The Firefox Frontier: How to switch from Microsoft Edge to Firefox in just a few minutes |
You’ve heard that the Firefox browser is fast, private and secure, thanks to its built-in Enhanced Tracking Protection. You’ve also heard it’s made by people who want the web to … Read more
The post How to switch from Microsoft Edge to Firefox in just a few minutes appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/switch-from-microsoft-edge-to-firefox/
|
|
Hacks.Mozilla.Org: Learn web technology at “sofa school” |
Lots of kids around the world are learning from home right now. In this post, I introduce free resources based on web technologies that will help them explore and learn from the safety of their living rooms. VR headsets and high-end graphics cards aren’t necessary. Really, all you need is a web browser!
Hubs by Mozilla lets you share a virtual room with friends right in your browser. You can watch videos, play with 3D objects, or just hang out. Then, once you get the hang of Hubs, you can build almost anything imaginable with Spoke: a clubhouse, adventure island, or magic castle . . . . In Hubs, your little world becomes a place to spend time with friends (and show off your skills).

When kids (or adults) want to color, you have some options besides pulp paper booklets of princesses and sea creatures, thanks to Lubna, a front-end developer from the UK. Just click the “Edit On Codepen” button, and start playing. (The CSS color guide on MDN is a helpful reference). Young and old can learn by experimenting with this fun little toy.
Bring Bright Colors Into A Gray Day

The seasons are changing around the world—toward spring and toward fall. It feels like time to get into the garden and meet the frogs hopping from plant to plant. The Grid Garden that is, and Flexbox Froggy, to be precise. Educational software vendor Codepip created these attractive online learning experiences. They’re a great place for the young—and the young at heart—to get started with CSS.
Enter the Garden
Meet Flexbox Froggy

You don’t need a bus, car, submarine, or rocketship to go on a field trip. Educator Kai has created a variety of free VR experiences for kids and adults over at KaiXR. No headset is needed. Visit the planets of the solar system, Martin Luther King Memorial, the Mayan city of Chichen Itza, and the Taj Mahal in India. See dinosaurs, explore the human body, dive under the sea . . . and much, much more.

