Mike Hommey: Are all integer overflows equal? |
Background: I’ve been relearning Rust (more about that in a separate post, some time later), and in doing so, I chose to implement the low-level parts of git (I’ll touch the why in that separate post I just promised).
Disclaimer: It’s friday. This is not entirely(?) a serious post.
So, I was looking at Documentation/technical/index-format.txt, and saw:
32-bit number of index entries.
What? The index/staging area can’t handle more than ~4.3 billion files?
There I was, writing Rust code to write out the index.
try!(out.write_u32::(self.entries.len())); (For people familiar with the byteorder crate and wondering what NetworkOrder is, I have a use byteorder::BigEndian as NetworkOrder)
And the Rust compiler rightfully barfed:
error: mismatched types:
expected `u32`,
found `usize` [E0308]And there I was, wondering: “mmmm should I just add as u32 and silently truncate or … hey what does git do?”
And it turns out, git uses an unsigned int to track the number of entries in the first place, so there is no truncation happening.
Then I thought “but what happens when cache_nr reaches the max?”
Well, it turns out there’s only one obvious place where the field is incremented.
What? Holy coffin nails, Batman! No overflow check?
Wait a second, look 3 lines above that:
ALLOC_GROW(istate->cache, istate->cache_nr + 1, istate->cache_alloc);Yeah, obviously, if you’re incrementing cache_nr, you already have that many entries in memory. So, how big would that array be?
struct cache_entry **cache;
So it’s an array of pointers, assuming 64-bits pointers, that’s … ~34.3 GB. But, all those cache_nr entries are in memory too. How big is a cache entry?
struct cache_entry { struct hashmap_entry ent; struct stat_data ce_stat_data; unsigned int ce_mode; unsigned int ce_flags; unsigned int ce_namelen; unsigned int index; /* for link extension */ unsigned char sha1[20]; char name[FLEX_ARRAY]; /* more */ };
So, 4 ints, 20 bytes, and as many bytes as necessary to hold a path. And two inline structs. How big are they?
struct hashmap_entry { struct hashmap_entry *next; unsigned int hash; }; struct stat_data { struct cache_time sd_ctime; struct cache_time sd_mtime; unsigned int sd_dev; unsigned int sd_ino; unsigned int sd_uid; unsigned int sd_gid; unsigned int sd_size; };
Woohoo, nested structs.
struct cache_time { uint32_t sec; uint32_t nsec; };
So all in all, we’re looking at 1 + 2 + 2 + 5 + 4 32-bit integers, 1 64-bits pointer, 2 32-bits padding, 20 bytes of sha1, for a total of 92 bytes, not counting the variable size for file paths.
The average path length in mozilla-central, which only has slightly over 140 thousands of them, is 59 (including the terminal NUL character).
Let’s conservatively assume our crazy repository would have the same average, making the average cache entry 151 bytes.
But memory allocators usually allocate more than requested. In this particular case, with the default allocator on GNU/Linux, it’s 156 (weirdly enough, it’s 152 on my machine).
156 times 4.3 billion… 670 GB. Plus the 34.3 from the array of pointers: 704.3 GB. Of RAM. Not counting the memory allocator overhead of handling that. Or all the other things git might have in memory as well (which apparently involves a hashmap, too, but I won’t look at that, I promise).
I think one would have run out of memory before hitting that integer overflow.
Interestingly, looking at Documentation/technical/index-format.txt again, the on-disk format appears smaller, with 62 bytes per file instead of 92, so the corresponding index file would be smaller. (And in version 4, paths are prefix-compressed, so paths would be smaller too).
But having an index that large supposes those files are checked out. So let’s say I have an empty ext4 file system as large as possible (which I’m told is 2^60 bytes (1.15 billion gigabytes)). Creating a small empty ext4 tells me at least 10 inodes are allocated by default. I seem to remember there’s at least one reserved for the journal, there’s the top-level directory, and there’s lost+found ; there apparently are more. Obviously, on that very large file system, We’d have a git repository. git init with an empty template creates 9 files and directories, so that’s 19 more inodes taken. But git init doesn’t create an index, and doesn’t have any objects. We’d thus have at least one file for our hundreds of gigabyte index, and at least 2 who-knows-how-big files for the objects (a pack and its index). How many inodes does that leave us with?
The Linux kernel source tells us the number of inodes in an ext4 file system is stored in a 32-bits integer.
So all in all, if we had an empty very large file system, we’d only be able to store, at best, 2^32 – 22 files… And we wouldn’t even be able to get cache_nr to overflow.
… while following the rules. Because the index can keep files that have been removed, it is actually possible to fill the index without filling the file system. After hours (days? months? years? decades?*) of running
seq 0 4294967296 | while read i; do touch $i; git update-index --add $i; rm $i; doneOne should be able to reach the integer overflow. But that’d still require hundreds of gigabytes of disk space and even more RAM.
Ok, it’s actually much faster to do it hundreds of thousand files at a time, with something like:
seq 0 100000 4294967296 | while read i; do j=$(seq $i $(($i + 99999))); touch $j; git update-index --add $j; rm $j; doneAt the rate the first million files were added, still assuming a constant rate, it would take about a month on my machine. Considering reading/writing a list of a million files is a thousand times faster than reading a list of a billion files, assuming linear increase, we’re still talking about decades, and plentiful RAM. Fun fact: after leaving it run for 5 times as much as it had run for the first million files, it hasn’t even done half more…
One could generate the necessary hundreds-of-gigabytes index manually, that wouldn’t be too hard, and assuming it could be done at about 1 GB/s on a good machine with a good SSD, we’d be able to craft a close-to-explosion index within a few minutes. But we’d still lack the RAM to load it.
So, here is the open question: should I report that integer overflow?
Wow, that was some serious procrastination.
Edit: Epilogue: Actually, oops, there is a separate integer overflow on the reading side that can trigger a buffer overflow, that doesn’t actually require a large index, just a crafted header, demonstrating that yes, not all integer overflows are equal.
|
|
Brian R. Bondy: Shutting down Code Firefox |
On October 07, 2016 I'll be shutting down Code Firefox.
With over 100k unique visits and over 30k full video views, it helped hundreds of Mozillians and Mozilla employees get ramped up for hacking on Firefox. It was from the start a personal side project and wasn't funded or sponsored in any way.
It isn't being shutdown because of a conflict of interest with Brave, but instead because over time the content naturally becomes more obsolete as better development methods surface.
