Daniel Stenberg: live-streamed curl development |
As some of you already found out, I’ve tried live-streaming curl development recently. If you want to catch previous and upcoming episodes subscribe on my twitch page.
For the fun of it. I work alone from home most of the time and this is a way for me to interact with others.
To show what’s going on in curl right now. By streaming some of my development I also show what kind of work that’s being done, showing that a lot of development and work are being put into curl and I can share my thoughts and plans with a wider community. Perhaps this will help getting more people to help out or to tickle their imagination.

For the feedback and interaction. It is immediately notable that one of the biggest reasons I enjoy live-streaming is the chat with the audience and the instant feedback on mistakes I do or thoughts and plans I express. It becomes a back-and-forth and it is not at all just a one-way broadcast. The more my audience interact with me, the more fun I have! That’s also the reason I show the chat within the stream most of the time since parts of what I say and do are reactions and follow-ups to what happens there.
I can only hope I get even more feedback and comments as I get better at this and that people find out about what I’m doing here.
And really, by now I also think of it as a really concentrated and devoted hacking time. I can get a lot of things done during these streaming sessions! I’ll try to keep them going a while.
I decided to go with twitch simply because it is an established and known live-streaming platform. I didn’t do any deeper analyses or comparisons, but it seems to work fine for my purposes. I get a stream out with video and sound and people seem to be able to enjoy it.
As of this writing, there are 1645 people following me on twitch. Typical recent live-streams of mine have been watched by over a hundred simultaneous viewers. I also archive all past streams on Youtube, so you can get almost the same experience my watching back issues there.
I announce my upcoming streaming sessions as “events” on Twitch, and I announce them on twitter (@bagder you know). I try to stick to streaming on European day time hours basically because then I’m all alone at home and risk fewer interruptions or distractions from family members or similar.
It’s not as easy as it may look trying to write code or debug an issue while at the same time explaining what I do. I learnt that the sessions get better if I have real and meaty issues to deal with or features to add, rather than to just have a few light-weight things to polish.
I also quickly learned that it is better to now not show an actual screen of mine in the stream, but instead I show a crafted set of windows placed on the output to look like it is a screen. This way there’s a much smaller risk that I actually show off private stuff or other content that wasn’t meant for the audience to see. It also makes it easier to show a tidy, consistent and clear “desktop”.
Streaming makes me have to stay focused on the development and prevents me from drifting off and watching cats or reading amusing tweets for a while
So far we’ve been spared from the worst kind of behavior and people. We’ve only had some mild weirdos showing up in the chat and nothing that we couldn’t handle.
I do all development on Linux so things have to work fine on Linux. Luckily, OBS Studio is a fine streaming app. With this, I can setup different “scenes” and I can change between them easily. Some of the scenes I have created are “emacs + term”, “browser” and “coffee break”.
When I want to show off me fiddling with the issues on github, I switch to the “browser” scene that primarily shows a big browser window (and the chat and the webcam in smaller windows).
When I want to show code, I switch to “emacs + term” that instead shows a terminal and an emacs window (and again the chat and the webcam in smaller windows), and so on.
OBS has built-in support for some of the major streaming services, including twitch, so it’s just a matter of pasting in a key in an input field, press ‘start streaming’ and go!
The rest of the software is the stuff I normally use anyway for developing. I don’t fake anything and I don’t make anything up. I use emacs, make, terminals, gdb etc. Everything this runs on my primary desktop Debian Linux machine that has 32GB of ram, an older i7-3770K CPU at 3.50GHz with a dual screen setup. The video of me is captured with a basic Logitech C270 webcam and the sound of my voice and the keyboard is picked up with my Sennheiser PC8 headset.
Some viewers have asked me about my keyboard which you can hear. It is a FUNC-460 that is now approaching 5 years, and I know for a fact that I press nearly 7 million keys per year.
In a reddit post about my live-streaming, user ‘digitalsin’ suggested “Maybe don’t slurp RIGHT INTO THE FUCKING MIC”.
How else am I supposed to have my coffee while developing?

https://daniel.haxx.se/blog/2019/05/06/live-streamed-curl-development/
|
|
Matthew Noorenberghe: Password Manager Improvements in Firefox 67 |
There have been many improvements to the password manager in Firefox and some of them may take a while to be noticed so I thought I would highlight some of the user-facing ones in version 67:
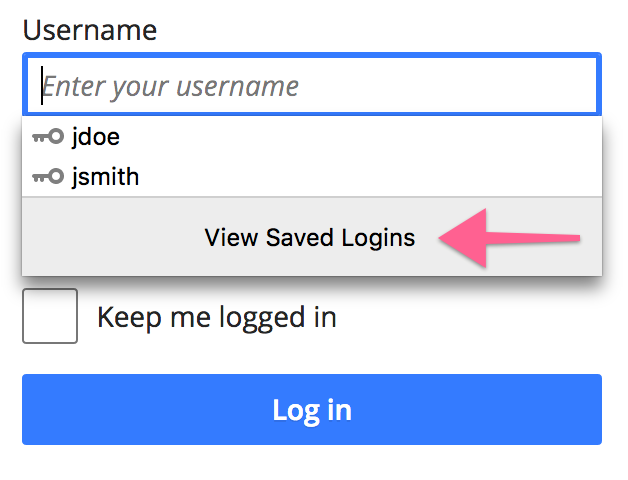
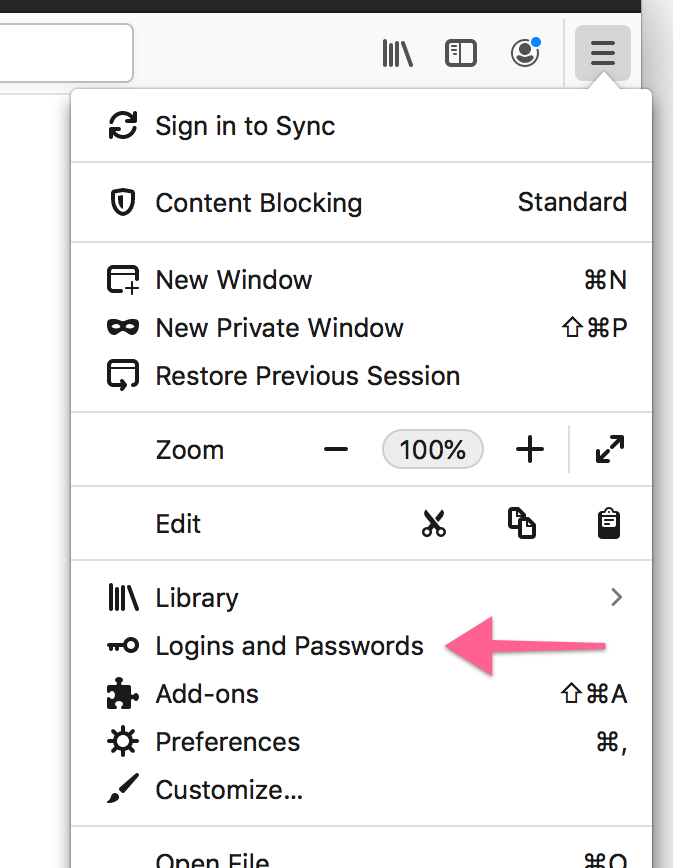
about:config.autocomplete attribute are no longer considered as potential username fields.autocomplete="new-password" will no longer be autofilled with saved logins. They will still be accessible via autocomplete and the context menu though.Credit for the fixes goes to Jared Wein, Sam Foster, Prathiksha Guruprasad, and myself. The full list of password manager improvements in Firefox 67 can be found on Bugzilla and there are many more to come in Firefox 68 so stay tuned…
