[Перевод] Эксплойт BlueBorne на Android, iOS, Linux и Windows: более 8 миллиардов устройств критически уязвимы |


|
Метки: author Cloud4Y стандарты связи сетевые технологии настройка linux беспроводные технологии блог компании cloud4y blueborne уязвимости bluetoth |
Уязвимость BlueBorne в протоколе Bluetooth затрагивает миллиарды устройств |

|
Метки: author LukaSafonov информационная безопасность блог компании pentestit blueborne bluetooth |
ReactOS 0.4.6 доступен для загрузки |

|
Метки: author Jeditobe реверс-инжиниринг разработка под windows open source блог компании фонд reactos reactos udf nfs usb twin peaks совсем не то чем кажется |
Профессиональное тестирование на проникновение: удел настоящих гиков-фанатов командной строки или уже нет? |
Когда речь заходит о хакинге, неважно, об этичном или не очень, многие из нас представляют темное помещение с мониторами и очкастым профессионалом с красными от постоянного недосыпания глазами. Действительно ли систему может взломать только гик-профессионал и действительно ли для того, чтобы протестировать защищенность своих систем необходимо привлекать только таких экспертов? А нельзя ли вооружить грамотного ИТ-специалиста хакерскими инструментами и логичной методологией и получить качественный результат? Попробуем разобраться.