I'm happy with what it is and the purpose it had, but shutting it down is the responsible thing to do.
|
|
Anjana Vakil: Marionette, Act I: We’ve got Firefox on a string |
As you may already know, I’m spending my summer interning with Mozilla’s Enginering Productivity team through the Outreachy program. Specifically, the project I’m working on is called Test-driven Refactoring of Marionette’s Python Test Runner. But what exactly does that mean? What is Marionette, and what does it have to do with testing?
In this two-part series, I’d like to share a bit of what I’ve learned about the Marionette project, and how its various components help us test Firefox by allowing us to automatically control the browser from within. Today, in Act I, I’ll give an overview of how the Marionette server and client make the browser our puppet. Later on, in Act II, I’ll describe how the Marionette test harness and runner make automated testing a breeze, and let you in on the work I’m doing on the Marionette test runner for my internship.
And since we’re talking about puppets, you can bet there’s going to be a hell of a lot of Being John Malkovich references. Consider yourself warned!
On the one hand, you probably want to make sure that the browser’s interface, or chrome, is working as expected; that users can, say, open and close tabs and windows, type into the search bar, change preferences and so on. But you probably also want to test how the browser displays the actual web pages, or content, that you’re trying to, well, browse; that users can do things like click on links, interact with forms, or play video clips from their favorite movies.
Because let's be honest, that's like 96% of the point of the internet right there, no?
These two parts, chrome and content, are the main things the browser has to get right. So how do you test them?
Well, you could launch the browser application, type “Being John Malkovich” into the search bar and hit enter, check that a page of search results appears, click on a YouTube link and check that it takes you to a new page and starts playing a video, type “I
|
|
Support.Mozilla.Org: What’s Up with SUMO – 7th July |
Hello, SUMO Nation!
Welcome to the hot-hot-hot July! Wherever you are, remember – don’t melt! It’s a bit hard to achieve that over here (air conditioning only gets you so far), so I hope you’ll have an easier challenge on your side. Speaking of hotness – here are the red-hot-
If you just joined us, don’t hesitate – come over and say “hi” in the forums!
We salute you!
So… Are you still following the Euro 2016 cup games? Are you watching cool movies? Know some great music that you think we should all know about? Tell us in our forums!
https://blog.mozilla.org/sumo/2016/07/07/whats-up-with-sumo-7th-july/
|
|
Air Mozilla: Reps weekly, 07 Jul 2016 |
 This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
|
|
Air Mozilla: Web QA Team Meeting, 07 Jul 2016 |
 They say a Mozilla Web QA team member is the most fearless creature in the world. They say their jaws are powerful enough to crush...
They say a Mozilla Web QA team member is the most fearless creature in the world. They say their jaws are powerful enough to crush...
|
|
Andi-Bogdan Postelnicu: A more detailed look on some of Coverity’s checkers for static analysis |
On my previous post i’ve talked about what tools do we use at Mozilla for static analysis, now i want to take a closer look on some specific checkers triggered by Coverity and why i do consider them very useful.
ASSERT(a = 3);
This is an actual issue from Coverity that signals the problem and the eventual side effects that there could be.

 From this example is obvious that pointer aAcc is null checked on line 649 and later on line 651 it is dereferenced without null checking it. But what causes the null pointer dereference and how Coverity figured out that this is an actual issue? Looking further in the code we find:
From this example is obvious that pointer aAcc is null checked on line 649 and later on line 651 it is dereferenced without null checking it. But what causes the null pointer dereference and how Coverity figured out that this is an actual issue? Looking further in the code we find:
class Test {
public:
void print(std::string str) {
std::cout<<str<<std::endl; } }; int main(int argc, const char **argv) { Test *myCls = nullptr; myCls->print("Just A Test");
return 0;
}
The pointer is not needed to call the function, the type of the pointer is known so the code for the function is known and inside print we don’t dereference pointer this. In case the method would have been virtual the call would have failed since this would have been dereferenced.





Coverity is a great tool, with a low rate of false positive, it really achieves at being one of the best, but despite this i was very sad that it doesn’t have a very good support for thread analysis and nor it has support for any thread sanitisation checkers.
|
|
Robert O'Callahan: Ordered Maps For Stable Rust |
The canonical ordered-map type for Rust is std::collections::BTreeMap, which looks nice, except that the range methods are marked unstable and so can't be used at all except with the nightly-build Rust toolchain. Those methods are the only way to perform operations like "find first element greater than a given key", so BTreeMap is mostly useless in stable Rust.
This wouldn't be a big deal if crates.io had a good ordered-map library that worked with stable Rust ... but, as far as I can tell, until now it did not. I didn't want to switch to Rust nightly just to use ordered maps, so I solved this problem by forking container-rs's bst crate, modifying it to work on stable Rust (which meant ripping out a bunch of "unstable" annotations, fixing a few places that required unstable "box" syntax, and fixing some test code that depended on unboxed closures), and publishing the result as stable_bst. (Note: I haven't actually gotten around to using it yet, so maybe it's broken, but at least its tests pass.)
So, if you want to use ordered maps with stable Rust, give it a try. bst has a relatively simple implementation and, no doubt, is less efficient than BTreeMap, but it should be comparable to the usual C++ std::map implementations.
Currently it supports only C++-style lower_bound and upper_bound methods for finding elements less/greater than a given key. range methods similar to BTreeMap could easily be added, using a local copy of the unstable standard Bound type. I'm not sure if I'll bother but I'd accept PRs.
Update I realized the lower_bound and upper_bound methods were somewhat useless since they only return forward iterators, so I bit the bullet, implemented the range/range_mut methods, removed lower_bound/upper_bound and the reverse iterators which are superseded by range, and updated crates.io.
FWIW I really like the range API compared to C++-style upper/lower_bound. I always have to think carefully to use the C++ API correctly, whereas the range API is easy to use correctly: you specify upper and lower bounds, each of which can be unbounded, exclusive or inclusive, just like in mathematics. A nice feature of the range API (when implemented correctly!) is that if you happen to specify a lower bound greater than the upper bound, it returns an empty iterator, instead of returning some number of wrong elements --- or crashing exploitably --- as the obvious encoding in C++ would do.
