Marco Zehe: WAI-ARIA menus, and why you should generally avoid using them |
|
|
Mozilla Localization (L10N): L10N Report: September Edition |
|
|
Daniel Stenberg: More curl bug bounty |
Together with Bountygraph, the curl project now offers money to security researchers for report security vulnerabilities to us.
https://bountygraph.com/programs/curl
The idea is that sponsors donate money to the bounty fund, and we will use that fund to hand out rewards for reported issues. It is a way for the curl project to help compensate researchers for the time and effort they spend helping us improving our security.
Right now the bounty fund is very small as we just started this project, but hopefully we can get a few sponsors interested and soon offer "proper" rewards at decent levels in case serious flaws are detected and reported here.
If you're a company using curl or libcurl and value security, you know what you can do...
Already before, people who reported security problems could ask for money from Hackerone's IBB program, and this new program is in addition to that - even though you won't be able to receive money from both bounties for the same issue.
After I announced this program on twitter yesterday, I did an interview with Arif Khan for latesthackingnews.com. Here's what I had to say:
Q: You have launched a self-managed bug bounty program for the first time. Earlier, IBB used to pay out for most security issues in libcurl. How do you think the idea of self-management of a bug bounty program, which has some obvious problems such as active funding might eventually succeed?
First, this bounty program is run on bountygraph.com so I wouldn't call it "self-managed" since we're standing on a lot of infra setup and handled by others.
To me, this is an attempt to make a bounty program that is more visible as clearly a curl bounty program. I love Hackerone and the IBB program for what they offer, but it is A) very generic, so the fact that you can get money for curl flaws there is not easy to figure out and there's no obvious way for companies to sponsor curl security research and B) they are very picky to which flaws they pay money for ("only critical flaws") and I hope this program can be a little more accommodating - assuming we get sponsors of course.
Will it work and make any differences compared to IBB? I don't know. We will just have to see how it plays out.
Q: How do you think the crowdsourcing model is going to help this bug bounty program?
It's crucial. If nobody sponsors this program, there will be no money to do payouts with and without payouts there are no bounties. Then I'd call the curl bounty program a failure. But we're also not in a hurry. We can give this some time to see how it works out.
My hope is though that because curl is such a widely used component, we will get sponsors interested in helping out.
Q: What would be the maximum reward for most critical a.k.a. P0 security vulnerabilities for this program?
Right now we have a total of 500 USD to hand out. If you report a p0 bug now, I suppose you'll get that. If we just get sponsors, I'm hoping we should be able to raise that reward level significantly. I might be very naive, but I think we won't have to pay for very many critical flaws.
It goes back to the previous question: this model will only work if we get sponsors.
Q: Do you feel there’s a risk that bounty hunters could turn malicious?
I don't think this bounty program particularly increases or reduces that risk to any significant degree. Malicious hunters probably already exist and I would assume that blackhat researchers might be able to extract more money on the less righteous markets if they're so inclined. I don't think we can "outbid" such buyers with this program.
Q: How will this new program mutually benefit security researchers as well as the open source community around curl as a whole?
Again, assuming that this works out...
Researchers can get compensated for the time and efforts they spend helping the curl project to produce and provide a more secure product to the world.
curl is used by virtually every connected device in the world in one way or another, affecting every human in the connected world on a daily basis. By making sure curl is secure we keep users safe; users of countless devices, applications and networked infrastructure.

Update: just hours after this blog post, Dropbox chipped in 32,768 USD to the curl bounty fund...
|
|
Daniel Pocock: Resigning as the FSFE Fellowship's representative |
I've recently sent the following email to fellows, I'm posting it here for the benefit of the wider community and also for any fellows who don't receive the email.
Dear fellows,
Given the decline of the Fellowship and FSFE's migration of fellows into a supporter program, I no longer feel that there is any further benefit that a representative can offer to fellows.
With recent blogs, I've made a final effort to fulfill my obligations to keep you informed. I hope fellows have a better understanding of who we are and can engage directly with FSFE without a representative. Fellows who want to remain engaged with FSFE are encouraged to work through your local groups and coordinators as active participation is the best way to keep an organization on track.
This resignation is not a response to any other recent events. From a logical perspective, if the Fellowship is going to evolve out of a situation like this, it is in the hands of local leaders and fellowship groups, it is no longer a task for a single representative.
There are many positive experiences I've had working with people in the FSFE community and I am also very grateful to FSFE for those instances where I have been supported in activities for free software.
Going forward, leaving this role will also free up time and resources for other free software projects that I am engaged in.
I'd like to thank all those of you who trusted me to represent you and supported me in this role during such a challenging time for the Fellowship.
Sincerely,
Daniel Pocock
|
|
Firefox UX: 8 tips for hosting your first participatory workshop |
|
|
Mozilla Addons Blog: The future of themes is here! |
Themes have always been an integral part of the add-ons ecosystem and addons.mozilla.org (AMO). The current generation of themes – also known as lightweight themes and previously known as Personas (long story) – were introduced to AMO in 2009. There are now over 400 thousand of them available on AMO. Today we’re announcing the AMO launch of the next major step in the evolution of Firefox themes.
If you follow this blog, this shouldn’t come as a surprise. We’ve talked about theme updates a few times before. We actually turned on the new theme submission flow for testing a couple of weeks ago, but didn’t remove the old one. We’ve now flipped the switch and AMO will only accept the new themes.
Lightweight themes allowed designers to set a background image for the main browser toolbox, as well as the text color and background color. With this update, themes let you do much more:
Here’s an example of one of the recently-submitted themes using some of these new properties:
![]()
A detailed list of the supported theme properties can be found in this MDN article. If you scroll down to the compatibility table, you’ll find many properties that only very recent versions of Firefox support. That’s because Firefox engineers are still adding new theme capabilities, making them more powerful with every release.
If you’re a theme designer, the submission flow for themes has changed a bit.
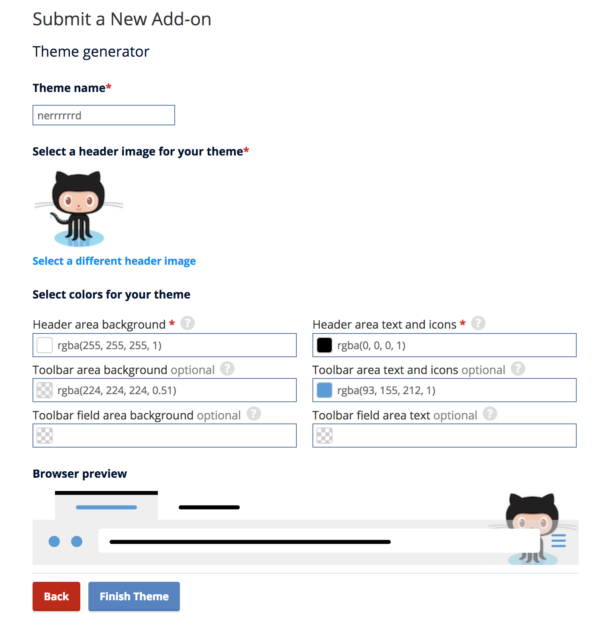
If you run into any problems with these new tools, please report it here.
The Personas Plus extension has been a handy companion for theme designers for years. It makes it easy to create themes, preview them, and use them locally. Its successor in the new world of themes is Firefox Color.
Firefox Color is exclusively a development tool for themes, so it doesn’t match all features in Personas Plus. However, it should cover what is needed for easy theme creation.
What about the 400K+ themes already hosted on AMO? We’re keeping them, of course, but we will transform them to the new format later this year. So, if you’re a theme designer and want your theme to be updated, don’t worry, we got you covered. And please don’t submit duplicate themes!
After the migration is done, we’ll notify you about it. The main difference you’ll notice is the new preview image in the theme page. You’ll then be able to submit new versions of your theme that take advantage of the new theme properties.
You’ll also notice that all new and migrated themes have different editing tools to change their descriptions. They are very similar to the tools we use for extensions. They may take a bit of getting used to, but they provide great benefits over the lightweight theme tools. You’ll be able to set a Contributions URL, so your users can compensate you for your work. Also, you get a detailed stats dashboard so you can learn about your users.
This level of success not guaranteed
This may seem like a small step, but it’s actually been a large undertaking. It’s taken years and over a dozen people on the Firefox and AMO teams to finally get this out the door. I won’t even try to list everyone because I’m sure I’ll forget some (but thank you all anyway!). We’re very excited with about these new themes, and hope they will lead to even more and better Firefox customization.
The post The future of themes is here! appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/09/20/future-themes-here/
|
|
Hacks.Mozilla.Org: Performance-Tuning a WebVR Game |
For the past couple of weeks, I have been working on a VR version of one of my favorite puzzle games, the Nonogram, also known as Picross or Griddlers. These are puzzles where you must figure out which cells in a grid are colored in by using column and row counts. I thought this would be perfect for a nice, relaxing VR game. I call it Lava Flow.

Since Lava Flow is meant to be a casual game, I want it to load quickly. My goal is for the whole game to be as small as possible and load under 10 seconds on a 3G connection. I also wanted it to run at a consistent 60 frames per second (fps) or better. Consistent frame rate is the most important consideration when developing WebVR applications.
Before I can improve the performance or size, I need to know where I’m starting. The best way to see how big my application really is is to use the Network tab of the Firefox Developer tools. Here’s how to use it.
 Open the Network tab of Firefox developer tools. Click disable cache, then reload the page. At the bottom of the page, I can see the total page size. When I started this project it was at 1.8MB.
Open the Network tab of Firefox developer tools. Click disable cache, then reload the page. At the bottom of the page, I can see the total page size. When I started this project it was at 1.8MB.
My application uses three.js, the popular open source 3D library. Not surprisingly, the biggest thing is three.js itself. I’m not using the minified version, so it’s over 1MB! By loading three.min.js instead, the size is now 536KB vs 1110KB. Less than half the size.
The game uses two 3D models of rocks. These are in GLB format, which is compressed and optimized for web usage. My two rocks are already weighing in at less than 3KB each, so there is not much to optimize there. The JavaScript code I’ve written is a bunch of small files. I could use a compressor later to reduce the fetch count, but it’s not worth worrying about yet.
The next biggest resources are the two lava textures. They are PNGs and collectively add up to 561KB.


I re-compressed the two lava textures as JPEGs with medium quality. Also, since the bump map image doesn’t need to be as high resolution as the color texture, I resized it from 512x512 to 128x128. That dropped the sizes from 234KB to 143KB and 339KB to 13KB. Visually there isn’t much difference, but the page is now down to 920KB.
The next two big things are a JSON font and the GLTFLoader JavaScript library. Both of those can be gzip compressed, so I won’t worry about them yet.
Now let’s play the game and make sure everything is still working. It looks good. Wait, what’s that? A new network request? Of course, the audio files! The sound isn’t triggered until the first user interaction. Then it downloads over 10MB of MP3s. Those aren’t accounted for by the DefaultLoader because I’m loading it through audio tags instead of JavaScript. Gah!
I don’t really want to wait for the background music to load, however it would be nice to have the sound effects preloaded. Plus audio elements don’t have the control I need for sound effects, nor are they 3D-capable. So I moved those to be loaded as Audio objects with the AudioLoader within three.js. Now they are fully loaded on app start and are accounted for in the download time.
With all of the audio (except the background theme), everything is 2.03 MB. Getting better.
There is a weird glitch where the whole scene pauses when rebuilding the game board. I need to figure out what’s going on there. To help debug the problems, I need to see the frames per second inside of VR Immersive mode. The standard stats.js module that most three.js apps use actually works by overlaying a DOM element on top of the WebGL canvas. That’s fine most of the time but won’t work when we are in immersive mode.
To address this, I created a little class called JStats which draws stats to a small square anchored to the top of the VR view. This way you can see it all the time inside of immersive mode, no matter what direction you are looking.

I also created a simple timer class to let me measure how long a particular function takes to run. After a little testing, I confirmed that anywhere from 250 to 450 msec is required to run the setupGame function that happens every time the player gets to a new level.
