Air Mozilla: Reps Weekly Meeting Dec. 01, 2016 |
 This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
|
|
Daniel Pocock: Using a fully free OS for devices in the home |
There are more and more devices around the home (and in many small offices) running a GNU/Linux-based firmware. Consider routers, entry-level NAS appliances, smart phones and home entertainment boxes.
More and more people are coming to realize that there is a lack of security updates for these devices and a big risk that the proprietary parts of the code are either very badly engineered (if you don't plan to release your code, why code it properly?) or deliberately includes spyware that calls home to the vendor, ISP or other third parties. IoT botnet incidents, which are becoming more widely publicized, emphasize some of these risks.
On top of this is the frustration of trying to become familiar with numerous different web interfaces (for your own devices and those of any friends and family members you give assistance to) and the fact that many of these devices have very limited feature sets.
Many people hail OpenWRT as an example of a free alternative (for routers), but I recently discovered that OpenWRT's web interface won't let me enable both DHCP and DHCPv6 concurrently. The underlying OS and utilities fully support dual stack, but the UI designers haven't encountered that configuration before. Conclusion: move to a device running a full OS, probably Debian-based, but I would consider BSD-based solutions too.
For many people, the benefit of this strategy is simple: use the same skills across all the different devices, at home and in a professional capacity. Get rapid access to security updates. Install extra packages or enable extra features if really necessary. For example, I already use Shorewall and strongSwan on various Debian boxes and I find it more convenient to configure firewall zones using Shorewall syntax rather than OpenWRT's UI.
There are various considerations when going down this path:
I recently started threads on the debian-user mailing list discussing options for routers and home NAS boxes. A range of interesting suggestions have already appeared, it would be great to see any other ideas that people have about these choices.
https://danielpocock.com/using-a-fully-free-os-for-devices-in-the-home
|
|
Giorgos Logiotatidis: Taco Bell Parallel Programming |
While working on migrating support.mozilla.org away from Kitsune (which is a great community support platform that needs love, remember that internet) I needed to convert about 4M database rows of a custom, Markdown inspired, format to HTML.
The challenge of the task is that it needs to happen as fast as possible so we can dump the database, convert the data and load the database onto the new platform with the minimum possible time between the first and the last step.
I started a fresh MySQL container and started hacking:
Kitsune's database weights about 35GiB so creating and loading the dump is a lengthy procedure. I used some tricks taken from different places with most notable ones:
Set innodb_flush_log_at_trx_commit = 2 for more speed. This should not be
used in production as it may break ACID compliance but for my use case it's
fine.
Set innodb_write_io_threads = 16
Set innodb_buffer_pool_size=16G and innodb_log_file_size=4G. I read that
the innodb_log_file_size is recommended to be 1/4th of
innodb_buffer_pool_size and I set the later based on my available memory.
Loading the database dump takes about 60 minutes. I'm pretty sure there's room for improvement there.
Extra tip: When dumping such huge databases from production websites make sure
to use a replica host and mysqldump's --single-transaction flag to avoid
locking the database.
Kitsune being a Django project I created extra fields named content_html in the
Models with markdown content, generated the migrations and run them against the
db.
An AWS m4.2xl gives 8 cores at my disposal and 32GiB of memory, of which 16 I allocated to MySQL earlier.
I started with a basic single core solution::
for question in Question.objects.all(): question.content_html = parser.wiki_2_html(question.content) question.save()
which obviously does the job but it's super slow.
Transactions take a fair amount of time, what if we could bundle multiple saves into one transaction?
def chunks(count, nn=500): """Yield successive n-sized chunks from l.""" offset = 0 while True: yield (offset, min(offset+nn, count)) offset += nn if offset > count: break for low, high in chunks(Question.objects.count()): with transaction.atomic(): for question in Question.objects.all().limit[low:high]: question.content_html = parser.wiki_2_html(question.content) question.save()
This is getting better. Increasing the chunk size to 20000 items in the cost of more RAM used produces faster results. Anything above this value seems to require about the same time to complete.
Tried pypy and I didn't get better results so I defaulted to CPython.
Let's add some more cores into the mix using Python's multiprocessing library.
I created a Pool with 7 processes (always leave one core outside the Pool so the
system remains responsive) and used apply_async to generate the commands to
run by the Pool.
results = [] it = Question.objects.all() number_of_rows = it.count() pool = mp.Pool(processes=7) [pool.apply_async(process_chunk), (chunk,), callback=results.append) for chunk in chunks(it)] sum_results = 0 while sum_results < number_of_rows: print 'Progress: {}/{}'.format(sum_results, number_of_rows) sum_results = sum(results) sleep(1)
Function process_chunk will process, save and return the number of rows
processed. Then apply_async will append this number to results which is used
in the while loop to give me an overview of what's happening while I'm
waiting.
So far so good, this is significantly faster. It took some tries before getting this right. Two things to remember when dealing with multiprocess and Django are:
./manage.py shell won't work. I don't know why but I went ahead and wrote
a standalone python script, imported django and run django.setup().
When a process forks, Django's database connection which was already
created by that time, needs to be cleared out and get re-created for every
process. First thing process_chunk does is db.connections.close_all().
Django will take care re-creating when needed.
OK I'm good to hit the road -I thought- and I launched the process with all the rows that needed parsing. As the time goes by I see the memory usage to increase dramatically and eventually the kernel would kill my process to free up memory.
It seems that the queries would take too much memory. I set the Pool to shutdown
and start a new process on every new chunk with maxtasksperchild=1 which
helped a bit but again, the farther in the process the more the memory usage. I
tried to debug the issue with different Django queries and profiling (good luck
with that on a multiprocess program) and I failed. Eventually I needed to figure
out a solution before it's too late, so back to the drawing board.
