Matt Brubeck: Rust: A unique perspective |
The Rust programming language is designed to ensure memory safety, using a mix of compile-time and run-time checks to stop programs from accessing invalid pointers or sharing memory across threads without proper synchronization.
The way Rust does this is usually introduced in terms of mutable and immutable borrowing and lifetimes. This makes sense, because these are mechanisms that Rust programmers must use directly. They describe what the Rust compiler checks when it compiles a program.
However, there is another way to explain Rust. This alternate story focuses on unique versus shared access to values in memory. I believe this version is useful for understanding why various checks exist and how they provide memory safety.
Most experienced Rust programmers are already familiar with this concept.
Five years ago, Niko Matsakis even proposed changing the mut keyword to
uniq to emphasize it. My goal is to make these important
ideas more accesssible to beginning and intermediate Rust programmers.
This is a very quick introduction that skips over many details to focus on high-level concepts. It should complement the official Rust documentation, not supplant it.
The first key observation is: If a variable has unique access to a value, then it is safe to mutate it.
By safe, I mean memory-safe: free from invalid pointer accesses, data races, or other causes of undefined behavior. And by unique access, I mean that while this variable is alive, there are no other variables that can be used to read or write any part of the same value.
Unique access makes memory safety very simple: If there are no other pointers to the value, then you don’t need to worry about invalidating them. Similarly, if variables on other threads can't access the value, you needn’t worry about synchronization.
One form of unique access is ownership. When you initialize a variable with a value, it becomes the sole owner of that value. Because the value has just one owner, the owner can safely mutate the value, destroy it, or transfer it to a new owner.
Depending on the type of the value, assigning a value to a new variable another will either copy it or move it. Either way, unique ownership is preserved. For a move type, the old owner becomes inaccessible after the move, so we still have one value owned by one variable:
let x = vec![1, 2, 3];
let y = x; // move ownership from x to y
// can’t access x after moving its value to yFor a copy type, the value is duplicated, so we end up with two values owned by two variables:
let x = 1;
let y = x; // copy the value of x into yIn this case, each variable ends up with a separate, independent value. Mutating one will not affect the other.
One value might be owned by another value, rather than directly by a variable.
For example, a struct owns its fields, a Vec owns the T items inside
it, and a Box owns the T that it points to.
If you have unique access to a value of type T, you can borrow a unique
reference to that value. A unique reference to a T has type &mut T.
Because it’s safe to mutate when you have a unique reference, unique references are also called “mutable references.“
The Rust compiler enforces this uniqueness at compile time. In any region of code where the unique reference may be used, no other reference to any part of the same value may exist, and even the owner of that value may not move or destroy it. Violating this rule triggers a compiler error.
A reference only borrows the value, and must return it to its owner.
This means that the reference can be used to mutate the value, but not to move
or destroy it (unless it overwrites it with a new value, for example using
replace). Just like in real life, you need to give back what you’ve
borrowed.
Borrowing a value is like locking it. Just like a mutex lock in a multi-threaded program, it’s usually best to hold a borrowed reference for as little time as possible. Storing a unique reference in a long-lived data structure will prevent any other use of the value for as long as that structure exists.
An &mut T cannot be copied or cloned, because this would result in
two ”unique” references to the same value. It can only be moved:
let mut a = 1;
let x = &mut a;
let y = x; // move the reference from x into y
// x is no longer accessible hereHowever, you can temporarily ”re-borrow” from a unique reference. This gives a new unique reference to the same value, but the original reference can no longer be accessed until the new one goes out of scope or is no longer used (depending on which version of Rust you are using):
let mut a = 1;
let x = &mut a;
{
let y = &mut *x;
// x is "re-borrowed" and cannot be used while y is alive
*y = 4; // y has unique access and can mutate `a`
}
// x becomes accessible again after y is dead
*x += 1; // now x has unique access again and can mutate the value
assert_eq!(*x, 5);Re-borrowing happens implicitly when you call a function that takes a unique reference. This greatly simplifies code that passes unique references around, but can confuse programmers who are just learning about these restrictions.
A value is shared if there are multiple variables that are alive at the same time that can be used to access it.
While a value is shared, we have to be a lot more careful about mutating it. Writing to the value through one variable could invalidate pointers held by other variables, or cause a data race with readers or writers on other threads.
Rust ensures that you can read from a value only while no variables can write to it, and you can write to a value only while no other variables can read or write to it. In other words, you can have a unique writer, or multiple readers, but not both at once. Some Rust types enforce this at compile time and others at run time, but the principle is always the same.
One way to share a value of type T is to create an Rc, or
“reference-counted pointer to T”. This allocates space on the heap for a T,
plus some extra space for reference counting (tracking the number of pointers
to the value). Then you can call Rc::clone to increment the reference count
and receive another Rc that points to the same value:
let x = Rc::new(1);
let y = x.clone();
// x and y hold two different Rc that point to the same memoryBecause the T lives on the heap and x and y just hold pointers to it, it
can outlive any particular pointer. It will be destroyed only when the last
of the pointers is dropped. This is called shared ownership.
Since Rc doesn't have unique access to its T, it can’t give out a
unique &mut T reference (unless it checks at run time that the reference
count is equal to 1, so it is not actually shared). But it can give out a
shared reference to T, whose type is written &T. (This is also called
an “immutable reference.”)
A shared reference is another “borrowed” type which can’t outlive its referent. The compiler ensures that a shared reference can’t be created while a unique reference exists to any part of the same value, and vice-versa. And (just like unique references) the owner isn’t allowed to drop/move/mutate the value while any shared references are alive.
If you have unique access to a value, you can produce many shared references
or one unique reference to it. However, if you only have shared access to a
value, you can’t produce a unique reference (at least, not without some
additional checks, which I’ll discuss soon). One consequence of this is that
you can convert an &mut T to an &T, but not vice-versa.
Because multiple shared references are allowed, an &T can be copied/cloned
(unlike &mut T).
Astute readers might notice that merely cloning an Rc mutates a value in
memory, since it modifies the reference count. This could cause a data race
if another clone of the Rc were accessed at the same time on a different
thread! The compiler solves this in typical Rust fashion: By refusing to
compile any program that passes an Rc to a different thread.
Rust has two built-in traits that it uses to mark types that can be accessed safely by other threads:
T: Send means it's safe to access a T on a single other thread,
where one thread at a time has exclusive access. A more descriptive name
for this trait might be UniqueThreadSafe.
T: Sync means it’s safe for many threads to access a T
simultaneously, with each thread having shared access.
Values of such types can be accessed on other threads via shared ownership
or shared references. A more descriptive name would be
SharedThreadSafe.
Rc implements neither of these traits, so an Rc cannot be moved or
borrowed into a variable on a different thread. It is forever trapped on the
thread where it was born.
The standard library also offers an Arc type, which is exactly like
Rc except that it implements Send, and uses atomic operations to
synchronize access to its reference counts. This can make Arc a little
more expensive at run time, but it allows multiple threads to share a value
safely.
These traits are not mutually exclusive. Many types are both Send and
Sync, meaning that it’s safe to give unique access to one other thread (for
example, moving the value itself or sending an &mut T reference) or shared
access to many threads (for example, sending multiple Arc or &T).
So far, we’ve seen that sharing is safe when values are not mutated, and mutation is safe when values are not shared. But what if we want to share and mutate a value? The Rust standard library provides several different mechanisms for shared mutability.
The official documentation also calls this “interior mutability” because it lets you mutate a value that is “inside” of an immutable value. This terminology can be confusing: What does it mean for the exterior to be “immutable” if its interior is mutable? I prefer “shared mutability” which puts the spotlight on a different question: How can you safely mutate a value while it is shared?
What’s the big deal about shared mutation? Let’s start by listing some of the ways it could go wrong:
First, mutating a value can cause pointer invalidation. For example, pushing to a vector might cause it to reallocate its buffer. If there are other variables that contained addresses of items in the buffer, they would now point to deallocated memory. Or, mutating an enum might overwrite a value of one type with a value of a different type. A pointer to the old value will now be pointing at memory occupied by the wrong type. Either of these cases would trigger undefined behavior.
