David Lawrence: Happy BMO Push Day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.

https://dlawrence.wordpress.com/2016/08/30/happy-bmo-push-day-27/
|
|
Aki Sasaki: 100% test coverage [in python] |
Tl;dr: I reached 100% test coverage (as measured by coverage) on several of my projects, and I'm planning on continuing that trend for the important projects I maintain. We were chatting about this, and I decided to write a blog post about how to get to 100% test coverage, and why.
Back in 2014, Apple issued a critical security update for iOS, to patch a bug known as #gotofail.
static OSStatus
SSLVerifySignedServerKeyExchange(SSLContext *ctx, bool isRsa, SSLBuffer signedParams,
uint8_t *signature, UInt16 signatureLen)
{
OSStatus err;
...
if ((err = SSLHashSHA1.update(&hashCtx, &serverRandom)) != 0)
goto fail;
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
...
fail:
SSLFreeBuffer(&signedHashes);
SSLFreeBuffer(&hashCtx);
return err;
}
The second highlighted goto fail caused SSLVerifySignedServerKeyExchange calls to jump to the fail block with a successful err. This bypassed the actual signature verification and returned a blanket success. With this bug in place, malicious servers would have been able to serve SSL certs with mismatched or missing private keys, and still look legit.
One might argue for strict indentation, using curly braces for all if blocks, better coding practices, or just Better Reviews. But 100% test coverage would have found it.
"For the bug at hand, even the simplest form of coverage analysis, namely line coverage, would have helped to spot the problem: Since the problematic code results from unreachable code, there is no way to achieve 100% line coverage.
"Therefore, any serious attempt to achieve full statement coverage should have revealed this bug."
Even though python has meaningful indentation, that doesn't mean it's foolproof against unreachable code. Simply marking each line as visited is enough to protect against this class of bug.
And even when there isn't a huge security issue at stake, unreachable code can clutter the code base. At best, it's dead weight, extra lines of code to work around, to refactor, to have to read when debugging. At worst, it's confusing, misleading, and hides serious bugs. Don't do unreachable code.
My first attempt at 100% test coverage was on a personal project, on a whim. I knew all my code was good, but full coverage was something I had never seen. It was a lark. A throwaway bit of effort to see if I could do it, and then something I could mention offhand. "Oh yeah, and by the way, it has 100% test coverage."
Imagine my surprise when I uncovered some non-trivial bugs.
This has been the norm. Every time I put forward a sustained effort to add test coverage to a project, I uncover some things that need fixing. And I fix them. Even if its as small as a confusing variable name or a complex bit of logic that could use a comment or two. And often it's more than that.
Certainly, if I'm able to find and fix bugs while writing tests, I should be able to find and fix those bugs when they're uncovered in the wild, no? The answer is yes. But. It's a difference of headspace and focus.
When I'm focused on isolating a discrete chunk of code for testing, it's easier to find wrong or confusing behavior than when when I'm deploying some large, complex production process that may involve many other pieces of software. There are too many variables, too little headspace for the problem, and often too little time. And Murphy says those are the times these problems are likely to crop up. I'd rather have higher confidence at those times. Full test coverage helps reduce those variables when the chips are down.
Software is the proverbial shark: it's constantly moving, or it dies. Small patches are pretty easy to eyeball and tell if they're good. Well written and maintained code helps here too, as does documentation, mentoring, and code reviews. But only tests can verify that the code is still good, especially when dealing with larger patches and refactors.
Tests can help new contributors catch problems before they reach code review or production. And sometimes after a long hiatus and mental context switch, I feel like a new contributor to my own projects. The new contributor you are helping may be you in six months.
Sometimes your dependencies release new versions, and it's nice to have a full set of tests to see if something will break before rolling anything out to production. And when making large changes or refactoring, tests can be a way of keeping your sanity.
whenever someone else's test prevents me from landing new code with a bug, i'm hella grateful pic.twitter.com/s1Yq6Es4ex
— Adrienne Porter Felt (@__apf__) August 26, 2016
There's the social aspect of codebase maintenance. If you want to ask a new contributor to write tests for their code, that's an easier ask when you're at 100% coverage than when you're at, say, 47%.
This can also carry over to your peers' and coworkers' projects. Enough momentum, and you can build an ecosystem of well-tested projects, where the majority of all bugs are caught before any code ever lands on the main repo.
Have you read Forget Technical Debt - Here's How to Build Technical Wealth? It's well worth the read.
Automated testing and self-validation loom large in that post. She does caution against 100% test coverage as an end in itself in the early days of a startup, for example, but that's when time to market and profitability are opportunity costs. When developing technical wealth at an existing enterprise, the long term maintenance benefits speak for themselves.
If you haven't watched Clean Architecture in Python, add it to your list. It's worth the time. It's the Python take on Uncle Bob Martin's original talk. Besides making your code more maintainable, it makes your code more testable. When I/O is cleanly separated from the logic, the logic is easily testable, and the I/O portions can be tested in mocked code and integration tests.
Some people swear by click. I'm not quite sold on it, yet, but it's easy to want something other than optparse or argparse when faced with a block of option logic like in this main() function. How can you possibly sanely test all of that, especially when right after the option parsing we go into the main logic of the script?
I pulled all of the optparse logic into its own function, and I called it with sys.argv[:1]. That let me start testing optparse tests, separate from my signing tests. Signtool is one of those projects where I haven't yet reached 100% coverage, but it's high on my list.
if __name__ == '__main__':
if __name__ == '__main__': is one of the first things we learn in python. It allows us to mix script and library functionality into the same file: when you import the file, __name__ is the name of the module, and the block doesn't execute, and when you run it as a script, __name__ is set to __main__, and the block executes. (More detailed descriptions here.)
There are ways to skip these blocks in code coverage. That might be the easiest solution if all you have under if __name__ == '__main__': is a call to main(). But I've seen scripts where there are pages of code inside this block, all code-coverage-unfriendly.
I forget where I found my solution. This answer suggests __name__ == '__main__' and main(). I rewrote this as
def main(name=None):
if name in (None, '__main__'):
...
main(name=__name__)
Either way, you don't have to worry about covering the special if block. You can mock the heck out of main() and get to 100% coverage that way. (See the mock and integration section.)
mimetypes.guess_type('foo.log') returns 'text/plain' on OSX, and None on linux. I fixed it like this:
content_type, _ = mimetypes.guess_type(path)
if content_type is None and path.endswith('.log'):
content_type = 'text/plain'
And that works. You can get full coverage on linux: a "foo.log" will enter the if block, and a "foo.unknown_extension" will skip it. But on OSX you'll never satisfy the conditional; the content_type will never be None for a foo.log.
More ugly mocking, right? You could. But how about:
content_type, _ = mimetypes.guess_type(path)
if path.endswith('.log'):
content_type = content_type or 'text/plain'
Coverage will mark that as covered on both linux and OSX.
I used to use nosetests for everything, just because that's what I first encountered in the wild. When I first hacked on PGPy I had to get accustomed to pytest, but that was pretty easy. One thing that drew me to it was @pytest.mark.parametrize (which is an alternate spelling.)
With @pytest.mark.parametrize, you can loop through multiple inputs with the same logic, without having to write the loops yourself. Like this. Or, for the PGPy unicode example, this.
This is doable in nosetests, but pytest encourages it by making it easy.
In nosetests, I would often write small functions to give me objects or data structures to test against. That, or I'd define constants, and I'd be careful to avoid changing any mutable constants, e.g. dicts, during testing.
pytest fixtures allow you to do that, but more simply. With a @pytest.fixture(scope="function"), the fixture will get reset every function, so even if a test changes the fixture, the next test will get a clean copy.
There are also built-in fixtures, like tmpdir, mocker, and event_loop, which allow you to more easily and succintly perform setup and cleanup around your tests. And there are lots of additional modules which add fixtures or other functionality to pytest.
