The Mozilla Blog: Emblematic Group and Mozilla Team Up to Showcase Next Generation of Storytelling on the Web |
Everything you share on the internet is a story. You read blog posts and watch videos that make you feel connected to people across the world. Virtual Reality has made these experiences even stronger, but it wasn’t available to most people as a storytelling tool, until now.
This breakthrough in accessibility comes from VR pioneer and award winning journalist, Nonny de la Pe~na, who is founder & CEO of the immersive technology company Emblematic Group. Their newest initiative was to launch a browser based platform that allows anyone to tap into the immersive power of virtual reality, regardless of their technical background. That is exactly what they did with REACH. With support from like minded partners such as Mozilla and the John S. and James L. Knight Foundation, de la Pe~na launched the platform at the 2019 Sundance Film Festival. REACH completely simplifies authorship and distribution of virtual reality experiences using a simple drag and drop interface which anyone can access from any device, including a laptop, tablet, or smartphone.

De la Pe~na was one of the first to recognize that VR is a powerful way to tell stories. As an international journalist, she knew what it took to write stories that touch people on a deep level. Putting people inside those stories made sense to her, and as supporters of a free and open web, Mozilla wanted to support her mission.
The stories de la Pe~na tells in virtual reality are beautiful and sometimes, gut-wrenching. You feel the raw emotion of a protect at an abortion clinic and experience the loneliness of a solitary confinement cell.
The team at Emblematic wanted to do more than create, they wanted to make it easy for people without coding experience to tell their own stories in VR. REACH gives all VR storytellers a voice, something that Mozilla knows is crucial for the future of the internet.
“What if VR took you somewhere you didn’t necessarily know you wanted to go, but needed to see to fully comprehend? That’s the goal of REACH.”
– Nonny de la Pe~na

REACH uses WebVR and other web technologies to allow anyone to create their own virtual reality experiences. It has a simple drag-and-drop interface that lets users place real people into high-res 3D environments and then share the results across multiple platforms.
With the REACH platform, you can host and distribute 3D models. These can be used by first-time content makers, veteran creators and news organizations to create innovative and inexpensive “walk around” VR content.
“I wanted people to feel the whole story with their bodies, not just with their minds.”
– Nonny de la Pe~na.”
Mozilla hosts Developer Roadshows to help people learn the skills to build the web. That’s why we partnered with Emblematic for a recent event. There, Rick Adams–a news correspondent for Los Angeles–who has been using an early version of REACH in news reporting said that it’s perfect for journalists with average technical skills.

“You can place yourself or any of your interviewees into the environment, create, and then open on the web with a link, which is revolutionary. You create a complex and rich story, allowing people to really feel like they are involved in the story themselves.”
REACH is revolutionary for a number of reasons but especially because it is \ built in WebVR. WebVR was created by Mozilla to make immersive content accessible on the web. This means that anyone with a computer, tablet or smartphone can use REACH. If you don’t have a pricey headset, you can still enjoy WebVR experiences like REACH through your browser. All it takes is a link.