Another somewhat obscure but cool feature of range is that the values for bounds don't have to be exactly the same type as the keys, if you set up traits correctly. ogoodman on github pointed out that in some obscure cases you want range endpoints that can't be expressed as key values. Their example is keys of type (A, B), lexicographically ordered, where B does not have min or max values (e.g., arbitrary-precision integers), and you want a range containing all keys with a specific value for A. With the BTreeMap and stable_bst::TreeMap APIs you can handle this by making the bounds be type B', where B' is B extended with artificial min/max values, and defining traits to order B/B' values appropriately.
http://robert.ocallahan.org/2016/07/ordered-maps-for-stable-rust.html
|
|
Nathan Froyd: on the usefulness of computer books |
I have a book, purchased during my undergraduate days, entitled Introduction to Algorithms. Said book contains a wealth of information about algorithms and data structures, has its own Wikipedia page, and even a snappy acronym people use (“CLRS”, for the first letters of its authors’ last names).
When I bought it, I expected it to be both an excellent textbook and a book I would refer to many times throughout my professional career. I cannot remember whether it was a good textbook in the context of my classes, and I cannot remember the last time I opened it to find some algorithm or verify some subtle point. Mostly, it has served two purposes: an excellent support for my monitor to position the monitor more closely to eye level, and as extra weight to move around when I have had to transfer my worldly possessions from place to place.
Whether this reflects on the sort of code I have worked on, or the rise of the Internet for answering questions, I am unsure.
I have another book, also purchased during my undergraduate days, entitled Programming with POSIX Threads. Said book contains a wealth of information about POSIX threads (“pthreads”), is only mentioned in “Further Reading” on the Wikipedia page for POSIX threads, and has no snappy acronym associated with it.
I purchased this book because I thought I might assemble a library of programming knowledge, and of course threads would be a part of that. Mostly, it would sit on the shelves to show people I was a Real Programmer(tm).
Instead, I have found it to be one of those books to always have close at hand, particularly working on Gecko. Its explanations of the basic concepts of synchronization are clear and extensive, its examples of how to structure multithreaded algorithms are excellent, and its secondary coverage of “real-world” things such as memory ordering and signals + threads (short version: “don’t”) have been helpful when people have asked me for opinions or to review multi-threaded code. When I have not followed the advice of this book, I have found myself in trouble later on.
My sense when searching for some of the same topics the book covers is that finding the same quality of coverage for those topics online is rather difficult, even taking into account that topics might be covered by disparate people.
If I had to trim my computer book library down significantly, I’m pretty sure I know what book I would choose.
What book have you found unexpectedly (un)helpful in your programming life?
https://blog.mozilla.org/nfroyd/2016/07/06/on-the-usefulness-of-computer-books/
|
|
Air Mozilla: The Joy of Coding - Episode 62 |
 mconley livehacks on real Firefox bugs while thinking aloud.
mconley livehacks on real Firefox bugs while thinking aloud.
|
|
Air Mozilla: Weekly SUMO Community Meeting July 6, 2016 |
 This is the sumo weekly call
This is the sumo weekly call
https://air.mozilla.org/weekly-sumo-community-meeting-july-6-2016/
|
|
Christian Heilmann: Things not to say on stage at a tech event |

This is also available on Medium
This is not about a post about trigger words or discriminatory expressions. There is a lot of information about this available, and even some excellent linting tools for your texts. It is also not about unconscious bias. Or well, maybe it is. Learned bias for sure.
This is a post about some sentences used in technical presentations that sound encouraging. In reality they may exclude people in the audience and make them feel bad about their level of knowledge. These are the following sentences and I’ll explain in detail how to replace them with something less destructive:
None of these are a show-stopper and make you a terrible presenter. There may even be ways to use them that are not confusing and destructive. This is language, and in some cultures they may be OK to use. I’m not here to tell people off. I am here to make you aware that something that sounds good might make people feel bad. And that’s not what we’re here for as presenters.
As a presenter your job is not only to give out technical information. You also need to inspire and to entertain. Often you overshoot the mark by simplifying things and trying to hard to please.
It is important to remind ourselves that we can not assume much of our audience. The room might be full of experts, but the video recording is also going out to everybody. Explaining things in a simple fashion is not dumbing them down. It may actually be the hardest task there is for a presenter.
It is stressful to be at an expert event. As an audience member you don’t want to appear less able than others. As a presenter, it is worse. Presenting is a balancing act. You neither want to sound condescending, overload the audience, make people feel stupid, appear too basic … and, and, and…
I’ve heard the following expressions at a lot of events and I always cringed a bit. Often they are OK, and no harm done. But,to improve as presenters it may be a good idea to be more conscious about what we do and what effects it can have.
We often try to calm down the audience by making what we show appear simple. The problem with that is that what is simple for us might still be confusing to the people in the room. Add peer-pressure to that and people will neither speak up that they don’t understand, nor feel empowered. The opposite applies – by saying something is easy and people failing to grasp or apply it, we make them feel stupid. If you make me feel stupid, you may inspire me to get better. But I don’t do it for the right reason – I do it out of guilt and self-doubt.
The worst way to use “this is easy” is when you rely on a lot of abstractions or tools to achieve the easy bit. Each of those could be a stumbling block for people applying your wisdom.
Replacements:
Using these you send people on a journey. They don’t tell them that the end result is already a given. Who knows, they may find a way to improve your “easy” one.
This expression just fell at a conference I attended and it made me cringe. The presenter meant to be encouraging in a “hey, we all are already on board” way, but it can come across as arrogant. Even worse, it already singles out those who do not know, and makes them feel like they are under a spotlight.
If the intention is to do a quick intro on what you want to build upon, it is better to phrase it as a reminder, not a “you already know, what am I doing here”.
Replacements
This adds your repetition into the flow instead of being an excuse.
If everybody can do it, why do I listen to you? Also, if everybody can do it, how come I never managed to? If you use this you either present something basic, or you over-simplify a complex matter. The latter can appear to be empowering; you take away the fear of approaching something. But, it backfires when people can’t use it. Then you exclude them from “everybody”. And that hurts.
Replacements:
This again makes it a reminder and a starting point of a journey. Not a given that is redundant to repeat.
Hooray for your product – it solves everything. Now buy it and impress people with wisdom you don’t have. And feel worse when you get praised for it. This is a classic sales pitch which works with end user products. As a developer you should always worry about what you use in your products as each part can become an issue. And it will be up to you to fix it.
Replacements
Pop open the hood, show how your product works. Don’t sell all-healing remedies.
Common knowledge is a myth and relies on your environment, access to information, time to consume news and the way you learn. Presenting something as common knowledge may make people think “so how come I ever heard of it?” and stop them in their tracks.
Replacements:
“Citation needed” is a wonderful way to say something and prove your point. You show people that you did your homework before you make an assumption. And you give those who did not the tools to do so.