Here are slides from a talk on advanced fixture use.
It's certainly possible to test the I/O and loop-laden main sections of your project. For unit tests, it's a matter of mocking the heck out of it. Pytest's mocker fixture helps here, although it's certainly possible to nest a bunch of with mock.patch blocks to avoid mocking that code past the end of your test.
Even if you have to include some I/O in a function, that doesn't mean you have to use mock to test it. Instead of
def foo():
requests.get(...)
you could do
def foo(request_function=requests.get):
request_function(...)
Then when you unit test, you can override request_function with something that raises the exception or returns the value that you want to test.
Finally, even after you get to 100% coverage on unit tests, it's good to add some integration testing to make sure the project works in the real world. For scriptworker, these tests are marked with @pytest.mark.skipif(os.environ.get("NO_TESTS_OVER_WIRE"), reason=SKIP_REASON), so we can turn them off in Travis.
Besides parameterization and the mocker fixture, pytest is easily superior to nosetests.
There's parallelization with pytest-xdist. The fixtures make per-test setup and cleanup a breeze. Pytest is more succinct:
assert x == y instead of self.assertEquals(x, y) ; because we don't have the self to deal with, the tests can be functions instead of methods. The following
with pytest.raises(OSError):
function(*args, **kwargs)
is a lot more legible than self.assertRaises(OSError, function, *args, **kwargs) . You've got @pytest.mark.asyncio to await a coroutine; the event_loop fixture is there for more asyncio testing goodness, with auto-open/close for each test.
Use tox, coveralls, and travis or taskcluster-github for per-checkin test and coverage results.
Use coverage>=4.2 for async code. Pre-4.2 can't handle the async.
Use coverage's branch coverage by setting branch = True in your .coveragerc.
I haven't tried hypothesis or other behavior- or property- based testing yet. But hypothesis does use pytest. There's an issue open to integrate them more deeply.
It looks like I need to learn more about mutation testing.
What other tricks am I missing?
|
|
Fr'ed'eric Harper: Free stickers – show others that you are a lion |

As I a mentioned in February, I decided to start my own business and go back to the marvelous world of freelancing with No lion is born king. No need to say that it’s an interesting time, not always easy, but overall, I’m quite happy! I’m also lucky as it’s going well, thanks to my amazing network I’ve built over the last couple of years and, of course, my personal brand.
Talking about branding, I love my company’s brand, and with the help of the talented Sylvain Grand’Maison, I’ve ordered some stickers to show how proud I am to the rest of the world. Since it’s more than just a company’s name, I would like to offer you some of those stickers so you can show others that you are a lion, a fighter, that you worked hard to become the king of your jungle. If you want some (size is 2X2 inches), please send me an email with your complete postal address and I’ll send you some for free. The only thing I’m asking in exchange is that you send me pictures of where you put them!
I can’t wait to see with which other stickers my lion will hang with…
http://feedproxy.google.com/~r/outofcomfortzonenet/~3/p-HFmqFAbMk/
|
|
David Lawrence: Happy BMO Push Day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.

https://dlawrence.wordpress.com/2016/08/30/happy-bmo-push-day-26/
|
|
Myk Melez: Graphene On Gecko Without B2G |
Recently, I’ve been experimenting with a reimplementation of Graphene on Gecko that doesn’t require B2G. Graphene is a desktop runtime for HTML apps, and Browser.html uses it to run on Servo. There’s a Gecko implementation of Graphene that is based on B2G, but it isn’t maintained and appears to have bitrotted. It also entrains all of B2G, although Browser.html doesn’t use many B2G features.
My reimplementation is minimal. All it does is load a URL in a native window and expose a few basic APIs (including ). But that’s enough to run Browser.html. And since Browser.html is a web app, it can be loaded from a web server (with this change that exposes to https: URLs).
I forked browserhtml/browserhtml to mykmelez/browserhtml, built it locally, and then pushed the build to my GitHub Pages website at mykmelez.github.io/browserhtml. Then I forked mozilla/gecko-dev to mykmelez/graphene-gecko and reimplemented Graphene in it. I put the implementation into embedding/graphene/, but I could have put it anywhere, including in a separate repo, per A Mozilla App Outside Central.
To try it out, clone, build, and run it:
git clone https://github.com/mykmelez/graphene-gecko
cd graphene-gecko
./mach build && ./mach run https://mykmelez.github.io/browserhtml/
You’ll get a native window with Browser.html running in Graphene:

https://mykzilla.org/2016/08/30/graphene-on-gecko-without-b2g/
|
|
This Week In Rust: This Week in Rust 145 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
No crate was suggested for this week. So I unilaterally declare ring, Brian Smith's Rust crypto implementation, which is finally on crates.io as this week's crate.
Can we have suggestions and votes next week? Pretty please?
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
BitAnd, BitOr, BitXor and Not for all
implementations of Filterstd::fs::remove_dir_all fn.If you are a Rust project owner and are looking for contributors, please submit tasks here.
138 pull requests were merged in the last two weeks.
if conditionschar::decode_utf8 now yields errors per Unicodeallocas for unused localsNoExpectation to check type of diverging fnVec growth to 0-terminate CStringFusedIterator (implements RFC #1581)impl CoerceUnsized for {Cell, RefCell, UnsafeCell}`fn item to pointer-sized types is now an errorcargo metadata now works with workspacesChanges to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now. This week's FCPs are:
mem::discriminant(). Add a function that extracts the discriminant from an enum variant as a comparable, hashable, printable, but (for now) opaque and unorderable type.dyn keyword.vis matcher to macro_rules! that matches valid visibility annotations.libstd::sys, the great libstd refactor.No new RFCs were proposed this week.
If you are running a Rust event please add it to the calendar to get it mentioned here. Email Erick Tryzelaar or Brian Anderson for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
My Rust memoirs will be called "Once in 'a lifetime".
Thanks to Vincent Esche for the suggestion.
Submit your quotes for next week!
This Week in Rust is edited by: nasa42, llogiq, and brson.
https://this-week-in-rust.org/blog/2016/08/30/this-week-in-rust-145/
|
|
Christian Heilmann: What does a developer evangelist/advocate do? |

Today I was asked to define the role of a developer evangelist in my company for a slide deck to be shown at hiring events and university outreach. This was a good opportunity to make a list of all the tasks we have to do in this job and why we do them. It might be useful for you to read through, and a good resource to point people to when they – once again – ask you “but, do you still code?”.
First things first: Whenever you write about this topic there is a massive discussion about the job title ” evangelist” and how it is terrible and has religious overtones and whatnot. So if that is what bothers you, please choose below what you’d like to read and your browser will change it accordingly to give you peace of mind:
Now, what is a developer evangelist? As defined in my developer evangelist handbook:
A developer evangelist is a spokesperson, mediator and translator between a company and both its technical staff and outside developers.
What do you need to know to be one? First there are the necessary skills:
Then there are also important skills to have:
Being a developer evangelist is a role that spans across several departments. Your job is to be a communicator. Whilst you are most likely reporting to engineering, you need to spend a lot of time making different departments talk to another. Therefore internal networking skills are very important. Your job also affects the work of other people (PR, legal, comms, marketing). Be aware of these effects and make sure to communicate them before you reach out.
As a translator, you have both outbound (company to people) and inbound (people to your company) tasks to fulfil. Let’s list most of them:
Provide a personal channel to ask about your company or products. People react much better to a human and interact more with them than with a corporate account. Be yourself – at no point you should become a corporate sales person. Do triage – point people to resources to use like feedback channels instead of talking on their behalf Don’t make decisions for your colleagues. Help them, don’t add to their workload.
You’re the ear on the ground – your job is to know what the competition does and what gets people excited. Use the products of your competition to see what works for you and their users and give that feedback to your teams. Detect trends and report them to your company.