This is critical if we want this new medium to grow and it’s why De La Pe~na chose to create a WebVR platform like REACH that lowers the barrier to entry and puts VR in the hands of the people.
Innovators like Nonny de la Pe~na have the vision, drive, and stubborn optimism to create positive change in the world. By supporting efforts like REACH, you can empower creators to build experiences that speak to you and tell stories that help break down the walls that divide us.
REACH is currently in beta. You can sign up to be a beta tester at beta.reach.love
To learn more about Mixed Reality at Mozilla, visit labs.mozilla.org/learn/mixed-reality
The post Emblematic Group and Mozilla Team Up to Showcase Next Generation of Storytelling on the Web appeared first on The Mozilla Blog.
|
|
Daniel Stenberg: curl 7.65.0 dances in |
After another eight week cycle was been completed, curl shipped a new release into the world. 7.65.0 brings some news and some security fixes but is primarily yet again a set of bug-fixes bundled up. Remember 7.64.1?
As always, download it straight from curl.haxx.se!
One fun detail on this release: we have 500 less lines of source code in the lib/ directory compared to the previous release!
Things that happened in curl since last release:
the 181st release
3 changes
56 days (total: 7,733)
119 bug fixes (total: 5,148)
215 commits (total: 24,326)
0 new public libcurl function (total: 80)
1 new curl_easy_setopt() option (total: 267)
0 new curl command line option (total: 221)
50 contributors, 24 new (total: 1,953)
32 authors, 12 new (total: 681)
2 security fixes (total: 89)
350 USD paid in Bug Bounties
This release comes with fixes for two separate security problems. Both rated low risk. Both reported via the new bug bounty program.
CVE-2019-5435 is an issue in the recently introduced URL parsing API. It is only a problem in 32 bit architectures and only if an application can be told to pass in ridiculously long (> 2GB) strings to libcurl. This bug is similar in nature to a few other bugs libcurl has had in the past, and to once and for all combat this kind of flaw libcurl now (in 7.65.0 and forward) has a “maximum string length” limit for strings that you can pass to it using its APIs. The maximum size is 8MB. (The reporter was awarded 150 USD for this find.)
CVE-2019-5436 is a problem in the TFTP code. If an application decides to uses a smaller “blksize” than 504 (default is 512), curl would overflow a buffer allocated on the heap with data received from the server. Luckily, very few people actually download data from unknown or even remote TFTP servers. Secondly, asking for a blksize smaller than 512 is rather pointless and also very rare: the primary point in changing that size is to enlarge it. (The reporter was awarded 200 USD for this find.)
Over one hundred bug-fixes landed in this release, but some of my favorites from release cycle include…
close_notify is a message in the TLS protocol that means that this connection is about to close. In most circumstances that message doesn’t actually provide information to curl that is needed, but in the case the connection is closed prematurely, understanding that this message preceded the closure helps curl act appropriately. This change was done for the OpenSSL backend only as that’s where we got the bug reported and worked on it this time, but I think we might have reasons to do the same for other backends going forward!
The verbose message that says “Trying 12.34.56.78…” means that curl has sent started a TCP connect attempt to that IP address. This message has now been modified to also include the target port number so when using -v with curl 7.65.0, connecting to that same host for HTTPS will instead say “Trying 12.34.56.78:443…”.
To aid debugging really. I think it gives more information faster at a place you’re already looking.
The test suite got a brand new SOCKS server! Previously, all SOCKS tests for both version 4 and version 5 were done by firing up ssh (typically openssh). That method was decent but made it hard to do a range of tests for bad behavior, bad protocol replies and similar. With the new custom test server, we can basically add whatever test we want and we’ve already extended the SOCKS testing to cover more code and use cases than previously.
curl allows user names and passwords provided in URLs and as separate options to be more or less unrestricted in size and that include if the credentials are used for SOCKS5 authentication – totally ignoring the fact that the protocol SOCKS5 has a maximum size of 255 for the fields. Starting now, curl will return an error if the credentials for SOCKS5 are too long.
The command line tool and the library are independent and separable, as in you can run one version of the curl tool with another version of the libcurl library. The libcurl API is solid enough to allow it and the tool is independent enough to not restrict it further.
We always release curl the command line tool and libcurl the library together, using the same version number – with the code for both shipped in the same single file.
There should rarely be a good reason to actually run curl and libcurl with different versions. Starting now, curl will show a little warning if this is detected as we have learned that this is almost always a sign of an installation or setup mistake. Hopefully this message will aid people to detect the mistake earlier and easier.
curl’s command line parser allows users to switch off boolean options by prefixing them with dash dash no dash. For example we can switch off compressed responses by using “–no-compression” since there regular option “–compression” switches it on.
It turned out we stripped the “–no-” thing no regarding if the option was boolean or not and presumed the logic to handle it – which it didn’t. So users could actually pass a proxy string to curl with the regular option “–proxy” as well as “–no-proxy”. The latter of course not making much sense and was just due to an oversight.
In 7.65.0, only actual boolean command line options can be used with “–no-“. Trying it on other options will cause curl to report error for it.
Remember when we added a new URL parsing API to libcurl back in 7.62.0? It wasn’t even a year ago! When we did this, we also changed the internals to use the same code. It turned out we caused a regression when we parsed numerical IPv6 addresses that provide the zone ID within the string. Like this: “https://[ffe80::1%25eth0]/index.html”
Starting in this release, you can both set and get the zone ID in a URL using the API, but of course setting it doesn’t do anything unless the host is a numeric IPv6 address.
We removed the separate proxy string parsing logic and instead switched that over to more appropriately use the generic URL parser for this purpose as well. This move reduced the code size, made the code simpler and makes sure we have a unified handling of URLs! Everyone is happy!
I naively wrote the URL parser to handle scheme names as long as the longest scheme we support in curl: 8 bytes. But since the parser can also be asked to parse URLs with non-supported schemes, that limit was a bit too harsh. I did a quick research, learned that the longest currently registered URI scheme is 36 characters (“microsoft.windows.camera.multipicker”). Starting in this release , curl accepts URL schemes up to 40 bytes long.
There’s several things brewing in the background that might be ready to show in next release. Parallel transfers in the curl tool and deprecating PolarSSL support seem likely to happen for example. Less likely for this release, but still being worked on slowly, is HTTP/3 support.
We’re also likely to get a bunch of changes and fine features we haven’t even thought about from our awesome contributors. In eight weeks I hope to write another one of these blog posts explaining what went into that release…
https://daniel.haxx.se/blog/2019/05/22/curl-7-65-0-dances-in/
|
|
Andrew Halberstadt: The Cost of Fragmented Communication |
Mozilla recently announced that we are planning to de-commission irc.mozilla.org in favour
of a yet to be determined solution. As a long time user and supporter of IRC, this decision causes
me some melancholy, but I 100% believe that it is the right call. Moreover, having had an inside
glimpse at the process to replace it, I’m supremely confident whatever is chosen will be the best
option for Mozilla’s needs.
I’m not here to explain why deprecating IRC is a good idea. Other people have already done so much more eloquently than I ever could have. I’m also not here to push for a specific replacement. Arguing over chat applications is like arguing over editors or version control. Yes, there are real and important differences from one application to the next, but if there’s one thing we’re spoiled for in 2019 it’s chat applications. Besides, so much time has been spent thinking about the requirements, there’s little anyone could say on the matter that hasn’t already been considered for hours.
This post is about an unrelated, but adjacent issue. An issue that began when mozilla.slack.com
first came online, an issue that will likely persist long after irc.mozilla.org rides off into
the sunset. An issue I don’t think is brought up enough, and which I’m hoping to start some
discussion on now that communication is on everyone’s mind. I’m talking about using two
communication platforms at once. For now Slack and IRC, soon to be Slack and something else.
Different platform, same problem.
|
|
Hacks.Mozilla.Org: Firefox 67: Dark Mode CSS, WebRender, and more |
Firefox 67 is available today, bringing a faster and better JavaScript debugger, support for CSS prefers-color-scheme media queries, and the initial debut of WebRender in stable Firefox.
These are just the highlights. For complete information, see:
New in Firefox 67, the prefers-color-scheme media feature allows sites to adapt their styles to match a user’s preference for dark or light color schemes, a choice that’s begun to appear in operating systems like Windows, macOS and Android. As an example of what this looks like in the real world, Bugzilla uses prefers-color-scheme to trigger a brand new dark theme if the user has set that preference.

The prefers-color-scheme media feature is currently supported in Firefox and Safari, with support in Chrome expected later this year.
Additionally, the revert keyword is now supported, making it possible to revert one or more CSS property values back to their original values specified by the user agent’s default styles (or by a custom user stylesheet if one is set). Defined in Cascading and Inheritance Level 4, revert is also supported by Safari.
Nearly four years ago we started work on a new rendering architecture for Firefox with the goal of better utilizing modern graphics hardware. Today, we’re beginning to gradually enable WebRender for users on Windows 10 with qualified hardware. This marks the first time that WebRender has been enabled outside of Nightly and Beta builds of Firefox, and we hope to expand the supported platforms in future releases.
You can read more about WebRender in The whole web at maximum FPS: How WebRender gets rid of jank.
Firefox 67 and 68 Developer Edition bring enormous improvements to Firefox’s JavaScript Debugger. Discover faster load times, amazing support for source maps, more predictable breakpoints, brand new logpoints, and much more.
We’ve collected the Debugger improvements in their own article: Faster, Smarter JavaScript Debugging in Firefox DevTools.
In addition to the Debugger, the Web Console saw numerous updates, including greater keyboard accessibility and support for importing modules into the current page.
We’ve also removed or deprecated a few seldom-used and experimental tools, including the Canvas Debugger, Shader Editor, Web Audio Inspector, and WebIDE.
Firefox now defaults to using different profiles for each installed version, making it easier than ever to run multiple copies of Firefox side-by-side.

In addition, the browser will warn you if you try to open a newer profile with an older version of Firefox, as such mismatches can occasionally lead to data loss. This protection can be bypassed with the new -allow-downgrade command line argument.
Firefox 67 better protects your privacy online with new Content Blocking options to avoid known cryptominers and fingerprinters.
 You also have more control over your extensions, which can be prevented from running in private browsing windows.
You also have more control over your extensions, which can be prevented from running in private browsing windows.
 This is the default for all newly installed extensions in Firefox 67, though your previously installed extensions will receive permission by default. You can adjust these permissions on a per-extension basis by visiting
This is the default for all newly installed extensions in Firefox 67, though your previously installed extensions will receive permission by default. You can adjust these permissions on a per-extension basis by visiting about:addons.
We’re working hard to make Firefox Accounts more useful and discoverable this year, starting with a new default icon in the browser toolbar.