https://matthew.noorenberghe.com/blog/2019/05/password-manager-improvements-firefox-67
|
|
The Mozilla Blog: The Firefox EU Elections Toolkit helps you to prevent pre-vote online manipulation |
What comes to your mind when you hear the term ‘online manipulation’? In the run-up to the EU parliamentary elections at the end of May, you probably think first and foremost of disinformation. But what about technical ways to manipulate voters on the internet? Although they are becoming more and more popular because they are so difficult to recognize and therefore particularly successful, they probably don’t come to mind first. Quite simply because they have not received much public attention so far. Firefox tackles this issue today: The ‘Firefox EU Election Toolkit’ not only provides important background knowledge and tips – designed to be easily understood by non-techies – but also tools to enable independent online research and decision-making.
Few other topics have been so present in public perception in recent years, so comprehensively discussed in everyday life, news and science, and yet have been demystified as little as disinformation. Also commonly referred to as ‘fake news’, it’s defined as “deliberate disinformation or hoaxes spread via traditional print and broadcast news media or online social media.” Right now, so shortly before the next big elections at the end of May, the topic seems to be bubbling up once more: According to the European Commission’s Eurobarometer, 73 percent of Internet users in Europe are concerned about disinformation in the run-up to the EU parliamentary elections.
However, research also proves: The public debate about disinformation takes place in great detail, which significantly increases awareness of the ‘threat’. The fact that more and more initiatives against disinformation and fact-checking actors have been sprouting up for some time now – and that governments are getting involved, too – may be related to the zeitgeist or connected to individuals’ impression that they are constantly confronted with ‘fake news’ and cannot protect themselves on their own.
It’s important to take action against disinformation. Also, users who research the elections and potential candidates on the Internet, for example, should definitely stay critical and cautious. After all, clumsy disinformation campaigns are still taking place, revealing some of the downsides of a global, always available Internet; and they even come with a wide reach and rapid dissemination. Countless actors, including journalists, scientists and other experts now agree that the impact of disinformation is extremely limited and traditional news is still the primary and reliable source of information. This does not, however, mean that the risk of manipulation has gone away; in fact, we must make sure to stay alert and not close our eyes to new, equally problematic forms of manipulation, which have just been less present in the media and science so far. At Firefox we understand that this may require some support – and we’re happy to provide it today.
Tracking has recently been a topic of discussion in the context of intrusive advertising, big data and GDPR. To refresh your memory: When browsing from site to site, users’ personal information may be collected through scripts or widgets on the websites. They’re called trackers. Many people don’t like that user information collected through trackers is used for advertising, often times without people’s knowledge (find more info here). But there’s another issue a lot less people are aware of and which hasn’t been widely discussed so far: User data can also be used for manipulation attempts, micro-targeted at specific groups or individuals. We believe that this needs to change – and in order to make that happen, more people need to hear about it.
Firefox is committed to an open and free Internet that provides access to independent information to everyone. That’s why we’ve created the ‘Firefox EU Elections Toolkit’: a website where users can find out how tracking and opaque online advertising influence their voting behavior and how they can easily protect themselves – through browser add-ons and other tools. Additionally, disinformation and the voting process are well represented on the site. The toolkit is now available online in English, German and French. No previous technical or policy-related knowledge is required. Among other things, the toolkit contains:
Of course, manipulation on the web is not only relevant in times of major political votes. With the forthcoming parliamentary elections, however, we find ourselves in an exceptional situation that calls for practical measures – also because there might be greater interest in the election, the programmes, parties and candidates than in recent years: More and more EU citizens are realizing how important the five-yearly parliamentary election is; the demands on parliamentarians are rising; and last but not least, there are numerous new voters again this May for whom Internet issues play an important role, but who need to find out about the election, its background and consequences.
Firefox wants to make sure that everyone has the chance to make informed choices. That detailed technical knowledge is not mandatory for getting independent information. And that the internet with all of its many advantages and (almost) unlimited possibilities is open and available to everyone, independent from demographics. Firefox fights for you.
