Ludovic Hirlimann: Recommendations are moving entities |
At my new job we publish an open source webapp map systems uxing a mix of technologies, we also offer it as SAS. Last Thursday I looked at how our Nginx server was configured TLS wise.
I was thrilled to see the comment in our nginx code saying the configuration had been built using mozilla's ssl config tool. At the same time I was shocked to see that the configuration that dated from early 2018 was completely out of date. Half of the ciphers were gone. So we took a modern config and applied it.
Once done we turned ourselves to the observatory to check out our score, and me and my colleague were disappointed to get an F. So we fixed what we could easily (the cyphers) and added an issue to our product to make it more secure for our users.
We'll also probably add a calendar entry to check our score on a regular basis, as the recommendation will change, our software configuration will change too.
https://www.hirlimann.net/Ludovic/carnet/?post/2020/05/09/Recommendations-are-moving-entities
|
|
Mozilla Security Blog: May 2020 CA Communication |
Mozilla has sent a CA Communication and Survey to inform Certification Authorities (CAs) who have root certificates included in Mozilla’s program about current expectations. Additionally this survey will collect input from CAs on potential changes to Mozilla’s Root Store Policy. This CA communication and survey has been emailed to the Primary Point of Contact (POC) and an email alias for each CA in Mozilla’s program, and they have been asked to respond to the following items:
The full communication and survey can be read here. Responses to the survey will be automatically and immediately published by the CCADB.
With this CA Communication, we reiterate that participation in Mozilla’s CA Certificate Program is at our sole discretion, and we will take whatever steps are necessary to keep our users safe. Nevertheless, we believe that the best approach to safeguard that security is to work with CAs as partners, to foster open and frank communication, and to be diligent in looking for ways to improve.
The post May 2020 CA Communication appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2020/05/08/may-2020-ca-communication/
|
|
William Lachance: This Week in Glean: mozregression telemetry (part 2) |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
This is a special guest post by non-Glean-team member William Lachance!
This is a continuation of an exploration of adding Glean-based telemetry to a python application, in this case mozregression, a tool for automatically finding the source of Firefox regressions (breakage).
When we left off last time, we had written some test scripts and verified that the data was visible in the debug viewer.
In many ways, this is pretty similar to what I did inside the sample application: the only significant difference is that these are shipped inside a Python application that is meant to be be installable via pip. This means we need to specify the pings.yaml and metrics.yaml (located inside the mozregression subirectory) as package data inside setup.py:
setup( name="mozregression", ... package_data={"mozregression": ["*.yaml"]}, ... )
There were also a number of Glean SDK enhancements which we determined were necessary. Most notably, Michael Droettboom added 32-bit Windows wheels to the Glean SDK, which we need to make building the mozregression GUI on Windows possible. In addition, some minor changes needed to be made to Glean’s behaviour for it to work correctly with a command-line tool like mozregression — for example, Glean used to assume that Telemetry would always be disabled via a GUI action so that it would send a deletion ping, but this would obviously not work in an application like mozregression where there is only a configuration file — so for this case, Glean needed to be modified to check if it had been disabled between runs.
Many thanks to Mike (and others on the Glean team) for so patiently listening to my concerns and modifying Glean accordingly.
At Mozilla, we don’t just allow random engineers like myself to start collecting data in a product that we ship (even a semi-internal like mozregression). We have a process, overseen by Data Stewards to make sure the information we gather is actually answering important questions and doesn’t unnecessarily collect personally identifiable information (e.g. email addresses).
You can see the specifics of how this worked out in the case of mozregression in bug 1581647.
Glean has some fantastic utilities for generating markdown-based documentation on what information is being collected, which I have made available on GitHub:
https://github.com/mozilla/mozregression/blob/master/docs/glean/metrics.md
The generation of this documentation is hooked up to mozregression’s continuous integration, so we can sure it’s up to date.
I also added a quick note to mozregression’s web site describing the feature, along with (very importantly) instructions on how to turn it off.
Once a Glean-based project has passed data review, getting our infrastructure to ingest it is pretty straightforward. Normally we would suggest just filing a bug and let us (the data team) handle the details, but since I’m on that team, I’m going to go a (little bit) of detail into how the sausage is made.
Behind the scenes, we have a collection of ETL (extract-transform-load) scripts in the probe-scraper repository which are responsible for parsing the ping and probe metadata files that I added to mozregression in the step above and then automatically creating BigQuery tables and updating our ingestion machinery to insert data passed to us there.
There’s quite a bit of complicated machinery being the scenes to make this all work, but since it’s already in place, adding a new thing like this is relatively simple. The changeset I submitted as part of a pull request to probe-scraper was all of 9 lines long:
diff --git a/repositories.yaml b/repositories.yaml index dffcccf..6212e55 100644 --- a/repositories.yaml +++ b/repositories.yaml @@ -239,3 +239,12 @@ firefox-android-release: - org.mozilla.components:browser-engine-gecko-beta - org.mozilla.appservices:logins - org.mozilla.components:support-migration +mozregression: + app_id: org-mozilla-mozregression + notification_emails: + - wlachance@mozilla.com + url: 'https://github.com/mozilla/mozregression' + metrics_files: + - 'mozregression/metrics.yaml' + ping_files: + - 'mozregression/pings.yaml'
With the probe scraper change merged and deployed, we can now start querying! A number of tables are automatically created according to the schema outlined above: notably “live” and “stable” tables corresponding to the usage ping. Using sql.telemetry.mozilla.org we can start exploring what’s out there. Here’s a quick query I wrote up:
SELECT DATE(submission_timestamp) AS date, metrics.string.usage_variant AS variant, count(*), FROM `moz-fx-data-shared-prod`.org_mozilla_mozregression_stable.usage_v1 WHERE DATE(submission_timestamp) >= '2020-04-14' AND client_info.app_display_version NOT LIKE '%.dev%' GROUP BY date, variant;
… which generates a chart like this:

This chart represents the absolute volume of mozregression usage since April 14th 2020 (around the time when we first released a version of mozregression with Glean telemetry), grouped by mozregression “variant” (GUI, console, and mach) and date - you can see that (unsurprisingly?) the GUI has the highest usage. I’ll talk about this more in an upcoming installment, speaking of…
We’re not done yet! Next time, we’ll look into making a public-facing dashboard demonstrating these results and making an aggregated version of the mozregression telemetry data publicly accessible to researchers and the general public. If we’re lucky, there might even be a bit of data science. Stay tuned!
|
|
Wladimir Palant: What data does Xiaomi collect about you? |
A few days ago I published a very technical article confirming that Xiaomi browsers collect a massive amount of private data. This fact was initially publicized in a Forbes article based on the research by Gabriel C^irlig and Andrew Tierney. After initially dismissing the report as incorrect, Xiaomi has since updated their Mint and Mi Pro browsers to include an option to disable this tracking in incognito mode.

Is the problem solved now? Not really. There is now exactly one non-obvious setting combination where you can have your privacy with these browsers: “Incognito Mode” setting on, “Enhanced Incognito Mode” setting off. With these not being the default and the users not informed about the consequences, very few people will change to this configuration. So the browsers will continue spying on the majority of their user base.
In this article I want to provide a high-level overview of the data being exfiltrated here. TL;DR: Lots and lots of it.
Disclaimer: This article is based entirely on reverse engineering Xiaomi Mint Browser 3.4.3. I haven’t seen the browser in action, so some details might be wrong. Update (2020-05-08): From a quick glance at Xiaomi Mint Browser 3.4.4 which has been released in the meantime, no further changes to this functionality appear to have been implemented.
When allowed, Xiaomi browsers will send information about a multitude of different events, sometimes with specific data attached. For example, an event will typically be generated when some piece of the user interface shows up or is clicked, an error occurs or the current page’s address is copied to clipboard. There are more interesting events as well however, for example:
Some pieces of data will be attached to every event. These are meant to provide the context, and to group related events of course. This data includes among other things:
Even with the recent changes, Xiaomi browsers are massively invading users’ privacy. The amount of data collected by default goes far beyond what’s necessary for application improvement. Instead, Xiaomi appears to be interested in where users go, what they search for and which videos they watch. Even with a fairly obscure setting to disable this tracking, the default behavior isn’t acceptable. If you happen to be using a Xiaomi device, you should install a different browser ASAP.
https://palant.info/2020/05/08/what-data-does-xiaomi-collect-about-you/
|
|
Daniel Stenberg: video: common mistakes when using libcurl |
As I posted previously, I did a webinar and here’s the recording and the slides I used for it.
https://daniel.haxx.se/blog/2020/05/08/video-common-mistakes-when-using-libcurl/
|
|
Daniel Stenberg: Review: curl programming |
Title: Curl Programming
Author: Dan Gookin
ISBN: 9781704523286
Weight: 181 grams

Not long ago I discovered that someone had written this book about curl and that someone wasn’t me! (I believe this is a first) Thrilled of course that I could check off this achievement from my list of things I never thought would happen in my life, I was also intrigued and so extremely curious that I simply couldn’t resist ordering myself a copy. The book is dated October 2019, edition 1.0.
I don’t know the author of this book. I didn’t help out. I wasn’t aware of it and I bought my own copy through an online bookstore.
It’s very thin! The first page with content is numbered 13 and the last page before the final index is page 110 (6-7 mm thick). Also, as the photo shows somewhat: it’s not a big format book either: 225 x 152 mm. I suppose a positive spin on that could be that it probably fits in a large pocket.

