This Week In Rust: This Week in Rust 334 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's crate is sudo, a library to let your program run as root.
Thanks to Stefan Schindler for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
367 pull requests were merged in the last week
#[track_caller] on functions in extern "Rust" { ... }impl Trait where Trait has an assoc type with missing boundsunused_bracesSmallVec for Cache::predecessorsfind_library_crateio::Write::write_all_vectoredVec functionsToOwned::clone_intoOrd bound that was plaguing drain_filterFuse implementationChain with Option fusesBTreeMap::into_iter to match range_mutBTreeMap first last proposal tweaksor_insert_with_key to Entry of HashMap/BTreeMapcargo tree commandChanges to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
Ok-wrapping for try blocks.Span::mixed_site.If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
This viewpoint is very controversial, and I have no capacity to debate it with anyone who disagrees with me. But Rust has a very powerful macro system, so I don’t have to.
– withoutboats blogging about failure/fehler
Thanks to lxrec for the suggestions!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nasa42 and llogiq.
https://this-week-in-rust.org/blog/2020/04/14/this-week-in-rust-334/
|
|
Daniel Stenberg: curl ootw: –append |
Previously mentioned command line options of the week.
--append is the long form option, -a is the short. The option has existed since at least May 1998 (present in curl 4.8). I think it is safe to say that if we would’ve created this option just a few years later, we would not have “wasted” a short option letter on it. It is not a very frequently used one.
The append in the option name is a require to the receiver to append to — rather than replace — a destination file. This option only has any effect when uploading using either FTP(S) or SFTP. It is a flag option and you use it together with the --upload option.
When you upload to a remote site with these protocols, the default behavior is to overwrite any file that happens to exist on the server using the name we’re uploading to. If you append this option to the command line, curl will instead instruct the server to append the newly uploaded data to the end of the remote file.
The reason this option is limited to just subset of protocols is of course that they are the only ones for which we can give that instruction to the server.
Append the local file “trailer” to the remote file called “begin”:
curl --append --upload trailer ftp://example.com/path/begin
|
|
Mozilla Addons Blog: What to expect for the upcoming deprecation of FTP in Firefox |
The Firefox platform development team recently announced plans to first disable, and then remove the implementation for built-in FTP from the browser. FTP is a protocol to transfer files from one host to another. It predates the Web and was not designed with security in mind. Now, we have decided to remove it because it is an infrequently used and insecure protocol. After FTP is disabled in Firefox, people can still use it to download resources if they really want to, but the protocol will be handled by whatever external application is supported on their platform.
FTP was disabled on the Firefox Nightly pre-release channel on April 9. To mitigate the risk of potentially causing breakages during the COVID-19 pandemic, FTP will not be disabled from the Firefox release channel until at least July 2020. If the pandemic situation has not improved by July 28 (the expected release date for Firefox 79), there may be further delays.
Add-ons that use FTP may experience breakage on Nightly but will continue to work as usual on the Beta and release channels. We want to help developers address these breakages as best as we can while this change is on Nightly. If you maintain an extension that uses FTP, please test it on Nightly (or on any current version of Firefox by flipping the preference network.ftp.enabled to false) and file a bug if you notice any issues. We will also evaluate whether new features should be added to help you maintain file transfer functionality.
In the long-term, we encourage developers to move away from using FTP in their extensions. However, if you would like to continue using FTP for as long as it is enabled, we encourage you to wrap any features that require FTP and use the browserSettings API to check whether FTP is enabled before exposing that functionality.
Please let us know if there are any questions on our developer community forum.
The post What to expect for the upcoming deprecation of FTP in Firefox appeared first on Mozilla Add-ons Blog.
|
|
Karl Dubost: Week notes - 2020 w14 - worklog - Human Core Dump |
I worked as normal and until Wednesday evening, April 1st, 2020 and in the early hours of Thursday, April 2nd, 2020, I had an erratic heart incident that I thought was a stroke, but was probably an epilepsy. Fast forward. The body has been repaired I passed all the details of brain surgery. I will be probably slowly coming back into actions gradually. Thanks to the full webcompat team for the love and support and Mike Taylor for being always so human.
Just tremendously happy to be alive.
The interrupted work week below…
alt textual alternative, but what is happening if a content: url() pointing an image is specified? See the examples given in the bugzilla issue.os.path.commonprefix()test_results = ["/a/b/c.html", "/a/b/d.html", "/a/b/e.html", "/a/b/f.html", "/a/b/g.html"] import os.path os.path.commonprefix(test_results) # '/a/b/'
but unfortunately it's not really path minded.
test_results = ["/a/b/cde.html", "/a/b/cdf.html"] import os.path os.path.commonprefix(test_results) # '/a/b/cd'
which both makes sense and is slightly unfortunate at the same time.
from types import MappingProxyType some_dict = {'fr': 'baguette', 'ja': 'furansupan'} frozen_dict = MappingProxyType(some_dict) frozen_dict['fr'] # 'baguette' frozen_dict['fr'] = 'pain de mie' # heresy # Traceback (most recent call last): # File "", line 1, in # TypeError: 'mappingproxy' object does not support item assignment
I'm inheriting a machine learning project where I had 0 participation. And the learning curve is steep because of two things:
No specific blame to do here, but just different ways on how to think about specific code. I'm adding my comments on the code little by little, so I can keep track of my thoughts. There are a least two comments about modifying the object in place which makes me a bit uncomfortable.
return selfself.df = df where df was not defined in __init__.Honestly I don't know if it's pythonic or not, but I find the code difficult to read and edgy if some operations are done in a different order
>>> class SomeClass: ... def create_var(self): "instance method initializing a var list" var = [] ... self.var = var ... def insert_to_var(self, value): ... self.var.append(value) ... >>> # This will work >>> my_instance = SomeClass() >>> my_instance.create_var() >>> my_instance.insert_to_var(5) >>> my_instance.var [5] >>> # But this will fail >>> my_instance = SomeClass() >>> my_instance.var Traceback (most recent call last): File "" , line 1, in <module> AttributeError: 'SomeClass' object has no attribute 'var' >>> my_instance.insert_to_var(5) Traceback (most recent call last): File "" , line 1, in <module> File "" , line 5, in insert_to_var AttributeError: 'SomeClass' object has no attribute 'var'
This seems more robust
>>> class SomeClass: ... def __init__(self): ... self.var = [] ... def insert_to_var(self, value): ... self.var.append(value) ... >>> my_instance = SomeClass() >>> my_instance.var [] >>>
but i need to learn more about it.
git notes related to what I was explaining last week about annotations in git.git notes: Add or inspect object notes
Adds, removes, or reads notes attached to objects, without touching the objects themselves.
By default, notes are saved to and read from refs/notes/commits, but this default can be overridden. See the OPTIONS, CONFIGURATION, and ENVIRONMENT sections below. If this ref does not exist, it will be quietly created when it is first needed to store a note.
A typical use of notes is to supplement a commit message without changing the commit itself. Notes can be shown by git log along with the original commit message.
There is a practical explanation given on AlBlue's blog.
It might also be possible to do it through comments on specific parts of the code. It might be simpler, plus it is sending a mail which will give nice links. I could even put a #tag inside the comment so it's easier to search, discriminate. To think.
Otsukare!
|
|
Mozilla VR Blog: Better User Performance and More in this Firefox Reality v9 release |

For the Firefox Reality v9 release, we focused on delivering a more polished user experience, here are some examples of what we improved:
A good chunk of this release was spent fixing bugs and making performance improvements.
In the exciting world of partnerships, we’re ramping up on PicoVR support across the board. Everything from controller support to G2 touchpad support are included in this release.
There’s a ton more coming in our next release, including 2 hand keyboard typing and downloading capabilities. We’re super thrilled to reveal what is to come. Stay tuned!
https://blog.mozvr.com/performance-improvements-better-user-performance-and-more-in-this-release/
|
|
The Talospace Project: Firefox 75 on POWER |
Total build time for opt on this dual-4 DD2.2 system was 36:36.67 (with -j24). Why mention it? Well, my dual-8 DD2.3 is almost here and this sounds like a convenient real-world benchmark to try out on the new box. I'm thinking -j48 sounds nice and still gives me a whole 16 threads for serious business during the compile.
The opt and debug .mozconfigs I'm using are unchanged from Firefox 67.
|
|
Daniel Stenberg: A QQGameHall storm |
Mar 31 2020, 11:13:38: I get a message from Frank in the #curl IRC channel over on Freenode. I’m always “hanging out” on IRC and Frank is a long time friend and fellow freuent IRCer in that channel. This time, Frank informs me that the curl web site is acting up:
“I’m getting 403s for some mailing list archive pages. They go away when I reload”
That’s weird and unexpected. An important detail here is that the curl web site is “CDNed” by Fastly. This means that every visitor of the web site is actually going to one of Fastly’s servers and in most cases they get cached content from those servers, and only infrequently do these servers come back to my “origin” server and ask for an updated file to send out to a web site visitor.
A 403 error for a valid page is not a good thing. I started checking out some of my logs – which then only are for the origin as I don’t do any logging at all at CDN level (more about that later) – and I could verify the 403 errors. So they’re in my log meaning it isn’t caused by (a misconfiguration of) the CDN. Why would a perfectly legitimate URL suddenly return 403 to have it go away again after a reload?
