Air Mozilla: Weekly SUMO Community Meeting July 13, 2016 |
 This is the sumo weekly call
This is the sumo weekly call
https://air.mozilla.org/weekly-sumo-community-meeting-july-13-2016-20160713/
|
|
Dietrich Ayala: Bubble and Tweak – IoT at the Ends of the Earth |

Last month I spent a week working on IoT projects with a group of 40 researchers, designers and coders… in Anstruther, a small fishing village in Scotland. Not a high-tech hub, but that was the point. We immersed ourselves in a small community with limited connectivity and interesting weather (and fantastic F&C) in order to explore how they use technology and how ubiquitous physical computing might be woven into their lives.
The ideamonsters behind this event were Michelle Thorne and Jon Rogers, who are putting on a series of these exploratory events around the world this year as part of the Mozilla Foundation’s Open IoT Studio. The two previous editions of this event were a train caravan in India and a fablab sprint in Berlin (which I also attended, and will write up as well. I SWEAR.).
Michelle and Jon will be writing a proper summary of the week as a whole, so I’m going to focus on the project my group built: Bubble.

From research conducted with local fishing folk, farmers from a bit inland, and a group of teenagers from the local school, we figured out a few things:
Initially we focused on the teens… fun things like virtual secret messaging at the red telephone boxes. Imagine you connect to the wifi at the phone box, and the captive portal is a web UI for leaving and receiving secret messages. Perhaps they’re only read once before dying, like a hyperlocal Snapchat. Perhaps the system is user-less, mediated only by secret combinations of emojis as keys. The street corner becomes the hangout, physically and digitally.
We meandered to public messaging from there, thinking about how there’s so much to learn and share about the physical space. What’s the story behind the messages to fairies that are being left in that phone box? I can see the island off the coast from here – what’s it called and what’s out there? Who the hell is Urquardt and what’s a “wynd”? Maybe we make a public message board as well – disconnected from the internet but connected to anything within view.
We kept going back to the physical space. We talked about a virtual graffiti wall, and then started exploring AR and ways of marking up the surroundings – the people, the history, the local pro-tip on which fish and chips shop is the best. But all of this available only to people in close physical proximity.

Given the context and the constraints, as well as watching direction some of the other groups were going in, we started designing a general approach to bringing digital interactivity to disconnected spaces.
The first cut is Bubble: A wi-fi access point with a captive portal that opens a web page that displays an augmented reality view of your immediate surroundings, with messages overlaid on what you’re seeing:

A few implementation notes:
Designs, board, battery and boxes:



Challenges:
Bubble was an experimental prototype. There are no plans to work further on it at this time. If you’re interested, everything is on Github here. You can read more about the design here (PDF).
Thanks to fellow team members Julia Gratsova, Katie Caldwell, Vladan Joler. (Sadly, no Julia in the phonebox!)


