Daniel Stenberg: The world’s biggest curl installations |
curl is quite literally used everywhere. It is used by a huge number of applications and devices. But which applications, devices and users are the ones with the largest number of curl installations? I've tried to come up with a list...
I truly believe curl is one of the world's most widely used open source projects.
If you have comments, other suggestions or insights to help me polish this table or the numbers I present, please let me know!
10 million Nintendo Switch game consoles all use curl, more than 20 million Chromebooks have been sold and they have curl as part of their bundled OS and there's an estimated 40 million printers (primarily by Epson and HP) that aren't on the top-10. To reach this top-list, we're looking at 50 million instances minimum...
There are many (Linux mainly)  servers on the Internet. curl and libcurl comes pre-installed on some Linux distributions and for those that it doesn't, most users and sysadmins install it. My estimate says there are few such servers out there without curl on them.
servers on the Internet. curl and libcurl comes pre-installed on some Linux distributions and for those that it doesn't, most users and sysadmins install it. My estimate says there are few such servers out there without curl on them.
This source says there were 75 million servers "hosting the Internet" back in 2013.
curl is a default HTTP provider for PHP and a huge percentage of the world's web sites run at least parts with PHP.
Bundled with the Operating system on this game console comes curl. Or rather libcurl I would expect. Sony says 75 million units have been sold.
curl is given credit on the screen Open Source software used in the Playstation 4.
![]() I've been informed by "people with knowledge" that libcurl runs on all Netflix's devices that aren't browsers. Some stats listed on the Internet says 70% of the people watching Netflix do this on their TVs, which I've interpreted as possible non-browser use. 70% of the total 130 million Netflix customers makes 90.
I've been informed by "people with knowledge" that libcurl runs on all Netflix's devices that aren't browsers. Some stats listed on the Internet says 70% of the people watching Netflix do this on their TVs, which I've interpreted as possible non-browser use. 70% of the total 130 million Netflix customers makes 90.
libcurl is not used for the actual streaming of the movie, but for the UI and things.
![]() The very long and rarely watched ending sequence to this game does indeed credit libcurl. It has also been recorded as having been sold in 100 million copies.
The very long and rarely watched ending sequence to this game does indeed credit libcurl. It has also been recorded as having been sold in 100 million copies.
There's an uncertainty here if libcurl is indeed used in this game for all platforms GTA V runs on, which then could possibly reduce this number if it is not.
![]() curl has shipped as a bundled component of macOS since August 2001. In April 2017, Apple's CEO Tim Cook says that there were 100 million active macOS installations.
curl has shipped as a bundled component of macOS since August 2001. In April 2017, Apple's CEO Tim Cook says that there were 100 million active macOS installations.
Now, that statement was made a while ago but I don't have any reason to suspect that the number has gone down notably so I'm using it here. No macs ship without curl!
 I wrote about this in a separate blog post. Eight of the top-10 most popular car brands in the world use curl in their products. All in all I've found curl used in over twenty car brands.
I wrote about this in a separate blog post. Eight of the top-10 most popular car brands in the world use curl in their products. All in all I've found curl used in over twenty car brands.
Based on that, rough estimates say that there are over 100 million cars in the world with curl in them today. And more are coming.
 This game is made by Epic Games and credits curl in their Third Party Software screen.
This game is made by Epic Games and credits curl in their Third Party Software screen.
In June 2018, they claimed 125 million players. Now, I supposed a bunch of these players might not actually have their own separate device but I still believe that this is the regular setup for people. You play it on your own console, phone or computer.
 We know curl is used in television sets made by Sony, Philips, Toshiba, LG, Bang & Olufsen, JVC, Panasonic, Samsung and Sharp - at least.
We know curl is used in television sets made by Sony, Philips, Toshiba, LG, Bang & Olufsen, JVC, Panasonic, Samsung and Sharp - at least.
The wold market was around 229 million television sets sold in 2017 and about 760 million TVs are connected to the Internet. Counting on curl running in 50% of the connected TVs (which I think is a fair estimate) makes 380 million devices.
![]() Since a while back, Windows 10 ships curl bundled by default. I presume most Windows 10 installations actually stay fairly updated so over time most of the install base will run a version that bundles curl.
Since a while back, Windows 10 ships curl bundled by default. I presume most Windows 10 installations actually stay fairly updated so over time most of the install base will run a version that bundles curl.
In May 2017, one number said 500 million Windows 10 machines.
 I posit that there are almost no smart phones or tablets in the world that doesn't run curl.
I posit that there are almost no smart phones or tablets in the world that doesn't run curl.
curl is bundled with the iOS operating system so all iPhones and iPads have it. That alone is about 1.3 billion active devices.
curl is bundled with the Android version that Samsung, Xiaomi and OPPO ship (and possibly a few other flavors too). According to some sources, Samsung has something like 30% market share, and Apple around 20% - for mobile phones. Another one billion devices seems like a fair estimate.
Further, curl is used by some of the most used apps on phones: Youtube, Instagram, Skype, Spotify etc. The three first all boast more than one billion users each, and in Youtube's case it also claims more than one billion app downloads on Android. I think it's a safe bet that these together cover another 700 million devices. Possibly more.
Of course we can't just sum up all these numbers and reach a total number of "curl users". The fact is that a lot of these curl instances are used by the same users. With a phone, a game console, a TV and some more an ordinary netizen runs numerous different curl instances in their daily lives.
Did I ever expect this level of success? No.
https://daniel.haxx.se/blog/2018/09/17/the-worlds-biggest-curl-installations/
|
|
Dave Hunt: EuroPython 2018 |
In July I took the train up to beautiful Edinburgh to attend the EuroPython 2018 conference. Despite using Python professionally for almost 8 years, this was my first experience of a Python conference. The schedule was packed, and it was challenging deciding what talks to attend, but I had a great time and enjoyed the strong community feeling of the event. We even went for a group run around Holyrood Park and Arthur’s Seat, which I hope is included in the schedule for future years.
Now that the videos of the talks have all been published, I wanted to share my personal highlights, and list the talks I saw during and since the conference. I still haven’t caught up on everything I wanted to see, so I’ve also included my watch list. First, here’s the full playlist of talks from the conference
Here are my top picks from the talks I either attended or have watched since:
I also wanted to highlight the following lightning talks:
Here is a list of the other talks I either attended at the conference or have watched since:
Here’s my list of talks I have yet to watch:
Were you at EuroPython 2018? Let me know if you have any favourite talks that aren’t already on my list! I’m keen to attend again next year, if my travel schedule allows for it.
|
|
Mozilla VR Blog: Firefox Reality Developers Guide |

Firefox Reality, Mozilla's VR web browser, is getting closer to release; so let's talk about how to make your experiences work well in this new browser.
