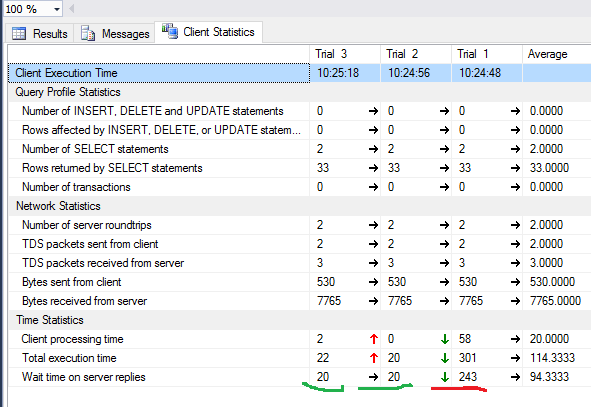
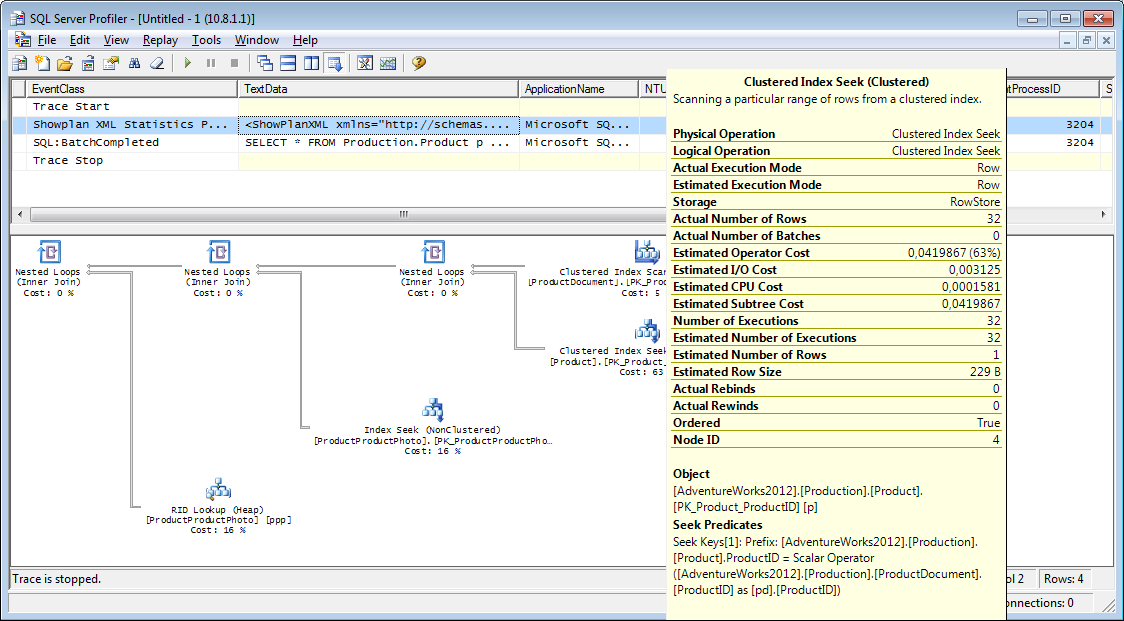
Некоторое время назад я восхитился от команды Facebook-а, запилившей для целей мониторинга специальную базу — RocksDB. При внимательном рассмотрении оказалось, что оно форк более раннего гугловского проекта, оно архивирует данные налету и оно, будучи «в душе» NoSQL, стыкуется к MySQL как storage engine.
Дальше прилетела новость, что MariaDB включили этот движок в upstream с версии 10.2. Ништяки вроде архивирования на лету и ttl на отдельные строки под капотом так и манили попробовать это на чем-то подходящем…
Подходящим генератором данных в моем хозяйстве оказался zabbix, который к тому же решили перетянуть на новое железо. Но «из коробки» zabbix про rocksdb не в курсе, так что пришлось пошаманить и потестировать. Если интересны результаты и выводы —
Ограничения
Первая проблема, вылезшая при планировании — myrocks не умеет CONSTRAINT FOREIGN KEY. Не умеет, и всё. И не планируется. NoSQL, однако. Казалось бы, на этом можно свернуть всю затею, но внимательный взгляд на схему данных zabbix-а показывает, что самые горячие таблицы — history_uint, history_text, history_log и history_str — куда, собственно, прилетают данные из всех щелей источников, не содержат внешних ключей. Вероятно, команда zabbix сделала это осознанно, чтобы упростить эти таблицы — но нам это только на руку.
Тут стоит упомянуть, что создатели myrocks не рекомендуют использовать микс из двух storage engine-ов в одном приложении, ссылаясь на то, что транзакции не будут атомарными в этом случае.
Но внимательное разглядывание вывода grep -r 'history_uint' zabbix-3.2.5 приводит к выводу, что хоть zabbix и учиняет транзакции при добавлении значений, внутри этих транзакций он не трогает других таблиц (зачем бы ему, действительно?) — так что пролезаем.
Ещё нужно поменять collation на табличках, которые мы переносим на rocksdb на latin1_bin или utf8_bin. И вообще — от кодировки latin1 лучше избавиться. В итоге получился вот такой perl-скриптик для преобразования дампа:
По неясным пока причинам, net-snmp из debian приводит к нерабочей сборке zabbix — valgrind ругается на утечки памяти там, где всё должно работать вполне линейно. В итоге заббикс падает.
Спасает — переборка net-snmp из исходников с наложением почти всех debian-овских патчей.
У меня собрался net-snmp-code-368636fd94e484a5f4be5c0fcd205f507463412a.zip
Возможно, более свежие тоже собирутся.
Ещё понадобится debian-овский архивчик с директорией debian.
Дальше как-то так:
version=368636fd94e484a5f4be5c0fcd205f507463412a
debian_version=net-snmp_5.7.2.1+dfsg-1.debian.tar.xz
unzip -q net-snmp-code-${version}.zip
cd net-snmp-code-${version}
tar -xvJf ../$debian_version
for i in 03_makefiles.patch 26_kfreebsd.patch 27_kfreebsd_bug625985.patch fix_spelling_error.patch fix_logging_option.patch fix_man_error.patch after_RFC5378 fix_manpage-has-errors_break_line.patch fix_manpage-has-errors-from-man.patch agentx-crash.patch TrapReceiver.patch ifmib.patch CVE-2014-3565.patch; do
rm debian/patches/$i
touch debian/patches/$i
done
cp ../rules debian/rules
dpkg-buildpackage -d -b
cd ..
dpkg -i *.deb
Фокус с rules-файлом — я в нём выключил --with-mysql (заменил на --without-mysql), чтобы не привязывать net-snmp к mysql — тогда при экспериментах с версиями mariadb не нужно пересобирать net-snmp. Можно и опустить.
Сборка zabbix
Сам zabbix приходится собирать уже после установки mariadb, так как он линкуется к динамическим библиотекам, прилетающим с ней. У меня получилось как-то так:
zabbixversion="3.2.7"
apt-get install libsnmp-dev libcurl4-openssl-dev python-requests
if [ ! -f zabbix-${zabbixversion}.tar.gz ]; then
wget https://downloads.sourceforge.net/project/zabbix/ZABBIX%20Latest%20Stable/${zabbixversion}/zabbix-${zabbixversion}.tar.gz
tar -xvzf zabbix-${zabbixversion}.tar.gz
fi
cd zabbix-${zabbixversion}
groupadd zabbix
useradd -g zabbix zabbix
sed -i 's/mariadbclient/mariadb/' configure
./configure --enable-proxy --enable-server --enable-agent --with-mysql --enable-ipv6 --with-net-snmp --with-libcurl --with-libxml2
make -j5
make install
Профит — удалось уменьшить аппетиты заббикса к месту, отказаться от ротации табличек по схеме «create partition/drop partition» — теперь housekeeper справляется со своей задачей сам (по крайней мере, на ssd-диске, хех. Тут бы проверить на innodb в свежей сборочке, но пока не успелось) и срок хранения данных вновь стал управляемым для каждого элемента данных по отдельности. При массовых проблемах очередь вычищается теперь в разы быстрее.
Что не опробовано (ровно потому, что housekeeper завёлся) — добавить в свойства табличек history* и trends* волшебную штуку COMMENT='ttl_duration=864000;ttl_col=clock;' имеющую, насколько я понял, смысл «хранить не более 864000 секунд, чистить на уровне storage engine».
Да, пока я всё это тестил и прикручивал, заббикс успел выкатить версию 3.4, на ней я всё это не проверял, но что-то мне подсказывает, что должно работать.
Полезные доки, которые пригодились при написании статьи:
Прим. перев.: kube-spawn — достаточно новый (анонсированный в августе) Open Source-проект, созданный в немецкой компании Kinvolk для локального запуска Kubernetes-кластеров. Он написан на Go, работает с Kubernetes версий 1.7.0+, использует возможности kubeadm и systemd-nspawn, ориентирован только на операционную систему GNU/Linux. В отличие от Minikube, он не запускает виртуальную машину для Kubernetes, а значит, что overhead будет минимальным и все процессы, запущенные внутри контейнеров, видны на хост-машине (в т.ч. и через top/htop). Представленная ниже статья — анонс этой утилиты, опубликованный одним из сотрудников компании (Chris K"uhl) в корпоративном блоге.
kube-spawn — инструмент для простого запуска локального кластера Kubernetes из множества узлов на Linux-машине. Изначально он создавался преимущественно для разработчиков самого Kubernetes, однако со временем превратился в утилиту, которая отлично подходит для того, чтобы попробовать и изучить Kubernetes. Эта статья предлагает общее введение в kube-spawn и показывает, как использовать этот инструмент.
Обзор
kube-spawn задаётся целью стать простейшим способом проведения тестов и других экспериментов с Kubernetes в Linux. Этот проект появился из-за сложностей, возникавших при запуске Kubernetes-кластера со множеством узлов на машинах для разработки. Утилиты, предлагающие нужную функциональность, обычно не предоставляют окружения, в которых Kubernetes будет впоследствии запущен, то есть полноценную операционную систему GNU/Linux.
Запуск кластера Kubernetes с kube-spawn
Итак, давайте запустим кластер. В kube-spawn достаточно одной команды, чтобы получить образ Container Linux, подготовить узлы (nodes) и развернуть кластер. Эти шаги можно выполнить отдельно с помощью machinectl pull-raw и подкоманд kube-spawn setup и init. Однако подкоманда up сделает всё за нас:
$ sudo GOPATH=$GOPATH CNI_PATH=$GOPATH/bin ./kube-spawn up --nodes=3
Когда команда закончит выполняться, вы получите кластер Kubernetes с 3 узлами. Придётся подождать, пока узлы будут готовы для использования.
$ export KUBECONFIG=$GOPATH/src/github.com/kinvolk/kube-spawn/.kube-spawn/default/kubeconfig
$ kubectl get nodes
NAME STATUS AGE VERSION
kube-spawn-0 Ready 1m v1.7.0
kube-spawn-1 Ready 1m v1.7.0
kube-spawn-2 Ready 1m v1.7.0
Теперь видно, что все узлы готовы. Двигаемся дальше.
Демонстрационное приложение
Работоспособность кластера мы проверим, развернув демонстрационное микросервисное приложение Sock Shop, созданное в Weaveworks. Sock Shop — сложное приложение, состоящее из микросервисов и использующее множество компонентов, которые обычно можно найти в реальных инсталляциях. Таким образом, оно позволяет проверить, что всё действительно работает, и даёт более существенную почву для исследований, чем простое «hello world».
Клонирование приложения
Чтобы продолжить, понадобится склонировать репозиторий microservices-demo и перейти в каталог deploy/kubernetes:
$ cd ~/repos
$ git clone https://github.com/microservices-demo/microservices-demo.git sock-shop
$ cd sock-shop/deploy/kubernetes/
Деплой приложения
Теперь всё готово для деплоя. Но первым делом необходимо создать пространство имён sock-shop — в deployment предполагается его наличие:
$ kubectl create namespace sock-shop
namespace "sock-shop" created
Теперь всё по-настоящему готово для деплоя приложения:
$ kubectl create -f complete-demo.yaml
deployment "carts-db" created
service "carts-db" created
deployment "carts" created
service "carts" created
deployment "catalogue-db" created
service "catalogue-db" created
deployment "catalogue" created
service "catalogue" created
deployment "front-end" created
service "front-end" created
deployment "orders-db" created
service "orders-db" created
deployment "orders" created
service "orders" created
deployment "payment" created
service "payment" created
deployment "queue-master" created
service "queue-master" created
deployment "rabbitmq" created
service "rabbitmq" created
deployment "shipping" created
service "shipping" created
deployment "user-db" created
service "user-db" created
deployment "user" created
service "user" created
После выполнения этих операций надо подождать, пока появятся все поды:
Когда все они готовы, останется выяснить, по какому порту и IP-адресу заходить, чтобы получить доступ к магазину. Чтобы узнать порт, давайте посмотрим, куда пробрасываются службы фронтенда:
Видно, что фронтенд (front-end) использует порт 30001 и внешний IP-адрес. Это означает, что мы можем достучаться до его служб через IP-адрес любого рабочего узла (worker) и порт 30001. Узнать IP-адреса всех узлов кластера можно через machinectl:
$ machinectl
MACHINE CLASS SERVICE OS VERSION ADDRESSES
kube-spawn-0 container systemd-nspawn coreos 1492.1.0 10.22.0.137...
kube-spawn-1 container systemd-nspawn coreos 1492.1.0 10.22.0.138...
kube-spawn-2 container systemd-nspawn coreos 1492.1.0 10.22.0.139...
Запомните, что первый узел — это мастер, а все остальные — рабочие узлы (workers). В нашем случае достаточно открыть браузер и зайти по адресу 10.22.0.138:30001 или 10.22.0.139:30001, где нас поприветствует магазин, продающий носки.
Остановка кластера
Когда покупки носков закончены, можете остановить кластер:
$ sudo ./kube-spawn stop
2017/08/10 01:58:00 turning off machines [kube-spawn-0 kube-spawn-1 kube-spawn-2]...
2017/08/10 01:58:00 All nodes are stopped.
Демонстрация с инструкциями
Для тех, кто предпочитает «экскурсии с гидом», смотрите видео на YouTube(около 7 минут на английском языке — прим. перев.).
Как упомянуто в видео, kube-spawn создаёт в текущей директории каталог .kube-spawn, в котором вы найдёте несколько файлов и директорий в default. Чтобы не ограничиваться размером каждого OS Container, мы монтируем сюда /var/lib/docker каждого узла. Благодаря этому мы можем использовать дисковое пространство хостовой машины. Наконец, на данный момент у нас нет команды очистки (clean). Желающие полностью замести следы деятельности kube-spawn могут выполнить команду rm -rf .kube-spawn/.
Заключение
Надеемся, вы тоже найдёте утилиту kube-spawn полезной. Для нас это простейший путь проверить изменения в Kubernetes или развернуть кластер для изучения Kubernetes.
В kube-spawn всё ещё можно привнести многочисленные улучшения (и некоторые из них весьма очевидны). Очень приветствуем pull requests!
P.S. от переводчика. Об установке и других особенностях kube-spawn написано в GitHub-репозитории проекта. Читайте также в нашем блоге:
Мой перевод, как и оригинальный доклад вызвали неоднозначную реакцию в комментариях. Поэтому я решил перевести статью-ответ дяди Боба на оригинальный материал.
Множество программистов на протяжении последних лет утверждают, что ООП и ФП — являются взаимоисключающими. С высоты башни из слоновой кости в облаках, ФП-небожители иногда поглядывают вниз на бедных наивных ООП-программистов и снисходят до надменных комментариев. Приверженцы ООП в свою очередь косо смотрят на «функционыльщиков», не понимая, зачем чесать левое ухо правой пяткой.
Эти точки зрения игнорируют саму суть ООП и ФП парадигм. Вставлю свои пять копеек.
ООП не про внутреннее состояние
Объекты (классы) – не структуры данных. Объекты могут использовать структуры данных, но их детали реализации скрыты. Вот почему существуют приватные члены классов. Извне вам доступны только методы (функции), поэтому объекты про поведение, а не состояние.
Использование объектов в качестве структур данных – признак плохого проектирования. Инструменты, вроде Hibernate называют себя ORM. Это некорректно. ORM не отображают реляционные данные на объекты. Они отображают реляционные данные на структуры данных. Эти структуры – не объекты. Объекты группируют поведение, а не данные.
Думаю, здесь дядя Боб ругает ORM за то они часто подталкивают к анемичной модели, а не к богатой.
Функциональные программы, как и объектно-ориентированные являются композицией функций преобразования данных. В ООП принято объединять данные и поведение. И что? Это действительно так важно? Есть огромная разница между f(o), o.f() и (f o)? Что, вся разница в синтаксисе. Так в чем же настоящие различия между ООП и ФП? Что есть в ООП, чего нет в ФП и наоборот?
ФП навязывает дисциплину в присвоение (immutability)
В «тру фп» нет оператора присвоения. Термин «переменная» вообще не применим к функциональным ЯП, потому что однажды присвоив значение его нельзя изменить.
Да. Да. Апологеты ФП часто указывают на то что функции – объекты первого класса. В Smalltalk функции – тоже объекты первого класса. Smaltalk – объектно-ориентированный, а не функциональный язык.
Ключевое отличие не в этом, а в отсутствии удобного оператора присваивания. Значит ли это, в ФП вообще нет изменяемого состояния? Нет. В ФП языках есть всевозможные уловки, позволяющие работать с изменяемым состоянием. Однако, чтобы сделать это, вам придется совершить определенную церемонию. Изменение состояния выглядит сложным, громоздким и чужеродным в ФП. Это исключительная мера, к которой прибегают лишь изредка и неохотно.
ООП навязывает дисциплину в работе с указателями на функции
ООП предлагает полиморфизм в качестве замены указателей на функции. На низком уровне полиморфизм реализуется с помощью указателей. Объектно-ориентированные языки просто делают эту работу за вас. И это здорово, потому что работать с указателями на функции напрямую (как в C) неудобно: всей команде необходимо придерживаться сложных и неудобных соглашений и следовать им в каждом случае. Обычно, это просто не реалистично.
В Java все функции виртуальные. Это значит, что все функции в Java вызываются не напрямую, а с помощью указателей на функции.
Если вы хотите использовать полиморфизм в C вам придется работать с указателями вручную и это сложно. Хотите полиморфизм в Lisp: придется передавать функции в качестве аргументов самостоятельно (кстати, это называется паттерном стратегия). Но в объектно-ориентированных языках все это есть из коробки: бери и пользуйся.
Взаимоисключающие?
Являются две эти дисциплины взаимоисключающими? Может ли ЯП навязывать дисциплину в присваивании и при работе с указателями на функции. Конечно может! Эти вещи вообще не связаны. Эти парадигмы – не взаимоисключающие. Это значит, что можно писать объектно-ориентированные функциональные программы.
Это также значит, что принципы и паттерны ООП могут использоваться и в функциональных программах, если вы принимаете дисциплину «указателей на функции». Но зачем это «функциональщикам»? Какие новые преимущества это им даст? И что могут получить объектно-ориентированные программы от неизменяемости.
Преимущества полиморфизма
У полиморфизма всего одно преимущество, но оно значительно. Это инверсия исходного кода и рантайм-зависимостей.
В болшинстве систем когда одна функция вызывает другую, рантайм-зависимости и зависимости на уровне исходного кода однонаправленны. Вызывающий модуль зависит от вызываемого модуля. Но в случае полиморфизма вызывающий модуль все еще зависит от вызываемого в рантайме, но исходный код вызываемого модуля не зависит от исходного кода вызываемого модуля. Вместо этого оба модуля зависят от полиморфного интерфейса.
Эта инверсия позволяет вызываемого модулю вести себя как плагину. Действительно, плагины так и работают. Архитектура плагинов крайне надежна, потому что стабильные и важные бизнес-правила могут храниться отдельно от подверженных изменениям и не столь важных правил.
Таким образом, для надежности системы должны применять полиморфизм, чтобы создать значимые архитектурные границы.
Преимущества неизменяемости
Преимущества неизменяемых данных очевидны – вы не столкнетесь с проблемами одновременных обновлений, если вы никогда ничего не обновляете.
Так как большинство функциональных ЯП не предлагает удобного оператора присвоения, в таких программах нет значительных изменений внутреннего состояния. Мутации зарезервированы для специфических ситуаций. Секции, содержащие прямое изменение состояния, могут быть отделены от многопоточного доступа.
Итого, функциональные программы гораздо безопаснее в многопоточной и многопроцессорной средах.
Занудные философствования
Конечно приверженцы ООП и ФП будут против моего редукционистского анализа. Они будут настаивать на том, что существуют значительные философские, филологические и математические причины, почему их любимый стиль лучше другого. Моя реакция следующая: Пфффф! Все думают, что их подход лучше. И все ошибаются.
Так что там про принципы и паттерны?
Что вызвало у меня такое раздражение? Первые слайды намекают на то что все принципы и паттерны, разработанные нами за десятилетия работы применимы только для ООП. А в ФП все решается просто функциями.
Вау, и после этого вы что-то говорите про редукционизм? Идея проста. Принципы остаются неизменными, независимо от стиля программирования. Факт, что вы выбрали ЯП без удобного оператора присвоения, не значит, что вы можете игнорировать SRP или OCP, что эти принципы будут каким-то образом работать автоматически. Если паттерн «Стратегия» использует полиморфизм, это еще не значит, что он не может применяться в функциональном ЯП (например Clojure).
Итого, ООП работает, если вы знаете, как его готовить. Аналогично для ФП. Функциональные объектно-ориентированные программы – вообще отлично, если вы действительно понимаете, что это значит.
Так сложилось, что в нашем коллективе добрых, милых и отзывчивых математиков (ДМОиМ) в качестве языка общего назначения используется Ceylon. Будучи отзывчивыми, мы не только используем этот язык, но и участвуем в его развитии, преимущественно багрепортами. С пулреквестами хуже, и первая причина тому: отсутствие в офисе прямого доступа в интернет, только через прокси-сервер. (Нулевая, конечно, нехватка времени.)
