Mozilla Open Policy & Advocacy Blog: Indian government allows expanded private sector use of Aadhaar through ordinance (but still no movement on data protection law) |
On Thursday, the Indian government approved an ordinance — an extraordinary procedure allowing the government to enact legislation without Parliamentary approval — that threatens to dilute the impact of the Supreme Court’s decision last September.
The Court had placed fundamental limits to the otherwise ubiquitous use of Aadhaar, India’s biometric ID system, including the requirement of an authorizing law for any private sector use. While the ordinance purports to provide this legal backing, its broad scope could dilute both the letter and intent of the judgment. As per the ordinance, companies will now be able to authenticate using Aadhaar as long as the Unique Identification Authority of India (UIDAI) is satisfied that “certain standards of privacy and security” are met. These standards remain undefined, and especially in the absence of a data protection law, this raises serious concerns.
The swift movement to foster expanded use of Aadhaar is in stark contrast to the lack of progress on advancing a data protection bill that would safeguard the rights of Indians whose data is implicated in this system. Aadhaar continues to be effectively mandatory for a vast majority of Indian residents, given its requirement for the payment of income tax and various government welfare schemes. Mozilla has repeatedly warned of the dangers of a centralized database of biometric information and authentication logs.
The implementation of these changes with no public consultation only exacerbates the lack of public accountability that has plagued the project. We urge the Indian government to consider the serious privacy and security risks from expanded private sector use of Aadhaar. The ordinance will need to gain Parliamentary approval in the upcoming session (and within six months) or else it will lapse. We urge the Parliament not to push through this law which clearly dilutes the Supreme Court’s diktat, and any subsequent proposals must be preceded by wide public consultation and debate.
The post Indian government allows expanded private sector use of Aadhaar through ordinance (but still no movement on data protection law) appeared first on Open Policy & Advocacy.
|
|
QMO: DevEdition 66 Beta 14 Friday, March 8th |
Hello Mozillians,
We are happy to let you know that Friday, March 8th, we are organizing DevEdition 66 Beta 14 Testday. We’ll be focusing our testing on: Firefox Screenshots, Search, Build installation & uninstallation.
Check out the detailed instructions via this etherpad.
No previous testing experience is required, so feel free to join us on #qa IRC channel where our moderators will offer you guidance and answer your questions.
Join us and help us make Firefox better!
See you on Friday!
https://quality.mozilla.org/2019/03/devedition-66-beta-14-friday-march-8th/
|
|
Daniel Stenberg: Julia’s cheat sheet for curl |
Julia Evans makes these lovely comic style cheat sheets for various linux/unix networking tools and a while ago she made one for curl. I figured I’d show it here if you happened to miss her awesome work.

And yes, people have already pointed out to her that
https://daniel.haxx.se/blog/2019/03/05/julias-cheat-sheet-for-curl/
|
|
Ian Bicking: The Firefox Experiments I Would Have Liked To Try |
|
|
Daniel Stenberg: alt-svc in curl |
The RFC 7838 was published already in April 2016. It describes the new HTTP header Alt-Svc, or as the title of the document says HTTP Alternative Services.
An alternative service in HTTP lingo is a quite simply another server instance that can provide the same service and act as the same origin as the original one. The alternative service can run on another port, on another host name, on another IP address, or over another HTTP version.

An HTTP server can inform a client about the existence of such alternatives by returning this Alt-Svc header. The header, which has an expiry time, tells the client that there’s an optional alternative to this service that is hosted on that host name, that port number using that protocol. If that client is a browser, it can connect to the alternative in the background and if that works out fine, continue to use that host for the rest of the time that alternative is said to work.
In reality, this header becomes a little similar to the DNS records SRV or URI: it points out a different route to the server than what the A/AAAA records for it say.
The Alt-Svc header came into life as an attempt to help out with HTTP/2 load balancing, since with the introduction of HTTP/2 clients would suddenly use much more persistent and long-living connections instead of the very short ones used for traditional HTTP/1 web browsing which changed the nature of how connections are done. This way, a system that is about to go down can hint the clients on how to continue using the service, elsewhere.
Alt-Svc: h2="backup.example.com:443"; ma=2592000;
Once that header was published, the by then already existing and deployed Google QUIC protocol switched to using the Alt-Svc header to hint clients (read “Chrome users”) that “hey, this service is also available over gQUIC“. (Prior to that, they used their own custom alternative header that basically had the same meaning.)
This is important because QUIC is not TCP. Resources on the web that are pointed out using the traditional HTTPS:// URLs, still imply that you connect to them using TCP on port 443 and you negotiate TLS over that connection. Upgrading from HTTP/1 to HTTP/2 on the same connection was “easy” since they were both still TCP and TLS. All we needed then was to use the ALPN extension and voila: a nice and clean version negotiation.
To upgrade a client and server communication into a post-TCP protocol, the only official way to it is to first connect using the lowest common denominator that the HTTPS URL implies: TLS over TCP, and only once the server tells the client what more there is to try, the client can go on and try out the new toys.
For HTTP/3, this is the official way for HTTP servers to tell users about the availability of an HTTP/3 upgrade option.

I want curl to support HTTP/3 as soon as possible and then as I’ve mentioned above, understanding Alt-Svc is a key prerequisite to have a working “bootstrap”. curl needs to support Alt-Svc. When we’re implementing support for it, we can just as well support the whole concept and other protocol versions and not just limit it to HTTP/3 purposes.
curl will only consider received Alt-Svc headers when talking HTTPS since only then can it know that it actually speaks with the right host that has the authority enough to point to other places.

This is the first feature and code that we merge into curl under a new concept we do for “experimental” code. It is a way for us to mark this code as: we’re not quite sure exactly how everything should work so we allow users in to test and help us smooth out the quirks but as a consequence of this we might actually change how it works, both behavior and API wise, before we make the support official.
We strongly discourage anyone from shipping code marked experimental in production. You need to explicitly enable this in the build to get the feature. (./configure –enable-alt-svc)
But at the same time we urge and encourage interested users to test it out, try how it works and bring back your feedback, criticism, praise, bug reports and help us make it work the way we’d like it to work so that we can make it land as a “normal” feature as soon as possible.
The experimental alt-svc code has been merged into curl as of commit 98441f3586 (merged March 3rd 2019) and will be present in the curl code starting in the public release 7.64.1 that is planned to ship on March 27, 2019. I don’t have any time schedule for when to remove the experimental tag but ideally it should happen within just a few release cycles.
The curl implementation of alt-svc has an in-memory cache of known alternatives. It can also both save that cache to a text file and load that file back into memory. Saving the alt-svc cache to disk allows it to survive curl invokes and to truly work the way it was intended. The cache file stores the expire timestamp per entry so it doesn’t matter if you try to use a stale file.
Caveat: I now talk about how a feature works that I’ve just above said might change before it ships. With the curl tool you ask for alt-svc support by pointing out the alt-svc cache file to use. Or pass a “” (empty name) to make it not load or save any file. It makes curl load an existing cache from that file and at the end, also save the cache to that file.
curl also already since a long time features fancy connection options such as –resolve and –connect-to, which both let a user control where curl connects to, which in many cases work a little like a static poor man’s alt-svc. Learn more about those in my curl another host post.
We start out the alt-svc support for libcurl with two separate options. One sets the file name to the alt-svc cache on disk (CURLOPT_ALTSVC), and the other control various aspects of how libcurl should behave in regards to alt-svc specifics (CURLOPT_ALTSVC_CTRL).