The new icon indicates whether or not you’re signed into a Firefox Account, and makes it easy to perform actions like sending tabs to other devices or manually triggering a sync. Like other toolbar buttons, you can freely move or hide the Firefox Account button according to your preferences.
Check out the many improvements to Firefox’s built-in password manager, including quicker access to your list of saved credentials. You can either click on the new “Logins and Passwords” item in the main menu, or the new “View Saved Logins” button in the login autocomplete popup.

This can be especially useful if you need to look up or edit a login outside of the normal autofill workflow. And, if you use Firefox Sync, you can access your saved passwords with the Firefox Lockbox app for Android or iOS.
We’ve enabled legacy FIDO U2F support to improve backwards compatibility with sites that have not yet upgraded to its standards-based successor, WebAuthn.
These APIs make it possible for websites to authenticate users with strong, hardware-backed authentication mechanisms like USB security keys or Windows Hello.
Firefox now supports AV1, a next-generation video codec, on all major desktop platforms. Also, playback on those platforms is now powered by dav1d, a faster and more efficient AV1 decoder developed by the VideoLAN and FFmpeg communities.
String.prototype.matchAll() and Dynamic ImportsFirefox joins Chrome in supporting the matchAll() String prototype method, which takes a regular expression and returns an iterator of all matching text, including capturing groups.
The import() function can now be used to dynamically load JavaScript modules, similarly to how the static import statement works. Now it’s possible to load modules conditionally or in response to user actions, though such imports are harder to reason about for build tools that use static analysis for optimizations like tree shaking.
This release includes plenty of other fixes and enhancements not covered here, and lots more to come. So what are you waiting for? Download Firefox 67 today and let us know what you think!
The post Firefox 67: Dark Mode CSS, WebRender, and more appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/05/firefox-67-dark-mode-css-webrender/
|
|
The Mozilla Blog: Latest Firefox Release is Faster than Ever |
|
|
The Firefox Frontier: No-Judgment Digital Definitions: What is Cryptocurrency? |
Cryptocurrency, cryptomining. We hear these terms thrown around a lot these days. It’s a new way to invest. It’s a new way to pay. It’s a new way to be … Read more
The post No-Judgment Digital Definitions: What is Cryptocurrency? appeared first on The Firefox Frontier.
|
|
The Firefox Frontier: Let Firefox help you block cryptominers from your computer |
Is your computer fan spinning up for no apparent reason? Your electricity bill inexplicably high? Your laptop battery draining much faster than usual? It may not be all the Netflix … Read more
The post Let Firefox help you block cryptominers from your computer appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/block-cryptominers-with-firefox/
|
|
The Firefox Frontier: How to block fingerprinting with Firefox |
If you wonder why you keep seeing the same ad, over and over, the answer could be fingerprinting. Fingerprinting is a type of online tracking that’s different from cookies or … Read more
The post How to block fingerprinting with Firefox appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/how-to-block-fingerprinting-with-firefox/
|
|
The Firefox Frontier: Save and update passwords in Private Browsing with Firefox |
Private browsing was invented 14 years ago, making it possible for users to close a browser window and erase traces of their online activity from their computers. Since then, we’ve … Read more
The post Save and update passwords in Private Browsing with Firefox appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/save-passwords-in-private-browsing-firefox/
|
|
Mozilla GFX: Graphics Team ships WebRender MVP! |
After many months of hard work and preparation, I’m pleased to announce the general availability of WebRender for selected Windows 10 devices. WebRender is a major rewrite of the Firefox rendering architecture using the same kind of GPU-based acceleration techniques used by games.
Until now, our browser rendering pipeline varied depending on the platform and OS. This has a number of drawbacks:
WebRender replaces this with a modern, unified architecture which consists of two major elements:
For more details, refer to Lin Clark’s excellent Hacks article.
This design provides very fast throughput and eliminates the need for complicated heuristics to guess which parts of the website might change in future frames. Moreover, a single backend that we control means bringing hardware acceleration to more of our users: we run the same code across Windows, Mac, Linux, and Android, and we’re much better-equipped to work around driver bugs and avoid blacklisting. It also moves GPU work out of the content process which will let us have stricter sandboxing in the content process.
We’ve seen significant performance improvements on many websites already, but we’ve only scratched the surface of what’s possible with this architecture. Expect to see even more performance improvements as we begin to take full advantage of our architectural investment in WebRender.
Since WebRender was quite a large undertaking, we decided to split up the release across a number of smaller targets. The aim of today’s release is to ship a WebRender MVP (minimum viable product) to one target; we plan to learn from that, and then gradually ship WebRender to additional platforms. This release of Firefox 67 will see us roll-out WebRender to users running Windows 10 on desktop machines with NVIDIA graphics cards. This currently represents approximately 4% of Firefox’s desktop population.
The go-live date for Firefox 67 is Tuesday, May 21st at 6am PST. WebRender will ship disabled by default. On May 27th, 25% of the qualified population will have WebRender enabled. We will then increase that rollout to 50% by Thursday, May 30th – assuming that everything is going smoothly. WebRender will then be enabled for 100% of the qualified population by the following week.
