Robert O'Callahan: rr 4.3.0 Released |
I've just released rr 4.3.0. This release doesn't have any major new user-facing features, just a host of small improvements:
In this release I've fixed the last known intermittent test failure! Some recent Linux kernels have a regression in performance counter code that very rarely causes some counts to be lost. This regression seems to be fixed in 4.7rc5 which I'm currently running.
Ubuntu 16.04 was released with gdb 7.11.0, which contains a serious regression that makes it very unreliable with rr. The bug is fixed in gdb 7.11.1 which is shipping as an update to 16.04, so make sure to update.
|
|
Support.Mozilla.Org: What’s Up with SUMO – 30th June |
Hello, SUMO Nation!
June is officially over! Well, almost. How was your first proper summer month? Also, have you seen the new Connected Devices blog already? How about CodeMoji? If you have, don’t forget to mention this to your friends who may have missed the news… Speaking of news – here we go!
We salute you!
…aaaaaand that’s it for the most recent updates. Oh yeah, I almost forgot… :wink:
PS. GO ICELAND!
https://blog.mozilla.org/sumo/2016/06/30/whats-up-with-sumo-30th-june/
|
|
Ben Hearsum: Building and Pushing Docker Images with Taskcluster-Github |
Earlier this year I spent some time modernizing and improving Balrog's toolchain. One of my goals in doing so was to switch from Travis CI to Taskcluster both to give us more flexibility in our CI configuration, as well as help dogfood Taskcluster-Github. One of the most challenging aspects of this was how to build and push our Docker image, and I'm hoping this post will make it easier for other folks who want to do the same in the future.
Let's start by breaking down Task definition from Balrog's .taskcluster.yml. Like other Taskcluster-Github jobs, we use the standard taskcluster.docker provisioner and worker.
- provisionerId: "{{ taskcluster.docker.provisionerId }}"
workerType: "{{ taskcluster.docker.workerType }}"
Next, we have something a little different. This section grants the Task access to a secret (managed by the Secrets Service). More on this later.
scopes:
- secrets:get:repo:github.com/mozilla/balrog:dockerhub
The payload has a few things of note. Because we're going to be building Docker images it makes sense to use Taskcluster's image_builder Docker image as well as enabling the docker-in-docker feature. The taskclusterProxy feature is needed to access the Secrets Service.
payload:
maxRunTime: 3600
image: "taskcluster/image_builder:0.1.3"
features:
dind: true
taskclusterProxy: true
command:
- "/bin/bash"
- "-c"
- "git clone $GITHUB_HEAD_REPO_URL && cd balrog && git checkout $GITHUB_HEAD_BRANCH && scripts/push-dockerimage.sh"
The extra section has some metadata for Taskcluster-Github. Unlike CI tasks, we limit this to only running on pushes (not pull requests) to the master branch of the repository. Because only a few people can push to this branch, it means that only these can trigger Docker builds.
extra:
github:
env: true
events:
- push
branches:
- master
Finally, we have the metadata, which is just standard Taskcluster stuff.
metadata:
name: Balrog Docker Image Creation
description: Balrog Docker Image Creation
owner: "{{ event.head.user.email }}"
source: "{{ event.head.repo.url }}"
I mentioned the "Secrets Service" earlier, and it's the key piece that enables us to securely push Docker images. Putting our Dockerhub password in it means access is limited to those who have the right scopes. We store it in a secret with the key "repo:github.com/mozilla/balrog:dockerhub", which means that anything with the "secrets:get:repo:github.com/mozilla/balrog:dockerhub" scope is granted access to it. My own personal Taskcluster account has it, which lets me set or change the password:

We also have a Role called "repo:github.com/mozilla/balrog:branch:master" which has that scope:

You can see from its name that this Role is associated with the Balrog repository's master branch. Because of this, any Tasks created for as a result of pushes to that branch in that repository and branch may assign the scopes that Role has - like we did above in the "scopes" section of the Task.
The last piece of the puzzle here is the actual script that does the building and pushing. Let's look at a few specific parts of it.
To start with, we deal with retrieving the Dockerhub password from the Secrets Service. Because we enabled the taskclusterProxy earlier, "taskcluster" resolves to the hosted Taskcluster services. Had we forgotten to grant the Task the necessary scope, this would return a 403 error.
password_url="taskcluster/secrets/v1/secret/repo:github.com/mozilla/balrog:dockerhub"
dockerhub_password=$(curl ${password_url} | python -c 'import json, sys; a = json.load(sys.stdin); print a["secret"]["dockerhub_password"]')
We build, tag, and push the image, which is very similar to building it locally. If we'd forgotten to enable the dind feature, this would throw errors about not being able to run Docker.
docker build -t mozilla/balrog:${branch_tag} .
docker tag mozilla/balrog:${branch_tag} "mozilla/balrog:${date_tag}"
docker login -e $dockerhub_email -u $dockerhub_username -p $dockerhub_password
docker push mozilla/balrog:${branch_tag}
docker push mozilla/balrog:${date_tag}
Finally, we attach an artifact to our Task containing the sha256 of the Docker images. This allows consumers of the Docker image to verify that they're getting exactly what we built, and not something that may have been tampered on Dockerhub or in transit.
sha256=$(docker images --no-trunc mozilla/balrog | grep "${date_tag}" | awk '/^mozilla/ {print $3}')
put_url=$(curl --retry 5 --retry-delay 5 --data "{\"storageType\": \"s3\", \"contentType\": \"text/plain\", \"expires\": \"${artifact_expiry}\"}" ${artifact_url} | python -c 'import json; import sys; print json.load(sys.stdin)["putUrl"]')
curl --retry 5 --retry-delay 5 -X PUT -H "Content-Type: text/plain" --data "${sha256}" "${put_url}"
Now that you've seen how it's put together, let's have a look at the end result. This is the most recent Balrog Docker build Task. You can see the sha256 artifact created on it:
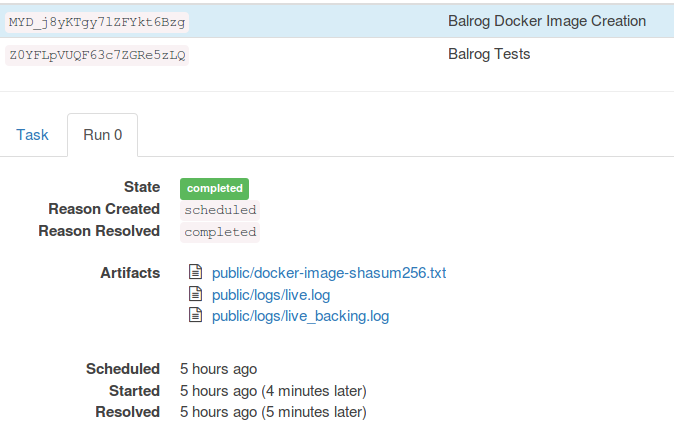
And of course, the newly built image has shown up on the Balrog Dockerhub repo:
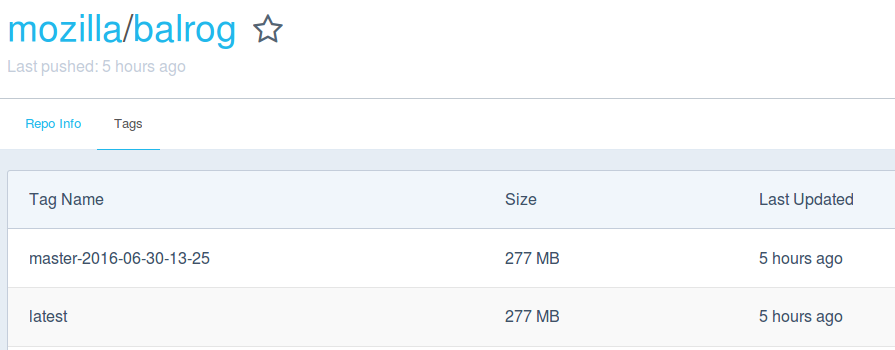
http://hearsum.ca/blog/building-and-pushing-docker-images-with-taskcluster-github.html
|
|
Air Mozilla: Web QA Weekly Team Meeting, 30 Jun 2016 |
 They say a Mozilla Web QA team member is the most fearless creature in the world. They say their jaws are powerful enough to crush...
