Daniel Stenberg: curl ootw: -v is for verbose |
(Previous entries in the curl option of the week series.)
This is one of the original 24 command line options that existed already in the first ever curl release in the spring of 1998. The -v option’s long version is --verbose.
Note that this uses the lowercase ‘v’. The uppercase -V option shows detailed version information.
In a blog post series of curl command line options you’d think that this option would basically be unnecessary to include since it seems to basic, so obvious and of course people know of it and use it immediately to understand why curl invokes don’t behave as expected!
Time and time again the first response to users with problems is to please add –verbose to the command line. Many of those times, the problem is then figured out, understood and sorted out without any need of further help.
--verbose should be the first action to try for everyone who runs a curl command that fails unexplainably.
First: there’s only one verbosity level in curl. There’s normal and there’s verbose. Pure binary; on or off. Adding more -v flags on the same line won’t bring you more details. In fact, adding more won’t change anything at all other than making your command line longer. (And yes, you have my permission to gently taunt anyone you see online who uses more than one -v with curl.)
Verbose mode shows outgoing and incoming headers (or protocol commands/responses) as well as “extra” details that we’ve deemed sensible in the code.
For example you will get to see which IP addresses curl attempts to connect to (that the host name resolved to), it will show details from the server’s TLS certificate and it will tell you what TLS cipher that was negotiated etc.
-v shows details from the protocol engine. Of course you will also see different outputs depending on what protocol that’s being used.
This option is meant to help you understand the protocol parts but it doesn’t show you everything that’s going on – for example it doesn’t show you the outgoing protocol data (like the HTTP request body). If -v isn’t enough for you, then the --trace and --trace-ascii options are there for you.
If you are in the rare situation where the trace options aren’t detailed enough, you can go all-in with full SSLKEYLOGFILE mode and inspect curl’s network traffic with Wireshark.
It’s not exactly “verbose level” but curl does by default for example show a progress meter and some other things. You can silence curl completely by using -s (--silent) or use the recently introduced option --no-progress-meter.
curl -v https://example.com/
https://daniel.haxx.se/blog/2020/04/06/curl-ootw-v-is-for-verbose/
|
|
Shing Lyu: Lessons learned in writing my first book |

You might have noticed that I didn’t update this blog frequently in the past year. It’s not because I’m lazy, but I focused all my creative energy on writing this book: Practical Rust Projects. The book is now available on Apress, Amazon and O’Reilly. In this post, I’ll share some of the lessons I learned in writing this book.
Although I’ve been writing Rust for quite a few years, I haven’t really studied the internals of the Rust language itself. Many of the Rust enthusiasts whom I know seem to be having much fun appreciating how the language is designed and built. But I take more joy in using the language to build tangible things. Therefore, I’ve been thinking about writing a cookbook-style book on how to build practical projects with Rust, ever since I finished the video course Building Reusable Code with Rust.
Out of my surprise, I received an email from Steve Anglin, an acquisition editor from Apress, in April 2019. He initially asked me to write a book on the RustPython project. But the project was still growing rapidly thanks to the contributors. I’ve already lost grip on the overall architecture, so I can’t really write much about it. So I proposed the topic I have in mind to Steve. Fortunately, the editorial board accepted my proposal, and we decided to write two books: one for general Rust projects and one for web-related Rust projects.
Since this is my first time writing a book that will be published in physical form (or as The Rust Book put it, “dead tree form”), I learned quite a lot throughout the process. Hopefully, these points will help you if you are considering or are already writing your own book.
It might be tempting to write a waterfall-style book writing plan, something along the lines of “I’ll write one section per day”. But there is a fundamental flaw with this approach: not all sections are of the same length and difficulty. A section about how to setup software might be very mechanical and easy to write, but a section about the history of a piece of software might take you days of research. Therefore, you can’t reliably predict how long it will take to finish a chapter, resulting in fear of starting and procrastination.
I find the Pomodoro Technique to be a constructive alternative in structuring my writing plan. The Pomodoro Technique is a time management method where you break your work into 25 minutes intervals and rest in between. Instead of saying, “I’ll finish this chapter by today”, say “I’ll do 2 Pomodoro sessions (25 x 2 = 50 min) today”. This way, no matter if you are making good progress or not, you know you are committing enough effort into the book writing project. A good side effect is that once I started writing, I got into the flow and ended up writing more Pomodoro sessions then I planned.
I usually write freely without and outline when I write my blog. But writing a book is a completely different thing. An outline will help you structure the content much better and avoid missing important topics. I usually start with a very high-level chapter outline, then add a section outline before I start writing each section. It’s nice to write the outline for all the chapters before starting. When you are writing Chapter 1 and suddenly have an idea about something in Chapter 3, you can quickly add that to the Chapter 3 outline as a reminder.
Example code is a crucial part of a programming book. It’s also beneficial to list down each step in the outline while you develop the example code. Because if you write all the example code in one go, you’ll forget about many steps that are not in the final code when you revisit it. For example,
These are all key points that need to be mentioned, but they don’t show up in the final code. Although you can dig that up by going through the git history, it’s still easier to write them down during development.
Version control is not only for code. The draft will go through multiple reviews and revise passes. You’ll usually have to revise the previous chapter while you are writing the next one. So use a format that is diff-friendly is very helpful. I use an unofficial LaTex template provided by Apress, with my own modifications. There are some random LaTex tips:
\clearpage to force the image to appear on the next page.I’m not a native English speaker, so I use aspell and Grammarly to check my grammar (disclaimer: Grammarly does not sponsor me). GNU Apsell is an open-source spell checker for the command line. Although it mostly checks for spelling, not grammar, it’s command-line interface and keyboard control is much more efficient than clicking the mouse. So I use Aspell to fix apparent typos. Then I copy-paste the LaTex source code into Grammarly’s web interface for a more thorough grammar check. However, many of the latex annotations like \texttt{code formatting} breaks the sentence, so Grammarly misses some sentences. So after the first round of Grammarly check, I render the LaTex code into PDF and use the pdftotext command to extract the rendered text from the PDF. I then run Grammarly through this text again.
Of course, to fix this problem once and for all, improving the writing skill is critical. I came across this Google Technical Writing Course after I finish this book, which helped me a lot in the writing process of my second book.
In this post, I focused on a few practical tips about book writing. I can maybe write another post about my LaTex setup and my observation about the Rust ecosystem. Leave a message using the “Message me” at the bottom right to let me know if that will be interesting to you.
Please grab a copy of the book at the book store of your choice and let me know what you think:
https://shinglyu.com/web/2020/04/05/lessons-learned-in-writing-my-first-book.html
|
|
Cameron Kaiser: TenFourFox FPR21 available |
In addition, language pack users should note that new langpacks are available for FPR21, thanks to Chris T's hard work as always. These updated langpacks have additional strings related to TLS 1.3 plus other sundry fixes; simply run the installer as in prior updates. They will go live on Monday too.
http://tenfourfox.blogspot.com/2020/04/tenfourfox-fpr21-available.html
|
|
Hacks.Mozilla.Org: Twitter Direct Message Caching and Firefox |
Editor’s Note: April 6, 7:00pm pt – After some more investigation into this problem, it appears that the initial analysis pointing to the Content-Disposition was based on bad information. The reason that some browsers were not caching direct messages was that Twitter includes the non-standard Pragma: no-cache header in responses. Using Pragma is invalid as it is defined to be equivalent to Cache-Control: no-cache only for requests. Though it is counter-intuitive, ‘no-cache’ does not prevent a cache from storing content; ‘no-cache’ only means that the cache needs to check with the server before reusing that response. That doesn’t change the conclusion: limited observations of behavior are no substitute for building to standards.
