Добавить любой RSS - источник (включая журнал LiveJournal) в свою ленту друзей вы можете на странице синдикации.
Исходная информация - http://planet.mozilla.org/. Данный дневник сформирован из открытого RSS-источника по адресу http://planet.mozilla.org/rss20.xml, и дополняется в соответствии с дополнением данного источника. Он может не соответствовать содержимому оригинальной страницы. Трансляция создана автоматически по запросу читателей этой RSS ленты. По всем вопросам о работе данного сервиса обращаться со страницы контактной информации.[Обновить трансляцию]
The DevTools GCLI has been removed from the Firefox codebase (bug), which roughly translates into 20k less lines of code to think about, and the associated tests which are not running anymore, so yay for saving both brain and automation power!
We triaged all the existing bugs, and moved a bunch worth keeping to DevTools -> Shared Components, to avoid losing track of them (they’re mostly about taking screenshots). Then the ever helpful Emma resolved the rest as incomplete, and moved the component to the DevTools Graveyard in Bugzilla, to avoid people filing bugs about code that does not exist anymore.
During this removal process we’ve heard from some of you that you miss certain features from GCLI, and we’ve taken note, and will aim to bring them back when time and resourcing allow. In the meantime, thank you for your feedback! It helps us better understand how you use the tools.
Also: A new Mozilla-Ipsos poll reveals a majority of respondents want privacy, and not publicity, as their default setting online
Earlier this week, Mozilla visited Venmo’s headquarters in New York City and delivered a petition signed by more than 25,000 Americans. The petition urges the payment app to put users’ privacy first and make Venmo transactions private by default.
Also this week: A new poll from Mozilla and Ipsos reveals that 77% of respondents believe payment apps should not make transaction details public by default. (More on our poll results below.)
Millions of Venmo users’ spending habits are available for anyone to see. That’s because Venmo transactions are currently public by default — unless users manually update their settings, anyone, anywhere can see whom they’re sending money to, and why.
Mozilla’s petition urges Venmo to change these settings. By making privacy the default, Venmo can better protect its seven million users — and send a powerful message about the importance of privacy. But so far, Venmo hasn’t formally responded to our petition and to the 25,000 Americans who signed their names.
Earlier this year, Mozilla Fellow Hang Do Thi Duc exposed the serious implications of Venmo’s settings. Her project, Public By Default, revealed how Venmo users’ drug habits, junk food vices, personal finances, and fights with significant others are available for all to see. Here’s what TV reporters had to say about Hang’s findings:
Mozilla and Ipsos conducted an opinion poll this month, asking 1,009 Americans how they feel about the policy of “public by default.” Americans’ opinions were clear:
77% of respondents believe payment apps should not make transaction details public by default.
92% of respondents do not support Venmo’s justification for making transactions public by default. (In July, Venmo told CNET that transactions should be public because “it’s fun to share [information] with friends in the social world.”)
89% of respondents believe the most responsible default setting for payment apps is for transactions to be visible only to those involved.
Bonjour everyone! Here comes the twenty third installment of WebRender’s very best newsletter. This time I’m trying something a bit different. Instead of going through each pull request and bugzilla entry that landed since the last post, I’m only sourcing information from the team’s weekly meeting. As a result only the most important items make it to the list and not all items have links to their bug or pull request. Doing this allows me to spend considerably less time preparing the newsletter and will hopefully help with publishing it more often.
Last time I mentioned WebRender being enabled on nightly by default for a small subset of the users, focusing on nVidia desktop GPUs on Windows 10. I’m happy to report that we didn’t set our nightly user population on fire and that WebRender is still enabled in these configurations (as expected, sure, but with a project as large and ambitious as WebRender it isn’t something that could be taken for granted). The choice of this particular configuration of hardware and driver led to a lot of speculation online, so I just want clarify a few things. We did not strike any deal with nVidia. nVidia didn’t send engineers to help us get WebRender to work on their hardware first. No politics, I promise. We learnt from past mistakes and chose to target a small population of Firefox users at first specifically because it is small. Each combination of OS/Vendor/driver exposes its own set of bugs and a progressive and targeted rollout means we’ll be better equipped to react in a timely manner to incoming bugs than we have been with past projects.
Worry not, the end game is for WebRender to be Firefox’s rendering engine for everyone. Until then, are welcome to enable WebRender manually if your OS, hardware or driver isn’t in the initial target.
