Jeff Walden: PSA: stop using mozilla::PodZero and mozilla::PodArrayZero |
I’ve blogged about surprising bits of the C++ object model before, and I’m back with more.
Executive summary: Don’t use mozilla::PodZero or mozilla::PodArrayZero. Modern C++ provides better alternatives that don’t presume that writing all zeroes will always correctly initialize the given type. Use constructors, in-class member initializers, and functions like std::fill to zero member fields.
C++ as a language really wants to know when objects are created so that compilers can know that this memory contains an object of this type. Compilers then can assume that writing an object of one type, won’t conflict with reads/writes of incompatible types.
double foo(double* d, int* i, int z)
{
*d = 3.14;
// int/double are incompatible, so this write may be
// assumed not to change the value of *d.
*i = z;
// Therefore *d may be assumed to still be 3.14, so this
// may be compiled as 3.14 * z without rereading *d.
return *d * z;
}
You can’t use arbitrary memory as your desired type after a cast. An object of that type must have been explicitly created there: e.g. a local variable of that type must be declared there, a field of that type must be defined and the containing object created, the object must be created via new, &c.
Misinterpreting an object using an incompatible type violates the strict aliasing rules in [basic.lval]p11.
memsetting an objectmemset lets you write characters over memory. C code routinely used this to fill an array or struct with zeroes or null pointers or similar, assuming all-zeroes writes the right value.
C++ code also sometimes uses memset to zero out an object, either after allocating its memory or in the constructor. This doesn’t create a T (you’d need to placement-new), but it often still “works”. But what if T changes to require initialization? Maybe a field in T gains a constructor (T might never be touched!) or a nonzero initializer, making T a non-trivial type. memset could hide that fresh initialization requirement or (depending when the memset happens) overwrite a necessary initialization.
Unfortunately, Mozilla code has provided and promoted a PodZero function that misuses memset this way. So when I built with gcc 8.0 recently (I usually use a home-built clang), I discovered a torrent of build warnings about memset misuse on non-trivial types. A taste:
In file included from /home/jwalden/moz/after/js/src/jit/BitSet.h:12,
from /home/jwalden/moz/after/js/src/jit/Safepoints.h:10,
from /home/jwalden/moz/after/js/src/jit/JitFrames.h:13,
from /home/jwalden/moz/after/js/src/jit/BaselineFrame.h:10,
from /home/jwalden/moz/after/js/src/vm/Stack-inl.h:15,
from /home/jwalden/moz/after/js/src/vm/Debugger-inl.h:12,
from /home/jwalden/moz/after/js/src/vm/DebuggerMemory.cpp:29,
from /home/jwalden/moz/after/js/src/dbg/js/src/Unified_cpp_js_src32.cpp:2:
/home/jwalden/moz/after/js/src/jit/JitAllocPolicy.h: In instantiation of ‘T* js::jit::JitAllocPolicy::maybe_pod_calloc(size_t) [with T = js::detail::HashTableEntry >; size_t = long unsigned int]’:
/home/jwalden/moz/after/js/src/dbg/dist/include/js/HashTable.h:1293:63: required from ‘static js::detail::HashTable::Entry* js::detail::HashTable::createTable(AllocPolicy&, uint32_t, js::detail::HashTable::FailureBehavior) [with T = js::HashMapEntry; HashPolicy = js::HashMap::MapHashPolicy; AllocPolicy = js::jit::JitAllocPolicy; js::detail::HashTable::Entry = js::detail::HashTableEntry >; uint32_t = unsigned int]’
/home/jwalden/moz/after/js/src/dbg/dist/include/js/HashTable.h:1361:28: required from ‘bool js::detail::HashTable::init(uint32_t) [with T = js::HashMapEntry; HashPolicy = js::HashMap::MapHashPolicy; AllocPolicy = js::jit::JitAllocPolicy; uint32_t = unsigned int]’
/home/jwalden/moz/after/js/src/dbg/dist/include/js/HashTable.h:92:69: required from ‘bool js::HashMap::init(uint32_t) [with Key = JS::Value; Value = unsigned int; HashPolicy = js::jit::LIRGraph::ValueHasher; AllocPolicy = js::jit::JitAllocPolicy; uint32_t = unsigned int]’
/home/jwalden/moz/after/js/src/jit/LIR.h:1901:38: required from here
/home/jwalden/moz/after/js/src/jit/JitAllocPolicy.h:101:19: warning: ‘void* memset(void*, int, size_t)’ clearing an object of type ‘class js::detail::HashTableEntry >’ with no trivial copy-assignment [-Wclass-memaccess]
memset(p, 0, numElems * sizeof(T));
~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~
In file included from /home/jwalden/moz/after/js/src/dbg/dist/include/js/TracingAPI.h:11,
from /home/jwalden/moz/after/js/src/dbg/dist/include/js/GCPolicyAPI.h:47,
from /home/jwalden/moz/after/js/src/dbg/dist/include/js/RootingAPI.h:22,
from /home/jwalden/moz/after/js/src/dbg/dist/include/js/CallArgs.h:73,
from /home/jwalden/moz/after/js/src/jsapi.h:29,
from /home/jwalden/moz/after/js/src/vm/DebuggerMemory.h:10,
from /home/jwalden/moz/after/js/src/vm/DebuggerMemory.cpp:7,
from /home/jwalden/moz/after/js/src/dbg/js/src/Unified_cpp_js_src32.cpp:2:
/home/jwalden/moz/after/js/src/dbg/dist/include/js/HashTable.h:794:7: note: ‘class js::detail::HashTableEntry >’ declared here
class HashTableEntry
^~~~~~~~~~~~~~
Unified_cpp_js_src36.o
In file included from /home/jwalden/moz/after/js/src/dbg/dist/include/js/HashTable.h:19,
from /home/jwalden/moz/after/js/src/dbg/dist/include/js/TracingAPI.h:11,
from /home/jwalden/moz/after/js/src/dbg/dist/include/js/GCPolicyAPI.h:47,
from /home/jwalden/moz/after/js/src/dbg/dist/include/js/RootingAPI.h:22,
from /home/jwalden/moz/after/js/src/dbg/dist/include/js/CallArgs.h:73,
from /home/jwalden/moz/after/js/src/dbg/dist/include/js/CallNonGenericMethod.h:12,
from /home/jwalden/moz/after/js/src/NamespaceImports.h:15,
from /home/jwalden/moz/after/js/src/gc/Barrier.h:10,
from /home/jwalden/moz/after/js/src/vm/ArgumentsObject.h:12,
from /home/jwalden/moz/after/js/src/vm/GeneratorObject.h:10,
from /home/jwalden/moz/after/js/src/vm/GeneratorObject.cpp:7,
from /home/jwalden/moz/after/js/src/dbg/js/src/Unified_cpp_js_src33.cpp:2:
/home/jwalden/moz/after/js/src/dbg/dist/include/mozilla/PodOperations.h: In instantiation of ‘void mozilla::PodZero(T*) [with T = js::NativeIterator]’:
/home/jwalden/moz/after/js/src/vm/Iteration.cpp:578:15: required from here
/home/jwalden/moz/after/js/src/dbg/dist/include/mozilla/PodOperations.h:32:9: warning: ‘void* memset(void*, int, size_t)’ clearing an object of type ‘struct js::NativeIterator’ with no trivial copy-assignment; use assignment or value-initialization instead [-Wclass-memaccess]
memset(aT, 0, sizeof(T));
~~~~~~^~~~~~~~~~~~~~~~~~
In file included from /home/jwalden/moz/after/js/src/vm/JSCompartment-inl.h:14,
from /home/jwalden/moz/after/js/src/vm/JSObject-inl.h:32,
from /home/jwalden/moz/after/js/src/vm/ArrayObject-inl.h:15,
from /home/jwalden/moz/after/js/src/vm/GeneratorObject.cpp:11,
from /home/jwalden/moz/after/js/src/dbg/js/src/Unified_cpp_js_src33.cpp:2:
/home/jwalden/moz/after/js/src/vm/Iteration.h:32:8: note: ‘struct js::NativeIterator’ declared here
struct NativeIterator
^~~~~~~~~~~~~~
mozilla::PodZeroHistorically you’d have to add every single member-initialization to your constructor, duplicating names and risking missing one, but C+11’s in-class initializers allow an elegant fix:
// Add " = nullptr" to initialize these function pointers.
struct AsmJSCacheOps
{
OpenAsmJSCacheEntryForReadOp openEntryForRead = nullptr;
CloseAsmJSCacheEntryForReadOp closeEntryForRead = nullptr;
OpenAsmJSCacheEntryForWriteOp openEntryForWrite = nullptr;
CloseAsmJSCacheEntryForWriteOp closeEntryForWrite = nullptr;
};
As long as you invoke a constructor, the members will be initialized. (Constructors can initialize a member to override in-class initializers.)
List-initialization using {} is also frequently helpful: you can use it to zero trailing (or all) members of an array or struct without naming/providing them:
class PreliminaryObjectArray
{
public:
static const uint32_t COUNT = 20;
private:
// All objects with the type which have been allocated. The pointers in
// this array are weak.
JSObject* objects[COUNT] = {}; // zeroes
public:
PreliminaryObjectArray() = default;
// ...
};
Finally, C++ offers iterative-mutation functions to fill a container:
#include// mozilla::Array's default constructor doesn't initialize array // contents unless the element type is a class with a default // constructor, and no Array overload exists to zero every // element. (You could pass 1024 zeroes, but....) mozilla::Array page; // array contents undefined std::fill(page.begin(), page.end(), 0); // now contains zeroes std::fill_n(page.begin(), page.end() - page.begin(), 0); // alternatively
After a long run of fixes to sundry bits of SpiderMonkey code to fix every last one of these issues last week, I’ve returned SpiderMonkey to warning-free with gcc (excluding imported ICU code). The only serious trickiness I ran into was a function of very unusual SpiderMonkey needs that shouldn’t affect code generally.