As the founder of the curl project and my role as lead developer there, I’m not really a good example of whom the author must’ve imagined when he wrote this book. Of course, my own several decades long efforts in documenting curl in hundreds of man pages and the Everything curl book makes me highly biased. When you read me say anything about this book below, you must remember that.
A primary motivation for getting this book was to learn. Not about curl, but how an experienced tech author like Dan teaches curl and libcurl programming, and try to use some of these lessons for my own writing and manual typing going forward.
Despite its size, the book is still packed with information. It contains the following chapters after the introduction:
As you can see it spends a total of 12 pages initially on explanations about curl the command line tool and some of the things you can do with it and how before it moves on to libcurl.
The book is explanatory in its style and it is sprinkled with source code examples showing how to do the various tasks with libcurl. I don’t think it is a surprise to anyone that the book focuses on HTTP transfers but it also includes sections on how to work with FTP and a little about SMTP. I think it can work well for someone who wants to get an introduction to libcurl and get into adding Internet transfers for their applications (at least if you’re into HTTP). It is not a complete guide to everything you can do, but then I doubt most users need or even want that. This book should get you going good enough to then allow you to search for the rest of the details on your own.
I think maybe the biggest piece missing in this book, and I really thing it is an omission mr Gookin should fix if he ever does a second edition: there’s virtually no mention of HTTPS or TLS at all. On the current Internet and web, a huge portion of all web pages and page loads done by browsers are done with HTTPS and while it is “just” HTTP with TLS on top, the TLS part itself is worth some special attention. Not the least because certificates and how to deal with them in a libcurl world is an area that sometimes seems hard for users to grasp.
A second thing I noticed no mention of, but I think should’ve been there: a description of curl_easy_getinfo(). It is a versatile function that provides information to users about a just performed transfer. Very useful if you ask me, and a tool in the toolbox every libcurl user should know about.
The author mentions that he was using libcurl 7.58.0 so that version or later should be fine to use to use all the code shown. Most of the code of course work in older libcurl versions as well.
Everything curl is a free and open document describing everything there is to know about curl, including the project itself and curl internals, so it is a much wider scope and effort. It is however primarily provided as a web and PDF version, although you can still buy a printed edition.
Everything curl spends more space on explanations of features and discussion how to do things and isn’t as focused around source code examples as Curl Programming. Everything curl on paper is also thicker and more expensive to buy – but of course much cheaper if you’re fine with the digital version.
First: decide if you need to buy it. Maybe the docs on the curl site or in Everything curl is already good enough? Then I also need to emphasize that you will not sponsor or help out the curl project itself by buying this book – it is authored and sold entirely on its own.
But if you need a quick introduction with lots of examples to get your libcurl usage going, by all means go ahead. This could be the book you need. I will not link to any online retailer or anything here. You can get it from basically anyone you like.
I’ve found some mistakes and ways of phrasing the explanations that I maybe wouldn’t have used, but all in all I think the author seems to have understood these things and describes functionality and features accurately and with a light and easy-going language.
Finally: I would never capitalize curl as Curl or libcurl as Libcurl, not even in a book. Just saying…
https://daniel.haxx.se/blog/2020/05/07/review-curl-programming/
|
|
The Talospace Project: Firefox 76 on POWER |
|
|
The Mozilla Blog: Mozilla announces the first three COVID-19 Solutions Fund Recipients |
In less than two weeks, Mozilla received more than 160 applications from 30 countries for its COVID-19 Solutions Fund Awards. Today, the Mozilla Open Source Support Program (MOSS) is excited to announce its first three recipients. This Fund was established at the end of March, to offer up to $50,000 each to open source technology projects responding to the COVID-19 pandemic.
VentMon, created by Public Invention in Austin, Texas, improves testing of open-source emergency ventilator designs that are attempting to address the current and expected shortage of ventilators.
The same machine and software will also provide monitoring and alarms for critical care specialists using life-critical ventilators. It is a simple inline device plugged into the airway of an emergency ventilator, that measures flow and pressure (and thereby volume), making sure the ventilator is performing to specification, such as the UK RVMS spec. If a ventilator fails, VentMon raises an audio and internet alarm. It can be used for testing before deployment, as well as ICU patient monitoring. The makers received a $20,000 award which enables them to buy parts for the Ventmon to support more than 20 open source engineering teams trying to build ventilators.
Based in the Bay Area, Recidiviz is a tech non-profit that’s built a modeling tool that helps prison administrators and government officials forecast the impact of COVID-19 on their prisons and jails. This data enables them to better assess changes they can make to slow the spread, like reducing density in prison populations or granting early release to people who are deemed to pose low risk to public safety.
It is impossible to physically distance in most prison settings, and so incarcerated populations are at dangerous risk of COVID-19 infection. Recidiviz’s tool was downloaded by 47 states within 48hrs of launch. The MOSS Committee approved a $50,000 award.
“We want to make it easier for data to inform everything that criminal justice decision-makers do,” said Clementine Jacoby, CEO and Co-Founder of Recidiviz. “The pandemic made this mission even more critical and this funding will help us bring our COVID-19 model online. Already more than thirty states have used the tool to understand where the next outbreak may happen or how their decisions can flatten the curve and reduce impact on community hospital beds, incarcerated populations, and staff.”
COVID-19 Supplies NYC is a project created by 3DBrooklyn, producing around 2,000 face shields a week, which are urgently needed in the city. They will use their award to make and distribute more face shields, using 3D printing technology and an open source design. They also maintain a database that allows them to collect requests from institutions that need face shields as well as offers from people with 3D printers to produce parts for the face shields. The Committee approved a $20,000 award.
“Mozilla has long believed in the power of open source technology to better the internet and the world,” said Jochai Ben-Avie, Head of International Public Policy and Administrator of the Program. “It’s been inspiring to see so many open source developers step up and collaborate on solutions to increase the capacity of healthcare systems to cope with this crisis.”
In the coming weeks Mozilla will announce the remaining winning applicants. The application form has been closed for now, owing to the high number of submissions already being reviewed.
The post Mozilla announces the first three COVID-19 Solutions Fund Recipients appeared first on The Mozilla Blog.
|
|
Hacks.Mozilla.Org: Firefox 76: Audio worklets and other tricks |
Hello folks, hope you are all doing well and staying safe.
A new version of your favourite browser is always worth looking forward to, and here we are with Firefox 76! Web platform support sees some great new additions in this release, such as Audio Worklets and Intl improvements, on the JavaScript side. Also, we’ve added a number of nice improvements into Firefox DevTools to make development easier and quicker.
As always, read on for the highlights, or find the full list of additions in the following articles:
There are interesting DevTools updates in this release throughout every panel. And upcoming features can be previewed now in Firefox Dev Edition.
Firefox JavaScript debugging just got even better.
Oftentimes, debugging efforts only focus on specific files that are likely to contain the culprit. With “blackboxing” you can tell the Debugger to ignore the files you don’t need to debug.
Now it’s easier to do this for folders as well, thanks to Stepan Stava‘s new context menu in the Debugger’s sources pane. You can limit “ignoring” to files inside or outside of the selected folder. Combine this with “Set directory root” for a laser-focused debugging experience.

The Console‘s multi-line editor mode is great for iterating on longer code snippets. Early feedback showed that users didn’t want the code repeated in the Console output, to avoid clutter. Thanks to thelehhman‘s contribution, code snippets with multiple lines are neatly collapsed and can be expanded on demand.

Copying stacks in the Debugger makes it possible to share snapshots during stepping. This helps you file better bugs, and facilitates handover to your colleagues. In order to provide collaborators the full context of a bug, the call stack pane‘s “Copy stack trace” menu now copies full URLs, not just filenames.

Built-in previews for JSON files make it easy to search through responses and explore API endpoints. This also works well for large files, where data can be expanded as needed. Thanks to a contribution from zacnomore, the “Expand All” option is now always visible.
Firefox 76 provides even easier access to network information via the Network Monitor.
WebSocket libraries use a variety of formats to encode their messages. We want to make sure that their payloads are properly parsed and formatted, so you can read them. Over the past releases, we added support for Socket.IO, SignalR, and WAMP WebSocket message inspection. Thanks to contributor Uday Mewada, Action Cable messages are now nicely formatted too.

WebSocket control frames are used by servers and browsers to manage real-time connections but don’t contain any data. Contributor kishlaya.j jumped in to hide control frames by default, cutting out a little more noise from your debugging. In case you need to see them, they can be enabled in the sent/received dropdown.
Network request and response data can be overwhelming as you move from scanning real-time updates to focus on specific data points. Customizing the visible Network panel columns lets you adapt the output to the problem at hand. In the past, this required a lot of dragging and resizing. Thanks to Farooq AR, you can now double-click the table’s resize handles to scale a column’s width to fit its content, as in modern data tables.