I read this interesting blog post the other day named Taco Bell Programming where Ted is claiming that many times you can achieve the desired functionality just by rearranging the Unix tool set, much like Taco Bell is producing its menu by rearranging basic ingredients.
What you win with Taco Bell Programming is battle-tested tools and throughout documentation which should save you time from actual coding and time debugging problems already solved.
I took a step back and re-thought by problem. The single core solution was working just fine and had no memory issues. What if I could find a program to paralellize multiple runs? And that tool (obviously) exists, it's GNU Parallel.
In the true spirit of other GNU tools, Parallel has a gazillion command line arguments and can do a ton of things related to parallelizing the run of a list of commands.
I mention just the most important to me at the moment:
I reverted to the original one core python script and refactored it a bit so I
can call it using python -c. I also removed the chunk generation code since
I'll do that elsewhere
def parse_to_html(it, from_field, to_field): with transaction.atomic(): for p in it: setattr(p, to_field, parser.wiki_to_html(getattr(p, from_field))) p.save()
Now to process all questions I can call this thing using
$ echo "import wikitohtml; it = Question.objects.all(); wikitohtml.parse_to_html(it, 'content', 'content_html')" | python -
Then I wrote a small python script to generate the chunks and print out commands to be later used by Parallel
CMD = '''echo "import wikitohtml; it = wikitohtml.Question.objects.filter(id__gte={from_value}, id__lt={to_value}); wikitohtml.parse_to_html(it, 'content', 'content_html')" | python - > /dev/null''' for i in range(0, 1200000, 10000): print CMD.format(from_value=i, to_value=i+step)
I wouldn't be surprised if Parallel can do the chunking itself but in this case it's easier for me to fine tune it using Python.
Now I can process all questions in parallel using
$ python generate-cmds.py | parallel -j 7 --eta --joblog joblog
So everything is working now in parallel and the memory leak is gone!
But I'm not done yet.
I left the script running for half an hour and then I started seeing MySQL
aborted transactions that failed to grab a lock. OK that's should be an easy fix
by increasing the wait lock time with SET innodb_lock_wait_timeout = 5000; (up
from 50). Later I added --retries 3 in Parallel to make sure that if anything
failed it would get retried.
That actually made things worse as it introduced everyone's favorite issue in
parallel programming, deadlocks. I reverted the MySQL change and looked deeper.
Being unfamiliar with Kitsune's code I was not aware that the model.save()
methods are doing a number of different things, including saving other objects
as well, e.g. Answer.save() also calls Question.save().
Since I'm only processing one field and save the result into another field which
is unrelated to everything else all the magic that happens in save() can be
skipped. Besides dealing with the deadlock this can actually get us a speed
increase for free.
I refactored the python code to use Django's
update()
which directly hits the database and does not go through save().
def parse_to_html(it, from_field, to_field, id_field='id'): with transaction.atomic(): for p in it: it.filter(**{id_field: getattr(p, id_field)}).update(**{to_field: parser.wiki_to_html(getattr(p, from_field))})
Everything works and indeed update() did increase things a lot and solved the
deadlock issue. The cores are 100% utilized which means that throwing more CPU
power into the problem would buy more speed. The processing of all 4 million
rows takes now about 30 minutes, down from many many hours.
Magic!
https://giorgos.sealabs.net/taco-bell-parallel-programming.html
|
|
Daniel Glazman: Eighteen years later |
In December 1998, our comrade Bert Bos released a W3C Note: List of suggested extensions to CSS. I thought it could be interesting to see where we stand 18 years later...
| Id | Suggestion |
active WD | CR, PR or REC | Comment |
|---|---|---|---|---|
| 1 | Columns |
http://www.glazman.org/weblog/dotclear/index.php?post/2016/12/01/Eighteen-years-later
|
|
Chris Finke: Reenact is dead. Long live Reenact. |
Last November, I wrote an iPhone app called Reenact that helps you reenact photos. It worked great on iOS 9, but when iOS 10 came out in July, Reenact would crash as soon as you tried to select a photo.

It turns out that in iOS 10, if you don’t describe exactly why your app needs access to the user’s photos, Apple will (intentionally) crash your app. For a casual developer who doesn’t follow every iOS changelog, this was shocking — Apple essentially broke every app that accesses photos (or 15 other restricted resources) if they weren’t updated specifically for iOS 10 with this previously optional feature… and they didn’t notify the developers! They have the contact information for the developer of every app, and they know what permissions every app has requested. When you make a breaking change that large, the onus is on you to proactively send some emails.
I added the required description, and when I tried to build the app, I ran into another surprise. The programming language I used when writing Reenact was version 2 of Apple’s Swift, which had just been released two months prior. Now, one year later, Swift 2 is apparently a “legacy language version,” and Reenact wouldn’t even build without adding a setting that says, “Yes, I understand that I’m using an ancient 1-year-old programming language, and I’m ok with that.”
After I got it to build, I spent another three evenings working through all of the new warnings and errors that the untouched and previously functional codebase had somehow started generating, but in the end, I didn’t do the right combination of head-patting and tummy-rubbing, so I gave up. I’m not going to pay $99/year for an Apple Developer Program membership just to spend days debugging issues in an app I’m giving away, all because Apple isn’t passionate about backwards-compatibility. So today, one year from the day I uploaded version 1.0 to the App Store (and serendipitously, on the same day that my Developer Program membership expires), I’m abandoning Reenact on iOS.

…but I’m not abandoning Reenact. Web browsers on both desktop and mobile provide all of the functionality needed to run Reenact as a Web app — no app store needed — so I spent a few evenings polishing the code from the original Firefox OS version of Reenact, adding all of the features I put in the iOS and Android versions. If your browser supports camera sharing, you can now use Reenact just by visiting app.reenact.me.