Notable changes in WebRender and Gecko
Bobby improved the memory reporting infrastructure for WebRender.
Bobby improved memory usage by better managing the lifetime of the render target pool items.
Bobby fixed a crash with clip masks.
Jeff Improved the performance of blob image rasterization.
Just a quick note that the October 2018 office hour slots are
now posted. If you’re having a problem with Rust, or have something
you’d like to talk out, please sign up!
By holding Section 57 of the Aadhaar Act to be unconstitutional, the Supreme Court of India has recognized the privacy risks created by the indiscriminate use of Aadhaar for private services. While this is welcome, by allowing the State wide powers to make Aadhaar mandatory for welfare subsidies and PAN, this judgment falls short of guaranteeing Indians meaningful choice on whether and how to use Aadhaar. This is especially worrisome given that India still lacks a data protection law to regulate government or private use of personal data. Now, more than ever, we need legal protections that will hold the government to account.
Firefox Accounts help you get more out of your Firefox experience. With a Firefox Account, you can get all your bookmarks, passwords, open tabs and more — everywhere you use … Read more
The Firefox Accounts team is in the process of releasing a new feature called Account Recovery. Previously, when a user resets their password, they would be given new encryption keys and could potentially risk losing any synced bookmarks, passwords and browsing history. With Account Recovery, a user can keep their encryption keys and not lose any data.
A more technical overview of how this feature works can be found here.
If you are interested in trying it out, simply goto your Firefox Account settings and click Account Recovery. If you do not see the Account Recovery option, you might not be in the rollout group yet. However, it can be manually enabled using these instructions.
From panel, click Generate, confirm your password and save the key displayed.
In the event you forget your password, you will be prompted for this key to recover your data.
Thanks and kudos to our security team, designers, developers, testers and everyone else that helped to make this feature happen!
Today, the advertising and technology sectors presented the world’s first ever Code of Practice on Disinformation. Brokered in Europe, and motivated by the European Commission’s Communication on Tackling Disinformation and the report of the High Level Expert Group on Fake News, the Code represents another step towards countering the spread of disinformation.
This initiative complements the work we’ve been doing at Mozilla to invest in technologies and tools, research and communities, to fight against information pollution and honour our commitment to an internet that elevates critical thinking, reasoned argument, shared knowledge, and verifiable facts.
The Code is the result of intensive work within the advertising and online platform sectors, including Google, Facebook, Twitter, Mozilla, and EDiMA, as well as IAB Europe, the World Federation of Advertisers, and EACA, EASA, and AIM. These organisations comprised the Working Group, which worked on the code within the Multistakeholder Forum on Disinformation, a process established and shepherded by the European Commission.
Building on the approach outlined in the High Level Group’s Report, the Code addresses five key areas and outlines a set of commitments for each. These include:
Scrutiny of ad placements: to deploy policies and processes to disrupt advertising and monetisation incentives for purveyors of disinformation;
Political and issue-based advertising: to enable public disclosure of political ads, and to work towards a common understanding of “issue-based advertising” and how to address it;
Integrity of services: to put in place – and enforce – clear policies related to the misuse of automated bots;
Empowering consumers: to invest in products, technologies, and programs to help people identify information that may be false, to develop and implement trust indicators; and to support efforts to improve critical thinking and digital media literacy; and
Empowering the research community: to strengthen collaboration with the research and fact checking communities and encourage good faith independent efforts to understand and track disinformation.
These key commitments are a good baseline for further work, and we’re hopeful this Code will serve to drive change in the platform and advertising sectors, and complement parallel approaches to tackle this issue. Of course, as with any law, policy, or joint initiative, the proof of its effectiveness will be in the implementation.
As we’ve underlined previously, disinformation is often legal content; it is crucial not to put private companies in the role of assessing truthfulness, nor should it be left to a government entity. This code achieves that balance by not encroaching on fundamental rights such as free expression and the right to privacy, while still outlining steps that companies should take to thwart disinformation.
The Code process isn’t quite finished — in early October the Commission plans to host an event where the Working Group members will officially sign the code and present a roadmap of actions to be carried out over the next year.
We are thankful for the diligence of those involved, and we look forward to finalising this process with the European Commission and our community to apply this Code in practice.
Find the Code and Annex of best practices here, and the statement of the Working Group here.