Building WebVR applications from scratch requires using WebGL, which is very low level. Most developers use some sort of a library, framework or game engine to do the heavy lifting for them. These are some commonly used libraries that support WebVR.
As of June 2018 ThreeJS has new and improved WebVR support. It should just work. See these official examples of how to use it.
AFrame is a framework built on top of ThreeJS that lets you build VR scenes using an HTML like syntax. It is the best way to get started with VR if you have never used it before.
Babylon.js is an open source high performance 3D engine for the web. Since version 2.5 it has full WebVR support. This doc explains how to use the WebVRFreeCamera class.
Amazon’s online Sumerian tool lets you easily build VR and AR experiences, and obviously supports WebVR out of the box.
Play Canvas is a web first game engine, and it supports WebVR out of the box.
If you have an existing WebGL application you can easily add WebVR support. This blog covers the details.
No matter what framework you use, make sure it supports the WebVR 1.1 API, not the newer WebXR API. WebXR will eventually be a full web standard but no browser currently ships with non-experimental support. Use WebVR for now, and in the future a polyfill will make sure existing applications continue to work once WebXR is ready.
Developing for VR headsets is just like developing for mobile. Though some VR headsets run attached to a desktop with a beefy graphics card, most users have a mobile device like a smartphone or dedicated headset like the Oculus Go or Lenovo Mirage. Regardless of the actual device, rendering to a headset requires at least twice the rendering cost of a non-immersive experience because everything must be rendered twice, one for each eye.
To help your VR application be fast, keep the draw call count to a minimum. The draw call count matters far more than the total polygons in your scene, though polygons are important as well. Drawing 10 polygons 100 times is far slower than 100 polygons 10 times.
Lighting also tends to be expensive on mobile, so use fewer lights or cheaper materials. If a lambert or phong material will work just as well as a full PBR material (physically based rendering), go for the cheaper option.
Compress your 3D models as GLB files instead of GLTF. Decompression time is about the same but the download time will be much faster. There are a variety of command line tool to do this, or you can use this web based tool by SBtron. Just drag in your files and get back a GLB.
Always use powers of 2 texture sizes and try to keep textures under 1024 x 1024. Mobile GPUs don’t have nearly as much texture memory as desktops.Plus big textures just take a long time to download. You can often use 512 or 128 for things like bump maps and light maps.
For your 2D content, don’t assume any particular screen size or resolution. Use good responsive design practices that work well on a screen of any shape or size.
Lazy load your assets so that the initial experience is good. Most VR frameworks have a way of loading resources on demand. ThreeJS uses the DefaultLoadingManager. Your goal is to get the initial screen up and running as quickly as possible. Keep the initial download to under 1MB if at all possible. A fast loading experience is one that people will want to come back to over and over.
Prioritize framerate over everything else. In VR having a high framerate and smooth animation matters far more than the details of your models. In VR the human eye (and ear) are more sensitive to latency, low framerates, skipped frames, and janky animation than on a 2D screen. Your users will be very tolerant of low polygon models and less realistic graphics as long as the experience is fun and smooth.
Don’t do browser sniffing. If you hard code in detection for certain devices your code may work today, but will break as soon as a new device comes to market. The WebVR ecosystem is constantly growing and changing and a new device is always around the corner. Instead check for what the VR API actually returns, or rely on your framework to do this for you.
Assume the controls could be anything. Some headsets have a full 6dof controller (six degrees of freedom). Some are 3dof. Some are on a desktop using a mouse or on a phone with a touch screen. And some devices have no input at all, relying on gaze based interaction. Make sure your application works in any of these cases. If you aren’t able to make it work in certain cases (say, gaze based won’t work), then try to provide a degraded view only experience instead. Whatever you do, don’t block viewers if the right device isn’t available. Someone who looks at your app might still have a headset, but just isn’t using it right now. Provide some level of experience for everyone.
Never enter VR directly on page load unless coming from a VR page. On some devices the page is not allowed to enter VR without a user interaction. On other devices audio may require user interaction as well. Always have some sort of a 2D splash page that explains where the user is and what the interaction will be, then have a big ‘Enter VR’ button to actually go into immersive mode. The exception is if the user is coming from another page and is already in VR. In this case you can jump right in. This A-Frame doc explains how it works.
The real key to creating a responsive and fun WebVR experience is debugging on both your desktop, a phone, and at least one real VR headset. Using a desktop browser is fine during development but there is no substitute for a actual device strapped to your noggin. Things which seem fine on desktop will be annoying in a real headset. The FoV (Field of View) of headsets is radically different than a phone or desktop window, so different things may be visible in each. You must test across form factors.
The Oculus Go is fairly easy to acquire and very affordable. If you have a smartphone also consider using a plastic or cardboard viewer, which are cheap and easy to find.
Firefox Reality supports remote debugging over USB so you can see the performance and console right in your desktop browser.
If you have a cool creation you want to share, let us know. We can help you get great exposure for your VR website. Submit your creation to this page. You must put in an email address or we can’t contact you back. To qualify your website must at least run in WebVR in FxR on the Oculus Go. If you don’t have one to test with then please contact us to help you test it.
Your site must support some sort of VR experience without having to create an account or pay money. Asking for money/account for a deeper experience is fine, but it must provide some sort of functionality right off the bat (intro level, tutorial, example, etc.)
We are so excited that the web is at the forefront of VR development. Our goal is to help you create fun and successful VR content. This post contains a few tips to help, but we are sure you will come up with your own tips as well. Please let us know in the comments. Happy coding.
|
|
Daniel Pocock: What is the difference between moderation and censorship? |
FSFE fellows recently started discussing my blog posts about Who were the fellowship? and An FSFE Fellowship Representative's dilemma.
Fellows making posts in support of reform have reported their emails were rejected. Some fellows had CC'd me on their posts to the list and these posts never appeared publicly. These are some examples of responses received by a fellow trying to post on the list:
The list moderation team decided now to put your email address on moderation for one month. This is not censorship.
One fellow forwarded me a rejected message to look at. It isn't obscene, doesn't attack anybody and doesn't violate the code of conduct. The fellow writes:
+1 for somebody to answer the original questions with real answers
-1 for more character assassination
Censors moderators responded to that fellow:
This message is in constructive and unsuited for a public discussion list.
