Mozilla Open Innovation Team: What’s Your Open Source Strategy? Here Are 10 Answers… |

A research report from Mozilla and Open Tech Strategies provides new perspectives on framing open source strategy. The report builds on Mozilla’s “Open by Design” strategy, which aims to increase the intent and impact of collaborative technology projects.
Mozilla is a radically open and participatory project. As part of the research we compiled into turning openness into a consistent competitive advantage, we identified that the application of open practices should always be paired with well-researched strategic intent. Without clarity of purpose, organizations will not (and nor should they) maintain long-term commitment to working with community. Indeed, we were not the first to observe this.
Mozilla benefits from many open practices, but open sourcing software is the foundation on which we build. Open source takes many forms at Mozilla. We enjoy a great diversity among the community structures of different Mozilla-driven open source projects, from Rust to Coral to Firefox (there are actually multiple distinct Firefox communities) and to others.
The basic freedoms offered by Mozilla’s open source projects — the famous “Four Freedoms” originally defined by the FSF — are unambiguous. But they only define the rights conveyed by the software’s license. People often have expectations that go well beyond that strict definition: expectations about development models, business models, community structure, even tool chains. It is even not uncommon for open source projects to be criticised for failing to comply with those unspoken expectations.
We recognise that there is no one true model. As Mozilla evolves more and more into a multi-product organization, there will be different models that suit different products and different environments. Structure, governance, and licensing policies should all be explicit choices based on the strategic goals of an open source project. A challenge for any organisation is how to articulate these choices, or to put it simply, how do you answer the question, “what kind of open source project is this?”.
To answer the question, we wanted to develop a set of basic models — “archetypes” — that projects could aim for, modifying them as needed, but providing a shared vocabulary for discussing how to think about any given project. We were delighted to be able to partner with one of the leading authorities in open source, Open Tech Strategies, in defining these archetypes. Their depth of knowledge and fresh perspective has created something we believe offers unique value.
The resulting framework consists of 10 common archetypes, covering things from business objectives to licensing, community standards, component coupling and project governance. It also contains some practical advice on how to use the framework and on how to set up your project.
20 years after the Open Source Initiative was founded, open source is widespread (and has inspired methods of peer production beyond the realm of software). Although this report was tailored to advance open source strategies and project design within Mozilla, and with the organizations and communities we work with, we also believe that this challenge is not unique to us. We suspect there will be many other organizations, both commercial and non-commercial, who will benefit from the model.
https://medium.com/media/9faa99d9c6b435593f9f6f5d21029b44/hrefYou can download the report here. Like so many things, it will never be “done”. After more hands-on-use with Mozilla projects, we intend to work with Open Tech Strategies on a version that expands its sights beyond Mozilla’s borders.
If you’re interested in collaborating, you can get in touch here: archetypes@opentechstrategies.com. The Github repository is up at https://github.com/OpenTechStrategies/open-source-archetypes.
What’s Your Open Source Strategy? Here Are 10 Answers… was originally published in Mozilla Open Innovation on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
Daniel Stenberg: curl user survey 2018 |
The curl user survey 2018 is up. If you ever use curl or libcurl, please donate some of your precious time and provide your answers!
The curl user survey is an annual tradition since 2014 and it is one of our primary ways to get direct feedback from a larger audience about what's good, what's bad and what to focus on next in the curl project. Your input really helps us!
The survey will be up and available to fill in during 14 days, from May 15th until the end of May 28th. Please help us share this and ask your curl using friends to join in as well.
If you submitted data last year, make sure you didn't miss the analysis of the 2017 survey.
https://daniel.haxx.se/blog/2018/05/15/curl-user-survey-2018/
|
|
Mozilla GFX: WebRender newsletter #19 |
I skipped a newsletter again (I’m trying to put publish one every two weeks or so), sorry! As usual a lot of fixes and a few performance improvement, and sometimes both the same time. For example the changes around image and gradient repetition were primarily motivated by bugs we were encountering when dealing with repeated backgrounds containing very large amounts of repetitions, and we decided to solve these issues by moving all images to the “brush” infrastructure (bringing better batching, faster fragment shader and the ability to move more pixels out of the alpha pass), and optimize the common cases by letting the CPU generate a single primitive that is repeated in the shader. I don’t always properly highlight fixes that benefit performance but they are here.
The most exciting (in my humble opinion) advancement lately is Kats’ work on integrating of asynchronous panning and zooming (which we refer to as APZ) with WebRender’s asynchronous scene building infrastructure. This lets us perform some potentially expensive operations (such as scene building) asynchronously and allow the critical path to prioritize scrolling, animations and video playback. It is a lot more complicated than it might sound (in part due to how it works on the Gecko side) and I am very impressed with how quickly it is taking shape.
Enough with my ramblings, let’s have a look at the highlight of the last two weeks month.
In about:config, just set “gfx.webrender.all” to true and restart the browser. No need to toggle any other pref.
The best place to report bugs related to WebRender in Gecko is the Graphics :: WebRender component in bugzilla.
Note that it is possible to log in with a github account.
https://mozillagfx.wordpress.com/2018/05/15/webrender-newsletter-19/
|
|
Daniel Stenberg: Now at 1000 mbit |
A little over six years since I got the fiber connection installed to my house. Back then, on a direct question to my provider, they could only offer 100/100 mbit/sec so that's what I went with. Using my Telia "Oppen Fiber and Tyfon (subsequently bought by Bahnhof) as internet provider.
In the spring of 2017 I bumped the speed to 250/100 mbit/sec to see if I would notice and actually take advantage of the extra speed. Lo and behold, I actually feel and experience the difference - frequently. When I upgrade my Linux machines or download larger images over the Internet, I frequently do that at higher speeds than 10MB/sec now and thus my higher speed saves me time and offers improved convenience.
However, ""Oppen Fiber" is a relatively expensive provider for little gain for me. The "openness" that allows me to switch between providers isn't really something that gives much benefit once you've picked a provider you like, it's then mostly a way for a middle man to get an extra cut. 250mbit/sec from Bahnhof cost me 459 SEK/month (55 USD) there.
Switching to Bahnhof to handle both the fiber and the Internet connection is a much better deal for me, price wise. I get an upgraded connection to a 1000/1000 mbit/sec for a lower monthly fee. I'll now end up paying 399/month (48 USD) (299 SEK/month the first 24 months). So slightly cheaper for much more speed!
My household typically consists of the following devices that are used for accessing the web regularly:
Our family of 4 consumes around 120GB average weeks. Out of this, Youtube is the single biggest hogger with almost 30% of our total bandwidth. I suppose this says something about the habits of my kids...
Out of these 13 most frequently used devices in our local network only 5 are RJ45-connected, the rest are WiFi.
I was told the switch-over day was May 15th, and at 08:28 in the morning my existing connection went away. I took that as the start signal. I had already gotten a box from Bahnhof with the new media converter to use.