I took a look at Fastly’s management web interface and I spotted that the curl web site was sending out data at an unusual high speed at the moment. An average speed of around 50mbps, while we typically average at below 20. Hm… something is going on.
While I continued to look for the answers to these things I noted that my logs were growing really rapidly. There were POSTs being sent to the same single URL at a high frequency (10-20 reqs/second) and each of those would get some 225Kbytes of data returned. And they all used the same User-agent: QQGameHall. It seems this started within the last 24 hours or so. They’re POSTs so Fastly basically always pass them through to my server.
Before I could figure out Franks’s 403s, I decided to slow down this madness by temporarily forbidding this user-agent access so that the bot or program or whatever would notice it starts to fail, and it would of course then stop bombarding the site.
Ok, a quick deny of the user-agent made my server start responding with 403s to all those requests and instead of a 225K response it now sent back 465 bytes per request. The average bandwidth on the site immediately dropped down to below 20Mbps again. Back to looking for Frank’s 403-problem

The answer was pretty simple and I didn’t have to search a lot. The clues existed in the error logs and it turned out we had “mod_evasive” enabled since another heavy bot load “attack” a while back. It is a module for “rate limiting” incoming requests and since a lot of requests to our server now comes from Fastly’s limited set of IP addresses and we had this crazy QQ thing hitting us, my server would return a 403 every now and then when it considered the rate too high.
I whitelisted Fastly’s requests and Frank’s 403 problems were solved.
The bot traffic showed no sign of slowing down. Easily 20 requests per second, to the same URL and they all get an error back and obviously they don’t care. I decided to up my game a little so with help, I moved my blocking of this service to Fastly. I now block their user-agent already there so the traffic doesn’t ever reach my server. Phew, my server was finally back to its regular calm state. They way it should be.
It doesn’t stop there. Here’s a follow-up graph I just grabbed, a little over a week since I started the blocking. 16.5 million blocked requests (and counting). This graph here shows number of requests/hour on the Y axis, peeking at almost 190k; around 50 requests/second. The load is of course not actually a problem, just a nuisance now. QQGameHall keeps on going.

What we know about this.
Friends on Twitter and googling for this name informs us that this is a “game launcher” done by Tencent. I’ve tried to contact them via Twitter (as I have no means of contacting them otherwise that seems even remotely likely to work).
I have not checked what these user-agent POSTs, because I didn’t log that. I suspect it was just a zero byte POST.
The URL they post to is the CA cert bundle file with provide on the curl CA extract web page. The one we convert from the Mozilla version into a PEM for users of the world to enjoy. (Someone seems to enjoy this maybe just a little too much.)
The user-agents seemed to come (mostly) from China which seems to add up. Also, the look of the graph when it goes up and down could indicate an eastern time zone.
This program uses libcurl. Harry in the #curl channel found files in Virus Total and had a look. It is, I think, therefore highly likely that this “storm” is caused by an application using curl!
My theory: this is some sort of service that was deployed, or an upgrade shipped, that wants to get an updated CA store and they get that from our site with this request. Either they get it far too often or maybe there are just a very large amount them or similar. I cannot understand why they issue a POST though. If they would just have done a GET I would never have noticed and they would’ve fetched perfectly fine cached versions from the CDN…
Feel free to speculate further!
I don’t have any logging of the CDN traffic to the curl site. Primarily because I haven’t had to, but also because I appreciate the privacy gain for our users and finally because handling logs at this volume pretty much requires a separate service and they all seem to be fairly pricey – for something I really don’t want. So therefore I don’t see the source IP addresses these things. (But yes, I can ask Fastly to check and tell me if I really really wanted to know.)
Also: I don’t run any analytics (Google or otherwise) on the site, primarily for privacy reasons. So that won’t give me that data or other clues either.
Update: it has been proposed I could see the IP address in the X-Forwarded-For: headers and it seems accurate. Of course I didn’t log that header during this period but I will consider starting doing it for better control and info in the future.
Top image by Elias Sch. from Pixabay
|
|
The Mozilla Blog: Our Journey to a Better Internet |
The internet is now our lifeline, as a good portion of humanity lives as close to home as possible. Those who currently don’t have access will feel this need ever more acutely. The qualities of online life increasingly impact all of our lives.
Mozilla exists to improve the nature of online life: to build the technology and products and communities that make a better internet. An internet that is accessible, safe, promotes human dignity, and combines the benefits of “open” with accountability and responsibility to promote healthy societies.
I’m honored to become Mozilla’s CEO at this time. It’s a time of challenge on many levels, there’s no question about that. Mozilla’s flagship product remains excellent, but the competition is stiff. The increasing vertical integration of internet experience remains a deep challenge. It’s also a time of need, and of opportunity. Increasingly, numbers of people recognize that the internet needs attention. Mozilla has a special, if not unique role to play here. It’s time to tune our existing assets to meet the challenge. It’s time to make use of Mozilla’s ingenuity and unbelievable technical depth and understanding of the “web” platform to make new products and experiences. It’s time to gather with others who want these things and work together to make them real.
There’s a ton of hard work ahead. It’s important work, meaningful today and for the future. I’m committed to the vision and the work to make it real. And honored to have this role in leading Mozilla through this crisis and into the future beyond.
The post Our Journey to a Better Internet appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/04/08/our-journey-to-a-better-internet/
|
|
The Mozilla Blog: Mitchell Baker Named CEO of Mozilla |
The independent directors of the Mozilla board are pleased to announce that Mitchell Baker has been appointed permanent CEO of Mozilla Corporation.
We have been conducting an external candidate search for the past eight months, and while we have met several qualified candidates, we have concluded that Mitchell is the right leader for Mozilla at this time.
Mozilla’s strategic plan is focused on accelerating the growth levers for the core Firefox browser product and platform while investing in innovative solutions to mitigate the biggest challenges facing the internet. There is incredible depth of technical expertise within the organization, but these problems cannot be solved by Mozilla alone, so the plan also calls for a renewed focus on convening technologists and builders from all over the world to collaborate and co-create these new solutions. The need for innovation not only at Mozilla, but for the internet at large is more important than ever, especially at a time when online technologies and tools have a material and enduring impact on our daily lives.
Since last August when it was announced that Mozilla would be seeking a new CEO, Mitchell has assumed an active role in day-to-day operations, formally becoming interim CEO in December 2019. Over the course of this time, she has honed the organization’s focus on long-term impact. Mitchell’s deep understanding of Mozilla’s existing businesses gives her the ability to provide direction and support to drive this important work forward. Her involvement in organizations such as the Oxford Internet Institute, the MIT Initiative on the Digital Economy, ICANN and the U.S. Department of Commerce Digital Economy Board gives her the ability to not only impact the broader internet landscape, but also bring those valuable outside perspectives back into Mozilla. And her leadership style grounded in openness and honesty is helping the organization navigate through the uncertainty that COVID-19 has created for Mozillians at work and at home.
This balance of urgency, transparency and empathy, coupled with an innate knowledge of Mozilla, along with connections into the communities that are influencing the trajectory of the internet, make Mitchell Baker the right person to lead Mozilla today to make an impact into the future.
Statements from Mozilla Corporation Board Members:
Bob Lisbonne, Lecturer at Stanford Graduate School of Business:
“I’ve known Mitchell since Mozilla.org originally started back in 1998. Her authentic leadership style, commitment to the organization, and passion for improving the internet inspire trust and respect from mozillians worldwide.”
Julie Hanna, Venture Partner at Obvious Ventures:
“Mitchell is the embodiment and soul of Mozilla, possessing both the aspirational vision and institutional memory of the organization. We are fortunate for her long-standing service, tireless commitment and the stabilizing effect of her presence and leadership, especially at such a critical juncture.”
Karim R. Lakhani, Professor Harvard Business School:
“Mitchell has a proven track record of enabling communities and companies to collaborate and innovate. As we look to Mozilla’s future, this experience is going to be crucial to our future success.”
The post Mitchell Baker Named CEO of Mozilla appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/04/08/mitchell-baker-named-ceo-of-mozilla/
|
|
The Mozilla Blog: Mozilla Supports the Open COVID Pledge: Making Intellectual Property Freely Available for the Fight Against COVID-19 |
COVID-19 has afflicted more than one million people worldwide, and the number continues to climb every day. However long the pandemic lasts, we know that scientists and others’ ability to share work toward solutions is critical to ending it.
The Open COVID Pledge, a project of an international coalition of scientists, technologists, and legal experts, has been created to address this issue. The project calls on companies, universities and other organizations to make their intellectual property (IP) temporarily available free of charge for use in ending the pandemic and minimizing its impact.
Mozilla is grateful to the organizers of and contributors to the Open COVID Pledge, and is proud to support this critical effort. We are an organization dedicated to keeping the internet open and accessible to all. We support the open exchange of ideas, technologies, and resources in our day-to-day work and recognize the power of removing barriers in this time of crisis to preserve the social fabric and save lives.
We invite others to join us in supporting this important initiative to help combat the spread of COVID-19.