On github, you can 'star' a project. It's a fairly meaningless way to mark your appreciation of a project hosted on that site and of course, the number doesn't really mean anything and it certainly doesn't reflect how popular or widely used or unused that particular software project is. But here I am, highlighting the fact that today I snapped the screenshot shown above when the curl project just reached this milestone: 10,000 stars.
In the great scheme of things, the most popular and starred projects on github of course have magnitudes more stars. Right now, curl ranks as roughly the 885th most starred project on github. According to github themselves, they host an amazing 25 million public repositories which thus puts curl in the top 0.004% star-wise.
There was appropriate celebration going on in the Stenberg casa tonight and here's a photo to prove it:
I took a photo when we celebrated 1,000 stars. It doesn't feel so long ago but was a little over 1500 days ago.
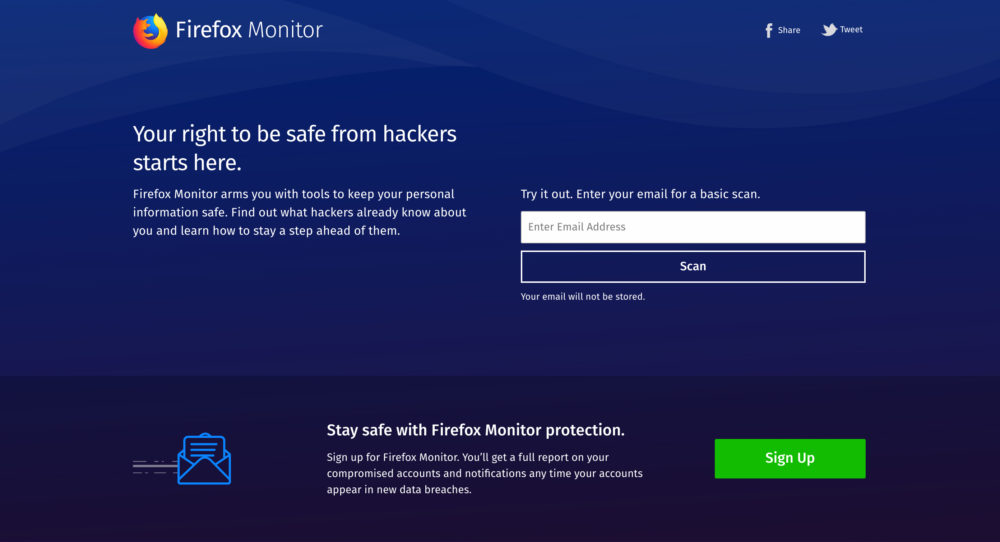
Data breaches, when information like your username and password are stolen from a website you use, are an unfortunate part of life on the internet today. It can be hard to keep track of when your information has been stolen, so we’re going to help by launching Firefox Monitor, a free service that notifies people when they’ve been part of a data breach. After testing this summer, the results and positive attention gave us the confidence we needed to know this was a feature we wanted to give to all of our users.
To give you a complete picture of what Firefox Monitor has to offer, here’s Cindy Hsiang, Product Manager for Firefox Monitor, to tell you more:
Here’s how Firefox Monitor helps you learn if you’ve been part of a data breach
Step 1 – Visit monitor.firefox.com to see if your email has been part of a data breach
Visit monitor.firefox.com and type in your email address. Through our partnership with Troy Hunt’s “Have I Been Pwned,” your email address will be scanned against a database that serves as a library of data breaches. We’ll let you know if your email address and/or personal info was involved in a publicly known past data breach. Once you know where your email address was compromised you should change your password and any other place where you’ve used that password.
Visit monitor.firefox.com and type in your email address
Step 2 – Learn about future data breaches
Sign up for Firefox Monitor using your email address and we will notify you about data breaches when we learn about them. Your email address will be scanned against those data breaches, and we’ll let you know through a private email if you were involved.
Firefox Monitor is just one of many things we’re rolling out this Fall to help people stay safe while online. Recently, we announced our roadmap to anti-tracking and in the next couple of months, we’ll release more features to arm and protect people’s rights online. For more on how to use Firefox Monitor, check out our Firefox Frontier blog. If you want to know more about the Firefox Monitor journey and how your feedback set this service in motion visit Matt Grimes’ Medium blog post.
Check out Firefox Monitor to see if you’ve been part of a data breach, and sign up to know if you’ve been affected the next time a data breach happens.
