Cameron Kaiser: Let's kill kittens with native messaging (or, introducing OverbiteNX: if WebExtensions can't do it, we will) |

WebExtensions (there is no XUL) took over with a thud seven months ago, which was felt as a great disturbance in the Force by most of us who wrote Firefox add-ons that, you know, actually did stuff. Many promises were made for APIs to allow us to do the stuff we did before. Some of these promises were kept and these APIs have actually been implemented, and credit where credit is due. But there are many that have not (that metabug is not exhaustive). More to the point, there are many for which people have offered to write code and are motivated to write code, but we have no parameters for what would be acceptable, possibly because any spec would end up stuck in a "boil the ocean" problem, possibly because it's low priority, or possibly because someone gave other someones the impression such an API would be acceptable and hasn't actually told them it isn't. The best way to get contribution is to allow people to scratch their own itches, but the urgency to overcome the (largely unintentional) institutional roadblocks has faded now that there is somewhat less outrage, and we are still left with a disordered collection of APIs that extends Firefox relatively little and a very slow road to do otherwise.
Or perhaps we don't have to actually rely on what's in Firefox to scratch our itch, at least in many cases. In a potentially strategically unwise decision, WebExtensions allows native code execution in the form of "native messaging" -- that is, you can write a native component, tell Firefox about it and who can talk to it, and then have that native component do what Firefox don't. At that point, the problem then becomes more one of packaging. If the functionality you require isn't primarily limited by the browser UI, then this might be a way around the La Brea triage tarpit.
Does this sound suspiciously familiar to anyone like some other historical browser-manipulated blobs of native code? Hang on, it's coming back to me. I remember something like this. I remember now. I remember them!
If you've been under a rock until Firefox 52, let me remind you that plugins were globs of native code that gave the browser wonderful additional capabilities such as playing different types of video, Flash and Shockwave games and DRM management, as well as other incredibly useful features such as potential exploitation, instability and sometimes outright crashes. Here in TenFourFox, for a variety of reasons I officially removed support for plugins in version 6 and completely removed the code with TenFourFox 19. Plugins served a historic purpose which are now better met by any number of appropriate browser and HTML5 APIs, and their disadvantages now in general outweigh their advantages.
Mozilla agrees with this, sort of. Starting with 52 many, though not all, plugins won't run. The remaining lucky few are Flash, Widevine and OpenH264. If you type about:plugins into Firefox, you'll still see them unless you're like me and you're running it on a POWER9 Talos II or some other hyper-free OS. There's a little bit of hypocrisy here in the name of utilitarianism, but I think it's pretty clear there would be a pretty high bar to adding a new plugin to this whitelist. Pithily, Mozilla has concluded regardless of any residual utility that plugins kill kittens.
It wasn't just plugins, either. Mozilla really doesn't like native code at all when it can be avoided; for a number of years in the Mozilla developer community I remember a lot of interest in making JavaScript so fast it could be used for all the media decoding and manipulation that native plugins then did. It's certainly gotten a lot faster since then, but now I guess the interest is having WASM do that instead (I'll wait). A certain subset of old-school extensions used to have binary components too, though largely to do funky system-level things that regular XPCOM in JavaScript and/or js-ctypes couldn't handle. This practice was strongly discouraged by Mozilla but many antiviruses implemented browser scanners in that fashion. This may have been a useful means to an end but binary components were a constant source of bugs when Mozilla altered something that the add-on authors didn't expect to change, and thus they kill kittens as well.
Nevertheless, we're back in a situation where we actually need certain APIs to be implemented to make certain types of functionality -- functionality which was perfectly acceptable in the XUL addons era, I might add -- actually still possible. These APIs are not a priority to Mozilla right now, but a certain subset of them can be provided by a (formerly discouraged) native component.
It's time to kill some kittens.

The particular kitten I need to kill is TCP sockets. I need to be able to talk over TCP to Gopher servers directly on a selection of port numbers. This was not easy to implement with XPCOM, but you could implement your own nsIChannel as a first-class citizen that looked to the browser like any other channel in pure JavaScript back in the day, and I did. That was OverbiteFF. I'm not the only one who asked for this feature, and I was willing to write it, but I'm not going to spend a lot of time writing code Mozilla won't accept and that means Mozilla needs to come up with an acceptable spec. This has gradually drowned under the ocean they're trying to boil by coming up with everyone's use cases whether they have anything in common or not and then somehow addressing the security concerns of all these disparate connection models and eventually forging the one ring to bind them all sometime around the natural heatdeath of the observable universe. I'm tired of waiting.
So here is OverbiteNX. OverbiteNX comes in two parts: the actual WebExtensions addon ("OverbiteNX" proper), and Onyx, a native component that the browser add-on asks to connect to a Gopher server and then receives data from it. Onyx is supported on Microsoft Windows, Linux and macOS (I've included binaries for Win32 and macOS 10.12+), and works probably anywhere else you can compile and run Firefox and Onyx as long as it supports Berkeley sockets. Onyx has no dependencies, is written in cross-platform C with a couple Windows-specific bits, and is currently presented in a single source file in an uncomplicated manner to not only serve the purpose of the extension but also to serve as an educational example of how to kill your own particular kitten. All of the pieces needed to hook it up (the Windows NSI and example JSON) are included and you can see how it connects with the front-end and the life cycle of a request in the source code. I discuss the architecture in more detail and how you can play with it. (If you are a current user of OverbiteWX, please remove it first.)
