Cameron Kaiser: And now for something completely different: The G5 that went to the dark side of the X-Force |
A few of these boxes leaked out into the wider community and recently one of them posted how he made his G5 development system work, with lots of cool pictures. It's possible to turn one of the early 2GHz G5 machines into one of these, using a compatible graphics card (he used a flashed ATI Radeon X800 XT, but it seems easier to just use the native Mac version) and a compatible Intel network card, and a proper selection of ATA devices. There's even a term for these; they call them FrankenXenons. (A reassurance: you won't need to modify your Mac substantially to run this, and you don't need to flash the G5's firmware. On the other hand, this also means that an Alpha can be recreated or even faked with off-the-shelf hardware, and you probably shouldn't drop a lot of coin trying to get a "genuine" one unless you can verify its provenance.)
Note that this probably won't make your Mac into an Xbox 360, or at least not sufficiently to replace a proper console. Many things don't run, particularly later games, and even though it has an original Xbox emulator some of those games still glitch. But at least some early games will run and the recovery image includes a few demo applications to play with.
Eventually the Alphas were replaced with actual pre-production console hardware, called Beta, which have a strange history as Microsoft actually rounded them up, intentionally fouled them to prevent reuse, and shipped them overseas for destruction. Naturally some folks saved a few, as is what usually happens when someone realizes a prototype with potential future value is in their possession, but they have a reputation for being difficult machines.
Even as an Xbox 360 fan, I don't feel highly compelled to seek out the proper hardware to turn an otherwise perfectly useful G5 into a doorstop that runs a few early games rather badly. It certainly doesn't argue much in support for the power of the dark Microsoft side of the (X-)force, and my slim 360 is much more convenient. But as a historical artifact it's cool that you can do so, if you want to.
http://tenfourfox.blogspot.com/2019/02/and-now-for-something-completely.html
|
|
Mozilla B-Team: happy bmo push day! |
Among bugfixes and enhancements, code blocks are now syntax highlighted using @prismjs.

the following changes have been pushed to bugzilla.mozilla.org:
- [1523317] Exclude Graveyard products from QuickSearch results
- [1512815] Optimize Bugzilla->active_custom_fields() for CPU and memory usage
- [1524213] phabricator revisions list on bug page has extra / in the revision link
- [1523404] Cannot clear all scopes when editing an oauth2 client. Throws DB error
- [1525308] Custom Bug…
|
|
Mozilla Open Innovation Team: Sustainable tech development needs local solutions: Voice tech ideation in Kigali |
Mozilla and GIZ co-host ideation hackathon in Kigali to create a speech corpus for Kinyarwanda and to lay the foundation for local voice-recognition applications.
Developers, researchers and startups around the globe working on voice-recognition technology face one problem alike: A lack of freely available voice data in their respective language to train AI-powered Speech-to-Text engines.
Although machine-learning algorithms like Mozilla’s Deep Speech are in the public domain, training data is limited. Most of the voice data used by large corporations is not available to the majority of people, expensive to obtain or simply non-existent for languages not globally spread. The innovative potential of this technology is widely untapped. In providing open datasets, we aim to take away the onerous tasks of collecting and annotating data, which eventually reduces one of the main barriers to voice-based technologies and makes front-runner innovations accessible to more entrepreneurs. This is one of the major drivers behind our project Common Voice.
Common Voice is our crowdsourcing initiative and platform to collect and verify voice data and to make it publicly available. But to get more people involved from around the world and to speed up the process of getting to data sets large enough for training purposes, we rely on partners — like-minded commercial and non-commercial organizations with an interest to make technology available and useful to all.
Complementary expertise and shared innovation goals
In GIZ (Deutsche Gesellschaft f"ur Internationale Zusammenarbeit) we are fortunate to have found an ally who, like us, believes that having access to voice data opens up a space for an infinite number of new applications. Voice recognition is well suited to reach people living in oral cultures and those who do not master a widespread language such as English or French. With voice interaction available in their own language we may provide millions of people access to information and ultimately make technology more inclusive.
When we learned about GIZ’s “Team V” currently exploring voice interaction and mechanisms to collect voice data in local languages — an effort supported by GIZ’s internal innovation fund — the opportunity to leverage complementary strengths became just too obvious.

Eventually we started working on a concrete collaboration that would combine Mozilla’s expertise in voice-enabled technology and data collection with GIZ’s immense regional experience and reach working with local organizations, public authorities and private businesses across various sectors. This resulted in an initial hackathon in Kigali, Rwanda, with the goal of unleashing the participants creativity to unlock novel means of collecting speech corpora for Kinyarwanda, a language spoken by at least 12 million people in Rwanda and surrounding regions.
Sustainable technology development needs local solutions
The hackathon took place on 12–13 February at kLab, a local innovation hub supported by the Rwandan government. 40 teams had applied with their novel incentive mechanisms for voice data collection, proving that AI and machine learning are of great interest to the Rwandan tech community. We invited 5 teams with the most promising approaches that took into account local opportunities not foreseen by the Common Voice team.

The event began with a rousing call to action for the participants by Antoine Sebera, Chief Government Innovation Officer of the Rwanda Information Society Association, a governmental agency responsible for putting Rwanda’s ambitious digital strategy into practice. GIZ then outlined the goals and evaluation criteria* of the hackathon, which was critical in setting the direction of the entire process. (*The developed solutions were evaluated against the following criteria: user centricity, incentive mechanism, feasibility, ease-of-use, potential to scale and sustainability.)

Kelly Davis, Head of Mozilla’s Machine Learning Group followed giving an overview of the design and motivations behind Deep Speech and Common Voice, that could quickly be adapted to Kinyarwanda.During the two-day event, the selected teams refined their initial ideas and took them to the street, fine-tuning them through interviews with potential contributors and partners. By visiting universities, language institutions, and even the city’s public transit providers (really!) they put their solutions to the test.
Winner of the hackathon was an idea uniquely Rwandese: With Umuganda 2.0 the team updated the concept of “Umuganda”, a regular national community work day taking place every last Saturday of the month, to the digital age. Building on the Common Voice website, the participants would collect voice data during monthly Umuganda sessions at universities, tech hubs or community spaces. The idea also taps into the language pride of Rwandans. User research led by GIZ with students, help workers and young Rwandan working on language or technology has shown that speaking and preserving Kinyarwanda in a digital context is seen as very important and a great motivation to contribute to the collection of voice data.

For jury members Olaf Seidel, Head of the GIZ project “Digital Solutions for Sustainable Development” in Rwanda, George Roter, Director Mozilla Open Innovation Programs, Kelly Davis, and Gilles Richard Mulihano, Chief Innovation Officer at the local software developer ComzAfrica, the idea also resonated because of its easy scalability throughout Rwanda. Moreover, it could be adapted to other projects and regions relying on collective efforts to build common infrastructures of the digital world — something GIZ is keenly interested in. Umuganda 2.0 shows that we need culturally appropriate solutions to lower barriers to make front-runner innovations accessible to more entrepreneurs.
Next steps
GIZ and the winning team are now working towards a first real-life test at a local university during next month’s Umuganda on March 30. It is the aim of this session to test if the spirit of Umuganda and the collection of voice data really go well together, what motivates people to take part and how we can make voice data collection during the community event fun and interesting. And last but not least, how many hours of voice data can be collected during such an event to determine if the outcome justifies the means.

