Air Mozilla: The Joy of Coding - Episode 70 |
 mconley livehacks on real Firefox bugs while thinking aloud.
mconley livehacks on real Firefox bugs while thinking aloud.
|
|
Air Mozilla: Weekly SUMO Community Meeting Sept 7, 2016 |
 This is the sumo weekly call
This is the sumo weekly call
https://air.mozilla.org/weekly-sumo-community-meeting-sept-7-2016/
|
|
Matej Cepl: StartSSL customers, it is time to leave. Now! |
While listening to the Security Now podcast, I have listened first with amusement then with horror to Steve reading email from Mozilla about the security problems with WoSign CA.
Their list of woes is long, read the linked email for details, but one thing turned up during the email which I was not aware of: StartCom (owner of the StartSSL certificate authority) was apparently recently bought by WoSign CA! Apparently one of the security bugs StartSSL has (had?) was that with properly modified POST request (yes, I guess you can do it in the Developer Tools of your Firefox) you can get certificate linked to the root ceritificate “CA
https://matej.ceplovi.cz/blog/startssl-customers-it-is-time-to-leave-now.html
|
|
Cameron Kaiser: System7SoonToBeYesterday |
The only Macs I have still running System 7 are all running 7.1 (not counting the NetBSD 68K systems, which just use System 7 as a bootloader): one is my IIci with a 50MHz DayStar '030 and a MacIvory Lisp card, another is my recapped SE/30 looking for a job to do, and the last is my super-cute Mystic Color Classic. I like 7.1 a lot more than 7.5 or 7.6, and you can transplant lots of the 7.5 CDEVs and such back to 7.1 for a slimmer but still feature-filled experience. That said, I have to confess that I jumped to OS 8, and then OS 9, whenever I got the chance on my Power Macs. Part of this was that I upgraded those systems aggressively -- all of my Old World Power Macs in regular use have G3 or G4 upgrade cards, including my beloved PowerBook 1400, so they all run 9.1 or 9.2.2 -- and part of it is to run Classilla, but the biggest reason was just that OS 8 looked nicer and felt better, and 8.1 and 8.6 were still pretty speedy. I still run OS 8 on my PowerBook 2300c and Quadra 800.
But still, nostalgia dies hard. (No doubt being a TenFourFox user, you'd empathize.) While I've got lots of classic System 7-era software backed up for posterity on the Floodgap gopher server, it just doesn't have System7Today's throwback vibe and playful attitude. I'll miss it dearly pending its inevitable slow-motion decommissioning, most of all because it remains a great example of doing the most you can with the little you've got. Typing this blog post on a 2002-vintage 1GHz iMac G4, us PowerPC holdouts are still living in that spirit today.
Watch for 45.4 later this week(end).
http://tenfourfox.blogspot.com/2016/09/system7soontobeyesterday.html
|
|
Mike Taylor: Goosebumps! empty img src error events in Firefox |
It's almost Septemberween, which means it's that time of the year we gather 'round our spinning MacBook fans and share website ghost stories:
The tale of the disappearing burger and lobster site content (i.e., webcompat bug 2760).
Once upon a time (that time being the present), there was this burger and lobster "restaurant" called, um well, burger and lobster. In Firefox, as of today, the site content never renders — you just end up with some fancy illustrations (none of which are burgers or lobsters).
Opening devtools, you've got the following mysterious stacktrace:
Error: node is undefined
compositeLinkFn@http://www.burgerandlobster.../angular-1.2.25.js:6108:13
compositeLinkFn@http://www.burgerandlobster.../angular-1.2.25.js:6108:13
nodeLinkFn@http://www.burgerandlobster.../angular-1.2.25.js:6705:24
(...stack frames descend into hell...)
jQuery@http://www.burgerandlobster.../jquery-1.11.1.js:73:10
@http://www.burgerandlobster.../jquery-1.11.1.js:3557:1
@http://www.burgerandlobster.../jquery-1.11.1.js:34:3
@http://www.burgerandlobster.../jquery-1.11.1.js:15:2
Cool, time to debug AngularJS.