To be sure, I'm not the first to have this idea, and it's hardly an optimal solution. Besides the fact I have to coax someone to install a binary on their system to use the add-on, if I change the communication protocol (which is highly likely given that I will need to add future support for multithreading and possibly session IDs when multiple tabs are in use) then I need to get them to upgrade both the add-on and the native component at the same time. Users on weird platforms, and as a user of a weird platform I certainly empathize, have to do more work to get it to run on their system by compiling and installing it manually. The dat extension I linked to at the beginning of this paragraph gets around the binary code limitation by running the "native" component as JavaScript under Node.js, but that requires you to run Node, which is an extra step that seems unrealistic for many end-users and actually adds more work to people on weird platforms.
On the other hand, this is the only way right now it's going to work at all. I don't think Mozilla is going to move on these pain points unless they get into the situation where half the add-ons on AMO depend on external components they don't manage. So let the kitten killing begin. If you've got an idea and the current APIs don't let you implement it, see if a native component will scratch your itch and increase the pressure on Mountain View. After all, if Mozilla doesn't add useful WebExtensions APIs, there's no alternative but feline mass murder.
Provocative hyperbole aside, bug reports and pull requests appreciated for OverbiteNX. At some point in the near future the add-on piece will be submitted to AMO, which I expect to pass the automatic scanner since it doesn't do any currently proscribed operations, and then it's just a matter of keeping the native component in sync for future releases. Watch the Github project for more. And enjoy Gopherspace. Just don't tell the EU about it.
(Note for the humourless: The cat pictured is my cat. She is purring on her ottoman as this was written. No cat was harmed during the making of this blog post, though she does get an occasional talking-to. The picture was taken when she was penned up in the laundry while I was out and she was not threatened with any projectile weapon.)
http://tenfourfox.blogspot.com/2018/06/lets-kill-kittens-with-native-messaging.html
|
|
K Lars Lohn: Things Gateway - Nest Thermostat & the Pellet Stove |




thermostat_state = WoTThing.wot_property((see this code in situ in the pellet_stove.py file in the pywot demo directory)
name='thermostat_state',
description='the on/off state of the thermostat',
initial_value=False,
value_source_fn=get_thermostat_state,
)
async def get_thermostat_state(self):(see this code in situ in the pellet_stove.py file in the pywot demo directory)
previous_thermostat_state = self.thermostat_state
self.thermostat_state = self._controller.get_thermostat_state()
self.logging_count += 1
if self.logging_count % 300 == 0:
logging.debug('still monitoring thermostat')
self.logging_count = 0
if previous_thermostat_state != self.thermostat_state:
if self.thermostat_state:
logging.info('start heating')
await self.set_stove_mode_to_heating()
else:
logging.info('start lingering shutdown')
self.lingering_shutdown_task = asyncio.get_event_loop().create_task(
self.set_stove_mode_to_lingering()
)
stove_state = WoTThing.wot_property((see this code in situ in the pellet_stove.py file in the pywot demo directory)
name='stove_state',
description='the stove intensity level',
initial_value='off', # off, low, medium, high
)
stove_automation_mode = WoTThing.wot_property((see this code in situ in the pellet_stove.py file in the pywot demo directory)
name='stove_automation_mode',
description='the current operating mode of the stove',
initial_value='off', # off, heating, lingering_in_medium, lingering_in_low, overridden
)
medium_linger_minutes = WoTThing.wot_property((see this code in situ in the pellet_stove.py file in the pywot demo directory)
name='medium_linger_minutes',
description='how long should the medium level last during lingering shutdown',
initial_value=5.0,
value_forwarder=set_medium_linger
)
low_linger_minutes = WoTThing.wot_property(
name='low_linger_minutes',
description='how long should the low level last during lingering shutdown',
initial_value=5.0,
value_forwarder=set_low_linger
)

2018-06-06 06:25:29,938 pellet_stove.py:100 INFO start heating
2018-06-06 06:53:39,008 pellet_stove.py:103 INFO start lingering shutdown
2018-06-06 06:53:39,014 pellet_stove.py:162 DEBUG stove set to medium for 120 seconds
2018-06-06 06:55:39,020 pellet_stove.py:171 DEBUG stove set to low for 300 seconds
2018-06-06 07:00:00,706 pellet_stove.py:100 INFO start heating
2018-06-06 07:00:00,707 pellet_stove.py:147 DEBUG canceling lingering shutdown
to turn stove back to high
2018-06-06 07:14:14,256 pellet_stove.py:162 DEBUG stove set to medium for 120 seconds
2018-06-06 07:16:14,262 pellet_stove.py:171 DEBUG stove set to low for 300 seconds
2018-06-06 07:21:14,268 pellet_stove.py:178 INFO stove turned off
http://www.twobraids.com/2018/06/things-gateway-nest-thermostat-pellet.html
|
|
Mozilla VR Blog: This week in Mixed Reality: Issue 9 |

This week the team is continously working on new features, making improvements and fixing bugs.