GIZ, with its deep connections to local communities in numerous countries, was a perfect partner for Mozilla in this endeavor, and we hope to — in fact look forward to — repeat this success elsewhere. In a long-term vision, Mozilla and GIZ aim to continue this promising cooperation building on our shared visions and objectives for a positive digital future. Allowing access to a wide range of services no matter which language you speak, is no doubt a powerful first step.
Alex Klepel, Kelly Davis (Mozilla) and Lea Gimpel (GIZ)
Sustainable tech development needs local solutions: Voice tech ideation in Kigali was originally published in Mozilla Open Innovation on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
Alex Gibson: Testing native ES modules using Mocha and esm |
|
|
Mozilla Localization (L10N): L10n report: February edition |
New localizers
The following contributors came to us through the Common Voice project.
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
This week we’re going to reach an important milestone for Fluent in Firefox, having more Fluent strings than DTDs in mozilla-central (currently 2466 vs 2489). There are already 5 patches in review to migrate more elements to Fluent, thanks to the work of the MSU Capstone students: Page Info window, contextual menu for tabs, print dialogs, about:privatebrowsing, Password Manager dialog.
Here are a few important dates for the current release cycles:
In terms of content, the priority currently remains on the profile-per-install feature already mentioned in the previous l10n report, and on the dev-l10n mailing list.
This has been a rather quiet month in regards to mobile localization updates.
Teams are mostly heads-down working on kicking off the Fenix browser project.
In the meantime, other mobile apps are following their usual timelines and schedule – so there is nothing much to call out this month.
Stay tuned for the next report, as we’ll have a few things in the pipeline to call out for sure!
We’ve added a new page ahead of the Firefox 66 release. Check in Pontoon and look for firefox/whatsnew_66.lang. To be part of the release, make sure to complete it by March 6. The demo URL is not ready at the moment. We will update you as soon as it becomes available.
A small but an important update is in the privacy/index.lang file. The change is urgent so please localize the string as soon as possible.
Have you taken a look of the newly designed navigation bar? It was recently rolled out with quite a bit of content to localize. Make it a high priority if it is not localized yet.
The team is super excited to launch the sentence collection tool! Though in Beta, it is fully functional. Moving forward, the site will be the place to submit, review and validate sentences in a more organized way and it is a lot easier for everyone, especially those who are not technical. Be sure to read the How To guide to make full use of the features. We want to thank all the key contributors who helped make the tool a reality.
Common Voice: The Privacy Notice and the Legal Terms have been updated in English. Only a select few languages are updated accordingly. These are the languages that have reached the threshold of collecting a minimum of 5000 sentences. If your community has the bandwidth, feel free to review and make necessary suggestions. All these suggestions are subject to peer review before the corrections are published. These are the languages that are recently updated: Catala, Chuvash, Dutch, Esperanto, German, French, Hakha Chin, Irish, Italian, Kabyle, Kyrgyz, Slovenian, Tatar, Traditional Chinese, Turkish, Welsh.
Firefox Lite: We’ve added Traditional Chinese and Vietnamese to the Privacy Notice. Feel free to review the document and make necessary changes.
The foundation’s impact goal — Better machine decision making — now has its public wiki page with a lot of resources explaining the Foundation’s goals and activities for 2019 and beyond. If you want to learn more about what MoFo is up to, this is a great way to dive in!
The fundraising team is starting to plan some mini-campaigns linked to specific events (the Internet Health Report publication, Fellowships, MozFest, and the traditional end-of-year fundraising) with the goal of explaining that Mozilla does much more than a browser and providing potential donors with a better understanding of the Foundation’s work.
We mentioned the new receipts in the previous L10N Report, those are still coming, they just needed further adjustments and another round of review from the Legal team. The team wants to get this right to have future-proof donation receipts.
The EU misinformation campaign has started! The survey mentioned last month went out, and on February 11th, the team sent an open letter to Facebook (simultaneously launched in English, French & German) asking for more transparency on political ads ahead of the EU elections. This letter was also signed by 38 partners including Access Now, Greenpeace and Reporters Without Borders.
Facebook responded in just a few hours, preventing us from publishing the open letter in more languages, but thanks to the dedication of localizers, the simultaneous launch in multiple languages has more than doubled the public engagement: while the team has sent more emails in English, engagement in the campaign in terms of clicks, open letter signatures and post-signing donations came primarily from localized emails in French and German! Mozilla has since responded to the announcement.
Next steps will be an opportunity to involve even more locales and will include launching a scorecard and an election bundle. Rooted in the principles outlined in the European Commission’s Code of Practice on Disinformation, the scorecard will compare how major social platforms are performing as they take steps to combat dis/misinformation.
There have been some important changes in Mozilla staff since the last report.
We need your help to review the following articles:
Want to follow the Firefox 66 modified articles to be published in the SUMO Discourse in the coming weeks? Please subscribe to the tag.
At the end of last year we held a community design sprint with aim of improving the review process in Pontoon. The proposed changes were mostly focused around one of the top requested features of Pontoon – translation comments.
The following product specification is a result of the design sprint. It defines the problem we’re solving, lists measurable goals we’d like to achieve, outlines the proposed solution and provides a rough timeline.
It’s a short, 7 minute read. Please have a look at it, or at least skim through the screenshot tour. As you’ll see, changes to the translate view are pretty substantial, so we’d like to hear your opinion. Either on Discourse or in the spec.

Did you enjoy reading this report? Let us know how we can improve by reaching out to any one of the l10n-drivers listed above.
https://blog.mozilla.org/l10n/2019/02/21/l10n-report-february-edition-2/
|
|
Mozilla VR Blog: Building an In-Game Editor |

This is part 4 of my series on how I built Jingle Smash, a block smashing WebVR game
Jingle Smash is a WebVR game where you shoot ornaments at blocks to knock them over. It has multiple levels, each which is custom designed with blocks to form the puzzle. Since you play in a first person perspective 3D, the levels must carefully designed for this unique view point. To make the design proess easier I created a simple in-game 3D editor.
While Jingle Smash is similar in concept to Angry Birds there is a big difference. The player sees the level head on from a 3D perspective instead of a side view. This means the player can’t see the whole level at once, requiring completely custom designed levels. Rovio is facing this challenge as well with their upcoming VR version of Angry Birds. The difficult part of editing a 3D game on a desktop is that you don’t really experience the levels the same way they will actually be played.
At first I went back and forth from 2D view to my VR headset every time I made a change to a level, even just sliding a few blocks around. As you can imagine this grew very tedious. The ideal tool would let me move objects around in the same mode where I play with them. I needed an in-game editor. So that’s what I built, and I created a minimal UI toolkit in the process.
Levels are stored as JSON files, loaded and saved from a server I had already created for another purpose. For moving objects around I used the TransformControls example code from ThreeJS. Doing transform controls right is hard, so I didn’t want to reinvent that wheel.