I went downstairs and started off my taking a photo of the existing installation...

So I unscrewed that old big thing from the wall and now my installation instead looks like

You can also see the Ethernet cable already jacked in.
Once connected, I got a link at once and then I spent another few minutes to try to "register" with my user name and password until I figured out that my router has 1.1.1.1 hardcoded as DNS server and once I cleared that, the login-thing worked as it should and I could tell Bahnhof that I'm a legitimate user and woof, my mosh session magically reconnected again etc.
All in all, I was offline for shorter than 30 minutes.
These days a short round-trip is all the rage and is often more important than high bandwidth when browsing the web. I'm apparently pretty close to the Stockholm hub for many major services and I was a bit curious how my new operator would compare.
To my amazement, it's notably faster. google.com went from 2.3ms to 1.3ms ping time, 1.1.1.1 is at 1.3ms, facebook.com is 1.0ms away. My own server is 1.2ms away and amusingly even if I'm this close to the main server hosting the curl web site, the fastly CDN still outperforms it so curl.haxx.se is an average 1.0ms from me.
So, the ping times were notably reduced. The bandwidth is truly at gigabit speeds in both directions according to bredbandskollen.se, which is probably the most suitable speed check site in Sweden.
A rather smooth change so far. Let's hope it stays this way.
|
|
Cameron Kaiser: Secure mail on Power Macs is not a good idea |
The EFAIL vulnerability is not as severe as it might sound because a key requirement is that an attacker already have access to the encrypted messages. If you used the tips in our security recommendations for PowerPC OS X to improve the security of your computer and your network connection, the odds of this occurring are not zero because the attacker may have already collected them in the past through other means, but are likely to be fairly low with the holes that remain. The risk can be mitigated further by disabling HTML rendering of E-mail (that means all E-mail, however, which might be a dealbreaker), and/or disabling automatic decryption of such messages (for example, I already cut and paste encrypted messages I receive into GPG directly in a Terminal window; my E-mail client never decrypts them automatically). A tool like Little Snitch could also be employed to block unexpected accesses to external servers, though this requires you to know what kinds of access would be unexpected for such messages.
Even with these recommendations, however, there may be other potential edge cases such that until someone(tm) updates Thunderbird or another mailer on Power Macs, secure encrypted mail on our systems should be handled with extreme caution and treated as if it were potentially exposed. If you require this kind of security from your E-mail and you must use a Power Mac, you're probably better off finding a webmail service with appropriate security and using TenFourFox (the webmail service then handles this), or building and using an E-mail client on some other system that is more up to date that you can access remotely and securely (which is what I do myself).
http://tenfourfox.blogspot.com/2018/05/secure-mail-on-power-macs-is-not-good.html
|
|
The Rust Programming Language Blog: Rust turns three |
Three years ago today, the Rust community released Rust 1.0 to the world, with our initial vision of fearless systems programming. As per tradition, we’ll celebrate Rust’s birthday by taking stock of the people and the product, and especially of what’s happened in the last year.
Rust is a people-centric, consensus-driven project. Some of the most exciting developments over the last year have to do with how the project itself has grown, and how its processes have scaled.
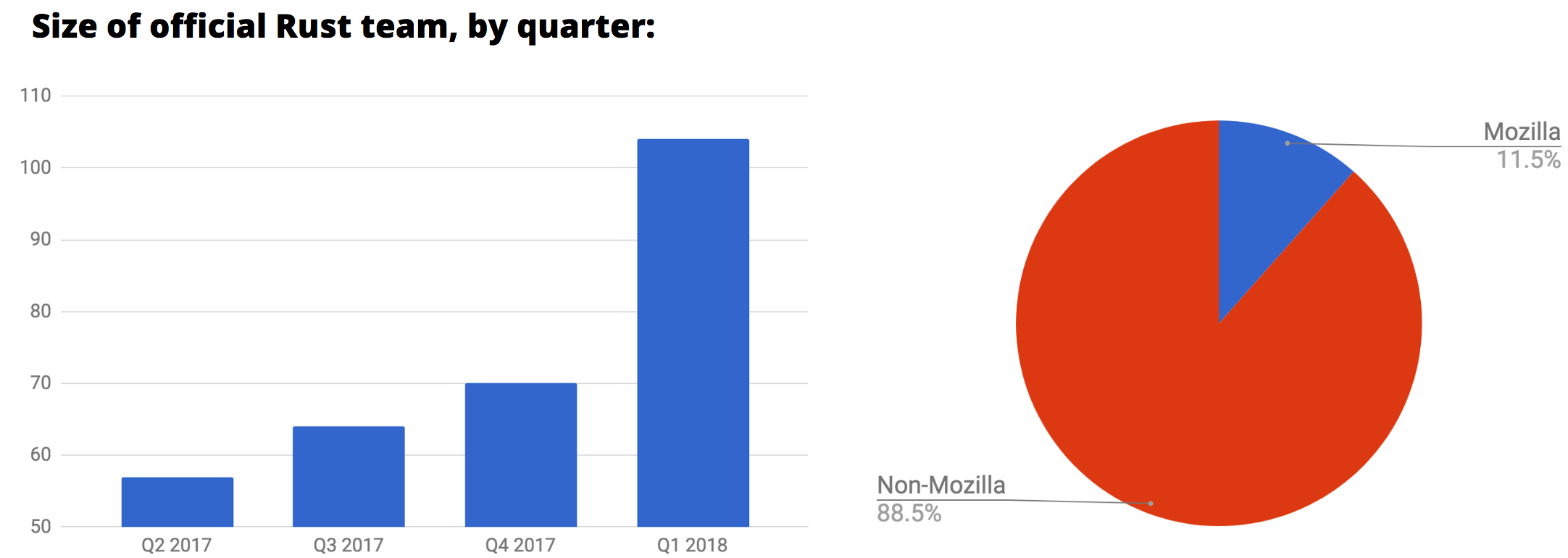