Для того, чтобы разобраться в составляющих современной методологии тестирования защищенности, нам необходимо рассмотреть основные ее «кирпичики» — базовые подходы: классический тест на проникновение, сканирование на наличие уязвимостей и анализ конфигурации.
В ходе теста на проникновение специалист по тестированию защищенности действует как настоящий хакер: находит те уязвимости, которые легче всего использовать, эксплуатирует их и получает доступ к нужной информации. Как правило, в качестве цели выступает необходимость получить административный доступ или доступ к конкретной информации (например, данные о зарплатах топ-менеджеров).
Ключевой особенностью тестирования на проникновение является то, что осуществляется поиск не всех имеющихся уязвимостей, а только тех, которые необходимы для достижения выбранных целей (как и в случае реального взлома). Так как происходит боевая эксплуатация уязвимостей, возможны негативные последствия в виде зависших сервисов, перезагрузки серверов, головной боли у системных администраторов, выслушивания менеджером по ИБ мата со стороны руководства компании.
Представьте, что вы решили взломать сайт «голыми руками». Что вы сделаете? В первую очередь, постараетесь определить версию используемого Web-сервера и/или CMS-системы. Зачем? Для того, чтобы «прогуглить» и найти информацию об уже известных уязвимостях и имеющихся эксплойтах. Так злоумышленники поступали 15 лет назад, так же поступают и сейчас.
Данный процесс можно автоматизировать, что и сделали многочисленные разработчики средств анализа защищенности: появились сканеры уязвимостей. Конечно, сканеры не пользуются Google, а ищут информацию об уязвимостях в собственной базе.
Сканирование уязвимостей позволяет быстро «перелопатить» ИТ-инфраструктуру и найти проблемные места. Но сканер действует линейно и может пропустить интересные комбинации уязвимостей, которые в совокупности создают серьезную брешь в защите.
Рассмотрим следующий пример. Крупная производственная компания заказала тестирование защищенности. В первый день внутреннего тестирования на ресепшн замечаем на стикере пароль учетной записи, записанный заботливой рукой секретаря. Мы его скрыто фотографируем и через пять минут с данной учеткой запускаем специальную утилиту для поиска «расшаренных» папок (сейчас такой сканер есть в составе того же Metasploit Framework). В результате находим рабочую станцию сотрудника технической поддержки, ответственного за «накатывание» образов ОС на машины новых сотрудников компании.
Для своего и нашего удобства ИТ-специалист «расшарил» для всех папку с подготовленными образами. Мы не преминули воспользоваться такой любезностью и «вытянули» хеш пароля локального администратора, который и «раскрутили» за ночь. Полный доступ ко всем рабочим станциям предприятия был получен за одни сутки! Применение обычного сканера позволило бы найти «расшаренную» папку, но сканер не смог бы ни заглянуть внутрь, ни раскрутить хеш.
Важный промежуточный вывод: применение сканеров уязвимостей ускоряет тестирование, но ни в коем случае не обеспечивает его полноту.
Любой компонент ИТ-инфраструктуры (ОС, СУБД, активное сетевое оборудование и т.п.) содержит массу настроек, которые и определяют уровень защищенности. Правильные настройки можно найти в документации вендора или в статьях экспертов, делящихся своим опытом. На основе подобных материалов такие организации, как National Institute of Standards and Technology и Center of Internet Security уже многие годы готовят чеклисты, позволяющие проводить аудит конфигурации различных систем. Существуют аналогичные закрытые проекты и в рамках сообществ ИТ-аудиторов компаний «Большой четверки» (BIG4).
Анализ конфигурации может проводиться как вручную, так и с помощью автоматизированных средств, но в любом случаем подразумевает наличие административного доступа к проверяемой системе. Это аналогично тому, если у нас на коленке сидит симпатичная девушка-системный администратор и показывает нам все. Анализ конфигурации самый безопасный вариант анализа защищенности, но в то же время и самый долгий.
Разобравшись с тремя подходами к тестированию защищенности, самое время вспомнить, что все это должно делаться с какой-то определенной целью.
Все чаще заказчики тестирования защищенности озвучивают следующие две цели: выявить максимальное количество реальных уязвимостей для того, чтобы их оперативно закрыть и проверить бдительность сотрудников компании.
Для достижения поставленных целей нельзя провести полноценное тестирование, воспользовавшись только одним из рассмотренных подходов. Чистым тестом на проникновение мы не покроем всех имеющихся уязвимостей, ограничившись только сканированием на наличие уязвимостей, мы закопаемся в большом количестве «мусорных» срабатываний, а ошибки в настройках, обнаруженные в ходе анализа конфигурации, далеко не всегда приведут к реальной возможности проникновения. Необходимо подходы комбинировать.
Для формирования подхода комплексного тестирования защищенности целесообразно взять последовательность действий злоумышленников и добавить применение эффективных инструментов, которые не могут позволить себе настоящие хакеры из-за их демаскирующих признаков.
Процесс тестирования защищенности разобьем на следующие этапы в соответствии с этапами реального взлома:
Единственный этап, которого в проекте по тестированию защищенности может и не быть, в случае, если заказчик сразу передал нам список целей.
Если тестирование внешнее, и заказчик сообщил нам только название компании, то на этом этапе мы занимаемся полноценной интернет-разведкой, целями которой являются информационные ресурсы заказчика и его сотрудники (особенно если проект предусматривает применение методов социальной инженерии).