In addition to moving blocks around I needed a way to create and delete them and set their properties like size, type, and weight. This called for a property sheet. The problem is when we go into immersive mode we no longer have access to the DOM. We can’t just reuse HTML buttons and labels like we would in a 2D editor.
One solution would be Dom2Texture, an API for rendering a chunk of the DOM to a texture, which we could then map into 3D space. Unfortunately that is disabled until we can find a way to address the security issues (though there are ways to hack around it). However, we do have HTML Canvas, which lets us draw anything we want in 2D then copy that bitmap to a texture in 3D space.
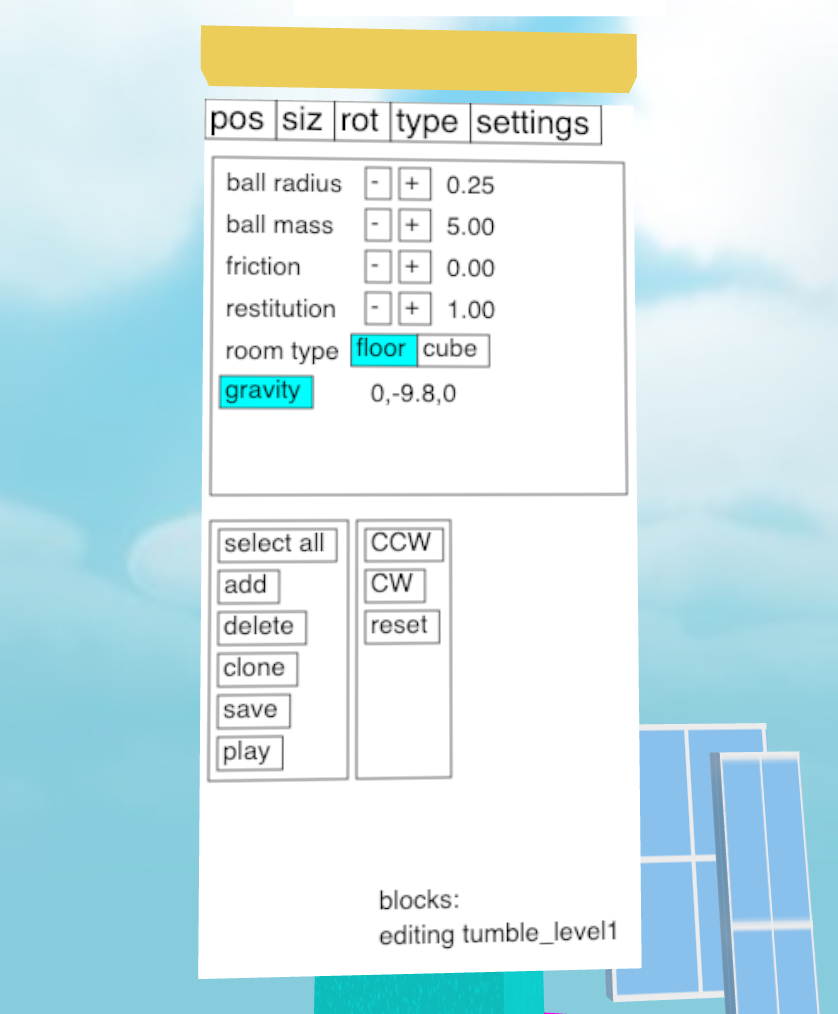
To link the 2D Canvas and 3D ThreeJS APIs I created an adapter class called Panel2D. What you see below is an abbreviated copy of the class. For the full code you can read it on Github.
export default class Panel2D extends THREE.Object3D {
this.canvas = document.createElement('canvas')
this.canvas.width = 256
this.canvas.height = 512
this.canvasTexture = new THREE.CanvasTexture(this.canvas)
this.mesh = new THREE.Mesh(
new THREE.PlaneGeometry(1,2),
new THREE.MeshBasicMaterial({color:'white',map:this.canvasTexture})
)
this.add(this.mesh)
this.comps = []
The code above creates an HTML Canvas element, a ThreeJS CanvasTexture to turn the canvas into a texture, and then a PlaneGeometry mesh to draw the texture in 3D space. This class holds a reference to all components internally in the this.comps variable.
To draw the 2D components the code calls them recursively with a reference to the canvas drawing context, then updates the texture.
redraw() {
const ctx = this.canvas.getContext('2d')
// fill background width white
ctx.fillStyle = 'white'
ctx.fillRect(0,0,this.canvas.width,this.canvas.height)
// draw each component
this.comps.forEach(comp => comp.draw(ctx))
// update the texture
this.canvasTexture.needsUpdate = true
}
In 3D we have pointer events which are fired whenever the user’s pointer moves around in 3D space at different angles. 2D UI toolkits really expect something like a mouse event measured in pixels. To bridge this gap we must convert from 3d coordinates to 2d coordinates on the canvas.
//inside constructor
on(this.mesh,POINTER_CLICK,(e)=>{
const uv = e.intersection.uv
const fpt = new THREE.Vector2(uv.x*256, 512-uv.y*512)
const comp = this.findAt(fpt)
if(comp) comp.fire(POINTER_CLICK)
})
//method to recursively find components at mouse coords
findAt(pt) {
for(let i=0; icode>The pointer events using my abstraction provide a reference to the intersection, which includes the UV value. The UV is from 0 to 1 in the vertical and horizontal directions across the texture. The above code multiplies the UV by size of the canvas (256x512px) and flips the y axis to get 2D canvas coords, then recursively finds which component is under the cursor using the findAt method. Each comp class implements findAt to return if the component matches the mouse cursor.
With the infrastructure in place we can create some actual UI controls. This isn’t meant to be a full UI toolkit that can handle every possible use case. Instead I tried to build the simplest thing possible. A UI control is an object with get, set, draw, and findAt methods. That’s it. There’s no hierarchy or theming, though that could be added later in a fancier version. There is just enough in the base to make it work for a property sheet.
export default class Button2D {
constructor() {
this.type = 'button'
this.text = 'foo'
this.x = 0
this.y = 0
this.fsize = 20
this.w = this.text.length*this.fsize
this.h = 20
}
draw(ctx) {
ctx.font = `${this.fsize}px sans-serif`
const metrics = ctx.measureText(this.text)
this.w = 5 + metrics.width + 5
this.h = 0 + this.fsize + 4
ctx.fillStyle = this.bg
ctx.fillRect(this.x,this.y,this.w,this.h)
ctx.fillStyle = 'black'
ctx.fillText(this.text,this.x+3,this.y+this.fsize-2)
ctx.strokeStyle = 'black'
ctx.strokeRect(this.x,this.y,this.w,this.h)
}
findAt(pt) {
if(pt.x < 0) return null
if(pt.x > 0 + this.w) return null
if(pt.y < 0) return null
if(pt.y > 0 + this.h) return null
return this
}
set(key,value) {
this[key] = value
this.fire('changed',{type:'changed',target:this})
return this
}
get(key) {
return this[key]
}
The code above is for a simple button that draws itself and can respond to click events. Note that HTML Canvas doesn’t have a way to tell you the height of some text, only the width (actually it does, but support isn’t universal yet), so I used font sizes in pixels.
The set method fires a changed event. The root component listens for these to know when to redraw and update the texture to the 3D scene.
From this base I created additional classes for labels and groups. A label is like a button but without any input. It’s findAt method always returns false. A group is a control that calls this.layout() before drawing its children. By overriding layout we can implement rows, grids, or any other layout we want. The example below creates a panel with a row layout.
const rowLayout = (panel)=>{
let x = 0
panel.comps.forEach((c)=>{
c.x=x
c.y=0
x += c.w+panel.padding
})
}
const tabPanel = new Group2D()
.set('x',0)
.set('y',0)
.set('w',250)
.set('h',32)
.set('layout',rowLayout)
.set('padding',0)
.set('border',0)
You’ll notice that I didn’t create any text input controls. That is because VR headsets generally don’t have physical keyboards attached, so I would have to implement a software keyboard from scratch. That is a lot of work and, honestly, point and click keyboards in VR are no fun.
Alternatively could temporarily jump out of immersive mode to do traditional text entry then jump back in. However this would be jarring, and would still require a software keyboard on standalone alone devices like the Oculus Go. Since I could get away without text input for this project I decided to skip it.
While it wasn’t pretty, the in-game editor got the job done and let me built levels far faster than I could have by editing JSON as text. I’m really happy with how it came out.
The code for the UI controls is in the webxr-experiments/physics git repo. If there is some interest I can clean up the code and move it into a standalone library that just requires ThreeJS.
Now that you've learned a bit about how I made Jingle Smash, you might want to watch my new Youtube Series on How to make VR with the Web.
|
|
Karl Dubost: 02 - They fixed it |
So on January 7, 2019, I wrote the first edition of "They Fixed It!"
This is a new chapter. I'll try to move forward in a semi-regular basis.
Let's see what are the cool things which have been fixed since that last report and helps webcompat to be better on the Web.
button associate a click event to it and then create a pseudo-element which comes on top of the button element through a position absolute. The button is not clickable anymore. Or at least, it was until event.target on interactive content inside button was fixed by Olly Petay. This fixed plenty of other issues which were making content in Firefox not clickable.overflow-x: hidden was specified, while you could do it on Chrome and Safari. Not anymore because Hiroyuki Ikezoe fixed it! And it's a pretty big win for usability.overflow other than visible would make an incorrect baseline alignment. This created issues on twitter layout. This was fixed again by Daniel Holbert.vertical-align:top differently for line-height. Not anymore since Thomas Wisniewki fixed it!Thanks to them!
Otsukare!
http://www.otsukare.info/2019/02/21/2019w08-fixed-it-webcompat
|
|
Mozilla Future Releases Blog: Enhanced Tracking Protection Testing Update |
Over the past couple of months since we announced that we would broaden our approach to anti-tracking we’ve been experimenting and testing Enhanced Tracking Protection, a feature that blocks cookies and storage access from third-party trackers. Recently, we published a set of policies that define which tracking practices will be blocked in Firefox, and a new set of redesigned controls for the Content Blocking section where users can choose their desired level of privacy protection. As the next step in our path to enable Enhanced Tracking Protection by default, this week we launched a study to observe how enabling this functionality for a group of Firefox users in our Release Channel would impact the online experience.
As part of the study, selected users will receive an onboarding experience which explains how to disable Content Blocking functionality like Enhanced Tracking Protection on specific websites. The onboarding looks like this:
 With Enhanced Tracking Protection, you just browse and Firefox helps to prevent you from being tracked from website to website. Most web pages will load just fine, and your privacy will be better protected.
With Enhanced Tracking Protection, you just browse and Firefox helps to prevent you from being tracked from website to website. Most web pages will load just fine, and your privacy will be better protected.
If you do happen to discover a web page not functioning as expected, you can report the issue by clicking on the shield icon in the address bar. Under “Content Blocking”, click on the “Report a problem” link. Your feedback will help us make the Enhanced Tracking Protection experience better for everyone.
 From the same menu, you can also click on the button that says “Turn off Blocking for This Site”. Firefox will reload the page with Enhanced Tracking Protection turned off.
From the same menu, you can also click on the button that says “Turn off Blocking for This Site”. Firefox will reload the page with Enhanced Tracking Protection turned off.
If you haven’t been selected for the study, but you would like to test the feature ahead of our rollout to more users, you can do so with the following steps:

What’s Next?
We will monitor the results of this experiment so as to ensure that we are able to turn on these default protections for users with few disruptions.
The post Enhanced Tracking Protection Testing Update appeared first on Future Releases.
https://blog.mozilla.org/futurereleases/2019/02/20/enhanced-tracking-protection-testing-update/
|
|
Hacks.Mozilla.Org: Web Design Survey Findings and Next Steps |
In November, I wrote about my team’s work on experimental new web design tools. We also ran a survey to rank the challenges of web design and development. A big thank you to everyone who participated in our open design process! We received over 900 responses in one month, and discovered major findings which continue to inform the Firefox DevTools’ 2019 roadmap.
With guidance from Mozilla’s data scientists, I chose the MaxDiff method for the challenge-ranking portion of the survey. MaxDiff requires the survey taker to make trade-offs within subsets of the pool of options. This works well for ranking a large number of options, which would be too overwhelming for a regular card sort. It also produces a more accurate overall ranking by emphasizing relative differences in priority.
In practice, this produced 10 survey pages that each showed a set of 4 random options from a pool of 23 total web design challenges. Participants had to choose the “least“ and “most” impactful options in each set. The ranking was then determined by scores computed using the following formula:
The second portion of the survey focused on specific frustrations with browser developer tools. For this section we only offered 7 options, so we used a simple drag-and-drop card sort.

The highest-ranked issues by far were related to CSS layout debugging—learning the root cause of mysteries like unwanted scrollbars and unexpected size and position. Accordingly, my highest priority right now is digging deeper into CSS debugging issues with further research and experiments. (You can help by taking my brief new CSS Debugging follow-up survey! More info below.)
Unsurprisingly, cross-browser compatibility was also a top choice. We’re investigating ways to ease the pain of debugging browser differences, including auditing, hints, and a more robust responsive design tool.
Mid-ranked issues included Flexbox, Grid, and Accessibility. We plan to continue improving our Accessibility Panel; however, for now we’ll step back a bit from our successfully launched Flexbox and Grid tools. Letting them breathe and collecting more real-world feedback will allow us to swing back with fresh new ideas later.
Lowest-ranked issues included Lack of Visual/WYSIWYG Tools, Animations, WebGL, and SVG. The visual tools part was surprising—we’ve seen a lot of love for click-and-drag visual tools like the beautifully designed Visbug and Webflow. I suspect my old-school wording here—WYSIWYG (“what you see is what you get”)—brought to mind less-delightful experiences of the past. There are clearly ways to improve developers’ lives with modern tools in this space.
As for the browser issues card sort, we hear you loud and clear on the issue of “Moving CSS changes back to my editor.” We’re currently in the process of adding export options to our Changes panel, and would love your input on our designs! DOM breakpoints are also in the plans for this year.
You can view the full MaxDiff and card sort rankings in this report.