https://autonome.wordpress.com/2016/07/12/bubble-and-tweak-iot-at-the-ends-of-the-earth/
|
|
Daniel Stenberg: curl stickers! |
![]()
I’m happy to announce that we now have an official set of curl stickers that you can get. Sorry, that came out wrong. That you should get! The first official curl stickers ever and they’re all based on our new and shiny logo.
These stickers are designed and sold by the great folks over at unixstickers.com and for every purchase you do, a small percentage of that adds up to stickers for me so that I can hand them out to peeps I meet.
|
|
Rail Aliiev: Thoughts about partial updates on demand |
Firefox has it's own built-in update system. The update system supports 2 types of updates: complete and incremental. Completes can be applied to any older version, unless there are some incompatible changes in the MAR format. Incremental updates can be applied only to a release they were generated for.
Usually for the beta and release channels we generate incremental updates against 3-4 versions. This way we try to minimize bandwidth consumption for our end users and increase the number of users on the latest version. For Nightly and Developer Edition builds we generate 5 incremental updates using funsize.
Both methods assume that we know ahead of time what versions should be used for incremental updates. For releases and betas we use ADI stats to be as precise as possible. However, these methods are static and don't use real-time data.
The idea to generate incremental updates on demand has been around for ages. Some of the challenges are:
Ben and I talked about this today and to recap some of the ideas we had, I'll put them here.
The only remaining thing is to implement all these changes. :)
https://rail.merail.ca/posts/thoughts-about-partial-updates-on-demand.html
|
|
Support.Mozilla.Org: Firefox 47 Support Release Report |
In London, Mozlondon, we had a session on creating a SUMO Release Report a few weeks after major updates to Mozilla products. This post will be the first to include testimonials from users and submissions from users in the community to make it unique to SUMO. With the intention to highlight all of the work that the community comes to accomplish together, the user testimonials, feedback, copious issues found, brought to attention and solved, knowledge base articles created, and collaborated on, as well as article translations to so many languages and organized social media this report shows how much we need your help. Core Community Members and new ones are equally as important. We have highlighted the issues that were and are actively being tracked down to improve Firefox and other Mozilla products.
We have lots of ways to contribute, from Support to Social to PR, the ways you can help shape our communications program and tell the world about Mozilla are endless. For more information: [https://goo.gl/NwxLJF]
1104 users said “thank you” out of the 7300 answers during this time.
We cannot include all of the thank yous that were received, however these are many of the community members that also received thank yous from Firefox users. Shout outs to Fred, cor-el, Seburo, philipp, Matt, Zenos, Scribe, jscher2000, James, Wayne Mary, Chris Ilias, Christ1, the-edmeister, Tonnes, Toad-Hall. They all received direct thank yous from users and their solved issues.
| Article | Voted “helpful” (English/US only) | Global views | Constructive User Feedback |
| Desktop
(June 7 – June 30) |
|||
| Allow Firefox to load multiple tabs in the background | 71-76% | 5340 | “Why do you think it is a good idea to confuse existing users with taking away the options they once had? Why change the options that they choose to set? I am mildly upset” |
| Pages appear tiny when I print or view them in Print Preview | 51-62% | 3281 | “Still having an issue.” “My print_paper_height and _width settings appear in millimeters even though the paper being used is set to 8.5 x 11 inches. Margin settings still appear in inches” “Prints half size in width. Followed instructions exactly” “page goes from very small when printing to very large font when using email” “actually my log in page is about the size of a dollar bill…..I cant see it because it is so small I can go to Internet Explorer and I have NO PROBLEM but firefox another story” |
| Firefox support has ended for OS X 10.6, 10.7 and 10.8 | 57-83% | 3222 | |
| Watch DRM content on Firefox | 66-70% | 209049 | “never had a problem watching videos on amazon prime till you people came up with this explanation that to non tech people is just jibberish” “all of a sudden not work to stream toytube or netfilx” “Has no mention of whether Linux will have Widevine support in the future. This seems odd given that Google Chrome already has that support built-in.” |
| Android
(June 7 – June 30) |
|||
| Turn off web fonts in Firefox for Android | 100% | 340 | none |
| What’s new in Firefox for Android | — | 8 | none |
| Firefox Marketplace Apps Stop Working on Firefox 47+ for Android | 71-95% | 26612 | none |
| iOS | |||
| What’s new in Firefox for iOS (version 4.0) | 60-87% | 1,618,561 | None |
| Add Firefox to the Today view on your iOS device | 75-85% | 18,071 | None |
| Certificate warnings in Firefox for iOS | 72-76% | 2,751 | none |
**No articles were linked from major publications (via Google Analytics.) but if you see any in your region, please mention them.
| Article | Top 10 locale coverage | Top 20 locale coverage |
| Desktop (June 7 – June 30) | ||
| Allow Firefox to load multiple tabs in the background | 100% | 66.6% |
| Pages appear tiny when I print or view them in Print Preview | 100% | 66.6% |
| Firefox support has ended for OS X 10.6, 10.7 and 10.8 | 40% | 23.8% |
| Watch DRM content on Firefox | 100% | 80% |
| Android (June 7 – June 30) | ||
| Turn off web fonts in Firefox for Android | 100% | 66.6% |
| What’s new in Firefox for Android | 60% | 33% |
| Firefox Marketplace Apps Stop Working on Firefox 47+ for Android | 100% | 57% |
One of the major impacted issues during the first three weeks of the release was an increase in reports to fake updates and malware from those updates. Many of them were reported and still be investigated.
Not solved top viewed threads – GA
In this spreadsheet: https://docs.google.com/spreadsheets/d/1YjeyJs-VrofC0qMkf5uv5DUtJzsZjrfopEBarZ-ePTI/edit#gid=1219676230
Brought to you by Sprinklr
Total contributors in program
In this time we had a total of 14 of you login and participate in the Firefox 47 release.
New users added in period of the report
Welcome Magno, Daniella, Luis, and TheoC to the team you were very active these past three weeks and thank you for supporting Mozilla Open Source users on Facebook and Twitter on the Sprinklr tool.
Top 5 Contributors
| User | Number of Replies |
| Andrew Truong | 56 |
| Noah Y | 24 |
| Jhonatas Rodrigues Machado | 12 |
| Alex_Mayorga | 6 |
| Magno Reis | 4 |
Number of Replies: 111
Each Facebook outbound post reached one person for support, the two major engagements overlapped with Code Emoji and the plane,
This version we removed the tag summary and are currently working on items that translate to more specific categories. Not working will be removed and more will be added. However taking a deep dive in the top categories for outbound messages to Mozilla Open Source product users this what we found.
https://blog.mozilla.org/sumo/2016/07/12/firefox-47-support-release-report/
|
|
Chris H-C: Units and Data: Pok'emon GO |
Topical Data Post: Pokemon Go
I live in Canada which means we hear a lot about things that are United States-only. The latest (and the largest, outstripping in volume and velocity even the iPhone (which I may misremember being the last must-have-thing back in 2007)) is the hit augmented-reality mobile game Pok'emon GO.
One gameplay mechanic of Pok'emon GO (I am told) revolves around hatching eggs. These eggs hatch not after a certain period of time, but after you have walked a certain distance with the application open on your phone.
The kicker is that the distance is measured in kilometres, a unit whose use the United States and United Kingdom have evaded (yes, despite the latter’s metrication since 1965). People in the United States are being confronted with unfamiliar distance units of 2km, 5km, and 10km.
This, via some Twitter jabs, lead me to Google Trends and a prediction: what if Pok'emon GO’s release date in a region that still uses miles as a unit of distance could be detected simply through the rise in search volume for the term “5km”?
So far, the data for the United States is consistent:
I await the UK launch date to follow-up.
:chutten