We will be keeping a close eye on various health metrics to ensure everything is working as expected. We also plan to conduct an A/B test to compare performance against non-WebRender-enabled Firefox instances in release. We have spent the past several months putting WebRender through its paces in Nightly and Beta and even conducted an experiment in the Firefox 66 release to help uncover any potential bugs and issues we might face.
This milestone is a significant one, and we are excited to get here! A big congrats goes out to everyone on the Graphics team and all of those who have pitched in to help us get to this point. We are all looking forward to shipping WebRender to more users throughout the rest of this year.
When it came to performance, our main goal for the MVP was to avoid regressing performance or correctness vs. making it wildly better right away. That said, during our experiments in Nightly and Beta, we’ve observed that users with WebRender experience less jank, and that a number of website performance problems disappear. We will keep a close eye on our metrics as we ship throughout Firefox 67 and will report back on how things are looking in Release.
We are also continuing to prioritize performance work in WebRender. Picture caching 2.0, various display list improvements, and document splitting are all enhancements that leverage our flexible, new architecture to speed things up further.
There are a couple of reasons why we choose to ship WebRender first on Windows 10 machines with NVIDIA graphics cards. This is the platform where we currently have the best performance with WebRender, and we wanted to compete with our flagship graphics experience to prove that this was a better architecture. Also the percentage of Firefox users with this combination in release (approximately 4%) is a safe number such that we don’t introduce too much risk for this first milestone.
In short: computers are hard.
WebRender started as an experiment in the Servo research project and as such, only needed to support a small number of use cases. Integrating WebRender into Gecko meant that we had to build on that and account for the multitude of variables possible to encounter in sites on the web today. As I am sure you can imagine, that has been no small feat.
Replacing the browser’s existing rendering engine is a task that required careful consideration, planning and thoughtfulness. We have basically been performing open heart surgery on a living, moving beast (that wasn’t put under anaesthesia).
The good news is that we have learned quite a bit throughout this process and are confident in our plans going forward when it comes to continuing to ship WebRender this year.
We currently have WebRender enabled in Nightly for:
To turn on WebRender, go to about:config, enable the gfx.webrender.all pref, and restart the browser. Note: doing so may cause pages to render incorrectly, your browser to crash, or other problems. Proceed with caution!
The best place to report bugs related to WebRender in Firefox is the Graphics :: WebRender component in Bugzilla.
Why, thank you! Our goal is to ship WebRender out to more users throughout the year while continuing to make it more performant. Our top priorities for the next few months will be the following:
We got together in Toronto in early April and created a high-level roadmap.
We will keep everyone posted as our plans develop.
https://mozillagfx.wordpress.com/2019/05/21/graphics-team-ships-webrender-mvp/
|
|
The Rust Programming Language Blog: The 2019 Rust Event Lineup |
We're excited for the 2019 conference season, which we're actually late in writing up. Some incredible events have already happened! Read on to learn more about all the events occurring around the world, past and future.
Yes, RustRush was actually in 2018, but we didn't cover it in the 2018 event lineup so we're counting it in 2019! This was the first Rust event in Russia. You can watch the talk videos and follow the conference on Twitter.
The Rust Latam Conference is Latin America's leading event about Rust. Their first event happened in Montevideo this year, and the videos are available to watch! Rust Latam plans to be a yearly event, so watch Twitter for information about next year's event.
RustCon Asia was the first Rust conference in Asia! The talk videos are already available on YouTube! Follow @RustConAsia on Twitter for future updates.
Oxidize was a conference specifically about using Rust on embedded devices that took place in Berlin. Videos aren't out yet, but there'll probably be tweets when they are!
RustLab is a new conference for this year that will be taking place in Florence, Italy. Their session and workshop lineup has been announced, and tickets are now available! Follow the conference on Twitter for the most up-to-date information.
The official RustConf will again be taking place in Portland, OR, USA. Thursday is a day of trainings and Friday is the main day of talks. See Twitter for the latest announcements!
Colorado Gold Rust is a new conference for this year, and is taking place in Denver, CO, USA. Their CFP and ticket sales are open now, and you can also follow them on twitter!
This year's Rust Belt Rust will be taking place in Dayton, OH, USA, the birthplace of flight! The CFP and ticket sales will open soon. Check Twitter for announcements.
The exact dates for RustFest Barcelona haven't been announced yet, but it's slated to happen sometime in November. Keep an eye on the RustFest Twitter for announcements!
We are so lucky and excited to have so many wonderful conferences around the world in 2019! Have fun at the events, and we hope there are even more in 2020!
https://blog.rust-lang.org/2019/05/20/The-2019-Rust-Event-Lineup.html
|
|
Cameron Kaiser: TenFourFox FPR14 available |
tell application "TenFourFoxG5"
tell front browser window
set URL of current tab to "https://www.google.com/"
repeat while (current tab is busy)
delay 1
end repeat
tell current tab
run JavaScript "let f = document.getElementById('tsf');f.q.value='tenfourfox';f.submit();"
end tell
repeat while (current tab is busy)