На данном шаге мы изучаем:
В итоге, мы формируем список IP-адресов информационных ресурсов, связанных с заказчиком, списки сотрудников и др.
В случае внутреннего тестирования защищенности этичный хакер получает физический доступ к розетке, прослушивает сетевой трафик и определяет диапазоны IP-сетей, с которых он может начать свою работу.
Зная цели, можно смело приступать к поиску уязвимостей. В основном, мы делаем это с помощью сканеров уязвимостей, но и не отказываемся от ручного поиска уязвимостей, особенно в случае Web-приложений.
В итоге мы получаем список потенциальных уязвимостей, который еще предстоит проверить.
Важное примечание: если мы с вами действуем на данном шаге без административного доступа к системам, то не ожидайте, что какой-либо сканер вам покажет все имеющиеся уязвимости на конкретном узле. Чтобы найти максимум уязвимостей, придется повторить это упражнение с уже добытыми потом и кровью административными учетными записями.
После того как мы составили список потенциальных уязвимостей, неплохо бы их проверить на возможность эксплуатации и еще поискать дополнительные, которые невозможно найти с помощью сканеров и Google. Зачем это нужно делать? Этому есть несколько причин.
Во-первых, закрытие любой уязвимости — это настоящая головная боль для системных администраторов, у которых полно другой работы. Также всегда есть шанс, что что-нибудь «отвалится» после накатывания патча или изменения настроек. Поэтому целесообразнее грузить наших любимых системных администраторов только стоящими проблемами: теми уязвимостями, которые действительно опасны, а это можно установить только, проверив возможность эксплуатации.
Во-вторых, существует множество уязвимостей, которые могут быть проверены только в процессе эксплуатации: например, слабый пароль, возможность SQL-инъекции или XSS.
На данном шаге мы с вами:
В результате данного шага мы выясняем, какие из обнаруженных уязвимостей реальны, находим «боевым» тестированием новые уязвимости и смотрим, что можно получить если эксплуатировать их.
Если получим желанный административный доступ, то сможем вернуться к предыдущему шагу и найти еще больше уязвимостей.
Получив доступ к какой-либо системе, мы пытаемся понять, к чему получили доступ и можно ли его расширить в рамках одной системы (например, до уровня администратора) или в рамках всей ИТ-инфраструктуры.
Простой пример. Подобрав пароль пользователя к одной системе, проверяем, не подойдет ли данная пара логин/пароль для доступа к другим системам.
Таким образом, рассмотренный подход позволяет обнаруживать максимальное количество реальных уязвимостей с помощью доступных инструментов.
Для настоящего взлома и тестирования на проникновение существует несколько сотен утилит.
Отдельно хочу отметить, что арсенал взломщиков не получится заменить каким-либо одним, пусть даже коммерческим сканером, соответственно, для полноценного тестирования защищенности необходимо использовать несколько инструментов.
Безусловным лидером среди подобных инструментов «в одной коробке» является сборка Kali Linux.
Сведем в один список наиболее полезные и чаще всего используемые этичными хакерами бесплатные программы:
Есть еще масса утилит, решающих узкоспециализированные задачи. Неплохой перечень подобных инструментов входит в уже упоминавшуюся сборку Kali Linux: https://tools.kali.org/tools-listing.
Основная проблема, с которой сталкивается специалист при работе с подобными инструментами, заключается в том, что большинство из них имеют нетривиальный пользовательский интерфейс, а зачастую, это просто командная строка и миллион непонятных параметров. Как раз данный момент способствует культивированию стереотипа, что тестирование на проникновение – удел лишь настоящих гиков.
В НПО «Эшелон» мы смогли эту проблему решить и сделать продукт, позволяющий проводить комплексное тестирование защищенности, не сталкиваясь со сложным интерфейсом хакерских утилит. В новой версии комплекса тестирования защищенности «Сканер-ВС» появился удобный Web-интерфейс, позволяющий, не выходя из одного рабочего пространства, провести:
Проведение тестирования защищенности с помощью «Сканер-ВС»
Для демонстрации реализации комплексного тестирования защищенности мы рассмотрим процесс анализа виртуальной машины Metasploitable 2
Загружаем «Сканер-ВС» с USB-носителя и открывается главное окно:
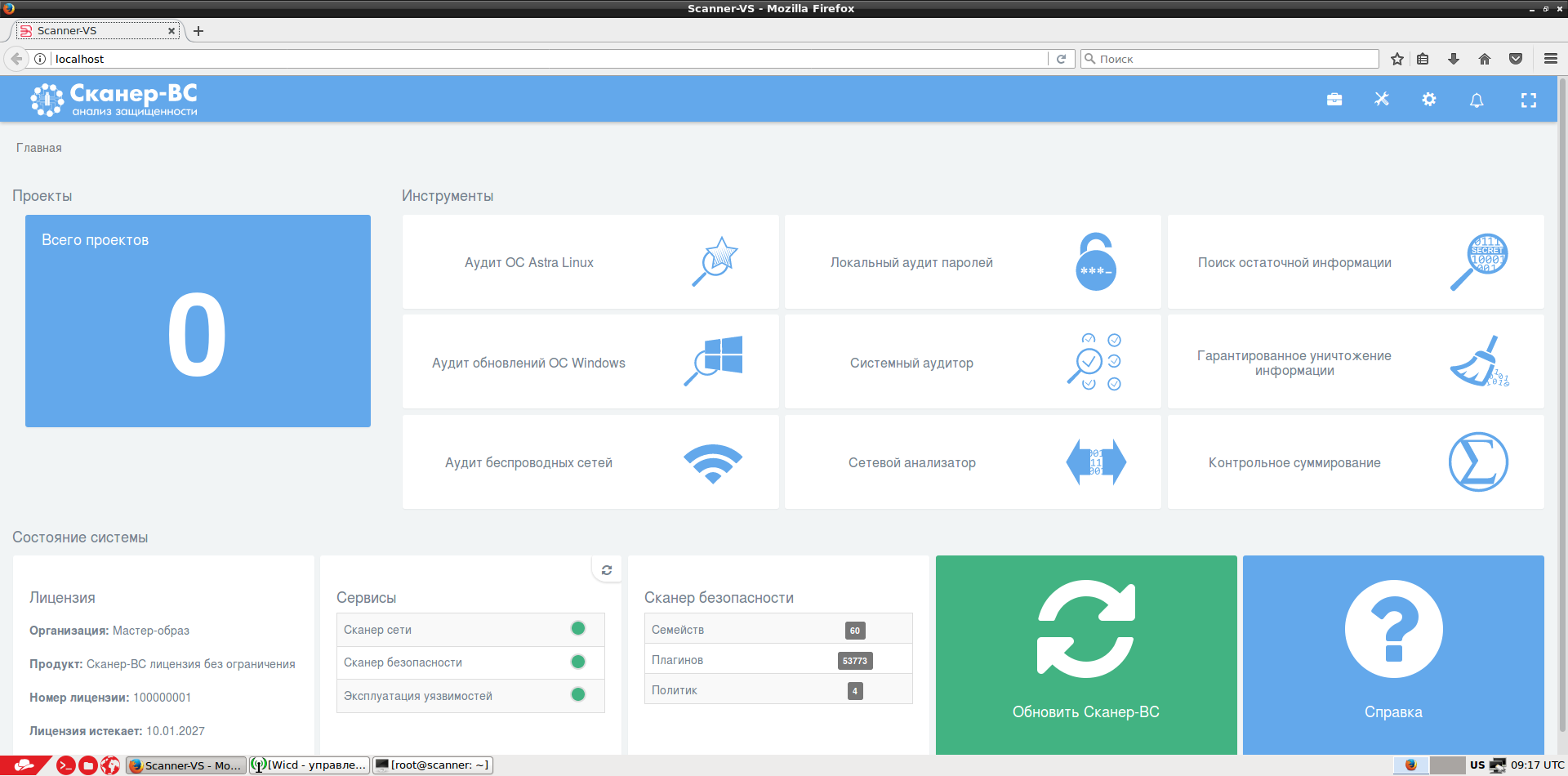
Создаем проект, внутри которого задачи уже связаны с соответствующими фазами тестирования защищенности. Мы последовательно проводим сканирование портов, уязвимостей, подбор паролей и эксплойтов и получаем общую картину:
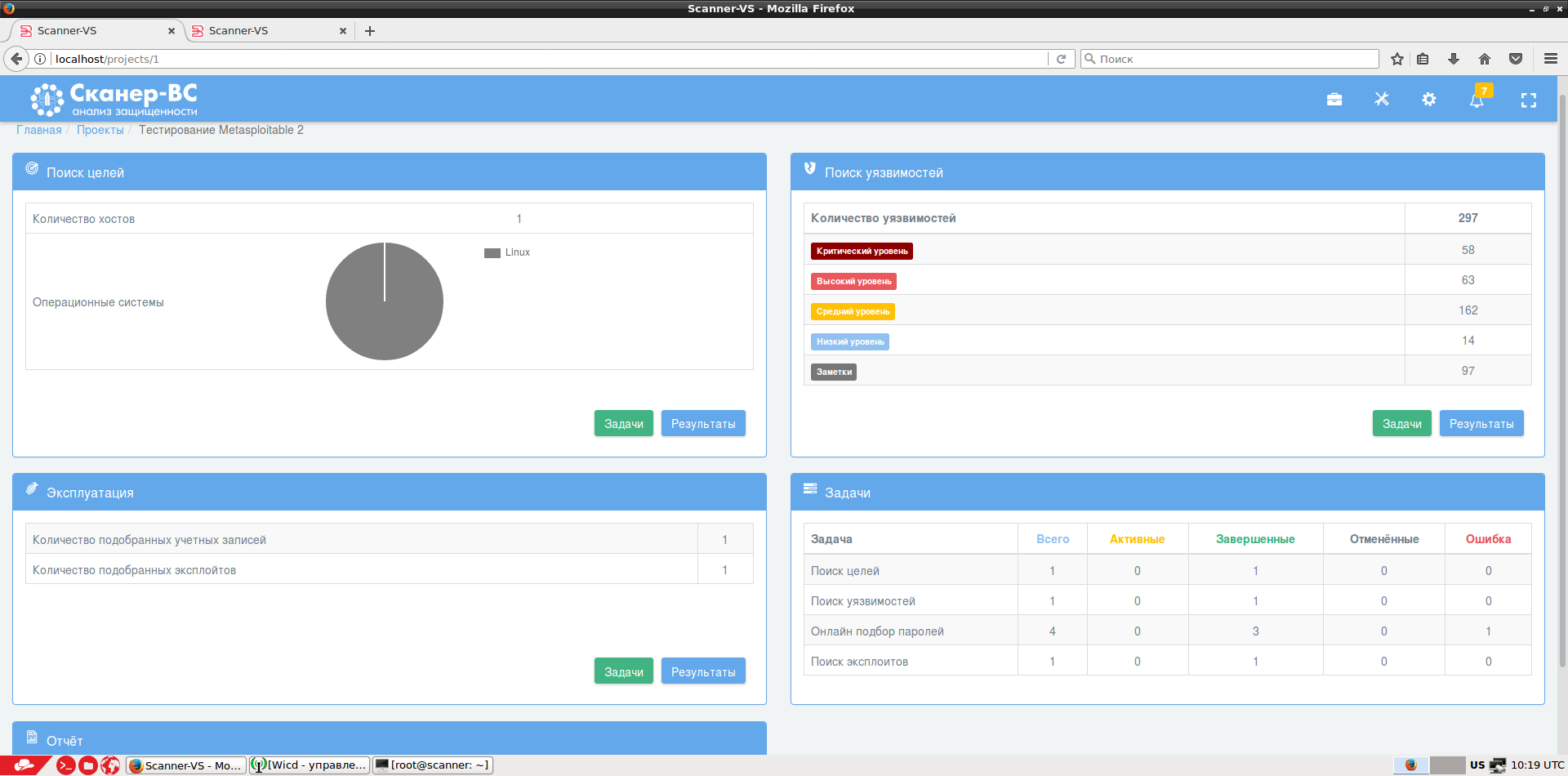
Внутри каждой фазы доступны соответствующие результаты.
Сканирование портов:
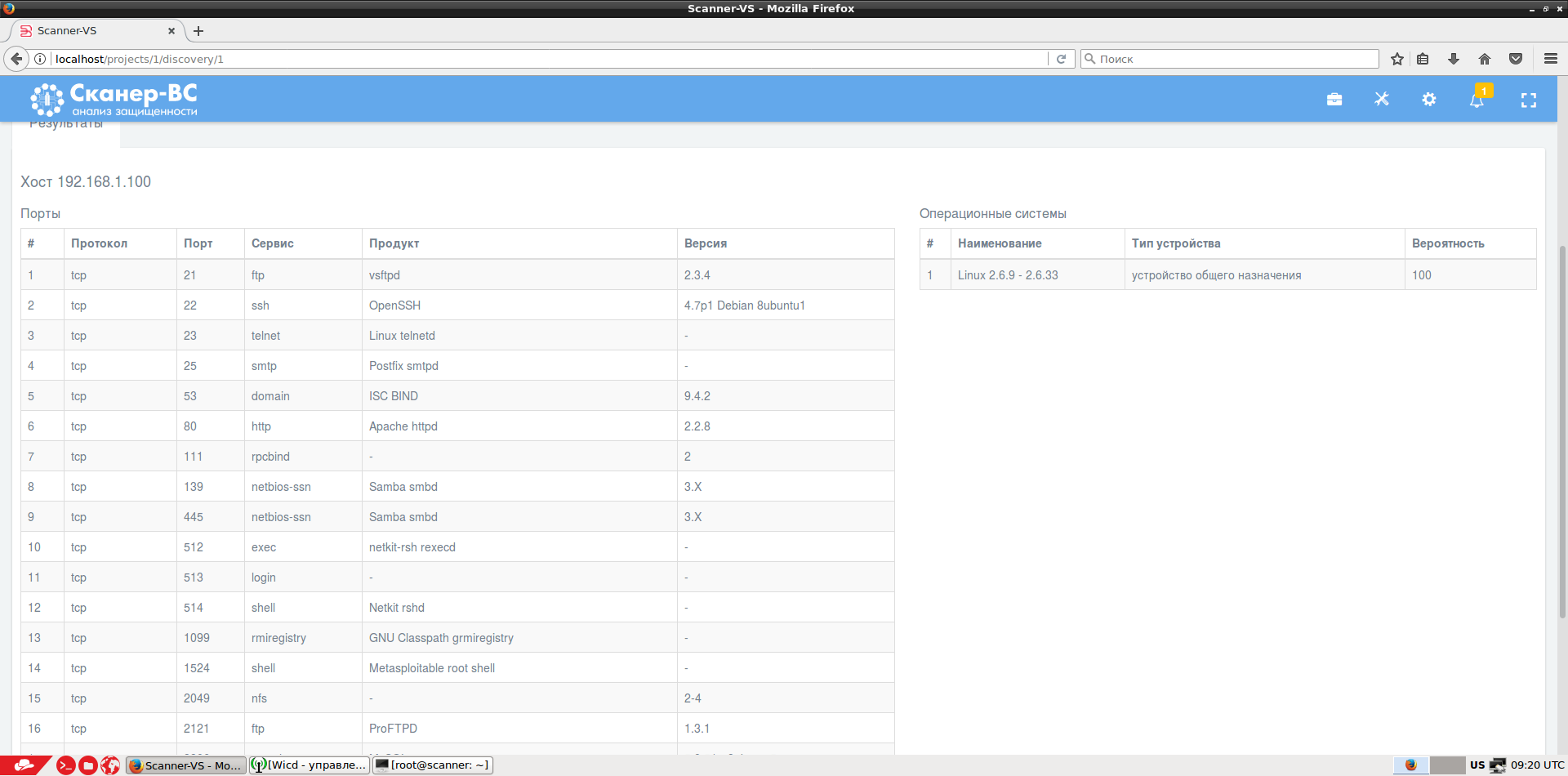
Сканирование уязвимостей с помощью готовых политик или своей собственной. Стоит отметить, что база уязвимостей обновляется еженедельно и содержит плагины для выявления уязвимостей в отечественных СЗИ. Мы также поддерживаем Банк данных угроз ФСТЭК России.
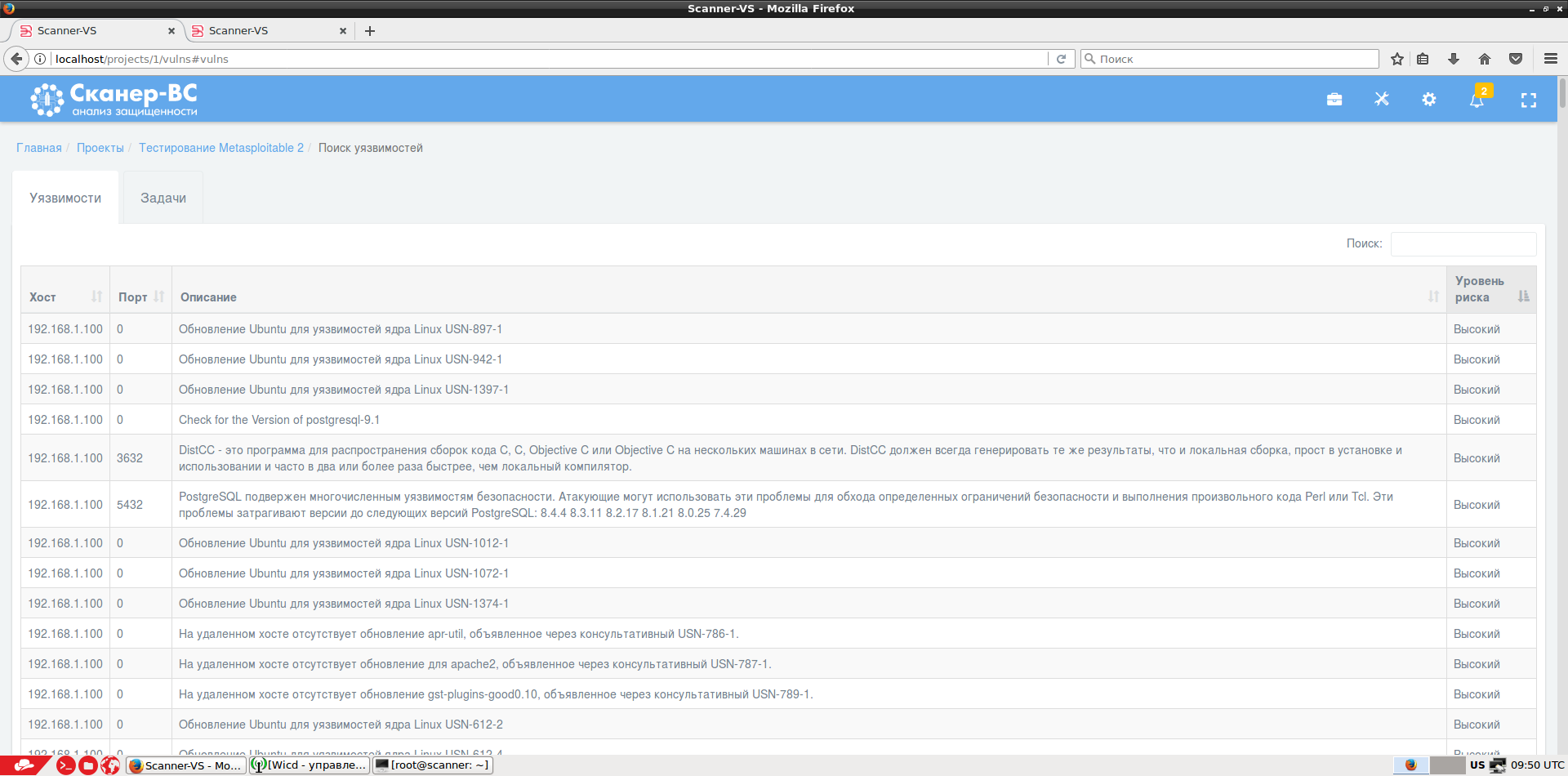
Подбор подходящих экплойтов из Metasploit Framework. Возможен как строгий поиск по версии сервиса, так и нестрогий по его типу.
Подбор паролей проводится к различным сетевым сервисам. При этом можно использовать как собственные наборы пользователей/паролей, так и встроенные списки, содержащие наиболее часто встречающиеся варианты.
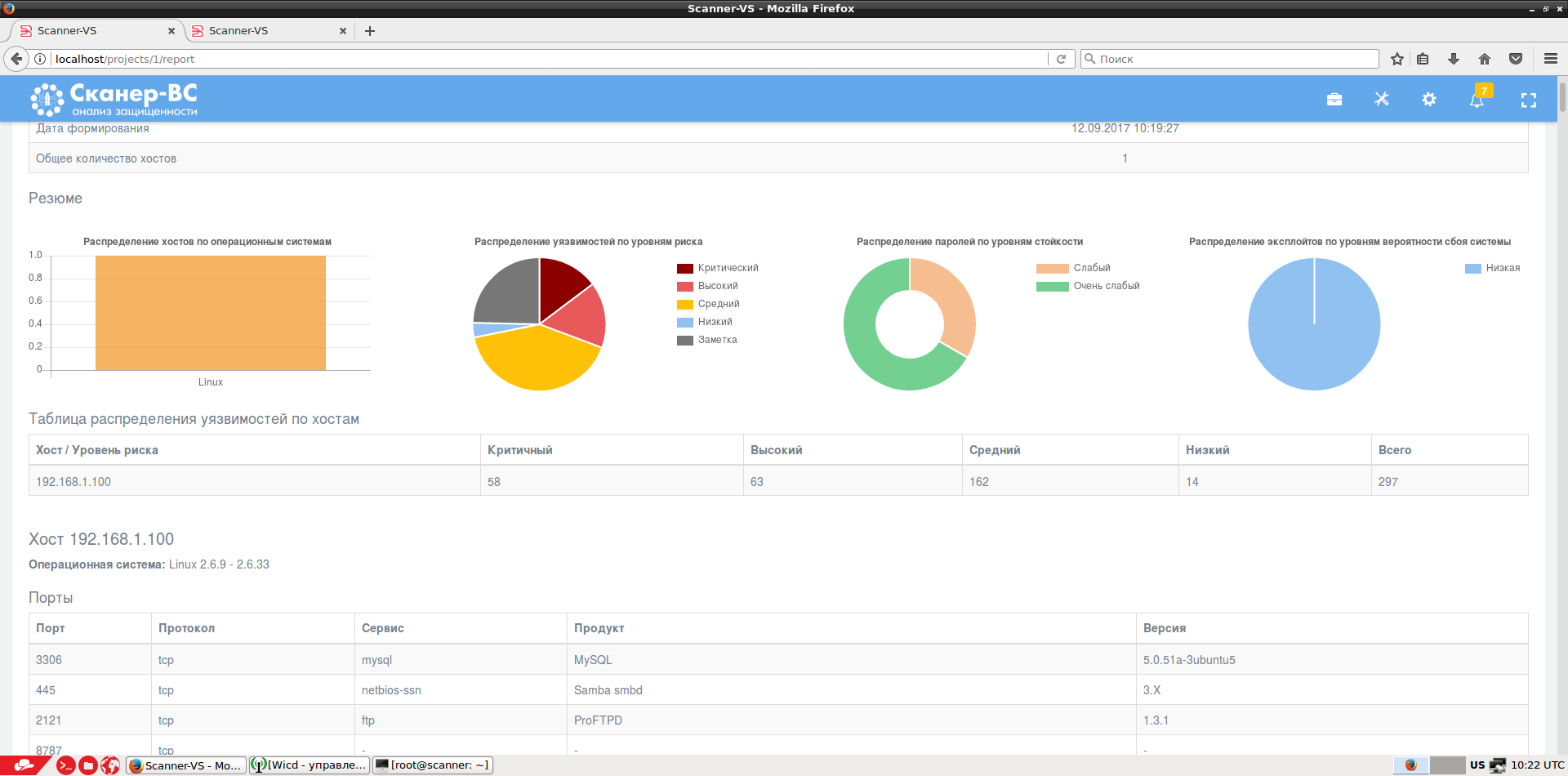
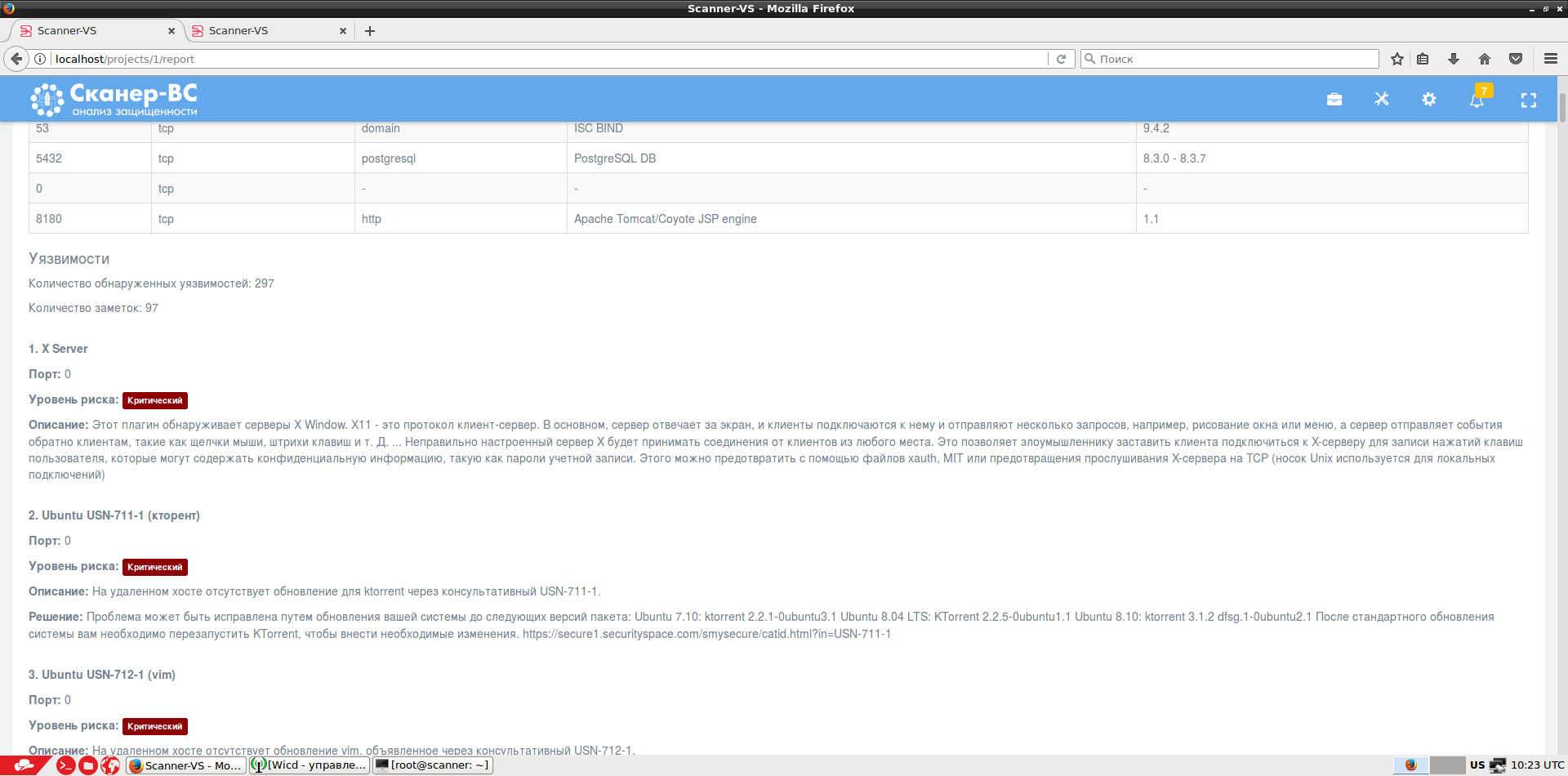
Результаты работы каждой задачи сохраняются в базе данных, и на их основе формируется итоговый отчет.