https://chuttenblog.wordpress.com/2016/07/12/units-and-data-pokemon-go/
|
|
Air Mozilla: Connected Devices Weekly Program Update, 12 Jul 2016 |
 Weekly project updates from the Mozilla Connected Devices team.
Weekly project updates from the Mozilla Connected Devices team.
https://air.mozilla.org/connected-devices-weekly-program-update-20160705/
|
|
Chris Cooper: RelEng & RelOps Weekly highlights - July 12, 2016 |
Q3 planning is in full swing. Chief priorities continue to be the migration to TaskCluster (TC) from buildbot, and release process improvements.
Modernize infrastructure:
Aki finished porting configman to python3 (merged!). https://github.com/mozilla/configman/pull/163
Windows try builds were enabled on TC Windows 2012 worker types in staging (allizom) (win32/win64, opt/debug). If all goes well, this will propagate to production in the coming days. This is the first set on non-Linux tasks we’ve had running reliably in TC, which is obviously a huge step in our migration away from buildbot.
Improve Release Pipeline:
Aki wrote dephash to pin python requirements to versions+hashes: http://escapewindow.dreamwidth.org/247093.html https://github.com/escapewindow/dephash https://pypi.python.org/pypi/dephash
Aki got signtool working with py3 (reproducibly this time), using requests. https://github.com/escapewindow/signtool https://pypi.python.org/pypi/signtool
We implemented a short cache for Balrog rules, which greatly reduced load on the database. https://bugzilla.mozilla.org/show_bug.cgi?id=1111032
Kim stood up beta builds with addon signing preferences disabled. This allows addon developers to test their addons prior to signing on release-equivalent builds. https://bugzilla.mozilla.org/show_bug.cgi?id=1135781
Improve CI Pipeline:
Francis disabled valgrind buildbot builds. Turning stuff off in buildbot #feelsgoodman. https://bugzilla.mozilla.org/show_bug.cgi?id=1278611
Kim enabled Android x86 builds on trunk running in TC. https://bugzilla.mozilla.org/show_bug.cgi?id=1174206
See you next week!
|
|
Hal Wine: End of an Experiment |
tl;dr: We’ll be shutting down the Firefox mirrors on Bitbucket.
A long time ago we started an experiment to see if there was any support for developing Mozilla products on social coding sites. Well, the community-at-large has spoken, with the results many predicted:
There was so much interest from GitHub users that the site has been clear win, from the very start. There are currently several efforts underway to make it easier for contributors on GitHub to contribute directly to Firefox (which remains hosted on our mercurial server).
However, there hasn’t been any similar interest on Bitbucket. Only one person ever forked even one of the repositories. In addition, the Firefox repos have grown to exceed the 2GiB maximum size that is supported by Bitbucket. (And has long been over the 1GiB maximum free hosting size, which means community members would need to pay to have a copy there.)
As we replace the legacy vcs-sync system with modern vcs-sync, we will stop updating the repositories on Bitbucket. As we stop updates, we’re remove the repositories to avoid confusion as to their status.
http://dtor.com/halfire/2016/07/12/end_of_an_experiment.html
|
|
This Week In Rust: This Week in Rust 138 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us an email! Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.