delay 1
end repeat
tell current tab
run JavaScript "return document.getElementsByTagName('h3')[0].innerText + ' ' + document.getElementsByTagName('cite')[0].innerText"
end tell
end tell
end tell
The font blacklist has also been updated and I have also hard-set the frame rate to 30 in the pref even though the frame rate is capped at 30 internally and such a change is simply a placebo. However, there are people claiming this makes a difference, so now you have your placebo pill and I hope you like the taste of it. :P The H.264 wiki page is also available, if you haven't tried MPEG-4/H.264 playback. The browser will finalize Monday evening Pacific as usual.
For FPR15, the JavaScript update that slipped from this milestone is back on. It's hacky and I don't know if it will work; we may be approaching the limits of feature parity, but it should compile, at least. I'm trying to reduce the changes to JavaScript in this release so that regressions are also similarly limited. However, I'm also looking at adding some later optimizations to garbage collection and using Mozilla's own list of malware scripts to additionally seed basic adblock, which I think can be safely done simultaneously.
http://tenfourfox.blogspot.com/2019/05/tenfourfox-fpr14-available.html
|
|
Mozilla VR Blog: Bringing WebXR to iOS |
The first version of the WebXR Device API is close to being finalized, and browsers will start implementing the standard soon (if they haven't already). Over the past few months we've been working on updating the WebXR Viewer (source on github, new version available now on the iOS App Store) to be ready when the specification is finalized, giving developers and users at least one WebXR solution on iOS. The current release is a step along this path.
Most of the work we've been doing is hidden from the user; we've re-written parts of the app to be more modern, more robust and efficient. And we've removed little-used parts of the app, like video and image capture, that have been made obsolete by recent iOS capabilities.
There are two major parts to the recent update of the Viewer that are visible to users and developers.
We've updated the app to support a new implementation of the WebXR API based on the official WebXR Polyfill. This polyfill currently implements a version of the standard from last year, but when it is updated to the final standard, the WebXR API used by the WebXR Viewer will follow quickly behind. Keep an eye on the standard and polyfill to get a sense of when that will happen; keep an eye on your favorite tools, as well, as they will be adding or improving their WebXR support over the next few months. (The WebXR Viewer continues to support our early proposal for a WebXR API, but that API will eventually be deprecated in favor of the official one.)
We've embedded the polyfill into the app, so the API will be automatically available to any web page loaded in the app, without the need to load a polyfill or custom API. Our goal is to have any WebXR web applications designed to use AR on a mobile phone or tablet run in the WebXR Viewer. You can try this now, by enabling the "Expose WebXR API" preference in the viewer. Any loaded page will see the WebXR API exposed on navigator.xr, even though most "webxr" content on the web won't work right now because the standard is in a state of constant change.
You can find the current code for our API in the webxr-ios-js, along with a set of examples we're creating to explore the current API, and future additions to the API.These examples are available online. A glance at the code, or the examples, will show that we are not only implementing the initial API, but also building implementations of a number of proposed additions to the standard, including anchors, hit testing, and access to real world geometry. Implementing support for requesting geospatial coordinate system alignment allows integration with the existing web Geolocation API, enabling AR experiences that rely on geospatial data (illustrated simply in the banner image above). We will soon be exploring an API for camera access to enable computer vision.
Most of these APIs were available in our previous WebXR API implementation, but the former here more closely aligns with the work of the Immersive Web Community group. (We have also kept a few of our previous ARKit-specific APIs, but marked them explicitly as not being on the standards-track yet.)
The most visible change to the application is a permissions API that is popped up when a web page requests a WebXR Session. Previously, the app was an early experiment and devoted to WebXR applications built with our custom API, so we did not explicitly ask for permission, inferring that anyone running an app in our experimental web browser intends to use WebXR capabilities.
When WebXR is released, browsers will need to obtain a user's permission before a web page can access the potentially sensitive data available via WebXR. We are particularly interested in what levels of permissions WebXR should have, so that users retain control of what data apps may require. One approach that seems reasonable is to differentiate between basic access (e.g., device motion, perhaps basic hit testing against the world), access to more detailed knowledge of the world (e.g., illumination, world geometry) and finally access to cameras and other similar sensors. The corresponding permission dialogs in the Viewer are shown here.
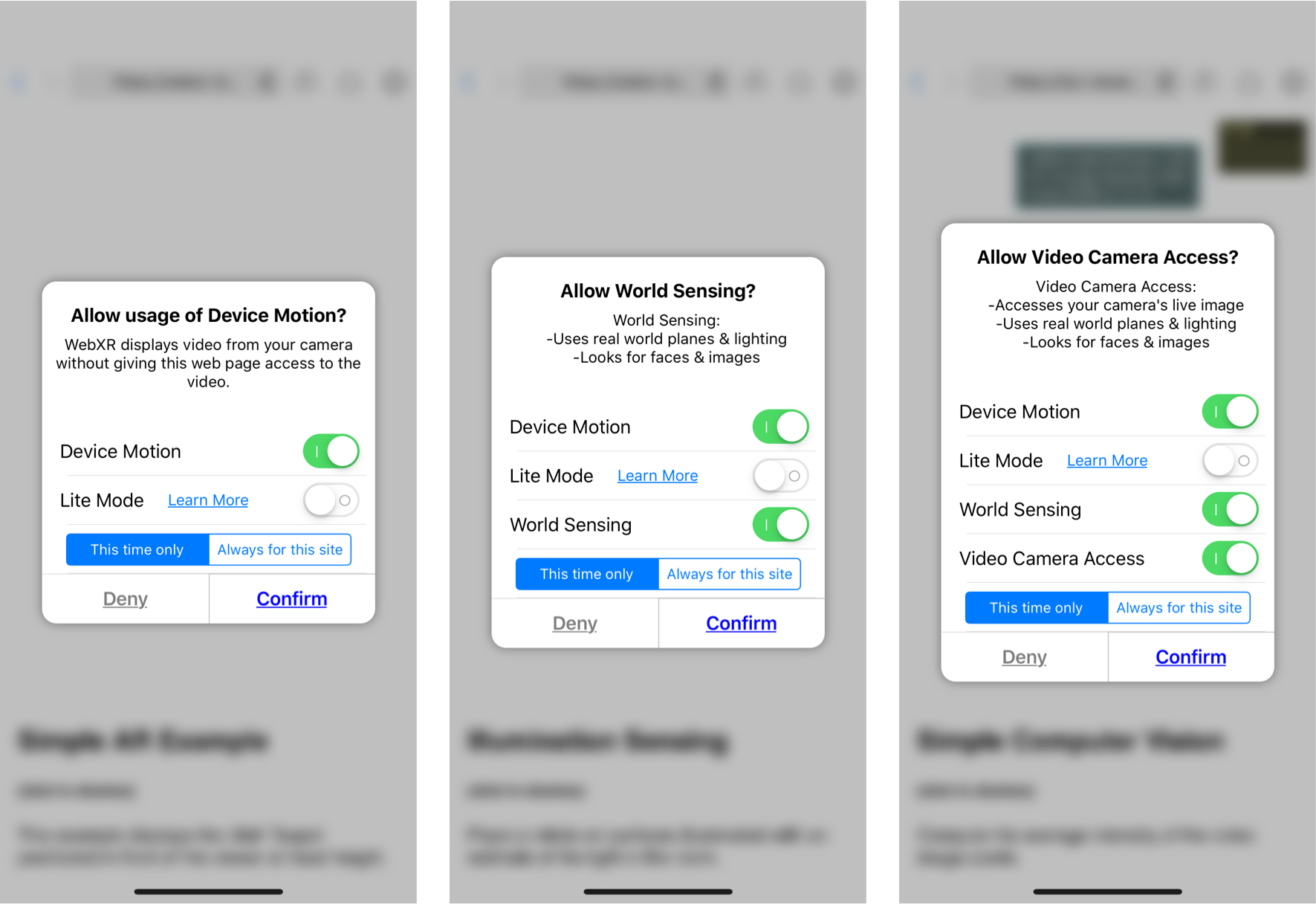
If the user gives permission, an icon in the URL bar shows the permission level, similar to the camera and microphone access icons in Firefox today.
![]()
Tapping on the icon brings up the permission dialog again, allowing the user to temporarily restrict the flow of data to the web app. This is particularly relevant for modifying access to cameras, where a mobile user (especially when HMDs are more common) may want to turn off sensors depending on the location, or who is nearby.
A final aspect of permissions we are exploring is the idea of a "Lite" mode. In each of the dialogs above, a user can select Lite mode, which brings up a UI allowing them to select a single ARKit plane.