Под катом подробности о том, какие именно проблемы возникли при сборке проекта Ceylon из исходного кода и как они были решены. В конце так же несколько слов о её конечной цели.
Что вообще за слон такой
Для начала несколько слов о Ceylon, как о проекте. (Как о языке программирования, кому интересно, читайте тут.) Двумя базовыми подпроектами (помимо такого инструментария, как плагины к IDE, собственный репозиторий) в нём являются ceylon и ceylon-sdk. Первый включает в себя непосредственно компилятор и набор консольных утилит, написан на Java. Второй — набор базовых библиотек, написанных на самом Ceylon. Сборка каждого из проектов осуществляется с помощью Apache Ant, так же, конечно, необходима установленная JDK.
Компилятор собирается командой ant clean dist, после чего его из каталога dist/dist можно скопировать в /usr/local/share/ceylon или куда-нибудь ещё по вкусу и сделать ссылку на исполняемый файл в каталоге, который виден в $PATH. Библиотеки собираются и копируются куда надо командой ant clean publish.
При наличии прямого доступа в интернет (вкупе с нужными версиями Java, Ant и исходников Ceylon) сборка проходит без каких-либо затруднений.
Проблема по курсу
Требования безопасности в нашей компании предписывают отсутствие прямого доступа в интернет с рабочих станций и большинства серверов, предполагая, что локальных зеркал и прокси-сервера хватит на все случаи жизни. Но противоположные случаи, всё же, бывают. Ещё при настройке CI для собственных проектов коллегам пришлось из-за этого помучаться.
При сборке на открытой палубе голом железе рабочей станции компилятор собрался спокойно (может, все зависимости включены в проект, может, помогли ранее сделанные настройки), а вот набор библиотек никак не хотел собираться. Казалось бы, и шлюз-прокси есть, и резервуары с библиотеками (Ceylon Herd, Maven Nexus), но чего-то не хватает. Наверно, «солёных брызг, порывов бешеного ветра…» (c) Бараш.
Самое смешное, что система сборки требует Java-зависимость из Maven в формате Ceylon (car), которой там быть не должно в принципе.
Упаковка сборки в контейнер
Что такое контейнер, местная аудитория должна быть в курсе. Для проходящих мимо — ссылка.
Итак, не добившись успеха, я решил: соберу Ceylon и Ceylon SDK в открытом море на компьютере с прямым доступом в интернет и в контейнере доставлю эту сборку в офисную сеть. По идее, контейнер будет содержать в себе все зависимости, после чего можно будет править код для собственных нужд и пулреквестов и запускать пересборку.
В качестве промежуточного уровня был подготовлен образ с JDK.
Dockerfile был позаимствован из корпоративных конфигураций, для обобщения закомментировано создание русской локали. Основная его задача: установить Oracle JDK (через вспомогательную программу, в силу лицензии Oracle) и Maven, так же в начале обновляются, а в конце чистятся данные для APT. Ant тоже присутствует, видимо, как зависимость.
Следующий этап: делаем образ со сборкой Ceylon. При создании образа рядом с Dockerfile должнен быть каталог ceylon-sources, а в нём — проекты ceylon и ceylon-sdk. Сперва хотел засунуть git clone прямо в создание образа, но редактировать исходники мы будем локально, а клонировать два раза смысла нет.
Dockerfile kopilov/ceylon_build:1.3.4-SNAPSHOT
FROM kopilov/java8:latest
#Именно эту версию мы будем собирать
ENV CEYLON_VERSION 1.3.4-SNAPSHOT
#Повторно скачаем данные APT (их удаляли, чтобы образ был тоньше),
#установим git (он каким-то образом участвует в сборке)
#и netcat (он потребуется немного позже)
RUN apt-get update -y && \
apt-get install -y git && \
apt-get install netcat-traditional
#Копируем исходники с рабочей станции. Теоретически,
#тут может быть git clone, но это много трафика, который уже выкачан.
WORKDIR /usr/src/ceylon
ADD ceylon-sources /usr/src/ceylon
#Собираем компилятор, ставим в систему
WORKDIR /usr/src/ceylon/ceylon
RUN ant clean dist && \
cp -a dist/dist /usr/local/share/ceylon-${CEYLON_VERSION} && \
ln -s /usr/local/share/ceylon-${CEYLON_VERSION}/bin/ceylon /usr/local/bin
#Собираем библиотеки
WORKDIR /usr/src/ceylon/ceylon-sdk
RUN ant clean publish
#Удаляем ненужное
RUN apt-get clean && rm -rf /var/lib/apt/lists/*
Сборка данного образа пройдёт успешно только при наличии прямого доступа в интернет. Собрав, я разместил его на hub.docker.com.
Пересборка с закрытым каналом
Ожидается, что контейнер с готовой сборкой включает все зависимости, и интернет больше не потребуется. Запускаем docker run -it kopilov/ceylon_build, затем ant clean publish — как бы не так.
Ошибка на этот раз:
[ceylon-compile] /usr/src/ceylon/ceylon-sdk/source/ceylon/interop/spring/CeylonRepositoryImpl.java:12: error: Ceylon backend error: package org.springframework.transaction.annotation does not exist
[ceylon-compile] import org.springframework.transaction.annotation.Transactional;
[ceylon-compile] ^
[ceylon-compile] /usr/src/ceylon/ceylon-sdk/source/ceylon/interop/spring/CeylonRepositoryImpl.java:29: error: Ceylon backend error: cannot find symbol
[ceylon-compile] @Transactional(readOnly = true)
[ceylon-compile] ^
[ceylon-compile] symbol: class Transactional
[ceylon-compile] /usr/src/ceylon/ceylon-sdk/source/ceylon/interop/spring/CeylonRepositoryImpl.java:44: error: Ceylon backend error: cannot find symbol
[ceylon-compile] @Override @Ignore @Transactional
[ceylon-compile] ^
Такая же ошибка на компьютере, где был создан образ, если отключить доступ в интернет. Чего же не хватает ещё? Без акулы трафика не разобраться.
При выключенном доступе в интернет трафик из Docker выглядит в Wireshark так:
После нескольких неудачных попыток определить IP сервера repo1.maven.org отображается вышеуказанная ошибка. А вот что происходит, если подключение восстановить:
Парадокс: система делает GET-запрос, чтобы получить ответ с ошибкой 404, после чего спокойно продолжает сборку. А если ей этот запрос не выполнить, пользователю выдаётся, вроде бы, абсолютно ортогональная тому GET-запросу ошибка. Ниже можно заметить запросы на modules.ceylon-lang.org (aka Herd) по HTTPS, но сперва попробуем разобраться с первым.
Первое, что решено было сделать: добавить строку «127.0.0.1 repo1.maven.org» в файл /etc/hosts. Теперь надо как-то сымитировать ответ «404 NOT FOUND». Недавний хабрасерфинг показал, что в роли простейшего веб-сервера может выступить netcat (пруф). Перед запуском сборки (но после запуска контейнера) набираю в параллельном терминале
После этого запускаю сборку (ant), дожидаюсь появления в терминале с netcat GET-запроса, печатаю в ответ HTTP/1.1 404 NOT FOUND
Server: nc
Вуаля! Сборка пошла дальше! Потом система делает ещё один точно такой же запрос (при сборке под JavaScript), и процесс успешно завершён.
Автоматизация вышеописанного и доработка библиотеки
Подготовленный образ включал сборку оригинальной библиотеки Ceylon SDK, а конечной целью было собрать доработанную. Поэтому был был сделан ещё один Dockerfile, замещающий исходники:
FROM kopilov/ceylon_build:1.3.4-SNAPSHOT
ENV CEYLON_VERSION 1.3.4-SNAPSHOT
WORKDIR /usr/src/ceylon/ceylon-sdk
RUN rm -rf *
ADD ceylon-sources/ceylon-sdk .
Он должен был быть максимально простым (ведь образ пересоздаётся для каждой тестовой пересборки — почти для каждой правки исходников), именно поэтому установка netcat была выполнена заранее. Трюк с netcat был завёрнут в следующий скрипт (plug.sh):
Ещё скрипт, чтобы достать сборку из контейнера (get_built_ceylon.sh):
CONTAINER_ID=$(docker container ls -a | grep kopilov/ceylon_patch_src | sed 's/ .*//')
rm -r ~/.sdkman/candidates/ceylon/1.3.4-SNAPSHOT/
docker cp $CONTAINER_ID:/usr/local/share/ceylon-1.3.4-SNAPSHOT .
mv ceylon-1.3.4-SNAPSHOT /home/akopilov/.sdkman/candidates/ceylon/1.3.4-SNAPSHOT
rm -r ~/.ceylon/repo/
docker cp $CONTAINER_ID:/root/.ceylon/repo ~/.ceylon
Дальше тяга к рационализации иссякла, оставалось действовать вручную. После каждой правки исходников сперва в одной вкладке терминала запускать docker build -t kopilov/ceylon_patch_src . && docker run -it kopilov/ceylon_patch_src, потом в соседней ./plug.sh, потом опять в первой ant clean publish. И, если сборка прошла без ошибок (и если уже есть, чего тестировать) — ./get_built_ceylon.sh.
Результаты и истоки
Главным результатом проделанной работы «на перспективу» стала возможность нашей (а может, и не только) команды отправлять предварительно протестированные пулреквесты в апстрим проекта. На данный момент лично мной отправлен этот, написанный по ходу дела: github.com/ceylon/ceylon-sdk/pull/688
Образы Docker kopilov/java8 и kopilov/ceylon_build доступны на hub.docker.com, если вдруг кому-нибудь нужно.
А началось всё с того, что на прошедшей неделе у меня было на редкость мало срочных, и даже не очень срочных задач, даже начальник отдела куда-то уехал. И, уезжая, сказал: «Подумай, что ещё полезное можно прикрутить к твоему проекту.» (Проект находится на стадии прототипа.) И захотелось мне прикрутить интернационализацию, и не костылями, а готовым решением.
Касательно беспроводных сетей у ритейла свои запросы и своя специфика. На складе важно качество и бесшовность покрытия, чтобы работали сканеры меток и штрих-кодов. А в торговых залах частенько возникают трудности с подводом питания к роутерам и предъявляются отдельные требования к внешнему виду.
В этой статье мы обозначим несколько типовых ситуаций и покажем, где и какие из наших моделей корпоративного класса окажутся наиболее уместными.
Учет товарооборота, актуализация данных в базе наличия товаров, а также работа с другими внутренними корпоративными системами просто невозможны без постоянного доступа мобильных терминалов и другого оборудования в корпоративную сеть.
Конечно же, для работы мобильных терминалов наиболее удобной технологией подключения будет Wi-Fi. Очевидно, что для условий торговых залов и складских помещений подходит не любое оборудование — под каждый тип помещений нужно подбирать соответствующие модели устройств.
Торговые помещения обычно не предполагают сложных условий по температуре и влажности, а складские и производственные — могут ограничить выбор оборудования моделями для уличного использования. С другой стороны, если для производства и складов внешний вид оборудования не критичен, то в торговых помещениях именно он может играть первоочередную роль. В торговых центрах возможны и другие ограничения. Например, согласование прокладки линий питания для нестандартного (того же потолочного) оборудования может потребовать множество времени и ресурсов или вовсе оказаться невозможным. Соответственно, в таких случаях выбор оборудования сводится к списку моделей с поддержкой PoE.
Auranet
Auranet — это как раз наша попытка учесть все нюансы. В этой линейке можно найти модели как для помещений, так и для наружной установки. Использование оборудования одного производителя для всех возможных сценариев существенно упрощает настройку и дальнейшее администрирование сети, соответственно, позволяет снизить затраты как на внедрение, так и на поддержку. В линейке две серии: EAP и CAP. Поподробнее остановимся на каждой из них.
Точки доступа CAP300 и EAP225
Серии во многом похожи: и та, и другая имеют одно- и двухдиапазонные модели
и устройства для внутреннего и внешнего использования. Различаются EAP и CAP в первую очередь дизайном. Кроме того, в CAP можно использовать аппаратные контроллеры, поддерживающие до 500 управляемых точек доступа, в то время как в серии EAP — программный контроллер, который весьма функционален и при этом абсолютно бесплатен.
Любая серия позволяет создать сеть как для помещений, так и для уличных и складских условий с пониженной температурой и повышенной влажностью.
Типовая инфраструктура на оборудовании TP-Link
На самом деле, на практике использование единой сети на базе оборудования одной линейки оказывается очень удобным. На оборудовании одного вендора гораздо проще организовать единый доступ в сеть с постоянной зоной покрытия. Кроме того, поскольку часть оборудования, которым пользуются сотрудники, требует постоянного подключения к сети, важно не только обеспечить достаточное покрытие сети, но и возможность роуминга.
Терминалы-сканеры штрих-кодов сегодня стали основным инструментом учета товаров, и для оперативного отслеживания товарооборота они должны иметь постоянный доступ в корпоративную сеть. Более того, при переходе из зоны действия одной точки доступа в зону действия другой они должны автоматически и быстро переподключаться, не требуя от пользователей никаких действий. Только такой сценарий позволит избежать проблем в работе, потери времени сотрудников и отсутствия актуальной информации о наличии товаров и цен на них в базе данных. И, как следствие, дополнительных затрат и бессмысленных потерь.
Кстати, в ближайшее время в нашем ассортименте продуктов появится точка доступа CAP1200, поддерживающая протоколы бесшовного роуминга 802.11k и 802.11v, а позже будет добавлена и поддержка 802.11r. С новой точкой доступа подключения станут еще стабильнее, а работа – удобнее.
Типовая инфраструктура сети для ритейла и логистических компаний в большинстве случаев вполне традиционна. Заказчик приходит к внедрению беспроводной сети либо частично со своим оборудованием, которое планирует использовать в инфраструктуре, либо без всего. Конечно же, всегда проще и удобнее строить сеть с нуля. В любом случае типовой набор оборудования будет состоять из нескольких точек доступа для внутреннего или наружного использования, контроллера (возможно программного, если принято решение использовать нашу серию EAP), а также PoE-коммутатора, необходимого для подключения и питания точек доступа, а зачастую и другого оборудования.
Среди моделей коммутаторов высоким спросом пользуется TL-SG1008PE, имеющий восемь гигабитных портов с поддержкой PoE+ (до 30 Вт на порт). Эта модель заслужила популярность благодаря невысокой цене, отличному качеству, а также достаточному количеству портов для применения на небольших складах и магазинах. В целом коммутаторы с поддержкой PoE – один из основных компонентов, спрос на которые постоянно растет. Повышенная стоимость PoE-коммутаторов компенсируется отсутствием необходимости прокладки кабелей питания во все, даже самые далекие места, где устанавливается оборудование, например точки доступа. PoE также используется для питания камер видеонаблюдения, IP-телефонов и множества других устройств, но об этом в другой раз.
PoE-коммутатор TL-SG1008PE
Выбор точек доступа и контроллеров
Основные параметры, которые учитываются при выборе точек доступа, отличаются от проекта к проекту. Первоочередными являются способ подключения питания и поддержка стандартов беспроводной передачи данных. Так, в торговых центрах предпочтительнее выбирать модели с поддержкой PoE и беспроводной сети в диапазоне 5 ГГц. Кроме того, иногда возникают ситуации, когда оборудование 2,4 ГГц мешает уже имеющемуся оборудованию, работающему в этом же диапазоне, например сети датчиков, используемых для отслеживания состояний складских помещений. Тогда приходится ограничиваться использованием сетевого оборудования с поддержкой сети в диапазоне 5 ГГц.
Среди других особенностей точек доступа отметим Beamforming. Она позволяет увеличить зону действия сети за счет формирования диаграммы направленности, используя специфичные настройки передачи и конфигурацию антенн.
Выбор контроллеров в какой-то степени проще. Здесь либо выбирается программное решение для серии EAP, которое бесплатно и позволяет управлять сотнями точек доступа, либо аппаратные контроллеры серии CAP (AC500 или AC50, поддерживающие до 500 или до 50 точек доступа соответственно).
Программный контроллер EAP
У каждого из решений есть свои преимущества, недостатки, стоимость и поддержка устройств. Так что при выборе также следует внимательно изучить спецификации и учесть возможности масштабирования сети.
Wi-Fi контроллер Auranet AC500
Первоначальное детальное проектирование сети с учетом ее потенциального роста и числа подключенных устройств позволяет подобрать правильное оборудование ещё на начальном этапе. И про него надо не забывать.
Реализованные проекты у наших клиентов
Не сегодняшний день многие ритейловые компании используют в своих торговых зонах и логистических комплексах наше оборудование, о чем нам периодически сообщают партнеры. Среди них Zenden, Nanolek (склады), Лэтуаль, МЮЗ, Магнит, Перекресток и ряд других. Некоторые из них, опробовав оборудование в пилотных проектах на одной или нескольких собственных площадках, переходят к масштабному внедрению на всех своих точках присутствия.
Проекты развертывания беспроводных сетей в производственных и складских помещениях заказчиков, зачастую, имеют ряд интересных особенностей. Они используются для обеспечения доступа терминального оборудования к единой корпоративной системе учета товаров. И тут возникает задача покрытия больших территорий со сложными условиями распространения беспроводного сигнала. В таких случаях приходится задействовать большое число точек доступа и прорабатывать схему их расположения.
В одном из недавних проектов пришлось серьезно вложиться в разработку структуры сети именно с учетом непростых условий и геометрии помещений. К счастью, складские зоны, в которых преимущественно располагалась сеть, не везде требовали использования оборудования для наружного размещения, поскольку на складах заказчика поддерживается температура около 20 градусов, хотя есть и холодильные камеры с температурным режимом 4 или 8 градусов. При этом условия по влажности везде были благоприятные и не требовали наличия влагозащиты. В итоге для развертывания сети были выбраны точки доступа EAP225 и ЕАР контроллер для центрального управления. При этом первоначально были опробованы точки ЕАР115, но от них пришлось отказаться из-за работы другого оборудования в том же частотном диапазоне (2,4 ГГц). Компанией использовались различные датчики и устройства для контроля температуры на складе, которые, после установки точек доступа EAP115 стали работать нестабильно.
В итоге основная цель — обеспечение работы сканирующего штрих-коды оборудования — была достигнута. В процессе внедрения наши сотрудники помогали оперативно решать возникающие нетривиальные задачи, благодаря чему проект не затянулся, а был реализован в очень сжатые сроки.
Другой удачный пример связан с использованием технологии PoE. В одном из недавних проектов наши партнеры столкнулись с ситуацией, когда потолочное расположение точки доступа оказалось возможным лишь при использовании питания по кабелям Ethernet, поскольку подведение отдельной линии питания потребовало бы множества согласований и дополнительных работот. Благодаря PoE удалось существенно ускорить завершение пилотного проекта и значительно упростить дальнейшее обслуживание такого решения. В настоящий момент оборудование по аналогичной схеме установлено уже в 30 магазинах этого заказчика. В ближайшее время они планируют развернуть Wi-Fi сети еще в нескольких сотнях торговых помещений по всей России, используя опыт пилотного проекта, выполненного на точках доступа EAP115 и EAP245 и коммутаторах PoE TL-SG1008PE.
Точка доступа EAP-115 Wall
В целом это достаточно простые примеры, которые мы привели скорее для того, чтобы показать, что наш офис также принимает активное участие в работе с клиентами и партнерами. Чаще всего мы консультируем, принимаем фидбек и даже добавляем новые функции в прошивки по отдельным запросам. О чем мы подробно расскажем в одном из следующих постов.
Вначале немного о названии. Слово «GiST» намекает на определенную схожесть с одноименным методом. Схожесть действительно есть: и тот, и другой — generalized search trees, обобщенные деревья поиска, предоставляющие каркас для построения разных методов доступа.
«SP» расшифровывается как space partitioning, разбиение пространства. В роли пространства часто выступает именно то, что мы и привыкли называть пространством — например, двумерная плоскость. Но, как мы увидим, имеется в виду любое пространство поиска, по сути произвольная область значений.
SP-GiST подходит для структур, в которых пространство рекурсивно разбивается на непересекающиеся области. В этот класс входят деревья квадрантов (quadtree), k-мерные деревья (k-D tree), префиксные деревья (trie).
Устройство
Итак, идея индексного метода SP-GiST состоит в разбиении области значений на неперекрывающиеся подобласти, каждая из которых, в свою очередь, также может быть разбита. Такое разбиение порождает несбалансированные деревья (в отличие от B-деревьев и обычного GiST).
Свойство непересечения упрощает принятие решений при вставке и поиске. С другой стороны, получающиеся деревья, как правило, слабо ветвисты. Например, узел дерева квадрантов обычно имеет четыре дочерних узла (в отличие от B-деревьев, где они измеряются сотнями) и большую глубину. Такие деревья хорошо подходят для работы в оперативной памяти, но индекс хранится на диске, и поэтому для сокращения числа операций ввода-вывода узлы приходится паковать в страницы — а это непросто сделать эффективно. Кроме того, время поиска разных значений в индексе может отличаться из-за разной глубины ветвей.
Так же, как и GiST, этот метод доступа берет на себя заботу о низкоуровневых задачах (одновременный доступ и блокировки, журналирование, собственно алгоритм поиска) и позволяет добавлять поддержку новых типов данных и алгоритмов разбиения, предоставляя для этого специальный упрощенный интерфейс.
Внутренний узел дерева SP-GiST хранит ссылки на дочерние узлы; для каждой ссылки может быть задана метка. Кроме того, внутренний узел может хранить значение, называемое префиксом. На самом деле это значение не обязано быть именно префиксом; его можно рассматривать как произвольный предикат, выполняющийся для всех дочерних узлов.
Листовые узлы SP-GiST содержат значение индексированного типа и ссылку на строку таблицы (TID). В качестве значения могут использоваться сами индексированные данные (ключ поиска), но не обязательно: может храниться и сокращенное значение.
Кроме того, листовые узлы могут собираться в списки. Таким образом, внутренний узел может ссылаться не на одно единственное значение, а на целый список.
Заметим, что префиксы, метки и значения в листовых узлах все могут быть совершенно разных типов данных.