You need to develop software products to keep up to date technically and show your audience that you’re not just talking but that you know what you’re doing. These should be openly available. In many cases, your company can’t release as freely as you can. Show the world that you’re trusted to do so. Building products also allows you to use tools outside developers use and feed back your experiences to your company
Take part in other people’s open source products. That way you know the pains and joys of using them. Your job is to be available. By providing helpful contributions to other products people judge you by your work and how you behave as a community member, not as a company person. Analysing how other products are run gives you great feedback for your teams.
A lot of discussion happens outside your company, on channels like Stackoverflow, Slack, Facebook Groups, Hacker News and many more. You should be monitoring those to a degree and be visible, bringing facts where discussions get heated. These are great places to find new influencers and partners in communication.
Taking part in other publications than your own and the ones of your company solidifies your status as a thought leader and influencer. Write for magazines, take part in podcasts and interview series. Help others to get their developer oriented products off the ground – even when they are your competition.
Creating short, informative and exciting videos is a great opportunity to reach new followers. Make sure you keep those personal – if there is a video about a product, help the product team build one instead. Show why you care about a feature. Keep these quick and easy, don’t over-produce them. These are meant as a “hi, look at this!”.
Present and give workshops at events. Introduce event organisers and colleagues or other presenters you enjoyed. Help promote events. Help marketing and colleagues at events to make your presence useful and yielding results.
People working on products should spend their time doing that – not arguing with people online
Your job is to take negative feedback and redirect it to productive results
This means in many cases asking for more detailed reporting before working with the team to fix it.
It also means managing expectations. Just because a competitor has a cool new thing doesn’t mean your company needs to follow. Explain why.
If you do your job right and talk to others a lot, what other people call ”influencers” are what you call friends and contacts. Show them how much you care by getting them preview information of things to come. Make sure that communication from your company to them goes through you as it makes outreach much less awkward. Find new upcoming influencers and talk to your company about them.
There is no way to be a developer evangelist for a company if you don’t know about the products your company does. You need to work with and on the products, only then can you be inspiring and concentrate on improving them. Working on the products also teaches you a lot about how they are created, which helps with triaging questions from the outside.
It is important to report to your product teams and engineers. This includes feedback about your own product, but also what positive and negative feedback the competition got. This also includes introducing the teams to people to communicate with in case they want to collaborate on a new feature.
Your colleagues bring great content, it is your job to give it reach. Amplify their messages by spreading them far and wide and explaining them in an understandable fashion to different audiences. Tell other influencers about the direct information channels your teams have.
It is great that you can represent your company, but sometimes the voice of someone working directly on a product has more impact. Coach people in the company and promote their presence on social media and at events. Connect conference organisers and internal people – make sure to check with their manager to have them available. Help people present and prepare materials for outreach.
Being at an event or running a campaign should be half the job. The other half is proving to the people in the company that it was worth it. Make sure to collect questions you got, great things you learned and find a good way to communicate them to the teams they concern. Keep a log of events that worked and those who didn’t – this is great information for marketing when it comes to sponsorship.
It is important to be involved in the events your company organises. Try not to get roped into presenting at those – instead offer to coach people to be there instead. Offer to be on the content board of these events – you don’t want to be surprised by some huge press release that says something you don’t agree with. Use your reach to find external speakers for your events.
Your work overlaps a lot with those departments. Be a nice colleague and help them out and you get access to more budget and channels you don’t even know about. Make sure that what you say or do in your job is not causing any legal issues.
You’re seen as a approachable channel for questions about your products. Make sure that requests coming through you are followed up swiftly. Point out communication problems to your internal teams and help them fix those. Use external feedback to ask for improvements of your own products. It is easy to miss problems when you are too close to the subject matter.
Your colleagues are busy building products. They shouldn’t have to deal with angry feedback that has no action items in it. Your job is to filter out rants and complaints and to analyse the cause of them. Then you report the root issue and work with the teams how to fix them.
Considering how full your plate is, the following question should come up:
Why would you want to become a developer evangelist (or developer advocate)?
There are perks to being someone in this role. Mostly that it is a natural progression for a developer who wants to move from a delivery role to one where they can influence more what the company does.
Before you jump on the opportunity, there are some very important points to remember:
It’s a versatile, morphing and evolving role. And that – to me – makes it really exciting.
https://www.christianheilmann.com/2016/08/29/what-does-a-developer-evangelistadvocate-do/
|
|
Mike Hoye: Free As In Health Care |
This is to some extent a thought experiment.
The video below shows what’s called a “frontal offset crash test” – your garden variety driver-side head-on collision – between a 2009 Chevrolet Malibu and a 1959 Chevrolet Bel Air. I’m about to use this video to make a protracted argument about software licenses, standards organizations, and the definition of freedom. It may not interest you all that much but if it’s ever crossed your mind that older cars are safer because they’re heavier or “solid” or had “real” bumpers or something you should watch this video. In particular, pay attention to what they consider a “fortunate outcome” for everyone involved. Lucky, for the driver in the Malibu, is avoiding a broken ankle. A Bel Air driver would be lucky if all the parts of him make it into the same casket.
[ https://www.youtube.com/watch?v=joMK1WZjP7g ]
Like most thought experiments this started with a question: what is freedom?
The author of the eighteenth-century tract “Cato’s Letters” expressed the point succinctly: “Liberty is to live upon one’s own Term; Slavery is to live at the mere Mercy of another.” The refrain was taken up with particular emphasis later in the eighteenth century, when it was echoed by the leaders and champions of the American Revolution.’ The antonym of liberty has ceased to be subjugation or domination – has ceased to be defenseless susceptibility to interference by another – and has come to be actual interference, instead. There is no loss of liberty without actual interference, according to most contemporary thought: no loss of liberty in just being susceptible to interference. And there is no actual interference – no interference, even, by a non-subjugating rule of law – without some loss of liberty; “All restraint, qua restraint, is evil,” as John Stuart Mill expressed the emerging orthodoxy.
– Philip Pettit, Freedom As Anti-Power, 1996
Most of our debates define freedom in terms of “freedom to” now, and the arguments are about the limitations placed on those freedoms. If you’re really lucky, like Malibu-driver lucky, the discussions you’re involved in are nuanced enough to involve “freedom from”, but even that’s pretty rare.
I’d like you to consider the possibility that that’s not enough.
What if we agreed to expand what freedom could mean, and what it could be. Not just “freedom to” but a positive defense of opportunities to; not just “freedom from”, but freedom from the possibility of.
Indulge me for a bit but keep that in mind while you exercise one of those freedoms, get in a car and go for a drive. Freedom of movement, right? Get in and go.
Before you can do that a few things have to happen first. For example: your car needs to have been manufactured.
Put aside everything that needs to have happened for the plant making your car to operate safely and correctly. That’s a lot, I know, but consider only the end product.
Here is a chart of the set of legislated standards that vehicle must meet in order to be considered roadworthy in Canada – the full text of CRC c.1038, the Motor Vehicle Safety Regulations section of the Consolidated Regulations of Canada runs a full megabyte, and contains passages such as:
H-point means the mechanically hinged hip point of a manikin that simulates the actual pivot centre of the human torso and thigh, described in SAE Standard J826, Devices for Use in Defining and Measuring Vehicle Seating Accommodation (July 1995); (point H)
H-V axis means the characteristic axis of the light pattern of a lamp, passing through the centre of the light source, used as the direction of reference (H = 0°, V = 0°) for photometric measurements and for the design of the installation of a lamp on a vehicle; (axe H-V)
… and
Windshield Wiping and Washing System
104 (1) In this section,
areas A, B and C means the areas referred to in Column I of Tables I, II, III and IV to this section when established as shown in Figures 1 and 2 of SAE Recommended Practice J903a Passenger Car Windshield Wiper Systems, (May 1966), using the angles specified in Columns III to VI of the above Tables; (zones A, B et C)
daylight opening means the maximum unobstructed opening through the glazing surface as defined in paragraph 2.3.12 of Section E, Ground Vehicle Practice, SAE Aerospace-Automotive Drawing Standards, (September 1963); (ouverture de jour)
glazing surface reference line means the intersection of the glazing surface and a horizontal plane 635 mm above the seating reference point, as shown in Figure 1 of SAE Recommended Practice J903a (May 1966); (ligne de r'ef'erence de la surface vitr'ee)
… and that mind-numbing tedium you’re experiencing right now is just barely a taste; a different set of regulations exists for crash safety testing, another for emissions testing, the list goes very far on. This 23 page PDF of Canada’s Motor Vehicle Tire Safety Regulations – that’s just the tires, not the brakes or axles or rims, just the rubber that meets the road – should give you a sense of it.