This assumes everybody went to a school with the same curriculum as you. A lot of people have not. This is especially destructive when it applies to knowledge that was part of a Computer Science degree.
Replacements:
A lot of people create the web. Not all took the official path.
This is common in advertising, especially in America. You show off your product by making others look worse. This is pointless and only invites criticism and retaliation by others. As a tech presenter, you should know that the other product is also built by people. Final decision of what gets shipped are not always based on technical merit. It is a cheap shot.
Replacements:
Showing you know about your competition prevents questions about it. Showing how they differ allows people to make up their mind which is better instead of you telling them and hoping they agree.
The amount of code has become a contrived way of showing how effective our solutions are. Almost always the “quick and small solution” blossoms into a much larger one once it is used in production. It makes much more pragmatic sense to tell people that this is inevitable, and praise the small starting point for what it is – a start.
Replacements:
A lot of times, this solves our own issue of showing only a few lines of code on a slide. Instead, let’s write understandable code that we explain in sections rather than one magical tidbit.
People have different opinions what a “professional” is. Whilst we worry about quality and maintenance, other people put more merit on fast delivery. The state of the art changes all the time, and a sentence like this can look silly in a few weeks.
Replacements:
You achieve professionalism with experience and by learning about new thing and retaining them. Things people say on stage and define as “best practice” need validation by professionals. It is not up to you as a presenter to define that.
There are more unintentional destructive expressions. Read through your talks and watch your videos and then ask yourself: “how would I feel listening to this if I didn’t know what I know?”. Then remove or rephrase accordingly.
Our market grew as fast as it did by being non-discriminatory of background or level of education. Granted, most of us grew up in safe environments and were lucky enough to have free schooling. But there are a lot of people in our midst who came from nowhere or at least nowhere near computer science. And they do great work. I’d go so far as to say that the diversity of backgrounds made the web what it is now: a beautiful mess that keeps evolving into who knows what. It is anything but boring. There is never “one way” to reach a goal. We discovered a lot of our solutions by celebrating different points of view.
Photo by alyona_fedotova
https://www.christianheilmann.com/2016/07/06/things-not-to-say-on-stage-at-a-tech-event/
|
|
Botond Ballo: Trip Report: C++ Standards Meeting in Oulu, June 2016 |
| Project | What’s in it? | Status |
| C++17 | See below | Committee Draft published; final publication on track for 2017 |
| Filesystems TS | Standard filesystem interface | Published! Part of C++17 |
| Library Fundamentals TS I | optional, any, string_view and more |
Published! Part of C++17 |
| Library Fundamentals TS II | source code information capture and various utilities | Resolution of comments from national standards bodies in progress |
| Concepts (“Lite”) TS | Constrained templates | Published! Not part of C++17 |
| Parallelism TS vI | Parallel versions of STL algorithms | Published! Part of C++17 |
| Parallelism TS v2 | TBD. Exploring task blocks, progress guarantees, SIMD. | Under active development |
| Transactional Memory TS | Transaction support | Published! Not part of C++17 |
| Concurrency TS v1 | future.then(), latches and barriers, atomic smart pointers |
Published! Not part of C++17 |
| Concurrency TS v2 | TBD. Exploring executors, synchronic types, atomic views, concurrent data structures | Under active development |
| Networking TS | Sockets library based on Boost.ASIO | Wording review of the spec in progress |
| Ranges TS | Range-based algorithms and views | Wording review of the spec in progress |
| Numerics TS | Various numerical facilities | Under active development |
| Array Extensions TS | Stack arrays whose size is not known at compile time | Withdrawn; any future proposals will target a different vehicle |
| Modules TS | A component system to supersede the textual header file inclusion model | Initial TS wording reflects Microsoft’s design; changes proposed by Clang implementers expected. Not part of C++17. |
| Graphics TS | 2D drawing API | Design review in progress |
| Coroutines TS | Resumable functions | Initial TS wording reflects Microsoft’s await design; changes proposed by others expected. Not part of C++17. |
| Reflection | Code introspection and (later) reification mechanisms | Introspection proposal undergoing design review; likely to target a future TS |
| Contracts | Preconditions, postconditions, and assertions | Design review in progress. Not part of C++17. |
Last week I attended a meeting of the ISO C++ Standards Committee (also known as WG21) in Oulu, Finland. This was the second committee meeting in 2016; you can find my reports on previous meetings here (October 2015, Kona) and here (February 2016, Jacksonville), and earlier ones linked from those. These reports, particularly the Jacksonville one, provide useful context for this post.
This meeting was sharply focused on C++17. The goal of the meeting was to publish a Committee Draft (CD) of the C++17 spec. The CD is the first official draft that’s sent out for comment from national standards bodies; that’s followed up by one or more rounds of addressing comments and putting out a new draft, and then eventual publication.
The procedure WG21 follows is that the spec needs to be feature-complete by the time the CD is published, so that national standards bodies have adequate opportunities to comment on the features. That means this was the last meeting to vote new features into C++17, and consequently, all committee subgroups were focused on finishing work on C++17-bound features. (The Evolution and Library Evolution groups did have a chance of review some post-C++17 proposals as well, which I’ll talk about below.)
Work on Technical Specifications (TS’s) continued as well, but was noticeably muted due to the focus on C++17.
As I mentioned, this meeting was the “feature complete” deadline for C++17, so by now we know what features C++17 will contain. Let’s see what made it:
See my Jacksonville report for features that were already voted into C++17 coming into the Oulu meeting.
pair p(42, "waldo"); // C++14
pair p(42, "waldo"); // C++17; template arguments deduced
// Would have deduced tuple,
// but tuple is a well-formed type in and of itself!
tuple t(42, "waldo", 2.0f);
template std::launder(). (Don’t ask. If you’re not one of the 5 or so people in the world who already know what this is, you don’t want or need to know.)if constexprconst, and constexpr on a namespace-scope variable no longer implies inline. This was mildly controversial, but was adopted nonetheless.
tuple foo();
auto [a, b, c] = foo(); // a, b, and c are bound to the elements of the tuple
std::variant, a discriminated union type (known as a “sum type” in functional programming languages).std::optional and the newly added std::variant to reflect the semantics of the contained object more closely.std::optional, std::any, and std::variant more uniformstd::string and std::string_viewhas_unique_object_representations (formerly called is_contiguous_layout)uninitialized_move(). This is mostly of interest to library implementers.emplace() methods of sequence containers return a reference to the newly created objectsstd::functionshared_ptr::weak_typemake_from_tuple()polymorphic_allocator‘s operator=not_fnstring_view support in filesystemterminate() if an exception escapes from a parallel algorithm. This is an interim solution until we can figure out a better way of handling this (see the link for some background). (This proposal is also notable for having by far the most amusing title of the bunch: it’s called “Hotel Parallelifornia”, because you can throw exceptions all you want inside a parallel algorithm, but they can never get out :)).memory_order_consume until we figure out how to improve itstd2 for future use. This foreshadows the eventual standardization of a “v2” of the C++ standard library that will not necessarily be backward-compatible with the current version. While we were at it, we also reserved std3 and all subsequent numbers.In my Jacksonville report, I talked about several features that were proposed for C++17 at that meeting, but didn’t make the cut: Concepts (available instead as a published Technical Specification), Coroutines (targeting instead a work-in-progress Technical Specification), and unified function call syntax (abandoned altogether, at least for now).