I dug into the code and found two things. First, each cell is using its own copy of the rounded rectangle geometry and material. Since this is the same for every cell, I can just create it once and reuse it for each cell. The other thing I discovered is that I’m creating the text overlays every time the level changes. This isn’t necessary. We only need one copy of each text object. They can be reused between levels. By moving this to a separate setupText function, I saved several hundred milliseconds. It turns out triangulating text is very expensive. Now the average board setup is about 100 msec, which shouldn’t be noticeable, even on a mobile headset.
As a final test I used the network monitor to throttle the network down to 3G speeds, with the cache disabled. My goal is for the screen to first be painted within 1 second and the game ready to play within 10 seconds. The network screen says it takes 12.36 seconds. Almost there!
As I worked on the game, I realized a few things were missing.
The progress bar is easy to build because the DefaultLoadingManager provides callbacks. I created a progress bar in the HTML overlay like this:
Then update it whenever the loading manager tells me something is loaded.
THREE.DefaultLoadingManager.onProgress = (url, loaded, total) => {
$("#progress").setAttribute('value',100*(loaded/total))
}
Combined with some CSS styling it looks like this:

Next up is music and effects. Adding the extra music is another 133KB + 340KB, which bloats the app up nearly another half a megabyte. Uh oh.
I can get a little bit of that back with fonts. Currently I’m using one of the standard three.js fonts which are in JSON format. This is not a terribly efficient format. Files can be anywhere from 100KB to 600KB depending on the font. It turns out three.js can now load TrueType fonts directly without first converting to JSON format. The font I picked was called Hobby of Night by deFharo, and it’s only 80KB. However, to load TTF file requires TTFLoader.js (4KB) and opentype.min.js which is 124KB. So I’m still loading more than before, but at least opentype.min.js will be amortized across all of the fonts. It doesn’t help today since I’m only using one font, but it will help in the future. So that’s another 100KB or so I’m using up.
The lesson I’ve learned today is that optimization is always two steps forward and one step back. I have to investigate everything and spend the time polishing both the game and loading experience.
The game is currently about 2.5MB. Using the Good 3G setting, it takes 13.22 seconds to load.
When I added the new sound effects, I thought of something. All of them are coming from FreeSound.org which generally provides them in WAV format. I have used iTunes to convert them to MP3s, but iTunes may not use the most optimized format. Looking at one of the files I discovered it was encoded at 192KBps, the default for iTunes. Using a command line tool, I bet I could compress them further.
I installed ffmpeg and reconverted the 30-second song like this:
ffmpeg -i piano.wav -codec:a libmp3lame -qscale:a 5 piano.mp3
It went from 348KB to 185KB. That’s a 163KB savings! In total the sounds went from 10MB to 4.7MB, greatly reducing the size of my app. The total download size to start the game without the background music is now 2.01MB.
I loaded the game to my web server here and tested it on my VR headsets to make sure everything still works. Then I tried loading the public version in Firefox again with the network tab open. I noticed something weird. The total download size is smaller! In the status bar it says: 2.01 MB/1.44 MB transferred. On my local web server where I do development, it says: 2.01 MB/2.01 MB transferred. That’s a huge difference. What accounts for this?

I suspect it’s because my public web server does gzip compression and my local web server does not. For an MP3 file this makes no difference, but for highly compressible files like JavaScript it can be huge. For example, the three.min.js file is 536.08KB uncompressed but an astounding 135.06KB compressed. Compression makes a huge difference. And now the download is just 1.44MB, and download time over Good 3G is 8.3 seconds. Success!
I normally do all of my development on the local web server and only use the public one when the project is ready. This is a lesson to look at everything and always measure.
These are the lessons I learned while tuning my application. Making the first version of a game is easy. Getting it ready for release is hard. It’s a long slog, but the end results are so worth it. The difference between a prototype and a game is sweating the little details. I hope these tips help you make your own great WebVR experiences.
The post Performance-Tuning a WebVR Game appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2018/09/performance-tuning-webvr-game/
|
|
Chris AtLee: So long Buildbot, and thanks for all the fish |
Last week, without a lot of fanfare, we shut off the last of the Buildbot infrastructure here at Mozilla.

Our primary release branches have been switched over to taskcluster for some time now. We needed to keep buildbot running to support the old ESR52 branch. With the release of Firefox 60.2.0esr earlier this month, ESR52 is now officially end-of-life, and therefore so is buildbot here at Mozilla.
Looking back in time, the first commits to our buildbot-configs repository was over 10 years ago on April 27, 2008 by Ben Hearsum: "Basic Mozilla2 configs". Buildbot usage at Mozilla actually predates that by at least two years, Ben was working on some patches in 2006.
Earlier in my career here at Mozilla, I was doing a lot of work with Buildbot, and blogged quite a bit about our experiences with it.
Buildbot served us well, especially in the early days. There really were no other CI systems at the time that could operate at Mozilla's scale.
Unfortunately, as we kept increasing the scale of our CI and release infrastructure, even buildbot started showing some problems. The main architectural limitations of buildbot we encountered were:
Long lived TCP sessions had to stay connected to specific server processes. If the network blipped, or you needed to restart a server, then any jobs running on workers were interrupted.
Its monolithic design meant that small components of the project were hard to develop independently from each other.
The database schema used to implement the job queue became a bottleneck once we started doing hundreds of thousands of jobs a day.
On top of that, our configuration for all the various branches and platforms had grown over the years to a complex set of inheritance rules, defaults, and overrides. Only a few brave souls outside of RelEng managed to effectively make changes to these configs.
Today, much much more of the CI and release configuration lives in tree. This has many benefits including:
Changes are local to the branches they land on. They ride the trains naturally. No need for ugly looooooops.
Developers can self-service most of their own requests. Adding new types of tests, or even changing the compiler are possible without any involvement from RelEng!
Buildbot is dead! Long live taskcluster!
|
|
QMO: Firefox 63 Beta 10 Testday, September 28th |
Hello Mozillians,
We are happy to let you know that Friday, September 28th, we are organizing Firefox 63 Beta 10 Testday. We’ll be focusing our testing on: Firefox Customize, Font UI, Tracking protection.
Check out the detailed instructions via this etherpad.
No previous testing experience is required, so feel free to join us on #qa IRC channel where our moderators will offer you guidance and answer your questions.
Join us and help us make Firefox better!
See you on Friday!
https://quality.mozilla.org/2018/09/firefox-63-beta-10-testday-september-27th/
|
|
Hacks.Mozilla.Org: Dweb: Creating Decentralized Organizations with Aragon |
In the Dweb series, we are covering projects that explore what is possible when the web becomes decentralized or distributed. These projects aren’t affiliated with Mozilla, and some of them rewrite the rules of how we think about a web browser. What they have in common: These projects are open source and open for participation, and they share Mozilla’s mission to keep the web open and accessible for all.
While many of the projects we’ve covered build on the web as we know it or operate like the browsers we’re familiar with, the Aragon project has a broader vision: Give people the tools to build their own autonomous organizations with social mores codified in smart contracts. I hope you enjoy this introduction to Aragon from project co-founder Luis Cuende.
– Dietrich Ayala
I’m Luis. I cofounded Aragon, which allows for the creation of decentralized organizations. The principles of Aragon are embodied in the Aragon Manifesto, and its format was inspired by the Mozilla Manifesto!
Here’s a quick summary.

With Aragon, developers can create new apps, such as voting mechanisms, that use smart contracts to leverage decentralized governance and allow peers to control resources like funds, membership, and code repos.
Aragon is built on Ethereum, which is a blockchain for smart contracts. Smart contracts are software that is executed in a trust-less and transparent way, without having to rely on a third-party server or any single point of failure.
Aragon is at the intersection of social, app platform, and blockchain.
The Aragon app is one of few truly decentralized apps. Its smart contracts and front end are upgrade-able thanks to aragonOS and Aragon Package Manager (APM). You can think of APM as a fully decentralized and community-governed NPM. The smart contracts live on the Ethereum blockchain, and APM takes care of storing a log of their versions. APM also keeps a record of arbitrary data blobs hosted on decentralized storage platforms like IPFS, which in our case we use for storing the front end for the apps.
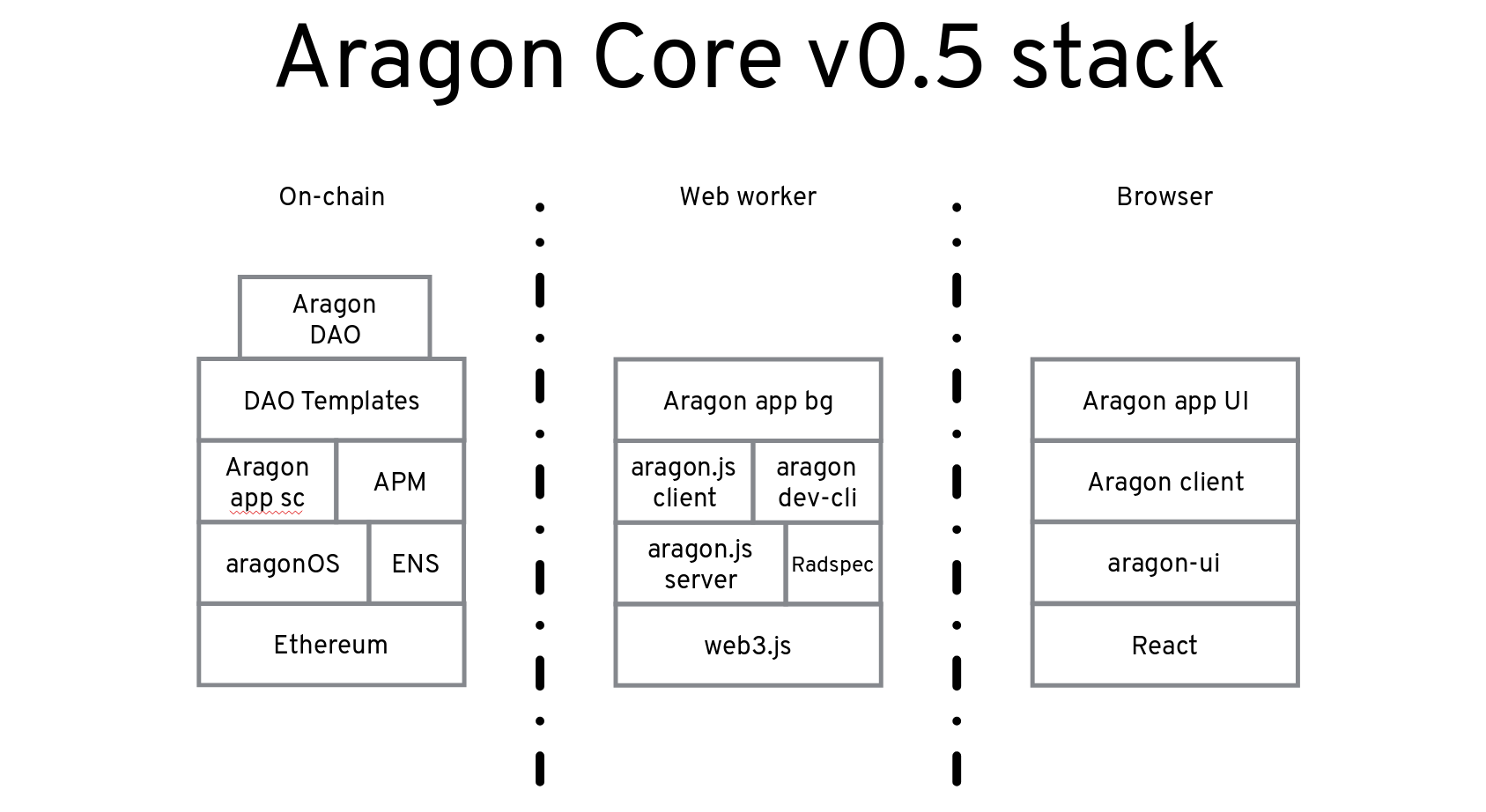
The Aragon app allows users to install new apps into their organization, and those apps are embedded using sandboxed iframes. All the apps use Aragon UI, therefore users don’t even know they are interacting with apps made by different developers. Aragon has a very rich permission system that allows users to set what each app can do inside their organization. An example would be: Up to $1 can be withdrawn from the funds if there’s a vote with 51% support.