They say a Mozilla Web QA team member is the most fearless creature in the world. They say their jaws are powerful enough to crush...
|
|
Air Mozilla: Reps weekly, 30 Jun 2016 |
 This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
|
|
The Rust Programming Language Blog: State of Rust Survey 2016 |
We recently wrapped up with a survey for the Rust community. Little did we know that it would grow to be one of the largest language community surveys. A huge thank you to the 3,086 people who responded! We’re humbled by the response, and we’re thankful for all the great feedback.
The goal of the survey was simple: we wanted to know how Rust was doing in its first year. We asked a variety of questions to better understand how Rust was being used, how well the Rust tools worked, and what the challenges are for people wanting to adopt Rust.
We plan to run a similar survey each year to track how we’re progressing and spot places we can improve. With that, let’s get started.
We wanted to make sure the survey was open to both users of Rust and to people who didn’t use Rust. Rust users give us a sense of how the current language and tools are working and where we need to improve. Rust non-users shed light on missing use-cases and obstacles for Rust’s adoption.
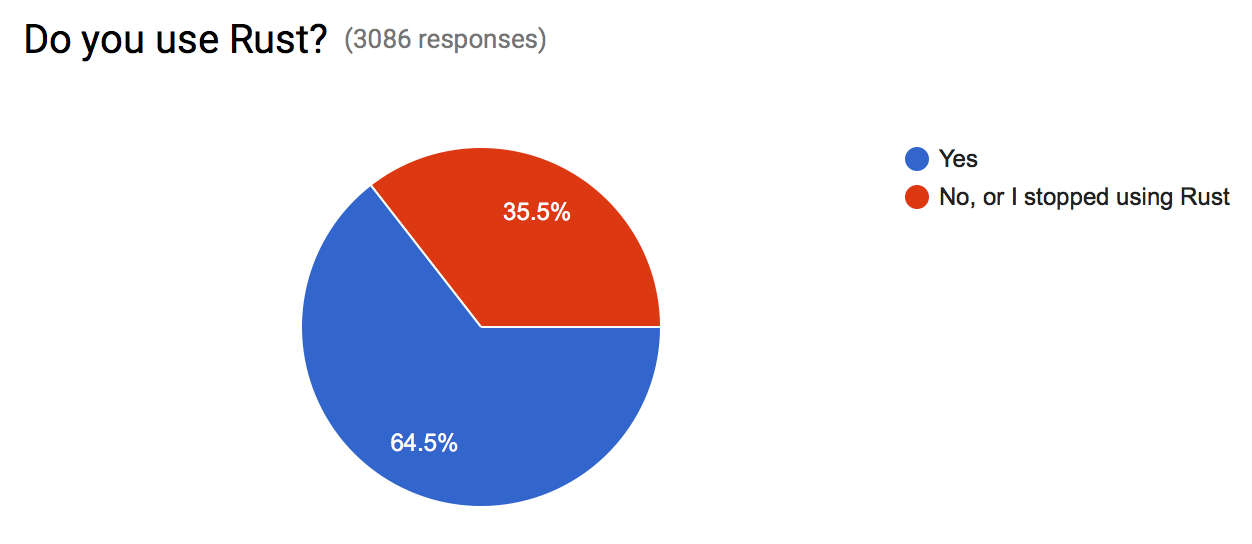
We’re happy to report that more than a third of the responses were from people not using Rust. These respondents gave a lot of great feedback on adoption roadblocks, which we’ll talk about later in this blog post.
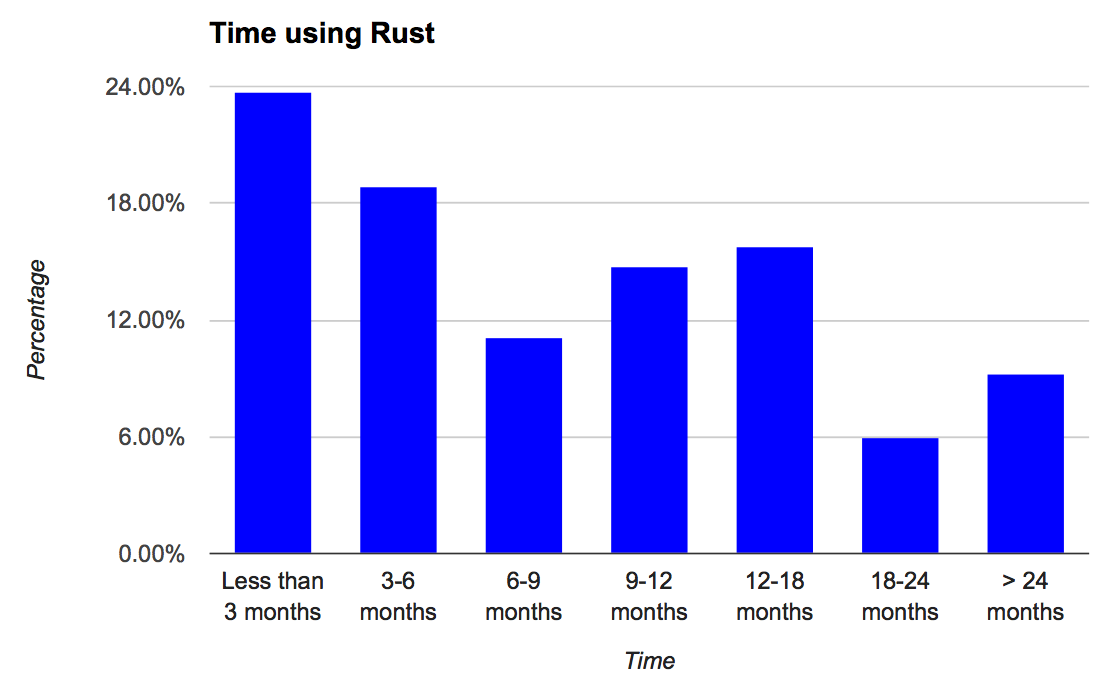
Almost 2,000 people responded saying they were Rust users. Of these, almost 24% were new users. This is encouraging to see. The community is growing, with a healthy portion of newcomers playing with Rust now that could become long-term users.
Equally encouraging is seeing that once someone has become a Rust user, they tend to stick around and continue using it. One might expect a sharp drop-off if users became quickly disenchanted and moved onto other technologies. Instead, we see the opposite. Users that come in and stay past their initial experiences tend to stay long-term, with a fairly even spread between 3 months to 12 months (when we first went 1.0). We’ve seen similar patterns looking at crates.io usage, as well as in the StackOverflow developer survey.
We asked a number of questions trying to get a clear picture of what it’s like to use Rust today. The first questions focused on the Rust compiler.