Fixing these issues is generally very doable. As people update to newer and newer gcc to build, the new -Wclass-memaccess warning that told me about these issues will bug more and more people, and I’m confident all these problems triggered by PodZero can be fixed.
mozilla::PodZero and mozilla::PodArrayZero are deprecatedPodZero and its array-zeroing variant PodArrayZero are ill-fitted to modern C++ and modern compilers. C++ now offers clean, type-safe ways to initialize memory to zeroes. You should avoid using PodZero and PodArrayZero in new code, replacing it with the initializer syntaxes mentioned above or with standard C++ algorithms to fill in zeroes.
As PodZero is used in a ton of places right now, it’ll likely stick around for some time. But there’s a good chance I’ll rename it to DeprecatedPodZero to highlight its badness and the desire to remove it. You should replace existing uses of it wherever and whenever you can.
http://whereswalden.com/2018/05/21/psa-stop-using-mozillapodzero-and-mozillapodarrayzero/
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 21 May 2018 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20180521/
|
|
Dustin J. Mitchell: Redeploying Taskcluster: Hosted vs. Shipped Software |
The Taskcluster team’s work on redeployability means switching from a hosted service to a shipped application.
A hosted service is one where the authors of the software are also running the main instance of that software. Examples include Github, Facebook, and Mozillians. By contrast, a shipped application is deployed multiple times by people unrelated to the software’s authors. Examples of shipped applications include Gitlab, Joomla, and the Rust toolchain. And, of course, Firefox!
Operating a hosted service can be liberating. Blog posts describe the joys of continuous deployment – even deploying the service multiple times per day. Bugs can be fixed quickly, either by rolling back to a previous deployment or by deploying a fix.
Deploying new features on a hosted service is pretty easy, too. Even a complex change can be broken down into phases and accomplished without downtime. For example, changing the backend storage for a service can be accomplished by modifying the service to write to both old and new backends, mirroring existing data from old to new, switching reads to the new backend, and finally removing the code to write to the old backend. Each phase is deployed separately, with careful monitoring. If anything goes wrong, rollback to the old backend is quick and easy.
Hosted service developers are often involved with operation of the service, and operational issues can frequently be diagnosed or even corrected with modifications to the software. For example, if a service is experiencing performance issues due to particular kinds of queries, a quick deployment to identify and reject those queries can keep the service up, followed by a patch to add caching or some other approach to improve performance.
A shipped application is sent out into the world to be used by other people. Those users may or may not use the latest version, and certainly will not update several times per day (the heroes running Firefox Nightly being a notable exception). So, many versions of the application will be running simultaneously. Some applications support automatic updates, but many users want to control when – and if – they update. For example, upgrading a website built with a CMS like Joomla is a risky operation, especially if the website has been heavily customized.
Upgrades are important both for new features and for bugfixes, including for security bugs. An instance of an application like Gitlab might require an immediate upgrade when a security issue is discovered. However, especially if the deployment is several versions old, that critical upgrade may carry a great deal of risk. Producers of shipped software sometimes provide backported fixes for just this purpose, at least for long term support (LTS) or extended support release (ESR) versions, but this has a substantial cost for the application developers.
Upgrading services like Gitlab or Joomla is made more difficult because there is lots of user data that must remain accessible after the upgrade. For major upgrades, that often requires some kind of migration as data formats and schemas change. In cases where the upgrade spans several major versions, it may be necessary to apply several migrations in order. Tools like Alembic help with this by maintaining and applying step-by-step database migrations.
Today, Taskcluster is very much a hosted application. There is only one “instance” of Taskcluster in the world, at taskcluster.net. The Taskcluster team is responsible for both development and operation of the service, and also works closely with the Firefox build team as a user of the service.
We want to make Taskcluster a shipped application. As the descriptions above suggest, this is not a simple process. The following sections highlight some of the challenges we are facing.
We currently deploy Taskcluster microservices independently. That is, when we make a change to a service like taskcluster-hooks, we deploy an upgrade to that service without modifying the other services. We often sequence these changes carefully to ensure continued compatibility: we expect only specific combinations of services to run together.
This is a far more intricate process than we can expect users to follow. Instead, we will ship Taskcluster releases comprised of a set of built Docker images and a spec file identifying those images and how they should be deployed. We will test that this particular combination of versions works well together.
Deploying a release involves combining that spec file with some
deployment-specific configuration and some infrastructure information
(implemented via Terraform) to produce a set of
Kubernetes resources for deployment with kubectl.
Kubernetes and Terraform both have limited support for migration from one
release to another: Terraform will only create or modify changed resources, and
Kubernetes will perform a phased roll-out of any modified resources.
By the way, all of this build-and-release functionality is implemented in the new taskcluster-installer.
The string taskcluster.net appears quite frequently in the Taskcluster source
code. For any other deployment, that hostname is not valid – but how will the
service find the correct hostname? The question extends to determining pulse
exchange names, task artifact hostnames, and so on. There are also security
issues to consider: misconfiguration of URLs might enable XSS and CSRF attacks
from untrusted content such as task artifacts.
The approach we are taking is to define a rootUrl from which all other URLs
and service identities can be determined. Some are determined by simple
transformations encapsulated in a new
taskcluster-lib-urls
library. Others are fetched at runtime from other services: pulse exchanges
from the taskcluster-pulse service, artifact URLs from the taskcluster-queue
service, and so on.
The rootUrl is a single domain, with all Taskcluster services available at
sub-paths such as /api/queue. Users of the current Taskcluster installation
will note that this is a change: queue is currently at
https://queue.taskcluster.net, not https://taskcluster.net/queue. We have
solved this issue by special-casing the rootUrl https://taskcluster.net to
generate the old-style URLs. Once we have migrated all users out of the current
installation, we will remove that special-case.
The single root domain is implemented using routing features supplied by
Kubernetes Ingress resources, based on an HTTP proxy. This has the
side-effect that when one microservice contacts another (for example,
taskcluster-hooks calling queue.createTask), it does so via the same Ingress,
a more circuitous journey than is strictly required.
The first few deployments of Taskcluster will not require great support for migrations. A staging environment, for example, can be completely destroyed and re-created without any adverse impact. But we will soon need to support users upgrading Taskcluster from earlier releases with no (or at least minimal) downtime.
Our Azure tables library (azure-entities) already has rudimentary support for schema updates, so modifying the structure of table rows is not difficult, although refactoring a single table into multiple tables would be difficult.
As we transition to using Postgres instead of Azure, we will need to adopt some of the common migration tools. Ideally we can support downtime-free upgrades like azure-entities does, instead of requiring downtime to run DB migrations synchronously. Bug 1431783 tracks this work.
As a former maintainer of Buildbot, I’ve had a lot of experience with CI applications as they are used in various organizations. The surprising observation is this: every organization thinks that their approach to CI is the obvious and only way to do things; and every organization does things in a radically different way. Developers gonna develop, and any CI framework will get modified to suit the needs of each user.
Lots of Buildbot installations are heavily customized to meet local needs. That has caused a lot of Buildbot users to get “stuck” at older versions, since upgrades would conflict with the customizations. Part of this difficulty is due to a failure of the Buildbot project to provide strong guidelines for customization. Recent versions of Buildbot have done better by providing clearly documented APIs and marking other interfaces as private and subject to change.
Taskcluster already has strong APIs, so we begin a step ahead. We might consider additional guidelines:
Users should not customize existing services, except to make experimental changes that will eventually be merged upstream. This frees the Taskcluster team to make changes to services without concern that those will conflict with users’ modifications.
Users are encouraged, instead, to develop their own services, either hosted within the Taskcluster deployment as a site-specific service, or hosted externally but following Taskcluster API conventions. A local example is the tc-coalesce service, developed by the release engineering team to support Mozilla-specific task-superseding needs and hosted outside of the Taskcluster installation. On the other hand, taskcluster-stats-collector is deployed within the Firefox Taskcluster deployment, but is Firefox-specific and not part of a public Taskcluster release.
While a Taskcluster release will likely encompass some pre-built worker images for various cloud platforms, sophisticated worker deployment is the responsibility of individual users. That may mean deploying workers to hardware where necessary, perhaps with modifications to the build configurations or even entirely custom-built worker implementations. We will provide cloud-provisioning tools that can be used to dynamically instantiate user-specified images.
The second point above raises an interesting quandry: Taskcluster uses code generation to create its API client libraries. Historically, we have just pushed the “latest” client to the package repository and carefully choreographed any incompatible changes. For users who have not customized their deployment, this is not too much trouble: any release of Taskcluster will have a client library in the package repository corresponding to it. We don’t have a great way to indicate which version that is, but perhaps we will invent something.
But when Taskcluster installations are customized by adding additional services, progress is no longer linear: each user has a distinct “fork” of the Taskcluster API surface containing the locally-defined services. Development of Taskcluster components poses a similar challenge: if I add a new API method to a service, how do I call that method from another service without pushing a new library to the package repository?
The question is further complicated by the use of compiled languages. While Python and JS clients can simply load a schema reference file at runtime (for example, a file generated at deploy time), the Go and Java clients “bake in” the references at compile time.
Despite much discussion, we have yet to settle on a good solution for this issue.
Mozilla is Open by Design, and so is Taskcluster: with the exception of data that must remain private (passwords, encryption keys, and material covered by other companies’ NDAs), everything is publicly accessible. While Taskcluster does have a sophisticated and battle-tested authorization system based on scopes, most read-only API calls do not require any scopes and thus can be made with a simple, un-authenticated HTTP request.
We take advantage of the public availability of most data by passing around
simple, authentication-free URLs. For example, the action
specification
describes downloading a decision task’s public/action.json artifact. Nowhere
does it mention providing any credentials to fetch the decision task, nor to
fetch the artifact itself.
This is a rather fundamental design decision, and changing it would be difficult. We might embark on that process, but we might also declare Taskcluster an open-by-design system, and require non-OSS users to invent other methods of hiding their data, such as firewalls and VPNs.