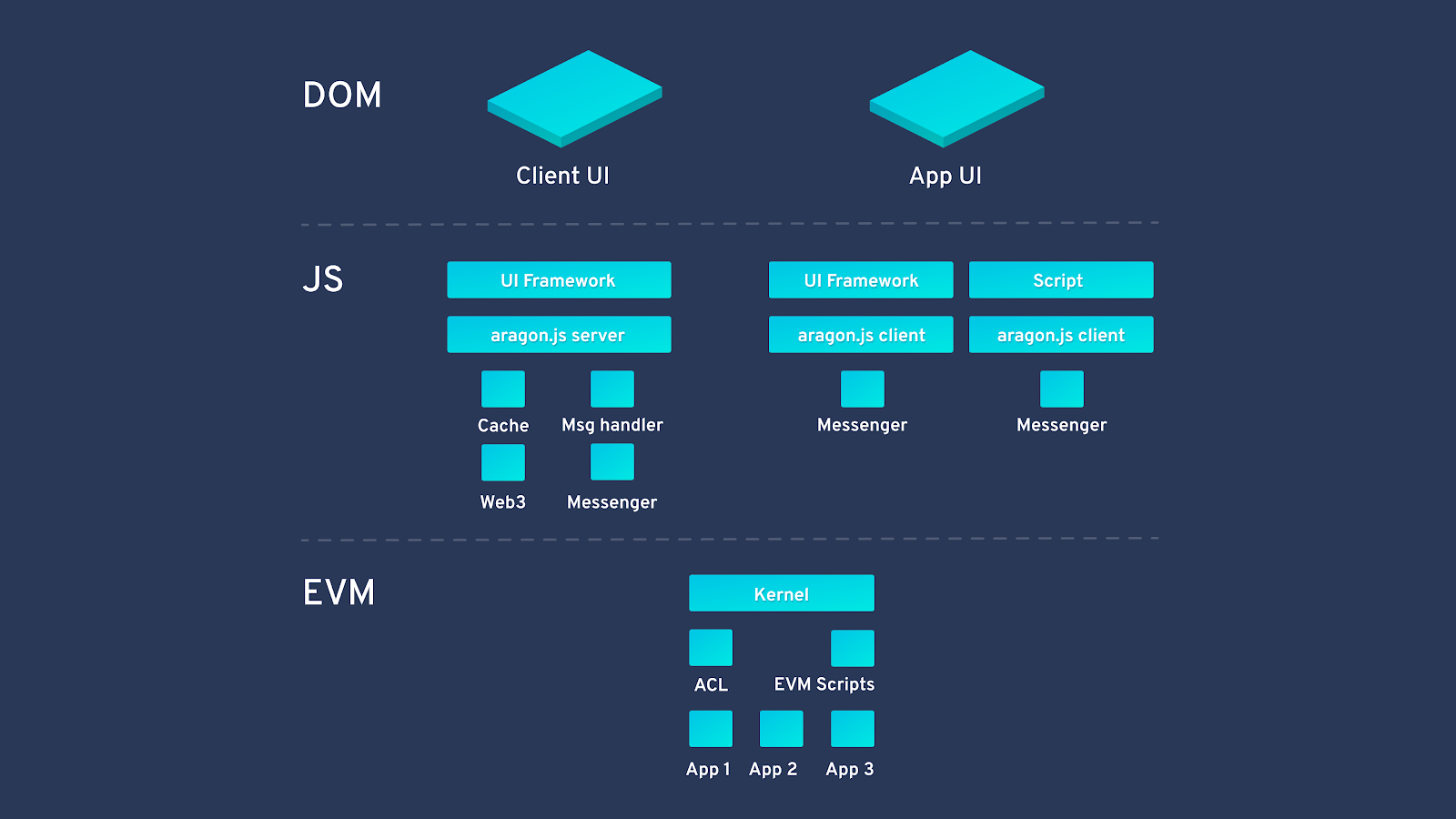
To create an Aragon app, you can go to the Aragon Developer portal. Getting started is very easy.
First, install IPFS if you don’t have it already installed.
Second, run the following commands:
$ npm i -g @aragon/cli
$ aragon init foo.aragonpm.eth
$ cd foo
$ aragon run
Here we will show a basic counter app, which allows members of an organization to count up or down if a democratic vote happens, for example.
This would be the smart contract (in Solidity) that keeps track of the counter in Ethereum:
contract Counter is AragonApp {
/**
* @notice Increment the counter by 1
*/
function increment() auth(INCREMENT_ROLE) external {
// ...
}
/**
* @notice Decrement the counter by 1
*/
function decrement() auth(DECREMENT_ROLE) external {
// ...
}
}
This code runs in a web worker, keeping track of events in the smart contract and caching the state in the background:
// app/script.js
import Aragon from '@aragon/client'
// Initialize the app
const app = new Aragon()
// Listen for events and reduce them to a state
const state$ = app.store((state, event) => {
// Initial state
if (state === null) state = 0
// Build state
switch (event.event) {
case 'Decrement':
state--
break
case 'Increment':
state++
break
}
return state
})
Some basic HTML (not using Aragon UI, for simplicity):
...
And the JavaScript that updates the UI:
// app/app.js
import Aragon, { providers } from '@aragon/client'
const app = new Aragon(
new providers.WindowMessage(window.parent)
)
const view = document.getElementById('view')
app.state().subscribe(
function(state) {
view.innerHTML = `The counter is ${state || 0}`
},
function(err) {
view.innerHTML = 'An error occurred, check the console'
console.log(err)
}
)
aragon run takes care of updating your app on APM and uploading your local webapp to IPFS, so you don’t need to worry about it!
You can go to Aragon’s website or the Developer Portal to learn more about Aragon. If you are interested in decentralized governance, you can also check out our research forum.
If you would like to contribute, you can look at our good first issues.
If you have any questions, please join the Aragon community chat!
The post Dweb: Creating Decentralized Organizations with Aragon appeared first on Mozilla Hacks - the Web developer blog.
|
|
Mozilla Open Policy & Advocacy Blog: Lessons from Carpenter – Mozilla panel discussion at ICDPPC |
The US Supreme Court recently released a landmark ruling in Carpenter vs. United States, which held that law enforcement authorities must secure a warrant in order to access citizens’ cell-site location data. At the upcoming 40th Conference of Data Protection and Privacy Commissioners, we’re hosting a panel discussion to unpack what Carpenter means in a globalised world.
Event blurb:
The Court’s judgement in Carpenter rested on the understanding that communications metadata can reveal sensitive information about individuals, and that citizens had a reasonable expectation of privacy with respect to that metadata.
This panel discussion will seek to unpack what Carpenter says about users’ expectations of privacy in the fully-connected world. It will make this assessment through both a legal and ethical lens, and compare the notion of expectation of privacy in Carpenter to other jurisdictions where data protection legislation is currently debated. Finally, the panel will examine the types of metadata implicated by the Carpenter ruling; how sensitive is that data and what legal standards should be applied given that sensitivity.
Speakers:
Logistics:
Thursday 25 October, 14:30-15:50
The Stanhope Hotel, Rue du Commerce 9, 1000 Brussels, Belgium
The post Lessons from Carpenter – Mozilla panel discussion at ICDPPC appeared first on Open Policy & Advocacy.
|
|
Mozilla Open Policy & Advocacy Blog: The future of online advertising – Mozilla panel discussion at ICDPPC |
At the upcoming 40th International Conference of Data Protection and Privacy Commissioners, we’re convening a timely high-level panel discussion on the future of advertising in an open and sustainable internet ecosystem.
Event title: Online advertising is broken: Can ethics fix it?
Description:
There’s no doubt that advertising is the dominant business model online today – and it has allowed a plethora of platforms, services, and publishers to operate without direct payment from end users. However, there is clearly a crisis of trust among these end users, driving skepticism of advertising, annoyance, and a sharp increase in adoption of content blockers. Ad fraud, adtech centralization, and [bad] practices like cryptojacking and pervasive tracking have made the web a difficult – and even hostile – environment for users and publishers alike.
While advertising is not the only contributing factor, it is clear that the status quo is crumbling. This workshop will bring together stakeholders from across the online ecosystem to examine the role that ethics, policy, and legislation (including the GDPR) play in increasing online trust, improving end user experience, and bolstering sustainable economic models for the web.
Speakers:
Logistics:
Tuesday 23 October 2018, 16:15-17:30
The Hotel, Boulevard de Waterloo 38, 1000 Bruxelles
Register here.
The post The future of online advertising – Mozilla panel discussion at ICDPPC appeared first on Open Policy & Advocacy.
|
|
Daniel Pocock: What is the relationship between FSF and FSFE? |
Ever since I started blogging about my role in FSFE as Fellowship representative, I've been receiving communications and queries from various people, both in public and in private, about the relationship between FSF and FSFE. I've written this post to try and document my own experiences of the issue, maybe some people will find this helpful. These comments have also been shared on the LibrePlanet mailing list for discussion (subscribe here)
Being the elected Fellowship representative means I am both a member of FSFE e.V. and also possess a mandate to look out for the interests of the community of volunteers and donors (they are not members of FSFE e.V). In both capacities, I feel uncomfortable about the current situation due to the confusion it creates in the community and the risk that volunteers or donors may be confused.
The FSF has a well known name associated with a distinctive philosophy. Whether people agree with that philosophy or not, they usually know what FSF believes in. That is the power of a brand.
When people see the name FSFE, they often believe it is a subsidiary or group working within the FSF. The way that brands work, people associate the philosophy with the name, just as somebody buying a Ferrari in Berlin expects it to do the same things that a Ferrari does in Boston.
To give an example, when I refer to "our president" in any conversation, people not knowledgeable about the politics believe I am referring to RMS. More specifically, if I say to somebody "would you like me to see if our president can speak at your event?", some people think it is a reference to RMS. In fact, FSFE was set up as a completely independent organization with distinct membership and management and therefore a different president. When I try to explain this to people, they sometimes lose interest and the conversation can go cold very quickly.
FSFE leadership have sometimes diverged from FSF philosophy, for example, it is not hard to find some quotes about "open source" and one fellow recently expressed concern that some people behave like "FSF Light". But given that FSF's crown jewels are the philosophy, how can an "FSF Light" mean anything? What would "Ferrari Light" look like, a red lawnmower? Would it be a fair use of the name Ferrari?

Some concerned fellows have recently gone as far as accusing the FSFE staff of effectively domain squatting or trolling the FSF (I can't link to that because of FSFE's censorship regime). When questions appear about the relationship in public, there is sometimes a violent response with no firm details. (I can't link to that either because of FSFE's censorship regime)
The FSFE constitution calls on FSFE to "join forces" with the FSF and sometimes this appears to happen but I feel this could be taken further.
FSF people have also produced vast amounts of code (the GNU Project) and some donors appear to be contributing funds to FSFE in gratitude for that or in the belief they are supporting that. However, it is not clear to me that funds given to FSFE support that work. As Fellowship representative, a big part of my role is to think about the best interests of those donors and so the possibility that they are being confused concerns me.
Given the vast amounts of money and goodwill contributed by the community to FSFE e.V., including a recent bequest of EUR 150,000 and the direct questions about this issue I feel it is becoming more important for both organizations to clarify the issue.
FSFE has a transparency page on the web site and this would be a good place to publish all documents about their relationship with FSF. For example, FSFE could publish the documents explaining their authorization to use a name derived from FSF and the extent to which they are committed to adhere to FSF's core philosophy and remain true to that in the long term. FSF could also publish some guidelines about the characteristics of a sister organization, especially when that organization is authorized to share the FSF's name.
In the specific case of sister organizations who benefit from the tremendous privilege of using the FSF's name, could it also remove ambiguity if FSF mandated the titles used by officers of sister organizations? For example, the "FSFE President" would be referred to as "FSFE European President", or maybe the word president could be avoided in all sister organizations.