Twitter is telling its users that their personal direct messages might be stored in Firefox’s web cache.
This problem affects anyone who uses Twitter on Firefox from a shared computer account. Those users should clear their cache.
This post explains how this problem occurred, what the implications are for those people who might be affected, and how problems of this nature might be avoided in future. To get there, we need to dig a little into how web caching works.
Over on The Mozilla Blog, Eric Rescorla, the CTO of Firefox, shares insights on What you need to know about Twitter on Firefox, with this important reminder:
The web is complicated and it’s hard to know everything about it. However, it’s also a good reminder of how important it is to have web standards rather than just relying on whatever one particular browser happens to do.
Caching is critical to performance on the web. Browsers cache content so that it can be reused without talking to servers, which can be slow. However, the way that web content is cached can be quite confusing.
The Internet Engineering Task Force published RFC 7234, which defines how web caching works. A key mechanism is the Cache-Control header, which allows web servers to say how they want caches to treat content.
Sites can to use Cache-Control to let browsers know what is safe to store in caches. Some content needs to be fetched every time; other content is only valid for a short time. Cache-Control tells the browser what can be cached and for how long. Or, as is relevant to this case, Cache-Control can tell the browser that content is sensitive and that it should not be stored.
Separately, in the absence of Cache-Control instructions from sites, browsers often make guesses about what can be cached. Sites often do not provide any caching information for content. But caching content makes the web faster. So browsers cache most content unless they are told not to. This is referred to as “heuristic caching”, and differs from browser to browser.
Heuristic caching involves the browsing guessing which content is cached, and for how long. Firefox heuristic caching stores most content without explicit caching information for 7 days.
There are a bunch of controls that Cache-Control provides, but most relevant to this case is a directive called ‘no-store’. When a site says ‘no-store’, that tells the browser never to save a copy of the content in its cache. Using ‘no-store’ is the only way to guarantee that information is never cached.
In this case, Twitter did not include a ‘no-store’ directive for direct messages. The content of direct messages is sensitive and so should not have been stored in the browser cache. Without Cache-Control or Expires, however, browsers used heuristic caching logic.
Testing from Twitter showed that the request was not being cached in other browsers. This is because some other browsers disable heuristic caching if an unrelated HTTP header, Content-Disposition, is present. Content-Disposition is a feature that allows sites to identify content for download and to suggest a name for the file to save that content to.
In comparison, Firefox legitimately treats Content-Disposition as unrelated and so does not disable heuristic caching when it is present.
The HTTP messages Twitter used for direct messages did not include any Cache-Control directives. For Firefox users, that meant that even when a Twitter user logged out, direct messages were stored in the browser cache on their computer.
As much as possible, Firefox maintains separate caches.
People who have different user accounts on the same computer will have their own caches that are completely inaccessible to each other. People who share an account but use different Firefox profiles will have different caches.
Firefox also provides controls that allow control over what is stored. Using Private Browsing means that cached data is not stored to permanent storage and any cache is discarded when the window is closed. Firefox also provides other controls, like Clear Recent History, Forget About This Site, and automatic clearing of history. These options are all documented here.
This problem only affects people who share an account on the same computer and who use none of these privacy techniques to clear their cache. Though they might have logged out of Twitter, their direct messages will remain in their stored cache.
It is not likely that other users who later use the same Firefox profile would inadvertently access the cached direct messages. However, a user that shares the same account on the computer might be able to find and access the cache files that contain those messages.
People who don’t share accounts on their computer with anyone else can be assured that their direct messages are safe. No action is required.
People who do use shared computer accounts can clear their Firefox cache. Clearing just the browser cache using Clear Recent History will remove any Twitter direct messages.
We recommend that sites carefully identify information that is private using Cache-Control: no-store.
A common misconception here is that Cache-Control: private will address this problem. The ‘private’ directive is used for shared caches, such as those provided by CDNs. Marking content as ‘private’ will not prevent browser caching.
More generally, developers that build sites need to understand the difference between standards and observed behavior. What browsers do today can be observed and measured, but unless behavior is based on a documented standard, there is no guarantee that it will remain that way forever.
The post Twitter Direct Message Caching and Firefox appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2020/04/twitter-direct-message-caching-and-firefox/
|
|
The Mozilla Blog: What you need to know about Twitter on Firefox |
Yesterday Twitter announced that for Firefox users data such as direct messages (DMs) might be left sitting on their computers even if they logged out. In this post I’ll try to help sort out what’s going on here.
First, it’s important to understand the risk: what we’re talking about is “cached” data. All web browsers store local copies of data they get from servers so that they can avoid downloading the same data over the internet repeatedly. This makes a huge performance difference because websites are full of large files that change infrequently. Ordinarily this is what you want, but if you share a computer with other people, then they might be able to see that cached data, even if you have logged out of Twitter. It’s important to know that this data is just stored locally, so if you don’t share a computer this isn’t a problem for you. If you do share a computer, you can make sure all of your Twitter data is deleted by following the instructions here. If you do nothing, the data will be automatically deleted after 7 days the next time you run Firefox.
Second, why is this just Firefox? The technical details are complicated but the high level is pretty simple: caching is complicated and each browser behaves somewhat differently; with the particular way that Twitter had their site set up, Chrome, Safari, and Edge don’t cache this data but Firefox will. It’s not that we’re right and they’re wrong. It’s just a normal difference in browser behavior. There is a standard way to ensure that data isn’t cached, but until recently Twitter didn’t use it, so they were just dependent on non-standard behavior on some browsers.
As a software developer myself, I know that this kind of thing is easy to do: the web is complicated and it’s hard to know everything about it. However, it’s also a good reminder of how important it is to have web standards rather than just relying on whatever one particular browser happens to do.
The post What you need to know about Twitter on Firefox appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/04/03/what-you-need-to-know-about-twitter-on-firefox/
|
|
Daniel Stenberg: Google Open Source Peer Bonus award 2020 |
I’m honored to – once again – be a recipient of this award Google hands out to open source contributors, annually. I was previously awarded this in 2011.

I don’t get a lot of awards. Getting this token of appreciation feels awesome and I’m humbled and grateful I was not only nominated but also actually selected as recipient. Thank you, Google!

Nine years ago I got 350 USD credits in the Google store and I got my family a set of jackets using them – my kids have grown significantly since then, so to them those black beauties are now just a distant memory, but I still actually wear mine from time to time!

This time, the reward comes with a 250 USD “payout” (that’s the gift mentioned in the mail above), as a real money transfer that can be spent on other things than just Google merchandise!
I’ve decided to accept the reward and the money and I intend to spend it on beer and curl stickers for my friends and fans. As I prefer to view it:
The Google Open Source Beer Bonus.
Thank you Google and thank you Gaspar!
https://daniel.haxx.se/blog/2020/04/03/google-open-source-peer-bonus-award-2020/
|
|
Daniel Stenberg: The curl roadmap 2020 video |
On March 26th 2020, I did a live webinar where I talked about my roadmap visions of what to work on in curl during 2020.
Below you can see the youtube recording of the event.
You can also browse the slides separately.
https://daniel.haxx.se/blog/2020/04/02/the-curl-roadmap-2020-video/
|
|
Mozilla Addons Blog: Extensions in Firefox 75 |
In Firefox 75 we have a good mix of new features and bugfixes. Quite a few volunteer contributors landed patches for this release please join me in cheering for them!
oldValue is passed in the storage.onChanged listener when the previous value was falsey.rangeIndex is not passed.toFileName property to the tabs.saveAsPDF API, to provide a filename suggestion to the user.Thank you everyone for continuing to make Firefox WebExtensions amazing. I’m glad to see some new additions this time around and am eager to discover what the community is up to for Firefox 76. Interested in taking part? Get involved!