Как и в GiST, основной функцией, которую надо определить для поиска, является функция согласованности. Эта функция вызывается для узла дерева и возвращает набор дочерних узлов, значения которых «согласуются» с поисковым предикатом (как обычно, вида «индексированное-поле оператор выражение»). Для листового узла функция согласованности определяет, удовлетворяет ли индексированное значение в этом узле поисковому предикату.
Поиск начинается с корневого узла. С помощью функции согласованности выясняется, в какие дочерние узлы имеет смысл заходить; алгоритм повторяется для каждого из найденных узлов. Поиск производится в глубину.
На физическом уровне узлы индекса упакованы в страницы, чтобы с ними можно было эффективно работать с точки зрения операций ввода-вывода. При этом на одной странице оказываются либо внутренние узлы, либо листовые, но не те и другие одновременно.
Пример: дерево квадрантов
Дерево квадрантов (quadtree) используется для индексирования точек на плоскости. Идея состоит в рекурсивном разбиении области на четыре части (квадранта) по отношению к центральной точке. Глубина ветвей такого дерева может различаться и зависит от плотности точек в соответствующих квадрантах.
Вот как это выглядит на картинках на примере демо-базы, дополненной аэропортами с сайта openflights.org. Кстати, недавно мы выпустили новую версию базы, в которой, помимо прочего, заменили долготу и широту одним полем типа point.
Сначала делим плоскость на четыре квадранта...
Затем делим каждый из квадрантов...
И так далее, пока не получим итоговое разбиение.
Рассмотрим теперь подробнее простой пример, который нам уже встречался в части про GiST. Вот как может выглядеть разбиение плоскости в этом случае:
Квадранты нумеруются так, как показано на первом рисунке; для определенности будем располагать дочерние узлы слева направо именно в такой последовательности. Возможная структура индекса в этом случае показана на рисунке ниже. Каждый внутренний узел ссылается максимум на четыре дочерних узла. Каждую ссылку можно пометить номером квадранта, как на рисунке. Но в реализации метки нет; удобнее хранить фиксированный массив из четырех ссылок, некоторые из которых могут быть пустыми.
Точки, лежащие на границах, относятся к квадранту с меньшим номером.
postgres=# create index points_quad_idx on points using spgist(p);
CREATE INDEX
В данном случае по умолчанию используется класс операторов quad_point_ops, в который входят следующие операторы:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'quad_point_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
<<(point,point) | 1 строго слева
>>(point,point) | 5 строго справа
~=(point,point) | 6 совпадает
<^(point,point) | 10 строго сверху
>^(point,point) | 11 строго снизу
<@(point,box) | 8 содержится в прямоугольнике
(6 rows)
Рассмотрим, например, как будет выполняться запрос select * from points where p >^ point '(2,7)' (найти все точки, лежащие выше заданной).
Начинаем с корневого узла и выбираем, в какие дочерние узлы надо спускаться с помощью функции согласованности. Для оператора >^ эта функция сравнивает точку (2,7) с центральной точкой узла (4,4) и выбирает квадранты, в которых могут находиться искомые точки — в данном случае первый и четвертый.
В узле, соответствующем первому квадранту, снова определяем дочерние узлы с помощью функции согласованности. Центральная точка (6,6), и нам снова требуется просмотреть первый и четвертый квадранты.
Первому квадранту соответствует список листовых узлов (8,6) и (7,8), из которых под условие запроса подходит только точка (7,8). Ссылка на четвертый квадрант пуста.
У внутреннего узла (4,4) ссылка на четвертый квадрант также пуста, и на этом писк завершен.
postgres=# set enable_seqscan = off;
SET
postgres=# explain (costs off) select * from points where p >^ point '(2,7)';
QUERY PLAN
------------------------------------------------
Index Only Scan using points_quad_idx on points
Index Cond: (p >^ '(2,7)'::point)
(2 rows)
Внутри
Внутреннее устройство индексов SP-GiST можно изучать с помощью расширения gevel, про которое мы уже говорили ранее. Плохая новость: из-за ошибки расширение некорректно работает на современных версиях PostgreSQL. Хорошая новость: мы планируем перенести функциональность gevel в pageinspect (обсуждение). И ошибка там уже исправлена.
Для примера возьмем расширенную демо-базу, которая использовалась для рисования картинок с картой мира.
demo=# create index airports_coordinates_quad_idx on airports_ml using spgist(coordinates);
CREATE INDEX
Об индексе можно, во-первых, узнать некоторую статистическую информацию:
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_quad_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix point, -- тип префикса
node_label int, -- тип метки (в данном случае не используется)
leaf_value point -- тип листового значения
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------------+------------------
(1,1) | 0 | 1 | (5,3) | (-10.220,53.588) |
(1,1) | 1 | 1 | (5,2) | (-10.220,53.588) |
(1,1) | 2 | 1 | (5,1) | (-10.220,53.588) |
(1,1) | 3 | 1 | (5,14) | (-10.220,53.588) |
(3,68) | | 3 | | | (86.107,55.270)
(3,70) | | 3 | | | (129.771,62.093)
(3,85) | | 4 | | | (57.684,-20.430)
(3,122) | | 4 | | | (107.438,51.808)
(3,154) | | 3 | | | (-51.678,64.191)
(5,1) | 0 | 2 | (24,27) | (-88.680,48.638) |
(5,1) | 1 | 2 | (5,7) | (-88.680,48.638) |
...
Но имейте в виде. что функция spgist_print выводит не все листовые значения, а только первое из списка, и поэтому показывает структуру индекса, а не полное его содержимое.
Пример: k-мерные деревья
Для тех же точек на плоскости можно предложить и другой способ разбиения пространства.
Проведем через первую индексируемую точку горизонтальную линию. Она разбивает плоскость на две части: верхнюю и нижнюю. Вторая индексируемая точка попадает в одну из этих частей. Через нее проведем вертикальную линию, которая разбивает эту часть на две: правую и левую. Через следующую точку снова проводим горизонтальную линию, через следующую — вертикальную и так далее.
У всех внутренних узлов дерева, построенного таким образом, будет всего два дочерних узла. Каждая из двух ссылок может вести либо на следующий в иерархии внутренний узел, либо на список листовых узлов.
Метод легко обобщается на k-мерные пространства, поэтому и деревья в литературе называются k-мерным (k-D tree).
На примере аэропортов:
Сначала делим плоскость на верх и низ...
Затем каждую часть на лево и право...
И так далее, пока не получим итоговое разбиение.
Чтобы использовать именно такое разбиение, нужно при создании индекса явно указать класс операторов kd_point_ops:
postgres=# create index points_kd_idx on points using spgist(p kd_point_ops);
CREATE INDEX
В этот класс входят ровно те же операторы, что и в «умолчательный» quad_point_ops.
Внутри
При просмотре структуры дерева надо учесть, что префиксом в данном случае является не точка, а всего одна координата:
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_kd_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix float, -- тип префикса
node_label int, -- тип метки (в данном случае не используется)
leaf_value point -- тип листового значения
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------+------------------
(1,1) | 0 | 1 | (5,1) | 53.740 |
(1,1) | 1 | 1 | (5,4) | 53.740 |
(3,113) | | 6 | | | (-7.277,62.064)
(3,114) | | 6 | | | (-85.033,73.006)
(5,1) | 0 | 2 | (5,12) | -65.449 |
(5,1) | 1 | 2 | (5,2) | -65.449 |
(5,2) | 0 | 3 | (5,6) | 35.624 |
(5,2) | 1 | 3 | (5,3) | 35.624 |
...
Пример: префиксное дерево
С помощью SP-GiST можно реализовать и префиксное дерево (radix tree) для строк. Идея префиксного дерева в том, что индексируемая строка не хранится целиком в листовом узле, а получается конкатенацией значений, хранящихся в узлах вверх от данного до корня.
Допустим, надо проиндексировать адреса сайтов: «postgrespro.ru», «postgrespro.com», «postgresql.org» и «planet.postgresql.org».
postgres=# insert into sites values ('postgrespro.ru'),('postgrespro.com'),('postgresql.org'),('planet.postgresql.org');
INSERT 0 4
postgres=# create index on sites using spgist(url);
CREATE INDEX
Дерево будет иметь следующий вид:
Во внутренних узлах дерева хранятся префиксы, общие для всех дочерних узлов. Например, в дочках узла «stgres» значения начинаются на «p» + «o» + «stgres».
Каждый указатель на дочерний узел, в отличие от дерева квадрантов, дополнительно помечен одним символом (на самом деле двумя байтами, но это не так важно).
Класс операторов text_ops поддерживает операторы, традиционные для b-tree: «равно», «больше», «меньше»:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'text_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
~<~(text,text) | 1
~<=~(text,text) | 2
=(text,text) | 3
~>=~(text,text) | 4
~>~(text,text) | 5
<(text,text) | 11
<=(text,text) | 12
>=(text,text) | 14
>(text,text) | 15
(9 rows)
Операторы с тильдами отличаются тем, что работают не с символами, а с байтами.
В ряде случаев представление в виде префиксного дерева может оказаться существенно компактнее B-дерева за счет того, что значения не хранятся целиком, а реконструируются по мере необходимости при движении по дереву.
Рассмотрим запрос: select * from sites where url like 'postgresp%ru'. Он может быть выполнен с помощью индекса:
postgres=# explain (costs off) select * from sites where url like 'postgresp%ru';
QUERY PLAN
------------------------------------------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: ((url ~>=~ 'postgresp'::text) AND (url ~<~ 'postgresq'::text))
Filter: (url ~~ 'postgresp%ru'::text)
(3 rows)
Фактически по индексу находятся значения, большие или равные «postgresp» и в то же время меньшие «postgresq» (Index Cond), а затем из результата отбираются подходящие значения (Filter).
Сначала функция согласованности должна решить, в какие дочерние узлы корня «p» нужно спуститься. Есть два варианта: «p» + «l» (не подходит, даже не заглядывая дальше) и «p» + «o» + «stgres» (подходит).
Для узла «stgres» снова требуется обращение к функции согласованности, чтобы проверить «postgres» + «p» + «ro.» (подходит) и «postgres» + «q» (не подходит).
Для узла «ro.» и всех его дочерних листовых узлов функции согласованности ответит «подходит», так что индексный метод вернет два значения: «postgrespro.com» и «postgrespro.ru». Из них — уже на этапе фильтрации — будет выбрано одно подходящее значение.
Внутри
При просмотре структуры дерева надо учесть типы данных:
postgres=# select * from spgist_print('sites_url_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix text, -- тип префикса
node_label smallint, -- тип метки
leaf_value text -- тип листового значения
)
order by tid, n;
Свойства
Посмотрим на свойства метода доступа spgist (запросы приводились ранее):
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
spgist | can_order | f
spgist | can_unique | f
spgist | can_multi_col | f
spgist | can_exclude | t
Индксы SP-GiST не могут использоваться для сортировки и поддержки уникальности. Кроме того, такие индексы нельзя строить по нескольким столбцам (в отличие от GiST). Использование для поддержки ограничений исключения допускается.
Свойства индекса:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t
bitmap_scan | t
backward_scan | f
Здесь отличие от GiST состоит в отсутствии возможности кластеризации.
И, наконец, свойства уровня столбца:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | t
search_array | f
search_nulls | t
Поддержки сортировки нет, что понятно. Операторы расстояния для поиска ближайших соседей в SP-GiST пока не доступны; скорее всего такая поддержка появится в будущем.
SP-GiST может использоваться для исключительно индексного сканирования, по крайней мере для рассмотренных классов операторов. Как мы видели, в каких-то случаях индексированные значения непосредственно хранятся в листовых узлах, а в каких-то — восстанавливаются по частям при спуске по дереву.
Неопределенные значения
До сих пор мы ничего не говорили про неопределенные значения, чтобы не усложнять картину. Как видно из свойств индекса, NULL поддерживается. И действительно:
postgres=# explain (costs off)
select * from sites where url is null;
QUERY PLAN
----------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: (url IS NULL)
(2 rows)
Однако неопределенное значение для SP-GiST — нечто чужеродное. Все операторы, входящие в класс операторов метода spgist, должны быть строгими: для неопределенных параметров они должны возвращать неопределенный результат. Это обеспечивает сам метод; неопределенные значения просто не передаются операторам.
Но, чтобы метод доступа мог использоваться для исключительно индексного сканирования, неопределенные значения все-таки нужно хранить в индексе. Они и хранятся, но в отдельном дереве со своим собственным корнем.
Другие типы данных
Помимо точек и префиксных деревьев для строк, в PostgreSQL реализованы и другие методы на основе SP-GiST:
Дерево квадрантов для прямоугольников обеспечивает класс операторов box_ops.
Каждый прямоугольник представляется точкой в четырехмерном пространстве, так что число квадрантов равно 16. Такой индекс может выиграть у GiST по производительности, когда среди прямоугольников много пересечений: в GiST невозможно провести границы так, чтобы отделить пересекающиеся объекты друг от друга, а вот с точками (пусть и четырехмерными) таких проблем нет.
Дерево квадрантов для диапазонов предоставляет класс операторов range_ops. Интервал представляется двумерной точкой: нижняя граница становится абсциссой, а верхняя — ординатой.
Под катом будет небольшая заметка о применении пространственного индекса
на основе zcurve для индексации точечных данных, расположенных на сфере.
А так же bencmark-и для PostgreSQL и сравнение с таким же (но совсем другим)
индексом на R-дереве.
В развитие темы (1, 2, 3, 4, 5, 6).
Собственно, возвращаемся к самому началу — идее индексировать географические координаты, размещая их на поверхности сферы. Обычная индексация пары широта/долгота приводит к искажениям вдали от экватора, работа с проекциями не универсальна. Поэтому мысль переводить географические координаты в трехмерное пространство выглядит довольно изящно.
Сама по себе идея эта не нова, аналогично работает, например, расширение PostgreSQL — PGSphere, которое использует для индексации 3-мерное R-дерево. С ним и будем сравнивать.
Подготовка данных.
PGSphere
Для начала придётся выкачать, собрать и инсталлировать расширение (автор использовал текущую версию 1.1.5)
Нам потребуется источник случайных данных.
Первый параметр программы — радиус, второй — число результатов.
Единственная тонкость — данные равномерно распределены внутри шара с заданным радиусом, иначе не получится равномерного распределения на сфере
Случайные данные пропустим через скрипт awk чтобы превратить в геокоординаты
# --- gendata.awk ------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
r2 = sqrt(x*x + y*y);
lat = atan2(z, r2) * rad;
lon = 180. + atan2(y, x) * rad;
printf ("(%14.10fd, %14.10fd)\n", lon, lat);
}
Собственно создание данных, здесь радиус не важен, важно чтобы и pgsphere и zcurve получили одни и те же данные. Сортировка весьма желательна для ускорения индексации.
Случайные данные пропустим через скрипт awk чтобы разместить их внутри куба со стороной в 2 000 000
#--- gendata2.awk ------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
ix = int(x+0.5+Grad);
iy = int(y+0.5+Grad);
iz = int(z+0.5+Grad);
print ix"\t"iy"\t"iz;
}
Собственно создание данных, здесь радиус важен. Сортировка не обязательна.
create index zcurve_test_points_3d on test_points_3d(zcurve_num_from_xyz(x,y,z));
Подготовка тестов
PGSphere
Для тестирования потребуется вот такой awk скрипт
#--- gentest.awk -------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
r2 = sqrt(x*x + y*y);
lat = atan2(z, r2) * rad;
lon = 180. + atan2(y, x) * rad;
# EXPLAIN (ANALYZE,BUFFERS)
printf ("select count(1) from spoint_data where sp @'<(%14.10fd,%14.10fd),.316d>'::scircle;\n", lon, lat);
}
Этот скрипт вполне симметричен тому, с помощью которого мы подготавливали данные. Стоит обратить внимание на число .316, это радиус сферы с центром в вычисленной случайной точке, в которой мы ищем данные
Подготовка серии запросов делается так:
Здесь 100 — размер тестовой серии, 1023 — seed рандомизатора.
ZCURVE
Для тестирования тоже потребуется awk скрипт
#--- gentest2.awk -------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
ix = int(x+0.5+Grad);
iy = int(y+0.5+Grad);
iz = int(z+0.5+Grad);
# EXPLAIN (ANALYZE,BUFFERS)
lrad = int(0.5 + Grad * sin(.316 * degra));
print "select count(1) from zcurve_3d_lookup_tidonly('zcurve_test_points_3d', "ix-lrad","iy-lrad","iz-lrad","ix+lrad","iy+lrad","iz+lrad");";
}
Этот скрипт вполне симметричен тому, с помощью которого мы подготавливали данные. Опять же, обращаем внимание на число .316, это половина стороны куба с центром в вычисленной случайной точке, в котором мы ищем данные.
Здесь 100 — размер тестовой серии, 1023 — seed рандомизатора, лучше, если он совпадает с оным от pgsphere.
Benchmark
Как и раньше, замеры проводились на скромной виртуальной машине с двумя ядрами и 4 Гб ОЗУ, поэтому времена не имеют абсолютной ценности, а вот числам прочитанных страниц по прежнему можно доверять.
Времена показаны на вторых прогонах, на разогретом сервере и виртуальной машине. Количества прочитанных буферов — на свеже-поднятом сервере.
Radius
AVG NPoints
Nreq
Type
Time(ms)
Reads
Hits
.01°
1.17
0.7631
(0.7615)
10 000
zcurve
rtree
.37
.46
1.4397
2.1165
9.5647
3.087
.0316°
11.6
7.6392
(7.6045)
10 000
zcurve
rtree
.39
.67
2.0466
3.0944
20.9707
2.7769
.1°
115.22
76.193
(76.15)
1 000
zcurve
rtree
.44
2.75 *
4.4184
6.073
82.8572
2.469
.316°
1145.3
758.37
(760.45)
1 000
zcurve
rtree
.59
18.3 *
15.2719
21.706
401.791
1.62
1.°
11310
7602
(7615)
100
zcurve
rtree
7.2
94.5 *
74.9544
132.15
1651.45
1.12
где Radius — размер поисковой области в градусах Npoints — среднее число точек в выдаче, в скобках — теоретически ожидаемое число
(в сфере 41252.96 кв. градусов, 100 000 000 точек, ~2424 точки на кв. градус) Nreq — число запросов в серии Type —
‘zcurve’ — оно и есть
’rtree’- PGSphere Time(ms) — среднее время выполнения запроса Reads — среднее число чтений на запрос Hits — число обращений к буферам
* в какой-то момент производительность R-tree начинает резко
проседать, связано это с тем, это дерево читает заметно больше
страниц и его рабочий набор перестаёт помещаться в кэше (по-видимому).
Отметим, что zcurve находит больше данных, что логично т.к. он ищет внутри куба, а не сферы как PGSphere. Поэтому требуется пост-фильтрация в духе HAVERSINE. Но здесь мы сравниваем только производительности индексов.
Попробуем оценить разницу. Вообще, задача найти площадь куска сферы, попавшей внутрь куба нетривиальна. Попробуем сделать оценку.
Предположим, что наш куб в среднем вырезает из сферы ту же площадь, что и сфера равного объема
Объем единичной сферы 1.33*3.14=4.19
Объем куба со стороной 2 = 8.
Тогда корень третьей степени из 8/4.19 = 1.24 — это отношение радиусов мнимой сферы к настоящей
соотношение площадей мнимой сферы к настоящей 1.24*1.24=1.54
имеем из экспериментальных данных 1.17/0.7631= 1.5332
Bingo!
Задача следующая. Провести совместный просмотр ролика с YouTube в реальном времени несколькими пользователями. Зрители должны получать видео одновременно, с минимальной задержкой.
Ролик как стрим
Понятно, что если каждый из зрителей просто начнет играть ролик, цель не будет достигнута, т.к. один будет получать видео быстрее, другой медленнее. Возникнет неконтролируемый разброс.
Для того, чтобы разброса не было, нужно раздавать этот ролик всем одновременно. Это можно реализовать, если обернуть ролик в Live-stream. Покажем как это сделать с помощью связки этой библиотеки с ffmpeg.
Нам нужно реализовать схему, описанную выше. А именно, ydl подключается к YouTube и начинает скачивать ролик. FFmpeg подхватывает скачивающийся ролик, оборачивает его в RTMP поток и отправляет на сервер. Сервер раздает полученный поток как WebRTC в реальном времени.
Установка youtube-dl
Начинаем с установки youtube-dl. Процесс установки на Linux предельно простой и подробно описан в Readme под Lin и под Win.
[youtube] 9cQT4urTlXM: Downloading webpage
[youtube] 9cQT4urTlXM: Downloading video info webpage
[youtube] 9cQT4urTlXM: Extracting video information
[youtube] 9cQT4urTlXM: Downloading MPD manifest
[info] Available formats for 9cQT4urTlXM:
format code extension resolution note
171 webm audio only DASH audio 8k , vorbis@128k, 540.24KiB
249 webm audio only DASH audio 10k , opus @ 50k, 797.30KiB
250 webm audio only DASH audio 10k , opus @ 70k, 797.30KiB
251 webm audio only DASH audio 10k , opus @160k, 797.30KiB
139 m4a audio only DASH audio 53k , m4a_dash container, mp4a.40.5@ 48k (22050Hz), 10.36MiB
140 m4a audio only DASH audio 137k , m4a_dash container, mp4a.40.2@128k (44100Hz), 27.56MiB
278 webm 256x144 144p 41k , webm container, vp9, 30fps, video only, 6.54MiB
242 webm 426x240 240p 70k , vp9, 30fps, video only, 13.42MiB
243 webm 640x360 360p 101k , vp9, 30fps, video only, 20.55MiB
160 mp4 256x144 DASH video 123k , avc1.4d400c, 15fps, video only, 24.83MiB
134 mp4 640x360 DASH video 138k , avc1.4d401e, 30fps, video only, 28.07MiB
244 webm 854x480 480p 149k , vp9, 30fps, video only, 30.55MiB
135 mp4 854x480 DASH video 209k , avc1.4d401f, 30fps, video only, 42.42MiB
133 mp4 426x240 DASH video 274k , avc1.4d4015, 30fps, video only, 57.63MiB
247 webm 1280x720 720p 298k , vp9, 30fps, video only, 59.25MiB
136 mp4 1280x720 DASH video 307k , avc1.4d401f, 30fps, video only, 62.58MiB
17 3gp 176x144 small , mp4v.20.3, mp4a.40.2@ 24k
36 3gp 320x180 small , mp4v.20.3, mp4a.40.2
43 webm 640x360 medium , vp8.0, vorbis@128k
18 mp4 640x360 medium , avc1.42001E, mp4a.40.2@ 96k
22 mp4 1280x720 hd720 , avc1.64001F, mp4a.40.2@192k (best)
Установка ffmpeg
Далее устанавливаем ffmpeg стандартными заклинаниями:
wget http://ffmpeg.org/releases/ffmpeg-3.3.4.tar.bz2
tar -xvjf ffmpeg-3.3.4.tar.bz2
cd ffmpeg-3.3.4
./configure --enable-shared --disable-logging --enable-gpl --enable-pthreads --enable-libx264 --enable-librtmp
make
make install
Проверяем что получилось
ffmpeg -v
Теперь самое интересное. Библиотека youtube-dl предназначена для скачивания. Она так и называется YouTube Download. Т.е. Можно скачать youtube ролик полностью и уже после этого застримить его через ffmpeg как файл.