Next week, the team will be in San Francisco for an all-Mozilla company meeting.
We just added a new browser design and assets to Firefox Reality and we now have the ability to display a 360 image as the background in VR while doing 2D browsing!
We can now import and display basic 2D web content in a shared room and continue to make improvements.
Join our public WebVR Slack #social channel to participate in on the discussion!
We are improving support for the Oculus Go on the Unity WebVR project on the Unity WebVR exporter tool.
Found a critical bug? File it in our public GitHub repo or let us know on the public WebVR Slack #unity channel and as always, join us in our discussion!
Stay tuned for new features and improvements across our three areas!
|
|
Hacks.Mozilla.Org: @media, MathML, and Django 1.11: MDN Changelog for May 2018 |
|
|
Will Kahn-Greene: Standup report: June 8th, 2018 |
Standup is a system for capturing standup-style posts from individuals making it easier to see what's going on for teams and projects. It has an associated IRC bot standups for posting messages from IRC.
Over the last six months, we've done:
The monthly library updates have helped with reducing technical debt. That takes a few hours each month to work through.
Paul redid how Standup does static assets. We no longer use django-pipeline, but instead use gulp. It works muuuuuuch better and makes it possible to upgrade to Djagno 2.0 soon. That was a ton of work over the course of a few days for both of us.
We've been keeping the Standup service running. That includes stage and production websites as well as stage and production IRC bots. That also includes helping users who are stuck--usually with accounts management. That's been a handful of hours.
Arai fixed the textareas so they're resizeable. That helps a ton! I'd love to get more help with UI/UX fixing.
Some GitHub stats:
GitHub
======
mozilla/standup: 15 prs
Committers:
pyup-bot : 6 ( +588, -541, 20 files)
willkg : 5 ( +383, -169, 27 files)
pmac : 2 ( +4179, -223, 58 files)
arai-a : 1 ( +2, -1, 1 files)
g-k : 1 ( +3, -3, 1 files)
Total : ( +5155, -937, 89 files)
Most changed files:
requirements.txt (11)
requirements-dev.txt (7)
standup/settings.py (5)
docker-compose.yml (4)
standup/status/jinja2/base.html (3)
standup/status/models.py (3)
standup/status/tests/test_views.py (3)
standup/status/urls.py (3)
standup/status/views.py (3)
standup/urls.py (3)
Age stats:
Youngest PR : 0.0d: 466: Add site-wide messaging
Average PR age : 2.3d
Median PR age : 0.0d
Oldest PR : 10.0d: 459: Scheduled monthly dependency update for May
All repositories:
Total merged PRs: 15
Contributors
============
arai-a
g-k
pmac
pyup-bot
willkg
That's it for the last six months!
Do you use Standup?
Did you use Standup, but the glacial pace of fixing issues was too much so you switched to something else?
Do you want to use Standup?
We think there's still some value in having Standup around and there are still people using it. There's still some technical debt to fix that makes working on it harder than it should be. We've been working through that glacially.
As a project, we have the following problems:
Why aren't users contributing? Probably a lot of reasons. Maybe everyone has their own reason! Have I spent a lot of time to look into this? No, because I don't have a lot of time to work on Standup.
Instead, we're just going to make some changes and see whether that helps. So we're doing the following:
What's that you say? What's swag-driven development?
I mulled over the idea in my post on swag-driven development.
It's a couple of things, but mainly an explicit statement that people work on Standup in our spare time at the cost of not spending that time on other things. While we don't feel entitled to feeling appreciated, it would be nice to feel appreciated sometimes. Not feeling appreciated makes me wonder whether I should spend the time elsewhere. (And maybe that's the case--I have no idea.) Maybe other people would be more interested in spending their spare time on Standup if they knew there were swag incentives?
So what does this mean?
It means that we're encouraging swag donations!
Paul and I were going to try to get together at the All Hands and discuss what's next.
We don't really have an agenda. I know I look at the issue tracker and go, "ugh" and that's about where my energy level is these days.
Possible things to tackle in the next 6 months off the top of my head:
If you're interested in meeting up with us, toss me an email at willkg at mozilla dot com.
http://bluesock.org/~willkg/blog/mozilla/standup_report_20180608.html
|
|
Daniel Stenberg: quic wg interim Kista |
 The IETF QUIC working group had its fifth interim meeting the other day, this time in Kista, Sweden hosted by Ericsson. For me as a Stockholm resident, this was ridiculously convenient. Not entirely coincidentally, this was also the first quic interim I attended in person.
The IETF QUIC working group had its fifth interim meeting the other day, this time in Kista, Sweden hosted by Ericsson. For me as a Stockholm resident, this was ridiculously convenient. Not entirely coincidentally, this was also the first quic interim I attended in person.