That’s the car. Next you need roads.
The Ontario Provincial Standards for Roads & Public Works consists of eight volumes. The first of them, General And Construction Specifications, is 1358 pages long. Collectively they detail how roads you’ll be driving on must be built, illuminated, made safe and maintained.
You can read them over if you like, but you can see where I’m going with this. Cars and roads built to these standards don’t so much enable freedom of motion and freedom from harm as they delimit in excruciating detail the space – on what road, at what speeds, under what circumstances – where people must be free from the possibility of specific kinds of harm, where their motion must be free from the possibility of specific kinds of restriction or risk.
But suppose we move away from the opposition to bare interference in terms of which contemporary thinkers tend to understand freedom. Suppose we take up the older opposition to servitude, subjugation, or domination as the key to construing liberty. Suppose we understand liberty not as noninterference but as antipower. What happens then?
– Philip Pettit, ibid.
Let me give away the punchline here: if your definition of freedom includes not just freedom from harassment and subjugation but from the possibility of harassment and subjugation, then software licenses and cryptography have as much to do with real digital rights and freedoms as your driver’s license has to do with your freedom of mobility. Which is to say, almost nothing.
We should be well past talking about the minutia of licenses and the comparative strengths of cryptographic algorithms at this point. The fact that we’re not is a clear sign that privacy, safety and security on the internet are not “real rights” in any meaningful sense. Not only because the state does not meaningfully defend them but because it does not mandate in protracted detail how they should be secured, fund institutions to secure that mandate and give the force of law to the consequences of failure.
The conversation we should be having at this point is not about is not what a license permits, it’s about the set of standards and practices that constitutes a minimum bar to clear in not being professionally negligent.
IMO there are lots of problems, but #1 is that actual costs of security risk failures fall primarily on service users, not software vendors.
If insurance companies said “your premiums will go from $10m to $2m if you parameterize your SQL” SQL-injection would all be dead tomorrow.
If WordPress’ board thought a multi-$bn lawsuit might come from the fact they *still* hadn’t parameterized their SQL, would change very fast
You know why buildings in the West burn down really infrequently? Fire insurance, regulation and litigation forcing buildings to be safer.
— Pwn All The Things (@pwnallthethings) August 22, 2016
The challenge here is that dollar sign. Right now the tech sector is roughly where the automotive sector was in the late fifties. You almost certainly know or know of somebody on Twitter having a very 1959 Bel-Air Frontal-Offset Collision experience right now, and the time for us to stop blaming the driver for that is long past. But if there’s a single grain of good news here’s it’s how far off your diminishing returns are. We don’t need detailed standards about the glazing surface reference line of automotive glass, we need standard seatbelts and gas tanks that reliably don’t explode.
But that dollars sign, and those standards, are why I think free software is facing an existential crisis right now.
[ https://www.youtube.com/watch?v=obSOaKTMLIc ]
I think it’s fair to say that the only way that standards have teeth is if there’s liability associated with them. We know from the automotive industry that the invisible hand of the free market is no substitute for liability in driving improvement; when the costs of failure are externalized, diffuse or hidden, those costs can easily be ignored.
According to the FSF, the “Four Freedoms” that define what constitutes Free Software are:
The cannier among you will already have noted – and scarred Linux veterans can definitely attest to the fact – that there’s no mention at all of freedom-from in there. The FSF’s unstated position has always been that anyone who wants to be free from indignities like an opaque contraption of a user experience, buggy drivers and nonexistent vendor support in their software, not to mention the casual sexism and racism of the free software movement itself, well. Those people can go pound sand all the way to the Apple store. (Which is what everyone did, but let’s put that aside for the moment.)
Let’s go back to that car analogy for a moment:
Toyota Motor Corp has recalled 3.37 million cars worldwide over possible defects involving air bags and emissions control units.
The automaker on Wednesday said it was recalling 2.87 million cars over a possible fault in emissions control units. That followed an announcement late on Tuesday that 1.43 million cars needed repairs over a separate issue involving air bag inflators.
About 930,000 cars are affected by both potential defects, Toyota said. Because of that overlap, it said the total number of vehicles recalled was 3.37 million.
No injuries have been linked to either issue.
Potential defects.
I think the critical insight here is that Stallman’s vision of software freedom dates to a time when software was contained. You could walk away from that PDP-11 and the choices you made there didn’t follow you home in your pocket or give a world full of bored assholes an attack surface for your entire life. Software wasn’t everywhere, not just pushing text around a screen but everywhere and in everything from mediating our social lives and credit ratings to pumping our drinking water, insulin and anti-lock brakes.
Another way to say that is: software existed in a well-understood context. And it was that context that made it, for the most part, free from the possibility of causing real human damage, and consequently liability for that damage was a non-question. But that context matters: Toyota doesn’t issue that recall because the brakes failed on the chopped-up fifteen year old Corolla you’ve welded to a bathtub and used as rally car, it’s for the safety of day to day drivers doing day to day driving.
I should quit dancing around the point here and just lay it out: If your definition of freedom includes freedom from the possibility of interference, it follows that “free as in beer” and “free as in freedom” can only coexist in the absence of liability.
This is only going to get more important as the Internet ends up in more and more Things, and your right – and totally reasonable expectation – to live a life free from arbitrary harassment enabled by the software around you becomes a life-or-death issue.
If we believe in an expansive definition of human freedom and agency in a world full of software making decisions then I think we have three problems, two practical and one fundamental.
The practical ones are straightforward. The first is that the underpinnings of the free-as-in-beer economic model that lets Google, Twitter and Facebook exist are fighting a two-ocean war against failing ad services and liability avoidance. The notion that a click-through non-contract can absolve any organization of their responsibility is not long for this world, and the nasty habit advertising and social networks have of periodically turning into semi-autonomous, weaponized misery-delivery platforms makes it harder to justify letting their outputs talk to your inputs every day.
The second one is the industry prisoner’s dilemma around, if not liability, then at a bare minimum responsibility. There’s a battery of high-caliber first-mover-disadvantages pointed at the first open source developer willing to say “if these tools are used under the following conditions, by users with the following user stories, then we can and should be held responsible for their failures”.
Neither of these problems are insoluble – alternative financial models exist, coalitions can be built, and so forth. It’ll be an upheaval, but not a catastrophic or even sudden one. But anyone whose business model relies on ads should be thinking about transitions five to ten years out, and your cannier nation-states are likely to start sneaking phrases like “auditable and replaceable firmware” in their trade agreements in the next three to five.
The fundamental problem is harder: we need a definition of freedom that encompasses the notion of software freedom and human agency, in which the software itself is just an implementation detail.
We don’t have a definition of freedom that’s both expansive in its understanding of what freedom and agency are, and that speaks to a world where the line between data security and bodily autonomy is very blurry, where people can delegate their agency to and gain agency from a construct that’s both an idea and a machine. A freedom for which a positive defense of the scope of the possible isn’t some weird semitangible idea, but a moral imperative and a hill worth dying on.