Но представим такой юзеркейс. Сидят в веб-конференции маркетолог, менеджер и программист. Маркетолог хочет показать всем в реальном времени ролик с YouTube, который весит, скажем 300 мегабайт. Согласитесь, возникнет некая неловкость, если нужно будет выкачать весь ролик перед тем, как начать его показ.
Маркетолог говорит — «А теперь, коллеги, давайте посмотрим этот ролик с котиками, он полностью отвечает нашей стратегии выхода на рынок», и жмет кнопку «показать всем ролик».
На экране появляется прелоадер: «Подождите, ролик с котиками скачивается. Это займет не более 10 минут».
Менеджер идет пить кофе, а программист — читать хабр.
Чтобы не заставлять людей ждать, нужен реалтайм. Нужно подхватывать ролик прямо во время скачивания, на лету оборачивать в стрим и раздавать в реальном времени. Далее мы покажем как это сделать.
Передача данных из youtube-dl в ffmpeg
Граббер youtube-dl сохраняет поток в файловой системе. Нужно подключиться к этому потоку и организовать зачитку из файла ffmpeg-ом по мере его скачивания с помощью youtube-dl.
Чтобы объединить эти два процесса: скачивание и стриминг ffmpeg, нам потребуется небольшой связывающий скрипт.
#!/usr/bin/python
import subprocess
import sys
def show_help():
print 'Usage: '
print './streamer.py url streamName destination'
print './streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM streamName rtmp://192.168.88.59:1935/live'
return
def streamer() :
url = sys.argv[1]
if not url :
print 'Error: url is empty'
return
stream_id = sys.argv[2]
if not stream_id:
print 'Error: stream name is empty'
return
destination = sys.argv[3]
if not destination:
print 'Error: destination is empty'
return
_youtube_process = subprocess.Popen(('youtube-dl','-f','','--prefer-ffmpeg', '--no-color', '--no-cache-dir', '--no-progress','-o', '-', '-f', '22/18', url, '--reject-title', stream_id),stdout=subprocess.PIPE)
_ffmpeg_process = subprocess.Popen(('ffmpeg','-re','-i', '-','-preset', 'ultrafast','-vcodec', 'copy', '-acodec', 'copy','-threads','1', '-f', 'flv',destination + "/" + stream_id), stdin=_youtube_process.stdout)
return
if len(sys.argv) < 4:
show_help()
else:
streamer()
Создает второй подпроцесс _ffmpeg_process, которому передаются данные из первого через pipe. Этот процесс уже создает RTMP поток и отправляет его на сервер по указанному адресу.
Тестирование скрипта
Для запуска скрипта нужно установить python. Скачать можно здесь.
Мы при тестировании использовали версию 2.6.6. Скорее всего подойдет любая версия, т.к. скрипт достаточно простой и его задача — передать из одного процесса в другой.
Имя потока, с которым будет проходить RTMP-трансляция.
stream1
Адрес RTMP-сервера.
rtmp://192.168.88.59:1935/live
Для тестирования мы будем использовать Web Call Server. Он умеет принимать RTMP потоки и раздавать их по WebRTC. Здесь можно скачать и установить WCS5 на свой VPS или локальный тестовый сервер под управлением Linux.
Схема тестирования с Web Call Server:
Ниже мы задействуем для теста один из демо-серверов:
rtmp://wcs5-eu.flashphoner.com:1935/live
Это RTMP адрес, который нужно передать скрипту streamer.py чтобы быстро протестировать трансляцию с нашим демо-сервером.
# python streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM stream1 rtmp://wcs5-eu.flashphoner.com:1935/live
ffmpeg version 3.2.3 Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 4.4.7 (GCC) 20120313 (Red Hat 4.4.7-11)
configuration: --enable-shared --disable-logging --enable-gpl --enable-pthreads --enable-libx264 --enable-librtmp --disable-yasm
libavutil 55. 34.101 / 55. 34.101
libavcodec 57. 64.101 / 57. 64.101
libavformat 57. 56.101 / 57. 56.101
libavdevice 57. 1.100 / 57. 1.100
libavfilter 6. 65.100 / 6. 65.100
libswscale 4. 2.100 / 4. 2.100
libswresample 2. 3.100 / 2. 3.100
libpostproc 54. 1.100 / 54. 1.100
]# [youtube] 9cQT4urTlXM: Downloading webpage
[youtube] 9cQT4urTlXM: Downloading video info webpage
[youtube] 9cQT4urTlXM: Extracting video information
[youtube] 9cQT4urTlXM: Downloading MPD manifest
[download] Destination: -
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'pipe:':
Metadata:
major_brand : mp42
minor_version : 0
compatible_brands: isommp42
creation_time : 2016-08-23T12:21:06.000000Z
Duration: 00:29:59.99, start: 0.000000, bitrate: N/A
Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], 288 kb/s, 30 fps, 30 tbr, 90k tbn, 60 tbc (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 125 kb/s (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Output #0, flv, to 'rtmp://192.168.88.59:1935/live/stream1':
Metadata:
major_brand : mp42
minor_version : 0
compatible_brands: isommp42
encoder : Lavf57.56.101
Stream #0:0(und): Video: h264 (Main) ([7][0][0][0] / 0x0007), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], q=2-31, 288 kb/s, 30 fps, 30 tbr, 1k tbn, 90k tbc (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream #0:1(und): Audio: aac (LC) ([10][0][0][0] / 0x000A), 44100 Hz, stereo, 125 kb/s (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream mapping:
Stream #0:0 -> #0:0 (copy)
Stream #0:1 -> #0:1 (copy)
frame= 383 fps= 30 q=-1.0 size= 654kB time=00:00:12.70 bitrate= 421.8kbits/s speed= 1x
Если бегло пробежать по этому логу, то можно понять, что происходит следующее:
Открывается страница с видеороликом.
Извлекаются данные о видео форматах.
Скачивается mp4 ролик 1280x720, H.264+AAC
Запускается ffmpeg, подхватывает скачиваемые данные и стримит по RTMP с битрейтом 421 kbps. Такой скудный битрейт объясняется выбранным роликом с таймером. Нормальный видеоролик даст на порядок большее значение битрейта.
После того, как процесс стриминга запустился, пытаемся проиграть поток в WebRTC плеере. Имя потока задается в поле Stream, а адрес сервера в поле Server. Подключение к серверу происходит по протоколу Websocket (wss), а поток приходит на плеер по WebRTC (UDP).
Мы специально взяли именно этот ролик на YouTube, чтобы иметь возможность протестировать реалтаймовость потока, ведь нашей конечной целью было доставить поток с YouTube ко всем зрителям одновременно, с минимальной задержкой и разбросом во времени. Ролик с миллисекундным таймером, как нельзя более подходит для такого теста.
Сам тест очень простой. Открываем две вкладки браузера (моделируем двух зрителей), играем этот поток с таймером по нашей схеме, и делаем несколько скриншотов, чтобы запечатлеть разницу во времени прибытия видео. Далее сравниваем миллисекунды и видим кто получил видео раньше, а кто позже и на сколько.
Получаем следующие результаты:
Test 1
Test 2
Test 3
Как видите, каждый из зрителей видит одно и то же видео, с разбросом не более 130 миллисекунд.
Таким образом задача реалтаймовой трансляции ролика с YouTube на WebRTC решена. Зрители получили поток практически одновременно. Менеджер не ушел пить кофе, программист — читать хабр, а маркетолог успешно показал всем ролик с котиками.
Хорошего стриминга!
Ссылки
youtube-dl — библиотека для скачивания видео с YouTube ffmpeg — RTMP encoder Web Call Server — сервер, умеющий раздвать RTMP поток по WebRTC streamer.py — скрипт для интеграции youtube-dl и ffmpeg с отправкой RTMP потока
как можно упростить поддержку DiffUtil в этой реализации;
как добавить поддержку вложенных RecyclerView.
Если прошлая статья тебе пришлась по душе, думаю, понравится и эта.
DiffUtil
Что такое DiffUtil, я думаю разбирать не стоит. Наверное, уже каждый разработчик опробовал его в своем проекте и получил приятные плюшки в виде анимации и производительности.
В первые дни после публикации первой статьи я получил пулл реквест с реализацией DiffUtil, давайте посмотрим как это реализовано. Напомню, что в результате оптимизации у нас получился адаптер с публичным методом setItems(ArrayList items). В данном виде не очень удобно использовать DiffUtil, нам необходимо где-то дополнительно сохранять старую копию списка, в результате мы получим что-то вроде этого:
...
final MyDiffCallback diffCallback = new MyDiffCallback(getOldItems(), getNewItems());
final DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(diffCallback);
mRecyclerViewAdapter.setItems(getNewItems());
diffResult.dispatchUpdatesTo(mRecyclerViewAdapter);
...
Классическая реализация DiffUtil.Callback
public class MyDiffCallback extends DiffUtil.Callback {
private final List mOldList;
private final List mNewList;
public MyDiffCallback(List oldList, List newList) {
mOldList = oldList;
mNewList = newList;
}
@Override
public int getOldListSize() {
return mOldList.size();
}
@Override
public int getNewListSize() {
return mNewList.size();
}
@Override
public boolean areItemsTheSame(int oldItemPosition, int newItemPosition) {
return mOldList.get(oldItemPosition).getID() == mNewList.get(
newItemPosition).getID();
}
@Override
public boolean areContentsTheSame(int oldItemPosition, int newItemPosition) {
BaseItemModel oldItem = mOldList.get(oldItemPosition);
BaseItemModel newItem = mNewList.get(newItemPosition);
return oldItem.equals(newItem);
}
@Nullable
@Override
public Object getChangePayload(int oldItemPosition, int newItemPosition) {
return super.getChangePayload(oldItemPosition, newItemPosition);
}
}
И расширенный интерфейс ItemModel:
public interface BaseItemModel extends ItemModel {
int getID();
}
В общем-то реализуемо и не сложно, но если это делать в нескольких местах, то стоит задуматься зачем столько много одинакового кода. Попробуем вынести общие моменты в свою реализацию DiffUtil.Callback:
public abstract static class DiffCallback extends DiffUtil.Callback {
private final List mOldItems = new ArrayList<>();
private final List mNewItems = new ArrayList<>();
void setItems(List oldItems, List newItems) {
mOldItems.clear();
mOldItems.addAll(oldItems);
mNewItems.clear();
mNewItems.addAll(newItems);
}
@Override
public int getOldListSize() {
return mOldItems.size();
}
@Override
public int getNewListSize() {
return mNewItems.size();
}
@Override
public boolean areItemsTheSame(int oldItemPosition, int newItemPosition) {
return areItemsTheSame(
mOldItems.get(oldItemPosition),
mNewItems.get(newItemPosition)
);
}
public abstract boolean areItemsTheSame(BM oldItem, BM newItem);
@Override
public boolean areContentsTheSame(int oldItemPosition, int newItemPosition) {
return areContentsTheSame(
mOldItems.get(oldItemPosition),
mNewItems.get(newItemPosition)
);
}
public abstract boolean areContentsTheSame(BM oldItem, BM newItem);
...
}
В общем получилось достаточно универсально, мы избавились от рутинны и сосредоточились на главных методах — areItemsTheSame() и areContentsTheSame(), которые обязательны к реализации и могут отличаться.
Реализация метода getChangePayload() намеренно пропущена, её реализацию можно посмотреть в исходниках.
Теперь мы можем добавить еще один метод с поддержкой DiffUtil в наш адаптер:
public void setItems(List items, DiffCallback diffCallback) {
diffCallback.setItems(mItems, items);
final DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(diffCallback);
mItems.clear();
mItems.addAll(items);
diffResult.dispatchUpdatesTo(this);
}
В общем то с DiffUtil это все, теперь при необходимости мы используем наш абстрактный класс — DiffCallback, и реализуем всего два метода.
Я думаю теперь мы разогрелись и освежили память, значит, можно перейти к более интересным вещам.
Вложенные RecyclerView
Часто по воле заказчика или веянию дизайнеров в нашем приложении появляются вложенные списки. До недавних пор я недолюбливал их, я сталкивался с такими проблемами:
сложность реализации ячейки, которая содержит RecyclerView;
сложность обновление данных во вложенных ячейках;
непереиспользуемость вложенных ячеек;
дублирование кода;
запутанность проброса кликов от вложенных ячеек в корневое место — Fragment/Activity;
Некоторые из этих проблем сомнительны и легко решаемы, а некоторые уйдут, если подключить наш оптимизированный адаптер из первой статьи :). Но, как минимум, сложность реализации у нас останется. Давайте сформулируем наши требования:
возможность легко добавлять новые типы вложенных ячеек;
переиспользуемость типа ячейки как для вложенного так и для основного элемента списка;
простота реализации;
Важно заметить, что здесь я разделил понятие ячейка и элемент списка: элемент списка — сущность используемая в RecyclerView. ячейка — набор классов, позволяющих отобразить один тип элемента списка, в нашем случае это реализация ранее известных классов и интерфейсов: ViewRenderer, ItemModel, ViewHolder.
И так, что мы имеем. Ключевым интерфесом у нас является ItemModel, очевидно что нам удобно будет далее с ним и работать. Наша композитная модель должна содержать в себе дочерние модели, добавляем новый интерфейс:
public interface CompositeItemModel extends ItemModel {
List getItems();
}
Выглядит неплохо, соответсвенно, композитный ViewRenderer должен знать о дочерних рендерерах — добавляем:
public abstract class CompositeViewRenderer extends ViewRenderer {
private final ArrayList mRenderers = new ArrayList<>();
public CompositeViewRenderer(int viewType, Context context) {
super(viewType, context);
}
public CompositeViewRenderer(int viewType, Context context, ViewRenderer... renderers) {
super(viewType, context);
Collections.addAll(mRenderers, renderers);
}
public CompositeViewRenderer registerRenderer(ViewRenderer renderer) {
mRenderers.add(renderer);
return this;
}
public void bindView(M model, VH holder) {}
public VH createViewHolder(ViewGroup parent) { return ...; }
...
}
Здесь я добавил два способа добавления дочерних рендереров, уверен, они нам пригодятся.
Так же обратите внимание на генерик CompositeViewHolder — это будет тоже отдельный класс для композитного ViewHolder, что там будет пока не знаю. А сейчас продолжим работу с CompositeViewRenderer, у нас осталось два обязательных метода — bindView(), createViewHolder(). В createViewHolder() нужно инициализировать адаптер и познакомить его с рендерами, а в bindView() сделаем простое, дефолтное обновление элементов:
public abstract class CompositeViewRenderer extends ViewRenderer {
private final ArrayList mRenderers = new ArrayList<>();
private RendererRecyclerViewAdapter mAdapter;
...
public void bindView(M model, VH holder) {
mAdapter.setItems(model.getItems());
mAdapter.notifyDataSetChanged();
}
public VH createViewHolder(ViewGroup parent) {
mAdapter = new RendererRecyclerViewAdapter();
for (final ViewRenderer renderer : mRenderers) {
mAdapter.registerRenderer(renderer);
}
return ???;
}
...
}
Почти получилось, как оказалось, для такой реализации в методе createViewHolder() нам нужен сам viewHolder, инициализировать мы его тут не можем — создаем отдельный абстрактный метод, заодно хотелось бы тут познакомить наш адаптер с RecyclerView, который мы можем взять у нереализованного CompositeViewHolder — реализуем:
public abstract class CompositeViewHolder extends RecyclerView.ViewHolder {
public RecyclerView mRecyclerView;
public CompositeViewHolder(View itemView) {
super(itemView);
}
}
public abstract class CompositeViewRenderer extends ViewRenderer {
public VH createViewHolder(ViewGroup parent) {
mAdapter = new RendererRecyclerViewAdapter();
for (final ViewRenderer renderer : mRenderers) {
mAdapter.registerRenderer(renderer);
}
VH viewHolder = createCompositeViewHolder(parent);
viewHolder.mRecyclerView.setLayoutManager(createLayoutManager());
viewHolder.mRecyclerView.setAdapter(mAdapter);
return viewHolder;
}
public abstract VH createCompositeViewHolder(ViewGroup parent);
protected RecyclerView.LayoutManager createLayoutManager() {
return new LinearLayoutManager(getContext(), LinearLayoutManager.HORIZONTAL, false);
}
...
}
Да, верно! Я добавил дефолтную реализацию с LinearLayoutManager :( посчитал что это принесет больше пользы, а при необходимости можно метод перегрузить и выставить другой LayoutManager.
Похоже что это все, осталось реализовать конкретные классы и посмотреть что получилось:
SomeCompositeItemModel
public class SomeCompositeItemModel implements CompositeItemModel {
public static final int TYPE = 999;
private int mID;
private final List mItems;
public SomeCompositeItemModel(final int ID, List items) {
mID = ID;
mItems = items;
}
public int getID() {
return mID;
}
public int getType() {
return TYPE;
}
public List getItems() {
return mItems;
}
}
SomeCompositeViewHolder
public class SomeCompositeViewHolder extends CompositeViewHolder {
public SomeCompositeViewHolder(View view) {
super(view);
mRecyclerView = (RecyclerView) view.findViewById(R.id.composite_recycler_view);
}
}
SomeCompositeViewRenderer
public class SomeCompositeViewRenderer extends CompositeViewRenderer {
public SomeCompositeViewRenderer(int viewType, Context context) {
super(viewType, context);
}
public SomeCompositeViewHolder createCompositeViewHolder(ViewGroup parent) {
return new SomeCompositeViewHolder(inflate(R.layout.item_composite, parent));
}
}
Регистрируем наш композитный рендерер:
public class SomeActivity extends AppCompatActivity {
protected void onCreate(final Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
...
SomeCompositeViewRenderer composite = new SomeCompositeViewRenderer(
SomeCompositeItemModel.TYPE,
this,
new SomeViewRenderer(SomeModel.TYPE, this, mListener)
);
mRecyclerViewAdapter.registerRenderer(composite);
...
}
...
}
Как видно из последнего семпла, для подписки на клики мы просто передаем необходимый интерфейс в конструктор рендерера, таким образом наше корневое место реализует этот интерфейс и знает о всех необходимых кликах
Пример проброса кликов
public class SomeViewRenderer extends ViewRenderer {
private final Listener mListener;
public SomeViewRenderer(int type, Context context, Listener listener) {
super(type, context);
mListener = listener;
}
public void bindView(SomeModel model, SomeViewHolder holder) {
...
holder.itemView.setOnClickListener(new View.OnClickListener() {
public void onClick(final View view) {
mListener.onSomeItemClicked(model);
}
});
}
...
public interface Listener {
void onSomeItemClicked(SomeModel model);
}
}
Заключение
Мы добились достаточной универсальности и гибкости при работе с вложенными списками, максимально упростили процесс добавления композитных ячеек. Теперь мы легко можем добавлять новые композитные ячейки и легко комбинировать одиночные ячейки во вложенных и основных списках.
Демонстрация, более детальная реализация и решения некоторых проблем доступны по ссылке.
«Сила машинного обучения окружает нас, методы её окружают нас и связывают. Сила вокруг меня, везде, между мной, тобой, решающим деревом, лассо, гребнем и вектором опорным»
Так бы, наверное, мне сказал Йода если бы он учил меня пути Data Science.
К сожалению, пока среди моих знакомых зеленокожие морщинистые личности не наблюдаются, поэтому просто продолжим вместе с вами наш совместный путь обучения науке о данных от уровня абсолютного новика до … настоящего джедая того, что в итоге получиться.
В прошлых двух статьях мы решали задачу классификации источников света по их спектру (на Python и C# соответственно). В этот раз попробуем решить задачу классификации светильников по их кривой силе света (по тому пятну которым они светят на пол).
Если вы уже постигли путь силы, то можно сразу скачать dataset на Github и поиграться с этой задачей самостоятельно. А вот всех, как и я новичков прошу подкат.
Благо задачка в этот раз совсем несложная и много времени не займет.
Очень хотелось начать оглавление разделов статьи с четвертого эпизода, но его название никак не вписывалось по смыслу.
Эпизод I: Скрытая угроза или что вам грозит если вы еще не прочитали весь предыдущий цикл статей.
Ну в принципе ничего не грозит, но если вы совсем новичок в науке о данных (Data Science), то я советую Вам все же посмотреть первые статьи в правильном хронологическом порядке, потому что это в некотором роде ценный опыт взгляда на Data Science глазами новичка, если бы мне пришлось сейчас описать свой путь, то я бы уже не смог вспомнить тех ощущений и часть проблем мне бы казалось совсем смешными. Поэтому, если вы только начали, посмотрите, как я мучался (и до сих пор мучаюсь) осваивая самые азы и вы поймете, что вы такой не один и все ваши проблемы в освоении машинного обучения и анализа данных вполне решаемы.
Итак, вот перечень статей в порядке появления (от первых к последним)
Эпизод II: Атака клонов или похоже, что эта задача не сильно отличается от прошлой.