 Announcing Rust 1.10.
Announcing Rust 1.10. No create was selected for CotW.
Submit your suggestions for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
--dry-run to cargo publish.imag forward --debug and --verbose to subcommands.iter.fold(Ok(()), ...).If you are a Rust project owner and are looking for contributors, please submit tasks here.
100 pull requests were merged in the last two weeks.
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now. This week's FCPs are:
global_asm! for module-level inline assembly.#[macro_use(not(...))].-C link-arg and -C llvm-arg which allow you to pass along argument with spaces.unwrap! macro.If you are running a Rust event please add it to the calendar to get it mentioned here. Email Erick Tryzelaar or Brian Anderson for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
No quote was selected for QotW.
Submit your quotes for next week!
This Week in Rust is edited by: nasa42, llogiq, and brson.
https://this-week-in-rust.org/blog/2016/07/12/this-week-in-rust-138/
|
|
Maja Frydrychowicz: Untangling WebDriver and the Browser Automation Landscape I Live In |
This piece is about too few names for too many things, as well as a kind of origin story for a web standard. For the past year or so, I’ve been contributing to a Mozilla project broadly named Marionette — a set of tools for automating and testing Gecko-based browsers like Firefox. Marionette is part of a larger browser automation universe that I’ve managed to mostly ignore so far, but the time has finally come to make sense of it.
The main challenge for me has been nailing down imprecise terms that have changed over time. From my perspective, “Marionette” may refer to any combination of two to four things, and it’s related to equally vague names like “Selenium” and “WebDriver”… and then there are things like “FirefoxDriver” and “geckodriver”. Blargh. Untangling needed.
Aside: integrating a new team member (like, say, a volunteer contributor or an intern) is the best! They ask big questions and you get to teach them things, which leads to filling in your own knowledge. Everyone wins.
Okay, so let’s work our way backwards, starting from the future. (“The future is now.”) We want to remotely control browsers so that we can do things like write automated tests for the content they run or tests for the browser UI itself. It sucks to have to write the same test in a different way for each browser or each platform, so let’s have a common interface for testing all browsers on all platforms. (Yay, open web standards!) To this end, a group of people from several organizations is working on the WebDriver Specification.
The main idea in this specification is the WebDriver Protocol, which provides a platform- and browser- agnostic way to send commands to the browser you want to control, commands like “open a new window” or “execute some JavaScript.” It’s a communication protocol1 where the payload is some JSON data that is sent over HTTP. For example, to tell the browser to navigate to a url, a client sends a POST request to the endpoint /session/{session id of the browser instance you're talking to}/url with body {"url": "http://example.com/"}.
The server side of the protocol, which might be implemented as a browser add-on or might be built into the browser itself, listens for commands and sends responses. The client side, such as a Python library for automating browsers, send commands and processes the responses.
This broad idea is already implemented and in use: an open source project for browser automation, Selenium WebDriver, became widely adopted and is now the basis for an open web standard. Awesome! (On the other hand, oh no! The overlapping names begin!)
Where does this WebDriver concept come from? You may have noticed that lots of web apps are tested across different browsers with Selenium — that’s precisely what it was built for back in 2004-20092. One of its components today is Selenium WebDriver.
(Confusingly3, the terms “Selenium Webdriver, “Webdriver”, “Selenium 2” and “Selenium” are often used interchangeably, as a consequence of the project’s history.)
Selenium WebDriver provides APIs so that you can write code in your favourite language to simulate user actions like this:
client.get("https://www.mozilla.org/")
link = client.find_element_by_id("participate")
link.click()
Underneath that API, commands are transmitted via JSON over HTTP, as described in the previous section. A fair name for the protocol currently implemented in Selenium is Selenium JSON Wire Protocol. We’ll come back to this distinction later.
As mentioned before, we need a server side that understands incoming commands and makes the browser do the right thing in response. The Selenium project provides this part too. For example, they wrote FirefoxDriver which is a Firefox add-on that takes care of interpreting WebDriver commands. There’s also InternetExplorerDriver, AndroidDriver and more. I imagine it takes a lot of effort to keep these browser-specific “drivers” up-to-date.
A while after Selenium 2 was released, browser vendors started implementing the Selenium JSON Wire Protocol themselves! Yay! This makes a lot of sense: they’re in the best position to maintain the server side and they can build the necessary behaviour directly into the browser.
It started with OperaDriver in 2009-2011, and then others followed such as ChromeDriver and Mozilla’s geckodriver with Marionette.4 This is where the motivation for a WebDriver standard comes from.
Selenium Webdriver (a.k.a. Selenium 2, WebDriver) provides a common API, protocol and browser-specific “drivers” to enable browser automation. Browser vendors started implementing the Selenium JSON Wire Protocol themselves, thus gradually replacing some of Selenium’s browser-specific drivers. Since WebDriver is already being implemented by all major browser vendors to some degree, it’s being turned into a rigorous web standard, and some day all browsers will implement it in a perfectly compatible way and we’ll all live happily ever after.
Is the Selenium JSON Wire Protocol the same as the W3C WebDriver protocol? Technically, no. The W3C spec is describing the future of WebDriver5, but it’s based on what Selenium WebDriver and browser vendors are already doing. The goal of the spec is to coordinate the browser automation effort and make sure we’re all implementing the same interface; each command in the protocol should mean the same thing across all browsers.
Now that I understand the context, my view of Marionette’s components is much clearer.
As you can see, “Marionette” may refer to many different things. I think this ambiguity will always make me a little nervous… Words are hard, especially as a loose collection of projects evolves and becomes unified. In a few years, the terms will firm up. For now, let’s be extra careful and specify which piece we’re talking about.
Thanks to David Burns for patiently answering my half-baked questions last week, and to James Graham and Andreas Tolfsen for providing detailed and delightful feedback on a draft of this article. Bonus high-five to Anjana Vakil for contributions to Marionette Test Runner this year and for inspiring me to write this post in the first place.
Terminology lesson: the WebDriver protocol is a wire protocol because it’s at the application level and requires several applications working together.
|
|
Asa Dotzler: Context Graph |
In the lead-up to the London all hands we had a Town Hall where Mark Mayo and Nick Nguyen previewed the three year strategy for Firefox. That talk mostly covered an emerging area of focus and investment we’re calling the Context Graph.
This last week, Nick posted a vision for the Context Graph over at Medium. If you haven’t, I encourage you to go read it at medium.com/@osunick