Second, it could violate aliasing assumptions. For example, the optimizing
compiler assumes by default that the referent of an &T reference will not
change while the reference exists. It might re-order code based on this
assumption, leading to undefined behavior when the assumption is violated.
Third, if one thread mutates a value at the same time that another thread is accessing it, this causes a data race unless both threads use synchronization primitives to prevent their operations from overlapping. Data races can cause arbitrary undefined behavior (in part because data races can also violate assumptions made by the optimizer during code generation).
To fix the problem of aliasing assumptions, we need UnsafeCell. The
compiler knows about this type and treats it specially: It tells the optimizer
that the value inside an UnsafeCell is not subject to the usual restrictions
on aliasing.
Safe Rust code doesn’t use UnsafeCell directly. Instead, it’s used by
libraries (including the standard library) that provide APIs for safe shared
mutability. All of the shared mutable types discussed in the following
sections use UnsafeCell internally.
UnsafeCell solves only one of the three problems listed above. Next, we'll
see some ways to solve the other two problems: pointer invalidation and data
races.
Rust programs can safely mutate a value that’s shared across threads, as long as the basic rules of unique and shared access are enforced: Only one thread at a time may have unique access to a value, and only this thread can mutate it. When no thread has unique access, then many threads may have shared access, but the value can’t be mutated while they do.
Rust has two main types that allow thread-safe shared mutation:
Mutex allows one thread at a time to “lock” a mutex and get unique
access to its contents. If a second thread tries to lock the mutex at the
same time, the second thread will block until the first thread unlocks it.
Since Mutex provides access to only one thread at a time, it can be used to
share any type that implements the Send (“unique thread-safe”) trait.
RwLock is similar but has two different types of lock: A “write”
lock that provides unique access, and a “read” lock that provides shared
access. It will allow many threads to hold read locks at the same time, but
only one thread can hold a write lock. If one thread tries to write while
other threads are reading (or vice-versa), it will block until the other
threads release their locks. Since RwLock provides both unique and shared
access, its contents must implement both Send (“unique thread-safe”) and
Sync (“shared thread-safe”).
These types prevent pointer invalidation by using run-time checks to enforce the rules of unique and shared borrowing. They prevent data races by using synchronization primitives provided by the platform’s native threading system.
In addition, various atomic types allow safe shared mutation of individual primitive values. These prevent data races by using compiler intrinsics that provide synchronized operations, and they prevent pointer invalidation by refusing to give out references to their contents; you can only read from them or write to them by value.
All these types are only useful when shared by multiple threads, so they are
often used in combination with Arc. Because Arc lets multiple threads
share ownership of a value, it works with threads that might outlive the
function that spawns them (and therefore can’t borrow references from it).
However, scoped threads are guaranteed to terminate before their spawning
function, so they can capture shared references like &Mutex instead of
Arc>.
The standard library also has two types that allow safe shared mutation
within a single thread. These types don’t implement the Sync trait, so the
compiler won't let you share them across multiple threads. This neatly avoids
data races, and also means that these types don’t need atomic operations
(which are potentially expensive).
Cell solves the problem of pointer invalidation by forbidding
pointers to its contents. Like the atomic types mentioned above, you can only
read from it or write to it by value. Changing the data “inside” of the
Cell is okay, because there are no shared pointers to that data – only to
the Cell itself, whose type and address do not change when you mutate its
interior. (Now we see why “interior mutability” is also a useful concept.)
Many Rust types are useless without references, so Cell is often too
restrictive. RefCell allows you to borrow either unique or shared
references to its contents, but it keeps count of how many borrowers are alive
at a time. Like RwLock, it allows one unique reference or many shared
references, but not both at once. It enforces this rule using run-time
checks. (But since it’s used within a single thread, it can’t block the
thread while waiting for other borrowers to finish. Instead, it panics
if a program violates its borrowing rules.)
These types are often used in combination with Rc, so that a value shared
by multiple owners can still be mutated safely. They may also be used for
mutating values behind shared references. The std::cell docs have some
examples.
To summarize some key ideas:
We also saw a couple of ways to classify Rust types. Here’s a table showing some of the most common types according to this classification scheme:
| Unique | Shared | |
|---|---|---|
| Borrowed | &mut T |
&T |
| Owned | T, Box |
Rc, Arc |
I hope that thinking of these types in terms of uniqueness and sharing will help you understand how and why they work, as it helped me.
As I said at the start, this is just a quick introduction and glosses over many details. The exact rules about unique and shared access in Rust are still being worked out. The Aliasing chapter of the Rustonomicon explains more, and Ralf Jung’s Stacked Borrows model is the start of a more complete and formal definition of the rules.
If you want to know more about how shared mutability can lead to memory-unsafety, read The Problem With Single-threaded Shared Mutability by Manish Goregaokar.
The Swift language has an approach to memory safety that is similar in some ways, though its exact mechanisms are different. You might be interested in its recently-introduced Exclusivity Enforcement feature, and the Ownership Manifesto that originally described its design and rationale.
https://limpet.net/mbrubeck/2019/02/07/rust-a-unique-perspective.html
|
|
Mozilla Localization (L10N): A New Year with New Goals for Mozilla Localization |
We had a really ambitious and busy year in 2018! Thanks to the help of the global localization community as well as a number of cross-functional Mozilla staff, we were able to focus our efforts on improving the foundations of our localization program. These are some highlights of what we accomplished in 2018:
Rather than plan out our goals for the full year in 2019, we’ve been encouraged to take it a quarter at a time. That being said, there are a number of interesting themes that will pop up in 2019 as well as the continuation of work from 2018:
There are still areas within our tool-chain as well as our processes that make it hard to scale localization to all of Mozilla. Over the course of 2018 we saw more and more l10n requests from internal teams that required customized processes. The good news here is that the organization as a whole wants to localize more and more content (that hasn’t been true in the past)!
While we’ve seen success in standardizing the processes for localizing product user interfaces, we’ve struggled to rein in the customizations for other types of content. In 2019, we’ll focus a lot of our energy on bringing more stability and consistency to localizers by standardizing localization processes according to specific content types. Once standardized, we’ll be able to scale to meet the the needs of these internal teams while keeping the amount of new content to translate in consistent volumes.
One of the primary focus areas for all of Mozilla this year is South East Asian markets. The Emerging Markets team in Taipei is focused on creating products for those markets that meet the needs of users there, building on the success of Screenshots Go and Firefox Lite. This year we’ll see more products coming to these markets and it will be more important than ever for us to know how to mobilize l10n communities in those regions in order to localize these exciting, new products.
Early this year we plan to hit a major milestone: Fluent 1.0! This is the culmination of over a decade’s worth of work and we couldn’t be more proud of this accomplishment. Fluent will continue to be implemented in Firefox as well as other Mozilla projects throughout 2019. We’re planning a roadmap for an ecosystem of tooling to support Fluent 1.0 as well as exploring how to build a thriving Fluent community.
Pontoon’s Translate view rewrite to React will be complete and we’ll be implementing features for a newly redesigned review process. Internationalizing the Pontoon Translate UI will be a priority, as well as addressing some long-requested feature updates, like terminology support as well as improved community and user profile metrics.
In 2018 we published clear descriptions of the responsibilities and expectations of localizers in specific community roles. These roles are mirror images of Pontoon roles, as Pontoon is the central hub for localization at Mozilla. In 2019, we plan to organize a handful of workshops in the latter half of the year to train Managers on how to be effective leaders in their communities and reliable extensions of the l10n-drivers team. We would like to record at least one of these and make the workshop training available to everyone through the localizer documentation (or some other accessible place).
We aim to report on the progress of these themes throughout the year in quarterly reports. In each report, we’ll share the outcomes of the objectives of one quarter and describe the objectives for the next quarter. In Q1 of 2019 (January – March), the l10n-drivers will:
As always, if you have questions about any of these objectives or themes for 2019, please reach out to an l10n-driver, we’d be very happy to chat.
https://blog.mozilla.org/l10n/2019/02/06/a-new-year-with-new-goals-for-mozilla-localization/
|
|
Daniel Stenberg: curl 7.64.0 – like there’s no tomorrow |