The post The Firefox EU Elections Toolkit helps you to prevent pre-vote online manipulation appeared first on The Mozilla Blog.
|
|
Mozilla Addons Blog: Add-ons disabled or failing to install in Firefox |
Updates – Last Updated: 16:25 EDT May 5 2019
Late on Friday May 3rd, we became aware of an issue with Firefox that prevented existing and new add-ons from running or being installed. We are very sorry for the inconvenience caused to people who use Firefox.
Our team identified and rolled-out a temporary fix for all Firefox Desktop users on Release, Beta and Nightly. The fix will be automatically applied in the background within 24 hours. No active steps need to be taken to make add-ons work again. In particular, please do not delete and/or re-install any add-ons as an attempt to fix the issue. Deleting an add-on removes any data associated with it, where disabling and re-enabling does not.
Please note: The fix does not apply to Firefox ESR or Firefox for Android. We’re working on releasing a fix for both, and will provide updates here and on social media.
To provide this fix on short notice, we are using the Studies system. This system is enabled by default, and no action is needed unless Studies have been disabled. Firefox users can check if they have Studies enabled by going to:

It may take up to six hours for the Study to be applied to Firefox. To check if the fix has been applied, you can enter “about:studies” in the location bar. If the fix is in the active, you’ll see “hotfix-update-xpi-signing-intermediate-bug-1548973” in either the Active studies or Completed studies as follows:

You may also see “hotfix-reset-xpi-verification-timestamp-1548973” listed, which is part of the fix and may be in the Active studies or Completed studies section(s).
We are working on a general fix that doesn’t use the Studies system and will keep this blog post updated accordingly. We will share a more substantial update in the coming days.
Additional sources of information:
The post Add-ons disabled or failing to install in Firefox appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2019/05/04/update-regarding-add-ons-in-firefox/
|
|
Cameron Kaiser: TenFourFox not affected by the addon apocalypse |
This brief post is just to reassure you that TenFourFox is unaffected -- I disagreed with signature enforcement on add-ons from the beginning and explicitly disabled it.
http://tenfourfox.blogspot.com/2019/05/tenfourfox-not-affected-by-addon.html
|
|
Mike Hoye: Goals And Constraints |

“Open” in this context inextricably ties source control to individual agency. The checks and balances of openness in this context are about standards, data formats, and the ability to export or migrate your data away from sites or services that threaten to go bad or go dark. This view has very little to say about – and is often hostile to the idea of – granular access restrictions and the ability to impose them, those being the tools of this worldview’s bad actors.
The blind spots of this worldview are the products of a time where someone on the inside could comfortably pretend that all the other systems that had granted them the freedom to modify this software simply didn’t exist. Those access controls were handled, invisibly, elsewhere; university admission, corporate hiring practices or geography being just a few examples of the many, many barriers between the network and the average person.
And when we’re talking about blind spots and invisible social access controls, of course, what we’re really talking about is privilege.
How many people get to have this, I wonder: the sense that they can sit down in front of a computer and be empowered by it. The feeling of being able, the certainty that you are able to look at a hard problem, think about it, test and iterate; that easy rapid prototyping with familiar tools is right there in your hands, that a toolbox the size of the world is within reach. That this isn’t some child’s wind up toy I turn a crank on until the powerpoint clown pops up.
It’s not a universal or uniform experience, to be sure; they’re machines made of other people’s choices, and computers are gonna computer. But the only reason I get to have that feeling at all is that I got my start when the unix command line was the only decent option around, and I got to put the better part of a decade grooving in that muscle memory on machines and forums where it was safe – for me at least – to be there, fully present, make mistakes and learn from them.
(Big shoutout to everyone out there who found out how bash wildcards work by inadvertently typing mv * in a directory with only two files in it.)
That world doesn’t exist anymore; the internet that birthed it isn’t coming back. But I want everyone to have this feeling, that the machine is more than a glossy appliance. That it’s not a constraint. That with patience and tenacity it can work with you and for you, not just a tool for a task but an extension and expression of ourselves and our intent. That a computer can be a tool for expressing ourselves, for helping us be ourselves better.
Last week I laid out the broad strokes of Mozilla’s requirements for our next synchronous-text platform. They were pretty straightforward, but I want to thank a number of people from different projects who’ve gotten in touch on IRC or email to ask questions and offer their feedback.
Right now I’d like to lay out those requirements in more detail, and talk about some of the reasons behind them. Later I’m going to lay out the process and the options we’re looking at, and how we’re going to gather information, test those options and evaluate what we learn.
While the Rust community is making their own choices now about the best fit for their needs, the Rust community’s processes are going to strongly inform the steps for Mozilla. They’ve learned a lot the hard way about consensus-building and community decision-making, and it’s work that I have both a great deal of respect for and no intention of re-learning the hard way myself. I’ll have more about that shortly as well.
I mentioned our list of requirements last week but I want to drill into some of them here; in particular:
This one implies a lot more than it states, and it would be pretty easy to lay out something trite like “we think holistically about accessibility” the way some organizations say “a diversity of ideas”, as though that means anything at all. But that’s just not good enough.
Diversity, accessibility and community are all tightly interwoven ideas we prize, and how we approach, evaluate and deploy the technologies that connect us speaks deeply to our intentions and values as an organization. Mozilla values all the participants in the project, whether they rely on a screen reader, a slow network or older hardware; we won’t – we can’t – pick a stack that treats anyone like second-class citizens. That will not be allowed.
Last week Dave Humphrey wrote up a reminiscence about his time on IRC soon after I made the announcement. Read the whole thing, for sure. Dave is wiser and kinder than I am, and has been for as long as we’ve known each other; his post spoke deeply to many of us who’ve been in and around Mozilla for a while, and two sentences near the end are particularly important:
“Having a way to get deeply engaged with a community is important, especially one as large as Mozilla. Whatever product or tool gets chosen, it needs to allow people to join without being invited.”
We’ve got a more detailed list of functional and organizational requirements for this project, and this is an important part of it: “New users must be able to join the service without manual intervention from a Mozilla employee.”