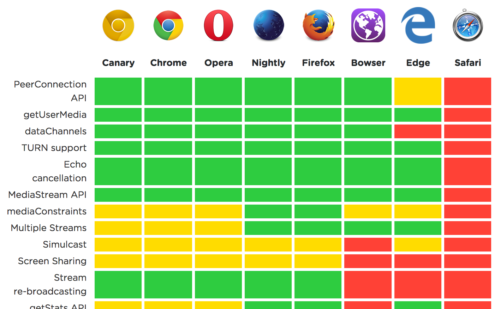
It runs great in Firefox, Chrome, Opera, and Amazon’s Silk browser. iOS users are still out of luck, because Safari supports precisely 0% of the necessary features. (Because if web pages can do everything apps can do, who will write apps?)
One of these things just doesn’t belong.
In summary: Reenact for iOS is dead. Reenact for the Web is alive. Both are open-source. Don’t trust anyone over 30. Leave a comment below.
https://www.chrisfinke.com/2016/11/30/reenact-is-dead-long-live-reenact/
|
|
Mozilla Security Blog: Fixing an SVG Animation Vulnerability |
At roughly 1:30pm Pacific time on November 30th, Mozilla released an update to Firefox containing a fix for a vulnerability reported as being actively used to deanonymize Tor Browser users. Existing copies of Firefox should update automatically over the next 24 hours; users may also download the updated version manually.
Early on Tuesday, November 29th, Mozilla was provided with code for an exploit using a previously unknown vulnerability in Firefox. The exploit was later posted to a public Tor Project mailing list by another individual. The exploit took advantage of a bug in Firefox to allow the attacker to execute arbitrary code on the targeted system by having the victim load a web page containing malicious JavaScript and SVG code. It used this capability to collect the IP and MAC address of the targeted system and report them back to a central server. While the payload of the exploit would only work on Windows, the vulnerability exists on Mac OS and Linux as well. Further details about the vulnerability and our fix will be released according to our disclosure policy.
The exploit in this case works in essentially the same way as the “network investigative technique” used by FBI to deanonymize Tor users (as FBI described it in an affidavit). This similarity has led to speculation that this exploit was created by FBI or another law enforcement agency. As of now, we do not know whether this is the case. If this exploit was in fact developed and deployed by a government agency, the fact that it has been published and can now be used by anyone to attack Firefox users is a clear demonstration of how supposedly limited government hacking can become a threat to the broader Web.
https://blog.mozilla.org/security/2016/11/30/fixing-an-svg-animation-vulnerability/
|
|
Robert Helmer: about:addons in React |
While working on tracking down some tricky UI bugs in about:addons, I wondered what it would look like to rewrite it using web technologies. I've been meaning to learn React (which the Firefox devtools use), and it seems like a good choice for this kind of application:
XBL is used for this in the current about:addons, but this is a non-standard Mozilla-specific technology that we want to move away from, along with XUL.
There is quite a bit of code in the current about:addons implementation to deal with undoing various actions. React makes it pretty easy to track this sort of thing through libraries like Redux.
To explore this a bit, I made a simple React version of about:addons. It's actually installable as a Firefox extension which overrides about:addons.
Note that it's just a proof-of-concept and almost certainly buggy - the way it's hooking into the existing sidebar in about:addons needs some work for instance. I'm also a React newb so pretty sure I'm doing it wrong. Also, I've only implemented #1 above so far, as of this writing.
I am finding React pretty easy to work with, and I suspect it'll take far less code to write something equivalent to the current implementation.
|
|
Daniel Glazman: Rest in peace, Opera... |
I think we can now safely say Opera, the browser maker, is no more. My opinions about the acquisition of the browser by a chinese trust were recently confirmed and people are let go or fleeing en masse. Rest in Peace Opera, you brought good, very good things to the Web and we'll miss you.
In fact, I'd love to see two things appear:
http://www.glazman.org/weblog/dotclear/index.php?post/2016/11/30/Rest-in-peace%2C-Opera...
|
|
Cameron Kaiser: 45.5.1 chemspill imminent |
TenFourFox is technically vulnerable to the flaw, but the current implementation is x86-based and tries to attack a Windows DLL, so as written it will merely crash our PowerPC systems. In fact, without giving anything away about the underlying problem, our hybrid-endian JavaScript engine actually reduces our exposure surface further because even a PowerPC-specific exploit would require substantial modification to compromise TenFourFox in the same way. That said, we will still implement the temporary safety fix as well. The bug is a very old one, going back to at least Firefox 4.
Meanwhile, 45.6 is going to be scaled back a little. I was able to remove telemetry from the entire browser (along with its dependencies), and it certainly was snappier in some sections, but required wholesale changes to just about everything to dig it out and this is going to hurt keeping up with the ESR repository. Changes this extensive are also very likely to introduce subtle bugs. (A reminder that telemetry is disabled in TenFourFox, so your data is never transmitted, but it does accumulate internal counters and while it is rarely on a hot codepath there is still non-zero overhead having it around.) I still want to do this but probably after feature parity, so 45.6 has a smaller change where telemetry is instead only removed from user-facing chrome JavaScript. This doesn't help as much but it's a much less invasive change while we're still on source parity with 45ESR.
Also, tests with the "non-volatile" part of IonPower-NVLE showed that switching to all, or mostly, non-volatile registers in the JavaScript JIT compiler had no obvious impact on most benchmarks and occasionally was a small negative. Even changing the register allocator to simply favour non-volatile registers, without removing volatiles, had some small regressions. As it turns out, Ion actually looks pretty efficient with saving volatile registers prior to calls after all and the overhead of having to save non-volatile registers upon entry apparently overwhelms any tiny benefit of using them. However, as a holdover from my plans for NVLE, we've been saving three more non-volatile general purpose registers than we allow the allocator to use; since we're paying the overhead to use them already, I added those unused registers to the allocator and this got us around 1-2% benefit with no regression. That will ship with 45.6 and that's going to be the extent of the NVLE project.