But it turns out that leads nowhere besides the abyss, AKA funtions that return functions that compose with other functions with dollar signs in them... and the bug is elsewhere. Besides, Chrome has a similar error, and the page works there. Just a haunted node, maybe.
Dennis Schubert discovered that adding a fixes the site, which happens to be required by Angular is later versions for $locationProvider.html5Mode. But this bug has nothing to do with pushState or history, or even SVG xlink:hrefs, all of which the element can affect.
Another (dead) rabbit hole, another dead end (spooky).
At some point, all your debugging tricks and intuitions fail and it's time to just page a thousand lines of framework-specific JS into your brain and see where that leads. Two hours later, if you're lucky, you notice something weird like so:
var illustArr = [
{
"url": "/Assets/images/illustrations/alert-man.png",
"x": "2508",
"y": "2028"
},
...
(bunch of similar objects objects, then...)
{
"url": "",
"x": "",
"y": ""
};
And you recall a method that dispatches a allImagesLoaded event which tells the app it's OK to load the rest of the page content. It looks like this:
b.allImagesLoaded = function() {
d += 1,
d === a.imageArr.length && $("body").trigger("allImagesLoaded")
}
But it only does that once it's counted that all images have loaded (or fired an error event):
l.loadImage = function(a) {
var b = $(document.createElement("div"))
, c = $(document.createElement("img"));
[...]
c.attr("src", a.url),
[...]
c.bind("load error", function(e) {
$(this).addClass("illustration--show"),
h.allImagesLoaded()
})
}
So yeah, that looks fishy. And that's why Firefox gets stuck—it doesn't fire error events when img.src is set to the empty string, which is required per HTML. Here's a small test case, which also demonstrates why the fixed the page—it'll fire an error event when requesting an image from the site root (and eventually barf on the HTML, I guess).
Anyways, the Gecko bug for that is Bug 599975. That will probably get fixed soon.
So what's the moral of this ghost story? There is none. Septemberween is cruel that way.
https://miketaylr.com/posts/2016/09/empty-img-src-error-events.html
|
|
Michael Kohler: Mozilla Switzerland – Community Meetup June 2016 |
On June 20th the Swiss Mozillians met in Zurich to discuss the second half of the year. The goal was to come up with objectives for mozilla.ch that are aligned with the current Mozilla strategy and the Participation Team and Mozilla Reps goals.
![]()
At first we did a retrospective, here are the key results:
What should we stop doing?
What should we start doing?
What should we continue doing?
With that in mind, we came up with two objectives. Both are aligned with overall Mozilla strategy pieces. The first one is Core Strength, the second one is Prototyping the Future. None of these Key Results are easy to achieve, but we think that with these we can achieve a good base for the upcoming years.
Objective 1: Grow our core contributor strengths and be amazing at being visible in Switzerland
Objective 2: We are a driver in prototyping Firefox for the future
What do you find intriguing? What would you like to know more about? Jump into a discussion on Discourse or participate in our GitHub Participation issue repository.
https://michaelkohler.info/2016/mozilla-switzerland-community-meetup-june-2016
|
|
Air Mozilla: Webdev Extravaganza: September 2016 |
 Once a month web developers across the Mozilla community get together (in person and virtually) to share what cool stuff we've been working on. This...
Once a month web developers across the Mozilla community get together (in person and virtually) to share what cool stuff we've been working on. This...
|
|
Ben Hearsum: Platform Operations Project of the Month: Balrog |
Hello from Platform Engineering Ops! Once a month we highlight one of our projects to help the Mozilla community discover a useful tool or an interesting contribution opportunity. This month's project is Balrog!
Balrog is the software that runs the server side component of the update system used by Firefox and other Mozilla products. It is the successor to AUS (Application Update Service), which did not scale to our current needs nor allow us to adapt to more recent business requirements. Balrog helps us ship updates faster and with much more flexibility than we've had in the past.