At this meeting, a few additional features originally targeting C++17 were axed.
I predicted in my last report that default comparisons might turn out to be controversial, and it turned out to be quite so.
Concerns raised about this fell into several broad categories:
operator== and operator!= made conceptual sense, but generating operator< and its counterparts (operator>, operator<=, and operator>=) did not.operator< meant that subsequent changes to the order of declaration of class members would change the semantics of the comparison.operator< and its counterparts, were not a good fit for the low-level model of the language. The details here are a bit sublime (see the proposal wording if you’re interested, particularly around operator<=), but the gist is that the generator operators don’t behave exactly the same as a hand-written function would have in some respects.As a result of the above concerns, the proposal did not gain consensus to go into C++17.
Most of the objections were to operator< and its counterparts; operator== and operator!= were, by comparison (no pun intended), relatively uncontroversial. The question of just moving forward with the operator== and != parts thus naturally came up. However, this met opposition from some who felt strongly that the two parts of the feature belonged together, and in any case there was no time to formulate a subsetted proposal and assess its implications. The feature thus missed the C++17 train altogether.
I fully expect default comparisons to come back for C++20, though perhaps with aspects of the design space (such as opt-in vs. opt-out) revisited.
Operator dot also attracted a fair amount of controversy. Among other things, a late-stage alternative proposal which presented some concerns with the original design and offered an alternative, was brought forward.
In the end, though, it wasn’t these concerns that defeated the original proposal. Rather, wording review of the proposal revealed some design issues that the proposal authors hadn’t considered. The issues were related to how operator dot invocations fit into conversion sequences – when are they considered, relative to base-to-derived conversions, other standard conversions, and user-defined conversions. It was too late to hash out a consistent design that answered these questions “on the spot”, so the proposal was withdrawn from consideration for C++17.
I expect this, too, will come back for C++20, with the alternative proposal as possible competition. [Update: I’ve since seen Herb Sutter’s trip report, where he hints that operator dot may in fact come back for C++17, by means of a national body comment on the C++17 Committee Draft asking that it be included. This way of sneakily adding features into a C++ release after the official feature-complete deadline sometimes works, but the bar is high and of course there are no guarantees.]
(It’s worth keeping a mind that there is yet another proposal for operator dot, which was handed to the Reflection Study Group, because it was sufficiently powerful to serve as the basis for a full-blown code reification mechanism. There remains a minority who believe that all other operator dot proposals should be put on hold while we wait for the Reflection Study Group to get to developing that.)
joining_thread, a proposed wrapper around std::thread whose destructor joins the thread if it’s still running, rather than terminating the program. A concern was brought forward that use of such a wrapper without sufficient care could lead to deadlocks and other more-subtle-than-termination misbehaviour. As a result, the proposal lost consensus to move forward. I personally don’t view this as a great loss; it’s straightforward for users to write such a wrapper themselves, and its absence in the standard library might prompt a prospective user to do enough research to become conscious of things like the deadlock issue that they otherwise may have overlooked.swap() accepts unequal allocators. This proved to be controversial during discussions in the library working groups, and was postponed for further study post-C++17.I mentioned that the primary goal of the meeting was to publish the Committee Draft or CD of C++17 for comment by national standards bodies. This goal was accomplished: the Committee voted to publish the C++17 Working Draft, with the approved proposals listed above merged into it, as the CD. (An updated Working Draft that includes the merges will be forthcoming within a few weeks of the meeting.)
This means C++17 is on track to be published in 2017! The “train” (referring to the 3-year release train model adopted by the Committee after C++11) is on schedule![]()
The features below weren’t in the limelight at this meeting, since they were previously decided not to target C++17, but as they’re very popular, I’ll give a status update on them all the same.
The Concepts TS was published last year, but was not merged into C++17. What does that mean going forward? It means it has a Working Draft, available to accept fixes (and in fact one such fix was voted in at this meeting) and larger changes (one such larger change was already proposed, and more are expected in the near future).
This Working Draft can eventually be published in a form of the Committee’s choosing – could be as a Concepts TS v2, or merged into a future version of the International Standard (such as C++20).
Coroutines are targeting a Technical Specification which is still a work in progress. The initial contents of the TS are set to be the latest draft of Microsoft’s co_await proposal, but there are also efforts to generalize that into a form that can also admit other execution models, such as “stackful” coroutines. EWG looked briefly at this latter proposal, but otherwise no notable progress was made; everyone was busy with C++17.
Modules is in a similar state to Coroutines: there’s a proposal by Microsoft which is slated to become the initial content of a Modules TS, and there are proposed design changes pending resolution. As with Coroutines, no notable progress was made this week, the focus being on C++17 features.
Reflection continues to be actively worked on by the Reflection Study Group, which met this meet to review the design of its chosen static introspection proposal; I talk about this meeting below.
As has become my habit, I sat in the Evolution Working Group (EWG) for the duration of the meeting. This group spends its time evaluating and reviewing the design of proposed language features.
As with all groups, EWG’s priority this meeting was C++17, but, being “ahead in the queue” of other groups (language proposals typically start in EWG and then progress to the Core Working Group (CWG) for wording review, and if appropriate, the Library groups for review of any library changes in them), it also had time to review a respectable number of C++20 features.