The post Mozilla Supports the Open COVID Pledge: Making Intellectual Property Freely Available for the Fight Against COVID-19 appeared first on The Mozilla Blog.
|
|
The Firefox Frontier: Keeping Firefox working for you during challenging times |
by Joe Hildebrand and Selena Deckelmann. There’s likely not a single person reading this who hasn’t been impacted in some way by the COVID-19 pandemic. We know that school and … Read more
The post Keeping Firefox working for you during challenging times appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/keeping-firefox-working-for-you-during-challenging-times/
|
|
The Mozilla Blog: Latest Firefox updates address bar, making search easier than ever |
We have all been spending a lot more time online lately whether it’s for work, helping our kids stay connected to their schools or keeping in touch with loved ones. While connecting is more important than ever as we face this pandemic together, we’ve also been relying on the power of “search” to access information, news and resources through the browser. Today’s Firefox release makes it even easier to get to the things that matter most to you online. Bringing this improved functionality to Firefox is our way of continuing to serve you now and in the future.
Did you know that there’s a super fast way to do your searches through the address bar? Simply press CTRL and L (command-L on a Mac). It’s just one of our many keyboard shortcuts. Check out the other ways we’ve made it easier to do searches right from the address bar.
Enlarged and simplified address bar for your searches
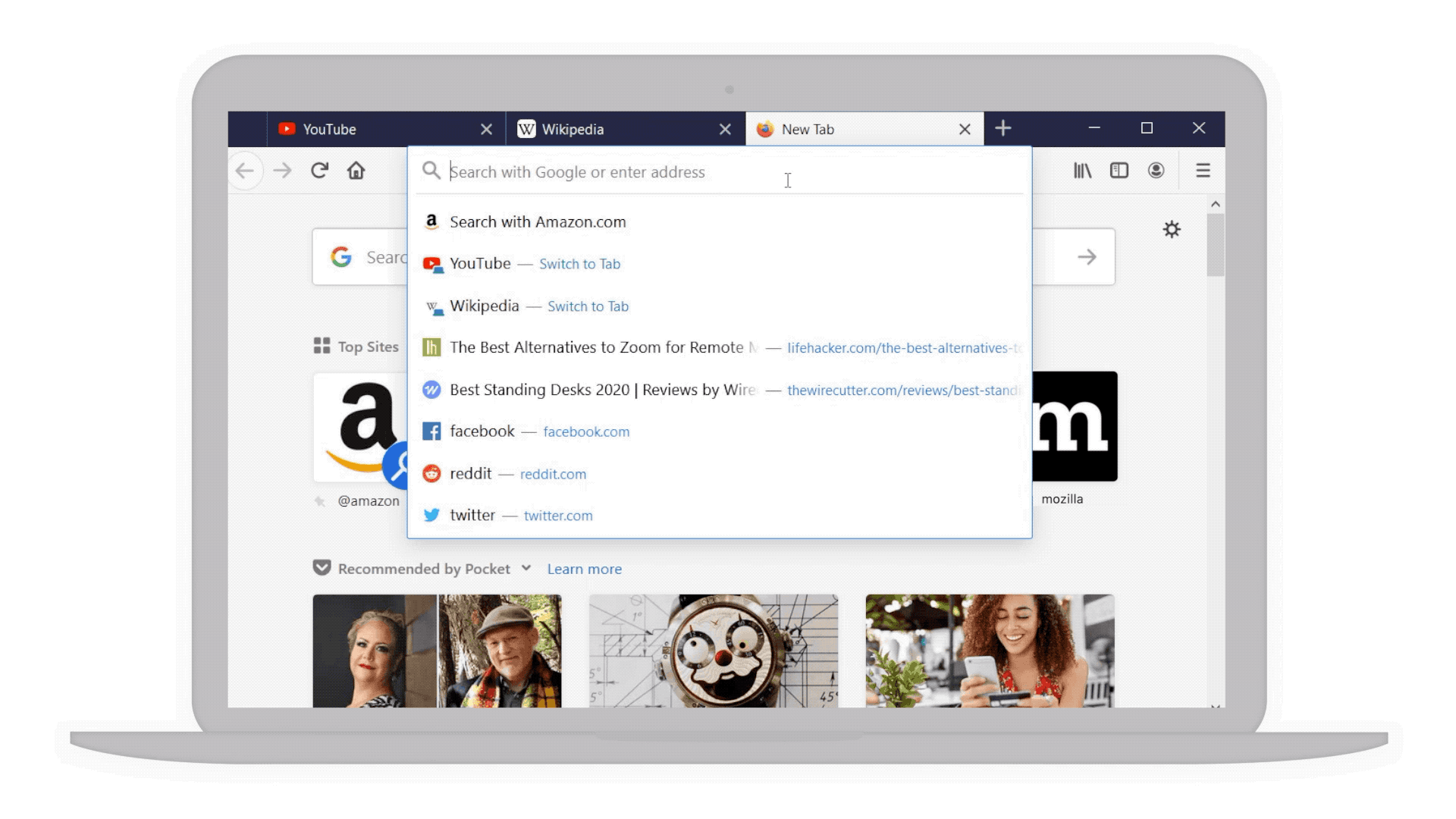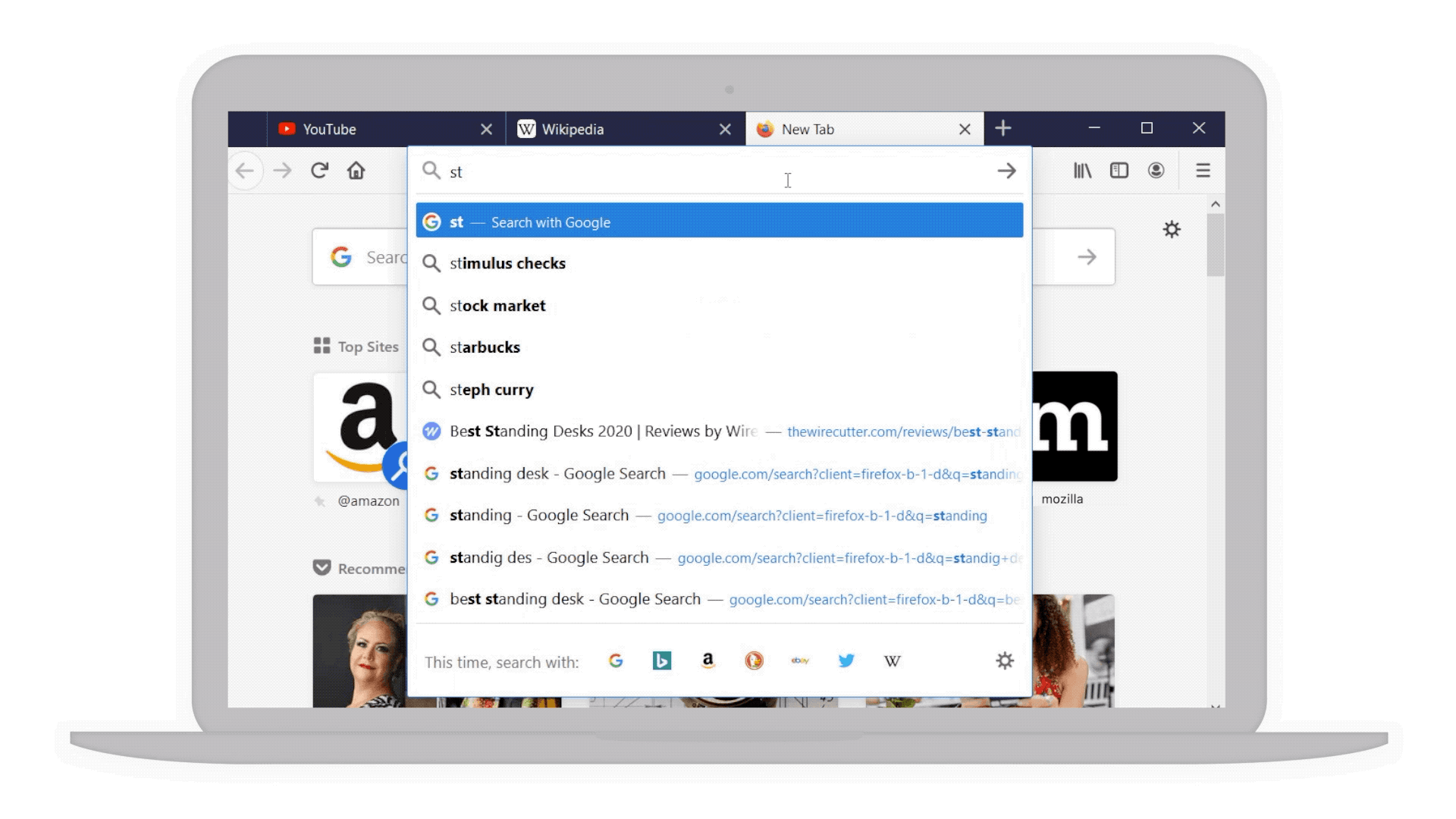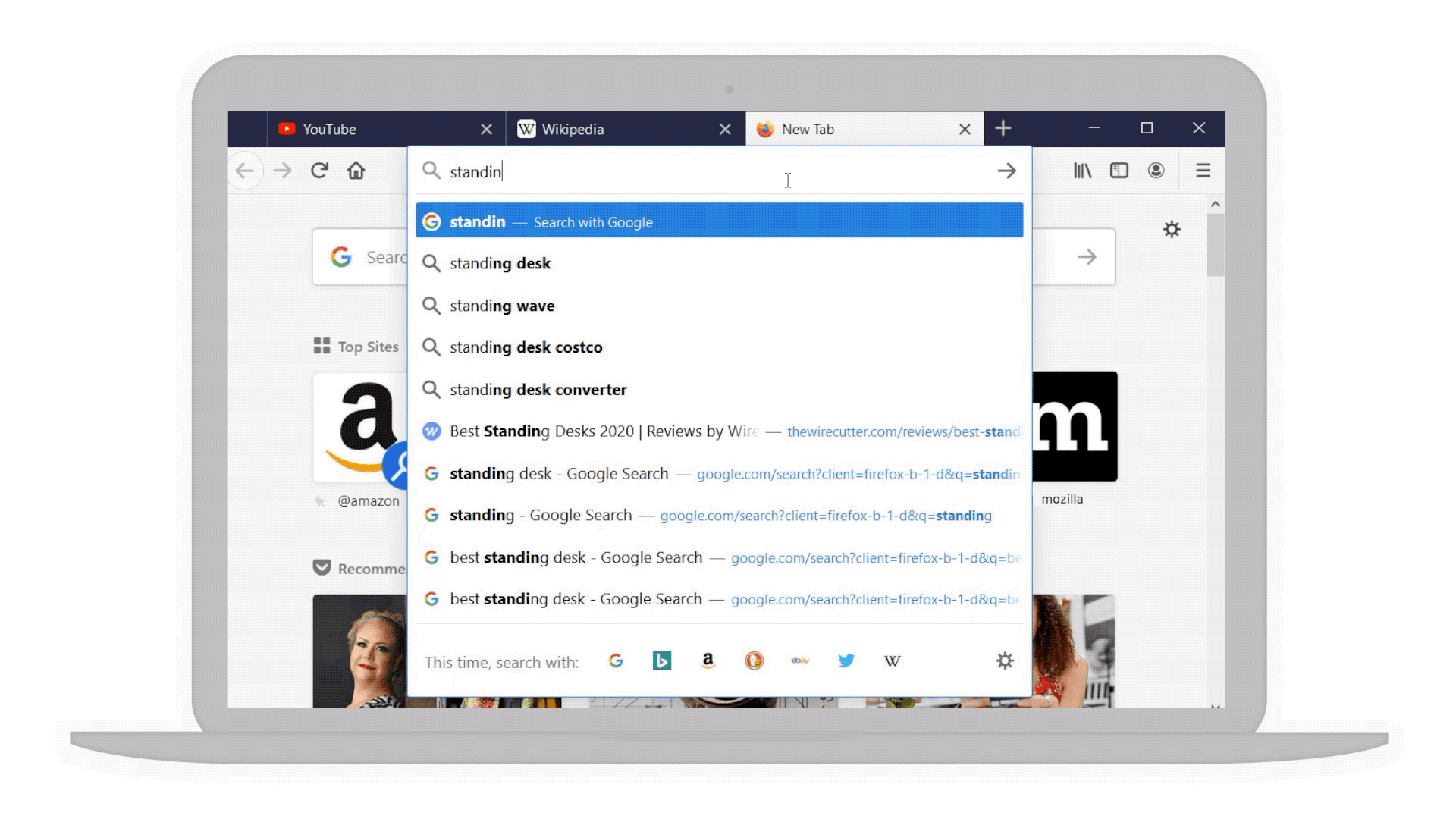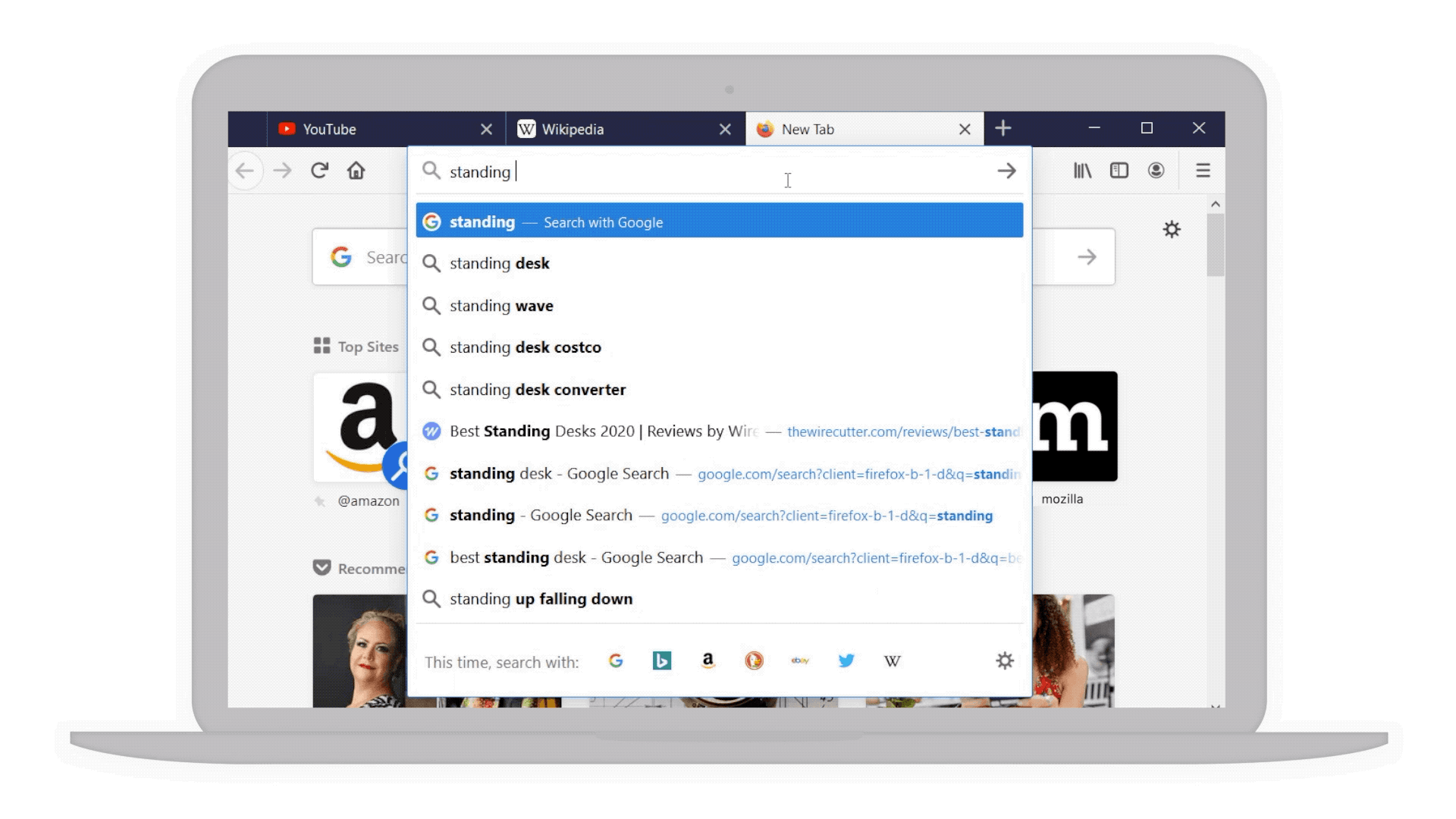
Popular keywords in bold to help narrow your search