Firefox build, test, and release processes run at massive scale on the existing Taskcluster instance at https://taskcluster.net, along with a number of smaller Mozilla-associated projects. As we work on this “redeployability” project, we must continue to deploy from master to that service as well – the rootUrl special-case mentioned above is a critical part of this compatibility. We will not be running either new or old instances from long-living Git branches.
Some day, we will need to move all of these projects to a newly redeployed
cluster and delete the old. That day is still in the distant future. It will
likely involve some running of tasks in parallel to expunge any leftover
references to taskcluster.net, then a planned downtime to migrate everything
over (we will want to maintain task and artifact history, for example). We will
likely finish up by redeploying a bunch of permanent redirects from
taskcluster.net domains.
That’s just a short list of some of the challenges we face in transmuting a hosted service into a shipped application.
All the while, of course, we must “keep the lights on” for the existing deployment, and continue to meet Firefox’s needs. At the moment that includes a project to deploy Taskcluster workers on arm64 hardware in https://packet.net, development of the docker-engine to replace the aging docker worker, using hooks for actions to reduce the scopes afforded to level-3 users, improving taskcluster-github to support defining decision tasks, and the usual assortment of contributed pull requests, issue debugging, service requests.
http://code.v.igoro.us/posts/2018/05/shipped-and-hosted-software.html
|
|
Karl Dubost: More Roads And Faster Browsers |
In the paper, The Fundamental Law of Road Congestion: Evidence from US cities, Turner and Duranton decipher this rule:
New roads will create new drivers, resulting in the intensity of traffic staying the same.
Basically adding more roads or more lanes usually does not improve the state of traffic into a city. By making it easy to reach the city, we just increase the capacity to clutter more the city.
And it's exactly what is happening with our Web pages. Browsers become more performant. So developers instead of using this extra performance to make the page extra-blazingly fast, we use it to pack more DOM nodes, CSS animations and JavaScript driven user experiences.
Why? Because we can. That's the sad part of it.
Otsukare!
http://www.otsukare.info/2018/05/21/more-roads-faster-browsers
|
|
The Mozilla Blog: Reality Redrawn Opens At The Tech |
The Tech Museum of Innovation in San Jose was filled on Thursday with visitors experiencing new takes on the issue of fake news by artists using mixed reality, card games and even scratch and sniff cards. These installations were the results of Mozilla’ Reality Redrawn challenge. We launched the competition last December to make the power of misinformation and its potential impacts visible and visceral. Winners were announced in February.
One contributor, Australian artist Sutu was previously commissioned by Marvel and Google to create Tilt Brush Virtual Reality paintings and was the feature subject of the 2014 ABC documentary, ‘Cyber Dreaming’. For Breaking News at the Tech, he used AR animation to show the reconstruction of an article in real time and illustrate the thought process behind creating a fake news story. Using the AR app EyeJack, you can see the front page of the New York Times come to life with animation and sound as the stories are deconstructed and multiple viewpoints are presented simultaneously:

Breaking News, by Sutu
(Photography by Nick Leoni)
Visitors on opening night of this limited run exhibition also enjoyed conversation on stage around the topic from Marketplace Tech Host Molly Wood, Wired Contributing Editor Fred Vogelstein, BBC North America Technology Correspondent Dave Lee and our own Fellow on Media, Misinformation and Trust, Ren'ee DiResta. There was a powerful message by video from the Miami Herald’s reporter Alex Harris. She found herself the target of a misinformation campaign while reporting on the tragedy at Marjory Stoneman Douglas High School in Parkland, Florida.
Reality Redrawn is open until June 2 at the Tech and admission is included with entry to the museum. Follow the link to find out more about ticket prices for the Tech.”>link to find out more about ticket prices for the Tech. If you’re visiting the Bay Area soon I hope you’ll make time to see how it’s possible to make some sense of the strange journeys our minds take when attacked by fake news and other misinformation.
The post Reality Redrawn Opens At The Tech appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/05/19/reality-redrawn-opens-at-the-tech/
|
|
Mike Hommey: Announcing git-cinnabar 0.5.0 beta 3 |
Git-cinnabar is a git remote helper to interact with mercurial repositories. It allows to clone, pull and push from/to mercurial remote repositories, using git.
These release notes are also available on the git-cinnabar wiki.
|
|
Andy McKay: Tangerine UI problems |
I've been a big fan of Tangerine for a while, it's a bank that doesn't charge fees and does what I need to do. They used to have a great app and website and then it all went a bit wrong.
It's now a HTML app for Desktop and mobile. This isn't the fault of the tools used, but there's some terrible choices in the app across both.
On my phone I get the notification number on my app screen. So, I open up the app and I get this little message:

But, you can't click on it. It's not a link, to find your notifications you have to go to Profile & Settings, scroll down to Inbox and then you can access the notifications. If notifications that are that important, how about you put a way to access them somewhere obvious.
Here's a notification:

When you open the app, a full 1/3 of the screen is an advert:

Let's dismiss that:

Oh come on Tangerine. I'm not logging into my phone to get "Insights", otherwise known as "Advertising". Stop taking up space with this crap.
Pop quiz. You are cancelling this transaction. What does the Cancel button do?

The Cancel button cancels the cancelling. The highlighted option Confirm actually continues the cancelling. You know what would be clearer? Yes or No.
Supposing I wanted to see my transactions on an account. There's about one half of the screen to scroll down. The black text Posted Transactions doesn't actually do anything. The transaction list is an infinite scroll. So instead they've put everything at the top of the page, such as Search, Transaction Breakdown and so on.
![]()
Then there's another title Transactions. Do you get the idea that in those 5 boxes saying Transactions, this might be about...
The overall feel of the app is that its full of spinners, far too cluttered and just to confusing. Hey not everything I've built is perfect, but even I can spot some real problems with this app. I pretty sure Tangerine can do better than this.
And yes, I'm writing this while drinking a beer I recently bought, as shown on my transaction page.
I'd still recommend Tangerine and their credit card. If you want to open an account, use my key: 20790922S1 to give get yourself a bonus.
|
|
Dustin J. Mitchell: PyCon US 2018 Wrapup |
I attended PyCon US in Cleveland over the last week. Here’s a quick summary of the conference.
Aside from my usual “you should go to PyCon” admonition, I’d like to suggest writing a summary like this every time you visit a conference. It’s a nice way to share what you found valuable with others, and also to evaluate the utility of attending the conference.
I barely write a lick of Python anymore, so I mostly attend PyCon for the people and for the ideas. ome themes are common to PyCon: data science, machine learning, education, and core language. Of course, there’s always a smattering of other topics, too.
During the poster session, I saw a poster on the Python Developers Survey 2017 from JetBrains. One statistic that surprised me: 50% of respondents use Python primarily for data analysis.
There were a lot of good talks this year, although few that will be remembered forever. Here are a few highlights from the talks I attended. Sadly, PyVideo does not have the videos up yet, but I’m sure they will soon be available at http://pyvideo.org/events/pycon-us-2018.html.
I’m trying to get more comfortable with the ideas around machine learning, without actually doing any of the work myself.
Deconstructing the US Patent Database - some technical issues cut the talk short, but Van went into lots of interesting details about analysis of the US patent database, both the language and the attached images. It seems the project was leading toward a way to find prior art quickly. On particularly neat tool was a concept unique identifier - CUI - that replaces technical terms with an arbitrary identifier. It comes from the medical field, and allows disambiguating similar terms and combining multiple terms for the same concept.
Birding with Python and Machine Learning was a much lighter approach to ML. Kirk set up a webcam in his backyard and used ML to identify the presence of birds in-frame, and then to try to identify the type of bird.
Listen, Attend, and Walk was a more research-focused talk about interpreting natural-language navigational instructions. Padmaja talked in detail about the configuration of a RNN to parse simple English sentences and use them to navigate a DOOM-like environment. While the result wasn’t exactly magical, I appreciaed the deep, but math-light explanation of the design of the system.
On the core language, I listened to Dataclasses: The code generator to end all code generators and Get your resources faster, with importlib.resources.
Maybe quantum computing is the next big thing? I sat in on Python for the quantum computing age, where Ravi gave a nice overview of what quantum computing is. He also gave some examples of controlling (real, cloud-based) quantum computers using Python. Quantum computers still have 10-20 gates, so they can’t exactly “run Python”, but you can build a basic quantum logic circuit with Python and execute it to get the result.
Sometimes the best talks are those that tell a great story. Don’t Look Back in Anger was one of those - Lilly told the story of Edward Orange Wildman Whitehouse and the failure of the first trans-Atlantic telegraph cable. Besides being funny and an interesting piece of history, she compared the experience to modern “go-live” events and helped illustrate the need for care and planning. Reinventing the Parser Generator was also a fun story. Dave described, using his typical live-coding style, what a parser generator is, how PLY worked back in the 90’s, and how SLY uses new Python magic to do similarly expressive, cool things. Dave is a fantastic teacher, from whom I have learned a great deal, and it’s worth noting you can take private classes with him. They are well worth your time.
Yi Ling gave a great keynote on web application vulnerabilities, told in the style of a children’s book. I found the content useful - basically, how not to be stupid when building a website - but the presentation was quite engaging.
I found What Is This Mess amusing and informative, too. Justin talked about writing tests for untested code – a common situation in my day-to-day work. His advice was good and illustrated with simple but clear examples. I think I liked the talk more for the “yes, someone understands me!” factor than anything I learned from it!
The hallway track – conference lingo for the interesting stuff that happens outside of the talks – is strong at PyCon. During the Expo (filled with vendors and swag I don’t really want) I made it a point to sit down at diverse-looking tables and chat with people. I met people from finance, college students, data scientists, googlers, and a whole host of interesting people. Working for Mozilla is, of course, a nice conversation starter.
Because I’m staying with family here in Cleveland, I did not participate in any of the evening activities. That’s been a bit of a disappointment – the dinners are always engaging – but probably best for family harmony.