We’ve understood this as an accessibility issue for a long time as well, though I don’t think we’ve ever given it a name. “Involvement friction”, maybe – everything about becoming part of a project and community that’s hard not because it’s inherently difficult, but because nobody’s taken the time to make it easy.
I spend a lot of time thinking about something Sid Wolinsky said about the first elevators installed in the New York subway system: “This elevator is a gift from the disability community and the ADA to the nondisabled people of New York”. If you watch who’s using the elevators, ramps or automatic doors in any public building long enough, anything with wheelchair logo on it, you’ll notice a trend: it’s never somebody in a wheelchair. It’s somebody pushing a stroller or nursing a limp. It’s somebody carrying an awkward parcel, or a bag of groceries. Sometimes it’s somebody with a coffee in one hand and a phone in the other. Sometimes it’s somebody with no reason at all, at least not one you can see. It’s people who want whatever thing they’re doing, however difficult, to be a little bit easier. It’s everybody.
If you cost out accessible technology for the people who rely on it, it looks really expensive; if you cost it out for everyone who benefits from it, though, it’s basically free. And none of us in the “benefit” camp are ever further than a sprained ankle away from “rely”.
We’re getting better at this at Mozilla in hundreds of different ways, at recognizing how important it is that the experience of getting from “I want to help” to “I’m set up to help” to “I’m helping” be as simple and painless as possible. As one example, our bootstrap scripts and mach-build have reduced our once-brittle, failure-prone developer setup process down to “answer these questions and wait for the downloads to finish”, and in the process have done more to make the Firefox codebase accessible than I ever will. And everyone relies on them now, first-touch contributors and veteran devs alike.
Getting involved in the community, though, is still harder than it needs to be; try watching somebody new to open source development try to join an IRC channel sometime. Watch them go from “what’s IRC” to finding a client to learning how to use the client to joining the right server, then the right channel, only to find that the reward for all that effort is no backscroll, no context, and no idea who you’re talking to or if you’re in the right place or if you’re shouting into the void because the people you’re looking for aren’t logged in at the same time. It’s like asking somebody to learn to operate an airlock on their own so they can toss themselves out of it.
It’s more than obvious that you don’t build products like that anymore, but I think it’s underappreciated that it’s just as true of communities. I think it’s critical that we bring that same discipline of caring about the details of the experience to our communications channels and community forums, and the CPG is the cornerstone of that effort.
It was easy not to care about this when somebody who wanted to contribute to an open source project with global impact had maybe four choices, the Linux kernel, the Mozilla suite, the GNU tools and maybe Apache. But that world was pre-Github, pre-NPM. If you want to work on hard problems with global impact now you have a hundred thousand options, and that means the experience of joining and becoming a part of the Mozilla community matters.
In short, the amount of effort a project puts into making the path from “I want to help” to “I’m helping” easier is a reliable indicator of the value that project puts on community involvement. So if we say we value our community, we need to treat community involvement and contribution like a product, with all the usability and accessibility concerns that implies. To drive involvement friction as close to zero as possible.
One tool we’ll be relying on – and this one, we did build in-house – is called Mozilla-IAM, Mozilla’s Identity and Access Management tool. I’ll have more to say about this soon, but at its core it lets us proxy authentication from various sources and methods we trust, Github, Firefox Accounts, a link in your email, a few others. We think IAM will let us support pseudonymous participation and a low-cost first-contact experience, but also let us keep our house in order and uphold the CPG in the process.
Anyway, here’s a few more bullet points; what requirements doc isn’t full of them?
A synchronous messaging system that meets our needs:
I doubt any of that will surprise anyone, but they might, and I’m keeping an eye out for questions. We’re still talking this out in #synchronicity on irc.m.o, and you’re welcome to jump in.
I suppose I should tip my hand at this point, and say that as much as I value the source part of open source, I also believe that people participating in open source communities deserve to be free not only to change the code and build the future, but to be free from the brand of arbitrary, mechanized harassment that thrives on unaccountable infrastructure, federated or not. We’d be deluding ourselves if we called systems that are just too dangerous for some people to participate in at all “open” just because you can clone the source and stand up your own copy. And I am absolutely certain that if this free software revolution of ours ends up in a place where asking somebody to participate in open development is indistinguishable from asking them to walk home at night alone, then we’re done. People cannot be equal participants in environments where they are subject to wildly unequal risk. People cannot be equal participants in environments where they are unequally threatened.
I think we can get there; I think we can meet our obligations to the Mission and the Manifesto as well as the needs of our community, and help the community grow and thrive in a way that grows and strengthens the web want and empowers everyone using and building it to be who we’re aspiring to be, better.
The next steps are going to be to lay out the evaluation process in more detail; then we can start pulling in information, stand up instances of the candidate stacks we’re looking at and trying them out.
http://exple.tive.org/blarg/2019/05/03/goals-and-constraints/
|
|
The Firefox Frontier: How to research smarter, not harder with 10 tools on Firefox. |
Whether you’re in school or working on a project, knowing how to research is an essential skill. However, understanding how to do something and doing it smarter are two different … Read more
The post How to research smarter, not harder with 10 tools on Firefox. appeared first on The Firefox Frontier.
|
|
Mozilla Addons Blog: Add-on Policy and Process Updates |
As part of our ongoing work to make add-ons safer for Firefox users, we are updating our Add-on Policy to help us respond faster to reports of malicious extensions. The following is a summary of the changes, which will go into effect on June 10, 2019.
We will also be clarifying our blocking process. Add-on or extension blocking (sometimes referred to as “blocklisting”), is a method for disabling extensions or other third-party software that has already been installed by Firefox users.
You can preview the policy and blocking process documents and ensure your extensions abide by them to avoid any disruption. If you have questions about these updated policies or would like to provide feedback, please post to this forum thread.
May 4, 2019 9:09 AM PST update: A certificate expired yesterday and has caused add-ons to stop working or fail to install. This is unrelated to the policy changes. We will be providing updates about the certificate issue in other posts on this blog.