At the heart of Balrog is its Rules table. The Rules allow us to filter incoming update requests by their product, channel, and other fields and using that information, respond with the correct Release. One of the key design goals of Balrog is to make these Rules easy for humans to understand and manipulate, while providing enough flexibility to meet business requirements.
Releases are the other major part of Balrog. These are models that contain metadata (platforms, locales, payload URLs, etc.) about a set of binaries that we ship (eg: Firefox 49.0).
You can learn more about Balrog's architecture and how it works on the main wiki page.
Earlier this year we modernized Balrog's toolchain, and it's now in a place where anyone with Python or JS experience should be able to contribute succesfully. Balrog has excellent unit test coverage, which will help you give confidence in any changes you make.
If you have Docker installed already, you can play with it with a few simple commands:
git clone https://github.com/mozilla/balrog cd balrog git submodule init git submodule update docker-compose up
Once running, you can access the admin interface at http://localhost:8080. You should see a splash page like this:
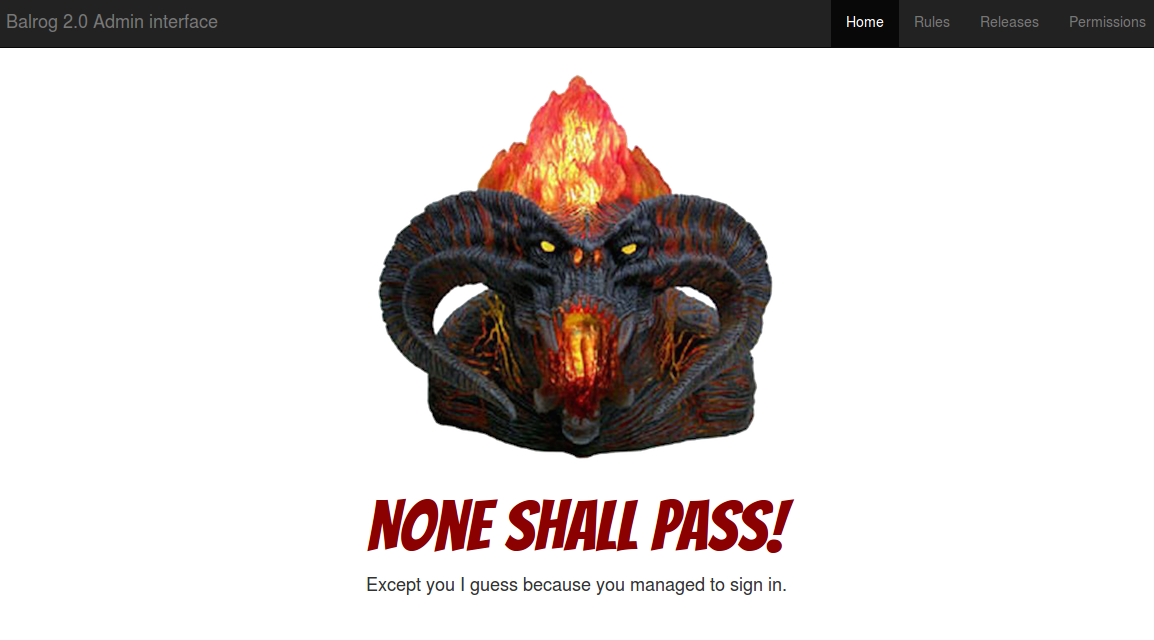
We do our best to always have good first bugs ready for new contributors. Here's a few of the current ones (you can find the rest on the wiki):
If you have any questions or need help you're welcome to join us in #balrog on irc.mozilla.org - we're happy to help!
http://hearsum.ca/blog/platform-operations-project-of-the-month-balrog.html
|
|
Mozilla Reps Community: Rep of the Month – August 2016 |
Please join us in congratulating Prathamesh Chavan, Rep of the Month for August 2016!