We’ve received feedback that it should be easier to copy parts of the network data for further analysis.
Now the “Response” section of Network details has been modernized to make inspection and copying easier, by rendering faster and being more reliable. We’ll be adding more ease of use improvements to Network analysis in the near future, thanks to your input.
--globoff to the generated command.Developer Edition is Firefox’s pre-release channel, which offers early access to tooling and platform features. Its settings enable more functionality for developers by default. We like to bring new features quickly to Developer Edition to gather your feedback, including the following highlights.
Foremost, in the release of Dev Edition 77 we are seeking input for our new compatibility panel. This panel will inform you about any CSS properties that might not be supported in other browsers, and will be accessible from the Inspector.

Please try it out and use the built-in “Feedback” link to report how well it works for you and how we can further improve it.
Let’s explore what Firefox 76 brings to the table in terms of web platform updates.
Audio worklets offer a useful way of running custom JavaScript audio processing code. The difference between audio worklets and their predecessor — ScriptProcessorNodes — worklets run off the main thread in a similar way to web workers, solving the performance problems encountered previously.
The basic idea is this: You define a custom AudioWorkletProcessor, which will handle the processing. Next, register it.
// white-noise-processor.js
class WhiteNoiseProcessor extends AudioWorkletProcessor {
process (inputs, outputs, parameters) {
const output = outputs[0]
output.forEach(channel => {
for (let i = 0; i < channel.length; i++) {
channel[i] = Math.random() * 2 - 1
}
})
return true
}
}
registerProcessor('white-noise-processor', WhiteNoiseProcessor)Over in your main script, you then load the processor, create an instance of AudioWorkletNode, and pass it the name of the processor. Finally, you connect the node to an audio graph.
async function createAudioProcessor() {
const audioContext = new AudioContext()
await audioContext.audioWorklet.addModule('white-noise-processor.js')
const whiteNoiseNode = new AudioWorkletNode(audioContext, 'white-noise-processor')
whiteNoiseNode.connect(audioContext.destination)
}Read our Background audio processing using AudioWorklet guide for more information.
Aside from worklets, we’ve added some other web platform features.
The HTML element’s min and max attributes now work correctly when the value of min is greater than the value of max, for control types whose values are periodic. (Periodic values repeat in regular intervals, wrapping around from the end back to the start again.) This is particularly helpful with date and time inputs for example, where you might want to specify a time range of 11 PM to 2 AM.
Intl improvementsThe numberingSystem and calendar options of the Intl.NumberFormat, Intl.DateTimeFormat, and Intl.RelativeTimeFormat constructors are now enabled by default.
Try these examples:
const number = 123456.789;
console.log(new Intl.NumberFormat('en-US', { numberingSystem: 'latn' }).format(number));
console.log(new Intl.NumberFormat('en-US', { numberingSystem: 'arab' }).format(number));
console.log(new Intl.NumberFormat('en-US', { numberingSystem: 'thai' }).format(number));
var date = Date.now();
console.log(new Intl.DateTimeFormat('th', { calendar: 'buddhist' }).format(date));
console.log(new Intl.DateTimeFormat('th', { calendar: 'gregory' }).format(date));
console.log(new Intl.DateTimeFormat('th', { calendar: 'chinese' }).format(date));The IntersectionObserver() constructor now accepts both Document and Element objects as its root. In this context, the root is the area whose bounding box is considered the viewport for the purposes of observation.
The Firefox Profiler is a tool to help analyze and improve the performance of your site in Firefox. Now it will show markers when network requests are suspended by extensions’ blocking webRequest handlers. This is especially useful to developers of content blocker extensions, enabling them to ensure that Firefox remains at top speed.
Here’s a screenshot of the Firefox profiler in action:
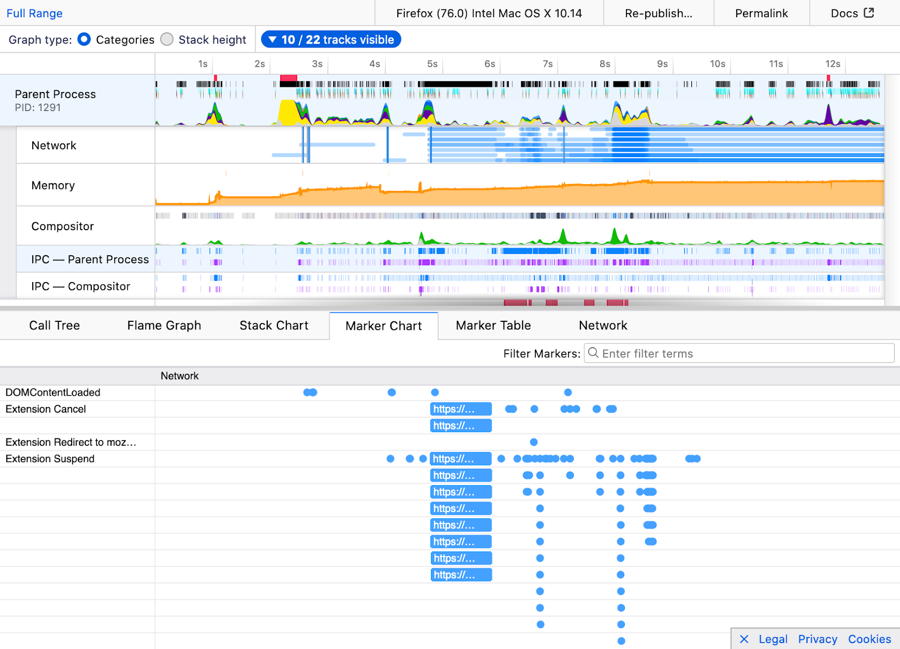
And that’s it for the newest edition of Firefox — we hope you enjoy the new features! As always, feel free to give feedback and ask questions in the comments.
The post Firefox 76: Audio worklets and other tricks appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2020/05/firefox-76-audio-worklets-and-other-tricks/
|
|
The Firefox Frontier: More reasons you can trust Firefox with your passwords |
There’s no doubt that during the last couple of weeks you’ve been signing up for new online services like streaming movies and shows, ordering takeout or getting produce delivered to … Read more
The post More reasons you can trust Firefox with your passwords appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/trust-firefox-with-your-passwords/
|
|
Daniel Stenberg: HTTP/3 in curl |
This is my presentation for curl up 2020 summing up where we’re at with HTTP/3 support in curl right now.
|
|
About:Community: Firefox 76 new contributors |
With the release of Firefox 76, we are pleased to welcome the 52 developers who contributed their first code change to Firefox in this release, 50 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
https://blog.mozilla.org/community/2020/05/04/firefox-76-new-contributors/
|
|
Wladimir Palant: Are Xiaomi browsers spyware? Yes, they are... |
In case you missed it, there was a Forbes article on Mi Browser Pro and Mint Browser which are preinstalled on Xiaomi phones. The article accuses Xiaomi of exfiltrating a history of all visited websites. Xiaomi on the other hand accuses Forbes of misrepresenting the facts. They claim that the data collection is following best practices, the data itself being aggregated and anonymized, without any connection to user’s identity.
TL;DR: It is really that bad, and even worse actually.
If you’ve been following my blog for a while, you might find this argumentation familiar. It’s almost identical to Avast’s communication after they were found spying on the users and browser vendors pulled their extensions from add-on stores. In the end I was given proof that their data anonymization attempts were only moderately successful if you allow me this understatement.
Given that neither the Forbes article nor the security researchers involved seem to provide any technical details, I wanted to take a look for myself. I decompiled Mint Browser 3.4.0 and looked for clues. This isn’t the latest version, just in case Xiaomi already modified to code in reaction to the Forbes article.
Disclaimer: I think that this is the first time I analyzed a larger Android application, so please be patient with me. I might have misinterpreted one thing or another, even though the big picture seems to be clear. Also, my conclusions are based exclusively on code analysis, I’ve never seen this browser in action.
The Forbes article explains that the data is being transmitted to a Sensors Analytics backend. The Xiaomi article then provides the important clue: sa.api.intl.miui.com is the host name of this backend. They then go on explaining how it’s a server that Xiaomi owns rather than a third party. But they are merely trying to distract us: if sensitive data from my browser is being sent to this server, why would I care who owns it?
We find this server name mentioned in the class miui.globalbrowser.common_business.g.i (yes, some package and class names are mangled). It’s used in some initialization code:
final StringBuilder sb = new StringBuilder();
sb.append("https://sa.api.intl.miui.com/sa?project=global_browser_mini&r=");
sb.append(A.e);
a = sb.toString();Looking up A.e, it turns out to be a country code. So the i.a static member here ends up holding the endpoint URL with the user’s country code filled in. And it is being used in the class’ initialization function:
public void a(final Context c) {
SensorsDataAPI.sharedInstance(this.c = c, i.a, this.d);
SensorsDataAPI.sharedInstance().identify(com.xiaomi.mistatistic.sdk.e.a(this.c));
this.c();
this.d();
this.e();
this.b();
}The Sensors Analytics API is public, so we can look up the SensorsDataAPI class and learn that the first sharedInstance() call creates an instance and sets its server URL. The next line calls identify() setting an “anonymous ID” for this instance which will be sent along with every data point, more on that later.
The call to this.c() is also worth noting as this will set a bunch of additional properties to be sent with each request:
public void c() {
final JSONObject jsonObject = new JSONObject();
jsonObject.put("uuid", (Object)com.xiaomi.mistatistic.sdk.e.a(this.c));
int n;
if (H.f(miui.globalbrowser.common.a.a())) {
n = 1;
}
else {
n = 0;
}
jsonObject.put("internet_status", n);
jsonObject.put("platform", (Object)"AndroidApp");
jsonObject.put("miui_version", (Object)Build$VERSION.INCREMENTAL);
final String e = A.e;
a(e);
jsonObject.put("miui_region", (Object)e);
jsonObject.put("system_language", (Object)A.b);
SensorsDataAPI.sharedInstance(this.c).registerSuperProperties(jsonObject);
}There we have the same “anonymous ID” sent as uuid parameter, just in case. In addition, the usual version, region, language data is being sent.
For me, it wasn’t entirely trivial to figure out where this class is being initialized from. Turns out, from class miui.globalbrowser.common_business.g.b:
public static void a(final String s, final Map<String, String> map) {
a(s, map, true);
}
public static void a(final String s, final Map<String, String> map, final boolean b) {
if (b) {
i.a().a(s, map);
}
miui.globalbrowser.common_business.g.d.a().a(s, map);
}So the miui.globalbrowser.common_business.g.b.a() call will set the third parameter to true by default. This call accesses a singleton miui.globalbrowser.common_business.g.i instance (will be created if it doesn’t exist) and makes it actually track an event (s is the event name here and map are the parameters being sent in addition to the default ones). The additional miui.globalbrowser.common_business.g.d.a() call triggers their MiStatistics analytics framework which I didn’t investigate.
And that’s it. We now have to find where in the code miui.globalbrowser.common_business.g.b class is used and what data it receives. All that data will be sent to Sensors Analytics backend regularly.
Looking up com.xiaomi.mistatistic.sdk.e.a() eventually turns up ID generation code very close to the one cited in the Xiaomi blog post:
public static String d(final Context context) {
if (!TextUtils.isEmpty((CharSequence)y.g)) {
return y.g;
}
final long currentTimeMillis = System.currentTimeMillis();
final String a = L.a(context, "anonymous_id", "");
final long a2 = L.a(context, "aigt", 0L);
final long a3 = L.a(context, "anonymous_ei", 7776000000L);
if (!TextUtils.isEmpty((CharSequence)a) && currentTimeMillis - a2 < a3) {
y.g = a;
}
else {
L.b(context, "anonymous_id", y.g = UUID.randomUUID().toString());
}
L.c(context, "aigt", currentTimeMillis);
return y.g;
}
The L.a() call is retrieving a value from context.getSharedPreferences() with fallback. L.b() and L.c() calls will store a value there. So Xiaomi is trying to tell us: “Look, the ID is randomly generated, without any relation to the user. And it is renewed every 90 days!”
Now 90 days are a rather long time interval even for a randomly generated ID. With enough data points it should be easy to deduce the user’s identity from it. But there is another catch. See that aigt preference? What is its value?
The intention here seems to be that aigt is the timestamp when the ID was generated. So if that timestamp deviates from current time by more than 7776000000 milliseconds (90 days) a new ID is going to be generated. However, this implementation is buggy, it will update aigt on every call rather than only when a new ID is generated. So the only scenario where a new ID will be generated is: this method wasn’t called for 90 days, meaning that the browser wasn’t started for 90 days. And that’s rather unlikely, so one has to consider this ID permanent.
And if this weren’t enough, there is another catch. If you look at the SensorsDataAPI class again, you will see that the “anonymous ID” is merely a fallback when a login ID isn’t available. And what is the login ID here? We’ll find it being set in the miui.globalbrowser.common_business.g.i class:
public void b() {
final Account a = miui.globalbrowser.common.c.b.a(this.c);
if (a != null && !TextUtils.isEmpty((CharSequence)a.name)) {
SensorsDataAPI.sharedInstance().login(a.name);
}
}That’s exactly what it looks like: a Xiaomi account ID. So if the user is logged into the browser, the tracking data will be connected to their Xiaomi account. And that one is linked to the user’s email address at the very least, probably to other identifying parameters as well.
As mentioned above, we need to look at the places where miui.globalbrowser.common_business.g.b class methods are called. And very often these are quite typical for product analytics, for example:
final HashMap<String, String> hashMap = new HashMap<String, String>();
if (ex.getCause() != null) {
hashMap.put("cause", ex.getCause().toString());
}
miui.globalbrowser.common_business.g.b.a("rv_crashed", hashMap);So there was a crash and the vendor is notified about the issue. Elsewhere the data indicates that a particular element of the user interface was opened, also very useful information to improve the product. And then there is this in class com.miui.org.chromium.chrome.browser.webview.k:
public void onPageFinished(final WebView webView, final String d) {
...
if (!this.c && !TextUtils.isEmpty((CharSequence)d)) {
miui.globalbrowser.common_business.g.b.a("page_load_event_finish", "url", this.a(d));
}
...
}
public void onPageStarted(final WebView webView, final String e, final Bitmap bitmap) {
...
if (!this.b && !TextUtils.isEmpty((CharSequence)e)) {
miui.globalbrowser.common_business.g.b.a("page_load_event_start", "url", this.a(e));
}
...
}That’s the code sending all visited websites to an analytics server. Once when the page starts loading, and another time when it finishes. And the Xiaomi blog post explains why this code exists: “The URL is collected to identify web pages which load slowly; this gives us insight into how to best improve overall browsing performance.”