The APIs that expose world knowledge to the web page (including hit testing in the most basic level, and geometry in the middle level) will only use that single plane as the source of their actions. Only that plane would produce hits, and only that plane would have it's geometry sent into the page. This would allow the user to limit the information passed to a page, while still being able to access AR apps on the web.
We are excited about the future of XR applications on the web, and will be using the WebXR Viewer to provide access to WebXR on iOS, as well as a testbed for new APIs and interaction ideas. We hope you will join us on the next step in the evolution of WebXR!
|
|
Chris H-C: Virtual Private Social Network: Tales of a BBM Exodus |

On Thursday April 18, my primary mechanism for talking to friends notified me that it was going away. I’d been using BlackBerry Messenger (BBM) since I started work at Research in Motion in 2008 and had found it to be tolerably built. It messaged people instantly over any data connection I had access to, what more could I ask for?
The most important BBM feature in my circle of contacts was its Groups feature. A bunch of people with BBM could form a Group and then messages, video, pictures, lists were all shared amongst the people in the group.
Essentially it acted as a virtual private social network. I could talk to a broad group of friends about the next time were getting together or about some cute thing my daughter did. I could talk to the subset who lived in Waterloo about Waterloo activities, and whose turn it was for Sunday Dinner. The Beers group kept track of whose turn it was to pay, and it combined nicely with the chat for random nerdy tidbits and coordinating when each of us arrived at the pub. Even my in-laws had a group to coordinate visits, brag about child developmental milestones, and manage Christmas.
And then BBM announced it was going away, giving users six weeks to find a replacement… or, as seemed more likely to me, replacements.
First thing I did, since the notice came during working hours, was mutter angrily that Mozilla didn’t have an Instant Messaging product that I could, by default, trust. (We do have a messaging product, but it’s only for Desktop and has an email focus.)
The second thing I did was survey the available IM apps, cross-correlating them with whether or not various of my BBM contacts already had it installed… the existing landscape seemed to be a mess. I found that WhatsApp was by far the most popular but was bought by Facebook in 2014 and required a real phone number for your account. Signal’s the only one with a privacy/security story that I and others could trust (Telegram has some weight here, but not much) but it, too, required a phone number in order to sign up. Slack’s something only my tech friends used, and their privacy policy was a shambles. Discord’s something only my gaming friends used, and was basically Slack with push-to-talk.
So we fragmented. My extended friend network went to Google Hangouts, since just about everyone already had a Google Account anyway (even if they didn’t use it for anything). The Beers group went to Discord because a plurality of the group already had it installed.
And my in-laws’ family group… well, we still have two weeks left to figure that one out. Last I heard someone was stumping for Facebook Messenger, to which I replied “Could we not?”
The lack of reasonable options and the (sad, understandable) willingness of my relatives to trade privacy for convenience is bothering me so much that I’ve started thinking about writing my own IM/virtual private social network.
You’d think I’d know better than to even think about architecting anything even close to either of those topics… but the more I think about it the more webtech seems like an ideal fit for this. Notifications, Push, ServiceWorkers, WebRTC peer connections, TLS, WebSockets, OAuth: stir lightly et voila.
But even ignoring the massive mistake diving into either of those ponds full of crazy would be, the time was too short for that four weeks ago, and is trebly so now. I might as well make my peace that Facebook will learn my mobile phone number and connect it indelibly with its picture of what advertisements it thinks I would be most receptive to.
Yay.
:chutten
https://chuttenblog.wordpress.com/2019/05/16/virtual-private-social-network-tales-of-a-bbm-exodus/
|
|
Hacks.Mozilla.Org: Faster smarter JavaScript debugging in Firefox DevTools |
Script debugging is one of the most powerful and complex productivity features in the web developer toolbox. Done right, it empowers developers to fix bugs quickly and efficiently. So the question for us, the Firefox DevTools team, has been, are the Firefox DevTools doing it right?
We’ve been listening to feedback from our community. Above everything we heard the need for greater reliability and performance; especially with modern web apps. Moreover, script debugging is a hard-to-learn skill that should work in similar fashion across browsers, but isn’t consistent because of feature and UI gaps.
With these pain points in mind, the DevTools Debugger team – with help from our tireless developer community – landed countless updates to design a more productive debugging experience. The work is ongoing, but Firefox 67 marks an important milestone, and we wanted to highlight some of the fantastic improvements and features. We invite you to open up Firefox Quantum: Developer Edition, try out the debugger on the examples below and your projects and let us know if you notice the difference.
Fast and reliable debugging is the result of many smaller interactions. From initial loading and source mapping to breakpoints, console logging, and variable previews, everything needs to feel solid and responsive. The debugger should be consistent, predictable, and capable of understanding common tools like webpack, Babel, and TypeScript.
We can proudly say that all of those areas have improved in the past months:
These are just a handful of highlights. We’ve also resolved countless bugs and polish issues.
Foremost, we must maintain a high standard of quality, which we’ll accomplish by explicitly setting aside time for polish in our planning. Guided by user feedback, we intend to use this time to improve new and existing features alike.
Second, continued investment in our performance and correctness tests ensures that the ever-changing JavaScript ecosystem, including a wide variety of frameworks and compiled languages, is well supported by our tools.
Finding and pausing in just the right location can be key to understanding a bug. This should feel effortless, so we’ve scrutinized our own tools—and studied others—to give you the best possible experience.

Why should breakpoints operate on lines, when lines can have multiple statements? Thanks to inline breakpoints, it’s now easier than ever to debug minified scripts, arrow functions, and chained method calls. Learn more about breakpoints on MDN or try out the demo.

Console logging, also called printf() debugging, is a quick and easy way to observe your program’s flow, but it rapidly becomes tedious. Logpoints break that tiresome edit-build-refresh cycle by dynamically injecting console.log() statements into your running application. You can stay in the browser and monitor variables without pausing or editing any code. Learn more about log points on MDN.

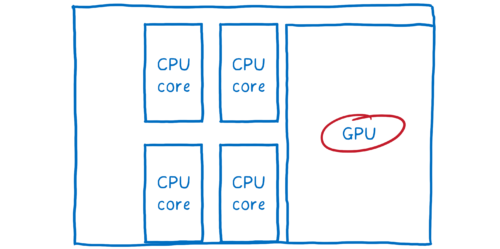
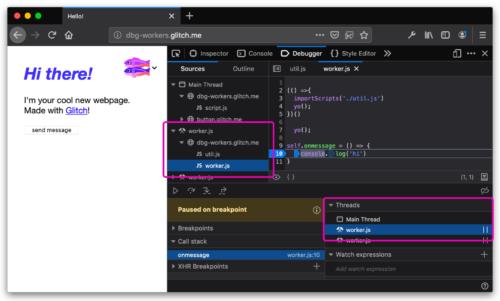
Web Workers power the modern web and need to be first-class concepts in DevTools. Using the new Threads panel, you can switch between and independently pause different execution contexts. This allows workers and their scripts to be debugged within the same Debugger panel, similarly to other modern browsers. Learn more about Worker debugging on MDN.
Debugging bundled and compressed code isn’t easy. The Source Maps project, started and maintained by Firefox, bridges the gap between minified code running in the browser and its original, human-friendly version, but the translation isn’t perfect. Often, bits of the minified build output shine through and break the illusion. We can do better!

By combining source maps with the Babel parser, Firefox’s Debugger can now preview the original variables you care about, and hide the extraneous cruft from compilers and bundlers. This can even work in the console, automatically resolving human-friendly identifiers to their actual, minified names behind the scenes. Due to its performance overhead, you have to enable this feature separately by clicking the “Map” checkbox in the Debugger’s Scopes panel. Read the MDN documentation on using the map scopes feature.
Developers frequently need to switch between browsers to ensure that the web works for everyone, and we want our DevTools to be an intuitive, seamless experience. Though browsers have converged on the same broad organization for tools, we know there are still gaps in both features and UI. To help us address those gaps, please let us know where you experience friction when switching browsers in your daily work.
As always, we would love to hear your feedback on how we can improve DevTools and the browser.
While all these updates will be ready to try out in Firefox 67, when it’s released next week, we’ve polished them to perfection in Firefox 68 and added a few more goodies. Download Firefox Developer Edition (68) to try the latest updates for devtools and platform now.
The post Faster smarter JavaScript debugging in Firefox DevTools appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/05/faster-smarter-javascript-debugging-in-firefox/
|
|
Mike Conley: A few words on main thread disk access for general audiences |
|
|
Mozilla VR Blog: Making ethical decisions for the immersive web |

