on the second half of the screen, or behind the “Advanced” button. Knowing users aren’t likely to click on “Advanced,” we moved any information that was more important, such as content about what action the user could take, to the first screen.
The “Advanced” section thus serves as a form of progressive disclosure. We avoided cluttering up our main screen with technical detail, while preserving a less obtrusive place for that information for the users who want it.
In the case of security errors, we don’t know for sure if the issue at hand is the result of an attack, or simply a misconfigured site. Hackers could be hijacking the site to steal credit card information…or a site may just not have its security certificate credentials in order, for example.
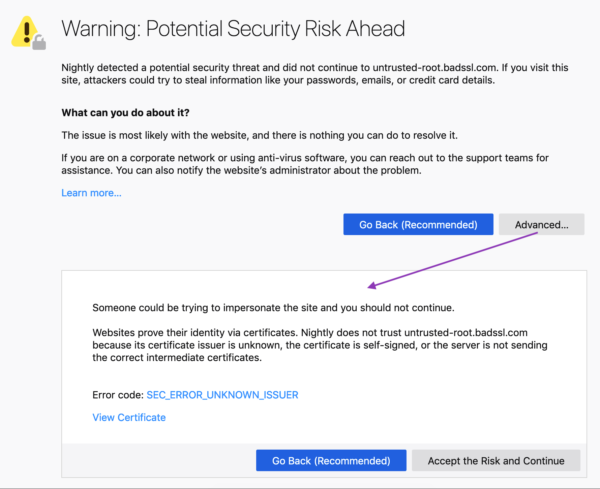
When there is chance of attack, communicate the potential risk, but be transparent about the uncertainty. Our messages employ language like “potential” and “attackers could,” and we acknowledge when there are two potential causes for the error (the former unsafe, the latter safe):
The website is either misconfigured or your computer clock is set to the wrong time.
Explain why you don’t trust a site, and offer the ability to learn more in a support article:
Websites prove their identity via certificates. Firefox does not trust example.com because its certificate issuer is unknown, the certificate is self-signed, or the server is not sending the correct intermediate certificates. Learn more about this error
A participant in our usability study shared his appreciation for this kind of transparency:
“I’m not frustrated, I’m enlightened. Often software tries to summarize things; they think the user doesn’t need to know, and they’ll just say something a bit vague. As a user, I would prefer it to say ‘this is what we think and this is how we determined it.’”— Participant from a usability study on redesigned error messages (User Research Firefox UX, Francis Djabri, 2018)
Illustration, iconography, and color treatment are important communication tools to accompany the copy. Visual cues can be even “louder” than words and so it’s critical to choose these carefully.
We wanted users to understand the risk at hand but we didn’t want to overstate the risk so that browsing feels like a dangerous act. We also wanted users to know and feel that Firefox was protecting them from potential threats.
Some warning messages employ more dramatic imagery like masked eyes, a robber, or police officer, but their efficacy is disputed.(11) Regardless, that sort of explicit imagery may best be reserved for instances in which we know the danger to be imminent, which was not our case.
The imagery must also be on brand and consistent with your design system. At Firefox, we don’t use human illustration within the product — we use whimsical critters. Critters would not be an appropriate choice for error messages communicating a threat. So, we decided to use iconography that telegraphs risk or danger.
We also selected color scaled according to threat level. At Firefox, yellow is a warning and red signifies an error or threat. We used a larger yellow icon for our messages as there is a potential risk but the risk is not guaranteed. We also added a yellow border as an additional deterrent for messages in which the user had the option to proceed to the unsafe site (this isn’t always the case).
Any good UX copy uses language that sounds and feels human, and that’s an explicit guiding principle in Firefox’s own Voice and Tone guidelines. By “human,” I mean language that’s natural and accessible.
If the context is right, you can go a bit farther and have some fun. One of our five error messages did not actually involve risk to the user — the user simply needed to adjust her clock. In this case, Communication Design Lead, Sean Martell, thought it appropriate to create an “Old Timey Berror” illustration. People in our study responded well… we even got a giggle:

The field of security messaging is challenging on many levels, but there are things we can do as designers and content strategists to help users navigate this minefield. Given the amount of frustration error messages can cause a user, and the risk these obstructions pose to business outcomes like retention, it’s worth the time and consideration to get these oft-neglected messages right…or, at least, better.
Special thanks to my colleagues: Bram Pitoyo for designing the messages and being an excellent thought partner throughout, Johann Hofmann and Dana Keeler for their patience and security expertise, and Romain Testard and Tony Cinotto for their mad PM skills. Thank you to Sharon Bautista, Betsy Mikel, and Michelle Heubusch for reviewing an earlier draft of this post.
Designing Better Security Warnings was originally published in Firefox User Experience on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
Mozilla VR Blog: VoxelJS Reboot |

If you’ve ever played Minecraft then you have used a voxel engine. My 7 year old son is a huge fan of Minecraft and asked me to make a Minecraft for VR. After some searching I found VoxelJS, a great open source library created by Max Ogden (@maxogden) and James Halliday (@substack). Unfortunately it hasn’t been updated for about five years and doesn't work with newer libraries.
So what to do? Simple: I dusted it off, ported it to modern ThreeJS & Javascript, then added WebXR support. I call it VoxelJS Next.
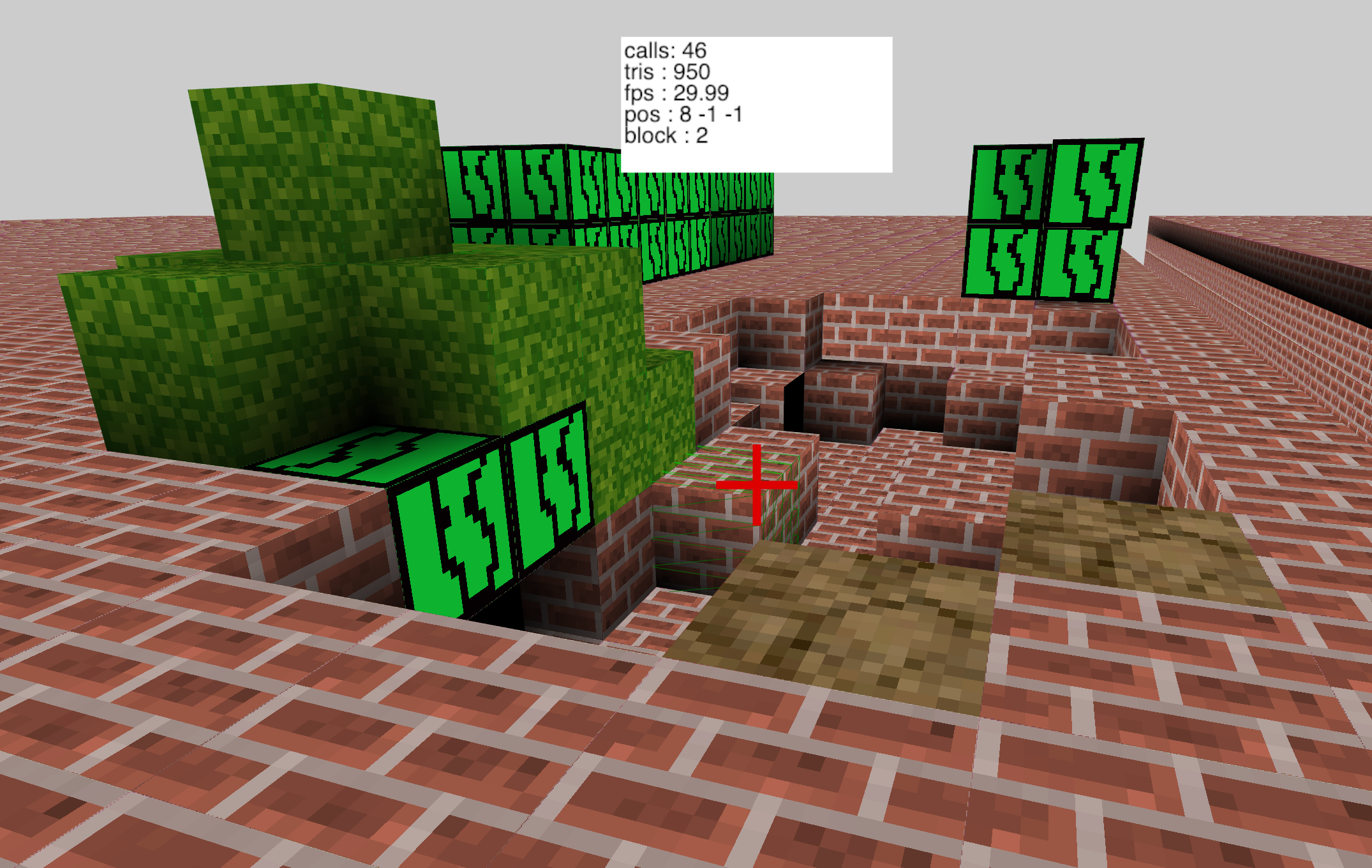
VoxelJS Next is a graphics engine, not a game. I think of Minecraft as a category of game, not a particular instance. I’d like to see Minecraft style voxels used for all sorts of experiences. Chemistry, water simulation, infinite runners, and many other fun experiences.