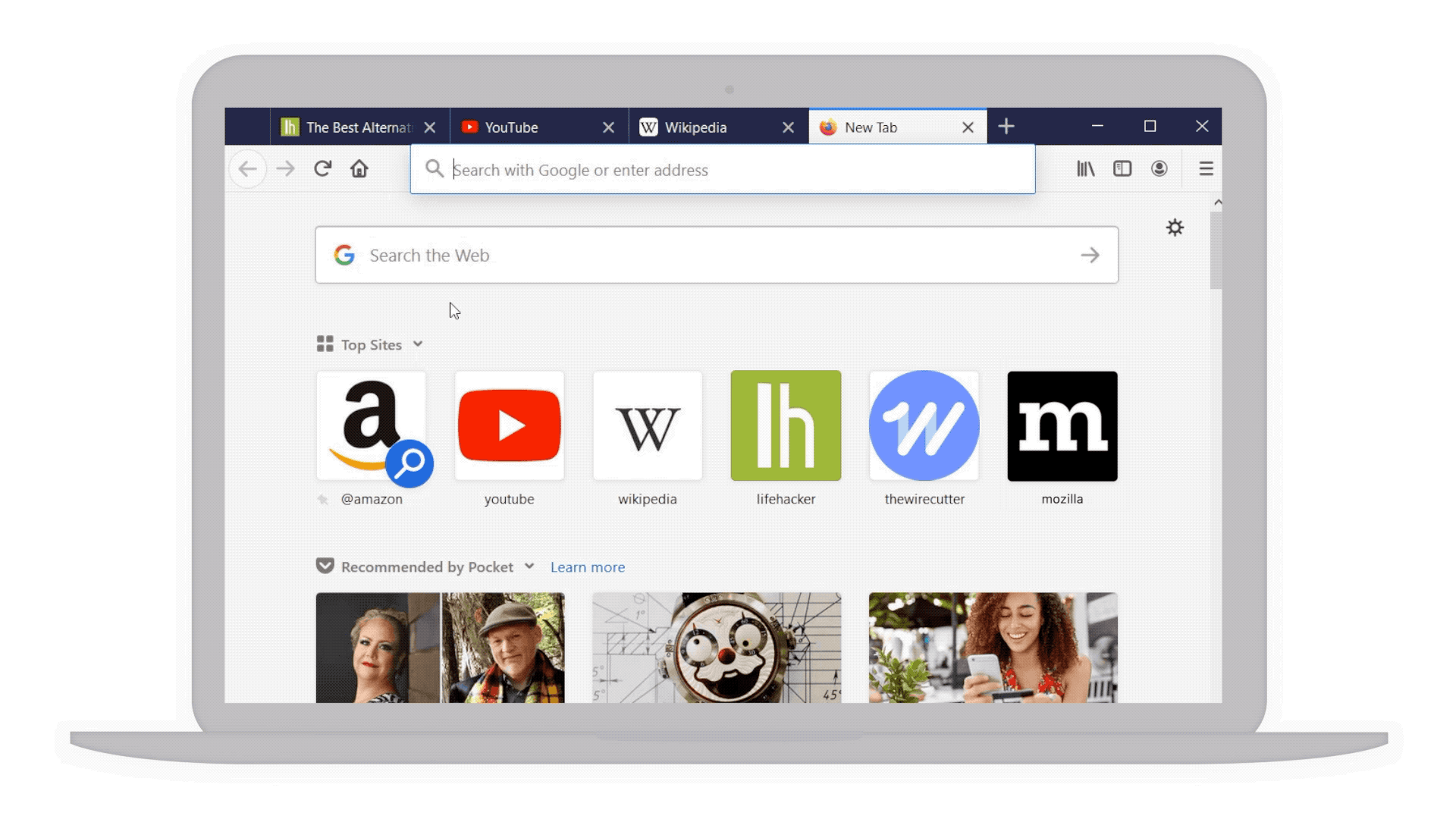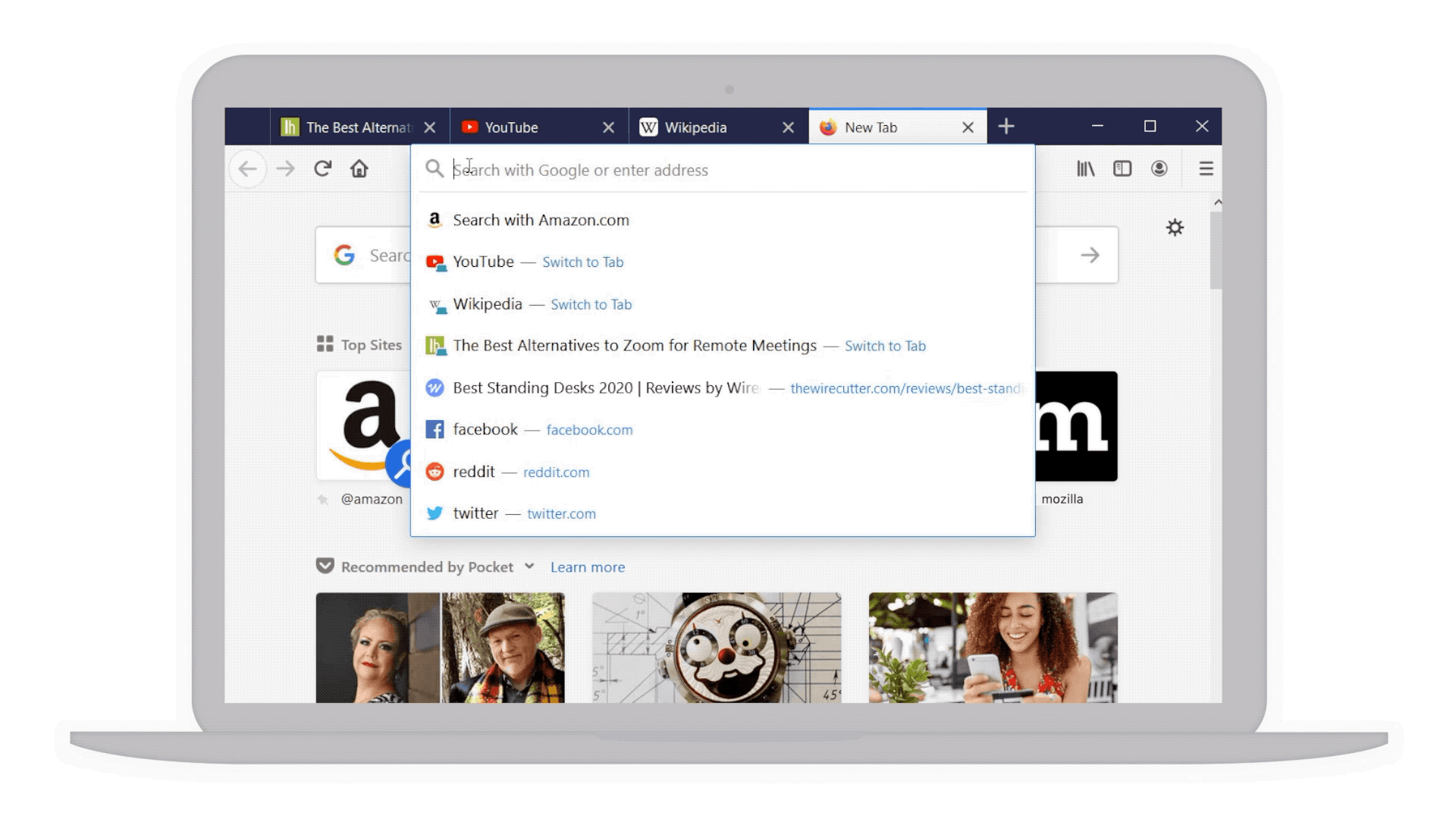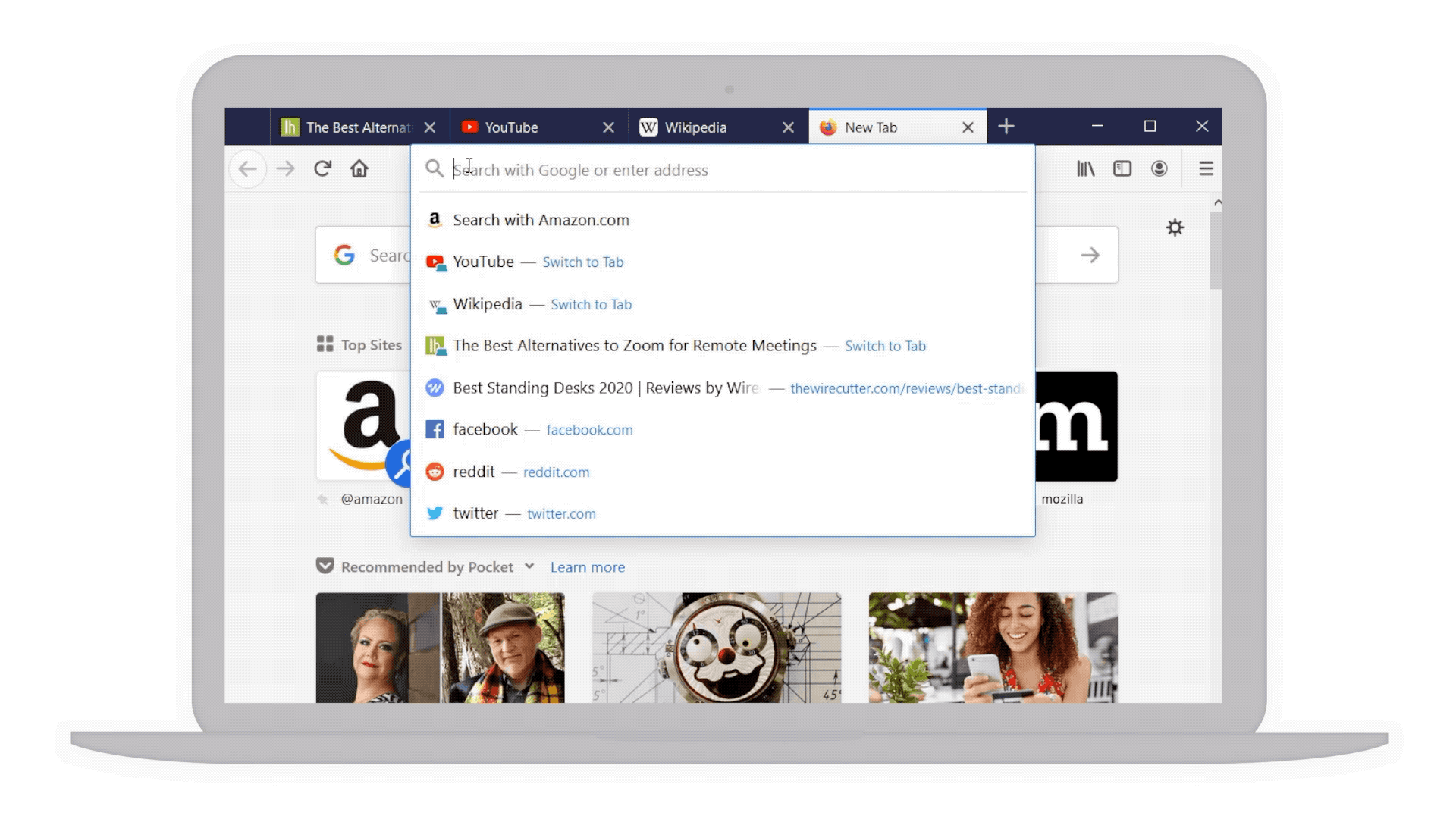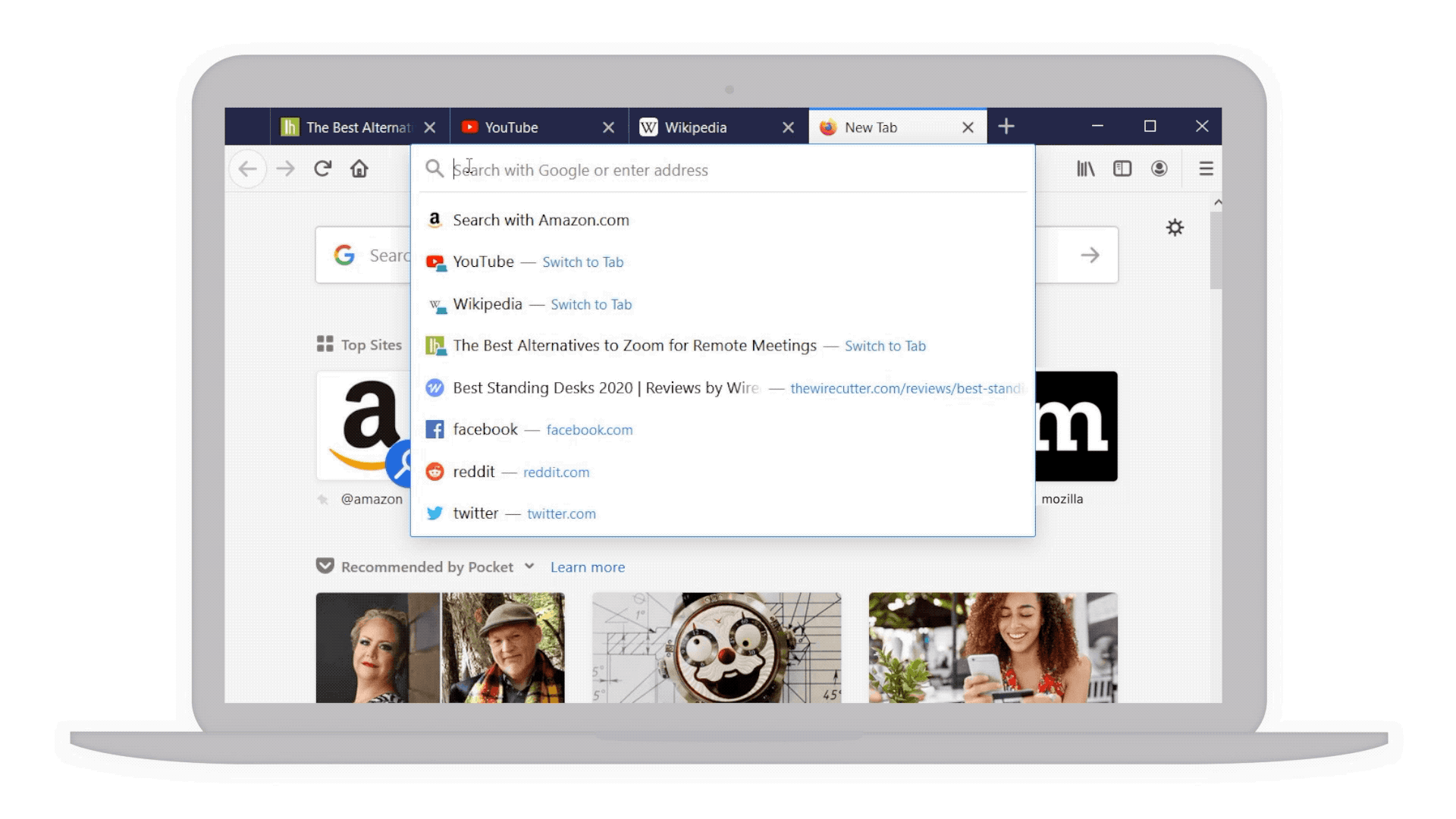
Top sites and shortcuts in your address bar
To see what else is new or what we’ve changed in today’s desktop and iOS release, you can check out our release notes.
Check out the latest updates to the address bar and download the latest version of Firefox available here.
The post Latest Firefox updates address bar, making search easier than ever appeared first on The Mozilla Blog.
|
|
Mozilla Security Blog: Firefox 75 will respect ‘nosniff’ for Page Loads |
Prior to being able to display a web page within a browser the rendering engine checks and verifies the MIME type of the document being loaded. In case of an html page, for example, the rendering engine expects a MIME type of ‘text/html’. Unfortunately, time and time again, misconfigured web servers incorrectly use a MIME type which does not match the actual type of the resource. If strictly enforced, this mismatch in types would downgrade a users experience. More precisely, the rendering engine within a browser will try to interpret the resource based on the ruleset for the provided MIME type and at some point simply would have to give up trying to display the resource. To compensate, Firefox implements a MIME type sniffing algorithm – amongst other techniques Firefox inspects the initial bytes of a file and searches for ‘Magic-Numbers’ which allows it to determine the MIME type of a file independently of the one set by the server.
Whilst sniffing of the MIME type of a document improves the browsing experience for the majority of users, it also enables so-called MIME confusion attacks. In more detail, imagine an application which allows hosting of images. Let’s further assume the application allows users