Prathamesh is an extremely active and super energetic Mozillian of the Indian community. He has successfully led several different events and shown unbelievable leadership skills. One of the most recent examples of his untiring energy was the Mozilla India Community meetup 2016. His skills at managing all the logistical work for such a huge event was a pleasant surprise for all the organizers and senior members of the community.
Prathamesh is famous of going around with a viral smile. If ever asked to do some work, he does it with a smile and also makes sure that the smile virus is perfectly passed on to you…leaving you smiling as well. Prathamesh is a strong supporter of the Open Web and believes that everyone deserves to have access to it. With this thought in mind, Prathamesh also initiated the MILE project here in the Indian community. The purpose of the MILE project is to teach the basics of web to the less fortunate section of our society.
Please join us in congratulating him on Discourse!
https://blog.mozilla.org/mozillareps/2016/09/06/rep-of-the-month-august-2016/
|
|
Daniel Stenberg: My first 20 years of HTTP |
During the autumn 1996 I took my first swim in the ocean known as HTTP. Twenty years ago now.
I had previously worked with writing an IRC bot in C, and IRC is a pretty simple text based protocol over TCP so I could use some experiences from that when I started to look into HTTP. That IRC bot was my first real application distributed to the world that was using TCP/IP. It was portable to most unixes and Amiga and it was open source.
1996 was the year the movie Independence Day premiered and the single hit song that plagued the world more than others that year was called Macarena. AOL, Webcrawler and Netscape were the most popular websites on the Internet. There were less than 300,000 web sites on the Internet (compared to some 900 million today).
I decided I should spice up the bot and make it offer a currency exchange rate service so that people who were chatting could ask the bot what 200 SEK is when converted to USD or what 50 AUD might be in DEM. – Right, there was no Euro currency yet back then!
I simply had to fetch the currency rates at a regular interval and keep them in the same server that ran the bot. I just needed a little tool to download the rates over HTTP. How hard can that be? I googled around (this was before Google existed so that was not the search engine I could use!) and found a tool named ‘httpget’ that made pretty much what I wanted. It truly was tiny – a few hundred  lines of code.
lines of code.
I don’t have an exact date saved or recorded for when this happened, only the general time frame. You know, we had no smart phones, no Google calendar and no digital cameras. I sported my first mobile phone back then, the sexy Nokia 1610 – viewed in the picture on the right here.
The HTTP/1.0 RFC had just recently came out – which was the first ever real spec published for HTTP. RFC 1945 was published in May 1996, but I was blissfully unaware of the youth of the standard and I plunged into my little project. This was the first published HTTP spec and it says:
HTTP has been in use by the World-Wide Web global information initiative since 1990. This specification reflects common usage of the protocol referred too as "HTTP/1.0". This specification describes the features that seem to be consistently implemented in most HTTP/1.0 clients and servers.
Many years after that point in time, I have learned that already at this time when I first searched for a HTTP tool to use, wget already existed. I can’t recall that I found that in my searches, and if I had found it maybe history would’ve made a different turn for me. Or maybe I found it and discarded for a reason I can’t remember now.
I wasn’t the original author of httpget; Rafael Sagula was. But I started contributing fixes and changes and soon I was the maintainer of it. Unfortunately I’ve lost my emails and source code history from those earliest years so I cannot easily show my first steps. Even the oldest changelogs show that we very soon got help and contributions from users.
The earliest saved code archive I have from those days, is from after we had added support for Gopher and FTP and renamed the tool ‘urlget’. urlget-3.5.zip was released on January 20 1998 which thus was more than a year later my involvement in httpget started.
The original httpget/urlget/curl code was stored in CVS and it was licensed under the GPL. I did most of the early development on SunOS and Solaris machines as my first experiments with Linux didn’t start until 97/98 something.

The first web page I know we have saved on archive.org is from December 1998 and by then the project had been renamed to curl already. Roughly two years after the start of the journey.