Have other suggestions to share, or favorite learning resources? Tell us about them in the comments. They may be included in a future edition of our developer newsletter, where a portion of this content has already appeared.
The post Learn web technology at “sofa school” appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2020/03/learn-web-technology-at-sofa-school/
|
|
Daniel Stenberg: A curl dashboard |
When I wrote up my looong blog post for the curl’s 22nd anniversary, I vacuumed my home directories for all the leftover scripts and partial hacks I’d used in the past to produce graphs over all sorts of things in the curl project. Being slightly obsessed with graphs, that means I got a whole bunch of them.
I dusted them off and made sure they all created a decent CSV output that I could use. I imported that data into libreoffice’s calc spreadsheet program and created the graphs that way. That was fun and I was happy with the results – and I could also manually annotate them with additional info. I then created a new git repository for the purpose of hosting the statistics scripts and related tools and pushed my scripts to it. Well, at least all the ones that seemed to work and were the most fun.
Having done the hard work once, it felt a little sad to just have that single moment snapshot of the project at the exact time I created the graphs, just before curl’s twenty-second birthday. Surely it would be cooler to have them updated automatically?
I of course knew of gnuplot since before as I’ve seen it used elsewhere (and I know its used to produce the graphs for the curl gitstats) but I had never used it myself.
How hard can it be?
I have a set of data files and there’s a free tool available for plotting graphs – and one that seems very capable too. I decided to have a go.
Of course I struggled at first when trying to get the basic concepts to make sense, but after a while I could make it show almost what I wanted and after having banged my head against it even more, it started to (partially) make sense! I’m still a gnuplot rookie, but I managed to tame it enough to produce some outputs!
I have a set of (predominantly) perl scripts that output CSV files. One output file for each script basically.
The statistics scripts dig out data using git from the source code repository and meta-data from the web site repository, and of course process that data in various ways that make sense. I figured a huge benefit of my pushing the scripts to a public repository is that they can be reviewed by anyone and the output should be possible to be reproduced by anyone – or questioned if I messed up somewhere!
The CSV files are then used as input to gnuplot scripts, and each such gnuplot script outputs its result as an SVG image. I selected SVG to make them highly scalable and yet be fairly small disk-space wise.
To spice things up a little, I decided that each new round of generated graph images should be put in a newly created directory with a random piece of string in its name. This, to make sure that we can cache the images on the curl web site very long and still not have a problem when we update the dashboard page on the site.
On the web site itself, the update script runs once every 24 hours, and it first updates its own clone of the source repo, and the stats code git repo before it runs over twenty scripts to make CSV files and the corresponding SVGs.
I like to view the final results as a dashboard. With over 20 up-to-date graphs showing the state of development, releases, commits, bug-fixes, authors etc it truly gives the reader an idea of how the project is doing and what the trends look like.
I hope to keep adding to and improving the graphs over time. If you have ideas of what to visualize and add to the collection, by all means let me know!
At the time of me writing this, the dashboard page looks like below. Click the image to go to the live dashboard.
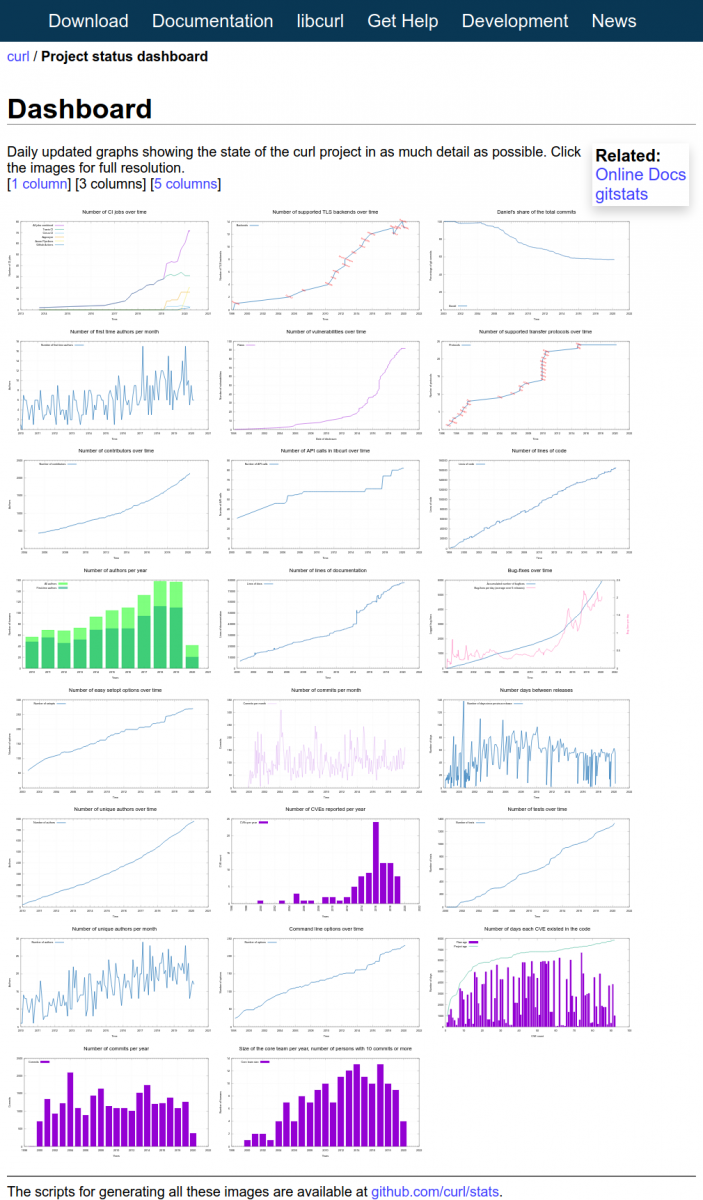
Nothing in this effort makes my scripts particularly unique for curl so they could all be used for other projects as well – with little to a lot of hands on required. My data extraction scripts of course get and use data that we have stored, collected and keep logged in the project etc, and that data and those logs are highly curl specific.
|
|
Cameron Kaiser: TenFourFox FPR21b1 available |
http://tenfourfox.blogspot.com/2020/03/tenfourfox-fpr21b1-available.html
|
|
The Mozilla Blog: Try our latest Test Pilot, Firefox for a Better Web, offering privacy and faster access to great content |
Today we are launching a new Test Pilot initiative called Firefox Better Web with Scroll. The Firefox Better Web initiative is about bringing the ease back to browsing the web. We know that publishers are getting the short end of the stick in the current online ad ecosystem and advertising networks make it difficult for excellent journalism to thrive. To give users what they want most, which is great quality content without getting tracked by third parties, we know there needs to be a change. We’ve combined Firefox and Scroll’s growing network of ad-free sites to offer users a fast and private web experience that we believe can be our future.
If we’re going to create a better internet for everyone, we need to figure out how to make it work for publishers. Last year, we launched Enhanced Tracking Protection by default and have blocked more than two trillion third-party trackers to date, but it didn’t directly address the problems that publishers face. That’s where our partner Scroll comes in. By engaging with a better funding model, sites in their growing network no longer have to show you ads to make money. They can focus on quality not clicks. Firefox Better Web with Scroll gives you the fast, private web you want and supports publishers at the same time.
To try the Firefox Better Web online experience, Firefox users simply sign up for a Firefox account and install a web extension. As a Test Pilot, it will only be available in the US. The membership is 50% off for the first six months at $2.50 per month. This goes directly to fund publishers and writers, and in early tests we’ve found that sites make at least 40% more money than they would have made from showing you ads.
In February of 2019, we announced that we were exploring alternative revenue models on the web. Before we committed to any particular approach, we wanted to better understand the problem space. The entire investigation followed a very similar arc to the work we did with Firefox Monitor. We let the user be our guide, putting their expressed needs and concerns at the forefront of all of our work. We also tested cheaply and frequently. At each stage increasing the level of investment, but also the clarity of data.