I know, has there been eight weeks since the previous release already? But yes it has – I double-checked! And then as the laws of nature dictates, there has been yet another fresh curl version released out into the wild.
the 179th release
5 changes
56 days (total: 7,628)
76 bug fixes (total: 4,913)
128 commits (total: 23,927)
0 new public libcurl functions (total: 80)
3 new curl_easy_setopt() options (total: 265)
1 new curl command line option (total: 220)
56 contributors, 29 new (total: 1,904)
32 authors, 13 new (total: 658)
3 security fixes (total: 87)
This release we have no less than three different security related fixes. I’ll describe them briefly here, but for the finer details I advice you to read the dedicated pages and documentation we’ve written for each one of them.
CVE-2018-16890 is a bug where the existing range check in the NTLM code is wrong, which allows a malicious or broken NTLM server to send a header to curl that will make it read outside a buffer and possibly crash or otherwise misbehave.
CVE-2019-3822 is related to the previous but with much worse potential effects. Another bad range check actually allows a sneaky NTLMv2 server to be able to send back crafted contents that can overflow a local stack based buffer. This is potentially in the worst case a remote code execution risk. I think this might be the worst security issue found in curl in a long time. A small comfort is that by disabling NTLM, you will avoid it until patched.
CVE-2019-3823 is a potential read out of bounds of a heap based buffer in the SMTP code. It is fairly hard to trigger and it will mostly cause a crash when it does.
Check out the full change log to see the whole list. Here are some of the bug fixes I consider to be most noteworthy:
The next release cycle will be one week shorter and we expect to ship next release on March 27 – just immediately after curl turns 22 years old. There are already several changes in the pipe so we expect that to become 7.65.0.
We love your help and support! File bugs you experience or see, submit pull requests for the features or corrections you work on!
https://daniel.haxx.se/blog/2019/02/06/curl-7-64-0-like-theres-no-tomorrow/
|
|
The Firefox Frontier: Stop texting yourself links. With Send Tabs there’s a better way. |
It’s 2019 friends. We don’t have to keep emailing and texting ourselves links. It’s fussy to copy and paste on a mobile device. It’s annoying to have to switch between … Read more
The post Stop texting yourself links. With Send Tabs there’s a better way. appeared first on The Firefox Frontier.
|
|
Julien Vehent: Interviewing tips for junior engineers |
I was recently asked by the brother of a friend who is about to graduate for tips about working in IT in the US. His situation is not entirely dissimilar to mine, being a foreigner with a permit to work in America. Below is my reply to him, that I hope will be helpful to other young engineers in similar situations.
For background, I've been working in the US since early 2011. I had a few years of experience as a security engineer in Paris when we moved. I first took a job as a systems engineer while waiting for my green card, then joined a small tech company in the email marketing space to work on systems and security, then joined Mozilla in 2013 as a security engineer. I've been at Mozilla for almost six years, now running the Firefox operations security team with a team of six people scattered across the US, Canada and the UK. I've been hiring engineers for a few years in various countries.
You're just getting started in your career, so employers will mostly look for technical proficiency and being a pleasant person to work with. Expectations are fairly low at this stage. If you can solve technical puzzles and people enjoy talking to you, you can pass the bar at most companies.
This changes after 5-ish years of experience, when employers want to see project management, technical leadership, and maybe a hint of people management too. But for now, I wouldn't worry about it.
I would say the most important thing is to have a plan: where do you want to be 10/15/20 years from now? My aim was toward Chief Security Officer roles, an executive position that requires technical skills, strategic thinking, communication, risk and project management, etc. It takes 15 to 20 years to get to that level, so I picked jobs that progressively gave me the experience needed (and that were a lot of fun, because I'm a geek).
Immigration is the only problem to solve. When I first applied for jobs in the US, I was on a J-1 visa doing my Master's internship at University of Maryland. I probably applied to 150 jobs and didn't get a single reply, most likely because no one wants to hire candidates that need a visa (a long and expensive process). i ended up going back to France for a couple years, and came back after obtaining my green card, which took the immigration question out of the way. So my advise here is to settle the immigration question in the country where you want to work before you apply for jobs, or if you need employer support to get a visa, be up front about it when talking to them. (I have several former students who now work for US companies that have hiring processes that incorporate visa applications, so it's not unheard of, but the bar is high).
I have a Master of Science from a small french university that is completely unknown to the US, yet that never came up as an issue. A Master is a Master. Should degree equivalence come up as an issue during an interview, offer to provide a grade comparison between US GPA and your country grades (some paid service provide that). That should put employers at ease.
Language has also never been an issue for me, even with my strong french accent. If you're good at the technical stuff, people won't pay attention to your accent (at least in the US). And I imagine you're fully fluent anyway, so having a deep-dive architecture conversation in English won't be a problem.
Resume are mostly useless. I spend between 30 and 60 seconds on a candidate's resume. The problem is most people pad their resumes with a lot of buzzwords and fancy-sounding projects I cannot verify, and thus cannot trust. It would seem the length of a resume is inversely proportional to the actual skills of a candidate. Recruiters use them to check for minimal requirements: has the right level of education, knows programming language X, has the right level of experience. Engineering managers will instead focus on actual technical questions to assess your skills.
At your level, keep you resume short. My rule of thumb is one page per five years of experience (you should only have a single page, I have three). This might contradict advise you're reading elsewhere that recommend putting your entire life story in your resume, so if you're concerned about not having enough details, make two versions: the one page short overview (linkedin-style), and the longer version hosted on your personal site. Offer a link to the longer version in the short version, so people can check it out if they want to, but most likely won't. Recruiters have to go through several hundred candidates for a single position, so they don't have time, or care for, your life story. (Someone made a short version of Marissa Meyer's resume that I think speaks volume).
Make sure to highlight any interesting project you worked on, technical or otherwise. Recruiters love discussing actual accomplishment. Back when I started, I had a few open source projects and articles written in technical magazines that I put on my resume. Nowadays, that would be a GitHub profile with personal (or professional, if you're lucky) projects. You don't need to rewrite the Linux kernel, but if you can publish a handful of tools you developed over the years, it'll help validate your credentials. Just don't go fork fancy projects to pad your GitHub profile, it won't fool anyone (I know, it sounds silly, but I see that all too often).
Another thing recruiters love is Hackerrank, a coding challenge website used by companies to verify the programming skills of prospective candidates. It's very likely US companies will send you some sort of coding challenge as part of the interview process (we even do it before talking to candidates nowadays). My advise is to spend a few weekends building a profile on Hackerrank and getting used to the type of puzzle they ask for. This is similar to what the GAFA ask for in technical interviews ("quicksort on a whiteboard" type of questions).
At the end of the day, I expect a junior engineer to be smart and excited about technology, if not somewhat easily distracted. Those are good qualities to show during an interview and on your resume.
My last advise would be to pick a path you want to follow for the next few years and be very clear about it when interviewing. You should have a goal. You have a lot of degrees, and recruiters will ask you what you're looking for. So if you want to go into the tech world, be up front about it and tell them you want to focus on engineering for the foreseeable future. In my experience, regardless of your level of education, you need to start at the bottom of the ladder and climb your way up. A solid education will help you climb a lot faster than other folks, and you could reach technical leadership in just a couple years at the right company, or move to a large corporation and use that fancy degree to climb the management path. In both cases, I would recommend getting those first couple years of programming and engineering work under your belt first. Heck, even the CTO of Microsoft started as a mere programmer!
I hope this helps folks who are getting started. And I'm always happy to answer questions from junior engineers, so don't hesitate to reach out!
https://j.vehent.org/blog/index.php?post/2019/02/05/Interviewing-tips-for-junior-engineers
|
|
Daniel Stenberg: My 10th FOSDEM |
I didn’t present anything during last year’s conference, so I submitted my DNS-over-HTTPS presentation proposal early on for this year’s FOSDEM. Someone suggested it was generic enough I should rather ask for main track instead of the DNS room, and so I did. Then time passed and in November 2018 “HTTP/3” was officially coined as a real term and then, after the Mozilla devroom’s deadline had been extended for a week I filed my second proposal. I might possibly even have been an hour or two after the deadline. I hoped at least one of them would be accepted.
Not only were both my proposed talks accepted, I was also approached and couldn’t decline the honor of participating in the DNS privacy panel. Ok, three slots in the same FOSDEM is a new record for me, but hey, surely that’s no problems for a grown-up..
I of coursed hoped there would be interest in what I had to say.
I spent the time immediately before my talk with a coffee in the awesome newly opened cafeteria part to have a moment of calmness before I started. I then headed over to the U2.208 room maybe half an hour before the start time.
It was packed. Quite literally there were hundreds of persons waiting in the area outside the U2 rooms and there was this totally massive line of waiting visitors queuing to get into the Mozilla room once it would open.