We were 30 something persons gathered in a room without windows, with another dozen or so participants joining from remote. This being a meeting in a series, most people already know each other from before so the atmosphere was relaxed and friendly. Lots of the participants have also been involved in other protocol developments and standards before. Many familiar faces.
As QUIC is supposed to be done "soon", the emphasis is now a lot to close issues, postpone some stuff to "QUICv2" and make sure to get decisions on outstanding question marks.
Kazuho did a quick run-through with some info from the interop days prior to the meeting.
After MT's initial explanation of where we're at for the upcoming draft-13, Ian took us a on a deep dive into the Stream 0 Design Team report. This is a pretty radical change of how the wire format of the quic protocol, and how the TLS is being handled.
The existing draft-12 approach...

Is suggested to instead become...

What's perhaps the most interesting take away here is that the new format doesn't use TLS records anymore - but simplifies a lot of other things. Not using TLS records but still doing TLS means that a QUIC implementation needs to get data from the TLS layer using APIs that existing TLS libraries don't typically provide. PicoTLS, Minq, BoringSSL. NSS already have or will soon provide the necessary APIs. Slightly behind, OpenSSL should offer it in a nightly build soon but the impression is that it is still a bit away from an actual OpenSSL release.
EKR continued the theme. He talked about the quic handshake flow and among other things explained how 0-RTT and early data works. Taken from that context, I consider this slide (shown below) fairly funny because it makes it look far from simple to me. But it shows communication in different layers, and how the acks go, etc.

Mike then presented the state of HTTP over quic. The frames are no longer that similar to the HTTP/2 versions. Work is done to ensure that the HTTP layer doesn't need to refer or "grab" stream IDs from the transport layer.
There was a rather lengthy discussion around how to handle "placeholder streams" like the ones Firefox uses over HTTP/2 to create "anchors" on which to make dependencies but are never actually used over the wire. The nature of the quic transport makes those impractical and we talked about what alternatives there are that could still offer similar functionality.

The subject of priorities and dependencies and if the relative complexity of the h2 model should be replaced by something simpler came up (again) but was ultimately pushed aside.
Alan presented the state of QPACK, the HTTP header compression algorithm for hq (HTTP over QUIC). It is not wire compatible with HPACK anymore and there have been some recent improvements and clarifications done.
Alan also did a great step-by-step walk-through how QPACK works with adding headers to the dynamic table and how it works with its indices etc. It was very clarifying I thought.
The discussion about the static table for the compression basically ended with us agreeing that we should just agree on a fairly small fixed table without a way to negotiate the table. Mark said he'd try to get some updated header data from some server deployments to get another data set than just the one from WPT (which is from a single browser).
Interop-testing of QPACK implementations can be done by encode + shuffle + decode a HAR file and compare the results with the source data. Just do it - and talk to Alan!
And the first day was over. A fully packed day.
Magnus started off with some heavy stuff talking Explicit Congestion Notification in QUIC and it how it is intended to work and some remaining issues.
He also got into the subject of ACK frequency and how the current model isn't ideal in every situation, causing to work like this image below (from Magnus' slide set):

Interestingly, it turned out that several of the implementers already basically had implemented Magnus' proposal of changing the max delay to min(RTT/4, 25 ms) independently of each other!
Subodh took us on a journey with some great insights from Facebook's deployment of mvfast internally, their QUIC implementation. Getting some real-life feedback is useful and with over 100 billion requests/day, it seems they did give this a good run.
Since their usage and stack for this is a bit use case specific I'm not sure how relevant or universal their performance numbers are. They showed roughly the same CPU and memory use, with a 70% RPS rate compared to h2 over TLS 1.2.
He also entertained us with some "fun issues" from bugs and debugging sessions they've done and learned from. Awesome.
The story highlights the need for more tooling around QUIC to help developers and deployers.
Martin talked about load balancers and servers, and how they could or should communicate to work correctly with routing and connection IDs.
The room didn't seem overly thrilled about this work and mostly offered other ways to achieve the same results.
During the last session for the day and the entire meeting, was mt going through a few things that still needed discussion or closure. On stateless reset and the rather big bike shed issue: implicit open. The later being the question if opening a stream with ID N + 1 implicitly also opens the stream with ID N. I believe we ended with a slight preference to the implicit approach and this will be taken to the list for a consensus call.
How should the QUIC protocol allow extensibility? The oldest still open issue in the project can be solved or satisfied in numerous different ways and the discussion waved back and forth for a while, debating various approaches merits and downsides until the group more or less agreed on a fairly simple and straight forward approach where the extensions will announce support for a feature which then may or may involve one or more new frame types (to be in a registry).
We proceeded to discuss other issues all until "closing time", which was set to be 16:00 today. This was just two days of pushing forward but still it felt quite intense and my personal impression is that there were a lot of good progress made here that took the protocol a good step forward.

The facilities were lovely and Ericsson was a great host for us. The Thursday afternoon cakes were great! Thank you!