People also raise the question of whether FSFE can speak for all Europeans given that it only has a large presence in Germany and other organizations are bigger in other European countries. Would it be fair for some of those other groups to aspire to sister organization status and name-sharing rights too? Could dozens of smaller FSF sister organizations dilute the impact of one or two who go off-script?
Even if FSFE was to distance itself from FSF or even start using a new name and philosophy, as a member, representative and also volunteer I would feel uncomfortable with that as there is a legacy of donations and volunteering that have brought FSFE to the position the organization is in today.
That said, I would like to emphasize that I regard RMS and the FSF, as the original FSF, as having the final authority over the use of the name and I fully respect FSF's right to act unilaterally, negotiate with sister organizations or simply leave things as they are.
If you have questions or concerns about this topic, I would invite you to raise them on the LibrePlanet-discuss mailing list or feel free to email me directly.
https://danielpocock.com/what-is-the-relationship-between-fsf-and-fsfe
|
|
Firefox Test Pilot: AutoFill your passwords with Firefox Lockbox in iOS |
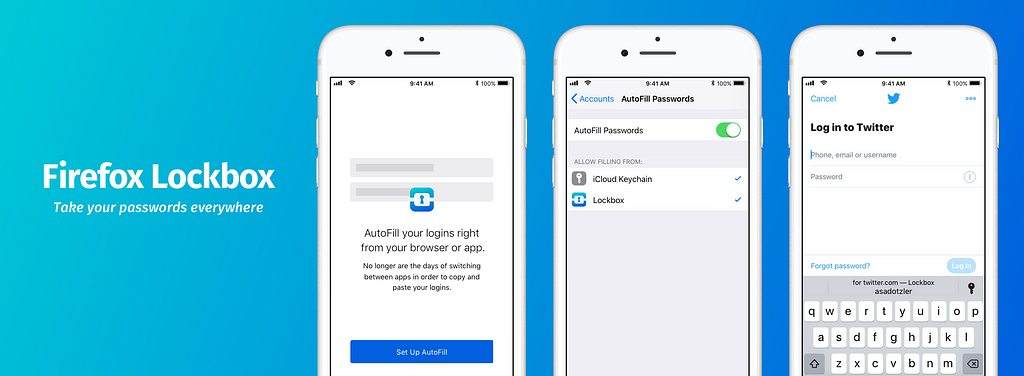
Today Firefox Lockbox 1.3 gives you the ability to automatically fill your username and password into apps and websites. This is available to anyone running the latest iOS 12 operating system.
If you just downloaded Firefox Lockbox, you’ll start with a screen which includes “Set Up Autofill”, which takes you directly to your device settings.
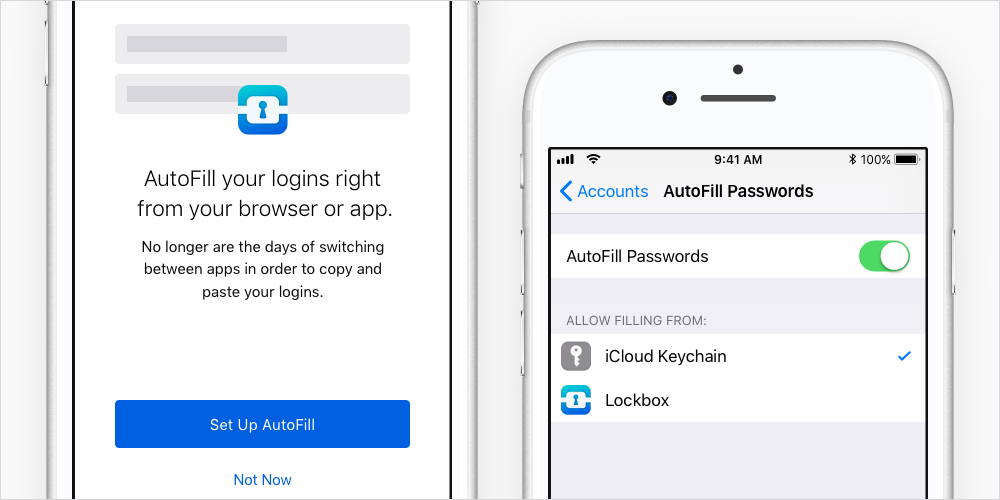
Here you can select Firefox Lockbox to autofill logins for you. You also want to make sure that “AutoFill Passwords” is green and toggled on.
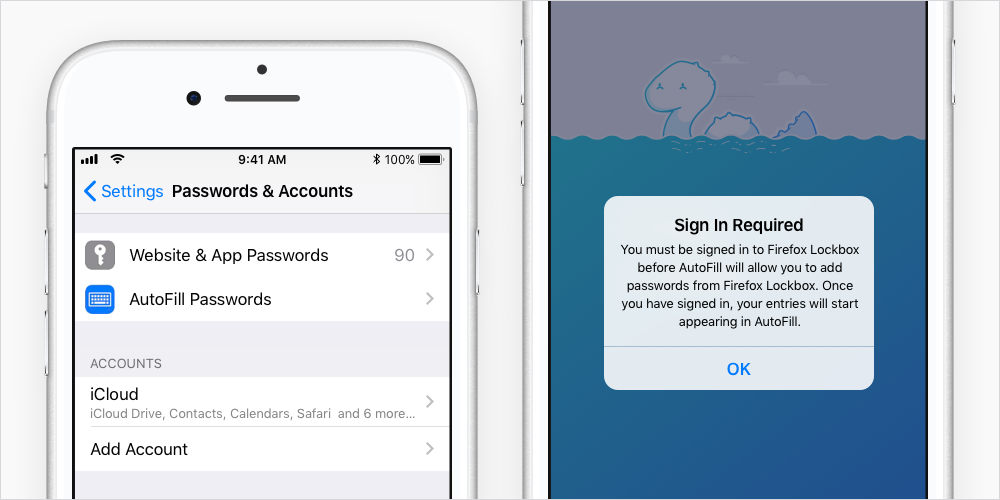
If you’re already using Firefox Lockbox, you can set Lockbox to autofill your logins by navigating through the device: Settings > Passwords & Accounts > AutoFill Passwords
While you’re here, unselect iCloud Keychain as an AutoFill provider. If you leave this enabled, it may be confusing when signing into apps and web forms.
If you haven’t yet signed in to Lockbox, you will be prompted to do so in order to authenticate the app to automatically fill passwords.
Your setup is now complete. You can now start using your saved logins in Lockbox.
NOTE: You can only have one third-party AutoFill provider enabled, in addition to iCloud Keychain.
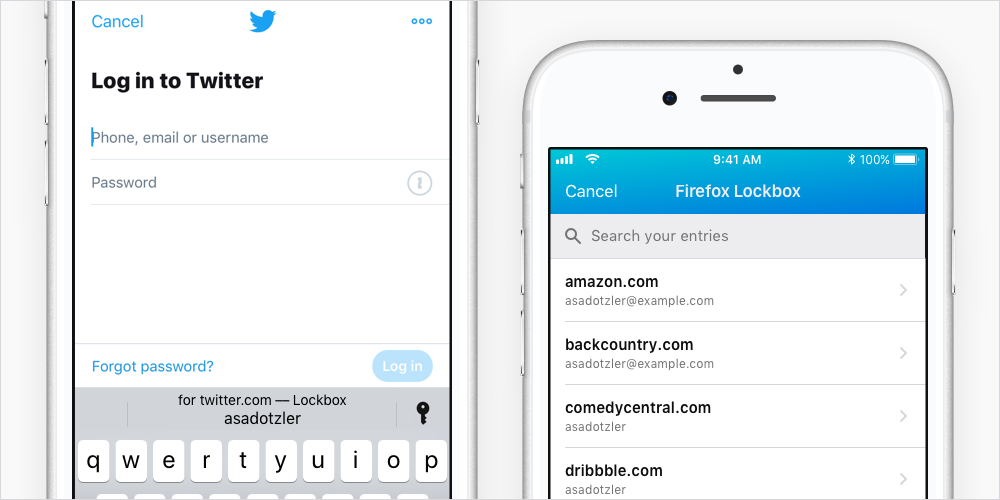
When you need to log into an app or an online account in a browser, tap in one of the entry fields. This will display the username and password you have saved in Lockbox.
From there, you can tap the information to enter it into the app or website’s login form.
If you can’t find the saved login you need, tap on the key icon. Then select Lockbox. There you can see all the accounts you have saved and can choose your desired entry to populate the login form.
Every time you invoke Lockbox to fill a form, you will need to confirm your identity with either Face ID or Touch ID to enter a password. This is to ensure that you are in fact asking Lockbox to fill in the username and password and unlocking the app to do so.
You can now easily use a Firefox saved login to get into a third-party app like Twitter or Instagram. Or you can use those Firefox saved logins to fill in website forms. You may recognize this but it’s something that used to only be available to iCloud Keychain users until today!
AutoFill your passwords with Firefox Lockbox in iOS was originally published in Firefox Test Pilot on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
Hacks.Mozilla.Org: Streaming RNNs in TensorFlow |
The Machine Learning team at Mozilla Research continues to work on an automatic speech recognition engine as part of Project DeepSpeech, which aims to make speech technologies and trained models openly available to developers. We’re hard at work improving performance and ease-of-use for our open source speech-to-text engine. The upcoming 0.2 release will include a much-requested feature: the ability to do speech recognition live, as the audio is being recorded. This blog post describes how we changed the STT engine’s architecture to allow for this, achieving real-time transcription performance. Soon, you’ll be able to transcribe audio at least as fast as it’s coming in.
When applying neural networks to sequential data like audio or text, it’s important to capture patterns that emerge over time. Recurrent neural networks (RNNs) are neural networks that “remember” — they take as input not just the next element in the data, but also a state that evolves over time, and use this state to capture time-dependent patterns. Sometimes, you may want to capture patterns that depend on future data as well. One of the ways to solve this is by using two RNNs, one that goes forward in time and one that goes backward, starting from the last element in the data and going to the first element. You can learn more about RNNs (and about the specific type of RNN used in DeepSpeech) in this article by Chris Olah.
The current release of DeepSpeech (previously covered on Hacks) uses a bidirectional RNN implemented with TensorFlow, which means it needs to have the entire input available before it can begin to do any useful work. One way to improve this situation is by implementing a streaming model: Do the work in chunks, as the data is arriving, so when the end of the input is reached, the model is already working on it and can give you results more quickly. You could also try to look at partial results midway through the input.
