Беспорядок в справочниках, хранящих основные данные компании – частая проблема, доставляющая не мало неприятностей, среди которых путаница в первичных документах из-за неправильного заведения номенклатуры или закупка товаров, по факту находящихся на складах компании. Этого можно избежать, внедрив MDM-систему и нормализовав данные.
Нормализация избавляет справочники от лишней информации, делает записи в них единообразными и стандартными. Это позволяет пользоваться качественными и структурированными данными, брать их из единого источника и быть уверенным, что они корректны.
Давайте рассмотрим, как принято нормализовывать справочники, хранящие основные данные компании, и как можно избежать дорогостоящего и трудоемкого процесса.
Для примера возьмем справочник материально-технических ресурсов (Номенклатура). Нормализация такого справочника требует большого количества времени, денег и экспертов для вычистки данных. Читать дальше →
Беспорядок в справочниках, хранящих основные данные компании – частая проблема, доставляющая не мало неприятностей, среди которых путаница в первичных документах из-за неправильного заведения номенклатуры или закупка товаров, по факту находящихся на складах компании. Этого можно избежать, внедрив MDM-систему и нормализовав данные.
Нормализация избавляет справочники от лишней информации, делает записи в них единообразными и стандартными. Это позволяет пользоваться качественными и структурированными данными, брать их из единого источника и быть уверенным, что они корректны.
Давайте рассмотрим, как принято нормализовывать справочники, хранящие основные данные компании, и как можно избежать дорогостоящего и трудоемкого процесса.
Для примера возьмем справочник материально-технических ресурсов (Номенклатура). Нормализация такого справочника требует большого количества времени, денег и экспертов для вычистки данных. Читать дальше ->
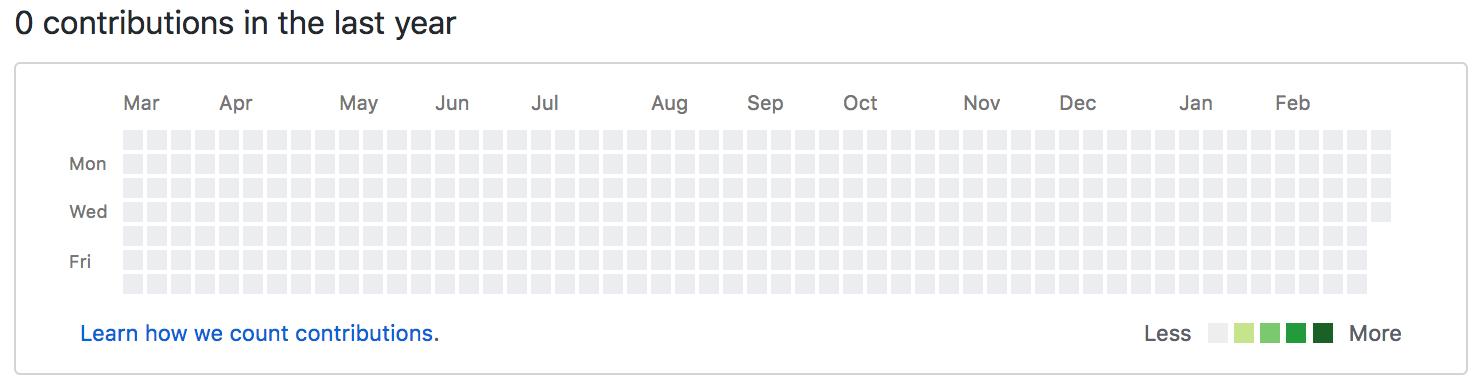
Один из моих текущих проектов связан со сбором данных из GitHub-профилей разработчиков. Профили GitHub затруднительно использовать как источник данных, поэтому хочу сразу перечислить проблемы при попытке оценить разработчика только по его вкладу на GitHub.