Are you convinced by this explanation? Because I’m not. If this is all about slow websites, why not calculate the page load times locally and transmit only the slow ones? This still wouldn’t be great for privacy but an order of magnitude better than what Xiaomi actually implemented. Xiaomi really needs to try harder if we are to assume incompetence rather than malice here. How was it decided that sending all visited addresses is a good compromise? Was privacy even considered in that decision? Would they still make the same decision today? And if not, how did they adapt their processes to reflect this?
But there are far more cases where their analytics code collects too much data. In class com.miui.org.chromium.chrome.browser.omnibox.NavigationBar we’ll see:
final HashMap<String, String> hashMap = new HashMap<String, String>();
hashMap.put("used_searchengine", com.miui.org.chromium.chrome.browser.search.b.a(this.L).f());
hashMap.put("search_position", miui.globalbrowser.common_business.g.e.c());
hashMap.put("search_method", miui.globalbrowser.common_business.g.e.b());
hashMap.put("search_word", s);
miui.globalbrowser.common_business.g.b.a("search", hashMap);So searching from the navigation bar won’t merely track the search engine used but also what you searched for. In the class miui.globalbrowser.download.J we see for example:
final HashMap<String, String> hashMap = new HashMap<String, String>();
hashMap.put("op", s);
hashMap.put("suffix", s2);
hashMap.put("url", s3);
if (d.c(s4)) {
s = "privacy";
}
else {
s = "general";
}
hashMap.put("type", s);
b.a("download_files", hashMap);This isn’t merely tracking the fact that files were downloaded but also the URLs downloaded. What kind of legitimate interest could Xiaomi have here?
And then this browser appears to provide some custom user interface for YouTube videos. Almost everything is being tracked there, for example in class miui.globalbrowser.news.YMTSearchActivity:
final HashMap<String, String> hashMap = new HashMap<String, String>();
hashMap.put("op", "search");
hashMap.put("search_word", text);
hashMap.put("search_type", s);
hashMap.put("page", this.w);
miui.globalbrowser.common_business.g.b.a("youtube_search_op", hashMap);Why does Xiaomi need to know what people search on YouTube? And not just that, elsewhere they seem to collect data on what videos people watch and how much time they spend doing that. Xiaomi also seems to know what websites people have configured in their speed dial and when they click those. This doesn’t leave a good impression, could it be surveillance functionality after all?
If you use Mint Browser (and presumably Mi Browser Pro similarly), Xiaomi doesn’t merely know which websites you visit but also what you search for, which videos you watch, what you download and what sites you added to the Quick Dial page. Heck, they even track which porn site triggered the reminder to switch to incognito mode! Yes, if Xiaomi wants anybody to believe that this wasn’t malicious they have a lot more explaining to do.
The claim that this data is anonymized cannot be maintained either. Even given the random user ID (which appears to be permanent by mistake) deducing user’s identity should be easy, we’ve seen it before. But they also transmit user’s Xiaomi account ID if they know it, which is directly linked to the user’s identity.
Xiaomi now announced that they will turn off collection of visited websites in incognito mode. That’s a step in the right direction, albeit a tiny one. Will they still collecting all the other data in incognito mode? And even if not, why collect so much data during regular browsing? What reason is there that justifies all these privacy violations?
Update (2020-05-07): I looked into the privacy-related changes implemented in Mint Browser 3.4.3. It’s was a bigger improvement than what it sounded like, the “statistics” collection functionality can be disabled entirely. However, you have to make sure that you have “Incognito Mode” turned on and “Enhanced Incognito Mode” turned off – that’s the only configuration where you can have your privacy.
https://palant.info/2020/05/04/are-xiaomi-browsers-spyware-yes-they-are.../
|
|
Jan-Erik Rediger: This Week in Glean: Bytes in Memory (on Android) |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean.)
Last week's blog post: This Week in Glean: Glean for Python on Windows by Mike Droettboom. All "This Week in Glean" blog posts are listed in the TWiG index (and on the Mozilla Data blog). This article is cross-posted on the Mozilla Data blog.
With the Glean SDK we follow in the footsteps of other teams to build a cross-platform library to be used in both mobile and desktop applications alike. In this blog post we're taking a look at how we transport some rich data across the FFI boundary to be reused on the Kotlin side of things. We're using a recent example of a new API in Glean that will drive the HTTP upload of pings, but the concepts I'm explaining here apply more generally.
Note: This blog post is not a good introduction on doing Rust on Android, but I do plan to write about that in the future as well.
Most of this implementation was done by Bea and I have been merely a reviewer, around for questions and currently responsible for running final tests on this feature.
The Glean SDK provides an FFI API that can be consumed by what we call language bindings. For the most part we pass POD over that API boundary: integers of various sizes (a problem in and of itself if the sides disagree about certain integer sizes and signedness), bools (but actually encoded as an 8-bit integer1), but also strings as pointers to null-terminated UTF-8 strings in memory (for test APIs we encode data into JSON and pass that over as strings).
However for some internal mechanisms we needed to communicate a bit more data back and forth. We wanted to have different tasks, where each task variant could have additional data. Luckily this additional data is either some integers or a bunch of strings only and not further nested data.
So this is the data we have on the Rust side:
enum Task { Upload(Request), Wait, Done, } struct Request { id: String, url: String, }
(This code is simplified for the sake of this blog post. You can find the full code online in the Glean repository.)
And this is the API a user would call:
fn get_next_task() -> Task
Before we can expose a task through FFI we need to transform it into something C-compatible:
use std::os::raw::c_char; #[repr(u8)] pub enum FfiTask { Upload { id: *mut c_char, url: *mut c_char, }, Wait, Done, }
We define a new enum that's going to be represent its variant as an 8-bit integer plus the additional data for Upload.
The other variants stay data-less.
We also provide conversion from the proper Rust type to the FFI-compatible type:
impl Fromfor FfiTask { fn from(task: Task) -> Self { match task { Task::Upload(request) => { let id = CString::new(request.id).unwrap(); let url = CString::new(request.url).unwrap(); FfiTask::Upload { id: document_id.into_raw(), url: path.into_raw(), } } Task::Wait => FfiTask::Wait, Task::Done => FfiTask::Done, } } }
The FFI API becomes:
#[no_mangle] extern "C" fn glean_get_next_task() -> FfiTask
With this all set we can throw cbindgen at our code to generate the C header, which will produce this snippet of code:
enum FfiTask_Tag { FfiTask_Upload, FfiTask_Wait, FfiTask_Done, }; typedef uint8_t FfiTask_Tag; typedef struct { FfiTask_Tag tag; char *id; char *url; } FfiTask_Upload_Body; typedef union { FfiTask_Tag tag; FfiTask_Upload_Body upload; } FfiTask;
This is the C representation of a tagged union. The layout of these tagged unions has been formally defined in Rust RFC 2195.
Each variant's first element is the tag, allowing us to identify which variant we have.
cbindgen automatically inlined the Wait and Done variants: they are nothing more than a tag.
The Upload variant however gets its own struct.
On the Kotlin side of things we use JNA (Java Native Access) to call C-like functions and interact with C types.
After some research by Bea we found that it already provides abstractions over C unions and structs
and we could implement the equivalent parts for our Task in Kotlin.
First some imports and replicating the variants our tag takes.
import com.sun.jna.Structure import com.sun.jna.Pointer import com.sun.jna.Union enum class TaskTag { Upload, Wait, Done }
Next is the body of our Upload variant. It's a structure with two pointers to strings.
Kotlin requires some annotations to specify the order of fields in memory.
We also inherit from Structure, a class provided by JNA, that will take care of reading from memory and making the data accessible in Kotlin.
@Structure.FieldOrder("tag", "id", "url") class UploadBody( @JvmField val tag: Byte = TaskTag.Done.ordinal.toByte(), @JvmField val id: Pointer? = null, @JvmField val url: Pointer? = null, ) : Structure() { }
And at last we define our union. We don't need a field order, it's a union afterall, only one of the fields is valid at a time.
open class FfiTask( @JvmField var tag: Byte = TaskTag.Done.ordinal.toByte(), @JvmField var upload: UploadBody = UploadBody() ) : Union() { class ByValue : FfiTask(), Structure.ByValue fun toTask(): Task { this.readField("tag") return when (this.tag.toInt()) { TaskTag.Upload.ordinal -> { this.readField("upload") val request = Request( this.upload.id.getRustString(), this.upload.url.getRustString() ) Task.Upload(request) } TaskTag.Wait.ordinal -> Task.Wait else -> Task.Done } } }
This also defines the conversion to a new Kotlin type that eases usage on the Kotlin side.
getRustString is a small helper
to copy the null-terminated C-like string to a Kotlin string.
The FFI function on the Kotlin side is defined as:
fun glean_get_next_task(): FfiTask.ByValue
The types we convert to and then work with in Kotlin are small classes around the data. If there's no attached data it's an object.
class Request( val id: String, val url: String, ) { } sealed class Task { class Upload(val request: Request) : Task() object Wait : Task() object Done : Task() }
As the final piece of this code on the Kotlin side we can now fetch new tasks, convert it to more convenient Kotlin objects and work with them:
val incomingTask = LibGleanFFI.INSTANCE.glean_get_next_task() when (val action = incomingTask.toTask()) { is Task.Upload -> upload(action.request.id, action.request.url) Task.Wait -> return Result.retry() Task.Done -> return Result.success() }
Currently our new upload mechanism is under testing. We're reasonably sure that our approach of passing rich data across the FFI boundary is sound and not causing memory safety issues for now.
The advantage of going the way of encoding Rust enums into tagged unions for us is that we can use this API in all our current API consumers. C structs and unions are supported in Kotlin (for Android), Swift (for our iOS users) and Python (e.g. Desktop apps such as mozregression). It didn't require new tooling or dependencies to get it working and it's reasonably cheap in terms of processing cost (it's copying around a few bytes of data in memory).
The disadvantage however is that it requires quite a bit of coordination of the different pieces of code. As you've seen above for Kotlin we need to be careful to replicate the exact layout of data and all of this is (currently) hand-written. Any change on the Rust side might break this easily. Swift is a bit easier on this front as it has direct C translation.
The application-services team faced the same problem of how to transport rich data across the FFI boundary. They decided to go with protocol buffers and generate code for both sides of the FFI. They wrote about it in Crossing the Rust FFI frontier with Protocol Buffers. We decided against this way (for now), as it requires a bit more of a heavy-handed setup initially. We might reconsider this if we need to expand this API further.
My dream solution is still a *-bindgen crate akin to wasm-bindgen that creates all this code.
Don't use a bool with JNA. JNA doesn't handle it well and has its own conception of the size of a bool that differs from what C and Rust think. See When to use what method of passing data between Rust and Java/Swift in the Glean SDK book.
|
|
Daniel Stenberg: curl ootw: –get |
(Previous options of the week.)
The long version option is called --get and the short version uses the capital -G. Added in the curl 7.8.1 release, in August 2001. Not too many of you, my dear readers, had discovered curl by then.
Back in the early 2000s when we had added support for doing POSTs with -d, it become obvious that to many users the difference between a POST and a GET is rather vague. To many users, sending something with curl is something like “operating with a URL” and you can provide data to that URL.
You can send that data to an HTTP URL using POST by specifying the fields to submit with -d. If you specify multiple -d flags on the same command line, they will be concatenated with an ampersand (&) inserted in between. For example, you want to send both name and bike shed color in a POST to example.com:
curl -d name=Daniel -d shed=green https://example.com/
Okay, so curl can merge -d data entries like that, which makes the command line pretty clean. What if you instead of POST want to submit your name and the shed color to the URL using the query part of the URL instead and you still would like to use curl’s fancy -d concatenation feature?
Enter -G. It converts what is setup to be a POST into a GET. The data set with -d to be part of the request body will instead be put after the question mark in the HTTP request! The example from above but with a GET:
curl -G -d name=Daniel -d shed=green https://example.com/
(The actual placement or order of -G vs -d is not important.)
The first example without -G creates this HTTP request:
POST / HTTP/1.1 Host: example.com User-agent: curl/7.70.0 Accept: / Content-Length: 22 Content-Type: application/x-www-form-urlencoded name=Daniel&shed=green
While the second one, with -G instead does this:
GET /?name=Daniel&shed=green HTTP/1.1 Host: example.com User-agent: curl/7.70.0 Accept: /
If you want to investigate exactly what HTTP requests your curl command lines produce, I recommend --trace-ascii if you want to see the HTTP request body as well.
One of the highest scored questions on stackoverflow that I’ve answered concerns exactly this.
-X is only for changing the actual method string in the HTTP request. It doesn’t change behavior and the change is mostly done without curl caring what the new string is. It will behave as if it used the original one it intended to use there.