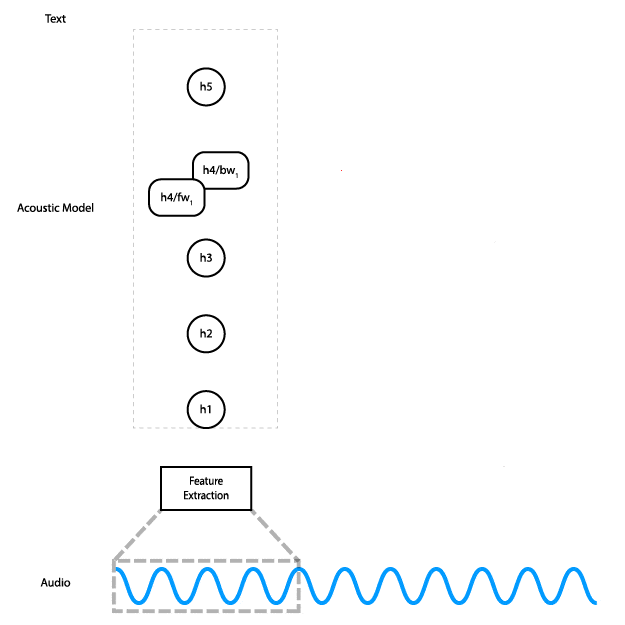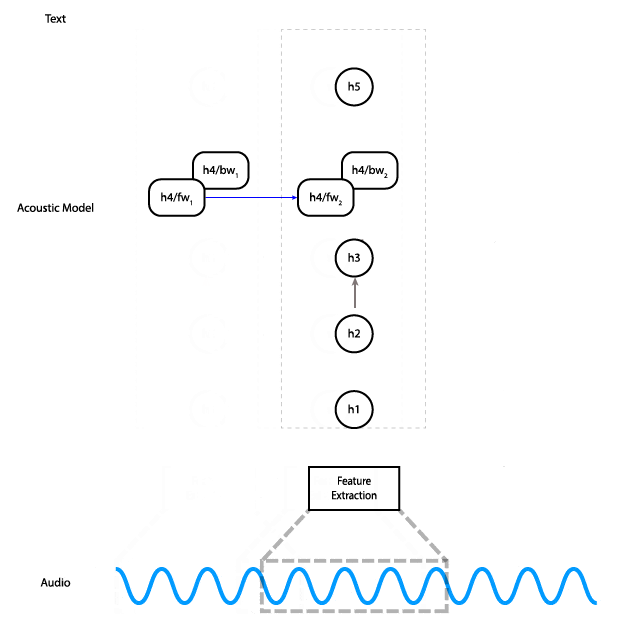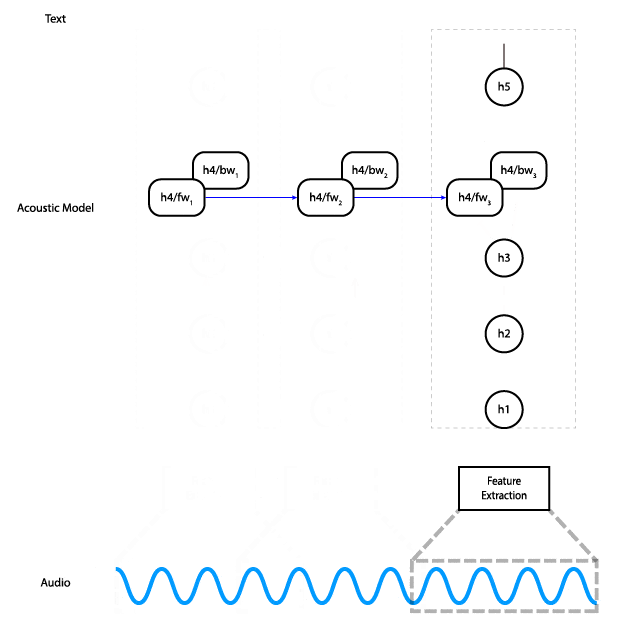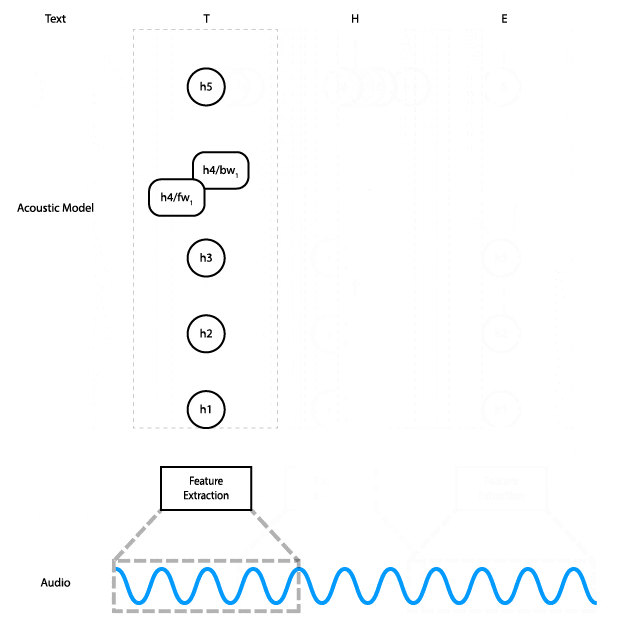
This animation shows how the data flows through the network. Data flows from the audio input to feature computation, through three fully connected layers. Then it goes through a bidirectional RNN layer, and finally through a final fully connected layer, where a prediction is made for a single time step.
In order to do this, you need to have a model that lets you do the work in chunks. Here’s the diagram of the current model, showing how data flows through it.
As you can see, on the bidirectional RNN layer, the data for the very last step is required for the computation of the second-to-last step, which is required for the computation of the third-to-last step, and so on. These are the red arrows in the diagram that go from right to left.
We could implement partial streaming in this model by doing the computation up to layer three as the data is fed in. The problem with this approach is that it wouldn’t gain us much in terms of latency: Layers four and five are responsible for almost half of the computational cost of the model.
Instead, we can replace the bidirectional layer with a unidirectional layer, which does not have a dependency on future time steps. That lets us do the computation all the way to the final layer as soon as we have enough audio input.
With a unidirectional model, instead of feeding the entire input in at once and getting the entire output, you can feed the input piecewise. Meaning, you can input 100ms of audio at a time, get those outputs right away, and save the final state so you can use it as the initial state for the next 100ms of audio.
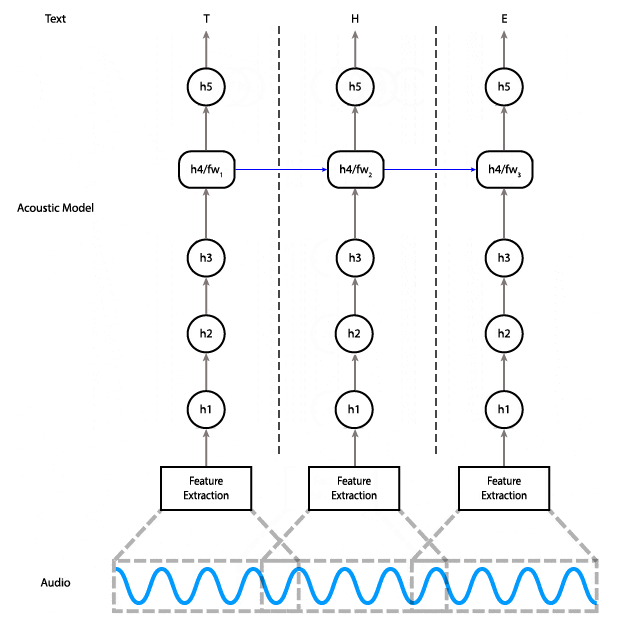
An alternative architecture that uses a unidirectional RNN in which each time step only depends on the input at that time and the state from the previous step.
Here’s code for creating an inference graph that can keep track of the state between each input window:
import tensorflow as tf
def create_inference_graph(batch_size=1, n_steps=16, n_features=26, width=64):
input_ph = tf.placeholder(dtype=tf.float32,
shape=[batch_size, n_steps, n_features],
name='input')
sequence_lengths = tf.placeholder(dtype=tf.int32,
shape=[batch_size],
name='input_lengths')
previous_state_c = tf.get_variable(dtype=tf.float32,
shape=[batch_size, width],
name='previous_state_c')
previous_state_h = tf.get_variable(dtype=tf.float32,
shape=[batch_size, width],
name='previous_state_h')
previous_state = tf.contrib.rnn.LSTMStateTuple(previous_state_c, previous_state_h)
# Transpose from batch major to time major
input_ = tf.transpose(input_ph, [1, 0, 2])
# Flatten time and batch dimensions for feed forward layers
input_ = tf.reshape(input_, [batch_size*n_steps, n_features])
# Three ReLU hidden layers
layer1 = tf.contrib.layers.fully_connected(input_, width)
layer2 = tf.contrib.layers.fully_connected(layer1, width)
layer3 = tf.contrib.layers.fully_connected(layer2, width)
# Unidirectional LSTM
rnn_cell = tf.contrib.rnn.LSTMBlockFusedCell(width)
rnn, new_state = rnn_cell(layer3, initial_state=previous_state)
new_state_c, new_state_h = new_state
# Final hidden layer
layer5 = tf.contrib.layers.fully_connected(rnn, width)
# Output layer
output = tf.contrib.layers.fully_connected(layer5, ALPHABET_SIZE+1, activation_fn=None)
# Automatically update previous state with new state
state_update_ops = [
tf.assign(previous_state_c, new_state_c),
tf.assign(previous_state_h, new_state_h)
]
with tf.control_dependencies(state_update_ops):
logits = tf.identity(logits, name='logits')
# Create state initialization operations
zero_state = tf.zeros([batch_size, n_cell_dim], tf.float32)
initialize_c = tf.assign(previous_state_c, zero_state)
initialize_h = tf.assign(previous_state_h, zero_state)
initialize_state = tf.group(initialize_c, initialize_h, name='initialize_state')
return {
'inputs': {
'input': input_ph,
'input_lengths': sequence_lengths,
},
'outputs': {
'output': logits,
'initialize_state': initialize_state,
}
}
The graph created by the code above has two inputs and two outputs. The inputs are the sequences and their lengths. The outputs are the logits and a special “initialize_state” node that needs to be run at the beginning of a new sequence. When freezing the graph, make sure you don’t freeze the state variables previous_state_h and previous_state_c.
Here’s code for freezing the graph:
from tensorflow.python.tools import freeze_graph
freeze_graph.freeze_graph_with_def_protos(
input_graph_def=session.graph_def,
input_saver_def=saver.as_saver_def(),
input_checkpoint=checkpoint_path,
output_node_names='logits,initialize_state',
restore_op_name=None,
filename_tensor_name=None,
output_graph=output_graph_path,
initializer_nodes='',
variable_names_blacklist='previous_state_c,previous_state_h')
With these changes to the model, we can use the following approach on the client side:
It wouldn’t make sense to drown readers with hundreds of lines of the client-side code here, but if you’re interested, it’s all MPL 2.0 licensed and available on GitHub. We actually have two different implementations, one in Python that we use for generating test reports, and one in C++ which is behind our official client API.
What does this all mean for our STT engine? Well, here are some numbers, compared with our current stable release:
Of particular importance to me is that we’re now faster than real time without using a GPU, which, together with streaming inference, opens up lots of new usage possibilities like live captioning of radio programs, Twitch streams, and keynote presentations; home automation; voice-based UIs; and so on. If you’re looking to integrate speech recognition in your next project, consider using our engine!
Here’s a small Python program that demonstrates how to use libSoX to record from the microphone and feed it into the engine as the audio is being recorded.
import argparse
import deepspeech as ds
import numpy as np
import shlex
import subprocess
import sys
parser = argparse.ArgumentParser(description='DeepSpeech speech-to-text from microphone')
parser.add_argument('--model', required=True,
help='Path to the model (protocol buffer binary file)')
parser.add_argument('--alphabet', required=True,
help='Path to the configuration file specifying the alphabet used by the network')
parser.add_argument('--lm', nargs='?',
help='Path to the language model binary file')
parser.add_argument('--trie', nargs='?',
help='Path to the language model trie file created with native_client/generate_trie')
args = parser.parse_args()
LM_WEIGHT = 1.50
VALID_WORD_COUNT_WEIGHT = 2.25
N_FEATURES = 26
N_CONTEXT = 9
BEAM_WIDTH = 512
print('Initializing model...')
model = ds.Model(args.model, N_FEATURES, N_CONTEXT, args.alphabet, BEAM_WIDTH)
if args.lm and args.trie:
model.enableDecoderWithLM(args.alphabet,
args.lm,
args.trie,
LM_WEIGHT,
VALID_WORD_COUNT_WEIGHT)
sctx = model.setupStream()
subproc = subprocess.Popen(shlex.split('rec -q -V0 -e signed -L -c 1 -b 16 -r 16k -t raw - gain -2'),
stdout=subprocess.PIPE,
bufsize=0)
print('You can start speaking now. Press Control-C to stop recording.')
try:
while True:
data = subproc.stdout.read(512)
model.feedAudioContent(sctx, np.frombuffer(data, np.int16))
except KeyboardInterrupt:
print('Transcription:', model.finishStream(sctx))
subproc.terminate()
subproc.wait()
Finally, if you’re looking to contribute to Project DeepSpeech itself, we have plenty of opportunities. The codebase is written in Python and C++, and we would love to add iOS and Windows support, for example. Reach out to us via our IRC channel or our Discourse forum.