9:55 am PST: Because a lot of comments on this post are related to the certificate issue, we are temporarily turning off comments for this post.
The post Add-on Policy and Process Updates appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2019/05/02/add-on-policy-and-process-updates/
|
|
Will Kahn-Greene: Socorro: April 2019 happenings |
Socorro is the crash ingestion pipeline for Mozilla's products like Firefox. When Firefox crashes, the crash reporter collects data about the crash, generates a crash report, and submits that report to Socorro. Socorro saves the crash report, processes it, and provides an interface for aggregating, searching, and looking at crash reports.
This blog post summarizes Socorro activities in April.
Read more… (6 min remaining to read)
https://bluesock.org/~willkg/blog/mozilla/socorro_2019_04.html
|
|
Axel Hecht: Migrate to Fluent |
A couple of weeks ago the Localization Team at Mozilla released the Fluent Syntax specification. As mentioned in our announcement, we already have over 3000 Fluent strings in Firefox. You might wonder how we introduced Fluent to a running project. In this post I’ll detail on how the design of Fluent plays into that effort, and how we pulled it off.
Fluent abstracts away the complexities of human languages from programmers. At the same time, Fluent makes easy things easy for localizers, while making complex things possible.
When you migrate a project to Fluent, you build on both of those design principles. You will simplify your code, and move the string choices from your program into the Fluent files. Only then you’ll expose Fluent to localizers to actually take advantage of the capabilities of Fluent, and to perfect the localizations of your project.
When building runtime implementations, we created several layers to tightly own particular tasks.
Bindings integrate Fluent into your development workflow. For Firefox, we focused on bindings to generate localized DOM. We also have bindings for React. These bindings determine how fluent Fluent feels to developers, but also how much Fluent can help with handling the localized return values. To give an example, integrating Fluent into Android app development would probably focus on a LayoutInflator. In the bindings we use at Mozilla, we decided to localize as close to the actual display of the strings as possible.
If you have declarative UI generation, you want to look into a declarative binding for Fluent. If your UI is generated programmatically, you want a programmatic binding.
The Localization classes also integrate IO into your application runtime, and making the right choices here has strong impact on performance characteristics. Not just on speed, but also the question of showing untranslated strings shortly.
Migrating your code will often be a trivial change from one API to another. Most of your code will get a string and show it, after all. You might convert several different APIs into just one in Fluent, in particular dedicated plural APIs will go away.
You will also move platform-specific terminology into the localization side, removing conditional code. You should also be able to stop stitching several localized strings together in your application logic.
As we’ll go through the process here, I’ll show an example of a sentence with a link. The project wants to be really sure the link isn’t broken, so it’s not exposed to localizers at all. This is shortened from an actual example in Firefox, where we link to our privacy policy. We’ll convert to DOM overlays, to separate localizable and non-localizable aspects of the DOM in Fluent. Let’s just look at the HTML code snippet now, and look at the localizations later.
Before:
After:
Last but not least, we’ll want to migrate the localizations. While migrating code is work, losing all your existing localizations is just outright a bad idea.
For our work on Firefox, we use a Python package named fluent.migrations. It’s building on top of the fluent.syntax package, and programmatically creates Fluent files from existing localizations.
It allows you to copy and paste existing localizations into a Fluent string for the most simple cases. It also concats several strings into a single result, which you used to do in your code. For these very simple cases, it even uses Fluent syntax, with specialized global functions to copy strings.
Example:
msg = {COPY(from_path,"msg-start")}{COPY(from_path,"msg-middle")}{COPY(from_path,"msg-end")}
Then there are a bit more complicated tasks, notably involving variable references. Fluent only supports its built-in variable placement, so you need to migrate away from printf and friends. That involves firstly normalizing the various ways that a printf parameter can be formatted and placed, and then the code can do a simple replacement of the text like %2$S with a Fluent variable reference like {user-name}.
We also have logic to read our Mozilla-specific plural logic from legacy files, and to write them out as select-expressions in Fluent, with a variant for each plural form.
These transforms are implemented as pseudo nodes in a template AST, which is then evaluated against the legacy translations and creates an actual AST, which can then be serialized.
Concluding our example, before:
After:
msg = This is a link to an example site.
Find out more about this package and its capabilities in the documentation.
Given that we’re OpenSource, we also want to carry over attribution. Thus our code not only migrates all the data, but also splits the migration into individual commits, one for each author of the migrated translations.
Once the baseline is migrated, localizers can dive in and improve. They can then start using parameterized Terms to adjust grammar, for example. Or add a plural form where English didn’t need one. Or introduce a platform-specific terminology that only exists in their language.
|
|
Mozilla Addons Blog: May’s featured extensions |

by nobzol
Sleek translation tool. Just highlight text, hit the toolbar icon and your translation appears right there on the web page itself. You can translate selected text (up to 1100 characters) or the entire page.
Bonus feature: the context menu presents an option to search your highlighted word or phrase on Wikipedia.
“Sehr einfache Bedienung, korrekte "Ubersetzung aller Texte.”
by Perflyst
Isolate your Google identity into a container. Make it difficult for Google to track your moves around the web.
(NOTE: Though similarly titled to Mozilla’s Facebook Container and Multi-Account Containers, this extension is not affiliated with Mozilla.)
“Thanks a lot for making this. Works great! I’m only sorry I did not find this extension sooner.”
The post May’s featured extensions appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2019/05/01/mays-featured-extensions-2/
|
|
Hacks.Mozilla.Org: Owning it: browser compatibility data and open source governance |
What does it mean to “own” an open-source project? With the browser-compat-data project (“BCD”), the MDN (Mozilla Developer Network) community and I recently had the opportunity to find out.
In 2017, the MDN Web Docs team invited me to work on what was described to me as a small, but growing project (previously on Hacks). The little project had a big goal: to provide detailed and reliable structured data about what Web platform features are supported by different browsers. It sounded ambitious, but my part was narrow: convert hand-written HTML compatibility tables on MDN into structured JSON data.