Есть несколько правильных статей, почему нельзя требовать от кандидатов профили GitHub. Особенно рекомендую «Этика неоплачиваемого труда и сообщество Open Source» и «Почему GitHub — не резюме». Обе статьи отлично объясняют причины, почему при найме не следует спрашивать о вкладе в свободные проекты. Но я не о том, что это неэтично или что GitHub не слишком подходит для демонстрации проектов.
Я о том, почему эти профили просто малополезны.
Разреженность данных
Если посмотрите публичный профиль лучшего инженера-программиста, с которым я когда-либо работал, то увидите примерно такое:
Один из моих текущих проектов связан со сбором данных из GitHub-профилей разработчиков. Профили GitHub затруднительно использовать как источник данных, поэтому хочу сразу перечислить проблемы при попытке оценить разработчика только по его вкладу на GitHub.
Есть несколько правильных статей, почему нельзя требовать от кандидатов профили GitHub. Особенно рекомендую «Этика неоплачиваемого труда и сообщество Open Source» и «Почему GitHub — не резюме». Обе статьи отлично объясняют причины, почему при найме не следует спрашивать о вкладе в свободные проекты. Но я не о том, что это неэтично или что GitHub не слишком подходит для демонстрации проектов.
Я о том, почему эти профили просто малополезны.
Разреженность данных
Если посмотрите публичный профиль лучшего инженера-программиста, с которым я когда-либо работал, то увидите примерно такое:
Иногда так случается, что возникает необходимость перейти на более новую версию ядра Linux и, соответственно, выполнить перенос уже существующих драйверов устройств.
Процесс переноса может занять от нескольких минут до более продолжительного промежутка времени. Зависит это не только от сложности драйвера, но и от того, с какой и на какую версию ядра вы собираетесь перейти (API имеет свойство меняться — отсюда лезут все проблемы), а также от качества реализации кода, бывает, что проще переписать, чем перенести, но об этом не будем.
К сожалению, я не могу прикрепить исходный код драйвера, но мы рассмотрим все проблемы, с которыми я и вы можете столкнуться в процессе переноса. Далее будет рассмотрен пример переноса простого драйвера c версии ядра 2.6.25 на 4.12.5, который расположен в drivers/serial/name_uart.c. Также нам очень поможет следующий ресурс 2.6.25 и 4.12.5, где можно посмотреть структуру ядра, а также исходные коды. Читать дальше ->
Иногда так случается, что возникает необходимость перейти на более новую версию ядра Linux и, соответственно, выполнить перенос уже существующих драйверов устройств.
Процесс переноса может занять от нескольких минут до более продолжительного промежутка времени. Зависит это не только от сложности драйвера, но и от того, с какой и на какую версию ядра вы собираетесь перейти (API имеет свойство меняться — отсюда лезут все проблемы), а также от качества реализации кода, бывает, что проще переписать, чем перенести, но об этом не будем.
К сожалению, я не могу прикрепить исходный код драйвера, но мы рассмотрим все проблемы, с которыми я и вы можете столкнуться в процессе переноса. Далее будет рассмотрен пример переноса простого драйвера c версии ядра 2.6.25 на 4.12.5, который расположен в drivers/serial/name_uart.c. Также нам очень поможет следующий ресурс 2.6.25 и 4.12.5, где можно посмотреть структуру ядра, а также исходные коды. Читать дальше ->
Существует классическая задача для собеседований, часто формулируемая следующим образом:
Имеется массив натуральных чисел. Каждое из чисел присутствует в массиве ровно два раза, и только одно из чисел не имеет пары. Необходимо предложить алгоритм, который за минимальное число проходов по массиву определяет число, не имеющее пары.
Полагаю, никто не обидится, если я тут же приведу и решение задачи: уникальный элемент будет совпадать с -суммой всех элементов массива, вычисляемой за линейное время.
Предлагаю поразмыслить над другой вариацией данной задачи. Что, если все элементы, кроме искомого, будут присутствовать в массиве не парами, а тройками? Насколько при этом усложнится решение и останется ли оно линейным?