Хм, всего второй заголовок, а я уже думаю, что тяжело будет и дальше придерживаться стиля.
Итак, напомню, что в прошлый раз мы с вами рассмотрели вопросы: создания своего собственного набора данных для задачи машинного обучения, обучения моделей классификаторов этих данных на примере логистической регрессии и случайного леса, а также визуализации и классификации с помощью PCA, T-SNE и DBSCAN.
В этот раз задача кардинальным образом не будет отличаться, правда признаков будет поменьше.
Забегая чуть-чуть вперед скажу, что для того чтобы задача не выглядела ну совсем уж клоном прошлой, в этот раз в примере мы встретим SVC классификатор, а также наглядно убедимся в том, что масштабирование исходных данных может быть очень полезным.
Эпизод III: Месть ситхов или немного о сложностях добычи данных.
Начнем с того что такое кривая силы света (КСС)?
Ну это примерно вот это:
Что бы было чуть понятней представьте, что у вас над головой лампа и именно такой конус света падает вам под ноги если вы стоите под ней (как в пятне света от уличного фонаря).
На этой картинке показана сила света (значения на кругах) в разных полярных углах (представьте что это продольный разрез лампы накаливания), в разрыве двух азимутальных углов 0-180 и 90 – 270 (представьте, что это поперечный разрез лампы накаливания). Возможно я не очень, точно объяснил, За подробностями к Юлиану Борисовичу Айзенбергу в справочник по светотехнике страница 833 и далее
Но вернемся к исходным данным, не сочтите за рекламу, но все светильники, которые мы будем сегодня классифицировать будут от одного производителя, а именно фирмы Световые технологии. Я с ними никак не связан и мои карманы «звонкой монетой» от их упоминания не наполнятся
Тогда почему они? Все очень просто, ребята позаботились, о том, чтобы нам было удобно.
Необходимые картинки с КСС и .ies файлы для вытаскивания данных уже собраны ими в соответствующих архивах оставалось только скачать, согласитесь это намного удобней, чем рыскать по всей сети собирая данные по крупицам.
Возможно внимательный читатель, уже ждет с нетерпением, чтобы спросить причем тут все это и почему раздел называется месть ситхов? Где же жестокая месть?!
Ну видимо месть стихов заключалась в том, что на протяжении многих лет я занимался чем угодно, кроме математики, программирования, светотехники и машинного обучения и теперь за это расплачиваюсь нервными клетками.
Внутри зашиты данные о производителе и лаборатории измерителе, а также непосредственно данные о светильнике в том числе сила света в зависимости от полярных и азимутальных углов, данные о которой нам и нужны.
В сумме я отобрал для вас 193 файла, и вряд ли я бы стал даже пытаться обрабатывать их в ручную.
С одной стороны все просто есть ГОСТ в котором подробно описана структура .ies файла с другой стороны, автоматически распознать и вынуть нужные данные оказалось сложней чем я думал, это стоило мне пары тревожных и бессонных ночей.
Но для вас, как в лучших традициях синематографа все сложные и нудные вещи останутся «за кадром». Поэтому перейдем к непосредственному описанию данных.
Эпизод IV: Новая надежда… на то, что все классифицируется легко и просто.
Итак, вникнув в ключевые вопросы с помощью литературы на которую я выше сослался мы с вами придем ко мнению, что для того, чтобы классифицировать светильники в нашем учебно-демонстрационном примере, нам хватит вполне среза данных при каком-то одном азимутальном угле в данном случае равном нулю и в диапазоне полярных углов от 0 до 180, с шагом 10 (меньше шаг нет смысла брать на качество это сильно не повлияет).
То есть в нашем случае, данные будут выглядеть не как на графике слева, а как на графике справа.
Кстати если кто не знал, то с помощью лепестковой диаграммы в MS Excel, можно удобно строить графики КСС.
Поскольку в архиве от Световых технологий светильникои с разными КСС распределены неравномерно, мы будем с вами анализировать 4 типа, которых больше всего в исходном наборе данных.
Итак, у нас есть следующие КСС:
Концентрированная (К), глубокая (Г), косинусная (Д) и полу-широкая (Л).
Их зоны направлений максимальной силы света находятся в следующиъх углах соответственно:
К = 0°-15°; Г = 0°-30°; Д = 0°-35°; Л = 35°-55°;
Метки им в наборе данных назначены соответствующие
К 1; Г = 2; Д = 3; Л = 4; (надо было с нуля начать, но теперь мне уже лень переделывать)
На самом деле, не будучи специалистом в области светотехники, трудно классифицировать светильники, например, светильник на рисунке выше я бы отнес к светильнику с глубокой КСС, но на 100% не уверен.
В принципе я старался избегать спорных моментов, смотреть в ГОСТ и на примеры, но вполне мог и ошибиться где-то, если найдете неточности в присвоении меток классов пишите, по возможности поправлю
Эпизод V: Империя наносит ответный удар или сложно в подготовке данных легко в «бою»
Ну что же похоже в эту игру могут играть двое если готовить данные было сложно, то анализировать как раз наоборот. Начнем потихоньку.
Еще раз напомню, что файл со всем представленным ниже исходным кодом в формате .ipynb (Jupyter) можно скачать с GitHub
Итак, для начала импортируем библиотеки:
#import libraries
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from sklearn.model_selection import train_test_split
from sklearn . svm import SVC
from sklearn.metrics import f1_score
from sklearn.ensemble import RandomForestClassifier
from scipy.stats import uniform as sp_rand
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import MinMaxScaler
from sklearn.manifold import TSNE
from IPython.display import display
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
%matplotlib inline
Затем обработаем данные
#reading data
train_df=pd.read_csv('lidc_data\\train.csv',sep='\t',index_col=None)
test_df=pd.read_csv('lidc_data\\test.csv',sep='\t',index_col=None)
print('train shape {0}, test shape {1}]'. format(train_df.shape, test_df.shape))
display('train:',train_df.head(4),'test:',test_df.head(4))
#divide the data and labels
X_train=np.array(train_df.iloc[:,1:-1])
X_test=np.array(test_df.iloc[:,1:-1])
y_train=np.array(train_df['label'])
y_test=np.array(test_df['label'])
Если вы читали предыдущие статьи или знакомы с машинным обучением на python, то весь представленный тут код не представит для вас сложности.
Но на всякий случай, в начале мы считали данные по учебной и тестовой выборке в таблицы, а потом вырезали из них массивы содержащие признаки (силы света в полярных углах) и метки классов, ну и конечно же для наглядности распечатали по первые 4 строки из таблицы, вот что получилось:
Можете мне поверить на слово, данные более мене сбалансированы за исключение класса №4( кривая Л) и в общем и целом для первых трех классов у нас соотношение — 40 образцов в учебной выборке и 12 в контрольной, для класса Л — 28 в учебной и 9 в контрольной в целом соотношение близкое к 1/4 между учебной и контрольной выборкой сохраняется.
Ну а если вы привыкли никому на слово не верить, то запустите код:
#draw classdistributions
test_n_max=test_df.label.value_counts().max()
train_n_max=train_df.label.value_counts().max()
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12,5))
train_df.label.plot.hist(ax=axes[0],title='train data class distribution', bins=7,yticks=np.arange(0,train_n_max+2,2), xticks=np.unique(train_df.label.values))
test_df.label.plot.hist(ax=axes[1],ti
И увидите следующее:
Давайте вернемся к нашим признакам, как вы понимаете с одной стороны все они отражают одну и туже величину, то есть грубо говоря мы не соотносим количество велосипедов и атмосферное давление, с другой стороны в отличие от прошлого раза , когда у нас все признаки имели примерно один уровень значений, в этот раз амплитуда значений может достигать десятков тысяч единиц.
Поэтому резонно отмасштабировать признаки. Однако, все модели масштабирования в scikit-learn похоже масштабируют по столбцам (или я не разобрался), а нам бессмысленно масштабировать по столбцам в данном случае, это не уравняет «богатые» и бедные» светильники, что приведёт так сказать к классовой классификационной напряженности товарищи!
Мы с вами будем вместо этого масштабировать данные по образцам (по строкам), чтобы сохранить характер распределения сил света по углам, но при этом загнать весь разброс в диапазон между 0 и 1.
По-хорошему в книгах, что я читал дают совет масштабировать обучающую выборку и контрольную одной моделью (обученной на обучающей выборке), но в нашем случае, так не получится из-за несовпадения числа признаков (в тестовой выборке меньше строк и транспонированная матрица будет иметь меньше столбцов), поэтому уравняем каждую выборку по своему.
Забегая в перед, применительно к данной задаче, в процессе классификации я ничего плохого в этом не обнаружил.
#scaled all data for final prediction
scl=MinMaxScaler()
X_train_scl=scl.fit_transform(X_train.T).T
X_test_scl=scl.fit_transform(X_test.T).T
#scaled part of data for test
X_train_part, X_test_part, y_train_part, y_test_part = train_test_split(X_train, y_train, test_size=0.20, stratify=y_train, random_state=42)
scl=MinMaxScaler()
X_train_part_scl=scl.fit_transform(X_train_part.T).T
X_test_part_scl=scl.fit_transform(X_test_part.T).T
Даже если вы совсем новичок, то по ходу статьи вы заметите, что у всех моделей из набора scikit-learn схожий интерфейс, мы обучаем модель передавая данные в метод fit, если нам надо трансформировать данные, то вызываем метод transform (в нашем случае используем метод 2 в 1), а если надо будет позже предсказать данные вызываем метод predict и скармливаем ему наши новые (контрольные) образцы.
Ну и еще 1 маленький момент, давайте представим, что у нас нет меток для контрольной выборки, например, мы решаем задачу на kagle, как нам тогда оценить качество предсказания модели?
Думаю, для нашего случая, где не требуется решение бизнес задач одним из самых простых способов будет поделить обучающую выборку на еще одну обучающую (но поменьше) и тестовую (из состава обучающей), это нам пригодится чуть позже. А пока вернемся к масштабированию и посмотрим, как нам это помогло, верхняя картинка без масштабирования признаков, нижняя с масштабированием.
На графиках показано по одному образцу из каждого класса и как мы видим и нам и компьютеру будет проще что-то понять по масштабированному графику, ибо на верхнем некоторые графики просто сливаются с нулем из-за разницы масштабов.
Для того, чтобы окончательно убедится в нашей правоте, давайте попробуем снизить размерность признаков до двухмерной, чтобы отобразить наши данные на двухмерных графиках и посмотреть на сколько наши данные разделимы (мы воспользуемся для этого t-SNE)
Слева без масштабирования справа с масштабированием
#T-SNE
colors = ["#190aff", "#0fff0f", "#ff641e" , "#ff3232"]
tsne = TSNE(random_state=42)
d_tsne = tsne.fit_transform(X_train)
plt.figure(figsize=(10, 10))
plt.xlim(d_tsne[:, 0].min(), d_tsne[:, 0].max() + 10)
plt.ylim(d_tsne[:, 1].min(), d_tsne[:, 1].max() + 10)
for i in range(len(X_train)):
# строим график, где цифры представлены символами вместо точек
plt.text(d_tsne[i, 0], d_tsne[i, 1], str(y_train[i]),
color = colors[y_train[i]-1],
fontdict={'weight': 'bold', 'size': 10})
plt.xlabel("t-SNE feature 0")
plt.ylabel("t-SNE feature 1")
“Забьем” это в разные ячейки (ну или сделаете subplot)
#T-SNE for scaled data
d_tsne = tsne.fit_transform(X_train_scl)
plt.figure(figsize=(10, 10))
plt.xlim(d_tsne[:, 0].min(), d_tsne[:, 0].max() + 10)
plt.ylim(d_tsne[:, 1].min(), d_tsne[:, 1].max() + 10)
for i in range(len(X_train_scl)):
# строим график, где цифры представлены символами вместо точек
plt.text(d_tsne[i, 0], d_tsne[i, 1], str(y_train[i]),
color = colors[y_train[i]-1],
fontdict={'weight': 'bold', 'size': 10})
plt.xlabel("t-SNE feature 0")
plt.ylabel("t-SNE feature 1")
Вычитаем единицу, потому что я начал вести отсчет меток не с нуля.
По рисункам видно, что на масштабированных данных, классы 1, 3, 4 более менее хорошо различимы, а класс 2 размазан между классами 1 и 3 (если вы скачаете и посмотрите КСС светильников, то вы поймете что так и должно быть)
Эпизод VI: Возвращение джедая или почувствую силу заранее написанных кем-то за тебя моделей!
Ну что же пора уже приступить к непосредственной классификации
Для начала обучим SVC на наших «урезанных данных»
#predict part of full data (test labels the part of X_train)
#not scaled
svm = SVC(kernel= 'rbf', random_state=42 , gamma=2, C=1.1)
svm.fit (X_train_part, y_train_part)
pred=svm.predict(X_test_part)
print("\n not scaled: \n results (pred, real): \n",list(zip(pred,y_test_part)))
print('not scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test_part,pred), f1_score(y_test_part,pred, average='macro')))
#scaled
svm = SVC(kernel= 'rbf', random_state=42 , gamma=2, C=1.1)
svm.fit (X_train_part_scl, y_train_part)
pred=svm.predict(X_test_part_scl)
print("\n scaled: \n results (pred, real): \n",list(zip(pred,y_test_part)))
print('scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test_part,pred), f1_score(y_test_part,pred, average='macro')))
Как видите разница более чем существенна, если в первом случае нам удалось достичь
результатов только немногим лучше чем случайное предсказание, то во втором случае мы получили 100% попадание.
Обучим нашу модель на полном наборе данных и убедимся, что и там будет 100% результат
Идеально! Надо отметить, что наряду с метрикой accuracy я решил использовать f1-score, которая нам бы пригодилась если бы наши классы имели существенно больший дисбаланс, а вот в нашем случае разницы между метриками почти никакой (но зато мы в этом убедились наглядно)
Ну и последнее, что мы с вами проверим это уже знакомый нам классификатор RandomForest
В книгах и в других материалах, я читал, что для RandomForest не критично масштабирование признаков, посмотрим так ли это.
Итак, можем сделать 2 заключения:
1. Иногда полезно масштабировать признаки даже для решающих деревьев.
2. SVC показал лучшую точность.
Надо отметить, что в этот раз я параметры подбирал вручную и если для scv я со второй по пытки подобрал нужный вариант, то для Random Forest не подобрал и с 10-го раза, плюнул и оставил по умолчанию (за исключением числа деревьев). Возможно есть параметры, которые доведут точность до 100%, попробуйте подобрать и обязательно расскажите в комментариях.
Ну вот вроде и все, но думаю, что фанаты Звездных войн, мне не простят, что я не упомянул седьмой фильм саги, поэтому…
Эпизод VII: Пробуждение силы – вместо заключения.
Машинное обучение оказалось, чертовски увлекательной штукой, я по-прежнему советую каждому попробовать придумать и решить задачу близкую именно вам.
Ну а если сразу что-то не получится, то не вешайте нос как на картинке снизу.
Да-да! Чтобы вы не подумали это именно «не вешай нос» и никаких других скрытых помыслов ;)
В этой очень небольшой заметке я расскажу об очень небольшом усовершенствовании процесса автоматической сборки приложения в Travis CI. Я это проделал на примере Андроид-приложения, но, естественно, это будет работать и для других языков. Постановка задачи очень проста — участники сообщества попросили автоматически собирать в выкладывать приложение после каждого коммита в репозитории на GitHub. То есть речь идёт не о сборке фиксированных версий, а именно о «ежедневных» сборках, которые можно сразу же установить и тестировать, не дожидаясь официальной версии. Я, как разработчик, подобную заинтересованность могу только приветствовать, так как это сильно повышает качество обратной связи. Реализация этого процесса очень проста, только штатные средства GitHub и Travis CI, никакой магии. Так что я до сих пор сомневаюсь, стоит ли вообще о таком писать и отвлекать уважаемых хаброжителей от более серьёзных тем. Но если кто заинтересовался — прошу под кат.
У всех этих репозиториев есть два общих момента — в них настроена автоматическая сборка приложения на сервере Travis CI после каждого коммита, и результаты этой автоматической сборки так и остаются на сервере Travis CI, то есть собранное проложение просто удаляется. Я же, как уже сказал во введении, хочу извлечь пользу из этого собранного APK-файла и поместить его обратно в GitHub репозиторий, чтобы он был сразу же доступен участникам сообщества для тестирования.
Travis CI предоставляет штатный метод загрузки собранного приложения на GitHub, но он предназначен для работы с тегами, то есть эта сборка, во первых, запускается при создании нового тега в GitHub-репозитории, и, во-вторых, позволяет загрузить APK-файл только в раздел GitHub Releases, но не в ветку репозитория. Так как создавать тег для каждого коммита — это, на мой взгляд, насилие над здравым смыслом, то этот метод я отбросил как несоответствующий духу и сути задачи.
Командный файл Travis CI (.travis.yml), расположенный в корне репозитория, имеет простую структуру:
Этот скрипт выполняется на виртуальной машине в корне git-репозитория, который клонирован в т.н. "detached HEAD" режиме, то есть не позволяет напрямую закоммитить что-либо в мастер-ветку удалённого (то есть оригинального) GitHub-репозитория.
Если внимательно посмотреть лог выполнения этого скрипта на виртуальной мишине, то в самом начале (секция git скрипта, которая в данном примере не сконфигурирована) Travis делает вот что:
$ git clone --depth=50 --branch=master https://github.com/user/repo.git user/repo
Cloning into 'user/repo'...
$ cd user/repo
$ git checkout -qf d7d29a59cef70bfce87dc4779e5cdc1e6356313a
Именно git checkout -qf и переводит локальную ветку в "detached HEAD" режим.
После того, как секция script отработала (в моём примере ./gradlew clean assembleDebug), и в директории ./app/build/outputs/apk появился сгенерированный APK-файл, вызывается секция after_success, где можно средствами Git закоммитить этот файл. Вопрос только, куда?
Есть несколько вариантов.
1) Можно использовать GitHub-Pages и помещать APK-файл туда, то есть коммитить в ветку gh-pages. Основной минус такого подхода в том, что GitHub-Pages рассчитаны на конечных пользователей, которые должны загружать приложение из официальных магазинов. Участники сообщества работают всё же с самим репозиторием, а не с GitHub-Pages. Поэтому я такой вариант не рассматриваю.
2) Можно коммитить обратно в мастер-ветку GitHub-репозитория, например, в папку autobuild. В этом случае, нужно деактивировать "detached HEAD", закоммитить файл, авторизоваться в удалённом репозитории и выполнить push.
#!/bin/sh
mv ./app/build/outputs/apk/snapshot.apk ./autobuild/
git config --global user.email "travis@travis-ci.org"
git config --global user.name "Travis CI"
git remote add origin-master https://${AUTOBUILD_TOKEN}@github.com/user/repo > /dev/null 2>&1
git add ./autobuild/snapshot.apk
# We don’t want to run a build for a this commit in order to avoid circular builds:
# add [ci skip] to the git commit message
git commit --message "Snapshot autobuild N.$TRAVIS_BUILD_NUMBER [ci skip]"
git push origin-master
В данном варианте после каждого коммита в мастер-ветке GitHub-репозитория Travis будет делать ещё один коммит, где файл snapshot.apk будет также помещён в мастер-ветку. С одной стороны, удобно, что все в одном месте. С другой, этот файл также нужно постоянно синхронизировать в локальных репозиториях, что не очень удобно для разработчиков.
3) Посте всех экспериментов мне больше всего понравился третий вариант. В репозитории создаётся ветка autobuild, но из неё удаляются все файлы и директории за исключением папки autobuild. Этот огрызок полноценной веткой не является, так как её нельзя синхронизировать с мастер-веткой. Скрипт push-apk.sh будет выглядеть в этом случае так:
#!/bin/sh
# Checkout autobuild branch
cd ..
git clone https://github.com/user/repo.git --branch autobuild --single-branch repo_autobuild
cd repo_autobuild
# Copy newly created APK into the target directory
mv ../repo/app/build/outputs/apk/snapshot.apk ./autobuild
# Setup git for commit and push
git config --global user.email "travis@travis-ci.org"
git config --global user.name "Travis CI"
git remote add origin-master https://${AUTOBUILD_TOKEN}@github.com/user/repo > /dev/null 2>&1
git add ./autobuild/snapshot.apk
# We don’t want to run a build for a this commit in order to avoid circular builds:
# add [ci skip] to the git commit message
git commit --message "Snapshot autobuild N.$TRAVIS_BUILD_NUMBER [ci skip]"
git push origin-master
Последняя пара слов про авторизацию. За неё отвечает переменная окружения AUTOBUILD_TOKEN. Эта переменная задаётся в разделе
env:
global:
secure:
Данный раздел содержит зашифрованный персональный ключ, который нужно сгенерировать на странице Personal access tokens. После чего он шифруется и добавляется в файл .travis.yml с помощью утилиты travis:
Вот такое небольшое усовершенствование. Кому интересно, можно посмотреть рабочий вариант в этом репозитории.
Удачного всем прогрева серверов непрерывной интеграции!
Многие люди представляют функциональное программирование как нечто очень сложное и «наукоемкое», а представителей ФП-сообщества – эстетствующими философами, живущими в башне из слоновой кости.
До недавнего времени такой взгляд на вещи действительно был недалек от истины: говорим ФП, подразумеваем Хаскель и теорию категорий. В последнее время ситуация изменилась и функциональная парадигма набирает обороты в web-разработке, не без помощи F#, Scala и React. Попробуем взглянуть на «паттерны» функционального программирования, полезные для решения повседневных задач с точки зрения ООП – парадигмы.
ООП широко распространено в разработке прикладного ПО не одно десятилетие. Все мы знакомы с SOLID и GOF. Что будет их функциональным эквивалентом?.. Функции! Функциональное программирование просто «другое» и предлагает другие решения.
Основные принципы функционального проектирования (дизайна)
Функции как объекты первого класса
В отличие от «классического» ООП (первые версии C++, C#, Java) функции в ФП представляют собой самостоятельные объекты и не должны принадлежать какому-либо классу. Удобно представлять функцию как волшебный железнодорожный тоннель: подаете на вход яблоки, а на выходе получаете бананы (apple -> banana).