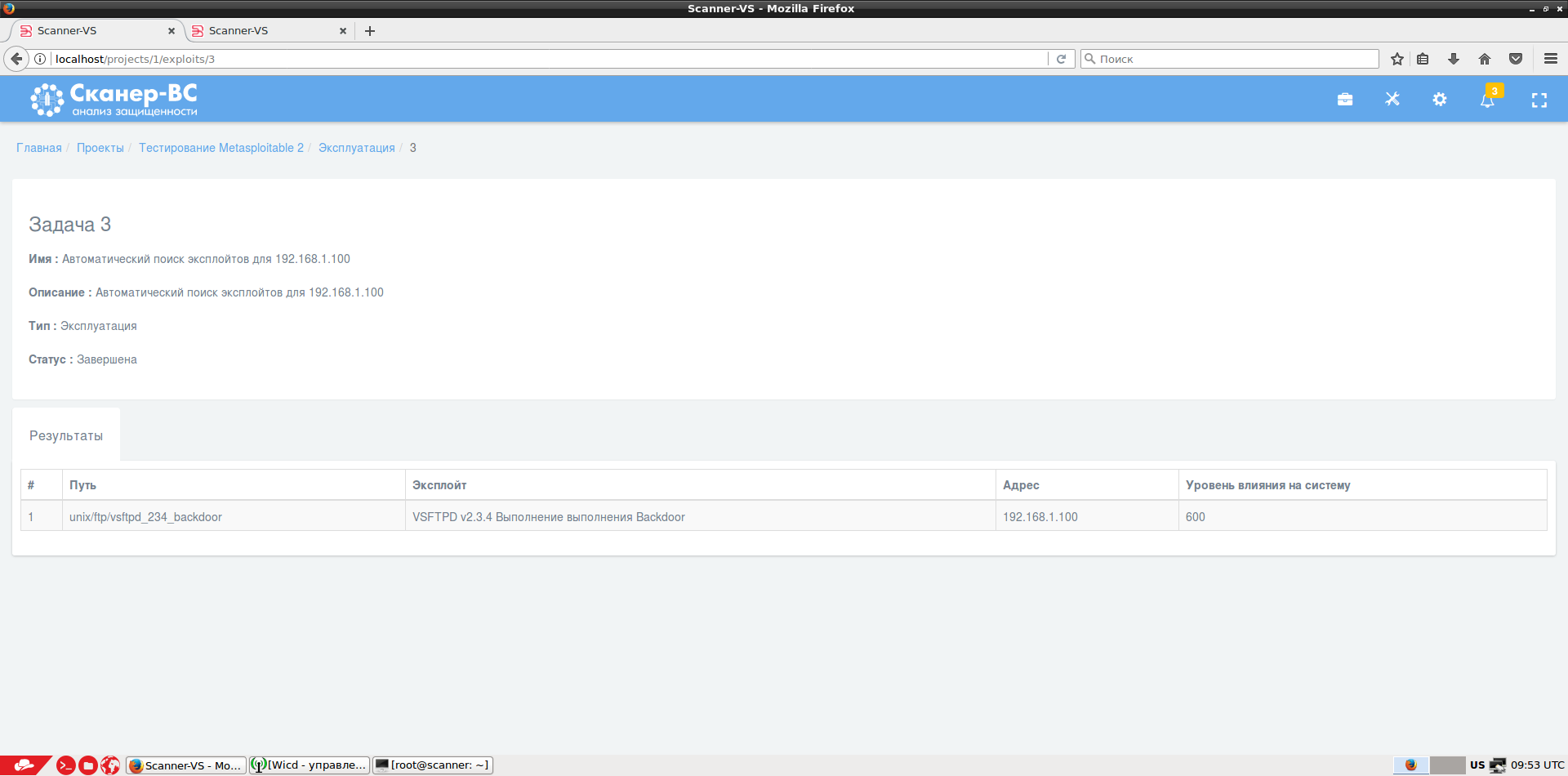
Так как «Сканер-ВС» построен на основе Kali Linux, пользователю доступны все стандартные утилиты из данной сборки хакерских инструментов. Также реализованы следующие инструменты, используемые для оценки эффективности средств защиты информации:
Чтобы дальше не скатываться в прямую рекламу нашей разработки, всех, кому интересно, попробовать наше решение в действии, приглашаем посетить сайт http://scaner-vs.ru и скачать самую последнюю версию решения для тестирования.
|
Метки: author alexdorofeeff информационная безопасность блог компании эшелон тестирование на проникновение анализ защищенности сканер уязвимостей сканеры портов сканер безопасности |
[Перевод] 67 полезных инструментов, библиотек и ресурсов для экономии времени веб-разработчиков |