One of our tests was an initial experiment with Scroll to discern whether there was an appetite and desire for this type of online experience. We wanted to get a better sense from our users on what they cared about the most and figure out the pain points for news sites as well, so we used multiple different value propositions to describe the service that Scroll offered. Here are our findings:
Firefox Better Web combines the work we’ve done with third-party tracking protection and Scroll’s network of outstanding publishers. This ensures you will get a top notch experience while still supporting publishers directly and keeping the web healthy. We use a customized Enhanced Tracking Protection setting that will block third-party trackers, fingerprinters, and cryptominers.This provides additional privacy and a significant performance boost. Scroll then provides a network of top publishers who provide their content ad-free.
Firefox Better Web is available everywhere, but BEST in Firefox! See for yourself with our images:
With Firefox Better Web extension
With Firefox Better Web extension
Your membership is paid directly to the publishers in Scroll’s network based on the content you read. Our hope is that the success of this model will demonstrate to publishers the value of having a more direct, uncluttered connection to their online audience. In turn, the publisher network will continue to grow to include every site you care about so that your money can go directly to pay for the quality journalism you want to read. If you’re a publisher who wants to join this initiative, contact Scroll and see how this funding model can drive more revenue for you.
We invite you to try out Firefox Better Web and experience a private and faster way to read the news and stories you care about.
The post Try our latest Test Pilot, Firefox for a Better Web, offering privacy and faster access to great content appeared first on The Mozilla Blog.
|
|
Daniel Stenberg: curl ootw: –retry-max-time |
Previous command line options of the week.
--retry-max-time has no short option alternative and it takes a numerical argument stating the time in seconds. See below for a proper explanation for what that time is.
curl supports retrying of operations that failed due to “transient errors”, meaning that if the error code curl gets signals that the error is likely to be temporary and not the fault of curl or the user using curl, it can try again. You enable retrying with --retry [tries] where you tell curl how many times it should retry. If it reaches the maximum number of retries with a successful transfer, it will return error.
A transient error can mean that the server is temporary overloaded or similar, so when curl retries it will by default wait a short while before doing the next “round”. By default, it waits one second on the first retry and then it doubles the time for every new attempt until the waiting time reaches 10 minutes which then is the max waiting time. A user can set a custom delay between retries with the --retry-delay option.
Transient errors mean either: a timeout, an FTP 4xx response code or an HTTP 408 or 5xx response code. All other errors are non-transient and will not be retried with this option.
Retrying can thus go on for an extended period of time, and you may want to limit for how long it will retry if the server really doesn’t work. Enter --retry-max-time.
It sets the maximum number of seconds that are allowed to have elapsed for another retry attempt to be started. If you set the maximum time to 20 seconds, curl will only start new retry attempts within a twenty second period that started before the first transfer attempt.
If curl gets a transient error code back after 18 seconds, it will be allowed to do another retry and if that operation then takes 4 seconds, there will be no more attempts but if it takes 1 second, there will be time for another retry.
Of course the primary --retry option sets the number of times to retry, which may reach the end before the maximum time is met. Or not.
Since curl 7.66.0 (September 2019), the server’s Retry-After: HTTP response header will be used to figure out when the subsequent retry should be issued – if present. It is a generic means to allow the server to control how fast clients will come back, so that the retries themselves don’t become a problem that causes more transient errors…
In curl 7.52.0 curl got this additional retry switch that adds “connection refused” as a valid reason for doing a retry. If not used, a connection refused is not considered a transient error and will cause a regular error exit code.
--max-time limits the entire time allowed for an operation, including all retry attempts.
https://daniel.haxx.se/blog/2020/03/24/curl-ootw-retry-max-time/
|
|
Support.Mozilla.Org: Introducing Leo McArdle |
Hi everyone,
We have good news from our team that I believe some of you might’ve already known. Finally, Tasos will no longer be a lone coder in our team as now we have a new additional member in SUMO. Please, say hi to Leo McArdle.
I’m sure Leo is not a new name for most of you. He’s been involved in the community for so long (some of you might know him as a “Discourse guy”) and now he’s taking a new role as a software engineer working in SUMO team.
Here is a short introduction from Leo:
Hey all, I’m Leo and joining the SUMO team as a Software Engineer. I’m very excited to be working on the SUMO platform, as it was through this community that I first started contributing to Mozilla. This led me to pursue programming first as a hobby, then as a profession, and ultimately end up back here! When I’m not programming, I’m usually watching some kind of motor racing, or attempting to cook something adventurous in the kitchen… and usually failing! See you all around!
Please join us to welcome him!
https://blog.mozilla.org/sumo/2020/03/23/introducing-leo-mcardle/
|
|
Daniel Stenberg: let’s talk curl 2020 roadmap |
tldr: join in and watch/discuss the curl 2020 roadmap live on Thursday March 26, 2020. Sign up here.
The roadmap is basically a list of things that we at wolfSSL want to work on for curl to see happen this year – and some that we want to mention as possibilities.(Yes, the word “webinar” is used, don’t let it scare you!)
If you can’t join live, you will be able to enjoy a recorded version after the fact.
I shown the image below in curl presentation many times to illustrate the curl roadmap ahead:

The point being that we as a project don’t really have a set future but we know that more things will be added and fixed over time.
This is a balancing act where there I have several different “hats”.
I’m the individual who works for wolfSSL. In this case I’m looking at things we at wolfSSL want to work on for curl – it may not be what other members of the team will work on. (But still things we agree are good and fit for the project.)
We in wolfSSL cannot control or decide what the other curl project members will work on as they are volunteers or employees working for other companies with other short and long term goals for their participation in the curl project.
We also want to try to communicate a few of the bigger picture things for curl that we want to see done, so that others can join in and contribute their ideas and opinions about these features, perhaps even add your preferred subjects to the list – or step up and buy commercial curl support from us and get a direct-channel to us and the ability to directly affect what I will work on next.
As a lead developer of curl, I will of course never merge anything into curl that I don’t think benefits or advances the project. Commercial interests don’t change that.
Sign up here. The scheduled time has been picked to allow for participants from both North America and Europe. Unfortunately, this makes it hard for all friends not present on these continents. If you really want to join but can’t due to time zone issues, please contact me and let us see what we can do!
Top image by Free-Photos from Pixabay
https://daniel.haxx.se/blog/2020/03/23/lets-talk-curl-2020-roadmap/
|
|
Karl Dubost: Week notes - 2020 w10, w11, w12 - worklog - Three weeks and the world is mad |
So my latest work notes were 3 weeks ago, and what I was afraid about, just came to realization. We are in there for a long time. I'm living in Japan which seems to be spared puzzling many people. My non-professional armchair-epidemiologist crystall-ball impression is that Japan will not escape it seeing the daily behavior of people around me. Japan seems to have been quite protected by long cultural habits and human-less contacts society (to the extreme point of hikikomori). I don't think it will stand for a long time in a globalized world, but I'll be super happy to be wrong.
So the coronavirus anxiety porn has eaten my week notes, but we managed to maintain a relatively reasonable curve for the needsdiagnosis. That's a good news. I would love to modify a bit this curve to highlight the growing influx of unattended chrome issues. If someone from Google could give a shot to them: 55 to address. Probably less given that when you let a bug rest too long it disappears because the website has been redesigned in the meantime.
We restarted the machine learning bot classifying invalid issues. It was not playing very well with our new workflow for anonymous reporting. We had to change the criteria for selecting bugs.
oh also this happens this week and talk about a wonderful shot of pure vitamin D. That's one of the reasons of Mozilla being awesome in difficult circumstances.
I'll try to be better at my week notes in the next couple of weeks.
Otsukare!
http://www.otsukare.info/2020/03/20/week-notes-2020-10-11-12
|
|
Nick Fitzgerald: Writing Programs! That Write Other Programs!! |
I gave a short talk about program synthesis at !!Con West this year titled “Writing Programs! That Write Other Progams!!” Here’s the abstract for the talk:
Why write programs when you can write a program to write programs for you? And that program writes programs that are faster than the programs you’d write by hand. And that program’s programs are actually, you know, correct. Wow!
Yep, it’s time to synthesize. But this ain’t Moog, this is program synthesis. What is that, and how can it upgrade our optimizers into super-optimizers? We’ll find out!!
The talk was a short, friendly introduction to the same stuff I wrote about in Synthesizing Loop-Free Programs with Rust and Z3.
The recording of the talk is embedded below. The presentation slides are available here.
Also make sure to also check out all the other talks from !!Con West 2020! !!Con West (and !!Con East) is a really special conference about the joy, surprise, and excitement of programming. It’s the anti-burnout conference: remembering all the fun and playfulness of programming, and embracing absurdist side projects because why not?! I love it, and I highly encourage you to come next year.
http://fitzgeraldnick.com/2020/03/20/bang-bang-con-west.html
|
|
Daniel Stenberg: curl: 22 years in 22 pictures and 2222 words |
curl turns twenty-two years old today. Let’s celebrate this by looking at its development, growth and change over time from a range of different viewpoints with the help of graphs and visualizations.
This is the more-curl-graphs-than-you-need post of the year. Here are 22 pictures showing off curl in more detail than anyone needs.
I founded the project back in the day and I remain the lead developer – but I’m far from alone in this. Let me take you on a journey and give you a glimpse into the curl factory. All the graphs below are provided in hires versions if you just click on them.
Below, you will learn that we’re constantly going further, adding more and aiming higher. There’s no end in sight and curl is never done. That’s why you know that leaning on curl for Internet transfers means going with a reliable solution.
Counting only code in the tool and the library (and public headers) it still has grown 80 times since the initial release, but then again it also can do so much more.
At times people ask how a “simple HTTP tool” can be over 160,000 lines of code. That’s basically three wrong assumptions put next to each other:

How much more is curl going to grow and can it really continue growing like this even for the next 22 years? I don’t know. I wouldn’t have expected it ten years ago and guessing the future is terribly hard. I think it will at least continue growing, but maybe the growth will slow down at some point?
Lots of people help out in the project. Everyone who reports bugs, brings code patches, improves the web site or corrects typos is a contributor. We want to thank everyone and give all helpers the credit they deserve. They’re all contributors. Here’s how fast our list of contributors is growing. We’re at over 2,130 names now.

When I wrote a blog post five years ago, we had 1,200 names in the list and the graph shows a small increase in growth over time…
I started the project. I’m still very much involved and I spend a ridiculous amount of time and effort in driving this. We’re now over 770 commits authors and this graph shows how the share of commits I do to the project has developed over time. I’ve done about 57% of all commits in the source code repository right now.

The graph is the accumulated amount. Some individual years I actually did far less than 50% of the commits, which the following graph shows
In the early days I was the only one who committed code. Over time a few others were “promoted” to the maintainer role and in 2010 we switched to git and the tracking of authors since then is much more accurate.
In 2014 I joined Mozilla and we can see an uptake in my personal participation level again after having been sub 50% by then for several years straight.

There’s always this argument to be had if it is a good or a bad sign for the project that my individual share is this big. Is this just because I don’t let other people in or because curl is so hard to work on and only I know my ways around the secret passages? I think the ever-growing number of commit authors at least show that it isn’t the latter.
What happens the day I grow bored or get run over by a bus? I don’t think there’s anything to worry about. Everything is free, open, provided and well documented.
The command line tool is really like a very elaborate Swiss army knife for Internet transfers and it provides many individual knobs and levers to control the powers. curl has a lot of command line options and they’ve grown in number like this.

Is curl growing too hard to use? Should we redo the “UI” ? Having this huge set of features like curl does, providing them all with a coherent and understandable interface is indeed a challenge…
Documentation is crucial. It’s the foundation on which users can learn about the tool, the library and the entire project. Having plenty and good documentation is a project ambition. Unfortunately, we can’t easily measure the quality.
All the documentation in curl sits in the docs/ directory or sub directories in there. This shows how the amount of docs for curl and libcurl has grown through the years, in number of lines of text. The majority of the docs is in the form of man pages.