Синтаксис F# подчеркивает, что функции и значения равны в правах:
Если у нас есть две функции, одна преобразующая яблоки в бананы (apple -> banana), а другая бананы в вишни (banana -> cherry), объединив их мы получим функции преобразования яблок в вишни (apple -> cherry). С точки зрения программиста нет разницы получена эта функция с помощью композиции или написана вручную, главное – ее сигнатура.
Композиция применима как на уровне совсем небольших функций, так и на уровне целого приложения. Вы можете представить бизнес-процесс, как цепочку вариантов использования (use case) и скомпоновать их в функцию httpRequest -> httpResponse. Конечно это возможно только для синхронных операций, но для асинхронных есть реактивное функциональное программирование, позволяющее сделать тоже самое.
Можно представлять себе композицию функций как фрактал. Определение фрактала в строгом смысле не совпадает с определением композиции. Представляя фрактал вы можете визуализировать как ваш control flow состоит из скомпонованных функций, состоящих из скомпонованных функций, состоящих из…
Шаблон компоновщик (Composite) в ООП тоже можно представлять себе «фракталом», но компоновщик работает со структурами данных, а не преобразованиями.
У системы типов в ФП больше общего с теорией множеств, чем с классами из ООП. int – это тип. Но тип не обязательно должен быть примитивом. Customer – это тоже тип. Функции могут принимать на вход и возвращать функции. int -> int – тоже тип. Так что «тип» — это название для некоторого множества.
Типы тоже можно компоновать. Большая часть функциональных ЯП работает с алгебраической системой типов, отличающейся от системы классов в ООП.
Перемножение (логическое «и», record type в F#)
На первый взгляд это может показаться странным, однако в этом есть смысл. Если взять множество людей и множество дат, «перемножив» их мы получим множество дней рождений.
type Birthday = Person * Date
Сложение (логическое «или», discriminated union type в F#)
type PaymentMethod =
| Cash
| Cheque of ChequeNumber
| Card of CardType * CardNumber
Discriminated union – сложное название. Проще представлять себе этот тип как выбор. Например, вы можете на выбор оплатить товар наличными, банковским переводом или с помощью кредитной карты. Между этими вариантами нет ничего общего, кроме того, все они являются способом оплаты.
Однажды нам пригодились «объединения» для моделирования предметной модели.
Entity Framework умеет работать с такими типами из коробки, нужно лишь добавить id.
Стремление к «полноте»
Давайте рассмотрим функцию «разделить 12 на». Ее сигнатура int -> int и это ложь! Если мы подадим на вход 0, функция выбросит исключение. Вместо этого мы можем заменить сигнатуру на NonZeroInteger -> int или на int -> int option.
ФП подталкивает вас к более строгому и полному описанию сигнатур функций. Если функции не выбрасывают исключений вы можете использовать сигнатуру и систему типов в качестве документации. Вы также можете использовать систему типов для создания предметной модели (Domain Model) и описания бизнес-правил (Business Rules). Таким образом можно гарантировать, что операции не допустимые в реальном мире не будут компилироваться в приложении, что дает более надежную защиту, чем модульные тесты. Подробнее об этом подходе вы можете прочитать в отдельной статье.
Функции в качестве аргументов
Хардкодить данные считается дурным тоном в программирование, вместо этого мы передаем их в качестве параметров (аргументов методов). В ФП мы идем дальше. Почему бы не параметризировать и поведение?
Вместо функции с одним аргументом опишем функцию с двумя. Теперь не важно, что это за список и куда мы выводим данные (на консоль или в лог).
let printList anAction aList =
for i in aList do
anAction i
Пойдем дальше. Рассмотрим императивный пример на C#. Очевидно, что в данном коде присутствует дублирование (одинаковые циклы). Для того чтобы устранить дублирование нужно выделить общее и выделить общее в функцию:
public static int Product(int n)
{
int product = 1; // инициализация
for (int i = 1; i <= n; i++) // цикл
{
product *= i; // действие
}
return product; // возвращаемое значение
}
public static int Sum(int n)
{
int sum = 0; // инициализация
for (int i = 1; i <= n; i++) // цикл
{
sum += i;
}
return sum; // возвращаемое значение
}
В F# для работы с последовательностями уже есть функция fold:
let product n =
let initialValue = 1
let action productSoFar x = productSoFar * x
[1..n] |> List.fold action initialValue
let sum n =
let initialValue = 0
let action sumSoFar x = sumSoFar+x
[1..n] |> List.fold action initialValue
Но, позвольте, в C# есть Aggregate, который делает тоже самое! Поздравляю, LINQ написан в функциональном стиле :)
Рекомендую цикл статей Эрика Липперта о монадах в C#. С десятой части начинается объяснение «монадической» природы SelectMany
Функции в качестве интерфейсов
Допустим у нас есть интерфейс.
interface IBunchOfStuff
{
int DoSomething(int x);
string DoSomethingElse(int x); // один интерфейс - одно дело
void DoAThirdThing(string x); // нужно разделить
}
Если взять SRP и ISP и возвести их в абсолют все интерфейсы будут содержать только одну функцию.
interface IBunchOfStuff
{
int DoSomething(int x);
}
Тогда это просто функция int -> int. В F# не нужно объявлять интерфейс, чтобы сделать функции взаимозаменяемыми, они взаимозаменяемы «из коробки» просто по своей сигнатуре. Таким образом паттерн «стратегия» реализуется простой передачей функции в качестве аргумента другой функции:
let DoSomethingWithStuff strategy x =
strategy x
Паттерн «декоратор» реализуется с помощью композиции функций
let isEvenWithLogging = log >> isEven >> log // int -> bool
Здесь автор для простоты изложения опускает вопросы семантики. При моделировании реальных предметных моделей одной сигнатуры функции не всегда достаточно.
Итак, использую одну только композицию мы можем проектировать целые приложения. Плохие новости: композиция работает только с функциями от одного параметра. Хорошие новости: в ФП все функции являются функциями от одного параметра.
Обратите внимание, сигнатура int -> int -> int не содержит скобок не случайно. Можно воспринимать сложение, как функцию от двух аргументов типа int, возвращающую значение типа int или как функцию от одного аргумента, возвращающую функциональный тип int -> int. Возвращаемая функция будет называться сумматор по основанию n, где n — число переданное аргументом в первую функцию. Повторив эту операцию рекурсивно можно функцию от любого числа аргументов преобразовать в функции от одного аргумента.
Такие преобразования возможны не только для компилируемых функций в программировании, но и для математических функций. Возможность такого преобразования впервые отмечена в трудах Готтлоба Фреге, систематически изучена Моисеем Шейнфинкелем в 1920-е годы, а наименование получило по имени Хаскелла Карри — разработчика комбинаторной логики, в которой сведение к функциям одного аргумента носит основополагающий характер.
Возможность преобразования функций от многих аргументов к функции от одного аргумента естественна для функциональных ЯП, поэтому компилятор не будет против, если вы передадите только одно значения для вычисления суммы.
let three = 1 + 2
let three = (+) 1 2
let three = ((+) 1) 2
let add1 = (+) 1
let three = add1 2
// эта функция требует зависимость
let getCustomerFromDatabase connection (customerId:CustomerId) =
from connection
select customer
where customerId = customerId
// а эта уже нет
let getCustomer1 = getCustomerFromDatabase myConnection
Продолжения (continuations)
Зачастую решения, закладываемые в реализацию, оказываются не достаточно гибкими. Вернемся к примеру с делением. Кто сказал, что я хочу, чтобы функция выбрасывала исключения? Может быть мне лучше подойдет «особый случай»
int Divide(int top, int bottom)
{
if (bottom == 0)
{
// кто решил, что нужно выбросить исключение?
throw new InvalidOperationException("div by 0");
}
else
{
return top/bottom;
}
}
Вместо того, чтобы решать за пользователя, мы можем предоставить решение ему:
Если вы когда-нибудь писали асинхронный код, то наверняка знакомы с «пирамидой погибели» (Pyramid Of Doom)
Продолжения позволяют исправить этот код и избавиться от уровней вложенности. Для этого необходимо инкапуслировать условный переход в функцию:
let ifSomeDo f opt =
if opt.IsSome then
f opt.Value
else
None
И переписать код, используя продолжения
let example input =
doSomething input
|> ifSomeDo doSomethingElse
|> ifSomeDo doAThirdThing
|> ifSomeDo (fun z -> Some z)
Монады
Монады – это одно из «страшных» слов ФП. В первую очередь, из-за того, что обычно объяснения начинаются с теории категорий. Во вторую — из-за того что «монада» — это очень абстрактное понятие, не имеющее прямой аналогии с объектами реального мира. Я большой сторонник подхода «от частного к общему». Поняв практическую пользу на конкретном примере проще двигаться дальше к более полному и абстрактному определению.
Зная о «продолжениях», вернемся к аналогии с рельсами и тоннелем. Функцию, в которую передаются аргумент и два «продолжения» можно представить как развилку.
Но такие функции не компонуются :(
На помощь приходит функция bind
let bind nextFunction optionInput =
match optionInput with
// передаем результат выполнения предыдущей функции в случае успеха
| Some s -> nextFunction s
// или просто пробрасываем значение None дальше
| None -> None
Код пирамиды погибели может быть переписан с помощью bind
// было
let example input =
let x = doSomething input
if x.IsSome then
let y = doSomethingElse (x.Value)
if y.IsSome then
let z = doAThirdThing (y.Value)
if z.IsSome then
let result = z.Value
Some result
else
None
else
None
else
None
// стало
let bind f opt =
match opt with
| Some v -> f v
| None -> None
let example input =
doSomething input
|> bind doSomethingElse
|> bind doAThirdThing
|> bind (fun z -> Some z)
Кстати, это называется «monadic bind». Скажите своим друзьям, любителям хаскеля, что вы знаете, что такое «monadic bind» и вас примут в тайное общество:)
Bind можно использовать для сцепления асинхронных операций (промисы в JS устроены именно так)
Bind для обработки ошибок
Если у вас появилось смутное ощущение, что дальше идет описание монады Either, так оно и есть
Рассмотрим код на C#. Он выглядит достаточно хорошо: все кратко и понятно. Однако в нем отсутствует обработка ошибок. Действительно, что может пойти не так?
Мы все знаем, что обрабатывать ошибки нужно. Добавим обработку.
string UpdateCustomerWithErrorHandling()
{
var request = receiveRequest();
var isValidated = validateRequest(request);
if (!isValidated)
{
return "Request is not valid"
}
canonicalizeEmail(request);
try
{
var result = db.updateDbFromRequest(request);
if (!result)
{
return "Customer record not found"
}
}
catch
{
return "DB error: Customer record not updated"
}
if (!smtpServer.sendEmail(request.Email))
{
log.Error "Customer email not sent"
}
return "OK";
}
Вместо шести понятных теперь 18 не понятных строчек. Это 200% дополнительных строчек кода. Кроме того, линейная логика метода теперь зашумлена ветвлениями и ранними выходами.
С помощью bind можно абстрагировать логику обработки ошибок. Вот так будет выглядеть метод без обработки ошибок, если его переписать на F#:
А вот этот код но уже с обработкой ошибок:
К сожалению, для объяснения моноидов не подходят простые аналогии. Приготовьтесь к математике.
Я предупредил, итак, математика
1 + 2 = 3
1 + (2 + 3) = (1 + 2) + 3
1 + 0 = 1
0 + 1 = 1
И еще немного
2 * 3 = 6
2 * (3 * 4) = (2 * 3) * 4
1 * 2 = 2
2 * 1 = 2
Что общего между этими примерами?
Есть некоторые объекты, в данном случае числа, и способ их взаимодействия. Причем результат взаимодействия — это тоже число (замкнутость).
Порядок взаимодействия не важен (ассоциативность).
Кроме того, есть некоторый специальный элемент, взаимодействие с которым не меняет исходный объект (нейтральный элемент).
За более строгим определением обратитесь к википедии. В рамках статьи обсуждается лишь несколько примеров применения моноидов на практике.
Замкнутость
Дает возможность перейти от попарных операций к операциям на списках
1 * 2 * 3 * 4
[ 1; 2; 3; 4 ] |> List.reduce (*)
Ассоциативность
Применение принципа «разделяй и властвуй», «халявная» параллелизация. Если у нашего процессора 2 ядра и нам нужно рассчитать значение 1 + 2 + 3 + 4. Мы можем вычислить 1 + 2 на первом ядре, а 3 + 4 — на втором, а результат сложить. Больше последовательных вычислений — больше ядер.
Нейтральный элемент
С reduce есть несколько проблем: что делать с пустыми списками? Что делать, если у нас нечетное количество элементов? Правильно, добавить в список нейтральный элемент.
Кстати, в математике часто встречается определение моноида как полугруппы с нейтральным элементом. Если нейтральный элемент отсутствует, то можно попробовать его доопределить, чтобы воспользоваться преимуществами моноида.
Функции с одинаковым типом входного и выходного значения являются моноидами и имеют специальное название — «эндоморфизмы» (название заимствовано из теории категорий). Что более важно, функции, содержащие эндоморфизмы могут быть преобразованы к эндоморфизмам с помощью частичного применения.
“Вы не можете управлять тем, что не можете измерить” — избитая фраза, которую любят употреблять консультанты на дорогостоящих тренингах. У многих людей выработалась аллергия к разного рода метрикам, из-за маниакального желания менеджеров навесить KPI куда только можно. Однако, без определенной системы измерений, невозможно говорить о систематическом улучшении качества программного продукта и процесса его разработки. В этой статье я расскажу о GQM (Goal — Question — Measure) подходе, который поможет определить действительно объективные метрики и приведу пару примеров.
Разрабатывая ПО, команды регулярно сталкиваются с проблемами неэффективности процесса и низкого качества продукта. Однако, проекты, содержащие несколько десятков тысяч строк кода, написанного сотнями разработчиков, невозможно охватить одним взглядом и принять какое-либо решение. В таких случаях, на помощь приходят специальные показатели, позволяющие “просветить” программный продукт.
Принимая решение о внесении изменений в продукт или процесс, команда начинает эксперимент, с целью проверить некоторую гипотезу. Каким образом можно понять, что гипотеза верна? Командам помогут заранее определенные метрики, характеризующие важные аспекты проводимого эксперимента.
GQM модель
Виктор Бэйзил предложил модель GQM ( Goal — Question — Metric; Цель — Вопрос — Показатель) [1]. Основная идея описывается тремя базовыми пунктами:
Определите цель, которую вы хотите достичь.
Сформулируйте вопросы, характеризующие важные аспекты, связанные с поставленной целью.
Подберите метрики, позволяющие ответить на заданные вопросы.
Для наглядности модель изображают в виде трехуровневой иерархической диаграммы.
Важные аспекты при построении GQM модели:
При формулировании цели, опирайтесь на критерии SMART. Это позволит избежать абстрактных философских целей.
Выбирая основные аспекты, обращайте внимание не только на очевидные характеристики, но и на те признаки, которые косвенно подвергаются изменениям.
При определении важных характеристик необходимо учитывать используемые технологии, процессные практики и инструменты разработки. Все перечисленные критерии влияют на то, какой именно показатель наиболее уместен в заданном контексте. Кроме того, выбирать необходимо те метрики, которые возможно собирать в автоматическом или полуавтоматическом режиме, поскольку ручной сбор метрик чреват невалидными результатами на выходе.
Примеры построения модели
Предположим, наша цель — уменьшить время бездействия системы (время, когда система не доступна для пользователей). GQM модель для этой ситуации представлена на рисунке:
Цели могут быть, как техническими, так и процессными. Команда, к примеру, может определить метрики, которые помогут ей улучшить качество оценивания трудозатрат или эффективность различных стандартов написания кода. Ниже представлена GQM модель для определения эффективности того или иного стандарта написания программного кода:
В некоторых случаях цели команды слишком глобальны и требуют некоторой декомпозиции. В этом случае, на помощь приходит GQM+ подход [2], предполагающий построение дерева целей команды или целой компании и построения отдельной модели для каждой цели дерева. Цель “снизить время доставки функции клиенту (time to market)” — глобальна. Ее можно декомпозировать следующим образом:
Подводя итог, стоит отметить, что данный инструмент наиболее эффективен, когда команды разработки самостоятельно определяют свои цели по улучшению программного продукта и выявляют подходящие метрики. В случае, когда показатели навязываются сверху — эффективность GQM модели резко снижается, поскольку команда начинает воспринимать метрики, как инструмент контроля, а не как важный аспект процесса совершенствования продукта.
Ссылки:
Basili V. R. Software modeling and measurement: the Goal/Question/Metric paradigm. – 1992.
Basili V. et al. GQM+ Strategies in a Nutshell //Aligning Organizations Through Measurement. – Springer International Publishing, 2014. – С. 9-17.
Аналитики Gartner в апреле сообщили, что мировые траты на дата-центры по сравнению с прошлым годом возрастут и перевалят за $170 млрд. Во столько Forbes оценивает бренд Apple, и именно такая сумма проходит через все магазины крупнейшего ретейлера в США Walmart. В этой статье мы рассмотрим, куда идут такие деньги в контексте ЦОД, и поговорим о том, из чего складываются затраты на виртуальную и физическую инфраструктуры.
Неважно, говорим ли мы об облачном решении или о «железе», расчет должен учитывать прямые, косвенные и скрытые затраты. Все эти группы расходов укладываются в показатель совокупной стоимости владения (TCO). Существует мнение, что большую часть затрат на физическую инфраструктуру составляет оборудование. Однако, по данным Intel, стоимость «железа» представляет собой 15% от общих затрат на IT-активы.
Помимо аппаратного обеспечения, прямые издержки включают стоимость программного обеспечения, расходуемого электричества и вспомогательных систем: отопительных, охладительных, вентиляционных. Косвенные затраты связаны с выплатой ЗП системному администратору или другим сотрудникам.
Что касается оборудования, компании потребуется приобрести сам сервер и продумать будущую архитектуру ЦОДа — будет ли это масштабируемая, модульная система, обладающая несколькими блоками, или традиционные стойки. Необходимо продумать стратегию дальнейшего расширения.
Стоимость сервера варьируется в зависимости от производительности. В этот момент для бизнеса открывается простор для экономии, ведь решение в пользу конкретного устройства принимается самостоятельно. Однако, более дешевый, но низкопроизводительный сервер — это не всегда выгодно. Важно обратить внимание на энергоэффективность, которая как раз и обеспечивает экономию в долгосрочной перспективе.
Серверное помещение оборудуется электрическими системами, которые включают основное и промежуточные распределительные устройства, освещение, ИБП, отопление, вентиляцию и кондиционирование, систему противопожарной защиты, мониторинга и безопасности.
Следующая остановка — программное обеспечение. Серверу нужна операционная система, например Windows Server 2016, которую придется приобрести. Предприятию могут понадобиться и другие инструменты для решения корпоративных задач: Microsoft SQL Server, Citrix Presentation Server и др. Также нужно организовать сеть. С рекомендациями по программному обеспечению для создания локальной сети можно познакомиться на профильных площадках.
Наконец, мы добрались до электроэнергии, стоимость которой достаточно велика. Весьма показательна история Марко Пончиелли (Marco Ponchielli) из Rackspace. Он приводит данные, согласно которым раньше стоимость электроэнергии в общих затратах была столь незначительна, что требовалось от 30 до 50 лет, чтобы она приблизилась к стоимости вычислений.
Теперь же, в районах с высокими тарифами, этот период сократился до двух лет, а в среднем — до четырех. Марко также рассказал об IT-отделе, который потратил $22 млн на блейд-серверы. Затраты на их обслуживание за три года вылились в $30 млн, а модернизация инфраструктуры для их установки — в $54 млн.
Есть и еще одна статья расходов — помещение. Здесь разброс цен полностью зависит от того, находится ли офис во владении компании, построен ли машинный зал и какую площадь он занимает.
Кроме этого, следует учитывать кадры. Даже в случае удаленного размещения сервера предприятию требуется администратор, средний уровень заработной платы которого, по данным портала Trud, в России составляет около 40 тыс. рублей. Размер штата будет зависеть от размеров инфраструктуры, поэтому расчеты здесь индивидуальны для каждого конкретного случая.
В течение 2–4 лет затраты как на локальные, так и на облачные решения ограничиваются обслуживанием и поддержкой. Однако примерно через пять лет, по мнению сетевых администраторов, компания сталкивается с необходимостью обновления корпоративных серверных решений.
В жизненном цикле физических серверов за этим следуют новые капитальные затраты — это основная статья скрытых расходов в долгосрочной перспективе. Кроме того, эффективность нового физического оборудования намного выше, чем старого. Поэтому между устаревшими технологиями и ростом затрат энергии часто можно поставить знак равенства.
Не стоит забывать о том, что эти инвестиции на внушительный срок еще и обесцениваются с течением времени по причине инфляции. Цены на оборудование увеличиваются, поскольку спрос со временем растет.
В условную смету для составления целостной картины также следует заложить нематериальные издержки: расходы на перенос программного обеспечения и баз данных на новую платформу и затраты на решения, снижающие риск миграции.
Таким образом, стоимость поддержания локальной инфраструктуры увеличивается от года к году, причем замкнута она на короткий жизненный цикл аппаратных средств.
С точки зрения потребителя, облачная экономика очень проста: выбираешь необходимую конфигурацию и оплачиваешь аренду. Достаточно учесть некоторые аспекты. Например, потребуется обучить персонал, чтобы сотрудники могли эффективно управлять облачной инфраструктурой. К тому же, в статью скрытых расходов стоит записать стоимость миграции в облако. Порой она включает в себя и неудачные попытки работы с различными провайдерами. Все это в конечном счете стоит денег.
Расчеты затрат для клиента в случае с облаком достаточно прозрачны, но из чего они складываются для самого провайдера? По большому счету, ситуация аналогична корпоративной инфраструктуре, но, конечно, масштабы куда больше.