Now we need your help again! The main takeaway from the first survey was that developers and designers of every experience level want to better understand CSS issues like unexpected scrollbars and sizing. We’ve started researching and prototyping potential tool ideas for investigating specific types of CSS bugs, but we need your feedback to guide our work.
Please take a moment with our quick single-page CSS Layout Debugging survey and help us rank the most time-consuming bugs. Your feedback will be immensely helpful in clarifying our plans in 2019 and beyond.
Thank you!
Victoria & the Firefox DevTools team
The post Web Design Survey Findings and Next Steps appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/02/web-design-challenges-survey-finding/
|
|
Cameron Kaiser: TenFourFox FPR13b1 available (now with WebP and AppleScript) |
WebP images are an up-and-coming format based on the WebM VP8 codec, another way Google will consume the Web from the inside out, but they do have image size advantages and Firefox now supports them in Firefox 65. Google has two demonstration WebP galleries you can use to view some samples, and there are colour-managed examples in the Skia test suite. TenFourFox's WebP support currently can display lossy, lossless, transparent and colour-managed images, and will properly use any embedded colour profile. However, it is not currently AltiVec-accelerated (we do have some AltiVec VP8 code, so this should be possible at some point), and it does not yet support animated WebP images, which will appear blank. For this reason we don't pass an Accept: header indicating we accept WebP images like mainline Firefox and certain other browsers, though we will naturally try to display it if we get one. If you encounter issues related to WebP, you can try setting image.webp.enabled to false, but I'm planning to ship this support in FPR13 final, so it defaults to true.
The other support is for AppleScript. One of the few advantages of being at feature parity instead of source parity is that we can feel free to implement features mainline Firefox doesn't want or consider a current priority, and one long-standing request going back to the pre-Firefox days is AppleScript support. In fairness, this is hard to achieve in Firefox, and getting harder because of its cross-platform asynchronous nature. Many of the assumptions AppleScript makes about an application and its internal object model are routinely violated for performance reasons in Firefox, and Firefox is not primarily written in Objective-C, so there need to be bridges written to regular C++ and JavaScript, proxy objects designed, etc. Since there was never any agreement on how this internal plumbing should look, only some speculative work was ever completed, and Firefox to this day only supports the basic AppleScript suite and some limited automation through GUI scripting methods.
However, one thing that would certainly be handy for those non-daily drivers who might have a Power Mac sitting around doing nothing is to automate some tasks with it, like a kiosk or a display, or to assist with certain rote tasks. For that, AppleScript would certainly be the most painless way of doing so, so here is a first cut of AppleScript support for TenFourFox. Essentially I took that 8-year-old speculative patch, modified it to work with Firefox 45 and 10.4 (some of the dictionary actually comes from the dearly departed Camino, which had rich AppleScript support of its own), and greatly expanded its feature set to yield TenFourFox's AppleScript module. With FPR13 beta, open the AppleScript Script Editor.app, switch to the Event Log tab, and try this script (substitute your TenFourFox application name for TenFourFoxG5):
tell application "TenFourFoxG5"
repeat with w in every browser window
repeat with t in every tab of w
repeat while (t is busy)
delay 1
end repeat
get name of t
get URL of t
end repeat
end repeat
end tell
This will iterate through every open browser window and every tab within that window, check an important synchronization property to make sure that the tab is not busy (being opened or being manipulated), and then report the name (title) and URL (location) of what's loaded in the Event Log. If you're an AppleScript jockey, you can well imagine what you can do with that information.
Tabs also have other useful properties, like plaintext and HTML to get the text or HTML contents respectively of a tab.
You might also want to create scripts for the Script menu (assuming you have that enabled) that act on text you have highlighted. TenFourFox can do that too:
tell application "TenFourFoxG5"
repeat while (current tab of front browser window is busy)
delay 1
end repeat
display dialog ("" & selected of current tab of front browser window)
end tell
If you put this script into the Script menu, then highlight some text and select this script. A dialogue box will appear with the text you have selected. (Similarly, paste it into the Script Editor and run it to see.)
You can also turn TenFourFox into an automated kiosk. Here's a script that opens a new window, makes it full screen, and then updates the display with what the New York state traffic cameras see on the Long Island Expressway every 15 seconds. It uses a second synchronization property called opening to determine when it's safe to manipulate the new window. (To stop it, Alt-Tab to the Script Editor, click Stop, then return to TenFourFox and close the fullscreen window with Cmd-W.)
tell application "TenFourFoxG5"
activate
make new browser window
repeat while (opening)
delay 1
end repeat
tell front browser window
set fullscreen to true
set URL to "https://511ny.org/map/Cctv/428834--20"
repeat
delay 15
reload current tab
end repeat
end tell
end tell
TenFourFox can also be automated with GUI scripting as well, which can be used to manipulate the pulldown menus and even deliver clicks and keyboard events on web pages and the browser chrome. The complete dictionary, like any scriptable app, can be viewed from the Script Editor's Open Dictionary... option. Do note there are a few gotchas and a few things that don't work as expected, and you cannot currently control foxboxes with AppleScript even if they use FPR13; you can read all about the current state of AppleScript support and get many more examples of scripting on the TenFourFox Github AppleScript wiki entry. It's not a perfect mapping of Firefox/TenFourFox onto AppleScript, but it's much better than mainline Firefox which can barely be script-controlled at all. Please consider this support to be a work in progress and there may be more bugs and features yet to add(ress). Post your comments as usual.
Like I say, I'm still concerned over the deficiencies accumulating in the browser that I don't know what to do with and don't have an easy means to patch into the browser core. That said, keep in mind that even if we did try to get a port of 52 off the ground to address these problems -- the functionality of which wouldn't guaranteed and has several major changes which would badly compromise TenFourFox's platform base -- we'd just have different deficiencies once Fx60 becomes the typical minimum, so it only delays the inevitable, and the Rust requirement for 54+ makes any later wholesale port impossible. Nevertheless, in the meantime these new features, although admittedly incomplete, at least give some additional functionality to the browser, and that's not worth nothing.
FPR13 will go final with Firefox 66 on March 19.
http://tenfourfox.blogspot.com/2019/02/tenfourfox-fpr13b1-available-now-with.html
|
|
Paul McLanahan: Multi-Stage Dockerfiles and Python Virtualenvs |
Using Docker’s multi-stage build feature and Python’s virtualenv tool, we can make smaller and more secure docker images for production.
https://pmac.io/2019/02/multi-stage-dockerfile-and-python-virtualenv/
|
|
Mozilla Addons Blog: Extensions in Firefox 66 |
Firefox 66 is currently in beta and, for extension developers, the changes to the WebExtensions API center primarily around improving performance, stability, and the development experience. A total of 30 issues were resolved in Firefox 66, including contributions from several volunteer community members.
I want to start by highlighting an important change that has a major, positive impact for Firefox users. Starting in release 66, extensions use IndexedDB as the backend for local storage instead of a JSON file. This results in a significant performance improvement for many extensions, while simultaneously reducing the amount of memory that Firefox uses.
This change is completely transparent to extension developers – you do not need to do anything to take advantage of this improvement. When users upgrade to Firefox 66, the local storage JSON file is silently migrated to IndexedDB. All extensions using the storage.local() API immediately realize the benefits, especially if they store small changes to large structures, as is true for ad-blockers, the most common and popular type of extension used in Firefox.
The video below, using Adblock Plus as an example, shows the significant performance improvements that extension users could see.
The remaining bug fixes and feature enhancements won’t be as noticeable as the change to local storage, but they nevertheless raise the overall quality of the WebExtensions API and make the development experience better. Some of the highlights include:
Thank you to everyone who contributed to the Firefox 66 release, but a special thank you to our volunteer community contributors, including: tossj, Varun Dey, and Edward Wu.
The post Extensions in Firefox 66 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2019/02/15/extensions-in-firefox-66/
|
|
Mozilla VR Blog: Jingle Smash: Geometry and Textures |

This is part 3 of my series on how I built Jingle Smash, a block smashing WebVR game
I’m not a designer or artist. In previous demos and games I’ve used GLTFs, which are existing 3D models created by someone else that I downloaded into my game. However, for Jingle Smash I decided to use procedural generation, meaning I combined primitives in interesting ways using code. I also generated all of the textures with code. I don’t know how to draw pretty textures by hand in a painting tool, but 20 years of 2D coding means I can code up a texture pretty easily.
Jingle Smash has three sets of graphics: the blocks, the balls, and the background imagery. Each set uses its own graphics technique.
The blocks all use the same texture placed on every side, depending on the block type. For blocks that you can knock over I called these ‘presents’ and gave them red ribbon stripes over a white background. I drew this into an HTML Canvas with standard 2D canvas code, then turned it into a texture using the THREE.CanvasTexture class.
const canvas = document.createElement('canvas')
canvas.width = 128
canvas.height = 128
const c = canvas.getContext('2d')
//white background
c.fillStyle = 'white'
c.fillRect(0,0,canvas.width, canvas.height)
//lower left for the sides
c.save()
c.translate(0,canvas.height/2)
c.fillStyle = 'red'
c.fillRect(canvas.width/8*1.5, 0, canvas.width/8, canvas.height/2)
c.restore()
//upper left for the bottom and top
c.save()
c.translate(0,0)
c.fillStyle = 'red'
c.fillRect(canvas.width/8*1.5, 0, canvas.width/8, canvas.height/2)
c.fillStyle = 'red'
c.fillRect(0,canvas.height/8*1.5, canvas.width/2, canvas.height/8)
c.restore()
c.fillStyle = 'black'
const tex = new THREE.CanvasTexture(canvas)
this.textures.present1 = tex
this.materials[BLOCK_TYPES.BLOCK] = new THREE.MeshStandardMaterial({
color: 'white',
metalness: 0.0,
roughness: 1.0,
map:this.textures.present1,
})
Once the texture is made I can create a ThreeJS material with it. I tried to use PBR (physically based rendering) materials in this project. Since the presents are supposed to be made of paper I used a metalness of 0.0 and roughness of 1.0. All textures and materials are saved in global variables for reuse.
Here is the finished texture. The lower left part is used for the sides and the upper left for the top and bottom.

The other two box textures are similar, a square and cross for the crystal boxes and simple random noise for the walls.