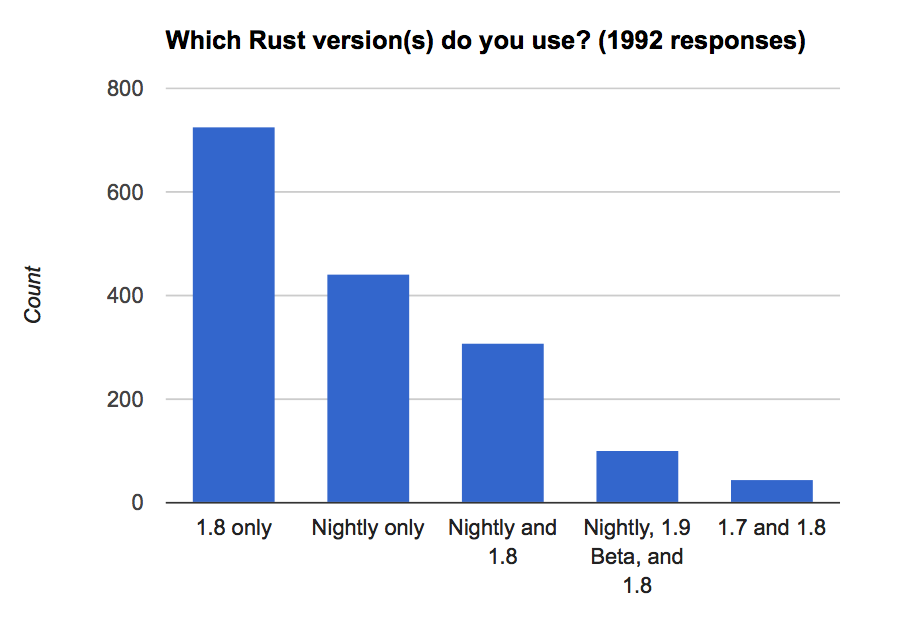
In the above chart, you see the top five rustc version combinations for users writing Rust. At the time of the survey, version 1.8 was the latest stable release. This factors strongly in the results as the most popular version of Rust to use. Perhaps surprisingly is how much the nightly also plays a key role in for many developers, with over 400 using it as their only Rust compiler version. Stabilizing features and APIs, and thereby encouraging transition to the stable channel, continues to be a priority for the team.
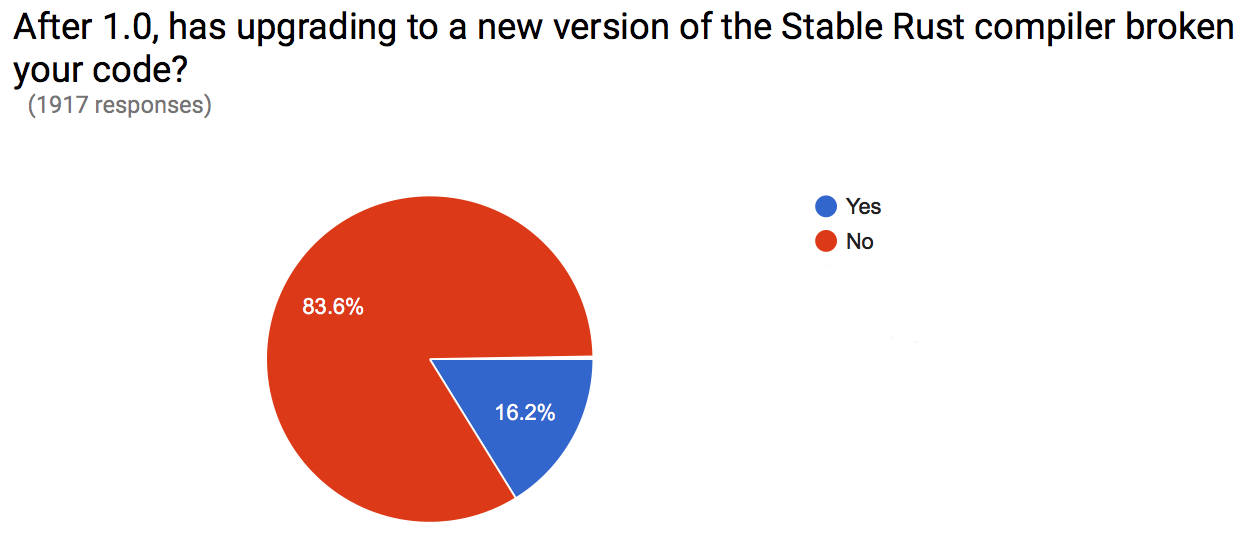
In the pre-1.0 days, Rust releases would regularly break user’s code. In reaching 1.0, we began releasing versions that maintained backwards compatibility with 1.0. For stable Rust, 83.6% of users did not experience any breakage in their project as they upgraded to the next stable version. Previous research based on automated testing against the ecosystem put this number closer to 96%, which is more in line with expectations.
Why the discrepancy? Looking at the data more closely, it seems people used this question as a catch-all for any kind of breakage, including packages in cargo, compiler plugins needing updates, and the changes to libc. We’ll be sure to word this question more clearly in the future. But we also plan to launch a forum discussion digging further into the details, to make sure that there’s not something missing from the test automation that runs against crates.io.
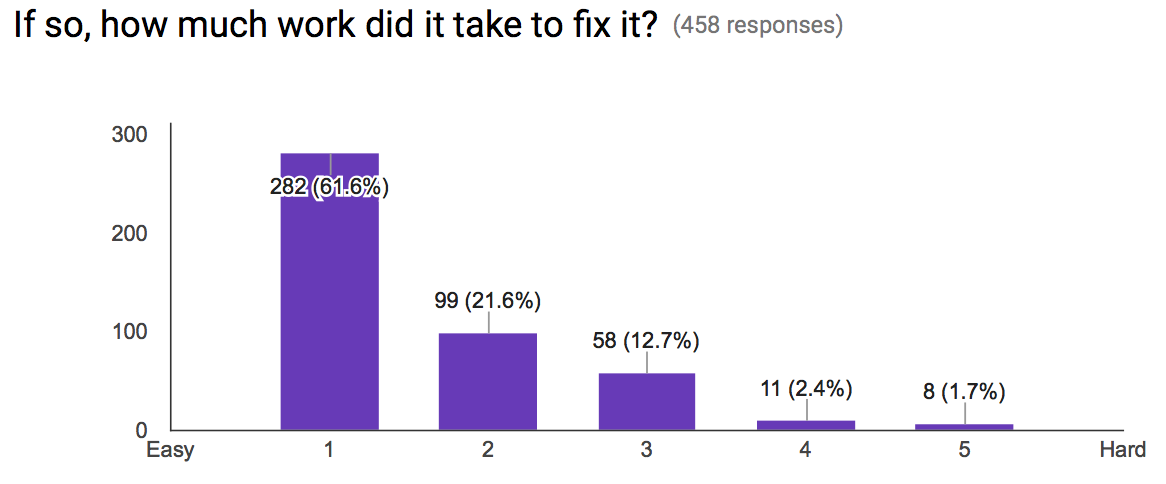
Luckily, regardless of what bucket the breakage fell into, they were largely easy to solve as people upgraded.