On the plus side, however, 45.6 does have HiDPI support completely removed (because no 10.6-compatible system has a retina display, let alone any Power Mac), which makes the widget code substantially simpler in some sections, and has a couple other minor performance improvements, mostly to scrolling on image-heavy pages, and interface fixes. I also have primitive performance sampling working, which is useful because of a JavaScript interpreter infinite loop I discovered on a couple sites in the wild (and may be the cause of the over-recursion problems I've seen other places). Although it's likely Mozilla's bug and our JIT is not currently implicated, it's probably an endian issue since it doesn't occur on any Tier-1 platform; fortunately, the rough sampler I threw together was successfully able to get a sensible callstack that pointed to the actual problem, proving its functionality. We've been shipping this bug since at least TenFourFox 38, so if I don't have a fix in time it won't hold the release, but I want to resolve it as soon as possible to see if it fixes anything else. I'll talk about my adventures with the mysterious NSSampler in a future post soonish.
Watch for 45.5.1 over the weekend, and 45.6 beta probably next week.
http://tenfourfox.blogspot.com/2016/11/4551-chemspill-imminent.html
|
|
Chris H-C: Privileged to be a Mozillian |
Mike Conley noticed a bug. There was a regression on a particular Firefox Nightly build he was tracking down. It looked like this:

A pretty big difference… only there was a slight problem: there were no relevant changes between the two builds. Being the kind of developer he is, :mconley looked elsewhere and found a probe that only started being included in builds starting November 16.
The plot showed him data starting from November 15.
He brought it up on irc.mozilla.org#telemetry. Roberto Vitillo was around and tried to reproduce, without success. For :mconley the regression was on November 5 and the data on the other probe started November 15. For :rvitillo the regression was on November 6 and the data started November 16. After ruling out addons, they assumed it was the dashboard’s fault and roped me into the discussion. This is what I had to say:

You see, :mconley is in the Toronto (as in Canada) Mozilla office, and Roberto is in the London (as in England) Mozilla office. There was a bug in how dates were being calculated that made it so the data displayed differently depending on your timezone. If you were on or East of the Prime Meridian you got the right answer. West? Everything looks like it happens one day early.
I hammered out a quick fix, which means the dashboard is now correct… but in thinking back over this bug in a post-mortem-kind-of-way, I realized how beneficial working in a distributed team is.
Having team members in multiple timezones not only provided us with a quick test location for diagnosing and repairing the issue, it equipped us with the mindset to think of timezones as a problematic element in the first place. Working in a distributed fashion has conferred upon us a unique and advantageous set of tools, experiences, thought processes, and mechanisms that allow us to ship amazing software to hundreds of millions of users. You don’t get that from just any cube farm.
#justmozillathings
:chutten

https://chuttenblog.wordpress.com/2016/11/29/privileged-to-be-a-mozillian/
|
|
Chris Cooper: RelEng & RelOps highlights - November 29, 2016 |
 Welcome back. As the podiatrist said, lots of exciting stuff is afoot.
Welcome back. As the podiatrist said, lots of exciting stuff is afoot.
Modernize infrastructure:
The big news from the past few weeks comes from the TaskCluster migration project where we now have nightly updates being served for both Linux and Android builds on the Date project branch. If you’re following along in treeherder, this is the equivalent of “tier 2” status. We’re currently working on polish bugs and a whole bunch of verification work before we attempt to elevate these new nightly builds to tier 1 status on the mozilla-central branch, effectively supplanting the buildbot-generated variants. We hope to achieve that goal before the end of 2017. Even tier 2 is a huge milestone here, so cheers to everyone on the team who has helped make this happen, chiefly Aki, Callek, Kim, Jordan, and Mihai.
A special shout-out to Dustin who helped organize the above migration work over the past few months but writing a custom dependency tracking tool. The code is here https://github.com/taskcluster/migration and you can see output here: http://migration.taskcluster.net/ It’s been super helpful!
Improve Release Pipeline:
Many improvements to Balrog were put into production this past week, including one from a new volunteer. Ben blogged about them in detail.
Aki released several scriptworker releases to stabilize polling and gpg homedir creation. scriptworker 1.0.0b1 enables chain of trust verification.
Aki added multi-signing-format capability to scriptworker and signingscript; this is live on the Date project branch.
Aki added a shared scriptworker puppet module, making it easier to add new instance types. https://bugzilla.mozilla.org/show_bug.cgi?id=1309293
Aki released dephash 0.3.0 with pip>=9.0.0 and hashin>=0.7.0 support.
Improve CI Pipeline:
Nick optimized our requests for AWS spot pricing, shaving several minutes off the runtime of the script which launches new instances in response to pending buildbot jobs.
Kim disabled Windows XP tests on trunk, and winxp talos on all branches (https://bugzilla.mozilla.org/show_bug.cgi?id=1310836 and https://bugzilla.mozilla.org/show_bug.cgi?id=1317716) Now Alin is rebalancing the Windows 8 pools so we can enable e10s testing on Windows 8 with the re-imaged XP machines. Recall that Windows XP is moving to the ESR branch with Firefox 52 which is currently on the Aurora/Developer Edition release branch.