I’m quite sure that we will have reason to slightly adjust these when the HTTP/3 support comes closer to actually merging.
|
|
Cameron Kaiser: Another choice for Intel TenFourFox users |
@OlgaTPark's Intel TenFourFox fork is a bit unusual in that it is based on 45.9 (yes, back before the FPR releases began), so it is missing later updates in the FPR series. On the other hand, it does support Tiger (mainline Intel TenFourFox requires at least 10.5), it additionally supports several features not supported by TenFourFox, i.e., by enabling Mozilla features in some of its operating system-specific flavours that are disabled in TenFourFox for reasons of Tiger compatibility, and also includes support for H.264 video with ffmpeg.
H.264 video has been a perennial request which I've repeatedly nixed for reasons of the MPEG LA threatening to remove and pur'ee the genitals of those who would use its patents without a license, and more to the point using ffmpeg in Firefox and TenFourFox probably would have violated the spirit, if not the letter, of the Mozilla Public License. Currently, mainline Firefox implements H.264 using operating system support and the Cisco decoder as an external plugin component. Olga's scheme does much the same thing using a separate component called the FFmpeg Enabler, so it should be possible to implement the glue code in mainline TenFourFox, "allowing" the standalone, separately-distributed enabler to patch in the library and thus sidestepping at least the Mozilla licensing issue. The provided library is a fat dylib with PowerPC and Intel support and the support glue is straightforward enough that I may put experimental support for this mechanism in FPR14.
(Long-time readers will wonder why there is MP3 decoding built into TenFourFox, using minimp3 which itself borrows code from ffmpeg, if I have these objections. There are three simple reasons: MP3 patents have expired, it was easy to do, and I'm a big throbbing hypocrite. One other piece of "OlgaFox" that I'll backport either for FPR13 final or FPR14 is a correctness fix for our MP3 decoder which apparently doesn't trip up PowerPC, but would be good for Intel users.)
Ordinarily I don't like forks using the same name, even if I'm no longer maintaining the code, so that I can avoid receiving spurious support requests or bug reports on code I didn't write. For example, I asked the Oysttyer project to change names from TTYtter after I had ceased maintaining it so that it was clearly recognized they were out on their own, and they graciously did. In this case, though it might be slightly confusing, I haven't requested my usual policy because it is clearly and (better be) widely known that no Intel version of TenFourFox, no matter what version or what features, is supported by me.
On the other hand, if someone used Olga's code as a basis for, say, a 10.5-specific PowerPC fork of TenFourFox enabling features supported in that OS (a la the dearly departed AuroraFox), I would have to insist that the name be changed so we don't get people on Tenderapp with problem reports about it. Fortunately, Olga's release uses the names TenFiveFox and TenSixFox for those operating system-specific versions, and I strongly encourage anyone who wants to do such a Leopard-specific port to follow suit.
Releases can be downloaded from Github, and as always, there is no support and no promises of updates. Do not send support questions about this or any Intel build of TenFourFox to Tenderapp.
http://tenfourfox.blogspot.com/2019/03/another-choice-for-intel-tenfourfox.html
|
|
Mozilla Addons Blog: March’s featured extensions |

by 8bit Solutions LLC
Store your passwords securely (via encrypted vaults) and sync across devices.
“Works great, looks great, and it works better than it looks.”
by DW-dev
Save complete pages or just portions as a single HTML file.
“Good for archiving the web!”
by Abdullah Diaa, Hugo, Michiel de Jong
A clever tool for cutting through the gibberish of common ToS contracts you encounter around the web.
“Excellent time and privacy saver! Let’s face it, no one reads all the legalese in the ToS of each site used.”
by Nodetics
An advanced reader for aggregating all of your RSS/Atom/RDF sources.
“The best of its kind. Thank you.”
by Jeroen Swen
Don’t let clicked links take control of your current tab and load content you didn’t ask for.
“Hijacking ads! Deal with it now!”
by DuckDuckGo
Search with enhanced security—tracker blocking, smarter encryption, private search, and other privacy perks.
“Perfect extension for blocking trackers while not breaking webpages.”
If you’d like to nominate an extension for featuring, please send it to amo-featured [at] mozilla [dot] org for the board’s consideration. We welcome you to submit your own add-on!
The post March’s featured extensions appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2019/03/01/marchs-featured-extensions-2/
|
|
Will Kahn-Greene: Bleach: stepping down as maintainer |
Bleach is a Python library for sanitizing and linkifying text from untrusted sources for safe usage in HTML.
In October 2015, I had a conversation with James Socol that resulted in me picking up Bleach maintenance from him. That was a little over 3 years ago. In that time, I:
I accomplished a lot.
I'm really proud of the work I did on Bleach. I took a great project and moved it forward in important and meaningful ways. Bleach is used by a ton of projects in the Python ecosystem. You have likely benefitted from my toil.
While I used Bleach on projects like SUMO and Input years ago, I wasn't really using Bleach on anything while I was a maintainer. I picked up maintenance of the project because I was familiar with it, James really wanted to step down, and Mozilla was using it on a bunch of sites--I picked it up because I felt an obligation to make sure it didn't drop on the floor and I knew I could do it.
I never really liked working on Bleach. The problem domain is a total fucking pain-in-the-ass. Parsing HTML like a browser--oh, but not exactly like a browser because we want the output of parsing to be as much like the input as possible, but as safe. Plus, have you seen XSS attack strings? Holy moly! Ugh!
Anyhow, so I did a bunch of work on a project I don't really use, but felt obligated to make sure it didn't fall on the floor, that has a pain-in-the-ass problem domain. I did that for 3+ years.
Recently, I had a conversation with Osmose that made me rethink that. Why am I spending my time and energy on this?
Does it further my career? I don't think so. Time will tell, I suppose.
Does it get me fame and glory? No.
Am I learning while working on this? I learned a lot about HTML parsing. I have scars. It's so crazy what browsers are doing.
Is it a community through which I'm meeting other people and creating friendships? Sort of. I like working with James, Jannis, and Greg. But I interact and work with them on non-Bleach things, too, so Bleach doesn't help here.
Am I getting paid to work on it? Not really. I did some of the work on work-time, but I should have been using that time to improve my skills and my career. So, yes, I spent some work-time on it, but it's not a project I've been tasked with to work on. For the record, I work on Socorro which is the Mozilla crash-ingestion pipeline. I don't use Bleach on that.
Do I like working on it? No.
Seems like I shouldn't be working on it anymore.
I moved Bleach forward significantly. I did a great job. I don't have any half-finished things to do. It's at a good stopping point. It's a good time to thank everyone and get off the stage.
I'm stepping down without working on what comes next. I think Greg is going to figure that out.
Jannis was a co-maintainer at the beginning because I didn't want to maintain it alone. Jannis stepped down and Greg joined. Both Jannis and Greg were a tremendous help and fantastic people to work with. Thank you!
Sam Snedders helped me figure out a ton of stuff with how Bleach interacts with html5lib. Sam was kind enough to deputize me as a temporary html5lib maintainer to get 1.0 out the door. I really appreciated Sam putting faith in me. Conversations about the particulars of HTML parsing--I'll miss those. Thank you!
While James wasn't maintaining Bleach anymore, he always took the time to answer questions I had. His historical knowledge, guidance, and thoughtfulness were crucial. James was my manager for a while. I miss him. Thank you!
There were a handful of people who contributed patches, too. Thank you!
My experience from 20 years of OSS projects is that many people are in similar situations: continuing to maintain something because of internal obligations long after they're getting any value from the project.
Take care of the maintainers of the projects you use! You can't thank them enough for their time, their energy, their diligence, their help! Not just the big successful projects, but also the one-person projects, too.