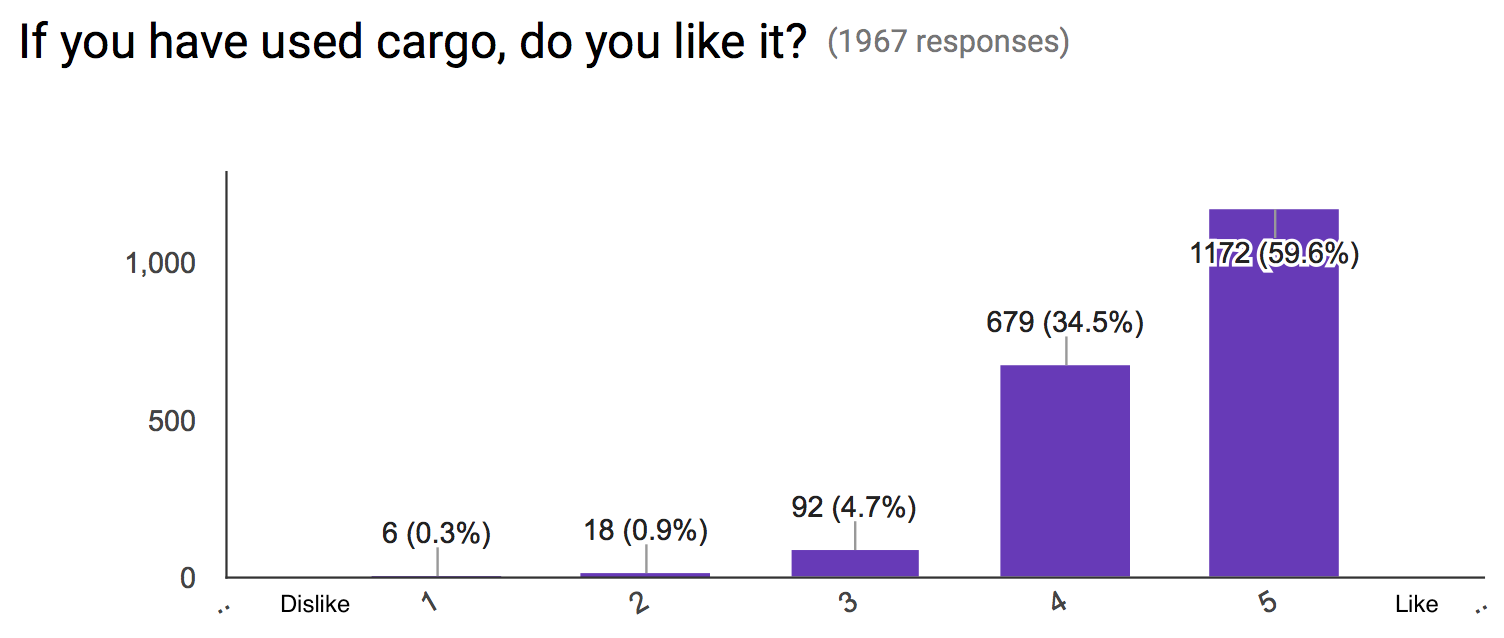
Another big piece of the Rust development experience is using the Cargo tool. Here we saw overwhelming support for Cargo, with 94.1% of people saying they would rate it a 4 or 5. This helps to emphasize that Cargo continues to be a core part of what it means to write Rust (and that people enjoy using it!)
An important part of a programming language’s success is that it’s used for “real” work. We asked a few questions to understand how Rust was doing in the workplace. Were people using it in their day jobs? How much was it being used?
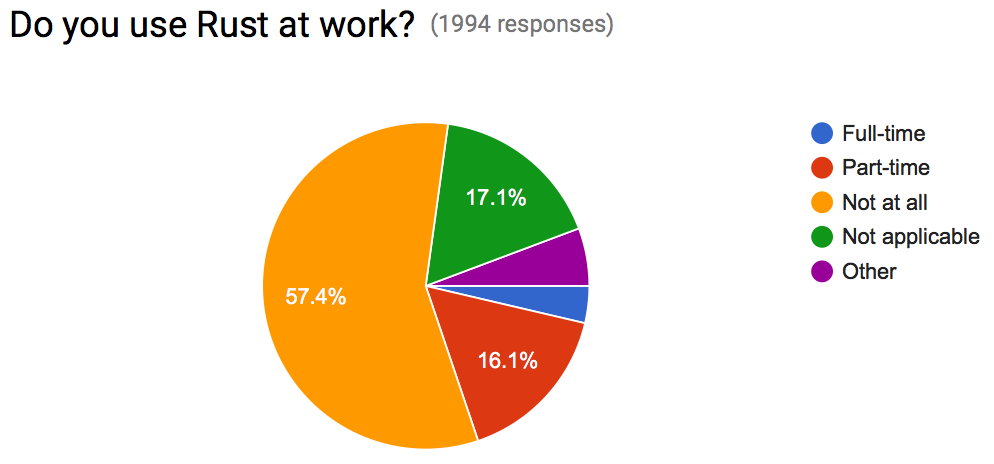
We were pleasantly surprised to see that already, in Rust’s first year, 16.1% of Rust users are using Rust at work part-time and 3.7% are using at work full-time. Combined, nearly 1/5th of Rust users are using Rust commercially. We’re seeing this reflected in the growing number of companies using Rust.
We also asked about the size of the codebases that Rust developers were building.
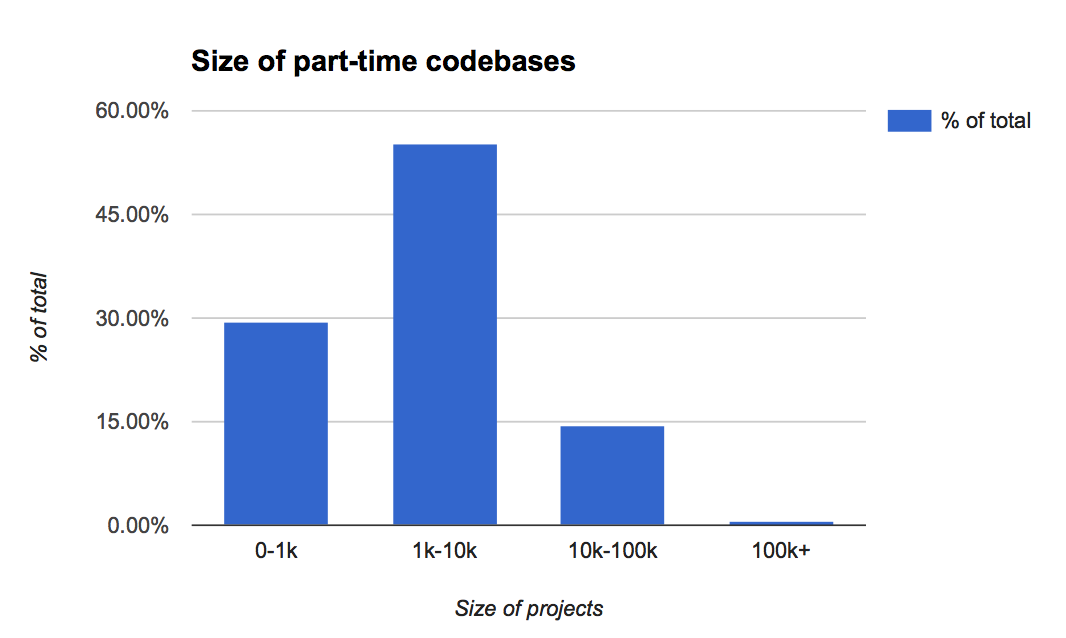
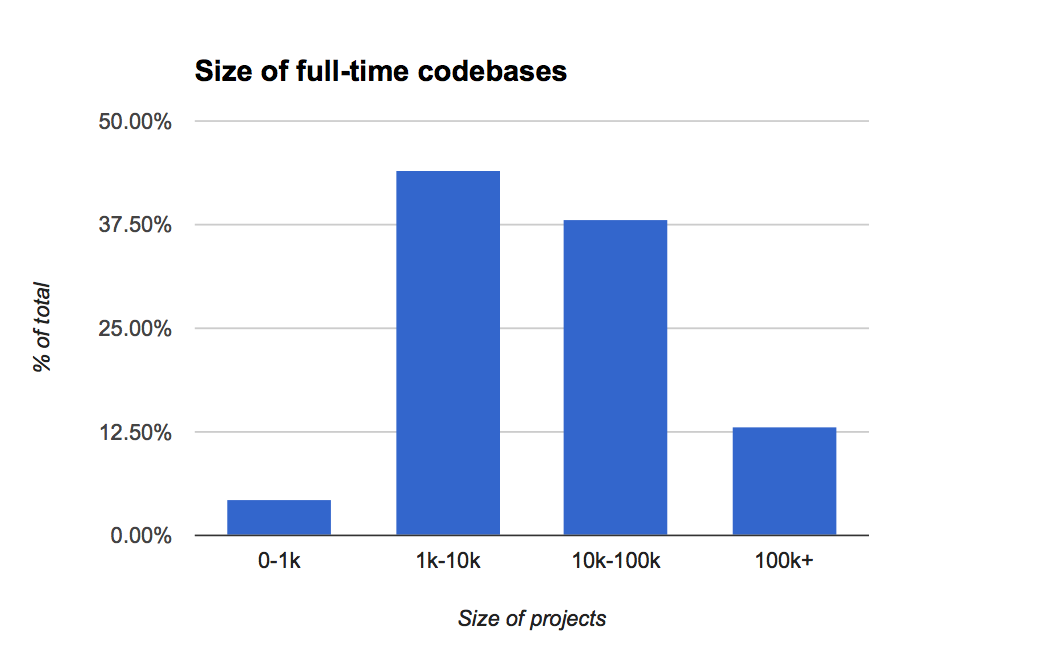
We see strong numbers in project size as developers put more time into Rust at work. Over half of the Rust users using Rust full-time at work have codebases that are tens or hundreds of thousands of lines of code.
Equally encouraging is the growth we expect to see in Rust in the workplace, as we see in the next chart.
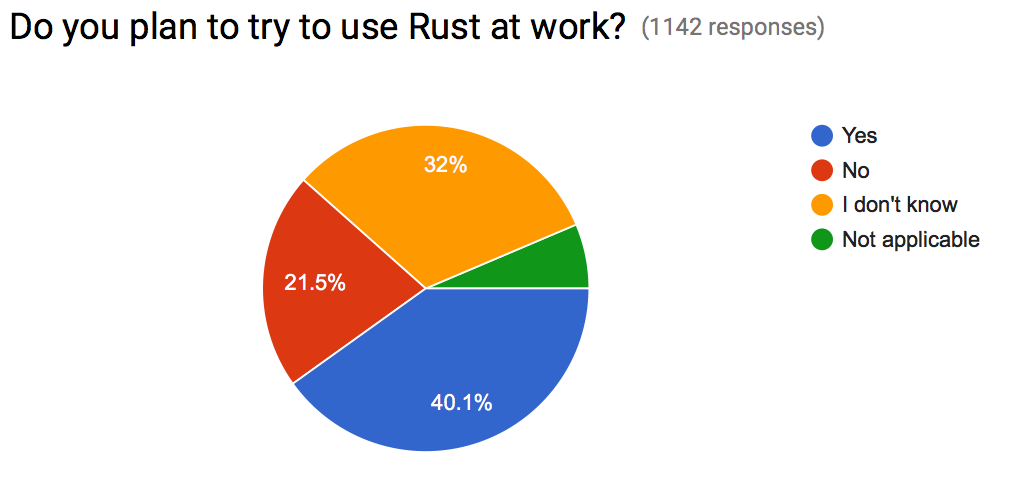