Существует классическая задача для собеседований, часто формулируемая следующим образом:
Имеется массив натуральных чисел. Каждое из чисел присутствует в массиве ровно два раза, и только одно из чисел не имеет пары. Необходимо предложить алгоритм, который за минимальное число проходов по массиву определяет число, не имеющее пары.
Полагаю, никто не обидится, если я тут же приведу и решение задачи: уникальный элемент будет совпадать с -суммой всех элементов массива, вычисляемой за линейное время.
Предлагаю поразмыслить над другой вариацией данной задачи. Что, если все элементы, кроме искомого, будут присутствовать в массиве не парами, а тройками? Насколько при этом усложнится решение и останется ли оно линейным?
В начале этого года информация о процессорных уязвимостях Meltdown и Spectre стала первой громкой темой кибербезопасности 2018 года. Незащищенность кэша программных команд чипов Intel, AMD и Arm, выпущенных за последние 20 лет, привела к целой плеяде судебных тяжб и до сих пор обсуждается в СМИ. Как считают в Управлении перспективных исследовательских проектов Министерства обороны США (DARPA), 40% всех программных эксплойтов можно избежать, если устранить недостатки аппаратного обеспечения.
Поэтому в Управлении задумались над разработкой невзламываемого процессора, который бы сделал эксплойты невозможными. Грант на создание чипа получила команда из Мичиганского университета. В статье разберем, что уже известно о процессоре.
В начале этого года информация о процессорных уязвимостях Meltdown и Spectre стала первой громкой темой кибербезопасности 2018 года. Незащищенность кэша программных команд чипов Intel, AMD и Arm, выпущенных за последние 20 лет, привела к целой плеяде судебных тяжб и до сих пор обсуждается в СМИ. Как считают в Управлении перспективных исследовательских проектов Министерства обороны США (DARPA), 40% всех программных эксплойтов можно избежать, если устранить недостатки аппаратного обеспечения.
Поэтому в Управлении задумались над разработкой невзламываемого процессора, который бы сделал эксплойты невозможными. Грант на создание чипа получила команда из Мичиганского университета. В статье разберем, что уже известно о процессоре.
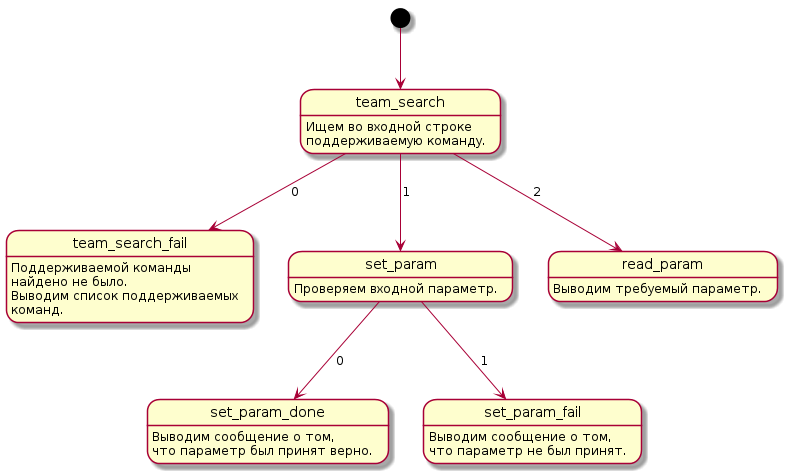
В моей практике часто возникали ситуации, когда применение конечного автомата являлось наиболее верным решением, однако от него приходилось отказываться ввиду срочности разработки, сложности поддержки, или же по каким-либо иным причинам. В этом посте мне хотелось бы поделиться с вами разработанным мною решением, позволяющим без труда встраивать в свои проекты конечные автоматы с возможностью наглядного отображения структуры дерева. Читать дальше ->
В моей практике часто возникали ситуации, когда применение конечного автомата являлось наиболее верным решением, однако от него приходилось отказываться ввиду срочности разработки, сложности поддержки, или же по каким-либо иным причинам. В этом посте мне хотелось бы поделиться с вами разработанным мною решением, позволяющим без труда встраивать в свои проекты конечные автоматы с возможностью наглядного отображения структуры дерева. Читать дальше ->
Привет, Хабр! Сегодня я решил поделиться с вами транскриптом второй части пятого выпуска подкаста «Правила игры», в котором мы общаемся с юристами и экспертами по налогам.