There's an IETF meeting in Montreal in July and there's a planned next QUIC interim probably in New York in September.
https://daniel.haxx.se/blog/2018/06/08/quic-wg-interim-kista/
|
|
Mozilla Open Design Blog: Paris, Munich, & Dresden: Help Us Give the Web a Voice! |
Text available in: English | Francais | Deutsche
In July, our Voice Assistant Team will be in France and Germany to explore trust and technology adoption. We’re particularly interested in how people use voice assistants and how people listen to content like Pocket and podcasts. We would like to learn more how you use technology and how a voice assistant or voice user interface (VUIs) could improve your Internet and open web experiences. We will be conducting a series of in-home interviews and participatory design sessions. No prior voice assistant experience needed!
We would love to meet folks in person in:
Paris: July 3 – 6, 2018
Munich: July 9 – 13, 2018
Dresden: July 16 – 20, 2018
If you are interested in participating in our in home interviews (2 hours) or participatory design sessions (1.5 hours), please let us know! We’d love to meet you in-person!
If you are interested in meeting us in Paris, please fill out this form.
If you are interested in meeting us in Germany, please fill out this form.
All information will be held under Mozilla’s Privacy Policy.
En juillet, notre 'equipe Assistants vocaux sera en France et en Allemagne pour explorer la confiance et l’adoption de ces technologies. Nous sommes particuli`erement int'eress'es par la facon dont les gens utilisent les assistants vocaux et par comment ils 'ecoutent du contenu comme Pocket ou des podcasts. Nous aimerions en savoir plus sur la facon dont vous utilisez cette technologie et sur la facon dont un assistant vocal ou une interface utilisateur vocale (VUI) pourrait am'eliorer vos exp'eriences sur le Web. Nous m`enerons une s'erie d’entrevues `a domicile et de s'eances de conception participatives. Aucune utilisation d’assistant vocal n’est requise au pr'ealable !
Nous aimerions rencontrer des gens en personne `a :
Paris : du 3 au 6 juillet 2018,
Munich : du 9 au 13 juillet 2018,
Dresde : du 16 au 20 juillet 2018.
Si vous ^etes int'eress'e(e)s `a participer `a nos interviews `a domicile (2 heures) ou `a des sessions de conception participative (1,5 heure), faites le nous savoir ! Nous aimerions vous rencontrer !
Si vous souhaitez nous rencontrer `a Paris, veuillez remplir ce formulaire.
Si vous souhaitez nous rencontrer en Allemagne, veuillez remplir ce formulaire.
Toutes les informations seront conserv'ees dans la politique de confidentialit'e de Mozilla.
Im Juli wird unser Voice Assistant Team in Frankreich und Deutschland sein, um Technologie-Akzeptanz und -Vertrauen zu erkunden. Uns interessiert besonders, wie Menschen Sprachassistenten benutzen und wie Menschen Inhalte wie Pocket und Podcasts h"oren. Wir w"urden gerne mehr dar"uber erfahren, wie Sie Technologie benutzen und wie ein Sprachassistent oder eine Sprachbenutzeroberfl"ache (VUIs) Ihr Internet- und freies Weberlebnis verbessern k"onnte. Wir werden eine Reihe von In-Home-Interviews und partizipativen Design-Sessions durchf"uhren. Keine vorherige Erfahrung des Sprachassistenten erforderlich!
Wir w"urden uns freuen Sie pers"onlich zu treffen in:
Paris: 3. – 6. Juli 2018;
M"unchen: 9. – 13. Juli 2018;
Dresden: 16. – 20. Juli 2018.
Wenn Sie daran interessiert sind, an unseren In-Home-Interviews (2 Stunden) oder partizipativen Design-Sessions (1,5 Stunden) teilzunehmen, lassen Sie es uns bitte wissen! Wir w"urden uns freuen, Sie pers"onlich zu treffen!
Wenn Sie Interesse haben, uns in Paris zu treffen, f"ullen Sie bitte dieses Formular aus.
Wenn Sie Interesse haben, uns in Deutschland zu treffen, f"ullen Sie bitte dieses Formular aus.
Alle Informationen werden unter der Datenschutzerkl"arung von Mozilla gespeichert.
The post Paris, Munich, & Dresden: Help Us Give the Web a Voice! appeared first on Mozilla Open Design.
https://blog.mozilla.org/opendesign/paris-munich-dresden-help-us-give-the-web-a-voice/
|
|
Dave Townsend: Searchfox in VS Code |
I spend most of my time developing flipping back and forth between VS Code and Searchfox. VS Code is a great editor but it has nowhere near the speed needed to do searches over the entire tree, at least on my machine. Searchfox on the other hand is pretty fast. But there’s something missing. I usually want to search Searchfox for something I found in the code. Then I want to get the file I found in Searchfox open in my editor.
Luckily VS Code has a decent extension system that allows you to add new features so I spent some time yesterday evening building an extension to integration some of Searchfox’s functionality into VS Code. With the extension installed you can search Searchfox for something from the code editor or pop open an input box to write your own query. The results show up right in VS Code.