People don’t know who I am by my appearance so I certainly didn’t get any special treatment, waiting for my talk to start. I waited in line with the rest and when the time for my presentation started to get closer I just had to excuse myself, leave my friends behind and push through the crowd. I managed to get a “sorry, it’s full” told to me by a conference admin before one of the room organizers recognized me as the speaker of the next talk and I could walk by a very long line of humans that eventually would end up not being able to get in. The room could fit 170 souls, and every single seat was occupied when I started my presentation just a few minutes late.
This presentation could have filled a much larger room. Two years ago my HTTP/2 talk filled up the 300 seat room Mozilla had that year.

The slides from my HTTP/3 presentation.
I tend to need a little “landing time” after having done a presentation to cool off an come back to normal senses and adrenaline levels again. I got myself a lunch, a beer and chatted with friends in the cafeteria (again). During this conversation, it struck me I had forgotten something in my coming presentation and I added a slide that I felt would improve it (the screenshot showing “about:networking#dns” output with DoH enabled). In what felt like no time, it was again to move. I walked over to Janson, the giant hall that fits 1,470 persons, which I entered a few minutes ahead of my scheduled time and began setting up my machine.
I started off with a little technical glitch because the projector was correctly detected and setup as a second screen on my laptop but it would detect and use a too high resolution for it, but after just a short moment of panic I lowered the resolution on that screen manually and the image appeared fine. Phew! With a slightly raised pulse, I witnessed the room fill up. Almost full. I estimate over 90% of the seats were occupied.

This was a brand new talk with all new material and I performed it for the largest audience I think I’ve ever talked in front of.
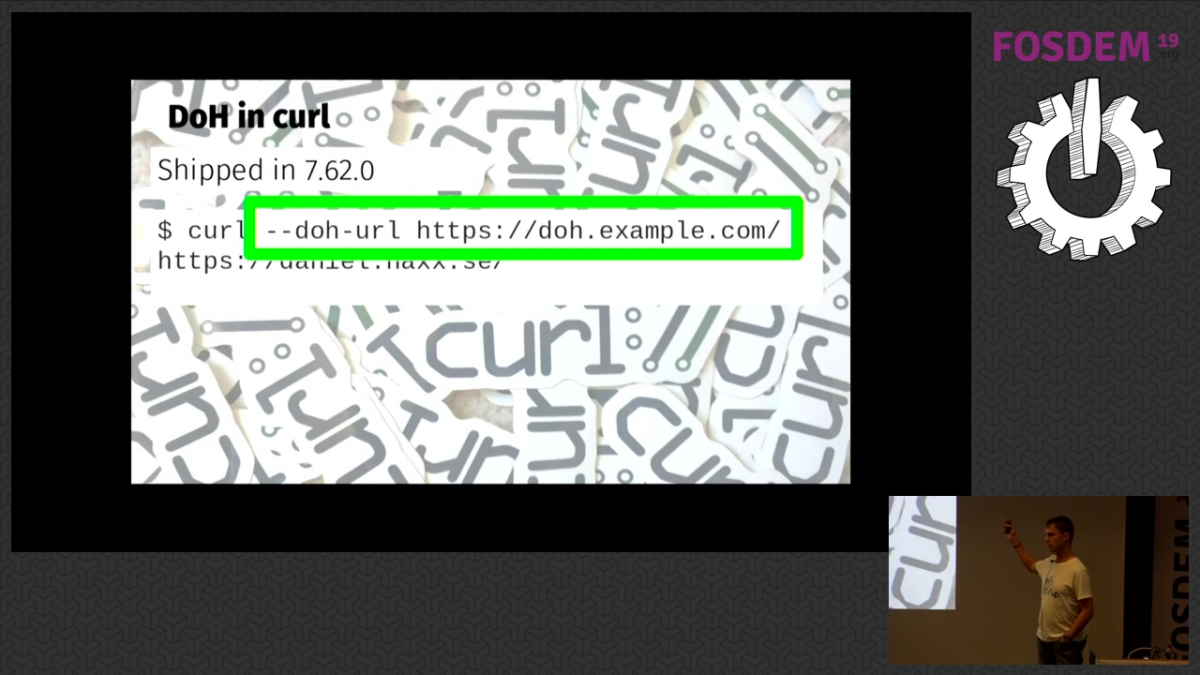
To no surprise, my talk triggered questions and objections. I spent a while in the corridor behind Janson afterward, discussing DoH details, the future of secure DNS and other subtle points of the different protocols involved. In the end I think I manged pretty good, and I had expected more arguments and more tough questions. This is after all the single topic I’ve had more abuse and name-calling for than anything else I’ve ever worked on before in my 20+ years in Internet protocols. (After all, I now often refer to myself and what I do as webshit.)
I never really intended to involve myself in DNS privacy discussions, but due to the constant misunderstandings and mischaracterizations (both on purpose and by ignorance) sometimes spread about DoH, I’ve felt a need to stand up for it a few times. I think that was a contributing factor to me getting invited to be part of the DNS privacy panel that the organizers of the DNS devroom setup.
There are several problems and challenges left to solve before we’re in a world with correctly and mostly secure DNS. DoH is one attempt to raise the bar. I was content to had the opportunity to really spell out my view of things before the DNS privacy panel.
While sitting next to these giants from the DNS world, St'ephane Bortzmeyer, Bert Hubert and me discussed DoT, DoH, DNS centralization, user choice, quad-dns-hosters and more. The discussion didn’t get very heated but instead I think it showed that we’re all largely in agreement that we need more secure DNS and that there are obstacles in the way forward that we need to work further on to overcome. Moderator Jan-Piet Mens did an excellent job I think, handing over the word, juggling the questions and taking in questions from the audience.