The official teams that oversee the project doubled in size in the last year; there are now over a hundred individuals associated with one or more of the teams. To accommodate this scale, the team structure itself has evolved. We have top-level teams covering the language, library ecosystem, developer tooling, documentation, community, and project operations. Nested within these are dozens of subteams and working groups focused on specific topics.
Rust is now used in a huge variety of companies, including both newcomers and big names like Google, Facebook, Twitter, Dropbox, Microsoft, Red Hat, npm and, of course, Mozilla; it’s also in the top 15 languages this year on GitHub. As a byproduct, more and more developers are being paid to contribute back to Rust, many of them full time. As of today, Mozilla employees make up only 11% of the official Rust teams, and just under half of the total number of people paid to work on Rust. (You can read detailed whitepapers about putting Rust into production here.)
Finally, the Rust community continues to work on inclusivity, through outreach programs like Rust Reach and RustBridge, as well as structured mentoring and investments in documentation to ease contribution. For 2018, a major goal is to connect and empower Rust’s global community, which we’re doing both through conference launches in multiple new continents, as well as work toward internationalization throughout the project.
If you spend much time reading this blog, you’ll know that the major theme of our work over the past year has been productivity. As we said in last year’s roadmap:
From tooling to libraries to documentation to the core language, we want to make it easier to get things done with Rust.
This work will culminate in a major release later this year: Rust 2018 Edition. The release will bring together improvements in every area of the project, polished into a new “edition” that bundles the changes together with updated documentation and onboarding. The roadmap has some details about what to expect.
The components that make up Rust 2018 will be shipped as they become ready on the stable compiler. Recent releases include:
impl Trait and match improvementsThe next couple of releases will
include stable SIMD support,
procedural macros, custom allocators, and more. The final big features
— lifetime system improvements
and async/await — should both
reach feature complete status on nightly within weeks. Vital tools like the RLS and
rustfmt are also being polished for the new edition, including RFCs for finalizing
the style
and stability stories.
To help tie all this work to real-world use-cases, we’ve also targeted four domains for which Rust provides a compelling end-to-end story that we want to show the world as part of Rust 2018. Each domain has a dedicated working group and is very much open for new contributors:
As Rust 2018 comes into focus, we plan to provide a “preview” of the new edition for cutting-edge community members to try out. Over the past couple of weeks we kicked off a sprint to get the basics nailed down, but we need more help to get it ready for testing. If you’re interested, you can dive into:
Rust’s growth continues to accelerate at a staggering rate. It has been voted the Most Loved Language on StackOverflow for all three years since it shipped. Its community has never been healthier or more welcoming. If you’re curious about using or contributing to Rust, there’s never been a better time to get involved.
Happy 3rd birthday, Rust.
|
|
Air Mozilla: Webby Lifetime Achievement Award to Mitchell Baker |
 Laurie Segall presents the 22nd Annual Webby Lifetime Achievement Award to Mitchell Baker
Laurie Segall presents the 22nd Annual Webby Lifetime Achievement Award to Mitchell Baker
https://air.mozilla.org/webby-lifetime-achievement-award-to-mitchell-baker/
|
|
Firefox Nightly: Deep Dive: New bookmark sync in Nightly |
For the last two years, the Firefox Sync team has been hard at work improving bookmarks on all our platforms. Last year, we added support for uploading bookmarks to Firefox for iOS, and made change tracking more durable on Android. Today, we’d like to tell you about our latest project to overhaul bookmark sync in Firefox for Desktop.