Kim enabled Android x86 nightly builds on the Date project branch: https://bugzilla.mozilla.org/show_bug.cgi?id=1319546
Kim enabled SETA on the graphics projects branch to reduce wait times for test machines: https://bugzilla.mozilla.org/show_bug.cgi?id=1319490
Operational:
Rok has deployed the first service based on the new releng microservices architecture. You can find the new version of TryChooser here: https://mozilla-releng.net/trychooser/ More information about the services and framework itself can be found here: https://docs.mozilla-releng.net/
Release:
Firefox 50 has been released. We’re are currently in the beta cycle for Firefox 51, which will be extra long to avoid trying to push out a major version release during the busy holiday season. We are still on-deck to release a minor security release during this period. Everyone involved in the process applauds this decision.
See you next *mumble* *mumble*!
|
|
Mozilla VR Blog: WebVR coming to Servo: Architecture and latency optimizations |

We are happy to announce that the first WebVR patches are landing in Servo.
For the impatients: You can download a highly experimental Servo binary compatible with HTC Vive. Switch on your headset and run servo.exe --resources-path resources webvr\room-scale.html
The current implementation supports the WebVR 1.2 spec that enables the API in contexts other than the main page thread, such as WebWorkers.
We’ve been working hard on an optimized render path for VR to achieve smooth FPS and the required less than 20ms of latency to avoid motion sickness. This is the overall architecture:

The Rust WebVR implementation is a dependency-free library providing both the WebVR spec implementation and the integration with the vendor specific SDKs (OpenVR, Oculus …). Having it decoupled on its own component comes with multiple advantages:
The API is inspired on the easy to use WebVR API but adapted to Rust design patterns. The VRService trait offers an entry point to access native SDKs like OpenVR and Oculus SDK. It allows to perform operations such as initialization, shutdown, event polling and VR Device discovery:
The VRDevice trait provides a way to interact with Virtual Reality headsets:
The integration with vendor specific SDKs (OpenVR, Oculus…) are built on top of the VRService and VRDevice traits. OpenVRService, for instance interfaces with Valve’s OpenVR API. While the code is written in Rust, native SDKs are usually implemented in C or C++. We use Rust FFI and rust-bindgen to generate Rust bindings from the native C/C++ header files.
MockService implements a mock VR device that can be used for testing or developing without having a physical headset available. You will be able to get some code done in the train or while attending a boring talk or meeting ;)
VRServiceManager is the main entry point to the rust-webvr library. It handles the life cycle and interfaces to all available VRService implementations. You can use cargo-features to register the default implementations or manually register your own ones. Here is an example of initialization in a vanilla Rust app:
Performance and security are both top priorities in a Web browser. DOM Objects are allowed to use VRDevices but they neither own them or have any direct pointers to native objects. There are many reasons for this:
The WebVRThread is a trusted component that fulfills all the performance and security requirements. It owns native VRDevices, handles their life cycle inside Servo and acts a doorman for untrusted VR requests from DOM Objects. Thanks to using Rustlang the implementation is guaranteed to be safe because ownership and thread safety rules are checked at compile-time. As other Servo components traits are splitted into a separate subcomponent to avoid cyclic dependencies in Servo.
In a nutshell, the WebVRThread waits for VR Commands from DOM objects and handles them in its trusted thread. This guarantees that there are not data racing conditions when receiving parallel requests from multiple JavaScript tabs. The back and forth communication is done using IPC-Channels. Here is how the main loop is implemented:
Not all VR Commands are initiated in the DOM. The WebVR spec defines some events that are fired when a VR Display is connected, disconnected, activated... The WebVR Thread polls this events from time to time and sends them to JavaScript. This is done using an Event Polling thread which wakes up the WebVRThread by sending a PollEvents message.
The current implementation tries to minimize the use of resources. The event polling thread is only created when there is at least one live JavaScript context using the WebVR APIs and shuts down it when the tab is closed. The WebVR thread is lazy loaded and only initializes the native VRServices the first time a tab uses the WebVR APIs. The WebVR implementation does not introduce any overhead on browser startup or tab creation times.
WebRender handles all the GPU and WebGL rendering work in Servo. Some of the native VR SDK functions need to run in the same render thread to have access to the OpenGL context:
WebVRThread can’t run functions in the WebGL render thread. Webrender is the only component allowed to run functions in the WebGL render thread. The VRCompositor trait is implemented by the WebVRThread using shared VRDevice instance references. It sets up the VRCompositorHandler instance into Webrender when it’s initialized.
A VRDevice instance can be shared via agnostic traits because Webrender is a trusted component too. Rust’s borrow checker enforces multithreading safety rules making very easy to write secure code. A great thing about the language is that it’s also flexible, letting you circumvent the safety rules when performance is the top priority. In our case we use old school raw pointers instead of Arc<> and Mutex<> to share VRdevices between threads in order to optimize the render path by reducing the levels of indirection and locks. Multithreading won’t be a concern in our case because:
To reduce latency we also have to minimize ipc-channel messages. By using a shared memory implementation Webrender is able to call VRCompositor functions directly. VR render calls originated from JavaScript like SubmitFrame are also optimized to minimize latency. When a JavaScript thread gains access to present to a headset, it receives a trusted IPCSender instance that allows to send messages back and forth to the Webrender channel without using WebVRThread as an intermediary. This avoids potential "JavaScript DDoS" attacks by design like a secondary JavaScript tab degrading performance by flooding the WebVRThread with messages while the JavaScript tab that is presenting to the headset.
These are the VR Compositor commands that an active VRDisplay DOM object is able to send to WebRender through the IPC-Channel:
You might wonder why a vector of bytes used to send the VRFrameData. This was a design decision to decouple Webrender and the WebVR implementation. This allows for a quicker pull request cycle and avoids dependency version conflicts. Rust-WebVR and WebVRThread can be updated, even adding new fields to the VRFrameData struct without requiring further changes in Webrender. IPC-Channel messages in Servo need to be serialized using serde-serialization, so the array of bytes is used as forward-serialization solution. Rust-webvr library implements the conversion from VRFrameData to bytes using a fast old school memory transmute memcpy.