|
Метки: author Arturo01 разработка веб-сайтов программирование библиотеки фреймворки инструменты ресурсы |
Автоматизируй это: десять применений пользовательского API для QIWI Кошелька |

|
Метки: author d_garmashev хакатоны блог компании qiwi qiwi qiwi api contest конкурс по тысяче рублей за идею конкурс идей |
Экспресс Купертино — Москва. Новые фичи iOS 11, обсуждение Apple Special Event и конкурс от Avito |
Мы все знаем, что почти каждый iOS-разработчик хотел бы оказаться вечером 12 сентября в театре Стива Джобса в Купертино. Вместо фокусов с телепортацией и материализацией приглашений на это событие мы устроили Avito Special iOS Event.
Сначала послушаем короткие тематические доклады от iOS-разработчиков из ведущих российских компаний, а затем будет совместный просмотр конференции Apple. Специально для Хабра будем вести здесь прямую видеотрансляцию той части, что с докладами, у нас в Avito, а затем — текстовую трансляцию из Калифорнии. Чтобы было ещё веселее, мы подготовили конкурс для тех, кто способен предвидеть будущее.

Итак, под катом:
Все большие события Apple окружены атмосферой тайны. Все пытаются угадать, что именно расскажут и покажут на конференции. Предлагаем вам сделать свои ставки в этой форме. Каждый ответ имеет свой вес в баллах. Тому (или тем), у кого наиболее развита интуиция/дар предвидения/etc, мы подарим сувенир от Avito. Ответы закончим принимать с началом трансляции конференции Apple. Теперь — к докладам.
Итак, максимально быстро окунаемся в дивный новый мир iOS 11. Мы позвали на митап специалистов из Rabler&Co, Avito и App in the Air. Сегодняшние рассказы — о практическом опыте реализации новых фич iOS 11. Даже если вы сильно не следили за обновлениями, после этого поста вы будете чётко знать, чего не хватает вашим приложениям, чтобы стать полностью iOS 11-совместимыми.
(UPD 18:28: Мы впервые решили вставить прямую трансляцию с YouTube в пост на Хабре, поэтому ниже уже есть запасная ссылка. Просто на всякий случай).
Разработчики приложения Афиша Рестораны, Самвел Меджлумян и Дмитрий Антышев, рассказывают о том, как они смогли прикрутить ARKit к своему проекту. Помимо тонны хайпа, видеодемок и кривой Гаттнера много внимания уделено вопросам алгоритмов расчета положения точек в пространстве и построения маршрутов. Если вы до сих пор сомневаетесь, что ARKit можно с пользой встроить в ваше приложение — опыт ребят может помочь вам изменить свое решение.
В Avito сильно развита традиция внутренних хакатонов, о чем мы уже писали в нашем блоге. На одном из них команда мобильных разработчиков решила известную боль пользователей — при подаче объявления они всеми возможными способами пытаются скрывать лица и номера машин. Кто-то одевает пакеты, кто-то прикрывается руками, наиболее продвинутые делают это в графическом редакторе, но суть остается — для обеспечения конфиденциальности люди тратят слишком много усилий.
Тимофей Хомутников рассказывает о том, как при помощи нового фреймворка Vision и набора костылей эта проблема была решена. И чтобы доклад не сводился к простому использованию системного SDK, Тимофей проводит ликбез по существующим способам и алгоритмам определения автомобильных номеров.
Разработчики App in the Air известны тем, что каждый год одними из первых реализуют все новые плюшки из обновления iOS – и неважно, насколько они на первый взгляд релевантны приложению, получается стабильно круто. Этот год тоже не стал исключением. Сергей Пронин, CTO компании, рассказывает про ключевую функциональность, реализованную командой до релиза iOS 11. В нее вошли Drag and Drop, iMessage Live Messages, ARKit, SiriKit и Notifications Privacy.
Особое внимание в докладе Сергей уделяет Drag and Drop. И на примере кейса из своего приложения показывает, что встроить его и кастомизировать для своих нужд достаточно просто.
Текстовая трансляция из телеграм-канала Tolstoy Live будет обновляться и здесь:
• 1:50:03 PM
Всем привет! Смело отписывайтесь от канала — сегодня по мере возможности буду вести трансляцию Apple Special Event для тех, кому лень или некогда смотреть самому. Ну и вообще, началась осень, куча ивентов и все такое.
И напоследок бонус: свежие картинки с Тимом Куком. Сделано с любовью.

Пишите в комментариях, что думаете о сегодняшней конференции, докладах и практическом применении iOS 11!
|
|
[Перевод] DevOps с Kubernetes и VSTS. Часть 1: Локальная история |

c:
cd \
minikube start --vm-driver hyperv --hyperv-virtual-switch minikube
kubectl config set-cluster minikube --server=https://kubernetes:8443 --certificate-authority=c:/users//.minikube/ca.crt PS:\> kubectl get nodes
NAME STATUS AGE VERSION
minikube Ready 11m v1.6.4