Качественный ЦОД уровня Tier III связывает многопроцессорные серверы, расположенные на дисковых массивах, с сетью по высокоскоростным каналам. Для этого используются несколько взаимозаменяемых магистральных маршрутизаторов. Облачная инфраструктура защищается системой глубокого анализа пакетов. За распределение сетевого трафика отвечают коммутаторы, формирующие между собой систему с дублированными соединениями. Хранение должно обеспечиваться надежными аппаратными и программными решениями, способными оперировать физическими дисками и обновлением ПО, а также балансировать нагрузку.
Высокий уровень доступности достигается дублирующими системами. Для стабильности и оптимизации работы набор ПО дополнен специальными решениями: контроль энергоэффективности, динамическое распределение нагрузки, панель управления, средства защиты и так далее.
Как уже было отмечено, человеческий ресурс является еще одной графой затрат в работе дата-центра. В зависимости от навыков персонала и географического положения годовые зарплаты всего штата, обслуживающего дата-центр, варьируются от $75 тыс. до более чем $125 тыс., по словам главы исследовательской компании Clabby Analytics Джо Клэбби (Joe Clabby). Не стоит забывать, что, кроме администраторов, ЦОД обслуживают и десятки других сотрудников. Например, дата-центры уровня Tier III требуют физической охраны серверов.
Но несмотря на такие масштабы, в некоторых случаях облачным провайдерам удается экономить деньги клиентам. Это возможно, потому что масштаб операций в дата-центрах позволяет операторам получать скидки на оборудование и решения.
При этом капитальные расходы на оборудование распределяются в пересчете на одну стойку или гигабайт ЗУ. Затраты амортизируются в течение всего жизненного цикла оборудования. К тому же не следует забывать об аппаратных средствах, которые обслуживают всю инфраструктуру — системы охлаждения, ИБП, системы защиты. Затраты на них «распределяются» между серверами.
Экосистема виртуальных провайдеров позволяет использовать меньшее количество серверов, что снижает потребление электроэнергии. К тому же с учетом масштабов и резервных систем появляется возможность для перераспределения и отключения серверов без ущерба для системы. По данным Uptime Institute, вывод из эксплуатации одной серверной стойки 1U может ежегодно экономить более $2 тыс.
По результатам исследования Uptime Institute, в 2015 году около 30% всех серверов не использовались, то есть они лежали «мертвым грузом» на плечах провайдеров. Во всем мире насчитывалось около 10 млн «коматозных» серверов. В денежном выражении это не менее $30 млрд. Вот почему облачные провайдеры «избавляются от балласта», экономя тем самым для себя и клиента приличные деньги.
Поэтому компании все чаще обращают внимание на облачные сервисы. Недавний отчет показал, что инвестирование в частные ЦОДы теряет смысл для IT-компаний. Вместо этого, руководители стараются нарастить вложения в разработку бизнес-приложений. Представители 70% опрошенных организаций заявили, что планируют увеличить расходы на безопасность в 2017 году, 67% отдали приоритет облачным приложениям, а еще 52% — облачной инфраструктуре.
Apple на этой неделе представила iPhone 8 и главную новинку — iPhone X. Многие уже называют его лучшим смартфоном в истории компании (кстати, Pixel 2 ждем 4 октября – очень интересно, чем ответит Google), ну а мы пока разбираемся как создавать приложения для него, как рендерить океаны на мобильных устройствах, кто лучший в материальном дизайне, в тестировании, атрибуции и росте.
Моделирование воды в компьютерной графике в реальном времени до сих пор остается весьма сложной задачей. Особенно актуально это при разработке компьютерных игр, в которых требуется создать визуально привлекательную картинку для игрока в рамках жесткого ограничения вычислительных ресурсов. И если на десктопах программист еще может рассчитывать на наличие мощной видеокарты и процессора, то в мобильных играх необходимо опираться на значительно более слабое железо.
Дайджест доступен и в виде рассылки. Подписаться вы можете тут.
часть 1
Продолжаем анализировать что происходит на нашем MS SQL сервере.
В этой части посмотрим как получить информацию о работе пользователей: кто и что делает, сколько ресурсов на это расходуется.
Думаю, вторая часть будет интересна не только админам БД, но и разработчикам (возможно даже разработчикам больше), которым необходимо разбираться, что не так с запросами на рабочем сервере, которые до этого отлично работали в тестовом.
Задачи анализа действий пользователей условно поделим на группы и рассмотрим каждую отдельно:
Анализ производительности требует глубокого понимания устройства и принципов работы сервера БД и ОС. Поэтому, чтение только этих статей не сделает из вас эксперта.
Рассматриваемые критерии и счетчики в реальных системах находятся в сложной зависимости друг от друга. Например высокая нагрузка HDD, часто связана с проблемой не самого HDD, а с нехваткой оперативной памяти. Даже если вы проведете некоторые из замеров — этого недостаточно для взвешенной оценки проблем.
Цель статей — познакомить с базовыми вещами на простых примерах. Рекомендации не стоит рассматривать как «руководство к действию», рассматривайте их как учебные задачи (упрощенно отражающие действительность) и как варианты «на подумать», призванные пояснить ход мысли.
Надеюсь, по итогу статей вы научитесь аргументировать цифрами свои заключения о работе сервера. И вместо слов «сервер тормозит» будете приводить конкретные величины конкретных показателей.
Анализируем конкретный запрос
Первый пункт довольно прост, остановимся на нем кратко. Рассмотрим только некоторые малоочевидные вещи.
SSMS, кроме результатов запроса, позволяет получать дополнительную информацию о выполнении запроса:
практически все знают, что план запроса получается кнопками «Display Estimated Execution Plan» (оценочный план) и «Include Actual Execution Plan» (фактический план). Отличаются они тем, что оценочный план строится без выполнения запроса. Соответственно, информация о количестве обработанных строк в нем будет только оценочная. В фактическом плане будут как оценочные данные, так и фактические. Сильные расхождения этих величин говорят о неактуальности статистики. Впрочем, анализ плана — тема для отдельной большой статьи — пока не будем углубляться.
менее известный факт — можно получать замеры затрат процессора и дисковых операций сервера. Для этого необходимо включить SET опции либо в диалоге через меню «Query» / «Query options...»
скрин
либо напрямую командами SET в запросе, например
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductID
В результате выполнения, получим данные по затратам времени на компиляцию и выполнение, а также, количество дисковых операций.
Пример вывода
Время синтаксического анализа и компиляции SQL Server:
время ЦП = 16 мс, истекшее время = 89 мс.
Время работы SQL Server:
Время ЦП = 0 мс, затраченное время = 0 мс.
Время работы SQL Server:
Время ЦП = 0 мс, затраченное время = 0 мс.
(32 row(s) affected)
Таблица «ProductProductPhoto». Число просмотров 32, логических чтений 96, физических чтений 5, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Таблица «Product». Число просмотров 0, логических чтений 64, физических чтений 0, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Таблица «ProductDocument». Число просмотров 1, логических чтений 3, физических чтений 1, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Время работы SQL Server:
Время ЦП = 15 мс, затраченное время = 35 мс.
Здесь стоит обратить внимание на время компиляции и текст «логических чтений 96, физических чтений 5». При втором и последующих выполнениях одного и того же запроса — физические чтения могут уменьшаться, а повторная компиляция может не потребоваться. Из-за этого часто возникает ситуация, что второй и последующие разы запрос выполняется быстрее чем первый. Причина, как вы поняли, в кэшировании данных и скомпилированных планов запросов.
еще полезная кнопочка рядом с кнопками планов — «Include Client Statistics» — выводит информацию по сетевому обмену, количестве выполненных операций и суммарном времени выполнения, с учетом затрат на сетевой обмен и обработку клиентом.
пример на котором видно что первое выполнение занимает больше времени
в SSMS 2016 версии появилась кнопка «Include Live Query Statistics». Отображает картинку как и в случае с планом запроса, только на ней цифры обработанных строк не статические, а меняются на экране прямо в процессе выполнения запроса. Картинка получается очень наглядная — по мигающим стрелкам и бегущим цифрам сразу видно где тратится время. Кнопка есть в 2016 студии, но работает с серверами начиная с 2014 версии.
Подытожим первую часть:
Затраты процессора смотрим используя SET STATISTICS TIME ON.
Дисковые операции: SET STATISTICS IO ON. Не забываем, что «логическое чтение» — это операция чтения, завершившаяся в кэше диска без физического обращения к дисковой системе. «Физическое чтение» требует значительно больше времени.
Объем сетевого трафика оцениваем с помощью «Include Client Statistics».
Детально алгоритм выполнения запроса анализируем по «плану выполнения» с помощью «Include Actual Execution Plan» и «Include Live Query Statistics».
Анализируем нагрузку от приложения
Для второго раздела вооружаемся profiler-ом. После запуска и подключения к серверу, необходимо выбрать журналируемые события. Можно пойти простым путем — запустить профилирование со стандартным темплэйтом трассировки. На закладке «General» в поле «Use the template» выбрать «Standard (default)» и нажать «Run».
картинка
Чуть более сложный путь — к выбранному шаблону добавить (или убавить) фильтров или событий. Данные опции на второй закладке диалога. Чтобы увидеть полный набор возможных событий и колонок для выбора — отметьте пункты «Show All Events» и «Show All Columns».
картинка
Из событий нам потребуются (лишние лучше не включать — чтобы создавать меньше трафика):
Stored Procedures \ RPC:Completed
TSQL \ SQL:BatchCompleted
Эти события фиксируют все внешние sql-вызовы к серверу. Они возникают, как видно из названия (Completed), после окончания обработки запроса. Имеются аналогичные события фиксирующие старт sql-вызова:
Stored Procedures \ RPC:Starting
TSQL \ SQL:BatchStarting
Но они нам подходят меньше, так как не содержат информации о затраченных на выполнение запроса ресурсах сервера. Очевидно, что такая информация доступна только по окончании выполнения. Соответственно, столбцы с данными по CPU, Reads, Writes в событиях *Starting будут пустыми.
Еще полезные события, которые мы пока не будем включать:
Stored Procedures \ SP:Starting (*Completed) — фиксирует внутренний вызов хранимой процедуры (не с клиента, а внутри текущего запроса или другой процедуры).
Stored Procedures \ SP:StmtStarting (*Completed) — фиксирует старт каждого выражения внутри хранимой процедуры. Если в процедуре цикл — будет столько событий для команд внутри цикла, сколько итераций было в цикле.
TSQL \ SQL:StmtStarting (*Completed) — фиксирует старт каждого выражения внутри SQL-batch. Если ваш запрос содержит несколько команд — будет по событию на каждую. Т.е. аналогично предыдущему, только действует не для команд внутри процедур, а для команд внутри запроса.
Эти события удобны для отслеживания шагов выполнения. Например, когда использование отладчика невозможно. По колонкам
Какие выбирать, как правило, понятно из названия колонки. Нам будут нужны:
TextData, BinaryData — для описанных выше событий содержат сам текст запроса.
CPU, Reads, Writes, Duration — данные о затратах ресурсов.
StartTime, EndTime — время начала/окончания выполнения. Удобны для сортировки.
Прочие колонки добавляйте на свой вкус.
По кнопке «Column Filters...» можно вызвать диалог установки фильтров событий. Если интересует активность конкретного пользователя — задать фильтр по номеру сессии или имени пользователя. К сожалению, в случае подключения приложения через app-server c пулом коннектов — отследить конкретного пользователя сложнее.
Фильтры можно использовать, например, для отбора только «тяжелых» запросов (Duration>X). Или запросов которые вызывают интенсивную запись (Writes>Y). Да хоть просто по содержимому запроса.
Что же еще нам нужно от профайлера? Конечно же план выполнения!
Такая возможность имеется. Необходимо добавить в трассировку событие «Performance \ Showplan XML Statistics Profile». Выполняя наш запрос, мы получим примерно следующую картинку.
Текст запроса
План выполнения
И это еще не всё
Трассу можно сохранять в файл или таблицу БД (а не только выводить на экран).
Настройки трассировки можно сохранить в виде личного template для быстрого запуска.
Запуск трассировки можно выполнять и без профайлера — с помощью t-sql кода, используя процедуры: sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Пример как это сделать. Данный подход может пригодиться, например, для автоматического старта записи трассы в файл по расписанию. Как именно использовать эти команды, можно подсмотреть у самого профайлера. Достаточно запустить две трассировки и в одной отследить что происходит при старте второй. Обратите внимание на фильтр по колонке «ApplicationName» — проконтролируйте, что там отсутствует фильтр на сам профайлер.
Список событий фиксируемых профайлером очень обширен и не ограничивается только получением текстов запросов. Имеются события фиксирующие fullscan, рекомпиляции, autogrow, deadlock и многое другое.
Анализируем активность пользователей в целом по серверу
Жизненные ситуации бывают и такими, когда информация из разделов выше не помогает:
Какой-то запрос висит на «выполнении» очень долго и непонятно, закончится он когда-нибудь или нет. Проанализировать проблемный запрос отдельно — хотелось бы — но надо сначала определить что за запрос. Профайлером ловить бесполезно — starting событие мы уже пропустили, а completed неясно сколько ждать.
А может висит и не пользовательский запрос совсем, а может это сам сервер что-то активно делает… Давайте разбираться
Все вы наверно видели «Activity Monitor». В старших студиях его функционал стал богаче. Чем он может нам помочь? В «Activity Monitor» много полезного и интересного, но третий раздел не о нем. Всё что нужно будем доставать напрямую из системных представлений и функций (а сам Монитор полезен тем, что на него можно натравить профайлер и посмотреть какие запросы он выполняет). Нам понадобятся:
sys.dm_exec_sessions — информация о сессиях. Отображает информацию по подключенным пользователям. Полезные поля (в рамках этой статьи) — идентифицирующие пользователя (login_name, login_time, host_name, program_name, ...) и поля с информацией о затраченных ресурсах (cpu_time, reads, writes, memory_usage, ...)
sys.dm_exec_requests — информация о запросах выполняющихся в данный момент. Полей тут тоже довольно много, рассмотрим только некоторые:
session_id — код сессии для связи с предыдущим представлением
start_time — время старта запроса
command — это поле, вопреки названию, содержит не запрос, а тип выполняемой команды. Для пользовательских запросов — обычно это что-то вроде select/update/delete/и т.п. (также, важные примечания ниже)
sql_handle, statement_start_offset, statement_end_offset — информация для получения текста запроса: хэндл, а также начальная и конечная позиция в тексте запроса — обозначающая часть выполняемую в данный момент (для случая когда ваш запрос содержит несколько команд).
plan_handle — хэндл сгенерированного плана.
blocking_session_id — при возникновении блокировок препятствующих выполнению запроса — указывает на номер сессии которая стала причиной блокировки
wait_type, wait_time, wait_resource — поля с информацией о причине и длительности ожидания. Для некоторых видов ожидания, например, блокировка данных — дополнительно указывается код заблокированного ресурса.
percent_complete — по названию понятно, что это процент выполнения. К сожалению, доступен только для команд у которых четко прогнозируемый прогресс выполнения (например, backup или restore).
sys.dm_exec_query_stats — сводная статистика выполнения в разрезе запросов. Показывает какой запрос сколько раз выполнялся и сколько ресурсов на это потрачено.
Важные примечания
Приведенный перечень — лишь малая часть. Полный список всех системных представлений и функций описан в документации. Также, имеется схема связей основных объектов в виде красивой картинки — можно распечатать на А1 и повесить на стену.
Текст запроса, его план и статистика исполнения — данные хранящиеся в процедурном кэше. Во время выполнения они доступны. После выполнения доступность не гарантируется и зависит от давления на кэш. Да, кэш можно очищать вручную. Иногда это советуют делать когда «поплыли» планы выполнения, но тут очень много нюансов… В общем, «Имеются противопоказания, рекомендовано проконсультироваться со специалистом».
Поле «command» — для пользовательских запросов оно практически бессмысленно — ведь мы можем получить полный текст… Но не всё так просто. Это поле очень важно для получения информации о системных процессах. Как правило, они выполняют какие-то внутренние задачи и не имеют текста sql. Для таких процессов, информация о команде единственный намек на тип активности. В комментариях к предыдущей статье был вопрос про то, чем занят сервер, когда он, вроде бы, ничем не должен быть занят — возможно ответ будет в значении этого поля. На моей практике, поле «command» для активных системных процессов всегда выдавало что-то вполне понятное: autoshrink/autogrow/checkpoint/logwriter/и т.п.
Как же это использовать
Перейдем к практической части. Я приведу несколько примеров использования, но не стоит ограничивать вашу фантазию. Возможности сервера этим не исчерпываются — можете придумывать что-то своё.
Пример 1: Какой процесс расходует cpu/reads/writes/memory
Для начала, посмотрим какие сессии больше всего потребляют, например, CPU. Информация в sys.dm_exec_sessions. Но данные по CPU (а также reads, writes) — накопительные. Т.е цифра в поле содержит «итого» за все время подключения. Понятно, что больше всего будет у того кто подключился месяц назад, да так и не отключался ни разу. Это вовсе не означает, что он прямо сейчас грузит систему.
Немного кода решает проблему, алгоритм примерно такой:
сначала сделаем выборку и сохраним во временную таблицу
затем подождем немного
делаем выборку второй раз
сравниваем результаты первой и второй выборки — разница, как раз и будет затратами возникшими на п.2
для удобства, разницу можем поделить на длительность п.2, чтобы получить усредненные «затраты в секунду».
Пример скрипта
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'ждем секунду для накопления статистики при первом запуске'
-- при последующих запусках не ждем, т.к. сравниваем с результатом предыдущего запуска
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [интервал времени, мс]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1
В коде я использую две таблицы: #tmp — для первой выборки, #tmp1 — для второй. При первом запуске, скрипт создает и заполняет #tmp и #tmp1 с интервалом в одну секунду, и делает остальную часть. При последующих запусках, скрипт использует результаты предыдущего выполнения в качестве базы для сравнения. Соответственно, длительность п.2 при последующих запусках будет равна длительности вашего ожидания между запусками скрипта. Пробуйте выполнять, можно сразу на рабочем сервере — скрипт создает только «временные таблицы» (доступны только внутри текущей сессии и самоуничтожаются при отключении) и не несёт в себе опасности.
Те, кто не любят выполнять запрос в студии — могут его завернуть в приложение написанное на своём любимом языке программирования. Я покажу как это сделать в MS Excel без единой строки кода.
В меню «Данные» подключаемся к серверу. Если будет требовать выбрать таблицу — выбираем произвольную — потом поменяем это. Как всегда, жмем «Next» и «Finish» пока не увидим диалог «Импорт данных» — в нем нужно нажать «Свойства...». В свойствах необходимо сменить «тип команды» на значение «SQL» и в поле «текст команды» вставить немного измененный наш запрос.
Запрос придется немного поменять:
добавим «SET NOCOUNT ON» — т.к. Excel не любит отсечки количества строк;
«временные таблицы» заменим на «таблицы переменные»;
задержка всегда будет 1сек — поля с усредненными значениями не нужны
Измененный запрос для Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id
Картинки процесса
Результат
Когда данные будут в Excel-е, можете их сортировать как вам нужно. Для актуализации информации — жмите «Обновить». В настройках книги, для удобства, можете поставить «автообновление» через заданный период времени и «обновление при открытии». Файл можете сохранить и передать коллегам. Таким образом, мы из навоза и веточек подручных средств собрали ЫнтерпрайзМониторингТул удобный и простой инструмент.
Пример 2: На что сессия расходует ресурсы
Итак, в предыдущем примере мы определили проблемные сессии. Теперь определим, что именно они делают. Используем sys.dm_exec_requests, а также функции получения текста и плана запроса.
текст запроса и план по номеру сессии
DECLARE @sql_handle varbinary(64)
DECLARE @plan_handle varbinary(64)
DECLARE @sid INT
Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT
-- для инфы по конкретному юзеру - указываем номер сессии
SELECT @sid=182
-- получаем переменные состояния для дальнейшей обработки
IF @sid IS NOT NULL
SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id
FROM sys.dm_exec_requests der WHERE der.session_id=@sid
--печатаем текст выполняемого запроса
DECLARE @txt VARCHAR(max)
IF @sql_handle IS NOT NULL
SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle)
PRINT @txt
-- выводим план выполняемого батча/процы
IF @plan_handle IS NOT NULL
select * from sys.dm_exec_query_plan(@plan_handle)
-- и план выполняемого запроса в рамках батча/процы
IF @plan_handle IS NOT NULL
SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml
from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Подставляйте в запрос номер сессии и выполняйте. После выполнения, на закладке «Results» будут планы (два: первый для всего запроса, второй для текущего шага — если шагов в запросе несколько), на закладке «Messages» — текст запроса. Для просмотра плана — необходимо кликнуть в строке на текст оформленный в виде url. План откроется в отдельной закладке. Иногда бывает что план открывается не в графическом виде, а в виде xml-текста. Это, скорее всего, связано с тем что версия студии ниже чем сервера. Попробуйте пересохранить полученный xml в файл с расширением sqlplan, предварительно удалив из первой строки упоминания «Version» и «Build», а затем отдельно открыть его. Если и это не помогает — напоминаю, что 2016 студия официально доступна бесплатно на сайте MS.
Картинки
Очевидно, полученный план будет «оценочным», т.к. запрос еще выполняется. Но некоторую статистику по выполнению получить всё равно можно. Используем представление sys.dm_exec_query_stats с фильтром по нашим хэндлам.
Допишем в конец предыдущего запроса
-- статистика по плану
IF @sql_handle IS NOT NULL
SELECT * FROM sys.dm_exec_query_stats QS WHERE QS.sql_handle=@sql_handle
После выполнения, в результатах получим информацию о шагах выполняемого запроса: сколько раз они выполнялись и какие ресурсы потрачены. Информация в статистику попадает после выполнения — при первом выполнении там, к сожалению, пусто. Статистика не привязана к пользователю, а ведется в рамках всего сервера — если разные пользователи выполняют один и тот же запрос — статистика будет суммарная по всем.
Пример 3: А можно всех посмотреть
Давайте объединим рассмотренные системные представления и функции в одном запросе. Это может быть удобно для оценки ситуации в целом.