If you use -d in a command line, and then add -X GET to it, curl will still send the request body like it does when -d is specified.
If you use -d plus -G in a command line, then as explained above, curl sends a GET in the command line and -X GET will not make any difference (unless you also follow a redirect, in which the -X may ruin the fun for you).
HTTP allows more kinds of requests than just POST or GET and curl also allows sending more complicated multipart POSTs. Those don’t mix well with -G; this option is really designed only to convert simple -d uses to a query string.
|
|
Dzmitry Malyshau: Point of WebGPU on native |
WebGPU is a new graphics and compute API designed on the grounds of W3C organization (mostly) by the browser vendors. It’s designed for the Web, used by JavaScript and WASM applications, and driven by the shared principles of Web APIs. It doesn’t have to be only for the Web though. In this post, I want to share the vision of why WebGPU on native platforms is important to me. This is highly subjective and doesn’t represent any organization I’m in.
The story of WebGPU-native is as old as the API itself. The initial hearings at Khronos had the same story heard at both the exploration “3D portability” meeting, and the “WebGL Next” one, told by the very same people. These meetings had similar goals: find a good portable intersection of the native APIs, which by that time (2016) clearly started diverging and isolating in their own ecosystems. The differences were philosophical: the Web prioritized security and portability, while the native wanted more performance. This split manifested in creation of two real working groups: one in W3C building the Web API, and another - “Vulkan Portability” technical subgroup in Khronos. Today, I’m the only person (“ambassador”) who is active in both groups, simply because we implement both of these APIs on top of gfx-rs.
Vulkan Portability attempts to make Vulkan available everywhere by layering it on top of Metal, D3D12, and others. Now, everybody starts using Vulkan, celebrate, and never look back, right? Not exactly. Vulkan may be fast, but its definition of “portable” is quite weak. Developing an app that doesn’t trigger Vulkan validation warnings(!) on any platform is extremely challenging. Reading Vulkan spec is exciting and eye opening in many respects, but applying it in practice is a different experience. Vulkan doesn’t provide low-level API to all GPU hardware, it has the head of a lion, the body of a bear, and the tail of a crocodile. Each piece of Vulkan matches some hardware (e.g. vkImageLayout matches AMD’s), but the other hardware treats it as a no-op at best, and as a burden at worst. It’s a jack of all trades.
Besides, real Vulkan isn’t everywhere. More specifically, there are no drivers for Intel Haswell/Broadwell iGPUs on Windows, it’s forbidden on Windows UWP (including ARM), it’s below 50% on Android, and totally absent on macOS and iOS. Vulkan Portability aims to solve it, but it’s another fairly complex layer for your application, especially considering the shader translation logic of SPIRV-Cross, and it’s still a WIP.
In gfx-rs community, we made a huge bet on Vulkan API when we decided to align our low-level Rusty API to it (see our Fosdem 2018 talk) instead of figuring out our own path. But when we (finally) understood that Vulkan API is simply unreachable by most users, we also realized that WebGPU on native is precisely the API we need to offer them. We saw a huge potential in a modern, usable, yet low-level API. Most importantly - WebGPU is safe, and that’s something Rust expresses in the type system, making this property highly desired for any library.
This is where wgpu project got kicked off. For a long while, it was only implementing WebGPU on native, and only recently became a part of Firefox (Nightly only).
Let’s start with a bold controversial statement: there was never a time where developers could target a single API and reach the users, consistently with high quality. On paper, there was OpenGL, and it was indeed everywhere. In practice, however, OpenGL drivers on both desktop and mobile were poor. It was wild west: full of bugs and hidden secrets on how to convince the drivers to not do the wrong thing. Most games targeted Windows, where at some point D3D10+ was miles ahead of OpenGL in both the model it presented to developers, and the quality of drivers. Today, Web browsers on Windows don’t run on OpenGL, even though they accept WebGL APIs, and Firefox has WebRender on OpenGL, and Chromium has SkiaGL. They run that all on top of Angle, which translates OpenGL to D3D11…
This is where WebGPU on native comes on stage. Don’t get fooled by the “Web” prefix here: it’s a sane native API that is extremely portable, fairly performant, and very easy to get right when targeting it. It’s an API that could be your default choice for writing a bullet hell shooter, medical visualization, or teaching graphics programming at school. And once you target it, you get a nice little bonus of being able to deploy on the Web as well.
From the very beginning, Google had both native and in-browser use of their implementation, which is now called Dawn. We have a shared interest in allowing developers to target a shared “WebGPU on native” target instead of a concrete “Dawn” or “wgpu-native”. Therefore, we are collaborating on a shared header, and we’ll provide the C-compatible libraries implementing it. The specification is still a moving target, and we haven’t yet aligned our external C interface to the shared header, but that’s the plan.
If you are developing an application today, the choice of the tech stack looks something like this:
Today’s engines are pretty good! They are powerful and cheap to use. But I think, a lot of appeal to them was driven by the lack of proper solutions in the space below. Dealing with different graphics APIs on platforms is hard. Leaving it to a third-party library means putting a lot of trust in it.
If WebGPU on native becomes practical, it would be strictly superior to (1) and (2). It will be supported by an actual specification, a rich conformance test suite, big corporations, and tested to death by the use in browsers. The trade-offs it provides would make it a solid choice even for developers who’d otherwise go for (3), (4), and (5), but not all of them of course.
I can see WebGPU on native being a go-to choice for amateur developers, students, indie professionals, mobile game studios, and many other groups. It could be the default GPU API, if it can deliver on its promises of safety, performance, and portability. We have a lot of interest and early adopters, as well as big forces in motion to make this real.
http://kvark.github.io/web/gpu/native/2020/05/03/point-of-webgpu-native.html
|
|
Cameron Kaiser: TenFourFox FPR22 available |
I don't have much on deck for FPR23 right now, but we'll see what low-hanging fruit is still to be picked.
http://tenfourfox.blogspot.com/2020/05/tenfourfox-fpr22-available.html
|
|
Mozilla GFX: moz://gfx newsletter #52 |
Hello everyone! I know you have been missing your favorite and only newsletter about software engineers staying at home, washing their hands often and fixing strange rendering glitches in Firefox’s graphics engine. In the last two months there has been a heap of fixes and improvements. Before the usual change list I’ll go through a few highlights:
In 76 we have improved DirectComposition usage for video playback. This reduces GPU usage during video play a lot. On an Intel HD 530 1080p60 video playback has 65% usage with WebRender on in 75, 40% with Webrender off, and 32% usage with WebRender on in 76.
The new vsync implementation on Windows, which improved our results on various benchmarks such as vsynctester.com and motionmark, reduced stuttering during video playback and scrolling.
Steady progress on WebRender’s software implementation (introduced at the top of the previous episode), codenamed SWGL (pronounced “swigle”), which will in the long run let us move even the most exotic hardware configurations to WebRender.
And hardware accelerated GL contexts on Wayland, and pre-optimized shaders, and WebGPU, and… So many other improvements everywhere it is actually quite hard to highlight only a few.
WebRender is a GPU based 2D rendering engine for the web written in Rust, currently powering Firefox‘s rendering engine as well as Mozilla’s research web browser Servo.
To enable WebRender in Firefox, in the about:config page, enable the pref gfx.webrender.all and restart the browser.
WebRender is available under the MPLv2 license as a standalone crate on crates.io (documentation) for use in your own rust projects.
WebGPU is a new Web API to access graphics and compute capabilities of the hardware. Firefox and Servo have implementations in progress that are based on wgpu project written in Rust.
To enable WebGPU, follow the steps in webgpu.io, which also shows the current implementation status in all browsers.
https://mozillagfx.wordpress.com/2020/04/30/moz-gfx-newsletter-52/
|
|
Mozilla Addons Blog: Extensions in Firefox 76 |
A lot of great work was done in the backend to the WebExtensions API in Firefox 76. There is one helpful feature I’d like to surface in this post. The Firefox Profiler, a tool to help analyze and improve Firefox performance, will now show markers when network requests are suspended by extensions’ blocking webRequest handlers. This can be useful especially to developers of content blocker extensions to ensure that Firefox remains at top speed.
Here’s a screenshot of the Firefox profiler in action:
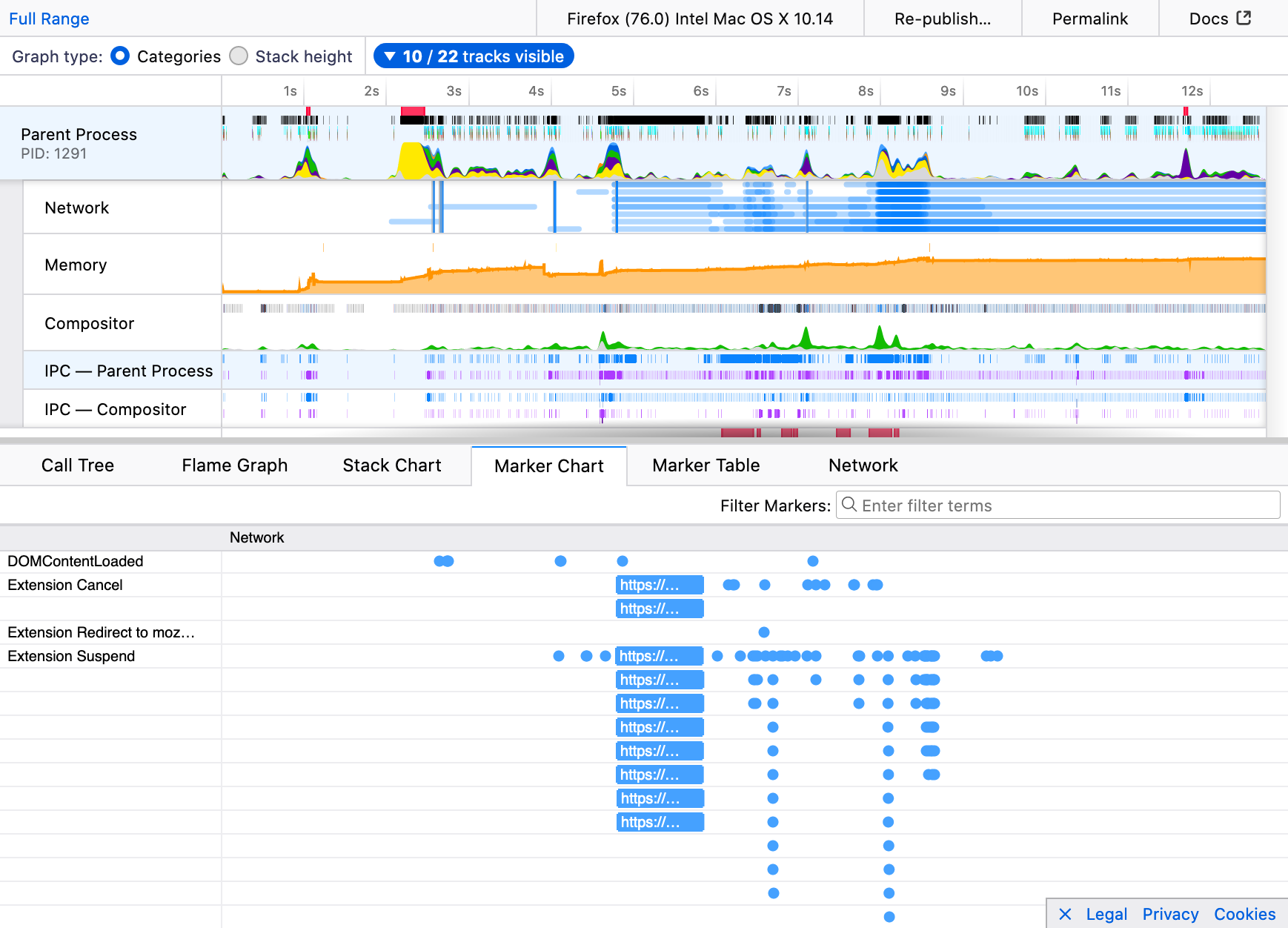 Many thanks to contributors Ajitesh, Myeongjun Go, Jayati Shrivastava, Andrew Swan and the team at Mozilla for not only working on the visible new features but also maintaining the groundwork that keeps extensions running.
Many thanks to contributors Ajitesh, Myeongjun Go, Jayati Shrivastava, Andrew Swan and the team at Mozilla for not only working on the visible new features but also maintaining the groundwork that keeps extensions running.
The post Extensions in Firefox 76 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/04/30/extension-in-firefox-76/
|
|
Hacks.Mozilla.Org: Fuzzing Firefox with WebIDL |
Fuzzing, or fuzz testing, is an automated approach for testing the safety and stability of software. It’s typically performed by supplying specially crafted inputs to identify unexpected or even dangerous behavior. If you’re unfamiliar with the basics of fuzzing, you can find lots more information in the Firefox Fuzzing Docs and the Fuzzing Book.
For the past 3 years, the Firefox fuzzing team has been developing a new fuzzer to help identify security vulnerabilities in the implementation of WebAPIs in Firefox. This fuzzer, which we’re calling Domino, leverages the WebAPIs’ own WebIDL definitions as a fuzzing grammar. Our approach has led to the identification of over 850 bugs. 116 of those bugs have received a security rating. In this post, I’d like to discuss some of Domino’s key features and how they differ from our previous WebAPI fuzzing efforts.
Before we begin discussing what Domino is and how it works, we first need to discuss the types of fuzzing techniques available to us today.
Fuzzers are typically classified as either blackbox, greybox, or whitebox. These designations are based upon the level of communication between the fuzzer and the target application. The two most common types are blackbox and greybox fuzzers.
Blackbox fuzzing submits data to the target application with essentially no knowledge of how that data affects the target. Because of this restriction, the effectiveness of a blackbox fuzzer is based entirely on the fitness of the generated data.
Blackbox fuzzing is often used for large, non-deterministic applications or those which process highly structured data.
Whitebox fuzzing enables direct correlation between the fuzzer and the target application in order to generate data that satisfies the application’s “requirements”. This typically involves the use of theorem solvers to evaluate branch conditions and generate data to intentionally exercise all branches. In doing so, the fuzzer can test hard-to-reach branches that might never be tested by blackbox or greybox fuzzers.
The downside of this type of fuzzing—it is computationally expensive. Large applications with complex branching may require a significant amount of time to solve. This greatly reduces the number of inputs tested. Outside of academic exercises, whitebox fuzzing is often not feasible for real-world applications.
Greybox fuzzing has emerged as one of the most popular and effective fuzzing techniques. These fuzzers implement a feedback mechanism, typically via instrumentation, to inform decisions on what data to generate in the future. Inputs which appear to cover more code are reused as the basis for later tests. Inputs which decrease coverage are discarded.
This method is incredibly popular due to its speed and efficiency in reaching obscure code paths. However, not all targets are good candidates for greybox fuzzing. Greybox fuzzing typically works best with smaller, deterministic targets that can process a large number of inputs quickly (several hundred a second).
We often use these types of fuzzers to test individual components within Firefox such as media parsers. If you’re interested in learning how to leverage these fuzzers to test your code, take a look at the Fuzzing Interface documentation here.
Unfortunately, we are somewhat limited in the techniques that we can use when fuzzing WebAPIs. The browser by nature is non-deterministic and the input is highly structured. Additionally, the process of starting the browser, executing tests, and monitoring for faults is slow (several seconds to minutes per test). With these limitations, blackbox fuzzing is the most appropriate solution.
However, since the inputs expected by these APIs are highly structured, we need to ensure that our fuzzer generates data that is considered valid.
Grammar-based fuzzing is a fuzzing technique that uses a formal language grammar to define the structure of the data to be generated. These grammars are typically represented in plain-text and use a combination of symbols and constants to represent the data. The fuzzer can then parse the grammar and use it to generate fuzzed output.