Click on a result in Searchfox and it will open the file in an editor in VS Code, right at the line you wanted to see.
It’s pretty early code so the usual disclaimers apply, expect some bugs and don’t be too surprised if it changes quite a bit in the near-term. You can check out the fairly simple code (rendering the Searchfox page is the hardest part of it) on Github.
If you want to give it a try, install the extension from the VS Code Marketplace or find it by searching for “Searchfox” in VS Code itself. Feel free to file issues for bugs or improvements that would be useful or of course submit pull requests of your own! I’d love to hear if you find it useful.
https://www.oxymoronical.com/blog/2018/06/Searchfox-in-VS-Code
|
|
Zibi Braniecki: Pseudolocalization in Firefox |
One of the core projects we did over 2017 was a major overhaul of the Localization and Internationalization layers in Gecko, and all throughout the first half of 2018 we were introducing Fluent into Firefox.
All of that work was “behind the scenes” and laid the foundation to enable us to bring higher level improvements in the future.
Today, I’m happy to announce that the first of those high-level features has just landed in Firefox Nightly!
Pseudolocalization is a technology allowing for testing the localizability of software UI. It allows developers to check how the UI they are working on will look like when translated, without having to wait for translations to become available.
It shortens the Test-Driven Development cycle and lowers the burden of creating localizable UI.
Here’s a demo of how it works:
At the moment, we don’t have any UI for this feature. You need to create a new preference called intl.l10n.pseudo and set its value to accented for a left-to-right, ~30% longer strategy, or bidi for a right-to-left strategy. (more documentation).
If you test the bidi strategy you also will likely want to switch another preference – intl.uidirection – to 1. This is because right now the directionality of text and layout are not connected. We will improve that in the future.
We’ll be looking into ways to expose this functionality in the UI, and if you have any ideas or suggestions for what you’d like to see, let’s talk!
Although the feature may seem simple to add, and the actual patch that adds it was less than 100 lines long, it took many years of prototyping and years of development to build the foundation layers to allow for it.
Many of the design principles of Project Fluent combined with the vision shaped by the L10n Drivers Team at Mozilla allowed for dynamic runtime locale switching and declarative UI localization bindings.
Thanks to all of that work, we don’t have to require special builds or increase the bundle size for this feature to work. It comes practically for free and we can extend and fine tune pseudolocalization strategies on fly.
If that feature looks cool, in the esoteric way localization and internationalization can, please, make sure to high-five the people who put a lot of work to get this done: Sta's Malolepszy, Axel Hecht, Francesco Lodolo, Jeff Beatty and Dave Townsend.
More features are coming! Stay tuned.
https://diary.braniecki.net/2018/06/07/pseudolocalization-in-firefox/
|
|
Daniel Glazman: Browser detection inside a WebExtension |
Just for the record, if you really need to know about the browser container of your WebExtension, do NOT rely on StackOverflow answers... Most of them are based, directly or not, on the User Agent string. So spoofable, so unreliable. Some will recommend to rely on a given API, implemented by Firefox and not Edge, or Chrome and not the others. In general valid for a limited time only... You can't even rely on chrome, browser or msBrowser since there are polyfills for that to make WebExtensions cross-browser.
So the best and cleanest way is probably to rely on chrome.extension.getURL("/") . It can start with "moz", "chrome" or "ms-browser". Unlikely to change in the near future. Simple to code, works in both content and background.
My pleasure 
|
|
Mozilla Open Innovation Team: More Common Voices |
Today we are excited to announce that Common Voice, Mozilla’s initiative to crowdsource a large dataset of human voices for use in speech technology, is going multilingual! Thanks to the tremendous efforts from Mozilla’s communities and our deeply engaged language partners you can now donate your voice in German, French and Welsh, and we are working to launch 40+ more as we speak. But this is just the beginning. We want Common Voice to be a tool for any community to make speech technology available in their own language.
Since we launched Common Voice last July, we have collected hundreds of thousands of voice samples in English through our website and iOS app. Last November, we published the first version of the Common Voice dataset. This data has been downloaded thousands of times, and we have seen the data being used in commercial voice products as well as open-source software like Kaldi and our very own speech recognition engine, project Deep Speech.
Up until now, Common Voice has only been available for voice contributions in English. But the goal of Common Voice has always been to support many languages so that we may fulfill our vision of making speech technology more open, accessible, and inclusive for everyone. That is why our main effort these last few months has been around growing and empowering individual language communities to launch Common Voice in their parts of the world, in their local languages and dialects.
In addition to localizing the website, these communities are populating Common Voice with copyright-free sentences for people to read that have the required characteristics for a high quality dataset. They are also helping promote the site in their countries, building a community of contributors, with the goal of growing the total number of hours of data available in each language.