On Sunday, there are simultaneous job fairs and poster sessions in the expo hall. I’m not looking for a job (although the Java recruiters remain hopeful), so I perused the posters. It’s a mix of topics, from genomic and ML research to cool new tools through programming education and civic data projects. A few were particularly interesting to me.
A poster on the Pulp project attracted my attention since it seems to solve a recurrent problem at Mozilla: mirroring large binary repositories in a consistent fashion. The system supports docker images as well as JS and Python packages, and can release repositories that are internally consistent: the packages are all known to work with each other. This may be useful for deploying Taskcluster, and is also useful for the Firefox CI system to ensure that it can reliably reproduce Firefox builds even if the sources for the build tools fail or disappear.
I talked for some time with some people from the Fedora CommOps team. They work on operational support for building and supporting the Fedora community. Since we have an ongoing Outreachy project to build a new version of Bugsahoy, I was interested in how Fedora connects new contributors to their first contribution. Their tool, easyfix, seems a little overwhelming to me, but can offer some inspiration for our effort. More interesting, Fedora uses an archived message bus (fedmsg) to track events in the Fedora ecosystem over time. This allows creation of leaderboards and other interesting, motivational statistics on new contributions.
PyCon’s sprints start after the main conference ends. The idea is to give projects time to gather together while everyone is in the same location. PyCon supplies space, power, wifi, and occasionally food. This year, the wifi and power were strong and the food somewhat disappointing. The spaces were small windowless conference rooms, and somehow I found them stifling - I guess I’ve gotten used to working at home in a room full of windows.
I spent the day hacking on Project Mesa, like I did last year. I have no real connection to this project, but the people who work on it are interesting and smart, and I can make a useful contribution in a short amount of time.
I had hoped to meet up with other Outreachy folks, but plans fell through, so I only stuch around for the first day of sprints. I suspect that if I was more engaged with Python software on a day-to-day basis, I would have found more to hack on. For example, the Pallets project (the new umbrella for lots of Python utilities like Click and Werkzeug) had a big crowd and seemed to be quite productive. We could also hear the Django room, where a round of applause went up every time a contribution was merged.
Plan to come next year!
PyCon is an easy conference to attend. It’s in Cleveland again next year, right on the waterfront, near the science museum and the rock-and-roll hall of fame, so if you bring family they will have ample activities. The conference provides childcare if your family is of the younger persuasion. Breakfast and lunch are included, and dinners are optional. Every talk is live-captioned on a big screen beside the presenter, so if you have difficulty hearing or understanding spoken English PyCon has your back. Finanical aid is available. There’s really no reason not to attend!
Registration starts in early spring.
http://code.v.igoro.us/posts/2018/05/pycon-us-2018-wrapup.html
|
|
Air Mozilla: Reps Weekly Meeting, 17 May 2018 |
 This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
|
|
Mozilla Addons Blog: Extensions in Firefox 61 |
Firefox 60 is now in the Release channel, which means that Firefox 61 has moved from Nightly to the Beta channel. As usual, Mozilla engineers and volunteer contributors have been hard at work, landing a number of new and improved WebExtensions API in this Beta release.
Before getting to the details, though, I’d like to note that the Firefox Quantum Extensions Challenge has come to an end. The contest was a huge success and the judges (myself included) were overwhelmed with both the creativity and quality of the entrants. A huge thank you to everyone who submitted an extension to the contest and congratulations to the winners.
In November of 2017, we made a commitment to enriching the WebExtensions API with additional tab management features, with tab hiding being a top priority. Since that time, several new and enhanced tab-related API have been added and today, with the release of Firefox 61 to the Beta channel, tab hiding is officially a WebExtensions API.
The usage of the tabs.hide() API was covered in the post on Extensions in Firefox 59. The main change now is that it is no longer necessary to set the extensions.webextensions.tabhide.enabled preference to true; tab hiding can be used by extensions without setting that preference. In fact, that preference will soon be going away in an upcoming release.
In the user interface, when tabs are hidden, a down-arrow is added to the end of the tab strip. When clicked, this icon shows all of your tabs, hidden and visible, and provides a quick and easy way to keep from losing things (see animation below, and thanks to Afnan Khan for the great Hide Tabs extension).
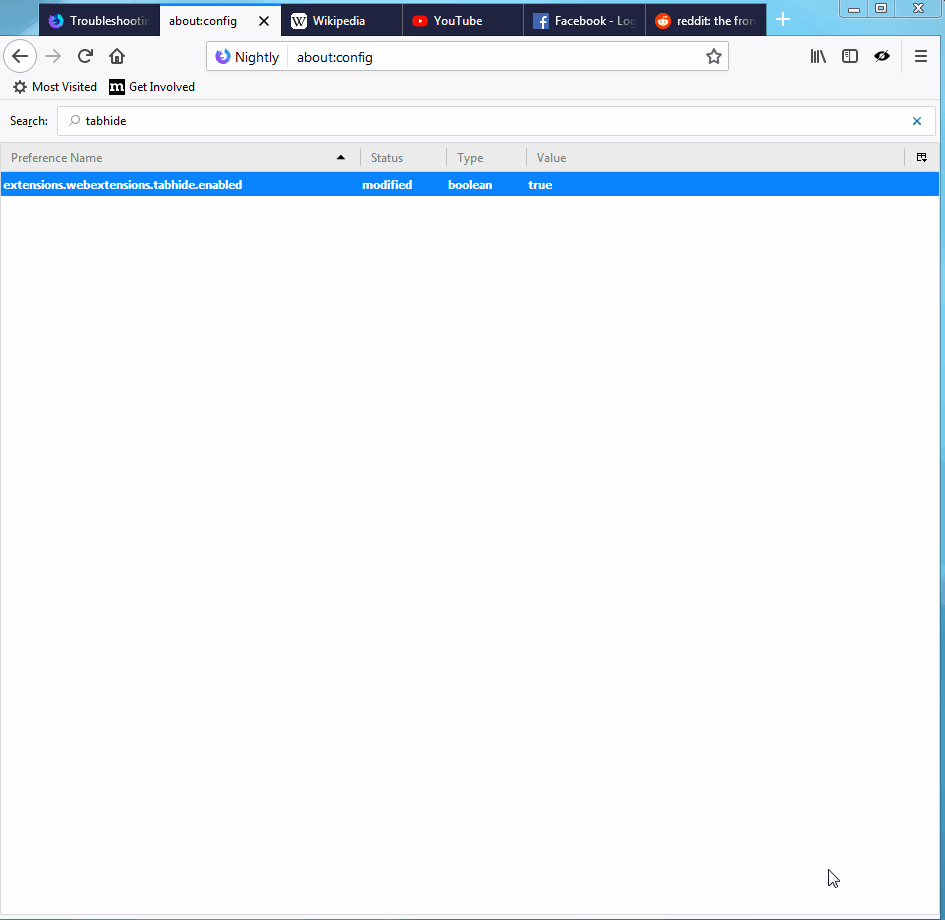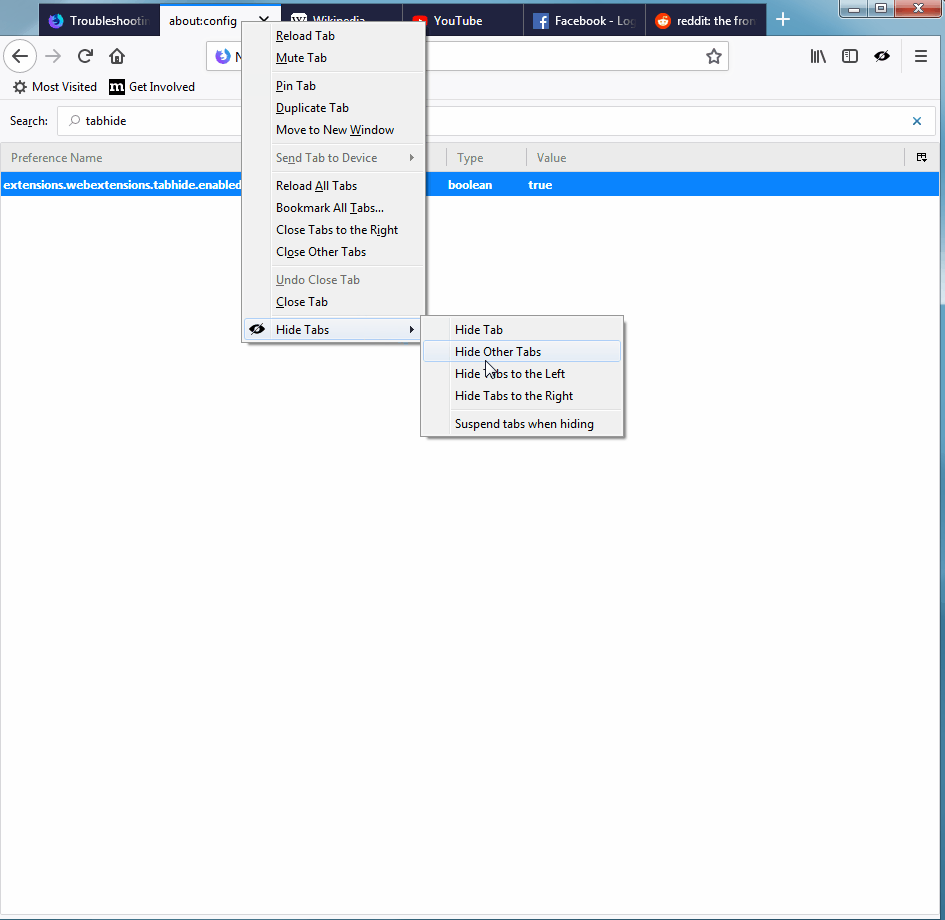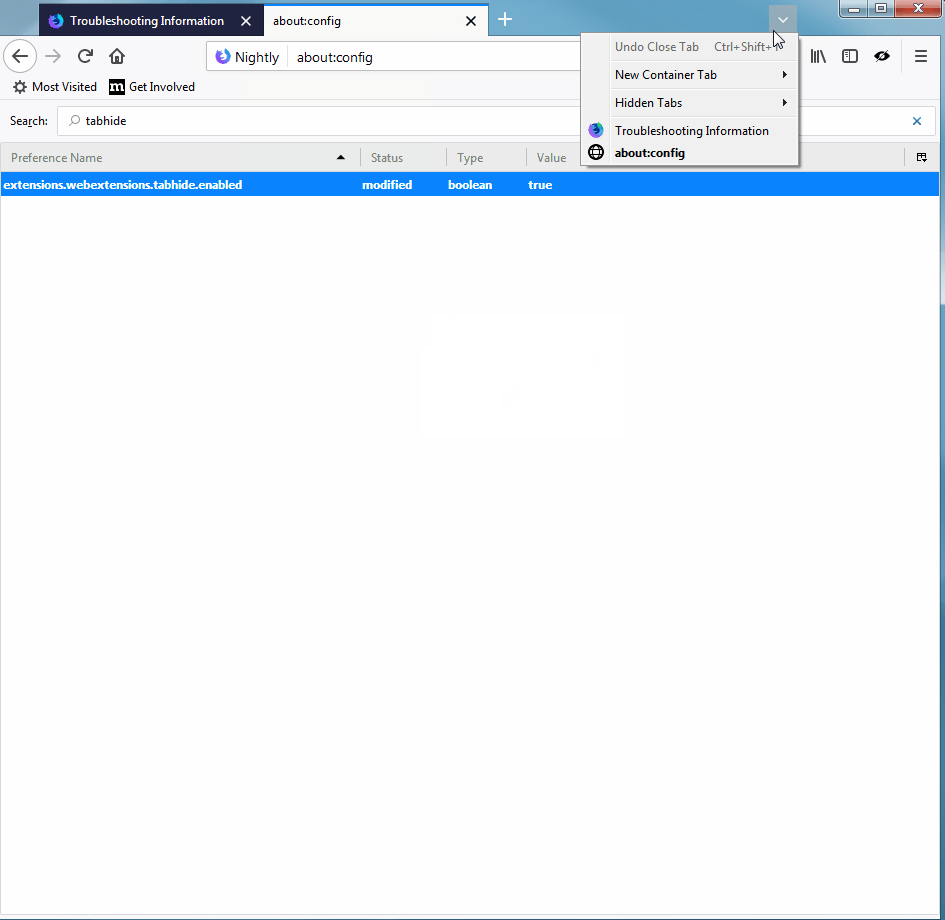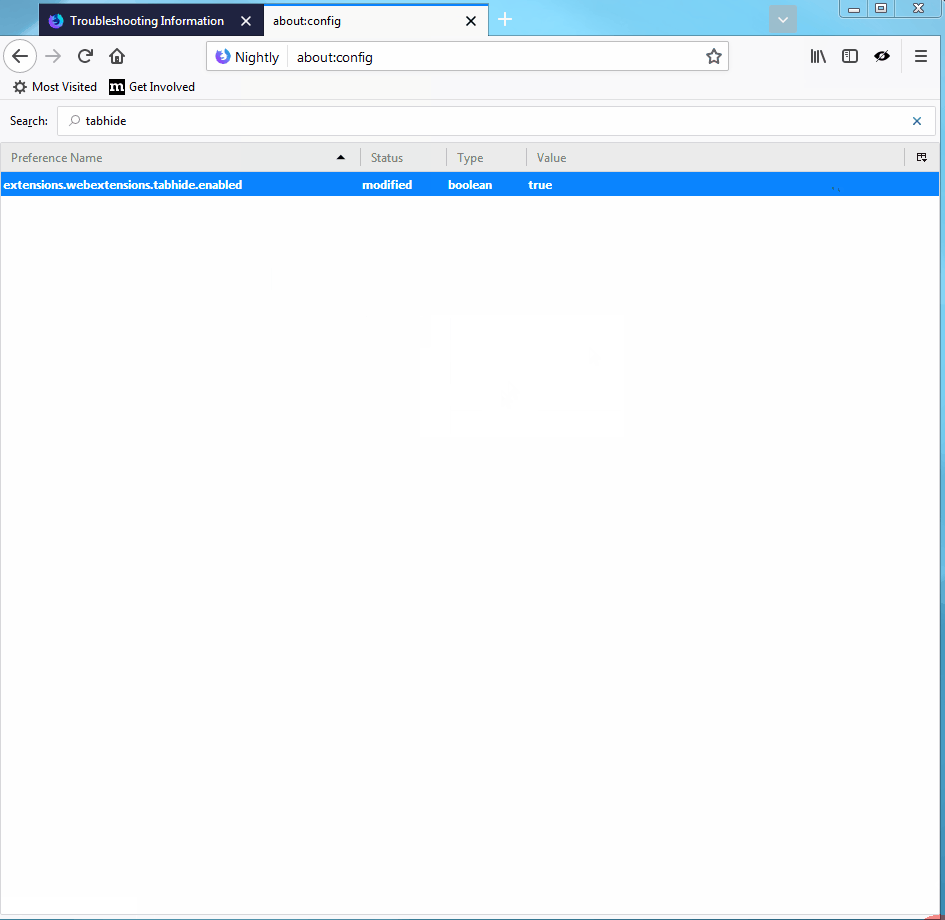