By default a BoxGeometry will put the same texture on all six sides of the box. However, we want to use different portions of the texture above for different sides. This is controlled with the UV values of each face. Fortunately ThreeJS has a face abstraction to make this easy. You can loop over the faces and manipulate the UVs however you wish. I scaled and moved them around to capture just the parts of the texture I wanted.
geo.faceVertexUvs[0].forEach((f,i)=>{
if(i === 4 || i===5 || i===6 || i===7 ) {
f.forEach(uv=>{
uv.x *= 0.5 //scale down
uv.y *= 0.5 //scale down
uv.y += 0.5 //move from lower left quadrant to upper left quadrant
})
} else {
//rest of the sides. scale it in
f.forEach(uv=>{
uv.x *= 0.5 // scale down
uv.y *= 0.5 // scale down
})
}
})
There are two different balls you can shoot. A spherical ornament with a stem and an oblong textured one. For the textures I just generated stripes with canvas.
{
const canvas = document.createElement('canvas')
canvas.width = 64
canvas.height = 16
const c = canvas.getContext('2d')
c.fillStyle = 'black'
c.fillRect(0, 0, canvas.width, canvas.height)
c.fillStyle = 'red'
c.fillRect(0, 0, 30, canvas.height)
c.fillStyle = 'white'
c.fillRect(30, 0, 4, canvas.height)
c.fillStyle = 'green'
c.fillRect(34, 0, 30, canvas.height)
this.textures.ornament1 = new THREE.CanvasTexture(canvas)
this.textures.ornament1.wrapS = THREE.RepeatWrapping
this.textures.ornament1.repeat.set(8, 1)
}
{
const canvas = document.createElement('canvas')
canvas.width = 128
canvas.height = 128
const c = canvas.getContext('2d')
c.fillStyle = 'black'
c.fillRect(0,0,canvas.width, canvas.height)
c.fillStyle = 'red'
c.fillRect(0, 0, canvas.width, canvas.height/2)
c.fillStyle = 'white'
c.fillRect(0, canvas.height/2, canvas.width, canvas.height/2)
const tex = new THREE.CanvasTexture(canvas)
tex.wrapS = THREE.RepeatWrapping
tex.wrapT = THREE.RepeatWrapping
tex.repeat.set(6,6)
this.textures.ornament2 = tex
}
The code above produces these textures:


What makes the textures interesting is repeating them on the ornaments. ThreeJS makes this really easy by using the wrap and repeat values, as shown in the code above.
One of the ornaments is meant to have an oblong double turnip shape, so I used a LatheGeometry. With a lathe you define a curve and ThreeJS will rotate it to produce a 3D mesh. I created the curve with the equations x = Math.sin(I*0.195) * radius and y = i * radius /7.
let points = [];
for (let I = 0; I <= 16; I++) {
points.push(new THREE.Vector2(Math.sin(I * 0.195) * rad, I * rad / 7));
}
var geometry = new THREE.LatheBufferGeometry(points);
geometry.center()
return new THREE.Mesh(geometry, new THREE.MeshStandardMaterial({
color: ‘white’,
metalness: 0.3,
roughness: 0.3,
map: this.textures.ornament1,
}))

For the other ornament I wanted a round ball with a stem on the end like a real Christmas tree ornament. To build this I combined a sphere and cylinder.
const geo = new THREE.Geometry()
geo.merge(new THREE.SphereGeometry(rad,32))
const stem = new THREE.CylinderGeometry(rad/4,rad/4,0.5,8)
stem.translate(0,rad/4,0)
geo.merge(stem)
return new THREE.Mesh(geo, new THREE.MeshStandardMaterial({
color: ‘white’,
metalness: 0.3,
roughness: 0.3,
map: this.textures.ornament2,
}))

Since I wanted the ornaments to appear shiny and plasticy, but a shiny as a chrome sphere, I used metalness and roughness values of 0.3 and 0.3.
Note that I had to center the oblong ornament with geometry.center(). Even though the ornaments have different shapes I represented them both as spheres on the physics side. If you roll the oblong one on the ground it may look strange seeing it perfectly like a ball, but it was good enough for this game. Game development is all about cutting the right corners.
It might not look like it if you are in a 3 degree of freedom (3dof) headset like the Oculus Go, but the background is not a static painting. The clouds in the sky are an image but everything else was created with real geometry.

The snow covered hills are actually full spheres placed mostly below the ground plane. The trees and candy are all simple cones. The underlying stripe texture I drew in Acorn, a desktop drawing app. Other than the clouds it is the only real texture I used in the game. I probably could have done the stripe in code as well but I was running out of time. In fact both the trees and candy mountains use the exact same texture, just with a different base color.
const tex = game.texture_loader.load(‘./textures/candycane.png’)
tex.wrapS = THREE.RepeatWrapping
tex.wrapT = THREE.RepeatWrapping
tex.repeat.set(8,8)
const background = new THREE.Group()
const candyCones = new THREE.Geometry()
candyCones.merge(new THREE.ConeGeometry(1,10,16,8).translate(-22,5,0))
candyCones.merge(new THREE.ConeGeometry(1,10,16,8).translate(22,5,0))
candyCones.merge(new THREE.ConeGeometry(1,10,16,8).translate(7,5,-30))
candyCones.merge(new THREE.ConeGeometry(1,10,16,8).translate(-13,5,-20))
background.add(new THREE.Mesh(candyCones,new THREE.MeshLambertMaterial({ color:’white’, map:tex,})))
const greenCones = new THREE.Geometry()
greenCones.merge(new THREE.ConeGeometry(1,5,16,8).translate(-15,2,-5))
greenCones.merge(new THREE.ConeGeometry(1,5,16,8).translate(-8,2,-28))
greenCones.merge(new THREE.ConeGeometry(1,5,16,8).translate(-8.5,0,-25))
greenCones.merge(new THREE.ConeGeometry(1,5,16,8).translate(15,2,-5))
greenCones.merge(new THREE.ConeGeometry(1,5,16,8).translate(14,0,-3))
background.add(new THREE.Mesh(greenCones,new THREE.MeshLambertMaterial({color:’green’, map:tex,})))