The post Extensions in Firefox 75 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/04/01/extensions-in-firefox-75/
|
|
Hacks.Mozilla.Org: Innovating on Web Monetization: Coil and Firefox Reality |
In the coming weeks, Mozilla will roll out a Web Monetization experiment using Coil to support payments to creators in the Firefox Reality ecosystem. Web Monetization is an alternative approach to payments that doesn’t rely on advertising or stealing your data and attention. We wrote about Web Monetization for game developers back in the autumn, and now we’re excited to invite more of you to participate, first as creators and soon as consumers of all kinds of digital and virtual content.

Problem: Now more than ever, digital content creators need new options for earning money from their work in a fast-changing world. Solution: Mozilla is testing Coil as an alternative to credit card or Paypal payments for authors and independent content creators.
If you’ve developed a 3D experience, a game, a 360 video, or if you’re thinking of building something new, you’re invited to participate in this experiment. I encourage you as well to contact us directly at creator_payments at mozilla dot com to showcase your work in the Firefox Reality content feed.
You’ll find details on how to participate below. I will also share answers and observations, from my own perspective as an implementer and investigator on the Mixed Reality team.
Tangentially, the COVID-19 pandemic is dominating our attention. Just to be clear: This project is not a promise to create revenue for you during a planetary crisis. We support people where they are emotionally in their lives at this time and we do feel that real-world concerns are far more important. Also, we send thanks to everybody at Coil and Mozilla and all of you who are supporting this work when we’re all juggling family, chores, and our own lives.
We know that many of you are looking for solutions to make money from your creative work online. We are here for you and we want you to create, share, and thrive on the net. Take a look the details on how to participate below. I will also share answers to other questions and observations from my own perspective as an implementer and investigator on the Mixed Reality team. Please let us know how this works for you!
Do you have a piece of content—a blog post, an interactive experience, a 360 video, a WebXR game—that you want to share with people in Firefox Reality? Here’s how you can web monetize this content:
The first step is to add a meta tag to the top of your site which will define a payment pointer (an email address for money). This article walks you through the process in detail:
From js13kGames to MozFest Arcade: A game dev Web Monetization story
Alternatively, this article is also good:
Web Monetization: Quick Start Guide
If you have a WordPress blog here’s another way to add a payment pointer.
The second step is to simply please let us know! You can message us at creator_payments@mozilla.com and we’ll make sure that your work is showcased in the Firefox Reality Content feed.
Coil is a for-profit membership service that charges users $5.00 a month and streams micropayments to creators based on member attention. Coil uses the Interledger network to move money, allowing creators to work in any currency they like.
Effectively you get paid for user attention—assuming those users are set up with web monetization. Web Monetization consists of an HTML tag, a JavaScript API, and uses the Interledger protocol for actually moving the money and enabling payments in many different currencies.
And just to be clear, Interledger is not a blockchain and there is no “Interledger token”. Interledger functions more like the Internet, in that it routes packets. Except the packets also represent money instead of just carrying data. You can find out more about how it works on interledger.org.
Coil is an example of how open standards help foster healthy ecosystems. Coil can be thought of as a user-facing appliance running on top of the emerging Web Monetization and Payment Pointers standard. As Coil succeeds, the possibilities for other payment services to succeed also increases. Once creators set up a payment pointer, they themselves are not tied to Coil. Anybody or any new service can send money to that creator—without using Coil itself. By lowering the “activation energy” this opens up the door for new payment services. Also, at the same time, we at Mozilla stay true to our values—fostering open standards, working internationally, and protecting user privacy.
On a desktop browser, if you have a Coil subscription you can visit Hubs by Mozilla right now, and by clicking on the Coil plugin you can see that it is being monetized.
For testing Coil in Firefox Reality, you can visit this test site to see if you are Coil enabled. (Note: Personally, I’m not a big fan of the depiction of gender and the rags to riches narrative at that URL. But the site works for testing.)
If you visit this Coil Checker site and enter the URL of your own site, it will report if your Coil implementation is working.
As a creator, you can detect if patrons are Coil-enabled using javaScript. The recommended practice is called the “100+20” rule: offer special content for visitors who are paying, but do not disable the site or user experience for other guests. Please see the following links:
Web Monetization: Exclusive Content
The 100+20 Rule for Premium Content
Ben has a great article on Probabilistic Revenue Sharing and Sabine has another one about a Web Monetized Image Gallery, showing how you can change where revenue is flowing based on which content is being examined.
If you are in the United States you can get an account at Stronghold. There are other web wallets that support Interledger and can convert payments to local currencies. This varies depending on which country you are in. Note that in the U.S, the Securities and Exchange Commission (SEC) has important Know Your Customer (KYC) requirements, which means you’ll need to provide a driver’s license or passport.
Of course, Web Monetization will work better once it is adopted by a large number of users, built into most browsers, and so on, but the goal of this phase is less to generate a cash-out for you today and more about gathering data and feedback. So please keep in mind that this is an experiment! Also, again, we are especially interested in hearing how this works for you. Please make sure to contact us at creator_payments at mozilla dot com once you set this up.
Stay tuned for a follow-up announcement in the not too distant future. In broad strokes, we will issue free Coil memberships to qualified users in the Firefox Reality ecosystem.
Astute observers will notice that Mozilla recently partnered with Scroll, a new ad-free subscription service. So how is this different from Scroll and why do we need both things?
The main difference today is that our collaboration with Coil today is to test adoption.
These two membership services are aimed at different use cases. Coil lets anybody be a content creator and get paid out of user attention. Because the payout rate is something like $0.36 per hour per user, Coil becomes useful if you have hundreds of people looking at your site. In contrast, Scroll partners with specific and often larger organizations such as publishers and media outlets with reporters, editors, and higher overheads. Their fees reflect the value of news in terms of quality and reputation.
Notably there are also other services such as Comixology, (also described here), Flattr, and Unlock. Each of these caters to different audience needs.
We can even imagine future services that have much higher payment rates, such as charging $30.00 an hour to allow a foreign language teacher in a virtual Hubs room to teach a small class of students and have a sustainable business. There will never be a single silver bullet that covers all consumer needs.
Grant for the Web is a separate series of grants that are definitely worth applying for. This initiative plans to distribute 100 million dollars to support creators on the web. This is especially suitable for web projects that require up-front funding.
Last year we interviewed web developers and creatives, asking them about how they monetized content on the web. They reported several challenges. These are two of the largest issues:
Note that there were many other related issues such as discoverability of content, consumer trust in content, defending intellectual property, better tools for building content and so on. But payments is one area that seems to require a known and trusted neutral third-party. And so, we believe that Mozilla is uniquely qualified to help with this.
If we step back and look beyond the web, digital content ecosystems are exploding. Social apps such as Facebook are a $50 billion dollar a year industry, driven by advertising. Mobile app subscription revenue is $4 billion dollars a year. Mobile native games were forecast to capture over $70 billion dollars in 2019.
Experiences on app stores such as Google Play or the Apple App Store can capture up to 30% of that energy in transaction fees. (Admittedly, they provide other valuable services mentioned above, such as quality, trust, discovery, and recourse).
Although the boundary between native and web is somewhat porous, some developers we spoke to were packaging their web apps as native apps and releasing them into app stores such as itch.io just to get cash out of the system for their labor.
However, the web is unique. The web is open and accessible to all parties, not owned or controlled by any one party. Content can be shared with a URL. Because of this, the web has become the place of the “great conversation” – where we can all talk freely about issues all over the world.
Thanks to the work of many engineers, the web has many of the rich visual capabilities of native apps delivered via open standards. Technologies like WebAssembly and high-performance languages such as Rust make it possible for a game like Candy Crush Saga to become a web experience.