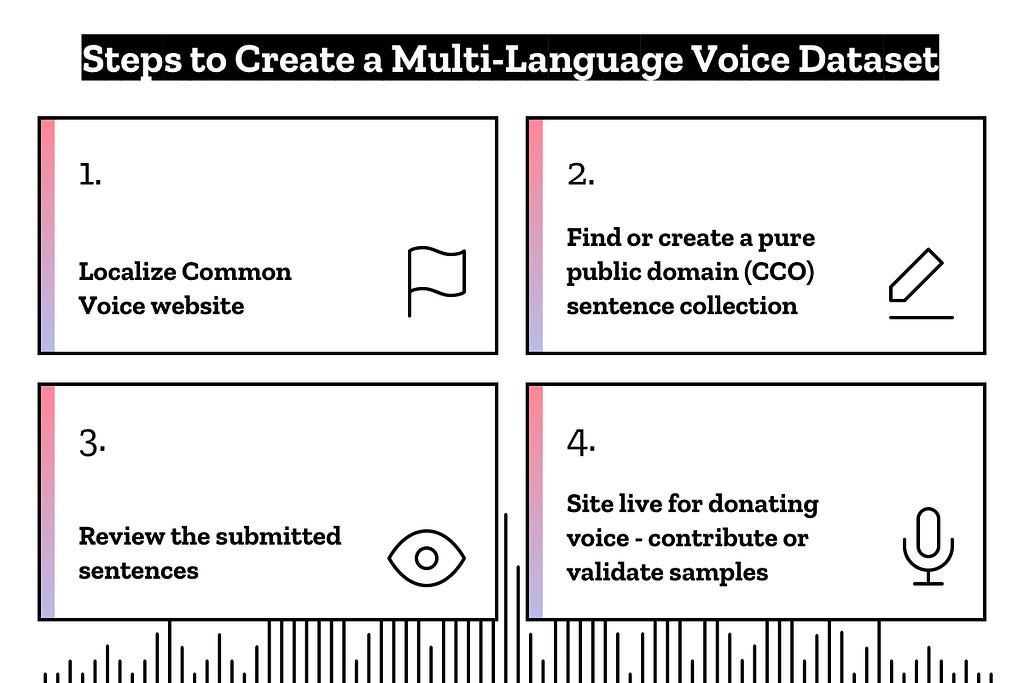
In addition to English, we are now collecting voice samples in French, German and Welsh. And there are already more than 40 other languages on the way — not only big languages like Spanish, Chinese or Russian, but also smaller ones like Frisian, Norwegian or Chuvash. For us, these smaller languages are important because they are often under-served by existing commercial speech recognition services. And so by making this data available, we can empower entrepreneurs and communities to address this gap on their own.
Going multilingual marks a big step for Common Voice and we hope that it’s also a big step for speech technology in general. Democratizing voice technology will not only lower the barrier for global innovation, but also the barrier for access to information. Especially so for people who traditionally have had less of this access — for example, vision impaired, people who never learned to read, children, the elderly and many others.
We are thrilled to see the growing support we are getting to build the world’s largest public, multi-language voice dataset. You can help us grow it right now by donating your voice. You can also use the iOS app. If you would like to help bring Common Voice and speech technology to your language, visit our language page. And if you are part of an organization and have an idea for participating in this project, please get in touch (dchinniah@mozilla.com).
Our Forum gives more details on how to help, as well as being a great place to ask questions and meet the communities.
Special Thanks
We would like to thank our Speech Advisory Group, people who have been expert advisors and contributors to the Common Voice project:
***
Common Voice complements Mozilla’s work in the field of speech recognition, which runs under the project name “Deep Speech”, an open-source speech recognition engine model that approaches human accuracy, which was released in November 2017. Together with the growing Common Voice dataset we believe this technology can and will enable a wave of innovative products and services, and that it should be available to everyone.
More Common Voices was originally published in Mozilla Open Innovation on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
The Mozilla Blog: Parlez-vous Deutsch? Rhagor o Leisiau i Common Voice |
We’re very proud to be announcing the next phase of the Common Voice project. It’s now available for contributors in three new languages, German, French and Welsh, with 40+ other languages on their way! But this is just the beginning. We want Common Voice to be a tool for any community to make speech technology available in their own language.
Speech interfaces are the next frontier for the Internet. Project Common Voice is our initiative to build a global corpus of open voice data to be used to train machine-learning algorithms to power the voice interfaces of the future. We believe these interfaces shouldn’t be controlled by a few companies as gatekeepers to voice-enabled services, and we want users to be understood consistently, in their own languages and accents.
As anyone who has studied the economics of the Internet knows, services chase money. And so it’s quite natural that developers and publishers seek to develop for the audience that will best reward their efforts. What we see as a consequence is an Internet that is heavily skewed towards English, in a world where English is only spoken by 20% of the global population, and only 5% natively. This is increasingly going to be an accessibility issue, as Wired noted last year, “Voice Is the Next Big Platform, Unless You Have an Accent”.
Inevitably, English is becoming a global language, spoken more and more widely, and this is a trend that was underway before the emergence of the Internet. However, the skew of Internet content to English is certainly accelerating this. And while global communications may be becoming easier, there is also a cultural wealth that we should preserve. Native languages provide a deeper shared cultural context, down to the level of influencing our thought patterns. This is a part of our humanity we surely wish to retain and support with technology. In doing so, we’re upholding a proud Mozilla tradition of enabling local ownership by a global community: Firefox is currently offered in 90 languages (and counting), powered by volunteers near you.