to upload ‘.jpg’ files but fails to correctly verify that users of that application actually upload only valid .jpg files. An attacker could craft an ‘evil.jpg’ file containing valid html and upload that through the application. The innocent victim of that application solely expects images to be displayed. Within the browser, however, the MIME sniffer steps in and determines that the file contains valid html and overrides the MIME type to load the file like any other page within the application. Additionally, embedded JavaScript fragments within that page will be treated as same-origin and hence be granted the same permissions as the host application. In turn, the granted permissions allow the attacker to gain access to confidential user information.
To mitigate such MIME confusion attacks Firefox expands support of the header ‘X-Content-Type-Options: nosniff’ to page loads (view specification). Firefox has been supporting ‘XCTO: nosniff’ for JavaScript and CSS resources since Firefox 50 and starting with Firefox 75 will use the provided MIME type for page loads even if incorrect.

Left: Firefox 74 ignoring XCTO, sniffing HTML, and executing script.
Right: Firefox 75 respecting XCTO, and defaulting to plaintext.
If the provided MIME type does not match the content, Firefox will not sniff the MIME type but will show an error to the user instead. As illustrated above, if no MIME type was provided at all, Firefox will try to use plaintext or prompt a download . Showing the user an error in the case of a detected MIME type mismatch instead of trying to sniff and render a potentially malicious page allows Firefox to mitigate such MIME confusion attacks.
The post Firefox 75 will respect ‘nosniff’ for Page Loads appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2020/04/07/firefox-75-will-respect-nosniff-for-page-loads/