minikube docker-env | Invoke-Expressionversion: '2'
services:
api:
image: api
build:
context: ./API
dockerfile: Dockerfile
frontend:
image: frontend
build:
context: ./frontend
dockerfile: DockerfileFROM microsoft/aspnetcore:1.1
ARG source
WORKDIR /app
EXPOSE 80
COPY ${source:-obj/Docker/publish} .
ENTRYPOINT ["dotnet", "API.dll"]cd API
dotnet restore
dotnet build
dotnet publish -o obj/Docker/publish
cd ../frontend
dotnet restore
dotnet build
dotnet publish -o obj/Docker/publish
cd ..
docker-compose -f docker-compose.yml build
apiVersion: v1
kind: Service
metadata:
name: demo-backend-service
labels:
app: demo
spec:
selector:
app: demo
tier: backend
ports:
- protocol: TCP
port: 80
nodePort: 30081
type: NodePort
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: demo-backend-deployment
spec:
replicas: 2
template:
metadata:
labels:
app: demo
tier: backend
spec:
containers:
- name: backend
image: api
ports:
- containerPort: 80
imagePullPolicy: Neverspec:
containers:
- name: frontend
image: frontend
ports:
- containerPort: 80
env:
- name: "ASPNETCORE_ENVIRONMENT"
value: "Production"
volumeMounts:
- name: config-volume
mountPath: /app/wwwroot/config/
imagePullPolicy: Never
volumes:
- name: config-volume
configMap:
name: demo-app-frontend-configapiVersion: v1
kind: ConfigMap
metadata:
name: demo-app-frontend-config
labels:
app: demo
tier: frontend
data:
config.json: |
{
"api": {
"baseUri": "http://kubernetes:30081/api"
}
}PS:\> cd k8s
PS:\> kubectl apply -f .\app-demo-frontend-config.yml
configmap "demo-app-frontend-config" created
PS:\> kubectl apply -f .\app-demo-backend-minikube.yml
service "demo-backend-service" created
deployment "demo-backend-deployment" created
PS:\> kubectl apply -f .\app-demo-frontend-minikube.yml
service "demo-frontend-service" created
deployment "demo-frontend-deployment" created
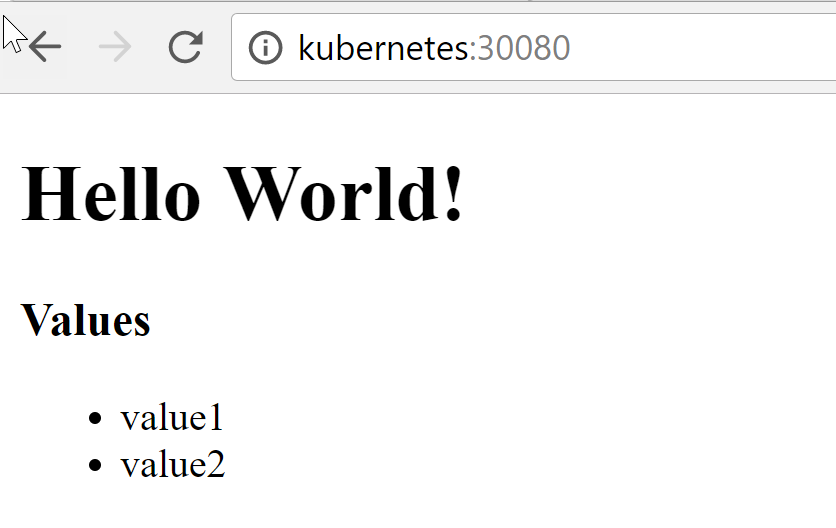
PS:> kubectl get pods
NAME READY STATUS RESTARTS AGE
demo-backend-deployment-951716883-fhf90 1/1 Running 0 28m
demo-backend-deployment-951716883-pw1r2 1/1 Running 0 28m
demo-frontend-deployment-477968527-bfzhv 1/1 Running 0 14s
demo-frontend-deployment-477968527-q4f9l 1/1 Running 0 24s
PS:> kubectl delete pods demo-backend-deployment-951716883-fhf90 demo
-backend-deployment-951716883-pw1r2 demo-frontend-deployment-477968527-bfzhv demo-frontend-deployment-477968527-q4f9l
pod "demo-backend-deployment-951716883-fhf90" deleted
pod "demo-backend-deployment-951716883-pw1r2" deleted
pod "demo-frontend-deployment-477968527-bfzhv" deleted
pod "demo-frontend-deployment-477968527-q4f9l" deleted
PS:> kubectl get pods
NAME READY STATUS RESTARTS AGE
demo-backend-deployment-951716883-4dsl4 1/1 Running 0 3m
demo-backend-deployment-951716883-n6z4f 1/1 Running 0 3m
demo-frontend-deployment-477968527-j2scj 1/1 Running 0 3m
demo-frontend-deployment-477968527-wh8x0 1/1 Running 0 3m|
Метки: author stasus программирование visual studio microsoft azure блог компании microsoft microsoft kubernetes k8s vsts devops minikube kubectl |
[Перевод] Правила и запреты веб-дизайна |


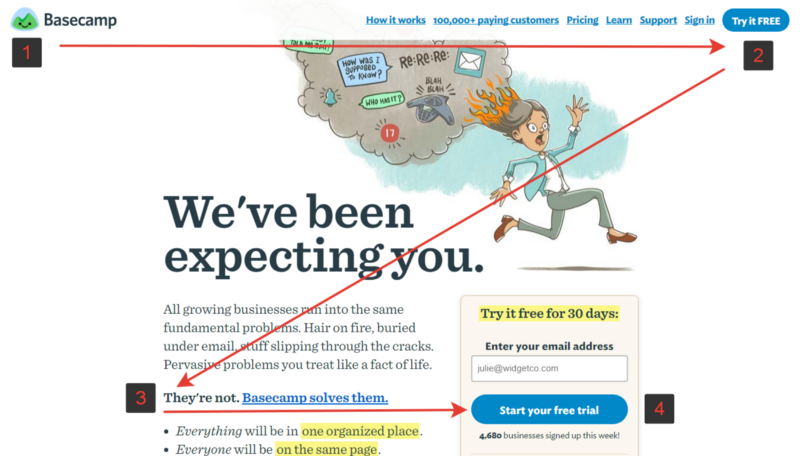

Предельное время концентрации пользователя на задаче — 10 секунд





|
Метки: author Logomachine интерфейсы дизайн мобильных приложений веб-дизайн usability блог компании логомашина бизнес дизайн совет |
Конкурс идей от ABBYY – куда бежать и что делать |
 Всем привет. Меня зовут Игорь Акимов, я руководитель направления мобильных продуктов ABBYY. Наверное, многие знают ABBYY по лучшим словарям Lingvo и помощнику любого студента FineReader, но кроме этого мы занимаемся ещё много чем интересным в сфере интеллектуальной обработки информации и лингвистики. За 28 лет накопили огромный багаж в сфере машинного обучения и нейросетей, а новых проектов и идей так много, что кажется, нам нужна помощь :) Поэтому мы приглашаем вас принять участие в конкурсе. Мы ищем идеи по применению новых технологий в мобильной разработке, которые будут близки большому числу людей. И назвали конкурс мы смело – mABBYYlity (тут и ABBYY, и мобильность, и ability – способность). Короче, всё основное тут – mobility.abbyy.com. А в статью за подробностями.
Всем привет. Меня зовут Игорь Акимов, я руководитель направления мобильных продуктов ABBYY. Наверное, многие знают ABBYY по лучшим словарям Lingvo и помощнику любого студента FineReader, но кроме этого мы занимаемся ещё много чем интересным в сфере интеллектуальной обработки информации и лингвистики. За 28 лет накопили огромный багаж в сфере машинного обучения и нейросетей, а новых проектов и идей так много, что кажется, нам нужна помощь :) Поэтому мы приглашаем вас принять участие в конкурсе. Мы ищем идеи по применению новых технологий в мобильной разработке, которые будут близки большому числу людей. И назвали конкурс мы смело – mABBYYlity (тут и ABBYY, и мобильность, и ability – способность). Короче, всё основное тут – mobility.abbyy.com. А в статью за подробностями.|
|
Охота на кремлевского демона |

Нельзя сказать, что я не искал с этим демоном встречи. Я дождался пока он вылезет и выследил его логово. Поиграл с ним немного. Потом демон исчез, как обычно, по расписанию — в 9.00. Я успокоился и занялся своими бытовыми делами.
Дело было в том, что у нас в Питере не найти в книжных магазинах рабочую тетрадь по английскому языку "Планета знаний" 3 класс. Ну как в Союзе было, дефицит. И мне жена дала задание — зайти в книжные в Москве. Дескать, в столице все есть, тетки на форуме оттуда заказывают, платят 500 рублей за доставку, а ты, пользуясь случаем, купишь сам и сэкономишь для семьи. Хоть какой-то толк от неудачника будет. Я включаю Гугль-карту, задаю фразу "книжные магазины" и не понимаю. Ни Красной площади, ни реки, какие-то непонятные улицы.
Черт! Он вылез опять! Я ведь еще успел только до Варварки дойти.
И, повинуясь зову природы, я расчехлил опять свое оружье.
Каждый охотник желает знать где сидит фазан.
Народная запоминалка по физике
Нам кажется, даже приятно оказаться испуганными. Не потому, что страх предупреждает нас о реальной опасности или побуждает предпринять какое-то действие против нее, но потому, что он делает наш опыт необычайно интенсивным.
Кори Робин. "Страх. История политической идеи"
Пока расчехляю — думаю так.
Он ведь, собака, мешает мне жить, выполнять простые бытовые надобности. И всем этим туристам, которые поднимаются из Китай-города на площадь тоже мешает. И тем парням, которые на Кремлевской набережной попали в ДТП тоже мешает. И бегунам, и таксистам, и их пассажирам. И еще многим людям, о которых я не вспомнил. А кто это у нас в России отвечает за радио частоты? Чтобы чисто все было, без помех. Кажется ГРЧЦ называется, Главный Радичастотный Центр. И сайт у него имеется — http://www.grfc.ru/grfc/. И он ведь может по массовой жалобе, например, людей в интернете проверить наличие демона и найти его, но не делает. А ну как президент спросит на следующей прямой линии, кто это кошмарит его население. Но я эти Радичастотные Центры могу понять. У них на носу мероприятие мощное в месте хорошем, на природе — Спектр-Форум. Бархатный сезон, курортный роман и все такое. Обсудят там чистоту спектра и с новыми силами за работу. Эх, где мои шестнадцать лет...
Но я их не буду ждать и все равно расчехляю, так как адреналин уже зашкаливает.
Где я еще смогу половить живого демона, как не на Родине? Вот возьмем Европу — скучно живут, бедолаги. Довольствуются, можно сказать, резиновыми демонами, благо стоят недорого. Настоящие-то у них вот так не гуляют по улицам. А если и прошмыгнут, то быстро и прячась, чтобы не дай бог не заметили.
Оружье мое выглядит так:

Про его внутреннее устройство можно прочитать в моей предыдущей статье.
Сейчас мне осталось рассказать только про кабель. Он кажется неказистым с виду, но по нему ходит целых 5 ГГц.