Sumana mentioned that PyCon 2019 has a maintainers summit. That looks fantastic! If you're in the doldrums of maintaining an OSS project, definitely go if you can.
Update March 2, 2019: I completely forgot to thank Sam Snedders which is a really horrible omission. Sam's the best!
https://bluesock.org/~willkg/blog/dev/bleach_stepping_down.html
|
|
Niko Matsakis: Async-await status report |
I wanted to post a quick update on the status of the async-await effort. The short version is that we’re in the home stretch for some kind of stabilization, but there remain some significant questions to overcome.
As part of this push, I’m happy to announce we’ve formed a async-await implementation working group. This working group is part of the whole async-await effort, but focused on the implementation, and is part of the compiler team. If you’d like to help get async-await over the finish line, we’ve got a list of issues where we’d definitely like help (read on).
If you are interested in taking part, we have an “office hours” scheduled for Tuesday (see the compiler team calendar) – if you can show up then on Zulip, it’d be ideal! (But if not, just pop in any time.)
I mentioned that there remain significant questions to overcome before stabilization. I think the most root question of all is this one: Who is the audience for this stabilization?
The reason that question is so important is because it determines how
to weigh some of the issues that currently exist. If the point of the
stabilization is to start promoting async-await as something for
widespread use, then there are issues that we probably ought to
resolve first – most notably, the await syntax, but also other
things.
If, however, the point of stabilization is to let ‘early adopters’ start playing with it more, then we might be more tolerant of problems, so long as there are no backwards compatibility concerns.
My take is that either of these is a perfectly fine answer. But if the answer is that we are trying to unblock early adopters, then we want to be clear in our messaging, so that people don’t get turned off when they encounter some of the bugs below.
OK, with that in place, let’s look in a bit more detail.
One of the first things that we did in setting up the implementation working group is to do a complete triage of all existing async-await issues. From this, we found that there was one very firm blocker, #54716. This issue has to do the timing of drops in an async fn, specifically the drop order for parameters that are not used in the fn body. We want to be sure this behaves analogously with regular functions. This is a blocker to stabilization because it would change the semantics of stable code for us to fix it later.
We also uncovered a number of major ergonomic problems. In a
follow-up meeting (available on YouTube), cramertj and I
also drew up plans for fixing these bugs, though these plans have
not yet been writting into mentoring instructions. These issues
include all focus around async fns that take borrowed references as
arguments – for example, the async fn syntax today doesn’t support
more than one lifetime in the
arguments, so
something like async fn foo(x: &u32, y: &u32) doesn’t work.
Whether these ergonomic problems are blockers, however, depends a bit on your perspective: as @cramertj says, a number of folks at Google are using async-await today productively despite these limitations, but you must know the appropriate workarounds and so forth. This is where the question of our audience comes into play. My take is that these issues are blockers for “async fn” being ready for “general use”, but probably not for “early adopters”.
Another big concern for me personally is the maintenance story. Thanks to the hard work of Zoxc and cramertj, we’ve been able to standup a functional async-await implementation very fast, which is awesome. But we don’t really have a large pool of active contributors working on the async-await implementation who can help to fix issues as we find them, and this seems bad.
Finally, we come to the question of the await syntax. At the All
Hands, we had a number of conversations on this topic, and it became
clear that we do not presently have consensus for any one syntax.
We did a lot of exploration here, however, and enumerated a number
of subtle arguments in favor of each option. At this moment,
@withoutboats is busily trying to write-up that exploration into a
document.
Before saying anything else, it’s worth pointing out that we don’t
actually have to resolve the await syntax in order to stabilize
async-await. We could stabilize the await!(...) macro syntax for the
time being, and return to the issue later. This would unblock “early
adopters”, but doesn’t seem like a satisfying answer if our target is
the “general public”. If we were to do this, we’d be drawing on the
precedent of try!, where we first adopted a macro and later moved
that support to native syntax.
That said, we do eventually want to pick another syntax, so it’s worth thinking about how we are going to do that. As I wrote, the first step is to complete an overall summary that tries to describe the options on the table and some of the criteria that we can use to choose between them. Once that is available, we will need to settle on next steps.
I am looking at the syntax question as a kind of opportunity – one of the things that we as a community frequently have to do is to find a way to resolve really hard questions without a clear answer. The tools that we have for doing this at the moment are really fairly crude: we use discussion threads and manual summary comments. Sometimes, this works well. Sometimes, amazingly well. But other times, it can be a real drain.
I would like to see us trying to resolve this sort of issue in other ways. I’ll be honest and say that I don’t entirely know what those are, but I know they are not open discussion threads. For example, I’ve found that the #rust2019 blog posts have been an incredibly effective way to have an open conversation about priorities without the usual ranchor and back-and-forth. I’ve been very inspired by systems like vTaiwan, which enable a lot of public input, but in a structured and collaborative form, rather than an “antagonistic” one. Similarly, I would like to see us perhaps consider running more experiments to test hypotheses about learnability or other factors (but this is something I would approach with great caution, as I think designing good experiments is very hard).
Anyway, this is really a topic for a post of its own. In this particular case, I hope that we find that enumerating in detail the arguments for each side leads us to a clear conclusion, perhaps some kind of “third way” that we haven’t seen yet. But, thinking ahead, it’d be nice to find ways to have these conversations that take us to that “third way” faster.
As someone who has not been closely following async-await thus far, I’m super excited by all I see. The feature has come a ridiculously long way, and the remaining blockers all seem like things we can overcome. async await is coming: I can’t wait to see what people build with it.
Cross-posted to internals here.
http://smallcultfollowing.com/babysteps/blog/2019/03/01/async-await-status-report/
|
|
Mozilla Open Innovation Team: Sharing our Common Voices |
Mozilla releases the largest the largest to-date public domain transcribed dataset of human voices available for use, including 18 different languages, adding up to almost 1,400 hours of recorded voice data from more than 42,000 contributors.
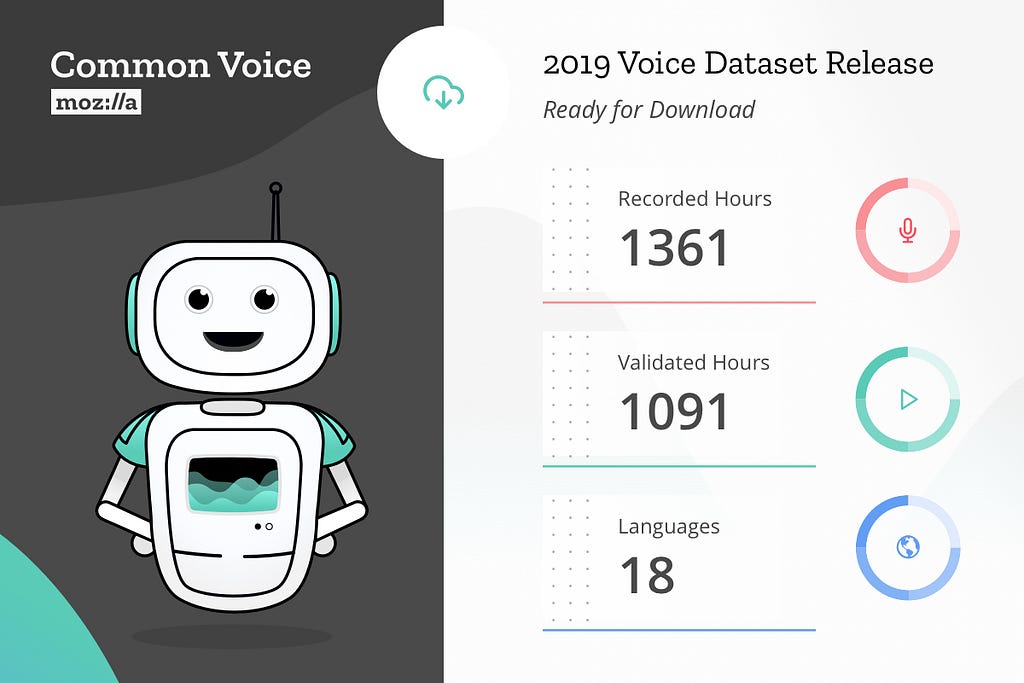
From the onset, our vision for Common Voice has been to build the world’s most diverse voice dataset, optimized for building voice technologies. We also made a promise of openness: we would make the high quality, transcribed voice data that was collected publicly available to startups, researchers, and anyone interested in voice-enabled technologies.