|
|
The Firefox Frontier: 13 Firefox browser extensions to make remote work and school a little better |
If you are newly working or going to school from home, the remote approach can be a big shift in how to get things done. Firefox has a number of … Read more
The post 13 Firefox browser extensions to make remote work and school a little better appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/firefox-extensions-work-from-home/
|
|
The Firefox Frontier: 6 Firefox browser extensions that make remote streaming even better |
More than ever these days, people are relying on the internet to stay informed, productive and connected to friends and family. A well-timed entertainment break also helps relieve stress and … Read more
The post 6 Firefox browser extensions that make remote streaming even better appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/firefox-extensions-streaming/
|
|
Robert Kaiser: Sending Encrypted Messages from JavaScript to Python via Blockchain |
eccrypto.encrypt() results in an object with 4 member strings while eciespy expects a string as input. Hmm.eccrypto.encrypt() to hex strings, stick them into a JSON and stringify that to hand it over to the blockchain function - using code very similar to this:var data = JSON.stringify(addressfields);
var eccrypto = require("eccrypto");
eccrypto.encrypt(pubkey, Buffer(data))
.then((encrypted) => {
var sendData = {
iv: encrypted.iv.toString("hex"),
ephemPublicKey: encrypted.ephemPublicKey.toString("hex"),
ciphertext: encrypted.ciphertext.toString("hex"),
mac: encrypted.mac.toString("hex"),
};
var finalString = JSON.stringify(sendData);
// Call the token shipping function with that final string.
OnChainShopContract.methods.shipToMe(finalString, tokenId)
.send({from: web3.eth.defaultAccount}).then(...)...