That sinking feeling. You’re reading the news and you learn about a data breach. Hackers have stolen names, addresses, passwords, survey responses from a service that you use. It seems … Read more
After months of prototyping and judging, Mozilla and the National Science Foundation are fueling the best and brightest ideas for bringing more Americans online
The grand prize winners are as novel as they are promising: An 80-foot tower in rural Appalachia that beams broadband connectivity to residents. And, an autonomous network that fits in two suitcases — and can be deployed after earthquakes and hurricanes.
Says Mark Surman, Mozilla’s Executive Director: “We launched NSF-WINS in early 2017 with the goal of bringing internet connectivity to rural areas, disaster-struck regions, and other offline or under-connected places. Currently, some 34 million Americans lack high-quality internet access. That means 34 million Americans are at a severe economic, educational, and social disadvantage.”
“Now — after months of prototyping and judging — Mozilla and NSF are awarding $1.6 million to the most promising projects in the competition’s two categories. It’s part of Mozilla’s mission to keep the internet open and accessible, and to empower the people on the front lines of that work.”
Says Jim Kurose, head of the Directorate for Computer and Information Science and Engineering (CISE) at the NSF: “By investing in affordable, scalable solutions like these, we can unlock opportunity for millions of Americans.”
The NSF-WINS ‘Off the Grid Internet Challenge’ $400,000 grand prize winner is…
HERMES
HERMES (High-frequency Emergency and Rural Multimedia Exchange System) by Rhizomatica in Philadelphia, PA.
When disasters strike, communications networks are among the first pieces of critical infrastructure to overload or fail.
HERMES bonds together an assortment of unexpected protocols — like GSM and short-wave radio — to fix this. HERMES enables local calling, SMS, and basic OTT messaging, all via equipment that can fit inside two suitcases.
“In an emergency, you want to be able to tell people you’re okay,” the Rhizomatica team says. “HERMES allows you to tell anyone, anywhere with a phone number that you’re okay. And that person can respond to you over text or with a voice message. It also allows someone from a central location to pass information to a disaster site, or to broadcast messages. We can now send a text message 700 miles through HERMES.”
The NSF-WINS ‘Smart Community Networks Challenge’ $400,000 grand prize winner is…
Southern Connected Communities Network
Southern Connected Communities Network (SCCN) by the Highlander Research and Education Center in New Market, TN.
Many communities across the U.S. lack reliable internet access. Sometimes commercial providers don’t supply affordable rates; sometimes a particular community is too isolated; sometimes the speed and quality of access is too slow.
SCCN leverages infrastructure and community to fix this and bring broadband to rural Appalachia. SCCN uses an 80-foot tower that draws wireless backbone from Knoxville, TN via the public 11 GHz spectrum. The tower then redistributes this broadband connectivity to local communities using line-of-sight technology. This tower is owned and operated by the local residents.
“When you live in the rural South, your kids’ education, your next job, your healthcare, and your right to a political voice all are limited by slow, expensive, unreliable, and corporate-controlled internet connectivity — and that’s if it exists at all,” says Allyn Maxfield-Steele, Co-Executive Director of the Highlander Center. “So we’re claiming internet like the human right it has become. We’re building a local digital economy governed by us and for us.”
In addition to these two grand prize winners, Mozilla and the NSF are awarding second-, third-, and fourth-place prizes in each category. The winners are:
Off-the-Grid Internet Challenge:
Second place ($250,000) — Project Lantern by Paper & Equator in New York, NY (and in collaboration with the Shared Reality Lab at McGill University). Project Lantern is a Wi-Fi hotspot device that lets you send maps and messages across town when the internet is down.
Third place ($100,000) — EmergenCell (previously SELN) by Spencer Sevilla in Seattle, WA. EmergenCell is an off-the-grid and self-contained LTE network in a box for emergency response.
Fourth place ($50,000) — Wind by the Guardian Project in Valhalla, NY. Wind is a network designed for opportunistic communication and sharing of local knowledge that provides off-grid services for everyday people, using the mobile devices they already have. The project also features decentralized software and a content distribution system.
Smart Community Networks Challenge:
Second place ($250,000) — The Equitable Internet Initiative by Allied Media Projects in Detroit, MI. The Equitable Internet Initiative (EII) is an effort to redistribute power, resources, and connectivity in Detroit through community Internet technologies. EII is working toward a future where neighbors are authentically connected, with relationships of mutual aid that sustain the social, economic, and environmental health of neighborhoods.