Firefox bookmark. Image credit: Lonnie Jacobsen
Historically, bookmark sync has been plagued by problems that were difficult to isolate and fix.
At the root of all these issues was an approach to syncing that didn’t consider the unique challenges of bookmarks. In this post, we’ll dive into an overview of how Sync works, why bookmarks are special, and the advantages of the new design. Whether you’re a new or long-time Sync user, we invite you to flip the pref, try the new bookmarks engine out, and send us your feedback!
The new bookmarks engine is currently behind a pref in Beta 61 and Nightly 62, but you can turn it on easily. First, we recommend you make a backup of your bookmarks, just in case:
Now, you can enable the new engine:
about:config.services.sync.engine.bookmarks.buffer.true, congrats, you’re already using the new engine! If it’s false, double-click the row to toggle the pref to true.That’s it! Keep an eye on your bookmarks: do you notice any issues when you sync? Try adding, deleting, and moving bookmarks around on all your devices, and see if your changes sync everywhere. If you’ve been using Sync for a while, there’s a good chance you have some inconsistencies on the server already. After you turn the new engine on for the first time, Sync will download all your bookmarks from the server, and run a full merge. This is a good time to notice if any of your bookmarks are deleted or rearranged.
If you start seeing problems:
about:sync.You don’t need to understand how bookmark sync works under the hood to use new bookmark sync, but read on if you’re curious!
Sync is a complicated beast—30 files and 25k lines of JavaScript, written over ten years—but the core ideas are simple. Every syncable data type (bookmarks, history, tabs, passwords, and so on) is backed by a tracker, a store, and an engine.
Sync is very generic, which has some important consequences that we’ll talk about later.
A record is just an encrypted JSON blob: it’s up to the store on each device to make sense of it, figure out how to represent items (for example, a record per bookmark, a record per page with a list of visits, or a record per device with all open tabs), and translate the records into the right format for the underlying data store.
Records are decrypted and applied to the store one at a time, in no particular order, and typically without a transaction. Conflict resolution considers each record in isolation, and uses timestamps to decide which is newer. Timestamps are subject to clock drift in the best case, and wildly inaccurate in the worst.
This approach is an artifact of Sync’s history more than a deliberate decision. Sync began its life in 2008 as an add-on called “Weave”, and integrated into Firefox in 2010. Backing stores like Places were designed long before this, and most weren’t built with syncing in mind.
The generic design works surprisingly well in most cases, but an important lesson that we’ve learned from working on Sync is that this only works well for the simplest data types. However, each data type has different requirements.
Bookmarks are probably the most complicated data type we sync, and one of the more valuable. You might visit dozens or hundreds of sites in a week, and it’s okay if some pages get lost in the shuffle. But when you bookmark a page, you’re signaling that it’s important in some way.
Bookmarks are versatile. Some folks use them as a reading list, or a drop file of things they’d like to see again. Others meticulously organize the bookmarks they’ve collected over many years, and use keywords and tags for easy access. Still others go with a mix of strategies. I have just under 4000 bookmarks that I’ve saved over eight years, most in “Other Bookmarks”, some organized into folders, and about a dozen in the toolbar.
It would be a shame if I took the time to tend to my bookmarks, only to have Sync lose or scramble them. Sadly, this has been a common complaint from folks over the years, eroding trust in Sync and Firefox.
What makes bookmarks so challenging? The short answer: they’re trees! Your bookmarks form a hierarchy, where each one lives in a folder, and has a unique position within that folder. Sometimes, the position and folder doesn’t matter; other times, it does. I’d be hard-pressed to remember that this awesome article about how SQLite works is #1480 in “Other Bookmarks”, but I’ll notice right away if my favorite recipes end up in the menu instead of my recipes folder, if the separators between my folders are off, or if my toolbar suddenly shows Bugzilla ahead of Purrli!
Sync can’t know how you use bookmarks, so it must be able to handle every case.
The server doesn’t distinguish between bookmarks and other data types: everything is stored in a collection of flat, unordered, and encrypted records. Folders keep pointers to their children, and children back to their parents. This means that some changes, like moving a bookmark between two folders, or deleting an entire folder, require uploading multiple records. Corruption happens when these changes are lost, not made in lockstep, or applied out of order.
Corruption doesn’t mean all your bookmarks are unrecoverable. They might be missing, or appear in different folders or the wrong order on different devices. Thanks to the magic of complex distributed systems, corruption also isn’t stable: inconsistent data can become eventually consistent, and much of Sync relies on this property to work.
In a common case, your desktop might realize halfway through the sync that the bookmark tree on the server doesn’t make sense, maybe because your laptop didn’t finish uploading all its changed bookmarks. At that point, it’s too late. Sync can’t undo the changes it made, because it already applied all the records it saw directly to Places.
Another case where corruption typically happens is when you connect a new device to your account. A first sync can take minutes for large trees, as inserting or updating into Places incurs a half-dozen database statements per bookmark. Since bookmarks are unordered on the server, the new device might see a child before its parent folder, and stash the bookmark in “Other Bookmarks” until the folder arrives. Some folks will notice this and try to help Sync out, which usually makes the problem worse.
Remember how I mentioned earlier that Sync records are encrypted and opaque to the server? This is still very much the case! It means that Mozilla can’t see any of your bookmarks, which is a core privacy guarantee. On the other hand, it means that Firefox needs to detect corruption and resolve merge conflicts locally. Everything must happen client-side; the server can’t help at all, because it can’t decrypt your bookmarks.
We’ve learned from experience, and many reports of bizarre bookmark issues, that “stash everything in Places and trust that we’ll get it right eventually” doesn’t work. Last summer, we set out to fix these problems once and for all.
For inspiration on how to fix bookmark syncing on Desktop, we turned to Firefox for iOS.
In contrast to Desktop, iOS was built to sync from the start. Bookmarks are stored in a database schema that separates “value”, like the title, URL, or description, and “structure”, or parent-child relationships. When you change a bookmark on your phone, or make a change on your laptop that’s synced to your phone, iOS doesn’t mutate the canonical representation of that bookmark in a “bookmarks” table, as on Desktop. Instead, iOS keeps the original bookmark value and structure in a “mirror” table, and records the changes in a separate table: “local” for changes that you make, and “buffer” for changes that Sync makes.
The mirror helps with conflict resolution; preserving the value and structure until the next sync, as well as keeping them separate, makes three-way merges possible. You might recognize this as the same idea behind version control systems like Git and Mercurial. The “shared parent” is the original value and structure, and the left and right sides are the “local” and “buffer” tables.
During a sync, iOS walks the mirror, local, and buffer trees to produce a complete, consistent merged tree. Any bookmarks added to a folder on one side that’s deleted on the other side are relocated to the deleted folder’s parent, to avoid data loss.
Three-way merges make value-structure conflicts, like renaming a folder on one side, and moving or reordering its children on the other, easy to resolve without resorting to the timestamp. iOS still uses the timestamp to break the tie in case of conflicting value and structure changes—this is where a system like Git would insert conflict markers and pause merging until they’re resolved—but these are rare.
We can’t redo bookmark storage on Desktop to match iOS. That would be an invasive change touching almost every part of Places, and require extensive regression and performance testing. But we can take away some insights from how iOS does things.
Instead of modifying “mirror” directly, iOS writes synced changes into a separate “buffer” table. This allows Sync to detect and bail on inconsistent or incomplete trees before merging. Likewise, changes that you make are staged in an outgoing “local” table, meaning Sync won’t upload partial changes if you happen to move or rename a bookmark at the exact time a sync is running.