And yet, even though you can share a web experience with somebody halfway around the planet, there’s no way for them to tip you a quarter if they like their experience. If money is a form of communication, then it makes sense to fix money as well—in an open, scalable way that is fair, and that discourages bad actors.
Right now advertising dominates on the web as a revenue model. Ads are important and valuable as a form of social signaling in a noisy landscape. However, this means creators may be beholden to advertisers more so than to their patrons.
There are strong market incentives today to profile, segment, and target users. Targeting can even become a vector for bad actors, such as we saw with Cambridge Analytica. Cross-site tracking in particular is a concern. As a result, browser vendors such as Apple, Microsoft and Mozilla are working to reduce cross-site tracking. This is reducing the effectiveness of advertising as a whole.
But nature abhors a vacuum. We need to do more. From an ecosystem perspective, if we can support alternative revenue options and protect user privacy this feels like a win.
There is some argument that services like Patreon and Kickstarter exist because people who enjoy online content want to think of themselves as patrons of the arts; not merely consumers. We are doing this experiment in part to test that idea.
Payments on the web is a complex topic. There are creator needs, user and patron needs, privacy concerns, international boundaries, payment frictions and costs, regulatory issues and so on. Consider even just the issue of people who don’t have credit cards; or artists, story-tellers, and creators around the world who don’t have bank accounts at all—especially women.
We’ve seen ideas over the years ranging from Beenz (now defunct) to Libra, and every imaginable point system and scheme. We see Brave and Puma providing browser-bound solutions. Industry-wide, we have working methods for purchases online for adults with credit cards such as through Stripe or Paypal. But there aren’t widely available solutions for smaller low-friction payments that hit all our criteria.
We will continue to explore a variety of options, but we want options like Web Monetization that are available today. We value options that have low activation energy; are transparent and easy to test; don’t require industry changes; handle small transactions; work over international boundaries; are abuse-resistant; help the unbanked; and protect user privacy.
We’re all familiar with the Error code 404 – page not found warning on the web. But probably not a single one of us has seen an “Error code 402 – payment required” warning. Payments are not something we as consumers use yet or encounter routinely in the wild.

Until we see “402 Payment Required” on the web it’s probably likely that we have not solved web payments.
Yes, we have W3C Web Payments—and this may become the right answer. There are some options from Paypal for micropayments, as well as a bewildering number of cryptocurrency solutions. Still, we have our work cut out for us.
Welcome to the future. It is August 1st, 2022. You’re surfing the web and you come across an amazing recipe site or blog post you really like, perhaps a kid-friendly indie game or photos of the northern lights, captured and shared by somebody in a different country. Or perhaps you’ve been watching a campaign to protect forests in Romania and you want to donate. Now imagine being able to easily send them money as a token of your appreciation.
Maybe you’ve become a fan of a new virtual reality interactive journalism site. Rather than subscribing to them specifically you use a service that streams background micropayments while you are on their site. As you and your friends join in, the authors get more and more support over time. The creator is directly supported in their work, and directly responsive to you, rather than having to chase grants. They’re able to vet their sources better and extend their reach.
This is the kind of vision that we want to support. Let’s get there together. If you have any other questions or comments please reach out!
The post Innovating on Web Monetization: Coil and Firefox Reality appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2020/03/web-monetization-coil-and-firefox-reality/
|
|
Mozilla VR Blog: Announcing the Mozilla Mixed Reality Merch Store! |

Ever wanted to up your wardrobe game with some stylish Mixed Reality threads, while at the same time supporting Mozilla's work? Dream no more! The Mozilla Mixed Reality team is pleased to announce that you can now wear your support for our efforts on your literal sleeve!
The store (powered by Spreadshirt) is available worldwide and has a variety of items including clothing tailored for women, men, kids and babies, and accessories such as bag, caps, mugs, and more. All with a variety of designs to choose from, including our “low poly” Firefox Reality logo, our adorable new mascot, Foxr, and more.
We hope that you find something that strikes your fancy!
https://blog.mozvr.com/announcing-the-mozilla-mixed-reality-merch-store/
|
|
The Mozilla Blog: MOSS launches COVID-19 Solutions Fund |
Mozilla is announcing today the creation of a COVID-19 Solutions Fund as part of the Mozilla Open Source Support Program (MOSS). Through this fund, we will provide awards of up to $50,000 each to open source technology projects which are responding to the COVID-19 pandemic in some way.
The MOSS Program, created in 2015, broadens access, increases security, and empowers users by providing catalytic funding to open source technologists. We have already seen inspiring examples of open source technology being used to increase the capacity of the world’s healthcare systems to cope with this crisis. For example, just a few days ago, the University of Florida Center for Safety, Simulation, and Advanced Learning Technologies released an open source ventilator. We believe there are many more life-saving open source technologies in the world.
As part of the COVID-19 Solutions Fund, we will accept applications that are hardware (e.g., an open source ventilator), software (e.g., a platform that connects hospitals with people who have 3D printers who can print parts for that open source ventilator), as well as software that solves for secondary effects of COVID-19 (e.g., a browser plugin that combats COVID related misinformation).
A few key details of the program:
To apply, please visit: https://mozilla.fluxx.io/apply/MOSS
For more information about the MOSS program, please visit: Mozilla.org/moss.
ABOUT MOSS
The Mozilla Open Source Support (MOSS) awards program, created in 2015, broadens access, increases security, and empowers users by providing catalytic funding to open source technologists. In addition to the COVID-19 Solutions Fund, MOSS has three tracks:
Tracks I and II and this new COVID-19 Solutions Fund accept applications on a rolling basis. For more information about the MOSS program, please visit: Mozilla.org/moss.
The post MOSS launches COVID-19 Solutions Fund appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/03/31/moss-launches-covid-19-solutions-fund/
|
|
The Mozilla Blog: We’re Fixing the Internet. Join Us. |
For over two decades, Mozilla has worked to build the internet into a global public resource that is open and accessible to all. As the internet has grown, it has brought wonder and utility to our lives, connecting people in times of joy and crisis like the one being faced today.
But that growth hasn’t come without challenges. In order for the internet and Mozilla to well serve people into the future, we need to keep innovating and making improvements that put the interests of people back at the center of online life.
To help achieve this, Mozilla is launching the Fix-the-Internet Spring MVP Lab and inviting coders, creators and technologists from around the world to join us in developing the distributed Web 3.0.
“The health of the internet and online life is why we exist, and this is a first step toward ensuring that Mozilla and the web are here to benefit society for generations to come,” said Mozilla Co-Founder and Interim CEO Mitchell Baker.
Mozilla’s Fix-the-Internet Spring MVP Lab is a day one, start from scratch program to build and test new products quickly. By energizing a community of creators who bring a hacker’s approach to vibrant experimentation, Mozilla aims to help find sustainable solutions and startup ideas around several key themes designed to fix the internet:
Participants in the Fix-the-Internet Spring MVP Lab will:
Visit http://www.mozilla.org/builders for additional details and information on how to apply by the April 6, 2020 deadline.
The post We’re Fixing the Internet. Join Us. appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/03/30/were-fixing-the-internet-join-us/
|
|
Mozilla Addons Blog: Add developer comments to your extension’s listing page on addons.mozilla.org |
In November 2017, addons.mozilla.org (AMO) underwent a major refresh. In addition to updating the site’s visual style, we separated the code for frontend and backend features and re-architected the frontend to use the popular combination of React and Redux.
With a small team, finite budget, and other competing priorities, we weren’t able to migrate all features to the new frontend. Some features were added to our project backlog with the hope that one day a staff or community member would have the interest and bandwidth to implement it.