This refers to protocols as in primary transfer protocols as in what you basically specify as a scheme in URLs (ie it doesn’t count “helper protocols” like TCP, IP, DNS, TLS etc). Did I tell you curl is much more than an HTTP client?

More protocols coming? Maybe. There are always discussions and ideas… But we want protocols to have a URL syntax and be transfer oriented to map with the curl mindset correctly.
The support for different HTTP versions has also grown over the years. In the curl project we’re determined to support every HTTP version that is used, even if HTTP/0.9 support recently turned disabled by default and you need to use an option to ask for it.

The initial curl release didn’t even support HTTPS but since 2005 we’ve support customizable TLS backends and we’ve been adding support for many more ones since then. As we removed support for two libraries recently we’re now counting thirteen different supported TLS libraries.

Okay, this graph is mostly in jest but we recently added support for HTTP/3 and we instantly made that into a multi backend offering as well.

An added challenge that this graph doesn’t really show is how the choice of HTTP/3 backend is going to affect the choice of TLS backend and vice versa.
For a long time we only supported a single SSH solution, but that was then and now we have three…

We take security seriously and over time people have given us more attention and have spent more time digging deeper. These days we offer good monetary compensation for anyone who can find security flaws.

An attempt to visualize how many known vulnerabilities previous curl versions contain. Note that most of these problems are still fairly minor and some for very specific use cases or surroundings. As a reference, this graph also includes the number of lines of code in the corresponding versions.
More recent releases have less problems partly because we have better testing in general but also of course because they’ve been around for a shorter time and thus have had less time for people to find problems in them.

libcurl is an Internet transfer library and the number of provided function calls in the API has grown over time as we’ve learned what users want and need.
Anything that has been built with libcurl 7.16.0 or later you can always upgrade to a later libcurl and there should be no functionality change and the API and ABI are compatible. We put great efforts into make sure this remains true.
The largest API additions over the last few year are marked in the graph: when we added the curl_mime_* and the curl_url_* families. We now offer 82 function calls. We’ve added 27 calls over the last 14 years while maintaining the same soname (ABI version).

We’ve had automatic testing in the curl project since the year 2000. But for many years that testing was done by volunteers who ran tests in cronjobs in their local machines a few times per day and sent the logs back to the curl web site that displayed their status.
The automatic tests are still running and they still provide value, but I think we all agree that getting the feedback up front in pull-requests is a more direct way that also better prevent bad code from ever landing.
The first CI builds were added in 2013 but it took a few more years until we really adopted the CI lifestyle and today we have 72, spread over 5 different CI services (travis CI, Appveyor, Cirrus CI, Azure Pipelines and Github actions). These builds run for every commit and all submitted pull requests on Github. (We actually have a few more that aren’t easily counted since they aren’t mentioned in files in the git repo but controlled directly from github settings.)

A single test case can test a simple little thing or it can be a really big elaborate setup that tests a large number of functions and combinations. Counting test cases is in itself not really saying much, but taken together and looking at the change over time we can at least see that we continue to put efforts into expanding and increasing our tests. It should also be considered that this can be combined with the previous graph showing the CI builds, as most CI jobs also run all tests (that they can).

A commit can be tiny and it can be big. Counting a commit might not say a lot more than it is a sign of some sort of activity and change in the project. I find it almost strange how the number of commits per months over time hasn’t changed more than this!

This shows number of unique authors per month (in red) together with the number of first-time authors (in blue) and how the amounts have changed over time. In the last few years we see that we are rarely below fifteen authors per month and we almost always have more than five first-time commit authors per month.
I think I’m especially happy with the retained high rate of newcomers as it is at least some indication that entering the project isn’t overly hard or complicated and that we manage to absorb these contributions. Of course, what we can’t see in here is the amount of users or efforts people have put in that never result in a merged commit. How often do we miss out on changes because of project inabilities to receive or accept them?

Operating systems on which you can build and run curl for right now, or that we know people have ran curl on before. Most mortals cannot even list this many OSes off the top of their heads. If you know of any additional OS that curl has run on, please let me know!

CPU architectures on which we know people have run curl. It basically runs on any CPU that is 32 bit or larger. If you know of any additional CPU architecture that curl has run on, please let me know!

Did I mention you can build curl in millions of combinations? That’s partly because of the multitude of different third party dependencies you can tell it to use. curl support no less than 32 different third party dependencies right now. The picture below is an attempt to some sort of block diagram and all the green boxes are third party libraries curl can potentially be built to use. Many of them can be used simultaneously, but a bunch are also mutually exclusive so no single build can actually use all 32.

If you’re looking for more explanations how libcurl ends up being used in so many places, here are 60 more. Languages and environments that sport a “binding” that lets users of these languages use libcurl for Internet transfers.

“number of downloads” could’ve been fun, but we don’t collect the data and most users don’t download curl from our site anyway so it wouldn’t really say a lot.
“number of users” is impossible to tell and while I’ve come up with estimates every now and then, making that as a graph would be doing too much out of my blind guesses.
“number of graphs in anniversary blog posts” was a contender, but in the end I decided against it, partly since I have too little data.
Every anniversary is an opportunity to reflect on what’s next.
In the curl project we don’t have any grand scheme or roadmap for the coming years. We work much more short-term. We stick to the scope: Internet transfers specified as URLs. The products should be rock solid and secure. The should be high performant. We should offer the features, knobs and levers our users need to keep doing internet transfers now and in the future.
curl is never done. The development pace doesn’t slow down and the list of things to work on doesn’t shrink.
https://daniel.haxx.se/blog/2020/03/20/curl-22-years-in-22-pictures-and-2222-words/
|
|
Mike Hoye: Notice |