In addition, if a hidden tab is playing audio, the audio icon is shown on top of the down-arrow icon. If you click on the down-arrow, the hidden tab with audio is pulled out so that it is easier to find (see animation below).
![]()
You can expect to see this user interface get a small update in Firefox 62. In particular, it will be modified so that it conforms to the Firefox Photon Design System.
As noted above, when an extension hides a tab, Firefox will display a down-arrow in the tab strip that gives users access to all of their tabs, both visible and hidden. This is a simple and easy way to manage hidden tabs, but it is also subtle. To make sure users are completely aware of hidden tabs, and to discourage malicious and deceitful use of them, Firefox will always show a door hanger when the first tab is hidden.
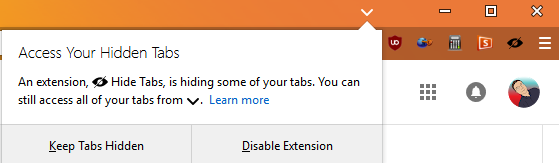
The door hanger informs the user that one or more tabs was hidden by an extension, explains the down-arrow on the tab strip (pointing to it), and gives the user the option to disable the extension.
While tab hiding is the biggest feature to land in Firefox 61, a few other highly requested tab features also made it into this release.
A new browserSettings API, openUrlbarResultsInNewTabs, allows extensions to specify if search results from the URL bar should open in the current tab or a new tab. This complements the existing browserSettings.openBookmarksInNewTabs and browserSettings.openSearchResultsInNewTabs settings.
Also, fine grain control of the opening position for new tabs is now provided via the browserSettings.newTabPosition API. This new API can take three different values:
Finally, listeners to the tabs.onUpdated event can now supply a filter to avoid the overhead of unwanted events. The filter supports URLs, window and tab ids, and various properties such as “audible”, “discarded”, “hidden”, “isarticle” and more. Not only does this simplify code inside the listener for developers, it significantly improves browser performance by keeping Firefox from dispatching so many events. Extension developers are strongly encouraged to use this new feature to make their extension and the browser more performant for users.
It seems we can’t let a release go by without adding to themes, and Firefox 61 is no exception. Check out the new improvements (and the improved documentation on MDN that shows examples of what each theme property modifies).
I usually end each blog post with a small section that notes some of the general improvements and/or bug fixes in the release. For Firefox 61, though, there was a concerted to improve the WebExtensions ecosystem. A substantial number of bug fixes and optimizations landed, enough that I wanted to make sure they were more than just a footnote.
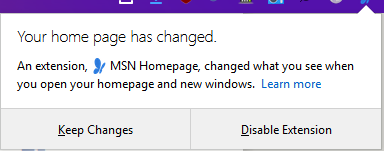
In addition to making sure users are fully aware of extensions using tab hiding, Firefox 61 also highlights when an extension modifies a user’s Home page by displaying a door hanger.
And to help users better understand when an extension is controlling the New Tab page or Home page, or using the tab hiding feature, the door hanger now shows the name of the controlling extension and includes a “Learn More” link that takes the user to a more detailed explanation on Mozilla’s support site.
After the release of Firefox 59, we discovered that the implementation of the proxyConfig API was not handling the settings for hostnames correctly, causing non-socks proxy settings to fail. The has been corrected in Firefox 61 and uplifted to Firefox 60.
The discovery and resolution of this bug, however, caused us to reevaluate how WebExtensions exposed proxy settings. In particular, we asked ourselves why these settings weren’t part of the browser.proxy.* namespace. It is true that the underlying implementation depends upon Firefox browser settings, which is how it ended up as part of the browser.browserSettings.* namespace, but that’s just an internal detail. Every major browser vendor supports proxy settings, and they all support basically the exact same set of settings.
Given that, and the fact that Mozilla should be championing web standards, we decided it made more sense to have the proxy settings live inside the browser.proxy.* namespace. So starting with Firefox 60, the browser.browserSettings.proxyConfig API is now the browser.proxy.settings API. Extensions developers who want to use this API should request the much more intuitive “proxy” permission instead of the “browserSettings” permission.
Finally, another patch was landed in Firefox 61 so that proxy extensions can start before requests bypass them.
A few new browser settings are now available to extension developers in Firefox 61:
This was a busy release for the WebExtensions API with a total of 95 features and improvements landed as part of Firefox 61. A sincere thank you goes to our many contributors for this release, especially our community volunteers including: Tim Nguyen, Oriol Brufau, Vivek Dhingra, Tomislav Jovanovic, Bharat Raghunathan, Zhengyi Lian, Bogdan Podzerca, Dylan Stokes, Satish Pasupuleti, and S"oren Hentzschel. It is only through the combined efforts of Mozilla and our amazing community that we can ensure continued access to the open web. If you are interested in contributing to the WebExtensions ecosystem, please take a look at our wiki.