Appearing in three scheduled slots during the same FOSDEM was a bit much, and it effectively made me not attend many other talks. They were all great fun to do though, and I appreciate people giving me the chance to share my knowledge and views to the world. As usually very nicely organized and handled. The videos of each presentation are linked to above.
I met many people, old and new friends. I handed out a lot of curl stickers and I enjoyed talking to people about my recently announced new job at wolfSSL.
After ten consecutive annual visits to FOSDEM, I have appeared in ten program slots!
I fully intend to go back to FOSDEM again next year. For all the friends, the waffles, the chats, the beers, the presentations and then for the waffles again. Maybe I will even present something…
|
|
The Mozilla Blog: Putting Users and Publishers at the Center of the Online Value Exchange |
Publishers are getting a raw deal in the current online advertising ecosystem. The technology they depend on to display advertisements also ensures they lose the ability to control who gets their users’ data and who gets to monetize that data. With third-party cookies, users can be tracked from high-value publishers to sites they have never chosen to trust, where they are targeted based on their behavior from those publisher sites. This strips value from publishers and fuels rampant ad fraud.
In August, Mozilla announced a new anti-tracking strategy intended to get to the root of this problem. That strategy includes new restrictions on third-party cookies that will make it harder to track users across websites and that we plan to turn on by default for all users in a future release of Firefox. Our motive for this is simple: online tracking is unacceptable for our users and puts their privacy at risk. We know that a large portion of desktop users have installed ad blockers, showing that people are demanding more online control. But our approach also offers an opportunity to rebalance the ecosystem in a way that is in the long-term interest of publishers.
There needs to be a profitable revenue ecosystem on the web in order to create, foster and support innovation. Our third-party cookie restrictions will allow loading of advertising and other types of content (such as videos and sponsored articles), but will prevent the cookie-based tracking that users cannot meaningfully control. This strikes a better balance for publishers than ad blocking – user data is protected and publishers are still able to monetize page visits through advertisements and other content.
Our new approach will deliver both upsides and downsides for publishers, and we want to be clear about both. On the upside, by removing more sophisticated, profile-based targeting, we are also removing the technology that allows other parties to siphon off data from publishers. Ad fraud that depends on 3rd party cookies to track users from high-value publishers to low-value fraudster sites will no longer work. On the downside, our approach will make it harder to do targeted advertising that depends on cross-site browsing profiles, possibly resulting in an impact on the bottomline of companies that depend on behavioral advertising. Targeting that depends on the context (i.e. what the user is reading) and location will continue to be effective.
In short, behavioral targeting will become more difficult, but publishers should be able to recoup a larger portion of the value overall in the online advertising ecosystem. This means the long-term revenue impact will be on those third-parties in the advertising ecosystem that are extracting value from publishers, rather than bringing value to those publishers.
We know that our users are only one part of the equation here; we need to go after the real cause of our online advertising dysfunction by helping publishers earn more than they do from the status quo. That is why we need help from publishers to test the cookie restrictions feature and give us feedback about what they are seeing and what the potential impact will be. Reach out to us at publisher-feedback@mozilla.com. The technical documentation for these cookie restrictions can be found here. To test this feature in Firefox 65, visit “about:preferences#privacy” using the address bar. Under “Content Blocking” click “Custom”, click the checkbox next to “Cookies”, and ensure the dropdown menu is set to “Third-party trackers”.
We look forward to working with publishers to build a more sustainable model that puts them and our users first.
The post Putting Users and Publishers at the Center of the Online Value Exchange appeared first on The Mozilla Blog.
|
|
Nika Layzell: Fission Engineering Newsletter #1 |
TL;DR Fission is happening and our first "Milestone" is targeted at the end of February. Please file bugs related to fission and mark them as "Fission Milestone: ?" so we can triage them into the correct milestone.
A little than more a year ago, a serious security flaw affecting almost all modern processors was publicly disclosed. Three known variants of the issue were announced with the names dubbed as Spectre (variants 1 and 2) and Meltdown (variant 3). Spectre abuses a CPU optimization technique known as speculative execution to exfiltrate secret data stored in memory of other running programs via side channels. This might include cryptographic keys, passwords stored in a password manager or browser, cookies, etc. This timing attack posed a serious threat to the browsers because webpages often serve JavaScript from multiple domains that run in the same process. This vulnerability would enable malicious third-party code to steal sensitive user data belonging to a site hosting that code, a serious flaw that would violate a web security cornerstone known as Same-origin policy.
Thanks to the heroic efforts of the Firefox JS and Security teams, we were able to mitigate these vulnerabilities right away. However, these mitigations may not save us in the future if another security vulnerability is released exploiting the same underlying problem of sharing processes (and hence, memory) between different domains, some of which may be malicious. Chrome spent multiple years working to isolate sites in their own processes.
We aim to build a browser which isn't just secure against known security vulnerabilities, but also has layers of built-in defense against potential future vulnerabilities. To accomplish this, we need to revamp the architecture of Firefox and support full Site Isolation. We call this next step in the evolution of Firefox’s process model "Project Fission". While Electrolysis split our browser into Content and Chrome, with Fission, we will "split the atom", splitting cross-site iframes into different processes than their parent frame.
Over the last year, we have been working to lay the groundwork for Fission, designing new infrastructure. In the coming weeks and months, we’ll need help from all Firefox teams to adapt our code to a post-Fission browser architecture.
Fission is a massive project, spanning across many different teams, so keeping track of what everyone is doing is a pretty big task. While we have a weekly project meeting, which someone on your team may already be attending, we have started also using a Bugzilla project tracking flag to keep track of the work we have in progress.
Now that we've moved past much of the initial infrastructure ground work, we are going to keep track of work with our milestone targets. Each milestone will contain a collection of new features and improved functionality which brings us incrementally closer to our goal.
Our first milestone, "Milestone 1" (clever, I know), is currently targeted for the end of February. In Milestone 1, we plan to have the groundwork for out-of-process iframes, which encompasses some major work, including, but not limited to, the following contributions:
Window object APIs exposed to cross-origin documents.
(Bug 1353867)If you want an up-to-date view of Milestone 1, you can see the current Milestone 1 status on Bugzilla.
If you have a bug which may be relevant to fission, please let us know by setting the "Fission Milestone" project flag to '?'. We'll swing by and triage it into the correct milestone.
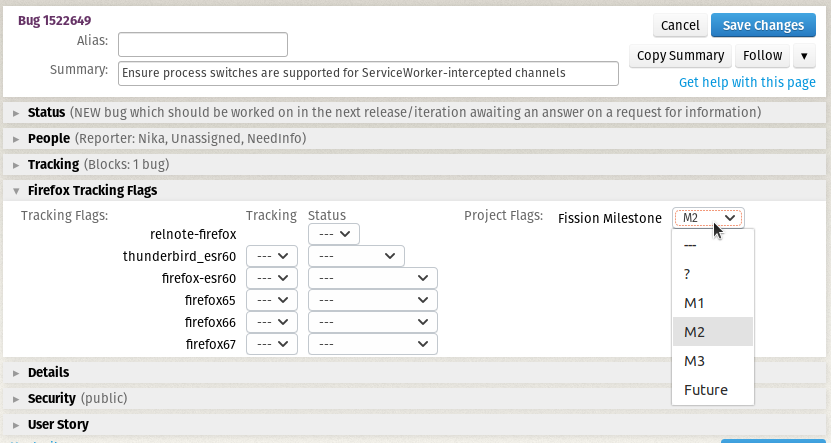
If you have any questions, feel free to reach out to one of us, and we'll get you answers, or guide you to someone who can:
<rmanning@mozilla.com> (Fission Engineering Project Manager)<nika@mozilla.com> (Fission Tech Lead)<nkochar@mozilla.com> (DOM Fission Engineering Manager)In order to make each component of Firefox successfully adapt to a post-Fission world, many of them are going to need changes of varying scale. Covering all of the changes which we're going to need would be impossible within a single newsletter. Instead, I will focus on the changes to actors, messageManagers, and document hierarchies.
Today, Firefox has process separation between the UI - run in the parent
process, and web content - run in content processes. Communication between
these two trees of "Browsing Contexts" is done using the TabParent and
TabChild actors in C++ code, and Message Managers in JS code. These systems
communicate directly between the "embedder", which in this case is the
However, in a post-Fission world, this layer for communication is no longer sufficient. It will be possible for multiple processes to render distinct subframes, meaning that each tab has multiple connected processes.
Components will need to adapt their IPC code to work in this new world, both by updating their use of existing APIs, and by adapting to use new Actors and APIs which are being added as part of the Fission project.
For many components, the full tree of Browsing Contexts is not important, rather communication is needed between the parent process and any specific document. For these cases, a new actor has been added which is exposed both in C++ code and JS code called PWindowGlobal.
Unlike other actors in gecko, such as Tab{Parent,Child}, this actor exists
for all window globals, including those loaded within the parent process. This
is handled using a new PInProcess manager actor, which supports sending main
thread to main thread IPDL messages.
JS code running within a FrameScript may not be able to inspect every frame at
once, and won't be able to handle events from out of process iframes. Instead,
it will need to use our new JS Window Actor APIs, which we are targeting to
land in Milestone 1. These actors are "managed" by the WindowGlobal actors,
and are implemented as JS classes instantiated when requested for any
particular window. They support sending async messages, and will be present for
both in-process and out-of-process windows.
C++ logic which walks the frame tree from the TabChild may stop working.
Instead, C++ code may choose to use the PWindowGlobal actor to send messages in
a manner similar to JS code.
BrowsingContext objectsC++ code may also maintain shared state on the BrowsingContext object. We are
targeting landing the field syncing infrastructure in Milestone 1, and it will
provide a place to store data which should be readable by all processes with a
view of the structure.
The parent process holds a special subclass of the BrowsingContext object:
CanonicalBrowsingContext. This object has extra fields which can be used in
the parent to keep track of the current status of all frames in one place.
TabParent, TabChild and IFramesThe Tab{Parent,Child} actors will continue to exist, and will always bridge
from the parent process to a content process. However, in addition to these
actors being present for toplevel documents, they will also be present for
out-of-process subtrees.
As an example, consider the following tree of nested browsing contexts:
+-- 1 --+
| a.com |
+-------+
/ \
+-- 2 --+ +-- 4 --+
| a.com | | b.com |
+-------+ +-------+
| |
+-- 3 --+ +-- 5 --+
| b.com | | b.com |
+-------+ +-------+
Under e10s, we have a single Tab{Parent,Child} pair for the entire tab, which
would connect to 1, and FrameScripts would run with content being the 1's
global.
After Fission, there will still be a Tab{Parent,Child} actor for the root of
the tree, at 1. However, there will also be two additional Tab{Parent,Child}
actors: one at 3 and one at 4. Each of these nested TabParent objects are
held alive in the parent process by a RemoteFrameParent actor whose
corresponding RemoteFrameChild is held by the embedder's iframe.
The following is a diagram of the documents and actors which build up the actor
tree, excluding the WindowGlobal actors. RF{P,C} stands for
RemoteFrame{Parent,Child}, and T{P,C} stands for Tab{Parent,Child}.
The RemoteFrame actors are managed by their embedding Tab actors, and use
the same underlying transport.
- within a.com's process -
+-------+
| TC: 1 |
+-------+
|
+-- 1 --+
| a.com |
+-------+
/ \
+-- 2 --+ +-------+
| a.com | | RFC:2 |
+-------+ +-------+
|
+-------+
| RFC:1 |
+-------+
- within b.com's process -
+-------+ +-------+
| TC: 2 | | TC: 3 |
+-------+ +-------+
| |
+-- 3 --+ +-- 4 --+
| b.com | | b.com |
+-------+ +-------+
|
+-- 5 --+
| b.com |
+-------+
- within the parent process -
+-------+
| TP: 1 |
+-------+
/ \ (manages)
+-------+ +-------+
| RFP:1 | | RFP:2 |
+-------+ +-------+
| |
+-------+ +-------+
| TP: 2 | | TP: 3 |
+-------+ +-------+
I hope to begin keeping everyone updated on the latest developments with Fission over the coming months, but am not quite ready to commit to a weekly or bi-weekly newsletter schedule.
If you're interested in helping out with the newsletter, please reach out and let me (Nika) know!.
Thanks for reading, and best of luck splitting the atom!
|
|
Gijs Kruitbosch: Getting Firefox artifact builds working on an arm64/aarch64 windows device |
If, like me, you’re debugging a frontend issue and you think “I can just create some artifact builds on this device” — you might run in to a few issues. In the main, they’re caused by various bits of the build system attempting to use 64-bit x86 binaries. arm64 can run 32-bit x86 code under emulation, but not 64-bit. Here are the issues I encountered, chronologically.
hg clone mozilla-central. It’ll take a while. You can also use pip to install/run other useful things, like mozregression (which seems to work but chokes when trying to kill off and delete Firefox processes when done; unsure why)../mach bootstrap mostly works if you pick artifact builds, but: ~/.mozbuild/node, download the 32-bit windows .zip from the NodeJS website and extract the contents at ~/.mozbuild/node to placate it.path/to/mozilla-build/python3 . Then you will also want to make a copy of python.exe in that directory available as python3.exe, because that’s the path mozilla-build expects.watchman.exe that mozilla-build has helpfully provided. Rename the watchman directory inside mozilla-build (or delete it if you’re feeling vengeful) to deal with this.That’s it! Now artifact builds should work – or at least, they did for me. Some of the issues are caused by bootstrap, and thus fixable, but obviously we can’t retrospectively change an old copy of mozilla-build. I’ve filed a bug to provide mozilla-build for aarch64.
|
|
Hacks.Mozilla.Org: Firefox 66 to block automatically playing audible video and audio |
Isn’t it annoying when you click on a link or open a new browser tab and audible video or audio starts playing automatically?
We know that unsolicited volume can be a great source of distraction and frustration for users of the web. So we are making changes to how Firefox handles playing media with sound. We want to make sure web developers are aware of this new autoplay blocking feature in Firefox.
Starting with the release of Firefox 66 for desktop and Firefox for Android, Firefox will block audible audio and video by default. We only allow a site to play audio or video aloud via the HTMLMediaElement API once a web page has had user interaction to initiate the audio, such as the user clicking on a “play” button.
Any playback that happens before the user has interacted with a page via a mouse click, printable key press, or touch event, is deemed to be autoplay and will be blocked if it is potentially audible.
Muted autoplay is still allowed. So script can set the “muted” attribute on HTMLMediaElement to true, and autoplay will work.
We expect to roll out audible autoplay blocking enabled by default, in Firefox 66, scheduled for general release on 19 March 2019. In Firefox for Android, this will replace the existing block autoplay implementation with the same behavior we’ll be using in Firefox on desktop.
There are some sites on which users want audible autoplay audio and video to be allowed. When Firefox for Desktop blocks autoplay audio or video, an icon appears in the URL bar. Users can click on the icon to access the site information panel, where they can change the “Autoplay sound” permission for that site from the default setting of “Block” to “Allow”. Firefox will then allow that site to autoplay audibly. This allows users to easily curate their own whitelist of sites that they trust to autoplay audibly.