RFC 2068 was the first HTTP/1.1 spec. It was released already in January 1997, so not that long after the 1.0 spec shipped. In our project however we stuck with doing HTTP 1.0 for a few years longer and it wasn’t until February 2001 we first started doing HTTP/1.1 requests. First shipped in curl 7.7. By then the follow-up spec to HTTP/1.1, RFC 2616, had already been published as well.
The IETF working group called HTTPbis was started in 2007 to once again refresh the HTTP/1.1 spec, but it took me a while until someone pointed out this to me and I realized that I too could join in there and do my part. Up until this point, I had not really considered that little me could actually participate in the protocol doings and bring my views and ideas to the table. At this point, I learned about IETF and how it works.
I posted my first emails on that list in the spring 2008. The 75th IETF meeting in the summer of 2009 was held in Stockholm, so for me still working on HTTP only as a spare time project it was very fortunate and good timing. I could meet a lot of my HTTP heroes and HTTPbis participants in real life for the first time.
I have participated in the HTTPbis group ever since then, trying to uphold the views and standpoints of a command line tool and HTTP library – which often is not the same as the web browsers representatives’ way of looking at things. Since I was employed by Mozilla in 2014, I am of course now also in the “web browser camp” to some extent, but I remain a protocol puritan as curl remains my first “child”.
https://daniel.haxx.se/blog/2016/09/06/my-first-20-years-of-http/
|
|
Karl Dubost: Figuring out viewport differences in between Gecko, Blink and WebKit |
We had a couple of Web Compatibility issues on the rendering of some sites related to the viewport information. Here after is a preliminary test for trying to figure out what are the sources of variability.
The major visible difference is only for the last case where Firefox and Chrome do something different.
initial-scale=0I haven't tested all combinations yet. Just a couple to have an idea. This is preliminary work to figure out the Web Compatibility space.
Maybe I can adjust tests in the future.
case A and case F below seems to highlight differences in between Gecko and Blink. Chrome seems to apply different logic for resizing the content.
Using this page instrospection tool
window.innerWidth = 320 window.outerWidth = 0 window.screen.width = 320 document.documentElement.clientWidth = 320 window.devicePixelRatio = 2
window.innerWidth = 360 window.outerWidth = 360 window.screen.width = 360 document.documentElement.clientWidth = 360 window.devicePixelRatio = 3
window.innerWidth = 360 window.outerWidth = 360 window.screen.width = 360 document.documentElement.clientWidth = 360 window.devicePixelRatio = 3
width=250 with 700px paragraphwidth=250 with free width paragraphwidth=450 with 700px paragraphwidth=450 with free width paragraph700px paragraph700px paragraph

















Otsukare!
http://www.otsukare.info/2016/09/06/viewport-differences-mobile
|
|
Mozilla Reps Community: RepsNext: introducing the Review Team |
TL;DR As part of the RepsNext a group of experienced Reps has been assembled to improve Reps resource request cycle times. This will enable all Reps to have more impact. This group, called the Review Team, will review bugs as of Monday the 5th of September.
It all started when we were working on the the future of the Reps program (also known as RepsNext). We realized that resources are a crucial part of the Program. In the past our budget process had been going extremely fast and easy. Unfortunately, it has slowed down due to multiple factors: 1) the program had grown but processes were not scaled appropriately, 2) Reps were not providing enough information on their initiatives, 3) mentors and council were not reviewing budgets on time, and 4) people were focused mainly on decreasing cost instead of maximizing impact.
Those factors created a lot of frustration across the program and disengagement among Reps. We also identified that we wanted to move away from just an events program to a program that would enable Reps to have all the resources needed (hardware, budget, helping documents, guidance on where to focus their energy) in order to have greater impact in their community. We want Reps to be able to do more and not constrain them. For that reason we’ve created the Resources Working Group.
After the Working Groups were formed, we’ve started having meetings on early February, 2016. The conversations were long and impactful and involved both Reps and Council members.