The post Extensions in Firefox 61 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/05/17/extensions-in-firefox-61/
|
|
Nicholas Nethercote: The Rust compiler is getting faster |
TL;DR: The Rust compiler has gotten 1.06x–4x faster over the past month.
As changes are made to the Rust compiler, a suite of benchmarks measuring compile time is run regularly on the development version. The data is viewable at http://perf.rust-lang.org. The default view is graphical, showing data from the past month.
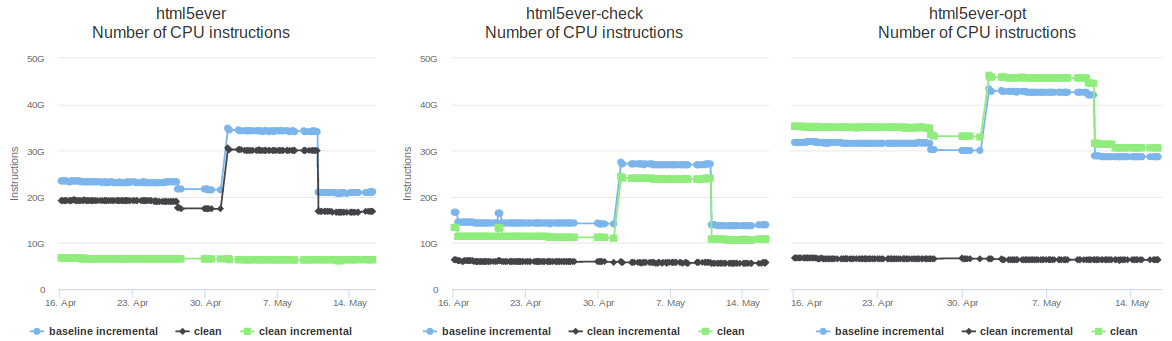
The screenshot above shows the graphs for a single benchmark called “html5ever”, which consists of an old version of the project of the same name. Each one shows measurements for a different kind of build: a debug build, a “check” build (which detect errors but don’t generate code), and an optimized build. Within each graph there are the following three data series.
If you visit the site yourself you’ll see that most of the benchmarks have more than three data series, including ones for incremental builds done after small code changes (a more realistic use case), and one for builds with non-lexical lifetimes enabled.
The x-axis shows time and the y-axis shows instruction counts. Other units of measurements are available, including cycles, time, and memory usage. Instruction counts are shown as the default; this isn’t ideal because it’s only a proxy for the measurement that really matters (time)… but it’s a pretty good proxy, and it has a lot lower variation than the time measurements, which is important when detecting changes.
This graphical view is particularly useful for detecting major changes. For example, you can see that in early May there was a major regression for “clean” and “baseline incremental” builds, which Alex Crichton fixed a few days later.
As well as the graphical view, the site also provides a textual “compare” view, which can be reached via the link at the top left of each page. This view compares measurements from two revisions of the compiler; by default it compares the most recently measured revision with one from a month ago. (It can also be used locally, which is very useful to evaluate changes that speed up the compiler.)
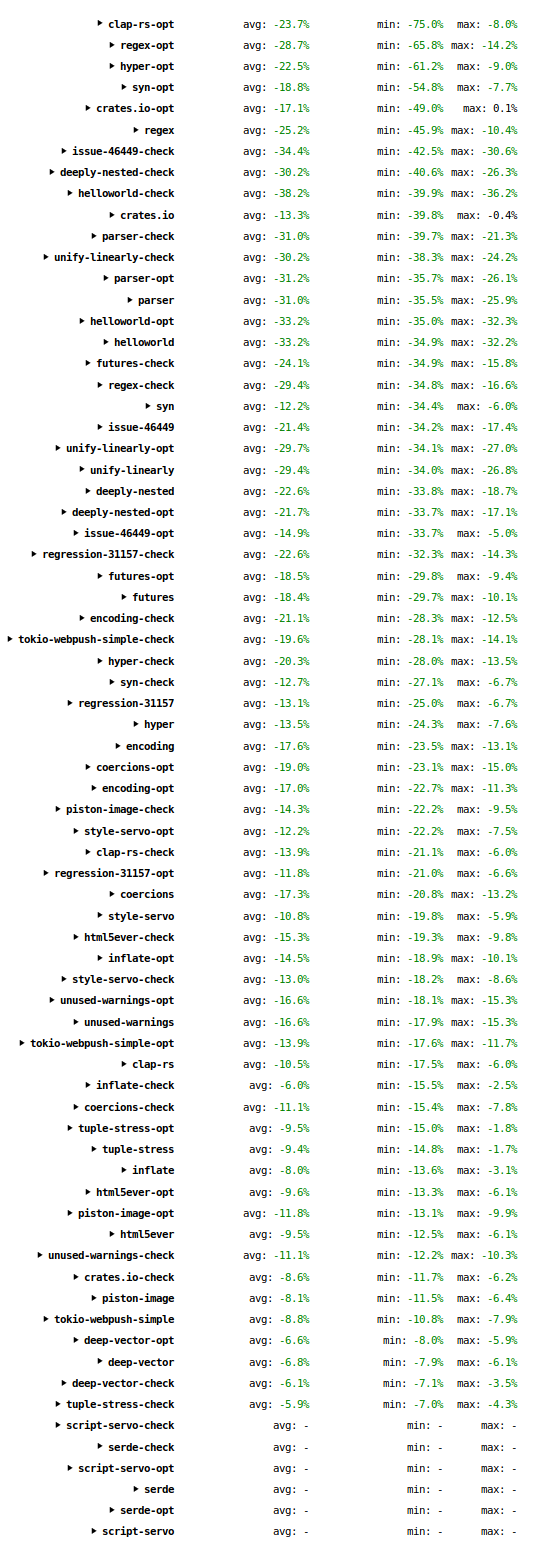
The screenshot above is of the “compare” view at the time of writing. Each line corresponds to a single graph from the graphical view. (If you visit the site and click on an individual entry it will expand and show all of the measurements. The resemblance between those measurements and this screenshot will of course diminish over time.) The “avg” column shows the average change across all the data series. The “min” and “max” columns show the minimum and maximum changes for any of the data series. The “serde” and “script-servo” lines are empty because those benchmarks were added to the suite less than a month ago, so no comparison can be made.
The table has many numbers, but the thing to take away is that they are almost all significantly negative, meaning that compile time has reduced. The “avg” numbers range from 6% to 38%; the “min” numbers (i.e. best result) go as high as 75%; the “max” numbers (i.e. worst result) go as high as 36%.
In conclusion: the Rust compiler has gotten significantly faster in the past month. Across a wide range of programs, and a wide range of build configurations, compile times have reduced by between 6% and 75%. To put it another way, the compiler has gotten between 1.06x and 4x faster.
These benefits are available right now to users of the Nightly channel. Users of the Release channel will see them more gradually, spread across one or two versions released over the next few months.
https://blog.mozilla.org/nnethercote/2018/05/17/the-rust-compiler-is-getting-faster/
|
|
Cameron Kaiser: A little Talos of your very own |
Yes, think of it as the Mac mini G4 to the Talos II's Quad G5. This comparison is not completely inappropriate because the T2L has only one CPU socket (the T2 has two) and thus only 24 PCIe lanes, split amongst an x16 and an x8 (the T2 fully loaded has two x8s and three x16s), and "only" 8 DDR4 slots (the T2 has 16). You can still cram one of the 22-core demons into one of those, though. Starting price is "just" $1399.99, though as with the Talos II the CPU is extra ($375 for 4-core to $2575 for 22-core), the RAM is extra ($255 for 16GB to $2950 for 128GB), and the storage is extra (Microsemi SAS starts at $300 plus drives, or a Samsung 960 EVO NVMe 500GB for $350, or a four-port SATA controller for $50 plus drives). You can also add the same Radeon WX 7100 workstation card that's in the big T2 ($800), too, or just use the same onboard VGA controller that comes with the T2 (built-in). It has USB 3.0 and dual Gig Ethernet, just like the big fella, though it doesn't seem to come with a BD-ROM.
However, the mini:Quad analogy falls down when you look at the actual size of the Lite. It, too, is an EATX behemoth, despite the leaner spec. Personally I would have hoped for something a little more manageably dimensioned. Raptor is taking about offering a smaller board but that would require a redesign and this was probably an artifact of getting it launched cheap(er)ly.
So would I have saved money with my T2 going Lite? Let's price it out: $1400 for the system (includes 500W PSU and EATX case), $595 for the octocore POWER9 (my T2 has two 4-core chips), $535 for 32GB ECC DDR4 RAM, $350 for the SAS card, $800 for the AMD Radeon WX 7100, $50 for the 4-port SATA card (this came installed "free" in my T2) and $350 for the 500GB Samsung NVMe SSD. Sticker price for that configuration is $4080 plus applicable tax and shipping; I repriced the same configuration for the Talos II and got a sticker cost of $7360, about $250 more than what I paid personally (the benefit of being an early adopter), so let's say a cost difference of $3300. That's substantial and a whole lot more palatable. $4080 is actually within Quad G5 range -- I paid not much less than that for my Quad G5 back in the day with the 7800GT and 8GB of RAM. A cheap SATA DVD-RW or something wouldn't add much more to the price if you want an optical drive.