VoxelJS lets you build your own Minecraft-like game easily on the web. It can run in desktop mode, on a touch screen, full screen, and even in VR thanks to WebXR support. VoxelJS is built on top of ThreeJS.
I’ll talk about how data is stored and drawn on screen in a future blog, but the short answer is this:
The world is divided into chunks. Each chunk contains a grid of blocks and is created on demand. These chunks are turned into ThreeJS meshes which are then added to the scene. The chunks come and go as the player moves around the world. So even if you have an infinitely large world only a small number of chunks need to be loaded at a time.
VoxelJS is built as ES6 modules with a simple entity system. This lets you load only the parts you want. There is a module each for desktop controls, touch controls, VR, and more. Thanks to modern browser module support you don’t need to use a build tool like Webpack. Everything works just by importing modules.
Check out a live demo and get the code.
I don’t want to over sell VoxelJS Next. This is a super alpha release. The code is incredibly buggy, performance isn’t even half of what it should be, only a few textures, and tons of features are missing. VoxelJS Next is just a start. However, it’s better to get early feedback than to build features no one wants, so please try it out.
You can find the full list of feature and issues here. And here are a good set of issues for beginners to start with.
I also created a #voxels channel in the ThreeJS slack group. You can join it here.
I find voxels really fun to play with, as they give you great freedom to experiment. I hope you'll enjoy building web creations with VoxelJS Next.
|
|
Hacks.Mozilla.Org: Sharpen your WebVR skills with experiments from Glitch and Mozilla |