Third place ($100,000) — SMARTI (previously Solar Mesh) by the San Antonio Housing Authority in San Antonio, TX. In efforts to bridge the digital divide in San Antonio, the 19th worst connected city in the U.S., the San Antonio Housing Authority has created a prototype that marries solar energy with Wi-Fi mesh technologies.
Fourth place ($50,000) — ESU 5 Homework Hotspot by Educational Service Unit 5 in Beatrice, NE. The ESU 5 Homework Hotspots are TV white space hotspots that help bridge the connectivity gap for students in Rural Nebraska.
Note: In February 2018, Mozilla and the NSF announced the first batch of winners: between $10,000 and $60,000 in grants for 20 promising design concepts. See those winners here.
Over two years ago I wrote about the C++ Lifetimes proposal and some of my concerns about it. Just recently, version 1.0 was released with a blog post by Herb Sutter.
Comparing the two versions shows many important changes. The new version is much clearer and more worked-out, but there are also significant material changes. In particular the goal has changed dramatically. Consider the "Goal" section of version 0.9.1.2: (emphasis original)
Goal: Eliminate leaks and dangling for */&/iterators/views/ranges We want freedom from leaks and dangling – not only for raw pointers and references, but all generalized Pointers such as iterators—while staying true to C++ and being adoptable: 1. We cannot tolerate leaks (failure to free) or dangling (use-after-free). For example, a safe std:: library must prevent dangling uses such as auto& bad = vec[0]; vec.push_back(); bad = 42;.
Version 1.0 doesn't have a "Goal" section, but its introduction says
This paper defines the Lifetime profile of the C++ Core Guidelines. It shows how to efficiently diagnose many common cases of dangling (use-after-free) in C++ code, using only local analysis to report them as deterministic readable errors at compile time.
The new goal is much more modest, I think much more reasonable, and highly desirable! (Partly because "modern C++" has introduced some extremely dangerousnew idioms.)
The limited scope of this proposal becomes concrete when you consider its definition of "Owner". An Owner can own at most one type of data and it has to behave much like a container or smart pointer. For example, consider a data structure owning two types of data:
This structure cannot be an Owner. It is also not an Aggregate (a struct/class with public fields whose fields are treated as separate variables for the purposes of analysis). It has to be a Value. The analysis has no way to refer to data owned by Values; as far as I can tell, there is no way to specify or infer accurate lifetimes for the return values of get_a and get_b, and apparently in this case the analysis defaults to conservative assumptions that do not warn. (The full example linked above has a trivial dangling pointer with no warnings.) I think this is the right approach, given the goal is to catch some common errors involving misuse of pointers, references and standard library features. However, people need to understand that code free of C++ Lifetime warnings can still easily cause memory corruption. (This vindicates the title of my previous blog post to some extent; insofar as C++ Lifetimes was intended to create a safe subset of C++, that promise has not eventuated.)
The new version has much more emphasis on annotation. The old version barely mentioned the existence of a [[lifetime]] annotation; the new version describes it and shows more examples. It's now clear you can use [[lifetime]] to group function parameters and into lifetime-equivalence classes, and you can also annotate return values and output parameters.
The new version comes with a partial Clang implementation, available on godbolt.org. Unfortunately that implementation seems to be very partial. For example the following buggy program is accepted without warnings:
int& f(int& a) { return a; } int& hello() { int x = 0; return f(x); }
It's pretty clear from the spec that this should report a warning, and the corresponding program using pointers does produce a warning. OTOH there are some trivial false positives I don't understand:
int* hello(int*& a) { return a; }
:2:5: warning: returning a dangling Pointer [-Wlifetime] return a; ^ :1:12: note: it was never initialized here int* hello(int*& a) { ^
The state of this implementation makes it unreliable as a guide to how this proposal will work in practice, IMHO.
On September 25th 2017, I received the email that first explained to me that I had been awarded the Polhem Prize.
Du har genom ett omfattande arbete vaskats fram som en v"ardig mottagare av arets Polhemspris. Det har skett genom en nomineringskommitt'e och slutligen ett rad med bred sammans"attning. Priset delas ut av Kungen den 19 oktober pa Tekniska mus'eet.