As a technical writer and consultant, it was an unusual project to get to work on. Ordinarily, I look at data and code and use them to write words for people. For BCD, I worked in the opposite direction: reading what people wrote and turning it into structured data for machines. But I think I was most excited at the prospect of working on an open source project with a lot of reach, something I’d never done before.
Plus the project appealed to my sense of order and tidiness. Back then, most of the compatibility tables looked something like this:

In their inconsistent state, they couldn’t be updated in bulk and couldn’t be redesigned without modifying thousands upon thousands of pages on MDN. Instead, we worked to liberate the data in the tables to a structured, validated JSON format that we could publish in an npm package. With this change, new tables could be generated and other projects could use the data too.

Since then, the project has grown considerably. If there was a single inflection point, it was the Hack on MDN event in Paris, where we met in early 2018 to migrate more tables, build new tools, and play with the data. In the last year and a half, we’ve accomplished so many things, including replacing the last of the legacy tables on MDN with shiny, new BCD-derived tables, and seeing our data used in Visual Studio Code.
We couldn’t have built BCD into what it is now without the help of the hundreds of new contributors that have joined the project. But some challenges have come along with that growth. My duties shifted from copying data into the repository to reviewing others’ contributions, learning about the design of the schema, and hacking on supporting tools. I had to learn so much about being a thoughtful, helpful guide for new and established contributors alike. But the increased size of the project also put new demands on the project as a whole.
Florian Scholz, the project leader, took on answering a question key to the long-term sustainability of the project: how do we make sure that contributors can be more than mere inputs, and can really be part of the project? To answer that question, Florian wrote and helped us adopt a governance document that defines how any contributor—not just MDN staff—can become an owner of the project.
Inspired by the JS Foundation’s Technical Advisory Committee, the ESLint project, and others, BCD’s governance document lays out how contributors can become committers (known as peers), how important decisions are made by the project leaders (known as owners), and how to become an owner. It’s not some stuffy rule book about votes and points of order; it speaks to the project’s ambition of being a community-led project.
Since adopting the governance document, BCD has added new peers from outside Mozilla, reflecting how the project has grown into a cross-browser community. For example, Joe Medley, a technical writer at Google, has joined us to help add and confirm data about Google Chrome. We’ve also added one new owner: me.
If I’m being honest, not much has changed: peers and owners still review pull requests, still research and add new data, and still answer a lot of questions about BCD, just as before. But with the governance document, we know what’s expected and what we can do to guide others on the journey to project ownership, like I experienced. It’s reassuring to know that as the project grows so too will its leadership.
We accomplished a lot in the past year, but our best work is ahead. In 2019, we have an ambitious goal: get 100% real data for Firefox, Internet Explorer, Edge, Chrome, Safari, mobile Safari, and mobile Chrome for all Web platform features. That means data about whether or not any feature in our data set is supported by each browser and, if it is, in what version it first appeared. If we achieve our goal, BCD will be an unparalleled resource for Web developers.
But we can’t achieve this goal on our own. We need to fill in the blanks, by testing and researching features, updating data, verifying pull requests, and more. We’d love for you to join us.
The post Owning it: browser compatibility data and open source governance appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/05/browser-compatibility-data-and-open-source-governance/
|
|
Andrew Halberstadt: Python 3 at Mozilla |
Mozilla uses a lot of Python. Most of our build system, CI configuration, test harnesses, command line tooling and countless other scripts, tools or Github projects are all handled by Python. In mozilla-central there are over 3500 Python files (excluding third party files), comprising roughly 230k lines of code. Additionally there are 462 repositories labelled with Python in the Mozilla org on Github (though many of these are not active). That’s a lot of Python, and most of it is Python 2.
With Python 2’s exaugural year well underway, it is a good time to take stock of the situation and ask some questions. How far along has Mozilla come in the Python 3 migration? Which large work items lie on the critical path? And do we have a plan to get to a good state in time for Python 2’s EOL on January 1st, 2020?
|
|
Mozilla VR Blog: Firefox Reality coming to SteamVR |
We are excited to announce that we’re working with Valve to bring the immersive web to SteamVR!
This January, we announced that we were bringing the Firefox Reality experience to desktop devices and the Vive stores. Since then, collaborating closely with Valve, we have been working to also bring Firefox Reality to the SteamVR immersive experience. In the coming months, users will be offered a way to install Firefox Reality via a new web dashboard button, and then launch a browser window over any OpenVR experience.
With a few simple clicks, users will be able to access web content such as tips or guides or stream a Twitch comment channel without having to exit their immersive experiences. In addition, users will be able to log into their Firefox account once, and access synced bookmarks and cookies across both Firefox and Firefox Reality — no need to log in twice!

We are excited to collaborate with Valve and release Firefox for SteamVR this summer.
|
|
Mozilla GFX: WebRender newsletter #44 |
WebRender is a GPU based 2D rendering engine for web written in Rust, currently powering Mozilla’s research web browser servo and on its way to becoming Firefox‘s rendering engine.
Right after the previous newsletter was published, Andrew and Jeff enabled WebRender for Linux users on Intel integrated GPUs with Mesa 18.2 or newer on Nightly if their screen resolution is 3440x1440 or less.
We decided to start with Mesa is thanks to the quality of the drivers. Users with 4k screens will have to wait a little longer though (or enable WebRender manually) as there are a number of specific optimizations we want to do before we are comfortable getting WebRender used on these very high resolution screens. While most recent discreet GPUs can stomach about anything we throw at them, integrated GPUs operate on a much tighter budget and compete with the CPU for memory bandwidth. 4k screens are real little memory bandwidth eating monsters.
Jessie put together a roadmap of the WebRender project and other graphics endeavors from the items discussed in the week in Toronto.
It gives a good idea of the topics that we are focusing on for the coming months.
In the previous newsletter I went over a number of the topics that we discussed during the graphics team’s last get-together in Toronto. Let’s continue here.