DOM Objects are the ones that communicate JavaScript code with native Rust code. They rely on all the components mentioned before:
The first step was to add WebIDL files files in order to auto generate some bindings. Servo requires a separate file for each object defined in WebVR. Code auto generation takes care of a lot of the boilerplate code and lets us focus on the logic specific to the API we want to expose to JavaScript.
A struct definition and trait methods implementation are required for each DOMObject defined in WebIDL files. This is what the struct for the VRDisplay DOMObject looks like:
A struct implementation for a DOMObject needs to follow some rules to ensure that the GC tracing works correctly. It requires interior mutability. The JS
Typed arrays are used in order to share efficiently all the VRFrameData matrices and quaternions with JavaScript. To maximize performance and avoid Garbage Collection issues we added new Rust templates to create and update unique instances of typed arrays. These templates automatically call the correct SpiderMonkey C functions based on the type of a rust slice. This is the API:
The render loop at native headset frame rate is implemented using a dedicated thread. Every loop iteration syncs pose data with the headset, submits the pixels to the display using a shared OpenGL texture and waits for Vsync. It’s optimized to achieve very low latency and a stable frame rate. Both the requestAnimationFrame call of a VRDisplay in the JavaScript thread and the VRSyncPoses call in the Webrender thread are executed in parallel. This allows to get some JavaScript code executed ahead while the render thread is syncing the VRFrameData to be used for the current frame.

The current implementation is able to handle the scenarios where the JavaScript thread calls GetFrameData before the render thread finishes pose synchronization. In that case JavaScript thread waits until the data is available. It also handles the case when JavaScript doesn’t call GetFrameData. When that happens it automatically reads the pending VRFrameData to avoid overflowing the IPC-Channel buffers.
To get the best out of WebVR render path, GetFrameData must be called as late as possible in your JavaScript code and SubmitFrame as soon as possible after calling GetFrameData.
It's been a lot of fun seeing Servo WebVR implementation take shape from the early stage without a WebGL backend until it's able to run WebVR samples at 90 fps and low latency. We found Rustlang to be a perfect language for simplifying the development of a complex parallel architecture while matching the high performance, privacy and memory safety requirements in WebVR. In addition Cargo package manager is great and makes handling optional features and complex dependency trees very straightforward.
For us the next steps will be to implement the GamePad API extensions for tracked controllers and integrate more VR devices while we continue improving the WebVR API performance and stability. Stay tuned!
https://blog.mozvr.com/webvr-servo-architecture-and-latency-optimizations/
|
|
Francois Marier: Persona Guiding Principles |
Given the impending shutdown of Persona and the lack of a clear alternative to it, I decided to write about some of the principles that guided its design and development in the hope that it may influence future efforts in some way.
There was no need for reliers (sites relying on Persona to log their users in) to ask for permission before using Persona. Just like a site doesn't need to ask for permission before creating a link to another site, reliers didn't need to apply for an API key before they got started and authenticated their users using Persona.
Similarly, identity providers (the services vouching for their users identity) didn't have to be whitelisted by reliers in order to be useful to their users.
Just like email, Persona was federated at the domain name level and put domain owners in control. Just like they can choose who gets to manage emails for their domain, they could:
Site owners were also in control of the mechanism and policies involved in authenticating their users. For example, a security-sensitive corporation could decide to require 2-factor authentication for everyone or put a very short expiry on the certificates they issued.
Alternatively, a low-security domain could get away with a much simpler login mechanism (including a "0-factor" mechanism in the case of http://mockmyid.com!).
While identity providers were the ones vouching for their users' identity, they didn't need to know the websites that their users are visiting. This is a potential source of control or censorship and the design of Persona was able to eliminate this.
The downside of this design of course is that it becomes impossible for an identity provider to provide their users with a list of all of the sites where they successfully logged in for audit purposes, something that centralized systems can provide easily.
The browser, whether it had native support for the BrowserID protocol or not, was the agent that the user needed to trust. It connected reliers (sites using Persona for logins) and identity providers together and got to see all aspects of the login process.
It also held your private keys and therefore was the only party that could impersonate you. This is of course a power which it already held by virtue of its role as the web browser.
Additionally, since it was the one generating and holding the private keys, your browser could also choose how long these keys are valid and may choose to vary that amount of time depending on factors like a shared computer environment or Private Browsing mode.
Other clients/agents would likely be necessary as well, especially when it comes to interacting with mobile applications or native desktop applications. Each client would have its own key, but they would all be signed by the identity provider and therefore valid.
Persona was a complex system which involved a number of different actors. In order to slowly roll this out without waiting on every actor to implement the BrowserID protocol (something that would have taken an infinite amount of time), fallbacks were deemed necessary:
In addition, to lessen the burden on the centralized identity provider fallback, Persona experimented with a number of bridges to provide quasi-native support for a few large email providers.
User research has shown that many users choose to present a different identity to different websites. An identity system that would restrict them to a single identity wouldn't work.
Persona handled this naturally by linking identities to email addresses. Users who wanted to present a different identity to a website could simply use a different email address. For example, a work address and a personal address.
Persona was an identity system which didn't stand between a site and its users. It exposed email address to sites and allowed them to control the relationship with their users.
Sites wanting to move away from Persona can use the email addresses they have to both:
Websites should not have to depend on the operator of an identity system in order to be able to talk to their users.
Instead of relying on the correct use of revocation systems, Persona used short-lived certificates in an effort to simplify this critical part of any cryptographic system.