The post Streaming RNNs in TensorFlow appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2018/09/speech-recognition-deepspeech/
|
|
The Mozilla Blog: Explore the immersive web with Firefox Reality. Now available for Viveport, Oculus, and Daydream |
Earlier this year, we shared that we are building a completely new browser called Firefox Reality. The mixed reality team at Mozilla set out to build a web browser that has been designed from the ground up to work on stand-alone virtual and augmented reality (or mixed reality) headsets. Today, we are pleased to announce that the first release of Firefox Reality is available in the Viveport, Oculus, and Daydream app stores.
At a time when people are questioning the impact of technology on their lives and looking for leadership from independent organizations like Mozilla, Firefox Reality brings to the 3D web and immersive content experiences the level of ease of use, choice, control and privacy they’ve come to expect from Firefox.
But for us, the ability to enjoy the 2D web is just table stakes for a VR browser. We built Firefox Reality to move seamlessly between the 2D web and the immersive web.
The Mixed Reality team here at Mozilla has invested a significant amount of time, effort, and research into figuring out how we can design a browser for virtual reality:
We had to rethink everything, including navigation, text-input, environments, search and more. This required years of research, and countless conversations with users, content creators, and hardware partners. The result is a browser that is built for the medium it serves. It makes a big difference, and we think you will love all of the features and details that we’ve created specifically for a MR browser.
– Andre Vrignaud, Head of Mixed Reality Platform Strategy at Mozilla
Among these features is the ability to search the web using your voice. Text input is still a chore for virtual reality, and this is a great first step towards solving that. With Firefox Reality you can choose to search using the microphone in your headset.

We spent a lot of time talking to early VR headset owners. We asked questions like: “What is missing?” “Do you love your device?” And “If not, why?” The feedback we heard the most was that users were having a hard time finding new games and experiences. This is why we built a feed of amazing content into the home screen of Firefox Reality.
– Andre Vrignaud, Head of Mixed Reality Platform Strategy at Mozilla
From the moment you open the browser, you will be presented with immersive experiences that can be enjoyed on a VR headset directly from the Firefox Reality browser. We are working with creators around the world to bring an amazing collection of games, videos, environments, and experiences that can be accessed directly from the home screen.


We know a thing or two about making an amazing web browser. Firefox Reality is using our new Quantum engine for mobile browsers. The result is smooth and fast performance that is crucial for a VR browser. We also take things like privacy and transparency very seriously. As a company, we are dedicated to fighting for your right to privacy on the web. Our values have guided us through this creation process, just as they do with every product we build.

We are in this for the long haul. This is version 1.0 of Firefox Reality and version 1.1 is right around the corner. We have an always-growing list of ideas and features that we are working to add to make this the best browser for mixed reality. We will also be listening and react quickly when we need to provide bug fixes and other minor updates.
If you notice a few things are missing (“Hey! Where are the bookmarks”), just know that we will be adding features at a steady pace. In the coming months, we will be adding support for bookmarks, 360 videos, accounts, and more. We intend to quickly prove our commitment to this product and our users.
Here at Mozilla, we make it a habit to work in the open because we believe in the power of transparency, community and collaboration. If you have an idea, or a bug report, or even if you just want to geek out, we would love to hear from you. You can follow @mozillareality on twitter, file an issue on GitHub, or visit our support site.
Are you creating immersive content for the web? Have you built something using WebVR? We would love to connect with you about featuring those experiences in Firefox Reality. Are you building a mixed reality headset that needs a best-in-class browser? Let’s chat.
Download for Oculus
(supports Oculus Go)
Download for Daydream
(supports all-in-one devices)
Download for Viveport (Search for “Firefox Reality” in Viveport store)
(supports all-in-one devices running Vive Wave)
The post Explore the immersive web with Firefox Reality. Now available for Viveport, Oculus, and Daydream appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/09/18/firefox-reality-now-available/
|
|
Mozilla Security Blog: September 2018 CA Communication |
Mozilla has sent a CA Communication to inform Certification Authorities (CAs) who have root certificates included in Mozilla’s program about current events relevant to their membership in our program and to remind them of upcoming deadlines. This CA Communication has been emailed to the Primary Point of Contact (POC) and an email alias for each CA in Mozilla’s program, and they have been asked to respond to the following 7 action items:
The full action items can be read here. Responses to the survey will be automatically and immediately published by the CCADB.
With this CA Communication, we reiterate that participation in Mozilla’s CA Certificate Program is at our sole discretion, and we will take whatever steps are necessary to keep our users safe. Nevertheless, we believe that the best approach to safeguard that security is to work with CAs as partners, to foster open and frank communication, and to be diligent in looking for ways to improve.
The post September 2018 CA Communication appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2018/09/17/september-2018-ca-communication/
|
|
Mozilla VR Blog: Remote Debugging Firefox Reality |
You can debug your web pages running in Firefox Reality remotely over USB from your computer using the latest release of Firefox for Windows, Mac, or Linux.
To set up debugging you will need to do a couple of things. Don’t worry, it’s easy.
First you will need adb, the Android command line debugging tool. There are many ways to get it. The command line tools come with the full install of the Android Developer Suite, but if you only need the command line tools you can install just those. If you are on a Mac follow these instructions to install it using Homebrew. However you get adb, you should be able to run it on the commandline to see your headset, like this:
MozMac:~ josh$ adb devices
List of devices attached
1KWPH813E48106 device
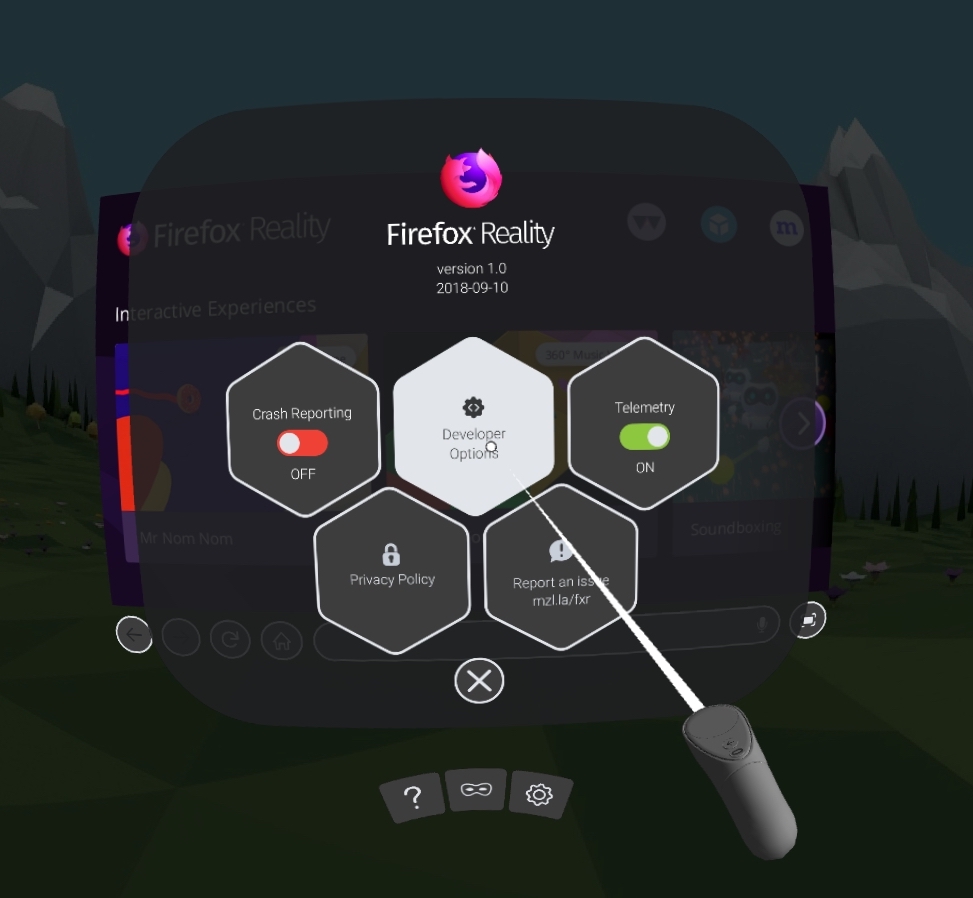
After you have installed Firefox Reality on your VR device, launch it and click the gear icon to open the settings dialog.
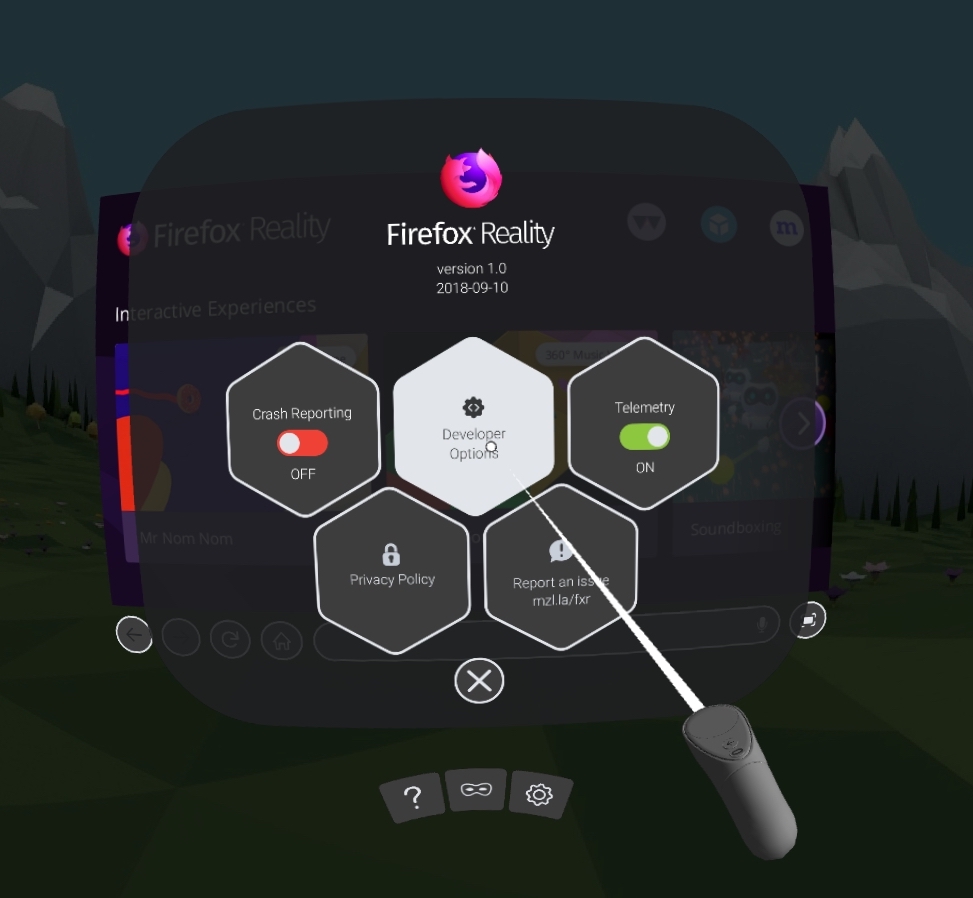
Then click the Developer Options button to open the developer settings, then turn on remote debugging with the toggle switch.