So what is the Context Graph. The context graph is an understanding of how pages on the web are connected to each other and to a user’s current context. With Context Graph, we’re going to build a recommendation engine for the Web and features that help people discover relevant content outside of the popular search and social silos.
What does that look like in practice? Well, if you’re learning about how to do something new, like bike repair, our recommender features should help you learn bike repair based on others who have already taken the same journey on the Web. If you’re on YouTube watching a music video, Firefox should help you find the top lyrics or commentary sites that embed or link to that YouTube video. Or, if you’re walking into a WalMart, our mobile apps should automatically show you WalMart’s website or perhaps a WalMart deals and coupons site.
Building a recommendation engine for thew Web is a large project that will take time and effort but we believe the payoff for users and the health of the Open Web is going to be well worth it.
To dig deeper, I highly recommend Nick’s post at medium.com/@osunick and check out the wiki page at wiki.mozilla.org/Context_Graph.
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 11 Jul 2016 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20160711/
|
|
QMO: Firefox 48 beta 6 Testday Results |
Hello mozillians!
Last week on Friday (July 8th), we held another successful event – Firefox 48 beta 6 Testday.
Thank you all for helping us making Mozilla a better place – akash, Karthikeya L K, Iryna Thompson, Moin Shaikh, Ilse Mac'ias, Corey Sheldon, Ciprian Georgiu, Julie Myers (a.k.a. SnoopyRules), Bhuvana Meenakshi.K, Prasanth p, Mano @Manokarr, Nazir Ahmed Sabbir, Hossain Al Ikram, Tanvir Rahman, Azmina Akter Papeya, Khalid Syfullah Zaman, Mohammad Maruf Islam, Md.Majedul islam, Samad Talukdar, Kazi Sakib Ahmad, Zayed News, Maruf Rahman, Md.Tarikul Islam Oashi, Aminul Islam Alvi, Akash, Rakib Rahman, Ria, Rezaul Huque Nayeem, Sayed Ibn Masud and Saddam Hossain.
A big thank you goes out to all our active moderators too!
Results:
https://quality.mozilla.org/2016/07/firefox-48-beta-6-testday-results/
|
|
Daniel Pocock: Let's Encrypt torpedoes cost and maintenance issues for Free RTC |
Many people have now heard of the EFF-backed free certificate authority Let's Encrypt. Not only is it free of charge, it has also introduced a fully automated mechanism for certificate renewals, eliminating a tedious chore that has imposed upon busy sysadmins everywhere for many years.
These two benefits - elimination of cost and elimination of annual maintenance effort - imply that server operators can now deploy certificates for far more services than they would have previously.
The TLS chapter of the RTC Quick Start Guide has been updated with details about Let's Encrypt so anybody installing SIP or XMPP can use Let's Encrypt from the outset.
For example, somebody hosting basic Drupal or Wordpress sites for family, friends and small community organizations can now offer them all full HTTPS encryption, WebRTC, SIP and XMPP without having to explain annual renewal fees or worry about losing time in their evenings and weekends renewing certificates manually.
Even people who were willing to pay for a single certificate for their main web site may have snubbed their nose at the expense and ongoing effort of having certificates for their SMTP mail server, IMAP server, VPN gateway, SIP proxy, XMPP server, WebSocket and TURN servers too. Now they can all have certificates.
In the early days, SIP messages would be transported across the public Internet in UDP datagrams without any encryption. SIP itself wasn't originally designed for NAT and a variety of home routers were created with "NAT helper" algorithms that would detect and modify SIP packets to try and work through NAT. Sadly, in many cases these attempts to help actually clash with each other and lead to further instability. Conversely, many rogue ISPs could easily detect and punish VoIP users by blocking their calls or even cutting their DSL line. Operating SIP over TLS, usually on the HTTPS port (TCP port 443) has been an effective way to quash all of these different issues.
While the example of SIP is one of the most extreme, it helps demonstrate the benefits of making encryption universal to ensure stability and cut out the "man-in-the-middle", regardless of whether he is trying to help or hinder the end user.
Modern SIP, XMPP and WebRTC require additional services, TURN servers and WebSocket servers. If they are all operated on port 443 then it is necessary to use different hostnames for each of them (e.g. turn.example.org and ws.example.org. Each different hostname requires a certificate. Let's Encrypt can provide those additional certificates too, without additional cost or effort.
The initial version of the Let's Encrypt client, certbot, fully automates the workflow for people using popular web servers such as Apache and nginx. The manual or certonly modes can be used for other services but hopefully certbot will evolve to integrate with many other popular applications too.
![]()
Currently, Let's Encrypt's certbot tool issues certificates to servers running on TCP port 443 or 80. These are considered to be a privileged ports whereas any port over 1023, including the default ports used by applications such as SIP (5061), XMPP (5222, 5269) and TURN (5349), are not privileged ports. As long as certbot maintains this policy, it is generally necessary to either run a web server for the domain associated with each certificate or run the services themselves on port 443. There are other mechanisms for domain validation and various other clients supporting different subsets of them. Running the services themselves on port 443 turns out to be a good idea anyway as it ensures that RTC services can be reached through HTTP proxy servers who fail to let the HTTP CONNECT method access any other ports.
Many configuration tasks are already scripted during the installation of packages on a GNU/Linux distribution (such as Debian or Fedora) or when setting up services using cloud images (for example, in Docker or OpenStack). Due to the heavily standardized nature of Let's Encrypt and the widespread availability of the tools, many of these package installation scripts can be easily adapted to find or create Let's Encrypt certificates on the target system, ensuring every service is running with TLS protection from the minute it goes live.
If you have questions about Let's Encrypt for RTC or want to share your experiences, please come and discuss it on the Free-RTC mailing list.
https://danielpocock.com/lets-encrypt-torpedoes-cost-free-rtc
|
|
Karl Dubost: [worklog] Edition 026. Summer in Japan |
Summer in its full heat has started in Japan. I'll follow the sun, Beatles.
Progress this week:
Today: 2016-07-11T09:55:26.360775 346 open issues ---------------------- needsinfo 5 needsdiagnosis 74 needscontact 33 contactready 50 sitewait 165 ----------------------
You are welcome to participate
We had a short team meeting.
(a selection of some of the bugs worked on this week).
NS_IMETHOD GetOffsetWidth(int32_t *aOffsetWidth) = 0; which leads to OffsetWidth() BUT Daniel found the culprit. This is fixed in Aurora and Nightly so will be soon working on production releases.Otsukare!
|
|
Tantek Celik: State of The IndieWeb — IndieWeb Summit 2016-06-04 |
I’m going to give you a short overview of The State of the IndieWebCat. IndieWebCat has had her own site for over a year. This is the first full year that IndieWebCat has been posting on her own.
IndieWebCat is pretty excited about this.
I’m Tantek Celik, and this is my website tantek.com.
[shows tantek.com homepage]
Throughout today and tomorrow, you’re going to hear a lot of encouragement to just get up and show your website. So I’m starting, this is my website, I’ve been posting on here by myself instead of Twitter since 2010.
It’s doable, and if that’s something you want to do this weekend, we can work on that.