One of these features, a dedicated section for developer comments on extension listing pages, has recently been re-enabled thanks to a contribution by community member Lisa Chan. Extension developers can use this section to inform users about any known issues or other transient announcements.
This section can be found below the “About this extension” area on an extension listing page. Here’s an example from NoScript:

Extension developers can add comments to this section by signing into the Developer Hub and clicking the “Edit Product Page” link under the name of the extension. On the next page, scroll down to the Technical Details section and click the Edit button to add or change the content of this section.
If you are an extension developer and you had used this section before the 2017 AMO refresh, please take a few minutes to review and update any comments in this field. Any text in that section will be visible on your extension’s listing page.
We’d like to extend a special thanks to Lisa for re-enabling this feature. If you’re interested in contributing code to addons.mozilla.org, please visit our onboarding wiki for information about getting started.
The post Add developer comments to your extension’s listing page on addons.mozilla.org appeared first on Mozilla Add-ons Blog.
|
|
Daniel Stenberg: curl ootw: –proxy-basic |
Previous command line options of the week.
--proxy-basic has no short option. This option is closely related to the option --proxy-user, which has as separate blog post.
This option has been provided and supported since curl 7.12.0, released in June 2004.
In curl terms, a proxy is an explicit middle man that is used to go through when doing a transfer to or from a server:
curl <=> proxy <=> server
curl supports several different kinds of proxies. This option is for HTTP(S) proxies.
Authentication: the process or action of proving or showing something to be true, genuine, or valid.
When it comes to proxies and curl, you typically provide name and password to be allowed to use the service. If the client provides the wrong user or password, the proxy will simply deny the client access with a 407 HTTP response code.
curl supports several different HTTP proxy authentication methods, and the proxy can itself reply and inform the client which methods it supports. With the option of this week, --proxy-basic, you ask curl to do the authentication using the Basic method. “Basic” is indeed very basic but is the actual name of the method. Defined in RFC 7616.
The Basic method sends the user and password in the clear in the HTTP headers – they’re just base64 encoded. This is notoriously insecure.
If the proxy is a HTTP proxy (as compared to a HTTPS proxy), users on your network or on the path between you and your HTTP proxy can see your credentials fly by!
If the proxy is a HTTPS proxy however, the connection to it is protected by TLS and everything is encrypted over the wire and then the credentials that is sent in HTTP are protected from snoopers.
Also note that if you pass in credentials to curl on the command line, they might be readable in the script where you do this from. Or if you do it interactively in a shell prompt, they might be viewable in process listings on the machine – even if curl tries to hide them it isn’t supported everywhere.
Use a proxy with your name and password and ask for the Basic method specifically. Basic is also the default unless anything else is asked for.
curl --proxy-user daniel:password123 --proxy-basic --proxy http://myproxy.example https://example.com
With --proxy you specify the proxy to use, and with --proxy-user you provide the credentials.
Also note that you can of course set and use entirely different credentials and HTTP authentication methods with the remote server even while using Basic with the HTTP(S) proxy.
There are also other authentication methods to selected, with --proxy-anyauth being a very practical one to know about.
https://daniel.haxx.se/blog/2020/03/30/curl-ootw-proxy-basic/
|
|
Francois Marier: How to get a direct WebRTC connections between two computers |
WebRTC is a standard real-time communication protocol built directly into modern web browsers. It enables the creation of video conferencing services which do not require participants to download additional software. Many services make use of it and it almost always works out of the box.
The reason it just works is that it uses a protocol called ICE to establish a connection regardless of the network environment. What that means however is that in some cases, your video/audio connection will need to be relayed (using end-to-end encryption) to the other person via third-party TURN server. In addition to adding extra network latency to your call that relay server might overloaded at some point and drop or delay packets coming through.
Here's how to tell whether or not your WebRTC calls are being relayed, and how to ensure you get a direct connection to the other host.
Before you place a real call, I suggest using the official test page which will test your camera, microphone and network connectivity.
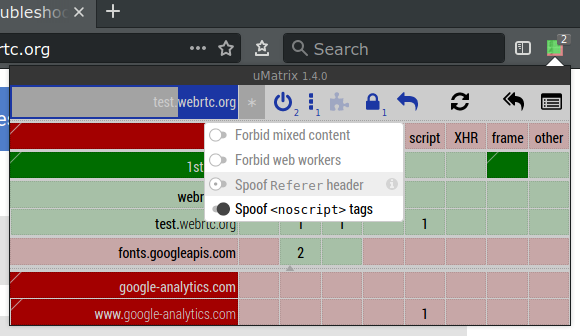
Note that this test page makes use of a Google TURN server which is locked to particular HTTP referrers and so you'll need to disable privacy features that might interfere with this:
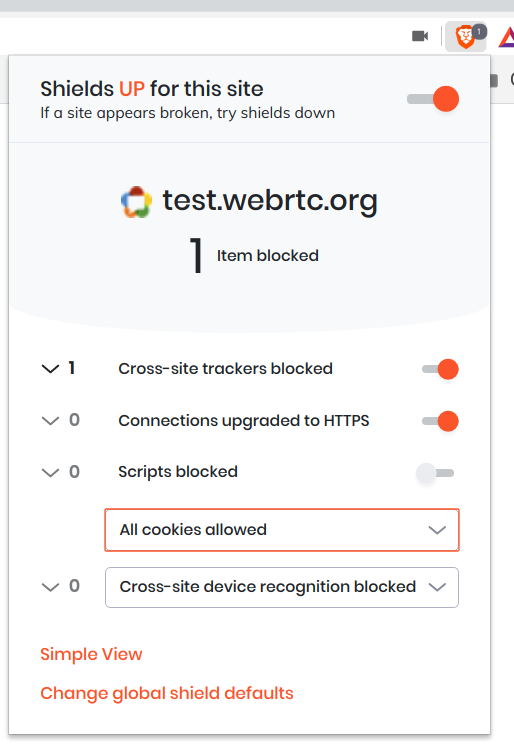
Firefox: Ensure that http.network.referer.spoofSource is set to false
in about:config, which it is by default.
uMatrix: The "Spoof Referer
header" option needs to be turned off for that site.
Once you know that WebRTC is working in your browser, it's time to establish a connection and look at the network configuration that the two peers agreed on.
My favorite service at the moment is Whereby (formerly Appear.in), so I'm going to use that to connect from two different computers:
canada is a laptop behind a regular home router without any port
forwarding.siberia is a desktop computer in a remote location that is also behind a
home router, but in this case its internal IP address (192.168.1.2) is
set as the DMZ
host.For all Chromium-based browsers, such as Brave, Chrome, Edge, Opera and
Vivaldi, the debugging page you'll need to open is called
chrome://webrtc-internals.
Look for RTCIceCandidatePair lines and expand them one at a time until you
find the one which says:
state: succeeded (or state: in-progress)nominated: truewritable: true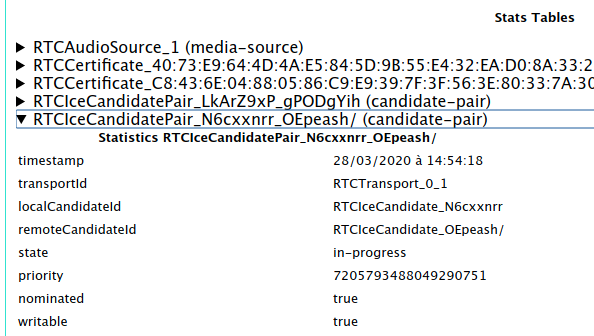
Then from the name of that pair (N6cxxnrr_OEpeash in the above example)
find the two matching RTCIceCandidate lines (one local-candidate and one
remote-candidate) and expand them.