Firefox expresses a blocked play() call to JavaScript by rejecting the promise returned by HTMLMediaElement.play() with a NotAllowedError. All major browsers which block autoplay express a blocked play via this mechanism. In general, the advice for web authors when calling HTMLMediaElement.play(), is to not assume that calls to play() will always succeed, and to always handle the promise returned by play() being rejected.
If you want to avoid having your audible playback blocked, you should only play media inside a click or keyboard event handler, or on mobile in a touchend event. Another strategy to consider for video is to autoplay muted, and present an “unmute” button to your users. Note that muted autoplay is also currently allowed by default in all major browsers which block autoplay media.
We are also allowing sites to autoplay audibly if the user has previously granted them camera/microphone permission, so that sites which have explicit user permission to run WebRTC should continue to work as they do today.
At this time, we’re also working on blocking autoplay for Web Audio content, but have not yet finalized our implementation. We expect to ship with autoplay Web Audio content blocking enabled by default sometime in 2019. We’ll let you know!
The post Firefox 66 to block automatically playing audible video and audio appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/02/firefox-66-to-block-automatically-playing-audible-video-and-audio/
|
|
The Servo Blog: This Week In Servo 125 |
In the past two weeks, we merged 80 PRs in the Servo organization’s repositories.
If Windows nightlies have crashed at startup in the past, try the latest nightly!
Our roadmap is available online. Plans for 2019 will be published soon.
This week’s status updates are here.
formdata DOM event.Interested in helping build a web browser? Take a look at our curated list of issues that are good for new contributors!
|
|
Bas Schouten: MQ to Changeset Evolution: A Dummy Guide |
So, not having had time to post on here for a long time. I realized there's a problem a bunch of us at Mozilla are facing, we've been using mercurial queues for I don't know how long, but we're increasingly facing a toolchain that isn't compatible with the MQ workflow. I found patches in my queue inadvertently being converted into actual commits and other such things. I'm no expert on versioning systems, and as such mercurial queues provided me with an easy method of just having a bunch of patches, and a file which orders them, and that was easy for me to understand and work with. Seeing an increasing amount of tools not supporting it though, I decided to make the switch, and I'd like to document my experience here, some of my suggestions may not be optimal, please let me know if any of my suggestions are unwise. I also use Windows as my primary OS, mileage on other operating systems may vary, but hopefully not by much.
First, preparation, make sure you've got the latest version of mercurial using ./mach bootstrap, when you get to the mercurial configuration wizard, enable all the history editing and evolve extensions, you will need them for this to work.
Now, to go through the commands, first, the basics:
hg qnew basically just becomes hg ci we're going to assume none of our commits are necessarily permanent, and we're fine having hidden, dead branches in our repository.
hg qqueue is largely replaced by hg bookmark, it allows you to create a new 'bookmarked branch', list the bookmarked branches and which is active. An important difference is that a bookmark describes the tips of the different branches. Making new commits on top of a bookmark will migrate the bookmark along with that commit.
hg up [bookmark name] will activate a different bookmark, hopping to the tip of that branch.
hg qpop once you've created a new commit becomes hg prev an important thing to note is that unlike with qpop, 'tip' will remain the tip of your current bookmark. Note that unlike with qpop, you can 'prev' right past the root of your patch set and through the destination repository, so make sure you're at the right changeset! It's also important to note this deactivates the current bookmark.
Once you've popped all the way to the tree you're working on top of, you can just use hg ci and hg bookmark again to start a new bookmarked branch (or queue, if you will).
hg qpush when you haven't made any changes bascially becomes hg next, it will take you to the next changeset, if there's multiple branches coming off here, it will offer you a prompt to select which one you'd like to continue on.
Making changes inside a queue
Now this is where it gets a little more complicated, there's essentially two ways one could make changes to an existing queue, first, there is the most common action of changing an existing changeset in the queue, this is fairly straightforward:
hg prev to go to the changeset you wish to modify, much like in mqhg ci --amend much like you would hg qref, this will orphan its existing childrenhg next --evolve as a qpush for your changesets, this will rebase them back on top of your change, and offer a 3-way merging tool if needed.In short qpop, make change, qref, qpush becomes prev, make change, ci --amend, next --evolve.
The second method to make changes inside a queue is to add a changeset inbetween two changesets already in the queue. In the past this was straightforward, you qpopped, made changes, qnewed, and just happily qpushed the rest of your queue on top of it, the new method is this:
hg prev to go to the changeset you wish to modify, much like in mqhg ci much like you would hg qnew, this will create a new branching pointhg rebase -b [bookmark name/revision], this will rebase your queue back on top of your change, and offer a 3-way merging tool if needed.hg next to go back down your 'queue'Pushing
Basically hg qfin is no longer needed, you go to the changeset where you want to push and you can push up until that changeset directly to, for example, central. ./mach try also seems to work as expected and submits the changeset you're currently at.
Some additional tips
The hg absorb extension I've found to be quite powerful in combination with the new system, particularly when processing review comments. Essentially you can make a bunch of changes from the tip of your patch queue, execute the command, and based on where the changes are it will attempt to figure out which commits they belong to, and essentially amend these commits with the changes, without you ever having to leave the tip of your branch. This not only takes away a bunch of work, it also means you don't retouch all of the files affected by your queue, greatly reducing rebuild times.
I've found that being able to create additional branching points, or queues, if you will, off some existing work on occasion is a helpful addition to the abilities I had with mercurial queues.
Final Thoughts
In the end I like my versioning system not to get in the way of my work, I'm not necessarily convinced that the benefits outweigh the cost of learning a new system or the slightly more complex actions required for what to me are the more common operations. But with the extensions now available I can keep my workflow mostly the same, with the added benefit of hg absorb I hope this guide will make the transition easy enough that in the end most of us can be satisfied with the switch.
If I missed something, am in error somewhere, or if a better guide exists out there somewhere (I wasn't able to find one or I wouldn't have written this :-)), do let me know!
Original post blogged on b2evolution.
https://www.basschouten.com/blog1.php/mq-to-changeset-evolution-a
|
|
Daniel Stenberg: I’m on team wolfSSL |
Let me start by saying thank you to all and everyone who sent me job offers or otherwise reached out with suggestions and interesting career moves. I received more than twenty different offers and almost every one of those were truly good options that I could have said yes to and still pulled home a good job. What a luxury challenge to have to select something from that! Publicly announcing me leaving Mozilla turned out a great ego-boost.
I took some time off to really reflect and contemplate on what I wanted from my next career step. What would the right next move be?
I love working on open source. Internet protocols, and transfers and doing libraries written in C are things considered pure fun for me. Can I get all that and yet keep working from home, not sacrifice my wage and perhaps integrate working on curl better in my day to day job?
I talked to different companies. Very interesting companies too, where I have friends and people who like me and who really wanted to get me working for them, but in the end there was one offer with a setup that stood out. One offer for which basically all check marks in my wish-list were checked.
On February 5, 2019 I’m starting my new job at wolfSSL. My short and sweet period as unemployed is over and now it’s full steam ahead again! (Some members of my family have expressed that they haven’t really noticed any difference between me having a job and me not having a job as I spend all work days the same way nevertheless: in front of my computer.)