};
pip install eciespy cryptography in our virtualenv - not sure if eciespy is still needed but it may for dependencies we end up using):from Crypto.Cipher import AES
import hashlib
import hmac
from cryptography.hazmat.primitives.asymmetric import ec
from cryptography.hazmat.backends import default_backend
def ecies_decrypt(privkey, message_parts):
# Do ECDH via the cryptography module to get the non-libsecp256k1 version.
sender_public_key_obj = ec.EllipticCurvePublicNumbers.from_encoded_point(ec.SECP256K1(), message_parts["ephemPublicKey"]).public_key(default_backend())
private_key_obj = ec.derive_private_key(Web3.toInt(hexstr=privkey),ec.SECP256K1(), default_backend())
aes_shared_key = private_key_obj.exchange(ec.ECDH(), sender_public_key_obj)
# Now let's do AES-CBC with this, including the hmac matching (modeled after eccrypto code).
aes_keyhash = hashlib.sha512(aes_shared_key).digest()
hmac_key = aes_keyhash[32:]
test_hmac = hmac.new(hmac_key, message_parts["iv"] + message_parts["ephemPublicKey"] + message_parts["ciphertext"], hashlib.sha256).digest()
if test_hmac != message_parts["mac"]:
logger.error("Mac doesn't match: %s vs. %s", test_hmac, message_parts["mac"])
return False
aes_key = aes_keyhash[:32]
# Actual decrypt is modeled after ecies.utils.aes_decrypt() - but with CBC mode to match eccrypto.
aes_cipher = AES.new(aes_key, AES.MODE_CBC, iv=message_parts["iv"])
try:
decrypted_bytes = aes_cipher.decrypt(message_parts["ciphertext"])
# Padding characters (unprintable) may be at the end to fit AES block size, so strip them.
unprintable_chars = bytes(''.join(map(chr, range(0,32))).join(map(chr, range(127,160))), 'utf-8')
decrypted_string = decrypted_bytes.rstrip(unprintable_chars).decode("utf-8")
return decrypted_string
except:
logger.error("Could not decode ciphertext: %s", sys.exc_info()[0])
return False
https://home.kairo.at/blog/2020-04/encrypted_messages_from_js_to_python
|
|
About:Community: Firefox 75 new contributors |
With the release of Firefox 75, we are pleased to welcome the 40 developers who contributed their first code change to Firefox in this release, 38 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
https://blog.mozilla.org/community/2020/04/06/firefox-75-new-contributors/
|
|
Nick Desaulniers: Off by Two |
“War stories” in programming are entertaining tales of truly evil bugs that kept you up at night. Inspired by posts like My Hardest Bug Ever, Debugging an evil Go runtime bug, and others from /r/TalesFromDebugging, I wanted to share with you one of my favorites from recent memory. Recent work has given me much fulfilment and a long list of truly awful bugs to recount. My blog has been quieter than I would have liked; hopefully I can find more time to document some of these, maybe in series form. May I present to you episode I; “Off by Two.”
Distracted in a conference grand ballroom, above what might be the largest mall in the world or at least Bangkok, a blank QEMU session has me seriously questioning my life choices. No output. Fuck! My freshly built Linux kernel, built with a large new compiler feature that’s been in development for months is finally now building but is not booting. Usually a panic prints a nice stack trace and we work backwards from there. I don’t know how to debug a panic during early boot, and I’ve never had to; with everything I’ve learned up to this point, I’m afraid I won’t have it in me to debug this.
Attaching GDB, the kernel’s sitting an infinite loop:
1 2 3 4 5 6 7 | |
Some sort of very early exception handler; better to sit busy in an infinite loop than run off and destroy hardware or corrupt data, I suppose. It seems this is some sort of exception handler for before we’re ready to properly panic; maybe the machinery is not in place to even collect a stack trace, unwind, and print that over the serial driver. How did things go so wrong and how did we get here? I decide to ask for help.
Setting breakpoints and rerunning my boot, it looks like the fourth call to __early_make_pgtable() is deterministically going awry. Reading through callers, from the early_idt_handler_common subroutine in arch/x86/kernel/head_64.S the address was stored in %cr2 (the “page fault linear address”). But it’s not clear to me who calculated that address that created the fault. My understanding is that early_idt_handler_common is an exception vector setup in early_idt_handler_array, which gets invoked upon access to “unmapped memory” which gets saved into %cr2.
Beyond that, GDB doesn’t want me to be able to read %cr2.
Jann Horn gets back to me first:
Can you use QEMU to look at the hardware frame (which contains values pushed by the hardware in response to the page fault) in early_idt_handler_common? RSP before the call to early_make_pgtable should basically point to a “struct pt_regs”
When the CPU encounters an exception, it pushes an exception frame onto the stack. That doesn’t happen in kernel code; the CPU does that on its own. That exception frame consists of the last six elements of struct pt_regs. This is also documented in a comment at the start of early_idt_handler_common (“hardware frame” and “error code” together are the exception frame):
/* * The stack is the hardware frame, an error code or zero, and the * vector number. */After the CPU has pushed that stuff, it picks one of the exception handlers that have been set up in idt_setup_early_handler(); so it jumps to &early_idt_handler_array[i]. early_idt_handler_array pushes the number of the interrupt vector, then calls into early_idt_handler_common; early_idt_handler_common spills the rest of the register state (which is still the way it was before the exception was triggered) onto the stack (which among other things involves reading the vector number into a register and overwriting the stack slot of the vector number with a register that hasn’t been spilled yet).
The combination of the registers that have been spilled by software and the values that have been pushed onto the stack by the CPU before that forms a struct pt_regs. (The normal syscall entry slowpath does the same thing, by the way.)
you’ll want to break on the “call early_make_pgtable” or something like that, to get the pt_regs to be fully populated and at RSP.
This is documented further in linux-insides.
So as far as “where does the address in %cr2 come from, it’s “the CPU.” To get %cr2, I can just break after an instruction that moves %cr2 into a general purpose register (GPR).
1 2 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Specifically mod in the above expression (ie. rbx) is not pointing to valid
memory in the page tables, triggering an unrecoverable early page fault.
My heart sinks further at the sight of jump_lable_update. It’s asm goto,
the large compiler feature we’ve been working on for months, and it’s subtly
broken. Welcome to hell, kids.
asm goto is a GNU C extension that allows for assembly code to transfer
control flow to a limited, known set of labels in C code. Typically, regular
asm statements
(the GNU C extension) are treated as a black box in the instruction stream by
the compiler; they’re called into (not in the sense of the C calling convention
and actual call/jmp/ret instructions) and control flow falls through to the
next instruction outside of the inline assembly. Then there’s an
“extended inline assembly”
dialect that allows for you to specify input and output constraints (in what
feels like a whole new regex-like language with characters that have
architecture specific
or
generic
meanings, and requires the reference manual to read or write) and whether to
treat all memory or specific registers otherwise unnamed as outputs as
clobbered. In the final variant, you may also specify a list of labels that
the assembly may jump control flow to. There’s also printf-like modifiers
called
Output Templates,
and a few other tricks that require their own post.
Within the compiler, we can’t really treat asm statements like a black box
anymore. With asm goto, we have something more akin to structured exception
handling in C++; we’re going to “call” something, and it may jump control flow
to an arbitrary location. Well, not arbitrary. Arbitrary would be an indirect
call through a pointer that could’ve been constructed from any number and may
or may not be a valid instruction (or meant to be interpreted as one, ie. a
“gadget.”) asm goto is like virtual method calls or structured expection
handling in C++ in that they all can only transfer control flow to a short list
of possible destinations.
You might be wondering what you can build with this, and why does the Linux kernel care? Turns out the Linux kernel has multiple forms of self modifying code that it uses in multiple different scenarios. If you do something like:
1 2 3 4 5 6 | |
You can squirrel away the address of comefrom in an arbitrary non-standard
ELF section. Then at runtime if you know how to find ELF sections, you can
lookup foo and find the address of comefrom and then either jump to it, or
modify the instructions it points to. I’ve used this trick to turn indirect
calls into direct calls (which is super dangerous and has many gotchas).
Luckily, the Linux kernel itself is an ELF executable, with all the machinery for finding sections (it needs to perform relocations on itself at runtime, after all), though it does something even simpler with the help of some linker script magic as we’ll see.
This LWN article sums up the Linux’s kernel’s original use case perfectly.
The kernel uses this for replacing runtime evaluation of conditionals with either unconditional jumps or nop sleds when tracing, which are relatively “expensive” to change when enabling or disabling tracing (requires machine wide synchronization), but has minimally low overhead otherwise at runtime; just enough nops in a sled to fit a small unconditional relative jump instruction otherwise. We can further tell the compiler whether the condition was likely taken or not, which further influences codegen.
For patching in and out unconditional jumps with nop sleds, the kernel stores
an array of struct jump_entry in a custom ELF section .jump_table, which
are triplets of:
code member of struct jump_entry.target member of
struct jump_entry. For the case of whether a conditional evaluates to
true or false.key
member of struct jump_entry.The kernel uses pointer compression for 1 and 2 above, for architectures that
define CONFIG_HAVE_ARCH_JUMP_LABEL_RELATIVE as documented near the end of
Documentation/x86/exception-tables.rst.
The kernel uses pointer packing for 3 above, to pack whether the branch is
likely taken or not and the address of a struct static_key as documented in
an ascii art table near the end of include/linux/jump_label.h. The pointed-to
struct static_key then uses pointer packing again to discriminate members of
an anonymous union, as documented in a comment within the definition of struct
static_key in include/linux/jump_label.h.
Naturally, helper functions exist and must be used for the above 3 cases to reconstitute pointers from these values.
A custom linker script then defines two symbols that mark the beginning and end
of the section. These symbols are forward declared in C as symbols with
extern linkage, then used to set boundaries when iterating the array of
struct jump_entry instances, when initializing the keys and when finding an
entry to patch.
Let’s take a quick peek at one architecture’s implementation of creating the
array of struct jump_entry in .jump_table, here’s
arm64’s implementation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
There’s a lot going on here, so let’s take a look. 1: is a local label for
references within the asm block; it will get a temporary symbol name when
emitted. 1: points to a literal nop sled, but after the nop sled is the C
code following the asm goto statement. That’s because the inline asm uses
the .pushsection directive to store the following data in an ELF section
that’s not .text. We set the alignment of elements, then store two 32b
values and one 64b. The .long directive has a comma that’s easy to miss, so
there’s two, and they’re compressed (- .) or made relative offsets of the
current location. The first is the address of the beginning of the nop sled.