Of those not currently using Rust at work, more than 40% plan on being able to use Rust at work. This will help carry Rust to more places and in more areas. Speaking of carrying to more areas, we saw a wide variety of job domains represented in the survey:
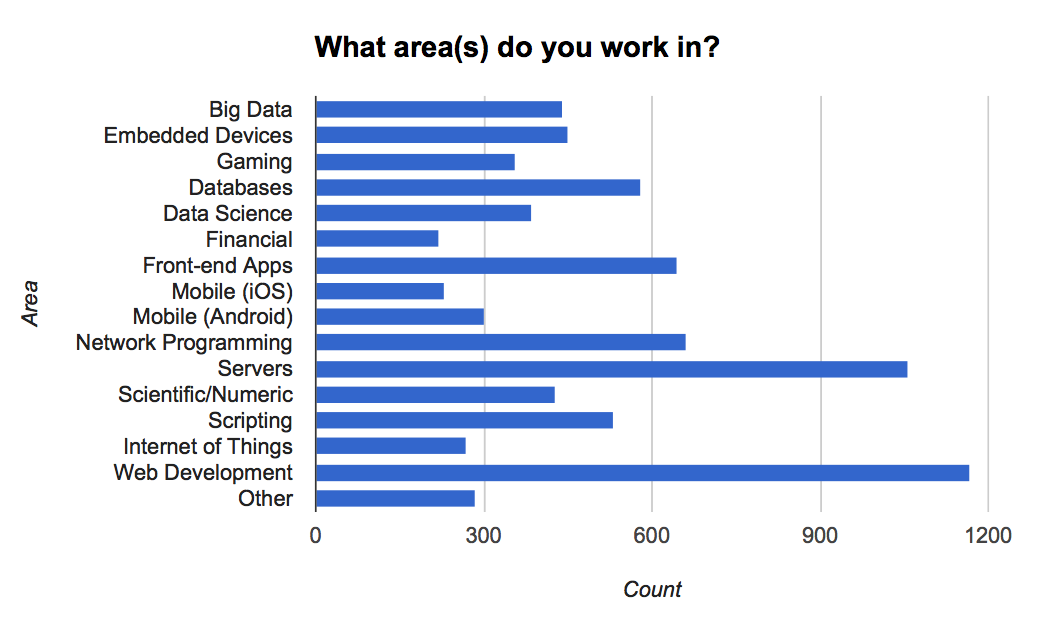
It’s encouraging to see people from so many different backgrounds interested in Rust. It underscores Rust’s potential across a broad spectrum of programming tasks and the need for libraries to support these areas.
An important part of the survey was understanding what’s getting in the way of people using Rust. This data can help guide our energies in the coming year. Over 1,900 people responded here, giving us a detailed picture of the challenges with using and promoting Rust. While we’ll be exploring these responses in upcoming blog posts, here we’ll look at three strong themes in the feedback: learning curve, immaturity of the language and libraries, and immaturity of the tools.
Rust is a unique language, introducing new concepts, like ownership, that are not usually explicit in languages. While these concepts are what make Rust so powerful, they can also be an obstacle when first getting to know the language.
In total, 1 in 4 people commented on the learning curve when talking about Rust’s challenges. Here are some of the comments:
“Borrow checker is hard to grasp for a beginner.”
“The borrow system, albeit powerful, can be difficult to learn.”