All of them were positioned by hand in code. To make this work I had to constantly adjust code then reload the scene in VR. At first I would just preview in my desktop browser, but to really feel how the scene looks you have to view it in a real 3D headset. This is one of the magical parts about VR development with the web. Iteration is so fast.
Note that even though I have many different cones I merged them all into just two geometries so they can be drawn together. It’s far better to have two draw calls instead of 10 for a static background.
I'm pretty happy with how the textures turned out. By sticking to just a few core colors I was able to create with both consistency and variety. Furthermore, I was able to do it without any 3D modeling. Just some simple canvas code and a lot of iteration.
Next time I'll dive into the in-game level editor.
|
|
Mozilla Security Blog: Why Does Mozilla Maintain Our Own Root Certificate Store? |
Mozilla maintains a database containing a set of “root” certificates that we use as “trust anchors”. This database, commonly referred to as a “root store”, allows us to determine which Certificate Authorities (CAs) can issue SSL/TLS certificates that are trusted by Firefox, and email certificates that are trusted by Thunderbird. Properly maintaining a root store is a significant undertaking – it requires constant effort to evaluate new trust anchors, monitor existing ones, and react to incidents that threaten our users. Despite the effort involved, Mozilla is committed to maintaining our own root store because doing so is vital to the security of our products and the web in general. It gives us the ability to set policies, determine which CAs meet them, and to take action when a CA fails to do so.
A major advantage to controlling our own root store is that we can do so in a way that reflects our values. We manage our CA Certificate Program in the open, and by encouraging public participation we give individuals a voice in these trust decisions. Our root inclusion process is one example. We process lots of data and perform significant due diligence, then publish our findings and hold a public discussion before accepting each new root. Managing our own root store also allows us to have a public incident reporting process that emphasizes disclosure and learning from experts in the field. Our mailing list includes participants from many CAs, CA auditors, and other root store operators and is the most widely recognized forum for open, public discussion of policy issues.
The value delivered by our root program extends far beyond Mozilla. Everyone who relies on publicly-trusted certificates benefits from our work, regardless of their choice of browser. And because our root store, which is part of the NSS cryptographic library, is open source, it has become a de-facto standard for many Linux distributions and other products that need a root store but don’t have the resources to curate their own. Providing one root store that many different products can rely on, regardless of platform, reduces compatibility problems that would result from each product having a unique set of root certificates.
Finally, operating a root store allows Mozilla to lead and influence the entire web Public Key Infrastructure (PKI) ecosystem. We created the Common Certificate Authority Database (CCADB) to help us manage our own program, and have since opened it up to other root store operators, resulting in better information and less redundant work for all involved. With full membership in the CA/Browser Forum, we collaborate with other root store operators, CAs, and auditors to create standards that continue to increase the trustworthiness of CAs and the SSL/TLS certificates they issue. Our most recent effort was aimed at improving the standards for validating IP Addresses.
The primary alternative to running our own root store is to rely on the one that is built in to most operating systems (OSs). However, relying on our own root store allows us to provide a consistent experience across OS platforms because we can guarantee that the exact same set of trust anchors is available to Firefox. In addition, OS vendors often serve customers in government and industry in addition to their end users, putting them in a position to sometimes make root store decisions that Mozilla would not consider to be in the best interest of individuals.
Sometimes we experience problems that wouldn’t have occurred if Firefox relied on the OS root store. Companies often want to add their own private trust anchors to systems that they control, and it is easier for them if they can modify the OS root store and assume that all applications will rely on it. The same is true for products that intercept traffic on a computer. For example, many antivirus programs unfortunately include a web filtering feature that intercepts HTTPS requests by adding a special trust anchor to the OS root store. This will trigger security errors in Firefox unless the vendor supports Firefox by turning on the setting we provide to address these situations.
Principle 4 of the Mozilla Manifesto states that “Individuals’ security and privacy on the internet are fundamental and must not be treated as optional.” The costs of maintaining a CA Certificate Program and root store are significant, but there are fundamental benefits for our users and the larger internet community that undoubtedly make doing it ourselves the right choice for Mozilla.
The post Why Does Mozilla Maintain Our Own Root Certificate Store? appeared first on Mozilla Security Blog.
|
|
Hacks.Mozilla.Org: Fearless Security: Thread Safety |
In Part 2 of my three-part Fearless Security series, I’ll explore thread safety.
Today’s applications are multi-threaded—instead of sequentially completing tasks, a program uses threads to perform multiple tasks simultaneously. We all use concurrency and parallelism every day:
While this allows programs to do more faster, it comes with a set of synchronization problems, namely deadlocks and data races. From a security standpoint, why do we care about thread safety? Memory safety bugs and thread safety bugs have the same core problem: invalid resource use. Concurrency attacks can lead to similar consequences as memory attacks, including privilege escalation, arbitrary code execution (ACE), and bypassing security checks.
Concurrency bugs, like implementation bugs, are closely related to program correctness. While memory vulnerabilities are nearly always dangerous, implementation/logic bugs don’t always indicate a security concern, unless they occur in the part of the code that deals with ensuring security contracts are upheld (e.g. allowing a security check bypass). However, while security problems stemming from logic errors often occur near the error in sequential code, concurrency bugs often happen in different functions from their corresponding vulnerability, making them difficult to trace and resolve. Another complication is the overlap between mishandling memory and concurrency flaws, which we see in data races.
Programming languages have evolved different concurrency strategies to help developers manage both the performance and security challenges of multi-threaded applications.
It’s a common axiom that parallel programming is hard—our brains are better at sequential reasoning. Concurrent code can have unexpected and unwanted interactions between threads, including deadlocks, race conditions, and data races.
A deadlock occurs when multiple threads are each waiting on the other to take some action in order to proceed, leading to the threads becoming permanently blocked. While this is undesirable behavior and could cause a denial of service attack, it wouldn’t cause vulnerabilities like ACE.
A race condition is a situation in which the timing or ordering of tasks can affect the correctness of a program, while a data race happens when multiple threads attempt to concurrently access the same location in memory and at least one of those accesses is a write. There’s a lot of overlap between data races and race conditions, but they can also occur independently. There are no benign data races.
The best-known type of concurrency attack is called a TOCTOU (time of check to time of use) attack, which is a race condition between checking a condition (like a security credential) and using the results. TOCTOU attacks are examples of integrity loss.
Deadlocks and loss of liveness are considered performance problems, not security issues, while information and integrity loss are both more likely to be security-related. This paper from Red Balloon Security examines some exploitable concurrency errors. One example is a pointer corruption that allows privilege escalation or remote execution—a function that loads a shared ELF (Executable and Linkable Format) library holds a semaphore correctly the first time it’s called, but the second time it doesn’t, enabling kernel memory corruption. This attack is an example of information loss.
The trickiest part of concurrent programming is testing and debugging—concurrency bugs have poor reproducibility. Event timings, operating system decisions, network traffic, etc. can all cause different behavior each time you run a program that has a concurrency bug.
Not only can behavior change each time we run a concurrent program, but inserting print or debugging statements can also modify the behavior, causing heisenbugs (nondeterministic, hard to reproduce bugs that are common in concurrent programming) to mysteriously disappear. These operations are slow compared to others and change message interleaving and event timing accordingly.
Concurrent programming is hard. Predicting how concurrent code interacts with other concurrent code is difficult to do. When bugs appear, they’re difficult to find and fix. Instead of relying on programmers to worry about this, let’s look at ways to design programs and use languages to make it easier to write concurrent code.
First, we need to define what “threadsafe” means:
“A data type or static method is threadsafe if it behaves correctly when used from multiple threads, regardless of how those threads are executed, and without demanding additional coordination from the calling code.” MIT
In languages that don’t statically enforce thread safety, programmers must remain constantly vigilant when interacting with memory that can be shared with another thread and could change at any time. In sequential programming, we’re taught to avoid global variables in case another part of code has silently modified them. Like manual memory management, requiring programmers to safely mutate shared data is problematic.

Generally, programming languages are limited to two approaches for managing safe concurrency:
Languages that limit threading either confine mutable variables to a single thread or require that all shared variables be immutable. Both approaches eliminate the core problem of data races—improperly mutating shared data—but this can be too limiting. To solve this, languages have introduced low-level synchronization primitives like mutexes. These can be used to build threadsafe data structures.
The reference implementation of Python, CPython, has a mutex called the Global Interpreter Lock (GIL), which only allows a single thread to access a Python object. Multi-threaded Python is notorious for being inefficient because of the time spent waiting to acquire the GIL. Instead, most parallel Python programs use multiprocessing, meaning each process has its own GIL.
Java is designed to support concurrent programming via a shared-memory model. Each thread has its own execution path, but is able to access any object in the program—it’s up to the programmer to synchronize accesses between threads using Java built-in primitives.
While Java has the building blocks for creating thread-safe programs, thread safety is not guaranteed by the compiler (unlike memory safety). If an unsynchronized memory access occurs (aka a data race), then Java will raise a runtime exception—however, this still relies on programmers appropriately using concurrency primitives.
While Python avoids data races by synchronizing everything with the GIL, and Java raises runtime exceptions if it detects a data race, C++ relies on programmers to manually synchronize memory accesses. Prior to C++11, the standard library did not include concurrency primitives.
Most programming languages provide programmers with the tools to write thread-safe code, and post hoc methods exist for detecting data races and race conditions; however, this does not result in any guarantees of thread safety or data race freedom.
Rust takes a multi-pronged approach to eliminating data races, using ownership rules and type safety to guarantee data race freedom at compile time.
The first post of this series introduced ownership—one of the core concepts of Rust. Each variable has a unique owner and can either be moved or borrowed. If a different thread needs to modify a resource, then we can transfer ownership by moving the variable to the new thread.
Moving enforces exclusion, allowing multiple threads to write to the same memory, but never at the same time. Since an owner is confined to a single thread, what happens if another thread borrows a variable?
In Rust, you can have either one mutable borrow or as many immutable borrows as you want. You can never simultaneously have a mutable borrow and an immutable borrow (or multiple mutable borrows). When we talk about memory safety, this ensures that resources are freed properly, but when we talk about thread safety, it means that only one thread can ever modify a variable at a time. Furthermore, we know that no other threads will try to reference an out of date borrow—borrowing enforces either sharing or writing, but never both.
Ownership was designed to mitigate memory vulnerabilities. It turns out that it also prevents data races.
While many programming languages have methods to enforce memory safety (like reference counting and garbage collection), they usually rely on manual synchronization or prohibitions on concurrent sharing to prevent data races. Rust’s approach addresses both kinds of safety by attempting to solve the core problem of identifying valid resource use and enforcing that validity during compilation.