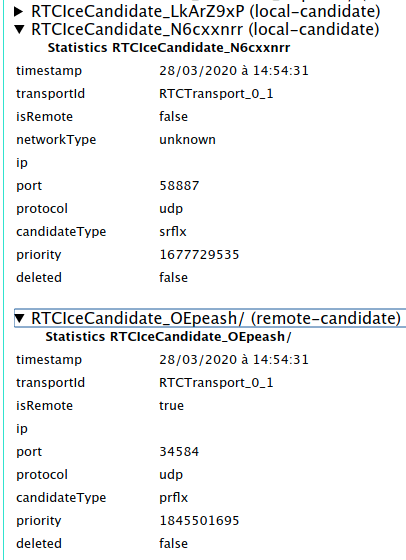
In the case of a direct connection, I saw the following on the
remote-candidate:
ip shows the external IP address of siberiaport shows a random number between 1024 and 65535candidateType: srflxand the following on local-candidate:
ip shows the external IP address of canadaport shows a random number between 1024 and 65535candidateType: prflxThese candidate types indicate that a STUN server was used to determine the public-facing IP address and port for each computer, but the actual connection between the peers is direct.
On the other hand, for a relayed/proxied connection, I saw the following
on the remote-candidate side:
ip shows an IP address belonging to the TURN servercandidateType: relayand the same information as before on the local-candidate.
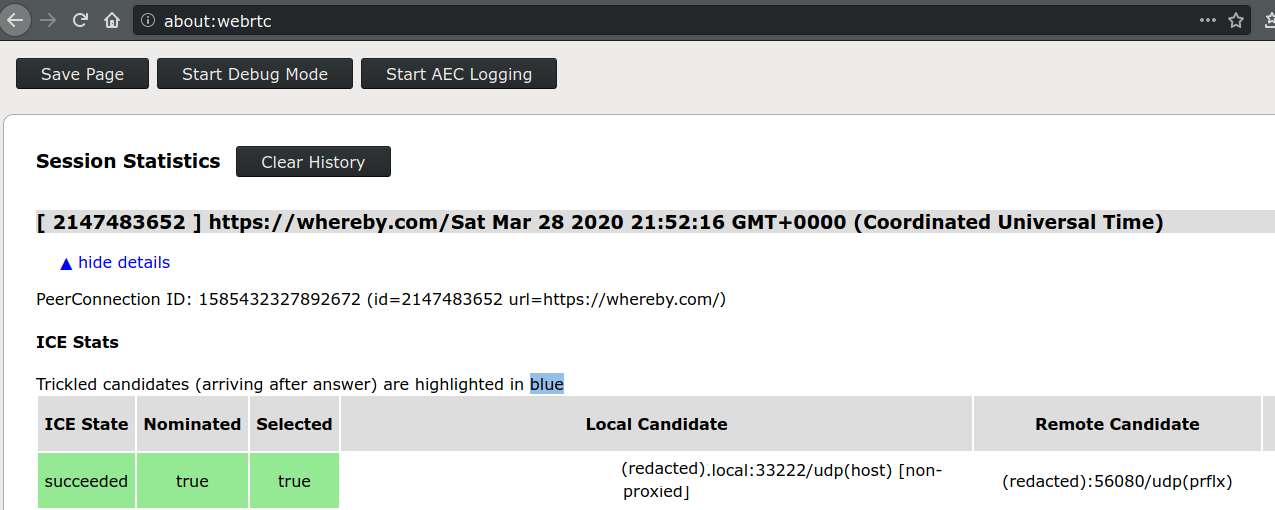
If you are using Firefox, the debugging page you want to look at is
about:webrtc.
Expand the top entry under "Session Statistics" and look for the line (should be the first one) which says the following in green:
ICE State: succeededNominated: trueSelected: truethen look in the "Local Candidate" and "Remote Candidate" sections to find the candidate type in brackets.
In order to get a direct connection to the other WebRTC peer, one of the
two computers (in my case, siberia) needs to open all inbound UDP
ports since there doesn't appear to be a way to restrict Chromium or
Firefox to a smaller port range for incoming WebRTC connections.
This isn't great and so I decided to tighten that up in two ways by:
siberia's ISP, andsiberia.To get the IP range, start with the external IP address of the machine (I'll
use the IP address of my blog in this example: 66.228.46.55) and pass it
to the whois command:
$ whois 66.228.46.55 | grep CIDR
CIDR: 66.228.32.0/19
To get the list of open UDP ports on siberia, I sshed into it and ran
nmap:
$ sudo nmap -sU localhost
Starting Nmap 7.60 ( https://nmap.org ) at 2020-03-28 15:55 PDT
Nmap scan report for localhost (127.0.0.1)
Host is up (0.000015s latency).
Not shown: 994 closed ports
PORT STATE SERVICE
631/udp open|filtered ipp
5060/udp open|filtered sip
5353/udp open zeroconf
Nmap done: 1 IP address (1 host up) scanned in 190.25 seconds
I ended up with the following in my /etc/network/iptables.up.rules (ports
below 1024 are denied by the default rule and don't need to be included
here):
# Deny all known-open high UDP ports before enabling WebRTC for canada
-A INPUT -p udp --dport 5060 -j DROP
-A INPUT -p udp --dport 5353 -j DROP
-A INPUT -s 66.228.32.0/19 -p udp --dport 1024:65535 -j ACCEPT
http://feeding.cloud.geek.nz/posts/how-to-get-direct-webrtc-connection-between-computers/
|
|
Karl Dubost: Week notes - 2020 w13 - worklog - everything is broken |
document.createEvent("KeyEvents"). This is now forbidden in Firefox. A site was failing they fixed it! Thanks.review_requested@noreply.github.com as one of the recipients. Easy to discover with a dynamic mailbox. I usually set my filtering on Mail.app with plenty of dynamic mailboxes. I have a couple of criteria but one which is always very useful to improve the performance is to add a "Received date" criteria with something around a couple of days I usually set around 14 days to 21 days.git annotate --lines 34-35 -m 'blablababalabla' module/verydope.pygit readnotes hash_ref --from kdubost@mozilla.comWe had an issue with the new form design. We switched to 100% of our users on March 16, 2020. but indeed all the bugs received didn't get the label that they were actually reporting with the new form design. Probably only a third got the new form.
So that was the state when I fell asleep on Monday night. Mike pushed the bits a bit more during my night and opened.
My feeling is that if we are out of the experimental phase, we probably need to just not go through the AB code at all, and all of it becomes a lot simpler.
We can keep in place the code for future AB experiments and open a new issue for removing the old form code and tests once ksenia has finished refactoring the rest of the code for the new form.
So on this hypothesis, let's create a new PR. I expect tests to break badly. That's an Achilles' heel of our current setup. The AB experiment was an experiment at the beginning. Never let an experiment grows without the proper setup. We need to fix it.
(env) ~/code/webcompat.com % pytest ============================= test session starts ============================== platform darwin -- Python 3.7.4, pytest-5.3.5, py-1.8.1, pluggy-0.13.1 rootdir: /Users/karl/code/webcompat.com collected 157 items tests/unit/test_api_urls.py ........... [ 7%] tests/unit/test_config.py .. [ 8%] tests/unit/test_console_logs.py ..... [ 11%] tests/unit/test_form.py ................. [ 22%] tests/unit/test_helpers.py ............................ [ 40%] tests/unit/test_http_caching.py ... [ 42%] tests/unit/test_issues.py ...... [ 45%] tests/unit/test_rendering.py ...... [ 49%] tests/unit/test_tools_changelog.py .. [ 50%] tests/unit/test_topsites.py ... [ 52%] tests/unit/test_uploads.py ... [ 54%] tests/unit/test_urls.py ................................. [ 75%] tests/unit/test_webhook.py ...................................... [100%] ============================= 157 passed in 21.28s =============================
Unit testing seems to work. There was a simple fix. The big breakage should happen on the functional tests side. Let's create a PR and see how much CircleCI is not happy about it.