Starting now, we offer commercial curl support and various services for and around curl that companies and organizations previously really haven’t been able to get. Time I do not spend on curl related activities for paying customers I will spend on other networking libraries in the wolfSSL “portfolio”. I’m sure I will be able to keep busy.
I’ve met Larry at wolfSSL physically many times over the years and every year at FOSDEM I’ve made certain to say hello to my wolfSSL friends in their booth they’ve had there for years. They’re truly old-time friends.
wolfSSL is mostly a US-based company – I’m the only Swede on the team and the only one based in Sweden. My new colleagues all of course know just as well as you that I’m prevented from traveling to the US. All coming physical meetings with my work mates will happen in other countries.
We offer all sorts of commercial support for curl. I’ll post separately with more details around this.
|
|
Hacks.Mozilla.Org: New in Firefox DevTools 65 |
We just released Firefox 65 with a number of new developer features that make it even easier for you to create, inspect and debug the web.
Among all the features and bug fixes that made it to DevTools in this new release, we want to highlight two in particular:
We hope you’ll love using these tools just as much as we and our community loved creating them.
The Firefox DevTools team is on a mission to help you master CSS layout. We want you to go from “trying things until they work” to really understanding how your browser lays out a page.
Flexbox is a powerful way to organize and distribute elements on a page, in a flexible way.
To achieve this, the layout engine of the browser does a lot of things under the hood. When everything works like a charm, you don’t have to worry about this. But when problems appear in your layout it may feel frustrating, and you may really need to understand why elements behave a certain way.
That’s exactly what the Flexbox Inspector is focused on.
First and foremost, the Flexbox Inspector highlights the elements that make up your flexbox layout: the container, lines and items.
Being able to see where these start and end — and how far apart they are — will go a long way to helping you understand what’s going on.