I’ll talk about the C++17-track features first. (Being listed here doesn’t mean they made C++17, just that they were considered for it; see above for what made it.) In most cases, these were features previously approved by EWG, which were revisited for specific reasons.
operator== and != only, which became a general discussion of the feature, during which many of the concerns mentioned above were articulated. EWG considered several changes in direction, including dropping the default generation of operator< and counterparts as suggested, and moving to an opt-in approach, but neither of these gained consensus, and the unmodified design was submitted for a vote in plenary (which then failed, as I related above).sizeof (that is, sizeof(my_smart_reference) still returns the size of the reference wrapper type, and not of the referred-to type).if constexpr and generic lambdas. The source of the problem is the semantics of default captures for generic lambdas. C++ says that if a lambda has a default capture, then a variable named inside the lambda is covered by the capture only if the the occurrence of the name is an odr-use (this is a term of art that roughly means “a use requiring the variable to have allocated storage and an address”); however, for a generic lambda, whether a use of a name is an odr-use can depend on the arguments you’re calling the lambda with. This leads to an interaction with if constexpr where determining captures can require instantiating a branch of code whose instantiation would otherwise have been disabled by an if constexpr, leading to an undesirable hard error. EWG’s suggestion was to revise the default capture rules for generic lambdas, perhaps to always require named variables to be captured. (Meanwhile, the if constexpr proposal itself isn’t held up over this or anything.)inline if they were const; this was meant to discourage mutable global state. It was pointed out that this can be worked around in several ways (for example, by making the variable a reference to a mutable object, or by making it a variable template, which has no such restrictions). Rather than trying to stymie these workaround approaches, EWG decided to just lift the restriction, making the feature simpler.constexpr imply inline. CWG pointed out that for namespace-scope variables, this would change the linkage of existing constexpr variables, breaking existing code. As a result, for namespace-scope variables, constexpr no longer implies inline (for static data members of classes, it still does, because there is no linkage issue there).
template struct small_vector { small_vector(T fill); };
small_vector<3> v(42); // N is specified, T is deduced
tuple t("waldo", 42, 2.0f);
tuple given that tuple is also a valid type.auto for the ones that should be deduced:
tuple t("waldo", 42, 2.0f);
tuple t(std::string("waldo"), 42, 2.0f); // all arguments deduced
template was briefly revisited to resolve an issue where certain code examples involving deduction of a non-type template parameter from an array bound would become ambiguous. EWG requested that the deduction rules be tweaked to avoid introducing the ambiguity, at the expense of making the already complicated deduction rules even more so; see the paper for details.std::tuple_size to return the number of elements, std::tuple_element to return the type of each element, and std::get to return a reference to each element. Several people, including the author of this paper, expressed a desire to have a customization point that’s more specific to this feature, and/or one that operated by ADL rather than by specialization. EWG was sympathetic to this, but believed that “tuple-like” should be at least one of the customization points (for consistency with operations like std::tuple_cat()), and that it’s good enough as the only customization point in C++17; the Library Evolution Working Group can then design a nicer customization point in the C++20 timeframe.std::get to return a proxy type that assigns through to the bitfield element; this was deemed a good enough solution until the problem of not being able to form a reference to a bitfield is addressed more comprehensively by the core language.if statements with an initializer.if statement if the variable’s type is contextually convertible to bool. For example, you can do this:
if (Type* foo = GetFoo()) {
...
}
if statement will execute if foo is not nullptr.foo above the if statement is that the scope of foo is limited to the if statement (including any else block).bool, but you still want to check something about it, and only use it if the check passes. This proposal allows you to do this while keeping the variable’s scope local to the if, by combining a declaration with an expression to test:
if (Type foo = func(); foo.isOk()) {
...
}
EWG really liked this, so much that they made an exception to the previously-agreed rule that new features first proposed at this meeting wouldn’t be considered for C++17. Two small modifications were requested: that the feature work for if constexpr and switch as well.
Now let’s move on to the C++20-track features. I’ll categorize these into my usual “accepted”, “further work encouraged”, and “rejected” categories:
Accepted proposals:
struct Point { int x; int y; };
void foo(Point);
...
foo({ .x = 2, .y = 3});
Proposals for which further work is encouraged:
void, a proposal to remove most instances of special-case treatment of void in the language, making it behave like any other type. The general idea enjoyed an increased level of support since its initial presentation two meetings ago, but some details were still contentious, most notably the ability to delete pointers of type void*. The author was encouraged to come back with a revised proposal, and perhaps an implementation to help rule out unexpected complications.decltype(return-expr), bringing it into the immediate context of the call.) The proposed solution is to extend SFINAE to function bodies in certain contexts, with some important limitations to avoid some of the problems with extending SFINAE to function bodies in general (such as the need to mangle the function’s body into the name).[[visible]] attribute, intended to be a standard version of things like __declspec(dllexport) and __attribute__((visibility("default"))). EWG recognized that there’s a widespread desire for something like this, but also noted that interactions with Modules should be considered, and suggested further exploration of the problem space.[](auto... args){ f(args...); }), but this proposal would allow you to just write f instead.f resolves to a single, non-template function, you can pass it as an argument today, and it becomes a pointer to the target function. Changing this (to “package” f into a function object as in the case where it’s an overloaded name) would break existing call sites, so the proposal restricts the “packaging” to the case where it is in fact an overloaded name. But this means that, for a given call site that passes f, whether or not it gets “packaged” depends on how many declarations of f are in scope at the call site. As argued in this paper, this can depend on what headers are included prior to the call site, which can vary from one translation unit to another, making it very easy to get into ODR violations. EWG agreed that to avoid this, a new syntax is necessary: []f will always package the name f into a function object, no matter how many declarations of f are in scope (a plain f, meanwhile, will retain its existing meaning of “function pointer if f is a single non-template function, ill-formed otherwise”).decltype(). EWG approved of the intent, but the exact rules need nailing down to ensure that we don’t allow situations that would require mangling a lambda expression into a symbol name.std::variant, which was standardized at this meeting. It would have named alternatives, which means it would be to std::variant as structs are to std::tuple.co_await syntax, and thus can have the same performance characteristics (for example, avoiding dynamic memory allocation in many cases), but can also be used in a stackful way when the flexibility offered by that (for example, the ability to suspend from inside code that the compiler hasn’t transformed into a coroutine representation) is desired. The machinery that would enable this to work is that the compiler, guided by “suspendable” annotations, would compile a function either normally, or into a coroutine representation (or both), much as how in the Transactional Memory TS, the compiler can create transaction-safe and transaction-unsafe versions of a function. The usual questions of whether such “suspendable” annotations are part of a function’s type, and what the impact of this bifurcation of the set of generated functions on binary size and linking time is, came up. The conclusion was that the area needs more exploration, and implementation experience would be particuarly helpful.... tokens sprinkled around fairly liberally). It was also pointed out that the proposal has the potential to bring significant compile-time gains by reducing the amount of metaprogramming required to achieve common tasks, and care should be taken to ensure this potential is realized to its fullest extent.Rejected proposals:
a <... b, because their expansion (a_1 < a_2 < ... < a_n < b if a is the pack) is almost certainly not what the user wants (in C++, a < b < c means “compare a and b, and then take the boolean result of that comparison and compare it to c“, not (a < b) && (b < c)). EWG’s view was that we don’t gain much by disallowing them; what we’d really want to do is specify them to do the sensible thing, but we can’t do that without also changing what a < b < c means (because consistency), and it’s too late to change that (because backwards compatibility).[[exhaustive]] attribute for enumerations, which tells the compiler this is an enumeration whose instances should only take on the value of one of the specified enumerators (as opposed to an enumeration that functions as a bit vector, or an enumeration whose set of values is meant to be extended by the user), and thus guides compiler diagnostics. EWG pointed out that most enumerations are exhaustive, and we want to be annotating the exception, not the norm. However, there wasn’t much appetite for a “non-exhaustive” annotation, either; implementers were of the opinion that current heuristics for diagnostics for switch statements on enumerations are sufficient.pmem to be called as pmem(obj, args) in addition to the current obj.*pmem(args). There was no consensus for making this change; the opposition was mainly over the fact that this looked like a step towards unified function call syntax, which was rejected at the last meeting (even though it was pointed out that this proposal is rather unlike unified call syntax, as it does not change any lookup ryules).unsigned long long. This was rejected, mostly because no one could remember what the original reason was for the restriction, and people were hesitant to move forward without knowing that.char8_t character type to represent UTF-8 data. EWG was of the opinion that this would be doable, but it would come with some cost (for example, it would be an ABI-breaking change for code that currently typedefs char8_t to be (unsigned) char, similar to how the introduction of the C++11 char16_t and char32_t types was; there is also code in the wild that uses char8_t as a completely different kind of type (e.g. an empty “tag” structure), which would break more severely). The suggested way forward was for the Library Evolution group to decide on a strategy for handling UTF-8 data (perhaps the answer is “just use std::string“, in which case no language changes are needed), and then see what the language can do to help accommodate that design.const inheritance, a new form of inheritance that would allow the derived class to access the base class only through a const reference. EWG did not find this change to be sufficiently motivated.
auto start = std::chrono::high_resolution_clock::now(); // #1
operation_to_be_timed(); // #2
auto end = std::chrono::high_resolution_clock::now(); // #3
clock::now() observes the current time; to make sure that a particular operation X is not re-ordered with clock::now(), that operation needs to be annotated as modifying the current time ; but every operation “modifies the current time” by taking time to run, so every operation would need to be so annotated. That same StackOverflow answer points to some practical ways to solve this problem..). EWG felt that having to modify call sites defeated the purpose.There were a few C++20-track proposals that weren’t looked at because no one was present to champion them, or because there was no time. They’ll be picked up in due course.
As I’ve been sitting in EWG for the week, I didn’t have a chance to follow the library side of things very closely, but I’ll mention some highlights.
First, obviously the Library Working Group (LWG) has been quite busy reviewing the wording for the variety of library proposals voted into C++17 at the end of the meeting. A particularly notable success story is variant being standardized in time for C++17; that proposal has come a long way since two meetings ago, when no one could agree on how to approach certain design issues. (There are still some who are unhappy with the current “valueless by exception” state, and are proposing inventive approaches for avoiding it; however, the consensus was to move forward with the current design.)
A notable library proposal that was pulled from C++17 is joining_thread, for reasons explained above.
The Library Evolution Working Group (LEWG) mostly looked at post-C++17 material (see here for a list of proposals). LEWG’s view on ship vehicles has shifted a bit; until recently, most proposals ended up targetting a Technical Specification of some sort (often one in the Library Fundamentals series), but going forward LEWG plans to target the International Standard directly more often. As a result, a lot of the proposals reviewed at this meeting will likely target C++20.
There are also various library Technical Specifications in flight.
The Library Fundamentals TS v2 has had a draft sent to national standards bodies for comment, and now needs these comments to be addressed prior to final publication. It was originally intended for this process to be completed at this meeting, but with the heavy focus on C++17, it slipped to the next meeting.
LEWG spent a significant amount of time reviewing the Graphics TS, which will provide 2D graphics primitives to C++ programmers. The proposal is progressing towards being sent onwards to LWG, but isn’t quite there yet.
Not much progress has been made on the Ranges TS and the Networking TS, again due to the focus on C++17. LEWG did review a proposal for minor design changes to the Ranges TS, and approved some of them.
Due to the meeting’s emphasis on C++17, most study groups did not meet, but I’ll talk about the few that did.
SG 1 spent some time reviewing concurrency-related proposals slated for C++17, such as the handling of exceptions in parallel algorithms, as well as advancing its post-C++17 work: the second revisions of the Concurrency and Parallelism Technical Specifications.
The Concurrency TS v2 is slated to contain, among other things, support for floating-point atomics, atomic_view, a synchronized value abstraction, and emplace() for promise and future.
The Parallelism TS v2 is expected to contain a low-level library vector facility (datapar), as well as more forward-looking things (see proposals tagged “Concurrency” here).
SG 7 met for an evening session to provide design feedback on an updated version of the proposal that was chosen as the preferred approach for static code introspection at the last meeting.
The discussion focused most heavily on a particular design choice made by the proposal: the ability to reflect typedefs as separate from their underlying types (so for example, the ability for the reflection facility to distinguish between a use of std::size_t and a use of unsigned long, even if the former is a typedef for the latter). The issue is that the language does not treat typedefs as semantic entities in their own right, and a reflection facility pretending t
|
|
Daniel Pocock: Avoiding SMS vendor lock-in with SMPP |
There is increasing demand for SMS notifications about monitoring alerts, trading notifications, flight delays and other events. Various companies are offering SMS transmission services to meet this demand and many of them aggressively pushing their own proprietary interfaces to the SMS world rather than using the more open and widely supported SMPP.
There is good reason for this: if users write lots of of scripts to access the REST API of an SMS service, the users won't be able to change their service provider without having to change all their code. Well, that is good if you are an SMPP vendor but not if you are their customer. If an SMS gateway company goes out of business or has a system meltdown, the customers linked to their REST API will have a much bigger effort to migrate to a new provider than those using SMPP.