The following decisions were made:
If you want to see how was the whole progress of the group, you could find more about it here
On the Reps Council and Peers Meeting held in April 2016 in Berlin we decided that we will implement our decisions step by step. First, we introduce the Review Team replacing the council for bug review. Then, we gradually start the training for our Resources Reps.

Reps and Peers meeting in Berlin, 2016. Photo credits to C. Bacharakis
In the London All Hands (June 2016) the council has agreed on onboarding 5 experienced Reps along with 1 employee and 1 council member on taking the responsibility to be part of the first Review team. You can find more about their selection criteria and responsibilities on this github issue.
The Review Team will be assembled from the following people:

The Review Team
The Review Team won’t take full responsibilities at once. Instead, there will be a 4 weeks transition period, where the Review Team will be coached by the council in order to better understand the needs of the program and effectively review the budget bugs.
For the first 2 weeks, the Review Team will follow all the upcoming budget requests by giving feedback as an advisor reviewer. For the next 2 weeks, the roles will be reversed: the Review Team will be the primary reviewers with the Council taking a supportive role. This transition period will start this Monday September the 5th.
Of course, we need to understand if our assumption of forming the Review Team will help us reduce cycle times in the program. For that reason, we will track approval time for budgets via bugzilla and how satisfied are our Reps with the new decision (via sending out feedback surveys to all our Reps).
Moreover, we will continue investing in the Reps Resources by working on the training for the Reps that want to join the track.
I am really happy for all the changes that have been made and more excited for what’s to come.
Special thanks to all the people who volunteered on contributing to this crucial domain
https://blog.mozilla.org/mozillareps/2016/09/05/repsnext-introducing-the-review-team/
|
|
Wladimir Palant: Easy Passwords moving forward - filling in user names |
My colleague Dave Barker is pushing me towards making Easy Passwords a full-featured LastPass alternative. Given the LastPass security vulnerabilities that were published recently and the ones I am about to publish myself soon I cannot really blame him. Getting there will take a while but we’ve reached an important milestone on the way: with Easy Passwords 1.1.0 user names will now be filled in automatically as well, so for most login forms you won’t need to type anything at all any more. Implementing this feature in a user-friendly way was more complicated than it sounds, if you are interested you can see the iteration process we went through in the corresponding issue.
Now that this is out of the way the next steps are:
Currently, Easy Passwords supports desktop browsers only (Firefox, Chrome, Opera, in future most likely Edge as well). Ideally, it would work with mobile browsers as well but mobile browsers aren’t exactly famous for being extensible, with Firefox on Android being the only exception. One idea is wrapping up something similar to the online version of Easy Passwords as an Android extension, albeit with sync functionality so that the right password could be selected from the list instead of replicating all of its parameters. It would still require typing the website name manually (not secure against phishing pages) and copying password to clipboard (not very convenient) however. Also, as I don’t need this functionality personally I’m not very likely to spend time developing it, so anybody is welcome to volunteer.
https://palant.de/2016/09/05/easy-passwords-moving-forward-filling-in-user-names
|
|
Karl Dubost: [worklog] Edition 034. A lot of triage |
Sometimes you just need to clean up the bottom of this drawer where bugs have accumulated and gathered dust. But by the end of it, it brings light to your work and process. Tune of the week: Jamiroquai - Cosmic Girl
Progress this week:
Today: 2016-09-05T08:10:37.674672 312 open issues ---------------------- needsinfo 9 needsdiagnosis 93 needscontact 17 contactready 31 sitewait 148 ----------------------
You are welcome to participate
(a selection of some of the bugs worked on this week).
input type='number' and its implementations.|
|
Shing Lyu: 2016 COSCUP, Modern Web and Taiwan Code Sprint |
August was quite a busy month for me. I went to two conferences and one workshop to promote Servo and Rust. Here are what I’ve observed in those events.