Why would moderators block something like that? In the same thread, they allowed some very personal attack messages in favour of existing management.
Moderation + Bias = Censorship
Even links to the public list archives are giving errors and people are joking that they will only work again after the censors PR team change all the previous emails to comply with the censorship communications policy exposed in my last blog.
Fellows have started noticing that the blog of their representative is not being syndicated on Planet FSFE any more.
Some people complained that my last blog didn't provide evidence to justify my concerns about censorship. I'd like to thank FSFE management for helping me respond to that concern so conclusively with these heavy-handed actions against the community over the last 48 hours.
The collapse of the fellowship described in my earlier blog has been caused by FSFE management decisions. The solutions need to come from the grass roots. A totalitarian crackdown on all communications is a great way to make sure that never happens.
FSFE claims to be a representative of the free software community in Europe. Does this behaviour reflect how other communities operate? How successful would other communities be if they suffocated ideas in this manner?
This is what people see right now trying to follow links to the main FSFE Discussion list archive:
https://danielpocock.com/what-is-the-difference-between-moderation-and-censorship
|
|
Josh Matthews: Bugs Ahoy: The Next Generation |
There’s a new Bugs Ahoy in town, and it’s called Codetribute.
I started the Bugs Ahoy project in October 2011 partly because I was procrastinating from studying for midterms, but mostly because I saw new contributors being overwhelmed by Bugzilla’s… Bugzilla-ness. I wanted to reduce the number of decisions that new contributors had to make by:
Bugs Ahoy was always something that was Good Enough, but I’ve never been able to focus on making it the best tool it could be. I’ve heard enough positive feedback over the past 7 years to convince me that it was better than nothing, at least!
Bugs Ahoy’s time is over, and I would like to introduce the new Codetribute site. This is the result of Fienny Angelina’s hard work, with Dustin Mitchell, Hassan Ali, and Eli Perelman contributing as well. It is the spiritual successor to Bugs Ahoy, built to address limitations of the previous system by people who know what they’re doing. I was thrilled by the discussions I had with the team while Codetribute was being built, and I’m excited to watch as the project evolves to address future needs.
Bugs Ahoy will redirect automatically to the Codetribute homepage, but you should update any project or language-specific bookmarks or links so they remain useful. If your project isn’t listed and you would like it to be, please go ahead and add it! Similarly, if you have suggestions for ways that Codetribute could be more useful, please file an issue!
https://www.joshmatthews.net/blog/2018/09/bugs-ahoy-the-next-generation/
|
|
Hacks.Mozilla.Org: Firefox Focus with GeckoView |
Firefox Focus is private browsing as an app: It automatically blocks ads and trackers, so you can surf the web in peace. When you’re done, a single tap completely erases your history, cookies, and other local data.
Protecting you from invasive tracking is part of Mozilla’s non-profit mission, and Focus’s built-in tracking protection helps keep you safe. It also makes websites load faster!
![]()
With Focus, you don’t have to worry about your browsing history coming back to haunt you in retargeted ads on other websites.
In the next weeks, we’ll release a new version of Focus for Android, and for the first time, Focus will come bundled with Gecko, the browser engine that powers Firefox Quantum. This is a major architectural change, so while every copy of Focus will include Gecko—hence the larger download size—we plan on enabling it gradually to ensure a smooth transition. You can help us test Gecko in Focus today by installing the Focus Beta.

Note: At time of publishing, Focus Beta is conducting an A/B test between the old and new engines. Look for “Gecko/62.0” in your User-Agent String to determine if your copy is using Gecko or not.
Up until this point, Focus has been powered exclusively by Android’s built-in WebView. This made sense for initial development, since WebView was already on every Android device, but we quickly ran into limitations. Foremost, it isn’t designed for building browsers. Despite being based on Chromium, WebView only supports a subset of web standards, as Google expects app developers to use native Android APIs, and not the Web, for advanced functionality. Instead, we’d prefer if apps had access to the entirety of the open, standards-based web platform.
In Focus’s case, we can only build next-generation privacy features if we have deep access to the browser internals, and that means we need our own engine. We need Gecko. Fortunately, Firefox for Android already uses Gecko, just not in a way that’s easy to reuse in other applications. That’s where GeckoView comes in.
GeckoView is Gecko packaged as a reusable Android library. We’ve worked to decouple the engine itself from its user interface, and made it easy to embed in other applications. Thanks to GeckoView’s clean architecture, our initial benchmarks of the new Focus show a median page load improvement of 20% compared to Firefox for Android, making GeckoView our fastest version of Gecko on Android yet.

We first put GeckoView into production last year, powering both Progressive Web Apps (PWAs) and Custom Tabs in Firefox for Android. These minimal, self-contained features were good initial projects, but with Focus we’re going much further. Focus will be our first time using GeckoView to completely power an existing, successful, and standalone product.
We’re also using GeckoView in entirely new products like Firefox Reality, a browser designed exclusively for virtual and augmented reality headsets. We’ll be sharing more about it later this year.
To build a web browser, you need more than just an engine. You also need common functionality like tabs, auto-complete, search suggestions, and so on. To avoid unnecessary duplication of effort, we’ve also created Android Components, a collection of independent, ready-to-use libraries for building browsers and browser-like applications on Android.
For Mozilla, GeckoView means we can leverage all of our Firefox expertise in building more compelling, safe, and robust online experiences, while Android Components ensures that we can continue experimenting with new projects (like Focus and Firefox Reality) without reinventing wheels. In many ways, these projects set the stage for the next generation of the Firefox family of browsers on Android.
For Android developers, GeckoView means control. It’s a production-grade engine with a stable and expansive API, usable either on its own or through Android Components. Because GeckoView is a self-contained library, you don’t have to compile it yourself. Furthermore, powering your app with GeckoView gives you a specific web engine version you can work with. Compare that to WebView, which tends to have quite a bit of variance between versions depending on the OS and Chrome version available on the device. With GeckoView, you always know what you’re getting — and you benefit from Gecko’s excellent, cross-platform support for web standards.
We’re really excited about what GeckoView means for the future of browsers on Android, and we’d love for you to get involved:
Let us know what you think of GeckoView and the new Focus in the comments below!