Пеленгатор подключается к планшету по USB3, а у него требования к качеству кабеля довольно серьезные. Благо кабель у меня должен быть не очень длинный, я беру кусочки простой витой пары UTP и соединяю разъем типа A с разъемом типа C. На пеленгаторе стоит тип C, так как нельзя толщину сильно увеличивать, будет некрасиво. Получается вот такая скрутка всех цветов радуги. И самое главное — надо добавить еще отдельных земляных проводов в эту скрутку. С одним, например, даже на такой длине USB-интерфейс выдает ошибки и связи с платой нет.
На стороне A все очень просто.

А на стороне C нужен еще резистор (согласно стандарта на type C), который я в формате SMD не нашел, поэтому поставил большой советский. Вот как спасают иногда старые запасы наших отцов!

Вернемся же к нашему подопечному, пока вы совсем не заскучали. Разные мобильные устройства реагируют на демона сильно по разному. У меня на руках был Samsung Duos и Lenovo Phab 2 Pro (звезда будущих статей про AR-пеленгаторы). Samsung даже в непосредственной близости от демона редко улетал во Внуково. Он просто не мог найти навигационное решение. Экран его GPSTest выглядел так:
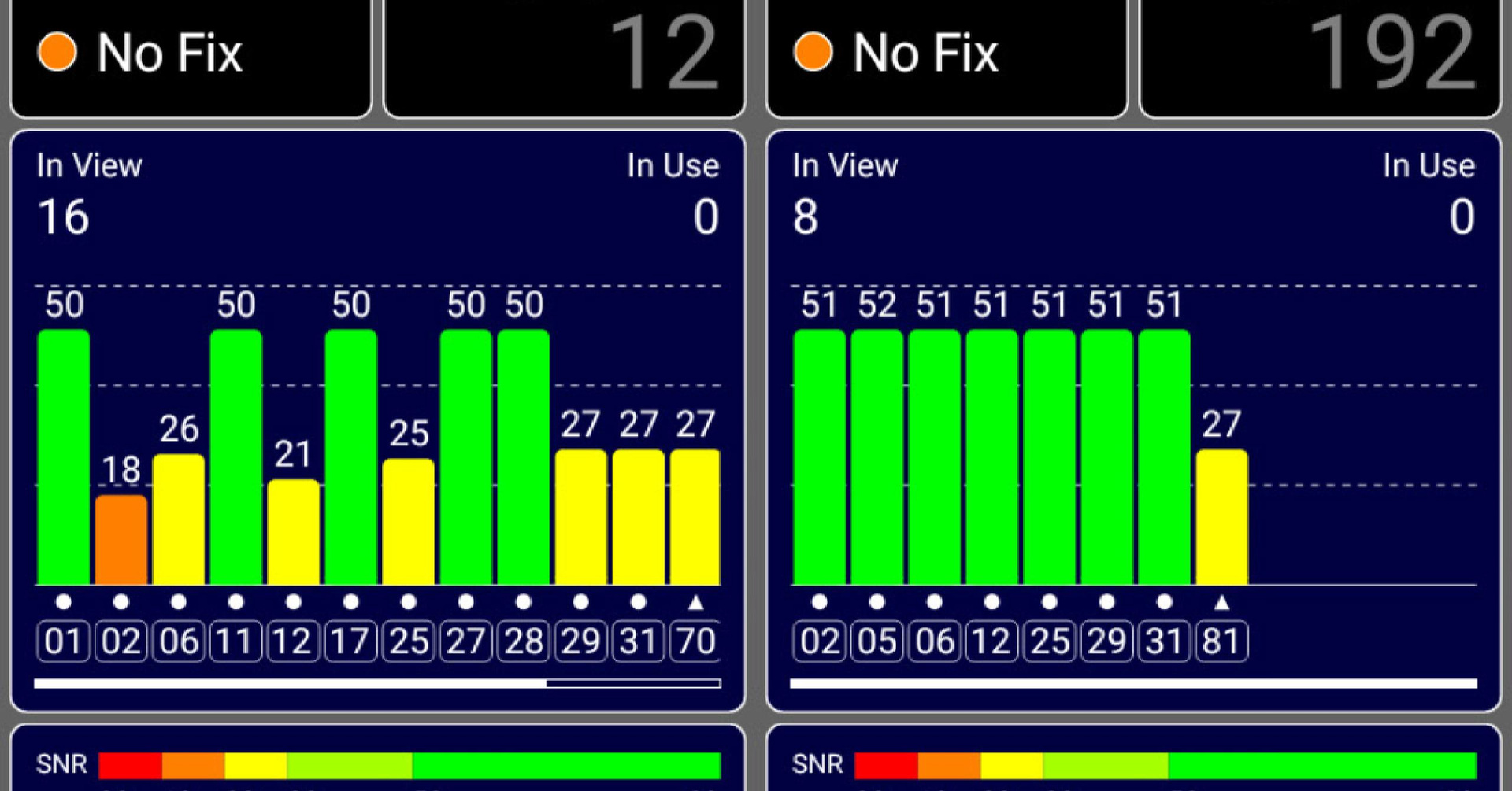
Здесь особо примечательно то, что значение ОСШ (SNR) около 50 дБ на этом смартфоне не бывает в принципе. Потери в антенне этого устройства приводят к довольно большому системному коэффициенту шума (System Noise Floor). Я при открытом небе видел всего 40 дБ с небольшим. И это является одним из признаков пришествия демона, наблюдаемым на обычных мобильных устройствах.
Еще необходимо заметить, что, наряду с поддельными спутниками, принимаются и настоящие. У них ОСШ (SNR) значительно меньше. Правый скриншот снят под Москворецким мостом, поэтому там есть только один настоящий спутник, но остальные (поддельные) принимаются так, как будто они все у меня в кармане.
А вот более новый гаджет — Lenovo Phab 2 Pro тупо показывает Внуково:
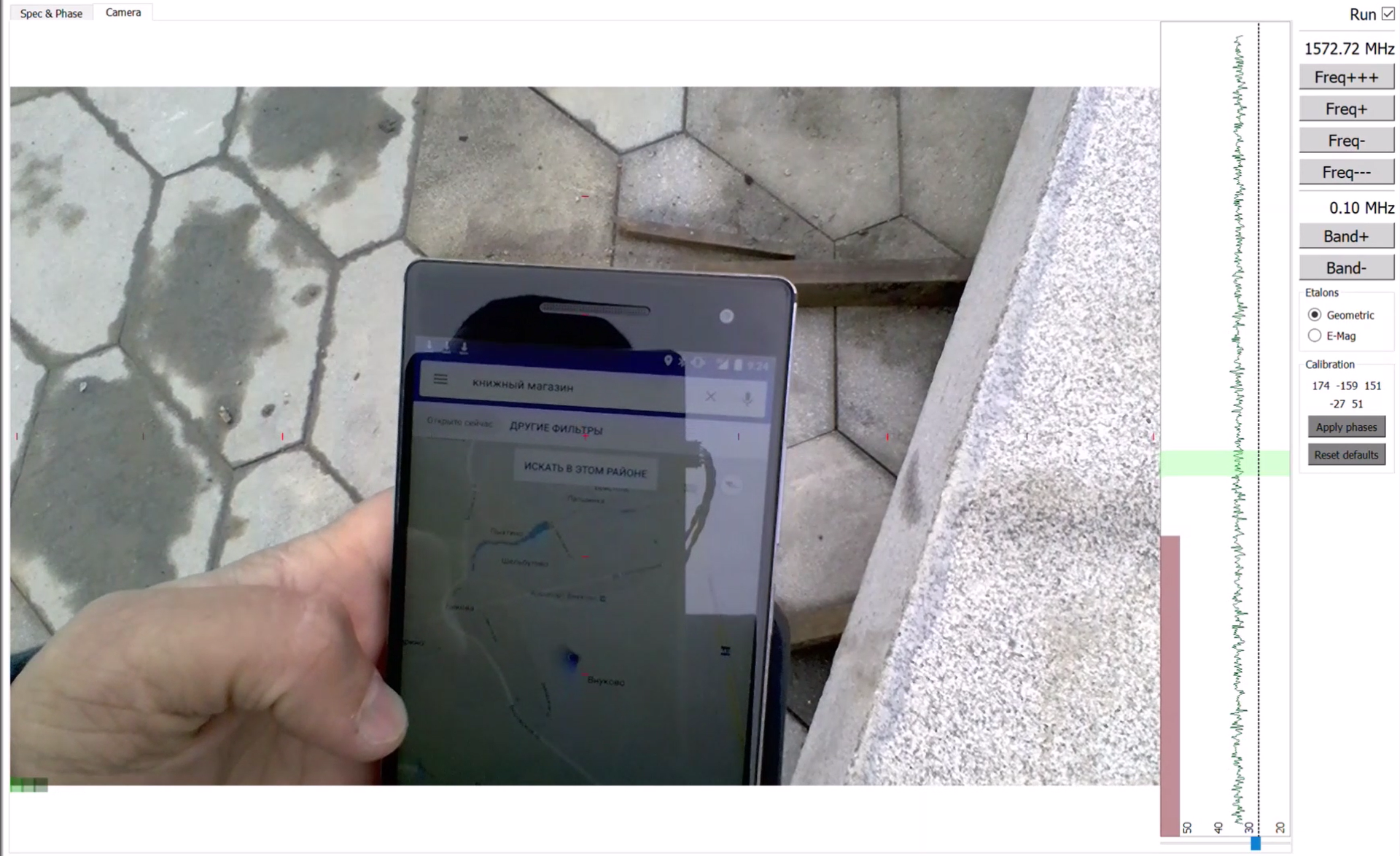
Вот в этот гаджет я и вставил московскую СИМку и планировал нормально ориентироваться в Москве. Но ...
Давайте рассмотрим спектр демона. Ниже на видео вы увидите его справа вертикально. Я развернул картинку, чтобы было нагляднее.