One of the promises of immersive technologies is real time communication unrestrained by geography. This is as transformative as the internet, radio, television, and telephones—each represents a pivot in mass communications that provides new opportunities for information dissemination and creating connections between people. This raises the question, “what’s the immersive future we want?”
We want to be able to connect without traveling. Indulge our curiosity and creativity beyond our physical limitations. Revolutionize the way we visualize and share our ideas and dreams. Enrich everyday situations. Improve access to limited resources like healthcare and education.
The internet is an integral part of modern life—a key component in education, communication, collaboration, business, entertainment and society as a whole.
— Mozilla Manifesto, Principle 1
My first instinct is to say that I want an immersive future that brings joy. Do AR apps that help me maintain my car bring me joy? Not really.
What I really want is an immersive future that respects individual creators and users. Platforms and applications that thoughtfully approach issues of autonomy, privacy, bias, and accessibility in a complex environment. How do we get there? First, we need to understand the broader context of augmented and virtual reality in ethics, identifying overlap with both other technologies (e.g. artificial intelligence) and other fields (e.g. medicine and education). Then, we can identify the unique challenges presented by spatial and immersive technologies. Given the current climate of ethics and privacy, we can anticipate potential problems, identify the core issues, and evaluate different approaches.
From there, we have an origin for discussion and a path for taking practical steps that enable legitimate uses of MR while discouraging abuse and empowering individuals to make choices that are right for them.
For details and an extended discussion on these topics, see this paper.
Whether you have a $30 or $3000 headset, you should be able to participate in the same immersive universe. No person should be excluded due to their skin color, hairstyle, disability, class, location, or any other reason.
The internet is a global public resource that must remain open and accessible.
— Mozilla Manifesto, Principle 2
The immersive web represents an evolution of the internet. Immersive technologies are already deployed in education and healthcare. It's unethical to limit their benefits to a privileged few, particularly when MR devices can improve access to limited resources. For example, Americans living in rural areas are underserved by healthcare, particularly specialist care. In an immersive world, location is no longer an obstacle. Specialists can be virtually present anywhere, just like they were in the room with the patient. Trained nurses and assistants would be required for physical manipulations and interactions, but this could dramatically improve health coverage and reduce burdens on both patients and providers.
While we can build accessibility into browsers and websites, the devices themselves need to be created with appropriate accomodations, like settings that indicate a user is in a wheelchair. When we design devices and experiences, we need to consider how they'll work for people with disabilities. It's imperative to build inclusive MR devices and experiences, both because it's unethical to exclude users due to disability, and because there are so many opportunities to use MR as an assistive technology, including:
The immersive web is for everyone.
Mixed reality offers new ways to connect with each other, enabling us to be virtually present anywhere in the world instantaneously. Like most technologies, this is both a good and a bad thing. While it transforms how we can communicate, it also offers new vectors for abuse and harassment.
All social VR platforms need to have simple and obvious ways to report abusive behavior and block the perpetrators. All social platforms, whether 2D or 3D should have this, but the VR-enabled embodiment intensifies the impact of harassment. Behavior that would be limited to physical presence is no longer geographically limited, and identities can be more obfuscated. Safety is not a 'nice to have' feature — it's a requirement. Safety is a key component in inclusion and freedom of expression, as well as being a human right.
Freedom of expression in this paradigm includes both choosing how to present yourself and having the ability to maintain multiple virtual identities. Immersive social experiences allow participants to literally build their identities via avatars. Human identity is infinitely complex (and not always very human — personally, I would choose a cat avatar). Thoughtfully approaching diversity and representation in avatars isn't easy, but it is worthwhile.
Individuals must have the ability to shape the internet and their own experiences on it.
— Mozilla Manifesto, Principle 5
Suppose Banksy, a graffiti artist known both for their art and their anonymity, is an accountant by day who used an HMD to conduct virtual meetings. Outside of work, Banksy is a virtual graffiti artist. However, biometric data could tie the two identities together, stripping Banksy of their anonymity. Anonymity enables free speech; it removes the threats of economic retailiation and social ostracism and allows consumers to process ideas free of predjudices about the creators. There's a long history of women who wrote under assumed names to avoid being dismissed for their gender, including JK Rowling and George Sand.
Immersive technologies differ from others in their ability to affect our physical bodies. To achieve embodiment and properly interact with virtual elements, devices use a wide range of data derived from user biometrics, the surrounding physical world, and device orientation. As the technology advances, the data sources will expand.
The sheer amount of data required for MR experiences to function requires that we rethink privacy. Earlier, I mentioned that gaze-based navigation can be used to allow mobility impaired users to participate more fully on the immersive web. Unfortunately, gaze tracking data also exposes large amounts of nonverbal data that can be used to infer characteristics and mental states, including ADHD and sexual arousal.
Individuals’ security and privacy on the internet are fundamental and must not be treated as optional.
— Mozilla Manifesto, Principle 4
While there may be a technological solution to this problem, it highlights a wider social and legal issue: we've become too used to companies monetizing our personal data. It's possible to determine that, although users report privacy concerns, they don't really care, because they 'consent' to disclosing personal information for small rewards. The reality is that privacy is hard. It's hard to define and it's harder to defend. Processing privacy policies feels like it requires a law degree and quantifying risks and tradeoffs is nondeterministic. In the US, we've focused on privacy as an individual's responsibility, when Europe (with the General Data Protection Regulation) shows that it's society's problem and should be tackled comprehensively.
Ethical principles aren't enough. We also need to take action — while some solutions will be technical, there are also legal, regulatory, and societal challenges that need to be addressed.
Tech needs to take responsibility. We've built technology that has incredible positive potential, but also serious risks for abuse and unethical behavior. Mixed reality technologies are still emerging, so there's time to shape a more respectful and empowering immersive world for everyone.
|
|
Hacks.Mozilla.Org: Empowering User Privacy and Decentralizing IoT with Mozilla WebThings |
Smart home devices can make busy lives a little easier, but they also require you to give up control of your usage data to companies for the devices to function. In a recent article from the New York Times’ Privacy Project about protecting privacy online, the author recommended people to not buy Internet of Things (IoT) devices unless they’re “willing to give up a little privacy for whatever convenience they provide.”
This is sound advice since smart home companies can not only know if you’re at home when you say you are, they’ll soon be able to listen for your sniffles through their always-listening microphones and recommend sponsored cold medicine from affiliated vendors. Moreover, by both requiring that users’ data go through their servers and by limiting interoperability between platforms, leading smart home companies are chipping away at people’s ability to make real, nuanced technology choices as consumers.
At Mozilla, we believe that you should have control over your devices and the data that smart home devices create about you. You should own your data, you should have control over how it’s shared with others, and you should be able to contest when a data profile about you is inaccurate.
Mozilla WebThings follows the privacy by design framework, a set of principles developed by Dr. Ann Cavoukian, that takes users’ data privacy into account throughout the whole design and engineering lifecycle of a product’s data process. Prioritizing people over profits, we offer an alternative approach to the Internet of Things, one that’s private by design and gives control back to you, the user.
Before we look at the design of Mozilla WebThings, let’s talk briefly about how people think about their privacy when they use smart home devices and why we think it’s essential that we empower people to take charge.
Today, when you buy a smart home device, you are buying the convenience of being able to control and monitor your home via the Internet. You can turn a light off from the office. You can see if you’ve left your garage door open. Prior research has shown that users are passively, and sometimes actively, willing to trade their privacy for the convenience of a smart home device. When it seems like there’s no alternative between having a potentially useful device or losing their privacy, people often uncomfortably choose the former.
Still, although people are buying and using smart home devices, it does not mean they’re comfortable with this status quo. In one of our recent user research surveys, we found that almost half (45%) of the 188 smart home owners we surveyed were concerned about the privacy or security of their smart home devices.