Structured tree merging. The Sync record format smushes value and structure for folders, which is why Sync has historically mishandled easy conflicts like renaming a folder on your laptop, and adding some bookmarks to the same folder on your phone. Deleting entire folders and moving bookmarks to new folders are other cases where Sync has done the wrong thing. Walking the entire tree to decide on a final structure solves these issues.
Sync tries to avoid creating duplicates where it can. If you bookmark the same page in the same folder on your desktop and tablet, it’ll only sync one. This is also handy if you import bookmarks from another browser before syncing. Thanks to structured merging, iOS can zip trees together, while Desktop looks for similar bookmarks anywhere in the tree, and takes the first match it finds. This causes interesting bugs like merging the contents of two untitled folders.
This improves performance by reducing writes, and makes interruptions safe. Quitting the app or interrupting the sync means the transaction doesn’t commit, and the merge can start over on the next sync. Merging in a transaction also allows iOS to roll back on errors like inconsistent trees.
The new bookmark sync borrows a lot from iOS.
There are two important parts: a mirror and a merger. The mirror maintains a local copy of the server’s bookmark tree in a separate SQLite database, applies merged trees back to Places, and stages locally changed bookmarks for upload. The merger takes the local bookmark tree in Places, the remote bookmark tree in the mirror, and builds a complete, consistent merged tree, with all conflicts resolved.
You can think of the new sync in iOS terms as “Desktop Mirror = iOS mirror + iOS buffer”, and “Desktop Places = iOS mirror + iOS local”.
Unlike iOS, Desktop doesn’t store the shared parent; it knows that a bookmark or folder changed, but not how. Since Desktop don’t know the shared parent, it only has enough information for a two-way merge of two complete trees. This is fine for resolving simple conflicts, which are usually “I added two different bookmarks to the same folder on two different devices.” The structured merge can still detect value and structure changes, and fix up Places or the server to match.
During each sync, the new engine stages incoming bookmarks in the mirror, instead of writing them directly to Places. The mirror handles missing children and parent folders, so the order of records doesn’t matter. The mirror also has weaker consistency guarantees; unlike Places, the mirror don’t need to worry about maintaining consistency until it’s ready to ‘inflate’ a tree for merging.
Unfortunately, Sync might have uploaded corruption to the server in the past, especially in the early days. For example, you might have bookmarks referencing nonexistent parent folders, folders referencing nonexistent children, or a bookmark and folder that disagree about where it belongs. The mirror tries to make the structure temporarily consistent, as the missing or updated records usually show up on the next sync.
Next, the merger recurses down the local and remote trees to build a merged tree, following the same process as iOS. You can dive into the code if you’re curious about how this works. Once the merger has built the new tree, the mirror stuffs the new structure into an in-memory SQL table, and applies the tree to Places using a pile of triggers. The triggers handle deduplication, URL, title, keyword, and tag changes. Much of the complexity is mapping the simpler Sync record model to the Places model, especially for keywords and tags.
Finally, the mirror ‘inflates’ Sync records for all outgoing bookmarks. The engine takes the records, uploads them to the server, and writes them back to the mirror at the end of the sync. This lets the engine resume cleanly if the sync is interrupted during or after upload.
In a fun turn of events, the strategy that we initially rejected—building a “shadow” bookmarking system that kept synced bookmarks separate, and merged with Places—was the strategy we implemented.
Bookmark merging is hard! Much of the work was about getting the semantics right, and adapting the three-way merger from iOS into a two-way merger on Desktop. “How should we resolve this conflict?” came up more often early on, than “what’s the best way to write the conflict resolution logic?”
Pushing more logic into SQL fixed many edge cases in the first cut of the mirror, which implemented most of the “apply to Places” step in JavaScript. Applying a complete merge tree to Places boils down to two views for value and structure, five INSTEAD OF DELETE triggers on the views to deduplicate and update existing bookmarks, insert new bookmarks, fix parent-child relationships and position, and flag folders with resolved merge conflicts for re-upload, and two DELETE statements to process every row in each view. This also makes the merge step more efficient, as everything is contained within SQLite. There’s no need to accumulate row objects in memory, pass results and statements back and forth between the main and storage threads, or cross the JavaScript-C++ barrier.
There are subtleties in handling keywords and tags, which Places associates with URLs instead of bookmarks.
Some of the performance characteristics of SQLite surprised us! For example, a query containing a WITH RECURSIVE expression (handy for walking trees in SQL!) and LEFT JOINs took 10 seconds to run for 5000 rows, compared to 5 milliseconds for a simpler query and recursing in JavaScript. An INSERT OR IGNORE...SELECT with a LEFT JOIN took over 4 minutes to insert 40000 rows, compared to 2 seconds with a subquery. Removing most LEFT JOINs on TEXT primary keys, and avoiding cascading TEXT foreign key deletes, reduced the merge time for 40000 bookmarks from over 4 minutes to under 10 seconds.
Shipping new bookmarks was a months-long team effort, and I’d like to close this post by acknowledging the awesome folks who made this happen. Bookmark merging wouldn’t have landed without their astute and insightful feedback, support and patience, planning, mentoring, hours of code review, data analysis, and testing.
https://blog.nightly.mozilla.org/2018/05/14/deep-dive-new-bookmark-sync-in-nightly/
|
|
Daniel Pocock: A closer look at power and PowerPole |
The crowdfunding campaign has so far raised enough money to buy a small lead-acid battery but hopefully with another four days to go before OSCAL we can reach the target of an AGM battery. In the interest of transparency, I will shortly publish a summary of the donations.
The campaign has been a great opportunity to publish some information that will hopefully help other people too. In particular, a lot of what I've written about power sources isn't just applicable for ham radio, it can be used for any demo or exhibit involving electronics or electrical parts like motors.
People have also asked various questions and so I've prepared some more details about PowerPoles today to help answer them.
In an unfortunate twist of fate while I've been blogging about power sources, one of the OSCAL organizers has a MacBook and the Apple-patented PSU conveniently failed just a few days before OSCAL. It is the 85W MagSafe 2 PSU and it is not easily found in Albania. If anybody can get one to me while I'm in Berlin at Kamailio World then I can take it to Tirana on Wednesday night. If you live near one of the other OSCAL speakers you could also send it with them.
If only Apple used PowerPole...
The first question many people asked is why use batteries and not a power supply. There are two answers for this: portability and availability. Many hams like to operate their radios away from their home sometimes. At an event, you don't always know in advance whether you will be close to a mains power socket. Taking a battery eliminates that worry. Batteries also provide better availability in times of crisis: whenever there is a natural disaster, ham radio is often the first mode of communication to be re-established. Radio hams can operate their stations independently of the power grid.
Note that while the battery looks a lot like a car battery, it is actually a deep cycle battery, sometimes referred to as a leisure battery. This type of battery is often promoted for use in caravans and boats.
Many amateur radio groups have already standardized on the use of PowerPole in recent years. The reason for having a standard is that people can share power sources or swap equipment around easily, especially in emergencies. The same logic applies when setting up a demo at an event where multiple volunteers might mix and match equipment at a booth.
WICEN, ARES / RACES and RAYNET-UK are some of the well known groups in the world of emergency communications and they all recommend PowerPole.
Sites like eBay and Amazon have many bulk packs of PowerPoles. Some are genuine, some are copies. In the UK, I've previously purchased PowerPole packs and accessories from sites like Torberry and Sotabeams.
The PowerPole plugs for 15A, 30A and 45A are all interchangeable and they can all be crimped with a single tool. The official tool is quite expensive but there are many after-market alternatives like this one. It takes less than a minute to insert the terminal, insert the wire, crimp and make a secure connection.