The examples here demonstrate two simplified grammar excerpts from the Domato and Dharma fuzzers. These grammars describe the process of creating an HTMLCanvasElement and manipulating its properties and operations.
Unfortunately, the level of effort required to develop a grammar is directly proportional to the size and complexity of the data you’re attempting to represent. This is the biggest downside of grammar-based fuzzing. For reference, WebAPIs in Firefox expose over 730 interfaces with approximately 6300 members. Keep in mind, this number does not account for other required data structures like callbacks, enums, or dictionaries, to name a few. Creating a grammar to describe these APIs accurately would be a huge undertaking; not to mention error-prone and difficult to maintain.
To more effectively fuzz these APIs, we wanted to avoid as much manual grammar development as possible.
typedef (BufferSource or Blob or USVString) BlobPart;
[Exposed=(Window,Worker)]
interface Blob {
[Throws]
constructor(optional sequence blobParts,
optional BlobPropertyBag options = {});
[GetterThrows]
readonly attribute unsigned long long size;
readonly attribute DOMString type;
[Throws]
Blob slice(optional [Clamp] long long start,
optional [Clamp] long long end,
optional DOMString contentType);
[NewObject, Throws] ReadableStream stream();
[NewObject] Promise text();
[NewObject] Promise arrayBuffer();
};
enum EndingType { "transparent", "native" };
dictionary BlobPropertyBag {
DOMString type = "";
EndingType endings = "transparent";
};A simplified example of the Blob WebIDL definition
WebIDL, is an interface description language (IDL) for describing the APIs implemented by browsers. It lists the interfaces, members, and values exposed by those APIs as well as the syntax.
The WebIDL definitions are well known among the browser fuzzing community because of the wealth of information contained within them. Previous work has been done in this area to extract the data from these IDLs for use as a fuzzing grammar, namely the WADI fuzzer from Sensepost. However, in each example we investigated, we found that the information from these definitions was extracted and re-implemented using the fuzzer’s native grammar syntax. This approach still requires a significant amount of manual effort. And further, the fuzzing grammars’ syntax make it difficult, if not impossible in some instances, to describe behaviors specific to WebAPIs.
Based on these issues, we decided to use the WebIDL definitions directly, rather than converting them to an existing fuzzing grammar syntax. This approach provides us with a number of benefits.
First and foremost, the WebIDL specification defines a standardized grammar to which these definitions must adhere. This lets us leverage existing tools, such as WebIDL2.js, for parsing the raw WebIDL definitions and converting them into an abstract syntax tree (AST). Then this AST can be interpreted by the fuzzer to generate testcases.
Second, the WebIDL defines the structure and behavior of the APIs we intend to target. Thus, we significantly reduce the amount of required rule development. In contrast, if we were to describe these APIs using one of the previously mentioned grammars, we would have to create individual rules for each interface, member, and value defined by the API.
Unlike traditional grammars, which only define the structure of data, the WebIDL specification provides additional information regarding the interface’s behavior via ECMAScript extended attributes. Extended attributes can describe a variety of behaviors including:
These types of behaviors are not typically represented by traditional grammars.
Finally, since the WebIDL files are linked with the interfaces implemented by the browser, we can ensure that updates to the WebIDL reflect updates to the interface.