“Steep learning curve at the beginning”
The proverbial gauntlet has been thrown. For Rust to do well, it will need to retain the power it has while also improving the experience of learning the language and mastering its ownership system. There are a few early initiatives here, including a new Rust book, an upcoming O'Reilly book, improvements to Rust error messages, as well as improvements to the borrow checker to give fewer false warnings. We expect learning curve and developer productivity to be an area of sustained focus.
Of those commenting on Rust’s challenges, 1 in 9 mentioned the relative immaturity of the Rust language was a factor. While some people pointed out their favorite missing feature, the consensus formed around the need to move the ecosystem onto the stable language and away from requiring the nightly builds of the compiler.
“a major blocker is how many crates still only put their best foot forward if you’re using a nightly compiler”
“I don’t like having to use a nightly plus a build.rs for parsing json with serde. It needs to be simpler.”
“I also found myself unable to use a lot of nice looking crates because many were locked on nightly because of feature usage.”
While there will always be a subset of users that want to live on the bleeding edge and use every new feature, it’s become clear that as Rust matures it will need to build more infrastructure around the stable language and compiler.
Closely related to the language are the libraries. People often mentioned both in the same sentence, seeing the experience of programming Rust as one built on the combination of language and library. In total, 1 in 7 commenters mentioned the lack of libraries. The kinds of libraries people mentioned ran the gamut in terms of topic, covering areas like GUIs, scientific/numeric computing, serialization support, web/networking, async I/O, parallel/concurrent patterns, and richer data structures (including more containers and broader coverage of general algorithms).
Of course, immaturity is to be expected one year in, and to some degree is a problem that only time can solve. But there was also a sense that people coming to Rust wanted more of a “batteries included” experience, gathering together the best of the ecosystem in a simple package. There are some proposals in the works for how best to build this experience, and we’re looking forward to discussing these ideas in the coming weeks.
Another strong theme for improvement was the relative immaturity of the tooling for Rust. While tools like Cargo have been invaluable to a number of Rust users, other tools need attention.
Of non-Rust users, 1 in 4 responded that they aren’t currently using Rust because of the lack of strong IDE support. As one user puts it “[f]or a complex language like Rust, good editor tooling makes the learning process interactive.” Modern IDEs have become a powerful way to explore unfamiliar APIs, unfamiliar language features, and unfamiliar error messages.
Investing in IDE support not only helps new users but also helps enable teams moving to Rust and the growth of larger codebases, as we see in some of the quotes about Rust’s challenges:
“I won’t use the language until there’s IDE support for it, and I know other devs that feel the same way. As productive as your language’s syntax is, I’m more productive in a worse language with an editor that has code-completion.”
“Users/projects considering switching languages often are not willing to sacrifice tooling quality even for a better language.”
“Proper IDE support (hard to get it accepted at work for that reason)”
Other languages have had years to build up their tooling muscle, and for Rust to stand on even footing, we’ll also have to build up our own muscle. There are some early experiments here, namely Racer and rustw, as well as a number of IDE plugins.
We’ve also been investing in other tooling muscles, including a new installer with cross-compilation support. These are just the first steps, and we’ll be exploring more ideas in further blog posts.
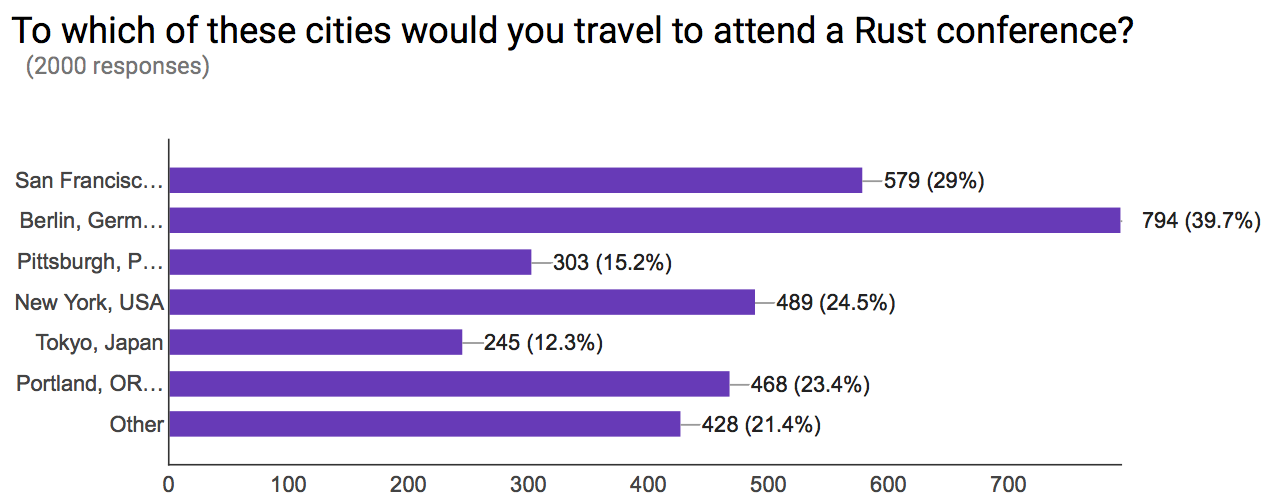
Today, Rust has a worldwide audience. Rather than being lumped in one place, we see Rust users in Europe, Japan, Australia, with new meetups popping up everyday. We also asked where people who responded lived, and over 1000 of the 3000 survey responses mentioned living in Europe (with USA following it up at 835).
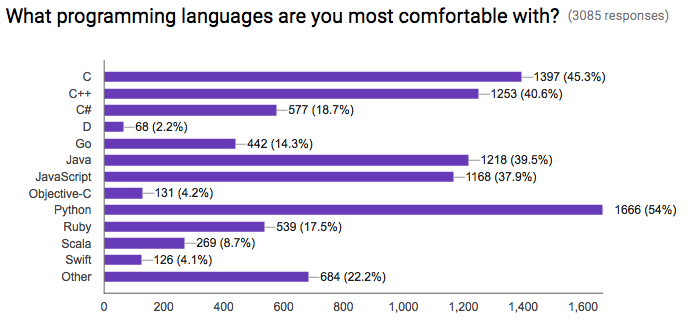
The parents of most modern languages, C and C++, show strongly in terms of the programming languages that people are most comfortable with. Close by are Java and JavaScript. Perhaps one surprising point here is the large number of Python users attracted to Rust.
For those who already have existing projects in other languages but want to use Rust, it’s worth mentioning here the on-going efforts to aide in using Rust with other languages, including work to integrate with Ruby and integrate with JavaScript/Node.js.