Here are some packets of PowerPoles in every size:

It is easy to make your own cables or to take any existing cables, cut the plugs off one end and put PowerPoles on them.
Here is a cable with banana plugs on one end and PowerPole on the other end. You can buy cables like this or if you already have cables with banana plugs on both ends, you can cut them in half and put PowerPoles on them. This can be a useful patch cable for connecting a desktop power supply to a PowerPole PDU:

Here is the Yaesu E-DC-20 cable used to power many mobile radios. It is designed for about 25A. The exposed copper section simply needs to be trimmed and then inserted into a PowerPole 30:

Many small devices have these round 2.1mm coaxial power sockets. It is easy to find a packet of the pigtails on eBay and attach PowerPoles to them (tip: buy the pack that includes both male and female connections for more versatility). It is essential to check that the devices are all rated for the same voltage: if your battery is 12V and you connect a 5V device, the device will probably be destroyed.

There are a wide range of power distribution units (PDUs) for PowerPole users. Notice that PowerPoles are interchangeable and in some of these devices you can insert power through any of the inputs. Most of these devices have a fuse on every connection for extra security and isolation. Some of the more interesting devices also have a USB charging outlet. The West Mountain Radio RigRunner range includes many permutations. You can find a variety of PDUs from different vendors through an Amazon search or eBay.
In the photo from last week's blog, I have the Fuser-6 distributed by Sotabeams in the UK (below, right). I bought it pre-assembled but you can also make it yourself. I also have a Windcamp 8-port PDU purchased from Amazon (left):

Despite all those fuses on the PDU, it is also highly recommended to insert a fuse in the section of wire coming off the battery terminals or PSU. It is easy to find maxi blade fuse holders on eBay and in some electrical retailers:

If you don't want to buy a crimper or you would like somebody to help you, you can bring some of your cables to a hackerspace or ask if anybody from the Debian hams team will bring one to an event to help you.
I'm bringing my own crimper and some PowerPoles to OSCAL this weekend, if you would like to help us power up the demo there please consider contributing to the crowdfunding campaign.
https://danielpocock.com/a-closer-look-at-power-and-powerpole
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 14 May 2018 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20180514/
|
|
QMO: Firefox 61 Beta 6 Testday, May 18th |
Hello Mozillians,
We are happy to let you know that Friday, May 18th, we are organizing Firefox 61 Beta 6 Testday. We’ll be focusing our testing on: Accessibility Inspector: Developer Tools, Audio Context using sampleRate and Web Compatibility.
Check out the detailed instructions via this etherpad.
No previous testing experience is required, so feel free to join us on #qa IRC channel where our moderators will offer you guidance and answer your questions.
Join us and help us make Firefox better!
See you on Friday!
https://quality.mozilla.org/2018/05/firefox-61-beta-6-testday-may-18th/
|
|
Robert O'Callahan: rr Chaos Mode Improvements |
rr's chaos mode introduces nondeterminism while recording application execution, to try to make intermittent bugs more reproducible. I'm always interested in hearing about bugs that cannot be reproduced under chaos mode, especially if those bugs have been diagnosed. If we can figure out why a bug was not reproducible under chaos mode, we can often extend chaos mode to make it reproducible, and this improves chaos mode for everyone. If you encounter such a bug, please file an rr issue about it.
I just landed one such improvement. To trigger a specific Spidermonkey JS engine bug, some thread X had to do a FUTEX_WAKE to wake up thread Y, then immediately yield to let thread Y run for a while without X running any further. rr chaos mode assigns random priorities to threads and strictly adheres to them, so in some runs it would assign X a low priority and Y a high priority and schedule Y whenever both were runnable. However, rr's syscall buffering optimization means the rr supervisor process is not notified after the FUTEX_WAKE and has no opportunity to interrupt X and schedule Y instead, so we keep running the lower-priority X thread, violating our scheduling policy. (Chaos mode randomizes scheduling intervals so it was possible for X to yield at the right point, but very unlikely because the "window of vulnerability" is very small.) The fix is quite easy: in chaos mode, FUTEX_WAKE should not use the syscall buffering optimization. This adds some overhead, but hopefully not all that much, because every FUTEX_WAKE is normally paired with a FUTEX_WAIT (futex-using code should not issue a FUTEX_WAKE if there are no waiters), and a FUTEX_WAIT yields, which is already an expensive operation.
The same sorts of issues exist for other system calls that can make another higher-priority thread runnable, and I've added some slightly more elaborate fixes for those.
One day I should do a proper evaluation of these techniques and publish them...
http://robert.ocallahan.org/2018/05/rr-chaos-mode-improvements.html
|
|
Mozilla VR Blog: This week in Mixed Reality: Issue 6 |