I don’t know what that looks like yet; I can see the rough outlines of the place it should be but isn’t. I can see the seeds of it in the quantified-self stuff, copyleft pushback and the idea that crypto is a munition. It’s crystal clear that a programmer clinging to the idea that algorithms are apolitical or that software is divorced from human bias or personal responsibility is a physicist holding to the aetheric model or phlogiston when other people are fuelling their rockets. The line between software freedom and personal freedom is meaningless now, and the way we’ve defined “software freedom” just about guarantees its irrelevancy. It’s just freedom now, and at the very least if our definition of freedom is – and our debate about what freedom could be – isn’t as vast and wide-ranging and weird and wonderful and diverse and inclusive and scary as it could possibly be, then the freedom we end up with won’t be either.
And I feel like a world full of the possible would be a hell of a thing to lose.
http://exple.tive.org/blarg/2016/08/29/free-as-in-health-care/
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 29 Aug 2016 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20160829/
|
|
Andy McKay: The luxury of cycling |
A few days ago a senator tweeted this:
Bicycles are a luxury, most of us use public transportation or walk. Never seen a bike rider obey traffic laws. They are special.
— Senator Eaton (@SenEaton) August 26, 2016
This weekend I attended the Ride to Conquer Cancer and cheered along my wife and the other members of her team as they completed a 250km ride from Vancouver to Seattle. It was moving to see cancer survivors and people who've lost loved ones to cancer, doing their bit to help fight cancer.
And let me tell you, these days I treat my ability to ride a bike as a luxury. It's all too easy to get struck down by any number of diseases and be unable to ride. To get into an accident and get injured so you can't ride. To live in a place that doesn't make riding possible. To have a family situation that makes it hard to ride.
A couple of years ago my sister got really sick. When I said I was thinking of doing the Gran Fondo "you are so lucky, I wish I could do that". So I did. And this year is my second race.
Oh and I pretty much obey all the traffic laws, unlike all the asshole car drivers who cut down the bicycle routes in Vancouver.
|
|
Smokey Ardisson: Quoting Brent Simmons |
One of the rules I’ve used […] is not to argue with “I bet lots of people are like me and want feature X,” but instead say why you specifically want feature X, or why you’d prefer some behavior or design change.
In other words: instead of just asserting that a thing would be better or more popular if done a different way, tell a story with details.
Maybe that’s not right for every beta test, but that’s what works for me. I like stories. A single person can convince me with a good story.
Brent has written about this point before, in the “Tuesday Whipper-Snapping” section of How to manipulate me (or, Tuesday Whipper-Snapping),1 but it’s an important point that bears repeating: when you are a user trying to explain to a developer/QA/support that you’d like feature X or think feature Y would work better in some other way, tell us why. Tell us what you’re trying to do, why you’re trying to do it. As Brent says, tell us a story, with details, about what you need/want to do with the software.
First, as the quotation above indicates, a good use-case (“story”) can often convince the person/people behind the software right off the bat of the importance and/or awesomeness of your proposed feature. Second, as Brent mentioned a decade ago (!) in the discussion of Expos'e in “Tuesday Whipper-Snapping,” your story is important because it may lead to the developer(s) devising a new or easier or more clever way of helping you to accomplish your task, rather than the specific implementation you may have conceived yourself.
So, tell us stories about what you hope to do.
1 Which I’ve linked to before in my compilation of great “Brent Simmons on software development for end-users” articles.
http://www.ardisson.org/afkar/2016/08/29/quoting-brent-simmons/
|
|
Karl Dubost: A Shr"odinger select menu with display: none on option |
Let's develop a bit more on an issue that we have identified last week.
On the croma Web site, they have a fairly common form.

As you can notice the instruction "Select City" for selecting an item is in the form itself. And the markup of the form looks like this.
<div class="ib"> <div id="citydropdown" name="citydropdown" class="inpBox"> <select id="city" name="city" onchange="drop_down_list1()"> <option value="" style="display: none">Select Cityspan>option> <option value="AHMEDABAD">AHMEDABADspan>option> <option value="AURANGABAD">AURANGABADspan>option> <option value="BANGALORE">BANGALOREspan>option> <option value="CHANDIGARH">CHANDIGARHspan>option> <option value="CHENNAI">CHENNAIspan>option> <option value="FARIDABAD">FARIDABADspan>option> <option value="GHAZIABAD">GHAZIABADspan>option> <option value="GREATER NOIDA">GREATER NOIDAspan>option> <option value="GURGAON">GURGAONspan>option> <option value="HYDERABAD">HYDERABADspan>option> <option value="MUMBAI">MUMBAIspan>option> <option value="NASIK">NASIKspan>option> <option value="NEW DELHI">NEW DELHIspan>option> <option value="NOIDA">NOIDAspan>option> <option value="PUNE">PUNEspan>option> <option value="RAJKOT">RAJKOTspan>option> <option value="SURAT">SURATspan>option> <option value="VADODARA">VADODARAspan>option> span>select> span>div> span>div>
Basically the developers are trying to make the "Select City" instruction non selectable. It works in Safari (WebKit) and Opera/Chrome (Blink) with slight differences. I put up a reduced test case if you want to play with it.
display: noneIt fails in Firefox (Gecko) in an unexpected way and only for e10s windows. The full list of options is not being displayed once the first one is set to display: none

Do not do this!
If you really want the instruction to be part of the form, choose to do
<div class="ib"> <div id="citydropdown" name="citydropdown" class="inpBox"> <select id="city" name="city" onchange="drop_down_list1()"> <option value="" hidden selected disabled>Select Cityspan>option> <option value="AHMEDABAD">AHMEDABADspan>option> <option value="AURANGABAD">AURANGABADspan>option> span>select> span>div> span>div>
This will have the intended effect and will "work everywhere". It is still not the best way to do it, but at least it is kind of working except in some cases for accessibility reasons (I added the proper way below).
That said, it should not fail in Gecko. I opened a bug on Mozilla Bugzilla and Neil Deakin already picked it up with a patch.
Quite cool! This will probably be uplifted to Firefox 49 and 50.
select menu form, the proper wayThere are a couple of issues with regards to accessibility and the proper way to create a form. This following would be better:
<div class="ib"> <div id="citydropdown" name="citydropdown" class="inpBox"> <label for="city">Select Cityspan>label> <select id="city" name="city" onchange="drop_down_list1()"> <option value="AHMEDABAD">AHMEDABADspan>option> <option value="AURANGABAD">AURANGABADspan>option> span>select> span>div> span>div>
The label is an instruction outside of the options list, that tools will pick up and associate with the right list.
I see the appeal for people to have the instruction to be part of the drop down. And I wonder if there would be an accessible way to create this design. I wonder if an additional attribute on label instructing the browser to put inside as a non selectable item of the select list of option it targets with the for attribute.
Otsukare!
http://www.otsukare.info/2016/08/29/option-instruction-selection
|
|
Karl Dubost: [worklog] Edition 033. Season of typhoons. Bugs clean-up |
A moderate typhoon landed this week just above us. Winds in one direction. The peace of the eye of the typhoon. Finally the winds in the opposite direction. Magnificent. The day after it was a cemetery for insects. Tragedy. So it was mostly a week for old bugs cleaning.
The spectacle of the society, the society of spectacle. The turn of international events and the rise of arguments instead of discussions is mesmerizingly sad. Tune of the week: DJ Shadow feat. Run The Jewels - Nobody Speak
Progress this week:
Today: 2016-08-29T07:47:04.454102 295 open issues ---------------------- needsinfo 4 needsdiagnosis 83 needscontact 18 contactready 28 sitewait 146 ----------------------
You are welcome to participate
display: flex on button elements(a selection of some of the bugs worked on this week).
option doesn't like display: none on Gecko at least. It hides the full list. I opened a new bug for Gecko. This is happening only in e10s windows. And there is already a patch in the making.Otsukare!
|
|
Seif Lotfy: Welcome to Ghost |
You're live! Nice. We've put together a little post to introduce you to the Ghost editor and get you started. You can manage your content by signing in to the admin area at
Ghost uses something called Markdown for writing. Essentially, it's a shorthand way to manage your post formatting as you write!