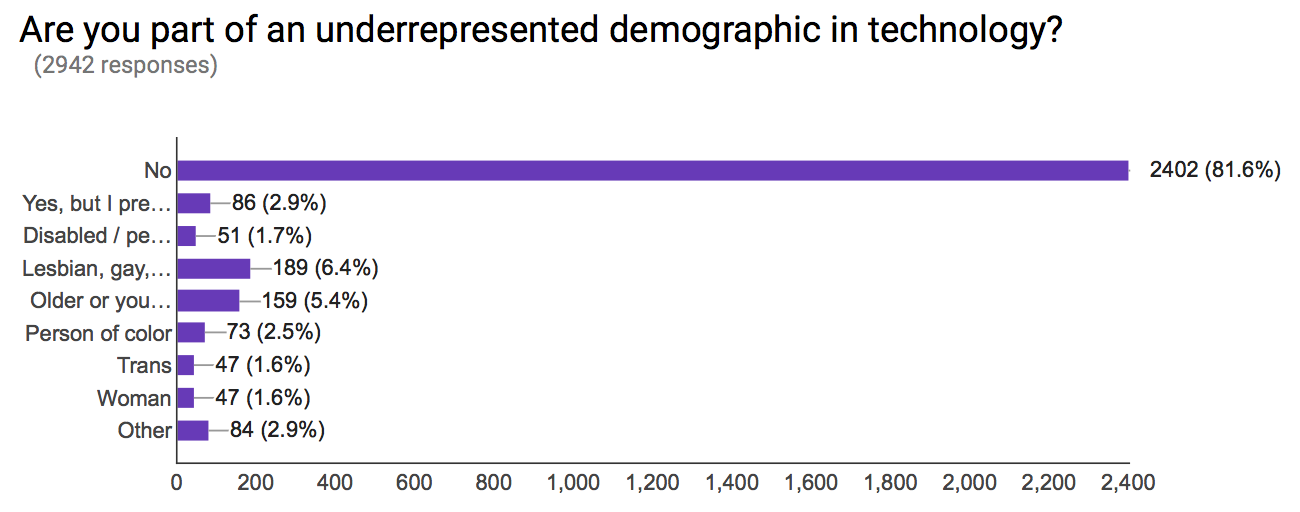
Rust strives to be a warm, welcoming and inclusive community. The survey shows that, despite that spirit, we have a ways to go in terms of diversity. We have nascent efforts, like RustBridge, to more proactively reach out to underrepresented groups and make Rust more accessible, but there is a lot more work to be done. We’ll be watching the results of this part of the survey closely and continue to invest in outreach, mentoring, and leadership to foster inclusivity.
At the end of the survey, we threw in a catch-all question: “Anything else you’d like to tell us?” Rather than being a large batch of additional things to look at, we received an outpouring of support from the community.
I’ll let some of the quotes speak for themselves:
“Rust has been an incredible productivity boon for me. Thank you so much, and keep up the good work!”
“Thank you for making Rust awesome!”
“Working in the Rust community has been an amazing experience.”
And we couldn’t agree more. One of the best things about working in Rust is that you’re part of a community of people working together to build something awesome. A big thank you(!!) to all of you who have contributed to Rust. Rust is what it is because of you.
We’d love to hear your comments and invite you to jump in and participate in the upcoming discussions on ways we can tackle the challenges brought up in this survey.
http://blog.rust-lang.org/2016/06/30/State-of-Rust-Survey-2016.html
|
|
Armen Zambrano: Q2 retropective |

http://feedproxy.google.com/~r/armenzg_mozilla/~3/bEFqFArH2PA/q2-retropective.html
|
|
Air Mozilla: The Joy of Coding - Episode 61 |
 mconley livehacks on real Firefox bugs while thinking aloud.
mconley livehacks on real Firefox bugs while thinking aloud.
|
|
Air Mozilla: Weekly SUMO Community Meeting June 29, 2016 |
 This is the sumo weekly call
This is the sumo weekly call
https://air.mozilla.org/weekly-sumo-community-meeting-june-29-2016-20160629/
|
|
Air Mozilla: France Connect |
 Pr'esentation de France Connect, service de l'Etat pour l'identification en ligne.
Pr'esentation de France Connect, service de l'Etat pour l'identification en ligne.
|
|
Yunier Jos'e Sosa V'azquez: C'omo se hace? Utilizar Flash en Firefox a trav'es de Pepper |
Hace ya un poco m'as de 4 a~nos Adobe dej'o de dar soporte a Flash en Linux por las v'ias tradicionales y a los usuarios de Firefox nos dej'o parados en la versi'on 11.2, un tanto desactualizados y vulnerables en la jungla de Internet. Pese a las fallas de seguridad que presenta el producto de Adobe y el avance de las tecnolog'ias web, a'un Flash sigue siendo empleado y aunque lo tengamos instalado a trav'es de gnash u otro paquete, los molestos carteles “Para ver esta p'agina aseg'urate que Adobe Flash Player 11.5 o superior est'a instalado” aparecen cuando menos lo esperamos.
El tiempo ha pasado y con unos sencillos pasos podemos utilizar Flash en Firefox a trav'es de la API Pepper. Para eso debemos contar con un sistema de 64 bits y tener instalado los paquetes browser-plugin-freshplayer-pepperflash (disponible en los repos) y chromium-pepper-flash (obtenido de los repos de OpenSuse y convertido a DEB mediante Alien).
Para 32 bits no he probado ya que en openSuse extraen el Flash incluido en Chrome y Google ya no libera versiones de 32 bits de su navegador.
Los pasos que siguen han sido probados en Debian 8, Testing y en Ubuntu 16.04 para sistemas de 64 bits pues como dije anteriormente, Chrome ya no libera versiones para 32 bits.
FLASH_VERSION=22.0.0.196-2.2
wget http://firefoxmania.uci.cu/common/plugins/chromium-pepper-flash_${FLASH_VERSION}_amd64.deb
sudo dpkg -i chromium-pepper-flash_${FLASH_VERSION}_amd64.deb
sudo echo 'deb http://debian.uci.cu/debian/ stable-backports main contrib non-free' >> /etc/apt/sources.list sudo apt update
sudo apt --no-install-recommends install browser-plugin-freshplayer-pepperflash
Los siguientes pasos han sidos probados en openSuse Leap 42.1.
FLASH_VERSION=22.0.0.196-1.2
wget http://firefoxmania.uci.cu/common/plugins/chromium-pepper-flash-${FLASH_VERSION}.x86_64.rpm
sudo rpm -i chromium-pepper-flash-${FLASH_VERSION}.x86_64.rpm
sudo zypper|yum install freshplayerplugin
Al terminar todos los pasos, en la secci'on Plugins del Administrador de complementos (about:addons) deben ver instalado Shockwave Flash en su versi'on 22 como se muestra en la siguiente imagen.

Administrador de complementos mostrando los plugins instalados
Eso es todo, ya tenemos la 'ultima versi'on estable de Flash en Linux lista para usar en Firefox. En este art'iculo y en la p'agina Plugins del sitio de los complementos publicaremos las actualizaciones de Flash para que se mantengan actualizados..
Espero que les haya sido 'util.
http://firefoxmania.uci.cu/como-se-hace-utilizar-flash-en-firefox-a-traves-de-pepper/
|
|
Daniel Glazman: Media Queries fun #1 |
So one of the painful bits when you have UI-based management of Media
Queries is the computation of what to display in that UI. No, it's not
as simple as browsing all your stylesheets and style rules to retrieve
only the media attribute of the CSS OM objects... Let's
take a very concrete example:
where file foo.css contains the following rules:
@media screen and (max-width: 500px) {
h1 { color: red; }
}What are the exact media constraints triggering a red foreground color for h1 elements in such a document? Right, it's screen and (min-width: 200px) and (max-width: 500px)... And to compute that from the inner style rule (theh1 { color: red; } bit), you have to climb up the CSS OM up to the most enclosing stylesheet and intersect the various media queries between that stylesheet and the final style rule:
| CSS OM object | applicable medium | applicable min-width | applicable max-width |
|---|---|---|---|
| embedded stylesheet | screen | 200px | - |
| imported stylesheet | screen | 200px | 750px |
| @media rule | screen | 200px | 750px |
| style rule | screen | 200px | 500px |
It becomes seriously complicated when the various constraints you have to intersect are expressed in different units because, unless you're working with computed values, you really can't intersect. In BlueGriffon, I am working on specified values and it's then a huge burden. In short, dealing with a width Media Query that is not expressed in pixels is just a no-go.