Today, we’re excited to share our first multi-language dataset with 18 languages represented, including English, French, German and Mandarin Chinese (Traditional), but also for example Welsh and Kabyle. Altogether, the new dataset includes approximately 1,400 hours of voice clips from more than 42,000 people.
With this release, the continuously growing Common Voice dataset is now the largest ever of its kind, with tens of thousands of people contributing their voices and original written sentences to the public domain (CC0). Moving forward, the full dataset will be available for download on the Common Voice site.

The Common Voice dataset is unique not only in its size and licence model but also in its diversity, representing a global community of voice contributors. Contributors can opt-in to provide metadata like their age, sex, and accent so that their voice clips are tagged with information useful in training speech engines.
This is a different approach than for other publicly available datasets, which are either hand-crafted to be diverse (i.e. equal number of men and women) or the corpus is as diverse as the “found” data (e.g. the TEDLIUM corpus from TED talks is ~3x men to women).
Since we enabled multi-language support in June 2018, Common Voice has grown to be more global and more inclusive. This has surpassed our expectations: Over the last eight months, communities have enthusiastically rallied around the project, launching data collection efforts in 22 languages with an incredible 70 more in progress on the Common Voice site.
As a community-driven project, people around the world who care about having a voice dataset in their language have been responsible for each new launch — some are passionate volunteers, some are doing this as part of their day jobs as linguists or technologists. Each of these efforts require translating the website to allow contributions and adding sentences to be read.
Our latest additions include Dutch, Hakha-Chin, Esperanto, Farsi, Basque, and Spanish. In some cases, a new language launch on Common Voice is the beginning of that language’s internet presence. These community efforts are proof that all languages — not just ones that can generate high revenue for technology companies — are worthy of representation.
We’ll continue working with these communities to ensure their voices are represented and even help make voice technology for themselves. In this spirit, we recently joined forces with the Deutsche Gesellschaft f"ur Internationale Zusammenarbeit (GIZ) and co-hosted an ideation hackathon in Kigali to create a speech corpus for Kinyarwanda, laying the foundation for local technologists in Rwanda to develop open source voice technologies in their own language.
The Common Voice Website is one of our main vehicles for building voice data sets that are useful for voice-interaction technology. The way it looks today is the result of an ongoing process of iteration. We listened to community feedback about the pain points of contributing while also conducting usability research to make contribution easier, more engaging, and fun.
People who contribute not only see progress per language in recording and validation, but also have improved prompts that vary from clip to clip; new functionality to review, re-record, and skip clips as an integrated part of the experience; the ability to move quickly between speak and listen; as well as a function to opt-out of speaking for a session.
We also added the option to create a saved profile, which allows contributors to keep track of their progress and metrics across multiple languages. Providing some optional demographic profile information also improves the audio data used in training speech recognition accuracy.
Mozilla aims to contribute to a more diverse and innovative voice technology ecosystem. Our goal is to both release voice-enabled products ourselves, while also supporting researchers and smaller players. Providing data through Common Voice is one part of this, as are the open source Speech-to-Text and Text-to-Speech engines and trained models through project DeepSpeech, driven by our Machine Learning Group.
We know this will take time, and we believe releasing early and working in the open can attract the involvement and feedback of technologists, organisations, and companies that will make these projects more relevant and robust. The current reality for both projects is that they are still in their research phase, with DeepSpeech making strong progress toward productization.
To date, with data from Common Voice and other sources, DeepSpeech is technically capable to convert speech to text with human accuracy and “live”, i.e. in realtime as the audio is being streamed. This allows transcription of lectures, phone conversations, television programs, radio shows, and and other live streams all as they are happening.
The DeepSpeech engine is already being used by a variety of non-Mozilla projects: For example in Mycroft, an open source voice based assistant; in Leon, an open-source personal assistant; in FusionPBX, a telephone switching system installed at and serving a private organization to transcribe phone messages. In the future Deep Speech will target smaller platform devices, such as smartphones and in-car systems, unlocking product innovation in and outside of Mozilla.
For Common Voice, our focus in 2018 was to build out the concept, make it a tool for any language community to use, optimise the website, and build a robust backend (for example, the accounts system). Over the coming months we will focus efforts on experimenting with different approaches to increase the quantity and quality of data we are able to collect, both through community efforts as well as new partnerships.
Our overall aim remains: Providing more and better data to everyone in the world who seeks to build and use voice technology. Because competition and openness are healthy for innovation. Because smaller languages are an issue of access and equity. Because privacy and control matters, especially over your voice.
Sharing our Common Voices was originally published in Mozilla Open Innovation on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
Hacks.Mozilla.Org: Implications of Rewriting a Browser Component in Rust |
|
|
The Mozilla Blog: Sharing our Common Voices – Mozilla releases the largest to-date public domain transcribed voice dataset |
Mozilla crowdsources the largest dataset of human voices available for use, including 18 different languages, adding up to almost 1,400 hours of recorded voice data from more than 42,000 contributors.
From the onset, our vision for Common Voice has been to build the world’s most diverse voice dataset, optimized for building voice technologies. We also made a promise of openness: we would make the high quality, transcribed voice data that was collected publicly available to startups, researchers, and anyone interested in voice-enabled technologies.
Today, we’re excited to share our first multi-language dataset with 18 languages represented, including English, French, German and Mandarin Chinese (Traditional), but also for example Welsh and Kabyle. Altogether, the new dataset includes approximately 1,400 hours of voice clips from more than 42,000 people.
With this release, the continuously growing Common Voice dataset is now the largest ever of its kind, with tens of thousands of people contributing their voices and original written sentences to the public domain (CC0). Moving forward, the full dataset will be available for download on the Common Voice site.

The Common Voice dataset is unique not only in its size and licence model but also in its diversity, representing a global community of voice contributors. Contributors can opt-in to provide metadata like their age, sex, and accent so that their voice clips are tagged with information useful in training speech engines.
This is a different approach than for other publicly available datasets, which are either hand-crafted to be diverse (i.e. equal number of men and women) or the corpus is as diverse as the “found” data (e.g. the TEDLIUM corpus from TED talks is ~3x men to women).
Since we enabled multi-language support in June 2018, Common Voice has grown to be more global and more inclusive. This has surpassed our expectations: Over the last eight months, communities have enthusiastically rallied around the project, launching data collection efforts in 22 languages with an incredible 70 more in progress on the Common Voice site.
As a community-driven project, people around the world who care about having a voice dataset in their language have been responsible for each new launch — some are passionate volunteers, some are doing this as part of their day jobs as linguists or technologists. Each of these efforts require translating the website to allow contributions and adding sentences to be read.