Writing in Markdown is really easy. In the left hand panel of Ghost, you simply write as you normally would. Where appropriate, you can use shortcuts to style your content. For example, a list:
or with numbers!
Want to link to a source? No problem. If you paste in a URL, like http://ghost.org - it'll automatically be linked up. But if you want to customise your anchor text, you can do that too! Here's a link to the Ghost website. Neat.
Images work too! Already know the URL of the image you want to include in your article? Simply paste it in like this to make it show up:

Not sure which image you want to use yet? That's ok too. Leave yourself a descriptive placeholder and keep writing. Come back later and drag and drop the image in to upload:
Sometimes a link isn't enough, you want to quote someone on what they've said. Perhaps you've started using a new blogging platform and feel the sudden urge to share their slogan? A quote might be just the way to do it!
Ghost - Just a blogging platform
Got a streak of geek? We've got you covered there, too. You can write inline blocks really easily with back ticks. Want to show off something more comprehensive? 4 spaces of indentation gets you there.
.awesome-thing {
display: block;
width: 100%;
}
Throw 3 or more dashes down on any new line and you've got yourself a fancy new divider. Aw yeah.
There's one fantastic secret about Markdown. If you want, you can write plain old HTML and it'll still work! Very flexible.
That should be enough to get you started. Have fun - and let us know what you think :)
|
|
Mozilla WebDev Community: Beer and Tell – August 2016 |
Once a month, web developers from across the Mozilla Project get together to talk about our side projects and drink, an occurrence we like to call “Beer and
Tell”.
There’s a wiki page available with a list of the presenters, as well as links to their presentation materials. There’s also a recording available courtesy of Air Mozilla.
First up was Osmose (that’s me!), who shared PyJEXL, an implementation of JEXL in Python. JEXL is an expression language based on JavaScript that computes the value of an expression when applied to a given context. For example, the statement 2 + foo, when applied to a context where foo is 7, evaluates to 9. JEXL also allows for defining custom functions and operators to be used in expressions.
JEXL is implemented as a JavaScript library; PyJEXL allows you to parse and evaluate JEXL expressions in Python, as well as analyze and validate expressions.
Next up was pmac, who shared rtoot.org, the website for “The Really Terrible Orchestra of the Triangle”. It’s a static site for pmac’s local orchestra built using lektor, an easy-to-use static site generator. One of the more interesting features pmac highlighted was lektor’s data model. He showed a lektor plugin he wrote that added support for CSV fields as part of the data model, and used it to describe the orchestra’s rehearsal schedule.
The site is deployed as a Docker container on a Dokku instance. Dokku replicates the Heroku style of deployments by accepting Git pushes to trigger deploys. Dokku also has a great Let’s Encrypt plugin for setting up and renewing HTTPS certificates for your apps.
Next was groovecoder, who previewed a lightning talk he’s been working on called “Scary JavaScript (and other Tech) that Tracks You Online”. The talk gives an overview of various methods that sites can use to track what sites you’ve visited without your consent. Some examples given include:
groovecoder plans to give the talk at a few local conferences, leading up to the Hawaii All Hands where he will give the talk to Mozilla.
rdalal was next with Therapist, a tool to help create robust, easily-configurable pre-commit hooks for Git. It is configured via a YAML file at your project root, and can run any command you want to run before committing code, such as code linting or build commands. Therapist is also able to detect which files were changed by the commit and only run commands on those to help save time.
Last up was gregtatum, who shared River – Paths Over Time. Inspired by the sight of rivers from above during the flight back from the London All Hands, Rivers is a simulation of rivers flowing and changing over time. The animation is drawn on a 2d canvas using rectangles that are drawn and then slowly faded over time; this slow fade creates the illusion of “drips” seeping into the ground as rivers shift position.
The source code for the simulation is available on Github, and is configured with several parameters that can be tweaked to change the behavior of the rivers.
If you’re interested in attending the next Beer and Tell, sign up for the dev-webdev@lists.mozilla.org mailing list. An email is sent out a week beforehand with connection details. You could even add yourself to the wiki and show off your side-project!
See you next month!
https://blog.mozilla.org/webdev/2016/08/27/beer-and-tell-august-2016/
|
|
Mozilla Reps Community: Reps Program Objectives – Q3 2016 |
With “RepsNext” we increased alignment between the Reps program and the Participation team. The main outcome is setting quarterly Objectives and Key Results together. This enables all Reps to see which contributions have a direct link to the Participation team . Of course, Reps are welcome to keep doing amazing work in other areas.
| Objective 1 | Reps are fired up about the Activate campaign and lead their local community to success through supporting that campaign with the help of the Review Team |
| KR1 | 80+ core mozillians coached by new mentors contribute to at least one focus activity. |
| KR2 | 75+ Reps get involved in the Activity Campaign, participating in at least one activity and/or mobilizing others. |
| KR3 | The Review Team is working effectively by decreasing the budget review time by 30% |
| Objective 2 | New Reps coaches and regional coaches bring leadership within the Reps program to a new level and increase the trust of local communities towards the Reps program |
| KR1 | 40 mentors and new mentors took coaching training and start at least 2 coaching relationships. |
| KR2 | 40% of the communities we act on report better shape/effectiveness thanks to the regional coaches |
| KR3 | At least 25% of the communities Regional Coaches work with report feeling represented by the Reps program |
Which of the above objectives are you most interested in? What key result would you like to hear more about? What do you find intriguing? Which thoughts cross your mind upon reading this?
Let’s keep the conversation going! Please provide your comments in Discourse.
https://blog.mozilla.org/mozillareps/2016/08/27/reps-program-objectives-q3-2016/
|
|
Cameron Kaiser: TenFourFox 45.3.0b2 available |
After a few days of screaming and angry hacking (backporting some future bug fixes, new code for dumping frames that can never be rendered, throwing out the entire queue if we get so far behind we'll never reasonably catch up) I finally got the G5 to be able to hold its own in Reduced Performance but it's just too far beyond the G4 systems to do so. That's a shame since when it does work it appears to work pretty well. Nevertheless, for release I've decided to turn MediaSource off entirely and it now renders mostly using the same pipeline as 38 (fortunately, the other improvements to pixel pushing do make this quicker than 38 was; my iBook G4/1.33 now maintains a decent frame rate for most standard definition videos in Automatic Performance mode). If the feature becomes necessary in the future I'm afraid it will only be a reasonable option for G5 machines in its current state, but at least right now disabling MediaSource is functional and sufficient for the time being to get video support back to where it was.
The issue with the Amazon Music player is not related to or fixed by this change, however. I'm thinking that I'll have to redo our minimp3 support as a platform MP3 decoder so that we use more of Mozilla's internal media machinery; that refactoring is not likely to occur by release, so we'll ship with the old decoder that works most other places and deal with it in a future update. I don't consider this a showstopper unless it's affecting other sites.
Other changes in 45.3 beta 2 are some additional performance improvements. Most of these are trivial (including some minor changes to branching and proper use of single-precision math in the JIT), but two are of note, one backport that reduces the amount of allocation with scrolling and improves overall scrolling performance as a result, and another one I backported that reduces the amount of scanning required for garbage collection (by making garbage collection only run in the "dirty" zones after cycle collection instead of effectively globally). You'll notice that RAM use is a bit higher at any given moment, but it does go back down, and the browser has many fewer random pauses now because much less work needs to be done. Additionally in this beta unsigned extensions should work again and the update source is now set to the XML for 45. One final issue I want to repair before launch is largely server-side, hooking up the TenFourFox help button redirector to use Mozilla's knowledge base articles where appropriate instead of simply redirecting to our admittedly very sparse set of help documents on Tenderapp. This work item won't need a browser update; it will "just work" when I finish the code on Floodgap's server.