I'd really love to have a CSS OM API doing the work described above for a given arbitrary rule and replying a MediaList. Maybe something for Houdini?
http://www.glazman.org/weblog/dotclear/index.php?post/2016/06/29/Media-Queries-fun-1
|
|
Robert O'Callahan: Relearning Debugging With rr |
As I've mentioned before, once you have a practical reverse-execution debugger like rr, you need to learn new debugging strategies to exploit its power, and that takes time. (Almost all of your old debugging strategies still work --- they're just wasting your time!) A good example presented itself this morning. A new rr user wanted to stop at a location in JIT-generated code, and modified the JIT compiler to emit an int3 breakpoint instruction at the desired location --- because that's what you'd do with a regular debugger. But with rr there's no need: you can just run past the generation of the code, determine the address of your generated instruction after the fact (by inserting a logging statement at the point where you would have triggered generation of int3, if you must), set a hardware execution breakpoint at that address, and reverse-execute until that location is reached.
One of the best reasons I've heard for not using rr was given by Jeff: "I don't want to forget how to debug on other platforms".
http://robert.ocallahan.org/2016/06/relearning-debugging-with-rr.html
|
|
Air Mozilla: Connected Devices Weekly Program Update, 28 Jun 2016 |
 Weekly project updates from the Mozilla Connected Devices team.
Weekly project updates from the Mozilla Connected Devices team.
https://air.mozilla.org/connected-devices-weekly-program-update-20160628/
|
|
Air Mozilla: Connected Devices Meetup: KittyCam with Tomomi |
 Tomomi gives us a look at her project KittyCam!
Tomomi gives us a look at her project KittyCam!
https://air.mozilla.org/connected-devices-meetup-kittycam-with-tomomi/
|
|
Air Mozilla: Connected Devices Meetup: Morgan Fabian from Autodesk |
Morgan Fabian from Autodesk
https://air.mozilla.org/connected-devices-meetup-morgan-fabian-from-autodesk/
|
|
Air Mozilla: Connected Devices Meetup: Willi Wu, Founder & CEO of Thermodo |
Willi Wu, Founder & CEO of Thermodo
https://air.mozilla.org/connected-devices-meetup-will-wu-thermodo/
|
|
The Mozilla Blog: Meet Codemoji: Mozilla’s New Game for Teaching Encryption Basics with Emoji |
|
|
Alexandre Poirot: Interfaces experiments for and from Firefox |
What about easily experimenting new interfaces for Firefox? Written with regular web technologies, served from http, refreshable via a key shortcut.
Follow these 4 steps:
You should see a page asking you to confirm testing this browser experiment. Once you click on the install button, the current Firefox interface will be replaced on the fly.
This interface is a old version of Browser.html. But instead of requiring a custom runtime, this is just a regular web site, written with web technologies and fetched from github at every startup. If you want to check if this is a regular web page, just look at the sources: view-source:http://rawgit.com/ochameau/planula-browser-advanced/addon-demo/
If needed you can revert at any time back to default Firefox UI using the “Ctrl + Alt + R” shortcut.
Want to see more interfaces, here are some links:
The addon itself is simple. It does 4 things:
The tag, while beeing non-standard, allows an iframe to act similarly to a or a
Last year, during Whistler All Hands, there was this “Kill XUL” meeting. Various options were discussed. But it is unclear that any has been really looked into. Except may be the electron option, via Tofino project.
Then a thread was posted on firefox-dev. At least Go faster and new Test Pilot addons started using HTML for new self-contained features of Firefox, which is already a great step forward!
But there was no experiment to measure how we could leverage HTML to build browsers within Mozilla.
Myself and Vivien started looking into this and ended up releasing this addon. But we also have some more concrete plan on how to slowly migrate Firefox full of XUL and cryptic XPCOM/jsm/chrome technologies to a mix of Web standards + Web extensions. We do have a way to make Web extensions to work within these new HTML interfaces. Actually, it already supports basic features. When you open the browserui:// links, it actually opens an HTML page from a Web extension.
First, you need to host some html page somewhere. Any website could be loaded. browserui://localhost/ if you are hosting files locally. But you may also just load google if you want to browserui://google.com/. Just remember the “Ctrl + Alt + R” shortcut to get back to the default Firefox UI!
The easiest is probably to fork this one-file minimal browser, or directly the demo browser. Host it somewhere and open the right browserui:// url. browserui:// just maps one to one to the same URL starting with “http” instead of “browserui”. Given that this addon is just a showcase, we don’t support https yet.
Then, change the files, hit “Ctrl + R” and your browser UI is going to be reloaded, fetching resources again from http.
Once you have something you want to share, using github is handy. If you push files to let say the “mozilla” account and “myui” as the repository name, then you can share simply via the following link:
browserui://rawgit.com/mozilla/myui/master/
But there is many ways to control which particular version you want to share. Sharing another branch, like the “demo” branch:
browserui://rawgit.com/mozilla/myui/demo/
Or a particular changeset:
browserui://rawgit.com/mozilla/myui/5a931e3e0046ccde6d4ad3a73e93016bcc3a9650/
This addon lives on github, over here: https://github.com/ochameau/browserui. Feel free to submit Issues or Pull requests!
Actually, we already have various patches to do that and would like to upstream them to Firefox!
|
|
Robert O'Callahan: Handling Read-Only Shared Memory Usage In rr |
One of rr's main limitations is that it can't handle memory being shared between recorded processes and not-recorded processes, because writes by a not-recorded process can't be recorded and replayed at the right moment. This mostly hasn't been a problem in practice. On Linux desktops, the most common cases where this occurs (X, pulseaudio) can be disabled via configuration (and rr does this automatically). However, there is another common case --- dconf --- that isn't easily disabled via configuration. When applications read dconf settings for the first time, the dconf daemon hands them a shared-memory buffer containing a one-byte flag. When those settings change, the flag is set. Whenever an application reads cached dconf settings, it checks this flag to see if it should refetch settings from the daemon. This is very efficient but it causes rr replay to diverge if dconf settings change during recording, because we don't replay that flag change.
Fortunately I've been able to extend rr to handle this. When an application maps the dconf memory, we map that memory into the rr supervisor process as well, and then replace the application mapping with a "shadow mapping" that's only shared between rr and the application. Then rr periodically checks to see whether the dconf memory has changed; if it is, then we copy the changes to the shadow mapping and record that we did so. Essentially we inject rr into the communication from dconf to the application, and forward memory updates in a controlled manner. This seems to work well.
That "periodic check" is performed every time the recorded process completes a traced system call. That means we'll forward memory updates immediately when any blocking system call completes, which is generally what you'd want. If an application busy-waits on an update, we'll never forward it and the application will deadlock, but that could easily be fixed by also checking for updates on a timeout. I'd really like to have a kernel API that lets a process be notified when some other process has modified a chunk of shared memory, but that doesn't seem to exist yet!
This technique would probably work for other cases where shared memory is used as a one-way channel from not-recorded to recorded processes. Using shared memory as a one-way channel from recorded to not-recorded processes already works, trivially. So this leaves shared memory that's read and written from both sides of the recording boundary as the remaining hard (unsupported) case.
http://robert.ocallahan.org/2016/06/handling-read-only-shared-memory-usage.html
|
|