So this is breaking. My local functional testing was deeply broken, and after investigating in many directions, I found the solution. I guess this week is the week where everything is broken.
I have been asked about the tools at Mozilla, I'm using for the job.
gather feedback from a semi-random set of engineers on various tooling that we have and translate it into actionable requests.
I was not sure which levels of details was needed and on which tools. This is what came from the top of my head.
short story version: I had to reinstall everything.
After writing this above, I wondered about the state of my mozilla central repo and how ready I would be to locally compile firefox. Plus I will need it very soon.
hg --version Mercurial Distributed SCM (version 4.3-rc) (see https://mercurial-scm.org for more information) Copyright (C) 2005-2017 Matt Mackall and others This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
oops. Let's download the new version. Mercurial 5.2.2 for MacOS X 10.14+ it seems.
hg --version *** failed to import extension firefoxtree from /Users/karl/.mozbuild/version-control-tools/hgext/firefoxtree: 'module' object has no attribute 'command' *** failed to import extension reviewboard from /Users/karl/.mozbuild/version-control-tools/hgext/reviewboard/client.py: No module named wireproto *** failed to import extension push-to-try from /Users/karl/.mozbuild/version-control-tools/hgext/push-to-try: 'module' object has no attribute 'command' Mercurial Distributed SCM (version 5.2.2) (see https://mercurial-scm.org for more information) Copyright (C) 2005-2019 Matt Mackall and others This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Hmmm not sure it is better. Let explore the Mozilla Source Tree Documentation.
~/code/mozilla-central % hg pull *** failed to import extension firefoxtree from /Users/karl/.mozbuild/version-control-tools/hgext/firefoxtree: 'module' object has no attribute 'command' *** failed to import extension reviewboard from /Users/karl/.mozbuild/version-control-tools/hgext/reviewboard/client.py: No module named wireproto *** failed to import extension push-to-try from /Users/karl/.mozbuild/version-control-tools/hgext/push-to-try: 'module' object has no attribute 'command' pulling from https://hg.mozilla.org/mozilla-central/ abandon : certificate for hg.mozilla.org has unexpected fingerprint `sha****` (check hostsecurity configuration)
.mozbuild directory.ok I removed the line of [hostsecurity] section in .hgrc. Let's try again
[hostsecurity] hg.mozilla.org:fingerprints = sha******
The update will take around 40 minutes. Perfect… it's time for lunch. hmmm another fail. let's remove the current error message.
% hg pull pulling from https://hg.mozilla.org/mozilla-central/ searching for changes adding changesets adding manifests transaction abort! rollback completed abandon : stream ended unexpectedly (got 9447 bytes, expected 32768)
let's try again
hg pull pulling from https://hg.mozilla.org/mozilla-central/ searching for changes adding changesets adding manifests adding file changes added 90459 changesets with 787071 changes to 208862 files new changesets 7a4290ed6a61:9f3f88599fff (run 'hg update' to get a working copy)
yeah it worked.
hg update 157775 files updated, 0 files merged, 42118 files removed, 0 files unresolved updated to "9f3f88599fff: Bug 1624113: Explicitly flip pref block_Worker_with_wrong_mime for test browser_webconsole_non_javascript_mime_worker_error.js. r=baku" 4 other heads for branch "default"
Then
./mach bootstrap
returns an error.
./mach bootstrap Note on Artifact Mode: Artifact builds download prebuilt C++ components rather than building them locally. Artifact builds are faster! Artifact builds are recommended for people working on Firefox or Firefox for Android frontends, or the GeckoView Java API. They are unsuitable for those working on C++ code. For more information see: https://developer.mozilla.org/en-US/docs/Artifact_builds. Please choose the version of Firefox you want to build: 1. Firefox for Desktop Artifact Mode 2. Firefox for Desktop 3. GeckoView/Firefox for Android Artifact Mode 4. GeckoView/Firefox for Android Your choice: 2 Looks like you have Homebrew installed. We will install all required packages via Homebrew. Traceback (most recent call last): 4: from /usr/local/Homebrew/Library/Homebrew/brew.rb:13:in `<main>' 3: from /usr/local/Homebrew/Library/Homebrew/brew.rb:13:in `require_relative' 2: from /usr/local/Homebrew/Library/Homebrew/global.rb:10:in `<top (required)>' 1: from /System/Library/Frameworks/Ruby.framework/Versions/2.6/usr/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require' /System/Library/Frameworks/Ruby.framework/Versions/2.6/usr/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require': cannot load such file -- active_support/core_ext/object/blank (LoadError) Error running mach: ['bootstrap'] The error occurred in code that was called by the mach command. This is either a bug in the called code itself or in the way that mach is calling it. You can invoke |./mach busted| to check if this issue is already on file. If it isn't, please use |./mach busted file| to report it. If |./mach busted| is misbehaving, you can also inspect the dependencies of bug 1543241. If filing a bug, please include the full output of mach, including this error message. The details of the failure are as follows: subprocess.CalledProcessError: Command '['/usr/local/bin/brew', 'list']' returned non-zero exit status 1. File "/Users/karl/code/mozilla-central/python/mozboot/mozboot/mach_commands.py", line 44, in bootstrap bootstrapper.bootstrap() File "/Users/karl/code/mozilla-central/python/mozboot/mozboot/bootstrap.py", line 442, in bootstrap self.instance.install_system_packages() File "/Users/karl/code/mozilla-central/python/mozboot/mozboot/osx.py", line 192, in install_system_packages getattr(self, 'ensure_%s_system_packages' % self.package_manager)(not hg_modern) File "/Users/karl/code/mozilla-central/python/mozboot/mozboot/osx.py", line 355, in ensure_homebrew_system_packages self._ensure_homebrew_packages(packages) File "/Users/karl/code/mozilla-central/python/mozboot/mozboot/osx.py", line 304, in _ensure_homebrew_packages universal_newlines=True).split() File "/Users/karl/code/mozilla-central/python/mozboot/mozboot/base.py", line 443, in check_output return subprocess.check_output(*args, **kwargs) File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/subprocess.py", line 395, in check_output **kwargs).stdout File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/subprocess.py", line 487, in run output=stdout, stderr=stderr)
I wonder if it's because I switched from python 2.7 to python 3.7 a while ago as a default on my machine. OK I had an old version of brew. I updated it with
brew update
And ran again
./mach bootstrap
hmmm it fails again.
In the process of being solved. I erased ~/.mozbuild/version-control-tools/
Then reinstalled
./mach vcs-setup
Ah understood. My old system was configured to use reviewboard but now they use phabricator. grmbl.
I wish there was a kind of reset configuration system. Maybe there is.
I remove from ~/.hgrc
reviewboard = /Users/karl/.mozbuild/version-control-tools/hgext/reviewboard/client.py
but short summary I needed to re-install everything… because everything was old and outdated.