We went over a number of the items in WebRender’s Android TODO-list. Getting WebRender to work at all on Android is one thing. A lot of platform-specific low level glue code which Sotaro has been steadily improving lately.
On top of that come mores questions:
Among the features that WebRender currently heavily relies on but are (surprisingly) not universally supported in this day and age:
We discussed various workarounds. Some of them will be easy to implement, some harder, some will come at a cost, some we are not sure will provide an acceptable user experience. As it turns out, building a modern rendering engine while also targetting devices that are everything but modern is quite a challenge, who would have thought!
Rendering a frame, from a change of layout triggered by some JavaScript to photons flying out of the screen, goes through a long pipeline. Sometimes some steps in that pipeline take longer than we would want but other parts of the pipeline sort of absorb and hide the issue and all is mostly fine. Sometimes, though, slowdowns in particular places with the wrong timing can cause a chain of bad interactions which results a back and forth between a rapid burst of a few frames followed by a couple of missed frames as parts the system oscillate between throttle themselves on and off.
I am describing this in the abstract because the technical description of how and why this can happen in Gecko is complicated. It’s a big topic that impacts the design of a lot of pieces in Firefox’s rendering engine. We talked about this and came up with some short and long term potential improvements.
I mentioned this towards the beginning of this post. Integrated GPUs tend to be more limited in, well in most things, but most importantly in memory bandwidth, which is exacerbated by sharing RAM with the CPU. When high resolution screens don’t fit in the integrated GPU’s dedicated caches, Jeff and Markus made the observation that it can be significantly faster to split the screen into a few large regions and render them one by one. This is at the cost of batch breaks and an increased amount of draw calls, however the restricting rendering to smaller portions of the screen gives the GPU a more cache-friendly workload than rendering the entire screen in a single pass.
This approach is interestingly similar to the way tiled GPUs common on mobile devices work.
On top of that there are some optimizations that we want to investigate to reduce the amount of batch breaks caused by text on platforms that do not support dual-source blending, as well as continued investigation in progress of what is slow specifically on Intel devices.
We went over a number of other technical topics such as WebRender’s threading architecture, gory details of support for backface-visibility, where to get the best Tha"i food in downtown Toronto and more. I won’t cover them here because they are somewhat hard and/or boring to explain (or because I wasn’t involved enough in the topics do them justice on this blog).
It’s been a very useful and busy week. The graphics team will meet next in Whistler in June along with the rest of Mozilla. By then Firefox 67 will ship, enabling WebRender for a subset of Windows users in the release channel which is huge milestone for us.
In about:config, enable the pref gfx.webrender.all and restart the browser.
The best place to report bugs related to WebRender in Firefox is the Graphics :: WebRender component in bugzilla.
Note that it is possible to log in with a github account.
WebRender is available as a standalone crate on crates.io (documentation)
https://mozillagfx.wordpress.com/2019/04/30/webrender-newsletter-44/
|
|
The Mozilla Blog: $2.4 Million in Prizes for Schools Teaching Ethics Alongside Computer Science |
Today, we are announcing the first winners of the Responsible Computer Science Challenge. We’re awarding $2.4 million to 17 initiatives that integrate ethics into undergraduate computer science courses.
The winners’ proposed curricula are novel: They include in-class role-playing games to explore the impact of technology on society. They embed philosophy experts and social scientists in computer science classes. They feature “red teams” that probe students’ projects for possible negative societal impacts. And they have computer science students partner with local nonprofits and government agencies.
The winners will receive awards of up to $150,000, and they span the following categories: public university, private university, liberal arts college, community college, and Jesuit university. Stage 1 winners are located across 13 states, with computer science programs ranging in size from 87 students to 3,650 students.
The Responsible Computer Science Challenge is an ambitious initiative by Omidyar Network, Mozilla, Schmidt Futures, and Craig Newmark Philanthropies. It aims to integrate ethics and responsibility into undergraduate computer science curricula and pedagogy at U.S. colleges and universities.
Says Kathy Pham, computer scientist and Mozilla Fellow co-leading the Challenge: “Today’s computer scientists write code with the potential to affect billions of people’s privacy, security, equality, and well-being. Technology today can influence what journalism we read and what political discussions we engage with; whether or not we qualify for a mortgage or insurance policy; how results about us come up in an online search; whether we are released on bail or have to stay; and so much more.”
Pham continues: “These 17 winners recognize that power, and take crucial steps to integrate ethics and responsibility into core courses like algorithms, compilers, computer architecture, neural networks, and data structures. Furthermore, they will release their materials and methodology in the open, allowing other individuals and institutions to adapt and use them in their own environment, broadening the reach of the work. By deeply integrating ethics into computer science curricula and sharing the content openly, we can create more responsible technology from the start.”
Says Yoav Schlesinger, principal at Omidyar Network’s Tech and Society Lab co-leading the Challenge: “Revamping training for the next generation of technologists is critical to changing the way tech is built now and into the future. We are impressed with the quality of submissions and even more pleased to see such outstanding proposals awarded funding as part of Stage I of the Responsible Computer Science Challenge. With these financial resources, we are confident that winners will go on to develop exciting, innovative coursework that will not only be implemented at their home institutions, but also scaled to additional colleges and universities across the country.”
Challenge winners are announced in two stages: Stage I (today), for concepts that deeply integrate ethics into existing undergraduate computer science courses, either through syllabi changes or teaching methodology adjustments. Stage I winners receive up to $150,000 each to develop and pilot their ideas. Stage II (summer 2020) supports the spread and scale of the most promising approaches developed in Stage I. In total, the Challenge will award up to $3.5 million in prizes.
The winners announced today were selected by a panel of 19 independent judges from universities, community organizations, and the tech industry. Judges deliberated over the course of three weeks.
(School | Location | Principal Investigator)
Allegheny College | Meadville, PA | Oliver Bonham-Carter
While studying fields like artificial intelligence and data analytics, students will investigate potential ethical and societal challenges. For example: They might interrogate how medical data is analyzed, used, or secured. Lessons will include relevant readings, hands-on activities, and talks from experts in the field.