My attempt of an English translation:
You have been selected as a worthy recipient of this year's Polhem prize through extensive work.It has been through a nomination committee and finally a council of broad composition.The prize is awarded by the King on October 19th at the Technical Museum.
A gold medal
At the award ceremony in October 2017 I received the gold medal at the most fancy ceremony I could ever wish for, where I was given the most prestigious award I couldn't have imagined myself even being qualified for, handed over by no other than the Swedish King.
An entire evening with me in focus, where I was the final grand finale act and where my life's work was the primary reason for all those people being dressed up in fancy clothes!
Things have settled down since. The gold medal has started to get a little dust on it where it lies here next to me on my work desk. I still glance at it every once in a while. It still feels surreal. It's a fricking medal in pure gold with my name on it!
I almost forget the money part of the prize. I got a lot of money as well, but in retrospect it is really the honors, that evening and the gold medal that stick best in my memory. Money is just... well, money.
So did the award and prize make my life any different? Yes sure, a little, and I'll tell you how.
What's all that time spent on?
My closest surrounding of friends and family got a better understanding of what I've actually been doing all these long hours, all these years and more than one phrase in the style of "oh, so you actually did something useful?!" have been uttered.
Certainly I've tried to explain to them before, but nothing works as good as a gold medal from an award committee to say that what I do is actually appreciated "out there" and it has made a serious impact on the world.
I think I'm considered a little less weird now when I keep spending night hours in front of my computer when the house is otherwise dark and silent. Well, maybe still weird, but at least my weirdness has proven to result in something useful for mankind and that's more than many other sorts of weird do... We all have hobbies.
What is curl?
Family and friends have gotten a rudimentary level of understanding of what curl is and what it does. I'm not suggesting they fully grasp it or know what an "internet protocol" is now, but at least a lot of people understand that it works with "internet transfers". It's not like people were totally uninterested before, but when I was given this prize - by a jury of engineers no less - that says this is a significant invention and accomplishment with a value that "can not be overestimated", it made them more interested. The little video that was produced helped:
Some mysteries remain
People in general still have a hard time to grasp the reach of the project, how much time I've spent so far on it, how I can find motivation to keep up the work and not the least how this is all given away for free for everyone.
The simple fact that these are all questions that I've been asked I think is a small reward in itself. I think the fact that I was awarded this prize for my work on Open Source is awesome and I feel honored to be a person who introduces this way of thinking to some of the people who previously would think that you have to sell proprietary things or earn a lot of money for your products in order to impact and change society as a whole.
Not widely known
The Polhem prize is not widely known in Sweden among the general populace and thus neither is the fact that I won it. Only a very special subset of people know about this. Of course it is even less known outside of Sweden and in fact the information about the prize given in English is very sparse.
Next year's winner
The other day I received my invitation to participate in this year's award ceremony on November 14. Of course I'll happily accept that and I will be there and celebrate the winner this year!
The curl project
How did the prize affect the project itself, the project that I was awarded for having cared for this long?
It hasn't affected it much at all (as far as I can tell). The project has moved along like before and we've worked on fixing bugs and added features and cool things over time after my award just as we did before it. That's how it has felt like. Business as usual.
If anything, I think I might have gotten some renewed energy and interest in the project and the commit author statistics actually show that my commit frequency has gone up since around the time I got the award. Our gitstats show that I've done more than half of the commits every single month the last year, most of this time even more than 70% of the commits.
I may have served twenty years here, but I'm not done yet!
A security vulnerability was found in the standard library where if a
large number was passed to str::repeat it could cause a buffer overflow
after an integer overflow. If you do not call the str::repeat function you
are not affected. This has been addressed by unconditionally panicking in
str::repeat on integer overflow. More details about this can be found in the
security announcement.
Понедельник, 24 Сентября 2018 г. 21:44
+ в цитатник
A farewell and au revoir to a great gentleman in making the most of your old Mac, Charles W. Moore, who passed away at his home in rural Canada on September 16 after a long illness. Mr Moore was an early fan of TenFourFox, even back in the old bad Firefox 4 beta days, and he really made his famous Pismo PowerBook G3 systems work hard for it. Charles definitely was of the same mind I think a lot of our readers here are: "Even after going on a decade and a half, I still find them [his Pismos] a pleasure to use within the context of what they’re still good at." I'm sure most of us will agree the same is true for any classic computer in general and particularly Power Macs as a whole given how underwhelming Apple's current Mac offerings are. While later on he upgraded to a 17" Big Al, and although I admire the Pismo my favourite Mac laptop to this day remains the wonderfully customizable PowerBook 1400 (with a G3/466, thank you very much, and still looking for a solar cover!), I can think of few people who bore the standard of the classic Mac as a useful productivity device for as long as he did. Even old tools can still be the right tools when given the right job to do.