There's a small problem here though: the Lite can't actually accommodate that loadout because there's not enough PCIe slots to get it all in there. In fact, I've got another 1GB NVMe drive to install in my T2, and I'm probably going to pull the now unused Sonnet FireWire/USB PCIe card (I prefer FireWire hubs) from the G5 to install in it too, which may mean temporarily pulling the SAS card until I'm ready to populate the front bays. Also, the Talos II out of the box doesn't support PCIe bifurcation, so I really do need both those slots for my SSDs. Per Raptor it can: with changes to the machine XML definition it could be made to "trifurcate" the x16 endpoint on slot 3 (CPU 2, PHB2) into an x8 and two x4, but that would mean that the available 4-way M.2 NVMe multicards would only have at most three slots available, and the system doesn't ship that way anyhow. Besides, even if you did get bifurcation working on the Lite, you'd only have the remaining x8 for anything else which couldn't be used for an x16 workstation video card.
But let's say you're not a maniac like me and you want a basic "budget" config. Let's drop the workstation card and the SAS card, and drop to a 4-core with 16GB, and we have a $2430 system. Wow! Not bad! You've still got the NVMe card and storage expansion over SATA, and you've still got USB ports for audio and the onboard VGA. But you've used up all your PCIe slots, so let's hope you don't need anything else to go internal (let alone 3D acceleration). If you really want that x16 slot back, drop the NVMe card and add some SATA drives ($2080 + devices), but now you're starting to strip this system down more than you might like to, and it doesn't get much cheaper that way.
Overall, that $3300 really does translate into greatly improved expandability in addition to the beefier power supplies, and thus it was never really an option for my needs personally. Maybe my mini:Quad analogy wasn't so off base. But if you want to join the POWER9 revolution on a budget and give Chipzilla the finger, as all right-thinking nerds should, you've now got an option that only requires passing a kidneystone of just half the size or less. It ships starting in July.
Another interesting thing Raptor pointed out: in the Phoronix performance tests, the Talos was running with full Spectre and Meltdown protections, but the x86 wasn't! Boooo! And if you really want to turn Spectre protections off on the Talos for even more grunty, you can do that. Meanwhile, as we speak, Intel is making people take down their firmware documentation and trying to stymie efforts to reverse engineer them. What system would you rather support?
http://tenfourfox.blogspot.com/2018/05/a-little-talos-of-your-very-own.html
|
|
The Mozilla Blog: Update on Fight for Net Neutrality in U.S. – Senate votes to save net neutrality, now it’s up to the House |
Today, the U.S. Senate passed a Congressional Review Act (CRA) resolution to save net neutrality and overturn the FCC’s disastrous order to end net neutrality protections.
We’re pleased this resolution passed – it’s a huge step, but the battle to protect net neutrality and reinstate the 2015 rules isn’t over. The next step is for the motion to go to the House of Representatives for a vote before the order is supposed to go into effect on June 11. Unfortunately, the rules in the House will make passage much harder than in the Senate; at this point, it’s not clear when, or if, there will be a vote there.
We will continue to fight for net neutrality in every way possible as we try to protect against erosion into a discriminatory internet, with ultimately a far worse experience for any users and businesses who don’t pay more for special treatment.
We are leading the legal battle in Mozilla v. FCC, working closely with policymakers, and educating consumers through advocacy for an open, equal, accessible internet.
And, we’re not alone – last week we partnered with organizations like Consumer Reports and the Electronic Frontier Foundation in the Red Alert protest to encourage Americans to call Congress in support of net neutrality. Consumers also share their support for the net neutrality fight- we recently conducted a poll that shows 91% of Americans believe consumers should be able to freely and quickly access their preferred content on the internet.
As I said in December– The FCC decision to obliterate the 2015 net neutrality protections is the result of broken processes, broken politics, and broken policies. The end of net neutrality would only benefit Internet Service Providers (ISPs) and it would end the internet as we know it, harming every day users and small businesses, eroding free speech, competition, innovation and user choice in the process.
Net neutrality is a core characteristic of the internet, and crucial for the economy and everyday lives. It is imperative that all internet traffic be treated equally, without discrimination against content or type of traffic — that’s how the internet was built and what has made it one of the greatest inventions of all time.
We’ll keep fighting for the open internet, and so we ask you to call your members of Congress to make sure that politicians decide to protect their constituents rather than increase the power of ISPs.
The post Update on Fight for Net Neutrality in U.S. – Senate votes to save net neutrality, now it’s up to the House appeared first on The Mozilla Blog.
|
|
Air Mozilla: The Joy of Coding - Episode 139 |
 mconley livehacks on real Firefox bugs while thinking aloud.
mconley livehacks on real Firefox bugs while thinking aloud.
|
|
Gregory Szorc: Scaling Firefox Development Workflows |
One of the central themes of my time at Mozilla has been my pursuit of making it easier to contribute to and hack on Firefox.
I vividly remember my first day at Mozilla in 2011 when I went to build Firefox for the first time. I thought the entire experience - from obtaining the source code, installing build dependencies, building, running tests, submitting patches for review, etc was quite... lacking. When I asked others if they thought this was an issue, many rightfully identified problems (like the build system being slow). But there was a significant population who seemed to be naive and/or apathetic to the breadth of the user experience shortcomings. This is totally understandable: the scope of the problem is immense and various people don't have the perspective, are blinded/biased by personal experience, and/or don't have the product design or UX experience necessary to comprehend the problem.
When it comes to contributing to Firefox, I think the problems have as much to do with user experience (UX) as they do with technical matters. As I wrote in 2012, user experience matters and developers are people too. You can have a technically superior product, but if the UX is bad, you will have a hard time attracting and retaining new users. And existing users won't be as happy. These are the kinds of problems that a product manager or designer deals with. A difference is that in the case of Firefox development, the target audience is a very narrow and highly technically-minded subset of the larger population - much smaller than what your typical product targets. The total addressable population is (realistically) in the thousands instead of millions. But this doesn't mean you ignore the principles of good product design when designing developer tooling. When it comes to developer tooling and workflows, I think it is important to have a product manager mindset and treat it not as a collection of tools for technically-minded individuals, but as a product having an overall experience. You only have to look as far as the Firefox Developer Tools to see this approach applied and the positive results it has achieved.
Historically, Mozilla has lacked a formal team with the domain expertise
and mandate to treat Firefox contribution as a product. We didn't have
anything close to this until a few years ago. Before we had such a team,
I took on some of these problems individually. In 2012, I wrote mach - a
generic CLI command dispatch tool - to provide a central, convenient,
and easy-to-use command to discover development actions and to run them.
(Read the announcement blog post for
some historical context.) I also
introduced
a one-line bootstrap tool (now mach bootstrap) to make it easier to
configure your machine for building Firefox. A few months later, I
was responsible for
introducing moz.build files,
which paved the way for countless optimizations and for rearchitecting
the Firefox build system to use modern tools - a project that is still
ongoing (digging out from ~two decades of technical debt is a massive
effort). And a few months after that, I started going down the version
control rabbit hole and improving matters there. And I was also heavily
involved with MozReview for improving the code review experience.
Looking back, I was responsible for and participated in a ton of foundational changes to how Firefox is developed. Of course, dozens of others have contributed to getting us to where we are today and I can't and won't take credit for the hard work of others. Nor will I claim I was the only person coming up with good ideas or transforming them into reality. I can name several projects (like Taskcluster and Treeherder) that have been just as or more transformational than the changes I can take credit for. It would be vain and naive of me to elevate my contributions on a taller pedestal and I hope nobody reads this and thinks I'm doing that.
(On a personal note, numerous people have told me that things like mach
and the bootstrap tool have transformed the Firefox contribution experience
for the better. I've also had very senior people tell me that they don't
understand why these tools are important and/or are skeptical of the need
for investments in this space. I've found this dichotomy perplexing and
troubling. Because some of the detractors (for lack of a better word) are
highly influential and respected, their apparent skepticism sews seeds of
doubt and causes me to second guess my contributions and world view. This
feels like a form or variation of imposter syndrome and it is something I
have struggled with during my time at Mozilla.)
From my perspective, the previous five or so years in Firefox development
workflows has been about initiating foundational changes and executing on
them. When it was introduced, mach was radical. It didn't do much and
its use was optional. Now almost everyone uses it. Similar stories have
unfolded for Taskcluster, MozReview, and various other tools and
platforms. In other words, we laid a foundation and have been steadily
building upon it for the past several years. That's not to say other
foundational changes haven't occurred since (they have - the imminent switch
to Phabricator is a terrific example). But the volume of foundational
changes has slowed since 2012-2014. (I think this is due to Mozilla
deciding to invest more in tools as a result of growing pains from
significant company expansion that began in 2010. With that investment, we
invested in the bigger ticket long-standing workflow pain points, such as
CI (Taskcluster), the Firefox build system, Treeherder, and code review.)
Over the past several years, the size, scope, and complexity of Firefox development activities has increased.
One way to see this is at the source code level. The following chart shows the size of the mozilla-central version control repository over time.
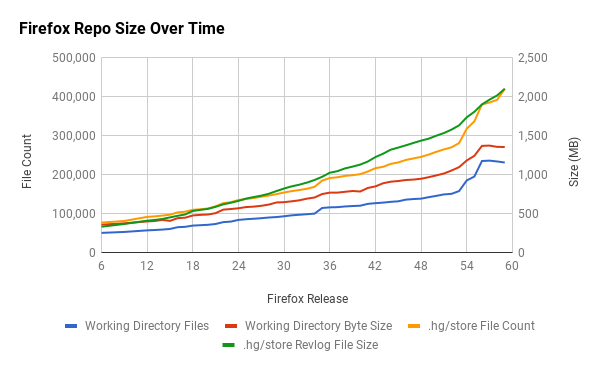
The size increases are obvious. The increases cumulatively represent new features, technologies, and workflows. For example, the repository contains thousands of Web Platform Tests (WPT) files, a shared test suite for web platform implementations, like Gecko and Blink. WPT didn't exist a few years ago. Now we have files under source control, tools for running those tests, and workflows revolving around changing those tests. The incorporation of Rust and components of Servo into Firefox is also responsible for significant changes. Firefox features such as Developer Tools have been introduced or ballooned in size in recent years. The Go Faster project and the move to system add-ons has introduced various new workflows and challenges for testing Firefox.