Our latest additions include Dutch, Hakha-Chin, Esperanto, Farsi, Basque, and Spanish. In some cases, a new language launch on Common Voice is the beginning of that language’s internet presence. These community efforts are proof that all languages—not just ones that can generate high revenue for technology companies—are worthy of representation.
We’ll continue working with these communities to ensure their voices are represented and even help make voice technology for themselves. In this spirit, we recently joined forces with the Deutsche Gesellschaft f"ur Internationale Zusammenarbeit (GIZ) and co-hosted an ideation hackathon in Kigali to create a speech corpus for Kinyarwanda, laying the foundation for local technologists in Rwanda to develop open source voice technologies in their own language.
The Common Voice Website is one of our main vehicles for building voice data sets that are useful for voice-interaction technology. The way it looks today is the result of an ongoing process of iteration. We listened to community feedback about the pain points of contributing while also conducting usability research to make contribution easier, more engaging, and fun.
People who contribute not only see progress per language in recording and validation, but also have improved prompts that vary from clip to clip; new functionality to review, re-record, and skip clips as an integrated part of the experience; the ability to move quickly between speak and listen; as well as a function to opt-out of speaking for a session.
We also added the option to create a saved profile, which allows contributors to keep track of their progress and metrics across multiple languages. Providing some optional demographic profile information also improves the audio data used in training speech recognition accuracy.
Common Voice started as a proof of concept prototype and has been collaboratively iterated over the past year
Mozilla aims to contribute to a more diverse and innovative voice technology ecosystem. Our goal is to both release voice-enabled products ourselves, while also supporting researchers and smaller players. Providing data through Common Voice is one part of this, as are the open source Speech-to-Text and Text-to-Speech engines and trained models through project DeepSpeech, driven by our Machine Learning Group.
We know this will take time, and we believe releasing early and working in the open can attract the involvement and feedback of technologists, organisations, and companies that will make these projects more relevant and robust. The current reality for both projects is that they are still in their research phase, with DeepSpeech making strong progress toward productization.
To date, with data from Common Voice and other sources, DeepSpeech is technically capable to convert speech to text with human accuracy and “live”, i.e. in realtime as the audio is being streamed. This allows transcription of lectures, phone conversations, television programs, radio shows, and and other live streams all as they are happening.
The DeepSpeech engine is already being used by a variety of non-Mozilla projects: For example in Mycroft, an open source voice based assistant; in Leon, an open-source personal assistant; in FusionPBX, a telephone switching system installed at and serving a private organization to transcribe phone messages. In the future Deep Speech will target smaller platform devices, such as smartphones and in-car systems, unlocking product innovation in and outside of Mozilla.
For Common Voice, our focus in 2018 was to build out the concept, make it a tool for any language community to use, optimise the website, and build a robust backend (for example, the accounts system). Over the coming months we will focus efforts on experimenting with different approaches to increase the quantity and quality of data we are able to collect, both through community efforts as well as new partnerships.
Our overall aim remains: Providing more and better data to everyone in the world who seeks to build and use voice technology. Because competition and openness are healthy for innovation. Because smaller languages are an issue of access and equity. Because privacy and control matters, especially over your voice.
The post Sharing our Common Voices – Mozilla releases the largest to-date public domain transcribed voice dataset appeared first on The Mozilla Blog.
|
|
Mozilla GFX: WebRender newsletter #41 |
Welcome to episode 41 of WebRender’s newsletter.
WebRender is a GPU based 2D rendering engine for web written in Rust, currently powering Mozilla’s research web browser Servo and on its way to becoming Firefox‘s rendering engine.
Today’s highlights are two big performance improvements by Kvark and Sotaro. I’ll let you follow the links below if you are interested in the technical details.
I think that Sotaro’s fix illustrates well the importance of progressively rolling out this type of project a hardware/OS configuration at a time, giving us the time and opportunity to observe and address each configuration’s strengths and quirks.
In about:config, enable the pref gfx.webrender.all and restart the browser.
The best place to report bugs related to WebRender in Firefox is the Graphics :: WebRender component in bugzilla.
Note that it is possible to log in with a github account.
WebRender is available as a standalone crate on crates.io (documentation)
https://mozillagfx.wordpress.com/2019/02/28/webrender-newsletter-41/
|
|
The Firefox Frontier: When an internet emergency strikes |
Research shows that we spend more time on phones and computers than with friends. This means we’re putting out more and more information for hackers to grab. It’s better to … Read more
The post When an internet emergency strikes appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/when-an-internet-emergency-strikes/
|
|
Mozilla Addons Blog: Design and create themes for Firefox |
Last September, we announced the next major evolution in themes for Firefox. With the adoption of static themes, you can now go beyond customizing the header of the browser and easily modify the appearance of the browser’s tabs and toolbar, and choose to distribute your theme publicly or keep it private for your own personal use. If you would like to learn about how to take advantage of these new features or are looking for an updated tutorial on how to create themes, you have come to the right place!
Designing themes doesn’t have to be complicated. The theme generator on AMO allows users to create a theme within minutes. You may enter hex, rgb, or rgba values or use the color selector to pick your preferred colors for the header, toolbar, and text. You will also need to provide an image which will be aligned to the top-right. It may appear to be simple, and that’s because it is!
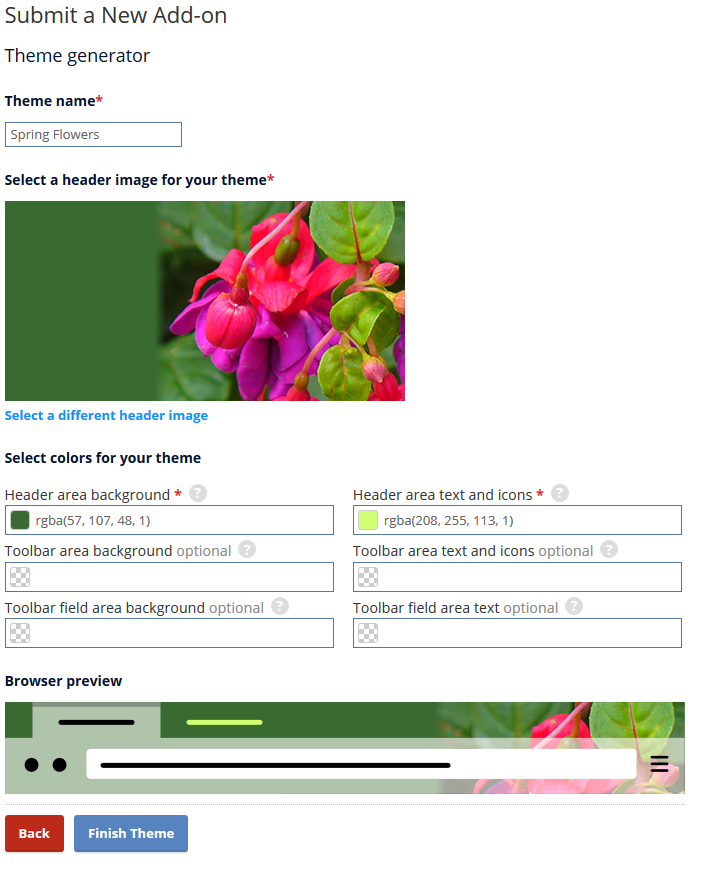
If you want to test what your theme will look like before you submit it to AMO, the extension Firefox Color will enable you to preview changes in real-time, add multiple images, make finer adjustments, and more. You will also be able to export the theme you create on Firefox Color.