User Research Survey Results
Last Fall 2018, our user research team conducted a diary study with eleven participants across the United States and the United Kingdom. We wanted to know how usable and useful people found our WebThings software. So we gave each of our research participants some Raspberry Pis (loaded with the Things 0.5 image) and a few smart home devices.

Smart Home Devices Given to Participants for User Research Study
We watched, either in-person or through video chat, as each individual walked through the set up of their new smart home system. We then asked participants to write a ‘diary entry’ every day to document how they were using the devices and what issues they came across. After two weeks, we sat down with them to ask about their experience. While a couple of participants who were new to smart home technology were ecstatic about how IoT could help them in their lives, a few others were disappointed with the lack of reliability of some of the devices. The rest fell somewhere in between, wanting improvements such as more sophisticated rules functionality or a phone app to receive notifications on their iPhones.
We also learned more about people’s attitudes and perceptions around the data they thought we were collecting about them. Surprisingly, all eleven of our participants expected data to be collected about them. They had learned to expect data collection, as this has become the prevailing model for other platforms and online products. A few thought we would be collecting data to help improve the product or for research purposes. However, upon learning that no data had been collected about their use, a couple of participants were relieved that they would have one less thing, data, to worry about being misused or abused in the future.
By contrast, others said they weren’t concerned about data collection; they did not think companies could make use of what they believed was menial data, such as when they were turning a light on or off. They did not see the implications of how collected data could be used against them. This showed us that we can improve on how we demonstrate to users what others can learn from your smart home data. For example, one can find out when you’re not home based on when your door has opened and closed.

Door Sensor Logs can Reveal When Someone is Not Home
From our user research, we’ve learned that people are concerned about the privacy of their smart home data. And yet, when there’s no alternative, they feel the need to trade away their privacy for convenience. Others aren’t as concerned because they don’t see the long-term implications of collected smart home data. We believe privacy should be a right for everyone regardless of their socioeconomic or technical background. Let’s talk about how we’re doing that.
Vendors of smart home devices have architected their products to be more of service to them than to their customers. Using the typical IoT stack, in which devices don’t easily interoperate, they can build a robust picture of user behavior, preferences, and activities from data they have collected on their servers.
Take the simple example of a smart light bulb. You buy the bulb, and you download a smartphone app. You might have to set up a second box to bridge data from the bulb to the Internet and perhaps a “user cloud subscription account” with the vendor so that you can control the bulb whether you’re home or away. Now imagine five years into the future when you have installed tens to hundreds of smart devices including appliances, energy/resource management devices, and security monitoring devices. How many apps and how many user accounts will you have by then?
The current operating model requires you to give your data to vendor companies for your devices to work properly. This, in turn, requires you to work with or around companies and their walled gardens.
Mozilla’s solution puts the data back in the hands of users. In Mozilla WebThings, there are no company cloud servers storing data from millions of users. User data is stored in the user’s home. Backups can be stored anywhere. Remote access to devices occurs from within one user interface. Users don’t need to download and manage multiple apps on their phones, and data is tunneled through a private, HTTPS-encrypted subdomain that the user creates.
The only data Mozilla receives are the instances when a subdomain pings our server for updates to the WebThings software. And if a user only wants to control their devices locally and not have anything go through the Internet, they can choose that option too.
Decentralized distribution of WebThings Gateways in each home means that each user has their own private “data center”. The gateway acts as the central nervous system of their smart home. By having smart home data distributed in individual homes, it becomes more of a challenge for unauthorized hackers to attack millions of users. This decentralized data storage and management approach offers a double advantage: it provides complete privacy for user data, and it securely stores that data behind a firewall that uses best-of-breed https encryption.
The figure below compares Mozilla’s approach to that of today’s typical smart home vendor.

Comparison of Mozilla’s Approach to Typical Smart Home Vendor
Mozilla’s approach gives users an alternative to current offerings, providing them with data privacy and the convenience that IoT devices can provide.
In designing Mozilla WebThings, we have consciously insulated users from servers that could harvest their data, including our own Mozilla servers, by offering an interoperable, decentralized IoT solution. Our decision to not collect data is integral to our mission and additionally feeds into our Emerging Technology organization’s long-term interest in decentralization as a means of increasing user agency.
WebThings embodies our mission to treat personal security and privacy on the Internet as a fundamental right, giving power back to users. From Mozilla’s perspective, decentralized technology has the ability to disrupt centralized authorities and provide more user agency at the edges, to the people.
Decentralization can be an outcome of social, political, and technological efforts to redistribute the power of the few and hand it back to the many. We can achieve this by rethinking and redesigning network architecture. By enabling IoT devices to work on a local network without the need to hand data to connecting servers, we decentralize the current IoT power structure.
With Mozilla WebThings, we offer one example of how a decentralized, distributed system over web protocols can impact the IoT ecosystem. Concurrently, our team has an unofficial draft Web Thing API specification to support standardized use of the web for other IoT device and gateway creators.
While this is one way we are making strides to decentralize, there are complementary projects, ranging from conceptual to developmental stages, with similar aims to put power back into the hands of users. Signals from other players, such as FreedomBox Foundation, Daplie, and Douglass, indicate that individuals, households, and communities are seeking the means to govern their own data.
By focusing on people first, Mozilla WebThings gives people back their choice: whether it’s about how private they want their data to be or which devices they want to use with their system.
This project is an ongoing effort. If you want to learn more or get involved, check out the Mozilla WebThings Documentation, you can contribute to our documentation or get started on your own web things or Gateway.
If you live in the Bay Area, you can find us this weekend at Maker Faire Bay Area (May 17-19). Stop by our table. Or follow @mozillaiot to learn about upcoming workshops and demos.
The post Empowering User Privacy and Decentralizing IoT with Mozilla WebThings appeared first on Mozilla Hacks - the Web developer blog.
|
|