Many of these changes are building upon the user-facing foundational
workflow infrastructure that was last significantly changed in 2012-2014.
This has definitely contributed to some growing pains. For example, there
are now 92 mach commands instead of like 5. mach help - intended to
answer what can I do and how should I do it - is overwhelming, especially
to new users. The repository is around 2 gigabytes of data to clone instead
of around 500 megabytes. We have 240,000 files in a full checkout instead
of 70,000 files. There's a ton of new pieces floating around. Any
product manager tasked with user acquisition and retention will tell you
that increasing the barrier to entry and use will jeopardize these
outcomes. But with the growth of Firefox's technical underbelly in the
previous years, we've made it harder to contribute by requiring users to
download and see a lot more files (version control) and be overwhelmed
by all the options for actions to take (mach having 92 commands). And
as the sheer number of components constituting Firefox increases, it
becomes harder and harder for everyone - not just new contributors - to
reason about how everything fits together.
I've been framing this general problem as scaling Firefox development workflows and every time I think about the high-level challenges facing Firefox contribution today and in the years ahead, this problem floats to the top of my list of concerns. Yes, we have pressing issues like improving the code review experience and making the Firefox build system and Taskcluster-based CI fast, efficient, and reliable. But even if you make these individual pieces great, there is still a cross-domain problem of how all these components weave together. This is why I think it is important to take a wholistic view and treat developer workflow as a product.
When I look at this the way a product manager or designer would, I see a few fundamental problems that need addressing.
First, we're not optimizing for comprehensive end-to-end workflows. By and large, we're designing our tools in isolation. We focus more on maximizing the individual components instead of maximizing the interaction between them. For example, Taskcluster and Treeherder are pretty good in isolation. But we're missing features like Treeherder being able to tell me the command to run locally to reproduce a failure: I want to see a failure on Treeherder and be able to copy and paste commands into my terminal to debug the failure. In the case of code review, we've designed two good code review tools (MozReview and Phabricator) but we haven't invested in making submitting code reviews turn key (the initial system configuration is difficult and we still don't have things like automatic bug filing or reviewer selection). We are leaving many workflow optimizations on the table by not implementing thoughtful tie-ins and transitions between various tools.
Second, by-and-large we're still optimizing for a single, monolithic user
segment instead of recognizing and optimizing for different users and
their workflow requirements. For example, mach help lists 92 commands.
I don't think any single person cares about all 92 of those commands. The
average person may only care about 10 or even 20. In terms of user
interface design, the features and workflow requirements of small user
segments are polluting the interface for all users and making the entire
experience complicated and difficult to reason about. As a concrete
example, why should a system add-on developer or a Firefox Developer Tools
developer (these people tend to care about testing a standalone Firefox
add-on) care about Gecko's build system or tests? If you aren't touching
Gecko or Firefox's chrome code, why should you be exposed to workflows
and requirements that don't have a major impact on you? Or something more
extreme, if you are developing a standalone Rust module or Python package
in mozilla-central, why do you need to care about Firefox at all? (Yes,
Firefox or another downstream consumer may care about changes to that
standalone component and you can't ignore those dependencies. But it
should at least be possible to hide those dependencies.)
Waving my hands, the solution to these problems is to treat Firefox development workflow as a product and to apply the same rigor that we use for actual Firefox product development. Give people with a vision for the entire workflow the ability to prioritize investment across tools and platforms. Give them a process for defining features that work across tools. Perform formal user studies. See how people are actually using the tools you build. Bring in design and user experience experts to help formulate better workflows. Perform user typing so different, segmentable workflows can be optimized for. Treat developers as you treat users of real products: listen to them. Give developers a voice to express frustrations. Let them tell you what they are trying to do and what they wish they could do. Integrate this feedback into a feature roadmap. Turn common feedback into action items for new features.
If you think these ideas are silly and it doesn't make sense to apply a product mindset to developer workflows and tooling, then you should be asking whether product management and all that it entails is also a silly idea. If you believe that aspects of product management have beneficial outcomes (which most companies do because otherwise there wouldn't be product managers), then why wouldn't you want to apply the methods of that discipline to developers and development workflows? Developers are users too and the fact that they work for the same company that is creating the product shouldn't make them immune from the benefits of product management.
If we want to make contributing to Firefox an even better experience for Mozilla employees and community contributors, I think we need to take a step back and assess the situation as a product manager would. The improvements that have been made to the individual pieces constituting Firefox's development workflow during my nearly seven years at Mozilla have been incredible. But I think in order to achieve the next round of major advancements in workflow productivity, we'll need to focus on how all of the pieces fit together. And that requires treating the entire workflow as a cohesive product.
http://gregoryszorc.com/blog/2018/05/16/scaling-firefox-development-workflows
|
|
Air Mozilla: Weekly SUMO Community Meeting, 16 May 2018 |
 This is the SUMO weekly call
This is the SUMO weekly call
https://air.mozilla.org/weekly-sumo-community-meeting-20180516/
|
|
Hacks.Mozilla.Org: New in Firefox 61: Developer Edition |
Firefox 61: Developer Edition is available now, and contains a ton of great new features and under-the-hood improvements.
Taking inspiration from Spinal Tap, Developer Edition’s dark theme now darkens more parts of the browser, including the new tab page.

Searchable websites can now be added to Firefox via the “Add Search Engine” item inside the Page Action menu. The sites must describe their search APIs using OpenSearch metadata.

And yes, the Page Action menu is also dark, if you’re using a dark theme.
More than just source maps, Firefox 61 understands how tools like Babel and Webpack work, making it possible to seamlessly inspect and interact with your original code right within the Debugger, as if it had never been bundled and minified in the first place. We’re also working to add native support for inspecting components and scopes in modern frameworks like React.
To learn more, see our separate, in-depth blog post: Debugging Modern Web Applications.
The Developer Tools have seen numerous quality-of-life improvements.
You can now rearrange tools to suit your individual workflow, and any tabs that don’t fit in the current window remain readily accessible in an overflow menu.

The Network panel also gained prominent drop-down menus for controlling network throttling and importing/exporting HTTP Archive (“HAR”) files.

We’ve also sped up the DevTools across the board, and are measuring and tracking performance as an explicit goal for the team. Even more improvements are on the way.
In Firefox Quantum, we re-implemented many of the DevTools using basic web technologies: HTML, JavaScript, and CSS. We’re even using React inside the DevTools themselves! This means that if you know how to build for the web, you know how to hack on the DevTools. If you’d like to get involved, we have a great getting started guide with pointers to good first bugs to tackle.
There’s also an entirely new tool available, the Accessibility Inspector, which reveals the logical structure of your page, as it might appear to a screen reader or other assistive software.

This is a low-level tool meant to help you understand how Firefox and screen readers “see” your content. To learn more, including how to enable and use this new tool, check out Marco Zehe’s article Introducing the Accessibility Inspector. If you’re looking for more opinionated tools to help audit and improve your site’s accessibility, consider add-ons like the aXe Developer Tools or the WAVE Accessibility Extension.
Lastly, we landed a number of improvements and refactorings that should make Firefox a better all-around browser.
Firefox 61 is currently available in Beta and Developer Edition, and it will become the stable version of Firefox on June 26th. If you’d like to keep up with Firefox development as it happens, we recommend reading the Firefox Nightly Blog, or following @FirefoxNightly on Twitter.
https://hacks.mozilla.org/2018/05/new-in-firefox-61-developer-edition/
|
|
Hacks.Mozilla.Org: Debugging Modern Web Applications |
Building and debugging modern JavaScript applications in Firefox DevTools just took a quantum leap forward. In collaboration with Logan Smyth, Tech Lead for Babel, we leveled up the debugger’s source map support to let you inspect the code that you actually wrote. Combined with the ongoing initiative to offer first-class JS framework support across all our devtools, this will boost productivity for modern web app developers.
Modern JS frameworks and build tools play a critical role today. Frameworks like React, Angular, and Ember let developers build declarative user interfaces with JSX, directives, and templates. Tools like Webpack, Babel, and PostCSS let developers use new JS and CSS features before they are supported by browser vendors. These tools help developers write simpler code, but generate more complicated code to debug.
In the example below, we use Webpack and Babel to compile ES Modules and async functions into vanilla JS, which can run in any browser. The original code on the left is pretty simple. The generated, browser-compatible code on the right is much more complicated.

Figure 1. Original file on the left, generated file on the right.
When the debugger pauses, it uses source maps to navigate from line 13 in the generated code to line 4 in the original code. Unfortunately, because pausing actually happens on line 13, it can be difficult for the user to figure out what the value of dancer is at that time. Moving the mouse over the variable dancer returns undefined and the only way to find the scope of dancer is to open all six of the available scopes in the Scopes pane followed by expanding the _emojis object! This complicated and frustrating process is why many people opt to disable source maps.

Figure 2. Value of dancer is undefined, six separate scopes in the Scopes pane.
To address this problem we teamed up with Logan Smyth to see if it was possible to make the interaction feel more natural, as if you were debugging your original code. The result is a new engine that maps source maps data with Babel’s syntax tree to show the variables you expect to see the way you want to see them.

Figure 3. Correct value of dancer is displayed, Scopes pane shows one scope.
These improvements were first implemented for Babel and Webpack, and we’re currently adding support for TypeScript, Angular, Vue, Ember, and many others. If your project already generates source maps there is a good chance this feature will work for you out of the box.
To try it out, just head over and download Firefox Developer Edition. You can help us by testing this against your own project and reporting any issues. If you want to follow along, say hello, or contribute, you can also find us on the devtools channel Github or Mozilla Discourse or in the devtools Slack!
Our 2018 goal is to improve the lives of web developers who are building modern apps using the latest frameworks, build tools and best practices. Fixing variables is just the beginning. The future is bright!
https://hacks.mozilla.org/2018/05/debugging-modern-web-applications/
|
|