1b means local label named 1 searching backwards. Finally, we store a
pointer to the struct static_key using pointer packing to add whether we’re
likely to take the branch or not. The accessor functions will reconstruct the
two separate values correctly.
All this documentation is scattered throughout:
In fact, once you know this trick of using .pushsection in extended inline
assembly and storing addresses of data, then using linker defined symbols to
delineate section boundaries for quick searching and iteration, we start to see
this pattern occur all throughout the kernel (with or without asm goto).
This LWN article discusses the trick and
the many custom ELF sections of a Linux image well.
Exception tables in the kernel in fact use very similar tricks of storing
addresses in custom ELF sections, __ex_tables and .fixups via inline
assembly. The Linux kernel also sorts this data in the __ex_table section at
boot or even possibly post-link of the kernel image via BUILDTIME_TABLE_SORT,
so that at runtime the lookup of the exception handler can be done in log(N)
time via binary search! The .fixup also captures the address of the instruction
after the one that caused the exception, in order to possibly return control
flow to after successfully handling the exception.
“Alternatives” use this for patching in instructions that take advantage of ISA extensions if we detect support for them at runtime.
A lot of kernel interfaces use function pointers that are written to once, then either rarely or never modified. It would be nice to replace these indirect calls with direct calls. In fact, patches have been proposed to lower the overhead of the Spectre & Meltdown mitigations by doing just that.
Anyways, back to our story of debugging…
From here, I changed course and pursued another lead. I had recently taught
LLVM’s inliner how to inline asm goto (or more so, when it was considered
safe to do so). It seemed that LLVM’s inliner was not always respecting
__attribute__((always_inline)) and could simply decide it wasn’t going to
perform an inline substitution. (The inliner is a complex system; a large
analysis of multiple inputs distilled into a single yes/no signal, and all the
machinery necessary to perform such a code transformation). The C standard (§
6.7.4
ISO/IEC 9899:202x)
says compilers are allowed to make their own decisions in regards to inline
substitution, so it’s generally more conservative to just say “no” when
presented with a highly complex or unusual case.
When the “always inline” function wasn’t inlined, it was no longer semantically
valid, since it was passing its parameters as input to the inline asm using the
“i” machine agnostic constraint for integral literals, amongst other
questionable uses of __attribute__((always_inline)) within the kernel.
I was working around this (before I fixed LLVM) by changing the
__attribute__((always_inline) functions into macros (because the preprocessor
doesn’t have the ability to silently fail to transform as the inliner does).
But everything was working when I did that; the kernel booted just fine. Had I
regressed something when inlining? Was there a corner case I wasn’t thinking
of, which happens all the time in compiler development? Was the compiler
haunted? Was my code bad? Probably. (Porque no los dos?)
I start bisecting object files used to link the kernel image, mixing code that is either called a static always inline vs a macro, and I narrow it down to 4 object files.
Reading the time stamp counter! No wonder the kernel is failing so early; initializing the clocks is one of the earlier tasks the kernel cares about. A preemptive multitasking operating system is obsessed with keeping track of time; you spend up your time slice and you’re scheduled out.
But why would a static inline __attribute__((always_inline)) function fail,
but succeed when the function was converted to a macro?
I mentioned this to my colleague Bill Wendling, who spotted a subtle
distinction in LLVM’s IR between the static inline
__attribute__((always_inline)) version of the functions (and their call sites)
vs the macro. Via
an email to the list:
The code below is triggering some weird behavior that’s different from how gcc treats this inline asm. Clang keeps the original type of “loc” as “bool”, which generates an “i1 true” after inlining. So far so good. However, during ISEL, the “true” is converted to a signed integer. So when it’s evaluated, the result is this:
.quad (42+(-1))-.Ltmp0(notice the “-1”). GCC emits a positive one instead:
.quad 42 + 1 - .Ltmp0I’m not sure where the problem lies. Should the inline asm promote the “i1” to “i32” during ISEL? Should it be promoted during inlining? Is there a situation where we require the value to be “i1”?
-bw
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Krzysztof Parzyszek responded the next day.
This is a bug in X86’s ISel lowering: it does not take “getBooleanContents” into account when extending the immediate value to 64 bits.”
Oh, shit! LLVM’s IR has support for arbitrary width integers which is fine for a high level language. Because real machines typically don’t have support for such integers of arbitrary width, the compiler typically has to find legal widths for these integers (we say it “legalizes the types”) during lowering from the high level abstract IR to low level concrete machine code.
To legalize a one bit integer into a 64 bit integer, we have to either zero extend or sign extend it. Generally, if we know the signedness of a number, we sign extend signed integers to preserve the signedness of the uppermost bit, or zero extend unsigned integers which don’t have a signedness bit to preserve.
But what happens when you have a boolean represented as a signed 1 bit number,
and you choose to sign extend it? 0x00 becomes 0x0000000000000000 which is
fine, but 0x01 becomes 0xFFFFFFFFFFFFFFFF, ie. -1. So when you expected
1, but instead got a -1, then you’re off by 2. Preceding to use that in an
address calculation is going to result in some spooky bugs.
Recalling our inline asm goto, we we’re using this boolean to construct an
instance of a struct jump_entry’s key member, which was using pointer
packing to both refer to a global address and store whether the branch was
likely taken or not in the LSB. When the value of branch was 0, we were
fine. But when branch was 1 and we sign extended it to -1, we kept the LSB as
1 but messed up the address of a global variable, resulting in the helper
function unpacking the pointer to a global struct static_key producing a bad
pointer. Since the bottom two bits were dropped reconstituting the pointer, a
hypothetical value of 0x1001 would become 0xFFC (0x1001 – 2 & ~3) which would
be wrong by 5 bytes. Thus we were interpreting garbage as a pointer, which led
to cascaded failure.
In this case, it looks like Bill spotted that during instruction selection
something unexpected was occuring, and Krystof narrowed it down from there.
Krystof had a fix available for x86, which
Kees Cook later extended to all architectures.
Since then,
Bill even extended LLVM’s implementation to allow for the mixed use of output constraints with asm goto,
something GCC doesn’t yet allow for, which is curious as Clang is now pushing a
GNU C extension further than GCC does.
(The true heroes of this story BTW are Alexander Ivchenko and Mikhail
Dvoretckii for
providing the initial implementation
of asm goto support in LLVM, and
Craig Topper and
Jennifer Yu (all Intel) for carrying the
implementation across the finish line. Kudos to Chandler Carruth for noting
the irony and uncanny coincidence that it was both Intel that
regressed the x86 kernel build with Clang for over a year by requiring asm goto / CONFIG_JUMP_LABEL,
and provided an implementation for it in Clang.)
0 based array indexing is the source of a common programmer error; off by one. In this case, sign extending a boolean led to our off by two. (Or were we off by one at being off by one?)
I’m lucky to have virtual machines and debuggers, and the ability to introspect my compiler, but I’m not sure if all of those were available back when Linux was first written. For fun, I asked Linus Torvalds what early debugging of the Linux kernel was like (reprinted with permission):
Nick:
What do you do for testing? Quick boot tests in QEMU are my smoke tests, but I’m always interested in leveling up my workflow.
Linus:
I basically never do virtual machines. It happens – but mainly when chasing kvm bugs. With half of the kernel being drivers, I find the whole “run it in emulation” to be kind of pointless from an actual testing perspective.
Yeah, qemu is useful for quick smoke-tests, and for all the automated stuff that gets run.
But the automation happens on the big farms, and I don’t do the quick smoke testing – if I get a pull requests from others, it had better be in good enough shape that something like that is pointless, and when I do my own development I prefer to think about the code and look at generated assembly over trying to debug a mistake.
So if something doesn’t work for me, that to me is a big red flag – I go and really stare at the code and try to understand it even better. I am not a huge believer in debuggers, it’s not how I’ve ever coded.
I feel you get into a mindset where your code is determined by testing and “it works”, rather than by actually thinking about it and knowing it and believing it is correct.
But I probably just make excuses for “this is how I started, because emulation or debuggers just weren’t an option originally, and now it’s how I work”.
Nick:
One thing I am curious about is how the hell you ever debugged anything when you were starting out developing Linux? Was the first step get something that could write out to the serial port? (Do folks use serial debuggers on x86? USB? We use them often on aarch64. Not for attaching a debugger, more so just for dmesg/printk). Surely, it was some mix of “just think really hard about the code” then at some point you had something a little nicer? Graphics developers frequently have to contend with black screens and use various colors like all-red/all-green/all-blue when debugging as a lone signal of what’s going wrong, which sucks, but is kind of funny.
Linus:
Hey, when you make a mistake early on in protected mode, the end result is generally a triple fault – which results in an instant reboot.
So my early debugging – before I had console output and printk – was literally “let’s put an endless loop here”, and if the machine locked up you were successful, and if it rebooted you knew you hadn’t reached that point because something went wrong earlier.
But it’s not like doing VGA output was all that complicated, so “write one character to the upper corner of the screen” came along pretty quickly. That gives you a positive “yeah, I definitely got this far” marker, and not just a “hmm, maybe it locked up even before I got to my endless loop”.
Fun days.
http://nickdesaulniers.github.io/blog/2020/04/06/off-by-two/
|
|