-- получаем список всех текущих запросов
SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt
--,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat
,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, *
from sys.dm_exec_requests der
left join sys.dm_exec_sessions s ON s.session_id = der.session_id
WHERE der.session_id<>@@SPID
-- AND der.session_id>50
Запрос выводит список активных сессий и тексты их запросов. Для системных процессов, напоминаю, обычно запрос отсутствует, но заполнено поле «command». Видна информация о блокировках и ожиданиях. Можете попробовать скрестить этот запрос с примером 1, чтобы еще и отсортировать по нагрузке. Но будьте аккуратны — тексты запросов могут оказаться очень большими. Выбирать их массово может оказаться ресурсоемко. Да и трафик будет большим. В примере я ограничил получаемый запрос первыми 500 символами, а получение плана не стал делать.
Было бы ещё неплохо, получить Live Query Statistics для произвольной сессии. По заявлению производителя, на текущий момент, постоянный сбор статистики требует значительных ресурсов и поэтому, по умолчанию, отключен. Включить не проблема, но дополнительные манипуляции усложняют процесс и уменьшают практическую пользу. Возможно, попробуем это сделать в отдельной статье.
В этой части мы рассмотрели анализ действий пользователей. Попробовали несколько способов: используя возможности самой студии, используя профайлер, а также прямые обращения к системным представлениям. Все эти способы позволяют оценить затраты на выполнение запроса и получить план исполнения. Ограничиваться одним из них не нужно — каждый способ удобен в своей ситуации. Пробуйте комбинировать.
Впереди у нас еще анализ нагрузки на память и сеть, а также прочие нюансы. Дойдем и до них. Материала еще на несколько статей.
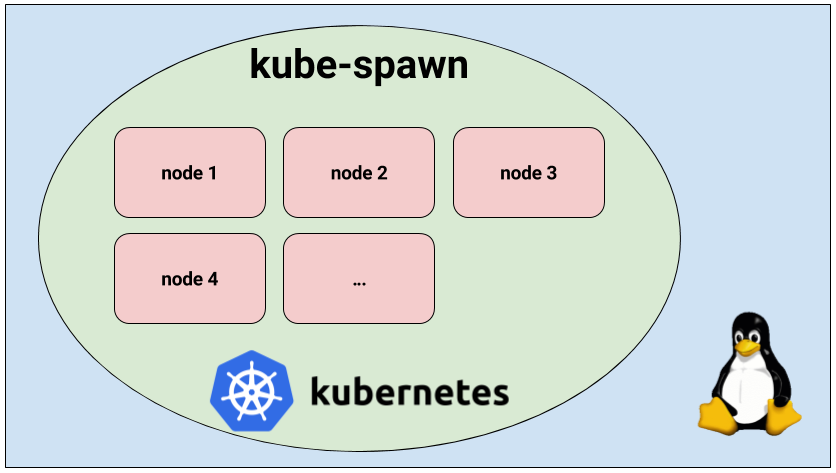








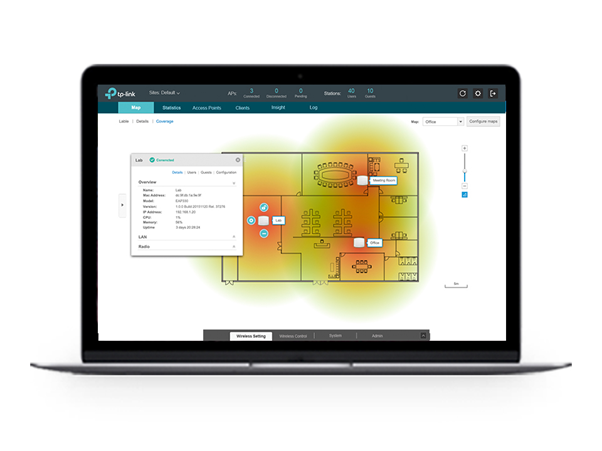



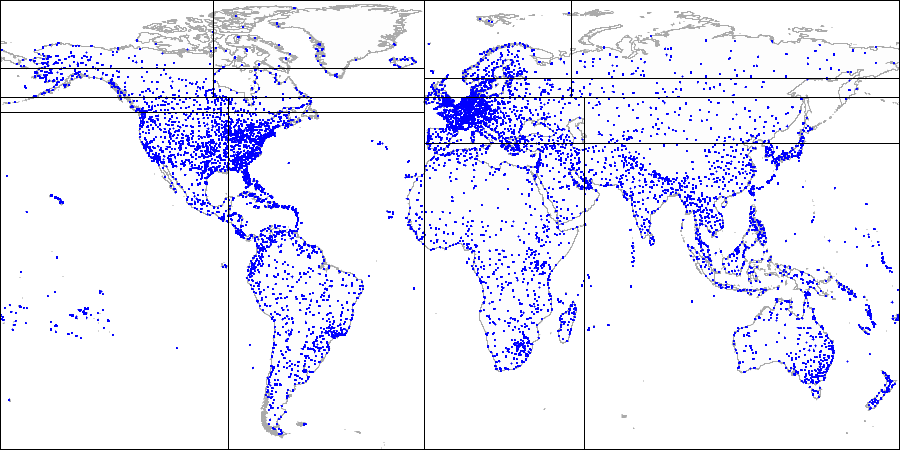
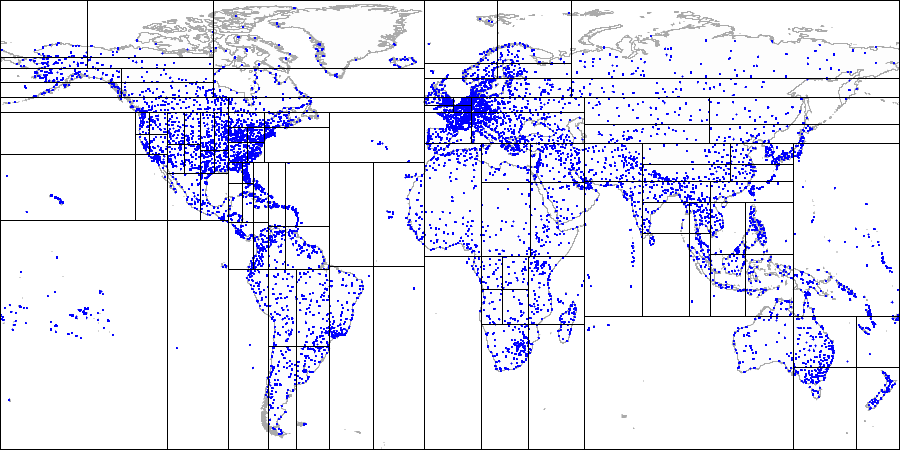
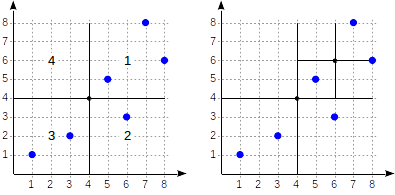
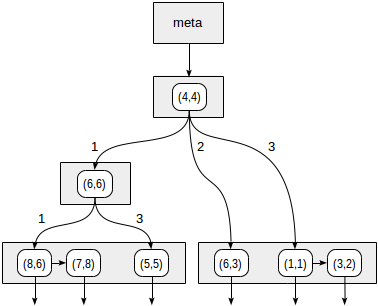
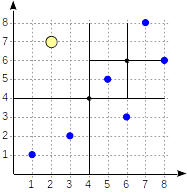
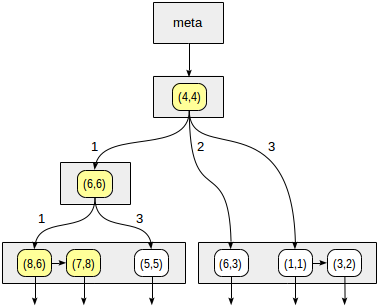
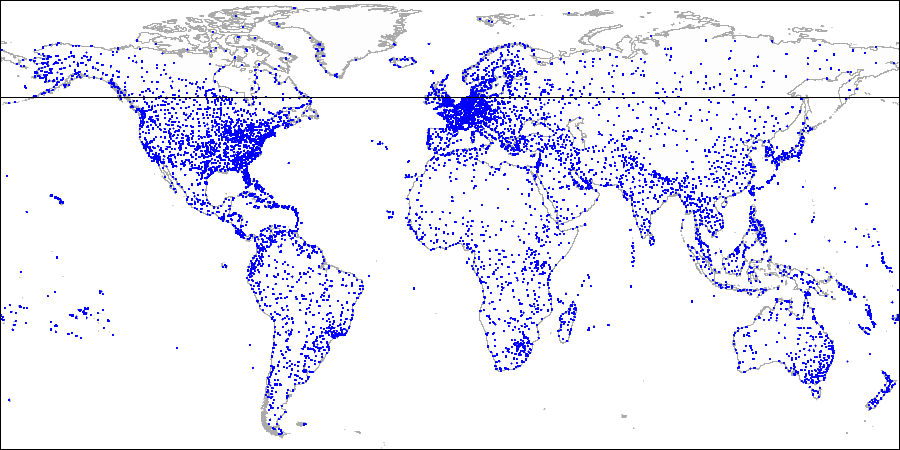
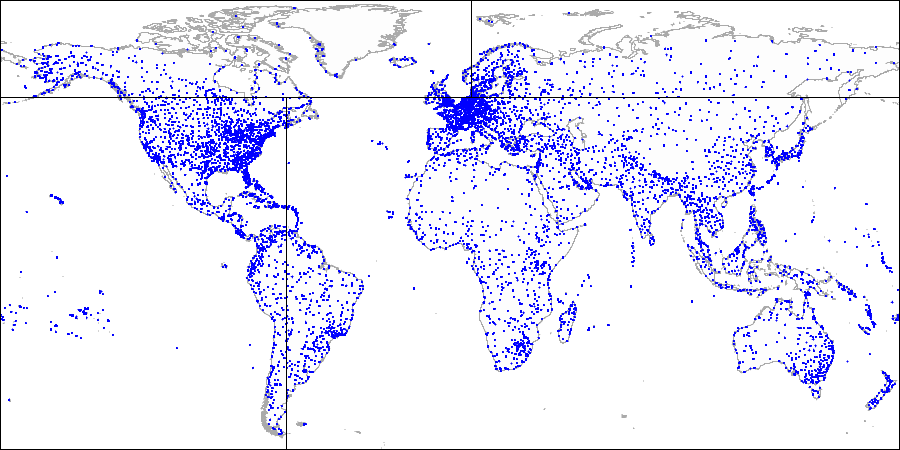

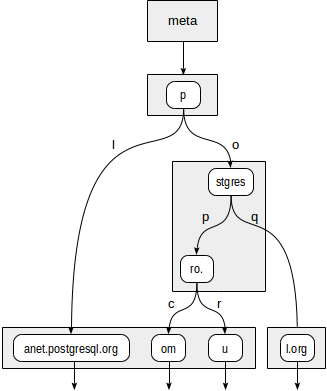








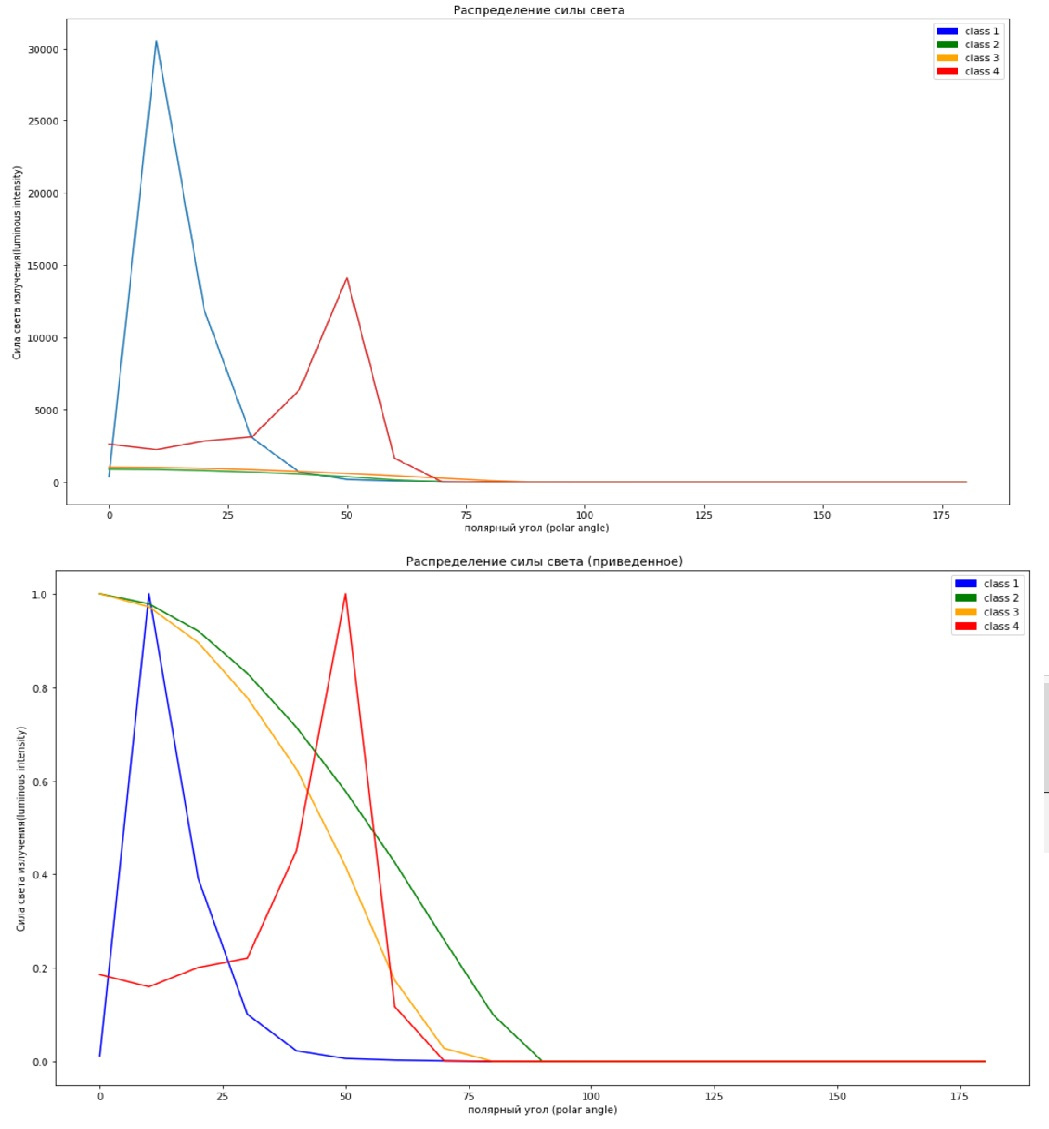






 У системы типов в ФП больше общего с теорией множеств, чем с классами из ООП.
У системы типов в ФП больше общего с теорией множеств, чем с классами из ООП. 













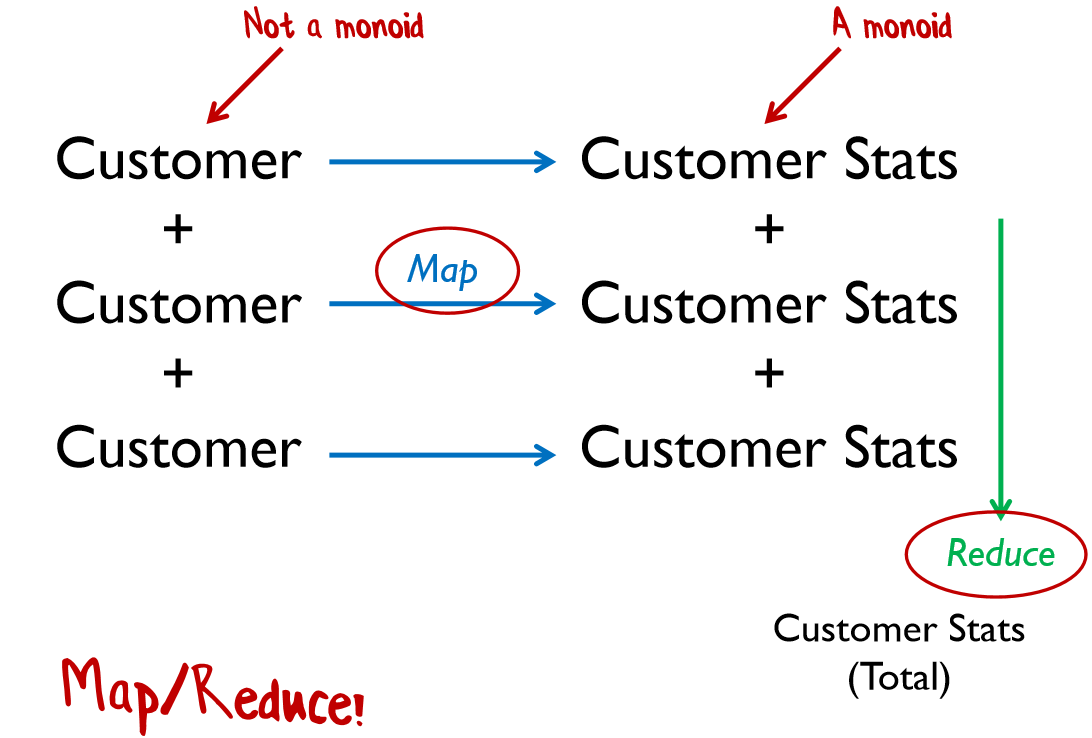
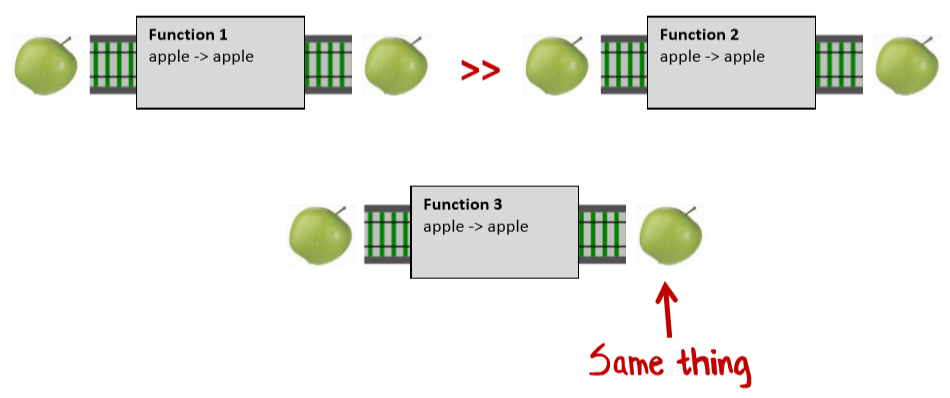 Функции с одинаковым типом входного и выходного значения являются моноидами и имеют специальное название — «эндоморфизмы» (название заимствовано из теории категорий). Что более важно, функции, содержащие эндоморфизмы могут быть преобразованы к эндоморфизмам с помощью частичного применения.
Функции с одинаковым типом входного и выходного значения являются моноидами и имеют специальное название — «эндоморфизмы» (название заимствовано из теории категорий). Что более важно, функции, содержащие эндоморфизмы могут быть преобразованы к эндоморфизмам с помощью частичного применения.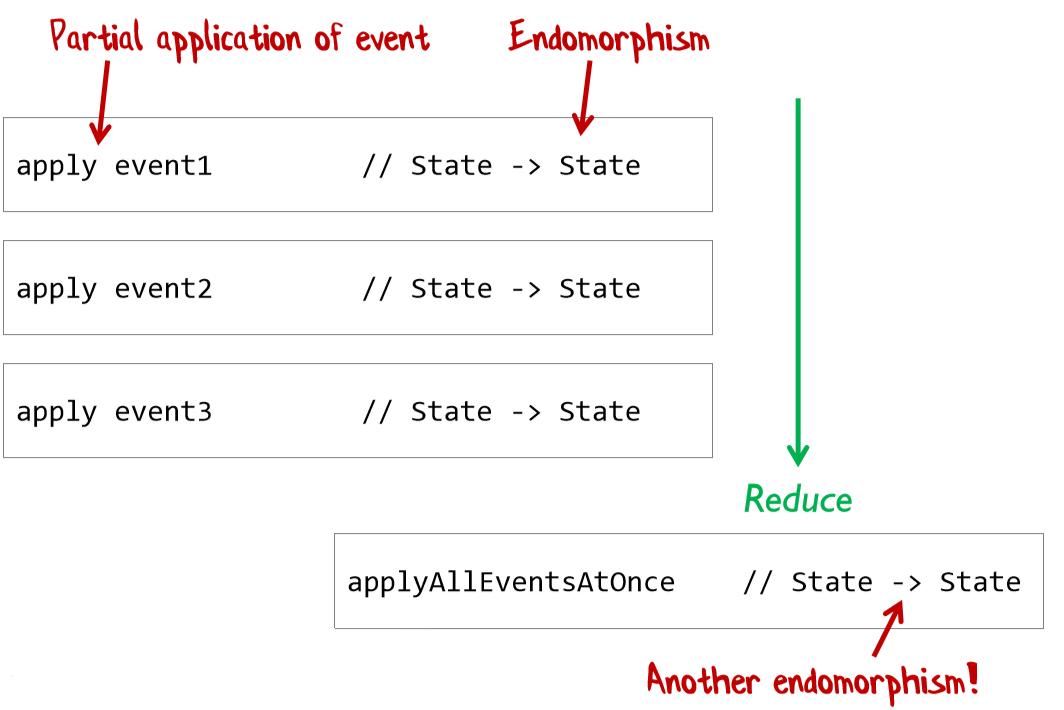






 iOS
iOS Используем SpriteKit для создания анимации загрузки watchOS
Используем SpriteKit для создания анимации загрузки watchOS Android
Android Android Dev Подкаст. Android Things (английский)
Android Dev Подкаст. Android Things (английский) Bubbble: клиент для Dribbble с использованием Clean Architecture + MVP
Bubbble: клиент для Dribbble с использованием Clean Architecture + MVP Разработка
Разработка Аналитика, маркетинг и монетизация
Аналитика, маркетинг и монетизация Устройства, IoT, AI
Устройства, IoT, AI