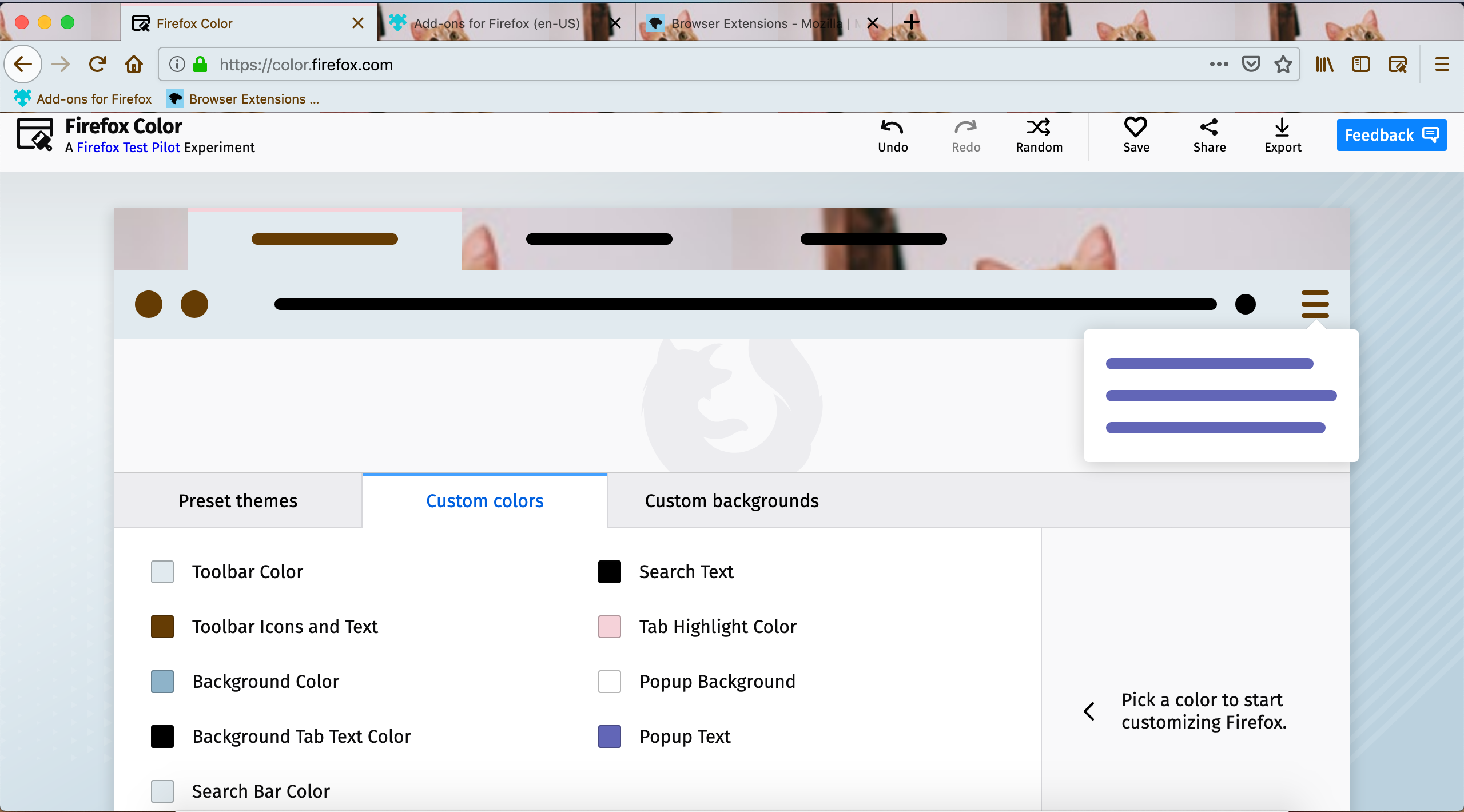
If you want to create a more detailed theme, you can use the static theme approach to create a theme XPI and make further modifications to the new tab background, sidebar, icons, and more. Visit the theme syntax and properties page for further details.
When your theme is generated, visit the Developer Hub to upload it for signing. The process of uploading a theme is similar to submitting an extension. If you are using the theme generator, you will not be required to upload a packaged file. In any case, you will need to decide whether you would like to share your design with the world on addons.mozilla.org, self-distribute it, or keep it for yourself. To keep a theme for yourself or to self-distribute, be sure to select “On your own” when uploading your theme.

Whether you are creating and distributing themes for the public or simply creating themes for private enjoyment, we all benefit by having an enhanced browsing experience. With the theme generator on AMO and Firefox Color, you can easily create multiple themes and switch between them.
The post Design and create themes for Firefox appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2019/02/27/design-and-create-themes-for-firefox/
|
|
Fr'ed'eric Wang: Review of Igalia's Web Platform activities (H2 2018) |
This blog post reviews Igalia’s activity around the Web Platform, focusing on the second semester of 2018.
During 2018 we have continued discussions to implement MathML in Chromium with Google and people interested in math layout. The project was finally launched early this year and we have encouraging progress. Stay tuned for more details!
As mentioned in the previous report, Igalia has proposed and developed the specification for BigInt, enabling math on arbitrary-sized integers in JavaScript. We’ve continued to land patches for
BigInt support in SpiderMonkey and JSC. For the
latter, you can watch this
video demonstrating the current support. Currently, these
two support are under a preference flag but we hope to make it enable by default
after we are done polishing the implementations. We also added support for BigInt to several Node.js APIs (e.g. fs.Stat or process.hrtime.bigint).
Regarding “object-oriented” features, we submitted patches private and public instance fields support to JSC and they are pending review. At the same time, we are working on private methods for V8
We contributed other nice features to V8 such as a spec change for template strings and iterator protocol, support for Object.fromEntries, Symbol.prototype.description, miscellaneous optimizations.
At TC39, we maintained or developed many proposals (BigInt, class fields, private methods, decorators, …) and led the ECMAScript Internationalization effort. Additionally, at the WebAssembly Working Group we edited the WebAssembly JS and Web API and early version of WebAssembly/ES Module integration specifications.
Last but not least, we contributed various conformance tests to test262 and Web Platform Tests to ensure interoperability between the various features mentioned above (BigInt, Class fields, Private methods…). In Node.js, we worked on the new Web Platform Tests driver with update automation and continued porting and fixing more Web Platform Tests in Node.js core.
We also worked on the new Web Platform Tests driver with update automation, and continued porting and fixing more Web Platform Tests in Node.js core. Outside of core, we implemented the initial JavaScript API for llnode, a Node.js/V8 plugin for the LLDB debugger.
Igalia has continued its involvement at the W3C. We have achieved the following:
We are also collaborating with Google to implement ATK support in Chromium. This work will make it possible for users of the Orca screen reader to use Chrome/Chromium as their browser. During H2 we began implementing the foundational accessibility support. During H1 2019 we will continue this work. It is our hope that sufficient progress will be made during H2 2019 for users to begin using Chrome with Orca.
On Web Platform Predictability, we’ve continued our collaboration with AMP to do bug fixes and implement new features in WebKit. You can read a review of the work done in 2018 on the AMP blog post.
We have worked on a lot of interoperability issues related to editing and selection thanks to financial support from Bloomberg. For example when deleting the last cell of a table some browsers keep an empty table while others delete the whole table. The latter can be problematic, for example if users press backspace continuously to delete a long line, they can accidentally end up deleting the whole table. This was fixed in Chromium and WebKit.