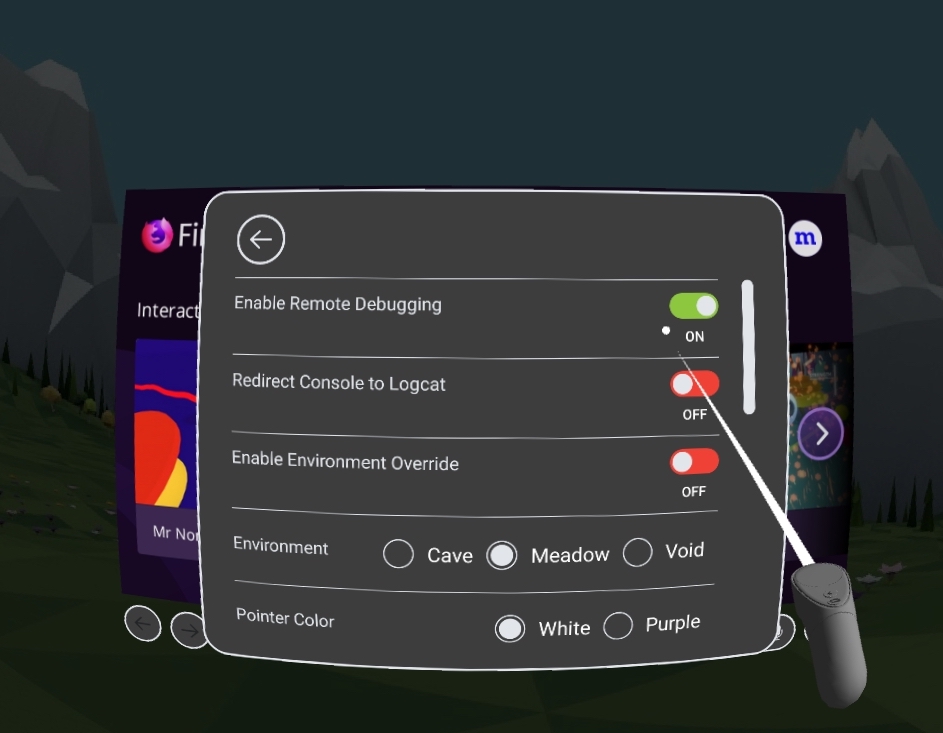
To set up debugging on your development computer, you must have the latest version of Firefox for Developers installed or the latest Nightly build.
Open the developer console then select the settings menu option.
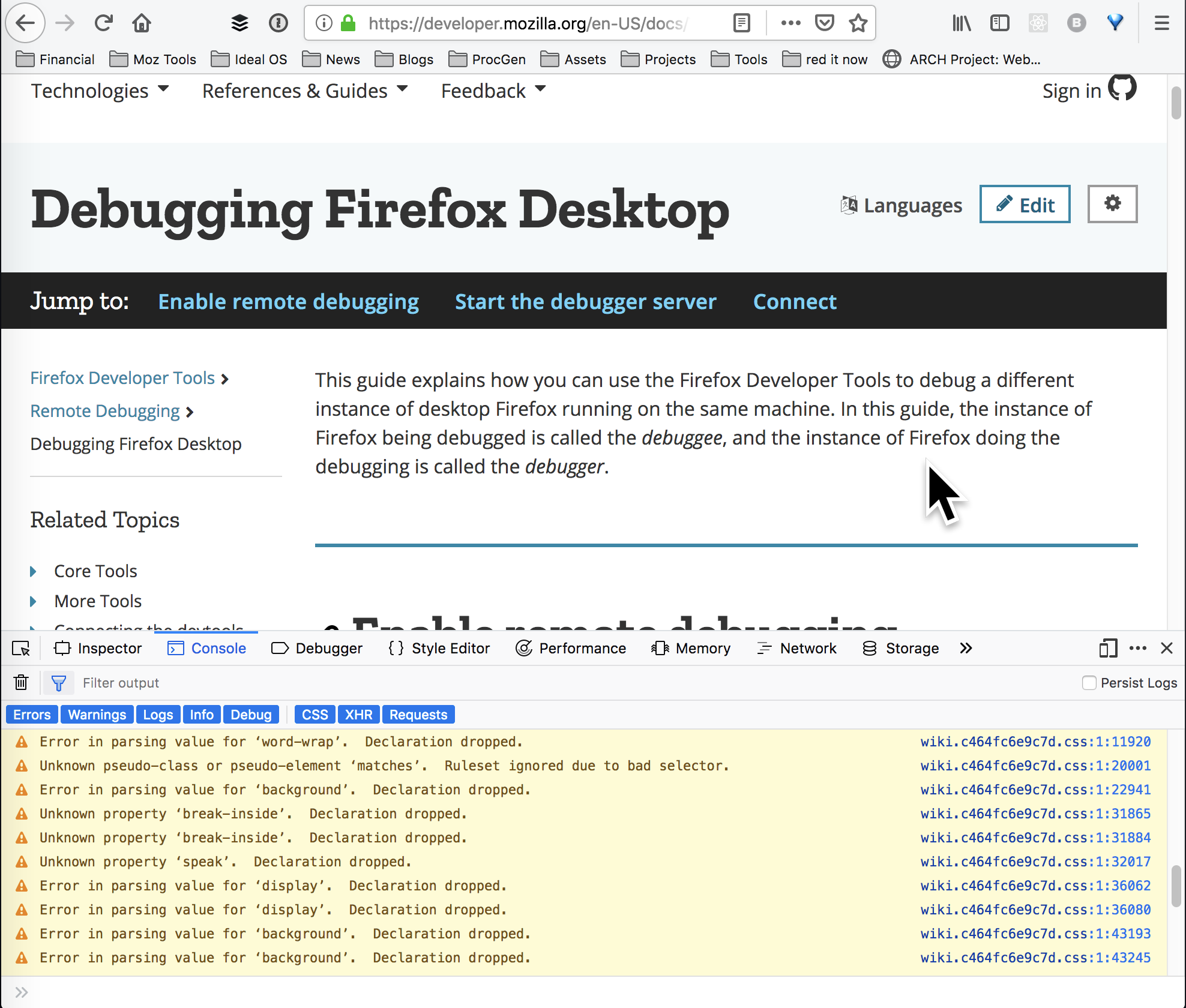
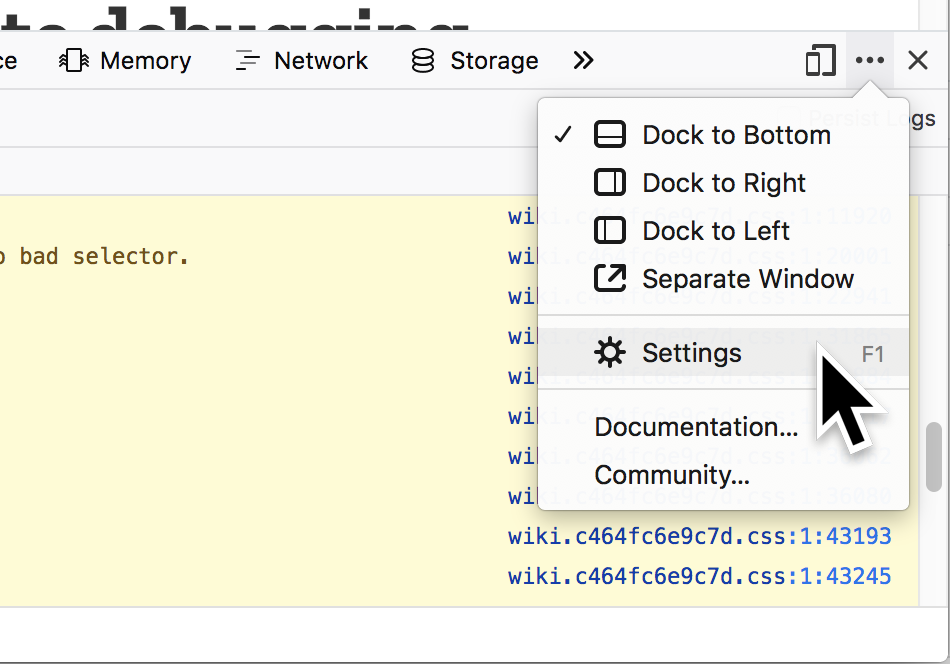
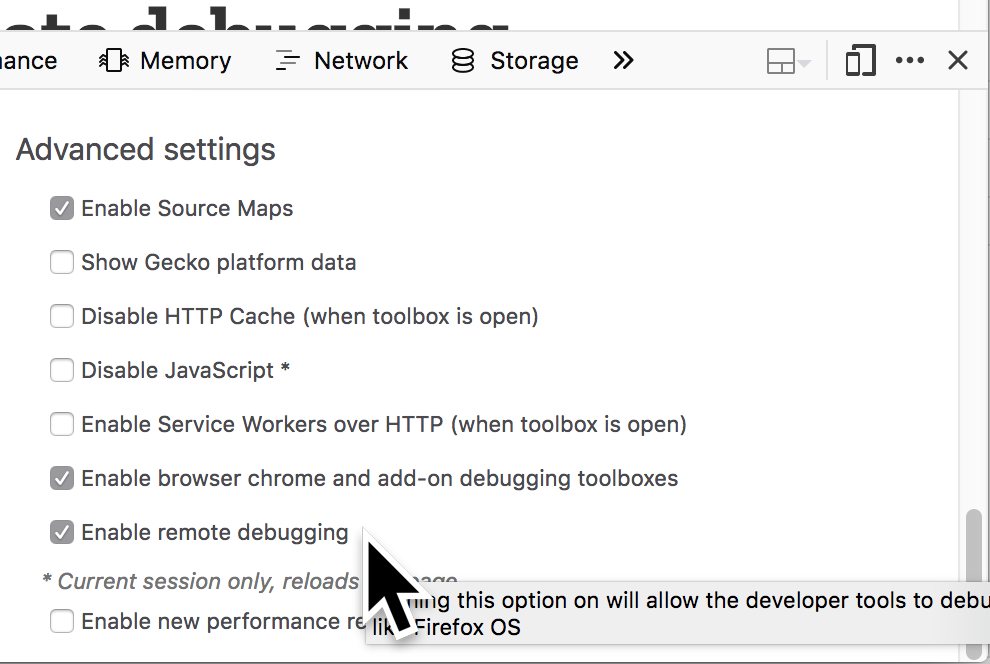
Scroll down to advanced settings and turn on the browser chrome and remote debugging options.
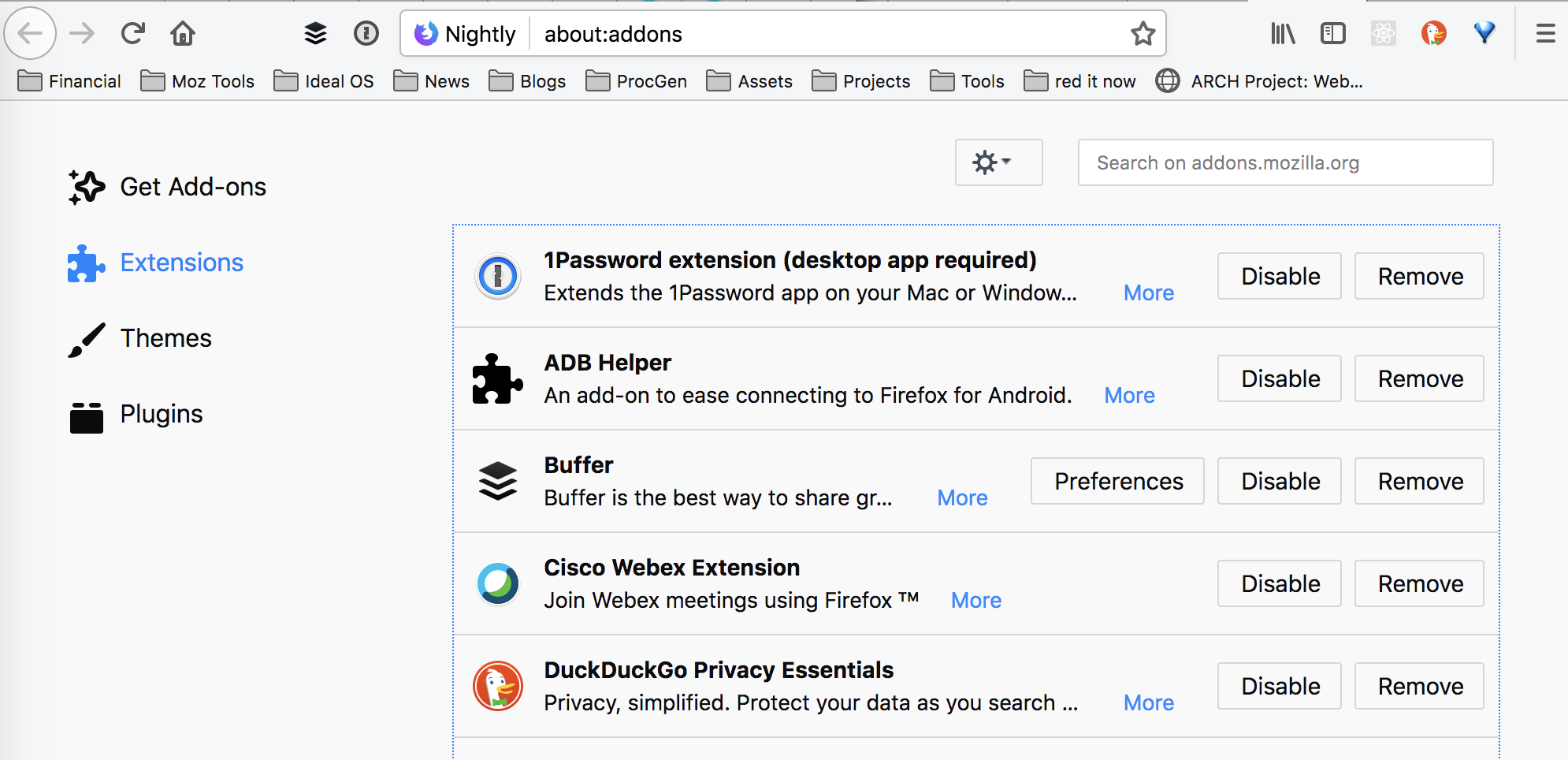
You should already have the ADB Helper addon installed. You can check it using the about:addons page. If it’s not there install it by searching for ADB Helper in the addons page.