And now the "funny" thing is that reinstalling from scratch from Japan takes a lot of time… twice it fails because the stream is just failing. :/
Finally!
hg clone https://hg.mozilla.org/mozilla-central/ destination directory: mozilla-central applying clone bundle from https://hg.cdn.mozilla.net/mozilla-central/9f3f88599fffa54ddf0c744b98cc02df99f8d0b8.zstd-max.hg adding changesets adding manifests adding file changes added 520018 changesets with 3500251 changes to 567696 files finished applying clone bundle searching for changes aucun changement trouv'e 520018 local changesets published updating to branch default 282924 files updated, 0 files merged, 0 files removed, 0 files unresolved
well that was not a smooth ride. After reinstalling from 0, I still had an issue because of the python 2.7 that brew installed in another location. Recommendations online were encouraging to reinstall it with brew. I really do not like brew. So I did the exact opposite and I removed the brew version of python 2.7. And it worked!
brew uninstall --ignore-dependencies python@2
Then
./mach build
and success…
3:22.01 0 compiler warnings present. 3:22.17 Overall system resources - Wall time: 200s; CPU: 0%; Read bytes: 0; Write bytes: 0; Read time: 0; Write time: 0 To view resource usage of the build, run |mach resource-usage|. 3:22.28 Your build was successful! To take your build for a test drive, run: |mach run| For more information on what to do now, see https://developer.mozilla.org/docs/Developer_Guide/So_You_Just_Built_Firefox
Otsukare!
|
|
The Firefox Frontier: Stay safe in your online life, too |
During the COVID-19 pandemic, many of us are turning to the internet to connect, learn, work and entertain ourselves from home. We’re setting up new accounts, reading more news, watching … Read more
The post Stay safe in your online life, too appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/stay-safe-in-your-online-life-too/
|
|
Mozilla Localization (L10N): L10n Report: March Edition |
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
New localizers
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
As you might have read in the past weeks, Mozilla turned off IRC and officially switched to a new system for synchronous communications (Matrix), available at: https://chat.mozilla.org/
We have a channel dedicated to l10n community conversations. You can also join the room, after creating an account in Matrix, by searching for the “l10n-community” room.
You can find detailed information on how to access Matrix via browser and mobile apps in this wiki page: https://wiki.mozilla.org/Matrix
Messages written in Matrix are also mirrored (“bridged”) to the “Mozilla L10n Community” Telegram channel.
As explained in the last l10n report, Firefox is now following a fixed 4-weeks release cycle:
In terms of upcoming content to localize, in Firefox 76 there’s a new authentication dialog, prompting users to authenticate with the Operating System when performing operations like setting a master password, or interacting with saved passwords in about:logins. Localizing this content is particularly challenging on macOS, since only part of the dialog’s text comes from Firefox (highlighted in red in the image below).

Make sure to read the instructions on the dev-l10n mailing list for some advice on how to localize this dialog.
A lot of pages were added in the last month. Many are content heavy. Make sure to prioritize the pages based on deadlines and the priority star rating, as well as against other projects.
New content will be ready for localization on a weekly basis, currently released on Fridays.
After the month of March, the team will cease active development. However, they will push translated content to production from time to time.
The localization of *Privacy Not Included has started! Privacy Not Included is Mozilla’s attempt, through technical research, to help people shop products that are safe, secure and private. The project has been enabled on Pontoon and a first batch of strings has been made available. You can test your work on the staging website, updated almost daily. For the locales that have access to the project, you can also opt-in to localize the About section. If you’re interested, reach out to Th'eo. Not all locales can translate the project yet but the team is exploring technical options to make it happen. The next edition of the guide is scheduled for this fall, and more content will be exposed over time.
MozFest is moving to Amsterdam! After 10 years in London, the Mozilla Festival will move to Amsterdam for its next edition in March 2021. The homepage is now localized, including in Dutch, and support for Frisian will be added soon. The team will make more content available for localization during the time leading to the next festival edition.
The SUMO team is going to decommission all old SUMO accounts by the 23rd of March 2020. If you have an account on SUMO, please take action to migrate it to the Firefox Accounts.
In order to migrate to Firefox Account, it’s better to always start by logging in to your old account and follow the prompt from there. Please read the FAQ and ask on this thread if you have any questions.
Introducing comments
We’ve shipped the ability to add comments in Pontoon. One of the top requested features enables reviewers to give feedback on proposed suggestions, as well as facilitates general discussions about a specific string. Read more on the feature and how to use it on the blog.
Huge thanks to our Outreachy intern April Bowler who developed the feature, and many Mozilla L10n community members who have been actively involved in the design process.

Pre-translation and post-editing
We’re introducing the ability to pre-translate strings using translation memory and machine translation. Pre-translations are marked on dashboards as needing attention, but they end up in repositories (and products). Note that the feature will go through substantial testing and evaluation before it gets enabled in any of the projects.
Thanks to Vishal for developing the feature and bringing us closer to the post-editing world.
Word count
Thanks to Oleksandra, Pontoon finally got the ability to measure project size in words in addition to strings. The numbers are not exposed anywhere in the UI or API yet. If you’re interested in developing such feature, please let us know!
Want to showcase an event coming up that your community is participating in? Reach out to any l10n-driver and we’ll include that (see links to emails at the bottom of this report)
Know someone in your l10n community who’s been doing a great job and should appear here? Contact one of the l10n-drivers and we’ll make sure they get a shout-out (see list at the bottom)!
Did you enjoy reading this report? Let us know how we can improve by reaching out to any one of the l10n-drivers listed above.
https://blog.mozilla.org/l10n/2020/03/26/l10n-report-march-edition-3/
|
|
Mozilla VR Blog: WebXR Emulator Extension AR support |

In September we released the WebXR Emulator Extension which enables testing WebXR VR applications in your desktop browser. Today we are happy to announce a new feature: AR support.
WebXR AR API
The WebXR Device API is an API which provides the interface to create immersive (VR and AR) applications on the web across a wide variety of XR devices. The WebXR 1.0 API for VR has shipped.
AR (Augmented Reality) is becoming popular thanks to the new platforms, ARCore and ARKit. You may have seen online shops which let you view their items in your room. The AR market has the potential to be huge.
The Immersive Web Working Group has been working on the WebXR API for AR to introduce a more open AR platform on the web. Chrome 81 (which was going to release March 17th but is now postponed) enables WebXR API for AR and Hit Test by default. Support in other browsers is coming soon, too.
Once it lands you will be able to play around with AR applications on compatible devices without installing anything. These are some WebXR AR examples you can try.
If you want to try on your android device now, you can use Chrome Android Beta. Install ARCore and Chrome Beta, and then access the examples above.
What the extension enables
You need AR compatible devices to play WebXR AR applications. Unfortunately you can’t run them on your desktop, even though the API is enabled, because your desktop doesn’t have the required hardware.
The WebXR Emulator Extension enables running WebXR AR applications on your desktop browser by emulating AR devices. As the following animation shows, you can test the application as if you run it on an emulated AR device in a virtual room. It includes the WebXR API polyfill so that it even works on browsers which do not natively support WebXR API for AR yet.

How to use it
No change is needed on the WebXR AR application side.
Benefits
The extension resolves the difficulties of AR content creation. Similar to VR content creation, currently there are some difficulties to create AR content.
This extension resolves these problems.
Although of course we strongly recommend testing on physical devices before product release, you will have a simpler workflow using the extension. You can test from the beginning to the end on desktop with the original application flow (open an application page, press button to enter immersive mode, and play AR) without any change in the application. Also you can keep using powerful desktop tools, for example screenshot capture, desktop video capture, and browser JavaScript debugger.
Virtual room advantage
Using a virtual room has another advantage in addition to the benefits I mentioned above. One of the difficulties in AR is recognizing objects in the world. For example Hit Test feature requires plane recognition in the world. Upcoming Lighting estimation feature requires lighting detection in the world. Generally AR devices have special cameras, chips, or software to smoothly solve this complex problem. But the extension doesn’t need them because it knows everything in a virtual room. So that we can easily add new AR features support when they are ready.
What’s next for WebXR AR?
We would love your feedback, feature requests, and bug reports. We are happy if you join us at the GitHub project.
And thanks to our Hello WebXR project and the asset author Diego. The very nice room asset is based on it.
|
|