Another issue is that style is lost when transforming some text into list items. When running execCommand() with insertOrderedList/insertUnorderedList on some styled paragraph, the new list item loses the original text’s style. This behavior is not interoperable and we have proposed a fix so that Firefox, Edge, Safari and Chrome behave the same for this operation. We landed a patch for Chromium. After discussion with Apple, it was decided not to implement this change in Safari as it would break some iOS rich text editor apps, mismatching the required platform behavior.
We have also been working on CSS Grid interoperability. We imported Web Platform Tests into WebKit (cf bugs 191515 and 191369 and at the same time completing the missing features and bug fixes so that browsers using WebKit are interoperable, passing 100% of the Grid test suite. For details, see 191358, 189582, 189698, 191881, 191938, 170175, 191473 and 191963. Last but not least, we are exporting more than 100 internal browser tests to the Web Platform test suite.
Bloomberg is supporting our work to develop new CSS features. One of the new exciting features we’ve been working on is CSS Containment. The goal is to improve the rendering performance of web pages by isolating a subtree from the rest of the document. You can read details on Manuel Rego’s blog post.
Regarding CSS Grid Layout we’ve continued our maintenance duties, bug triage of the Chromium and WebKit bug trackers, and fixed the most severe bugs. One change with impact on end users was related to how percentages row tracks and gaps work in grid containers with indefinite size, the last spec resolution was implemented in both Chromium and WebKit. We are finishing the level 1 of the specification with some missing/incomplete features. First we’ve been working on the new Baseline Alignment algorithm (cf. CSS WG issues 1039, 1365 and 1409). We fixed related issues in Chromium and WebKit. Similarly, we’ve worked on Content Alignment logic (see CSS WG issue 2557) and resolved a bug in Chromium. The new algorithm for baseline alignment caused an important performance regression for certain resizing use cases so we’ve fixed them with some performance optimization and that landed in Chromium.
We have also worked on various topics related to CSS Text 3. We’ve fixed several bugs to increase the pass rate for the Web Platform test suite in Chromium such as bugs 854624, 900727 and 768363. We are also working on a new CSS value ‘break-spaces’ for the ‘white-space’ property. For details, see the CSS WG discussions: issue 2465 and pull request. We implemented this new property in Chromium under a CSSText3BreakSpaces flag. Additionally, we are currently porting this implementation to Chromium’s new layout engine ‘LayoutNG’. We have plans to implement this feature in WebKit during the second semester.
Last October, we organized the Web Engines Hackfest at our A Coru~na office. It was a great event with about 70 attendees from all the web engines, thank you to all the participants! As usual, you can find more information on the event wiki including link to slides and videos of speakers.
Again in October, but this time in Lyon (France), 12 people from Igalia attended TPAC and participated in several discussions on the different meetings. Igalia had a booth there showcasing several demos of our last developments running on top of WPE (a WebKit port for embedded devices). Last, Manuel Rego gave a talk on the W3C Developers Meetup about how to contribute to CSS.
In December, we also participated with other browser developers to the online This.Javascript: State of Browsers event organized by ThisDot. We talked more specifically about the current work in WebKit.
We are excited to announce that new Igalians are joining us to continue our Web platform effort:
Cathie Chen, a Chinese engineer with about 10 years of experience working on browsers. Among other contributions to Chromium, she worked on the new LayoutNG code and added support for list markers.
Caio Lima a Brazilian developer who recently graduated from the Federal University of Bahia. He participated to our coding experience program and notably worked on BigInt support in JSC.
Oriol Brufau a recent graduate in math from Barcelona who is also involved in the CSSWG and the development of various browser engines. He participated to our coding experience program and implemented the CSS Logical Properties and Values in WebKit and Chromium.
Last fall, Sven Sauleau joined our coding experience program and started to work on various BigInt/WebAssembly improvements in V8.
We are thrilled with the web platform achievements we made last semester and we look forward to more work on the web platform in 2019!
http://frederic-wang.fr/review-of-igalia-s-web-platform-activities-H2-2018.html
|
|
Mozilla VR Blog: Jingle Smash: Performance Work |

This is part 5 of my series on how I built Jingle Smash, a block smashing WebVR game
Performance was the final step to making Jingle Smash, my block tumbling VR game, ready to ship. WebVR on low-end mobile devices like the Oculus Go can be slow, but with a little work we can at least get over a consistent 30fps, and usually 45 or above. Here's the steps I used to get Jingle Smash working well.
I learned from previous demos like my Halloween game that the limiting factor on a device like the Oculus Go isn't texture memory or number of polygons. No, the limiting factor is draw calls. In general we should try to keep draw calls under 100, preferably a lot under.
One of the easiest way to reduce draw calls is to combine multiple objects into one. If two objects have the same material (even if they use different UVs for the textures), then you can combine their geometry into one object. However, this is generally only effective for geometry that won't change.
In Jingle Smash the background is composed of multiple cones and spheres that make up the trees and hills. They don't move so they are a good candidate for geometry merging. Each color of cone trees uses the same texture and material so I was able to combine them all into a single object per color. Now 9 draw calls become two.
const tex = game.texture_loader.load('./textures/candycane.png')
tex.wrapS = THREE.RepeatWrapping
tex.wrapT = THREE.RepeatWrapping
tex.repeat.set(8,8)
const background = new THREE.Group()
const candyCones = new THREE.Geometry()
candyCones.merge(new THREE.ConeGeometry(1,10,16,8).translate(-22,5,0))
candyCones.merge(new THREE.ConeGeometry(1,10,16,8).translate(22,5,0))
candyCones.merge(new THREE.ConeGeometry(1,10,16,8).translate(7,5,-30))
candyCones.merge(new THREE.ConeGeometry(1,10,16,8).translate(-13,5,-20))
background.add(new THREE.Mesh(candyCones,new THREE.MeshLambertMaterial({ color:'white', map:tex,})))
const greenCones = new THREE.Geometry()
greenCones.merge(new THREE.ConeGeometry(1,5,16,8).translate(-15,2,-5))
greenCones.merge(new THREE.ConeGeometry(1,5,16,8).translate(-8,2,-28))
greenCones.merge(new THREE.ConeGeometry(1,5,16,8).translate(-8.5,0,-25))
greenCones.merge(new THREE.ConeGeometry(1,5,16,8).translate(15,2,-5))
greenCones.merge(new THREE.ConeGeometry(1,5,16,8).translate(14,0,-3))
background.add(new THREE.Mesh(greenCones,new THREE.MeshLambertMaterial({color:'green', map:tex,})))
The hills also use only a single material (white with lambert reflectance) so I combined them into a single object as well.
const dome_geo = new THREE.Geometry()
//left
dome_geo.merge(new THREE.SphereGeometry(6).translate(-20,-4,0))
dome_geo.merge(new THREE.SphereGeometry(10).translate(-25,-5,-10))
//right
dome_geo.merge(new THREE.SphereGeometry(10).translate(30,-5,-10))
dome_geo.merge(new THREE.SphereGeometry(6).translate(27,-3,2))
//front
dome_geo.merge(new THREE.SphereGeometry(15).translate(0,-6,-40))
dome_geo.merge(new THREE.SphereGeometry(7).translate(-15,-3,-30))
dome_geo.merge(new THREE.SphereGeometry(4).translate(7,-1,-25))
//back
dome_geo.merge(new THREE.SphereGeometry(15).translate(0,-6,40))
dome_geo.merge(new THREE.SphereGeometry(7).translate(-15,-3,30))
dome_geo.merge(new THREE.SphereGeometry(4).translate(7,-1,25))
background.add(new THREE.Mesh(dome_geo,new THREE.MeshLambertMaterial({color:'white'})))
The next big thing I tried was texture compression. Before I started this project I thought texture compression enabled textures to be uploaded to the GPU faster and take up less RAM, so the init time would be reduced but drawing speed would be un-affected. How wrong I was!