But I’ll to go back to what Shane was talking about which was the very first IndieWebCamp that we did here in Portland in 2011. And I actually see a lot of people here today from that first IndieWebCamp.
Will was there, Shane was there, Aaron was there, Ed was there.
Since then we have held these main IndieWebCamps in Portland once a year every year. This year we acknowledged that our main IndieWebCamp really is our annual summit, let’s plan it like a summit, let’s call it a summit, and let’s do proper introduction talks like all the stuff we are doing, showing off etc.
This is the State of The IndieWeb.
This is our website:

Or rather this was our website until late lastnight.
This is our website now. [Update: or was until July 4th! That’s another post. -t]

There are a couple of big changes I want to point out.

We have a new logo that you may have seen on t-shirts, and that’s thanks to Shane, who started with our first logo, drawn by one of our co-founders Crystal Beasley. He talked to her about some ideas for revising our logo and asked: do you mind if I do it? May I have the files? Crystal gave him the files and told Shane to go for it.
Shane worked on a new logo, presented it to the community, and asked what did people think? The community was generally positive, yet pointed out a few suggested improvements and ideas. But Shane kept his wits in the face of impending design by committee, gathered the input, made some revisions, kept revising and iterating, and now we have this amazing new logo. He contributed it to the community, and we really appreciate that. Thanks Shane!
The second big change is that we switched our wiki theme.
We switched from a custom theme that has been doing a lot of hard work for us for many years, to the standard MediaWiki Vector theme, which is consistently updated by the MediaWiki project. We are going to keep this theme up to date, so that we can keep MediaWiki itself up to date, to help keep our community running smoothly.
We started in 2011 with distinguishing ourselves as a community. All communities start with what makes us different from everyone else.
The real distinguishing things were three things that came out of the 2010 Federated Social Web Summit that Aaron and I atteneded, or rather in reaction to it, which was:
We started with those three things — there’s been some discussions recently about what are the essential qualities of a community — and those are the essential qualities that IndieWebCamp started with: Show don’t tell. Scratch your own itch. Selfdogfood.
We’ve evolved a bit since 2011, and we’ve generalized beyond owning your identity and owning your stuff:
The reality is that all of this starts with one goal, which is self-empowerment. If I could say the one thing that IndieWebCamp is about, that is what IndieWebCamp is about. Self-empowerment.
As we achieve various different levels of self-empowerment with our own websites, our hope is that together, we have also built a community that can spread empowerment.
We start with self-empowerment, and then second, spread empowerment.
I see this as a specific instance of: if you’re an idealist, before you go out there and save the world, you have to save yourself. Learn how to take care of yourself, then go save the world. That’s one of the things we try to encourage as a community.
We’re not just individuals working to empower ourselves, we’re collaborating to empower each other, like during this very weekend. Beyond empowering each other, we encourage everyone to openly share, to empower people that are beyond those that we know, beyond those that could make it here this weekend.
By sharing your stuff publicly on the web, putting open source in places like GitHub, we empower those that we haven’t even met.
Documenting and open sourcing your stuff are two of our principles.
You can read our principles, I’m not going to go over all of them.
[shows Posts about the IndieWeb: 2016]
Let’s look at milestones from this past year. You can see more and more people talking about how they’ve either found the community, or they’ve figured out how to own their data, or own their identity, or own their photos, or own their audio bits.
Empower yourself, and talk about it, blog about it. We like to highlight folks that are doing that. There’s been a lot of good positive posts like that.
Once in a while, however, there are occasional unfortunate rants, like click on this one here — Anywhere but Medium — but fortunately this site depends on javascript to view the content, and I have that turned off by default, so you don’t actually get to see the rant.
We focus on creating to build ourselves up, more than tearing others down.
Let me just leave you with:
Don’t Hate, Go Create.
That’s an important value of our community.
If you find yourself wanting to rant about something, sadly I find that all the time, and then ask myself instead, what am I actually frustrated with, let’s see if I can go build something, and then post some minor update like even hey look I changed my CSS.
I think a minor update to your own site is much better than a long screed about being opressed by some silo that is free and you can just choose not to use it.
We have developed a lot of awesome technologies in the last year.
A bunch of members in the community have contributed to, worked with the W3C, to take some of the standards and specifications and protocols and formats that we’ve incubated and dogfooded ourselves, through a formal standardization process which involves a lot more work to get lots of details right.
[shows Webmention CR on w3.org]
One of the more recent results of that is that the Webmention specification, developed in this community, has become a W3C Candidate Recommendation (CR), which is a huge milestone. I just want to congratulate Aaron, the editor, on that work.
What this means is that W3C has now broadcast this candidate recommendation saying, hey everyone in the world doing web development, we invite you to implement this, and submit to us your implementation reports.
I encourage all of you to do so as well. We have a lot of implementations of Webmention. There’s a validator, webmention.rocks. You can go through validator and test suite, check all the different interactions that your site supports, fill out an implementation report, and submit it. That’s how the standard makes progress in CR, through implementation reports and feedback.
That’s the most advanced spec we’ve got but not the only one.
[shows Micropub WD on w3.org]
Aaron has also worked on and contributed the Micropub specification which is currently a W3C working draft, the phase before candidate recommendation. He has been iterating on it and adding features. Especially during the last year, it’s gone from being a simple way to create a post on a site, to now a way to create, delete, undelete, read, or update posts on a site, and I think we have at least two implementations of all that.
[shows Post Type Discovery ED on w3.org]
There’s more coming along the way. Post Type Discovery is an editor’s draft, but it’s got a really lazy editor that hasn’t managed to produce a working draft yet so we gotta get on his case about that. ;)
[shows indiewebcamp.com/Salmentions]
There’s other technologies that have made good iterations in the indiewebcamp community, which we haven’t taken through standardization yet, but people are working on getting working, across sites.
One of those is Salmentions.
Last year there was implementation of a challenge called SWAT0 which is short for Social Web Acid Test 0 which depends on Salmentions. Since then more people have implemented Salmentions, provided feedback, and we’ve iterated on the protocol accordingly.
[shows indiewebcamp.com/Vouch]
The other emerging technology I want to bring up is Vouch. This is a way of vouching for a Webmention, or finding a way for someone to vouch for your webmention.
If you’re commenting on someone’s blog, you’ve never met them before, and you want to say hey, I’m not a spammer, you can accept my post, because we have this link in common, this friend in common, or some other form of this other entity vouches for me. I think this is going to become more and more important in the next year.
Those are the big technologies and there’s been a lot more building blocks that have been built out. There’s one more that we’ve iterated on and advanced a lot in the last year, which is person-tagging.
[shows indiewebcamp.com/person-tags]
Person-tagging was something we mostly figured out but not really implemented until the SWAT0 test last year which requires tagging someone in a photo. We figured out how to do that and developed implementations.
The big thing we figured out in the past year is how to POSSE person-tags from an indie post across to different social media silos.
[shows brid.gy]
There’s a service called Bridgy Publish that will syndicate your posts to other sites like Twitter, Facebook, or Flickr. Your site can send Bridgy a Webmention as a way of asking it to post a copy of your original post on social media sites, so you don’t have to deal with calling a proprietary API.
Bridgy Publish started with syndicating just text notes, added articles, photos, videos, and now in the last year, the ability to read person-tags on a photo on your site, and include them on the copy it posts to another site!
Instead of just telling you, I’ll show you an example.