The ownership rules prevent multiple threads from writing to the same memory and disallow simultaneous sharing between threads and mutability, but this doesn’t necessarily provide thread-safe data structures. Every data structure in Rust is either thread-safe or it’s not. This is communicated to the compiler using the type system.
A well-typed program can’t go wrong. Robin Milner, 1978
In programming languages, type systems describe valid behaviors. In other words, a well-typed program is well-defined. As long as our types are expressive enough to capture our intended meaning, then a well-typed program will behave as intended.
Rust is a type safe language—the compiler verifies that all types are consistent. For example, the following code would not compile:
let mut x = "I am a string";
x = 6;
error[E0308]: mismatched types
--> src/main.rs:6:5
|
6 | x = 6; //
| ^ expected &str, found integral variable
|
= note: expected type `&str`
found type `{integer}`
All variables in Rust have a type—often, they’re implicit. We can also define new types and describe what capabilities a type has using the trait system. Traits provide an interface abstraction in Rust. Two important built-in traits are Send and Sync, which are exposed by default by the Rust compiler for every type in a Rust program:
Send indicates that a struct may safely be sent between threads (required for an ownership move)Sync indicates that a struct may safely be shared between threadsThis example is a simplified version of the standard library code that spawns threads:
fn spawn(closure: Closure){ ... }
let x = std::rc::Rc::new(6);
spawn(|| { x; });
The spawn function takes a single argument, closure, and requires that closure has a type that implements the Send and Fn traits. When we try to spawn a thread and pass a closure value that makes use of the variable x, the compiler rejects the program for not fulfilling these requirements with the following error:
error[E0277]: `std::rc::Rc` cannot be sent between threads safely
--> src/main.rs:8:1
|
8 | spawn(move || { x; });
| ^^^^^ `std::rc::Rc` cannot be sent between threads safely
|
= help: within `[closure@src/main.rs:8:7: 8:21 x:std::rc::Rc]`, the trait `std::marker::Send` is not implemented for `std::rc::Rc`
= note: required because it appears within the type `[closure@src/main.rs:8:7: 8:21 x:std::rc::Rc]`
note: required by `spawn`
The Send and Sync traits allow the Rust type system to reason about what data may be shared. By including this information in the type system, thread safety becomes type safety. Instead of relying on documentation, thread safety is part of the compiler’s law.
This allows programmers to be opinionated about what can be shared between threads, and the compiler will enforce those opinions.

While many programming languages provide tools for concurrent programming, preventing data races is a difficult problem. Requiring programmers to reason about complex instruction interleaving and interaction between threads leads to error prone code. While thread safety and memory safety violations share similar consequences, traditional memory safety mitigations like reference counting and garbage collection don’t prevent data races. In addition to statically guaranteeing memory safety, Rust’s ownership model prevents unsafe data modification and sharing across threads, while the type system propagates and enforces thread safety at compile time.

The post Fearless Security: Thread Safety appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/02/fearless-security-thread-safety/
|
|
The Mozilla Blog: Firefox for iOS Amps Up Private Browsing and More |
Today we’re rolling out updated features for iPhone and iPad users, including a new layout for menu and settings, persistent Private Browsing tabs and new organization options within the New Tabs feature. This round of updates is the result of requests we received straight from our users, and we’re taking your feedback to make this version of iOS work harder and smarter for you.
With this in mind, in the latest update of Firefox for iOS we overhauled both the Settings and Menu options to more closely mirror the desktop application. Now you can access bookmarks, history, Reading List and downloads in the “Library” menu item.
Private browsing tabs can now live across sessions, meaning, if you open a private browsing tab and then exit the app, Firefox will automatically launch in private browsing the next time you open the app. Keeping your private browsing preferences seamless is just another way we’re making it simple and easy to give you back control of the privacy of your online experience.

Private browsing tabs can now live across sessions
Today’s release also includes a few different options for New Tabs organization. You can now choose to have new tabs open with your bookmark list, in Firefox Home (with top sites and Pocket stories), with a list of recent history, a custom URL or in a blank page.
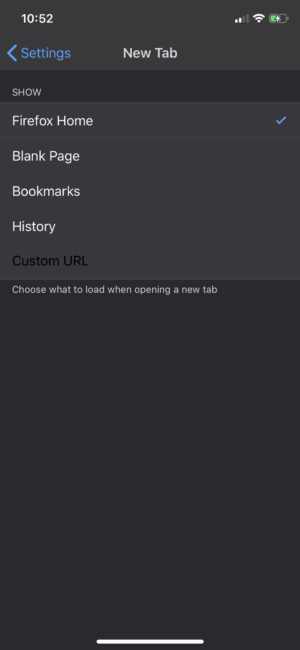
More options for New Tabs organization
We’re also making it easier to customize Firefox Home with top sites and Pocket content. All tabs can now be rearranged by dragging a tab into the tab bar or tab tray.
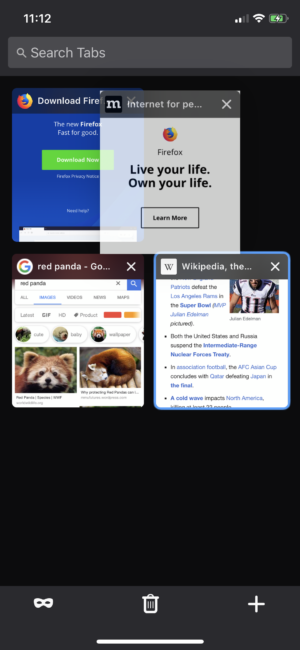
Customize Firefox Home with top sites and Pocket content
Whether it’s your personal data or how you organize your online experience, Firefox continues to bring more privacy and control to you.
To get the latest version of Firefox for iOS, visit the App Store.
The post Firefox for iOS Amps Up Private Browsing and More appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2019/02/14/firefox-for-ios-amps-up-private-browsing-and-more/
|
|
Mozilla GFX: WebRender newsletter #40 |
WebRender is a GPU based 2D rendering engine for web written in Rust, currently powering Mozilla’s research web browser Servo and on its way to becoming Firefox‘s rendering engine.
Only 0 P2 bugs and 4 P3 bugs left (two of which have fixes up for review)!
The best place to report bugs related to WebRender in Firefox is the Graphics :: WebRender component in bugzilla.
Note that it is possible to log in with a github account.
https://mozillagfx.wordpress.com/2019/02/14/webrender-newsletter-40/
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla statement on the conclusion of EU copyright directive ‘trialogue’ negotiations |
Yesterday the EU institutions concluded ‘trialogue’ negotiations on the EU Copyright directive, a procedural step that makes the final adoption of the directive a near certainty.
Here’s a statement from Raegan MacDonald, Mozilla’s Head of EU Public Policy –
The Copyright agreement gives the green light to new rules that will compel online services to implement blanket upload filters, with an overly complex and limited SME carve out that will be unworkable in practice. At the same time, lawmakers have forced through a new ancillary copyright for press publishers, a regressive and disproven measure that will undermine access to knowledge and the sharing of information online.
The legal uncertainty that will be generated by these complex rules means that only the largest, most established platforms will be able to fully comply and thrive in such a restricted online environment.
With this development, the EU institutions have squandered the opportunity of a generation to bring European copyright law into the 21st century. At a time of such concern about web centralisation and the ability of small European companies to compete in the digital marketplace, these new rules will serve to entrench the incumbents.
We recognise the efforts of many Member States and MEPs who laboured to find workable solutions that would have rectified some of the gravest shortcomings in the proposal. Unfortunately the majority of their progressive compromises were rejected.
The file is expected to be adopted officially in a final European Parliament vote in the coming weeks. We’re continuously working with our allies in the Parliament and the broader community to explore any and every opportunity to limit the potential damage of this outcome.
The post Mozilla statement on the conclusion of EU copyright directive ‘trialogue’ negotiations appeared first on Open Policy & Advocacy.
|
|