Во-первых, есть рог демона центральный гармонический сигнал, который, видимо, должен забивать приемники, чтобы они хуже принимали настоящие спутники. Ниже на 20 дБ идет уже тело демона широкий сигнал, который имитирует спутниковый.
Чувствую, что вы уже достаточно разогрелись, приступим в основному блюду. Так как пеленгатор построен на дополненной реальности, я предлагаю просто посмотреть пару видео с поля боя.
На первом я спускаюсь по парку Зарядье, который отмывают от строительной грязи. Это поэтому у меня ботинки такие грязные.
На втором я прогуливаюсь по Кремлевской набережной.
Я внимательно читал статью на Медузе и не вижу смысла не верить авторам. Раз коллеги нашли демона там, значит он там и был.
Просто он переехал.
P.S.
Может мой Phab 2 Pro так завис, но я увидел, что демон пропал только в 10.30, ровно. И было это аж возле хакспейса Нейрон на Хохловском. Меня удивляет и возмущает, как же далеко он бьет. Зачем? Также я подозреваю демона в формализме. Почему он включается и выключается в моменты времени, кратные часу или получасу? Нехорошо все это. Демон, надо бы поберечь население.
|
|
10 интересных нововведений в JUnit 5 |
|
Метки: author atygaev тестирование it-систем проектирование и рефакторинг java junit unit-testing unit-tests development |
[Из песочницы] Каждая неблокирующая операция в Node.js имеет дополнительную «цену» и она не всегда выгодна |
Прочитав статью Episode 8: Interview with Ryan Dahl, Creator of Node.js и комментарии к переводу, я решил протестировать эффективность блокирующей и неблокирующей операции чтения файла в Node.js, под катом таблицы и графики.
Блокирующая операция (fs.readFileSync одна из таких) предполагает что исполнение всего приложения будет приостановлено пока не связанные с JS на прямую операции не будут выполнены.
Неблокирующие опрации позволяют выполнять не связанные с JS операции асинхронно в параллельных потоках (например, fs.readFile).
Больше об blocking vs non-blocking здесь.
Хоть Node.js исполняется в одном потоке, с помощью child_process или cluster можно распределить исполнение кода на несколько потоков.
Проведя тесты с параллельным и последовательным чтением разных по величине файлов, я получил следующие результаты.
При чтении 3.3 kB файла 10 000 раз
| Symbol | Name | ops/sec | Percents |
|---|---|---|---|
| A | Loop readFileSync | 7.4 | 100% |
| B | Promise chain readFileSync | 4.47 | 60% |
| C | Promise chain readFile | 1.09 | 15% |
| D | Promise.all readFileSync | 4.58 | 62% |
| E | Promise.all readFile | 1.69 | 23% |
| F | Multithread loop readFileSync | 1.35 | 18% |
При чтении 3.3 kB файла 100 раз
| Symbol | Name | ops/sec | Percents |
|---|---|---|---|
| A | Loop readFileSync | 747 | 100% |
| B | Promise chain readFileSync | 641 | 86% |
| C | Promise chain readFile | 120 | 16% |
| D | Promise.all readFileSync | 664 | 89% |
| E | Promise.all readFile | 238 | 32% |
| F | Multithread loop readFileSync | 1.55 | 0.2% |
При чтении 6.5 MB файла 100 раз
| Symbol | Name | ops/sec | Percents |
|---|---|---|---|
| A | Loop readFileSync | 0.63 | 83% |
| B | Promise chain readFileSync | 0.66 | 87% |
| C | Promise chain readFile | 0.61 | 80% |
| D | Promise.all readFileSync | 0.66 | 87% |
| E | Promise.all readFile | 0.76 | 100% |
| F | Multithread loop readFileSync | 0.56 | 74% |
Загрузка процессора при чтении 3.3 kB файла 10 000 раз (без Multithread loop readFileSync)

Загрузка процессора при чтении 6.5 MB файла 100 раз

Как видим fs.readFileSync всегда исполняется в одном потоке на одном ядре. fs.readFile в своей работе использует несколько потоков, но ядра при этом загружены не на полную мощность. Для небольших файлов fs.readFileSync работает быстрее чем fs.readFile, и только при чтении больших файлов при ноде запущенной в одном потоке fs.readFile исполняется быстрее чем fs.readFileSync.
Следовательно, чтение небольших файлов лучше проводить с помощью fs.readFileSync, а больших файлов с помощью fs.readFile (насколько файл должен быть большой зависит от компьютера и софта).
Для некоторых задач fs.readFileSync может быть предпочтительнее и для чтения больших файлов. Например при длительном чтении и обработке множества файлов. При этом нагрузку между ядрами надо распределять с помощью child_process. Грубо говоря, запустить саму ноду, а не операции в несколько потоков.
Пример ситуации чтения файла.
Допустим у нас крутится веб сервер на ноде в одном потоке T1. На сервер одновременно приходит два запроса (P1 и P2) чтения и обработки небольших файлов (по одному на запрос). При использовании fs.readFileSync последовательность исполнения кода в потоке Т1 будет выглядеть так:
P1 -> P2
При использовании fs.readFile последовательность исполнения кода в потоке Т1 будет выглядеть так:
P1-1 -> P2-1 -> P1-2 -> P2-2
Где P1-1, P2-1 — делегирование чтения в другой поток, P1-2, P2-2 — получение результатов чтения и обработка данных.
При чтении небольших файлов операции делегирование чтения и получение результатов чтения длятся дольше чем само чтение. Отсюда и результаты тестов. Поправьте меня, если я ошибаюсь.
|
Метки: author Shvab node.js javascript performance libuv |
Сигнатура Snort для уязвимости CVE-2017-9805 в Apache Struts |
|
|
Робоотчет о GDD Europe 2017 |








|
Метки: author redmadrobot разработка под android блог компании redmadrobot redmadrobot мобильная разработка |
DevFest North в первый раз в Петербурге |








 «Начинал с реверс-инжиниринга игр в 2006 и ковыряния линуксов в 2008. Сейчас занимаюсь разработкой под Android и Ruby on Rails. Посматриваю на Go и Angular. Люблю данные. Не люблю горячий кофе.»
«Начинал с реверс-инжиниринга игр в 2006 и ковыряния линуксов в 2008. Сейчас занимаюсь разработкой под Android и Ruby on Rails. Посматриваю на Go и Angular. Люблю данные. Не люблю горячий кофе.»



|
Метки: author Developers_Relations конференции блог компании google google android mobile web chrome gdg devfest gdgspb gdgpetrazavodsk |
[Из песочницы] Опыт обучения программированию детей от 8 лет онлайн |
«Моему сыну 9 лет, он сейчас пошел в 3-й класс гимназии и параллельно занимается на IT-курсах для детей. Впечатления сложные, скорее, негативные. Там слабо следят за тем, что делают дети за компьютерами. Пока учитель читает лекцию, некоторые ребята умудряются переписать на компьютер с принесенной флэшки Counter-Strike и подначивать соседей по классу поиграть с ними. Ребенку не хватает нормального общения со сверстниками, т.к. нужно завязывать новые отношения. Он тянется к ребятам, прогибается под них и не всегда, к сожалению, ищет общения с примерными одноклассниками. Так и там получилось. Например, один раз его сосед открыл во время лекции на своем компьютере google images и стал искать там фотографии, простите, говна. А мой сын громко смеялся над этими фотографиями, за что его в конце концов и наказали двойкой, настоящего зачинщика при этом не обнаружив. Кроме того, в отличие от гимназии, где ребята в основном хорошие и круг общения в основном складывается из сверстников, на курсах контингент очень разнообразный, и по возрасту, и по воспитанию. В результате общения с разными ребятами у сына на телефоне появляются такие приложения, за которые должно быть стыдно, и которые приходится вычищать, объясняя, почему это гадость. Мы обращались в учебный отдел, нам ответили, мол, учитель физически не может ни видеть, что на каждом экране, ни блокировать компьютеры. Ещё один момент был: если сын что-то где-то не успевал, он стеснялся сразу уточнить задание или попросить помощи у учителя, а потом было уже слишком поздно. Ему явно больше подойдет индивидуальное обучение».
|
Метки: author PolinaV учебный процесс в it обучение программированию детей программирование для детей онлайн обучение |
[Перевод] JavaScript: загадочное дело выражения null >= 0 |
|
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com разработка стандарты |
Импортозамещение в нефтегазовом секторе: как добывающие компании на «Эльбрус» собрались |

|
|
[recovery mode] 4% усилий – 60% результата, или 5 простых способов увеличения эффективности отдела продаж |
|
Метки: author Flexbby управление продажами ecm/ сэд crm- системы блог компании flexbby crm система управление продажми автоматизация предприятий flexbby parametric |