At this point barring some other major crisis I consider the browser shippable as 45.4 on time on 13 September, with Amazon Music being the highest priority issue to fix, and then we can start talking about what features we will add while we remain on feature parity. There will also be a subsequent point release of TenFourFoxBox to update foxboxes for new features in 45; stay tuned for that. Meanwhile, we could sure use your help on a couple other things:
http://tenfourfox.blogspot.com/2016/08/tenfourfox-4530b2-available.html
|
|
Air Mozilla: Outreachy Participant Presentations Summer 2016 |
 Outreachy program participants from the summer 2016 cohort present their contributions and learnings. Mozilla has hosted 15 Outreachy participants this summer, working on technical projects...
Outreachy program participants from the summer 2016 cohort present their contributions and learnings. Mozilla has hosted 15 Outreachy participants this summer, working on technical projects...
https://air.mozilla.org/outreachy-participant-presentations-summer-2016/
|
|
Christian Heilmann: Songsearch – using ServiceWorker to make a 4 MB CSV easily searchable in a browser |
A few days ago I got an email about an old project of mine that uses YQL to turn a CSV into a “web services” interface. The person asking me for help was a Karaoke DJ who wanted to turn his available songs into a search interface. Maintenance of the dataset happens in Excel, so all that was needed was a way to display it on a laptop.
The person had a need and wanted a simple solution. He was OK with doing some HTML and CSS, but felt pretty lost at anything database related or server side. Yes, the best solution for that would be a relational DB, as it would also speed up searches a lot. As I don’t know for how much longer YQL is reliably usable, I thought I use this opportunity to turn this into an offline app using ServiceWorker and do the whole work in client side JavaScript. Enter SongSearch – with source available on GitHub.
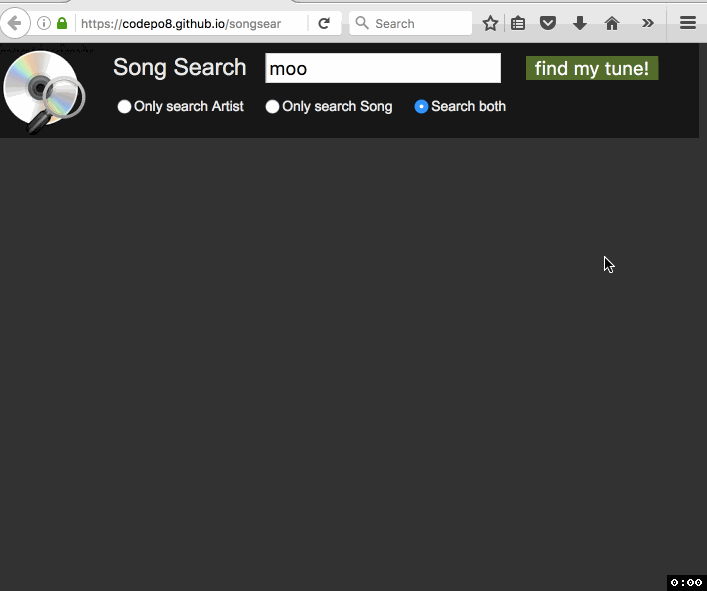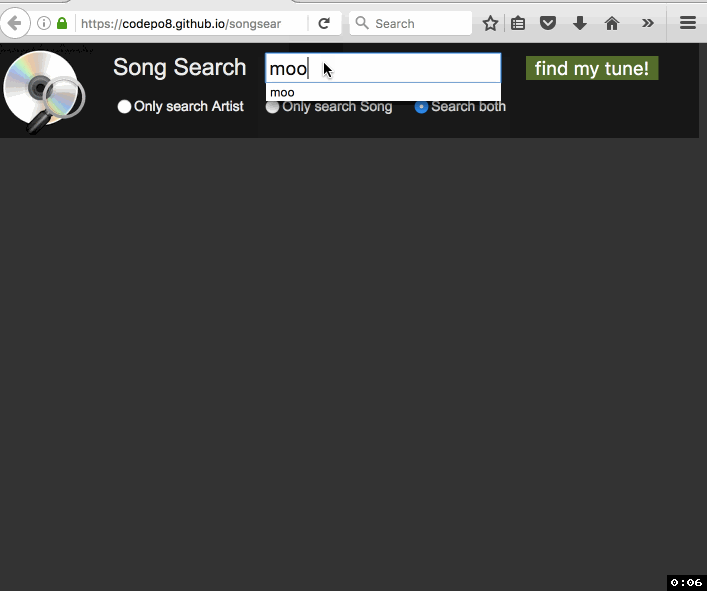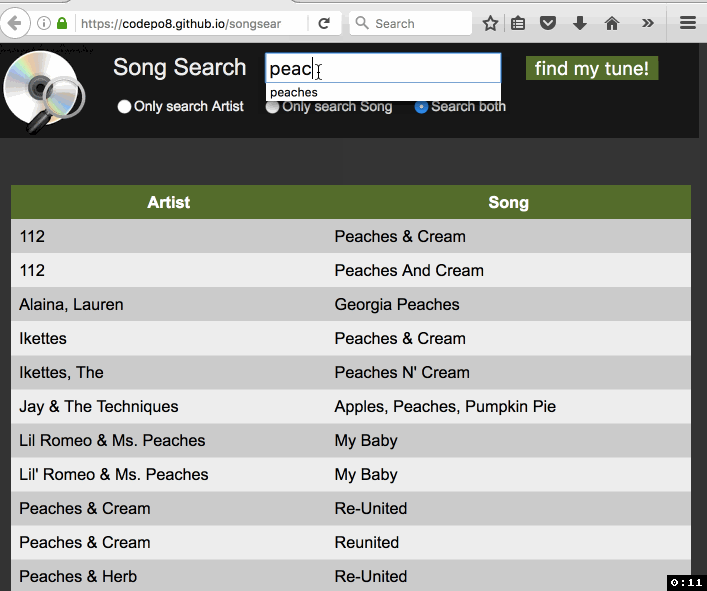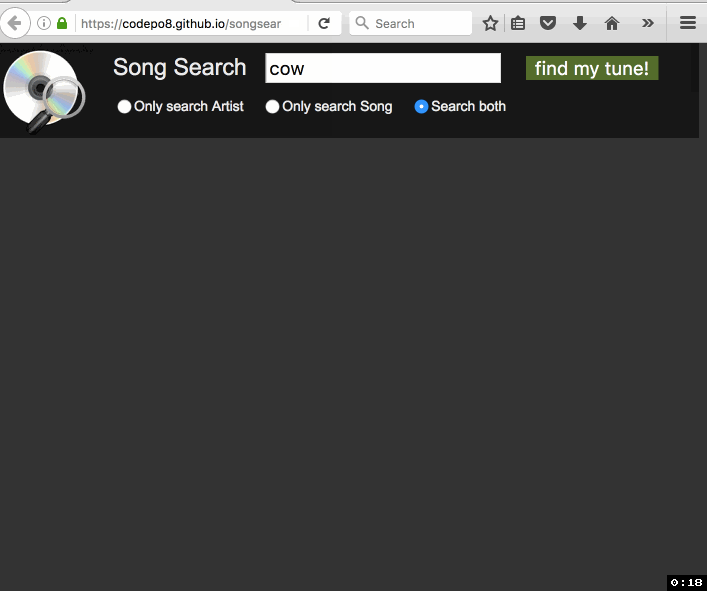
Here’s how I built it:
As you can see the first load gets the whole batch, but subsequent reloads of the app are almost immediate as all the data is cached by the ServiceWorker.