The post Firefox Focus with GeckoView appeared first on Mozilla Hacks - the Web developer blog.
|
|
Mozilla Future Releases Blog: DNS over HTTPS (DoH) – Testing on Beta |
DNS is a critical part of the Internet, but unfortunately has bad security and privacy properties, as described in this excellent explainer by Lin Clark. In June, Mozilla started experimenting with DNS over HTTPS, a new protocol which uses encryption to protect DNS requests and responses. As we reported at the end of August, our experiments in the Nightly channel look very good: the slowest users show a huge improvement, anywhere up to hundreds of milliseconds, and most users see only a small performance slowdown of around 6 milliseconds, which is acceptable given the improved security.
This is a very promising result and the next step is to validate the technique over a broader set of users on our Beta channel. We will once again work with users who are already participating in Firefox experiments, and continue to provide in-browser notifications about the experiment and details about the DoH service provider so that everyone is fully informed and has a chance to decline participation in this particular experiment. A soft rollout to selected Beta users in the United States will begin the week of September 10th.
As before, this experiment will use Cloudflare’s DNS over HTTPS service. Cloudflare has been a great partner in developing this feature and has committed to very strong privacy guarantees for our users. Moving forward, we are working to build a larger ecosystem of trusted DoH providers that live up to this high standard of data handling, and we hope to be able to experiment with other providers soon.
The post DNS over HTTPS (DoH) – Testing on Beta appeared first on Future Releases.
https://blog.mozilla.org/futurereleases/2018/09/13/dns-over-https-doh-testing-on-beta/
|
|
The Rust Programming Language Blog: Announcing Rust 1.29 |
The Rust team is happy to announce a new version of Rust, 1.29.0. Rust is a systems programming language focused on safety, speed, and concurrency.
If you have a previous version of Rust installed via rustup, getting Rust 1.29.0 is as easy as:
$ rustup update stable
If you don’t have it already, you can get rustup from the
appropriate page on our website, and check out the detailed release notes for
1.29.0 on GitHub.
The 1.29 release is fairly small; Rust 1.30 and 1.31 are going to have a lot in them, and so much of the 1.29 cycle was spent preparing for those releases. The two most significant things in this release aren’t even language features: they’re new abilities that Cargo has grown, and they’re both about lints.
cargo fix can automatically fix your code that has warningscargo clippy is a bunch of lints to catch common mistakes and improve your Rust codecargo fixWith the release of Rust 1.29, Cargo has a new subcommand: cargo fix. If you’ve written
code in Rust before, you’ve probably seen a compiler warning before. For example, consider
this code:
fn do_something() {}
fn main() {
for i in 0..100 {
do_something();
}
}
Here, we’re calling do_something a hundred times. But we never use the variable i.
And so Rust warns:
> cargo build
Compiling myprogram v0.1.0 (file:///path/to/myprogram)
warning: unused variable: `i`
--> src\main.rs:4:9
|
4 | for i in 1..100 {
| ^ help: consider using `_i` instead
|
= note: #[warn(unused_variables)] on by default
Finished dev [unoptimized + debuginfo] target(s) in 0.50s
See how it suggests that we use _i as a name instead? We can automatically
apply that suggestion with cargo fix:
> cargo fix
Checking myprogram v0.1.0 (file:///C:/Users/steve/tmp/fix)
Fixing src\main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
If we look at src\main.rs again, we’ll see that the code has changed:
fn do_something() {}
fn main() {
for _i in 0..100 {
do_something();
}
}
We’re now using _i, and the warning will no longer appear.
This initial release of cargo fix only fixes up a small number of warnings.
The compiler has an API for this, and it only suggests fixing lints that
we’re confident recommend correct code. Over time, as our suggestions
improve, we’ll be expanding this to automatically fix more warnings.
if you find a compiler suggestion and want to help make it fixable, please leave a comment on this issue.
cargo clippySpeaking of warnings, you can now check out a preview of cargo clippy through Rustup.
Clippy is a large number of additional warnings that you can run against your Rust code.
For example:
let mut lock_guard = mutex.lock();
std::mem::drop(&lock_guard)
operation_that_requires_mutex_to_be_unlocked();
This code is syntactically correct, but may have a deadlock! You see, we
dropped a reference to lock_guard, not the guard itself. Dropping
a reference is a no-op, and so this is almost certainly a bug.
We can get the preview of Clippy from Rustup:
$ rustup component add clippy-preview
and then run it:
$ cargo clippy
error: calls to `std::mem::drop` with a reference instead of an owned value. Dropping a reference does nothing.
--> src\main.rs:5:5
|
5 | std::mem::drop(&lock_guard);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: #[deny(drop_ref)] on by default
note: argument has type &std::result::Result, std::sync::PoisonError'_, i32>>>
--> src\main.rs:5:20
|
5 | std::mem::drop(&lock_guard);
| ^^^^^^^^^^^
= help: for further information visit https://rust-lang-nursery.github.io/rust-clippy/v0.0.212/index.html#drop_ref
As you can see from that help message, you can view all of the lints that clippy offers on the web.
Please note that this is a preview; clippy has not yet reached 1.0. As such,
its lints may change. We’ll release a clippy component once it has stabilized;
please give the preview a try and let us know how it goes.
Oh, and one more thing: you can’t use clippy with cargo-fix yet,
really. It’s in the works!
See the detailed release notes for more.
Three APIs were stabilized this release:
Additionally, you can now compare &str and
OsString.
See the detailed release notes for more.
We covered the two new subcommands to Cargo above, but additionally, Cargo
will now try to fix up lockfiles that have been corrupted by a git
merge. You can pass
--locked to disable this behavior.
cargo doc has also grown a new flag:
--document-private-items. By
default, cargo doc only documents public things, as the docs it produces are
intended for end-users. But if you’re working on your own crate, and you have
internal documentation for yourself to refer to, --document-private-items
will generate docs for all items, not just public ones.
See the detailed release notes for more.
Many people came together to create Rust 1.29. We couldn’t have done it without all of you. Thanks!
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla reacts to EU Parliament vote on copyright reform |
Today marks a very sad day for the internet in Europe. Lawmakers in the European Parliament have just voted to turn their backs on key principles on which the internet was built; namely openness, decentralisation, and collaboration.
Parliamentarians have given a green light to new rules that will compel online services to implement blanket upload filters, a crude and ineffective measure that could well spell an end to the rich creative fabric of memes, mashups, and GIFs that make internet culture so great. The Parliament’s vote also endorses a ‘link tax’ that will undermine access to knowledge and the sharing of information in Europe.
We recognise the efforts of many MEPs who attempted to find workable solutions that would have rectified some of the grave shortcomings in this proposal. Sadly, the majority dismissed those constructive solutions, and the open internet that we’ve taken for granted the last 20 years is set to turn into something very different in Europe.