Common Voice contribution sprints in Berlin (credit: Michael Kohler), Mexico City (credit: Luis A. S'anchez), Jakarta (credit: Irayani Queencyputri) and Taipei (credit: Irvin Chen), from the top left to the bottom right
With Common Voice it’s the same volunteer passion that drives the project further and we’re grateful for all contributors who already said, “We want to help bringing speech recognition technology to my part of the world – what can we do?”. It is the underlying stories which also make this project so rewarding for me personally:
In Indonesia 20 community members came to our community space in Jakarta for a meet-up to write up sentences for the text corpus that will become the basis for voice recordings. They went into overdrive and submitted around 4,000 sentences within two days.
In Kenya a group of volunteers interested in Mozilla projects found out about Common Voice and started both localizing the website and submitting sentences in Swahili, Jibana and Kikiyu, all highly underrepresented languages, which we’re extremely happy to support. This is in addition to working with language experts in these communities like Laurent Besacier, the initiator of ALFFA, an interdisciplinary project bundling resources and expertise in speech analysis and speech technologies for African languages.
If we look at the country where I’m from, there has been one particular contributor to the Common Voice github project since the very early days. He originally contributed to the English effort, but he is German and wanted to see Common Voice come to Germany. He set himself on a strict schedule, wrote a few sentences every day for the next 6 months (while commuting to school or work), and collected 11,000 (!) sentences, ranging from poetry to day-to-day conversations.
Speaking of which: Another German contributor joined the Global Sprint in our Berlin office, utterly frustrated about a lengthy but fruitless discussion at the post office (Sounds familiar, Germany?). He may not have gotten his package, but I’d like to believe he had his personal cathartic moment when he submitted his whole experience in written form. Now Germans everywhere will help him voice his frustrations.
These are only a few of many wonderful examples from around the world – Taiwan, Slovenia, Macedonia, Hungary, Brazil, Serbia, Thailand, Spain, Nepal, and many more. They show that anyone can help grow the Common Voice project. Any individual or organization that has an interest in its native language, or an interest in open voice interfaces, will find it worth their while. You can contribute your voice at https://voice.mozilla.org/en/languages, or if you have a larger corpus of transcribed speech data, we’d love to hear from you.
***
Common Voice complements Mozilla’s work in the field of speech recognition, which runs under the project name “Deep Speech“, an open-source speech recognition engine model that approaches human accuracy, which was released in November 2017. Together with the growing Common Voice dataset we believe this technology can and will enable a wave of innovative products and services, and that it should be available to everyone.
The post Parlez-vous Deutsch? Rhagor o Leisiau i Common Voice appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/06/07/parlez-vous-deutsch-rhagor-o-leisiau-i-common-voice/
|
|
David Lawrence: Happy BMO Push Day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
https://dlawrence.wordpress.com/2018/06/06/happy-bmo-push-day-44/
|
|
Air Mozilla: Bugzilla Project Meeting, 06 Jun 2018 |
 The Bugzilla Project Developers meeting.
The Bugzilla Project Developers meeting.
|
|
Armen Zambrano: AreWeFastYet UI refresh |
For a long time Mozilla’s JS team and others have been using https://arewefastyet.com to track the JS engine performance against various benchmarks.
In the last little while, there’s been work moving those benchmarks to another continuous integration system and we have the metrics in Mozilla’s Perfherder. This rewrite will focus on using the new generated data.
If you’re curious on the details about the UI refresh please visit this document. Feel free to add feedback. Stay tuned for an update next month.
http://feedproxy.google.com/~r/armenzg_mozilla/~3/-RW21RnGokw/arewefastyet-ui-refresh-328129d21742
|
|
Air Mozilla: The Joy of Coding - Episode 141 |
 mconley livehacks on real Firefox bugs while thinking aloud.
mconley livehacks on real Firefox bugs while thinking aloud.
|
|
Air Mozilla: Weekly SUMO Community Meeting, 06 Jun 2018 |
 This is the SUMO weekly call
This is the SUMO weekly call
https://air.mozilla.org/weekly-sumo-community-meeting-20180606/
|
|
Mark C^ot'e: Phabricator and Lando Launched |
The Engineering Workflow team at Mozilla is happy to announce that Phabricator and Lando are now ready for use with mozilla-central! This represents about a year of work integrating Phabricator with our systems and building out Lando.
There are more details in my post to the dev.platform list.
https://mrcote.info/blog/2018/06/06/phabricator-and-lando-launched/
|
|
The Firefox Frontier: A Socially Responsible Way to Internet |
Choices matter. That might sound flippant or obvious, but we’re not just talking about big, life-changing decisions. Little choices — daily choices — add up in a big way, online and off. This is … Read more
The post A Socially Responsible Way to Internet appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/a-socially-responsible-way-to-internet/
|
|