The team and community continue to add new features, fix bugs, and respond to early user and developer feedback to deliver a solid experience across Firefox Reality, Hubs and the content related projects.
Next week, the team will be in Chicago for a workweek. Come see us at a Chicago VR & AR meetup on Thursday, May 17th if you are in the area!
We are continuing to build towards a MVP:
Here is a video of the new keyboard!
In addition to Gecko, we also now have the experimental Servo engine running inside of Firefox Reality!
Since the announcement of Hubs by Mozilla preview release, we are putting our efforts on a variety of post-launch tasks:
Join our public WebVR Slack #social channel to participate in on the discussion!
We’re focusing on showing navigation between Unity experiences and adding more content examples to the Unity WebVR Exporter.
We'd like to invite Unity game designers and developers to try it out and reach out to us on the public WebVR Slack #unity channel to participate in on the discussion!
Blair released a new article on extending our WebXR iOS Viewer application with more computer vision features. As the W3C Immersive Web Community group settles on a more stable WebXR API this summer, we expect to begin adding WebXR support to our browsers. Now that Google is also starting to add experimental WebXR support to Chrome mobile, it will be great to collaborate more with them on future Augmented Reality and Computer Vision experiments!
We’re really excited to share our journey of building our products, week after week. Check out what we’re shipping next, next week!
|
|
Air Mozilla: Martes Mozilleros, 11 May 2018 |
 Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
|
|
Marco Zehe: Firefox 60 and JAWS 2018 back in good browsing conditions together |
When Firefox Quantum was first released in November of 2017, it temporarily regressed users of the JAWS screen reader. I’m happy to report that both Firefox and JAWS once again deliver a first class browsing experience together!
When Mozilla released Firefox Quantum, starting with version 57, in November of 2017, it introduced a number of technical changes that improve the browsing experience for our users. Tabs run in separate processes now, so that if one tab crashes, it does not bring the whole browser down with it. This is also better for security on multiple levels. Web sites load faster due to a much improved and modernized rendering engine. And a lot of other new features which you’ve probably read all about by now.
However, due to these massive technical changes under the hood, we unfortunately temporarily regressed screen reader users. And while we quickly regained much of the lost performance with Firefox 58 for NVDA users, for JAWS these improvements helped only slightly.
Therefore, a collaboration was started to bring both JAWS and Firefox back to a state together where the experience can be considered a first-class browsing experience. Over the past few months, accessibility engineers from Mozilla and VFO have identified and worked on performance and other usability issues together to improve both products to make that happen. This involved mutual understanding of what answers were required by JAWS from Firefox when it asked certain questions, particularly those that had not been dealt with in the work for Firefox 58 and 59. There were also some more architectural changes required on the Firefox side to handle very Windows-specific mechanisms. And while we were at it, we found and fixed some big memory leaks that had been bothering us since the release of Firefox 57, and which NVDA users will also have noticed improving in Firefox 59.
We’re happy to report that the combination of Firefox 60, released on May 9, 2018, and JAWS 2018, starting with the April 2018 update, are the result of this collaboration. With the combination of these versions or later, users of the JAWS screen reading software can again use the latest and greatest version of Firefox and be confident that they can browse the web in a speedy manner.
First, if you’re on JAWS 2018, make sure to get the latest update from the Check for updates item in the JAWS Help menu. The version you should be using with Firefox 60 is at least 2018.1804.26. If it says anything older, like 2018.1803.xx or less, please update.
Second, go ahead and download Firefox 60 (opens in new tab) from the Mozilla download pages. Please use the regular version, not the ESR, if you’re not required to do so by your employer. The regular version will get more frequent updates than ESRs, and you’ll always get the latest features and enhancements when you update the browser to a new version every few weeks.
Third, uninstall the version 52 ESR from Programs And Features.
Fourth, install the downloaded version 60 of Firefox. Your profile and settings should be retained, and you should still have all your bookmarks and history present. To be safe, you can also use Firefox Sync to save your bookmarks, history, login information, and settings to a secure Mozilla cloud so even if something does go wrong with your profile at some point, you can restore from sync and be back to your usual browser in minutes.
Unfortunately, due to the big technnical changes, it was not possible to retain compatibility with versions of JAWS older than 2018. More information can also be found in this knowledge base article.
As with all software, enhancements and improvements are continuously being added. In the case of Firefox 60 and JAWS, a number of issues have already been identified, in part thanks to community members who tested the JAWS April 2018 update with Firefox 60 when it was in beta. The below is a list of fixes provided to us by Freedom Scientific that can be expected in an upcoming update to JAWS 2018, slatted for release later in May, and which we’re publishing with Freedom Scientific’s permission.
If you are currently seeing one of these issues, you can be sure that these will go away once the May 2018 update of JAWS is released.
As always, if you encounter problems not mentioned above, feel free to report them to either Freedom Scientific or Mozilla. We’ll check the reports out and will make sure they get addressed.
Happy browsing!
|
|
Nick Cameron: These Weeks in Dev-Tools, issue 4 |
2018-05-10
Welcome to the 4th issue of these weeks in dev-tools! We've re-organised the
teams a little bit and have been working hard towards the 2018 edition release.
These Weeks in Dev-Tools will keep you up to date with all the exciting dev
tools news. We plan to have a new issue every few weeks. If you have any news
you'd like us to report, please comment on the tracking issue.
If you're interested in Rust's developer tools and want to contribute or ask
questions, come chat to us on Gitter.
Find all meeting notes here, some highlights:
http://www.ncameron.org/blog/these-weeks-in-dev-tools-issue-4/
|
|
Gian-Carlo Pascutto: Linux sandboxing improvements in Firefox 60 |
http://www.morbo.org/2018/05/linux-sandboxing-improvements-in_10.html
|
|
Mozilla Addons Blog: Switching to JSON for update manifests |
We plan on switching completely to JSON update manifests on Firefox and AMO. If you self-distribute your add-on please read ahead for details.
AMO handles automatic updates for all add-ons listed on the site. For self-hosted add-ons, developers need to set an update URL and manage the update manifest file it returns. Today, AMO returns an RDF file, a common legacy add-on feature. A JSON equivalent of this file is now supported in Firefox. JSON files are smaller and easier to read. This also brings us closer to removing complex RDF parsing from Firefox code.
Firefox 62, set to release September 5, 2018, will stop supporting the RDF variant of the update manifest. Firefox ESR users can continue using RDF manifests until the release of Firefox 68 in 2019. Nevertheless, all developers relying on RDF for their updates should read the documentation and switch soon. Firefox 45 introduced this feature, so all current versions of Firefox support it.
Developers of add-ons hosted on AMO don’t need to take any action. AMO will switch to JSON updates in the coming weeks. You don’t need to make any changes for add-ons hosted on AMO to update normally. Users on versions of Firefox older than 45 will no longer receive automatic updates. However, that should be a very small number of users. It’s also a very small number of active add-ons, since Firefox 45 predates the move to WebExtensions.
If you have any questions about this, please post a comment on the Discourse thread.
The post Switching to JSON for update manifests appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/05/10/switching-json-update-manifests/
|
|
Hacks.Mozilla.Org: Visualizing Your Smart Home Data with the Web of Things |
Today we’re mashing up two very different applications to make a cool personal dashboard for investigating all our internet-connected things, and their behavior over time. We can use one of the Web Thing API’s superpowers: its flexibility. Like Elastigirl or Mr. Fantastic, it can bend and stretch to fit into any situation.
This adaptability allows us to create a bridge between the Project Things gateway and Cloud Native Computing Foundation’s Prometheus.
Prometheus is a time-series database originally intended for supervising large clusters of servers. However, it’s easy to teach all of our internet-connected devices to pretend to be part of a fancy server farm.
We do this by squishing data from the Web Thing API into a series of raw data points stored in Prometheus. We’ll be getting all of this done using only free and open-source software without any data leaving our local network.
First, let’s set up the translation layer. This small utility will take data from the Web of Things API and translate it into values for Prometheus to consume and turn into pretty graphs. It starts off with a call to the gateway’s /things path to get a list of Thing Descriptions.
Next, it reads from the property resources of each described Thing to get the initial property values to send to Prometheus. The Translator then opens a WebSocket connection on each Thing to get future updates to properties. Finally, it makes all the property values available to Prometheus as a specially-formatted web page.
You can download this utility from GitHub. If you’re running the gateway on a Raspberry Pi you can log in and use the following commands to get the translator installed.
cd ~/mozilla-iot
git clone https://github.com/hobinjk/gateway-prometheus-translator/
cd gateway-prometheus-translator
npm installNext, it’s time to make sure the translation layer knows where your gateway is. In my case, this is https://hobinjk.mozilla-iot.org, but if you’re just trying it out the gateway locally it might be http://localhost:8080 or http://gateway.local.
As long as you can visit the URL and see the main Things page of the gateway you’ve filled it out correctly. Save this URL for later, when we run the translator.
Now that the translator knows where it should get its data, we need to give it the proper identification to talk to our gateway securely. We can authorize the translator by issuing it an “identification card” from the gateway’s Local Token Service.
To start off, enter the “Settings” section of your Gateway by clicking on the menu button then on the settings tab.