Join us for a week of Web VR experiments.
Earlier this year, we partnered with Glitch.com to produce a WebVR starter kit. In case you missed it, the kit includes a free, 5-part video course with interactive code examples that teach the fundamentals of WebVR using A-Frame. The kit is intended to help anyone get started – no coding experience required.
Today, we are kicking off a week of WebVR experiments. These experiments build on the basic fundamentals laid out in the starter kit. Each experiment is unique and is meant to teach and inspire as you craft your own WebVR experiences.
To build these, we once again partnered with the awesome team at Glitch.com as well as Glitch creator Andr'es Cuervo. Andr'es has put together seven experiments that range from incorporating motion capture to animating torus knots in 3D.
Today we are releasing the first 3 WebVR experiments, and we’ll continue to release a new one every day. If you want to follow along, you can click here and bookmark this page. The first three are shared below:
This example takes free motion capture data and adds it to a VR scene.
The Noisy Sphere will teach you how to incorporate 3D models and textures into your project.
In this example, you get a deeper dive on the torus knot shape and the animation component that is included in A-Frame.
If you are enjoying these experiments, we invite you to visit this page throughout the week as we’ll add a new experiment every day. We will post the final experiment this Friday.
Visit a week of WebVR Experiments.
The post Sharpen your WebVR skills with experiments from Glitch and Mozilla appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/04/sharpen-your-webvr-skills-with-experiments/
|
|
Mozilla Addons Blog: Recommended Extensions program — coming soon |
In February, we blogged about the challenge of helping extension users maintain their safety and security while preserving their ability to choose their browsing experience. The blog post outlined changes to the ecosystem to better protect users, such as making them more aware of the risks associated with extensions, reducing the visibility of extensions that haven’t been vetted, and putting more emphasis on curated extensions.
One of the ways we’re helping users discover vetted extensions will be through the Recommended Extensions program, which we’ll roll out in phases later this summer. This program will foster a curated list of extensions that meet our highest standards of security, utility, and user experience. Recommended extensions will receive enhanced visibility across Mozilla websites and products, including addons.mozilla.org (AMO).
We anticipate the eventual formation of this list to number in the hundreds, but we’ll start smaller and build the program carefully. We’re currently in the process of identifying candidates and will begin reaching out to selected developers later this month. You can expect to see changes on AMO by the end of June.
On AMO, Recommended extensions will be visually identifiable by distinct badging. Furthermore, AMO search results and filtering will be weighted higher toward Recommended extensions
Recommended extensions will also supply the personalized recommendations on the “Get Add-ons” page in the Firefox Add-ons Manager (about:addons), as well as any extensions we may include in Firefox’s Contextual Feature Recommender.
Editorial staff will select the initial batch of extensions for the Recommended list. In time, we’ll provide ways for people to nominate extensions for inclusion.
When evaluating extensions, curators are primarily concerned with the following:
Participation in the program will require commitment from developers in the form of active development and a willingness to make improvements.
It’s our intent to develop a Recommended list that can remain relevant over time, which is to say we don’t anticipate frequent turnover in the program. The objective is to promote Recommended extensions that users can trust to be useful and safe for the lifespan of the software they install.
We recognize the need to keep the list current, and will make room for new, emerging extensions. Firefox users want the latest, greatest extensions. Talented developers all over the world continue to find creative ways to leverage the powerful capabilities of extensions and deliver fantastic new features and experiences. Once the program launches later this summer, we’ll provide ways for people to suggest extensions for inclusion in the program.
We believe it’s important to maintain community involvement in the curatorial process. The Community Advisory Board—which for years has contributed to helping identify featured content—will continue to be involved in the Recommended extensions program.
We’ll have more details to share in the coming months as the Recommended extensions program develops. Please feel free to post questions or comments on the add-ons Discourse page.
The post Recommended Extensions program — coming soon appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2019/04/08/recommended-extensions-program-coming-soon/
|
|
Daniel Stenberg: curl says bye bye to pipelining |
HTTP/1.1 Pipelining is the protocol feature where the client sends off a second HTTP/1.1 request already before the answer to the previous request has arrived (completely) from the server. It is defined in the original HTTP/1.1 spec and is a way to avoid waiting times. To reduce latency.
HTTP/1.1 Pipelining was badly supported by curl for a long time in the sense that we had a series of known bugs and it was a fragile feature without enough tests. Also, pipelining is fairly tricky to debug due to the timing sensitivity so very often enabling debug outputs or similar completely changes the nature of the behavior and things are not reproducing anymore!
HTTP pipelining was never enabled by default by the large desktop browsers due to all the issues with it, like broken server implementations and the likes. Both Firefox and Chrome dropped pipelining support entirely since a long time back now. curl did in fact over time become more and more lonely in supporting pipelining.
The bad state of HTTP pipelining was a primary driving factor behind HTTP/2 and its multiplexing feature. HTTP/2 multiplexing is truly and really “pipelining done right”. It is way more solid, practical and solves the use case in a better way with better performance and fewer downsides and problems. (curl enables multiplexing by default since 7.62.0.)
In 2019, pipelining should be abandoned and HTTP/2 should be used instead.
Starting with this commit, to be shipped in release 7.65.0, curl no longer has any code that supports HTTP/1.1 pipelining. It has been disabled in the code since 7.62.0 already so applications and users that use a recent version already should not notice any difference.
Pipelining was always offered on a best-effort basis and there was never any guarantee that requests would actually be pipelined, so we can remove this feature entirely without breaking API or ABI promises. Applications that ask libcurl to use pipelining can still do that, it just won’t have any effect.
https://daniel.haxx.se/blog/2019/04/06/curl-says-bye-bye-to-pipelining/
|
|
Emily Dunham: Rustacean Hat Pattern |
Based on feedback from the crab plushie pattern, I took more pictures this time.
There are 40 pictures of the process below the fold.