As far as I can tell, 100% of the google results for “burnout” or “recognizing burnout” boil down to victim-blaming; they’re all about you, and your symptoms, and how to recognize when you’re burning out. Are you frustrated, overwhelmed, irritable, tired? Don’t ask for help, here’s how to self-diagnose! And then presumably do something.
What follows is always the most uselessly vague advice, like “listen to yourself” or “build resiliency” or whatever, which all sounds great and reinforces that the burden of recovery is entirely on the person burning out. And if you ask about the empirical evidence supporting it, this advice is mostly on par with leaving your healing crystals in the sun, getting your chakras greased or having your horoscope fixed by changing your birthday.
Resiliency and self-awareness definitely sound nice enough, and if your crystals are getting enough sun good for them, but just about all of this avoiding-burnout advice amounts to lighting scented candles downwind of a tire fire. If this was advice about a broken leg or anaphylaxis we’d see it for the trash it is, but because it’s about mental health somehow we don’t call it out. Is that a shattered femur? Start by believing in yourself, and believing that change is possible. Bee stings are just part of life; maybe you should take the time to rethink your breathing strategy. This might be a sign that breathing just isn’t right for you.
Even setting that aside: if we could all reliably self-assess and act on the objective facts we discerned thereby, burnout (and any number of other personal miseries) wouldn’t exist. But somehow here we are in not-that-world-at all. And as far as I can tell approximately none percent of these articles are ever about, say, “how to foster an company culture that doesn’t burn people out”, or “managing people so they don’t burn out”, or “recognizing impending burnout in others, so you can intervene.”
I’ll leave why that might be as an exercise for the reader.
Fortunately, as in so many cases like this, evidence comes to the rescue; you just need to find it. And the best of the few evidence-based burnout-prevention guidelines I can find come from the field of medicine where there’s a very straight, very measurable line between physician burnout and patient care outcomes. Nothing there will surprise you, I suspect; “EHR stress” (Electronic Health Records) has a parallel in our lives with tooling support, and the rest of it – sane scheduling, wellness surveys, agency over meaningful work-life balance and so on – seems universal. And it’s very clear from the research that recognizing the problem in yourself and in your colleagues is only one, late step. Getting support to make changes to the culture and systems in which you find yourself embedded is, for the individual, the next part of the process.
The American Medical Association has a “Five steps to creating a wellness culture” document, likewise rooted in gathered evidence, and it’s worth noting that the key takeaways are that burnout is a structural problem and mitigating it requires structural solutions. “Assess and intervene” is the last part of the process, not the first. “Self-assess and then do whatever” is not on the list at all, because that advice is terrible and the default setting of people burning out is self-isolation and never, ever asking people for the help they need.
We get a lot of things right where I work, and we’re better at taking care of people now than just about any other org I’ve ever heard of, but we still need to foster an “if you see something, say something” approach to each others’ well being. I bet wherever you are, you do too. Particularly now that the whole world has hard-cutover to remote-only and we’re only seeing each other through screens.
Yesterday, I told some colleagues that “if you think somebody we work with is obviously failing at self-care, talk to them”, and I should have been a lot more specific. This isn’t a perfect list by any means, but if you ask someone how they’re doing and they can’t so much as look you in the eye when they answer, see that. If you’re talking about work and they start thumbing their palms or rubbing their wrists or some other reflexive self-soothing twitch, notice. If you ask them about what they’re working on and they take a long breath and longer choosing their words, pay attention. If somebody who isn’t normally irritable or prone to cynical or sardonic humor starts trending that way, if they’re hunched over in meetings looking bedraggled when they normally take care of posture and basic grooming, notice that and say so.
If “mental health” is just “health” – and I guarantee it is – then burnout is an avoidable workplace injury, and I don’t believe in unavoidable mental-health injuries any more than I believe in unavoidable forklift accidents. Keep an eye out for your colleagues. If you think somebody you work with is failing at self-care, talk to them. Maybe talk to a friend, maybe talk to their manager or yours.
But say something. Don’t let it slide.
|
|
Jan-Erik Rediger: Review Feedback: a response to the Feedback Ladder |
|
|
Daniel Stenberg: curl up 2020 goes online only |
curl up 2020 will not take place in Berlin as previously planned. The corona times are desperate times and we don’t expect things to have improved soon enough to make a physical conference possible at this date.
curl up 2020 will still take place, and at the same date as planned (May 9-10), but we will change the event to a pure online and video-heavy occasion. This way we can of course also even easier welcome audience and participants from even furher away who previously would have had a hard time to participate.
We have not worked out the details yet. What tools to use, how to schedule, how to participate, how to ask questions or how to say cheers with your local favorite beer. If you have ideas, suggestions or even experiences to share regarding this, please join the curl-meet mailing list and help!
https://daniel.haxx.se/blog/2020/03/18/curl-up-2020-goes-online-only/
|
|
Daniel Stenberg: curl write-out JSON |
This is not a command line option of the week post, but I feel a need to tell you a little about our brand new addition!
--write-out [format]This option takes a format string in which there are a number of different “variables” available that let’s a user output information from the previous transfer. For example, you can get the HTTP response code from a transfer like this:
curl -w 'code: %{response_code}' https://example.org >/dev/null
There are currently 34 different such variables listed and described in the man page. The most recently added one is for JSON output and it works like this:
%{json}It is a single variable that outputs a full json object. You would for example invoke it like this when you get data from example.com:
curl --write-out '%{json}' https://example.com -o saved
That command line will spew some 800 bytes to the terminal and it won’t be very human readable. You will rather take care of that output with some kind of script/program, or if you want an eye pleasing version you can pipe it into jq and then it can look like this:
{
"url_effective": "https://example.com/",
"http_code": 200,
"response_code": 200,
"http_connect": 0,
"time_total": 0.44054,
"time_namelookup": 0.001067,
"time_connect": 0.11162,
"time_appconnect": 0.336415,
"time_pretransfer": 0.336568,
"time_starttransfer": 0.440361,
"size_header": 347,
"size_request": 77,
"size_download": 1256,
"size_upload": 0,
"speed_download": 0.002854,
"speed_upload": 0,
"content_type": "text/html; charset=UTF-8",
"num_connects": 1,
"time_redirect": 0,
"num_redirects": 0,
"ssl_verify_result": 0,
"proxy_ssl_verify_result": 0,
"filename_effective": "saved",
"remote_ip": "93.184.216.34",
"remote_port": 443,
"local_ip": "192.168.0.1",
"local_port": 44832,
"http_version": "2",
"scheme": "HTTPS",
"curl_version": "libcurl/7.69.2 GnuTLS/3.6.12 zlib/1.2.11 brotli/1.0.7 c-ares/1.15.0 libidn2/2.3.0 libpsl/0.21.0 (+libidn2/2.3.0) nghttp2/1.40.0 librtmp/2.3"
}
It always outputs the entire object and the object may of course differ over time, as I expect that we might add more fields into it in the future.
The names are the same as the write-out variables, so you can read the --write-out section in the man page to learn more.
The feature landed in this commit. This new functionality will debut in the next pending release, likely to be called 7.70.0, scheduled to happen on April 29, 2020.
This is the result of fine coding work by Mathias Gumz.
Top image by StartupStockPhotos from Pixabay
|
|
Ludovic Hirlimann: New Job |
I started working for a new Gig, at the beginning of this month. It's a nice little company focused on mapping solutions. They work on open source software, QGIS and Postgis, and have developed a nice webapp called lizmap. I am a sysadmin there managing their SAS offering.
https://www.hirlimann.net/Ludovic/carnet/?post/2020/03/17/New-Job
|
|
David Humphrey: Teaching in the time of Corona |
Like so many of my post-secondary colleagues around the world, I've been trying to figure out what it means to conduct the remainder of the Winter 2020 term in a 100% online format. I don't have an answer yet, but here is some of what I'm currently thinking.
It seems crazy to give background or provide links to what's going on, but for my future self, here is the context of the current situation. On Thursday March 12, the Ontario government announced the closure of all publicly funded schools (K-12) in the province. This measure was part of a series of closures that were cascading across the US and Canada. The effect was that suddenly every teacher, parent, student, and all their family members were now part of the story. What was happening on Twitter, at airports, or "somewhere else" had now landed with a thud on everyone's doorstep.
What we didn't hear on Thursday was any news about post-secondary institutions. If K-12 had to close, how could we possibly keep colleges and universities open? Our classes are much larger, and our faculty and student populations much more mobile. It made no sense, and many of my colleagues were upset.