COSCUP is one of the largest volunteer-organized conference on open source software in Taiwan. When I was a student I tried to attend all the sessions, wishing to learn from the talks. But in recent years I realize that it’s really not about the talks, but more about meeting people. Half of the talks are about introducing people to new tools or libraries. You can learn them by yourself more efficiently by reading tutorial articles online. The most rewarding part is actually socializing with people. Because most of the open source participants will attended this conference, you can easily meet a lot of new friends through mutual friends. So this year I spend most of my time at social events, for example the speaker dinner party, Mozilla BoF (bird of a feather), and chatting with my friend’s friends.
But I still listened to quite a few interesting sessions. This year’s talk (schedule) has a high percentage of Internet of Things talk. But they are still fundamental programming stuff like Linux kernel and LLVM. There are also a lot of presence of Mozilla-related topics: connected devices projects like Webby End SensorWeb, Bob Chao’s talk on Mozilla Community Space Project, and Gary Kwong talked about fuzzy testing in the Unconf. We also have a booth for Mozilla, in which we show off the Taiwan community. I also attended the BoF and had a nice chat with the community. My talk also went pretty well, I’ll talk more about them later.
Overall it was a nice event. I meant a lot of old and new friends, including two or three people approaching me saying that they want to contribute to Servo. The atmosphere is pretty relaxed, it feels more like an open source community reunion than a technical conference. One of the best idea I saw in the conference is the souvenir sticker collection book. This solves a huge problem we tech geeks have: having too many stickers but too little laptop surface area.
The second conference I attended is the Modern Web Conference hosted by iThome, a technical publisher in Taiwan. The conference is much more expensive (~$200 USD) so the logistics are better. Each room has a dedicated AV team which handles the projector, audio and video recording. A good arrangement is that after a talk, the speaker can move to a Q&A space outside the meeting room, so people can ask follow-up questions without blocking the next session. They also have a cool Dojo booth, you can get a 15 minute hands-On tutorial on topics like frontend testing and responsive CSS design, etc.
The hottest topics in the conference is React.js and React Native. A lot of companies are trying to merge their frontend and Android/iOS app team, to encourage code sharing and create a unified experience across platforms. To my surprise, most them are pretty satisfied with the solution, I believe that’s partially because for most of them, the app is not the most critical factor in their business. They just want to have some presence in every platform, so having one or two taking care of all the platform sound like a better investment then having dedicated engineer for each platform. There is even a thing called “React Native for Web”, we are porting web to native, now we are porting them back to web?! There is also a high interest in backend performance tuning. There are talks about NGINX performance tuning, container orchestration, and various tricks for speeding up your website from even the network protocol level. I also heard an interesting talk about the status of HTML emails. Although I know HTML email is hard to work with, I didn’t know the support is so different across mail clients.
I gave roughly the same talk in the above two conferences. The COSCUP audiences are more interested in the system library side of Servo, they asked about do we have Wayland support (yes, we do), and the status of our media support through ffmpeg. The Modern Web crowd are less interested in our internal implementation, but on how and when Servo will become a real product. They also asked a lot about the future of Servo together with Firefox, which I think might get clearer in the following months.
WebRender’s performance and its promise to allow web dev to write 60 fps animation without understanding the internal implementation resonates well with the audiences. There was a talk in Modern Web about how to get the best CSS animation performance, which is basically about which API for avoid, hopefully with WebRender we don’t need to worry about them anymore. They also wants to know the detail about out Web Platform Test effort. In general, people excited rather then worried (by the need to support yet another browser) about Servo. The doge sticker also helped me attracting the crowd! The Modern Web staff also helped me making the sticker into this cute button:

This is the third event I attended in one week, and also the most exhausting one. This is a new event hosted by a bunch of collage students, who wants to connect potential open source project contributors with mentors. I signed up as a Servo mentor and received roughly six applications. They rented two classrooms in the National Normal University in Taipei, and all mentors and students stay there for 2 days to hack on easy issues. There are people from Firefox, Ubuntu, LibreOffice, Linux Kernel, etc.