This is a photo of the Homebrew Website Club San Francisco meetup that I posted last week. You can see there in the bottom it says "with" and a bunch of person-tags.

I’m linking their names to their personal site (if any), and then in parentheses, linking to their Facebook and Twitter profiles if they have any. There’s seven people tagged in that photo (each with an h-card with one or more URLs). Let’s look at the copies.
[shows Twitter Status 738438870077833216]
There’s the POSSE copy on Twitter. There are no person-tags on that copy because Twitter does not have an API to let you set the person-tags in a photo yet. We’re waiting for them on that.
[shows Flickr photo tantek 27387113266]
Here’s the copy on Flickr. And here’s the copy on Facebook.
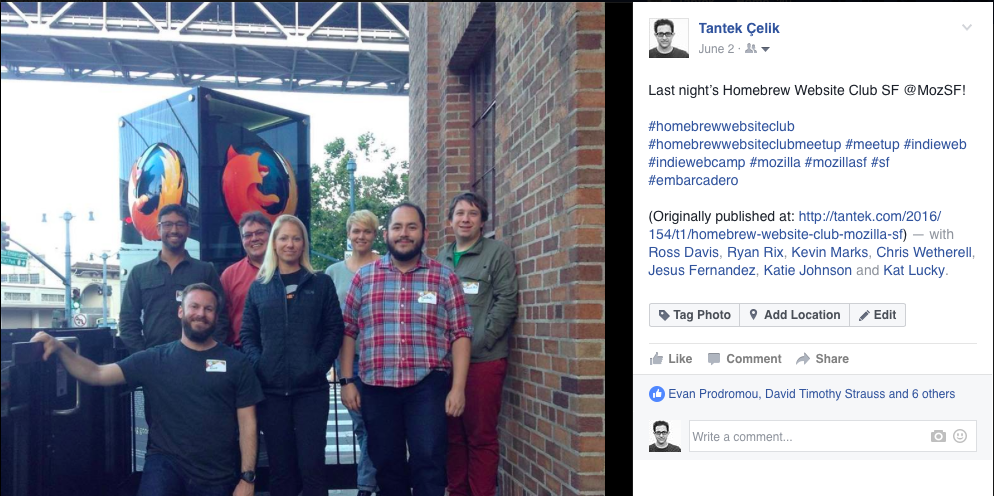
All seven of the person-tags made it across (Bridgy also added the "Originally published at:" parenthetical original post citation at the end of the post text).