Now open the WebIDE. You should see the connected device in the upper right corner:
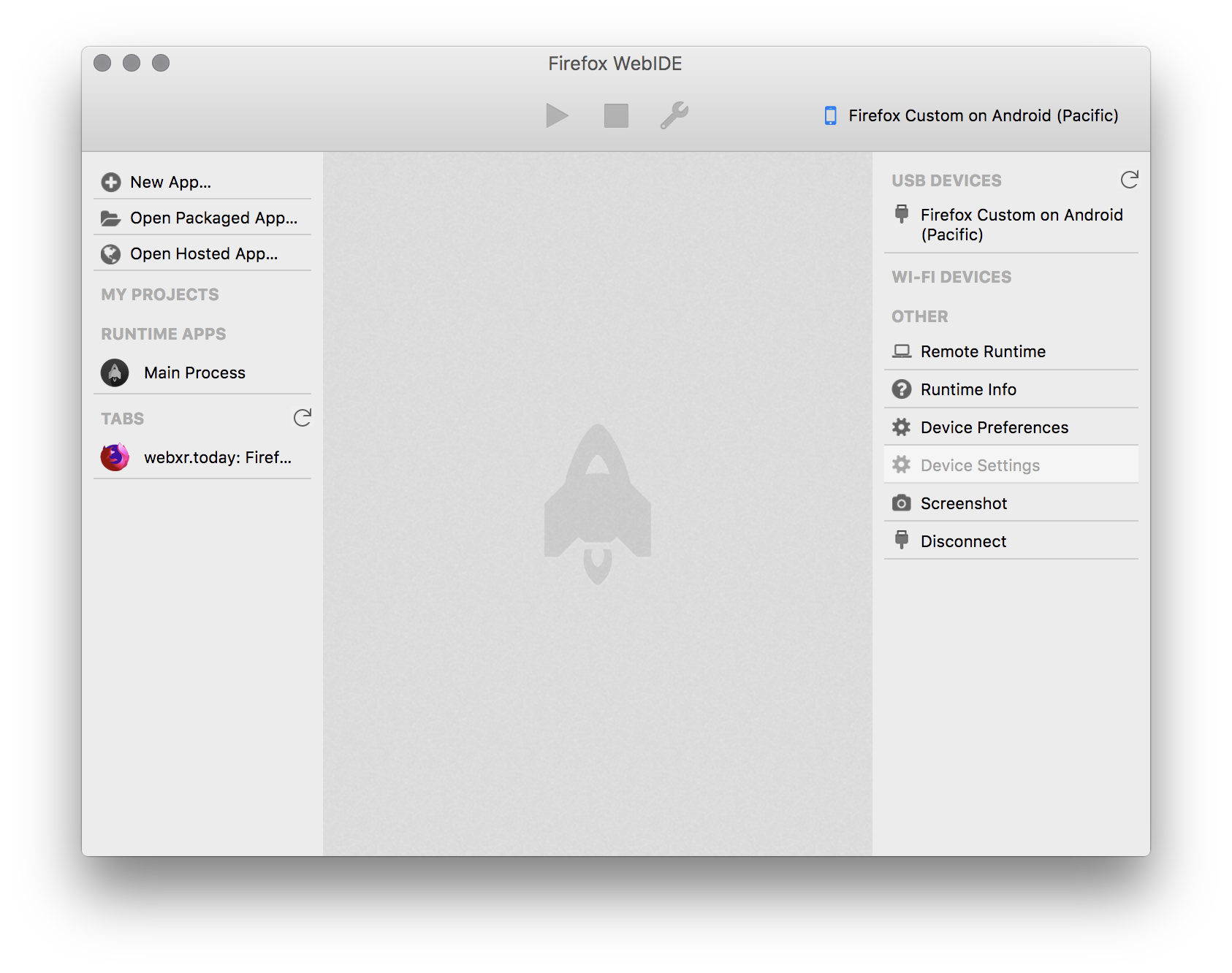
Now you can select the device and connect to the main Firefox Reality process. Underneath that are entries for each live tab where you can view the console, take screenshots, and get performance information.
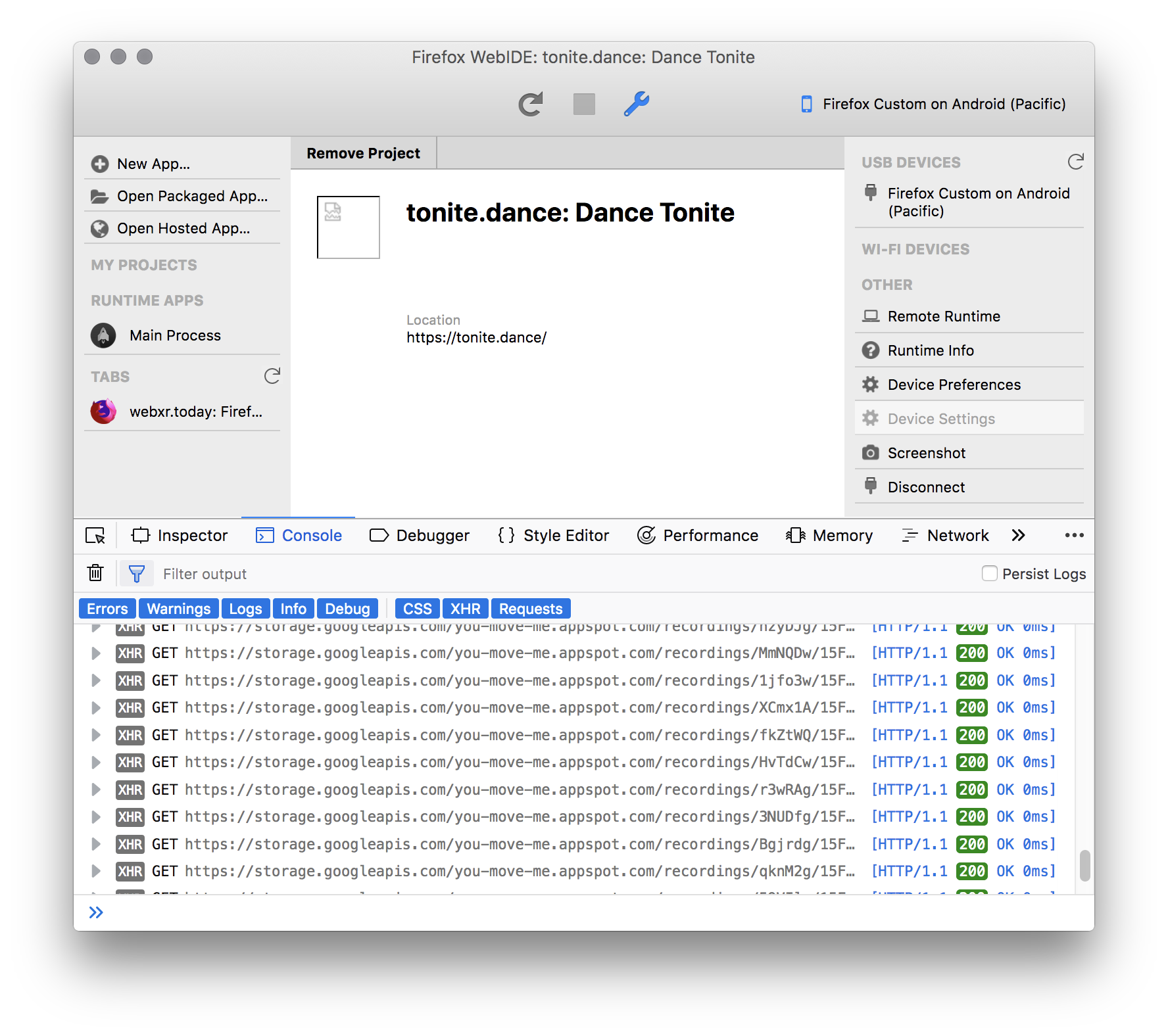

That’s it. Debugging pages in Firefox Reality is easy. Once you are connected the experience is much like debugging regular desktop pages. To learn more about how to make web content for Firefox Reality, check out the Developer’s Guide.
|
|
Emily Dunham: CFP tricks 1 |
Or, “how to make a selection committee do one of the hard parts of your job as a speaker for you”. For values of “hard parts” that include fine-tuning your talk for your audience.
I’m giving talk advice to a friend today, which means I’m thinking about talk advice and realizing it’s applicable to lots of speakers, which means I’m writing a blog post.
Deciding who you’re speaking to is one of the trickiest bits of writing an abstract, because a good abstract is tailored to bring in people who will be interested in and benefit from your talk. One of the reasons that it’s extra hard for a speaker to choose the right audience, especially at a conference that they haven’t attended before, is because they’re not sure who’ll be at the conference or track.
Knowing your audience lets you write an abstract full of relevant and interesting questions that your talk will answer. Not only do these questions show that you can teach your subject matter, but they’re an invaluable resource for assessing your own slides to make sure your talk delivers everything that you promised it would!
Some strategies I’ve recommended in the past for dealing with this include looking at the conference’s marketing materials to imagine who they would interest, and examining the abstracts of past years’ talks.
Once you narrow down the possible audiences, a good way to get the right talk in is to offload the final choice onto the selection committee! A classic example is to offer both a “Beginner” and an “Advanced” talk, on the same topic, so that the committee can pick whichever they think will be a better fit for the audience they’re targeting and the track they choose to schedule you for.
If the CFP allows notes to the committee, it can be helpful to add a note about how your talks are different, especially if their titles are similar: “This is an introduction to Foo, whereas my other proposal is a deep dive into Foo’s Bar and Baz”.
I always encourage resume writers to use the same buzzwords as the job posting to which they’re applying when possible. This shows that you’re paying attention, and makes it easy for readers to tell that you meet their criteria.
In the same way, if your talk concept ties into a buzzword that the organizers have used to describe their conference, or directly answers a question that their marketing materials claim the conference will answer, don’t be afraid to repeat those words!
When choosing between several possible talk titles, keep in mind that any jargon you use can show off your ability, or lack thereof, to relate to the conference’s target audience. For instance, a talk with “Hacking” in the title may be at an advantage in an infosec conference but at a disadvantage in a highly professional corporate conf. Another example is that spinning my Rust Community Automation talk to “Life is Better with Rust’s Community Automation” worked great for a conference whose tagline and theme was “Life is Better with Linux”, but would not have been as successful elsewhere.
Good luck with your talks!
|
|