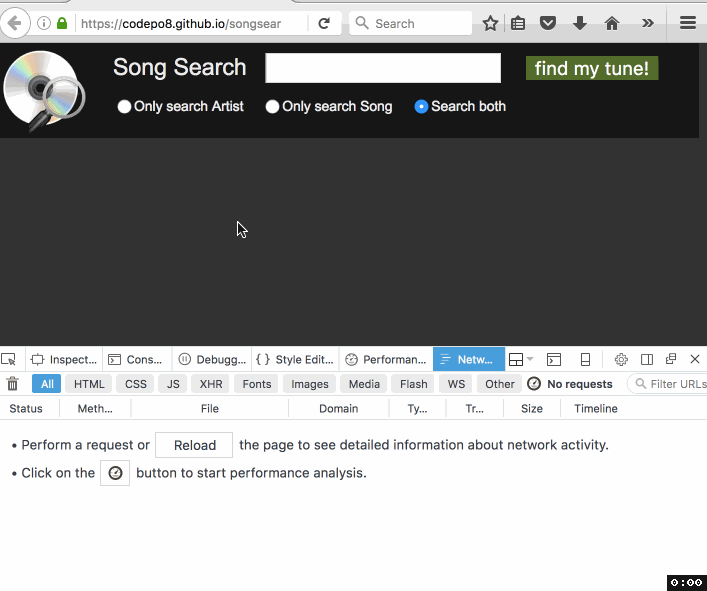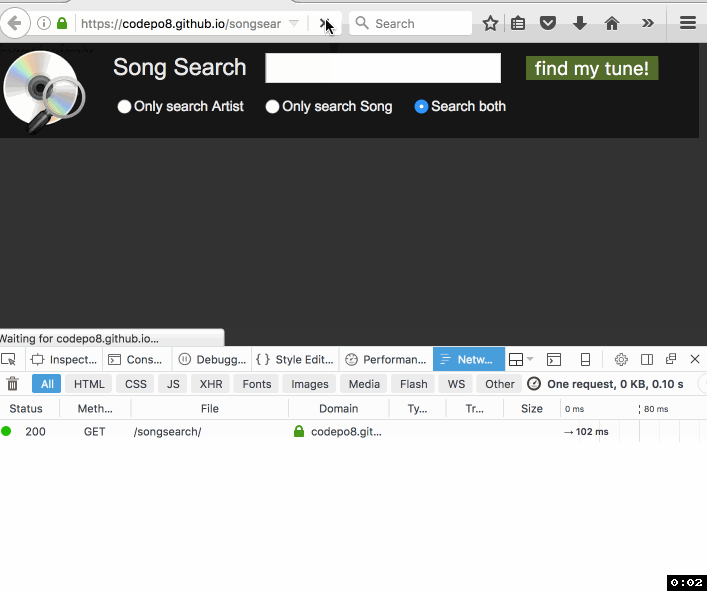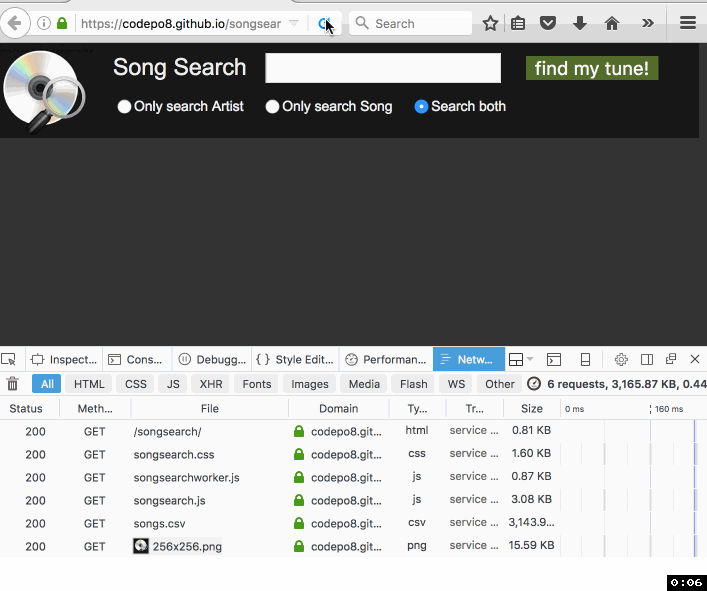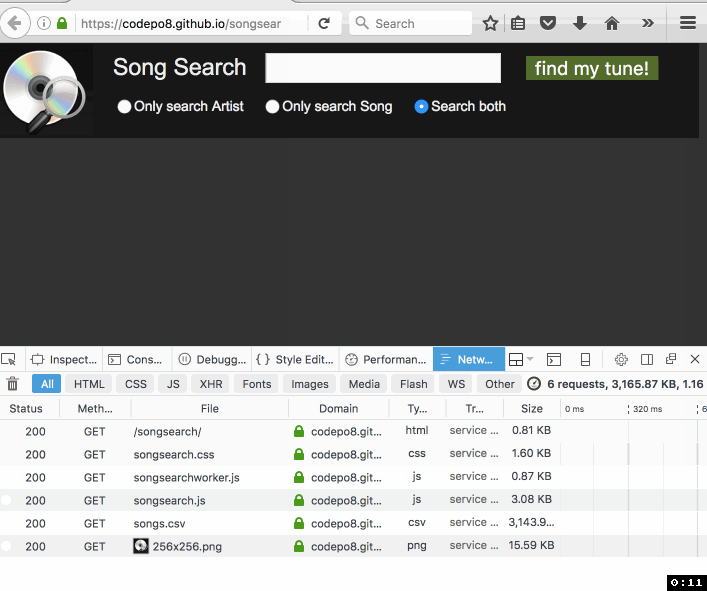
It’s not rocket science, it is not pretty, but it does the job and I made someone very happy. Take a look, maybe there is something in there that inspires you, too. I’m especially “proud” of the logo, which wasn’t at all done in Keynote :)
|
|
Mozilla Security Blog: Mitigating MIME Confusion Attacks in Firefox |
Scanning the content of a file allows web browsers to detect the format of a file regardless of the specified Content-Type by the web server. For example, if Firefox requests script from a web server and that web server sends that script using a Content-Type of “image/jpg” Firefox will successfully detect the actual format and will execute the script. This technique, colloquially known as “MIME sniffing”, compensates for incorrect, or even complete absence of metadata browsers need to interpret the contents of a page resource. Firefox uses contextual clues (the HTML element that triggered the fetch) or also inspects the initial bytes of media type loads to determine the correct content type. While MIME sniffing increases the web experience for the majority of users, it also opens up an attack vector known as MIME confusion attack.
Consider a web application which allows users to upload image files but does not verify that the user actually uploaded a valid image, e.g., the web application just checks for a valid file extension. This lack of verification allows an attacker to craft and upload an image which contains scripting content. The browser then renders the content as HTML opening the possibility for a Cross-Site Scripting attack (XSS). Even worse, some files can even be polyglots, which means their content satisfies two content types. E.g., a GIF can be crafted in a way to be valid image and also valid JavaScript and the correct interpretation of the file solely depends on the context.
Starting with Firefox 50, Firefox will reject stylesheets, images or scripts if their MIME type does not match the context in which the file is loaded if the server sends the response header “X-Content-Type-Options: nosniff” (view specification). More precisely, if the Content-Type of a file does not match the context (see detailed list of accepted Content-Types for each format underneath) Firefox will block the file, hence prevent such MIME confusion attacks and will display the following message in the console:
![]()
Valid Content-Types for Stylesheets:
– “text/css”
Valid Content-Types for images:
– have to start with “image/”
Valid Content-Types for Scripts:
– “application/javascript”
– “application/x-javascript”
– “application/ecmascript”
– “application/json”
– “text/ecmascript”
– “text/javascript”
– “text/json”
https://blog.mozilla.org/security/2016/08/26/mitigating-mime-confusion-attacks-in-firefox/
|
|