I went to work on Friday in order to give two previously scheduled tests. As I was handing out the test papers, an email came to my laptop. Our college's president was announcing an end of all in-person classes, and move to "online."
The plan is as follows:
I've been working and teaching online for at least 15 years, much of it as part of Mozilla. I love it, and as an introvert and writer, it's my preferred way of working. However, I've never done everything online, especially not lecturing.
I love lecturing (just ask my teenagers!), and it's really hard to move it out of an in-person format. I've given lots of online talks and lectures in the past. Sometimes it happened because a conference needed to accommodate a larger audience than could safely fit in the room. Other times I've had a few remote people want to join an event. Once I gave a lecture to hundreds of CS students in France from Toronto, and I've even given a talk in English from Stanford that was simultaneously translated in real-time into Japanese and broadcast in Japan.
It can be done. But it's not how I like to work. A good lecture is dynamic, and includes the audience, their questions and comments, but also their desired pace, level of understanding, etc. I rarely use notes or slides anymore, preferring to have a more conversational, authentic interaction with my students. I don't think it's possible to "move this online" the way I do it, or at least, I don't know how (yet).
I was lucky to have a chance to meet with many of my students on Friday, and talk with them about how they were feeling, and what their needs would be. When we talk about moving a course online, much of the conversation gets focused on technology needs.
In the past few days, I've been amazed to watch my colleagues grapple with the challenge of doing everything online. Here's some of what I've seen:
Imagine being a faculty member who suddenly has to evaluate and learn some or all of these. I've used them all before, but many of my colleagues haven't. I spent Friday afternoon showing some of my peers how to setup a few of the tools, and it's a lot to pick up quickly.
Now imagine being a student who suddenly has faculty wanting you to use all of these new tools in parallel, and everyone doing things slightly differently! That's also a lot, and I have a lot of empathy for what the students are facing.
Thankfully, technology isn't the problem: we have so much of it, and lots of it is "good enough." The real problem is trying to figure out how to support our students in ways that are actually helpful to the learning process.
I asked my students what they wanted me to do. Here's some of what I heard
How do you pivot "celebrate 1.0 with cake together" to purely online?
I've always wanted to do more of my courses online, and it feels like this is an interesting time to experiment. At the same time, everyone (including myself) is totally overwhelmed with what's happening in society. My wife told me to be realistic with my expectations for myself and the process, and as always, I know she's right.
I'm going to go slower and smaller than I might if I was building these courses online from day one. Here's my current thinking:
All of the courses I'm teaching right now are really "open web" courses. It's nice for me because the act of moving my courses online is itself a case study of what it means to apply what we're learning in the classroom.
In the coming weeks, where possible, I'm going to try and use examples that touch on the parts of the web that are most critical right now. For example, I'd love to use WebSockets and WebRTC if possible, to show the students how the tech they're using in all their classes are also within their grasp as developers (as an aside, I'm looking for some easy ways to have them work with WebRTC in the browser only, and need to figure out some public signaling solutions, in case you know of any).
I've been amazed to watch just how significant the web has been to the plans of countries all around the world in the face of the Coronavirus. Working from home and teaching and learning online are impossible without the open web platform to support the needs of everybody right now.
In 2020, the web is a utility, and society expects it to work. Understanding how the web works is critical to the functioning of a modern society, and I'm proud to have dedicated my career to building and teaching all this web technology. It's amazing to see it being used for so much good, and an honour to teach the next generation how to keep it working.
|
|
Daniel Stenberg: curl ootw happy eyeballs timeout |
Previous options of the week.
This week’s option has no short option and the long name is indeed quite long:
This option was added to curl 7.59.0, March 2018 and is very rarely actually needed.
To understand this command line option, I think I should make a quick recap of what “happy eyeballs” is exactly and what timeout in there that this command line option is referring to!
This is the name of a standard way of connecting to a host (a server really in curl’s case) that has both IPv4 and IPv6 addresses.
When curl resolves the host name and gets a list of IP addresses back for it, it will try to connect to the host over both IPv4 and IPv6 in parallel, concurrently. The first of these connects that completes its handshake is considered the winner and the other connection attempt then gets ditched and is forgotten. To complicate matters a little more, a host name can resolve to a list of addresses of both IP versions and if a connect to one of the addresses fails, curl will attempt the next in a way so that IPv4 addresses and IPv6 addresses will be attempted, simultaneously, until one succeeds.
curl races connection attempts against each other. IPv6 vs IPv4.
Of course, if a host name only has addresses in one IP version, curl will only use that specific version.
For hosts having both IPv6 and IPv4 addresses, curl will first fire off the IPv6 attempt and then after a timeout, start the first IPv4 attempt. This makes curl prefer a quick IPv6 connect.
The default timeout from the moment the first IPv6 connect is issued until the first IPv4 starts, is 200 milliseconds. (The Happy Eyeballs RFC 6555 claims Firefox and Chrome both use a 300 millisecond delay, but I’m not convinced this is actually true in current versions.)
By altering this timeout, you can shift the likeliness of one or the other connect to “win”.
Example: change the happy eyeballs timeout to the same value said to be used by some browsers (300 milliseconds):
curl --happy-eyeballs-timeout-ms 300 https://example.com/
There’s a Happy Eyeballs version two, defined in RFC 8305. It takes the concept a step further and suggests that a client such as curl should start the first connection already when the first name resolve answers come in and not wait for all the responses to arrive before it starts the racing.
curl does not do that level “extreme” Happy Eyeballing because of two simple reasons:
1. there’s no portable name resolving function that gives us data in that manner. curl won’t start the actual connection procedure until the name resolution phase is completed, in its entirety.
2. getaddrinfo() returns addresses in a defined order that is hard to follow if we would side-step that function as described in RFC 8305.
Taken together, my guess is that very few internet clients today actually implement Happy Eyeballs v2, but there’s little to no reason for anyone to not implement the original algorithm.
curl has done Happy Eyeballs connections since 7.34.0 (December 2013) and yet we had this lingering bug in the code that made it misbehave at times, only just now fixed and not shipped in a release yet. This bug makes curl sometimes retry the same failing IPv6 address multiple times while the IPv4 connection is slow.
--connect-timeout limits how long to spend trying to connect and --max-time limits the entire curl operation to a fixed time.
https://daniel.haxx.se/blog/2020/03/16/curl-ootw-happy-eyeballs-timeout/
|
|
Daniel Stenberg: Warning: curl users on Windows using FILE:// |
The Windows operating system will automatically, and without any way for applications to disable it, try to establish a connection to another host over the network and access it (over SMB or other protocols), if only the correct file path is accessed.
When first realizing this, the curl team tried to filter out such attempts in order to protect applications for inadvertent probes of for example internal networks etc. This resulted in CVE-2019-15601 and the associated security fix.
However, we’ve since been made aware of the fact that the previous fix was far from adequate as there are several other ways to accomplish more or less the same thing: accessing a remote host over the network instead of the local file system.
The conclusion we have come to is that this is a weakness or feature in the Windows operating system itself, that we as an application and library cannot protect users against. It would just be a whack-a-mole race we don’t want to participate in. There are too many ways to do it and there’s no knob we can use to turn off the practice.
We no longer consider this to be a curl security flaw!
If you use curl or libcurl on Windows (any version), disable the use of the FILE protocol in curl or be prepared that accesses to a range of “magic paths” will potentially make your system try to access other hosts on your network. curl cannot protect you against this.
We have updated relevant curl and libcurl documentation to make users on Windows aware of what using FILE:// URLs can trigger (this commit) and posted a warning notice on the curl-library mailing list.
This was previously considered a curl security problem, as reported in CVE-2019-15601. We no longer consider that a security flaw and have updated that web page with information matching our new findings. I don’t expect any other CVE database to update since there’s no established mechanism for updating CVEs!
Many thanks to Tim Sedlmeyer who highlighted the extent of this issue for us.
https://daniel.haxx.se/blog/2020/03/16/warning-curl-users-on-windows-using-file/
|
|