Привет, Хабр! Сегодня я решил поделиться с вами транскриптом второй части пятого выпуска подкаста «Правила игры», в котором мы общаемся с юристами и экспертами по налогам.
Прошло уже достаточно времени с момента публикации моей первой статьи на тему обработки естественного языка. Я продолжал активно исследовать данную тему, каждый день открывая для себя что-то новое.
Сегодня я бы хотел поговорить об одном из способов классификации поисковых запросов, по отдельным категориям с помощью нейронной сети на Keras. Предметной областью запросов была выбрана сфера автомобилей.
За основу был взят датасет размером ~32000 поисковых запросов, размеченных по 14ти классам: Автоистория, Автострахование, ВУ (водительское удостоверение), Жалобы, Запись в ГИБДД, Запись в МАДИ, Запись на медкомиссию, Нарушения и штрафы, Обращения в МАДИ и АМПП, ПТС, Регистрация, Статус регистрации, Такси, Эвакуация.Читать дальше ->
Прошло уже достаточно времени с момента публикации моей первой статьи на тему обработки естественного языка. Я продолжал активно исследовать данную тему, каждый день открывая для себя что-то новое.
Сегодня я бы хотел поговорить об одном из способов классификации поисковых запросов, по отдельным категориям с помощью нейронной сети на Keras. Предметной областью запросов была выбрана сфера автомобилей.
За основу был взят датасет размером ~32000 поисковых запросов, размеченных по 14ти классам: Автоистория, Автострахование, ВУ (водительское удостоверение), Жалобы, Запись в ГИБДД, Запись в МАДИ, Запись на медкомиссию, Нарушения и штрафы, Обращения в МАДИ и АМПП, ПТС, Регистрация, Статус регистрации, Такси, Эвакуация.Читать дальше ->
Мир пережил взрыв открытости. Начиная отдельными художниками, показывающими свои творения в ожидании вклада от других людей, заканчивая правительствами, которые требуют чтобы публично финансируемые работы были доступны для общественности. Как дух, так и практика совместного использования набирают обороты и дают результаты.
Creative Commons стали предоставлять лицензии для открытого обмена всего лишь десять лет назад. В настоящее время более 400 миллионов лицензий CC доступны в интернете: от музыки и фотографий до результатов исследований и целых курсов колледжа. Creative Commons создала юридическую и техническую инфраструктуру, которая позволяет эффективно использовать знания, искусство и данные отдельными лицами, организациями и правительством. А самое главное, что миллионы создателей использовали эту инфраструктуру для обмена работами, которые обогащают глобальное достояние для всего человечества. Читать дальше ->
Мир пережил взрыв открытости. Начиная отдельными художниками, показывающими свои творения в ожидании вклада от других людей, заканчивая правительствами, которые требуют чтобы публично финансируемые работы были доступны для общественности. Как дух, так и практика совместного использования набирают обороты и дают результаты.
Creative Commons стали предоставлять лицензии для открытого обмена всего лишь десять лет назад. В настоящее время более 400 миллионов лицензий CC доступны в интернете: от музыки и фотографий до результатов исследований и целых курсов колледжа. Creative Commons создала юридическую и техническую инфраструктуру, которая позволяет эффективно использовать знания, искусство и данные отдельными лицами, организациями и правительством. А самое главное, что миллионы создателей использовали эту инфраструктуру для обмена работами, которые обогащают глобальное достояние для всего человечества. Читать дальше ->

 Читать дальше ->
Читать дальше ->
 Читать дальше ->
Читать дальше ->