In order to leverage WebIDL for fuzzing, we first need to parse it. Fortunately for us, we can use the WebIDL2.js library to convert the raw IDL files into an abstract-syntax tree (AST). The AST generated by WebIDL2.js describes the data as a series of nodes on a tree. Each of these nodes defines some construct of the WebIDL syntax.
Further information on the WebIDL2 AST structure can be found here.
Once we have our AST, we simply need to define translations for each of these constructs. In Domino, we’ve implemented a series of tools for traversing the AST and translating AST nodes into JavaScript. The diagram above demonstrates a few of these translations.
Most of these nodes can be represented using a static translation. This means that a construct in the AST will always have the same representation in JavaScript. For example, the constructor keyword will always be replaced with the JavaScript “new” operator in combination with the interface name. There are however, several instances where the WebIDL construct can have many meanings and must be generated dynamically.
The WebIDL specification lists a number of types used for representing generic values. For each of these types, Domino implements a function that will either return a randomly generated value matching the requested type or a previously recorded object of the same type. For example, when iterating over the AST, occurrences of the numeric types octet, short, and long will return values within those numeric ranges.
In places where the construct type references another IDL definition and is used as an argument, these values require an object instance of that IDL type. When one of these values is identified, Domino will attempt to create a new instance of the object (via its constructor). Or, it will attempt to do so by identifying and accessing another member which returns an object of that type.
The WebIDL specification also defines a number of types which represent functions (i.e., promises, callbacks, and event listeners). For each of these types, Domino will generate a unique function that performs random operations on the supplied arguments (if present.
Of course the steps above only account for a small fraction of what is necessary to fully translate the IDLs to JavaScript. Domino’s generator implements support for the entire WebIDL specification. Let’s take a look at what our output might look like using the Blob WebIDL as a fuzzing grammar.
> const { Domino } = require('~/domino/dist/src/index.js')
> const { Random } = require('~/domino/dist/src/strategies/index.js')
> const domino = new Domino(blob, { strategy: Random, output: '~/test/' })
> domino.generateTestcase()
…
const o = []
o[2] = new ArrayBuffer(8484)
o[1] = new Float64Array(o[2])
o[0] = new Blob([o[1]])
o[0].text().then(function (arg0) {
o[0].text().then(function (arg1) {
o[3] = o[0].slice()
o[3].stream()
o[3].slice(65535, 1, ‘foobar’)
})
})
o[0].arrayBuffer().then(function (arg2) {
o[3].text().then(function (arg3) {
O[4] = arg3
o[0].slice()
})
})As we can see here, the information provided by the IDL is enough to generate valid testcases. These cases exercise a fairly large portion of the Blob-related code. In turn, this allows us to quickly develop baseline fuzzers for new APIs with zero manual intervention.
Unfortunately, not everything is as precise as we would prefer. Take, for instance, the values supplied to the slice operation. After reviewing the Blob specification, we see that the start and end arguments are expected to be byte-order positions relative to the size of the Blob. We’re currently generating these numbers at random. As such, it seems unlikely that we’ll be able to return values within the limits of the Blob length.
Furthermore, both the contentType argument of the slice operation and the type property on the BlobPropertyBag dictionary are defined as DOMString. Similar to our numeric values, we generate strings at random. However, further review of the specification indicates that these values are used to represent the media type of the Blob data. Now, it doesn’t appear that this value has much effect on the Blob object directly. Nevertheless, we can’t be certain that these values won’t have an effect on the APIs which consume these Blobs.
To address these issues, we needed to develop a way of differentiating between these generic types.