Thanks to the help from the Servo community around the world, especially jdm and KiChjang, we were able to get around 14 patches landed in just two days. The new contributors are very impressed by the friendliness of the contribution flow. What confuses them is some Rust-specific syntax like matching on Rust’s enum, or working with unwrap(). Some of the contributors who are not familiar with the GitHub workflow needs some help with rebasing, pushing new modifications and squashing, but in general they are able to work through the easy bugs pretty fast.
With six of the new contributors joining the Servo project, we now have about fifteen Servo contributors in Taiwan. Our Rust book study group also finished reading the basic part of the book, and we are moving on to build side projects in Rust. Hopefully we can create a strong Servo/Rust community here in Taiwan!
https://shinglyu.github.io/web/2016/09/04/2016-conferences.html
|
|
Alan Starr: E10S and Me |
|
|
The Mozilla Blog: Fighting Back Against Secrecy Orders |
Mozilla today is joining a coalition of technology companies, including Apple, Lithium, and Twilio, in filing an amicus brief in support of Microsoft’s case against indiscriminate use of gag orders. Such orders prevent companies from notifying users about government requests for their data.
Transparency is the core pillar for everything we do at Mozilla. It is foundational to how we build our products, with an open code base that anybody can inspect, and is critical to our vision of an open, trusted, secure web that places users in control of their experience online. Our reform efforts in the areas of vulnerability disclosure and government surveillance are also centered on the transparency ideal.
And transparency – or more appropriately the lack thereof – is why we care about this case. When requesting user data, these gag orders are sometimes issued without the government demonstrating why the gag order is necessary. Worse yet, the government often issues indefinite orders that prevent companies from notifying users even years later, long after everyone would agree the gag order is no longer needed. These actions needlessly sacrifice transparency without justification. That’s foolish and unacceptable.
We have yet to receive a gag order that would prevent us from notifying a user about a request for data. Nonetheless, we believe it is wrong for the government to indefinitely delay a company from providing user notice. We said this when we released our transparency report in May, and we said then that we would take steps to enforce this belief. That is just what we’ve done today.
https://blog.mozilla.org/blog/2016/09/02/fighting-back-against-secrecy-orders/
|
|
Seif Lotfy: Log levels described as sh*t hitting the fan |
| Log Level | Description |
|---|---|
| DEBUG | poop contains corn |
| TRACE | poop currently moving into colon |
| WARN | sh*t is approaching the fan |
| ERROR | sh*t has hit the fan |
| SEVERE | sh*t is spraying into the fan |
| CRITICAL | sh*t is spraying all over the room |
| ALERT | sh*t is piling up |
| FATAL | the room is flooding with sh*t |
| EMERGENCY | the fan has stopped spinning |
| VERBOSE | censored |
By Chris Andrews, narrated by Devin Villegas
http://seif.codes/log-levels-described-as-sh-t-hitting-the-fan/
|
|
Mike Hoye: The Planet Is Safe For Now |
This is a followup to this post – The Future Of The Planet – where I said we had four choices about what to do next:
To give away the punchline, we’re going with option two.
I reviewed all the feedback from various places that post ended up – the Mozilla Community discourse forums, HackerNews, Reddit, my inbox, a handful of others – and was delighted to find that it was was generally positive and spoke to Planet’s ongoing relevance. The suggestions for improving the situation were also generally good and helpful, and even the person who accused me of planning to destroy Planet just so that I could put something on my CV that made me sound like a supervillain was worth a laugh.
In broad terms, that feedback was:
With that in mind, I think we can do the following things in no particular order to improve Planet as both a tool and an experience.
Some of these are more work than others, but I’ll open bugs for the ones that need them the next little while.
Thanks for your feedback, everyone.
http://exple.tive.org/blarg/2016/09/02/the-planet-is-safe-for-now/
|
|
Air Mozilla: Foundation Demos September 2 2016 |
 Foundation Demos September 2 2016
Foundation Demos September 2 2016
|
|