All that silo person-tagging happened automatically thanks to Bridgy.
I did not use Facebook’s user interface to post this photo; I did not do any user interactions to make this photo appear on Facebook or add the person-tags there. Bridgy did that for me. Bridgy was able to tag 100% of the people I tagged on the photo, on Facebook.
Those are the kind of building blocks we’re improving, iterating, and just getting to the point where you can post on your own site, you don’t need to worry about being on the silos as much because Bridgy will take care of that.
All your friends that happen to use those social media sites, you don’t need to talk them into reading your own site. You can tell them: Hey, you use Facebook? Great, keep reading stuff there, you’ll see my stuff there. Or check it out directly on my own site.
Those are some of the technologies we made progress with last year. How about some numbers.
[shows indiewebcamp.com/IndieWebCamps]
We did a ton of IndieWebCamps in the past year. We just completed D"usseldorf, which was the second one in D"usseldorf. We did N"urnberg, the first IndieWebCamp N"urnberg in April, MIT in March, New York City in January, San Francisco in December, and MIT in November.
Last year we had the first IndieWebCamp Edinburgh in July, which was organized by Amy, who we’re very happy to have with us here today. Thanks Amy. And there’s last year’s main IndieWebCamp which you probably recognize a lot of the people there. There’s a lot of IndieWebCamps, we had some new ones, we hope to have some new ones this year too.
[shows indiewebcamp.com/Homebrew_Website_Club]
We’ve also had a bunch of new Homebrew Website Club meetups.
The San Francisco and Portland chapters are going strong, Washington DC started up, Brighton’s been going well, Los Angeles started up as well and that’s going to continue in July (update: September). There’s a couple in Sweden which are doing well.
Homebrew Website Club N"urnberg just started last week, with great attendance, and is doing another one next week. The number of cities with regular meetups have grown and we’re pretty happy about that.
[shows indiewebcamp Special wiki users page, first 1000]
We have finally broken 1000 users on the wiki.
Over a 1000 people have logged into the wiki with their own domain name, which I think is an awesome high watermark for IndieAuth, for owning your identity. Thanks everyone that put a lot of hard work into that, especially Aaron. He’s made IndieAuth.com easier and easier to use, and I think the numbers will just keep growing.
If you click on next 1000, let’s see what it shows here.
[shows indiewebcamp Special wiki users page, next 1000]
I kind of hacked the MediaWiki query URL. Here it starts at T, and it goes down to lots of WWWs as you might expect, and goes down to Z. zzzzen dot com.
The next milestone, just confirmed by Ben Werdm"uller, is that there are now tens of thousands of IndieWeb sites.
These are sites where people have their own URL, control their own identity, which is a great measure of independence, and something we encourage. And they are something more.
These 10s of thousands of sites are actively deploying and supporting IndieWeb building blocks. They support microformats, they support webmentions, out of the box, and that’s kind of amazing.
[shows withknown.com]
A lot of that is due to the open source Known project and the withknown.com service.
Known is something that Ben Werdmuller and Erin Jo Richey created just three years ago. I’m really glad that Ben is here again this year to talk about what he’s done.
Five years ago we had maybe 10s of indieweb sites. Last year we were at 1000s, and now we’re at 10s of thousands of indieweb sites.
Remember that technology I was talking about, Vouch?
I would say at this point we’re at Defcon 3, that much closer to when we’re going to see a massive spam attack with Webmention.
This possibility raises the importance of looking at Vouch, implementing Vouch, making sure it works in the positive use-cases at least. We have to make sure Vouch works for making comments and reactions back and forth across indieweb sites, and also blocks any automated spam as well.
Success is great, but also brings new challenges. If we continue on this trend of 10xing the number of indieweb sites per year, it’s going to happen real soon. Something to be proud of and to be keeping in mind.
The last thing I want to show you is what we finished at the end of last year’s main IndieWebCamp.
How many people were here last year? (show of hands)
A lot of new folks this year.
This is the SWAT0 demo. I’m going to play it for you.
[plays SWAT0 Demo video]
Achieiving SWAT0 was pretty awesome. If you want to get your site working on SWAT0, as one of the players like that, I think that would be a great goal for the weekend.
The key thing this weekend is to make something, anything, for yourself, for your own site. Whatever that is, nothing is too small.
Try to meet someone you don’t know. There are a lot of new folks this year. Go meet somebody you don’t know.
Help somebody out. One of the reasons we are a community is because we have different levels of expertise in different things, whether it is in engineering, development, different languages or frameworks, whether it’s design, visual design, or copy-editing, people that are really good at writing small bits of text, which is sometimes one of the hardest tasks.
This is a really diverse community, with diverse skills. When you meet people, find out what you can help them with, what they can help you with, and help each other out.
Lastly, show something. This is where I really want to emphasize:
Don’t let the pursuit of perfection stop you from making progress.
It’s really easy to think I have to get things just right before I show them, to my peers, to be proud of what I do, I don’t want to have it be off by a pixel. Don’t worry about it.
Get something working, make some progress, don’t let the goal of perfection stop you from doing that, show it, and then iterate.
We’re all iterating here, as you can see even the wiki itself with the new theme, that’s something that could use some iteration.
Dream something up, make something, and share it.
And that’s the State of IndieWeb 2016.
Thank you.
Thanks to Ryan Barrett and Kevin Marks for proofreading this post.
|
|
Aki Sasaki: signtool py3 support |
requests, and refactored it a bit to make it a little easier to test. There are still some overly complex functions and I only have 65% test coverage right now, but it's working in py3.|
|
Aki Sasaki: configman py3 support |
DotDict __getattr__ hack. I wrote about that here.|
|
Marcia Knous: Reflections from my Outreachy mentorship |

|
|