Once toggled, the highlighter shows three main parts:
One way to toggle the highlighter for a flexbox container is by clicking its “flex” badge in the inspector. This is an easy way to find flex containers while you’re scanning elements in the DOM. Additionally, you can turn on the highlighter from the flex icon in the CSS rules panel, as well as from the toggle in the new Flexbox section of the layout sidebar.

The beauty of Flexbox is that you can leave the browser in charge of making the right layout decisions for you. How much should an element stretch, or should an element wrap to a new line?
But when you give up control, how do you know what the browser is actually doing?
The Flexbox Inspector comes with functionality to show how the browser distributed the sizing for a given item.

The layout sidebar now contains a Flex Container section that lists all the flex items, in addition to providing information about the container itself.
Clicking any of these flex items opens the Flex Item section that displays exactly how the browser calculated the item size.

The diagram at the top of the flexbox section shows a quick overview of the steps the browser took to give the item its size.
It shows your item’s base size (either its minimum content size or its flex-basis size), the amount of flexible space that was added (flex-grow) or removed (flex-shrink) from it, and any minimum or maximum defined sizes that restricted the item from becoming any shorter or longer.
If you are reading this on Firefox 65, you can take this for a spin right now!
Open the Inspector on this page, and select the div.masthead.row element. Look for the Flex Container panel in the sidebar, and click on the 2 items to see how their sizes are computed by the browser.

Let’s suppose you have fixed a flexbox bug thanks to the Flexbox Inspector. To do so, you’ve made a few edits to various CSS rules and elements. That’s when you’re usually faced with a problem we’ve all had: “What did I actually change to make it work?”.
In Firefox 65, we’ve also introduced a new Changes panel to do just that.

It keeps track of all the CSS changes you’ve made within the inspector, so you can keep working as you normally would. Once you’re happy, open the Changes tab and see everything you did.
We’re really excited for you to try these two new features and let us know what you think. But there’s more in store.
You’ve been telling us exactly what your biggest CSS challenges are, and we’ve been listening. We’re currently prototyping layout tools for debugging unwanted scrollbars, z-indexes that don’t work, and more tools like the Flexbox Inspector but for other types of layouts. Also, we’re going to make it even easier for you to extract your changes from the Changes panel.
When developing JavaScript, the Console and Debugger are your windows into your code’s execution flow and state changes. Over the past releases we’ve focused on making debugging work better for modern toolchains. Firefox 65 continues this theme.
If you’re working with frameworks and build tools, then you’re used to seeing really long error stack traces in the Console. The new smarter stack traces identify 3rd party code (such as frameworks) and collapse it by default. This significantly reduces the information displayed in the Console and lets you focus on your code.

The Collapsing feature works in the Console stack traces for errors and logs, and in the Debugger call stacks.
If you are tired of smashing the arrow key to find that awesome one-liner you ran one hour ago in the console, then this is for you. Reverse search is a well known command-line feature that lets you quickly browse recent commands that match the entered string.

To use it in the Console, press F9 on Windows/Linux or Ctrl+R on MacOS and start typing. You can then use Ctrl+R to move to the previous or Ctrl+S to the next result. Finally, hit return to confirm.
JavaScript getters are very useful for dynamic properties and heavily used in frameworks like vue.js for computed properties. But when you log an object with a getter to the Console, the reference to the method is logged, not its return value. The method does not get invoked automatically, as that could change your application’s state. Since you often actually want to see the value, you can now manually invoke getters on logged objects.

Wherever objects can be inspected, in the Console or Debugger, you’ll see >> icons next to getters. Clicking these will execute the method and print the return value.
Console logging is just one aspect of understanding application state. For complex issues, you need to pause state at precisely the right moment. Fetching data is usually one of those moments, and it is now made “pausable” with the new XHR/Fetch Breakpoint in the Debugger.

Kudos to Firefox DevTools code contributor Anshul Malik for “casually” submitting the patch for this useful feature and for his ongoing contributions.
You might have noticed that we’ve been heads down over recent releases to make the JavaScript debugging experience rock solid – for breakpoints, stepping, source maps, performance, etc. Raising the quality bar and continuing to polish and refine remains the focus for the entire team.
There’s work in progress on much requested features like Column Breakpoints, Logpoints, Event and DOM Breakpoints. Building out the authoring experience in the Console, we are adding an multi-line editing mode (inspired by Firebug) and a more powerful autocomplete. Keep an eye out for those features in the latest release of Firefox Developer Edition.
Countless contributors helped DevTools staff by filing bugs, writing patches and verifying them. Special thanks go to:
Also, thanks to Patrick Brosset, Nicolas Chevobbe and the whole DevTools team & friends for helping put together this article.
As always, we would love to hear your feedback on how we can improve DevTools and the browser.
Download Firefox Developer Edition to get early access to upcoming tooling and platform.
The post New in Firefox DevTools 65 appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/01/new-in-firefox-devtools-65/
|
|
Mozilla GFX: WebRender newsletter #38 |
Greetings! WebRender’s best and only newsletter is here. The number of blocker bugs is rapidly decreasing, thanks to the efforts of everyone involved (staff and volunteers alike). The project is in a good enough shape that some people are now moving on to other projects and we are starting to experiment with webrender on new hardware. WebRender is now enabled by default in Nightly for some subset of AMD GPUs on Windows and we are looking into Intel integrated GPUs as well. As usual we start with small subsets with the goal of gradually expanding in order to avoid running into an overwhelming amount of platform/configuration specific bugs at once.
The team keeps going through the remaining blockers (3 P2 bugs and 11 P3 bugs at the time of writing).
In about:config, set the pref “gfx.webrender.all” to true and restart the browser.
The best place to report bugs related to WebRender in Firefox is the Graphics :: WebRender component in bugzilla.
Note that it is possible to log in with a github account.
https://mozillagfx.wordpress.com/2019/01/31/webrender-newsletter-38/
|
|
The Mozilla Blog: Mozilla Raises Concerns Over Facebook’s Lack of Transparency |
Today Denelle Dixon, Mozilla’s Chief Operating Officer, sent a letter to the European Commission surfacing concerns about the lack of publicly available data for political advertising on the Facebook platform.
It has come to our attention that Facebook has prevented third parties from conducting analysis of the ads on their platform. This impacts our ability to deliver transparency to EU citizens ahead of the EU elections. It also prevents any developer, researcher, or organization to develop tools, critical insights, and research designed to educate and empower users to understand and therefore resist targeted disinformation campaigns.
Mozilla strongly believes that transparency cannot just be on the terms with which the world’s largest, most powerful tech companies are most comfortable. To have true transparency in this space, the Ad Archive API needs to be publicly available to everyone. This is all the more critical now that third party transparency tools have been blocked. We appreciate the work that Facebook has already done to counter the spread of disinformation, and we hope that it will fulfill its promises made under the Commission’s Code of Practice and deliver transparency to EU citizens ahead of the EU Parliamentary elections.
Mozilla’s letter to European Commission on Facebook Transparency 31 01 19
The post Mozilla Raises Concerns Over Facebook’s Lack of Transparency appeared first on The Mozilla Blog.
|
|