The HTTP REST APIs offered by many vendors hide some details of the SMS protocol and payload. At first glance, this may feel easier. In fact, this leads to unpredictable results when delivering messages to users in different countries and different character sets/languages. It is better to start with SMPP from the beginning and avoid discovering those pitfalls later. The SMS Router free/open source software project helps overcome the SMPP learning curve by using APIs you are already familiar with.
More troublesome for large organizations, some of the REST APIs offered by SMS gateways want to make callbacks to your own servers: this means your servers need public IP addresses accessible from the Internet. In some organizations that can take months to organize. SMPP works over one or more outgoing TCP connections initiated from your own server(s) and doesn't require any callback connections from the SMPP gateway.
SMS Router lets SMS users have the best of both worlds: the flexibility of linking to any provider who supports SMPP and the convenience of putting messages into the system using any of the transports supported by an Apache Camel component. Popular examples include camel-jms (JMS) for Java and J2EE users, STOMP for scripting languages, camel-mail (SMTP and IMAP) for email integration and camel-sip (SIP) or camel-xmpp (XMPP) for chat/instant messaging systems. If you really want to, you can also create your own in-house HTTP REST API too using camel-restlet for internal applications. In all these cases, SMS Router always uses standard SMPP to reach any gateway of your choice.
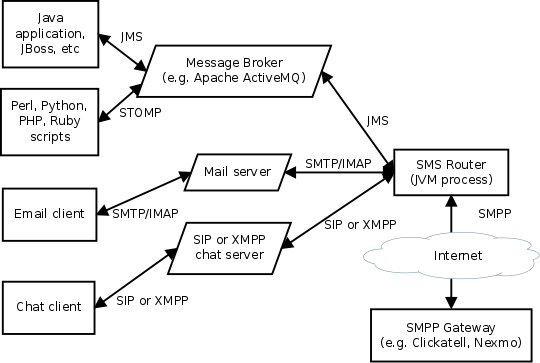
SMS Router is based on Apache Camel. Multiple instances can be operated in parallel for clustering, load balancing and high availability. It can be monitored using JMX solutions such as JMXetric.
The SMPP support is based on the camel-smpp component which is in turn based on the jSMPP library, which comprehensively implements the SMPP protocol in Java. camel-smpp can be used with minimal configuration but for those who want to, many SMPP features can be tweaked on a per-message basis using various headers.
The SMPP gateway settings can be configured and changed at will using the sms-router.properties file. The process doesn't require any other files or databases at runtime.
The SMS Router is ready-to-run with one queue for sending messages and another queue for incoming messages. The routing logic can be customized by editing the RouteBuilder class to use other Camel components or any of Camel's wide range of functions for inspecting, modifying and routing messages. For example, you can extend it to failover to multiple SMPP gateways using Camel's load-balancer pattern.
SMS Router based projects are already used successfully in production, for example, the user registration mechanism for the Lumicall secure VoIP app for Android.
See the README for instructions. Feel free to ask questions about this project on the Camel users mailing list.
SMS is not considered secure, the SMS Router developers and telecommunications industry experts discourage the use of this technology for two-factor authentication. Please see the longer disclaimer in the README file and my earlier blog about SMS logins: an illusion of security. The bottom line: if your application is important enough to need two-factor authentication, do it correctly using smart cards or tokens. There are many popular free software projects based on these full cryptographic solutions, for example, the oath-toolkit and dynalogin.
https://danielpocock.com/avoiding-sms-vendor-lock-in-with-smpp
|
|
Air Mozilla: RMLL 2016 : The Security Track, 06 Jul 2016 |
 No global RMLL this year ? True ! However, the Security Track will be held at Paris Mozilla office next July. Come and enjoy listening...
No global RMLL this year ? True ! However, the Security Track will be held at Paris Mozilla office next July. Come and enjoy listening...
|
|
Air Mozilla: Webdev Extravaganza: July 2016 |
 Once a month web developers across the Mozilla community get together (in person and virtually) to share what cool stuff we've been working on. This...
Once a month web developers across the Mozilla community get together (in person and virtually) to share what cool stuff we've been working on. This...
|
|
Matjaz Horvat: Define preferred locales in Pontoon |
When translating a string, Pontoon displays all existing translations to other languages in the Locales tab. This is helpful for localizers that understand other languages than English and their native language.
However, the list can get pretty long sometimes, making it hard and time-consuming to find translations one can actually understand. To overcome this problem, localizers can now select preferred locales in the settings, which are shown on top of the list.
Translation counts from preferred and other locales are displated separately in the Locales tab header, making it clear if translations from your preferred list are available before even openning the tab.

Get involved
This feature has been developed by our volunteer contributor jotes. Would you like to get involved, too? Start here!
|
|
The Mozilla Blog: Support Public Education and Web Literacy in California |

Web literacy — the ability to read, write, and participate online — is one of the most important skills of the 21st century. We believe it should be enshrined as the fourth “R,” alongside Reading, Writing and Arithmetic. From our open source learning tools to our free educational curriculum, we are dedicated to empowering individuals by teaching Web literacy.
In 2015, 65% of California public schools offered no computer science courses at all. Public schools should do more to expose students to Web literacy: a paucity of funding and the elimination of digital skills classes and curriculum are a disservice to students and the state’s future.
On June 30, we submitted an amicus letter to the California Supreme Court urging review of the case Campaign for Quality Education v. State of California. The issue in this case is whether the California Constitution requires California to provide its public school students with a quality education. We wrote this letter because we believe that California students risk being left behind in our increasingly digitized society without a quality education that includes Web literacy skills.
The internet has become an integral part of life for many and continues to grow in its global impact. Empowering a Web literate generation of students is crucial to their success, that of the broader online ecosystem and to our local economy. Using technology is an important part of Web literacy but it is not all. Web literacy needs to include a deeper understanding of technology itself and of its impact to empower students and allow meaningful participation in their online lives.
We hope the California Supreme Court takes this case. Ultimately, a quality education, including Web literacy, unlocks opportunities for students to be more engaged citizens as well as making them more college and career ready in today’s technology-driven market.
https://blog.mozilla.org/blog/2016/07/05/public-education-and-web-literacy-in-california/
|
|
Air Mozilla: Martes mozilleros, 05 Jul 2016 |
 Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
|
|
Cameron Kaiser: Did Juno is a PowerPC? |
Remember: when you absolutely have to get to Jupiter, choose PowerPC. (Heck, Mars too.)
http://tenfourfox.blogspot.com/2016/07/did-juno-is-powerpc.html
|
|