If you’re using polar fleece, you don’t have to pre-wash it. Fold it in half. In these pictures, I have the fold on the left and the selvedges on the right.
The first step is to chop off a piece from the bottom of the fleece. We’ll use it to make the legs and spines later. Basically like this:

Next, measure the circumference you want the hat to be. I’ve measured on a hat to show you.

Find 1/4 of that circumference. If you measured with a string, you can just fold it, like I folded the tape measure. Or you could use maths.

That quarter-of-the-circumference is the distance that you fold over the left side of the big piece of fabric. Like so:

Leave it folded over, we’ll get right back to it. Guesstimate the height that a hat piece might need to be, so that we can sketch a piece of the hat on it. I do this by measuring front to back on a hat and folding the string, I mean tape measure, in half:

Back on the piece we folded over, put down the measurement so we make sure not to cut the hat too short. That measurement tells you roughly where to draw a curvy triangle on the folded fabric, just like this:

Now cut it out. Make sure not to cut off that folded edge. Like this:

Congratulations, you just cut out the lining of the hat! It should be all one piece. If we unfold the bit we just cut and the bit we cut it from, it’ll look like this:

Now we’re going to use that lining piece as a template to cut the outside pieces. Set it down on the fabric like so:

And cut around it. Afterwards you have 1 lining piece and 2 outer pieces:

Now grab that black and white scrap fabric and cut a couple eye sized black circles, and a couple bits of white for the light glints on the eyes. Also cut a black D shape to be the mouth if you want your hat to have a happy little mouth as well as just eyes.

Put the black and white together, and sew an eye glint kind of shape in the same spot on both, like so:

Pull the top threads to the back so the stitching looks all tidy. Then cut off the excess white fabric so it looks all pretty:

Now the fun part: Grab one of those outside pieces we cut before. Doesn’t matter which. Sew the eyes andmouth onto it like so:

Now it’s time to give the hat some shape. On both outside pieces – the one with the face and also the one without – sew that little V shaped gap shut. Like so:

Now they look kind of 3D, like so:

Let’s sew up the lining piece next. It’s the bit we cut off of the fold earlier. Fold then sew the Vs shut, thusly:

Next, sew most of the remaining seam of the lining, but leave a gap at the top so we can turn the whole thing inside out later:

Now that the lining is sewn, let’s sew 10 little legs. Grab that big rectangular strip we cut out at the very beginning, and sew its layers together into a bunch of little triangles with open bottoms. Then cut them apart and turn them inside out to get legs. Here’s how I did those steps:

Those little legs should have taken up maybe 1/3 of big rectangular strip. With the rest of it, let’s make some spines to go across Ferris’s back. They’re little triangles, wider than the legs, sewn up the same way.

Now put those spines onto one of the outside hat pieces. Leave some room at the bottom, because that’s where we’ll attach the claws that we’ll make later. The spines will stick toward the face when you pin them out, so when the whole thing turns right-side-out after sewing they’ll stick out.

Put the back of the outside onto this spine sandwich you’re building. Make sure the seam that sticks out is on the outside, because the outsides of this sandwich will end up inside the hat.

Pin and sew around the edge:

Note how the bottoms of the spines make the seam very bulky. Trim them closer to the seam, if you’re using a fabric which doesn’t fray, such as polar fleece.

The outer layer of the hat is complete!

At this point, we remember that Ferris has some claws that we haven’t accounted for yet. That’s ok because there was some extra fabric left over when we cut out the lining and outer for the hat. On that extra fabric, draw two claws. A claw is just an oval with a pie slice misisng, plus a little stem for the arm. Make sure the arms are wide enough to turn the claw inside out through later. It’s ok to draw them straight onto the fabric with a pen, since the pen marks will end up inside the claw later.

Then sew around the claws. It doesn’t have to match the pen lines exactly; nobody will ever know (except the whole internet in this case). Here are the front and back of the cloth sandwich that I sewed claws with:

Cut them out, being careful not to snip through the stitching when cutting the bit that sticks inward, and turn them right-side out:

Now it’s time to attach the liner and the hat outer together. First we need to pin the arms and legs in, making another sandwich kind of like we did with the spines along the back. I like to pin the arms sticking straight up and covering the outer’s side seams, like so:

Remember those 10 little legs we sewed earlier? Well, we need those now. And I used an extra spine from when we sewed the spines along Ferris’s back, in the center back, as a tail. Pin them on, 5 on each side, like little legs.

And finally, remember that liner we sewed, with a hole in the middle? Go find that one real quick:

Now we’re going to put the whole hat outer inside of the lining, creating Ferris The Bowl. All the pretty sides of things are INSIDE the sandwich, so all the seam allowances are visible.

Rearrange your pins to allow sewing, then sew around the entire rim of Ferris The Bowl.

Snip off the extra bits of the legs and stuff, just like we snipped off the extra bits of the spines before, like this:

Now Ferris The Bowl is more like Ferris The Football:

Reach in through the hole in the end of Ferris The Football, grab the other end, and pull. First it’ll look like this...

And then he’ll look like this:

Sew shut that hole in the bottom of the lining...

Stuff that lining into the hat, to make the whole thing hat-shaped, and you’re done!

|
|