It offered three ways to limit the lifetime of crypto keys:
The main drawback of such a pure expiration-based system is the increased window of time between a password change (or a similar signal that the user would like to revoke access) and the actual termination of all sessions. A short expirty can mitigate this problem, but it cannot be eliminated entirely unlike in a centralized identity system.
http://feeding.cloud.geek.nz/posts/persona-guiding-principles/
|
|
Nathan Froyd: accessibility tools for everyone |
From The Man Who Is Transforming Microsoft:
[Satya Nadella] moves to another group of kids and then shifts his attention to a teenage student who is blind. The young woman has been working on building accessibility features using Cortana, Microsoft’s speech-activated digital assistant. She smiles and recites the menu options: “Hey Cortana. My essentials.” Despite his transatlantic jet lag Nadella is transfixed. “That’s awesome,” he says. “It’s fantastic to see you pushing the boundaries of what can be done.” He thanks her and turns toward the next group.
“I have a particular passion around accessibility, and this is something I spend quite a bit of cycles on,” Nadella tells me later. He has two daughters and a son; the son has special needs. “What she was showing me is essentially how she’s building out as a developer the tools that she can use in her everyday life to be productive. One thing is certain in life: All of us will need accessibility tools at some point.”
https://blog.mozilla.org/nfroyd/2016/11/29/accessibility-tools-for-everyone/
|
|
David Lawrence: Happy BMO Push Day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.

https://dlawrence.wordpress.com/2016/11/29/happy-bmo-push-day-30/
|
|
Mike Hommey: Announcing git-cinnabar 0.4.0 release candidate |
Git-cinnabar is a git remote helper to interact with mercurial repositories. It allows to clone, pull and push from/to mercurial remote repositories, using git.
These release notes are also available on the git-cinnabar wiki.
git cinnabar download command to download a helper on platforms where one is available.And since I realize I didn’t announce beta 3:
|
|
The Mozilla Blog: The Glass Room: Looking into Your Online Life |
It’s that time of year! The excitement of Black Friday carries into today – CyberMonday – the juxtaposition of the analog age and the digital age. Both days are fueled by media and retailers alike and are about shopping. And both days are heavily reliant on the things that we want, that we need and what we think others want and need. And, all of it is powered by the data about us as consumers. So, today – the day of electronic shopping – is the perfect day to provoke some deep thinking on how our digital lives impact our privacy and online security. How do we do this?
One way is by launching “The Glass Room” – an art exhibition and educational space that teaches visitors about the relationship between technology, privacy and online security. The Glass Room will be open in downtown New York City for most of the holiday shopping season. Anyone can enter the “UnStore” for free to get a behind the scenes look at what happens to your privacy online. You’ll also get access to a crew of “InGeniouses” who can help you with online privacy and data tips and tricks. The Glass Room has 54 interactive works that show visitors the relationship between your personal data and the technology services and products you use.

This is no small task. Most of us don’t think about our online security and privacy every day. As with our personal health it is important but presumed. Still, when we don’t take preventative care of ourselves, we are at greater risk for getting sick.
The same is true online. We are impacted by security and privacy issues everyday without even realizing it. In the crush of our daily lives, few of us have the time to learn how to better protect ourselves and preserve our privacy online. We don’t always take enough time to get our checkups, eat healthily and stay active – but we would be healthier if we did. We are launching The Glass Room to allow you to think, enjoy and learn how to do a checkup of your online health.
We can buy just about anything we imagine on CyberMonday and have it immediately shipped to our door. We have to work a little harder to protect our priceless privacy and security online. As we collectively exercise our shopping muscles, I hope we can also think about the broader importance of our online behaviors to maintaining our online health.
If you are in New York City, please come down to The Glass Room and join the discussion. You can also check out all the projects, products and stories that The Glass Room will show you to look into your online life from different perspectives by visiting The Glass Room online.
https://blog.mozilla.org/blog/2016/11/28/the-glass-room-looking-into-your-online-life/
|
|
Seif Lotfy: Rustifying IronFunctions |
As mentioned in my previous blog post there is new open-source, lambda compatible, on-premise, language agnostic, server-less compute service called IronFunctions.
![]()
While IronFunctions is written in Go. Rust is still very much admired language and it was decided to add support for it in the fn tool.
So now you can use the fn tool to create and publish functions written in rust.
The easiest way to create a iron function in rust is via cargo and fn.
First create an empty rust project as follows:
$ cargo init --name func --bin
Make sure the project name is func and is of type bin. Now just edit your code, a good example is the following "Hello" example:
use std::io;
use std::io::Read;
fn main() {
let mut buffer = String::new();
let stdin = io::stdin();
if stdin.lock().read_to_string(&mut buffer).is_ok() {
println!("Hello {}", buffer.trim());
}
}
You can find this example code in the repo.
Once done you can create an iron function.
$ fn init --runtime=rust /
in my case its fn init --runtime=rust seiflotfy/rustyfunc, which will create the func.yaml file required by functions.
$ fn build
Will create a docker image
You can run this locally without pushing it to functions yet by running:
$ echo Jon Snow | fn run
Hello Jon Snow
In the directory of your rust code do the following:
$ fn publish -v -f -d ./
This will publish you code to your functions service.
Now to call it on the functions service:
$ echo Jon Snow | fn call seiflotfy rustyfunc
which is the equivalent of:
$ curl -X POST -d 'Jon Snow' http://localhost:8080/r/seiflotfy/rustyfunc
In the next post I will be writing a more computation intensive rust function to test/benchmark IronFunctions, so stay tune :D
|
|
William Lachance: Training an autoclassifier |
Here at Mozilla, we’ve accepted that a certain amount of intermittent failure in our automated testing of Firefox is to be expected. That is, for every push, a subset of the tests that we run will fail for reasons that have nothing to do with the quality (or lack thereof) of the push itself.