Понедельник, 24 Сентября 2018 г. 07:00
+ в цитатник
This is a report on the second “office hours”, in which we
discussed how to setup a series of services or actors that communicate
with one another. This is a classic kind of problem in Rust: how to
deal with cyclic data. Usually, the answer is that the cycle is not
necessary (as in this case).
The setup
To start, let’s imagine that we were working in a GC’d language, like
JavaScript. We want to have various “services”, each represented by an
object. These services may need to communicate with one another, so we
also create a directory, which stores pointers to all the
services. As each service is created, they add themselves to the
directory; when it’s all setup, each service can access all other
services. The setup might look something like this:
If you try to translate this to Rust, you will run into a big mess.
For one thing, Rust really prefers for you to have all the pieces of
your data structure ready when you create it, but in this case when we
make the directory, the services don’t exist. So we’d have to make the
struct use Option, sort of like this:
This is annoying though because, once the directory is initialized, these
fields will never be None.
And of course there is a deeper problem: who is the “owner” in this
cyclic setup? How are we going to manage the memory? With a GC, there
is no firm answer to this question: the entire cycle will be collected
at the end, but until then each service keeps every other service
alive.
You could setup something with Arc (atomic reference counting)
in Rust that has a similar flavor. For example, the directory might
have an Arc to each service and the services might have weak refs
back to the directory. But Arc really works best when the data is
immutable, and we want services to have state. We could solve that
with atomics and/or locks, but at this point we might want to step
back and see if there is a better way. Turns out, there is!
Translating the setup to Rust without cycles
Our base assumption was that each service in the system needed access
to one another, since they will be communicating. But is that really
true? These services are actually going to be running on different
threads: all they really need to be able to do is to send each other
messages. In particular, they don’t need access to the private bits
of state that belong to each service.
In other words, we could rework out directory so that – instead of
having a handle to each service – it only has a handle to a
mailbox for each service. It might look something like this:
#[derive(Clone)]structDirectory{service1:Sender<Message1>,service2:Sender<Message2>,}/// Whatever kind of message service1 expects.structMessage1{..}/// Whatever kind of message service2 expects.structMessage2{..}
What is this Sender type? It is part of the channels that ship in
Rust’s standard library. The idea of a channel is that when you create
it, you get back two “entangled” values: a Sender and a Receiver. You
send values on the sender and then you read them from the receiver;
moreover, the sender can be cloned many times (the receiver cannot).
The idea here is that, when you start your actor, you create a channel
to communicate with it. The actor takes the Receiver and the
Sender goes into the directory for other servies to use.
Using channels, we can refactor our setup. We begin by making the
channels for each actor. Then we create the directory, once we have
all the pieces it needs. Finally, we can start the actors themselves:
fnmake_directory(){usestd::sync::mpsc::channel;// Create the channelslet(sender1,receiver1)=channel();let(sender2,receiver2)=channel();// Create the directoryletdirectory=Directory{service1:sender1,service2:sender2,};// Start the actorsstart_service1(&directory,receiver1);start_service2(&directory,receiver1);}
Starting a service looks kind of like this:
fnstart_service1(directory:&Directory,receiver:Receiver<Message1>){// Get a handle to the directory for ourselves.// Note that cloning a sender just produces a second handle// to the same receiver.letmutdirectory=directory.clone();std::thread::spawn(move||{// For each message received on `receiver`...formessageinreceiver{// ... process the message. Along the way,// we might send a message to another service:matchdirectory.service2(Message2{..}){Ok(())=>/* message successfully sent */,Err(_)=>/* service2 thread has crashed or otherwise stopped */,}}});}
This example also shows off how Rust channels know when their
counterparts are valid (they use ref-counting internally to manage
this). So, for example, we can iterate over a Receiver to get every
incoming message: once all senders are gone, we will stop
iterating. Beware, though: in this case, the directory itself holds one of
the senders, so we need some sort of explicit message to stop the actor.