Texture compression is a very special form of compression that makes the texture images fast to decompress. They are stored compressed in GPU memory then decompressed when accessed. This means less memory must be accessed so memory download becomes faster at the cost of doing decompression. However, GPUs have special hardware for decompression so that part becomes free.
Second, the texture compression formats are specifically designed to fit well into GPU core caches and be able to decompress just a portion of a texture at a time. In some cases this can reduce drawing time by an order of magnitude.
Texture compression is clearly a win, but it does have a downside. The formats are designed to be fast to decompress at the cost of being very slow to do the initial compression. And I don't mean two or three times slower. It can take many minutes to compress a texture in some of the newer formats. This means texture compression must be done offline, and can't be used for textures generated on the fly like I did for most of the game.
So, sadly, texture compression wouldn't help me much here. The big sky image with clouds could benefit but almost nothing else will. Additonally, every GPU supports different formats so I'd have to compress the image multiple times. WebGL2 introduces some new common formats that are supported on most GPUs, but currently ThreeJS doesn't use WebGL2.
In any case, when I tried compressing the sky it essentially made no difference, and I didn't know why. I started measure different parts of my game loop and discovered that the rendering time was only a fraction of my loop. My game is slow because of CPU stuff, not GPU, so I stopped worrying about Texture Compression for this project.
I noticed while playing my game that peformance would be reduced whenever I pointed the ornament slingshot towards the floor. I thought that was very odd, so I did some more measurements. It turns out I was wasting many milliseconds, on raycasting. I knew my raycasting wasn't as fast as it could be, buy why would it be slower pointed at the floor when it shouldn't intersect anything but the snow?
The default ThreeJS Raycaster is recursive. It will loop through every object in the scene from the root you provide to the intersectObject() function. Alternatively you can turn off recursion and it will check just the object passed in.
I use the Raycaster in my Pointer abstraction which is designed to be useful for all sorts of applications, so it recurses through the whole tree. More importantly, it starts at the scene, so it is recursing through the entire scene graph. I did provide a way to filter objects from being selected, but that doesn't affect the recursion, just the returned list.
Think of it like this: the scene graph is like a tree. By default the raycaster has to look at every branch and every leaf on the entire tree, even if I (the programmer) know that the possible targets are only in one part of the tree. What I needed was a way to tell the raycaster which entire branches could be safely skipped: like the entire background.
Raycaster doesn't provide a way to customize its recursive path but since ThreeJS is open source so I just made a copy and added a property called recurseFilter. This is a function that the raycaster calls on every branch with the current Object3D. It should return false if the raycaster can skip that branch.
For Jingle Smash I used the filter like this:
const pointer_opts = {
//Pointer searches everything in the scene by default
//override this to match just certain things
intersectionFilter: ((o) => o.userData.clickable),
//eliminate from raycasting recursion to make it faster
recurseFilter: (o) => {
if(o.userData && o.userData.skipRaycast === true) return false
return true
},
... // rest of the options
}
Now I can set userData.skipRaycast to true on anything I want. For Jingle Smash I skip raycasting on the camera, the sky sphere, the slingshot itself, the particle system used for explosions, the lights, and everything in the background (hills and cones). These changes dropped the cost of raycasting from sometimes over 50 milliseconds to always less than 1 ms. The end result was at least 10fps improvement.
I'm pretty happy with how the game turned out. In the future the main change I'd like to make is to find a faster physics engine. WebAssembly is enabling more of the C/C++/Rust physics engines to compiled for the web, so I will be able to switch to one of those at some point in the future.
The standard WebXR boilerplate I've been using for the past six months is starting to show it's age. I plan to rewrite it from scratch to better handle common use cases, and integrate the raycaster hack. It will also switch to be fully ES6 module compliant now that browsers support it everywhere and ThreeJS itself and some of it's utils are being ported to modules. (check out the jsm directory of the ThreeJS examples).
|
|
Mike Conley: Firefox Front-End Performance Update #13 |
|
|
Mozilla Future Releases Blog: Exploring alternative funding models for the web |
The online advertising ecosystem is broken. The majority of digital advertising revenue is going to a small handful of companies, leaving other publishers with scraps. Meanwhile users are on the receiving end of terrible experiences and pervasive tracking designed to get them to click on ads or share even more personal data.
Earlier this month, we shared our perspective about the need to find a better web ecosystem balance that puts publishers and users at the center of the online value exchange. For users, we began our efforts with curbing pervasive tracking as we believe that this is necessary to protect privacy as a fundamental human right. For publishers, we believe that these same measures will help shift long-term ecosystem incentives which are currently stripping value from publishers and fueling rampant ad fraud. However, it is important to acknowledge that such change can take time and that publishers are hurting today.
That’s why we’ve turned our attention toward finding a more sustainable ecosystem balance for publishers and users alike. But unlike other companies that would explore possible solutions behind closed doors, we’re transparent and experiment with new ideas in the open, especially when those ideas could have a significant impact on how the web ecosystems works, or fundamentally change the value exchange we have with the people who rely on our products and services. In 2019, we will continue to explore new product features and offerings, including our ongoing focus on identifying a more sustainable ecosystem balance for both publishers and users.
Product Explorations
As part of these product explorations small groups of browser users will be invited at random to respond to surveys, provide feedback and potentially test proposed new features, products or services. In addition, some explorations may involve partners who are working on product or service offerings targeted at this problem space. One such partner that we are collaborating with is Scroll.
Upcoming Collaboration with Scroll
Scroll is a consumer service powering an ad-free web that rewards great user experience and funds essential journalism. The service enables web users to pay for an ad-free experience on their favorite sites, across their devices. By enabling more direct funding of publishers, Scroll’s model may offer a compelling alternative in the ecosystem. We will be collaborating with Scroll to better understand consumer attitudes and interest towards an ad-free experience on the web as part of an alternative funding model.
Next Steps
We expect that these initiatives, and our collaboration with Scroll, will help shape our direction with respect to finding alternatives to the status quo advertising models. As always, we will continue to put users first and operate transparently as our explorations progress towards more concrete product plans. Stay tuned for more!
The post Exploring alternative funding models for the web appeared first on Future Releases.
https://blog.mozilla.org/futurereleases/2019/02/25/exploring-alternative-funding-models-for-the-web/
|
|
Mozilla VR Blog: Bringing Firefox Reality to HoloLens 2 |

We are excited to announce that we’re working together with Microsoft to bring the immersive web to one of the most-anticipated mixed reality headsets in the market: HoloLens 2. Building on Microsoft’s years of experience with the current HoloLens, we will work together to learn from developers and users about bringing AR content to the web.
Our Mixed Reality program at Mozilla is focused on bringing the best browsers, services, and tools for developers to ensure that users have a safe, private experience with open, accessible technology. Alongside our desktop and standalone VR browser efforts, this prototype of Firefox Reality for HoloLens 2 will ensure that the immersive web works for all users, regardless of device they are on.
In the coming months, we will be working with the Rust community to bring the language and runtime that enable us to deliver a more secure experience to the HoloLens platforms. And we will then build on our previous work on AR headsets to bring our next generation web platform, Servo, to the HoloLens 2 when it is available this summer.
Please watch this space for new builds of the browser or get involved in our projects if you’re eager to help move the needle today.
https://blog.mozvr.com/bringing-firefox-reality-to-hololens-2/
|
|