On the main integration branches that developers commit code to, we have dedicated staff and volunteers called sheriffs who attempt to distinguish these expected failures from intermittents through a manual classification process using Treeherder. On any given push, you can usually find some failed jobs that have stars beside them, this is the work of the sheriffs, indicating that a job’s failure is “nothing to worry about”:

This generally works pretty well, though unfortunately it doesn’t help developers who need to test their changes on Try, which have the same sorts of failures but no sheriffs to watch them or interpret the results. For this reason (and a few others which I won’t go into detail on here), there’s been much interest in having Treeherder autoclassify known failures.
We have a partially implemented version that attempts to do this based on structured (failure line) information, but we’ve had some difficulty creating a reasonable user interface to train it. Sheriffs are used to being able to quickly tag many jobs with the same bug. Having to go through each job’s failure lines and manually annotate each of them is much more time consuming, at least with the approaches that have been tried so far.

It’s quite possible that this is a solvable problem, but I thought it might be an interesting exercise to see how far we could get training an autoclassifier with only the existing per-job classifications as training data. With some recent work I’ve done on refactoring Treeherder’s database, getting a complete set of per-job failure line information is only a small SQL query away:
1 2 3 4 5 |
select bjm.id, bjm.bug_id, tle.line from bug_job_map as bjm left join text_log_step as tls on tls.job_id = bjm.job_id left join text_log_error as tle on tle.step_id = tls.id where bjm.created > '2016-10-31' and bjm.created < '2016-11-24' and bjm.user_id is not NULL and bjm.bug_id is not NULL order by bjm.id, tle.step_id, tle.id; |
Just to give some explanation of this query, the “bug_job_map” provides a list of bugs that have been applied to jobs. The “text_log_step” and “text_log_error” tables contain the actual errors that Treeherder has extracted from the textual logs (to explain the failure). From this raw list of mappings and errors, we can construct a data structure incorporating the job, the assigned bug and the textual errors inside it. For example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "bug_number": 1202623, "lines": [ "browser_private_clicktoplay.js Test timed out -", "browser_private_clicktoplay.js Found a tab after previous test timed out: http:/ |
Some quick google searching revealed that scikit-learn is a popular tool for experimenting with text classifications. They even had a tutorial on classifying newsgroup posts which seemed tantalizingly close to what we needed to do here. In that example, they wanted to predict which newsgroup a post belonged to based on its content. In our case, we want to predict which existing bug a job failure should belong to based on its error lines.
There are obviously some differences in our domain: test failures are much more regular and structured. There are lots of numbers in them which are mostly irrelevant to the classification (e.g. the “expected 12 pixels different, got 10!” type errors in reftests). Ordering of failures might matter. Still, some of the techniques used on corpora of normal text documents for training a classifier probably map nicely onto what we’re trying to do here: it seems plausible that weighting words which occur more frequently less strongly against ones that are less common would be helpful, for example, and that’s one thing their default transformers does.
In any case, I built up a small little script to download a subset of the downloaded data (from November 1st to November 23rd), used it as training data for a classifier, then tested that against another subset of test failures between November 24th and 28th.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import os from sklearn.datasets import load_files from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from sklearn.linear_model import SGDClassifier training_set = load_files('training') count_vect = CountVectorizer() X_train_counts = count_vect.fit_transform(training_set.data) tfidf_transformer = TfidfTransformer() X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts) clf = SGDClassifier(loss='hinge', penalty='l2', alpha=1e-3, n_iter=5, random_state=42).fit(X_train_tfidf, training_set.target) num_correct = 0 num_missed = 0 for (subdir, _, fnames) in os.walk('testing/'): if fnames: bugnum = os.path.basename(subdir) print bugnum, fnames for fname in fnames: doc = open(os.path.join(subdir, fname)).read() if not len(doc): print "--> (skipping, empty)" X_new_counts = count_vect.transform([doc]) X_new_tfidf = tfidf_transformer.transform(X_new_counts) predicted_bugnum = training_set.target_names[clf.predict(X_new_tfidf)[0]] if bugnum == predicted_bugnum: num_correct += 1 print "--> correct" else: num_missed += 1 print "--> missed (%s)" % predicted_bugnum print "Correct: %s Missed: %s Ratio: %s" % (num_correct, num_missed, num_correct / float(num_correct + num_missed)) |
With absolutely no tweaking whatsoever, I got an accuracy rate of 75% on the test data. That is, the algorithm chose the correct classification given the failure text 1312 times out of 1959. Not bad for a first attempt!
After getting that working, I did some initial testing to see if I could get better results by reusing some of the error ETL summary code in Treeherder we use for bug suggestions, but the results were pretty much the same.
So what’s next? This seems like a wide open area to me, but some initial areas that seem worth exploring, if we wanted to take this idea further:
If you’d like to experiment with the data and/or code, I’ve put it up on a github repository.
https://wlach.github.io/blog/2016/11/training-an-autoclassifier/?utm_source=Mozilla&utm_medium=RSS
|
|
Mike Hoye: Planet: A Minor Administrative Note |
I will very shortly be adding some boilerplate to the Planet homepage as well as the Planet.m.o entry on Wikimo, to the effect that:
All of this was true before, but we’re going to highlight it on the homepage and make it explicit in the wiki; we want Planet to stay what it is, open, participatory, an equal and accessible platform for everyone involved, but we also don’t want Planet to become an attack surface, against Mozilla or anyone else, and won’t allow that to happen out of willful blindness or neglect.
If you’ve got any questions or concerns about this, feel free to leave a comment or email me.
http://exple.tive.org/blarg/2016/11/28/planet-a-minor-administrative-note/
|
|