Next, enter the Authorization section and create a new local authorization.


Allow the authorization request and copy the local token issued by the Local Token Service. This is the identification card the translator will present to the gateway to confirm its identity.


Our translator is fully kitted out and ready to embark on its expedition to harvest the secrets of the Web Thing API. For now, let’s just run it using the following command:
node translator.js "https://your-domain-here.mozilla-iot.org" "paste the local token here"If you can visit http://gateway.local:3060/metrics and see a lot of text and numbers, you’re good to go. Otherwise, check out the troubleshooting section of the translator’s GitHub repo.
Second, let’s install and configure Prometheus by running the following commands:
sudo apt install prometheus
sudo cp ~/mozilla-iot/gateway-prometheus-translator/prometheus.yml /etc/prometheus/
sudo systemctl stop prometheus
# Clear all existing metrics (don’t typo this!)
sudo rm -r /var/lib/prometheus/metrics
sudo systemctl start prometheusNow let’s kick back and enjoy the graphs. If we visit http://gateway.local:9090, we can draw graphs and run queries on our historical thing data. For starters, we can get a simple graph of any thing’s property value by clicking on “insert metric at cursor” and selecting the property we want to graph. In my case, I first selected my smart plug’s voltage as a sanity check.

In the United States 120 volts AC is the accepted standard for household voltage so we’re in the clear with a few extra volts to spare.
Let’s dive a bit deeper and find out how much power my laptop charger consumes over a typical day. For this we want the instantaneousPower metric. Here you can see clear differences based on whether my laptop is plugged in and whether it’s performing a strenuous task. At around 05:00 on the graph I plug in my laptop and go to sleep (note that all times are in GMT, not my local time zone). The laptop charges to full, displaying some fancy trickle-charge style ramping down of power consumption towards the end.

One insight I wanted to get from this graph is how much power I waste by leaving my laptop charged through the night. From the graph, I can see that the charger consumes around 0.6 watts while keeping my laptop fully charged. Assuming I sleep for 8 hours, this means that it consumes 4.8 watt-hours of power. Factoring in the average cost of electricity, over an entire month this costs me 0.14 kilowatt-hours which corresponds to the princely sum of two cents. I can sleep easy knowing that it doesn’t matter whether my laptop is plugged in.

This only scratches the surface of what’s possible with Prometheus consuming the Web Thing API. From this point we can perform all the advanced queries Prometheus supports. For example, over the last 24 hours the average power consumption of my charger was 38 watts.
We can also configure alerts, set up a shinier graphing frontend, or export our data to external storage. To make this setup permanent, follow the translator’s installation instructions.
We’re looking at integrating this time-series functionality with the gateway on a lower level to make this kind of cool analytics easier for people to access. Our goal is to build a homogenous graphing platform optimized for the Web Thing API.
We want to make the Web of Things accessible and open to all. If you want to help, participate in our planning on GitHub at the time-series tracking issue. You could also build translators for other analytics tools like Huginn or Munin.
https://hacks.mozilla.org/2018/05/visualizing-your-smart-home-data-with-the-web-of-things/
|
|