The fight is not over yet. Lawmakers still need to finalise the new rules, and we at Mozilla will do everything we can to achieve a modern reform that safeguards the health of the internet and promotes the rights of users. There’s simply too much at stake not to.
The post Mozilla reacts to EU Parliament vote on copyright reform appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2018/09/12/eucopyrightreform/
|
|
Mozilla Open Policy & Advocacy Blog: EU terrorism regulation threatens internet health in Europe |
The European Commission has today proposed a troublesome new regulation regarding terrorist content online. As we have said, illegal content – of which terrorist content is a particularly striking example – undermines the overall health of the internet. We welcome effective and sustainable efforts to address illegal content online. But the Commission’s proposal is a poor step in that direction. It would undermine due process online; compel the use of ineffective content filters; strengthen the position of a few dominant platforms while hampering European competitors; and, ultimately, violate the EU’s commitment to protecting fundamental rights.
Under the Commission’s proposal, government-appointed authorities – not independent courts – would have the unilateral power to suppress speech on the internet. Longstanding norms around due process and the separation of powers would be swept aside, with little evidence to support such a drastic departure from established norms. These authorities would have vague, indeterminate authority to require additional proactive measures (including but not limited to content filters) from platforms where they deem them appropriate.
In keeping with a worrying global policy trend, this proposal falls victim to the flawed and dangerous assumption that technology is a panacea to complex problems. It would force private companies to play an even greater role in defining acceptable speech online. In practice it would force online services throughout the internet ecosystem to adapt the standards of speech moderation designed for the largest platforms, strengthening their role in the internet economy and putting European competitors at a disadvantage. At a time when lawmakers around the world are increasingly concerned with centralisation and competition in the digital marketplace, this would be a step backwards.
A regulation that poses broad threats to free expression outside of a rule-of-law framework is incompatible with the EU’s long-standing commitment to protecting fundamental rights. As a mission-driven technology company and not-for-profit foundation, both maker of the Firefox web browser and steward of a community of internet builders, we believe user rights and technical expertise must play an essential part in this legislative debate. We have previously presented the Commission with a framework to guide effective policy for illegal content in the European legal context. This proposal falls far short of what is needed for the health of the internet in Europe.
The post EU terrorism regulation threatens internet health in Europe appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2018/09/12/euterrorismreg/
|
|
Mike Hommey: Firefox is now built with clang LTO on all* platforms |
You might have read that Mozilla recently switched Windows builds to clang-cl. More recently, those Windows builds have seen both PGO (Profile-Guided Optimization) and LTO (Link-Time Optimization) enabled.
As of next nightly (as of writing, obviously), all tier-1 platforms are now built with clang with LTO enabled. Yes, this means Linux, Mac and Android arm, aarch64 and x86. Linux builds also have PGO enabled.
Mac and Android builds were already using clang, so the only difference is LTO being enabled, which brought some performance improvements.
The most impressive difference, though, was on Linux, where we’re getting more than 5% performance improvements on most Talos tests (up to 18% (!) on some tests) compared to GCC 6.4 with PGO. I must say I wasn’t expecting switching from GCC to clang would make such a difference. And that is with clang 6. A quick test with upcoming clang 7 suggests we’d additionally get between 2 and 5% performance improvement from an upgrade, but our static analysis plugin doesn’t like it.
This doesn’t mean GCC is being unsupported. As a matter of fact, we still have automated jobs using GCC for some static analysis, and we also have jobs ensuring everything still builds with a baseline of GCC 6.x.
You might wonder if we tried LTO with GCC, or tried upgrading to GCC 8.x. As a matter of fact, I did. Enabling LTO turned up linker errors, and upgrading to GCC 7.x turned up breaking binary compatibility with older systems, and if I remember correctly had some problems with our test suite. GCC 8.1 was barely out when I was looking into this, and we all know to stay away from any new major GCC version until one or two minor updates. Considering the expected future advantages from using clang (cross-language inlining with Rust, consistency between platforms), it seemed a better deal to switch to clang than to try to address those issues.
Update: As there’s been some interest on reddit and HN, and I failed to mention it originally, it’s worth noting that comparing GCC+PGO vs. clang+LTO or GCC+PGO vs. clang+PGO was a win for clang overall in both cases, although GCC was winning on a few benchmarks. If I remember correctly, clang without PGO/LTO was also winning against GCC without PGO.
Anyways, what led me on this quest was a casual conversation at our last All Hands, where we were discussing possibly turning on LTO on Mac, and how that should roughly just be about turning a switch.
Famous last words.
At least, that’s a somehow reasonable assumption. But when you have a codebase the size of Firefox, you’re up for “interesting” discoveries.
This involved compiler bugs, linker bugs (with a special mention for a bug in ld64 that Apple has apparently fixed in Xcode 9 but hasn’t released the source of), build system problems, elfhack issues, crash report problems, clang plugin problems (would you have guessed that __attribute__((annotate("foo"))) can affect the generated machine code?), sccache issues, inline assembly bugs (getting inputs, outputs and clobbers correctly is hard), binutils bugs, and more.
I won’t bother you with all the details, but here we are, 3 months later with it all, finally, mostly done. Counting only the bugs assigned to me, there are 77 bugs on bugzilla (so, leaving out anything in other bug trackers, like LLVM’s). Some of them relied on work from other people (most notably, Nathan Froyd’s work to switch to clang and then non-NDK clang on Android). This spread over about 150 commits on mozilla-central, 20 of which were backouts. Not everything went according to plan, obviously, although some of those backouts were on purpose as a taskcluster trick.
Hopefully, this sticks, and Firefox 64 will ship built with clang with LTO on all tier-1 platforms as well as PGO on some. Downstreams are encouraged to do the same if they can. The build system will soon choose clang by default on all builds, but won’t enable PGO/LTO.
As a bonus, as of a few days ago, Linux builds are also finally using Position Independent Executables, which improves Address Space Layout Randomization for the few things that are in the executables instead of some library (most notably, mozglue and the allocator). This was actually necessary for LTO, because clang doesn’t build position independent code in executables that are not PIE (but GCC does), and that causes other problems.
Work is not entirely over, though, as more inline assembly bugs might be remaining only not causing visible problems by sheer luck, so I’m now working on a systematic analysis of inline assembly blocks with our clang plugin.
|
|
Mozilla Security Blog: Protecting Mozilla’s GitHub Repositories from Malicious Modification |
At Mozilla, we’ve been working to ensure our repositories hosted on GitHub are protected from malicious modification. As the recent Gentoo incident demonstrated, such attacks are possible.