Similarly, when you send a message on a Rust channel, it knows if the
receiver has gone away. If so, send will return an Err value, so
you can recover (e.g., maybe by restarting the service).
Implementing our own (very simple) channels
Maybe it’s interesting to peer “beneath the hood” a bit into channels.
It also gives some insight into how to generalize what we just did
into a pattern. Let’s implement a very simple channel, one with a fixed
length of 1 and without all the error recovery business of counting
channels and so forth.
To start with, we need to create our Sender and Receiver types.
We see that each of them holds onto a shared value, which contains
the actual state (guarded by a mutex):
usestd::sync::{Arc,Condvar,Mutex};pubstructSender<T:Send>{shared:Arc<SharedState<T>>}pubstructReceiver<T:Send>{shared:Arc<SharedState<T>>}// Hidden shared state, not exposed// to end-usersstructSharedState<T:Send>{value:Mutex<Option<T>>,condvar:Condvar,}
To create a channel, we make the shared state, and then give the
sender and receiver access to it:
Finally, we can implement send on the sender. It will try to
store the value into the mutex, blocking so long as the mutex is None:
impl<T:Send>Sender<T>{pubfnsend(&self,value:T){letmutshared_value=self.shared.value.lock().unwrap();loop{ifshared_value.is_none(){*shared_value=Some(value);self.shared.condvar.notify_all();return;}// wait until the receiver readsshared_value=self.shared.condvar.wait(shared_value).unwrap();}}}
Finally, we can implement receive on the Receiver. This just waits
until the shared.value field is Some, in which case it overwrites
it with None and returns the inner value:
impl<T:Send>Receiver<T>{pubfnreceive(&self)->T{letmutshared_value=self.shared.value.lock().unwrap();loop{ifletSome(value)=shared_value.take(){self.shared.condvar.notify_all();returnvalue;}// wait until the sender sendsshared_value=self.shared.condvar.wait(shared_value).unwrap();}}}
In our example thus far we used a static Directory struct with
fields. We might like to change to a more flexible setup, in which the
set of services grows and/or changes dynamically. To do that, I would
expect us to replace the directory with a HashMap mapping from kind
of service name to a Sender for that service. We might even want to
put that directory behind a mutex, so that if one service panics, we
can replace the Sender with a new one. But at that point we’re
building up an entire actor infrastructure, and that’s too much for
one post, so I’ll stop here. =)
Generalizing the pattern
So what was the general lesson here? In often happens that, when
writing in a GC’d language, we get accustomed to lumping together all
kinds of data together, and then knowing what data we should and
should not touch. In our original JS example, all the services had a
pointer to the complete state of one another – but we expected them
to just leave messages and not to mutate the internal variables of
other services. Rust is not so trusting.
In Rust, it often pays to separate out the “one big struct” into
smaller pieces. In this case, we separated out the “message
processing” part of a service from the rest of the service state. Note
that when we implemented this message processing – e.g., our channel
impl – we still had to use some caution. We had to guard the data
with a lock, for example. But because we’ve separated the rest of the
service’s state out, we don’t need to use locks for that, because no
other service can reach it.
This case had the added complication of a cycle and the associated
memory management headaches. It’s worth pointing out that even in our
actor implementation, the cycle hasn’t gone away. It’s just reduced in
scope. Each service has a reference to the directory, and the
directory has a reference to the Sender for each service. As an example
of where you can see this, if you have your service iterate over all
the messages from its receiver (as we did):
formsginself.receiver{..}
This loop will continue until all of the senders associated with this
Receiver go away. But the service itself has a reference to the
directory, and that directory contains a Sender for this receiver,
so this loop will never terminate – unless we explicitly
break. This isn’t too big a surprise: Actor lifetimes tend to
require “active management”. Similar problems arise in GC systems when
you have big cycles of objects, as they can easily create leaks.











 At the award ceremony in October 2017 I received the gold medal at the most fancy ceremony I could ever wish for, where I was given the most prestigious award I couldn't have imagined myself even being qualified for, handed over by no other than the Swedish King.
At the award ceremony in October 2017 I received the gold medal at the most fancy ceremony I could ever wish for, where I was given the most prestigious award I couldn't have imagined myself even being qualified for, handed over by no other than the Swedish King.