Bemidji State University | Bemidji, MN | Marty J. Wolf, Colleen Greer
The university will lead workshops that guide faculty at other institutions in developing and implementing responsible computer science teaching modules. The workshops will convene not just computer science faculty, but also social science and humanities faculty.
Bowdoin College | Brunswick, ME | Stacy Doore
Computer science students will participate in “ethical narratives laboratories,” where they experiment with and test the impact of technology on society. These laboratories will include transformative engagement with real and fictional narratives including case studies, science fiction readings, films, shows, and personal interviews.
Columbia University | New York, NY | Augustin Chaintreau
This approach integrates ethics directly into the computer science curriculum, rather than making it a stand-alone course. Students will consult and engage with an “ethical companion” that supplements a typical course textbook, allowing ethics to be addressed immediately alongside key concepts. The companion provides examples, case studies, and problem sets that connect ethics with topics like computer vision and algorithm design.
Georgetown University | Washington, DC | Nitin Vaidya
Georgetown’s computer science department will collaborate with the school’s Ethics Lab to create interactive experiences that illuminate how ethics and computer science interact. The goal is to introduce a series of active-learning engagements across a semester-long arc into selected courses in the computer science curriculum.
Georgia Institute of Technology | Atlanta, GA | Ellen Zegura
This approach embeds social responsibility into the computer science curriculum, starting with the introductory courses. Students will engage in role-playing games (RPGs) to examine how a new technology might impact the public. For example: How facial recognition or self-driving cars might affect a community.
Harvard University | Cambridge, MA | Barbara Grosz
Harvard will expand the open-access resources of its Embedded EthiCS program which pairs computer science faculty with philosophy PhD students to develop ethical reasoning modules that are incorporated into courses throughout the computer science curriculum. Computer science postdocs will augment module development through design of activities relevant to students’ future technology careers.
Miami Dade College | Miami, FL | Antonio Delgado
The college will integrate social impact projects and collaborations with local nonprofits and government agencies into the computer science curriculum. Computer science syllabi will also be updated to include ethics exercises and assignments.
Northeastern University | Boston, MA | Christo Wilson
This initiative will embed an ethics component into the university’s computer science, cybersecurity, and data science programs. The ethics component will include lectures, discussion prompts, case studies, exercises, and more. Students will also have access to a philosophy faculty advisor with expertise in information and data ethics.
Santa Clara University | Santa Clara, CA | Sukanya Manna, Shiva Houshmand, Subramaniam Vincent
This initiative will help CS students develop a deliberative ethical analysis framework that complements their technical learning. It will develop software engineering ethics, cybersecurity ethics, and data ethics modules, with integration of case studies and projects. These modules will also be adapted into free MOOC materials, so other institutions worldwide can benefit from the curriculum.
University of California, Berkeley | Berkeley, CA | James Demmel, Cathryn Carson
This initiative integrates a “Human Contexts and Ethics Toolkit” into the computer science/data science curriculum. The toolkit helps students discover when and how their work intersects with social power structures. For example: bias in data collection, privacy impacts, and algorithmic decision making.
University at Buffalo | Buffalo, NY | Atri Rudra
In this initiative, freshmen studying computer science will discuss ethics in the first-year seminar “How the internet works.” Sophomores will study responsible algorithmic development for real-world problems. Juniors will study the ethical implications of machine learning. And seniors will incorporate ethical thinking into their capstone course.
University of California, Davis | Davis, CA | Annamaria (Nina) Amenta, Gerardo Con D'iaz, and Xin Liu
Computer science students will be exposed to social science and humanities while pursuing their major, culminating in a “conscientious” senior project. The project will entail developing technology while assessing its impact on inclusion, privacy, and other factors, and there will be opportunities for projects with local nonprofits or government agencies.
University of Colorado, Boulder | Boulder, CO | Casey Fiesler
This initiative integrates an ethics component into introductory programming classes, and features an “ethics fellows program” that embeds students with an interest in ethics into upper division computer science and technical classes.
University of Maryland, Baltimore County | Baltimore, MD | Helena Mentis
This initiative uses three avenues to integrate ethics into the computer science curriculum: peer discussions on how technologies might affect different populations; negative implications evaluations, i.e. “red teams” that probe the potential negative societal impacts of students’ projects; and a training program to equip teaching assistants with ethics and equality literacy.
University of Utah | Salt Lake City, UT | Suresh Venkatasubramanian, Sorelle A. Friedler (Haverford College), Seny Kamara (Brown University)
Computer science students will be encouraged to apply problem solving and critical thinking not just to design algorithms, but also the social issues that their algorithms intersect with. For example: When studying bitcoin mining algorithms, students will focus on energy usage and environmental impact. The curriculum will be developed with the help of domain experts who have expertise in sustainability, surveillance, criminal justice, and other issue areas.
Washington University | St. Louis, MO | Ron Cytron
Computer science students will participate in “studio sessions,” or group discussions that unpack how their technical education and skills intersect with issues like individual privacy, data security, and biased algorithms.
The Responsible Computer Science Challenge is part of Mozilla’s mission to empower the people and projects on the front lines of internet health work. Learn more about Mozilla Awards.
Launched in October 2018, the Responsible Computer Science Challenge, incubated at Omidyar Network’s Tech and Society Solutions Lab, is part of Omidyar Network’s growing efforts to mitigate the unintended consequences of technology on our social fabric, and ensure products are responsibly designed and brought to market.
The post $2.4 Million in Prizes for Schools Teaching Ethics Alongside Computer Science appeared first on The Mozilla Blog.
|
|
About:Community: Firefox 67 new contributors |
With the release of Firefox 67, we are pleased to welcome the 75 developers who contributed their first code change to Firefox in this release, 66 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
https://blog.mozilla.org/community/2019/04/30/firefox-67-new-contributors/
|
|