Mozilla’s original usage of GitHub was an alternative way to provide access to our source code. Similar to Gentoo, the “source of truth” repositories were maintained on our own infrastructure. While we still do utilize our own infrastructure for much of the Firefox browser code, Mozilla has many projects which exist only on GitHub. While some of those project are just experiments, others are used in production (e.g. Firefox Accounts). We need to protect such “sensitive repositories” against malicious modification, while also keeping the barrier to contribution as low as practical.
This describes the mitigations we have put in place to prevent shipping (or deploying) from a compromised repository. We are sharing both our findings and some tooling to support auditing. These add the protections with minimal disruption to common GitHub workflows.
The risk we are addressing here is the compromise of a GitHub user’s account, via mechanisms unique to GitHub. As the Gentoo and other incidents show, when a user account is compromised, any resource the user has permissions to can be affected.
GitHub is a wonderful ecosystem with many extensions, or “apps”, to make certain workflows easier. Apps obtain permission from a user to perform actions on their behalf. An app can ask for permissions including modifying or adding additional user credentials. GitHub makes these permission requests transparent, and requires the user to approve via the web interface, but not all users may be conversant with the implications of granting those permissions to an app. They also may not make the connection that approving such permissions for their personal repositories could grant the same for access to any repository across GitHub where they can make changes.
Excessive permissions can expose repositories with sensitive information to risks, without the repository admins being aware of those risks. The best a repository admin can do is detect a fraudulent modification after it has been pushed back to GitHub. Neither GitHub nor git can be configured to prevent or highlight this sort of malicious modification; external monitoring is required.
The following are taken from our approach to addressing this concern, with Mozilla specifics removed. As much as possible, we borrow from the web’s best practices, used features of the GitHub platform, and tried to avoid adding friction to the daily developer workflows.
There are some costs to implementing these protections – especially those around the signing of commits. We have developed some internal tooling to help with auditing the configurations, and plan to add tools for auditing commits. Those tools are available in the mozilla-services/GitHub-Audit repository.

Here’s an example of using the audit tools. First we obtain a local copy of the data we’ll need for the “octo_org” organization, and then we report on each repository:
$ ./get_branch_protections.py octo_org
2018-07-06 13:52:40,584 INFO: Running as ms_octo_cat
2018-07-06 13:52:40,854 INFO: Gathering branch protection data. (calls remaining 4992).
2018-07-06 13:52:41,117 INFO: Starting on org octo_org. (calls remaining 4992).
2018-07-06 13:52:59,116 INFO: Finished gathering branch protection data (calls remaining 4947).
Now with the data cached locally, we can run as many reports as we’d like. For example, we have written one report showing which of the above recommendations are being followed:
$ ./report_branch_status.py --header octo_org.db.json
name,protected,restricted,enforcement,signed,team_used
octo_org/react-starter,True,False,False,False,False
octo_org/node-starter,False,False,False,False,False
We can see that only “octo_org/react-starter” has enabled protection against force pushes on it’s production branch. The final output is in CSV format, for easy pasting into spreadsheets.
We are still rolling out these recommendations across our teams, and learning as we go. If you think our Repository Security recommendations are appropriate for your situation, please help us make implementation easier. Add your experience to the Tips ‘n Tricks page, or open issues on our GitHub-Audit repository.
The post Protecting Mozilla’s GitHub Repositories from Malicious Modification appeared first on Mozilla Security Blog.
|
|
Hacks.Mozilla.Org: Converting a WebGL application to WebVR |
A couple months ago I ported the Pathfinder demo app to WebVR. It was an interesting experience, and I feel like I learned a bunch of things about porting WebGL applications to WebVR that would be generally useful to folks, especially folks coming to WebVR from non-web programming backgrounds.
Pathfinder is a GPU-based font rasterizer in Rust, and it comes with a demo app that runs the Rust code on the server side but does all the GPU work in WebGL in a TypeScript website.
We had a 3D demo showing a representation of the Mozilla Monument as a way to demo text rasterization in 3D. What I was hoping to do was to convert this to a WebVR application that would let you view the monument by moving your head instead of using arrow keys.
I started working on this problem with a decent understanding of OpenGL and WebGL, but almost zero background in VR or WebVR. I’d written an Android Cardboard app three years previously and that was about it.
I’m hoping this article may be useful for others from similar backgrounds.

The converted triangle demo running in WebVR
WebVR is a set of APIs for writing VR applications on the web. It lets us request jumping into VR mode, at which point we can render things directly to the eyes of a VR display, rather than rendering to a flat surface browser within the display. When the user is on a device like the Cardboard or Daydream where a regular phone substitutes for the VR display, this is the point where the user puts their phone within the headset.
WebVR APIs help with transitioning to/from VR mode, obtaining pose information, rendering in VR, and dealing with device input. Some of these things are being improved in the work in progress on the new WebXR Device API specification.
Ideally, a good VR device will make it easier to test your work in progress, but depending on how much resolution you need, a Daydream or Cardboard (where you use your phone in a headset casing) is enough. You can even test stuff without the headset casing, though stuff will look weird and distorted.
For local testing Chrome has a WebVR API emulation extension that’s pretty useful. You can use the devtools panel in it to tweak the pose, and you get a non-distorted display of what the eyes see.
Firefox supports WebVR, and Chrome Canary supports it if you enable some flags. There’s also a polyfill which should work for more browsers.
I think not understanding this part was the source of a lot of confusion and bugs for me when I was getting started. The core of the API is basically “render something to a canvas and then magic happens”, and I had trouble figuring how that magic worked.
Essentially, there’s a bunch of work we’re supposed to do, and then there’s extra work the browser (or polyfill) does.
Once we enter VR mode, there’s a callback triggered whenever the device requests a frame. Within this callback we have access to pose information.
Using this pose information, we can figure out what each eye should see, and provide this to the WebVR API in some form.
What the WebVR API expects is that we render each eye’s view to a canvas, split horizontally (this canvas will have been passed to the API when we initialize it).
That’s it from our side, the browser (or polyfill) does the rest. It uses our rendered canvas as a texture, and for each eye, it distorts the rendered half to appropriately work with the lenses used in your device. For example, the distortion for Daydream and Cardboard follows this code in the polyfill.
It’s important to note that, as application developers, we don’t have to worry about this — the WebVR API is handling it for us! We need to render undistorted views from each eye to the canvas — the left view on the left half and the right view on the right half, and the browser handles the rest!