Out of this need, we developed another tool named GrIDL. GrIDL leverages the WebIDL2.js library for converting our IDL definitions into an AST. It also makes several optimizations to the AST to better support its use as a fuzzing grammar.
However, the most interesting feature of GrIDL is this: We can dynamically patch IDL declarations where a more precise value is required. Using a rule-based matching system, GrIDL identifies the target value and inserts a unique identifier. Those identifiers correspond with a matching generator implemented by Domino. While iterating over the AST, if one of these identifiers is encountered, Domino calls the matching generator and emits the value returned.

The diagram above demonstrates the correlation between GrIDL identifiers and Domino generators. Here we’ve defined two generators. One returns byte offsets and the other returns a valid MIME type.
It’s important to note that each generator will also receive access to a live representation of the current object being fuzzed. This provides us with the ability to generate values informed by the current state of the object.
In the example above, we leverage this object to generate byte offsets for the slice function that are relative to its length. However, consider any of the attributes or operations associated with the WebGLRenderingContextBase interface. This interface could be implemented by either a WebGL or WebGL2 context. The arguments required by each may vary drastically. By referencing the current object being fuzzed, we can determine the context type and return values accordingly.
> domino.generateTestcase()
…
const o = []
o[1] = new Uint8Array(14471)
o[0] = new Blob([null, null, o[1]], {
'type': 'image/*',
'endings': 'transparent'
})
o[2] = o[0].slice((1642420336 % o[0].size), (3884321603 % o[0].size), 'application/xhtml+xml')
o[0].arrayBuffer().then(function (arg0) {
setTimeout(function () { o[0].text().then(function (arg1) { o[0].stream() }) }, 180)
o[2].arrayBuffer().then(function (arg2) {
o[0].slice((3412050218 % o[0].size), (646665894 % o[0].size), 'text/plain')
o[0].stream()
})
o[2].text().then(function (arg3) {
o[2].slice((2025414481 % o[2].size), (2615146387 % o[2].size), 'text/html')
o[3] = o[0].slice((753872984 % o[0].size), (883984089 % o[0].size), 'text/xml')
o[3].stream()
})
})
With our newly created rules, we’re now able to generate values that more closely resemble those described by the specification.
The examples included in this post have been greatly simplified. It can often be hard to see how an approach like this might be applied to more complex APIs. With that, I’d like to leave you with an example of one of the more complex vulnerabilities uncovered by Domino.

In bug 1558522, we identified a critical use-after-free vulnerability affecting the IndexedDB API. This vulnerability is very interesting from a fuzzing perspective due to the level of complexity required to trigger the issue. Domino was able to trigger this vulnerability by creating a file in the global context, then passing the file object to a worker context where an IndexedDB database connection is established.
This level of coordination between contexts would often be difficult to describe using traditional grammars. However, due to the detailed descriptions of these APIs provided by the WebIDL, Domino can identify vulnerabilities like this with ease.
A final note: Domino continues to find security-sensitive vulnerabilities in our code. Unfortunately, this means we cannot release it yet for public use. However, we have plans to release a more generic version in the near future. Stay tuned. If you’d like to get started contributing code to the development of Firefox, there are plenty of open opportunities. And, if you are a Mozilla employee or NDA’d code contributor and you’d like to work on Domino, feel free to reach out to the team in the Fuzzing room on Riot (Matrix)!
The post Fuzzing Firefox with WebIDL appeared first on Mozilla Hacks - the Web developer blog.
|
|