I’m going to try and keep this self contained, however I’ll mention off the bat that some really good resources for learning this stuff can be found at webvr.info and MDN. webvr.info has a bunch of neat samples if, like me, you learn better by looking at code and playing around with it.
First up, we need to be able to get access to a VR display and enter VR mode.
let vrDisplay;
navigator.getVRDisplays().then(displays => {
if (displays.length === 0) {
return;
}
vrDisplay = displays[displays.length - 1];
// optional, but recommended
vrDisplay.depthNear = /* near clip plane distance */;
vrDisplay.depthFar = /* far clip plane distance */;
}
We need to add an event handler for when we enter/exit VR:
let canvas = document.getElementById(/* canvas id */);
let inVR = false;
window.addEventListener('vrdisplaypresentchange', () => {
// no VR display, exit
if (vrDisplay == null)
return;
// are we entering or exiting VR?
if (vrDisplay.isPresenting) {
// We should make our canvas the size expected
// by WebVR
const eye = vrDisplay.getEyeParameters("left");
// multiply by two since we're rendering both eyes side
// by side
canvas.width = eye.renderWidth * 2;
canvas.height = eye.renderHeight;
const vrCallback = () => {
if (vrDisplay == null || !inVR) {
return;
}
// reregister callback if we're still in VR
vrDisplay.requestAnimationFrame(vrCallback);
// render scene
render();
};
// register callback
vrDisplay.requestAnimationFrame(vrCallback);
} else {
inVR = false;
// resize canvas to regular non-VR size if necessary
}
});
And, to enter VR itself:
if (vrDisplay != null) {
inVR = true;
// hand the canvas to the WebVR API
vrDisplay.requestPresent([{ source: canvas }]);
// requestPresent() will request permission to enter VR mode,
// and once the user has done this our `vrdisplaypresentchange`
// callback will be triggered
}
Well, we’ve entered VR, now what? In the above code snippets we had a render() call which was doing most of the hard work.
Since we’re starting with an existing WebGL application, we’ll have some function like this already.
let width = canvas.width;
let height = canvas.height;
function render() {
let gl = canvas.getContext("gl");
gl.viewport(0, 0, width, height);
gl.clearColor(/* .. */);
gl.clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT);
gl.useProgram(program);
gl.bindBuffer(/* .. */);
// ...
let uProjection = gl.getUniformLocation(program, "uProjection");
let uModelView = gl.getUniformLocation(program, "uModelview");
gl.uniformMatrix4fv(uProjection, false, /* .. */);
gl.uniformMatrix4fv(uModelView, false, /* .. */);
// set more parameters
// run gl.drawElements()
}
So first we’re going to have to split this up a bit further, to handle rendering the two eyes:
// entry point for WebVR, called by vrCallback()
function renderVR() {
let gl = canvas.getContext("gl");
// set clearColor and call gl.clear()
clear(gl);
renderEye(true);
renderEye(false);
vrDisplay.submitFrame(); // Send the rendered frame over to the VR display
}
// entry point for non-WebVR rendering
// called by whatever mechanism (likely keyboard/mouse events)
// you used before to trigger redraws
function render() {
let gl = canvas.getContext("gl");
// set clearColor and call gl.clear()
clear(gl);
renderSceneOnce();
}
function renderEye(isLeft) {
// choose which half of the canvas to draw on
if (isLeft) {
gl.viewport(0, 0, width / 2, height);
} else {
gl.viewport(width / 2, 0, width / 2, height);
}
renderSceneOnce();
}
function renderSceneOnce() {
// the actual GL program and draw calls go here
}
This looks like a good step forward, but notice that we’re rendering the same thing to both eyes, and not handling movement of the head at all.
To implement this we need to use the perspective and view matrices provided by WebVR from the VRFrameData object.
The VRFrameData object contains a pose member with all of the head pose information (its position, orientation, and even velocity and acceleration for devices that support these). However, for the purpose of correctly positioning the camera whilst rendering, VRFrameData provides projection and view matrices which we can directly use.
We can do this like so:
let frameData = new VRFrameData();
vrDisplay.getFrameData(frameData);
// use frameData.leftViewMatrix / framedata.leftProjectionMatrix
// for the left eye, and
// frameData.rightViewMatrix / framedata.rightProjectionMatrix for the right
In graphics, we often find ourselves dealing with the model, view, and projection matrices. The model matrix defines the position of the object we wish to render in the coordinates of our space, the view matrix defines the transformation between the camera space and the world space, and the projection matrix handles the transformation between clip space and camera space (also potentially dealing with perspective). Sometimes we’ll deal with the combination of some of these, like the “model-view” matrix.
One can see these matrices in use in the cubesea code in the stereo rendering example from webvr.info.
There’s a good chance our application has some concept of a model/view/projection matrix already. If not, we can pre-multiply our positions with the view matrix in our vertex shaders.
So now our code will look something like this:
// entry point for non-WebVR rendering
// called by whatever mechanism (likely keyboard/mouse events)
// we used before to trigger redraws
function render() {
let gl = canvas.getContext("gl");
// set clearColor and call gl.clear()
clear(gl);
let projection = /*
calculate projection using something
like glmatrix.mat4.perspective()
(we should be doing this already in the normal WebGL app)
*/;
let view = /*
use our view matrix if we have one,
or an identity matrix
*/;
renderSceneOnce(projection, view);
}
function renderEye(isLeft) {
// choose which half of the canvas to draw on
let projection, view;
let frameData = new VRFrameData();
vrDisplay.getFrameData(frameData);
if (isLeft) {
gl.viewport(0, 0, width / 2, height);
projection = frameData.leftProjectionMatrix;
view = frameData.leftViewMatrix;
} else {
gl.viewport(width / 2, 0, width / 2, height);
projection = frameData.rightProjectionMatrix;
view = frameData.rightViewMatrix;
}
renderSceneOnce(projection, view);
}
function renderSceneOnce(projection, view) {
let model = /* obtain model matrix if we have one */;
let modelview = glmatrix.mat4.create();
glmatrix.mat4.mul(modelview, view, model);
gl.useProgram(program);
gl.bindBuffer(/* .. */);
// ...
let uProjection = gl.getUniformLocation(program, "uProjection");
let uModelView = gl.getUniformLocation(program, "uModelview");
gl.uniformMatrix4fv(uProjection, false, projection);
gl.uniformMatrix4fv(uModelView, false, modelview);
// set more parameters
// run gl.drawElements()
}
This should be it! Moving your head around should now trigger movement in the scene to match it! You can see the code at work in this demo app that takes a spinning triangle WebGL application and turns it into a WebVR-capable triangle-viewing application using the techniques from this blog post.
If we had further input we might need to use the Gamepad API to design a good VR interface that works with typical VR controllers, but that’s out of scope for this post.
The post Converting a WebGL application to WebVR appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2018/09/converting-a-webgl-application-to-webvr/
|
|
Ryan Kelly: Security Bugs in Practice: SSRF via Request Splitting |
One of the most interesting (and sometimes scary!) parts of my job at Mozilla is dealing with security bugs. We don’t always ship perfect code – nobody does – but I’m privileged to work with a great team of engineers and security folks who know how to deal effectively with security issues when they arise. I’m also privileged to be able to work in the open, and I want to start taking more advantage of that to share some of my experiences.
One of the best ways to learn how to write more secure code is to get experience watching code fail in practice. With that in mind, I’m planning to write about some of the security-bug stories that I’ve been involved in during my time at Mozilla. Let’s start with a recent one: Bug 1447452, in which some mishandling of unicode characters by the Firefox Accounts API server could have allowed an attacker to make arbitrary requests to its backend data store.
https://www.rfk.id.au/blog/entry/security-bugs-ssrf-via-request-splitting/
|
|
The Mozilla Blog: Fast Company Innovation by Design Award for Common Voice |
|
|
Mozilla Open Innovation Team: We’re intentionally designing open experiences, here’s why. |
At Mozilla, our Open Innovation team is driven by the guiding principle of being Open by Design. We are intentionally designing how we work with external collaborators and contributors — both at the individual and organizational level — for the greatest impact and shared value. This includes foundational strategic questions from business objectives to licensing through to overall project governance. But importantly, it also applies to how we design experiences for our communities. Including how we think about creating interactions, from onboarding to contribution.

In a series of articles we will share deeper insight as to why, and how, we’re applying experience design practices throughout our open innovation projects. It is our goal in sharing these learnings that further Open Source projects and experiments may benefit from their application and a holistic Service Design approach. As a relevant example, throughout the series, we’ll point often to the Common Voice project where we’ve enabled these practices from its inception.
What is now Common Voice, an multi-language voice collection experience, started merely as an identified need. Since early 2016 Mozilla’s Machine Learning Group has been working on an Open Source speech recognition engine and model, project “Deep Speech”. Any high quality speech-to-text engines require thousands of hours of voice data to train them, but publicly available voice data is very limited and the cost of commercial datasets is exorbitant. This prompted the question, how might we collect large quantities of voice data for Open Source machine learning?

We hypothesized that creating an Open Source voice dataset could lead to more diverse and accurate machine learning capabilities. But how to do this? The best way to ideate and capture multiple potential solutions is to leverage some additional minds and organize a design sprint. In the case of Common Voice our team gathered in Taipei to lead a group of Mozilla community members through various design thinking exercises. Multiple ideas emerged around crowdsourcing voice data and ultimately resulted in testable paper prototypes.
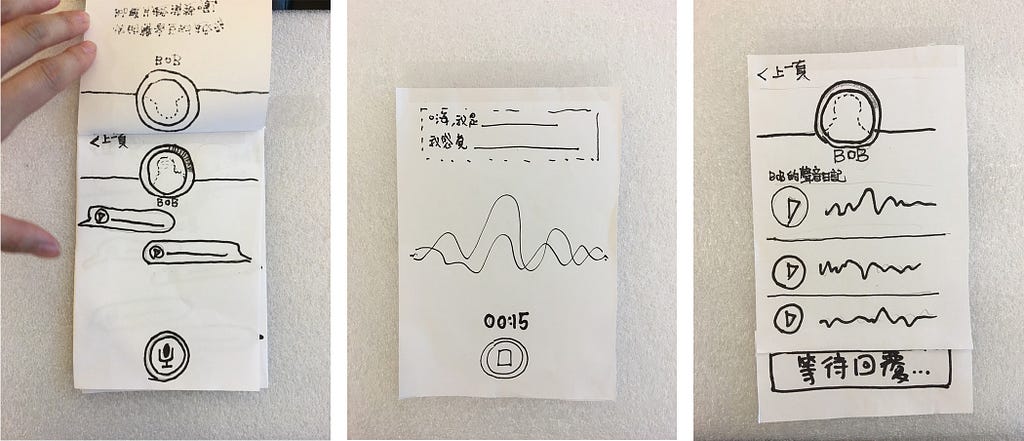
At this point we could have gone immediately to a build phase, and may have in the past. However we chose to pursue further human interaction, by engaging people via in person feedback. The purpose of this human-centered research being to both understand what ideas resonated with people and to narrow in on what design concepts we should move forward with. Our test audience consisted of the people we hoped to ultimately engage with our data collection efforts — everyday internet citizens. We tested concepts by taking to the streets of Taipei and utilizing guerilla research methods. These concepts were quite varied and included everything from a voice-only dating app to a simple sentence read back mechanism.

We went into this research phase fully expecting the more robust app concepts to win out. Our strongly held belief was that people wanted to be entertained or needed an ulterior motive in order to facilitate this level of voice data collection. What resulted was surprisingly intriguing (and heartening): it was the experience of voice donation itself that resonated most with people. Instead of using a shiny app that collects data as a side-effect to its main features, people were more interested in the voice data problem itself and wanted to help. People desired to understand more about why we were doing this type of voice collection at all. This research showed us that our initial assumptions about the need to build an app were wrong. Our team had to let go of their first ideas in order to make way for something more human-centered, resonant and effective.
This is why we built Common Voice. To tell the story of voice data and how it relates to the need for diversity and inclusivity in speech technology. To better enable this storytelling, we created a robot that users on our website would “teach” to understand human speech by speaking to it through reading sentences. This interaction model has proved effective and has already evolved significantly. The robot is still a mainstay, but the focus has shifted. True to experience design practices, we are consistently iterating, currently with a focus on building the largest multi-language voice dataset to date.
As we continue our series we’ll break down the subsequent phases of our Common Voice work. Highlighting where we put into action our experience design practice of prototyping with intention. We’ll take learnings from the human interaction research and walk through how the project has moved from an early MVP prototype to its current multi-language contribution model, all with the help of our brilliant communities.
If you’d like to learn more in the meantime, share thoughts or news about your projects, please reach out to the Mozilla Open Innovation team at openinnovation@mozilla.com.
We’re intentionally designing open experiences, here’s why. was originally published in Mozilla Open Innovation on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|






